
论文:(CVPR 2022) CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields
项目主页:https://cassiepython.github.io/clipnerf/
Overview
- 提出了第一个统一文本和图像驱动的NeRF编辑框架,使得用户可以使用文本提示或示例图像对3D内容进行灵活编辑。
- Zs 和Za,分别控制形状和外观。
- 提出feed forward mapper,能够实现快速推理出用户输入对物体形状和外观的改变量。
- 提出了一种反演方法,利用EM算法从真实的图像中推断出相机位姿、Zs 和 Za,进而实现编辑现有物体的形状、外观、姿态。
Network architecture
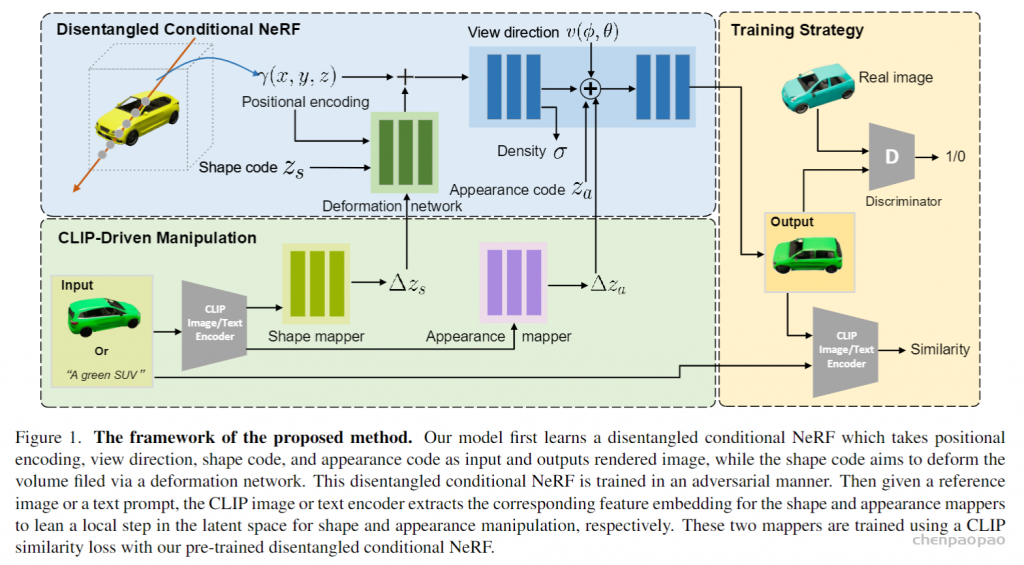
- 与GRAF不同,该网络并不是将 Zs 直接与positional encoding拼接起来送入神经辐射场,而是先用deformation network(受到Nerfies启发)生成原始位置编码的偏移量并与原始位置编码相加,再送入后续辐射场中。优点:使用tanh函数限制deformation network输出的偏移量的值域,提升了shape操控的鲁棒性与稳定性,同时使得对shape的操纵对于appearance无影响(传统conditional NeRF,如GRAF,实际上改变 Zs会对appearance产生一些影响)。
- 先预训练好一个解耦条件NeRF,使得NeRF能够充分学习到场景的3D信息以及生成出真实的场景物体。
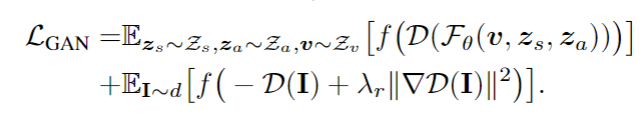
- 然后利用CLIP distance训练CLIP分支中的shape mapper and appearance mapper(固定其他模块的参数)。使得mapper能够正确学习到如何将用户输入的modify 信息映射为 Zs, Za 的改变量以使得NeRF正确生成目标结果
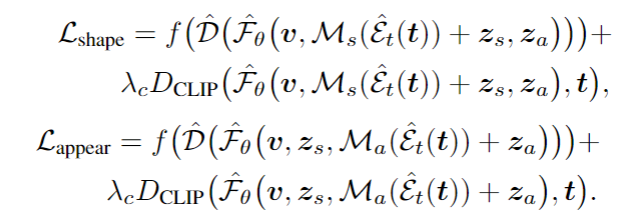
Inverse Manipulation
为了获得某物体对应的latent code以便对其实施编辑,作者根据EM算法( Expectation Maximization Algorithm。期望最大算法)设计了一种迭代方法来交替优化 、Zs、Za 和相机位姿 v ,本质是优化各项参数,使得在该组参数下得到的生成结果接近于实际结果。
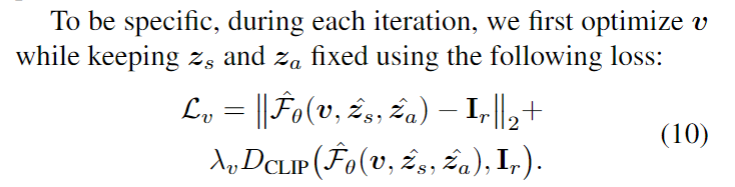
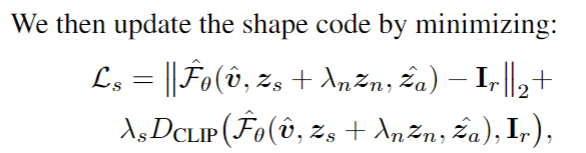
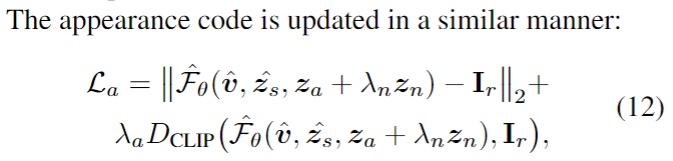
其中Zn是扰动,用于提升优化过程的鲁棒性, 入n 从1decay到0,表示越往后参数已经优化得差不多了,那么扰动也就相应地减小。
当获得某物体对应的 Zs,Za,v 后,输入文本便可以输出编辑后的物体。
Experiment results
- Text-Driven

- Exemplar-Driven Editing Results

- Convert real image into corresponding latent code and camera pose, then use prompt to edit real image
实现编辑应该就是先反演出目标图像对应的各个latent codes,然后向CLIP encoder输入参考图像/文字,再通过shape/appearancce mapper得到相应的编辑改变量,将改变量和原始推算出的latent codes相加,再利用NeRF前向渲染出最终编辑后的图像。

Limitations
- 无法进行细粒度的物体修改,比如修改车轮为红色。根源在于隐空间和预训练CLIP的固有局限性,比如CLIP就没有学到轮胎的语义信息。
- 局限于使用文本和示例图像对于单个物体进行修改,没有扩展到复杂场景(如object-nerf处理的现实场景)。如何实现多物体场景的text/img guided modify?结合object-nerf和clip-nerf?
- 先训练好NeRF,再训练mapping network,那就限定了模型只能用参考文字/参考图像编辑固定场景中的物体,而且通过模型结构不难推测出,该模型迁移到多物体数据集上是不可行的。在多物体场景下,由于文本只能影响全局的 Za,Zs ,因此编辑会影响场景中的所有物体。