最近有个项目关于FPGA加速神经网络,因此需要了解相关PS和pl交互的方法,从而将权重数据存放在PS的DDR中 ,并在需要时完成数据的存入和读出。这是一篇归纳性的文章,具体的还需要自行查阅资料。

PS-PL数据交互方式
1、IO
个数 | 分布 | 控制 | |
|---|---|---|---|
| MIO | 54 | BANK0, 1 | PS直接控制 |
| EMIO | 64 | BANK2, 3 | 需要PL配置引脚 |
| GPIO | AXI-GPIO |
MIO :ZYNQ 分为 PS 和 PL 两部分,那么器件的引脚(Pin)资源同样也分成了两部分。ZYNQ PS 中的外设可以通过 MIO(Multiuse I/O,多用输入/输出)模块连接到 PS 端的引脚上,也可以通过 EMIO 连接到 PL 端的引脚。Zynq-7000 系列芯片一般有 54 个 MIO,个别芯片如 7z007s 只有 32 个。
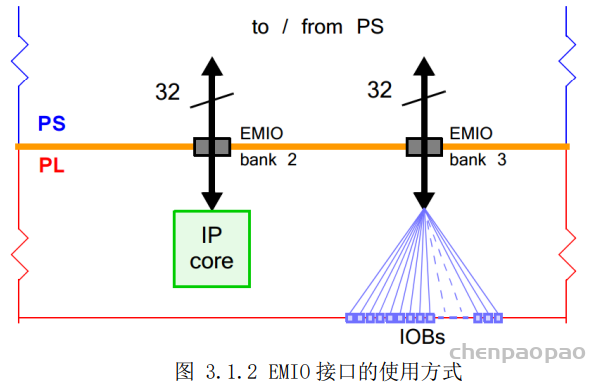
EMIO : PS 和外部设备之间的通信主要是通过复用的输入/输出(Multiplexed Input/Output,MIO)实现的。除此之外,PS 还可以通过扩展的 MIO(Extended MIO,EMIO)来实现与外部设备的连接。EMIO 使用了 PL 的I/O 资源,当 PS 需要扩展超过 54 个引脚的时候可以用 EMIO,也可以用它来连接 PL 中实现的 IP 模块。
在大多数情况下,PS 端经由 EMIO 引出的接口会直接连接到 PL 端的器件引脚上,通过 IO 管脚约束来指定所连接 PL 引脚的位置。通过这种方式,EMIO 可以为 PS 端实现额外的 64 个输入引脚或 64 个带有输出使能的输出引脚。EMIO 还有一种使用方式,就是用于连接 PL 内实现的功能模块(IP 核),此时 PL 端的 IP 作为 PS 端的一个外部设备。(EMIO既可以将ps和pl端的引脚相连,也可以和pl中的模块相连)
PS 与 PL 最主要的连接方式则是一组 AXI 接口。AXI 互联和接口作为 ZYNQ PS 和 PL 之间的桥梁,能够使两者协同工作,进而形成一个完整的、高度集成的系统。
