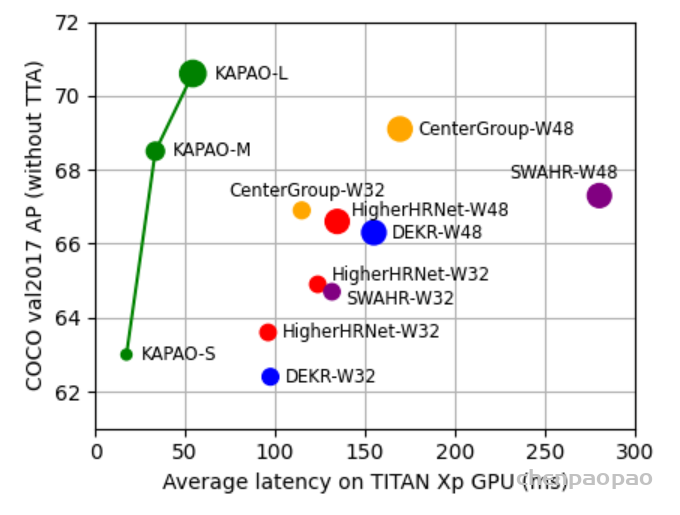
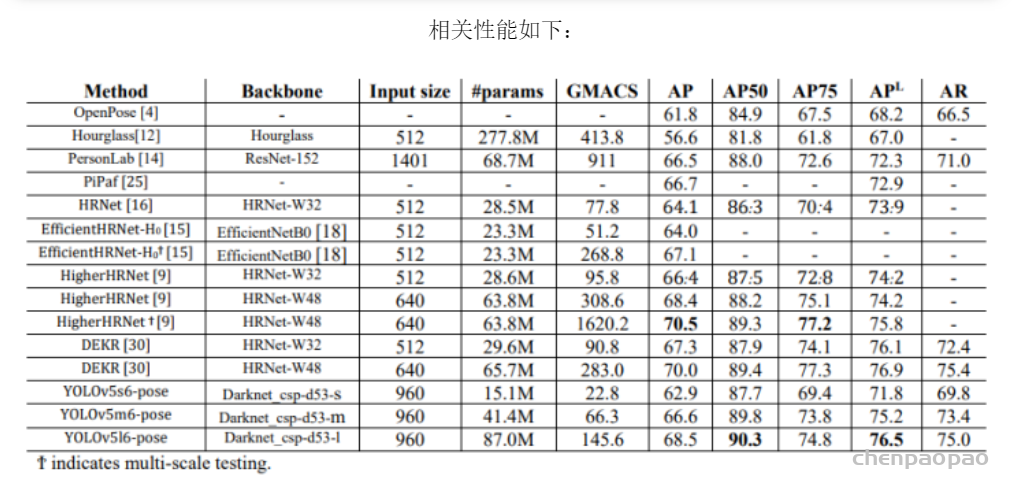
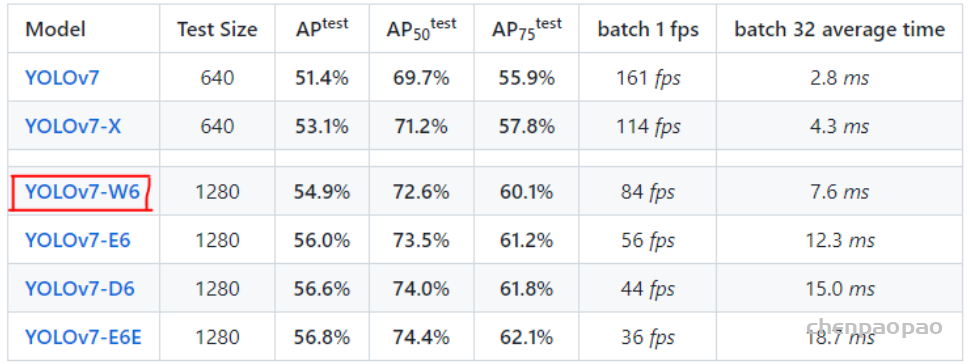
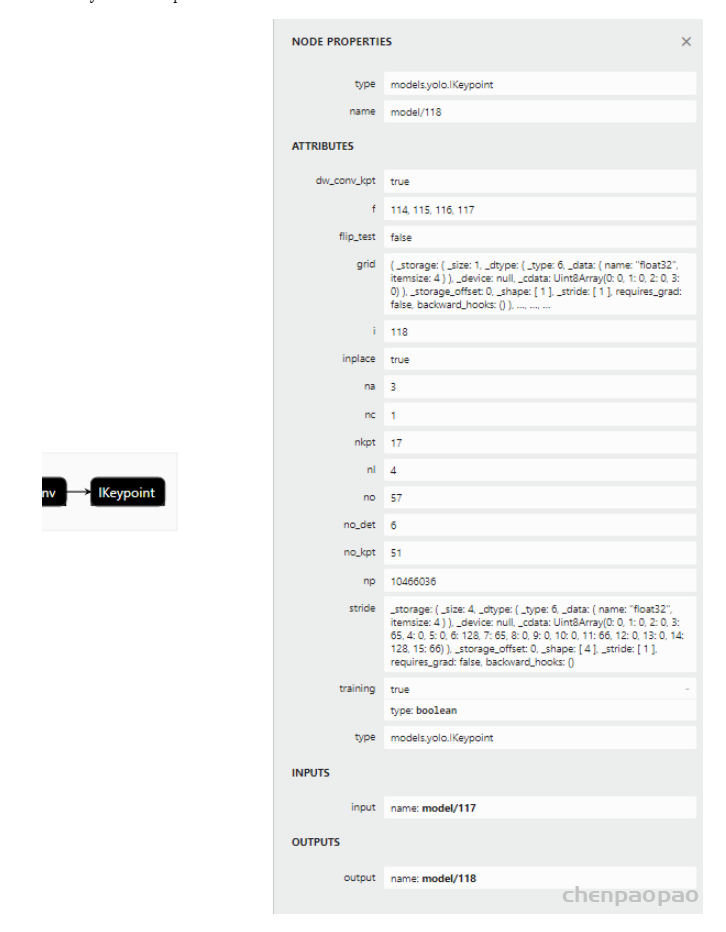
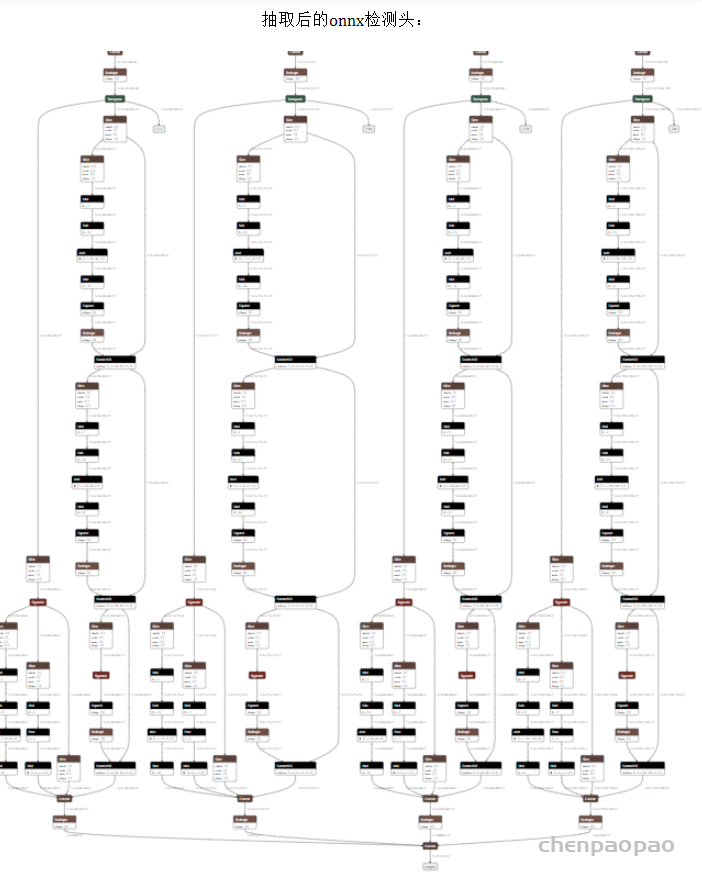
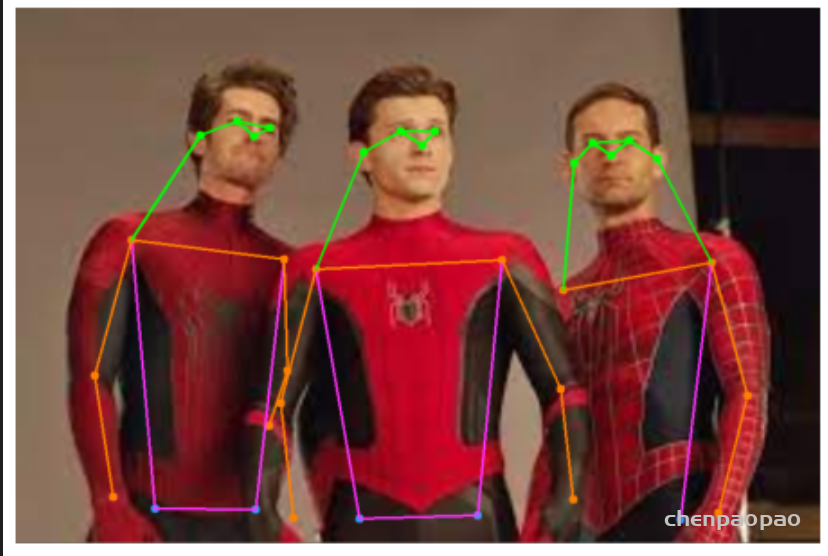
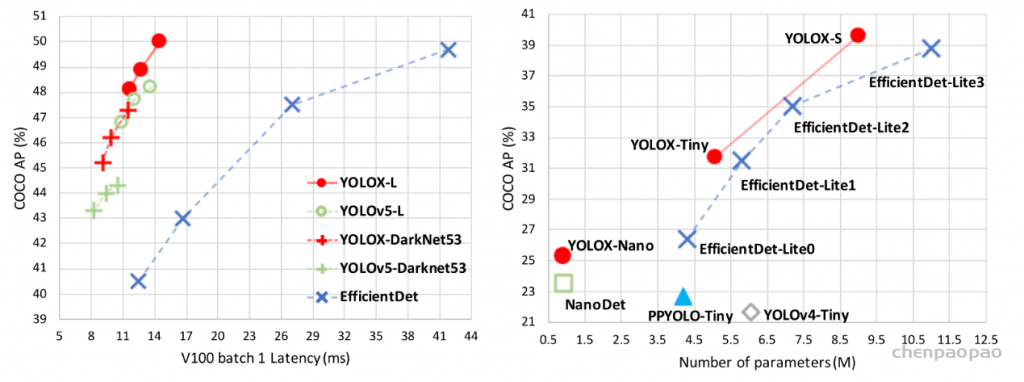
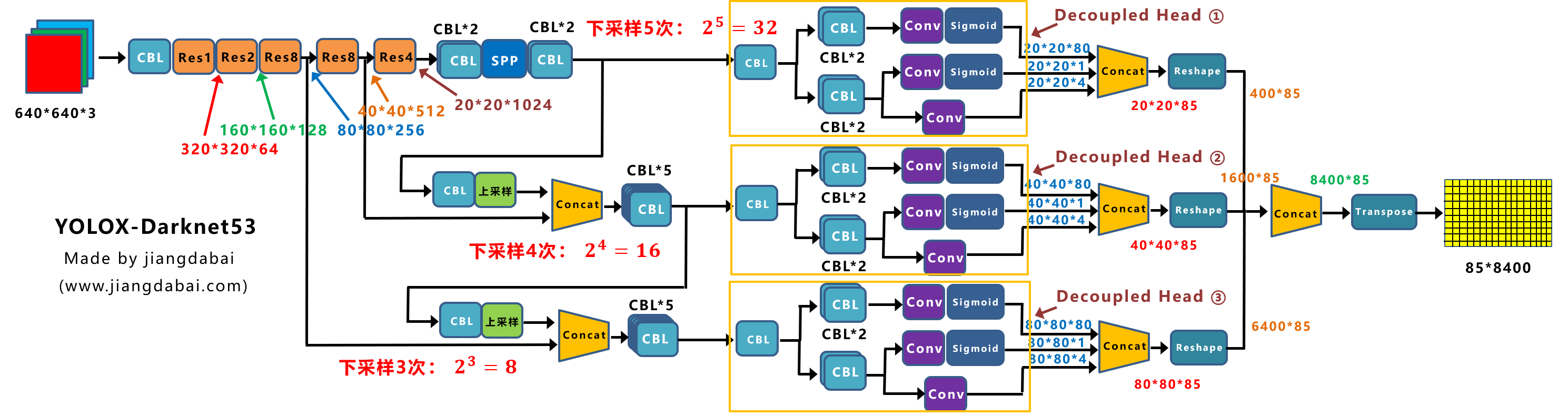
