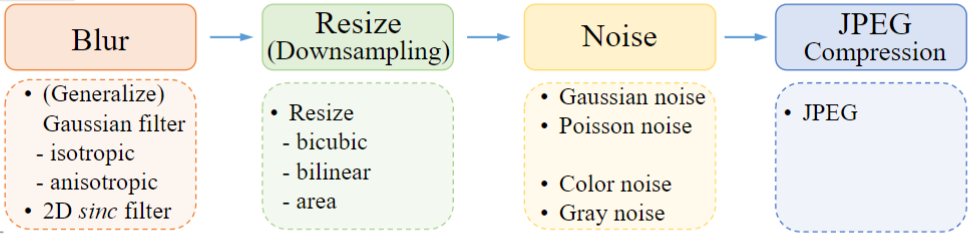
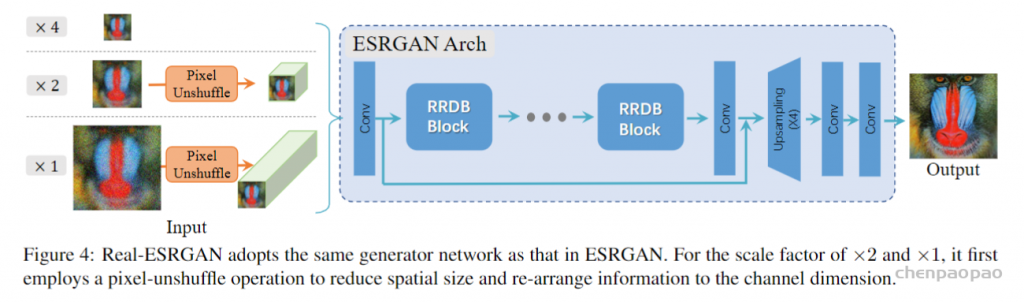
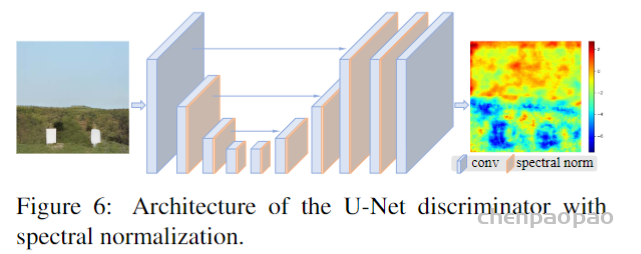
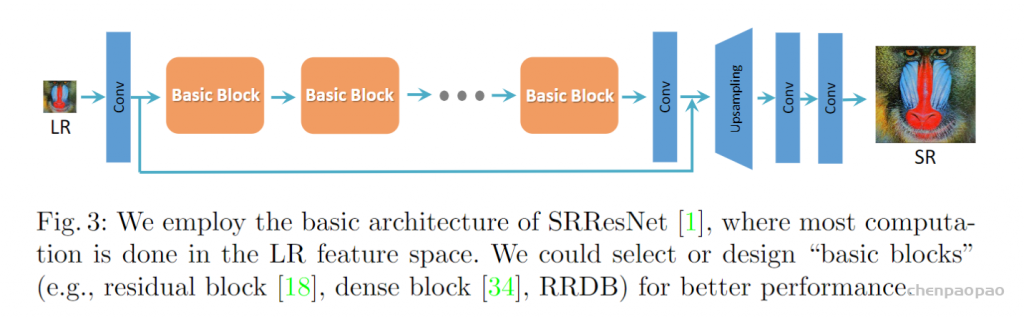
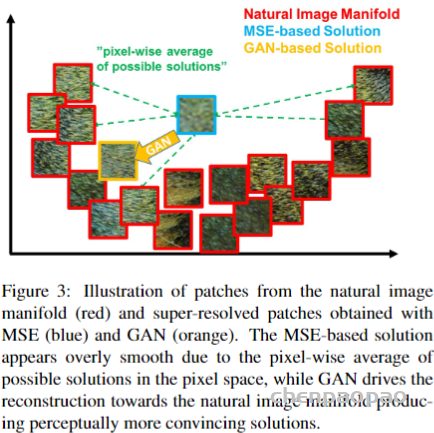
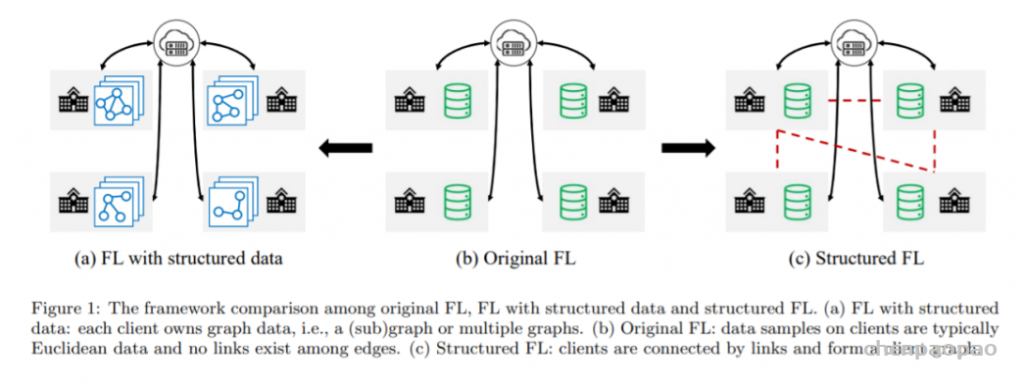
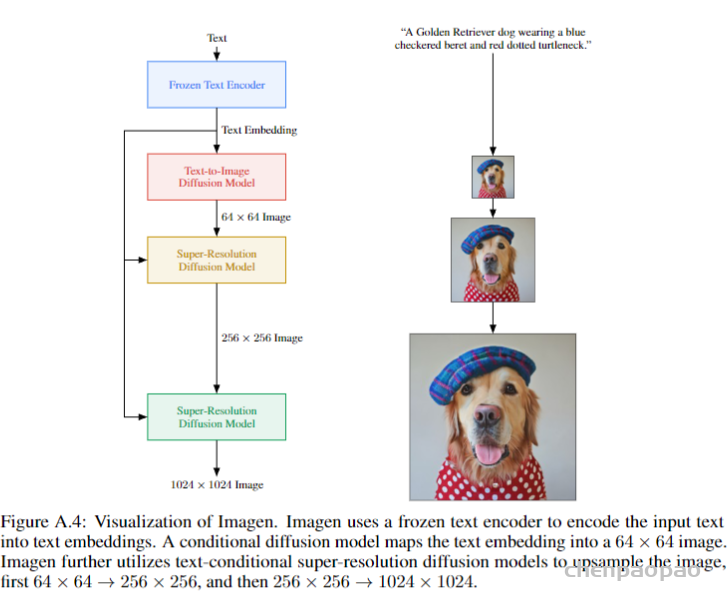
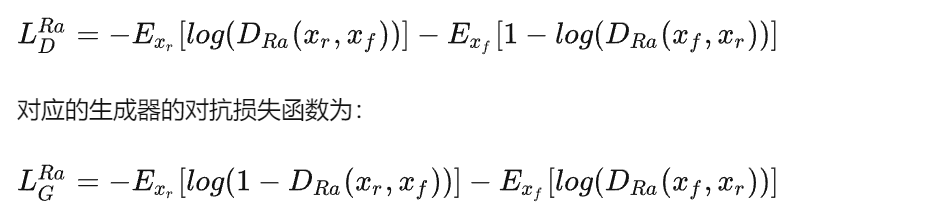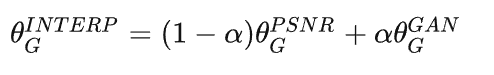For example, when we take a photo with our cellphones, the photos may have several degradations, such as camera blur, sensor noise, sharpening artifacts, and JPEG compression. We then do some editing and upload to a social media APP, which introduces further compression and unpredictable noises.