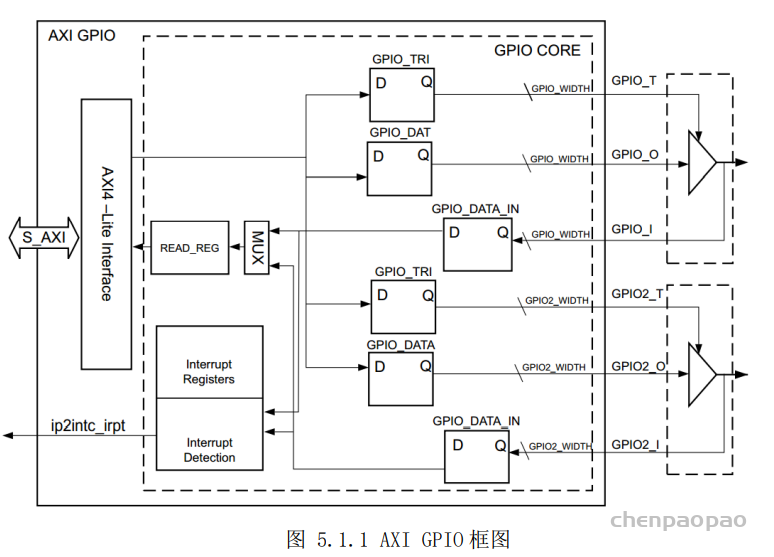
GPIO : AXI GPIO IP 核为 AXI 接口提供了一个通用的输入/输出接口。与 PS 端的 GPIO 不同,AXI GPIO 是一个软核(Soft IP),即 ZYNQ 芯片在出厂时并不存在这样的一个硬件电路,而是由用户通过配置 PL 端的逻辑资源来实现的一个功能模块。而 PS 端的 GPIO 是一个硬核(Hard IP),它是一个生产时在硅片中实现的功能电路。 AXI GPIO IP 模块的左侧实现了一个 32 位的 AXI4-Lite 从接口,用于主机访问 AXI GPIO 内部各通道的寄存器。
中断
参考:
https://blog.csdn.net/wangjie36/article/details/116081755
中断是一种当满足要求的突发事件发生时通知处理器进行处理的信号。中断可以由硬件处理单元和外部设备产生,也可以由软件本身产生。对硬件来说,中断信号是一个由某个处理单元产生的异步信号,用来引起处理器的注意。对软件来说,中断还是一种异步事件,用来通知处理器需要改变代码的执行,不过,轮询所产生的中断的过程是同步的。
Zynq 芯片的 PS 部分是基于使用双核 Cortex-A9 处理器和 GIC pl390 中断控制器的 ARM 架构。中断结构与 CPU 紧密链接,并接受来自 I/O 外设(IOP)和可编程逻辑(PL)的中断。
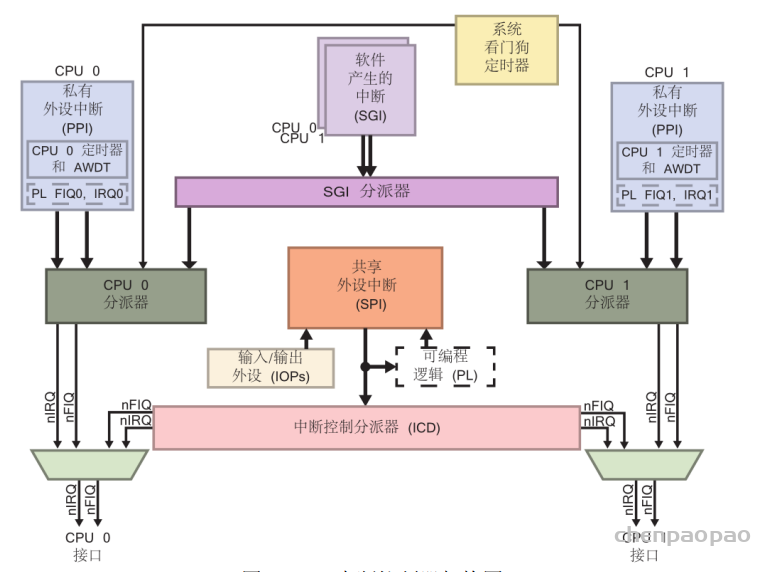
ZYNQ CPU 软件中断(SGI,Software generatedinterrupts):ZYNQ 共有两个 CPU,每个 CPU 具备各自的 16 个软件中断(中断号0-15)(16–26 reserved):被路由到一个或者两个CPU上,通过写ICDSGIR寄存器产生SGI。
CPU私有外设中断(PPI,private peripheralinterrupts ):私有中断是固定的不能修改。这里有 2 个 PL 到 CPU 的快速中断 nFIQ(中断号27-31):每个CPU都有一组PPI,包括全局定时器、私有看门狗定时器、私有定时器和来自PL的FIQ/IRQ。
