Control groups 虽然有了NameSpace技术可以实现资源隔离,但进程还是可以不受控的访问系统资源,比如CPU、内存、磁盘、网络等,为了控制容器中进程对资源的访问,Docker采用control groups技术(也就是cgroup),有了cgroup就可以控制容器中进程对系统资源的消耗了,比如你可以限制某个容器使用内存的上限、可以在哪些CPU上运行等等。
+————–+———————+——————+———-+ | Address Type | Destination Address | Destination Port | Data | +————–+———————+——————+———-+ | 1 | Variable | 2 | Variable | +————–+———————+——————+———-+
Possible values of address type are 1 (IPv4), 4 (IPv6), 3 (hostname). For IPv4 address, it’s packed as a 32-bit (4-byte) big-endian integer. For IPv6 address, a compact representation (16-byte array) is used. For hostname, the first byte of destination address indicates the length, which limits the length of hostname to 255. The destination port is also a big-endian integer.
The request is encrypted using the specified cipher with a random IV and the pre-shared key, it then becomes so-called payload.
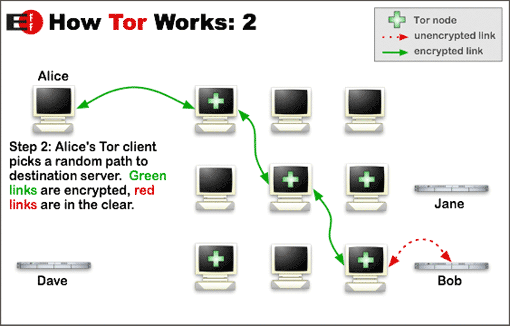
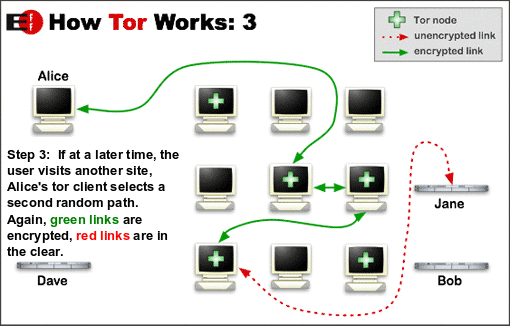
The Tor network is a group of volunteer-operated servers that allows people to improve their privacy and security on the Internet. Tor’s users employ this network by connecting through a series of virtual tunnels rather than making a direct connection, thus allowing both organizations and individuals to share information over public networks without compromising their privacy. Along the same line, Tor is an effective censorship circumvention tool, allowing its users to reach otherwise blocked destinations or content. Tor can also be used as a building block for software developers to create new communication tools with built-in privacy features.
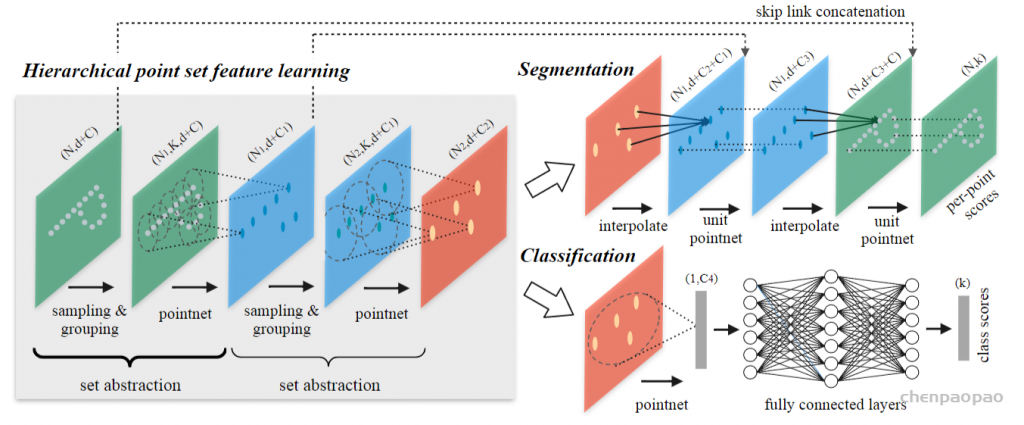
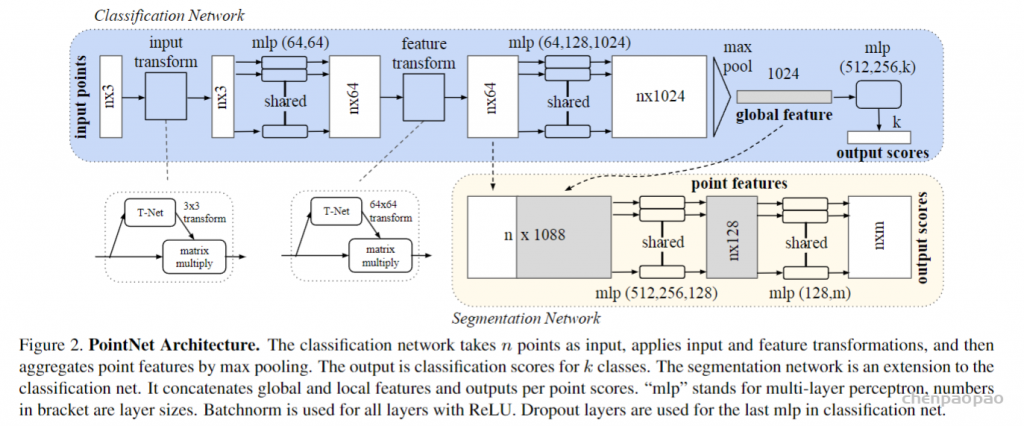
def pointnet_sa_module(xyz, points, npoint, radius, nsample, mlp, mlp2, group_all, is_training, bn_decay, scope, bn=True, pooling='max', knn=False, use_xyz=True, use_nchw=False):