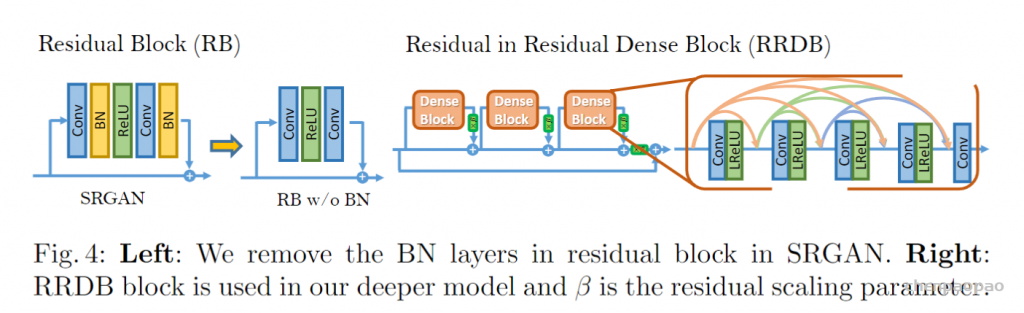
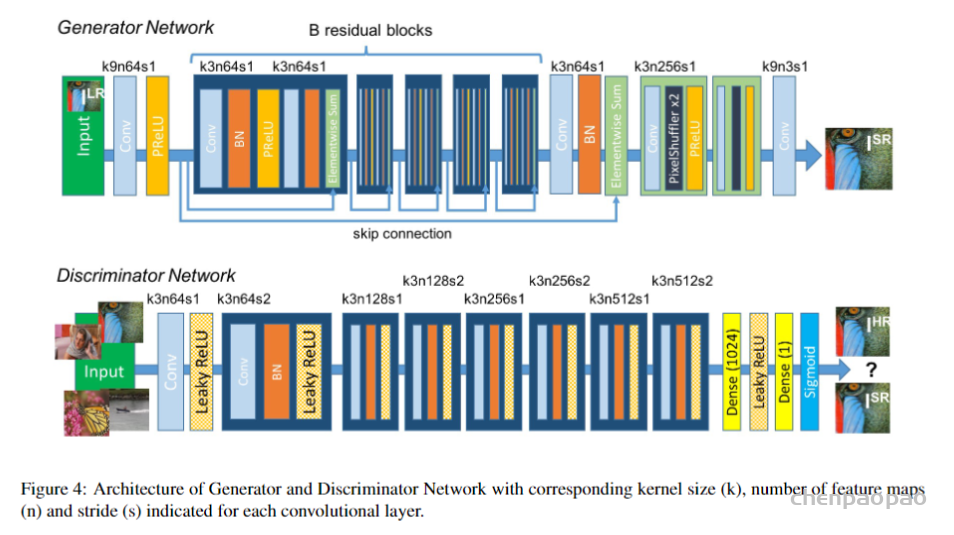
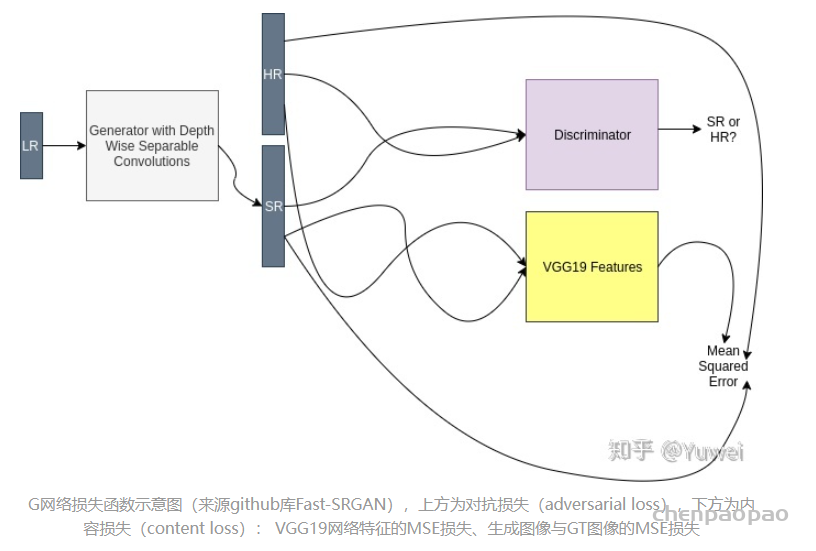
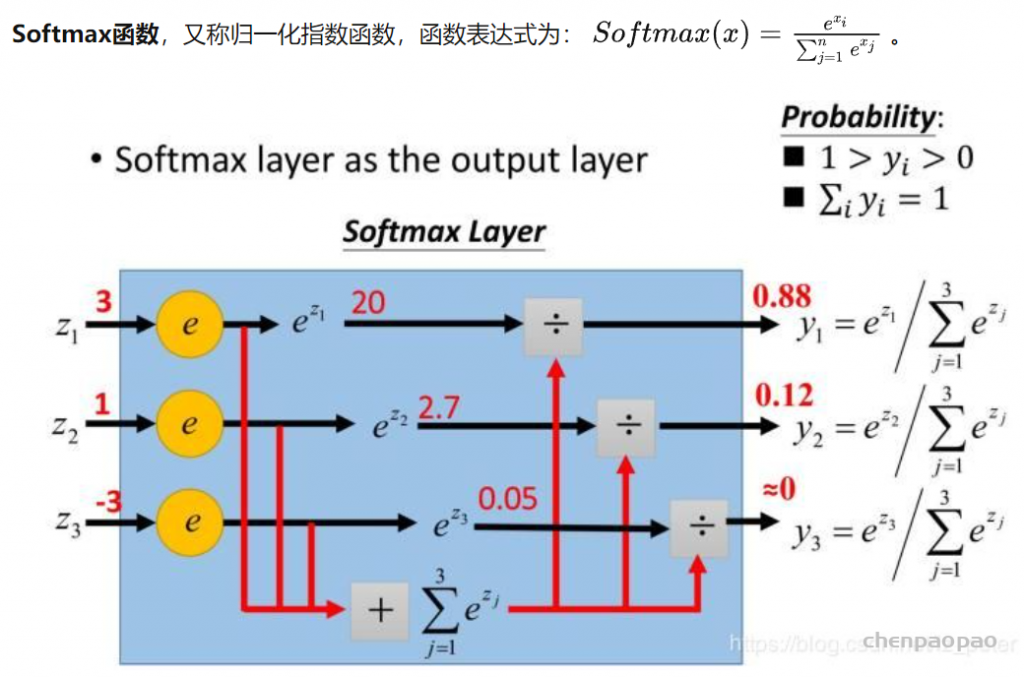
文章对这三点做出改进:1.网络的基本单元从基本的残差单元变为Residual-in-Residual Dense Block (RRDB);2.GAN网络改进为Relativistic average GAN (RaGAN);3.改进感知域损失函数,使用激活前的VGG特征,这个改进会提供更尖锐的边缘和更符合视觉的结果。
class MINCNet(nn.Module):
def __init__(self):
super(MINCNet, self).__init__()
self.ReLU = nn.ReLU(True)
self.conv11 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv12 = nn.Conv2d(64, 64, 3, 1, 1)
