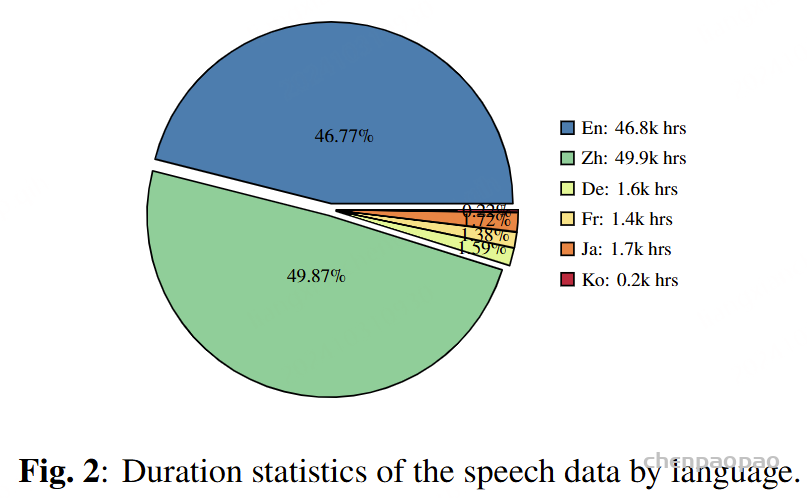
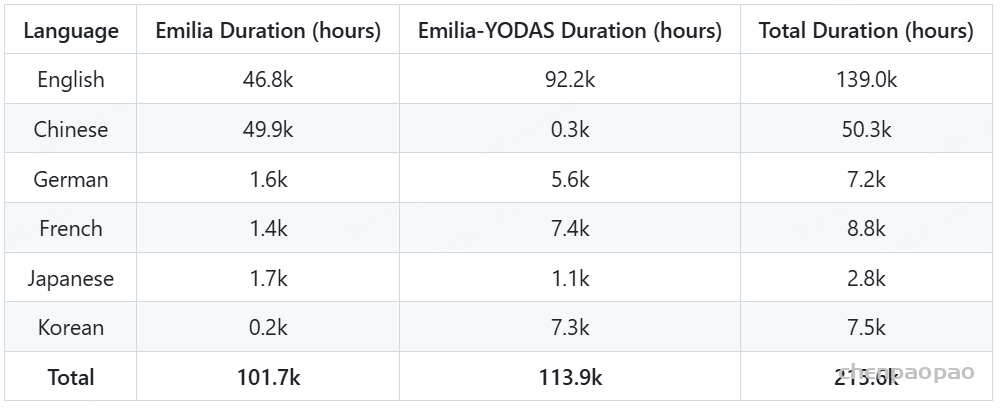
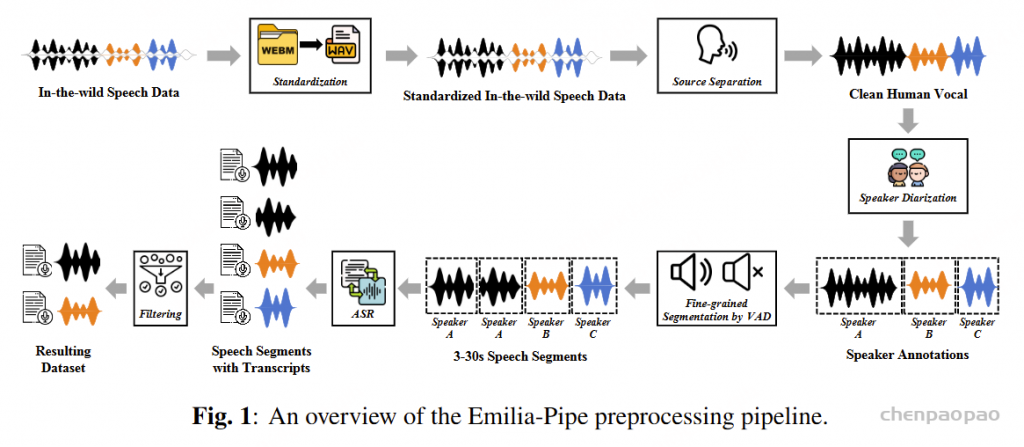
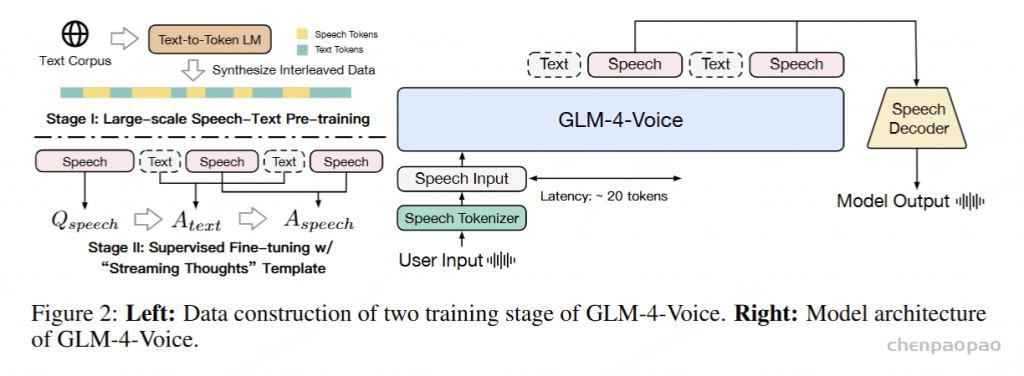
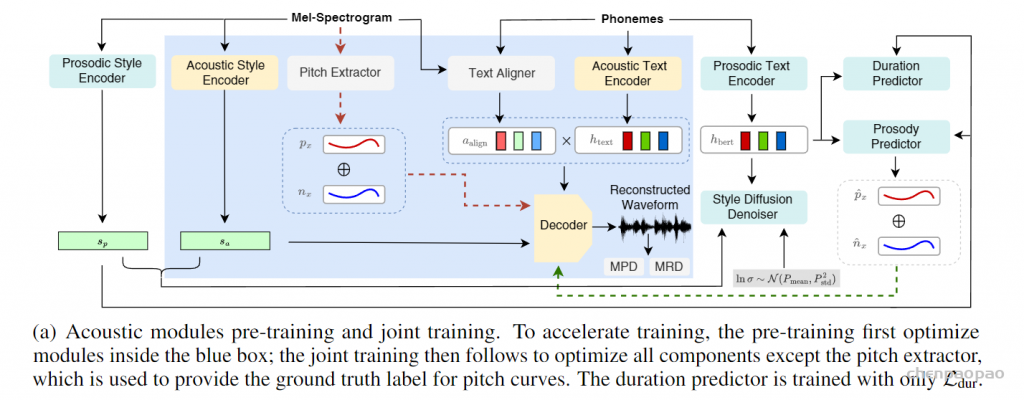
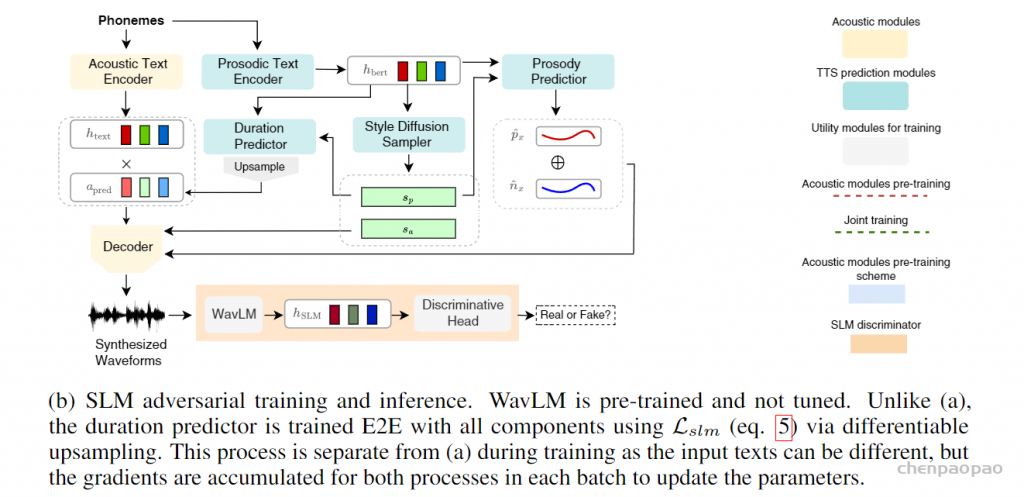