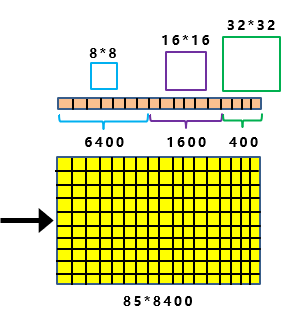
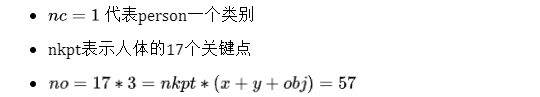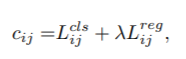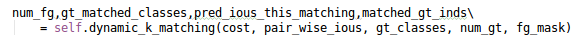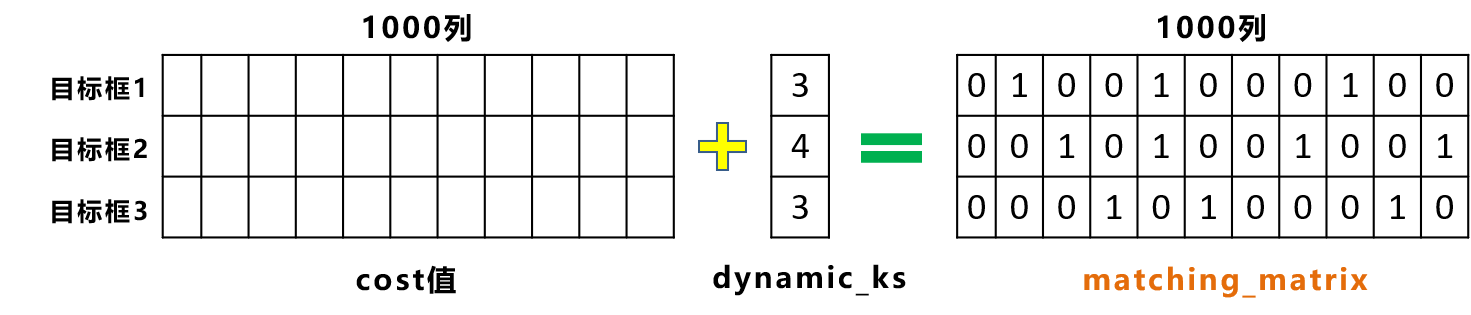去年11月,滑铁卢大学率先提出了 KaPao:Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation,基于YOLOv5进行关键点检测,该文章目前已被ECCV 2022接收,该算法所取得的性能如下:
