
我们通常所说的语音token是离散的。如果使用对应码本中的embedding来表示语音的话,它也可以是连续的低维度的latent变量。既然是低维度的连续latent变量,那图像合成领域中大火的LDM(latent diffusion model,其实就是stable diffsion 1&2采用的模型)模型自然也可以用到语音的合成上。这方面的经典工作有很多,比如说:NaturalSpeech 2&3、AudioLDM 2、VoiceLDM。但这里面只有NaturalSpeech2用到了语音离散化部分提及的声学/语义token,NaturalSpeech3的属性分解形式的VQ更像是另一种形式的RVQ。
- AudioLDM2 :https://arxiv.org/abs/2308.05734
- NaturalSpeech 2:https://arxiv.org/abs/2304.09116
- NaturalSpeech 3: https://arxiv.org/abs/2403.03100
- VoiceLDM: https://arxiv.org/abs/2309.13664
NaturalSpeech 2
NaturalSpeech 2基本上就是VALL-E的连续版本。它用的latent也是来自Encodec,对其中不同层次的latent做了求和,然后将其作为扩散模型的训练目标。值得注意地是,扩散模型和FastSpeech2一样也用了时长和音高作为合成的先验条件。这一点也被后来的RALL-E采用。该工作中的扩散模型采用WaveNet实现,同时预测不加噪的latent和后验均值,和图像合成领域的扩散模型在实现方式上还是有所不同的。
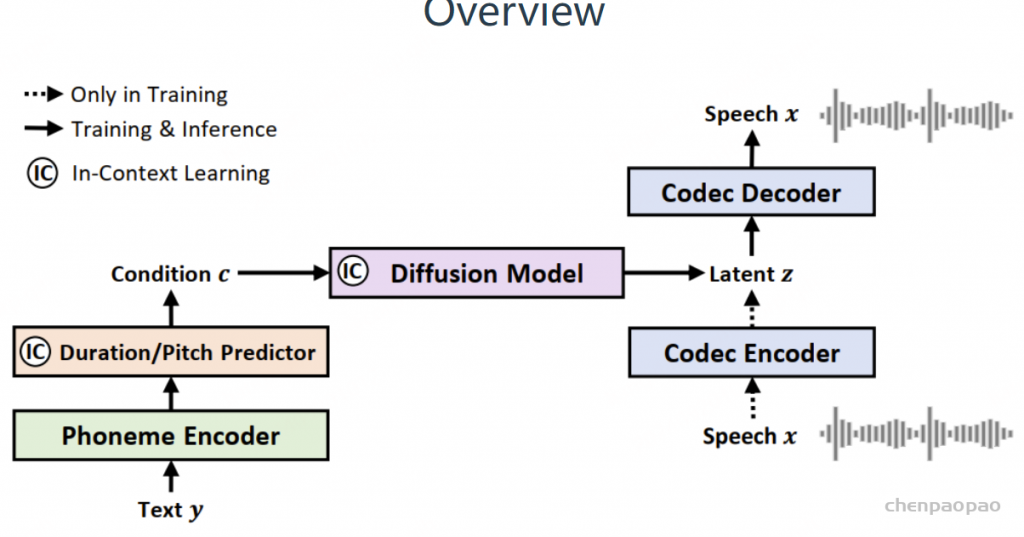
NaturalSpeech 3
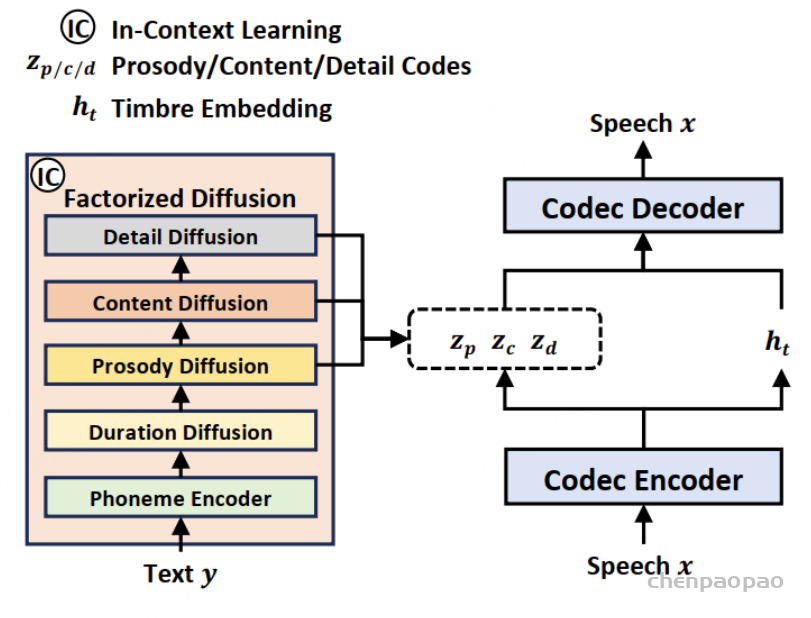
NaturalSpeech 3,还是非自回归的,而且非自回归的正统性味道更加浓厚,借用了不少FastSpeech2和megatts1&2的设计思想。像megatts 1&2一样,同样采用(自)监督信号对语音token编码的内容做了限制,而不再像是VALL-E/NaturalSpeech2那样一把抓。相应地,语音token化的方法也用VQ就行。具体而言,文章将语音信号分解为时长、内容、韵律和细节四个部分,然后每个部分用离散化的扩散模型来建模。不过,原文使用GRL来促进语音属性的分解,这一点的靠谱程度存疑。尝试过文章的FACodec,但效果很差。三级扩散模型级联的结构,预测起来似乎也非常麻烦。
