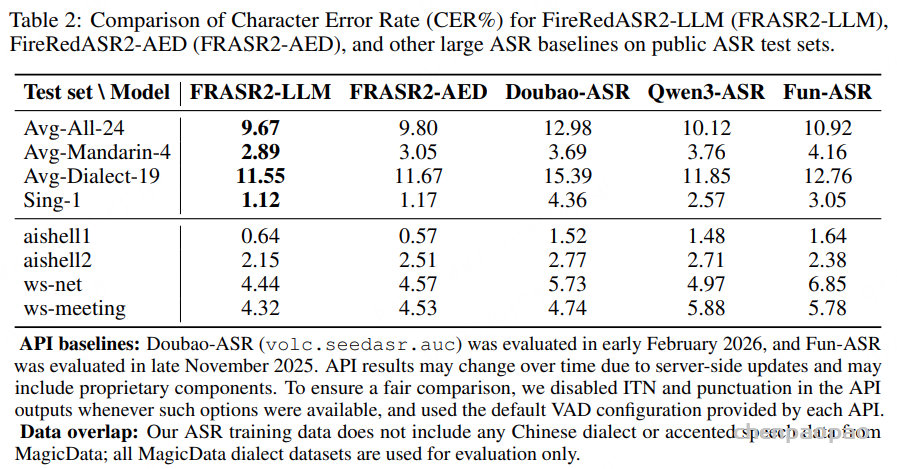
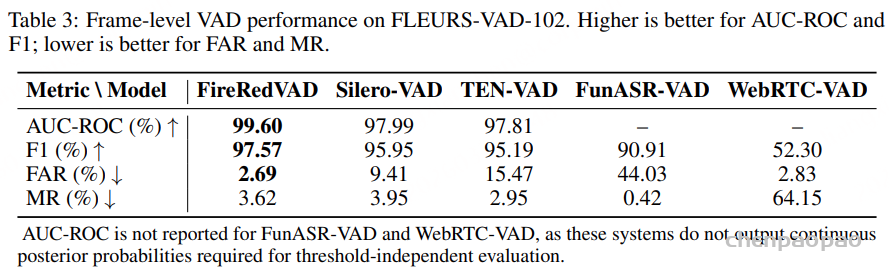
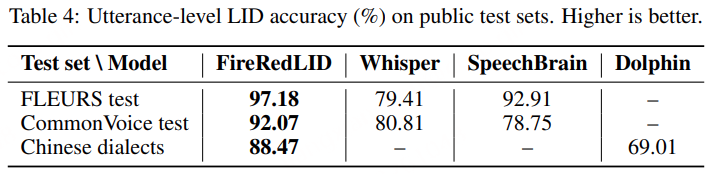
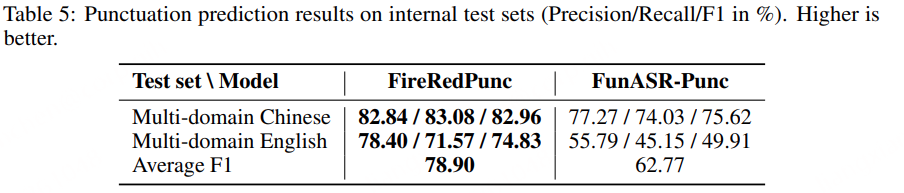
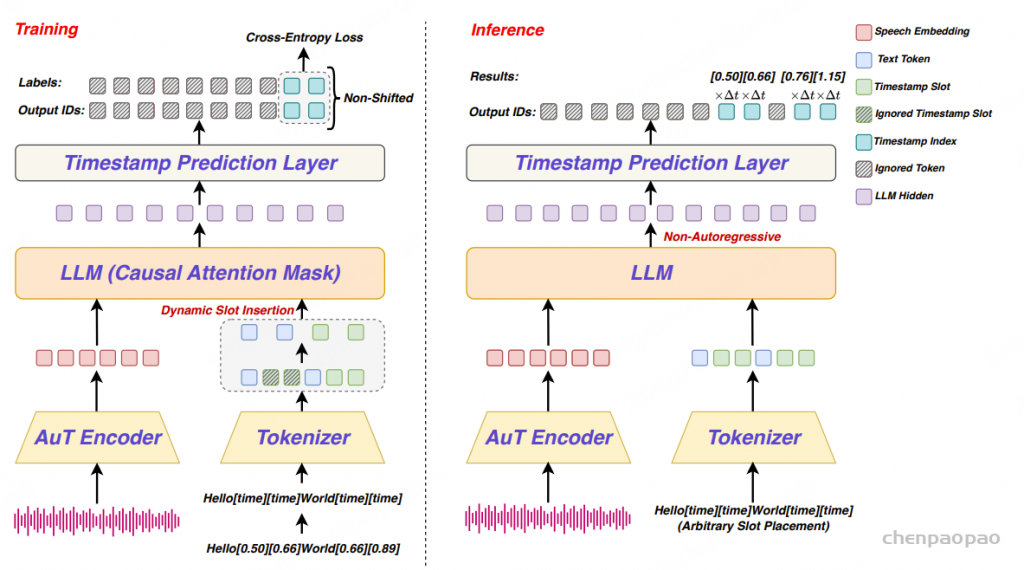
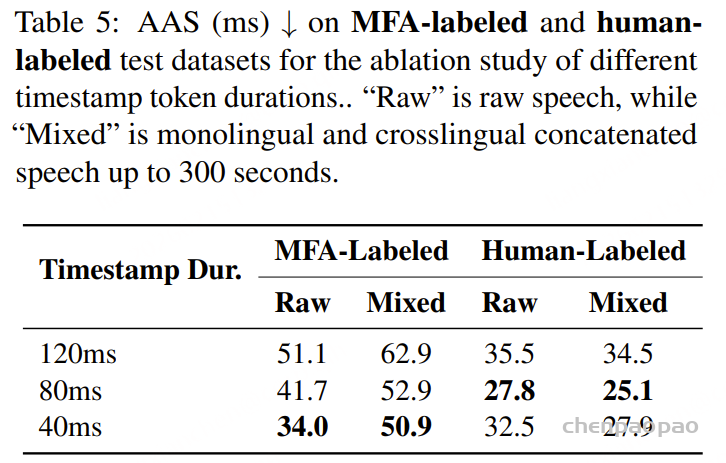
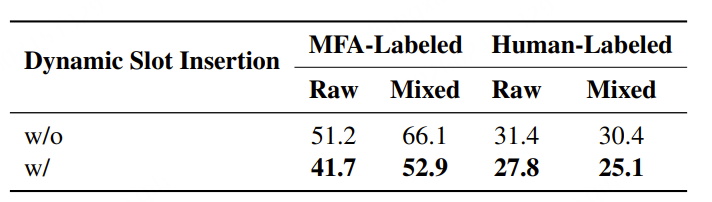
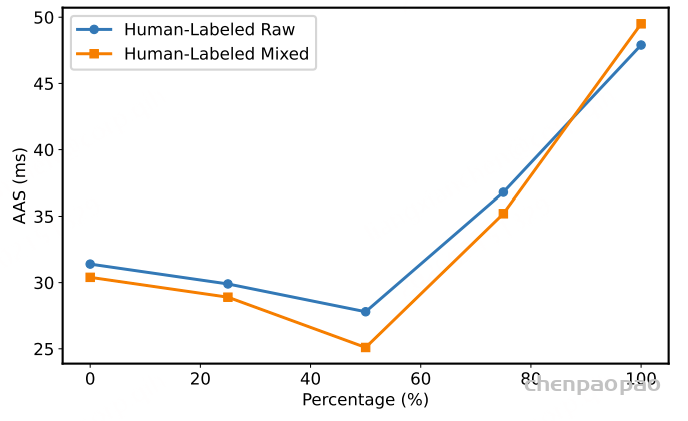
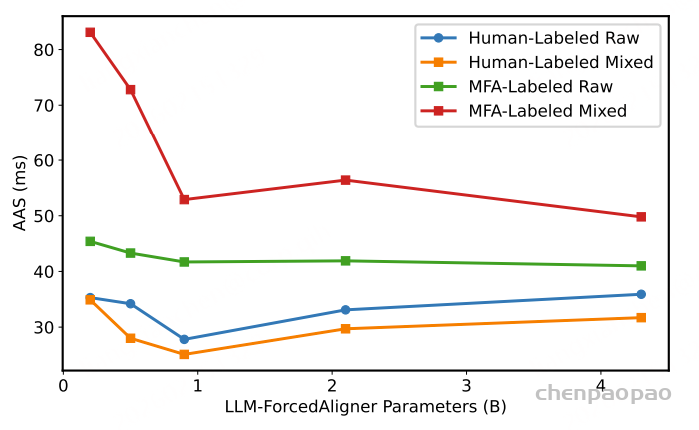
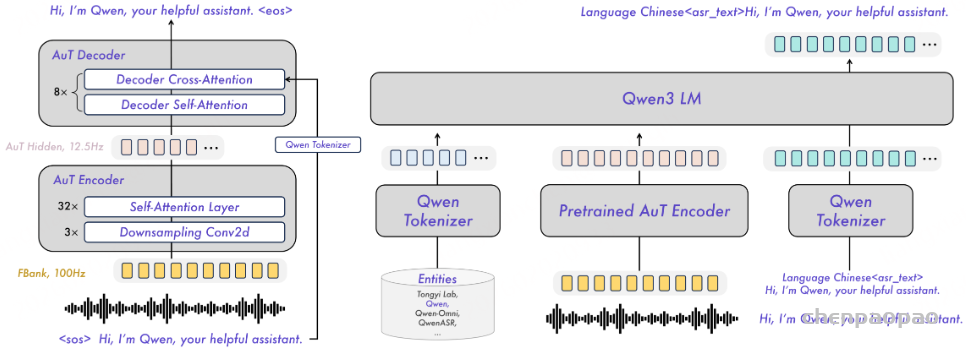
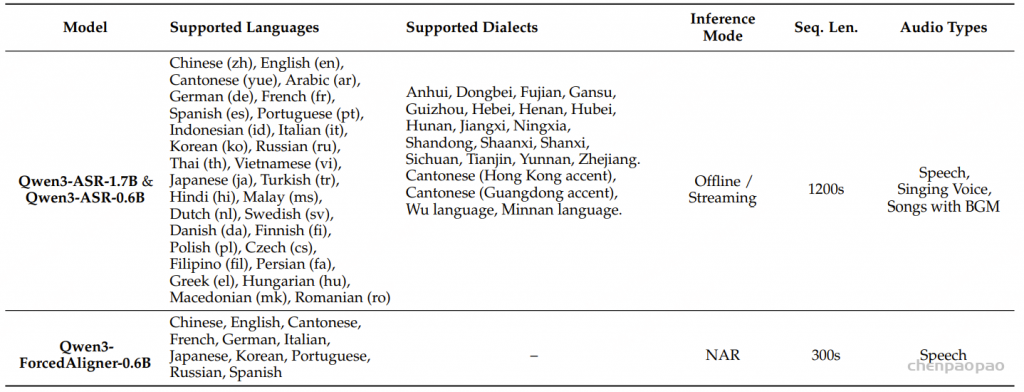
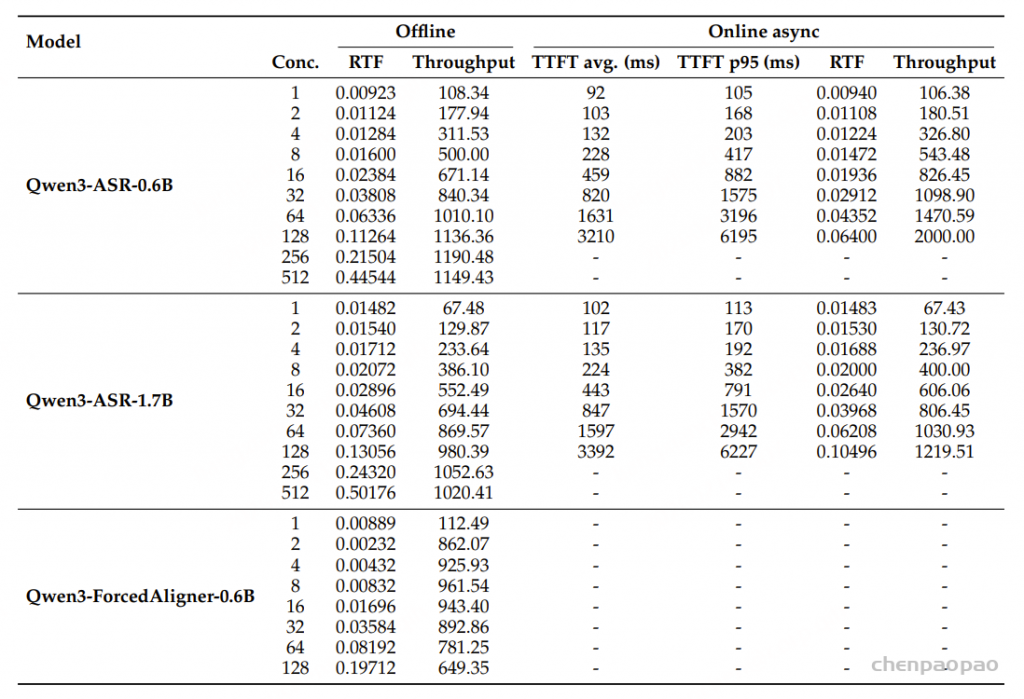
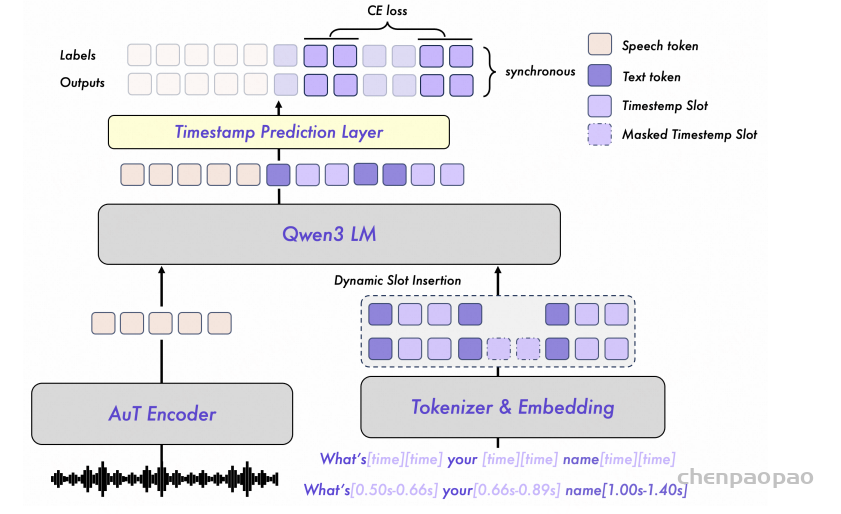
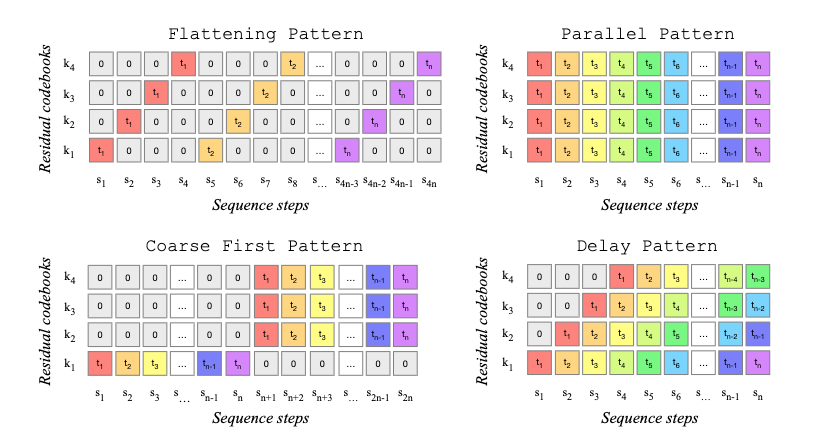
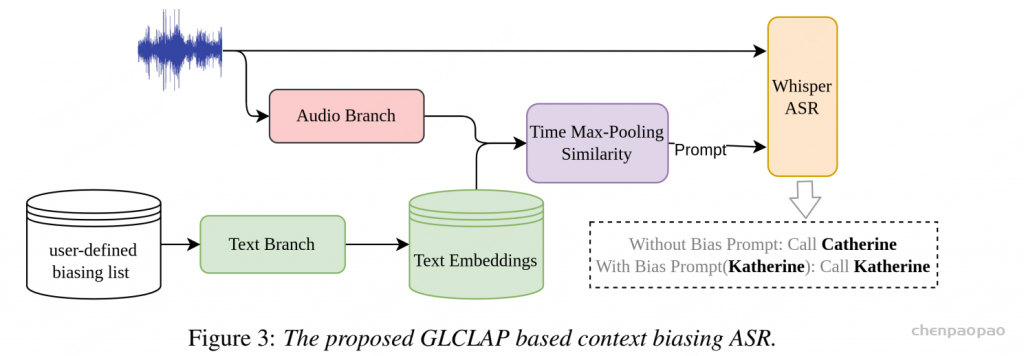
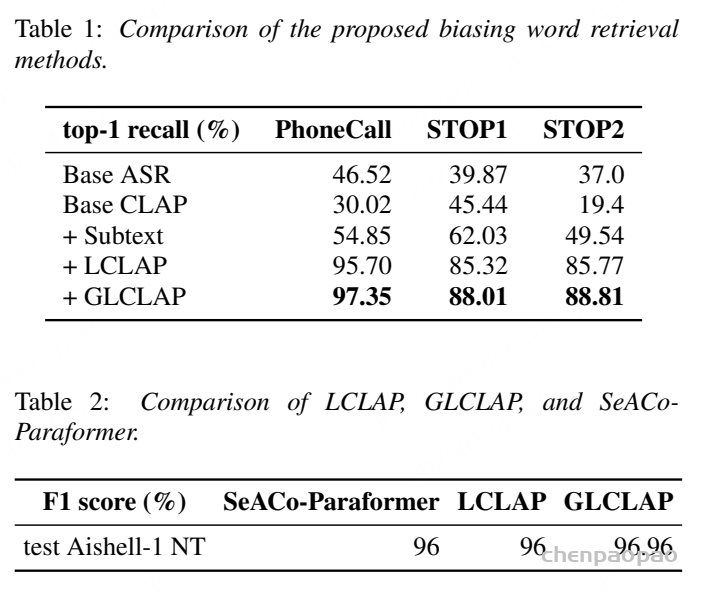
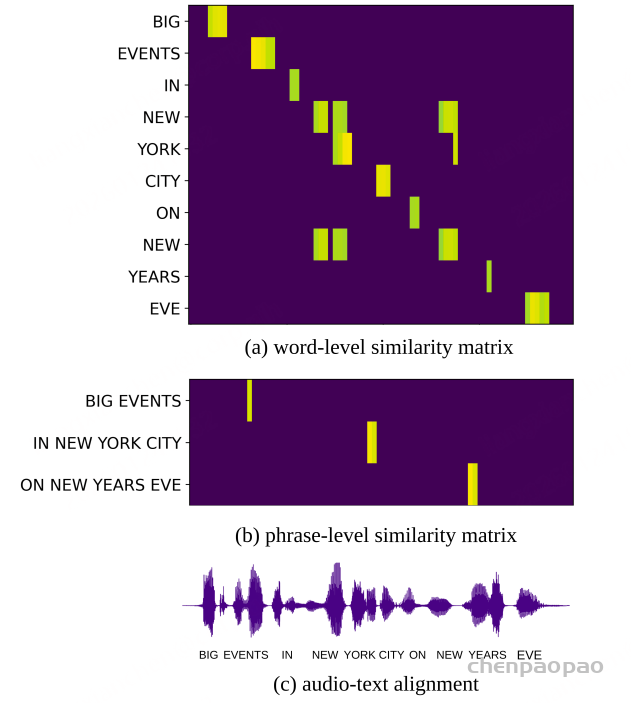
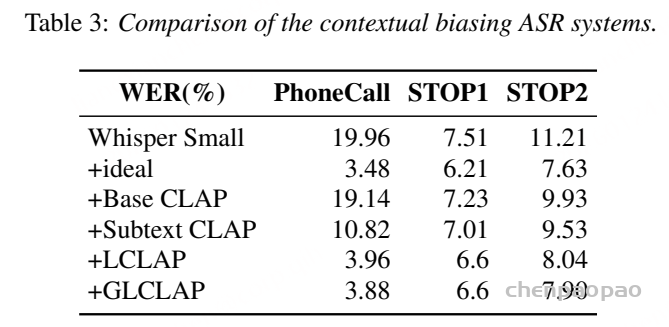
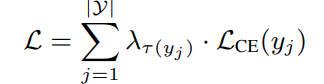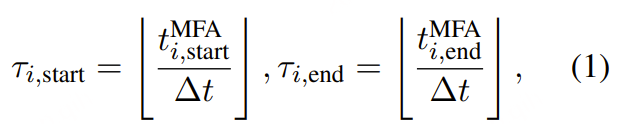原创:贾彦
时间范围:2022.01–2026.04,共收录17 篇 代表性论文,按时间顺序排列。每篇包含:简介、架构、关键创新、训练数据、实验结果、犀利点评、评分。⭐⭐ = 里程碑论文;⭐ = 值得精读
2022–2023:奠基期——LLM 如何接管 ASR
这一阶段的核心问题是:”能不能把LLM用到语音识别上? ” 研究者们刚刚开始尝试把 Whisper、LLaMA 等模型引入 ASR,流式能力还是次要问题,主要在验证可行性。
1. Prompting Large Language Models with Speech Recognition Abilities ⭐
arXiv ID : 2307.11795
发布日期 : 2023-07-21
发表状态 : ICASSP 2024
机构 : Meta AI
论文链接 : https://arxiv.org/abs/2307.11795
📌 简介
最早系统验证”把小音频编码器直接接到冻结 LLM 前端做 ASR”这个 GPT-style 范式可行的论文之一。将 Conformer encoder 输出作为 prefix embedding 拼接到 LLaMA-7B 的 text token 前,验证多语言 ASR 能力,以及 LLM 冻结时是否仍可学到多语言识别。
🔧 架构示意
音频 → Conformer Encoder → Prefix Embedding
↓
文本 Token Embedding → LLaMA-7B (可冻结) → 转录输出💡 关键创新
- 建立了”Speech Prompt + LLM”的 GPT-style baseline 范式
- 验证:LLM 冻结 + 仅训练 encoder 时仍有效,无需 LLM 参与 ASR 训练
- 大步长 striding(~1s)下仍保持多语言识别能力
📊 训练数据&实验结果
- 数据:Multilingual LibriSpeech(MLS,44.5k h,多语言)
- MLS 英语 WER 4.3%,多语言超过 monolingual baseline 18%
☠️ 犀利点评
这篇的历史价值在于”第一批验证者”而非”创新者”。Encoder 接 LLM 做 ASR 这件事大家都在想,它只是第一批做出来并写清楚的。不支持流式是硬伤——GPT-style 必须把整段音频先编好再喂 LLM,实时场景完全用不了。论文本身偏工程报告,ablation 也比较粗糙。不过作为这个方向的开山之作必须了解。
⭐ 评分 : 6/10
2. Chunked Attention-based Encoder-Decoder for Streaming Speech Recognition ⭐
arXiv ID : 2309.08436
发布日期 : 2023-09-15
发表状态 : ICASSP 2024
机构 : RWTH Aachen / Google
论文链接 : https://arxiv.org/abs/2309.08436
📌 简介
将 AED(Attention Encoder-Decoder)模型改造为 chunk-wise 流式模型,用特殊的 End-of-Chunk(EOC)符号代替传统 EOS 符号驱动 chunk 间跳转。理论分析表明 Chunked-AED 等价于一个 chunk 级别的 Transducer (RNN-T)。同时研究了长音频泛化、beam size、length normalization 等实际部署问题。
PS: RNN-T consists of three major building blocks:

🔧 架构示意
音频流 → Chunk-aware Encoder(限制未来帧可见范围)
↓
Chunk-wise Decoder(EOC token 驱动 chunk 跳转)
↓
流式转录输出(chunk-by-chunk)💡 关键创新
- AED 流式改造:EOC token 替换 EOS,使 decoder 可 chunk-wise 生成
- 理论证明 Chunked-AED ≈ Chunk-level Transducer,统一两类模型
- 长音频泛化:串联短音频序列训练,无需专门长音频数据
📊 训练数据&实验结果
- 数据:LibriSpeech(960h)+ TED-LIUM-v2
- LibriSpeech test-clean 流式 WER 2.7%,与非流式差距极小
☠️ 犀利点评
这篇的意义被低估了。它把 AED 和 Transducer 的理论关系说清楚了,后续很多流式 LLM-ASR 设计都是这个思路的变体。但它本身并没有引入 LLM,是”流式 AED 优化”论文,和”LLM-ASR”严格来说不在一个赛道。CHAT(2602.24245)可以直接看作这篇的 LLM 时代续作。
⭐ 评分 : 7/10
3. Smoothed Label Distillation for Decoder-Only ASR(SLD)
arXiv ID : 2311.04534
发布日期 : 2023-11-08
发表状态 : ICASSP 2024
机构 : Alibaba DAMO Academy
