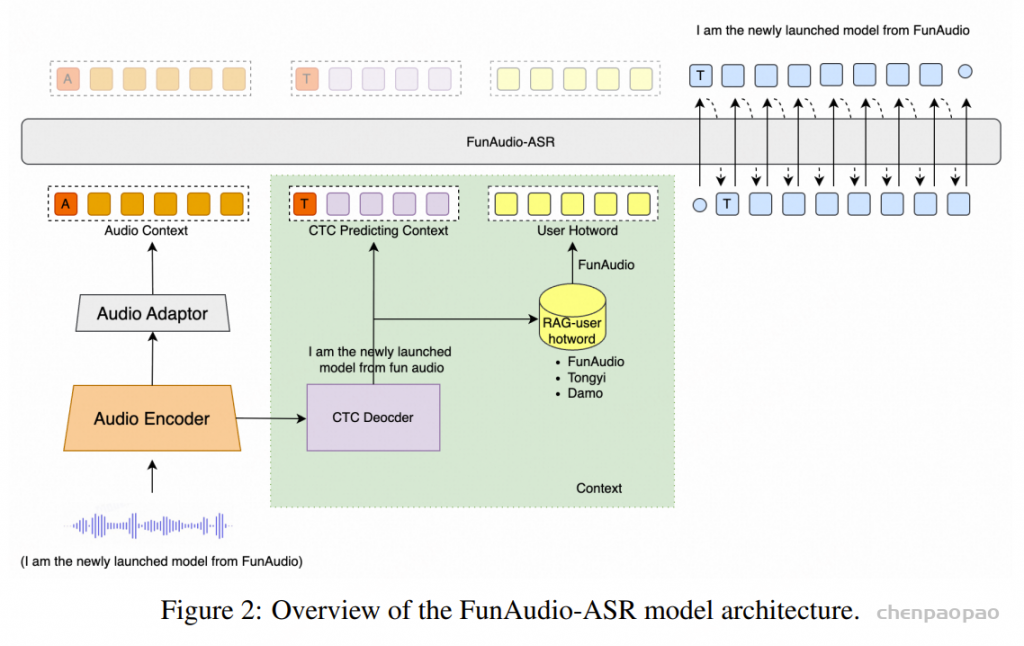
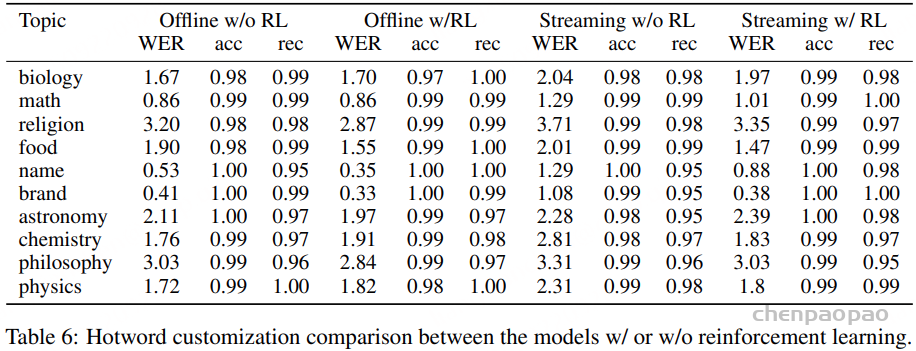
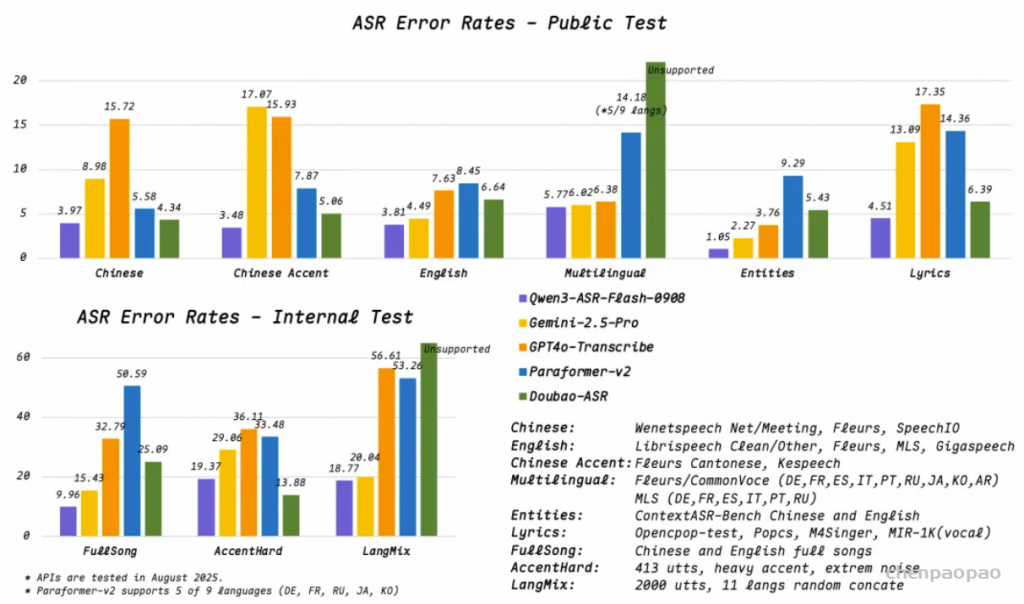
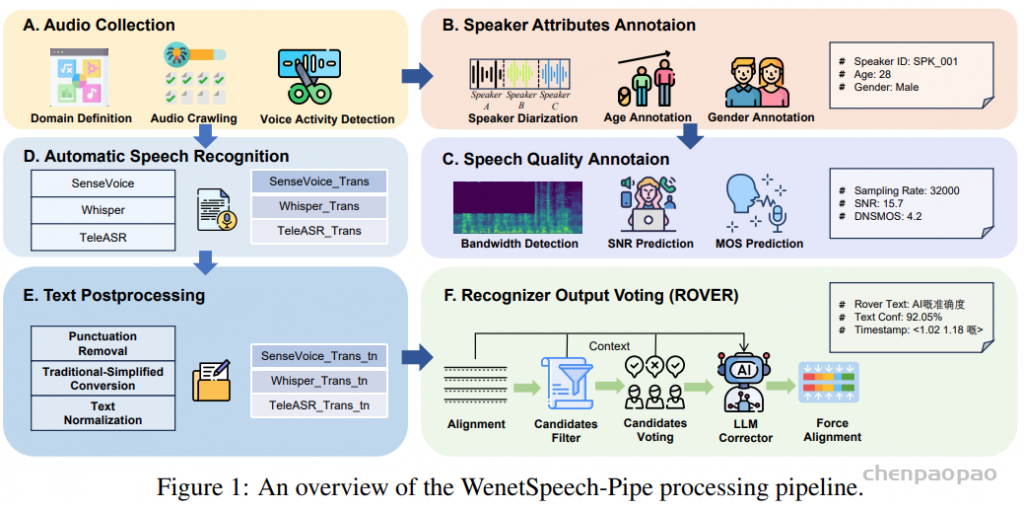
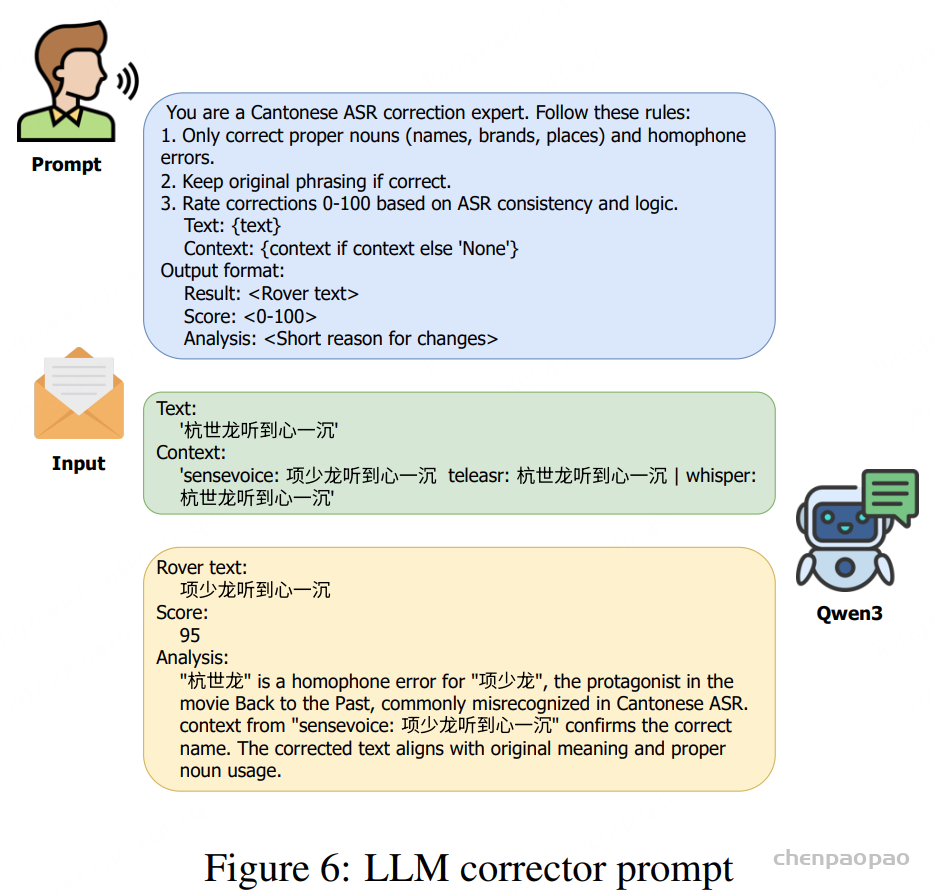
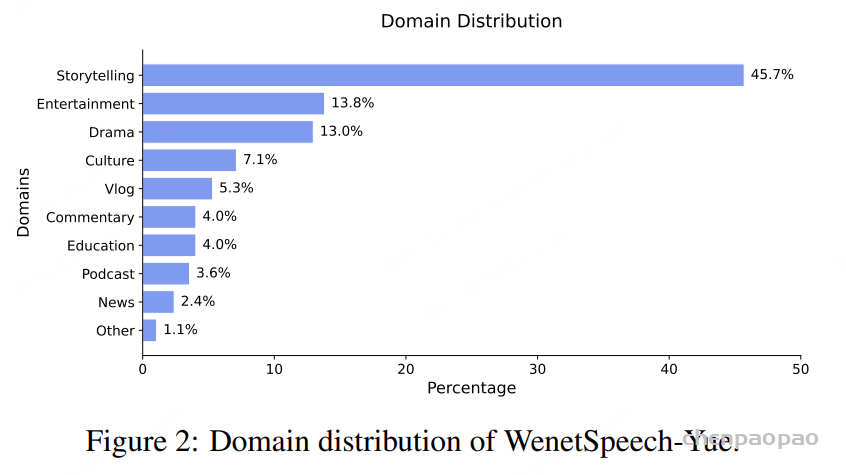
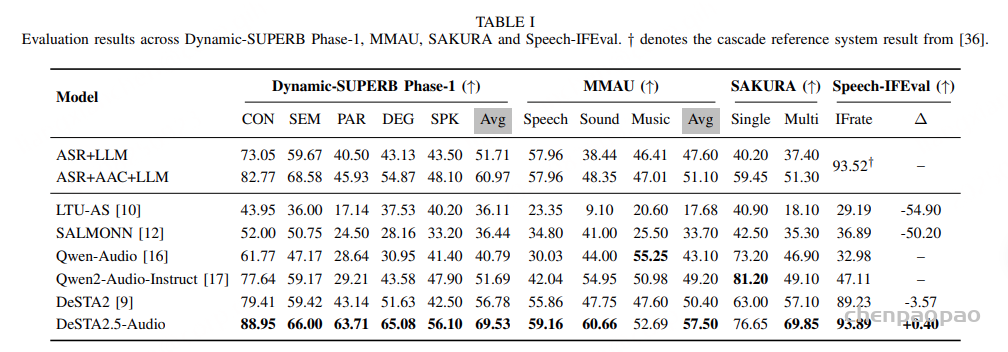
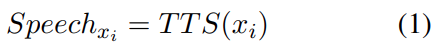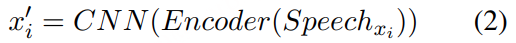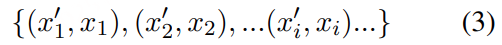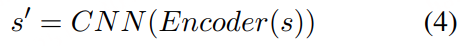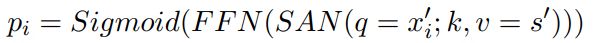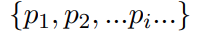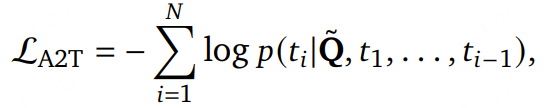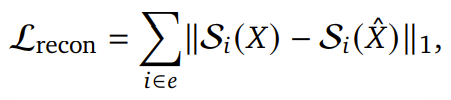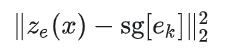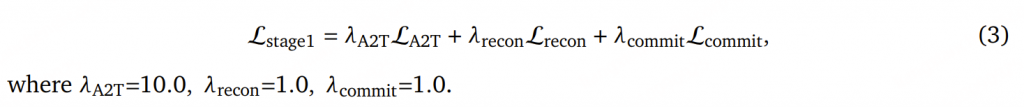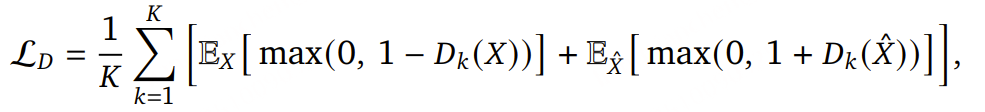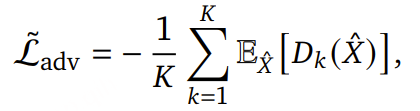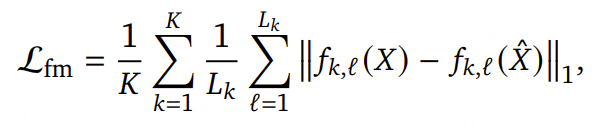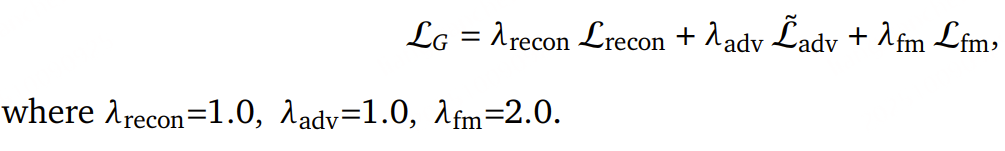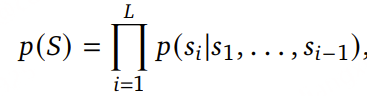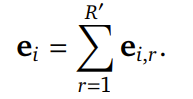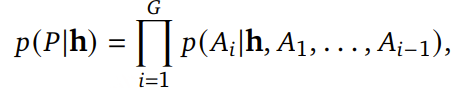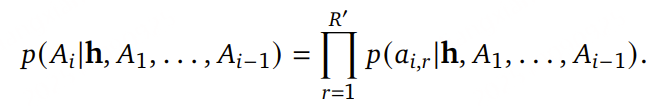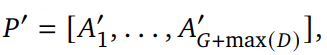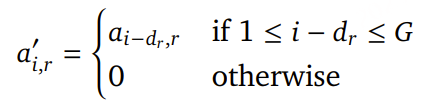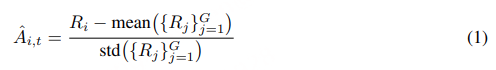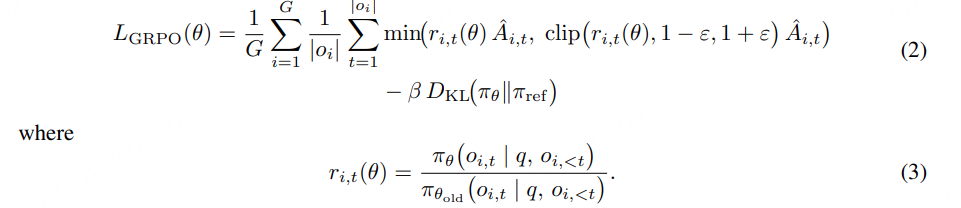五年前,GPT-3 首次展示了通过自回归语言模型+大规模无标注数据训练,可获得强大 In-Context Learning(ICL) 能力 [模型只靠上下文里的提示和少量示例,就能快速适应新任务,不必重新训练] ,并能通过少样本迁移到新任务,从而使语言开启通用人工智能(AGI)新纪元。然而在语音领域,现有模型仍严重依赖大规模标注数据,难以快速适应新任务达到类人智能。
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio ,它基于创新预训练架构 和上亿小时训练数据 ,首次在语音领域实现基于 ICL [ In-context Learning ] 的少样本泛化 [通过在 prompt 中放少量示例,利用模型在大规模预训练中学到的“上下文学习”能力,让模型无需再训练就能适应新任务 。], 并在预训练观察到明显的“涌现” 行为。后训练进一步激发了 Xiaomi-MiMo-Audio 的智商、情商、表现力与安全性在内的跨模态对齐能力,语音对话在自然度、情感表达和交互适配上呈现极高的拟人化水准。
核心:
如何完整的表征语音,不能损失任何语音声学/语义信息,需要建立一个无损传递语音信息的模型架构 。大规模数据扩展(scaling up),将训练数据扩展到上亿小时持续扩大预训练数据的规模将带来性能的持续提升,并可能产生意想不到的涌现能力 。Introduction
现有的音频语言模型通常依赖于针对特定任务的微调 来完成特定的音频任务。相比之下,人类只需少量示例或简单指令就能将能力推广到新的音频任务上。GPT-3 已经证明,通过扩展下一个 token 预测的预训练 可以在文本上实现强大的泛化能力,我们认为这一范式同样适用于音频领域。通过将 MiMo-Audio 的预训练数据规模扩展到超过一亿小时,我们观察到其在多种音频任务上出现了少样本学习能力 。我们对这些能力进行了系统评估,发现 MiMo-Audio-7B-Base 在开源模型中,在语音智能和音频理解基准上均实现了SOTA性能。
除了标准指标外,MiMo-Audio-7B-Base 还能泛化到训练数据中未出现的任务,例如语音转换、风格迁移和语音编辑 。它还展现了强大的语音延续能力 ,能够生成高度逼真的脱口秀、朗诵、直播及辩论内容。在后训练阶段 ,我们整理了多样化的指令调优语料,并在音频理解与生成中引入了思维机制。
最终,MiMo-Audio-7B-Instruct 在音频理解基准(MMSU、MMAU、MMAR、MMAU-Pro)、语音对话基准(Big Bench Audio、MultiChallenge Audio)以及指令式 TTS 评测中达到了开源 SOTA 水平,接近或超越了闭源模型。
语音领域中基于下一个 token 预测(next-token prediction) 的预训练有两个关键要素。