ZYNQ PS 和 PL 共享中断(SPI,shared peripheralinterrupts):共享中断就是一些端口共用一个中断请求线:(中断号32-95)。由PS和PL上的各种I/O控制器和存储器控制器产生,这些中断信号被路由到相应的CPU, PL部分有16个共享中断,它们的触发方式可以设置。
FIFO
https://zhuanlan.zhihu.com/p/47847664
| FIFO类型 | 读接口 | 写接口 |
|---|---|---|
| AXI Data FIFO | AXI4-full | AXI4-full |
| AXI-Stream FIFO | PS axi4-lite | PL axi-stream |
| AXI4-Stream Data FIFO | axi-stream | axi-stream |
通过AXI-Stream FIFO完成PS和PL部分的数据交互
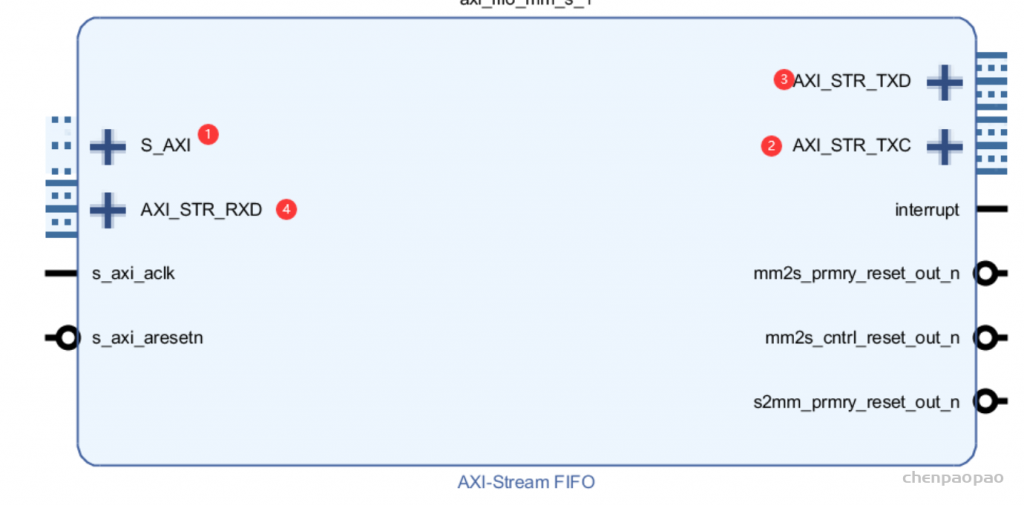
- S_AXI, PS读写FIFO数据接口
- AXI_STR_TXC, 发送控制端口
- AXI_STR_TXD,发送数据端口
- AXI_STR_RXD,接收数据端口
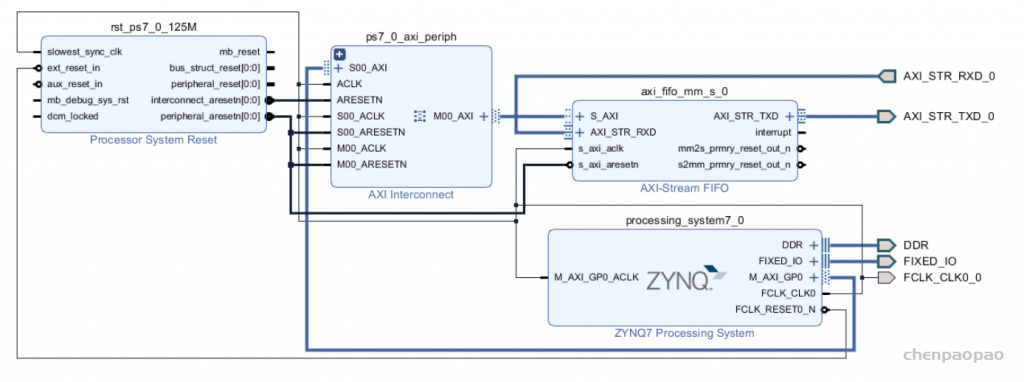
读写fifo例程:
写fifo
//write fifo us1
always@(posedge wrclk, negedge sys_reset_n_i)
begin
if (!sys_reset_n_i)
begin
fifo_wrreq_ddr3_us <= 0 ;
fifo_data_ddr3_us <= 0 ;
end
else
begin
if(fifo_prog_full_ddr3_us!= 1)
fifo_wrreq_ddr3_us <= 1 ;
else
fifo_wrreq_ddr3_us <= 0 ;
if(fifo_wrreq_ddr3_us == 1)
begin