''' PointNet Set Abstraction (SA) Module
Input:
xyz: (batch_size, ndataset, 3) TF tensor
points: (batch_size, ndataset, channel) TF tensor
npoint: int32 -- #points sampled in farthest point sampling
radius: float32 -- search radius in local region
nsample: int32 -- how many points in each local region
mlp: list of int32 -- output size for MLP on each point
mlp2: list of int32 -- output size for MLP on each region
group_all: bool -- group all points into one PC if set true, OVERRIDE
npoint, radius and nsample settings
use_xyz: bool, if True concat XYZ with local point features, otherwise just use point features
use_nchw: bool, if True, use NCHW data format for conv2d, which is usually faster than NHWC format
Return:
new_xyz: (batch_size, npoint, 3) TF tensor
new_points: (batch_size, npoint, mlp[-1] or mlp2[-1]) TF tensor
idx: (batch_size, npoint, nsample) int32 -- indices for local regions
'''
data_format = 'NCHW' if use_nchw else 'NHWC'
with tf.variable_scope(scope) as sc:
# Sample and Grouping
if group_all:
nsample = xyz.get_shape()[1].value
new_xyz, new_points, idx, grouped_xyz = sample_and_group_all(xyz, points, use_xyz)
else:
new_xyz, new_points, idx, grouped_xyz = sample_and_group(npoint, radius, nsample, xyz, points, knn, use_xyz)
# Point Feature Embedding
if use_nchw: new_points = tf.transpose(new_points, [0,3,1,2])
for i, num_out_channel in enumerate(mlp):
new_points = tf_util.conv2d(new_points, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, is_training=is_training,
scope='conv%d'%(i), bn_decay=bn_decay,
data_format=data_format)
if use_nchw: new_points = tf.transpose(new_points, [0,2,3,1])
# Pooling in Local Regions
if pooling=='max':
