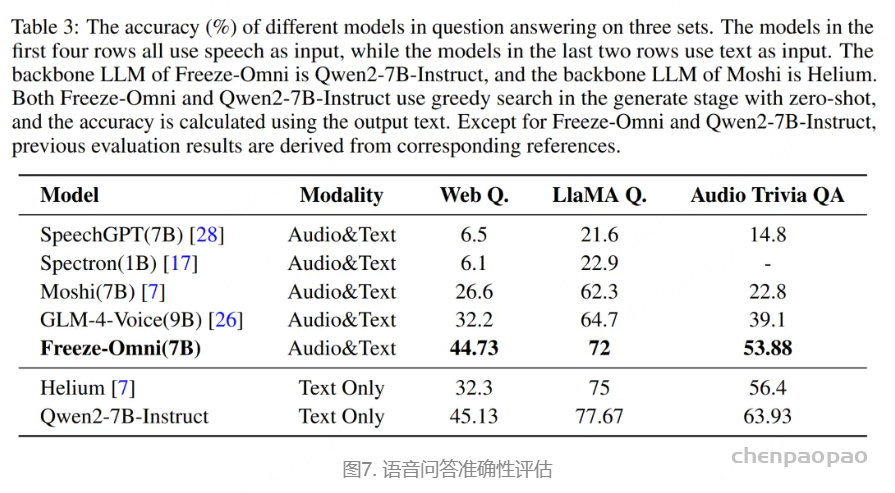
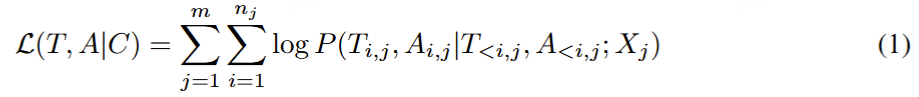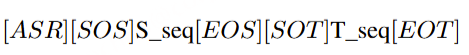语音问答准确性评估:Freeze-Omni提供了其在LlaMA-Questions, Web Questions, 和Trivia QA三个集合上的语音问答准确率评估,从结果中可以看出Freeze-Omni的准确率具有绝对的领先水平,超越Moshi与GLM-4-Voice等目前SOTA的模型,并且其语音模态下的准确率相比其基底模型Qwen2-7B-Instruct的文本问答准确率而言,差距明显相比Moshi与其文本基底模型Helium的要小,足以证明Freeze-Omni的训练方式可以使得LLM在接入语音模态之后,聪明度和知识能力受到的影响最低。
论文:通过使用超过 60,000 小时的合成语音对话数据扩展监督微调来推进语音语言模型Advancing Speech Language Models by Scaling Supervised Fine-Tuning with Over 60,000 Hours of Synthetic Speech Dialogue Data
最后,VQ本质上可以理解为一种稀疏训练方案,所以SimVQ所带来的启发和改动,也许还能用于其他稀疏训练模型,比如MoE(Mixture of Experts)。当前的MoE训练方案中,Expert之间的更新也是比较独立的,只有被Router选中的Expert才会更新参数,那么是不是有可能像SimVQ一样,所有的Expert后都接一个共享参数的线性变换,用来提高Expert的利用效率?当然MoE本身跟VQ也有很多不同之处,这还只是个猜测。
