

本文的主要参考是李沐老师关于 GPT 系列的解读:论文精读
GPT1: Improving Language Understanding by Generative Pre-Training (Generative Pre-Train Model 就是GPT模型的名字由来)
GPT2: Language Models are Unsupervised Multitask Learners
GPT3: Language Models are Few-Shot Learners
GPT3开发的demo: https://gpt3demo.com/
GPT-3: Demos, Use-cases, Implications
More concretely:
- Language model performance scales as a power-law of model size, dataset size, and the amount of computation.
- A language model trained on enough data can solve NLP tasks that it has never encountered. In other words, GPT-3 studies the model as a general solution for many downstream jobs without fine-tuning.
关于BERT和GPT
Transformer/BERT/GPT 时间线:Transformer —> GPT —> BERT —-> GPT2 —> GPT3。
如果去查 GPT 系列和 BERT 的引用数量,会发现 BERT 一篇的引用比 GPT 系列三篇加起来还多几倍,因此 BERT 在学界影响力更大是毋庸置疑的。但这并不能说明 BERT 的预训练任务就比 GPT 的更 “好”。首先,GPT 早于 BERT 提出在无监督的语料上进行大规模预训练,BERT 一定程度上也是受到 GPT 的启发。其次,GPT 的预训练任务是标准的语言模型(Language Model),即自回归式(auto-regressive)地预测句子中的下一个单词,相比于 BERT “完形填空” 式的预训练任务,无疑要难上许多。这使得 GPT 必须模型够大、数据够多才能训练起来,得到比较好的结果。这也是为什么 BERT 只有一篇论文,而 GPT 还有 GPT-2、GPT-3,通过不断扩增模型和数据的规模,最终使得 GPT-3 有如此惊艳的效果。对于这样困难的预训练任务和巨大的资源需求,一般的公司或个人根本玩不转。而 BERT 由于任务难度较小,相对并不需要那么多资源就可以进行预训练和微调,这也是为什么 BERT 的后续工作那么多(体现在引用量上)。但是,语言模型预测下一个单词的生成式任务,使得 GPT 的上限极高,GPT-3 通过写出足以以假乱真的文章,成为了最火出圈的 NLP 模型。另外,由于语言模型生成式任务的灵活性和巨大的预训练规模,GPT 甚至可以不需要(更新模型参数的)微调,而是通过文本 prompt 提示,就可以直接处理下游任务。
另外,很多人喜欢从从模型结构上来将 BERT 和 GPT 进行区分:BERT 使用了 Transformer 的编码器,适合于判别式任务;GPT 使用了 Transformer 的解码器,适合于生成式任务。然而,使用什么样的模型结构并不是 BERT 和 GPT 的本质区别。二者的本质区别在于选用了什么样的预训练目标函数,选用 Transformer 的编码器或解码器只是在确定了目标函数之后的必然选择。GPT 选用的是标准语言模型的目标函数,预测句子中的下一个单词,此时模型应该只能看到当前词和它之前的词,所以必须将当前词后面的词全部 mask 掉,故而选用带有 masked self-attention 的 Transfomer 解码器;而 BERT 是设计了一种 “完形填空” 式的预训练任务,根据当前词前后的内容还原当前词,此时模型应该可以看到整个序列的所有单词(当前词已被替换为特殊 token),故而选用了 Transformer 的编码器。当然,在讨论 BERT 与 GPT 时,将它们各自选用的架构作为直观的区分方式也是没有问题的。
