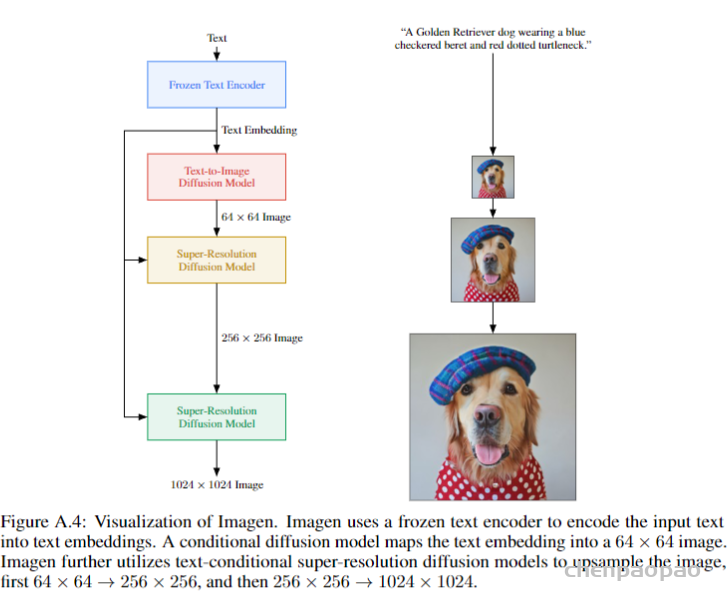
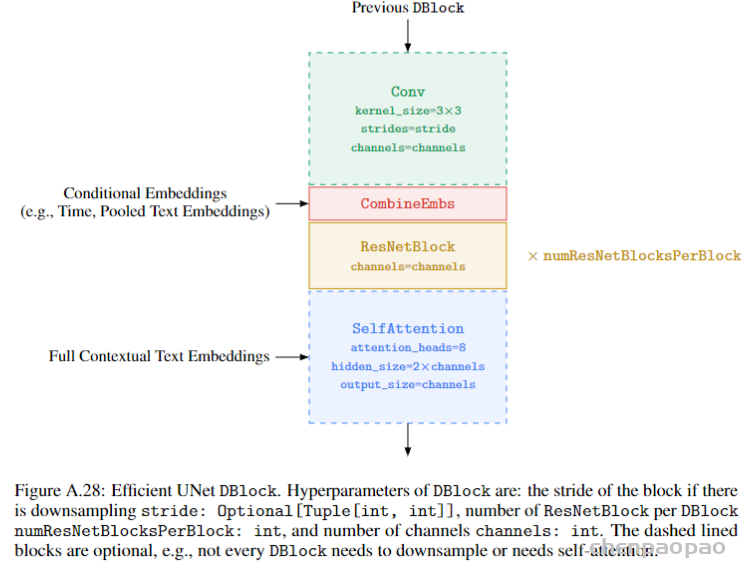
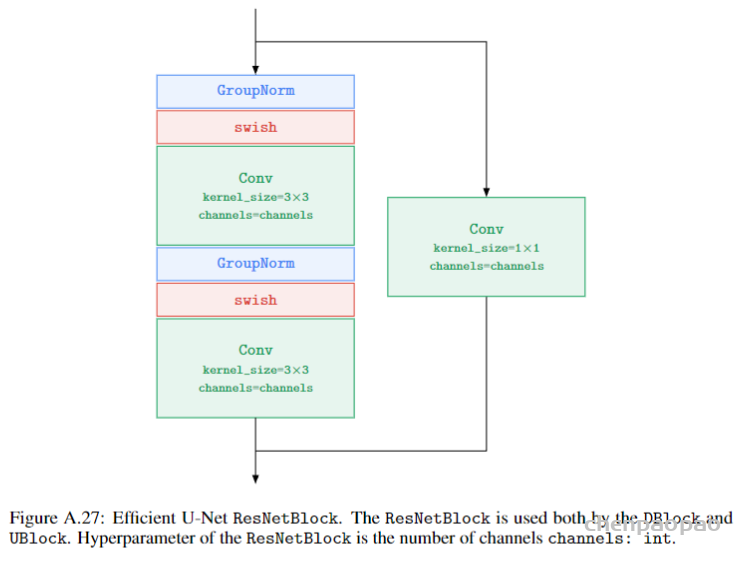
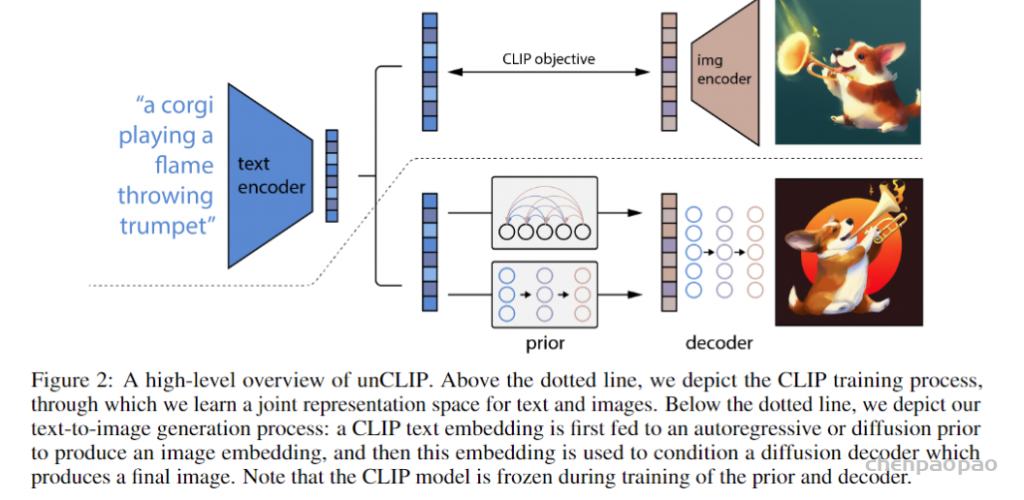
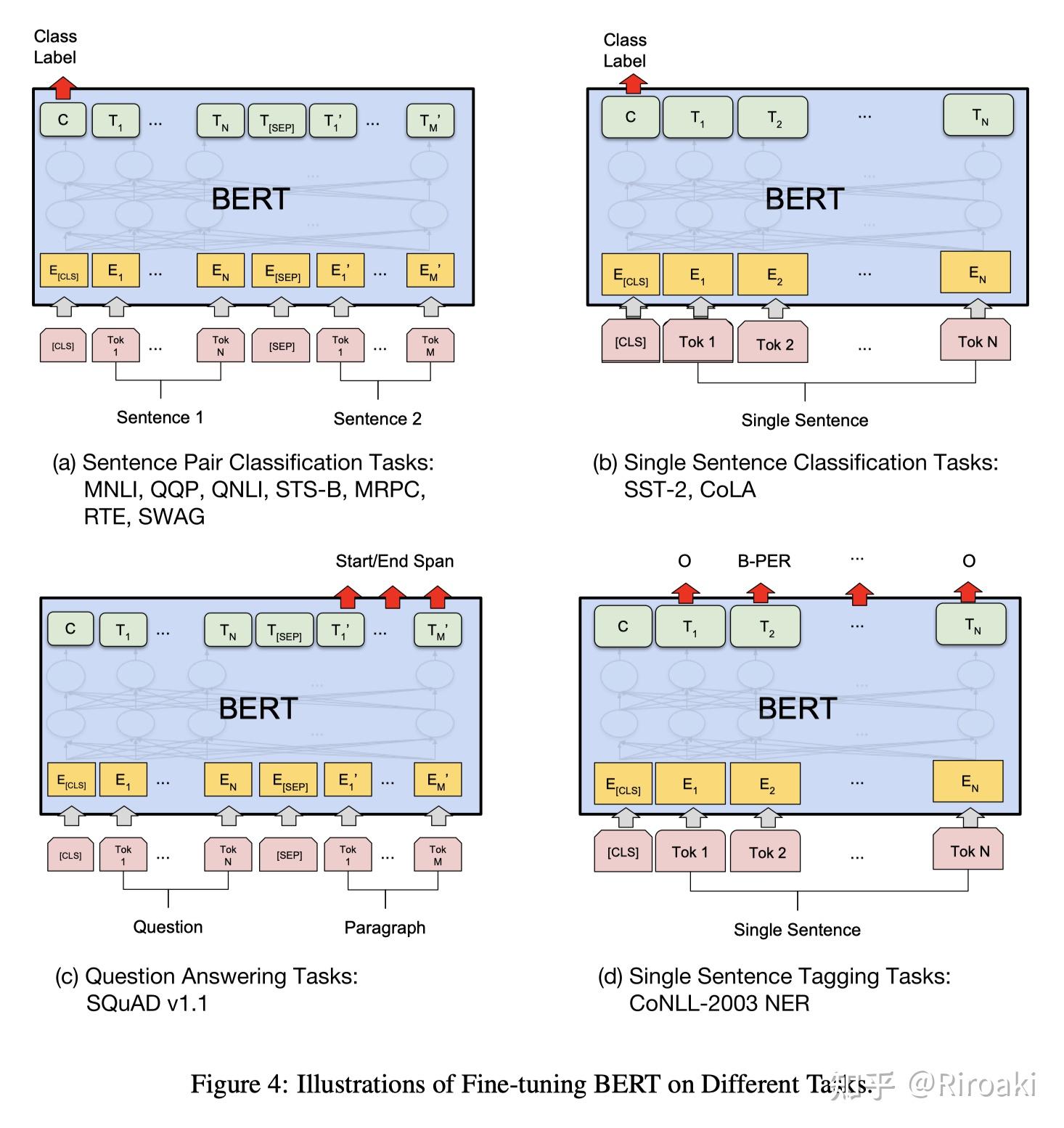
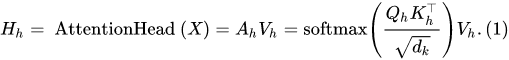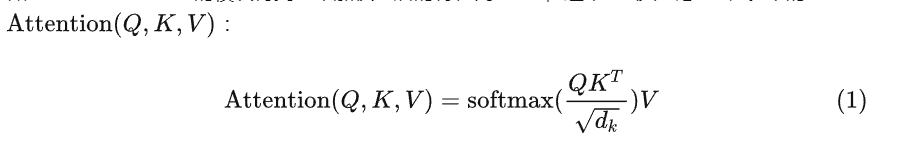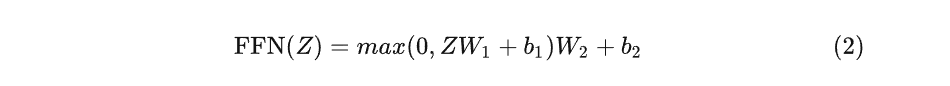3、DALL·E 2 can make realistic edits to existing images from a natural language caption. It can add and remove elements while taking shadows, reflections, and textures into account.
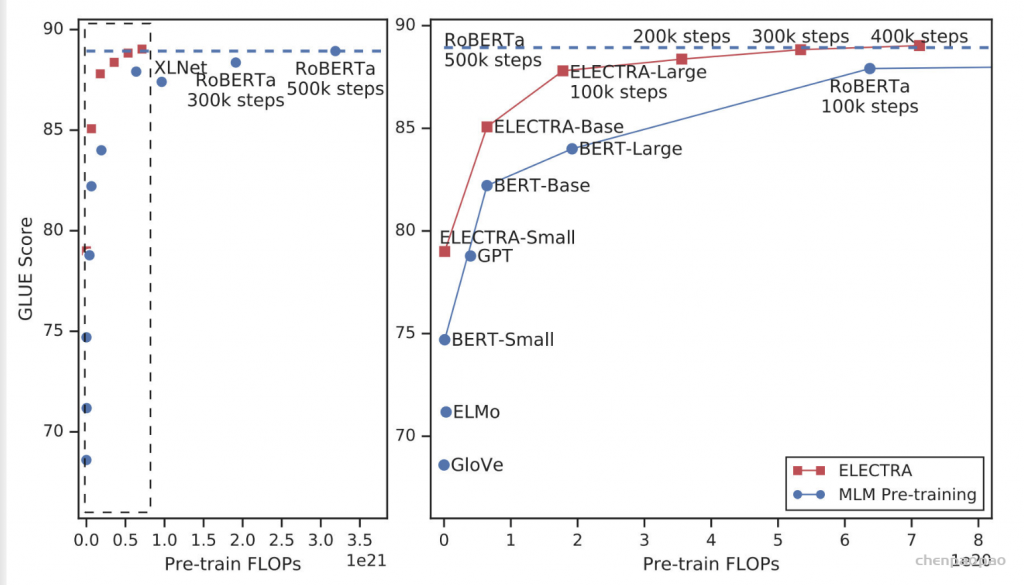
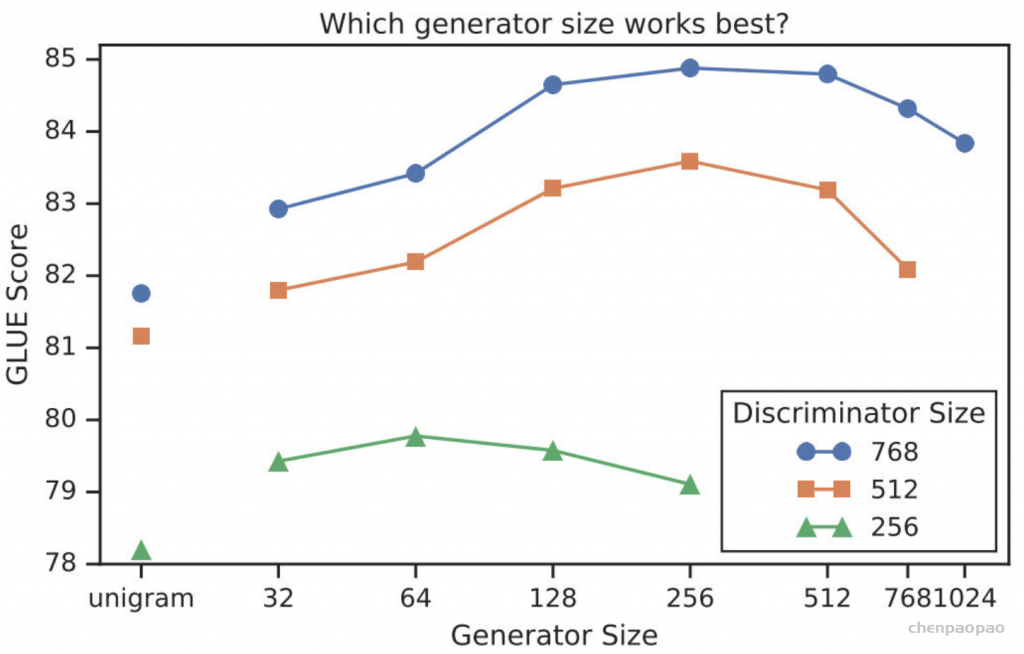
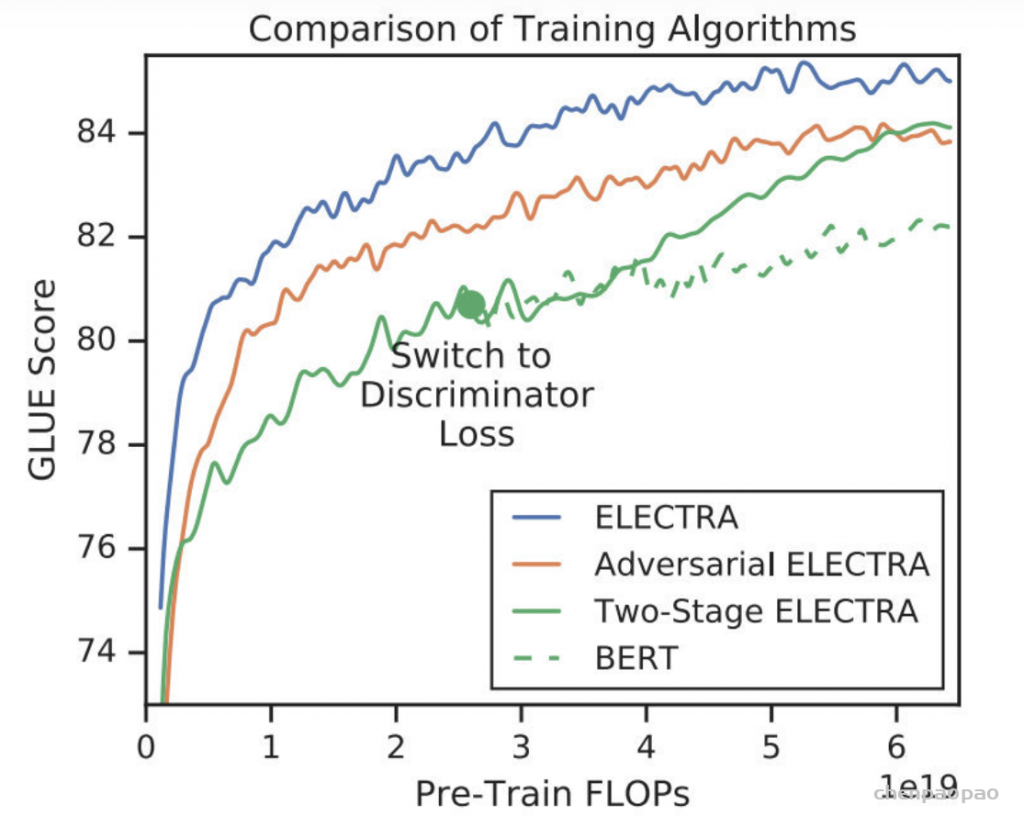
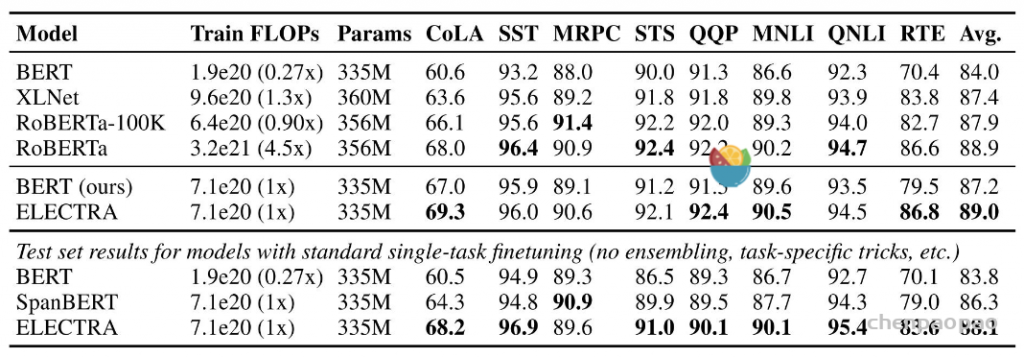