1、 能够无损传递语音信息的模型架构 。为了充分发挥 next-token 预测范式的潜力,我们希望语音信号中的全部信息都能在模型中循环流动 。这意味着我们不能采用会导致副语言信息(如情感、语调、说话风格等)丢失的语音表示方式 。这一点使我们的方法与当前主流方案Kimi- Audio[基于ASR任务训练的语义编码器+预训练的whisper声学编码器] 和 Step-Audio 2[encoder 基于speech and audio understanding tasks 进行训练]有所不同。
2、第二个关键要素是大规模扩展(scaling up) 。持续扩大预训练数据的规模将带来性能的持续提升 ,并可能产生意想不到的涌现能力 。因此,我们将训练数据扩展到超过上亿小时的音频 ,这一规模比现有最大开源语音模型所使用的数据量大一个数量级。
预训练 预训练的目标 是让模型具备语音领域的任务泛化能力 ——也就是说,模型在训练阶段学习到一系列基础的“原子技能”,并在推理阶段利用这些能力快速适应或识别任何语音任务 。我们在预训练方法上的指导原则是:确保语音信号中的所有信息都能被完整保留并在模型架构中无损流动。
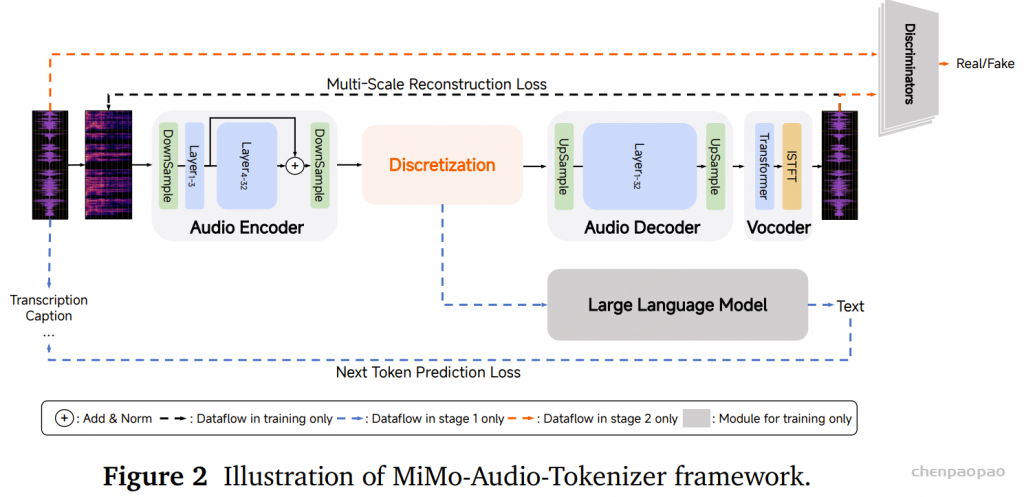
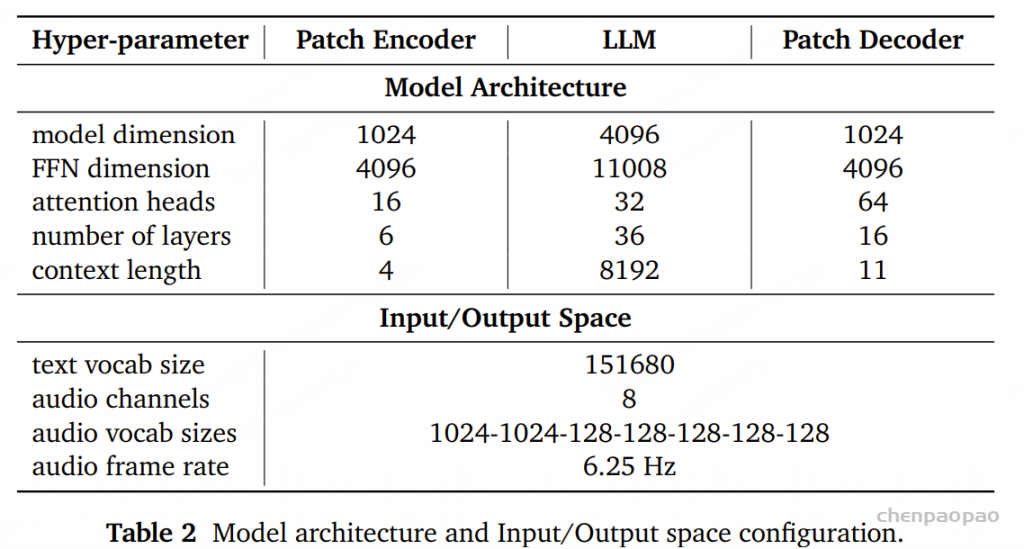
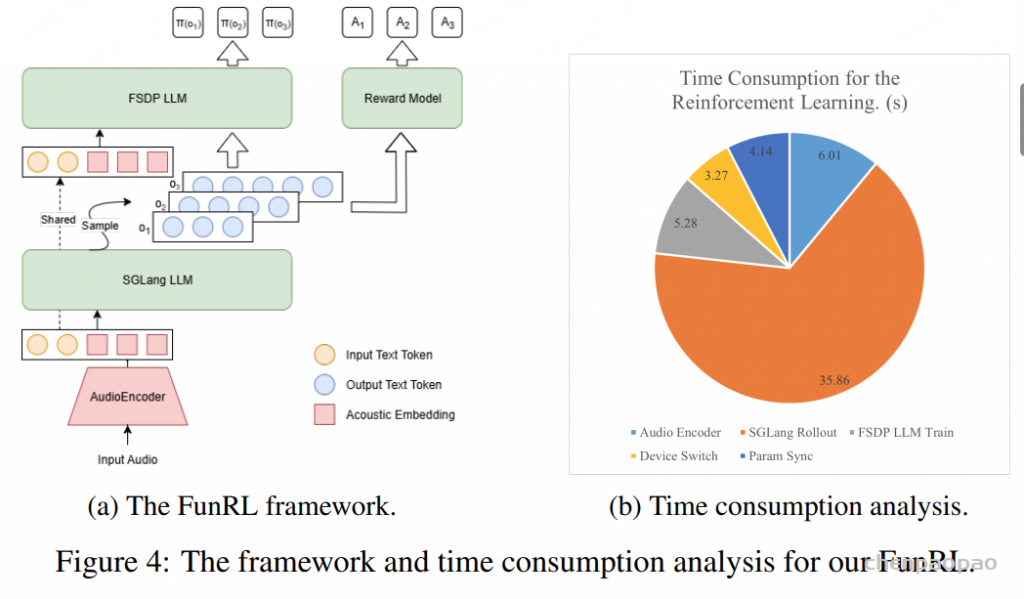
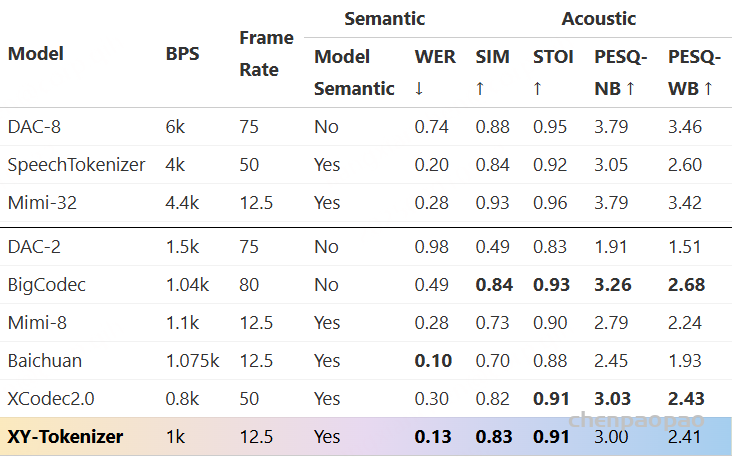
Tokenizer(分词器) :我们认为,音频分词器最重要的评判标准 是其重建保真度(reconstruction fidelity) ,同时其生成的 token 应该便于下游语言建模使用。基于这一理念,我们提出了 MiMo-Audio-Tokenizer 。该模型包含 12 亿参数(1.2B) ,采用基于 Transformer 的架构,由编码器、离散化层和解码器组成,以 25Hz 的帧率 运行,并通过 8 层残差向量量化(RVQ) 每秒生成约 200 个 token 。我们在训练中结合了语义与重建双重目标 ,从零开始在一个 1000 万小时规模的语音语料库 上进行训练,获得了优异的重建质量,同时显著提升了下游语言建模的效果。架构(Architecture) 。为了提升对高 token 速率序列(200 token/秒)的建模效率,并缓解语音与文本模态间的长度差异,我们提出了一种创新架构 ,将 patch 编码器(patch encoder) 、大语言模型(LLM) 和 patch 解码器(patch decoder) 相结合。Patch 编码器 将连续 4 个时间步的 RVQ token 聚合为一个 patch,从而将序列下采样为 6.25Hz 表示 ,输入至 LLM。Patch 解码器 则以自回归方式(autoregressive)重建完整的 25Hz RVQ token 序列 。ps:OR 选择性地使用其中一个输入 (Audio 或 Text),但一次只走一个分支 。训练 。为了实现统一的理解与生成预训练范式 ,并赋予模型更强的“语音智能”,我们设计了一个两阶段训练策略 ,并以 MiMo-7B-Base 作为初始化模型:阶段1 专注于语音理解任务,阶段2 将理解与生成统一于一个框架中,进行联合训练数据 。将预训练语料规模扩展至超过 1 亿小时的语音数据 ,这一规模比现有任何开源语音模型的数据量大一个数量级 。这一庞大数据集的获取和处理依托于我们自研的端到端数据管线 ,涵盖预处理、标注与数据筛选全过程。评估。构建了一个全面的评测基准(benchmark) ,用于严格评估模型在语音领域的上下文学习能力。该基准涵盖模态不变的常识知识、听觉理解与推理能力以及多样化的语音到语音生成任务 多个维度。 经过大规模预训练 后,MiMo-Audio-7B-Base 展现出强大的少样本学习能力 。在我们构建的 SpeechMMLU 基准上(该基准源自 MMLU,并将其任务合成为语音形式),MiMo-Audio-7B-Base 在“语音智能(Speech Intelligence)”和跨模态对齐(modality alignment)方面表现出极高的水准。
在语音输入与输出 条件下,它取得了接近文本版 MMLU 的卓越成绩,文本任务的性能仅出现极小幅度下降 。更重要的是,它在未见过的任务上也具有优异的泛化能力 :只需在上下文中提供少量示例 ,它就能完成包括语音转换、风格迁移、语速控制、去噪 以及语音翻译 等任务。
MiMo-Audio-7B-Base 还展现出强大的语音延续能力(speech continuation) ,能够生成高度逼真且语义连贯的独白或多说话人对话,涵盖脱口秀、演讲、辩论、播客 以及游戏解说 等多种场景。
后训练
后训练(post-training)的核心目标是将模型在预训练阶段获得的泛化能力与指令跟随能力对齐 。为此,我们构建了一个高度多样化的音频指令微调语料库 ,涵盖音频理解与生成 任务,并整合了来自多个领域的高质量开源与自建数据。
为了进一步增强模型的跨模态推理能力(cross-modal reasoning) ,我们还为音频理解和生成任务构建了高质量的“思维链”数据集。
同时,为了获得类人、可控风格的语音对话数 据,我们训练了一个基于超过 700 万小时语音数据 的 MiMo-TTS-7B 模型,用于将文本对话转换为语音形式。
主要贡献 首次提供了实证证据 ,证明将基于无损压缩的语音预训练规模扩展至 前所未有的 1 亿小时 ,能够激发出任务泛化的涌现能力 ,具体体现为强大的少样本学习能力(few-shot learning) 。我们认为,这标志着语音领域迎来了类似 GPT-3 时刻(“GPT-3 moment”) 的重要突破。提出了首个全面且可复现的生成式语音预训练方案,包括全新的音频分词器 、可扩展的模型架构 、分阶段的训练策略 、系统化的整体评测体系 。 首次在语音理解与生成的建模过程中引入了“思维机制(thinking)” ,实现了从感知(perception)到复杂认知任务(complex cognitive tasks)之间的桥接,为语音模型的发展开辟了新的方向。Model Architecture
