参考:https://programmercarl.com/
回溯法,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
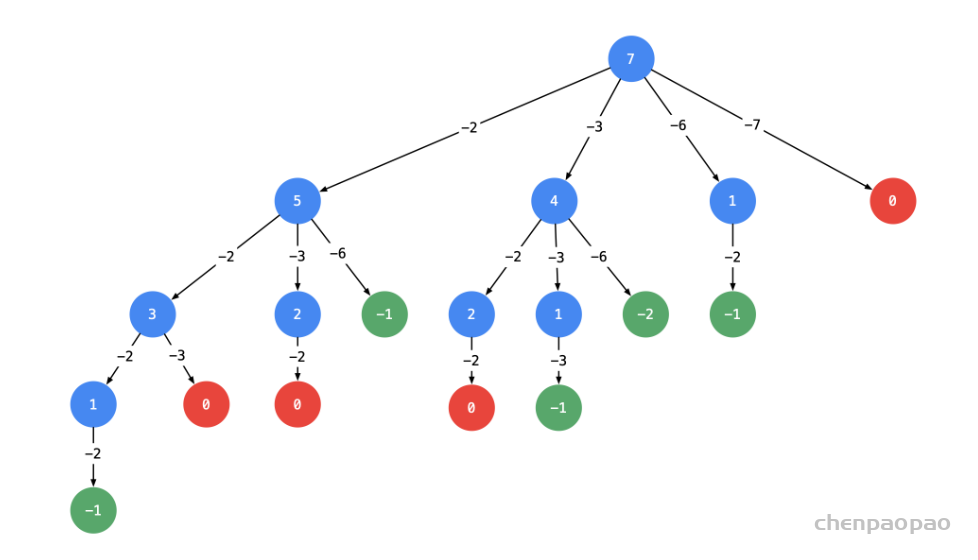
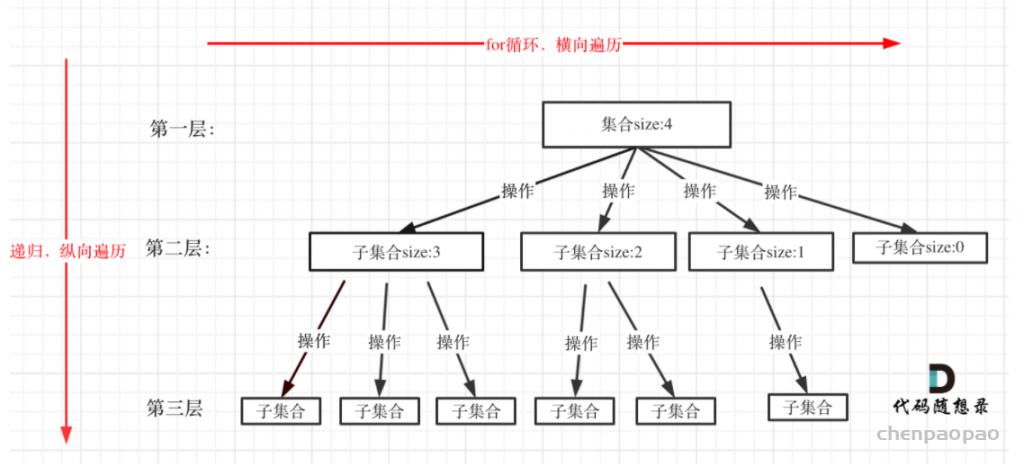
回溯法解决的问题都可以抽象为树形结构,是的,我指的是所有回溯法的问题都可以抽象为树形结构!因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,都构成的树的深度。递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
- 回溯函数模板返回值以及参数
在回溯算法中,我的习惯是函数起名字为backtracking,这个起名大家随意。
回溯算法中函数返回值一般为void。
再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
- 回溯函数终止条件
既然是树形结构,那么我们在讲解二叉树的递归 (opens new window)的时候,就知道遍历树形结构一定要有终止条件。
所以回溯也有要终止条件。
什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
所以回溯函数终止条件伪代码如下:
if (终止条件) {
存放结果;
return;
}
回溯函数遍历过程伪代码如下:
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。 backtracking这里自己调用自己,实现递归。
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
分析完过程,回溯算法模板框架如下:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
这份模板很重要,后面做回溯法的题目都靠它了!
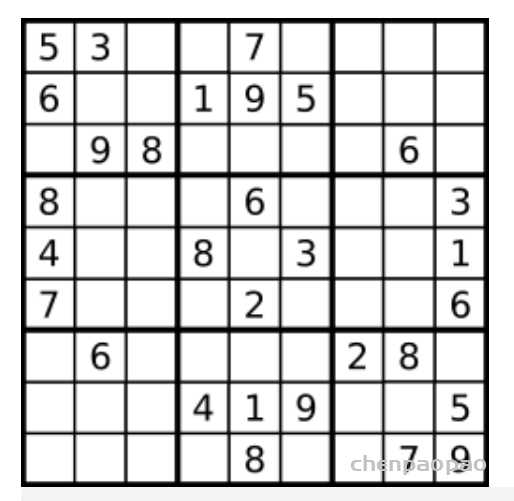
实例: 解数独 (回溯法)
#回溯法
"""
回溯法(探索与回溯法)是一种选优搜索法,又称为试探法,
按选优条件向前搜索,以达到目标。但当探索到某一步时,
发现原先选择并不优或达不到目标,就退回一步重新选择,
这种走不通就退回再走的技术为回溯法,
而满足回溯条件的某个状态的点称为“回溯点”。
"""
# @lc code=start
class Solution:
def solveSudoku(self, board)->None:
"""
Do not return anything, modify board in-place instead.
"""
#判断改行、列、3*3小格子是否满足数独规则:
def isRowSafe(row,value):
for i in range(9):
if board[row][i]==value:
return False
return True
def isColSafe(col,value):
for i in range(9):
if board[i][col]==value:
return False
return True
def isSmallboxSafe(row,col,value):
inirow=row//3*3
inicol=col//3*3
for i in range(3):
for j in range(3):
if board[i+inirow][j+inicol]==value:
return False
return True
#判断该位置是否可行
def isSafe(row,col,value):
return isRowSafe(row,value) and isColSafe(col,value) and isSmallboxSafe(row,col,value)
#解数独,结束条件(回溯法,递归调用)
def solve(row,col):
if row==8 and col ==9:
return True
if col ==9:
col=0
row+=1
if board[row][col]!=".":
return solve(row,col+1)
for i in range(1,10):
if isSafe(row,col,str(i)):
i=str(i)
board[row][col] = i
if solve(row, col+1):
return board
board[row][col]="."
return False
solve(0,0)
print(board)