右边的图是左边的放大版,纵轴是GLUE分数,横轴是FLOPs (floating point operations),Tensorflow中提供的浮点数计算量统计。从上图可以看到,同等量级的ELECTRA是一直碾压BERT的,而且在训练更长的步数之后,达到了当时的SOTA模型——RoBERTa的效果。从左图曲线上也可以看到,ELECTRA效果还有继续上升的空间
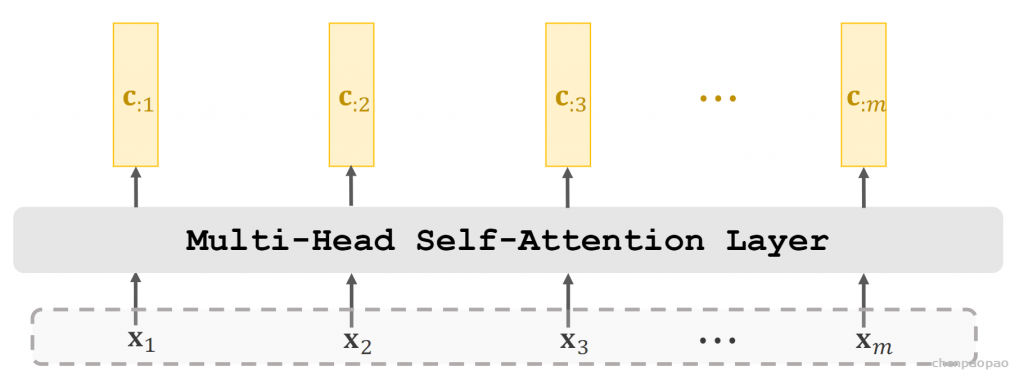
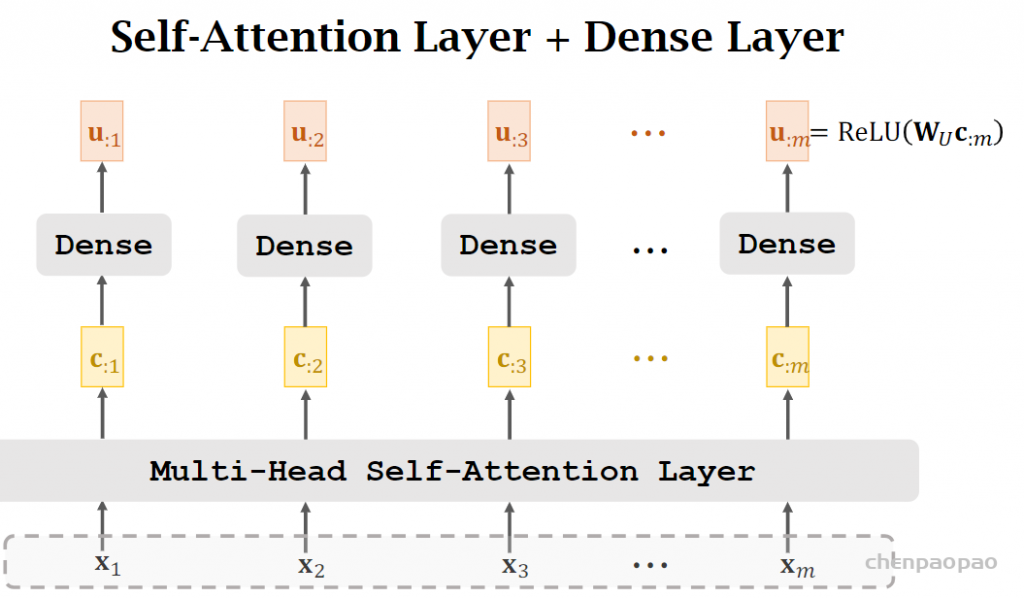
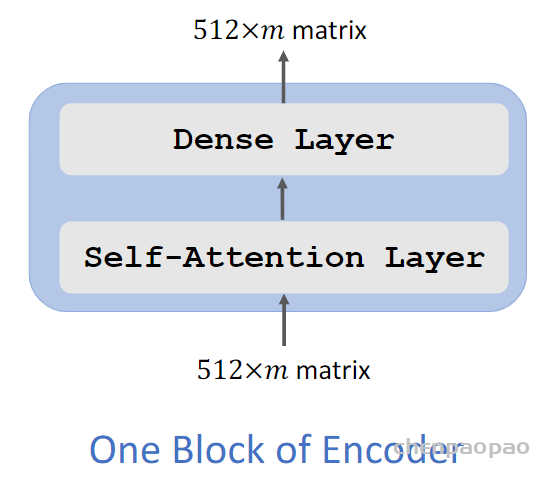
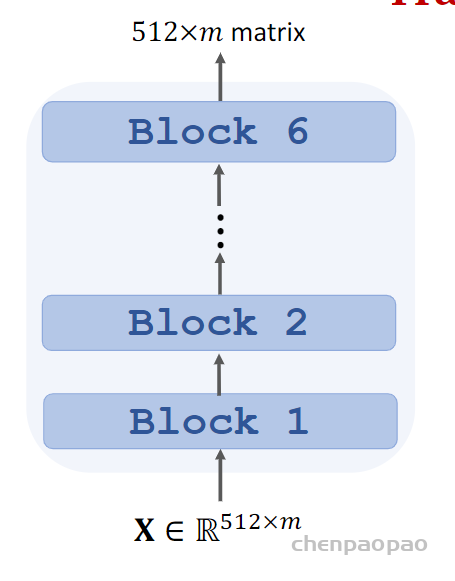
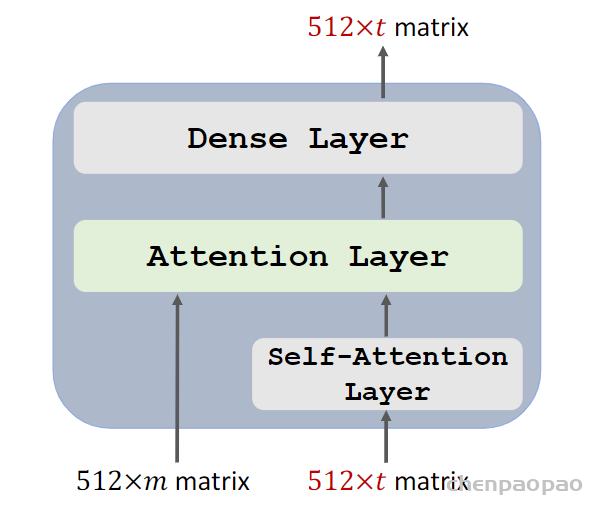
2. 模型结构
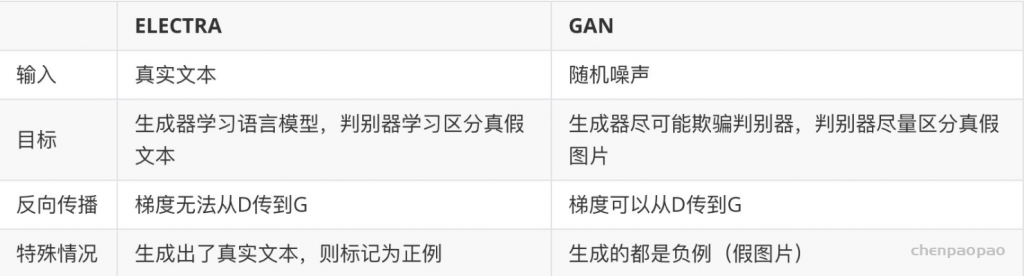
NLP式的Generator-Discriminator
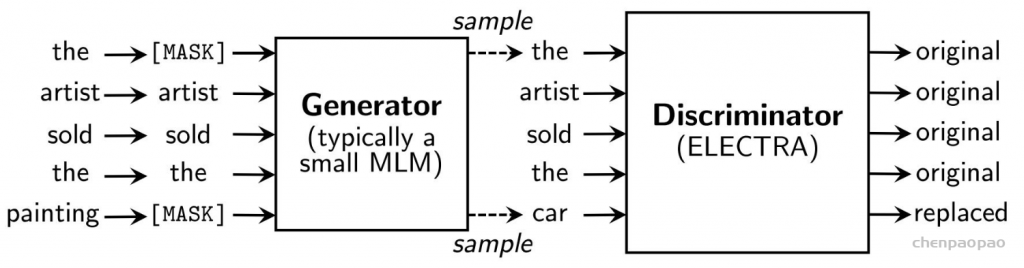
ELECTRA最主要的贡献是提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。那么问题来了,我随机替换一些输入中的字词,再让BERT去预测是否替换过可以吗?可以的,因为我就这么做过,但效果并不好,因为随机替换太简单了。
class BertTokenizer(PreTrainedTokenizer):
"""
Construct a BERT tokenizer. Based on WordPiece.
This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods.
Users should refer to this superclass for more information regarding those methods.
...
"""
class BertModel(BertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in `Attention is
all you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the :obj:`is_decoder` argument of the configuration
set to :obj:`True`. To be used in a Seq2Seq model, the model needs to initialized with both :obj:`is_decoder`
argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as an
input to the forward pass.
"""
# BertEncoder的前向传播返回部分,即上面的encoder_outputs
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
def apply_chunking_to_forward(
forward_fn: Callable[..., torch.Tensor], chunk_size: int, chunk_dim: int, *input_tensors
) -> torch.Tensor:
"""
This function chunks the :obj:`input_tensors` into smaller input tensor parts of size :obj:`chunk_size` over the
dimension :obj:`chunk_dim`. It then applies a layer :obj:`forward_fn` to each chunk independently to save memory.
If the :obj:`forward_fn` is independent across the :obj:`chunk_dim` this function will yield the same result as
directly applying :obj:`forward_fn` to :obj:`input_tensors`.
...