论文链接 : https://arxiv.org/abs/2311.04534
代码链接 : https://github.com/alibaba-damo-academy/SpokenNLP
📌 简介
研究 decoder-only Transformer(GPT-style)做 ASR 时如何处理离散语音 token 的训练损失问题。发现直接在音频 token 上用 CE loss 并不稳定,提出 Smoothed Label Distillation(SLD),用 KL 散度 + 平滑标签对音频 token 进行自回归建模。
🔧 架构示意
音频 → 离散化(HuBERT/EnCodec等) → 音频离散 token
↓
Decoder-Only Transformer(GPT-style)
↓ ↓
音频 token 预测 文本 token 预测
(SLD: KL散度+平滑标签) (标准 CE loss)💡 关键创新
- 指出 Loss Masking(忽略音频 token 的 loss)和直接 CE 都不是最优的
- SLD:KL 散度 + 平滑标签,让模型学到音频 token 间的自回归依赖
- 对 SpeechGPT 等离散 token ASR 范式的训练目标优化有指导意义
📊 训练数据&实验结果
- 数据:LibriSpeech(960h)
- 超越 Loss Masking 策略,在多种语音离散化方法下一致改善
☠️ 犀利点评
这是一篇”找到真正问题并解决它”的小而精的工作。离散 token ASR 的训练损失该怎么设计这个问题在当时没人仔细研究,它认真研究了。但离散 token ASR 的精度上限本来就比连续特征差,SLD 改善的是”训练方式”而非”架构上限”。流式能力没有涉及,属于 decoder-only ASR 的训练基础研究。
⭐ 评分 : 6/10
▌2024:爆发期——流式框架、多任务、工程化
2024 年是流式 LLM-ASR 真正爆发的一年。BESTOW 确立了 read-write policy 框架,Transducer-Llama 给出 RNN-T 下最优 LLM 集成方案,Seed-ASR 展示了工业 LLM-ASR 的真实边界。
4. BESTOW: Efficient and Streamable Speech Language Model ⭐⭐
arXiv ID : 2406.19954
发布日期 : 2024-06-28
发表状态 : Interspeech 2024 / NeurIPS 2024 Workshop
机构 : NVIDIA
论文链接 : https://arxiv.org/abs/2406.19954
代码链接 : https://github.com/NVIDIA/NeMo(含 BESTOW 实现)
📌 简介
提出 BESTOW 架构,将 GPT-style(预拼接音频 embedding)和 T5-style(逐层 cross-attention)的优点融合。核心是用文本 query + 音频 key/value 的 cross-attention 替代音频 prefix 拼接,既保持高效率又天然支持流式。将流式 SpeechLLM 重新定义为 read-write policy 问题,统一离线与流式研究框架。
🔧 架构示意
音频流 → 流式 Speech Encoder → 音频特征(Key/Value)
↓
文本 Prompt → LLM 内各层 Cross-Attention(文本作 Query)
↓
read-write policy 网络
(决定何时输出 token,何时继续 read)
↓
流式多任务输出(ASR/AST/SQA)💡 关键创新
- 首个同时支持流式和多任务(ASR/AST/SQA)的开源 SpeechLLM
- 将流式问题转化为 read-write policy,借鉴同步翻译领域成熟研究
- text query 驱动音频 cross-attention,效率优于 GPT-style prefix 拼接
- 87k 小时数据规模,一天内可完成训练
📊 训练数据&实验结果
- 数据:87,000 小时多语言语音(公开 + 私有)
- ASR、AST、SQA 多任务 SOTA;LibriSpeech test-clean WER 1.9%
☠️ 犀利点评
2024 年流式 LLM-ASR 里最值得精读的论文,没有之一。它把”流式 SpeechLLM”的问题空间定义清楚了——read-write policy——并给出了第一个能跑、能开源的多任务流式解法。但 87k 小时数据不是普通团队能复现的,且流式性能上没有做细致的延迟分析(只说”支持流式”,没给具体 latency 数字)。研究者必读;工程师注意数据门槛。
⭐ 评分 : 8/10
5. Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
arXiv ID : 2407.04675
发布日期 : 2024-07-05
发表状态 : ICASSP 2025
机构 : ByteDance / Seed Team
论文链接 : https://arxiv.org/abs/2407.04675
📌 简介
字节跳动 Seed 团队的大规模工业 LLM-ASR 系统报告。将 LLM 与语音编码器深度融合,支持上下文感知识别(热词、场景提示)、多方言、噪声鲁棒。采用分阶段训练:预训练弥合模态差距、SFT 对齐、RLHF 提升质量。注:论文本身为离线系统 ,不涉及 流式架构设计或流式实验 。
🔧 架构示意
音频 → 大规模 Speech Encoder(Conformer/类似结构)
↓ Adapter
LLM(Decoder-Only)
├── 预训练:弥合模态差距
├── SFT:任务对齐
└── RLHF:识别质量与鲁棒性提升
↓
上下文 Prompt(热词/领域/方言信息)→ 注入 LLM 输入
↓
离线转录输出(论文不涉及流式推理)💡 关键创新
- 工业级 LLM-ASR 全流程:从预训练到 RLHF 的完整 pipeline
- 上下文感知:支持 prompt 注入热词和领域信息,无需重新训练
- RLHF 首次系统应用于 ASR 质量提升
- 多方言、噪声鲁棒大规模验证(论文不涉及流式)
📊 训练数据&实验结果
- 数据:数十万小时中英双语(字节内部,规模未完全公开)
- 内部多场景 benchmark SOTA,普通话 CER 和英语 WER 均优于 Whisper-v3
☠️ 犀利点评
字节在 LLM-ASR 上的第一次全面亮相,工程深度足。上下文 prompt 注入对产品场景特别有用——会议、垂直领域的识别质量问题本质是”模型不懂这些词”,prompt 是性价比最高的解法。但 RLHF 在 ASR 里的 reward 设计细节披露不够。论文本身为离线系统,不涉及流式内容,纳入本调研是作为重要工业离线 LLM-ASR 参考基线。
⭐ 评分 : 7/10
6. Transducer-Llama: Integrating LLMs into Streamable Transducer-based ASR ⭐