if(fifo_data_ddr3_us < 64'b1111_1111_1111_1111_1111_1111)
fifo_data_ddr3_us <=fifo_data_ddr3_us + 1 ;
else
fifo_data_ddr3_us <= 0 ;
end
else
fifo_data_ddr3_us <= fifo_data_ddr3_us ;
end
end
endmodule
读fifo
assign fifo_rdreq_ddr3_ds = !fifo_empty_ddr3_ds;
always@(posedge sys_clk_i,negedge sys_reset_n_i)
begin
if(!sys_reset_n_i)
rd_ck_flag_cp<= 1'b0;
else
begin
if (fifo_q_ddr3_ds_r!==fifo_q_ddr3_ds)
rd_ck_flag_cp<= 1'b1;
else
rd_ck_flag_cp<= 1'b0;
end
end
//jiao yan cuo wu ji shu jiao yan wei zi zeng
always@(posedge sys_clk_i,negedge sys_reset_n_i)
begin
if(!sys_reset_n_i)
begin
rd_ck_cnt <= 64'b0;
fifo_q_ddr3_ds_r <= 64'b0 ;
end
else
begin
if(rd_ck_flag_cp==1)
rd_ck_cnt <=rd_ck_cnt+1'b1;
else
rd_ck_cnt <= rd_ck_cnt;
if ( ( fifo_rdreq_ddr3_ds==1 ) && (fifo_q_ddr3_ds_r < 64'b1111_1111_1111_1111_1111_1111) )
fifo_q_ddr3_ds_r <= fifo_q_ddr3_ds_r + 1'b1 ;
else
fifo_q_ddr3_ds_r <= 64'b0;
end
end
endmoduleBRAM