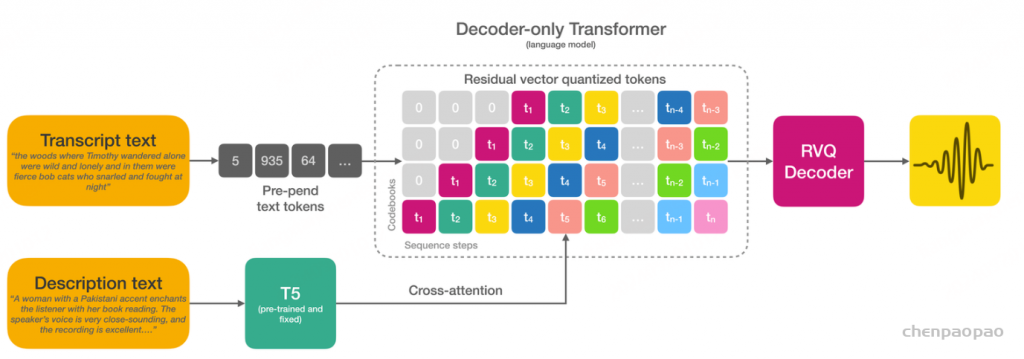
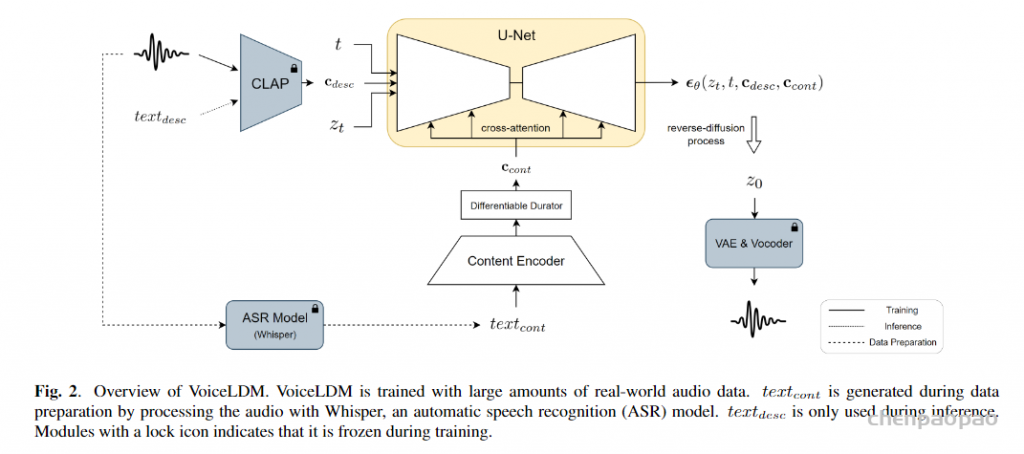
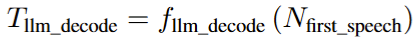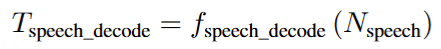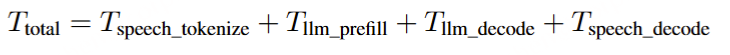|-- openemilia_all.tar.gz (all .JSONL files are gzipped with directory structure in this file)
|-- EN (114 batches)
| |-- EN_B00000.jsonl
| |-- EN_B00000 (= EN_B00000.tar.gz)
| | |-- EN_B00000_S00000
| | | `-- mp3
| | | |-- EN_B00000_S00000_W000000.mp3
| | | `-- EN_B00000_S00000_W000001.mp3
| | |-- ...
| |-- ...