arXiv ID : 2412.16464
发布日期 : 2024-12-21
发表状态 : ICASSP 2025
机构 : Meta AI
论文链接 : https://arxiv.org/abs/2412.16464
📌 简介
将 LLM 集成到 Factorized Transducer(FT)框架中,天然继承 RNN-T 的流式能力。提出”弱到强 LM swap”策略:先用弱 LM 做 RNN-T 训练,再替换为强 LLM 预测器,通过 MWER loss 微调完成集成。还引入词汇表适配技术缓解 LLM 大词汇表带来的数据稀疏问题。
🔧 架构示意
音频流 → 流式 Conformer/Emformer Encoder
↓
Factorized Transducer
┌────────────────────────────────┐
│ Blank Predictor(轻量网络) │
│ Non-Blank Predictor(LLM) │← 弱→强 swap
│ Joint Network(sigmoid/softmax混合)│
└────────────────────────────────┘
↓ MWER 微调
流式转录输出💡 关键创新
- “弱到强 LM swap”:先用弱 LM 训 RNN-T,再换 LLM——绕过联合训练的优化陷阱
- 词汇表适配:将 LLM 大词表映射到语音系统词表,降低训练代价
- MWER loss 端到端调优 LLM 集成效果
📊 训练数据 & 实验结果
- 数据:LibriSpeech(960h 英语)+ MLS 多语言(en 44.7k h、fr 1.1k h、it 0.2k h、nl 1.6k h)
- 相对 FT baseline WER -17%;相对 RNN-T baseline -32%(LibriSpeech)
☠️ 犀利点评
这篇方法论含金量最高。”弱到强 swap”直接击中 RNN-T+LLM 联合训练效果差的核心原因——强 LM 在 RNN-T loss 训练期间会让 encoder 偷懒靠语言先验而不好好学声学信息,swap 后 MWER 才能把 LLM 能力真正释放出来。词汇表适配技巧也务实,工程里直接能用。但 Meta 的数据资源(44.7k 小时英语)不是普通团队能比的,中文等其他语系泛化性存疑。
⭐ 评分 : 8/10
7. Multi-token Prediction for Faster Speech LLaMA Decoding
arXiv ID : 2409.12116
发布日期 : 2024-09
发表状态 : Interspeech 2024 Workshop
机构 : JHU / Meta AI
论文链接 : https://arxiv.org/abs/2409.12116
📌 简介
针对 decoder-only LLM-ASR 推理速度慢的问题,引入 multi-token prediction:每个解码步骤同时预测多个未来 token。利用 ASR 任务的特殊性——音频条件化使 token 间依赖比纯语言建模弱——使多 token 预测接受率更高。
🔧 架构示意
音频 → Encoder → Embedding
↓
Decoder-Only LLM
↓
每步预测 K 个未来 token(并行解码头)
↓
验证接受 → 推进 K 步;拒绝 → 回退
💡 关键创新
- Multi-token prediction 应用于 LLM-ASR 解码加速
- 利用 ASR 任务中音频条件化降低 token 间强依赖的特性,保证接受率
- LibriSpeech 上 ~3.2x 解码速度提升,WER 无损
📊 训练数据&实验结果
- 数据:LibriSpeech(960h)
- 3.2x 解码加速,WER 不变
☠️ 犀利点评
和后来的 SpecASR 方向相近,但发布更早、思路更简单直接。Multi-token prediction 没有专门为 ASR 特性设计,更像是把 NLP 领域 speculative decoding 的前身直接迁移。SpecASR 后来做得更系统,工程价值已被超越。这篇的贡献在于”第一个在 LLM-ASR 上想到并实现了这个方向”。
⭐ 评分 : 6/10
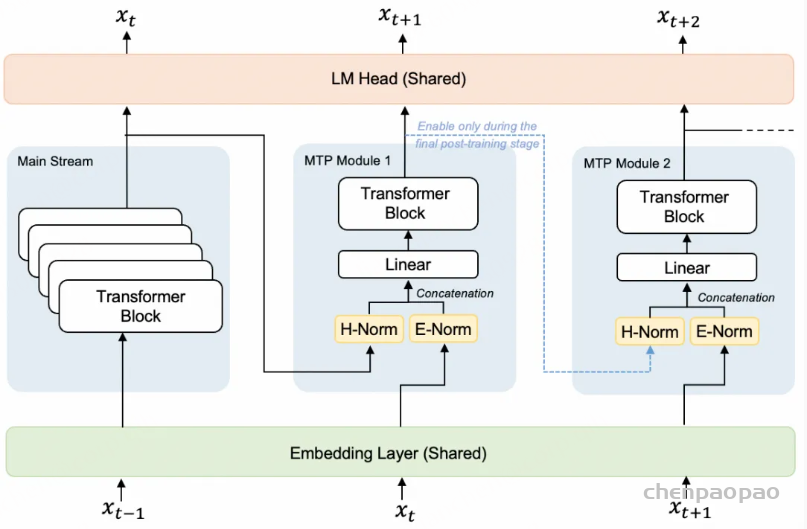
PS:阶跃 StepAudio 2.5 ASR,模型的核心突破在于速度与精度的兼得。我们率先将大语言模型(LLM)的推理加速技术引入语音识别领域,基于 ASR+MTP-5 深度融合架构,实测推理速度提升 400%、时延降低 60%,推理峰值达 500 tokens/s,推理成本直降 80%。传统语音识别模型受限于自回归生成机制,必须逐个 Token 依次输出,就像打字员一个字一个字地敲键盘。StepAudio 2.5 ASR 将 Step 3.5 Flash 同款的 MTP(多 Token 预测)技术移植至语音识别领域,使模型能够一次预测多个候选 Token,并通过并行验证机制快速确认结果。
▌2025:成熟期——推理加速、端侧部署、多任务融合
2025 年流式 LLM-ASR 已经成熟,核心问题变成:怎么更快、更省、更全能 。推理加速、端侧部署、多任务联合成为三条主线。
8. MFLA: Monotonic Finite Look-ahead Attention for Streaming Speech Recognition ⭐
arXiv ID : 2506.03722
发布日期 : 2025-06-04
发表状态 : Interspeech 2025
机构 : Honor Device Co. / 上海交通大学
论文链接 : https://arxiv.org/abs/2506.03722
📌 简介
提出 Streaming-Whisper 框架:在 Whisper 上通过 LoRA fine-tune 实现流式识别,无需从头训练。核心是将 CIF(Continuous Integrate-and-Fire)机制引入 LLM-ASR,让模型自己学习”音频帧到 token 的软对齐”,用 MFLA(Monotonic Finite Look-ahead Attention)让 decoder 每个 token 在解码时看到无限左上下文 + 有限右上下文 ,替代传统固定 chunk 切割,从根本上缓解切块边界截断问题。
🔧 架构示意
音频流 → Whisper Encoder(MoChA chunk 自注意力,chunk size 均匀采样 [32,128])
↓ hidden states H
CIF Predictor(两层线性 + ReLU)
├── 预测每帧权重 α,累积触发 token 边界(MRE loss)
└── 推理时追踪解码进度、防止边界幻觉
↓ 动态分段对齐
Decoder(Whisper Decoder + MFLA)
├── 每个 token 可见:无限左上下文 + 有限右上下文(look-ahead span ~ Poisson(λ=3))