"""
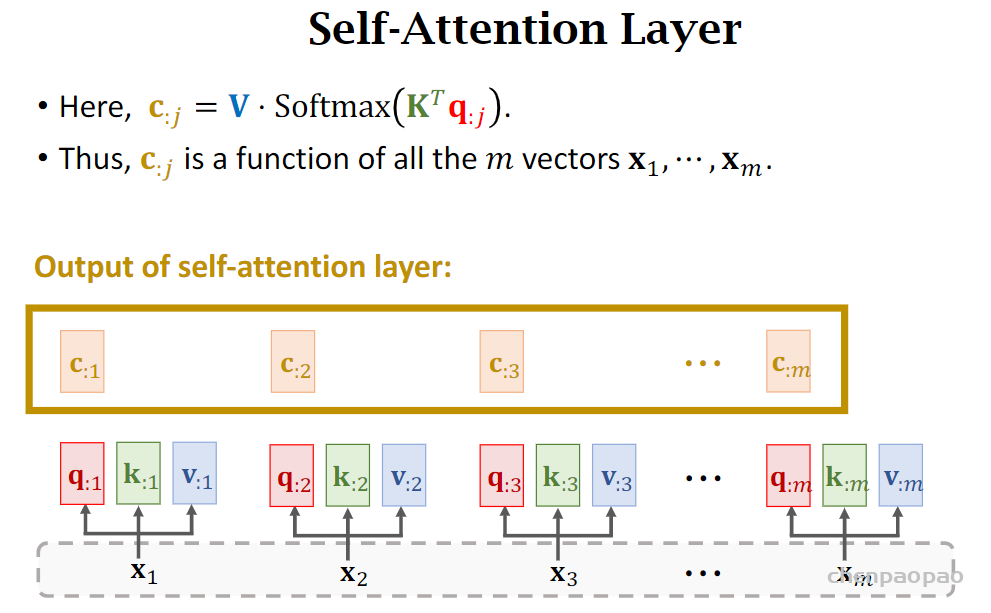
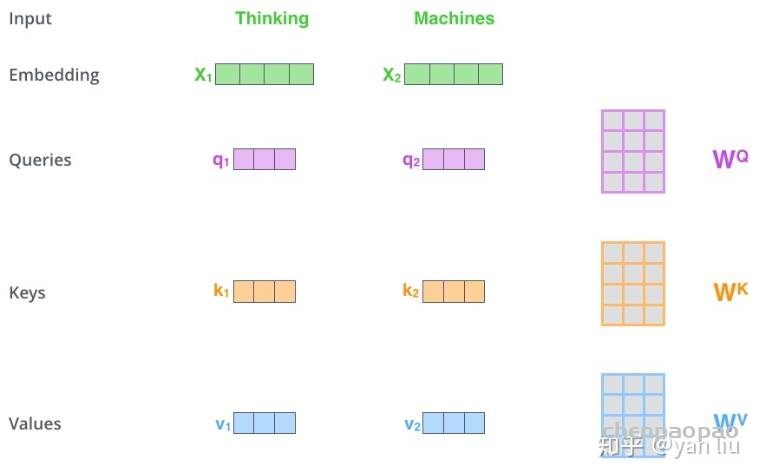
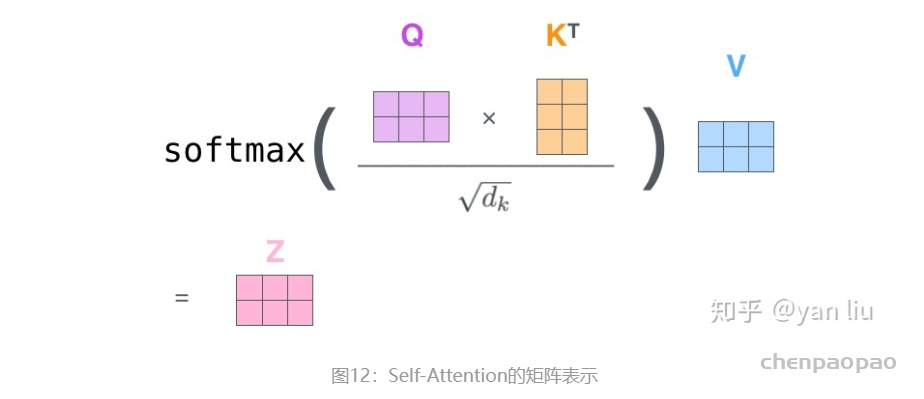
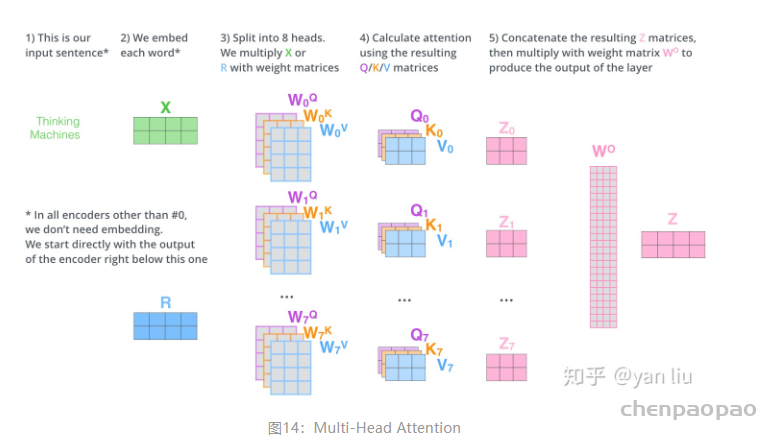
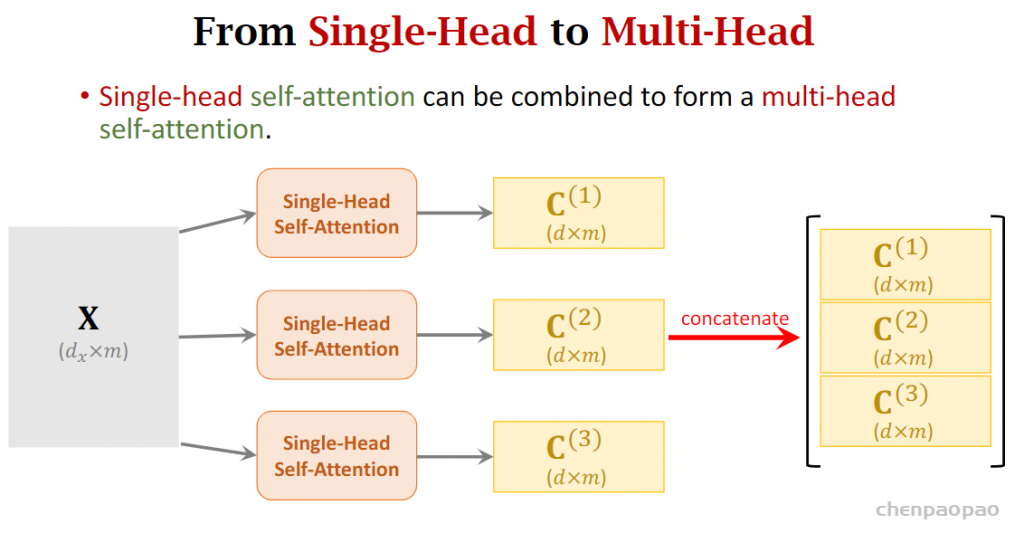
补充:原论文中多头的理由为Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.而另一个比较靠谱的分析有:
# ...
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask # 这里为什么是+而不是*?# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
# 省略decoder返回值部分……
return outputs
def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple[int], device: device) -> Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
Arguments:
attention_mask (:obj:`torch.Tensor`):
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
input_shape (:obj:`Tuple[int]`):
The shape of the input to the model.
device: (:obj:`torch.device`):
The device of the input to the model.