MiMo-Audio-Tokenizer
现有音频分词方法的一个主要挑战在于如何有效平衡音频信号中语义信息与声学信息之间的固有权衡 。语义 token 通常来源于自监督学习模型或 ASR 模型,它们与语言内容高度相关,有助于与文本模态对齐 。然而,其主要缺点是丢失了细粒度的声学信息 ,限制了原始波形重建的质量。声学 token 则由神经音频编解码器生成,能够实现高保真音频重建 ,但难以与文本语义空间建立有效对齐。
MiMo-Audio-Tokenizer 将语义和声学统一,同时捕获语义信息并实现高保真音频重建 ,通过扩大模型参数规模和训练数据量 ,进一步缓解语义-声学表示冲突,从而提升跨模态对齐能力 和语音重建质量 。
架构
MiMo-Audio-Tokenizer 的架构由四个主要组件组成:音频编码器(audio encoder)、离散化模块(discretization module)、音频解码器(audio decoder)以及 声码器(vocoder) 。
音频编码器: 双向注意力Transformer编码器,在输入和输出端各配备 2 层下采样,包含 32 层、20 个注意力头 ,使用 Rotary Position Embeddings(RoPE) 和 GELU 激活函数 ,模型维度设为 1280 ,前馈网络(FFN)内维度设为 5120 。为缓解语义信息与声学信息之间的冲突 ,将第 3 层的隐藏状态通过元素级求和加入到最终层输出中。
离散化模块: 20-layer残差向量量化器,前两层码本(codebook)大小为 1024 ,其余层码本大小为 128 。
音频解码器: 结构与编码器镜像,但采用因果自注意力(causal self-attention) ,以支持流式生成 。
声码器 :采用 Vocos 设计 ,将 ConvNeXt骨干替换为 Transformer ,从而支持序列打包(sequence packing)以提高训练效率。 Transformer 参数:16 层、16 个头,模型维度 256,FFN 维度 1024。集成 RoPE 与滑动窗口注意力(sliding window attention) ,窗口大小为 [40, 10],分别对应 [6.4 秒, 1.6 秒] 的感受野 。
前向流程 :
对采样率为 24 kHz 的单通道音频波形 𝑋 进行梅尔谱图(melspectrogram)转换 ,帧率为 100 Hz。 将该谱图输入音频编码器 ,转化为长度为 𝑀 的连续表示序列(frame rate 25 Hz)。 离散化模块中的 RVQ 将连续表示量化为二维索引矩阵 𝐴 ∈ ℕ^{M×R} ,其中 R 为 RVQ 层数。 利用码本查找并求和对应的嵌入向量,从而重建量化表示 Q 。 最后,音频解码器 和声码器 根据 Q 重建音频波形 𝑋̂ 。 Training
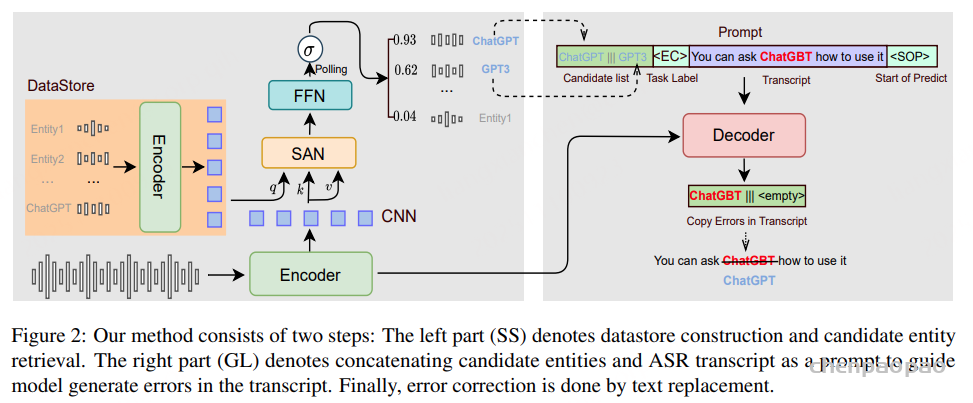
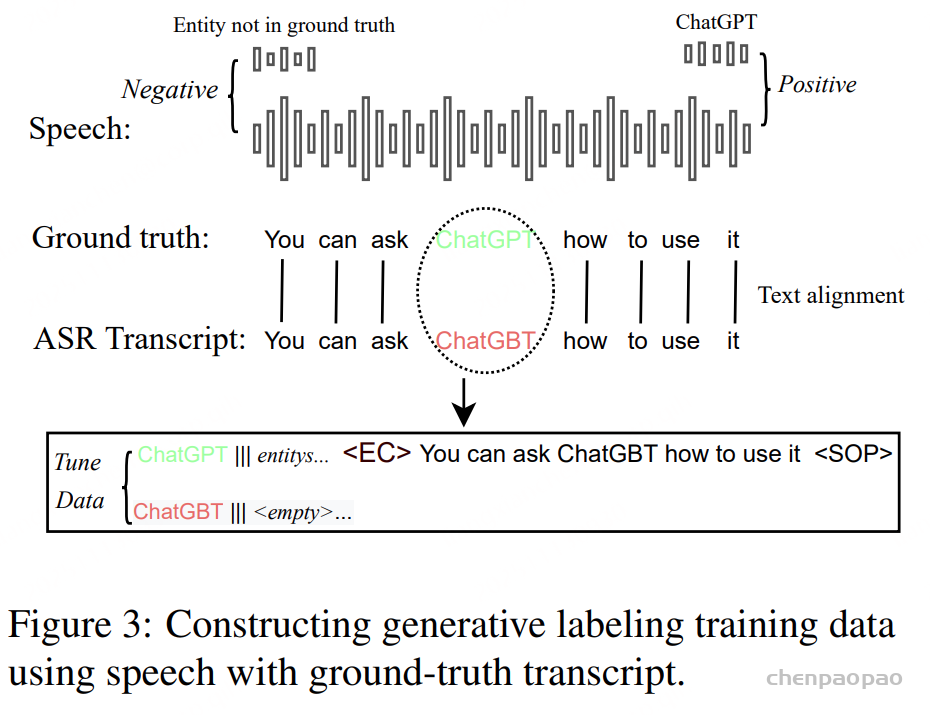
采用两阶段训练范式(two-stage training paradigm) 以提升训练效率,如图 2 所示。
阶段 1:
模型在大规模数据集 上进行多任务学习(multi-task learning) [包括A2T跟语音重建任务 ],训练数据规模扩展至 超过 1100 万小时 。通过这一大规模训练,模型能够联合编码语义信息与声学信息 ,实现对音频信号的全面表征。
统一表示学习:在阶段 1 中,将音频重建任务(audio reconstruction task)与 音频到文本任务(audio-to-text, A2T)结合,以 对齐音频与文本的表示空间 ,同时确保声学信息的完整保留。为 A2T 任务提供监督,我们引入了一个 LLM ,与 MiMo-Audio-Tokenizer 联合训练 。MiMo-Audio-Tokenizer 与 LLM 的所有参数均 从零开始训练 。
A2T 目标被形式化为 下一个 token 预测损失(next-token prediction loss) ,作用于 LLM 的文本输出,具体定义如下:
其中,𝑇 = [𝑡₁, …, 𝑡ₙ] 表示目标文本序列,Q̃ 表示量化后的音频表示,𝑁 为文本序列的总长度。对于音频重建任务 ,采用多尺度梅尔谱图重建损失 ,定义为 L₁ 距离(𝐿₁ distance) :
其中,S𝑖 表示尺度 𝑖 下的梅尔谱图(mel-spectrogram),具有 2^i 个频带 ,通过STFT, Short-Time Fourier Transform计算得到,窗长为 15·2^(i−1) ,步长为 15·2^(i−2) 。尺度集合定义为 𝑒 = {5, 6, 7} 。
还额外增加一个训练loss:commitment loss ,这个主要是约束encoder的输出和embedding空间保持一致,以避免encoder的输出变动较大(从一个embedding向量转向另外一个)。commitment loss 也比较简单,直接计算encoder的输出ze(x)和对应的量化得到的embedding向量ek的L2误差:
阶段 1 的总损失被定义为各项损失的 加权和:
阶段 2 :
冻结音频编码器和离散化模块的参数 。引入判别器 训练音频解码器和 声码器 ,重点提升原始音频波形的细粒度重建质量 ,并消除声码器生成的伪影(vocoding artifacts)。