├── 训练:hybrid-attention(full-attention + MFLA 混合)
└── 推理:wait-k decoding(wait-3 为默认)
↓
流式转录输出(可延续 buffer state 减少重复计算)
扩展 SpeechLLM 版本:
音频 → Whisper-Large-V3 Encoder → Adapter(2层 cross-attention)→ Qwen2.5-3B-Instruct → 流式转录💡 关键创新
- CIF-driven 软对齐 :用 CIF predictor 估计帧级 token 权重,建立准单调对齐,替代 fixed-chunk 硬切割,缓解边界截断问题
- MFLA :有限右上下文注意力机制,每个 token 动态决定看多少右侧音频帧,实现 prefix-to-prefix 训练范式
- wait-k + buffer state 延续 :wait-3† 方案在 decoder buffer 中保留状态,比 Local Agreement baseline 减少 60.86% 冗余计算,延迟 1.41s
- 统一离线/在线框架 :look-ahead span→∞ 即退化为离线系统,单模型同时支持两种模式
- SpeechLLM 扩展验证 :接入 Qwen2.5-3B,在线解码 WER 仅比离线高 0.98%
📊 训练数据 & 实验结果
- 数据:WenetSpeech4TTS Premium + LibriSpeech + MLS + VoxPopuli,覆盖中/英/德/西语
- Whisper-Large-V3-Turbo:离线 WER 5.63%,在线 WER 7.17%(1s chunk,wait-3),差距 1.54%
- 延迟对比(vs Local Agreement baseline DAL=1.65s):wait-3 DAL=1.41s(-14.5%),wait-1 DAL=0.93s(-43.6%)
- SpeechLLM 在线 WER:WenetSpeech4TTS Premium 3.41%,LibriSpeech test-clean 2.38%
☠️ 犀利点评
CIF + 有限右上下文注意力这个组合是对的,比 fixed-chunk 切割聪明——让模型自己学对齐而不是按时钟切。wait-3† 的 buffer state 延续把 FLOPs 压到 12.77G(vs baseline 37.56G),工程上非常实用。但两个核心局限论文自己也承认:CIF predictor 太简单(只有两个线性层),帧级权重估计有偏差;LoRA fine-tune 对 encoder 的流式适配效果有限,online 和 offline WER 差距(1.54%)还是显著。更根本的问题是:CIF 感知的是”该输出第几个 token 了”,并不是真正的语义/韵律边界——说话人停顿、重读、换气这些信息 predictor 感知不到,只是比 fixed-chunk 随机切割好一点而不是彻底解决了边界问题。SpeechLLM 扩展部分只用了 LibriSpeech + WenetSpeech4TTS 评测,覆盖场景有限。整体是一篇把正确思路做出来了但还没做完的工作,predictor 升级和 encoder 流式改造是明显的后续方向。
⭐ 评分 : 7/10
9. SpecASR: Accelerating LLM-based ASR via Speculative Decoding ⭐
arXiv ID : 2507.18181
发布日期 : 2025-07-24
发表状态 : DAC 2025
机构 : 厦门大学 / 多校联合
论文链接 : https://arxiv.org/abs/2507.18181
📌 简介
针对 LLM-ASR 的推测解码框架。核心观察:ASR 解码是音频条件化的,小模型与大模型输出对齐率极高。提出自适应草稿序列生成(动态调整草稿长度)、草稿序列复用策略(减少草稿模型延迟)和两步稀疏 token 树生成算法。
🔧 架构示意
音频 → 小型 Draft LLM-ASR(快速生成候选 token 树)
↓ 自适应长度控制
大型 Target LLM-ASR(并行验证 token 树)
├── 音频条件化保障高接受率
└── 稀疏 token 树减少 draft 开销
↓
加速后流式转录输出💡 关键创新
- ASR 专用推测解码:利用音频条件化保障 draft/target 高对齐率
- 自适应草稿长度:动态调节 draft 长度,平衡验证开销与接受率
- 两步稀疏 token 树:减少 draft 模型的冗余计算
📊 训练数据 & 实验结果
- 数据:LibriSpeech + 多个英文公开 benchmark(评测数据集)
- 3.04x–3.79x 加速(vs 自回归基线),1.25x–1.84x(vs 标准推测解码),精度零损失
☠️ 犀利点评
推测解码在 LLM 推理加速里已经成熟,这篇把它移植到 LLM-ASR 是顺理成章,但做了足够多的 ASR 专有设计。3.04x–3.79x 加速是真实 end-to-end 数字,不是理论上界。但前提是你已经有一个 LLM-ASR 系统,且能负担同时运行一大一小两个 LLM。资源受限场景帮助有限;draft 模型选型和训练策略披露也不够细致。
⭐ 评分 : 8/10
10. WhisperKit: On-device Real-time ASR with Billion-Scale Transformers ⭐
arXiv ID : 2507.10860
发布日期 : 2025-07-14
发表状态 : ICML 2025 On-Device Learning Workshop
机构 : Argmax
论文链接 : https://arxiv.org/abs/2507.10860
代码链接 : https://github.com/argmaxinc/WhisperKit
📌 简介
面向端侧部署的 Whisper 实时 ASR 推理优化系统。在 Apple 设备本地运行,匹配甚至超越云端 gpt-4o-transcribe、Deepgram nova-3 的精度,延迟低至 0.46s,WER 仅 2.2%。核心贡献是块对角 mask 自蒸馏、Apple ANE 极致优化和量化压缩。
🔧 架构示意
原始 Whisper Large v3 Turbo
↓ 块对角 mask 自蒸馏(d750:15s block)
流式化 Audio Encoder(块对角自注意力,静音缓存)
↓
Text Decoder + LocalAgreement 流式确认策略
↓ 量化(1.6GB → 0.6GB)
Apple Neural Engine(ANE)原生加速部署
↓
0.46s 延迟端侧实时转录💡 关键创新
- 块对角 mask 自蒸馏:原生支持 Whisper 流式推理,静音缓存减少无效前向
- 量化 1.6GB→0.6GB,WER 损失 <1%