自从全卷积网络(Fully Convolutional Networks, FCN)和UNet提出以来,主流的改进思路是围绕着编解码结构来进行的。但又一些改进在当时看来却不是那么“主流”,其中有一些是针对如何提升网络的全局信息提取能力来进行改进的。FCN提出之后,一些学者认为FCN忽略了图像作为整张图的全局信息,因而在一些应用场景下不能有效利用图像的语义上下文信息。图像全局信息除了增加对图像的整体理解之外,还有助于模型对局部图像块的判断,此前一种主流的方法是将概率图模型融入到CNN训练中,用于捕捉图像像素的上下文信息,比如说给模型加条件随机场(Conditional Random Field,CRF),但这种方式会使得模型难以训练并且变得低效。
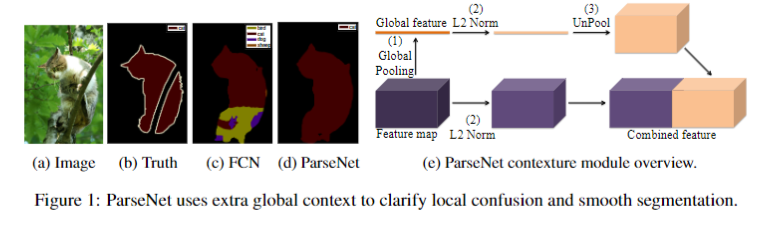
针对如何高效利用图像的全局信息问题,相关研究在FCN结构的基础上提出了ParseNet,一种高效的端到端的语义分割网络,旨在利用全局信息来指导局部信息判断,并且引入太多的额外计算开销。提出ParseNet的论文为ParseNet: Looking Wider to See Better,发表于2015年,是在FCN基础上基于上下文视角的一个改进设计。在语义分割中,上下文信息对于提升模型表现非常关键,在仅有局部信息情况下,像素的分类判断有时候会变得模棱两可。