对抗微调(Adversarial Fine-tuning):引入了额外的判别器进行 对抗训练(adversarial training) ,以提升音频波形重建质量。在该阶段,音频分词相关的所有参数均被冻结 ,以保持音频 token 空间的语义结构。
采用多任务 GAN 训练方案 ,联合优化以下目标:梅尔谱图重建损失、对抗损失、判别器特征匹配损失,为了在时域(time domain)和频域(frequency domain)同时提供监督,使用了Multi-Period Discriminator 和 Multi-Scale STFT Discriminator,训练框架采用 Hinge-GAN 。
真实波形 𝑋 与生成波形 𝑋̂ ,判别器的目标可被形式化为:
生成器的对抗目标:
特征匹配(feature matching):
生成器的训练目标结合了多任务 GAN 训练中的各项损失 :
Evaluation
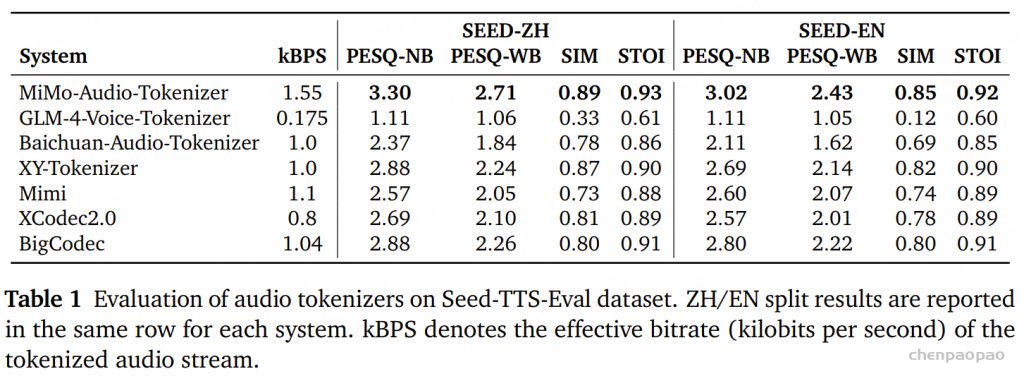
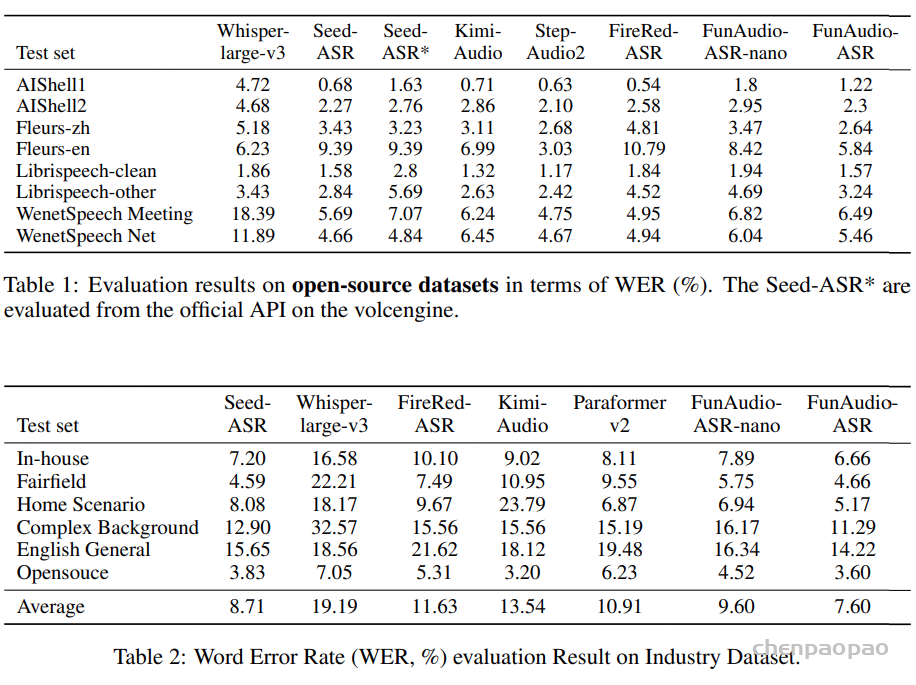
使用 说话人相似度 、Short-Time Objective Intelligibility、语音质量感知评估来评估音频分词在保留声学信息 方面的表现。考虑到下游 MiMo-Audio 模型仅使用 MiMo-Audio-Tokenizer 前八个码本(codebooks) 生成的音频 token,我们在评测中也仅使用这八个码本解码波形,从而真实反映下游语言模型可访问音频的保真度。
结果(Results) 如 表 1 所示。MiMo-Audio-Tokenizer 在 Seed-TTS-Eval 上展现出出色的重建质量 。关键在于,这些提升是在下游建模所使用的码本上测得的 ,说明 MiMo-Audio 完整保留了语音信息的声学特性 ,从而在各种语音任务中展现出强大的泛化能力 。
MiMo-Audio
MiMo-Audio 是一个统一的生成式音频-语言模型(generative audio-language model) ,能够同时建模文本 token 与 音频 token 序列。
ps:OR 选择性地使用其中一个输入 (Audio 或 Text),但一次只走一个分支 该模型既可以接收文本 token,也可以接收音频 token 作为输入,并以自回归的方式预测文本或音频 token,从而支持各种文本与音频模态任意组合 的任务,例如:
语音识别(ASR) 语音合成(TTS) 语音翻译 声音编辑 多模态对话生成 这种统一建模方式使得 MiMo-Audio 能够在理解和生成任务之间实现无缝切换,成为通用的语音-语言基础模型。
𝑇 = [𝑡1, . . . , 𝑡𝑁] 表示文本序列,语音序列用 𝐴 = [𝐴1, . . . , 𝐴𝑀], 𝐴𝑖 ≜ (𝑎𝑖,1, . . . , 𝑎𝑖,𝑅′), 𝑁 表示文本序列长度 ,𝑀 表示音频序列长度 ,𝑅′ = 8 表示在大语言模型(LLM)训练中使用的 RVQ码本数量 。
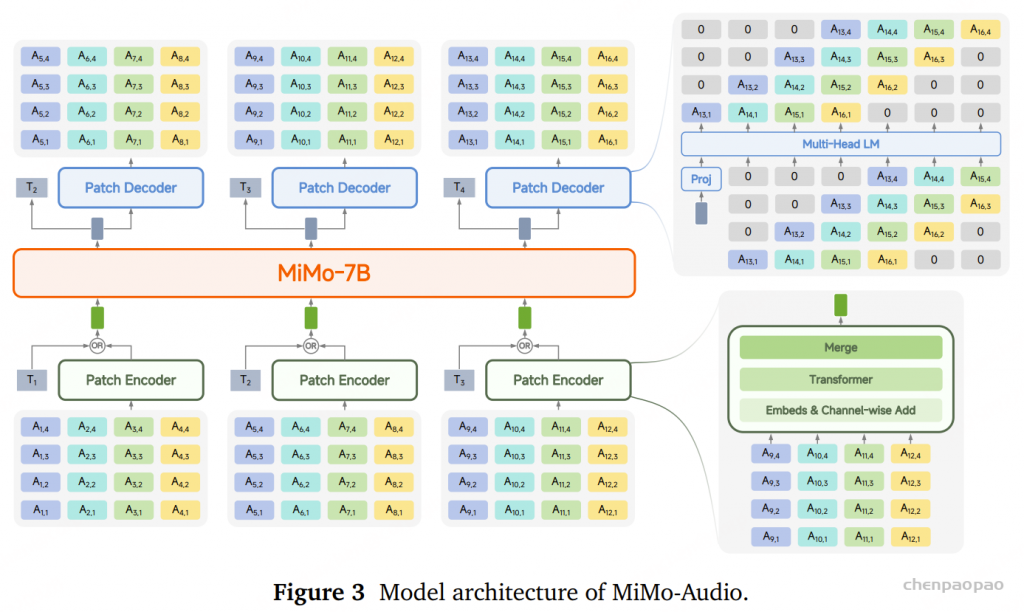
由于音频序列的信息密度较低 ,单个音频帧所包含的信息量远小于一个文本 token。缓解不同模态间粒度不匹配的问题 ,并促进跨模态知识迁移 ,我们将音频序列划分为由连续 𝐺 个帧(frames) 组成的分组,称为 audio patches 。
𝑃 = [𝑃1, . . . , 𝑃𝑀/𝐺], 𝑃𝑖 = [𝐴(𝑖−1)𝐺+1, . . . , 𝐴𝑖𝐺].
MiMo-Audio 的输入是交错排列的文本 token 与音频 patch 序列 ,S=[s1 ,…,sL ] 为交错序列,其中每个元素 si 要么是一个文本 token,要么是一个音频 patch。模型采用自回归方式进行训练:
这种统一建模策略 使模型能够无缝处理任意的文本-音频混合序列 。
MiMo-Audio 主要由三个核心组件构成:
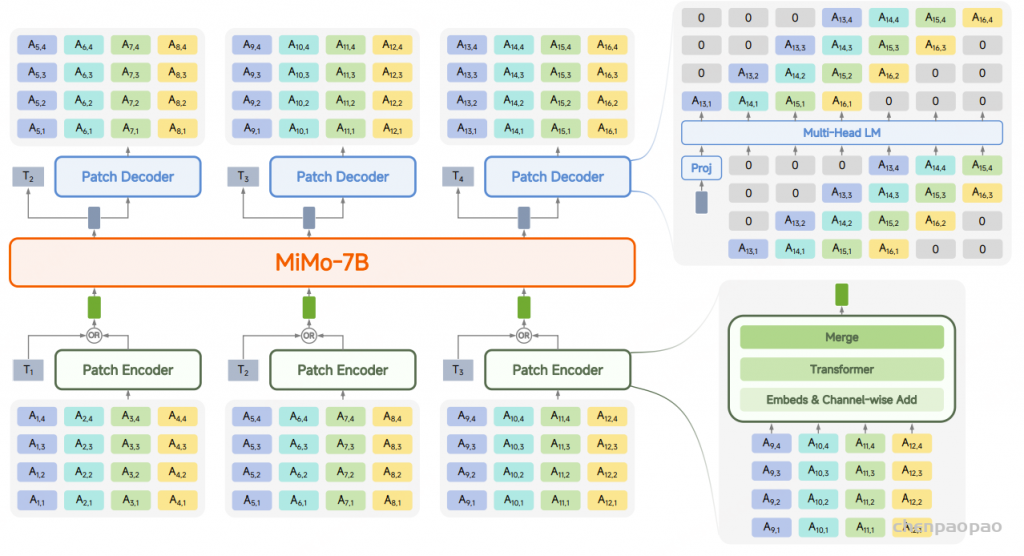
Patch 编码器(Patch Encoder) LLM 主干网络(LLM Backbone) Patch 解码器(Patch Decoder) Patch Encoder
Patch 编码器将每个 patch 内的音频 token 转换为一个隐藏向量。我们维护 R′ 个独立的embedding表{Er }r=1 R′ ,用于将音频 token 映射到对应的嵌入向量。对于每个音频 token ai,r ei,r =Er (ai,r ) ,然后,将该帧在所有 RVQ codebook 上的嵌入进行聚合,形成统一表示:
得到的每个 patch 内的序列会经过一个 Transformer 编码器 ,该编码器共有 Lenc=6 层。1024 ,注意力头数为 64 ,前馈层(FFN)的维度为 4096 。该编码器采用双向自注意力(bidirectional self-attention) ,使模型能够捕获 patch 内帧级的局部上下文信息 。随后,patch 中所有帧的输出被拼接并通过一个线性变换层 ,以匹配 LLM 输入的维度。
Large Language Model
采用 MiMo-7B-Base 作为 LLM 主干网络。该模型在每个位置上都可以接收两种类型的输入:
文本 token 的嵌入向量 ,或由 patch 编码器生成的音频 patch 表示 。模型输出的隐藏状态(hidden states)可以有两种用途:
经过 输出投影层(output projection layer) ,用于 文本 token 预测 ; 或输入至 patch 解码器(patch decoder) ,用于 音频 patch 生成 。 Patch Decoder