GPT-1
Paper:Improving Language Understanding by Generative Pre-Training
前言
GPT 首先提出了在无监督的大规模预料上进行预训练,再在下游任务上进行微调的训练范式。至于为什么使用 Transformer 模型,而非 RNN,作者指出:Transformer 模型有更结构化的记忆(more structured memory),能够更好地处理文本中的长距离(long-term)依赖关系,从而能更好地抽取出句子层面和段落层面的语义信息,因此在迁移学习中,Tranformer 学习到的特征更加稳健。在迁移学习时,GPT 设计了各种任务相关(task-specific)的输入表示。
这里所谓的更结构化的记忆、长距离文本信息的论述,笔者是这样理解的:RNN(如 LSTM) 需要一步一步地处理序列内容,如果序列距离过长,可能走到后面时,前面的信息会有所丢失;而在 Transformer 中,自注意力机制的计算是完全并行的,序列的位置信息是通过位置嵌入来编码的,就不会有这个问题,即李宏毅老师所说的:“天涯若比邻”。
方法
原文方法部分分为三个小节,分别介绍如何在无标注的数据上进行自监督预训练、怎样进行微调、怎样对于不同的 NLP 下游任务构造输入。
预训练:

微调
方法部分的第二小节介绍了如何在预训练完成之后,在下游任务上进行微调。
假设有带标签数据集C ,其中每个样本是一个由一系列单词组成的句子和标签 y 组成。将句子输入到 GPT 模型中,取最后一个 transformer block 最后一个单词的输出特征,将它送入到线性层中进行预测:

不同任务的输出构造
介绍完如何微调之后,接下来就要介绍如何将 NLP 中不同的下游任务的输入表示成第二小节中句子+标签 的形式。如下图右侧所示,图中展示了几种不同类型的 NLP 下游任务适配 GPT 预训练模型的输入构造方法:
分类任务
- 任务简介:任务给定一段文本,输出分类结果。例如:情感分类。
- 构造方法:将给定的文本首尾各加上一个 token Start/Extract,然后送到 GPT 预训练模型中,将输出特征接一个线性层进行分类。分类任务与之前微调小节介绍的做法是完全一致的,
蕴含任务(非对称性句子关系任务)
- 任务简介:给定两段文本,判断前者对后者关系。例如:蕴含任务,判断第一句对第二句的关系是蕴含/不蕴含/无关。
- 构造方法:将两个句子中间添加一个分割 token Delim,然后将整个文本的首尾再加上 Start/Extract,送入 GPT 预训练模型,将输出特征送入线性层分类。
相似度任务(对称性句子关系任务)
- 任务简介:给定两段文本,判断二者关系。例如:相似度任务,判断两个句子是否相似。
- 构造方法:将两个句子分别作为前句或后句,构造两个完整文本,各自送入 GPT 预训练模型,提取出特征并进行融合,再送入线性层分类。
多选任务
- 任务简介:给定一段文本和多个答案,判断哪个正确。
- 构造方法:将给定文本和 N 个答案结合,构造 N 个完整文本,各自送入 GPT 预训练模型,提取出特征并送入线性层,取置信度最大者。
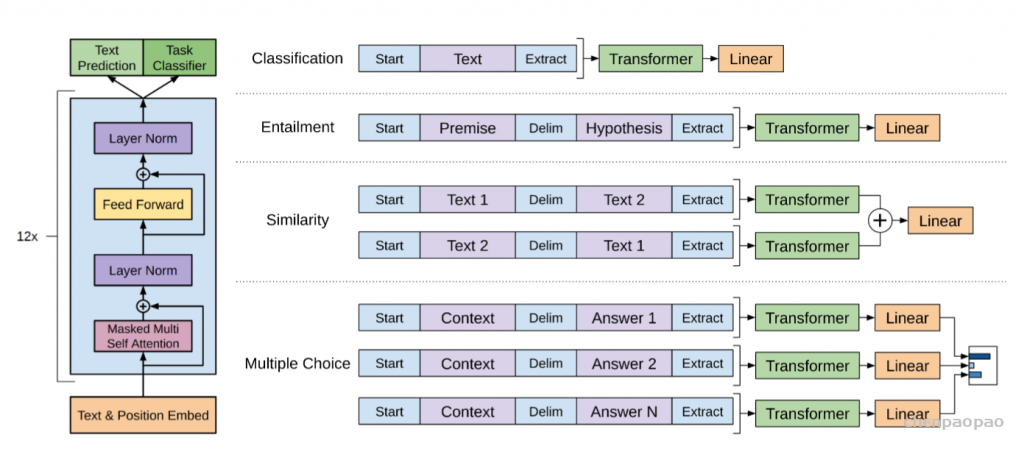
GPT模型结构(左)与微调下游任务输入构造方式(右)
注意图中的开始符(Start)、分隔符(Delim)、结束符(Extract)不是这几个单词本身,而是三个特殊的符号。
GPT-2
前言
GPT 出现后不久,BERT 就提出了。通过新型的 MLM(Masked Language Model)任务和更大的模型、更大的训练数据量,在多项指标上超越了 GPT。GPT 的作者想要再次反超,首先肯定要扩大模型和数据的规模。但是除此之外,GPT-2 还有一个惊人的设定:zero-shot(零样本)。顾名思义,在 zero-shot 设定下,模型在预训练完成之后不需要任何下游任务的标注数据来进行微调,而是直接进行预测。
