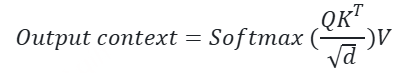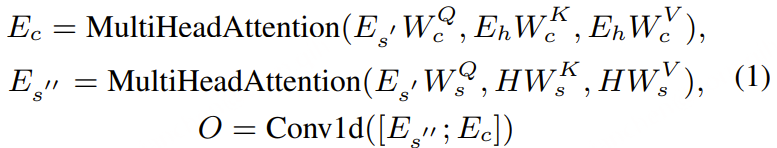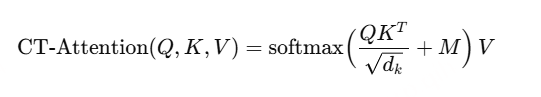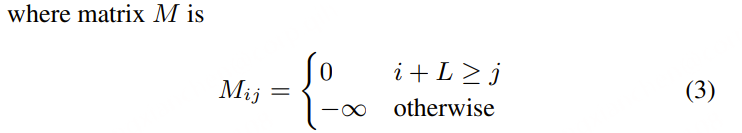- 论文地址:
- https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
- 博客地址:https://qwenlm.github.io/blog/qwen2.5-omni/
- GitHub 地址:https://github.com/QwenLM/Qwen2.5-Omni
- Hugging Face 地址:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
这是 Qwen 系列中全新的旗舰级多模态大模型,专为全面的多模式感知设计,可以无缝处理包括文本、图像、音频和视频的各种输入,同时支持流式的文本生成和自然语音合成输出。
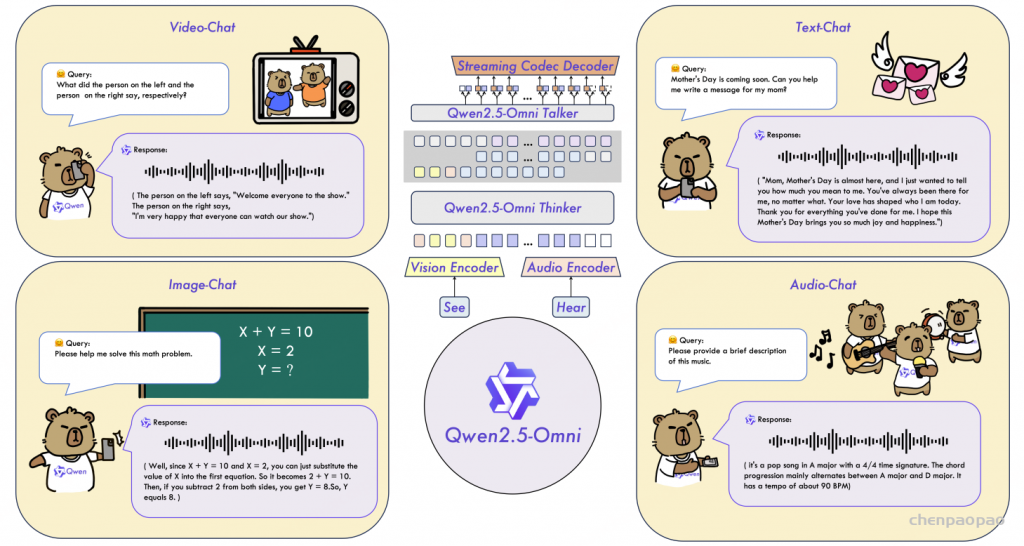
主要特点
- 全能创新架构:我们提出了一种全新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。我们提出了一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。
- 实时音视频交互:架构旨在支持完全实时交互,支持分块输入和即时输出。
- 自然流畅的语音生成:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。Qwen2.5-Omni 支持修改输出语音的音色类型,目前支持2种音色类型。
- 全模态性能优势:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。Qwen2.5-Omni在音频能力上优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。
- 卓越的端到端语音指令跟随能力:Qwen2.5-Omni在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在MMLU通用知识理解和GSM8K数学推理等基准测试中表现优异。
摘要:
Qwen2.5-Omni,这是一种端到端的多模态模型,能够感知多种模态信息,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。为了实现多模态信息输入的流式处理,Qwen2.5-Omni 的音频和视觉编码器采用了 分块处理(block-wise processing) 方法。该策略有效地解耦了长序列多模态数据的处理,将感知任务交由多模态编码器,而将长序列建模任务交由大语言模型(LLM),这种分工机制通过共享注意力机制增强了不同模态的融合。
