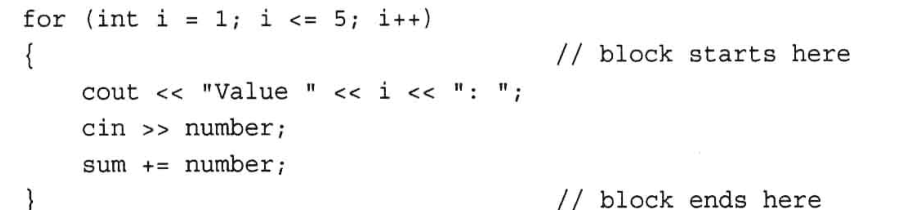给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
示例 3:
输入:nums1 = [0,0], nums2 = [0,0]
输出:0.00000
示例 4:
输入:nums1 = [], nums2 = [1]
输出:1.00000
第一次解题:
# @lc code=start
class Solution:
def findMedianSortedArrays(self, nums1: List[int], nums2: List[int]) -> float:
nums3=sorted(nums1+nums2)
length= len(nums3)
return nums3[length//2] if length%2==1 else (nums3[length//2]+nums3[length//2-1])/2
# @lc code=end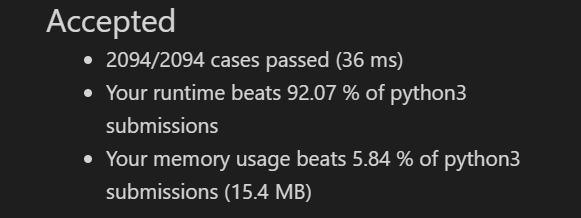
占用的内存太高了….
改进:
不需要合并两个有序数组,只要找到中位数的位置即可。由于两个数组的长度已知,因此中位数对应的两个数组的下标之和也是已知的。维护两个指针,初始时分别指向两个数组的下标 0 的位置,每次将指向较小值的指针后移一位(如果一个指针已经到达数组末尾,则只需要移动另一个数组的指针),直到到达中位数的位置。
class Solution:
def findMedianSortedArrays(self, nums1: List[int], nums2: List[int]) -> float:
def getKthElement(k):
“””
– 主要思路:要找到第 k (k>1) 小的元素,那么就取 pivot1 = nums1[k/2-1] 和 pivot2 = nums2[k/2-1] 进行比较
– 这里的 “/” 表示整除
– nums1 中小于等于 pivot1 的元素有 nums1[0 .. k/2-2] 共计 k/2-1 个
– nums2 中小于等于 pivot2 的元素有 nums2[0 .. k/2-2] 共计 k/2-1 个
– 取 pivot = min(pivot1, pivot2),两个数组中小于等于 pivot 的元素共计不会超过 (k/2-1) + (k/2-1) <= k-2 个
– 这样 pivot 本身最大也只能是第 k-1 小的元素
– 如果 pivot = pivot1,那么 nums1[0 .. k/2-1] 都不可能是第 k 小的元素。把这些元素全部 “删除”,剩下的作为新的 nums1 数组
– 如果 pivot = pivot2,那么 nums2[0 .. k/2-1] 都不可能是第 k 小的元素。把这些元素全部 “删除”,剩下的作为新的 nums2 数组
– 由于我们 “删除” 了一些元素(这些元素都比第 k 小的元素要小),因此需要修改 k 的值,减去删除的数的个数
“””
index1, index2 = 0, 0
while True:
# 特殊情况
if index1 == m:
return nums2[index2 + k - 1]
if index2 == n:
return nums1[index1 + k - 1]
if k == 1:
return min(nums1[index1], nums2[index2])
# 正常情况
newIndex1 = min(index1 + k // 2 - 1, m - 1)
newIndex2 = min(index2 + k // 2 - 1, n - 1)
pivot1, pivot2 = nums1[newIndex1], nums2[newIndex2]
if pivot1 <= pivot2:
k -= newIndex1 - index1 + 1
index1 = newIndex1 + 1
else:
k -= newIndex2 - index2 + 1
index2 = newIndex2 + 1
m, n = len(nums1), len(nums2)
totalLength = m + n
if totalLength % 2 == 1:
return getKthElement((totalLength + 1) // 2)
else:
return (getKthElement(totalLength // 2) + getKthElement(totalLength // 2 + 1)) / 2









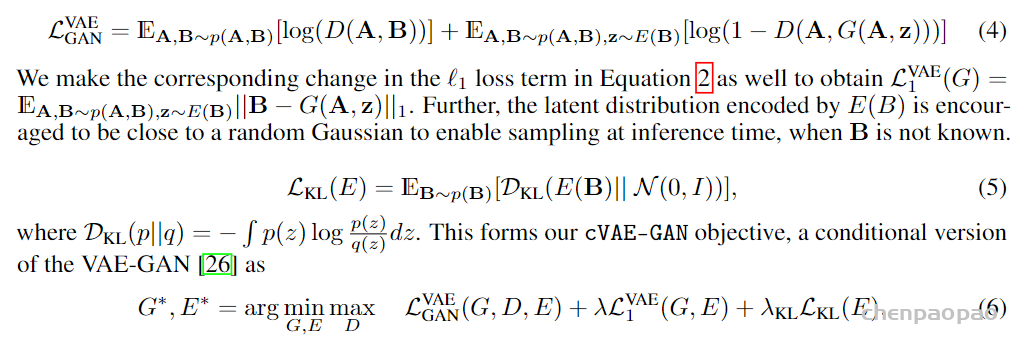
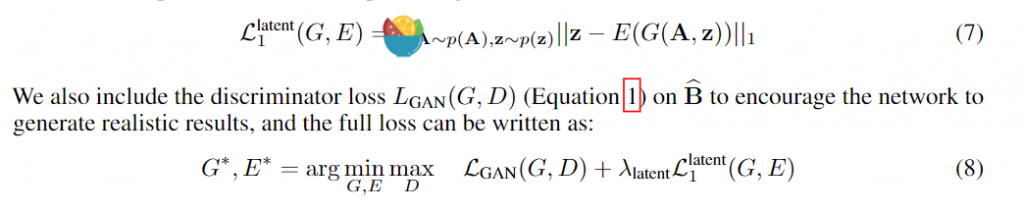

 。 此时为了衡量重构和真实的误差,这里用了L1损失和GAN的对抗思想实现,我们在后面损失函数分析部分再说。这样cVAE-GAN部分就可以训练了,cVAE GAN的重点还是在得到的embedding z。
。 此时为了衡量重构和真实的误差,这里用了L1损失和GAN的对抗思想实现,我们在后面损失函数分析部分再说。这样cVAE-GAN部分就可以训练了,cVAE GAN的重点还是在得到的embedding z。