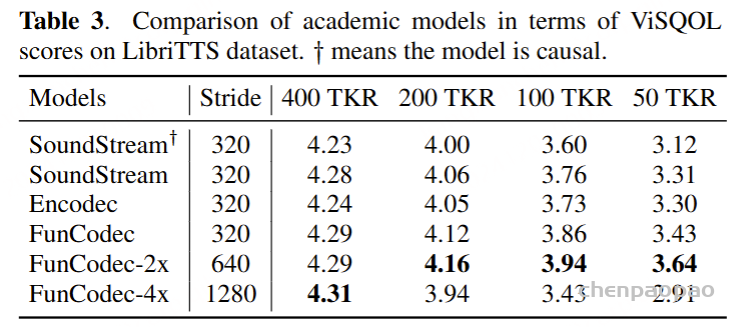
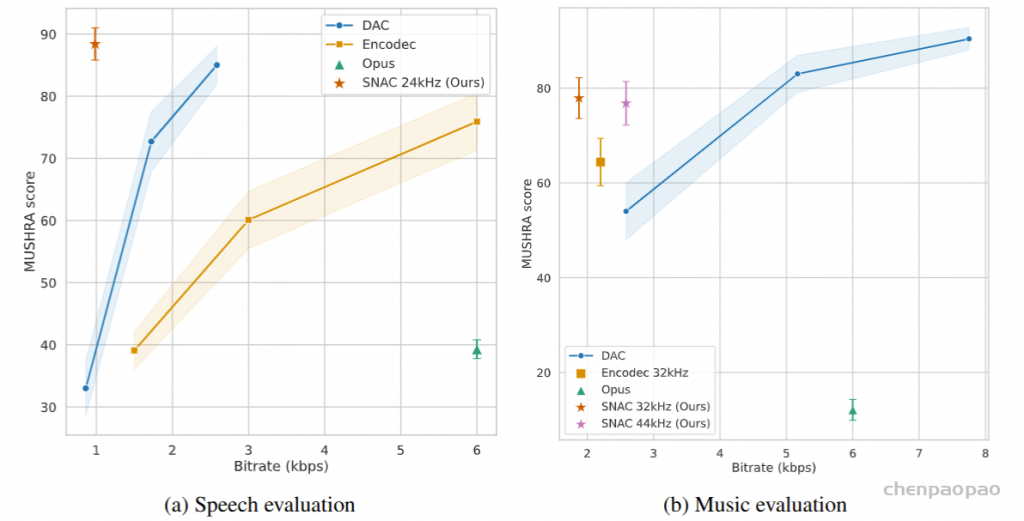
1. Comparison of academic models in terms of ViSQOL scores on LibriTTS dataset. † means the model is causal.
2. Comparison between FunCodec and other toolkits under (a) lower and (b) higher token rate. LS denotes Librispeech test sets. While Librispeech and gigaspeech are English corpora, aishell and Wenet are Mandarin corpora.
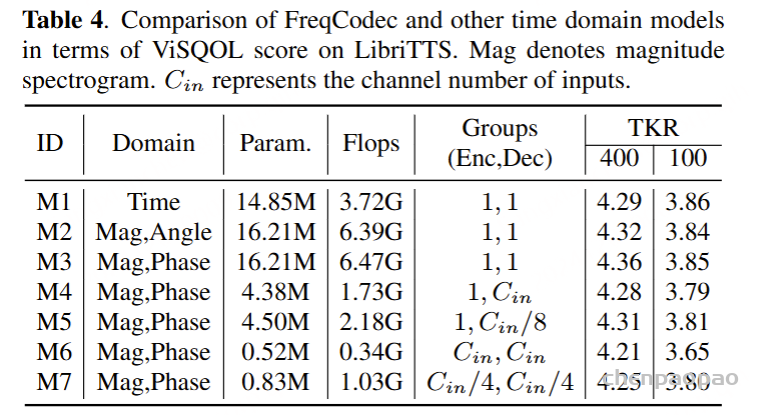
3. Comparison of FreqCodec and other time domain models in terms of ViSQOL score on LibriTTS. Mag denotes magnitude spectrogram. C_in represents the channel number of inputs.