为同步视频输入的时间戳与音频,我们采用 交错(interleaved) 方式对音视频数据进行序列化,并提出了一种新颖的位置编码方法——TMRoPE(Time-aligned Multimodal RoPE,时间对齐多模态旋转位置编码)。 ps:关于旋转位置编码
在同时生成文本和语音的过程中,为了避免两种模态之间的相互干扰,我们提出了 Thinker-Talker 架构。在该框架下:
- Thinker 作为大语言模型,负责文本生成;
- Talker 是一个 双轨自回归模型(dual-track autoregressive model),它直接利用 Thinker 的隐藏表示来生成音频标记(audio tokens)作为输出。
Thinker 和 Talker 均以端到端方式进行训练和推理。此外,为了实现流式音频标记解码,我们引入了 滑动窗口 DiT(sliding-window DiT),通过限制感受野来减少初始数据包延迟。
Qwen2.5-Omni 的关键特性可总结如下:
- Qwen2.5-Omni 是一个 统一多模态模型,能够感知所有模态信息,并以流式方式同时生成文本和自然语音响应。
- 我们提出了一种新颖的位置编码算法 TMRoPE(Time-aligned Multimodal RoPE),该方法显式融入时间信息,以实现音视频的同步。
- 我们设计了 Thinker-Talker 架构,以支持 实时理解 和 语音生成。
- 在多模态基准测试中,Qwen2.5-Omni 展示了卓越的性能,相较于类似规模的单模态模型表现更优,尤其在语音指令跟随任务上,其能力可与纯文本输入任务相媲美。
- 在需要整合多种模态的信息处理任务中(如 OmniBench 评测),Qwen2.5-Omni 达到了 最先进(state-of-the-art) 的性能。
- 在语音生成方面,Qwen2.5-Omni 在 seed-tts-eval 评测中表现出色,展现出强大的语音生成能力和稳健性。
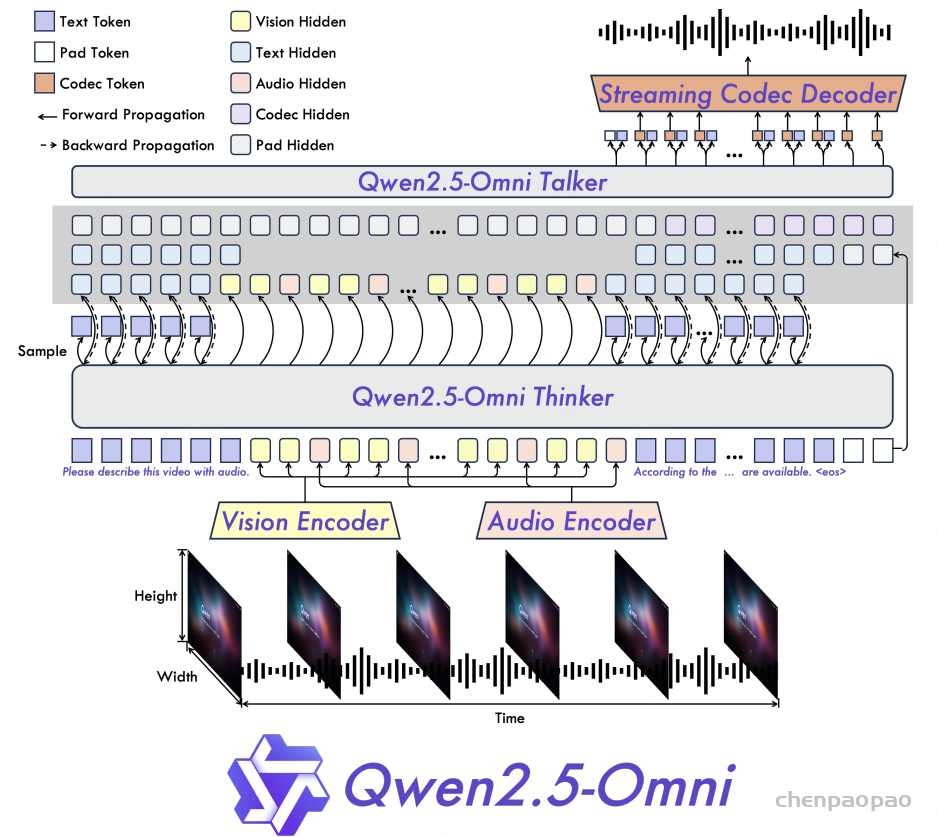
Talker 通过直接接收 Thinker 提供的高级表示,专注于 流式语音标记生成。
Architecture:
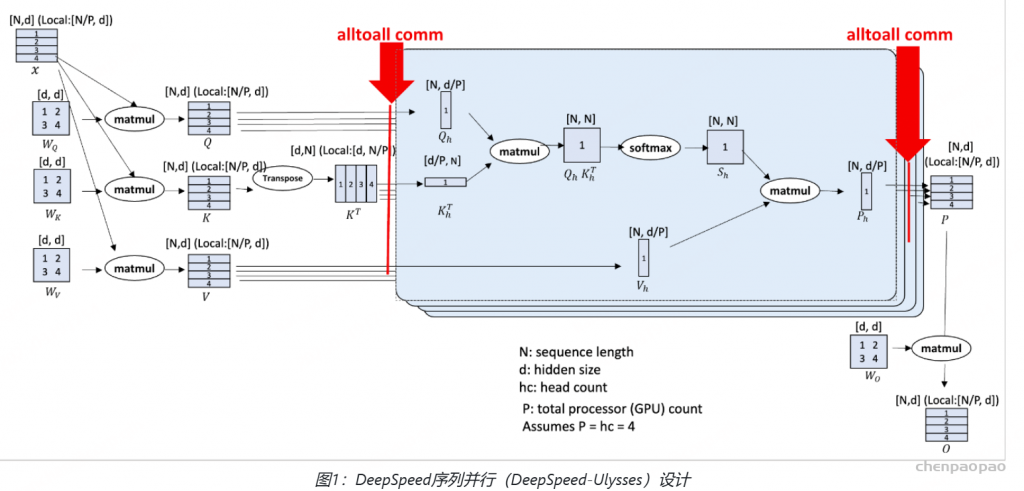
如 图 2 所示,Qwen2.5-Omni 采用 Thinker-Talker 架构,其中:
- Thinker 类似于大脑,负责处理和理解 文本、音频、视频 等模态输入,生成高级表示和对应的文本输出。