音频生成过程中,patch 解码器 以自回归(autoregressive)的方式在每个 patch 内生成音频 token。该解码器由 𝐿_dec = 16 层 Transformer 组成,每层的结构参数如下:
隐藏维度(hidden dimension):1024 注意力头数(attention heads):64 前馈层维度(FFN dimension):4096 解码器的自注意力机制中采用 因果掩码 ,以确保生成过程的自回归特性。此外,patch 解码器与 patch 编码器共用相同的 𝑅′ 个embedding tables ,每个嵌入表对应一个 RVQ 码本。为支持 RVQ token 的生成,Transformer 配备了 𝑅′ 个独立的输出头 ,每个输出头专门负责预测对应 RVQ 码本中的 token。
具体来说给定来自 LLM 的隐藏状态 h ,设要生成的音频 patch 为 P=[A1 ,A2 ,…,AG ] ,即由连续的音频帧组成。一个朴素的生成方式 是:在时间维度上对每个音频帧进行自回归生成,其概率建模为:
其中,每个音频帧 Ai 的概率又可以在 RVQ 的各个码本之间分解:
然而,由于 不同 RVQ 层(codebook layer)之间的 token 存在依赖关系 ,在每个时间步同时预测所有 RVQ token 会导致生成质量下降,音频往往不自然或带噪。
为缓解这一问题,论文引入了 音频 token 延迟生成机制 。具体地,为每个 RVQ 层设置一个层特定的延迟向量:𝐷 = [𝑑1, . . . , 𝑑𝑅′],其中 dr 表示 RVQ 第 r 层的生成延迟(以时间步为单位)。引入延迟后,延迟后的音频 patch 表示为:
其中:
其中,i∈[1,G+max(D)],r∈[1,R′]。符号 0 表示“空 token”,在编码和解码阶段都会被忽略。最终,patch 解码器(patch decoder) 按上述方式对延迟后的音频 patch 进行自回归建模,并在解码过程中保持相同的延迟模式,从而改善不同 RVQ 层之间的依赖建模和音频生成质量。
Pre-Training
Data
预训练语料库包含三类数据:单模态数据:文本-only 、语音-only ;多模态数据 :语音–文本配对 。语音模态目标是为模型提供大规模、高质量、多样化的音频数据 。开发了一个完整的数据处理流水线 用于确保预训练语料既丰富又可靠,为模型的语音理解与生成能力奠定坚实基础。
数据处理 :
预训练数据包含数亿小时的“野外采集(in-the-wild)”音频数据 ,并确保数据在来源和内容上的多样性:
来源多样性:数据涵盖公开播客、有声书、新闻广播、访谈、会议录音等,保证模型不会偏特定的录音环境或说话风格。 内容多样性:数据涵盖的话题包括日常交流、娱乐媒体、商业与创业、艺术与文化、科学研究等。 为了将大规模原始音频转化为高质量训练数据 ,我们设计并实现了一个高效且可扩展的自动化流水线 ,包括以下模块:
音频标准化 说话人分离 语音活动检测 自动语音识别 音频质量评估 数据标注 :
构建了一个自动化标注系统 ,覆盖语义(semantic)与非语义(non-semantic)两个维度 ,为每条数据生成丰富且结构化的属性标签:
语义维度 :基于 ASR 等模块的转写结果,我们构建了文本质量评估模型(text quality assessment model) 。该模型可以从多个角度对内容的语义价值进行评分,例如:
会话质量(conversational quality) 知识密度(knowledge density) 逻辑推理能力(logical reasoning) 非语义维度 :为获取非语义层面的信息,我们训练了一个音频描述模型,模型能够直接生成音频的丰富自然语言描述 :音色特征、情绪风格、背景环境。
双维度标注方法 不仅可以评估数据质量,还为语料库提供了更细粒度的属性信息 ,从而支持更高效、目标更明确的筛选和训练。
数据整理
对多维度数据标注进行数据筛选采样。
低质量数据过滤:噪声过多/低质量音频/不安全内容 高质量数据采样:综合语义和非语义维度的评分指标,设计采样策略,确保模型能够高效地从高质量语料中学习 。 训练
基于MiMo-7B-Base 模型 ,为了在最大程度保留其文本能力 的同时,使模型具备语音理解与生成能力 ,MiMo-Audio 采用了渐进式的两阶段预训练方法 。
理解阶段训练
在第一阶段中,我们训练模型的 patch encoder 和 LLM 组件。该阶段的目标是让模型掌握语音理解能力 。
我们共构建了一个 总计 2.6 万亿(T)token 的数据集,其中包括 1.2T 的文本 token 和 1.4T 的语音相关 token (以 6.25Hz 的语音帧率计算)。数据涵盖四种任务格式:
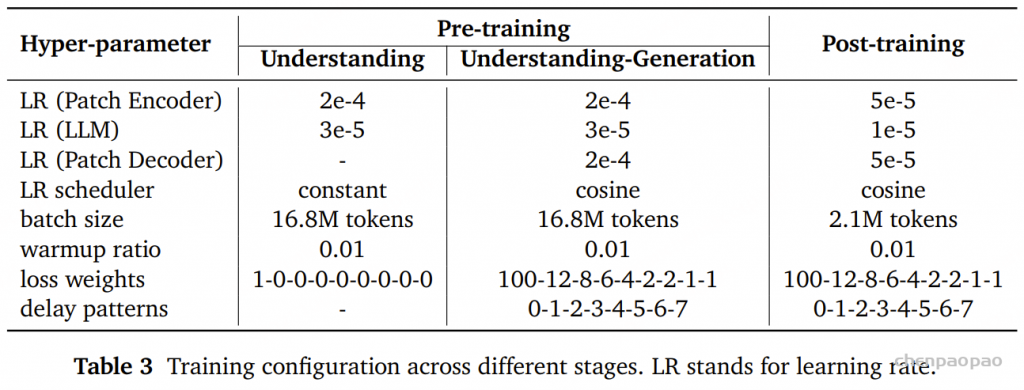
语音-文本交错数据 自动语音识别数据 通用音频描述数据 仅文本预训练数据 在该阶段中,我们仅对文本 token 计算损失(loss) 。patch encoder 的学习率设为 2e-4 ,LLM 的学习率设为 3e-5 ,并使用常数学习率调度器 。每个 batch 包含 1680 万个 token ,训练的上下文长度为 8192 。
理解-生成联合训练
在第二阶段,我们训练模型的所有参数 ,包括 patch encoder、LLM 和 patch decoder 。该阶段旨在赋予模型语音理解与生成的综合能力 。