在 ZYNQ SOC 开发过程中,PL 和 PS 之间经常需要做数据交互。对于传输速度要求较高、数据量大、地址连续的场合,可以通过 AXI DMA 来完成。而对于数据量较少、地址不连续、长度不规则的情况,此时 AXIDMA 便不再适用了。针对这种情况,可以通过 BRAM 来进行数据的交互。
BRAM(Block RAM)是 PL 部分的存储器阵列,PS 和 PL 通过对 BRAM 进行读写操作,来实现数据的交互。在 PL 中,通过输出时钟、地址、读写控制等信号来对 BRAM 进行读写操作;而在 PS 中,处理器并不需要直接驱动 BRAM 的端口,而是通过 AXI BRAM 控制器来对 BRAM 进行读写操作。AXI BRAM 控制器是集成在 Vivado 设计软件中的软核,可以配置成 AXI4-lite 接口模式或者 AXI4 接口模式。
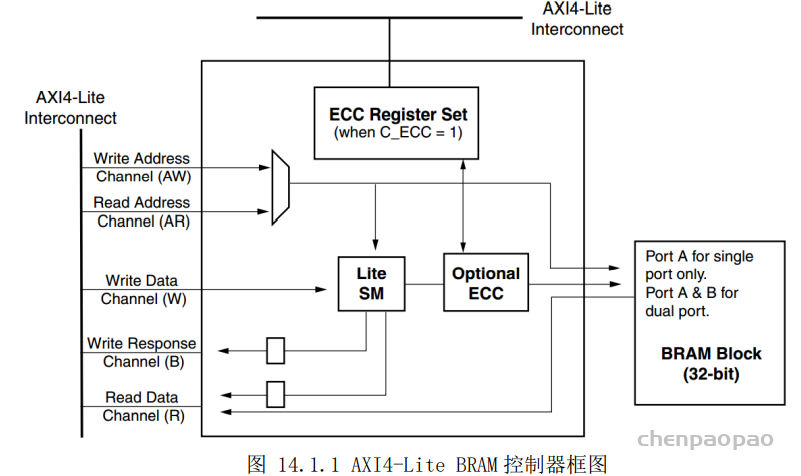
AXI4 接口模式的 BRAM 控制器支持的数据位宽为 32 位、64 位、128 位、512 位和 1024 位,而 AXI4-Lite 接口仅支持 32 位数据位宽。由图 14.1.1 可知,PS 通过 AXI4-Lite 接口访问 BRAM,当使能 ECC 选项时,ECC 允许 AXI 主接口检测和纠正 BRAM 块中的单位和双位错误。AXI BRAM 控制器作为 AXI 总线的从接口,和 AXI 主接口实现互联,来对 BRAM 进行读写操作。针对不同的应用场合,该 IP 核支持单次传输和突发传输两种方式。
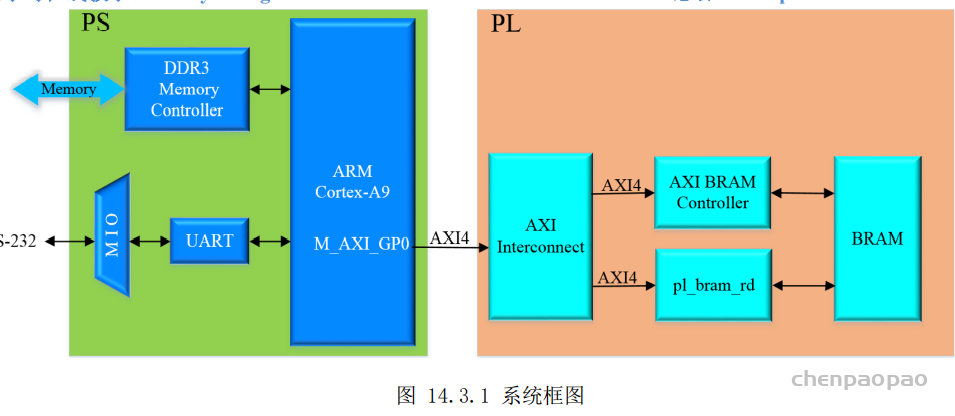
PS 端的 M_AXI_GP0 作为主端口,与 PL 端的 AXI BRAM 控制器 IP 核和 PL 读 BRAMIP 核(pl_bram_rd)通过 AXI4 总线进行连接。其中,AXI 互联 IP(AXI Interconnect)用于连接 AXI 存储器映射(memory-mapped)的主器件和从器件;AXI BRAM 控制器作为 PS 端读写 BRAM 的 IP 核;PL 读BRAM IP 核是我们自定义的 IP 核,实现了 PL 端从 BRAM 中读出数据的功能,除此之外,PS 端通过 AXI总线来配置该 IP 核读取 BRAM 的起始地址和个数等。