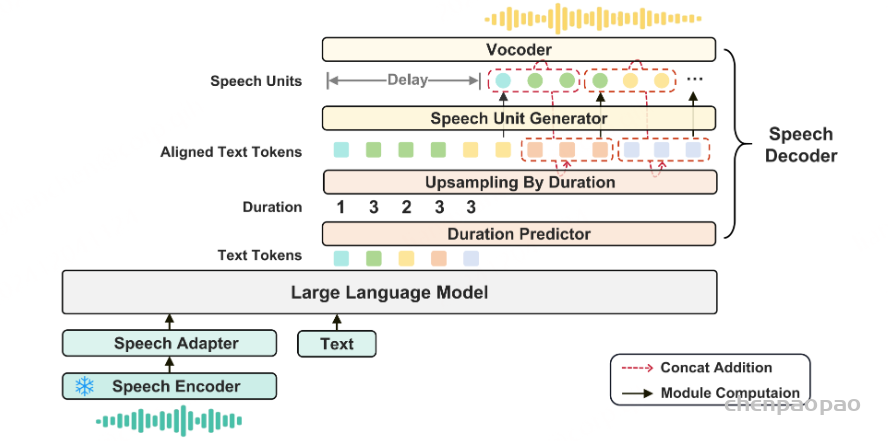
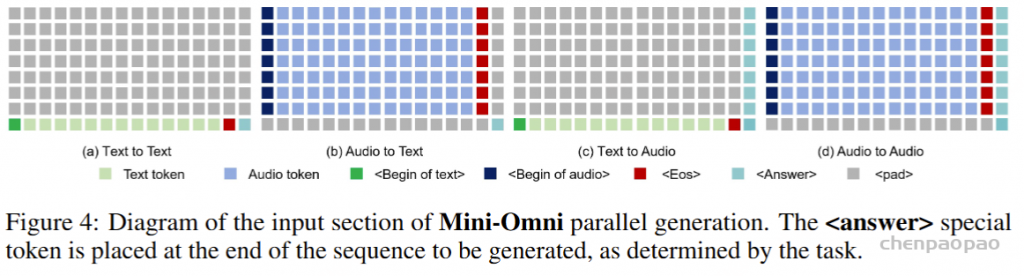
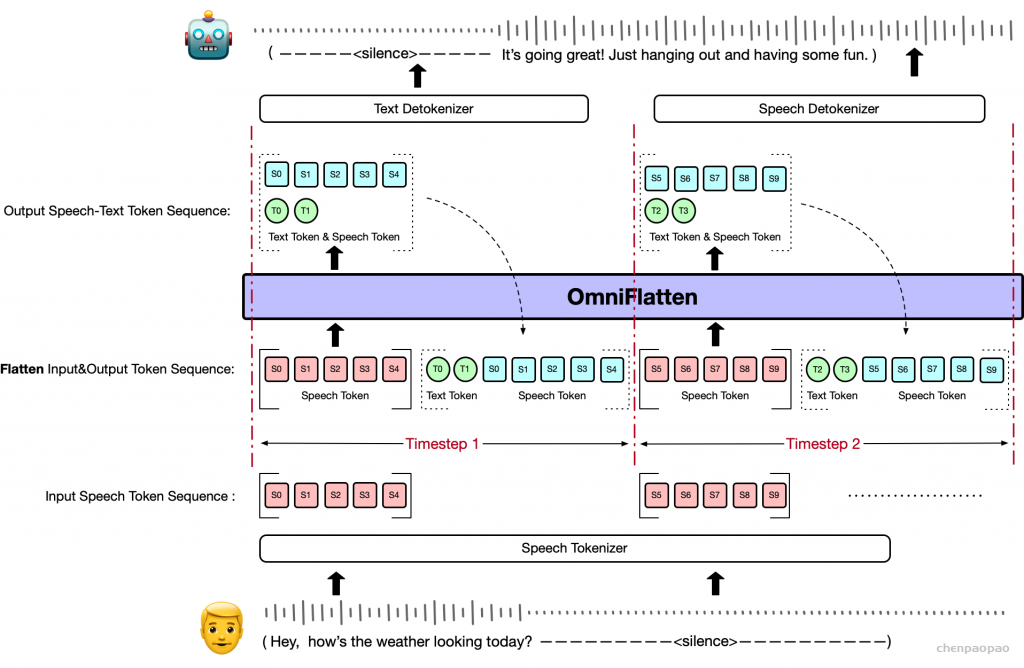
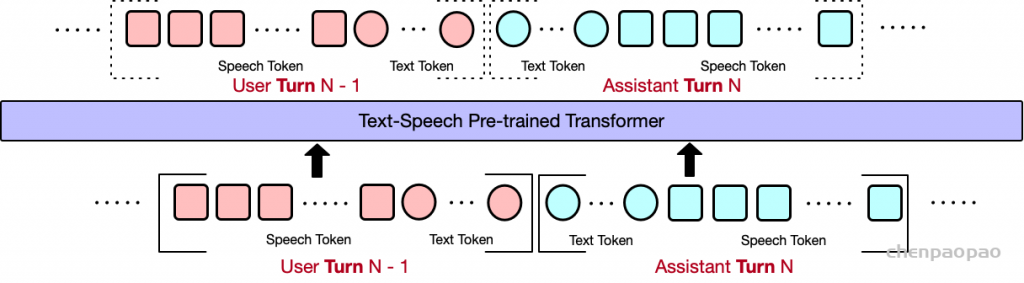
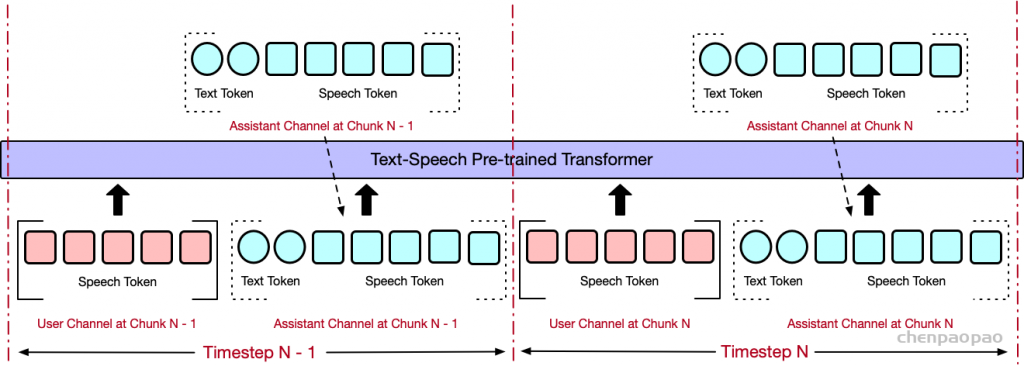
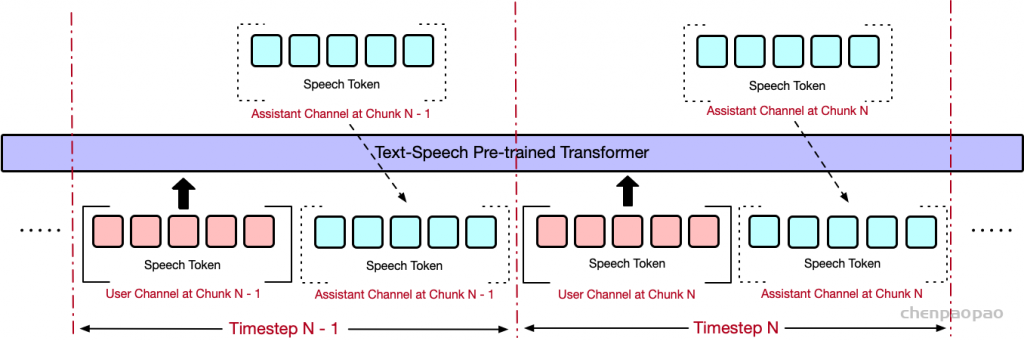
生成音频token时以对应文本token为条件,类似在线语音合成系统,且生成音频前用 N 个pad token填充,确保先产生文本token。
模型可依据说话者和风格的embedding,控制说话者特征和风格元素。
Introduction
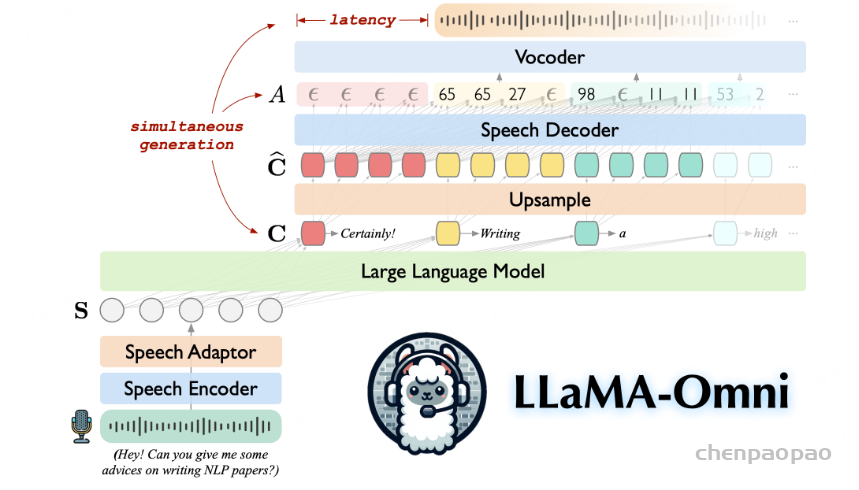