尽管理论上深层卷积层的会有非常大的感受野,但在实际中有效感受野却小很多,不足以捕捉图像的全局信息。ParseNet通过全局平均池化的方法在FCN基础上直接获取上下文信息,图1为ParseNet的上下文提取模块,具体地,使用全局平均池化对上下文特征图进行池化后得到全局特征,然后对全局特征进行L2规范化处理,再对规范化后的特征图反池化后与局部特征图进行融合,这样的一个简单结构对于语义分割质量的提升的巨大的。如图2所示,ParseNet能够关注到图像中的全局信息,保证图像分割的完整性。
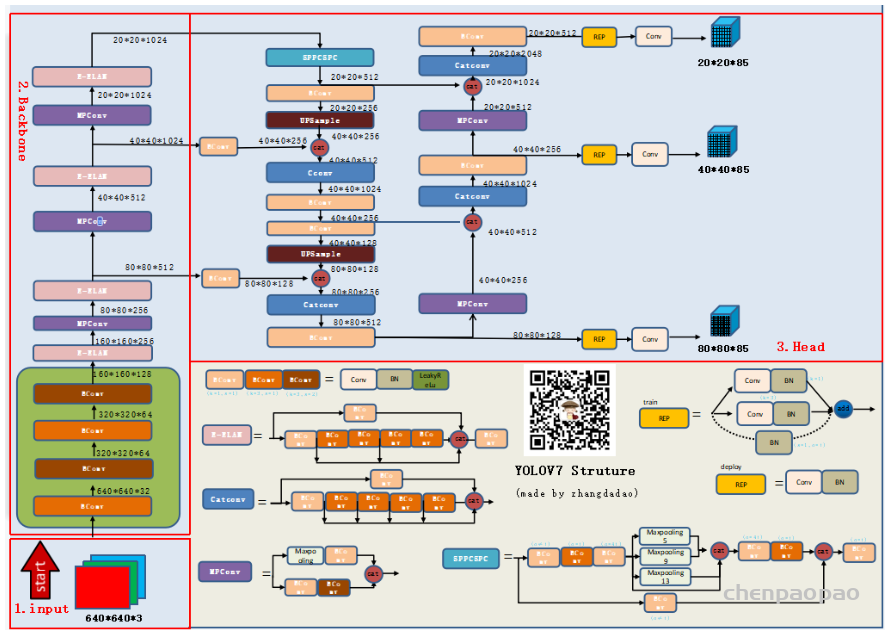
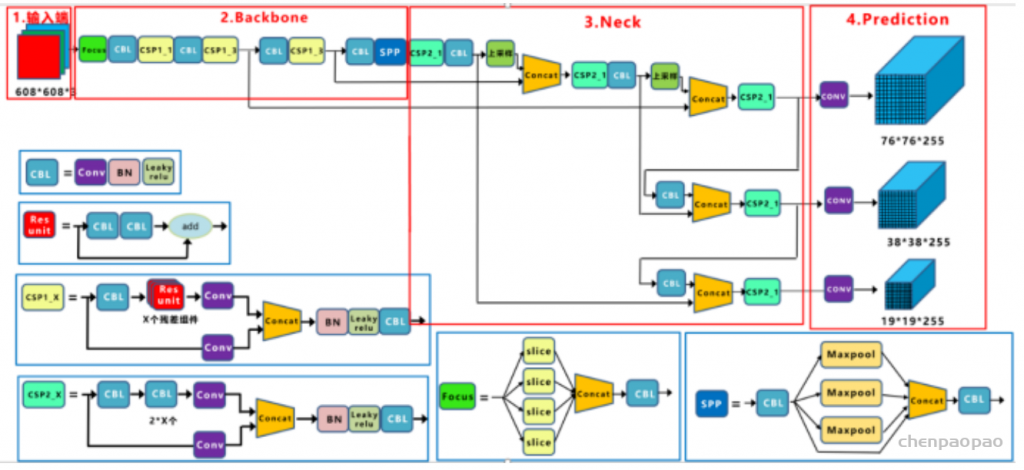