GPT-2 在研究思路上带给我们的启示是:有时候做研究不一定要在一个既定指标上死磕。在方法没有大创新的情况下,通过 “大力出奇迹” ,即使能够比之前方法有所提升,文章也会显得有些无聊。这时可以思考一些设定上的创新,如本文的 zero-shot,这时即使指标上提升不多甚至持平,也会有更有新意、更有趣。
方法
GPT2还是做语言模型,但是在做到下游任务的时候,会用一个叫做zero-shot的设定,zero-shot是说,在做到下游任务的时候,不需要下游任务的任何标注信息,那么也不需要去重新训练已经预训练好的模型。这样子的好处是我只要训练好一个模型,在任何地方都可以用。
如果作者就是在GPT1的基础上用一个更大的数据集训练一个更大的模型,说我的结果比Bert好一些,可能也就好那么一点点,不是好那么多的情况下,大家会觉得gpt2这篇文章就没什么意思了,工程味特别重。那么我换一个角度,选择一个更难的问题,我说做zero-shot。虽然结果可能没那么厉害了,没那么有优势,但是新意度一下就来了。
GPT-2 的模型跟 GPT-1 一样,这里就不再过多介绍。本节主要来说一下 zero-shot 要怎么做。
在 GPT-1 中,模型预训练完成之后会在下游任务上微调,在构造不同任务的对应输入时,我们会引入开始符(Start)、分隔符(Delim)、结束符(Extract)。虽然模型在预训练阶段从未见过这些特殊符号,但是毕竟有微调阶段的参数调整,模型会学着慢慢理解这些符号的意思。现在,在 GPT-2 中,要做的是 zero-shot,也就是没有任何调整的过程了。这时我们在构造输入时就不能用那些在预训练时没有出现过的特殊符号了。所幸自然语言处理的灵活性很强,我们只要把想要模型做的任务 “告诉” 模型即可,如果有足够量预训练文本支撑,模型想必是能理解我们的要求的。
举个机器翻译的例子,要用 GPT-2 做 zero-shot 的机器翻译,只要将输入给模型的文本构造成 translate english to chinese, [englist text], [chinese text] 就好了。比如:translate english to chinese, [machine learning], [机器学习] 。这种做法就是日后鼎鼎大名的 prompt。
在训练数据的收集部分,作者提到他们没有使用 Common Crawl 的公开网页爬取数据,因为这些数据噪声太多,太多无意义的内容。他们是去 Reddit 爬取了大量有意义的文本。作者还指出,在 Reddit 的高质量文本中,很可能已经有类似 zero-shot 构造方式的样本供模型学习。一个机器翻译的例子如下所示。
In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: ”Mentez mentez, il en restera toujours quelque chose,” which translates as, ”Lie lie and something will always remain.”
实验
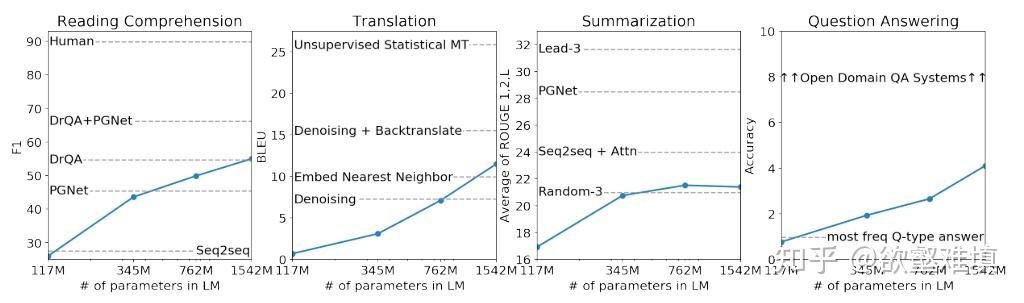
在与同样为 zero-shot 模型的对比上,肯定是吊打了之前的 SOTA,这里就不展示了。可以关注一下下面 GPT-2 模型 zero-shot 性能关于模型规模的曲线。在有些任务上已经接近、超过之前某些有监督的方法;在比较困难的任务上,比如开放域问答,完全还看不到别人的影子。然而,看看曲线末端性能随模型规模提升的趋势,完全没有收敛的意思,这最后一段翘起的曲线,昭示着 GPT-3 继续大力出奇迹,从量变到质变的希望。
GPT-3
前言