训练数据集 5 万亿(T)token ,其中 2.6T 为文本 token ,2.4T 为音频 token (按 6.25Hz 语音帧率计算)。语音续写 语音-文本交错数据 自动语音识别(ASR) 文本转语音(TTS) 通用音频描述 指令跟随 TTS(instruction-following TTS) 文本预训练数据 损失计算 对文本和音频 token同时计算损失。 文本 token 的损失权重为 100 各 RVQ token 的权重分别为 12, 8, 6, 4, 2, 2, 1, 1 学习率与调度 (如表 3 所示)patch encoder 和 decoder 学习率:2e-4 LLM 学习率:3e-5 学习率调度器采用 余弦衰减(cosine decay) 其他设置 batch 大小和上下文长度与阶段 1 保持一致。 评估 我们对 MiMo-Audio-7B-Base 进行了两类评估:
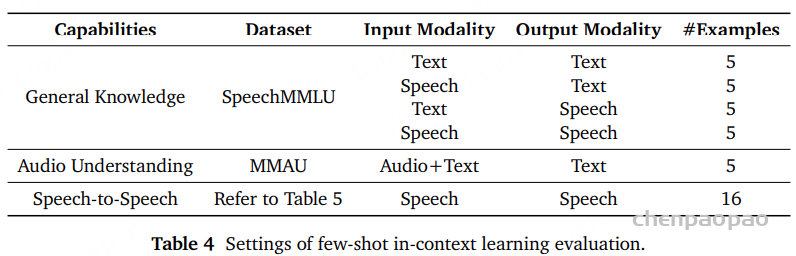
少样本上下文学习评估(Few-Shot In-Context Learning Evaluation) 语音续写评估(Speech Continuation Evaluation) Few-shot In-context Learning
从三个维度评估模型的语音–文本能力:
模态无关的通用知识 听觉理解与推理 语音到语音生成 模态无关的通用知识 :模型无论输入或输出模态为何(语音或文本),都能访问并表达相同底层知识的能力。为了跨语音与文本评估这一能力,我们构建了 SpeechMMLU 数据集:
基于 MMLU原始数据集,将问题与选项合成为语音,保持语义一致。按主题与长度筛选后,共包含 8,549 条样本 ,覆盖 34 个学科 。使用多样化声音的商用 TTS 系统进行语音合成。数据集划分为四个平行子集,便于在相同问题下进行跨模态对照测试:
文本 → 文本(T2T):评估模型是否在语音–文本联合预训练后仍保留文本理解与生成能力;同时为语音相关任务提供性能上界参考。 语音 → 文本(S2T):衡量模型从语音输入中提取语义并以文本输出作答的能力,反映语音到语义映射的跨模态代价 。 文本 → 语音(T2S):检验模型能否在文本到语音生成中保持语义一致性与表达可控性。 语音 → 语音(S2S):综合测量模型在端到端语音交互中的潜力,完整覆盖“听—思考—说”的循环过程。 听觉理解与推理 :基于MMAU数据集, 包含 音频信息抽取 与 推理问答 两类任务,覆盖语音、环境声音、音乐三个领域。
语音到语音生成 :MiMo-Audio 使用高保真音频 token 表征语音,这些 token 既用于感知,也用于生成,构成了语音理解与生成的统一接口。这种机制将预训练过程视为对大规模语音语料的高保真压缩 。我们假设:只要压缩机制足够有效,模型便能自然地具备上下文学习(in-context learning)能力 ,并能在无需参数更新 的情况下泛化至各种下游语音到语音任务。
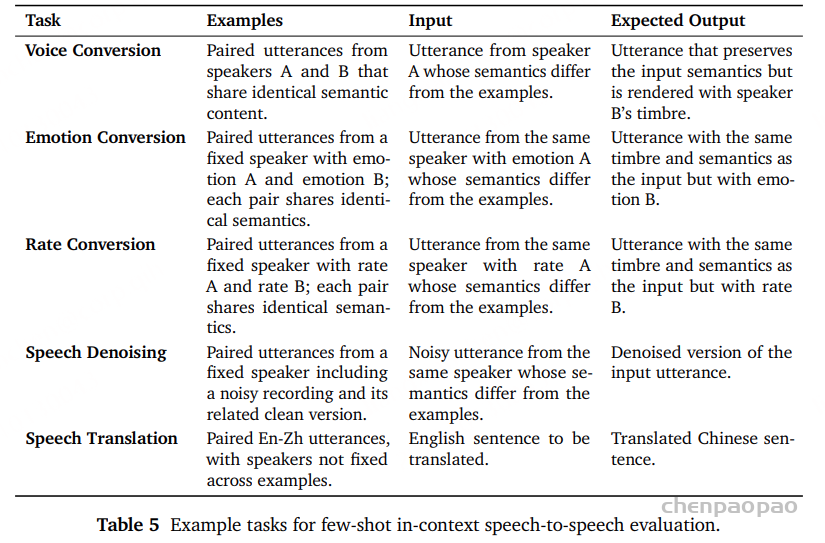
为验证这一假设,我们设计了一种 few-shot 语音到语音生成评测协议 :
模型仅以配对语音示例(speech exemplars) 作为上下文条件; 无需文本提示或梯度更新; 直接生成目标语音。 语音续写
“续写”能力是自回归语言模型的基础能力之一。通过在大规模文本语料上进行生成式预训练,诸如 GPT-3等文本语言模型能够从输入提示中生成语义连贯的文本续写。
MiMo-Audio 经过在大规模语音语料上的生成式预训练,对高保真音频 token 进行语言建模,从而具备了通用的语音续写能力 :MiMo-Audio-7B-Base 能够生成在语义上连贯且在声学特征上自然衔接的续写语音,同时保持输入语音的关键声学属性,包括:
说话人特征 —— 如身份、音色等个体化特征;韵律特征 —— 包括节奏、语调与语速;环境声学特征 —— 包括空间声效与非语音音素(如掌声、笑声、叹息声等)。为评估这种能力,我们从多个领域采集了语音提示样本,涵盖:
单人独白类:脱口秀 、公众演讲 、新闻播报 、诗歌朗诵 、有声书叙述 、学术讲座 ; 多人对话类:辩论 、访谈 、戏剧表演 。 结果
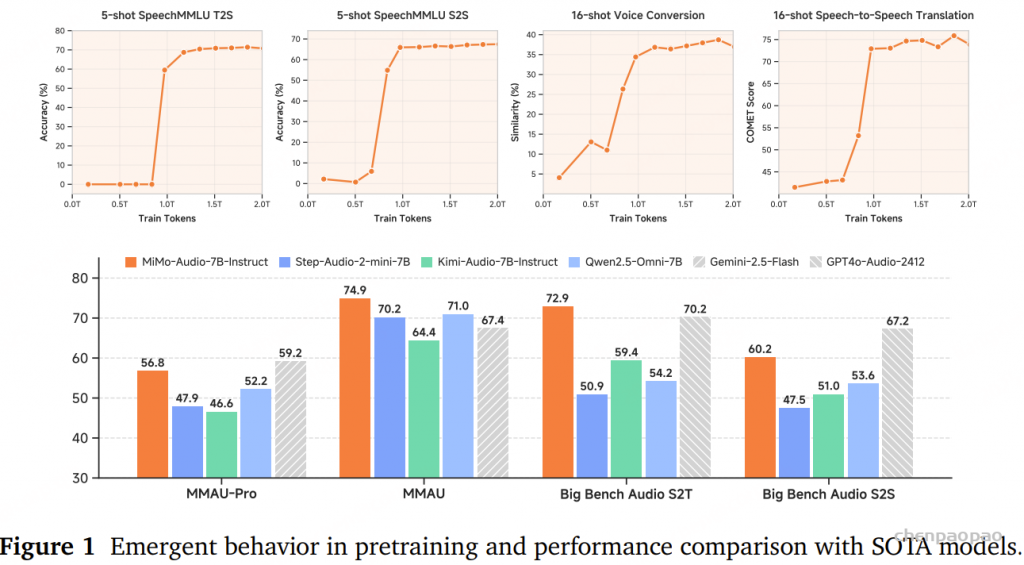
涌现能力 :在多个评测基准上观察到了显著的能力涌现现象 ,包括 5-shot SpeechMMLU(T2S 与 S2S) 、16-shot 语音转换 、以及 16-shot 语音到语音翻译 。
在训练的早期阶段(即当训练数据量尚未达到约 0.7 万亿 tokens 时),模型在这些任务上的表现几乎可以忽略不计,表明它尚未具备解决这些复杂任务所需的基本原子能力。超过这一临界阈值 后,模型的性能出现了显著的非线性跃升 ,表现出典型的“相变”特征。
在经历这一突变后,模型性能持续稳步提升,并最终趋于稳定,表明模型已经完全掌握并巩固了这一新能力 。这种从近乎零起点的能力涌现,而非循序渐进的提升,直接体现了模型通过大规模学习自主形成高级泛化能力 的过程。
这标志着语音领域的 “GPT-3 时刻”——自发学会解决复杂、前所未见的任务 ,从而实现任务泛化 。
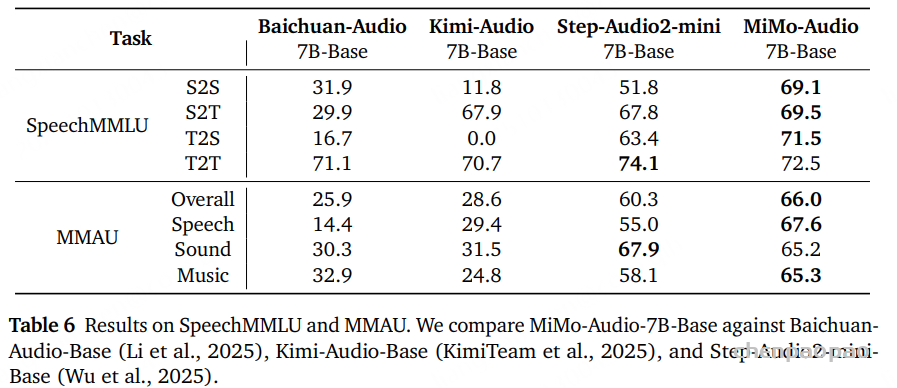
语音智能 :MiMo-Audio 模型在语音智能任务中展现出了卓越的性能 ,其优势主要体现在SpeechMMLU 得分和模态差距两个关键维度
1、SpeechMMLU 评估模型直接以语音作为输入或输出时,执行复杂推理与知识问答(QA)任务的能力。MiMo-Audio 在三个主要指标上均取得了最高分
相比之下:
Step-Audio2 mini-base 虽在 S2T 上取得了 67.8 的相对竞争力成绩,但在 S2S 上骤降至 51.8 ,显示出跨任务不稳定性。Kimi-Audio-base 在 S2T 上表现一般(67.9),但在 S2S 上存在明显短板。Baichuan-Audio-base 在两项任务中表现均较低(31.9 与 29.9)。综上,MiMo-Audio 是唯一能在所有语音推理任务中保持高水平性能的模型 ,体现了其在语音理解与生成间的深度整合能力。
