
Learning to Resize Images for Computer Vision Tasks
论文地址:https://arxiv.org/abs/2103.09950
代码:https://github.com/KushajveerSingh/resize_network_cv

尽管近年来卷积神经网络很大地促进了计算机视觉的发展,但一个重要方面很少被关注:图像大小对被训练的任务的准确性的影响 。通常,输入图像的大小被调整到一个相对较小的空间分辨率(例如,224×224),然后再进行训练和推理。这种调整大小的机制通常是固定的图像调整器(image resizer)(如:双行线插值)但是这些调整器是否限制了训练网络的任务性能呢? 作者通过实验证明了典型的线性调整器可以被可学习的调整器取代,从而大大提高性能 。虽然经典的调整器通常会具备更好的小图像感知质量(即对人类识别图片更加友好),本文提出的可学习调整器不一定会具备更好的视觉质量,但能够提高CV任务的性能。
在不同的任务中,可学习的图像调整器与baseline视觉模型进行联合训练。这种可学习的基于cnn的调整器创建了机器友好的视觉操作,因此在不同的视觉任务中表现出了更好的性能 。作者使用ImageNet数据集来进行分类任务,实验中使用四种不同的baseline模型来学习不同的调整器,相比于baseline模型,使用本文提出的可学习调整器能够获得更高的性能提升。
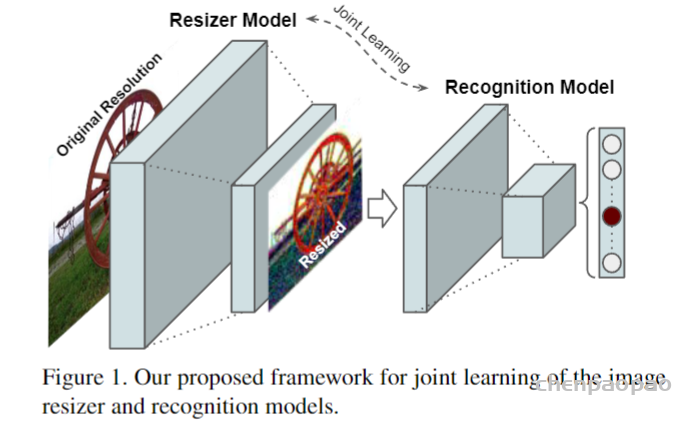
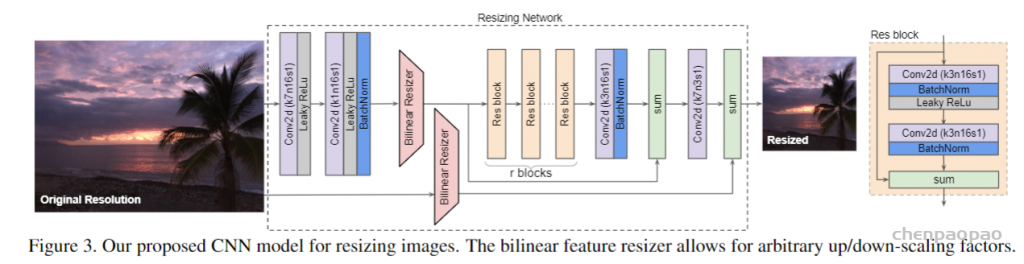
主要包括了两个重要的特性:(1) 双线性特征调整大小(bilinear feature resizing),以及(2)跳过连接(skip connection),该连接可容纳双线性调整大小的图像和CNN功能的组合。
第一个特性考虑到以原始分辨率计算的特征与模型的一致性。跳过连接可以简化学习过程,因为重定大小器模型可以直接将双线性重定大小的图像传递到基线任务中。
与一般的编码器-解码器架构不同,这篇论文中所提出的体系结构允许将图像大小调整为任何目标大小和纵横比(注意:这个大小必须是我们自己设定的,而不是网络 自己学习的)。并且可学习的resizer性能几乎不依赖于双线性重定器的选择,这意味着它可以直接替换其他现成的方法。
以上之后,就没有别的了,还以为是什么样子的惊天设计,最后不就是:给网络变得复杂了吗,把这种复杂说成是可学习的resizer,这样的话,普通网络的浅层都可以说成是可学习的resizer不是吗?