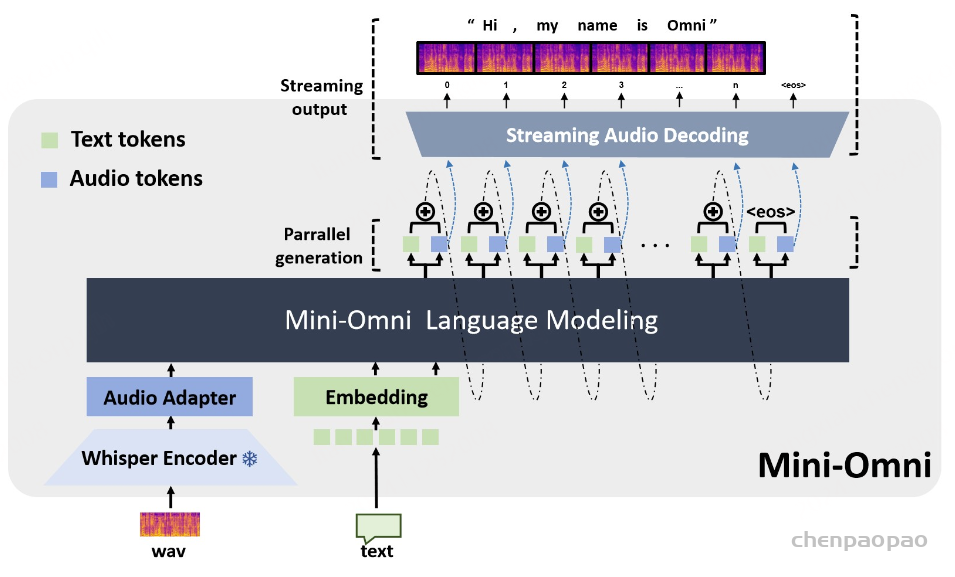
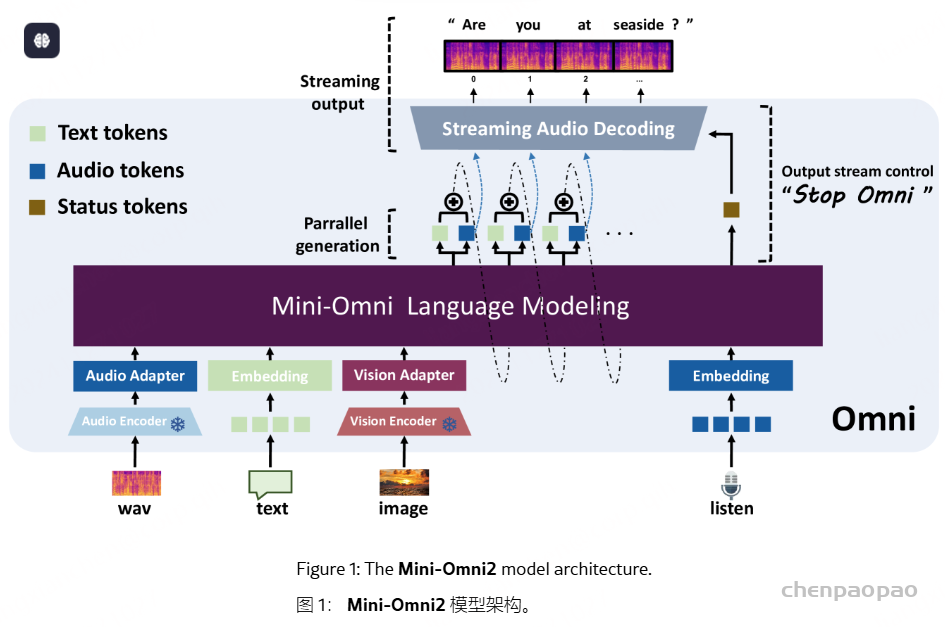
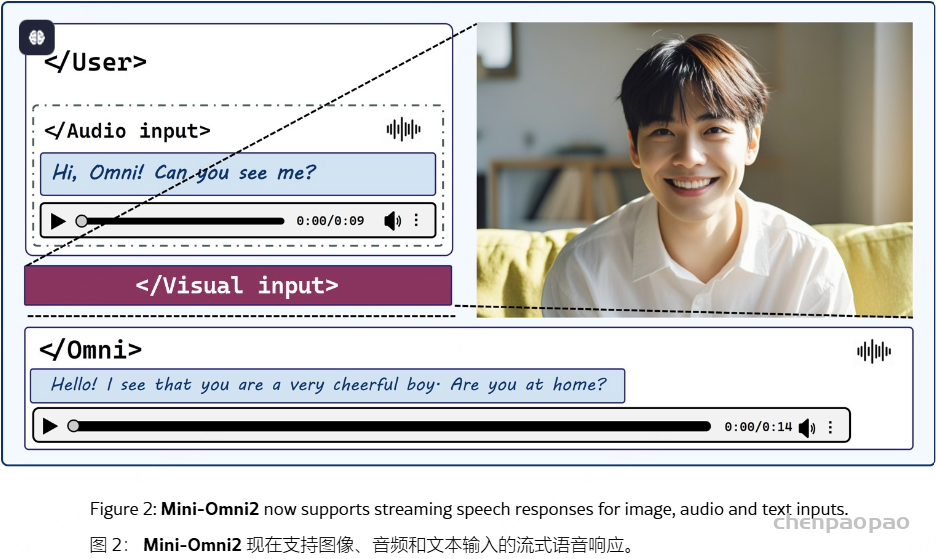
Mini-Omni,这是一种基于音频的端到端对话模型,能够进行实时语音交互。为了实现这种能力,提出了一种文本指导的语音生成方法,以及推理过程中的批处理并行策略,以进一步提高性能。该方法还有助于以最小的退化保留原始模型的语言能力,使其他工作能够建立实时交互能力。我们将这种训练方法称为 “Any Model Can Talk”。我们还引入了 VoiceAssistant-400K数据集,以微调针对语音输出优化的模型。据我们所知,Mini-Omni是第一个用于实时语音交互的完全端到端的开源模型,为未来的研究提供了宝贵的潜力。