| |-- EN_B00113.jsonl
| `-- EN_B00113
|-- ZH (92 batches)
|-- DE (9 batches)
|-- FR (10 batches)
|-- JA (7 batches)
|-- KO (4 batches)
JSONL 文件示例:
{"id": "EN_B00000_S00000_W000000", "wav": "EN_B00000/EN_B00000_S00000/mp3/EN_B00000_S00000_W000000.mp3", "text": " You can help my mother and you- No. You didn't leave a bad situation back home to get caught up in another one here. What happened to you, Los Angeles?", "duration": 6.264, "speaker": "EN_B00000_S00000", "language": "en", "dnsmos": 3.2927}
{"id": "EN_B00000_S00000_W000001", "wav": "EN_B00000/EN_B00000_S00000/mp3/EN_B00000_S00000_W000001.mp3", "text": " Honda's gone, 20 squads done. X is gonna split us up and put us on different squads. The team's come and go, but 20 squad, can't believe it's ending.", "duration": 8.031, "speaker": "EN_B00000_S00000", "language": "en", "dnsmos": 3.0442}
团队介绍:本项目的核心开发团队主要由上海交通大学 GAIR 研究组的本科三年级、四年级学生以及直博一年级研究生组成。项目得到了来自 NYU 等一线大型语言模型领域顶尖研究科学家的指导。详细作者介绍见:https://github.com/GAIR-NLP/O1-Journey#about-the-team。
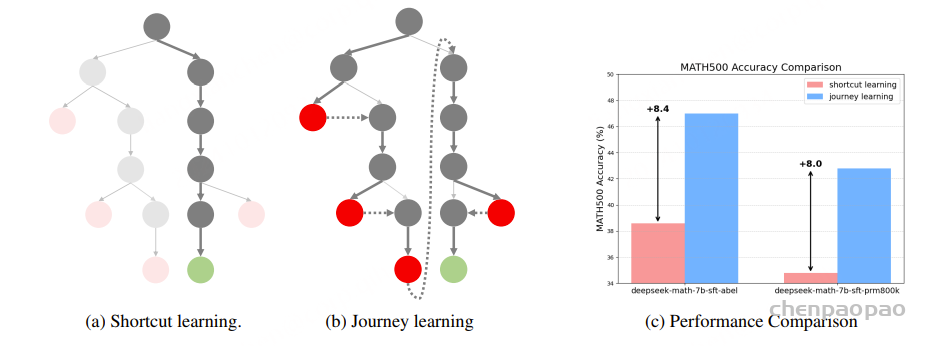
在人工智能领域掀起巨浪的 OpenAI o1 模型发布三周后,一支由高校年轻研究者组成的团队今天发布了题为 “o1 Replication Journey: A Strategic Progress Report (o1 探索之旅:战略进展报告)” 的研究进展报告。这份报告的独特之处在于 (1)不仅提出并验证了 “旅程学习” 的技术的巨大潜力(研究者也认为是 o1 取得成功的关键技术):通过 327 条训练样本,鼓励模型学会反思、纠错、回溯,其在复杂数学题目上表现 绝对性能就超过了传统监督学习 8% 以上,相对性能提升超过 20%;(2)并且,其前所未有的透明度和即时性,不仅详细记录了团队在复现过程中的发现、挑战、试错和创新方法,更重要的是,它倡导了一种全新的 AI 研究范式。研究团队负责人表示:” 我们的主要目标不是达到与 OpenAI 的 o1 相当的性能 —— 考虑到可用资源有限,这是一个极具挑战性的任务。相反,我们的使命是透明地记录和分享我们的探索过程,聚焦于我们遇到的根本问题,发现新的科学问题,并识别导致 o1 的成功的关键因素,并与更广泛的 AI 社区分享我们的试错经验。o1 技术无疑会成为全球各大 AI 科技公司争相复现的目标。如果我们能够及早分享一些复现过程中的经验教训,就能帮助其他公司减少不必要的试错,从而降低全球范围内 o1 技术复现的总体成本和时间。这不仅有利于推动技术的快速发展,也能促进整个 AI 行业的共同进步。”