模态差距 :模态差距衡量模型在语音模态与文本模态间能力一致性的程度。
Modality Gap = Text2Text Score − Speech2Speech (S2S) Score
结果如下:
MiMo-Audio:3.4 Step-Audio2 mini-base:22.3 Kimi-Audio-base:58.9 Baichuan-Audio-base:39.2 MiMo-Audio 的模态差距最小 ,说明其在语音与文本两种输入模态之间能高度保持一致的推理与理解能力。这也表明其模型架构设计在跨模态知识迁移与能力保持方面最为高效 ,有效实现了语音与语言智能的统一 。
通用音频理解 :MiMo-Audio 在当前所有开源模型中展现出了最强的通用音频理解能力 。性能均衡性 。在 MMAU 总得分 上,MiMo-Audio 取得了 66.0 分 ,比排名第二的 Step-Audio2 mini-base(60.3 分) 高出 5.7 分 。相比 Kimi-Audio-base(28.6 分) 和 Baichuan-Audio-base(25.9 分) ,MiMo-Audio 的成绩有显著优势。这种总分上的领先直观地体现了模型整体性能的优越性 。
MiMo-Audio 在通用音频理解上表现尤为突出,展现出均衡且稳健的能力分布 :
语音(Speech) :67.6音效(Sound Effects) :65.2音乐(Music) :65.3三者之间没有明显短板,说明模型在多类型音频场景中都能保持高质量表现。
语音任务泛化 :16-shot in-context learning 设置下,模型在语音转换(Voice Conversion)和 语音到语音翻译(Speech-to-Speech Translation)任务中的结果 说明:MiMo-Audio 的语音到语音生成能力 与模态无关知识能力在相似的训练规模上同时出现。这种一致性表明,模型在大规模训练中正在形成一种 统一的语音理解能力 ,能够泛化至控制层面的语音特征变换,如说话人身份、情感、语速等。
语音续写 :在多种场景下(游戏直播、教学、朗诵、歌唱、脱口秀、辩论 等),MiMo-Audio-Base 都能进行自然流畅的语音续写,无需任何参数调整。
具体表现包括:
歌唱续写 :生成旋律连贯、音色悦耳的歌声;脱口秀续写 :在适当时机生成观众掌声与笑声;双人辩论续写 :生成两人立场一致、语义流畅、韵律平衡的对话;方言续写 :保持一致的口音特征;游戏直播 / 教学场景 :生成具备情绪张力和口语化表达的语音,适时插入语气词或结巴;朗诵续写 :生成具备专业朗诵语气和情感表达的语音。Post-Training
Data
后训练阶段的数据策略目标,是通过一系列有监督的指令微调数据集 ,激活预训练模型在不同任务上的理解与生成能力。
音频理解 为了激活模型的音频理解与推理能力 ,我们整合了多个涵盖语音、声音和音乐 的开源数据集。针对这些数据中存在的标签噪声 与任务单一性 问题,我们设计了一套基于 LLM 的数据清洗与增强管线 。通过该管线,我们生成了大量多样化的音频理解数据,涵盖任务类型包括音频描述 与音频问答 等。
语音生成 为了激活模型的语音生成能力 ,我们从预训练数据中提取了一个高质量语音子集 ,并基于音频描述构建了指令数据 。模型需要根据给定的文本指令生成匹配的音频 。这种训练方式旨在增强模型的指令遵循能力 ,从而实现可控且高质量的语音生成 。
口语对话
为了激活模型在不同对话场景下生成多样化、富有表现力语音 的能力,我们构建了一个大规模口语对话数据集 ,涵盖单轮与多轮对话。这些对话包含用户提问与助手回复,内容主要来源于经过严格筛选的文本数据 ,以确保质量可靠。
为使 MiMo-Audio 能适应多样化的会话风格,我们首先对问答对进行口语化风格重写 ,然后使用内部的 MiMo-TTS 系统 合成具有相应风格与情感的语音。随机选择提示音频(prompt audio) ,以覆盖不同的声音表现力范围。
训练
在后训练阶段,模型的所有参数 ——包括 patch encoder(音频块编码器) 、LLM(语言模型) 和 patch decoder(音频块解码器) ——都进行了微调。
为此,我们构建了一个规模达 1000 亿 tokens 的综合训练数据集,涵盖以下 六种任务形式 :
自动语音识别(ASR) 语音合成(TTS) 音频理解(Audio Understanding) 口语对话(Spoken Dialogue) 指令驱动语音生成(Instruction-Following TTS) 文本对话(Text Dialogue) 其中,ASR、TTS 和文本对话 的数据来源于开源数据集;而其余任务使用了上面中介绍的高质量自建数据集。
在损失加权方面,文本 token 的权重设为 100 ,音频 token 的权重分别为 12、8、6、4、2、2、1、1 ,与预训练第二阶段保持一致。
模型的训练上下文长度为 8192 tokens ,batch size为 210 万 tokens 。
评估
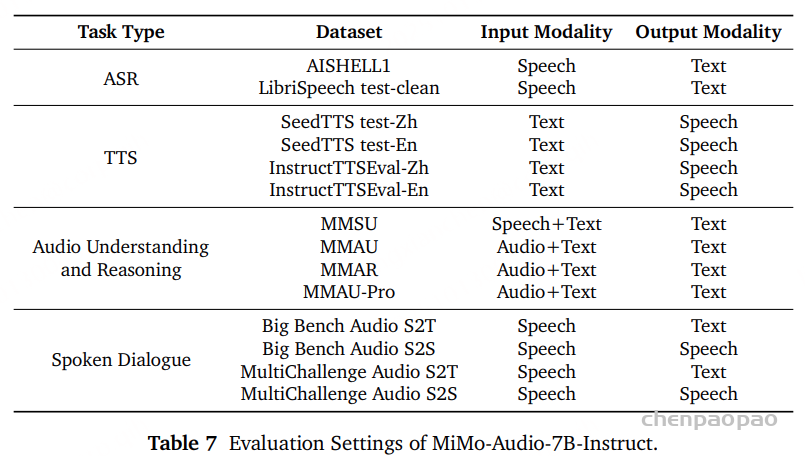
在后训练阶段完成后,我们对 MiMo-Audio-7B-Instruct 模型进行了系统性的综合评估,涵盖了以下主要任务领域:
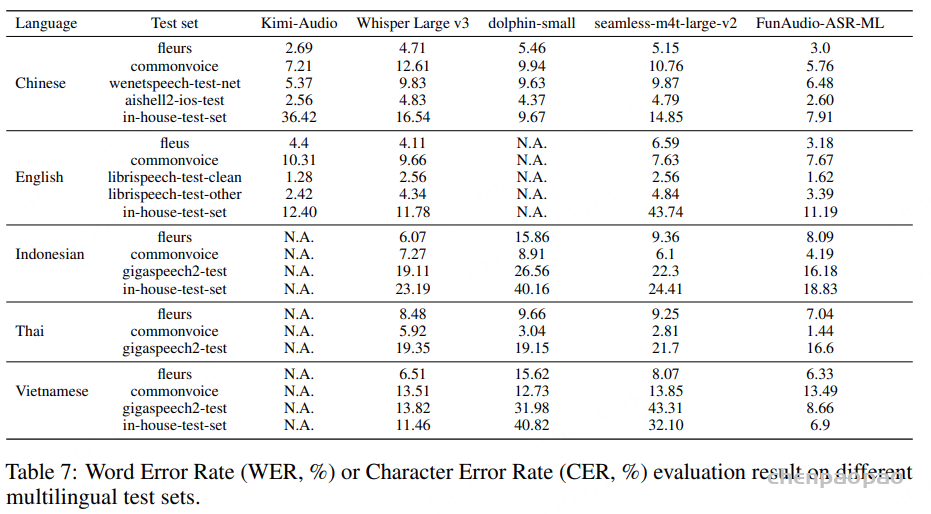
音频理解 口语对话 语音识别与生成(Speech Recognition & Generation) 各类任务的具体评测配置列于 表 7 。