self.maxpool1 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv21 = nn.Conv2d(64, 128, 3, 1, 1)
self.conv22 = nn.Conv2d(128, 128, 3, 1, 1)
self.maxpool2 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv31 = nn.Conv2d(128, 256, 3, 1, 1)
self.conv32 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv33 = nn.Conv2d(256, 256, 3, 1, 1)
self.maxpool3 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv41 = nn.Conv2d(256, 512, 3, 1, 1)
self.conv42 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv43 = nn.Conv2d(512, 512, 3, 1, 1)
self.maxpool4 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv51 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv52 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv53 = nn.Conv2d(512, 512, 3, 1, 1)
def forward(self, x):
out = self.ReLU(self.conv11(x))
out = self.ReLU(self.conv12(out))
out = self.maxpool1(out)
out = self.ReLU(self.conv21(out))
out = self.ReLU(self.conv22(out))
out = self.maxpool2(out)
out = self.ReLU(self.conv31(out))
out = self.ReLU(self.conv32(out))
out = self.ReLU(self.conv33(out))
out = self.maxpool3(out)
out = self.ReLU(self.conv41(out))
out = self.ReLU(self.conv42(out))
out = self.ReLU(self.conv43(out))
out = self.maxpool4(out)
out = self.ReLU(self.conv51(out))
out = self.ReLU(self.conv52(out))
out = self.conv53(out)
return out
再引入预训练参数,就可以进行特征提取:
class MINCFeatureExtractor(nn.Module):
def __init__(self, feature_layer=34, use_bn=False, use_input_norm=True, \
device=torch.device('cpu')):
super(MINCFeatureExtractor, self).__init__()