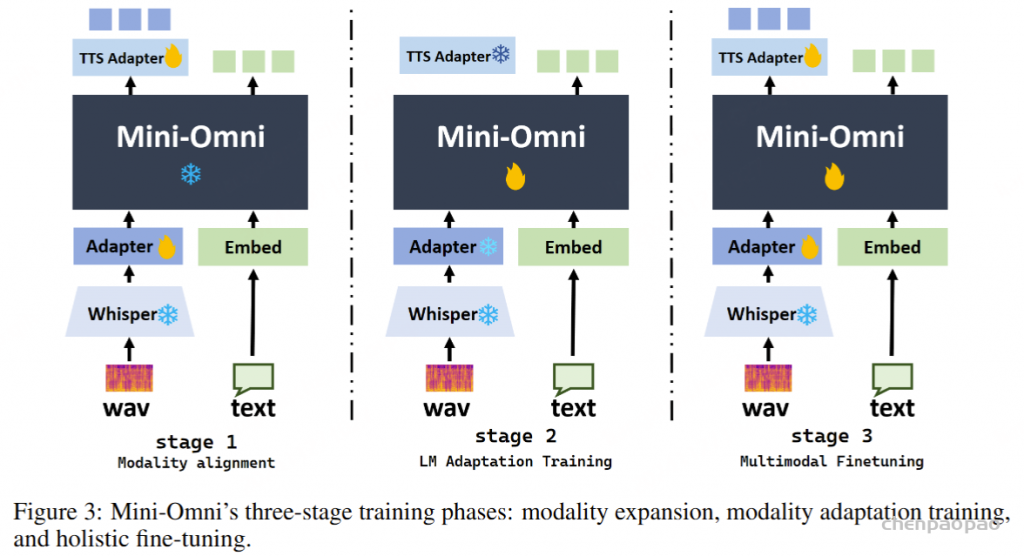
我们还提出了一种方法,该方法只要对原始模型进行最少的训练和修改,使其他工作能够快速发展自己的语音能力。我们将这种方法称为 “Any Model Can Talk”,旨在使用有限数量的附加数据实现语音输出。该方法通过额外的适配器和预先训练的模型来扩展语音功能,并使用少量合成数据进行微调。这与上述并行建模方法相结合,可以在新模态中启用流式输出,同时保留原始模型的推理能力。
提出了一种同时生成文本和音频的新方法。这种方法假设文本输出具有更高的信息密度,因此可以通过更少的标记实现相同的响应。在生成音频标记的过程中,模型能够高效地基于对应的文本标记进行条件生成,类似于在线 TTS 系统。为确保在生成音频标记之前先生成对应的文本标记,我们在模型中引入了以 N 个标记进行填充的机制,该值可作为超参数进行调整。此外,模型还能够基于说话人嵌入和风格嵌入进行条件生成,从而实现对说话人特征和风格元素的控制。