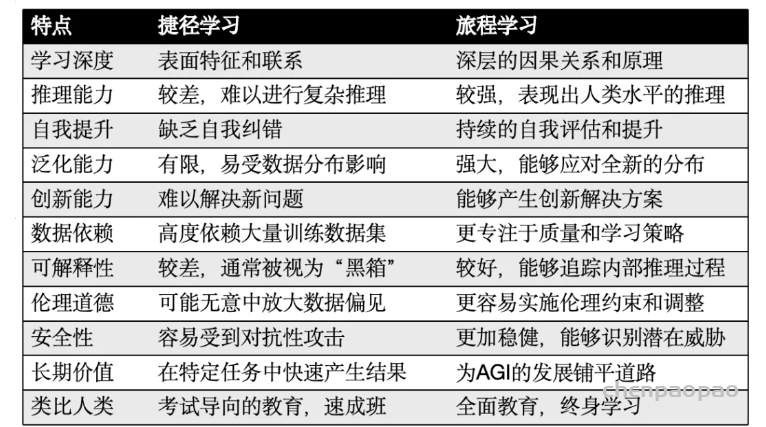
团队强调了探索过程的重要性,而不仅仅关注最终结果。这种重视科研探索过程的思路与团推提出的 “旅程学习” 范式相一致,强调了在复杂、动态环境中不断试错、纠错的持续学习和适应的重要性。通过这个过程,不仅获得了关于 o1 技术的深入理解,还开发了一套探索未知 AI 技术的系统方法。研究过程涉及决策分析、挑战识别以及创新解决方案的开发。最终,这项研究不仅仅是对 o1 技术的探索,更是对先进 AI 系统研究方法的一次实践和验证。通过分享研究过程,包括成功和失败的经验,旨在为 AI 研究社区提供有价值的见解,促进该领域的集体进步。 这个探索过程展示了开放、协作的 AI 研究在推动技术边界方面的重要性,为未来更复杂的 AI 系统研究提供了有益的参考和指导。 具体地,团队凝炼了复现 o1 过程中的几个关键问题,并做了非常细致的探索分享:
构建推理树需要一个能够执行单步推理的策略模型。给定一个问题及其相应的最终答案,策略模型从问题作为根节点开始,不断向树中添加新节点。它首先生成 w 个可能的第一步推理步骤作为根节点的子节点。然后,它迭代地进行前向推理,为每个当前节点(如第一步推理)生成 w 个可能的后续推理步骤作为该节点的子节点。这个过程重复进行,直到达到预设的最大深度或所有叶节点达到最终答案。
策略模型和步骤分段 构建推理树需要清晰定义推理步骤。为此,团队采用 Abel 提出的数据格式,将数学问题解决方案转化为具有清晰步骤的形式,将答案分成多行,每行以行号开始,并包含该行内的推理。因此,使用 Abel 数据集对 DeepSeekMath-7B-Base 进行微调,得到 Abel-DSMath,作为策略模型。在这种特定格式数据上微调的模型可以方便地控制单个推理步骤的生成。
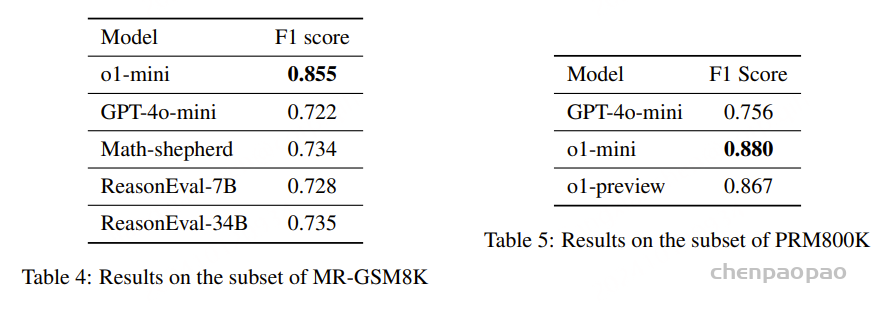
Q9: 什么是人类和 AI 协同标注的有效策略? 团队开发了一种人类和 AI 协作的数据标注流程,用于生成基于 MATH 数据集的高质量、长文本推理数据。通过这个流程,我们将短短几行人类标注的解题方案扩展为包含数千个 token 的、符合 “旅程学习” 范式的详细推理过程。在构建流程的过程中,我们发现了下面几种有效的标注技巧:
团队借本项目正式引出 “核桃计划” (https://gair-nlp.github.io/walnut-plan),团队成员表示:“对 o1 技术路线的探索及复现工作,仅仅是我们核桃计划的一部分。核桃计划旨在成为人工智能复杂推理和深度思考能力研究的开放先锋,致力于推动 AI 从简单的信息处理工具演变为具备 “牛顿” 和 “爱因斯坦” 级别深度思考能力的智能系统。我们将着眼于更长远的研究,最终的伟大愿景是让未来可以呈现 AI 驱动的科研范式,即 AI 完全具备参与人类科研的水准,从而更好地服务人类、改变世界。”
To speed up pretraing in our experiments, we pre-train the model with sequence length of 128 for 90% of the steps. Then, we train the rest 10% of the steps of sequence of 512 to learn the positional embeddings.