- Apple ANE 近峰值硬件利用率,端侧超越云端 baseline
📊 训练数据 & 实验结果
- 数据:CommonVoice 17(5 语种 fine-tune);LibriSpeech + earnings22 评测
- WER 2.2%,延迟 0.46s;超越 gpt-4o-transcribe 和 Deepgram nova-3
☠️ 犀利点评
最接近纯工程论文的形态,每步都有充分 ablation 支撑——真实的工程成就。但整体是工程优化论文,不是算法创新论文:块对角 mask 引用自刘等人的先验工作,LocalAgreement 也是既有方法。价值在于”把现有技术栈在 Apple ANE 上极致优化”。如果你不做苹果端侧部署,快速浏览即可。
⭐ 评分 : 7/10
11. Train Short, Infer Long: Speech-LLM Enables Zero-Shot Streamable Joint ASR and Diarization(JEDIS-LLM)⭐
arXiv ID : 2511.16046
发布日期 : 2025-11-20
发表状态 : ICASSP 2026
机构 : 微软 UCLA
📌 简介
论文链接 : https://arxiv.org/abs/2511.16046
JEDIS-LLM:端到端 Speech-LLM,支持联合流式说话人分离(Diarization)+ ASR。模型仅在 ≤20s 短音频上训练,但可零样本泛化到任意长度长音频流式推理。通过 Speaker Prompt Cache(SPC)机制实现跨 chunk 说话人一致性传播,并支持预注册说话人 profile。
🔧 架构示意
音频流 → 流式 Speech Encoder
├── Spk-Decoder(Word-level Speaker Supervision)
└── Projector
↓
LLM(LoRA 适配)
↓
流式 chunk 推理:
Speaker Prompt Cache(SPC)
┌─────────────────────────────┐
│ 每个说话人存储代表音频片段 │
│ 跨 chunk 传递,实时更新 │
└─────────────────────────────┘
↓
说话人归属转录("谁说了什么")💡 关键创新
- 首个零样本流式长音频联合 ASR + 说话人分离 Speech-LLM
- SPC:借助 LLM 自回归 KV cache 机制,无需后处理全局聚类即可保持跨 chunk 说话人一致性
- Word-level Speaker Supervision:单词级说话人标签增强 encoder 说话人判别能力
- 仅短音频(≤20s)训练,零样本泛化到任意长音频
📊 训练数据 & 实验结果
- 数据:内部多说话人数据(短音频 ≤20s);CALLHOME / AMI 标准 benchmark 评测
- 超越 Sortformer、Meta-Cat(短音频场景);超越 DiarizationLM(长音频场景)
☠️ 犀利点评
这篇解决了一个真实且棘手的问题——流式长音频多说话人转录。SPC 设计优雅:用 LLM 自回归的 KV cache 机制天然延伸到说话人一致性跨 chunk 传播,不需要后处理全局聚类,也不需要重新训练。”仅在 <20s 短音频训练但零样本泛化到长音频”如果可复现,非常有价值。但实验数据集(CALLHOME、AMI)并非最新最难的 benchmark,和 DiarizationLM 的对比有主场优势之嫌(后者是 cascade 系统)。chunk size、SPC 更新频率的 ablation 还不够充分。
⭐ 评分 : 8/10
12. Audio-Conditioned Diffusion LLMs for ASR and Deliberation Processing(Whisper-LLaDA)
arXiv ID : 2509.16622
发布日期 : 2025-09-20
发表状态 : ICASSP 2026
机构 : IDIAP Research Institute / 多校联合
论文链接 : https://arxiv.org/abs/2509.16622
代码链接 : https://github.com/liuzhan22/Diffusion-ASR
📌 简介
将扩散 LLM(LLaDA-8B)引入 ASR,探索非自回归解码路径。首先作为 Whisper-LLaMA 转录的外部 deliberation 模块,利用 LLaDA 的双向注意力 + 去噪能力修正转录错误。进一步验证 LLaDA 作为独立 ASR 解码器时,扩散解码比自回归更快,但精度略低。
🔧 架构示意
音频 → Whisper-Large-v3 Encoder(冻结)
↓
Q-Former(44 trainable queries,0.33s window)
↓ Projection
LLaDA-8B-Instruct(LoRA 微调)
├── 模式1:Deliberation(修正 Whisper-LLaMA 初始转录)
│ ├── 随机 mask 策略
│ ├── 最低置信度 mask 策略
│ └── 半自回归策略
└── 模式2:独立 ASR 解码器(扩散解码/半自回归解码)💡 关键创新
- 首次系统验证扩散 LLM 用于 ASR 任务
- 音频条件化嵌入是关键:纯文本 LLaDA(无声学特征)做 deliberation 无效
- 半自回归解码策略:平衡扩散解码的速度与精度
📊 训练数据 & 实验结果
- 数据:LibriSpeech(960h 英语)
- 最佳级联 WER:test-clean 2.25% / test-other 4.94%(vs Whisper-LLaMA baseline -12.3%)
- 独立扩散解码:速度快于 AR,但精度略低
☠️ 犀利点评
态度很诚实的探索性论文——明确说”扩散 LLM 做 ASR 的精度比自回归低,但速度更快”,没有粉饰结果。核心 insight 有价值:音频条件化嵌入对扩散 LLM 有效运作是必要条件。但实验只在 LibriSpeech 上(960h 英语有声书,难度偏低),无法说明噪声/口音/真实对话场景的鲁棒性。”更快但不够好”对生产场景吸引力有限。更适合定位为”验证可行性的技术报告”。
⭐ 评分 : 7/10
▌2026 Q1:持续演进期——统一架构、生产落地、全双工
13. Streaming Speech Recognition with Decoder-Only LLMs and Latency Optimization(MoCha-ASR)⭐
arXiv ID : 2601.22779
发布日期 : 2026-01-30
发表状态 : ICASSP 2026
机构 : 合肥工业大学 / 多校
论文链接 : https://arxiv.org/abs/2601.22779
📌 简介