- Talker 类似于人类的嘴巴,以流式方式接收 Thinker 生成的高级表示和文本,并顺畅地输出离散语音标记。
架构细节
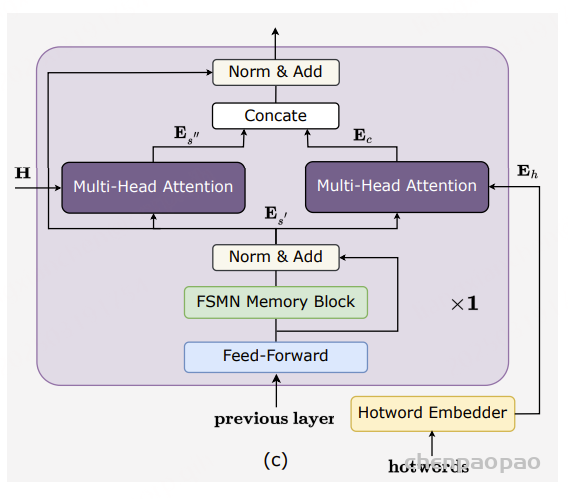
- Thinker 采用 Transformer 解码器,并配备 音频编码器 和 图像编码器,以增强信息提取能力。
- Talker 采用 双轨【同时接收文本token和语音token】自回归 Transformer 解码器 结构(受 Mini-Omni [Xie & Wu, 2024] 启发)。
- 在 训练和推理 过程中,Talker 直接接收 Thinker 的高维表示,并共享其全部历史上下文信息,使整个架构作为一个统一模型进行 端到端训练和推理。

感知:
Qwen2.5-Omni 通过 Thinker 对 文本、音频、图像和视频(无音频) 进行处理,将它们转化为一系列隐藏表示作为输入。具体步骤如下:
- 文本输入
- 对于文本输入,我们采用 Qwen 的分词器(Byte-level Byte-pair Encoding),词汇表包含 151,643 个常规标记。
- 音频输入和视频中的音频
- 音频输入(包括视频中的音频部分)首先被重采样至 16kHz 的频率,然后将原始波形转化为 128 通道的梅尔频谱图(mel-spectrogram),窗口大小为 25ms,步幅为 10ms。
- 音频编码器采用 Qwen2-Audio 的音频编码器(Chu et al., 2024b),每一帧音频表示大约对应于 原始音频信号的 40ms 时长。
- 图像和视频输入
- 对于图像输入,我们采用 Qwen2.5-VL 的视觉编码器(基于 Vision Transformer(ViT) 模型,约 6.75 亿个参数),能够有效处理图像和视频输入。
- 视觉编码器使用混合训练方法,结合图像和视频数据,确保其在图像理解和视频理解上的高效表现。
- 为了最大程度地保留视频信息并适应音频采样率,我们采用 动态帧率(dynamic frame rate) 来进行视频采样。此外,为保持一致性,每个图像都被视为两个相同的帧。
视频与TMRoPE
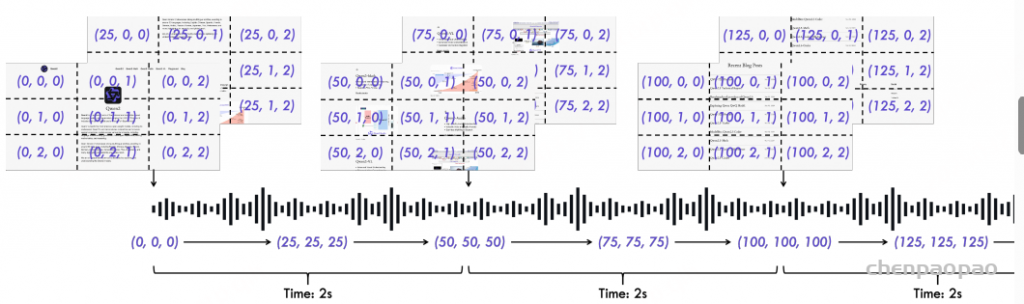
我们提出了一种 音视频时间交错算法(time-interleaving),并引入了新的 位置编码方法 —— TMRoPE(Time-aligned Multimodal RoPE)。如 图 3 所示,TMRoPE 编码了多模态输入的三维位置,采用 多模态旋转位置编码(M-RoPE)【ps: Qwen2-VL多模态旋转位置编码 多模位置编码】,并结合绝对时间位置。具体方法是将原始的旋转位置编码分解为三个组件:时间、图像高度和宽度。
- 文本输入 使用相同的位置信息(位置 ID)来处理各组件,使得 M-RoPE 在文本输入中与 1D-RoPE 等效。