Returns:
:obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
"""
# 省略一部分……# Since attention_mask is 1.0 for positions we want to attend and 0.0 for# masked positions, this operation will create a tensor which is 0.0 for# positions we want to attend and -10000.0 for masked positions.# Since we are adding it to the raw scores before the softmax, this is# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
return extended_attention_mask
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class BertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
不止BERT,所有huggingface实现的PLM的word embedding和masked language model的预测权重在初始化过程中都是共享的:
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin):
# ...
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
If the :obj:`torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning
the weights instead.
"""
output_embeddings = self.get_output_embeddings()
if output_embeddings is not None and self.config.tie_word_embeddings:
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
if self.config.is_encoder_decoder and self.config.tie_encoder_decoder:
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
# ...
# model: a Bert-based-model object# learning_rate: default 2e-5 for text classification
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(
nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(
nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters,
lr=learning_rate)
# ...
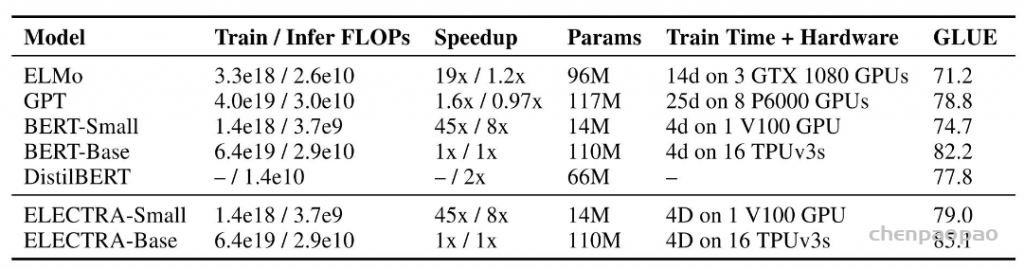
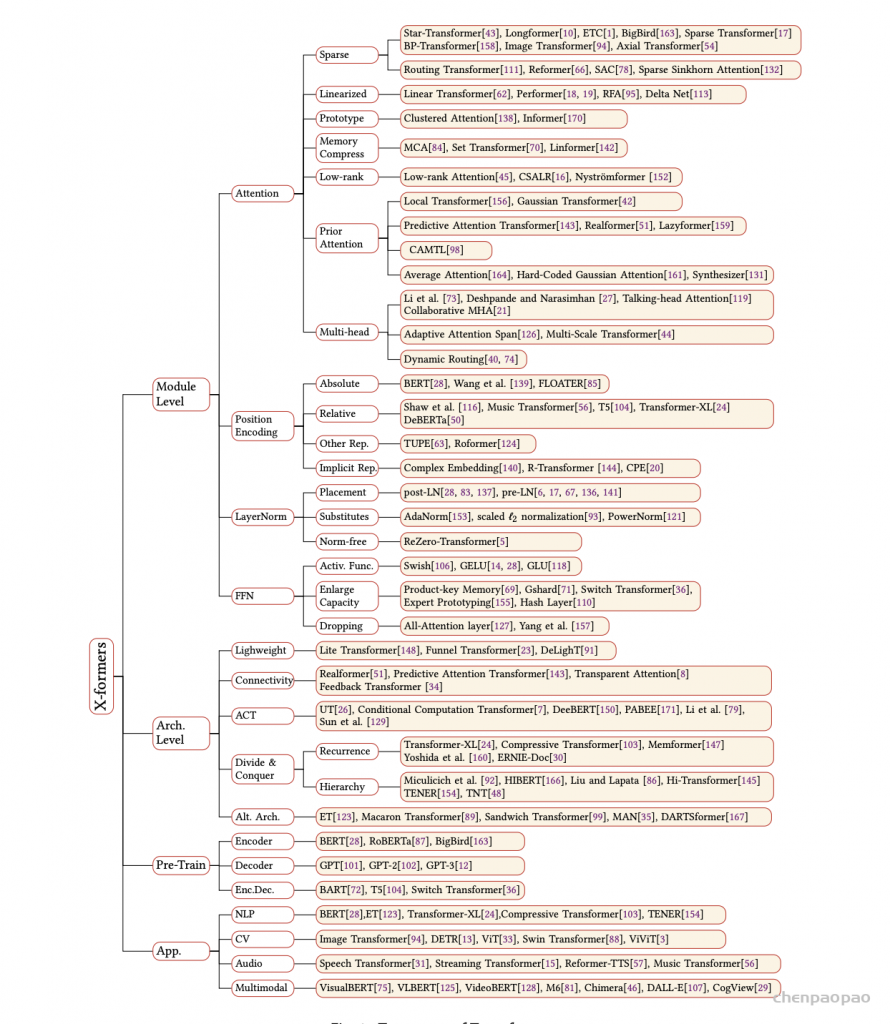
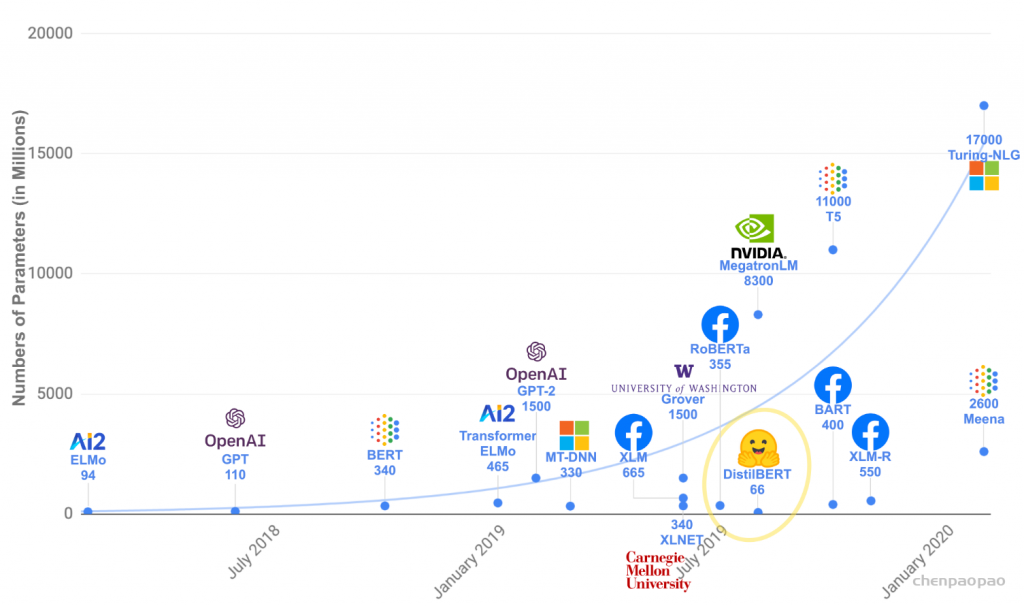
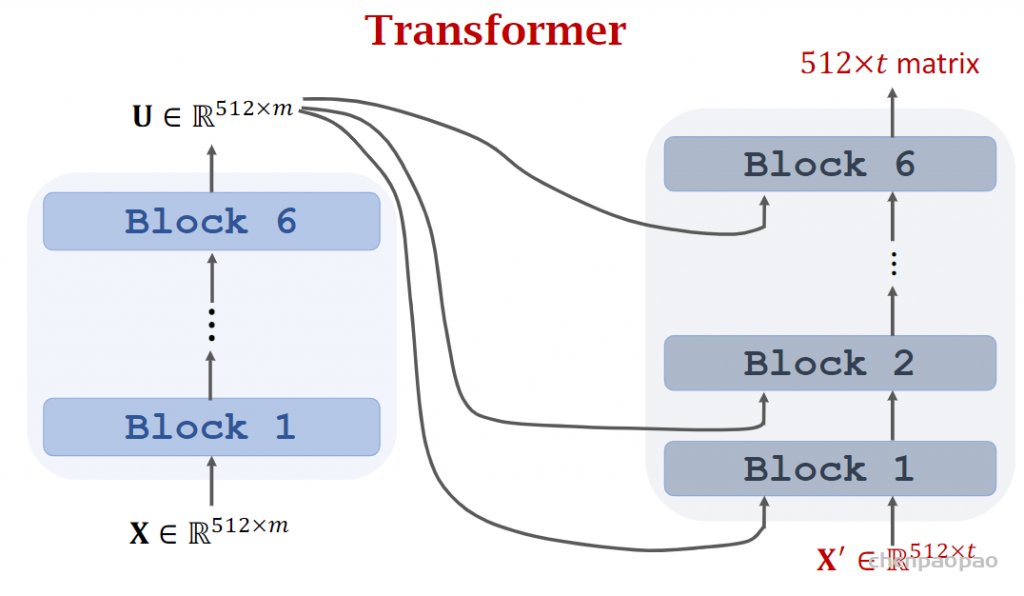
2017年,Attention Is All You Need论文首次提出了Transformer模型结构并在机器翻译任务上取得了The State of the Art(SOTA, 最好)的效果。2018年,BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding使用Transformer模型结构进行大规模语言模型(language model)预训练(Pre-train),再在多个NLP下游(downstream)任务中进行微调(Finetune),一举刷新了各大NLP任务的榜单最高分,轰动一时。2019年-2021年,研究人员将Transformer这种模型结构和预训练+微调这种训练方式相结合,提出了一系列Transformer模型结构、训练方式的改进(比如transformer-xl,XLnet,Roberta等等)。如下图所示,各类Transformer的改进不断涌现。
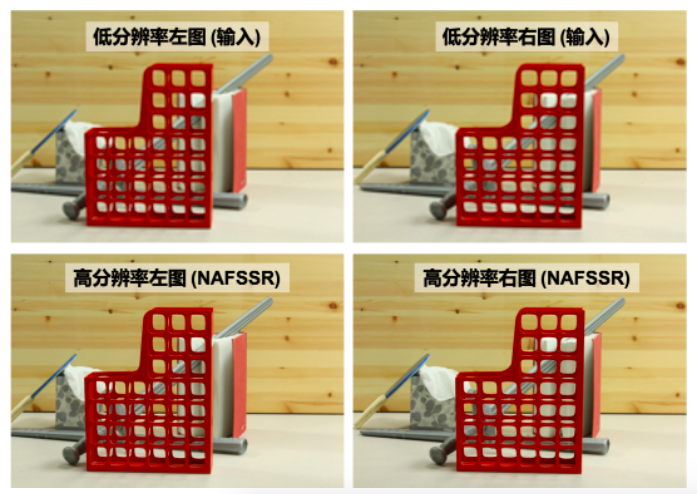
近日,New Trends in Image Restoration and Enhancement (以下简称:NTIRE) 比赛结果揭晓,旷视研究院荣获双目图像超分辨率赛道的冠军。NTIRE 即“图像恢复与增强的新趋势”,是近年来计算机图像恢复领域最具影响力的一场全球性赛事,由苏黎世联邦理工学院计算机视觉实验室(Computer Vision Laboratory, ETH Zurich)主办,每年都会吸引大量的关注者和参赛者。
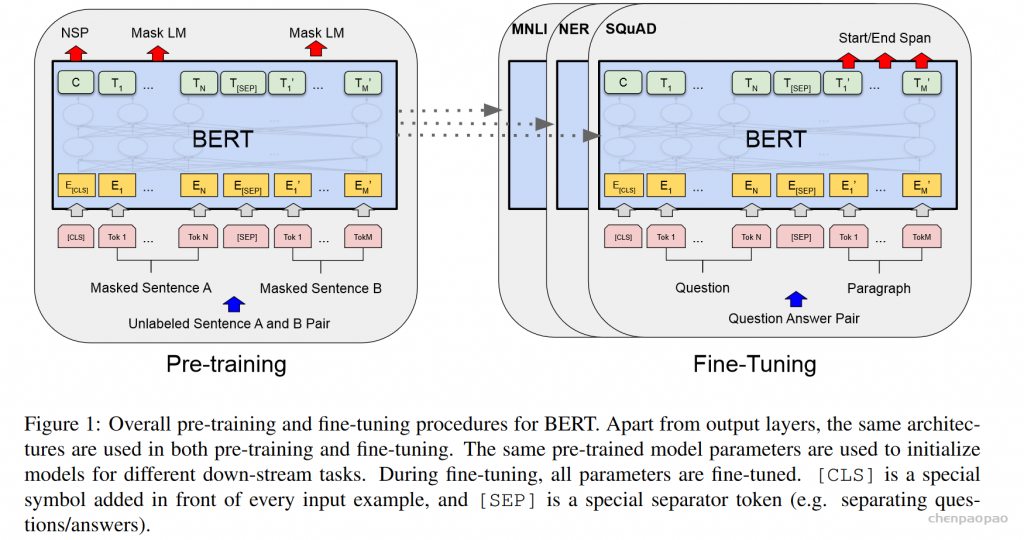
Transformer模型是目前机器翻译等NLP问题最好的解决办法,比RNN有大幅提高。Bidirectional Encoder Representations from Transformers (BERT) 是预训练Transformer最常用的方法,可以大幅提升Transformer的表现。
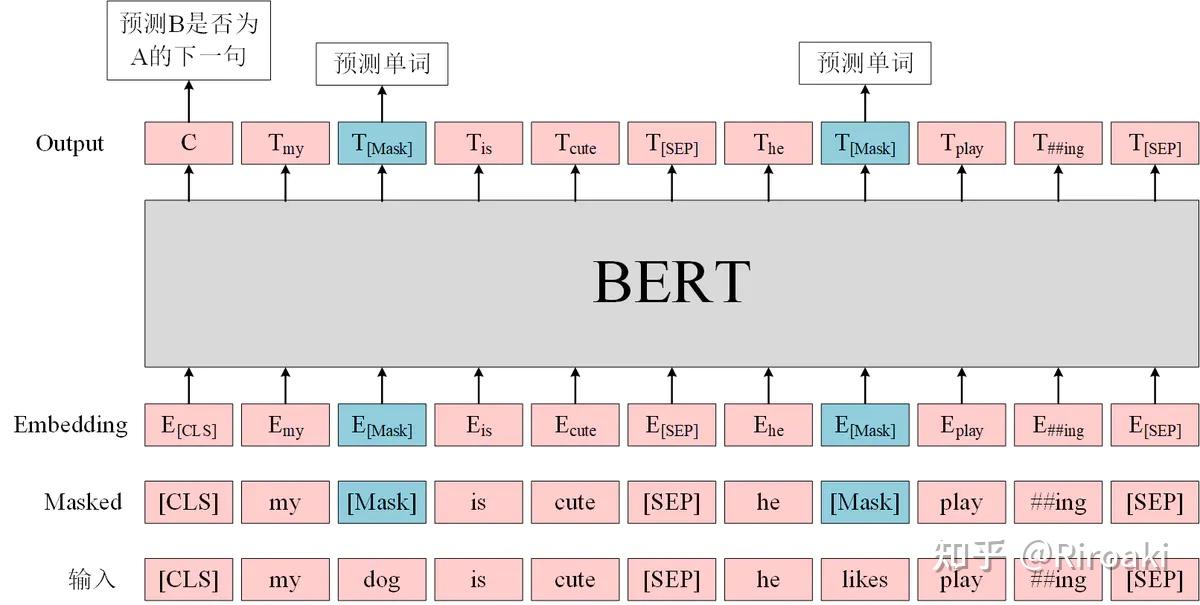
bert主要使用两个任务做训练:
1、预测被遮挡的单词
2、判断两句话是否相邻
任务一:
·𝐞: one-hot vector of the masked word “cat”. • 𝐩: output probability distribution at the masked position. • Loss = CrossEntropy(𝐞, 𝐩) . • Performing one gradient descent to update the model parameters.