提出将 read/write 策略网络与 MoChA(Monotonic Chunkwise Attention,单调分块注意力)结合,让 Decoder-Only LLM 支持流式 ASR。引入最小延迟训练目标(minLT loss),token 生成延迟降低 62.5%,无需 CTC 强制对齐,端到端可优化。
🔧 架构示意
音频流 → 流式 Conformer Encoder(context-sensitive chunking)
↓ LoRA 微调
MoChA Policy Network(决定 read/write)
├── read:继续接收音频帧
└── write:触发 LLM 生成下一 token
↓
Qwen2.5-1.5B(Decoder-Only LLM)
音频/文本 token 交错输入
↓
minLT loss 约束对齐边界 → 延迟降低 62.5%💡 关键创新
- 端到端流式 LLM-ASR,无需 CTC 强制对齐
- minLT(Minimum Latency Training)损失约束对齐边界,显著压缩生成延迟
- 流式/非流式模型参数共享,联合训练降低开发成本
📊 训练数据 & 实验结果
- 数据:AISHELL-1(165h)+ AISHELL-2(1000h)+ 内部多领域数据
- AISHELL-1 CER 5.1% / AISHELL-2 CER 5.5%,优于所有流式 baseline;token 生成延迟降低 62.5%
☠️ 犀利点评
踏实的工作。别人做流式 LLM-ASR 要么靠外挂 CTC 对齐、要么用 wait-k 硬切块,它真的用 MoChA 自适应分段、端到端训练。minLT loss 把延迟压了 62.5% 这个数字有真实工程价值。但实验只在中文数据集(AISHELL-1/2)上跑,基线列表里 BESTOW 是他们自己复现的,存在选择性对比嫌疑。MoChA 本身并不新,核心贡献是把它接到 LLM 上——有价值,但不算突破性创新。
⭐ 评分 : 8/10
14. Chunk-wise Attention Transducers(CHAT)for Fast and Accurate Streaming Speech-to-Text
arXiv ID : 2602.24245
发布日期 : 2026-02-27(提交于 2025 年底)
发表状态 : ICASSP 2026
机构 : Apple / Google
论文链接 : https://arxiv.org/abs/2602.24245
📌 简介
提出 CHAT,将 RNN-T 的逐帧 additive joiner 替换为 chunk 内 cross-attention joiner。保留 RNN-T 流式能力同时引入局部对齐建模的灵活性,无需对齐时间戳信息。对语音翻译(ST)的提升尤其显著。
🔧 架构示意
音频流 → 流式 FastConformer Encoder(chunk-aware)
↓ 按固定 chunk 输出
CHAT Joiner(替换原 RNN-T joiner)
┌─────────────────────────────────────┐
│ Predictor 输出(文本历史)→ Query │
│ Encoder chunk 输出(音频)→ Key/Value │
│ ↓ cross-attention(chunk 内) │
│ ↓ + Predictor 残差 + ReLU │
│ ↓ → 词表空间概率分布 │
└─────────────────────────────────────┘
↓ blank → 下一 chunk;非 blank → 输出 token💡 关键创新
- chunk 内 cross-attention joiner 放宽 RNN-T 严格单调对齐约束
- 无需时间戳信息训练,改动极小但效果稳健
- 对语音翻译(ST)提升尤其显著(+18% BLEU)
📊 训练数据 & 实验结果
- 数据:NeMo 多语种数据;语音翻译:MuST-C v2
- ASR WER -6.3%;ST BLEU +18.0%;训练内存 -46.2%;训练速度 1.36x;推理速度 1.69x
☠️ 犀利点评
增量但扎实。chunk 内交叉注意力在 AED 框架里早就做过了,迁移到 Transducer joiner 上有工程价值但创新幅度有限。实验在 NeMo 框架内做,没有和 LLM-ASR 系统正面对比,不清楚在最新 LLM-based pipeline 中是否还有竞争力。对语音翻译(ST)的提升(+18% BLEU)更惊艳——RNN-T 严格单调约束对翻译是真正的硬伤,这篇有效解决了这个问题。
⭐ 评分 : 7/10
15. Uni-ASR: Unified LLM-Based Architecture for Non-Streaming and Streaming ASR
arXiv ID : 2603.11123
发布日期 : 2026-03-11
发表状态 : Submitted to Interspeech 2026
机构 : 科大讯飞 / 多校
论文链接 : https://arxiv.org/abs/2603.11123
📌 简介
提出 Uni-ASR,用统一 LLM 框架同时支持非流式和流式语音识别,无需任何架构改动即可切换两种模式。引入三种训练范式联合训练(NS/SS/CS)和 latest-token fallback 解码策略,在不增加延迟的前提下提升流式精度。
🔧 架构示意
音频 → FireRedASR Conformer Encoder(full + dynamic chunk attention)
↓ Adapter
Qwen3-1.7B(Decoder-Only LLM)
训练时:NS / SS / CS 三范式 1:1:1 采样
├── NS:非流式,全序列输入
├── SS:流式,强制对齐切块,speech-text interleaved
└── CS:context-aware 流式,输入最后 token 置 <pad>,学跨 chunk 重解码
推理时:
流式:KV Cache 跨 chunk 增量复用
latest-token fallback(最后 token 等下一 chunk 再确认)
非流式:直接全序列解码💡 关键创新
- 单模型统一流式/非流式,三范式 1:1:1 联合训练
- context-aware streaming(CS)训练范式消除训练推理 mismatch
- latest-token fallback 解码策略:边界 token 延一 chunk 确认,实测无额外延迟
📊 训练数据 & 实验结果
- 数据:中英双语混合——WeNetSpeech(10000h+)+ AISHELL + LibriSpeech + GigaSpeech + 内部数据
- 流式 AISHELL-1 CER 2.15% / LibriSpeech test-clean WER 2.44%(1000ms chunk)
- 超越 Speech ReaLLM、SpeechLLM-XL、MoCha-ASR
☠️ 犀利点评