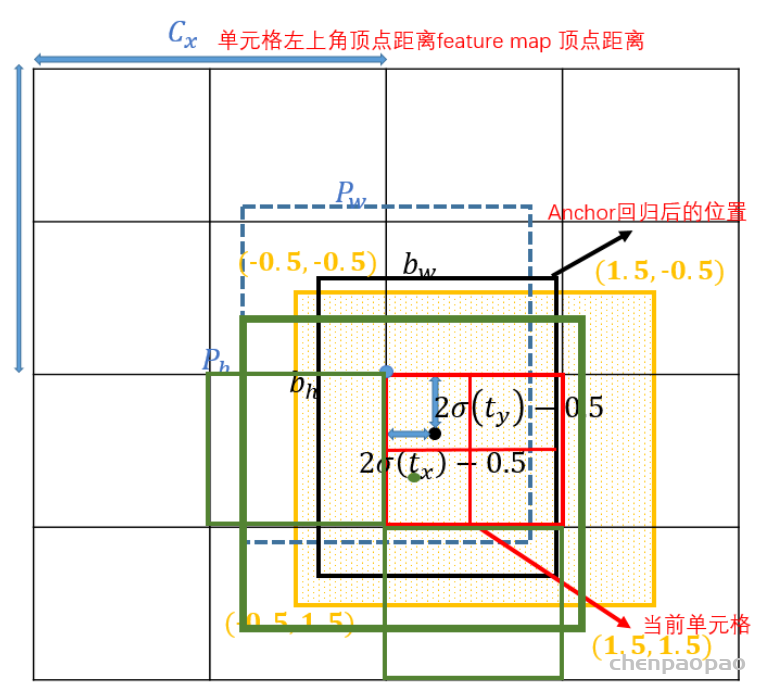
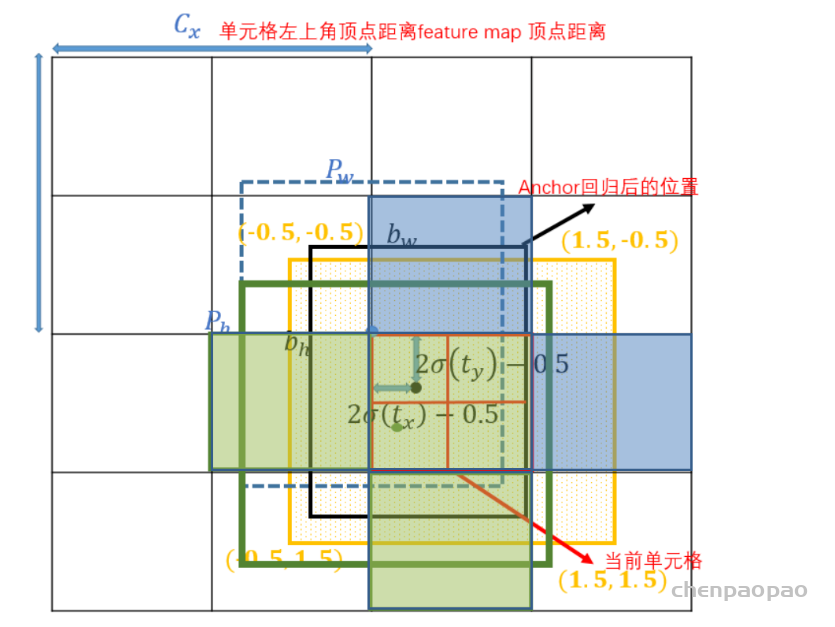
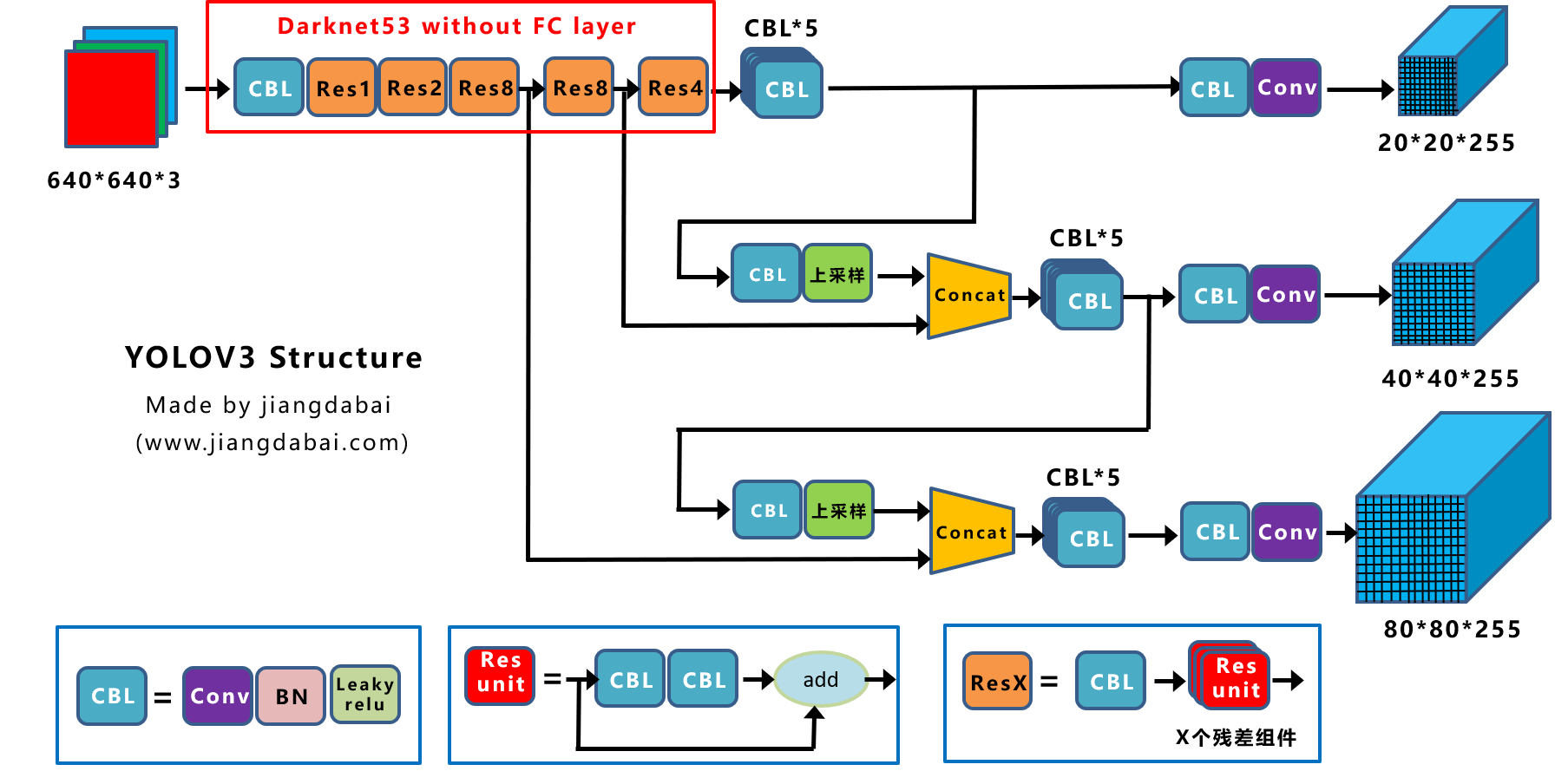
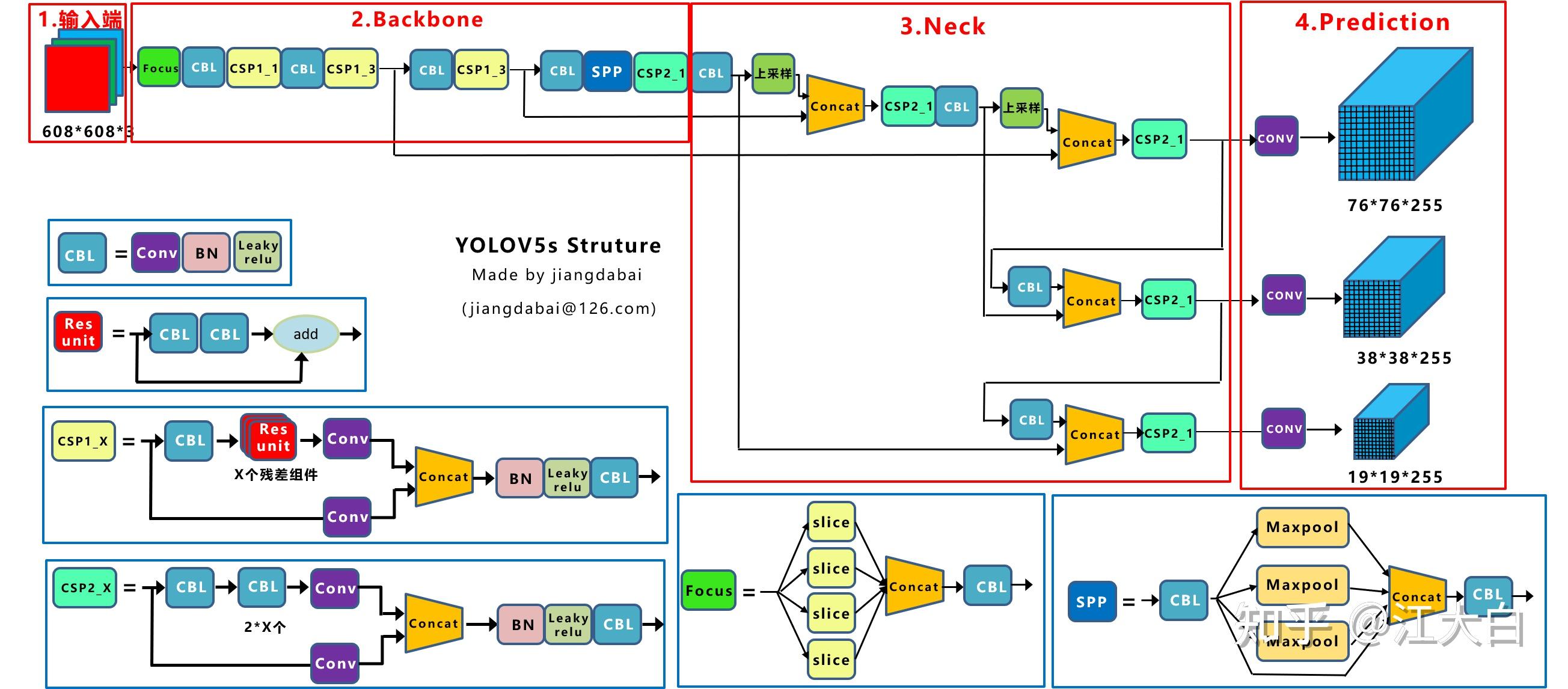
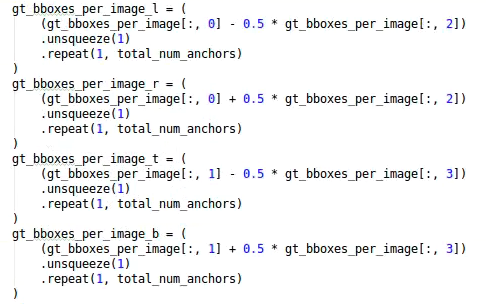
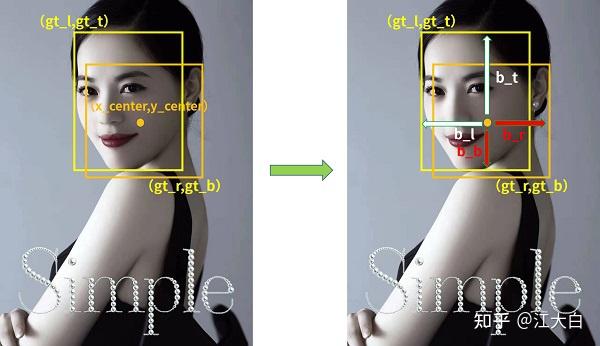
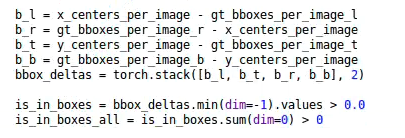
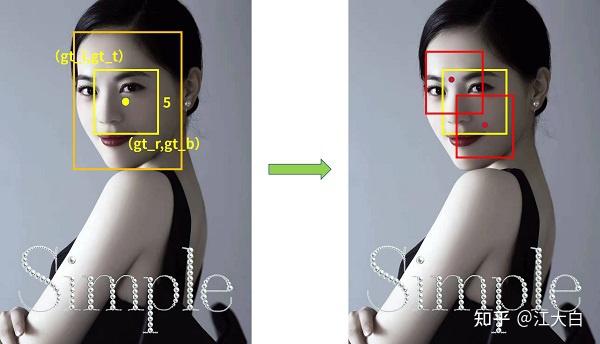