new_points = tf.reduce_max(new_points, axis=[2], keep_dims=True, name='maxpool')
elif pooling=='avg':
new_points = tf.reduce_mean(new_points, axis=[2], keep_dims=True, name='avgpool')
elif pooling=='weighted_avg':
with tf.variable_scope('weighted_avg'):
dists = tf.norm(grouped_xyz,axis=-1,ord=2,keep_dims=True)
exp_dists = tf.exp(-dists * 5)
weights = exp_dists/tf.reduce_sum(exp_dists,axis=2,keep_dims=True) # (batch_size, npoint, nsample, 1)
new_points *= weights # (batch_size, npoint, nsample, mlp[-1])
new_points = tf.reduce_sum(new_points, axis=2, keep_dims=True)
elif pooling=='max_and_avg':
max_points = tf.reduce_max(new_points, axis=[2], keep_dims=True, name='maxpool')
avg_points = tf.reduce_mean(new_points, axis=[2], keep_dims=True, name='avgpool')
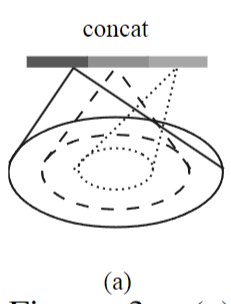
new_points = tf.concat([avg_points, max_points], axis=-1)
# [Optional] Further Processing
if mlp2 is not None:
if use_nchw: new_points = tf.transpose(new_points, [0,3,1,2])
for i, num_out_channel in enumerate(mlp2):
new_points = tf_util.conv2d(new_points, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, is_training=is_training,
scope='conv_post_%d'%(i), bn_decay=bn_decay,
data_format=data_format)
if use_nchw: new_points = tf.transpose(new_points, [0,2,3,1])
new_points = tf.squeeze(new_points, [2]) # (batch_size, npoints, mlp2[-1])
return new_xyz, new_points, idx
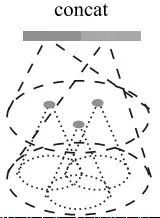
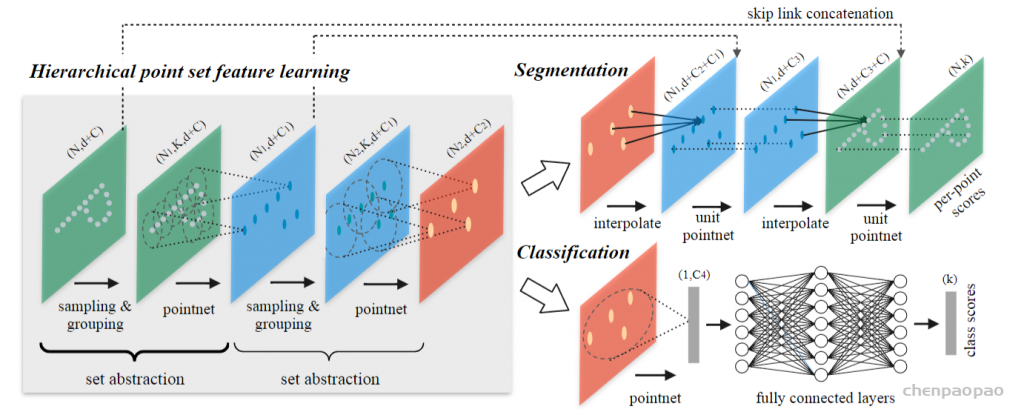
还有个问题:query ball point如何保证对于每个局部邻域,采样点的数量都是一样的呢? 事实上,如果query ball的点数量大于规模 K ,那么直接取前 K 个作为局部邻域;如果小于,那么直接对某个点重采样,凑够规模 K
KNN和query ball的区别:(摘自原文)Compared with kNN, ball query’s local neighborhood guarantees a fixed region scale thus making local region feature more generalizable across space, which is preferred for tasks requiring local pattern recognition (e.g. semantic point labeling).也就是query ball更加适合于应用在局部/细节识别的应用上,比如局部分割。