- 音频输入 也使用相同的位置信息,并引入绝对时间位置编码,每 40ms 对应一个时间 ID。
- 图像输入,每个视觉标记的时间 ID 保持不变,而高度和宽度组件则根据标记在图像中的位置分配不同的 ID。
- 音视频输入 情况下,音频依然使用相同的时间位置 ID 编码,每帧 40ms。视频则作为一系列图像处理,每帧对应的时间 ID 增量,同时高度和宽度组件的 ID 分配与图像一致。由于视频的帧率不是固定的,我们根据每帧实际时间动态调整时间 ID,以确保每个时间 ID 对应 40ms。
在多模态输入场景下,每种模态的位置信息初始化时会将前一模态的最大位置 ID 增加 1。
视频与音频时间交错方法
为了使模型能够同时接收视觉和听觉信息,我们采用 时间交错方法(time-interleaving) 对带有音频的视频进行特殊设计。具体做法是:
- 将视频的音频表示按 实际时间 每 2 秒 切分为块。
- 在每个 2 秒块中,先安排视频的视觉表示,再安排音频表示,从而将视频和音频的表示交错排列。
生成:
文本生成由 Thinker 直接生成,其逻辑与广泛使用的大型语言模型(LLM)相同,文本通过基于词汇表的概率分布进行自回归采样生成。生成过程中可能会采用一些技术,如 重复惩罚(repetition penalty) 和 top-p 采样,以提高文本生成的多样性。
语音生成中,Talker 接收 Thinker 生成的高维表示和采样的文本标记。高维表示和离散采样标记的结合是这个过程中的关键。作为流式算法,语音生成需要在整个文本完全生成之前预测文本的语气和态度。Thinker 提供的高维表示隐含了这些信息,使得语音生成过程更自然。此外,Thinker 的表示主要体现语义相似性而非语音相似性,因此,即使是发音上差异较大的词,其高维表示可能非常相似,这就需要输入离散的采样标记来消除这种不确定性。
我们设计了一个高效的语音编解码器 qwen-tts-tokenizer,它能够高效地表示语音的关键信息,并通过因果音频解码器流式解码成语音。接收到信息后,Talker 开始自回归地生成音频标记和文本标记。语音生成过程中不需要与文本进行逐字和逐时间戳的对齐,这大大简化了训练数据的要求和推理过程。
流式设计:
在音频和视频流式交互的背景下,初始包延迟是衡量系统流式性能的关键指标。这个延迟受到多个因素的影响:1)多模态信息输入处理引起的延迟;2)从接收到第一个文本输入到输出第一个语音标记之间的延迟;3)将第一个语音段转换为音频的延迟;4)架构本身的固有延迟,这与模型大小、计算 FLOP 数以及其他因素相关。本文将随后讨论在这四个维度上减少这些延迟的算法和架构改进。
支持预填充(Support Prefilling)