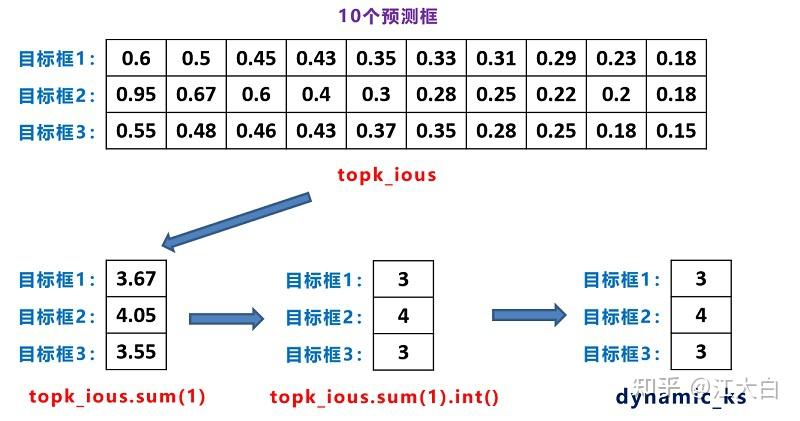
Yolov5基于anchor based,在开始训练前,会基于训练集中gt(ground truth 框),通过k-means聚类算法,先验获得9个从小到大排列的anchor框。先将每个gt与9个anchor匹配(以前是IOU匹配,Yolov5中变成shape匹配,计算gt与9个anchor的长宽比,如果长宽比小于设定阈值,说明该gt和对应的anchor匹配),
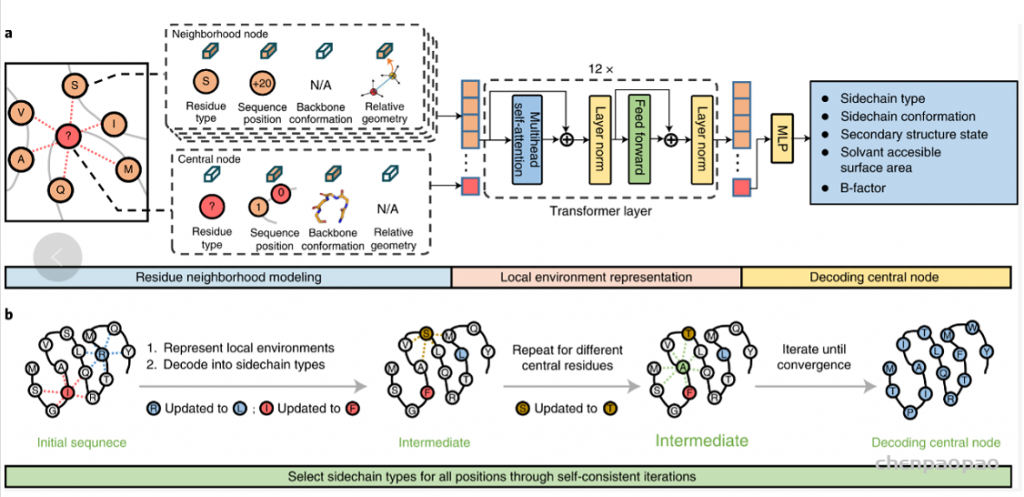
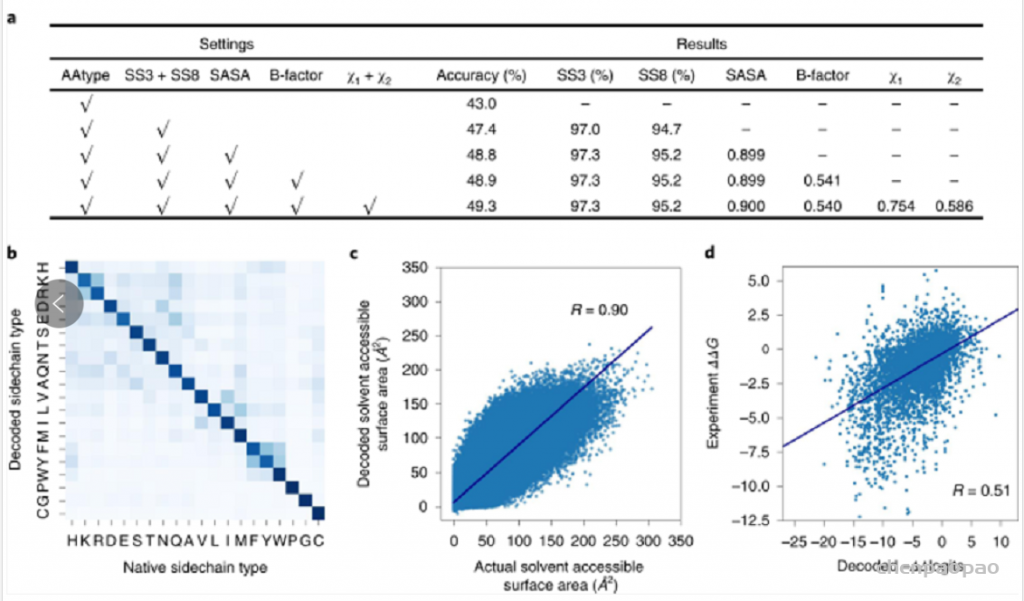