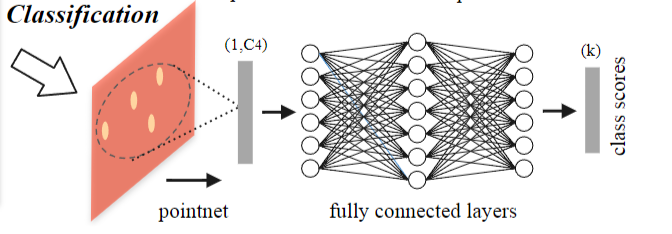
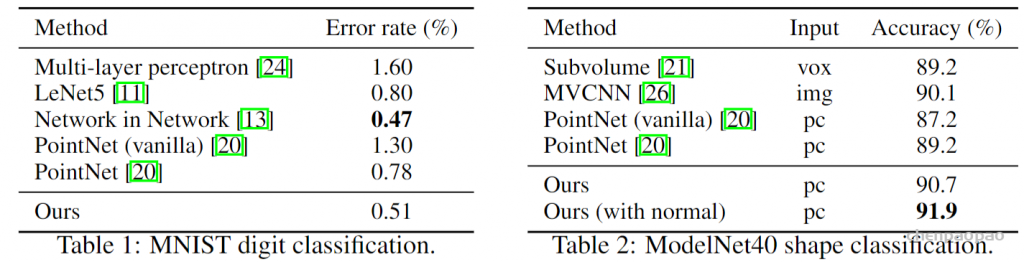
MNIST: Images of handwritten digits with 60k training and 10k testing samples.(用于分类)
ModelNet40: CAD models of 40 categories (mostly man-made). We use the official split with 9,843 shapes for training and 2,468 for testing. (用于分类)
SHREC15: 1200 shapes from 50 categories. Each category contains 24 shapes which are mostly organic ones with various poses such as horses, cats, etc. We use five fold cross validation to acquire classification accuracy on this dataset. (用于分类)
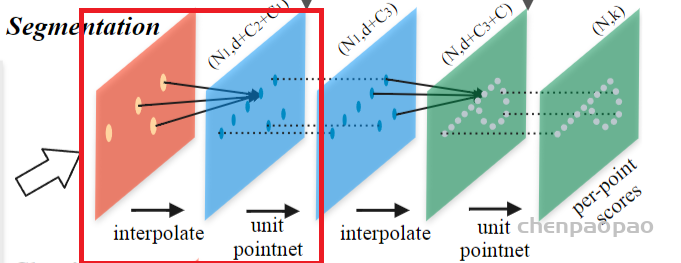
ScanNet: 1513 scanned and reconstructed indoor scenes. We follow the experiment setting in [5] and use 1201 scenes for training, 312 scenes for test. (用于分割)


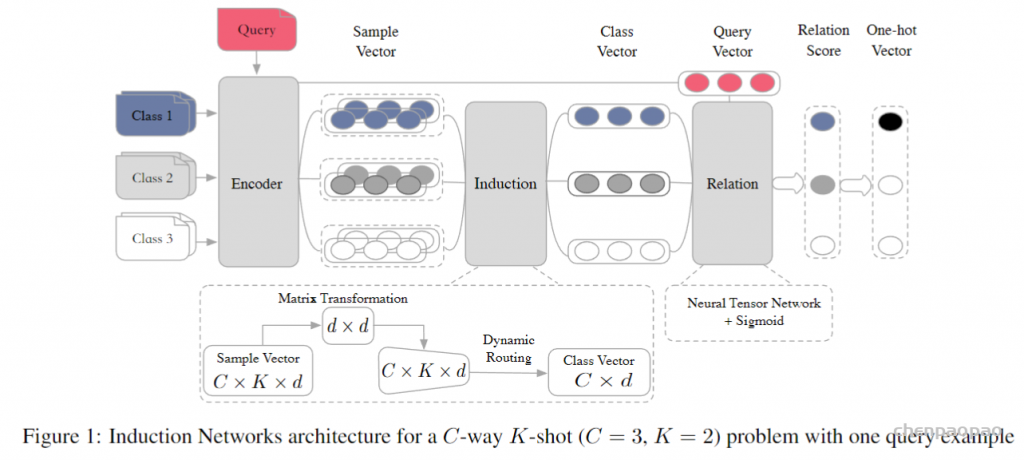