块状预填充(Chunked-prefills) 是现代推理框架中广泛使用的一种机制。为了支持模态交互中的预填充机制,我们修改了音频和视觉编码器,以支持沿时间维度的 块状注意力(block-wise attention)。具体而言,音频编码器从对整个音频的全局注意力改为对每个 2 秒 的音频块进行注意力计算。视觉编码器则使用 Flash Attention 来实现高效的训练和推理,并通过一个简单的 MLP 层 将相邻的 2×2 标记合并为一个标记。补丁大小设置为 14,允许不同分辨率的图像被打包成一个序列。
流式编解码器生成(Streaming Codec Generation)
为了促进音频的流式传输,特别是对于长序列的流式处理,我们提出了一种 滑动窗口块注意力机制(sliding window block attention),该机制限制了当前标记访问的上下文范围。具体来说,我们采用了 Flow-Matching 的 DiT 模型。输入的code通过 Flow-Matching 转换为 梅尔频谱图(mel-spectrogram),然后通过修改后的 BigVGAN 将生成的梅尔频谱图重建回波形。
预训练
Qwen2.5-Omni 由三个训练阶段组成。在第一阶段,我们锁定大型语言模型(LLM)的参数,专注于训练视觉编码器和音频编码器,利用大量的音频-文本和图像-文本对来增强 LLM 的语义理解能力。在第二阶段,我们解冻所有参数,并使用更广泛的多模态数据进行训练,以实现更全面的学习。在最后阶段,我们使用长度为 32k 的数据来提升模型理解复杂长序列数据的能力。
该模型在一个多样化的数据集上进行预训练,数据类型包括图像-文本、视频-文本、视频-音频、音频-文本和文本语料库。我们将层次标签替换为自然语言提示,遵循 Qwen2-Audio(Chu et al., 2024a)的方法,这可以提高模型的泛化能力和指令跟随能力。
在初始预训练阶段,Qwen2.5-Omni 的 LLM 组件使用 Qwen2.5(Yang et al., 2024b)中的参数初始化,视觉编码器与 Qwen2.5-VL 相同,音频编码器则使用 Whisper-large-v3(Radford et al., 2023)初始化。两个编码器分别在固定的 LLM 上进行训练,最初都专注于训练各自的适配器,然后再训练编码器。这个基础训练对装备模型具有坚实的视觉-文本和音频-文本关系和对齐的理解至关重要。
预训练的第二阶段标志着一个重要的进展,它增加了 8000 亿个图像和视频相关的数据标记,3000 亿个音频相关的数据标记,以及 1000 亿个视频带音频相关的数据标记。这一阶段引入了更多的混合多模态数据和更广泛的任务,增强了听觉、视觉和文本信息之间的互动,并加深了理解。加入多模态、多任务数据集对于培养模型同时处理多任务和多模态的能力至关重要,这是一项处理复杂现实世界数据集的关键能力。此外,纯文本数据在保持和提高语言能力方面也起着重要作用。