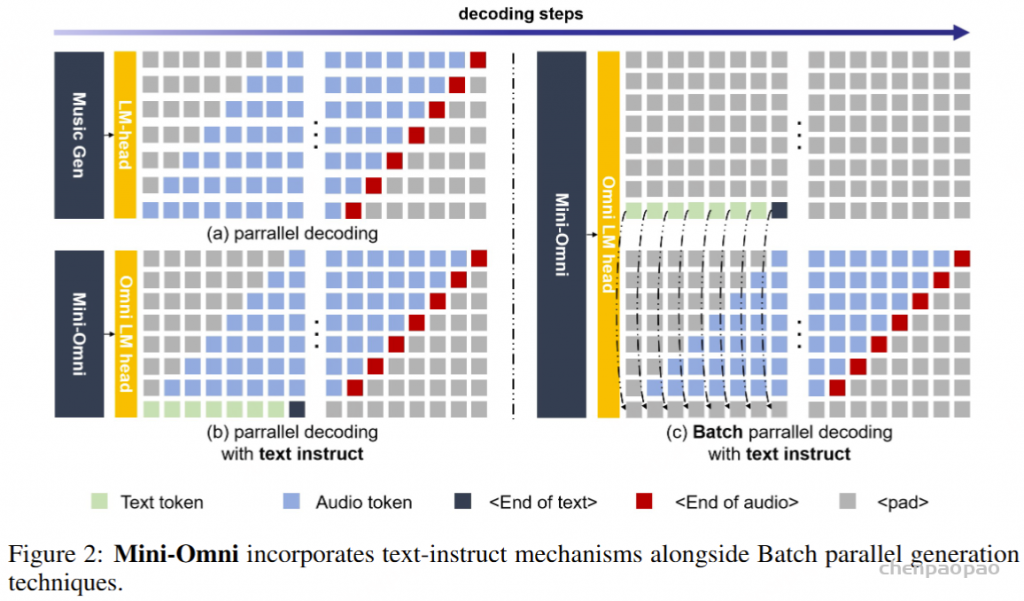
Mini-Omni,这是第一个具有直接语音转语音功能的多模态模型。在以前使用文本引导语音生成的方法的基础上,我们提出了一种并行文本和音频生成方法,该方法利用最少的额外数据和模块将语言模型的文本功能快速传输到音频模态,支持具有高模型和数据效率的流式输出交互。我们探索了文本指令流式并行生成和批量并行生成,进一步增强了模型的推理能力和效率。我们的方法使用只有 5 亿个参数的模型成功地解决了具有挑战性的实时对话任务。我们开发了基于前适配器和后适配器设计的 Any Model Can Talk 方法,以最少的额外训练促进其他模型的快速语音适应。