DMA
DMA(Direct Memory Access,直接存储器访问)是计算机科学中的一种内存访问技术。它允许某些计算机内部的硬件子系统可以独立地直接读写系统内存,而不需中央处理器(CPU)介入处理。DMA 是一种快速的数据传送方式,通常用来传送数据量较多的数据块,很多硬件系统会使用 DMA,包括硬盘控制器、绘图显卡、网卡和声卡,在使用高速 AD/DA 时使用 DMA 也是不错的选择。DMA 是用硬件实现存储器与存储器之间或存储器与 I/O 设备之间直接进行高速数据传输。使用 DMA时,CPU 向 DMA 控制器发出一个存储传输请求,这样当 DMA 控制器在传输的时候,CPU 执行其它操作,传输操作完成时 DMA 以中断的方式通知 CPU。
为了发起传输事务,DMA 控制器必须得到以下数据:
• 源地址 — 数据被读出的地址
• 目的地址 — 数据被写入的地址
• 传输长度 — 应被传输的字节数
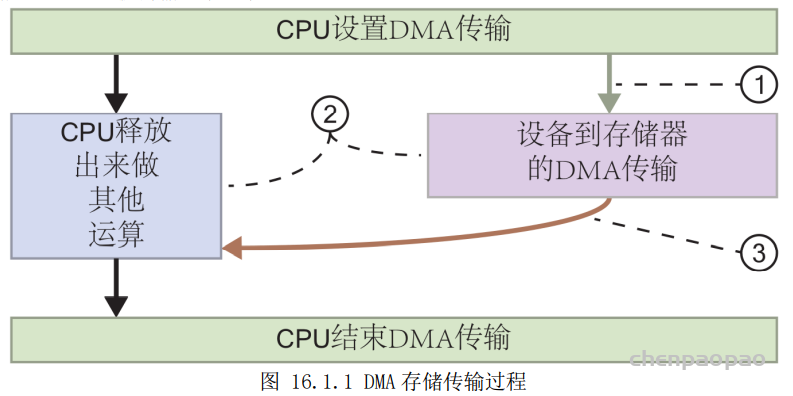
DMA 存储传输的过程如下:
- 为了配置用 DMA 传输数据到存储器,处理器发出一条 DMA 命令
- DMA 控制器把数据从外设传输到存储器或从存储器到存储器,而让 CPU 腾出手来做其它操作。
- 数据传输完成后,向 CPU 发出一个中断来通知它 DMA 传输可以关闭了。
ZYNQ 提供了两种 DMA,一种是集成在 PS 中的硬核 DMA,另一种是 PL 中使用的软核 AXI DMAIP。在 ARM CPU 设计的过程中,已经考虑到了大量数据搬移的情况,因此在 CPU 中自带了一个 DMA 控制器 DAMC,这个 DAMC 驻留在 PS 内,而且必须通过驻留在内存中的 DMA 指令编程,这些程序往往由CPU 准备,因此需要部分的 CPU 参与。DMAC 支持高达 8 个通道,所以多个 DMA 结构的核可以挂在单个DMAC 上。DAMC 与 PL 的连接是通过 AXI_GP 接口,这个接口最高支持到 32 位宽度,这也限制了这种模式下的传输速率,理论最高速率为 600MB/s。这种模式不占用 PL 资源,但需要对 DMA 指令编程,会增加软件的复杂性。为了获取更高的传输速率,可以以空间换时间,在 PL 中添加 AXI DMAIP 核,并利用 AXI_HP 接口完成高速的数据传输。