Task 2: Predict the Next Sentence
Given the sentence: “calculus is a branch of math”. • Is this the next sentence? “it was developed by newton and leibniz”
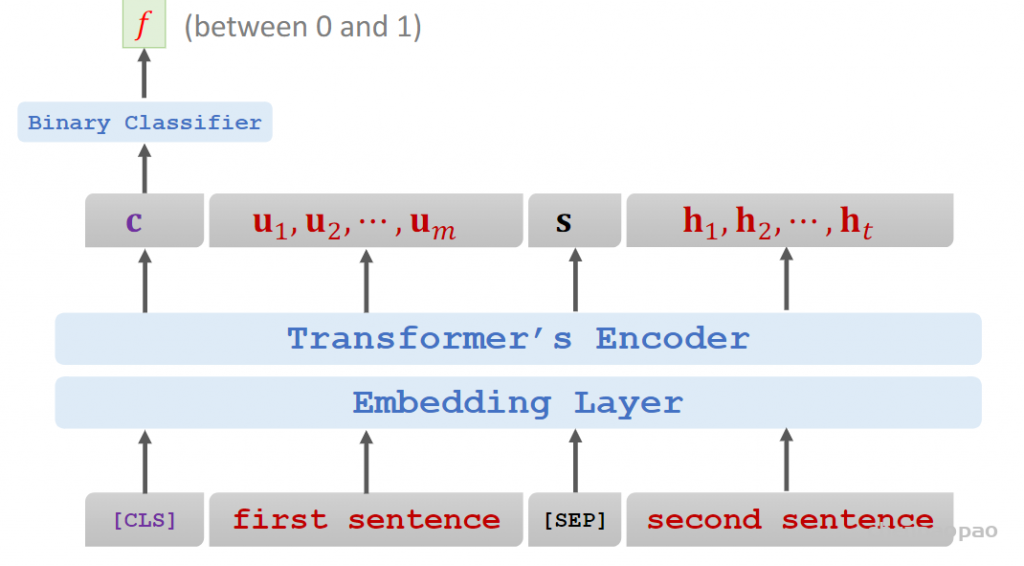
Input:两句话之间有sep符号分开,cls表示分类任务 [CLS] “calculus is a branch of math” [SEP] “it was developed by newton and leibniz” • [CLS] is a token for classification. • [SEP] is for separating sentences.
Input: [CLS] “calculus is a branch of math” [SEP] “it was developed by newton and leibniz” • Target: true
Combining the two methods:
• Input: “[CLS] calculus is a [MASK] of math [SEP] it [MASK] developed by newton and leibniz”. • Targets: true, “branch”, “was”.
bert同时使用两种任务结合:
Loss 1 is for binary classification (i.e., predicting the next sentence.) • Loss 2 and Loss 3 are for multi-class classification (i.e., predicting the masked words.) • Objective function is the sum of the three loss functions. • Update model parameters by performing one gradient descent
数据集:
BERT的bidirectional如何体现的?
论文研究团队有理由相信,深度双向模型比left-to-right 模型或left-to-right and right-to-left模型的浅层连接更强大。从中可以看出BERT的双向叫深度双向,不同于以往的双向理解,以往的双向是从左到右和从右到左结合,这种虽然看着是双向的,但是两个方向的loss计算相互独立,所以其实还是单向的,只不过简单融合了一下,而bert的双向是要同时看上下文语境的,所有不同。
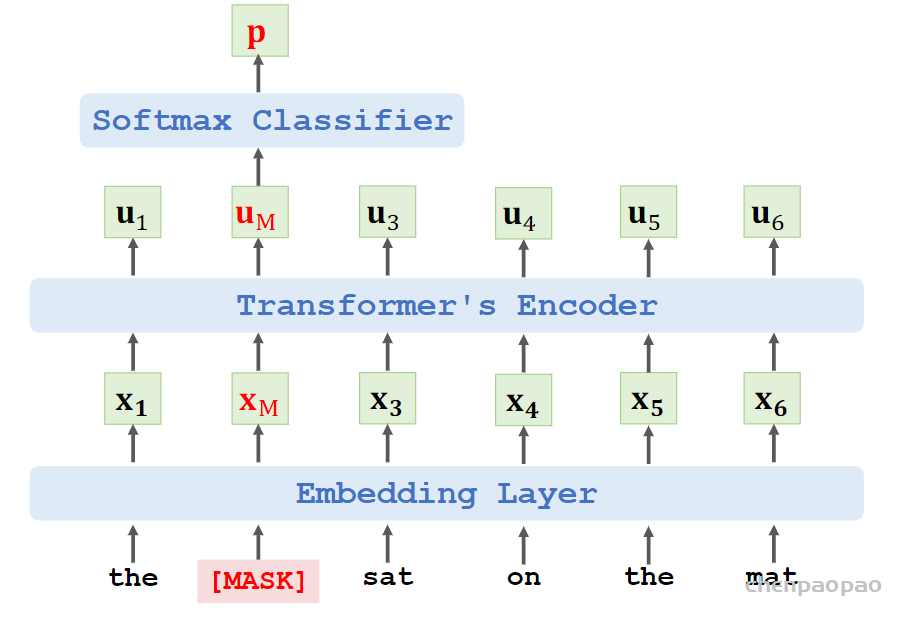
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token,(我理解这种情况下,模型如果想预测出这个masked的词,就必须结合上下文来预测,所以就达到了双向目的,有点类似于我们小学时候做的完形填空题目,你要填写对这个词,就必须结合上下文,BERT就是这个思路训练机器的,看来利用小学生的教学方式,有助于训练机器)。论文将这个过程称为“Masked Language Model”(MLM)。
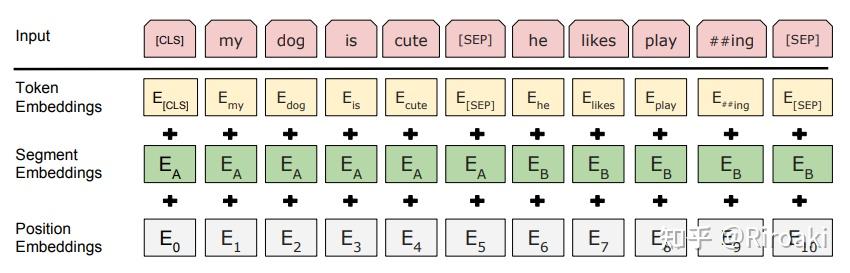
例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK] 10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple 10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。