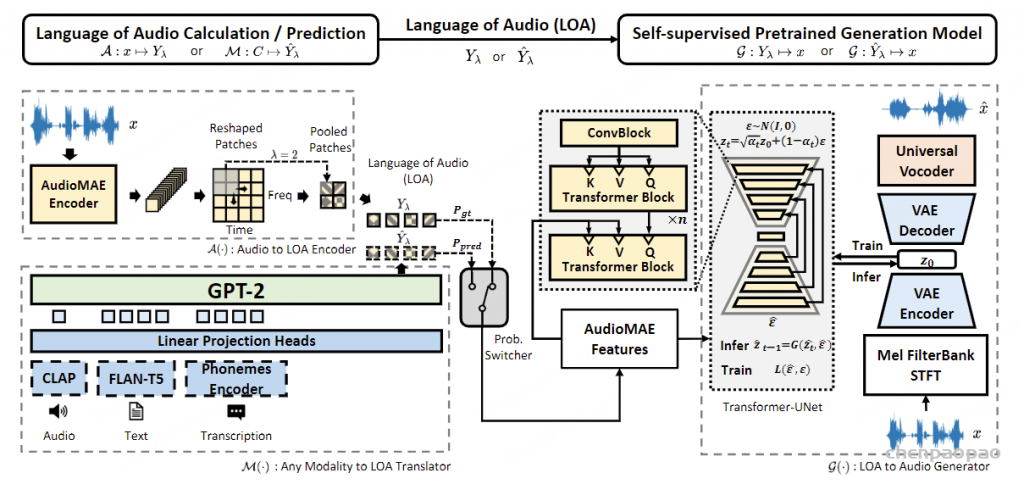
AudioLDM 2
- AudioLDM2 :https://arxiv.org/abs/2308.05734
- Code:https://audioldm.github.io/audioldm2/
- 核心思想是引入一种新的“音频语言”(LOA),它是表示音频剪辑语义信息的向量序列。 这种方法使我们能够将人类可理解的信息转换为 LOA,并合成以 LOA 为条件的音频表示。具体来说,我们利用基于 GPT 的语言模型(Radford等人,2019)将调节信息转换为 AudioMAE 特征。 GPT的输入条件很灵活,包括文本、音频、图像、视频等的表示。然后,我们使用潜在扩散模型(Rombach等人,2022)基于AudioMAE 功能。 潜在扩散模型可以以自监督的方式进行优化,从而允许使用大规模未标记的音频数据进行预训练。 我们的语言建模方法使我们能够利用语言模型的最新进展(Zhao等人,2023),同时缓解先前音频自回归模型中出现的高推理计算成本和错误累积等挑战(Zeghidour 等人,2021;Agostinelli 等人,2023)。 这是由于连续 AudioMAE 特征的长度较短,它也比以前使用的离散标记提供了更丰富的表示能力(Lam 等人,2023;Borsos 等人,2023;Agostinelli 等人,2023) 。
VoiceLDM
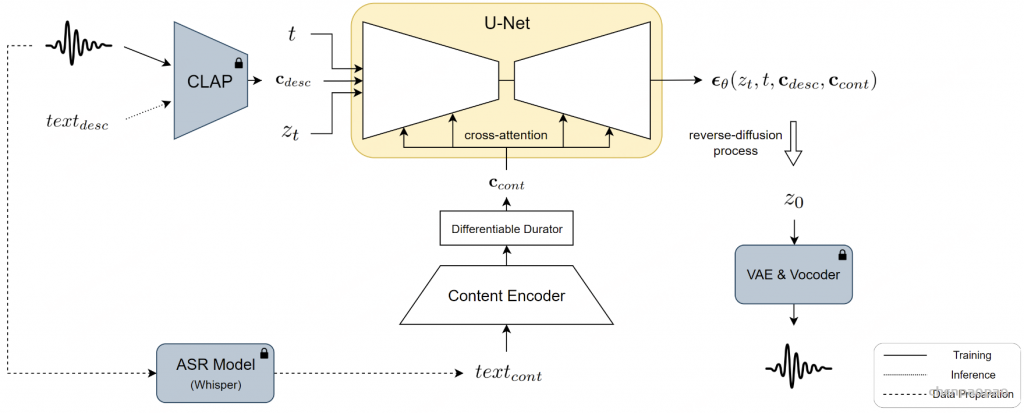
VoiceLDM,这是一种旨在生成准确遵循两种不同自然语言文本提示的音频的模型:描述提示和内容提示。前者提供有关音频的整体环境上下文的信息,而后者则传达语言内容。为了实现这一目标,我们采用了基于潜在扩散模型的文本到音频 (TTA) 模型,并扩展了其功能以将额外的内容提示作为条件输入。通过利用预先训练的对比语言音频预训练 (CLAP) 和 Whisper,VoiceLDM 可以在大量真实音频上进行训练,而无需手动注释或转录。此外,我们采用双无分类器指导来进一步增强 VoiceLDM 的可控性。