class PositionalEmbedding(nn.Module):
"""
位置编码。
*** 注意: Bert中的位置编码完全不同于Transformer中的位置编码,
前者本质上也是一个普通的Embedding层,而后者是通过公式计算得到,
而这也是为什么Bert只能接受长度为512字符的原因,因为位置编码的最大size为512 ***
# Since the position embedding table is a learned variable, we create it
# using a (long) sequence length `max_position_embeddings`. The actual
# sequence length might be shorter than this, for faster training of
# tasks that do not have long sequences.
———————— GoogleResearch
https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/modeling.py
"""
def __init__(self, hidden_size, max_position_embeddings=512, initializer_range=0.02):
super(PositionalEmbedding, self).__init__()
self.embedding = nn.Embedding(max_position_embeddings, hidden_size)
self._reset_parameters(initializer_range)
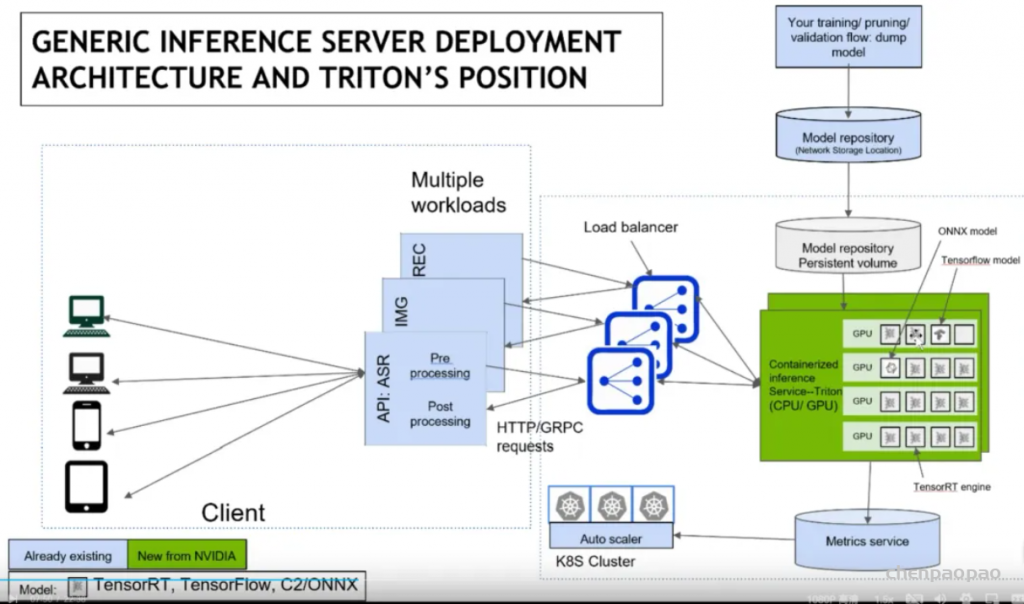
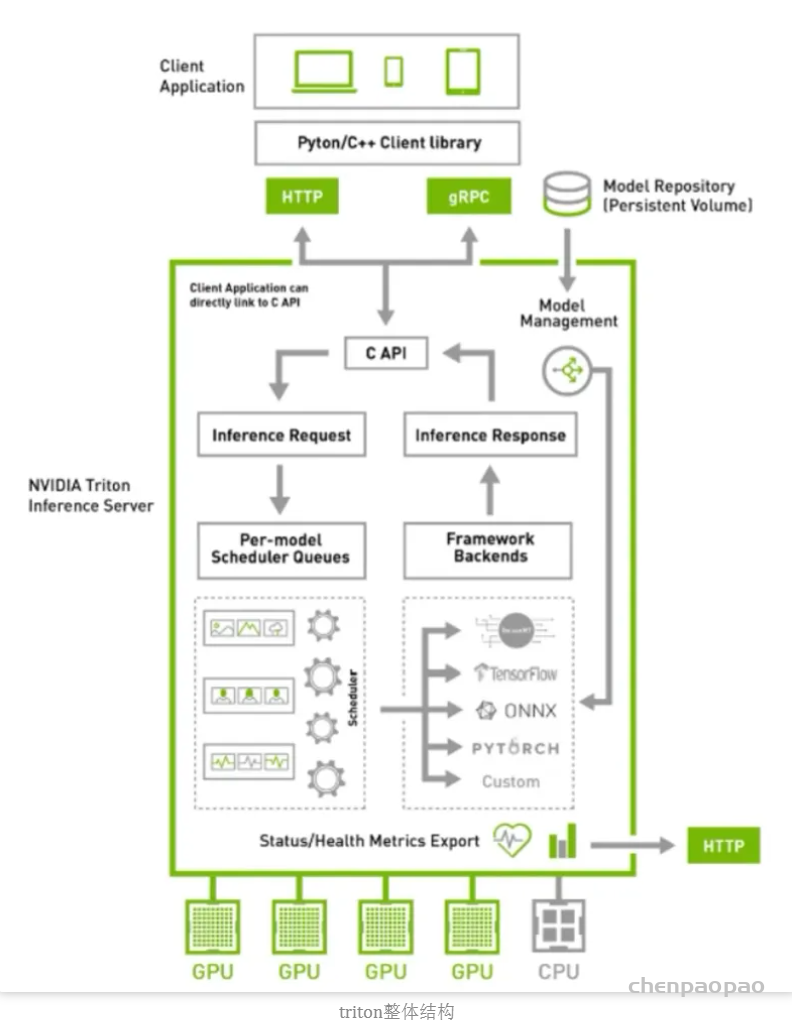
高性能:Triton提供了dynamic batching、concurrent execution、optimal model configuration、model ensemble、dali model 等策略来提升在线推理的性能;同时也提供了perf analyze和model analyze工具来辅助我们进行性能调优。
MLOps:Triton提供了Prometheus exporter、模型在线更新、http server 、grpc server等多种在线服务策略以满足用户生产场景多样化的部署和运维需求
# 第一步,创建 model repository git clone -b r22.09 https://github.com/triton-inference-server/server.git cd server/docs/examples ./fetch_models.sh
# 第二步,从 NGC Triton container 中拉取最新的镜像并启动 docker run --gpus=1 --rm --net=host -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:22.09-py3 tritonserver --model-repository=/models
# 第三步,发送 # In a separate console, launch the image_client example from the NGC Triton SDK container docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:22.09-py3-sdk /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
# Inference should return the following Image '/workspace/images/mug.jpg': 15.346230 (504) = COFFEE MUG 13.224326 (968) = CUP 10.422965 (505) = COFFEEPOT
Failed to recurse into submodule path 'third_party/bloaty' CMake Error at /tmp/tritonbuild/tritonserver/build/_deps/repo-third-party-build/grpc-repo/tmp/grpc-repo-gitclone.cmake:52 (message): Failed to update submodules in: '/tmp/tritonbuild/tritonserver/build/_deps/repo-third-party-build/grpc-repo/src/grpc'
# # Get the protobuf and grpc source used for the GRPC endpoint. We must # use v1.25.0 because later GRPC has significant performance # regressions (e.g. resnet50 bs128). # ExternalProject_Add(grpc-repo PREFIX grpc-repo # GIT_REPOSITORY "https://gitee.com/Oldpann/grpc.git" # GIT_TAG "v1.25.x" SOURCE_DIR "${CMAKE_CURRENT_BINARY_DIR}/grpc-repo/src/grpc" CONFIGURE_COMMAND "" BUILD_COMMAND "" INSTALL_COMMAND "" TEST_COMMAND "" PATCH_COMMAND python3 ${CMAKE_CURRENT_SOURCE_DIR}/tools/install_src.py --src <SOURCE_DIR> ${INSTALL_SRC_DEST_ARG} --dest-basename=grpc_1.25.0 )
说了这么多,总之,最好的办法当然还是开科学,全局一下就OK,省去那么多麻烦事儿。
搞定好网络问题,编译triton就很简单了!
git clone --recursive https://github.com/triton-inference-server/server.git cd server python build.py --enable-logging --enable-stats --enable-tracing --enable-gpu --endpoint=http --repo-tag=common:r22.06 --repo-tag=core:r22.06 --repo-tag=backend:r22.06 --repo-tag=thirdparty:r22.06 --backend=ensemble --backend=tensorrt
I1016 08:25:38.055627 51771 http_server.cc:3303] Started HTTPService at 0.0.0.0:8000 I1016 08:25:38.097213 51771 http_server.cc:178] Started Metrics Service at 0.0.0.0:8001