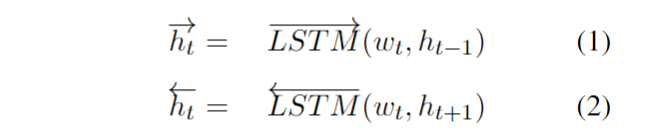
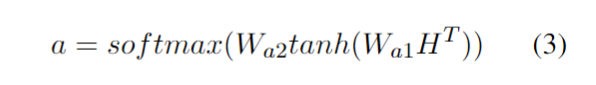
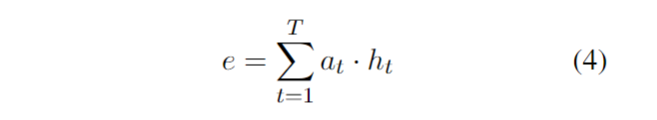
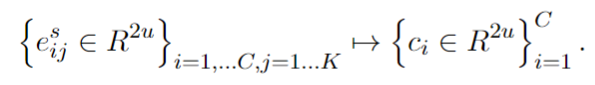


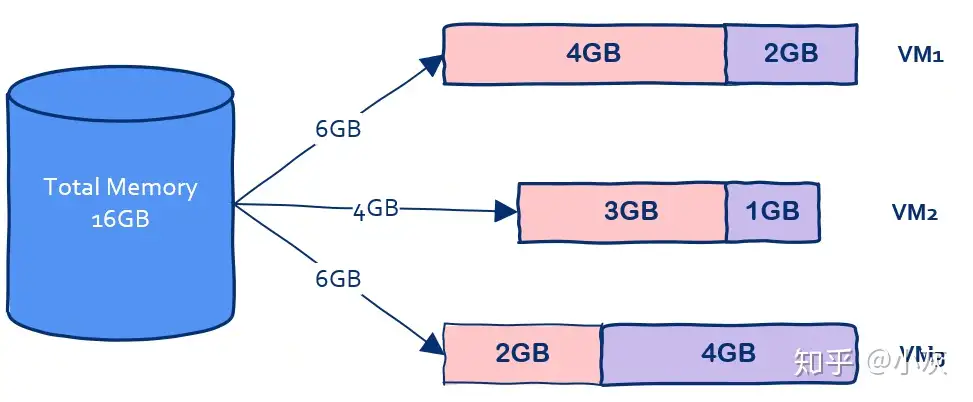

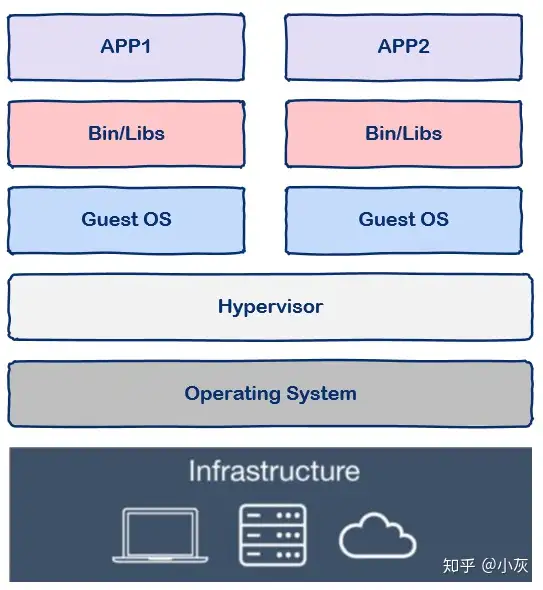
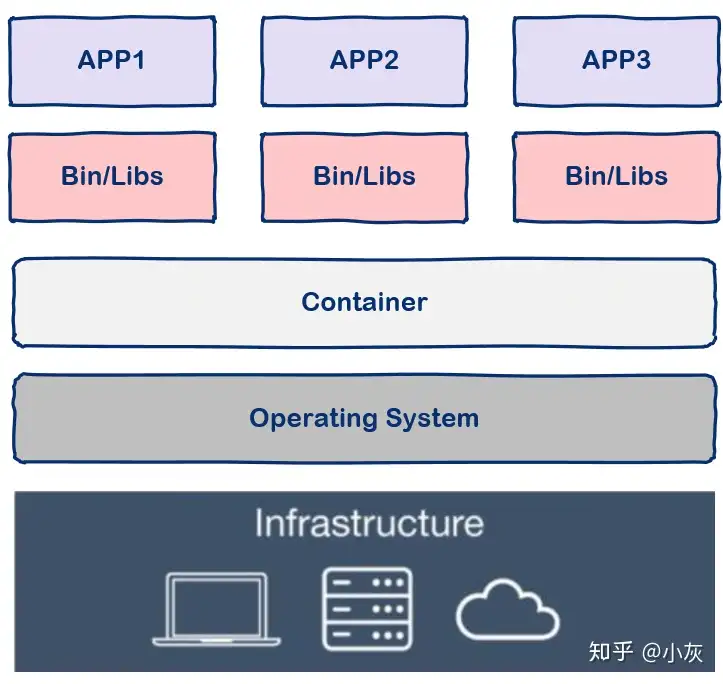
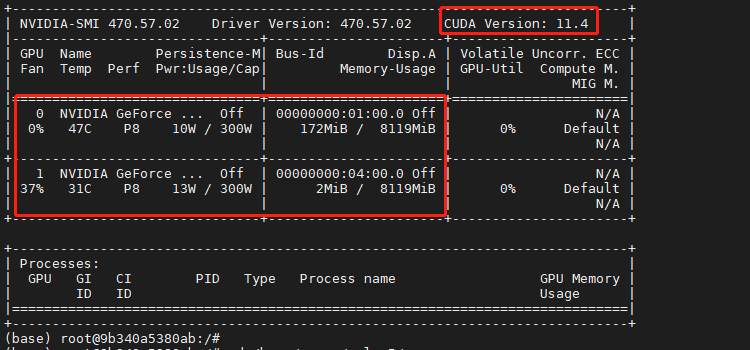
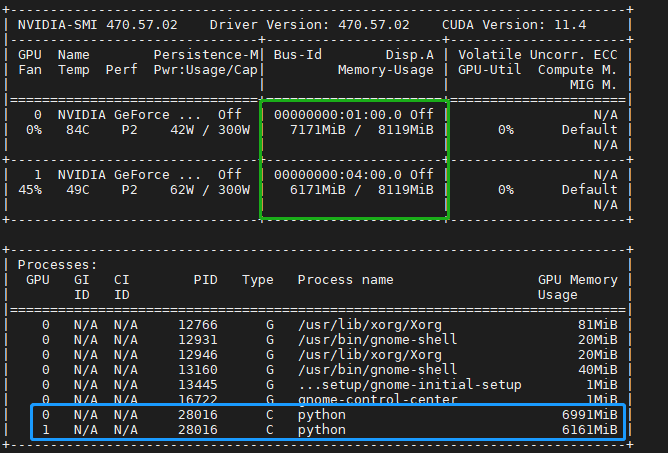
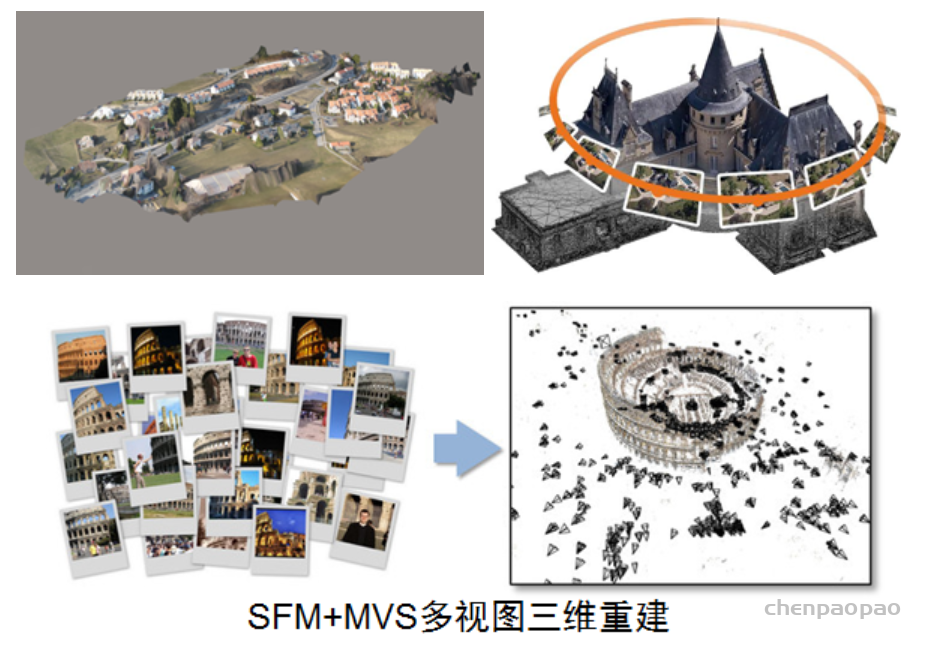
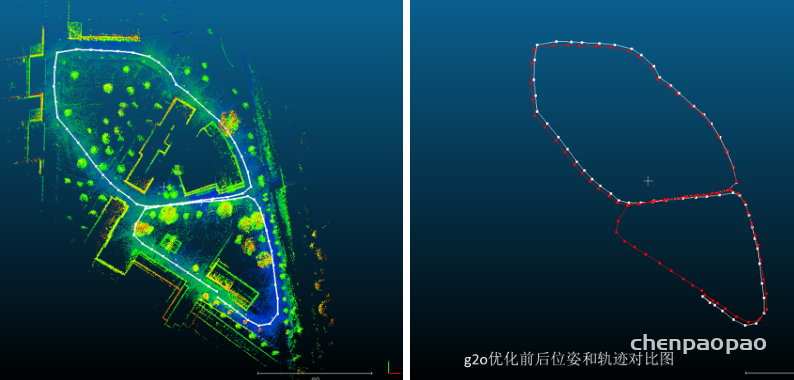





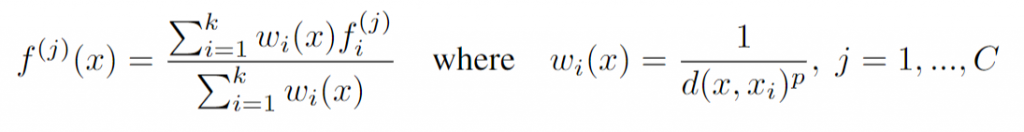





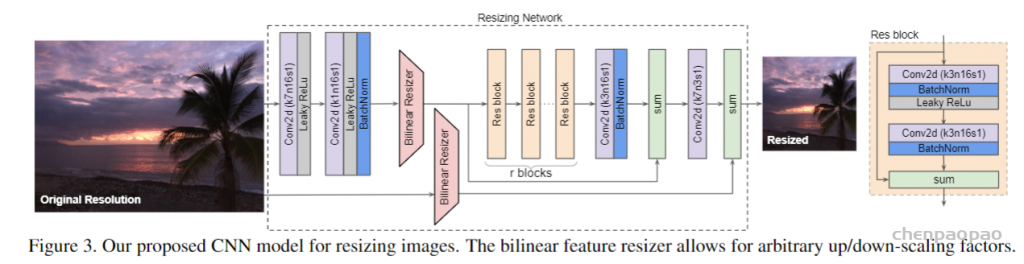

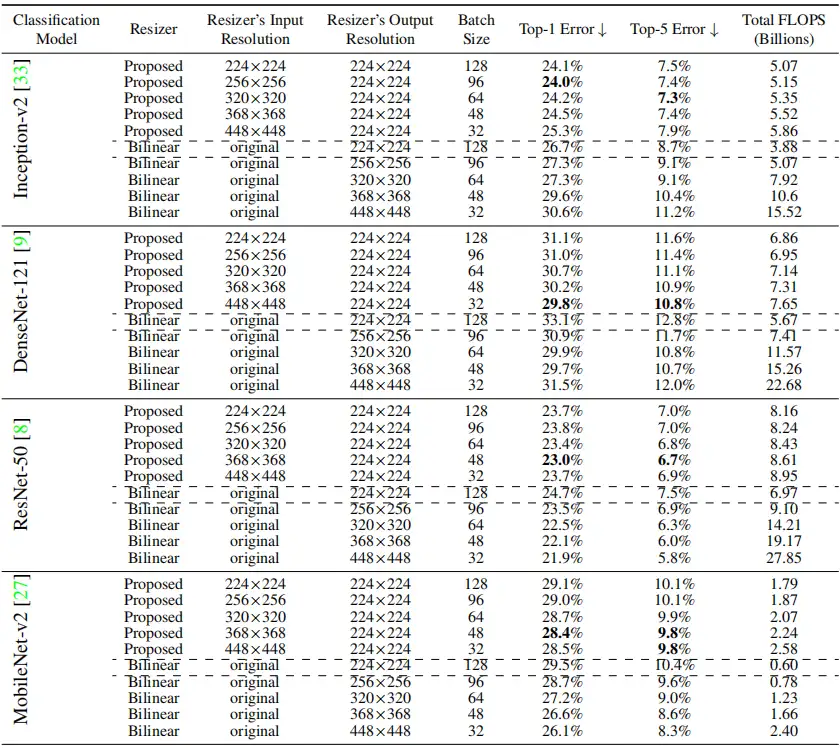





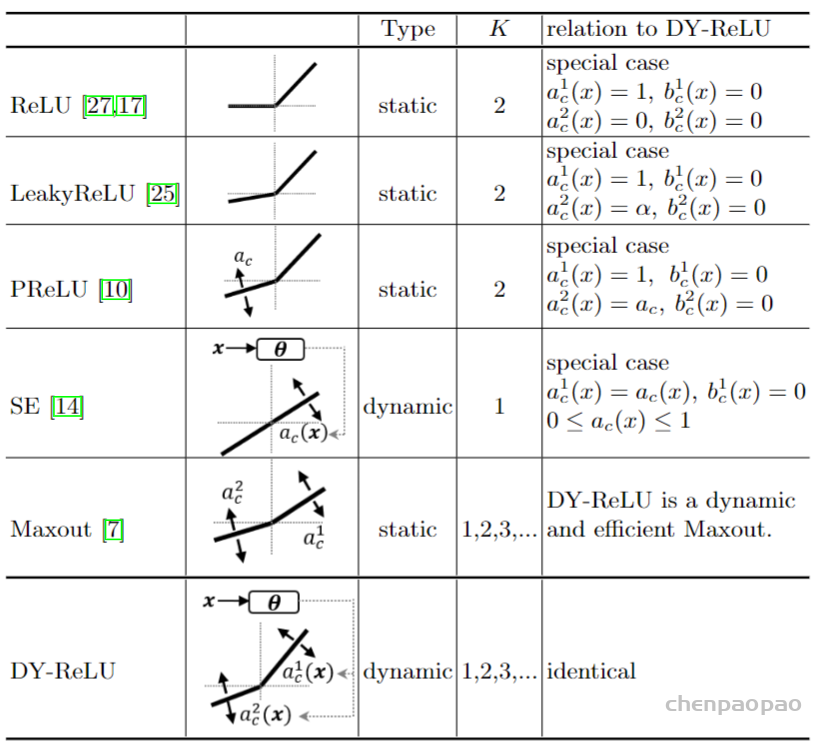
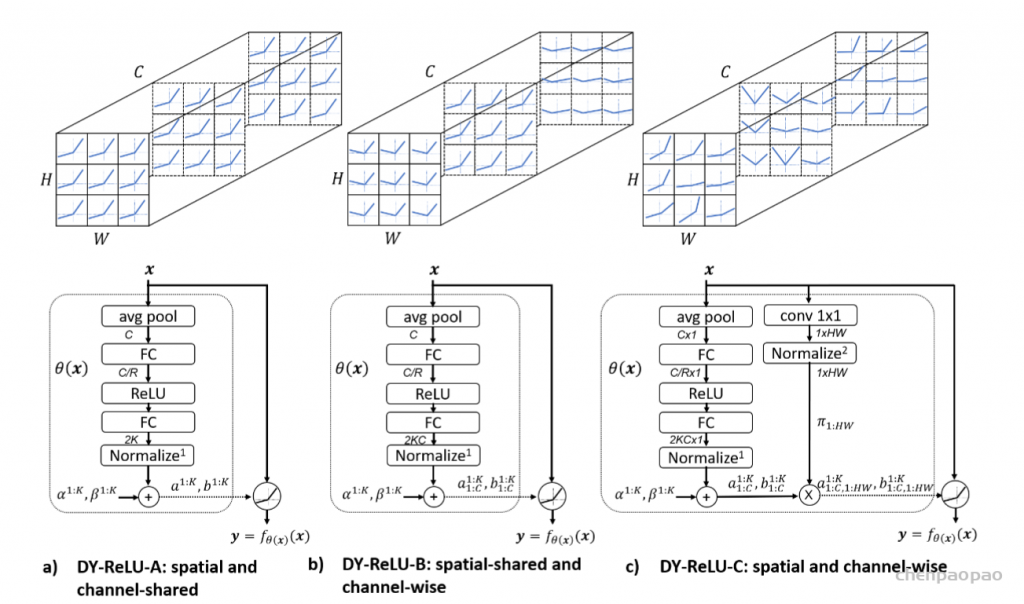


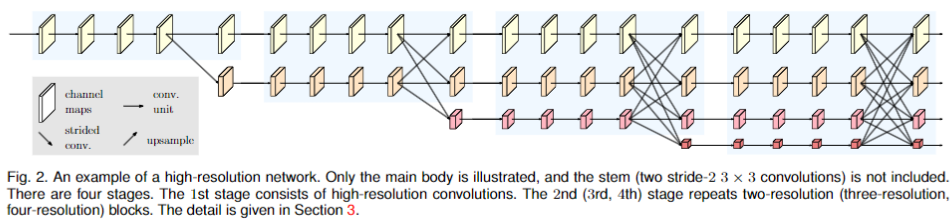
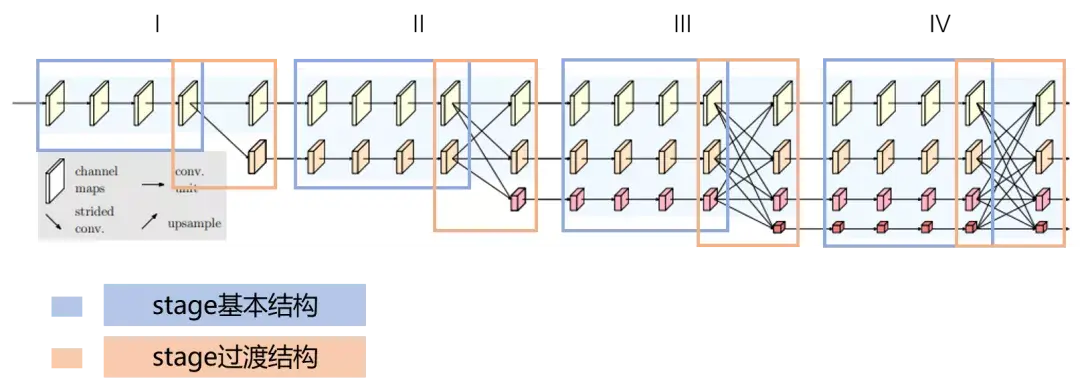
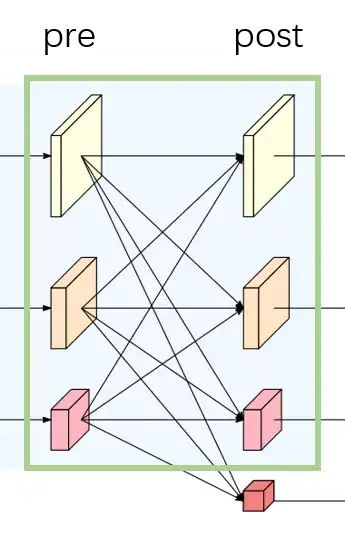
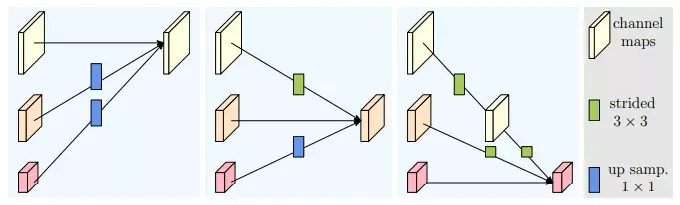
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}