为了提高训练效率,我们在之前的阶段将最大标记长度限制为 8192 个标记。随后,我们引入了长音频和长视频数据,并将原始文本、音频、图像和视频数据扩展到 32,768 个标记进行训练。实验结果表明,我们的数据在支持长序列数据方面取得了显著的改进。
Post-training
数据格式:

Thinker
在后训练阶段,我们采用 ChatML 格式(OpenAI, 2022)进行指令跟随数据的微调。我们的数据集包括纯文本对话数据、视觉模态对话数据、音频模态对话数据以及混合模态对话数据。
Talker
我们为 Talker 引入了一个三阶段训练过程,使 Qwen2.5-Omni 能够同时生成文本和语音响应。在第一阶段,我们训练 Talker 学习上下文延续。在第二阶段,利用 DPO(Rafailov et al., 2023)增强语音生成的稳定性。在第三阶段,我们应用了多语者指令微调,以提高语音响应的自然性和可控性。
在 上下文学习(ICL) 训练阶段,除了像 Thinker 那样使用文本监督外,我们还通过下一标记预测执行语音延续任务,利用包含多模态上下文和语音响应的广泛对话数据集。Talker 学会了从语义表示到语音的单调映射,同时获得了根据上下文生成具有多样化属性(如韵律、情感和口音)的语音的能力。此外,我们还实施了音色解耦技术,以防止模型将特定的声音与不常见的文本模式关联。
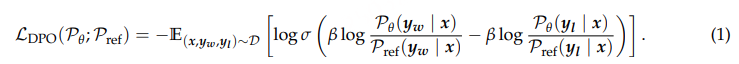
为了扩大语者和场景的覆盖范围,预训练数据不可避免地包含标签噪声和发音错误,这可能导致模型产生幻觉。为了解决这个问题,我们引入了强化学习阶段来提高语音生成的稳定性。具体来说,对于每个请求和响应文本与参考语音配对的情况,我们构建了一个数据集 D,其中包含三元组数据 (x, yw, yl),其中 x 是输入序列的输入文本,yw 和 yl 分别是良好和不良生成的语音序列。我们根据这些样本的奖励分数进行排名,奖励分数与 词错误率(WER) 和 标点停顿错误率 相关。
最后,我们对上述基础模型进行了语者微调,使 Talker 能够采用特定的声音并提高其自然性。
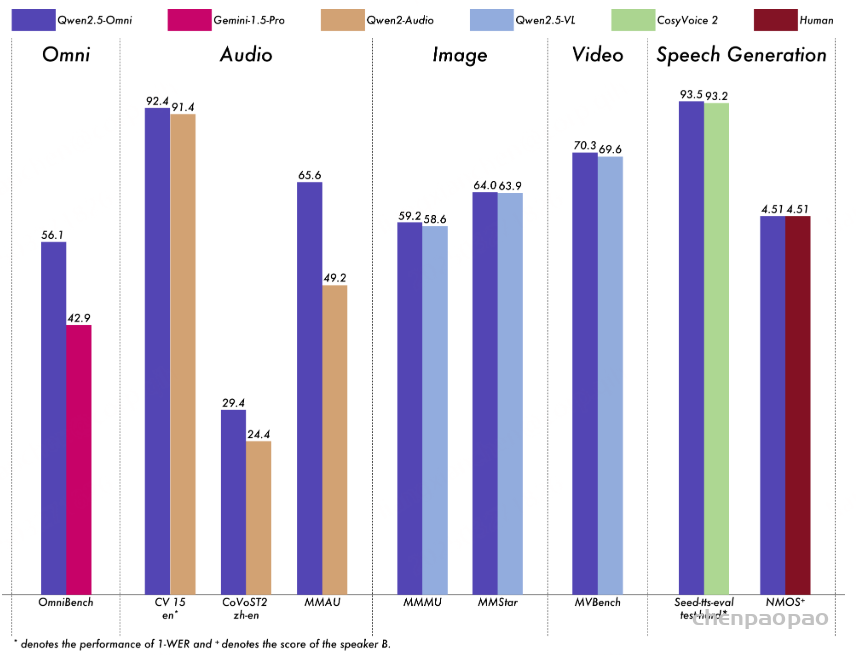
Performance
我们对 Qwen2.5-Omni 进行了全面评估,与类似大小的单模态模型和 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro 等闭源模型相比,该模型在所有模态中均表现出色。在需要集成多种模态的任务(例如 OmniBench)中,Qwen2.5-Omni 实现了最佳性能。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval 和主观自然度)等领域表现出色。