“大而全”路线的代表作,工程细心度高。但本质是既有技术的精心组合:interleaved speech-text(借鉴 CosyVoice2)、hold-n 策略(已有)、KV cache reuse(已有)。fallback 解码的 idea 小而实用,但不算重大创新。Qwen3-ASR-1.7B 在他的 streaming benchmark 里数字更好,但 Qwen3 是靠重复非流式解码凑出来的流式,计算量差了一个数量级——Uni-ASR 没把计算复杂度公平列出是一个败笔。
⭐ 评分 : 7/10
https://mp.weixin.qq.com/s/rSk0WBc4VjW0dkqBspKofA
16. NIM4-ASR: Towards Efficient, Robust, and Customizable Real-Time LLM-Based ASR ⭐
arXiv ID : 2604.18105
发布日期 : 2026-04-20
机构 : NIO / 蔚来汽车
论文链接 : https://arxiv.org/abs/2604.18105
📌 简介
面向生产部署的 LLM-ASR 框架,系统解决轻量化、幻觉抑制、热词定制三大痛点。基于 phoneme-level encoder 预训练减少模态差距,引入 Iterative Asynchronous SFT(IA-SFT)防止 representation drift,设计 ASR 专用 RL 提升识别质量,并以 phoneme RAG 实现百万量级热词定制。
🔧 架构示意
音频 → 600M Conformer Encoder(phoneme CTC 预训练,CKA 监控 drift)
├── 流式:dynamic-chunk mechanism(预训练期内嵌)
└── phoneme CTC head → 音素假设
MLP Adapter(4x 下采样,160ms/token)
↓
Qwen3-1.7B(LLM 解码器)
↑
Phoneme RAG:音素假设 → 检索热词数据库(<1ms)→ Prompt 注入
训练 pipeline:
Stage1: Encoder 预训练(phoneme CTC,CR-CTC)
Stage2: Alignment(仅训练 Adapter,冻结其余)
Stage3: IA-SFT(异步并行,CKA 监控 encoder 稳定性)
Stage4+5: Late Joint SFT + Context SFT + ASR-RL💡 关键创新
- Phoneme-level encoder 预训练:低熵表示减少模态差距,天然支持流式
- IA-SFT:异步 SFT 在对齐阶段即开始,CKA 监控防止 representation drift
- ASR-RL:专为 ASR 设计的强化学习,进一步提升识别质量和幻觉鲁棒性
- Phoneme RAG:百万热词定制,检索延迟小于1ms
📊 训练数据 & 实验结果
- 数据:25 个 benchmark(15 公开 + 10 内部);中英双语大规模内部数据
- 2.3B 参数达到多个公开 benchmark SOTA;内部 entity-intensive 场景大幅领先
☠️ 犀利点评
NIO 车载场景出发的工业论文,工程诚意十足。phoneme-level encoder 预训练、IA-SFT 防 drift、ASR-RL、百万热词 RAG——每个模块都是真实生产痛点的解法。CKA 动态监控 encoder 表示偏移这个手段很细。但核心数据不公开,学术可复现性为零;”25 个 benchmark SOTA”要打折——主要赢在内部实体密集场景;Streaming 支持是”优化了”而非”重新设计了”,技术细节披露克制。
⭐ 评分 : 8/10
17. UAF: A Unified Audio Front-end LLM for Full-Duplex Speech Interaction
arXiv ID : 2604.19221
发布日期 : 2026-04-21
机构 : NIO / 蔚来汽车
论文链接 : https://arxiv.org/abs/2604.19221
📌 简介
提出第一个面向全双工语音系统的统一音频前端 LLM(UAF)。将 VAD、轮换检测(TD)、说话人识别(SR)、ASR、QA 等多种前端任务统一为单一自回归序列预测问题,以 600ms 固定时长流式音频块为输入,输出控制状态 token 驱动系统状态机。
🔧 架构示意
音频流(600ms 固定块)
↓
音频编码器 → 特征提取
↓
LLM(自回归)
├── 语义 token(转录内容)
└── 控制 token(VAD状态/说话人切换/打断信号/QA触发)
↓
全双工系统状态机(接收控制 token 驱动)💡 关键创新
- 首个统一全双工前端任务的 LLM 方案(VAD + TD + SR + ASR + QA)
- 600ms 块级流式输入,覆盖打断检测等实时控制场景
- 控制 token 与语义 token 联合自回归生成,端到端降低系统延迟
📊 训练数据 & 实验结果
- 数据:内部全双工系统数据(规模未公开)
- 全双工响应延迟和打断检测精度显著改善(具体数值未完整披露)
☠️ 犀利点评
方向正确,全双工语音系统是当下最热的方向,把 VAD、轮换检测、说话人识别、ASR 统一成一个 LLM 在实际部署里最省事。600ms 块级输入跑打断检测,延迟在可接受范围。但这篇信息密度偏低,关键性能数字语焉不详(”显著改善”没有具体数值),训练数据完全不透明,和 Moshi、Mini-Omni2 等全双工系统的横向对比缺失。暂时更像一篇系统描述报告,不是严谨研究论文。值得关注方向,不值得深度跟踪。
⭐ 评分 : 7/10
全景速览对比表(17 篇)
| # | 论文 / 系统 | 年份 | 机构 | 核心方法 | 关键创新 | 数据规模 | 流式支持 | 主要效果 | 评分 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Prompting LLMs with Speech (2307.11795) | 2023 | Meta AI | GPT-style: Conformer prefix + LLaMA-7B | 首批验证 Speech+LLM 范式;冻结 LLM 可学多语言 | MLS 44.5k h | ❌ | WER 4.3%(MLS en) | 6/10 |
| 2 | Chunked AED Streaming (2309.08436) | 2023 | RWTH/Google | EOC token 驱动 chunk-wise AED | AED ≈ Transducer 理论统一;长音频泛化 | LibriSpeech 960h | ✅ chunk | WER 2.7%(test-clean) | 7/10 |
| 3 | SLD Decoder-Only ASR (2311.04534) | 2023 | Alibaba DAMO | 离散 token + KL 散度 SLD 训练损失 | 优化音频 token 自回归建模训练目标 | LibriSpeech 960h | ❌ | 超越 Loss Masking | 6/10 |