音频理解 :采用MMSU 基准评估多任务语音理解,采用MMAU基准评估声音/音乐等更广泛的音频理解任务。采用 MMAR 和 MMAU-Pro 基准用于评估模型处理混合音频输入 (如语音、音乐与环境音)以及理解音频知识 的能力。
口语对话 :借鉴 OpenAI 的评估流程来评估模型在多轮对话中遵循用户指令与完成任务的能力。使用 Big Bench Audio 基准衡量音频语言模型的智能水平,模型的回答质量通过基于 GPT 的自动评估获得。对于语音形式的回答,首先使用 Whisper-Large-V3 模型将其转写为文本,然后由 GPT-4o-mini 进行质量评估。为了测试模型在更复杂对话任务 中的表现,使用 Multi-Challenge 数据集,该数据集要求模型生成与上下文语义一致的、符合情境的对话回应,以评估模型的多轮语音交互能力,对该数据集进行语音版本转换,构建了 MultiChallenge Audio :
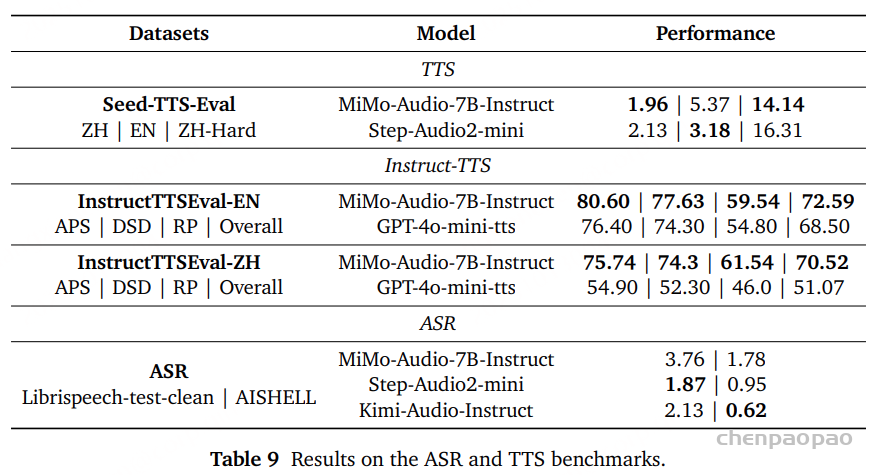
S2T(speech-to-text):对话历史以文本形式呈现; S2S(speech-to-speech):对话历史完全以语音形式呈现。 语音识别与生成 :ASR 采用了广泛使用的 LibriSpeech test-clean 集合来评估英语识别性能,并使用 AISHELL-1 测试集来评估中文识别性能。ASR 任务的评估指标为 词错误率(WER) 。除了识别能力外,我们还评估了 MiMo-Audio-7B-Instruct 的语音生成能力。SeedTTS 基准上测试其 TTS 性能,该基准涵盖中英文两个子集,并包含一个更具挑战性的中文 hardcase 子集。除传统的 TTS 评估外,我们还在 InstructTTSEval 基准上进行了更高级别的测试,用以衡量模型根据自然语言风格控制指令生成相应语音的能力,从而联合评估其保真度与表达力 。
在 TTS 任务中,同样采用 WER 作为基本评价指标:生成的语音首先通过 ASR 模型转录为文本,然后与参考文本进行比较。此外,InstructTTSEval 还利用基于 Gemini 的评分体系进一步评估生成语音与输入指令之间的匹配度,从而更全面地反映模型的语音生成理解与控制能力。
结果
在音频理解任务中,如表 8 所示,MiMo-Audio-7B-Instruct 在 MMSU 和 MMAU 基准上的结果显示出卓越表现,在语音、音频与音乐问答任务上均取得领先成绩。该模型在这两个基准上的总体得分不仅超过了所有开源模型,也超过了部分闭源模型,如 Gemini 2.5 Flash 和 Gemini 1.5 Pro 。
对于更具挑战性的音频推理任务,MiMo-Audio-7B-Instruct 在 MMAU-Pro 和 MMAR 基准上同样表现领先,其结果已接近 Gemini 2.5 Flash 。这些结果共同表明,MiMo-Audio-7B-Instruct 是一个通用且强大的音频理解模型 ,具备广泛的跨模态推理与理解能力。
口语对话 :MiMo-Audio-7B-Instruct 在 Big-Bench-Audio 与 Multi-Challenge-Audio 两个任务上,均在开源模型中表现最佳,并且性能接近闭源模型 gpt-4o 。在 Big-Bench-Audio 基准上,MiMo-Audio-7B-Instruct 分别取得 72.90(S2T) 和 60.20(S2S) 的分数,仅次于 gpt-4o,但显著优于所有其他开源模型。同样地,在 Multi-Challenge-Audio 基准上,该模型分别取得 15.15(S2T) 与 10.10(S2S) ,再次以明显优势领先开源阵营。
总体而言,MiMo-Audio-7B-Instruct 不仅在开源模型中遥遥领先,还进一步缩小了与最先进的闭源模型 gpt-4o 之间的差距 ,展现出极强的竞争力与实际应用潜力。
语音识别与生成(Speech Recognition and Generation) ASR(语音识别) 和 TTS(语音合成) 任务上均展现出强劲性能。
在 ASR 与 TTS 的基准测试中,其表现与其他开源模型(如 Step-Audio2-mini 和 Kimi-Audio-Instruct )相当。但在 InstructTTS 评测中,MiMo-Audio-7B-Instruct 在英语与中文两个子集上均超越了 gpt-4o-mini-tts ,尤其在综合指标上表现尤为突出。这些结果充分证明了 MiMo-Audio-7B-Instruct 在可控文本转语音生成方面的高效性 ,确立了其作为领先的开源语音生成解决方案的地位
结论 在本研究中,我们展示了在大规模、无损音频数据上进行“下一个 token 预测”预训练,是实现通用语音智能的可行路径。通过在超过 1 亿小时的前所未有的数据语料上进行预训练,MiMo-Audio 成功突破了现有音频语言模型以任务特定微调为主的局限性。
主要贡献是实证验证了在语音领域同样可以出现类似 GPT-3 的“临界时刻”。我们观察到,在跨越关键数据量阈值后,模型的少样本学习能力显著涌现,使其能够在无需任务特定训练的情况下泛化到广泛任务,包括复杂的语音转换、风格迁移以及语音编辑等。此外,我们提出了这一范式的完整蓝图,包括:新颖的统一高保真音频编码器、可扩展模型架构以及分阶段训练策略。MiMo-Audio-7B-Instruct 在多个基准测试中取得了最先进的性能,并可与闭源系统媲美。
总体而言,本研究为构建真正多功能的音频语言模型提供了基础方法论。我们认为,这标志着向创建更自然、灵活、智能的系统迈出了重要一步,使其能够以类人适应性理解和生成语音。
限制与未来工作
有限的上下文学习能力
不稳定的语音对话性能
有限的思维能力表现