此外,我们还发布了 VoiceAssistant-400K 数据集,用于微调语音输出,旨在最大限度地减少代码符号的生成,并以类似语音助手的方式帮助人类。我们所有的数据、推理和训练代码都将在 https://github.com/gpt-omni/mini-omni 逐步开源。
深度可分离卷积最初被引入是为了在视觉应用中构建更轻量的模型。通过对每个输入通道应用单个滤波器,该方法显著减少了计算量和模型大小。建议在生成器中使用深度卷积,不仅可以减少参数数量,还能稳定训练过程。基于 GAN 的声码器(vocoders)以其训练的不稳定性而闻名,通常在早期训练阶段会出现梯度发散,导致训练不稳定甚至模型崩溃。
HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis
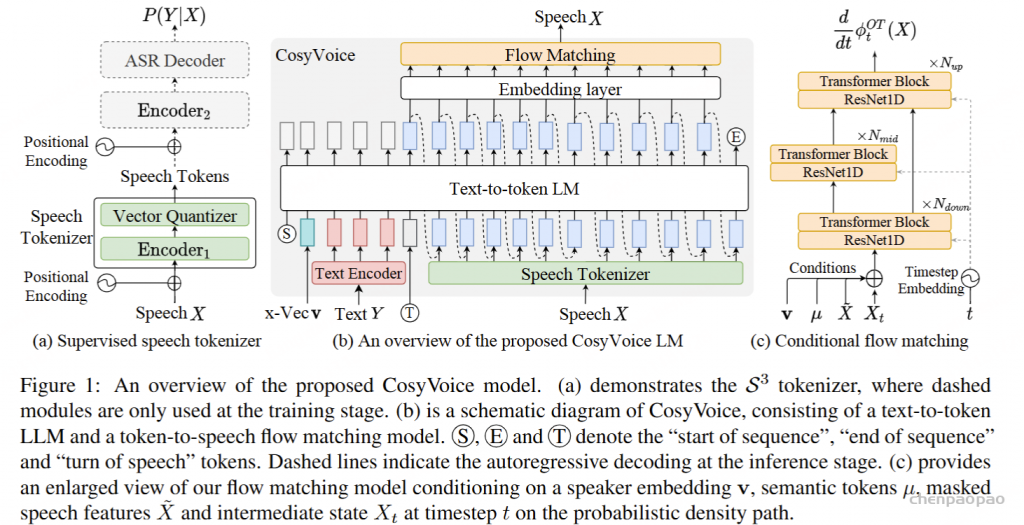