| 4 | BESTOW (2406.19954) | 2024 | NVIDIA | text query cross-attention + read-write policy | 首个开源多任务流式 SpeechLLM | 87k h 多语言 | ✅ adaptive | WER 1.9%(LibriSpeech clean) | 8/10 |
| 5 | Seed-ASR (2407.04675) | 2024 | ByteDance | 预训练→SFT→RLHF + 上下文 prompt | RLHF 用于 ASR;prompt 注入热词/领域 | 数十万 h 中英 | ❌ 离线 | 内部多场景 SOTA | 7/10 |
| 6 | Transducer-Llama (2412.16464) | 2024 | Meta AI | Factorized Transducer + 弱到强 LM swap | swap 绕过 RNN-T+LLM 联合训练陷阱 | MLS 44.7k h 多语言 | ✅ Transducer | WER -32% vs RNN-T | 8/10 |
| 7 | Multi-token Prediction (2409.12116) | 2024 | JHU / Meta | 每步预测多个未来 token | ASR 条件化使多 token 接受率高 | LibriSpeech 960h | ✅ | 3.2x 加速,WER 无损 | 6/10 |
| 8 | MFLA (2506.03722) | 2025 | Honor / 上交 | CIF predictor + MFLA 有限右上下文 | CIF 软对齐替代 fixed-chunk;统一离线/在线 | WenetSpeech4TTS + LibriSpeech + MLS | ✅ wait-k | 在线 WER 7.17%;延迟 -14.5% | 7/10 |
| 9 | SpecASR (2507.18181) | 2025 | 厦大 / 多校 | Draft+Target LLM 推测解码 | 自适应草稿长度;稀疏 token 树 | 公开 benchmark | ✅ | 3.04x–3.79x 加速,精度零损失 | 8/10 |
| 10 | WhisperKit (2507.10860) | 2025 | Argmax | 块对角 mask 自蒸馏 + ANE 量化 | 端侧原生流式;静音缓存;1.6G→0.6G | CommonVoice 17 | ✅ 0.46s | WER 2.2%,超越云端 GPT-4o | 7/10 |
| 11 | JEDIS-LLM (2511.16046) | 2025 | 阿里巴巴 | SPC + Word-level Speaker Supervision | 首个零样本流式长音频联合 ASR+说话人分离 | 短音频 ≤20s | ✅ chunk | 超越 Sortformer/DiarizationLM | 8/10 |
| 12 | Whisper-LLaDA (2509.16622) | 2025 | IDIAP / 多校 | Whisper encoder + LLaDA-8B 扩散解码 | 首次验证扩散 LLM 用于 ASR;音频条件化是关键 | LibriSpeech 960h | ❌ | 级联 WER 2.25%/4.94%;扩散更快但精度略低 | 7/10 |
| 13 | MoCha-ASR (2601.22779) | 2026 | 合工大 / 多校 | MoChA 策略网络 + Qwen2.5 + minLT loss | 端到端无 CTC 对齐流式 LLM-ASR | AISHELL-1/2 + 内部 | ✅ adaptive | AISHELL-1 CER 5.1%;延迟 -62.5% | 8/10 |
| 14 | CHAT (2602.24245) | 2026 | Apple / Google | Chunk 内 cross-attention joiner | 放宽 RNN-T 严格单调约束;AST 显著提升 | NeMo 多语言 | ✅ chunk | WER -6.3%;BLEU +18%;推理 1.69x | 7/10 |
| 15 | Uni-ASR (2603.11123) | 2026 | 科大讯飞 / 多校 | NS/SS/CS 三范式联合训练 + fallback 解码 | 单模型统一流式/非流式 | WeNetSpeech 10k h+ | ✅ 多 chunk size | AISHELL-1 CER 2.15%(1s chunk) | 7/10 |
| 16 | NIM4-ASR (2604.18105) | 2026 | NIO / 蔚来 | phoneme CTC 预训练 + IA-SFT + RL + RAG | 百万热词 RAG小于1ms;IA-SFT 防 drift | 25 benchmark + 内部大规模 | ✅ chunk | 2.3B 多 benchmark SOTA | 8/10 |
| 17 | UAF (2604.19221) | 2026 | NIO / 蔚来 | 600ms chunk LLM + 多任务统一 | 首个全双工前端 LLM;控制 token 驱动状态机 | 内部全双工数据 | ✅ 600ms | 全双工延迟和打断精度改善(未披露具体数值) | 7/10 |
趋势演变与技术脉络
三条主线演进路径
① 解码框架进化 :GPT-style prefix(2023)→ read-write policy BESTOW(2024)→ MoChA adaptive MoCha-ASR(2026)→ 统一 NS/SS/CS Uni-ASR(2026)
② 效率工程化 :Multi-token prediction(2024)→ Speculative Decoding SpecASR(2025)→ 端侧 ANE 极致优化 WhisperKit(2025)→ 热词 Phoneme RAG NIM4-ASR(2026)
③ 多任务融合 :单纯 ASR(2023)→ 上下文感知 Seed-ASR(2024)→ 联合说话人分离 JEDIS-LLM(2025)→ 全双工前端统一 UAF(2026)
里程碑节点
- 2023 : LLM-ASR 范式成立(Speech Prompt + LLM),流式是空白
- 2024 : BESTOW 确立 read-write policy 框架,Transducer-Llama 给出 RNN-T 最优解,Seed-ASR 工业化落地
- 2025 : 推理加速爆发(SpecASR 3x+),端侧部署成熟(WhisperKit 0.46s),多任务融合(JEDIS-LLM)
- 2026 : 统一架构(Uni-ASR),生产全功能(NIM4-ASR),全双工前端(UAF)