为了获取更高的传输速率,可以以空间换时间,在 PL 中添加 AXI DMAIP 核,并利用 AXI_HP 接口完成高速的数据传输,通过 PL 的 DMA 和 AXI_HP 接口的传输适用于大块数据的高性能传输,带宽高。各种接口方式的比较如下表所示:
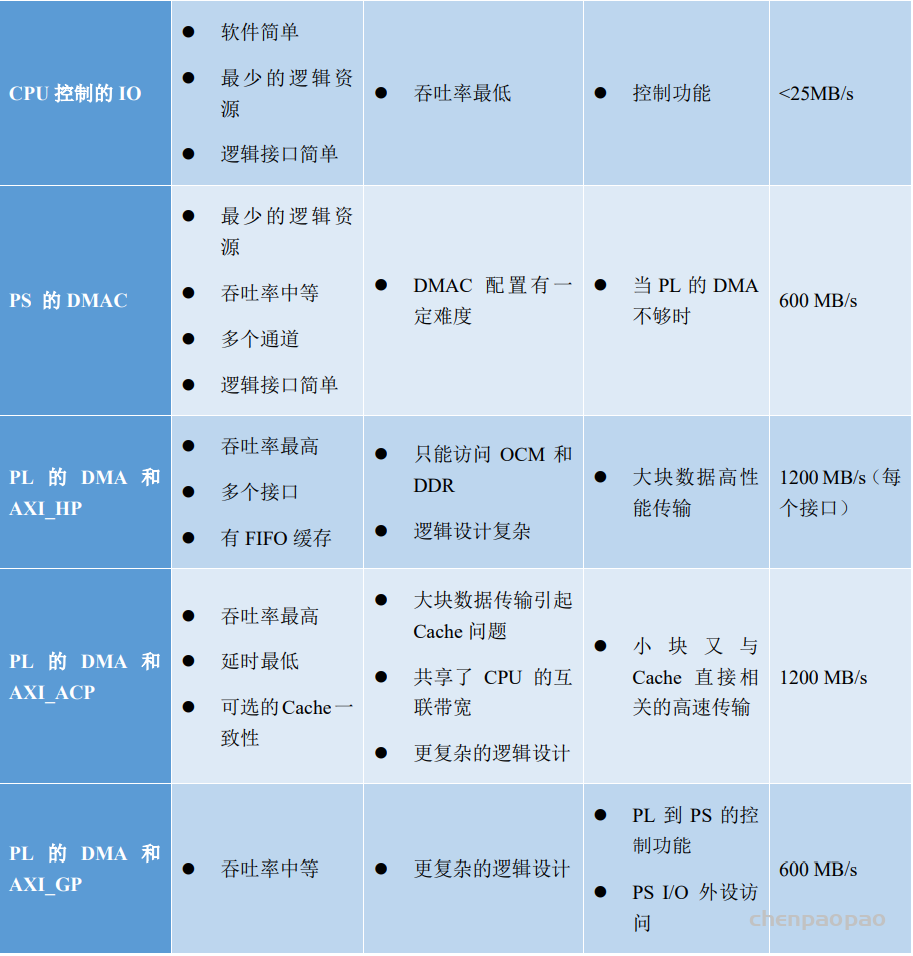
ZYNQ 开发板上使用 PL 的 AXI DMA IP 核从 DDR3 中读取数据,并将数据写回到 DDR3 中。
在实际应用中,DMA 一般与产生数据或需求数据的 IP 核相连接,该 IP 核可以是带有 Stream 接口的高速的 AD(模拟转数字)或 DA(数字转模拟) IP 核。不失一般性,在本次实验中,我们使用 AXI4 Stream Data FIFO IP 核来充当这类 IP 进行 DMA 环回实验。
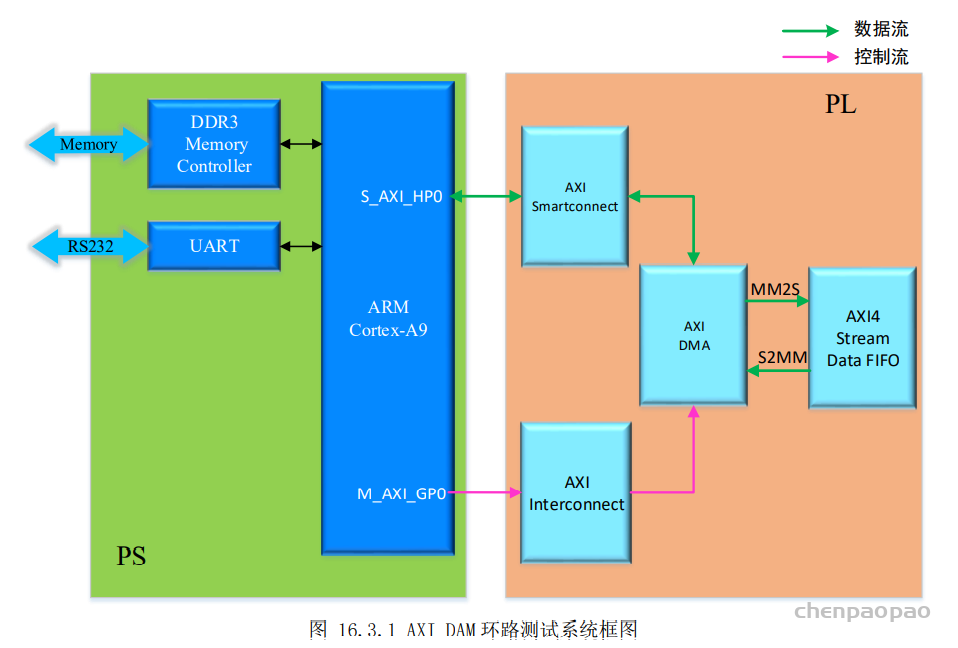
AXI Direct Memory Access重要端口说明:
- S_AXI_LITE: 配置DMA工作模式
- M_AXI_MM2S:DDR到DMA数据接口
- M_AXI_S2MM:DMA数据到DDR接口
- S_AXIS_S2MM: 接收的DMA数据输出端口
- M_AXIS_MM2S: 想通过DMA输出的数据写入端口
DDR3
通过对AXI HP接口的操作来实现
AXI 的英文全称是 Advanced eXtensible Interface,即高级可扩展接口,它是 ARM 公司所提出的 AMBA(Advanced Microcontroller Bus Architecture)协议的一部分。
AXI4 协议支持以下三种类型的接口:
1、 AXI4:高性能存储映射接口。
2、 AXI4-Lite:简化版的 AXI4 接口,用于较少数据量的存储映射通信。