在将离散的语音Token重新转换回音频时,作者同样使用了与CosyVoice中相同的Optimal Transport Conditional Flow Matching模型(OTCFM)。OTCFM将语音Token序列转化为Mel频谱图,然后使用HifiGAN语音生成器生成最终的音频输出。先前的研究表明,相比于更简单的梯度扩散概率模型(DPM),OTCFM在训练更容易且生成更快方面表现更优。
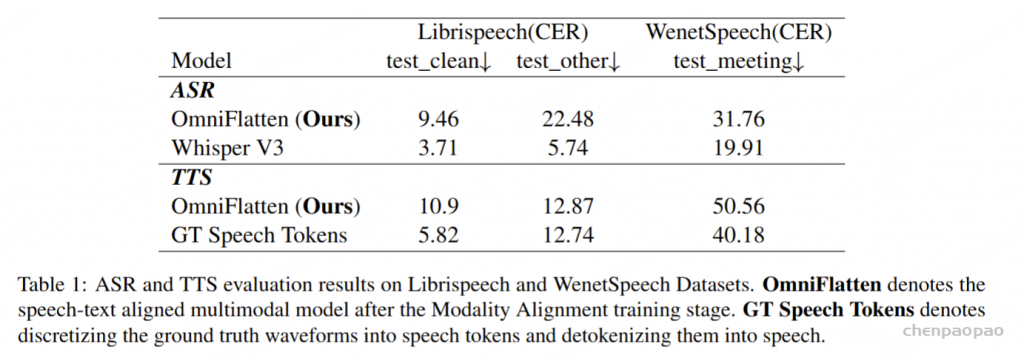
对于TTS评估,作者基于输入文本生成语音Token,然后使用CosyVoice的随机英语女性声音合成为音频。合成的音频随后使用Whisper Large V3模型进行识别,ASR的输出则与输入文本进行对比评分。ASR和TTS评估均在公开可用的LibriSpeech和VoNet Speech数据集上进行,采用字符错误率(CER)作为评估指标。