self.features = MINCNet()
self.features.load_state_dict(
torch.load('../experiments/pretrained_models/VGG16minc_53.pth'), strict=True)
self.features.eval()
# No need to BP to variable
for k, v in self.features.named_parameters():
v.requires_grad = False
def forward(self, x):
output = self.features(x)
return output
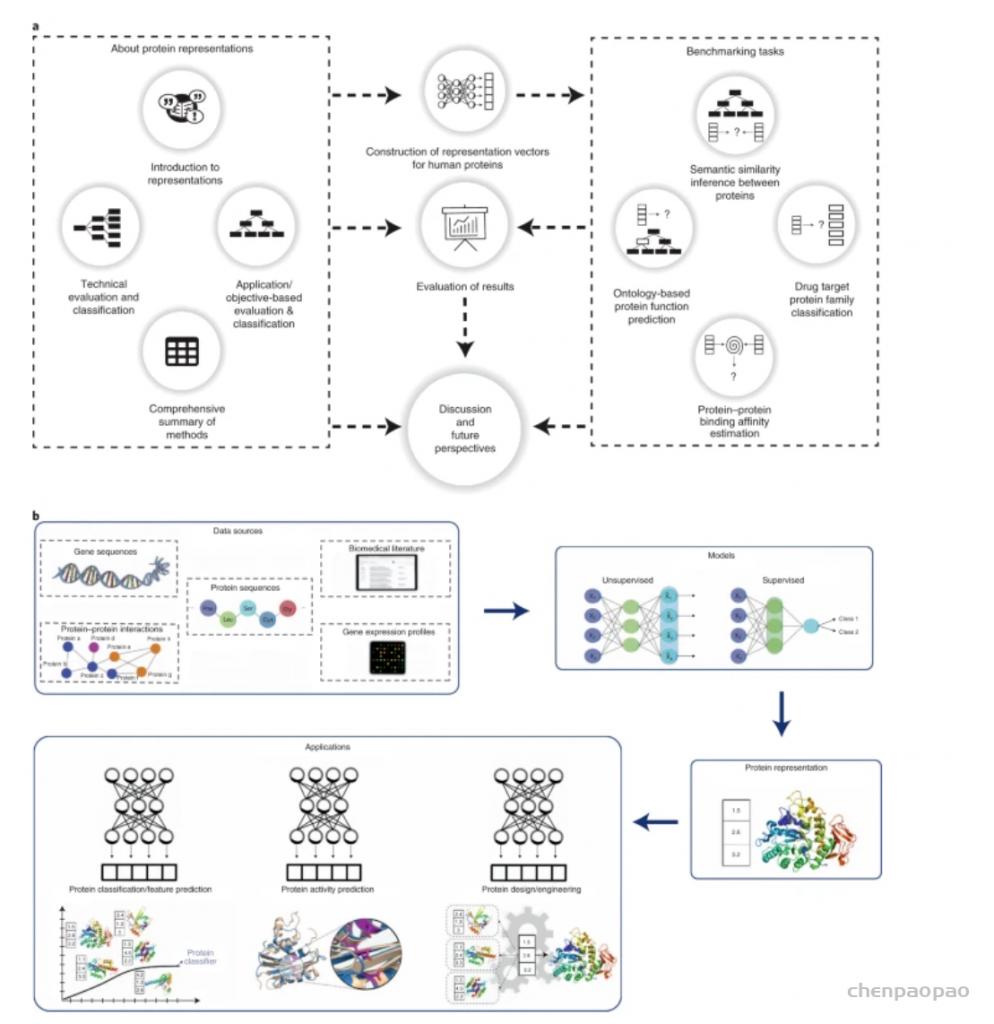
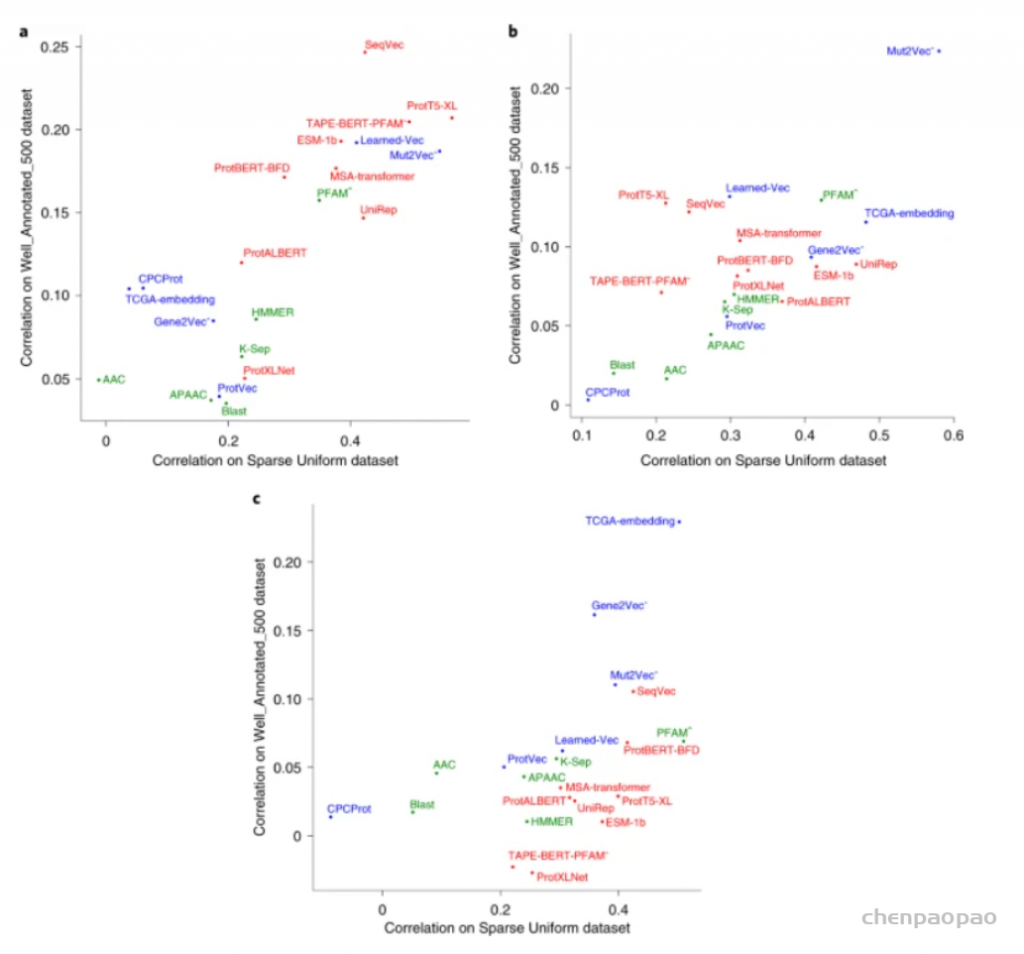
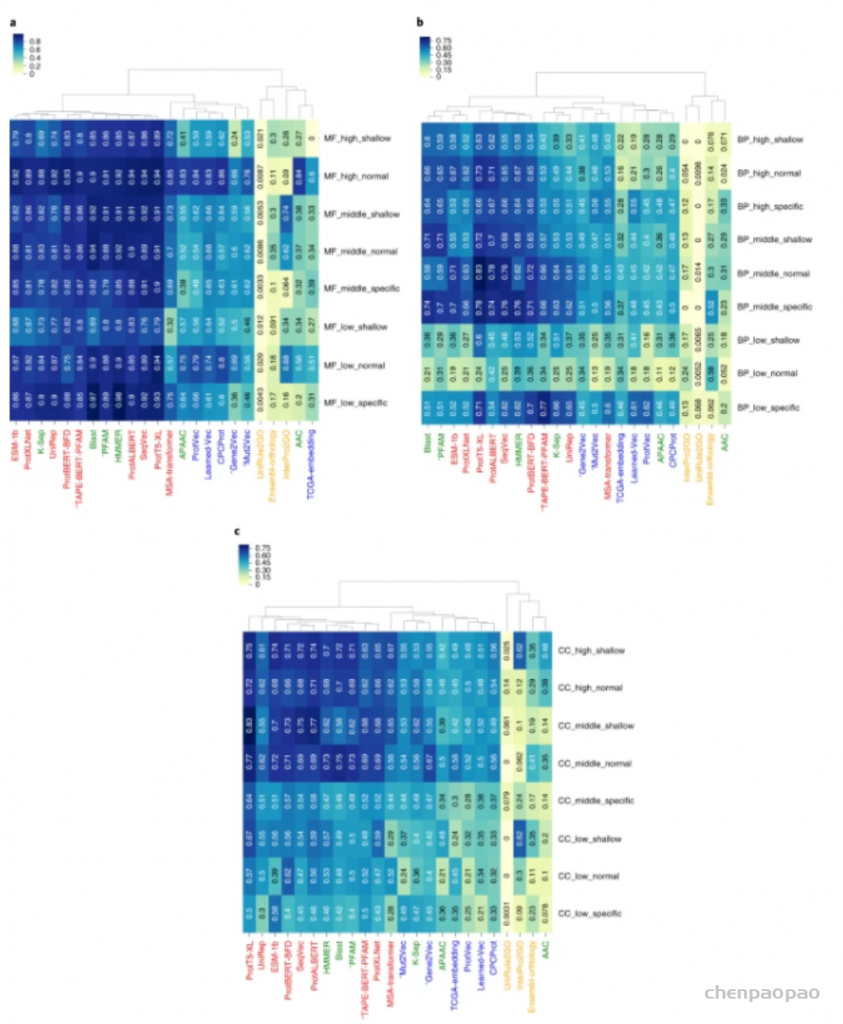
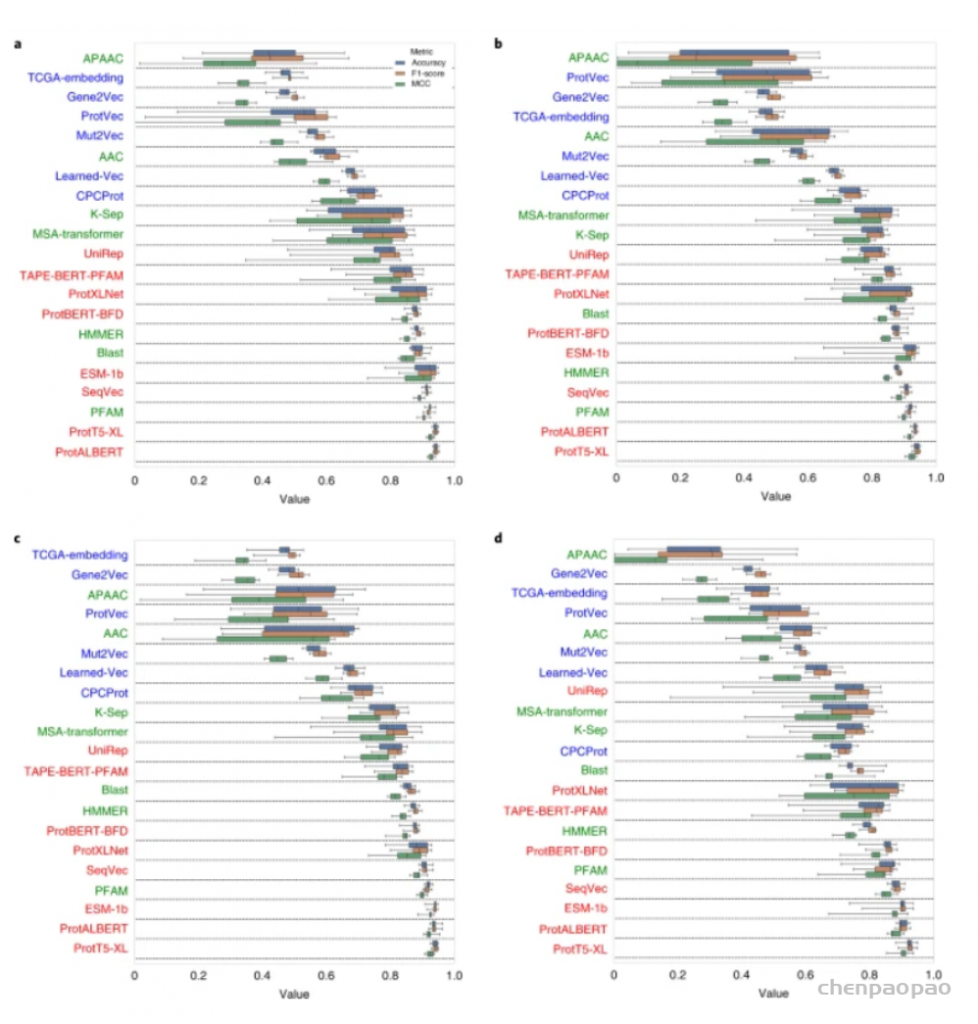
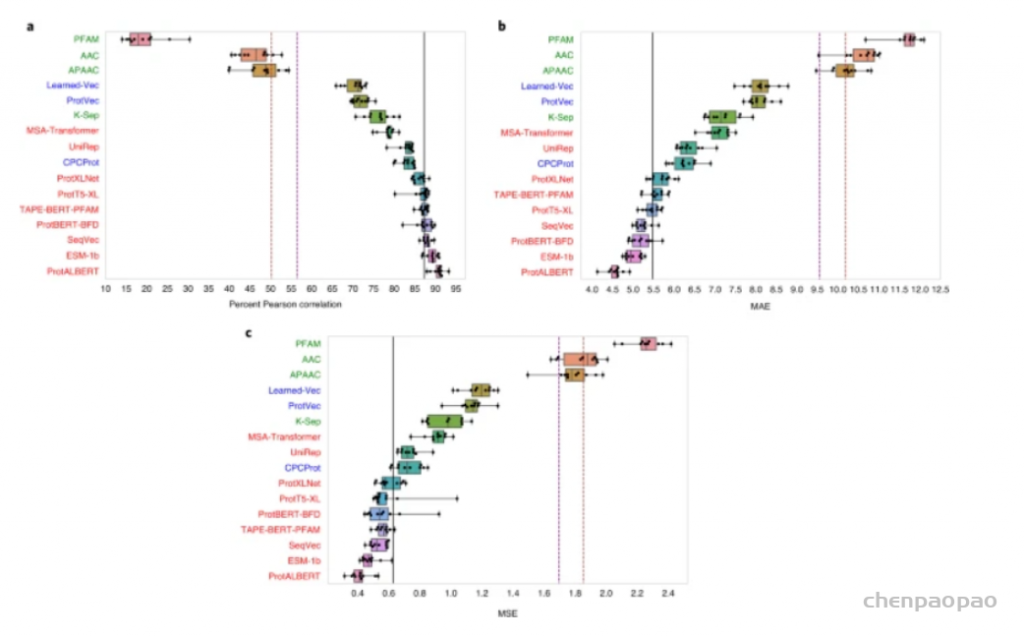
以数据为中心的方法已被用于开发用于阐明蛋白质未表征特性的预测方法;然而,研究表明,这些方法应进一步改进,以有效解决生物医学和生物技术中的关键问题,这可以通过更好地代表手头的数据来实现。新的数据表示方法主要从在自然语言处理方面取得突破性改进的语言模型中汲取灵感。最近,这些方法已应用于蛋白质科学领域,并在提取复杂的序列-结构-功能关系方面显示出非常有希望的结果。在这项研究中,土耳其中东科技大学(Middle East Technical University)的研究人员,首先对每种方法进行分类/解释,然后对它们的预测性能进行基准测试,对蛋白质表示学习进行了详细调查:(1)蛋白质之间的语义相似性,(2)基于本体的蛋白质功能,(3)药物靶蛋白家族和(4)突变后蛋白质-蛋白质结合亲和力的变化。这项研究的结论将有助于研究人员将基于机器/深度学习的表示技术应用于蛋白质数据以进行各种预测任务,并激发新方法的发展。该研究以「Learning functional properties of proteins with language models」为题,于 2022 年 3 月 21 日发布在《Nature Machine Intelligence》。