3、 AXI4-Stream:用于高速数据流传输,非存储映射接口。
AXI4 协议支持突发传输,主要用于处理器访问存储器等需要指定地址的高速数据传输场景。AXI-Lite为外设提供单个数据传输,主要用于访问一些低速外设中的寄存器。而 AXI-Stream 接口则像 FIFO 一样,数据传输时不需要地址,在主从设备之间直接连续读写数据,主要用于如视频、高速 AD、PCIe、DMA 接口等需要高速数据传输的场合。
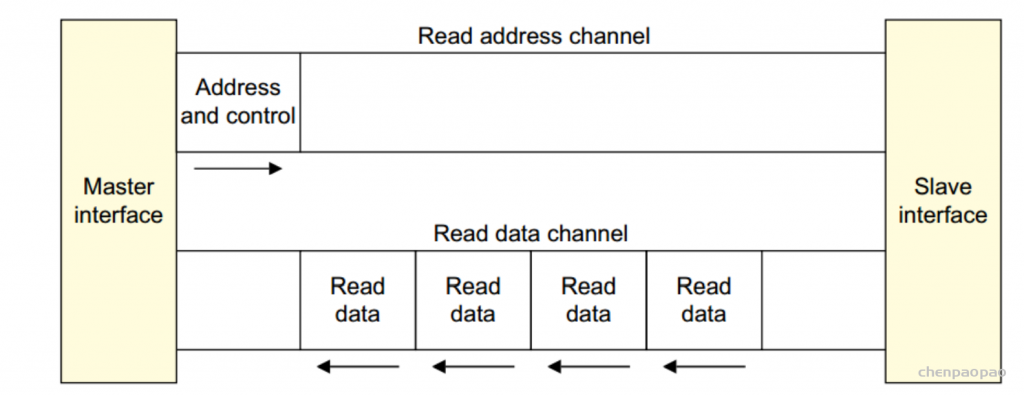
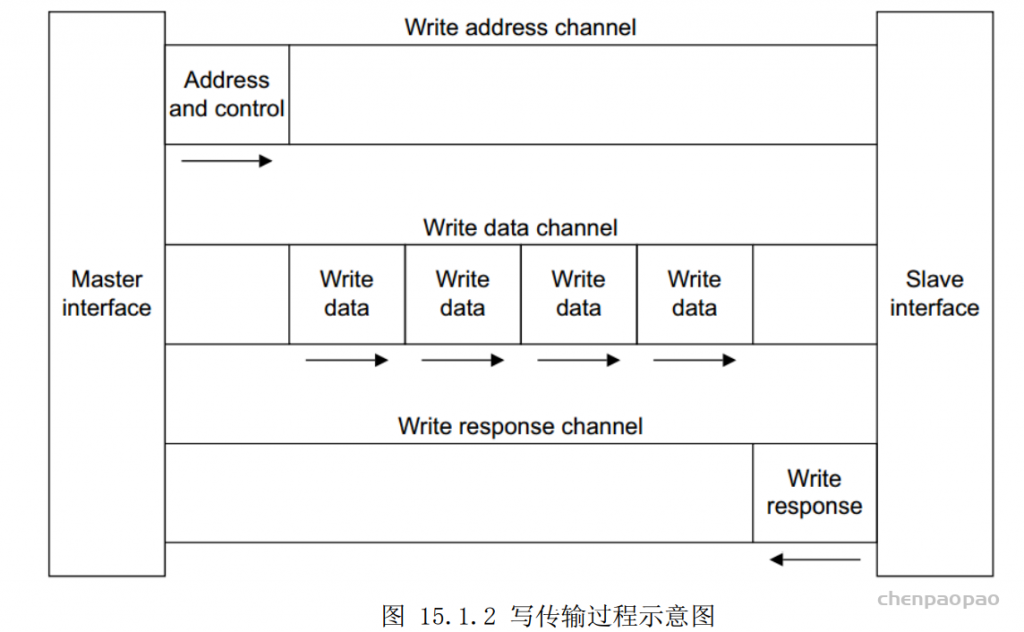
AXI 总线中的每个通道都包含了一组信息信号,还有一个 VALID 和一个 READY 信号,VALID 信号由源端(source)产生,表示当前地址或者数据线上的信息是有效的;而 READY 信号由目的端(destination)产生,则表示已经准备好接收地址、数据以及控制信息。
通过自定义一个 AXI4 接口的 IP 核,通过 AXI_HP 接口对 PS 端 DDR3 进行读写测试。
AXI_HP总线:只能单向传输,从PL到PS端,适用于大数据传输。
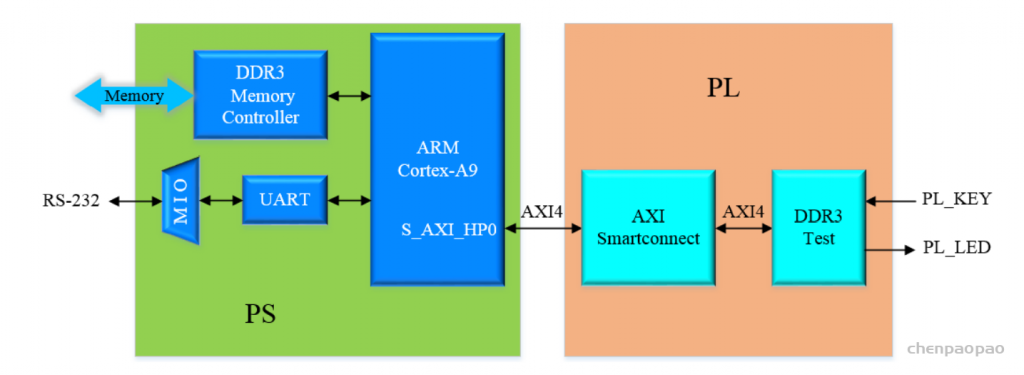
PL实现AXI4接口,通过S_AXI_HP接口读取ps侧DDR3数据. 例程功能:PL,PS向指定地址写数据,对方来读.
AXI-DMA:实现从PS内存到PL高速传输高速通道AXI-HP<—->AXI-Stream的转换
AXI-Datamover:实现从PS内存到PL高速传输高速通道AXI-HP<—->AXI-Stream的转换,只不过这次是完全由PL控制的,PS是完全被动的。
AXI-VDMA:实现从PS内存到PL高速传输高速通道AXI-HP<—->AXI-Stream的转换,只不过是专门针对视频、图像等二维数据的。
AXI-CDMA IP: 这个是由PL完成的将数据从内存的一个位置搬移到另一个位置,无需CPU来插手。这个和我们这里用的Stream没有关系
自定义AXI接口IP
一般应用场景在于PS对某些寄存器的配置,传输少量的数据信息。