根据沐神关于论文价值给出的公式:论文价值 = 有效性 * 新意度 * 问题的大小。GPT-2 虽然通过 zero-shot 的设定,将自己的新意度凸显了出来,但是有效性(绝对性能)还是不太令人满意。GPT-3 ,众所周知的 “大力出奇迹” 式的文章,通过海量数据训练了一个 175 Billion 参数的预训练语言模型,性能直接拉满。甚至有点从量变到质变的意思,GPT-3 通过自回归式语言模型的生成能力,可以生成一些像模像样的文章,有时人类都很难读出这些文章是出自于 AI 模型生成,这也是为什么 GPT-3 能够成为 NLP 领域最火出圈的模型,文本生成能力使得它玩法众多。在任务设定上,GPT-3 没有固守于 GPT-2 的 zero-shot 方式。因为即使对于人类来说,要完成一个新任务,如果一个示例也不给的话,也有点强人所难了。如标题所示,GPT-3 采用了 few-shot 的任务设定,即给出下游任务的一两个例子,然后要求模型对该任务的新问题给出预测。当然,如此大规模的模型,即使是一两个样本,用梯度下降法微调模型权重也很费劲。因此,GPT-3 中所谓的 “few-shot”,与一般的根据支持集(下游任务示例)进行梯度下降更新参数的 few-shot 方法不同,它是利用自然语言的灵活性,将支持集示例放到 prompt 里,让模型自己理解示例,完成下游任务 few-shot 预测。
下图展示了 GPT-3 在不同的 NLP 任务上的性能随模型规模的变化,橙、绿、蓝分别代表 few-/one-/zero shot 方式,淡化的曲线是在不同任务上各自的准确率。实线是平均准确率。可以看到,随着模型规模的增大,性能还是有一定提升的。

方法
GPT-3 的预训练方式和之前还是一样的,模型结构也改动不大。还是在 Transformer 解码器上做标准语言模型的预训练,但是模型规模和数据规模大了几个数量级。这里我们还是主要来看一下 GPT-3 中所谓的 few-/one-/zero- shot 方式分别是什么意思。
下图展示了 GPT-3 中的 few-/one-/zero- shot 方式与常规的微调方式。
- 微调方式的小样本学习,需要根据给出的下游任务样本和标注,构造损失函数,方向传播梯度,更新模型权重,然后进行预测。GPT-3 中完全没有采取这种方式。
- Zero-shot,给定任务描述,如
Translate English to French,然后直接给出问题,要求模型给出答案。这种方式与 GPT-2 一致。 - One-shot,给定任务描述,然后给一个例子,包括问题和答案,如
sea otter => loutre de mer,之后再给出问题,将上述整一段文本作为输入,要求模型给出答案。这种方式期望模型利用预训练阶段海量的文本数据积累和 Tranformer 的自注意力机制,理解问题和示例,然后仿照示例给出预测。
笔者认为这种方式可行的根本原因是自然语言的灵活性和生成式模型的创造性,使得我们能够直接跟模型进行交互,把要做什么任务、任务示例直接 “打字告诉它”。在计算机视觉领域,好像很难做到类似的事情。 - Few-shot,与 One-shot 类似,只是给的示例更多。
GPT-3 中的任务设定很惊艳,但是细想之下,也是无奈之举并且也有缺点。一方面,模型规模实在太大,微调来更新权重参数不可行,只好采用 few-shot 的方式。另一方面,模型权重不能更新,每次理解下游任务之后不能保存下来,也就是说每次做同一个下游任务都要给同样的例子。还有,下游任务的示例也不能太多,因为模型可能无法处理过长的输入序列。如果在我们的实际下游任务中确实有不少可供学习的样本,GPT-3 恐怕不是一个好的选择。所以,虽然 GPT-3 能做到的事情似乎听起来更接近 “人工智能”,但是相关的跟进工作并不多。
这应该是作者们充分挖掘模型能力,规避模型缺点,扬长避短设计出的任务设定,这种思路值得学习。

关于大规模预训练的调参、数据准备与清洗、工程实践等,GPT-3 论文中也有讨论,这里就不提了,有兴趣可以参考原文。
再后面关于实验、GPT-3 的不足以及可能的社会影响作者写了很多,本文主要关注算法部分,后面就不一一介绍了,同样请参考原文。