另外,通过一些实验 来说,确实能够提升效果。个人认为 作者提出的resizer模型实际上是一个可训练的数据增强方法,甚至也可以认为就是将模型变得更加复杂。整体的网络就像是一般模型中resblock。
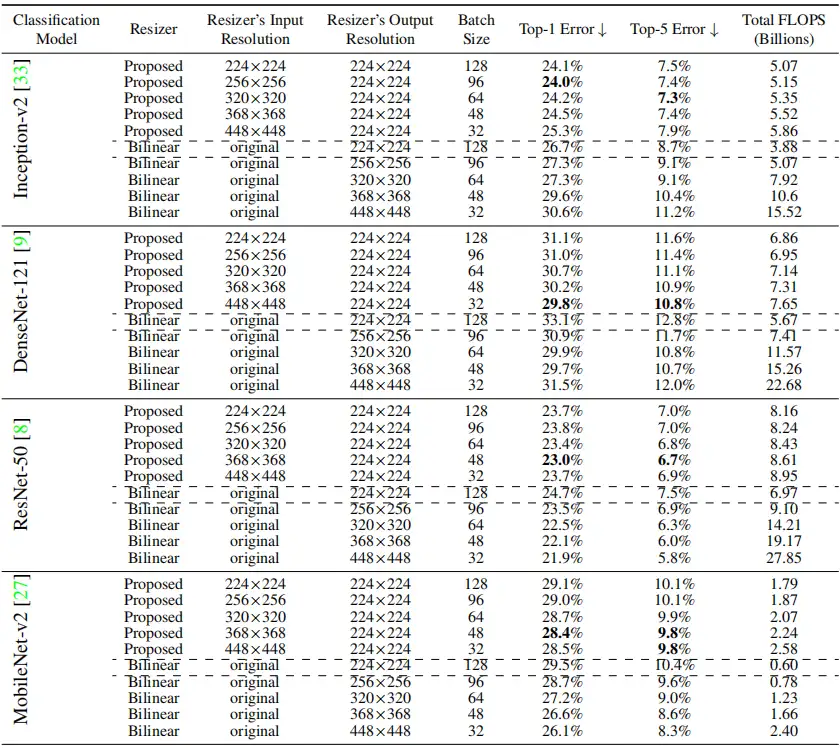
作者的对比试验是这样做的:首先通过常用的reisze方法训练网络模型,作为baseline,然后在训练好的网络模型前面添加可学习的resizer,然后进行训练,作为自己的方法。感受一下作者的实验结果吧。如表3和表4

四. 总结
文章写得好,加上点运气,都可以发高质量论文,以上
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
"""
Learning to Resize Images for Computer Vision Tasks
https://arxiv.org/pdf/2105.04714.pdf
"""
def conv1x1(in_chs, out_chs = 16):
return nn.Conv2d(in_chs, out_chs, kernel_size=1, stride=1, padding=0)
def conv3x3(in_chs, out_chs = 16):
return nn.Conv2d(in_chs, out_chs, kernel_size=3, stride=1, padding=1)
def conv7x7(in_chs, out_chs = 16):
return nn.Conv2d(in_chs, out_chs, kernel_size=7, stride=1, padding=3)
class ResBlock(nn.Module):
def __init__(self, in_chs,out_chs = 16):
super(ResBlock, self).__init__()
self.layers = nn.Sequential(
conv3x3(in_chs, out_chs),
nn.BatchNorm2d(out_chs),
nn.LeakyReLU(0.2),
conv3x3(out_chs, out_chs),
nn.BatchNorm2d(out_chs)
)
def forward(self, x):
identity = x
out = self.layers(x)
out += identity
return out
class Resizer(nn.Module):
def __init__(self, in_chs, out_size, n_filters = 16, n_res_blocks = 1, mode = 'bilinear'):
super(Resizer, self).__init__()
self.interpolate_layer = partial(F.interpolate, size=out_size, mode=mode,
align_corners=(True if mode in ('linear', 'bilinear', 'bicubic', 'trilinear') else None))
self.conv_layers = nn.Sequential(
conv7x7(in_chs, n_filters),
nn.LeakyReLU(0.2),
conv1x1(n_filters, n_filters),
nn.LeakyReLU(0.2),
nn.BatchNorm2d(n_filters)
)
self.residual_layers = nn.Sequential()
for i in range(n_res_blocks):
self.residual_layers.add_module(f'res{i}', ResBlock(n_filters, n_filters))
self.residual_layers.add_module('conv3x3', conv3x3(n_filters, n_filters))
self.residual_layers.add_module('bn', nn.BatchNorm2d(n_filters))
self.final_conv = conv7x7(n_filters, in_chs)
def forward(self, x):
identity = self.interpolate_layer(x)
conv_out = self.conv_layers(x)
conv_out = self.interpolate_layer(conv_out)
conv_out_identity = conv_out
res_out = self.residual_layers(conv_out)
res_out += conv_out_identity
out = self.final_conv(res_out)
out += identity
return