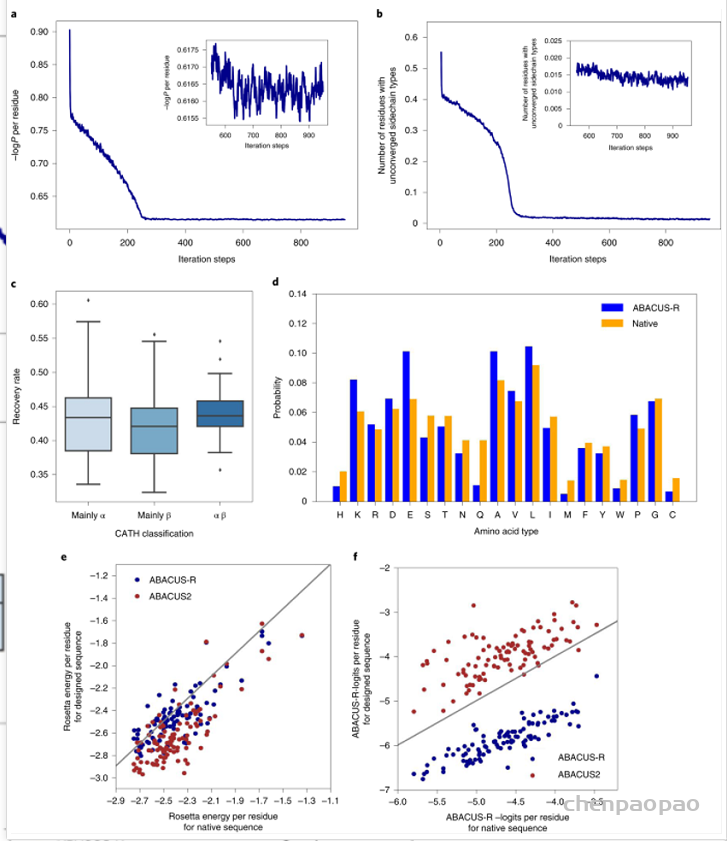
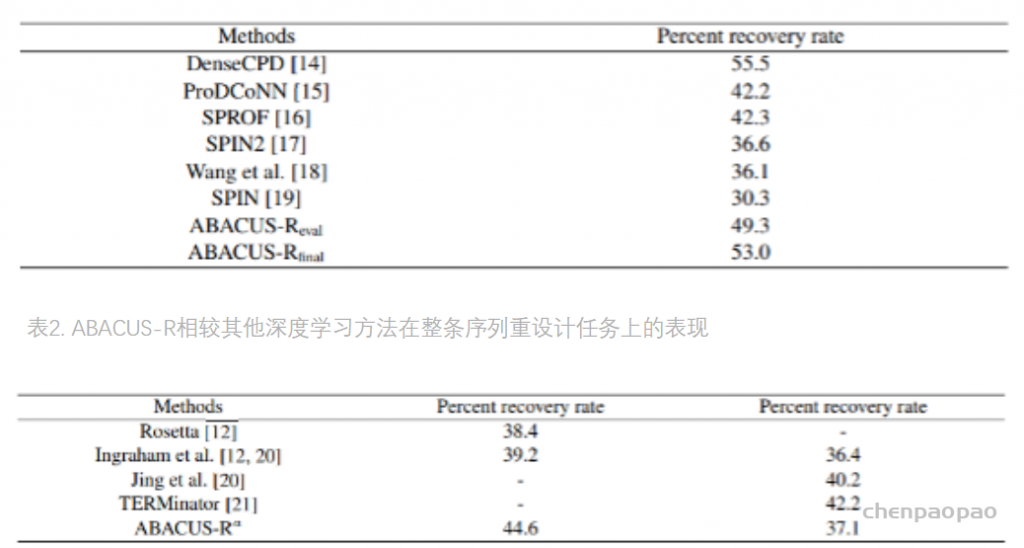
现有的基于蛋白结构的深度学习序列设计方法,虽然在测试的计算指标上取得了很好的成果,但是还鲜有方法经过实验的考验仍然超越传统的能量函数方法。基于这一挑战,中国科学技术大学的刘海燕教授课题组,发展了名为ABACUS-R方法,相关工作名为Rotamer-free protein sequence design based on deep learning and self-consistency,于近期发表在Nature Computational Science上。
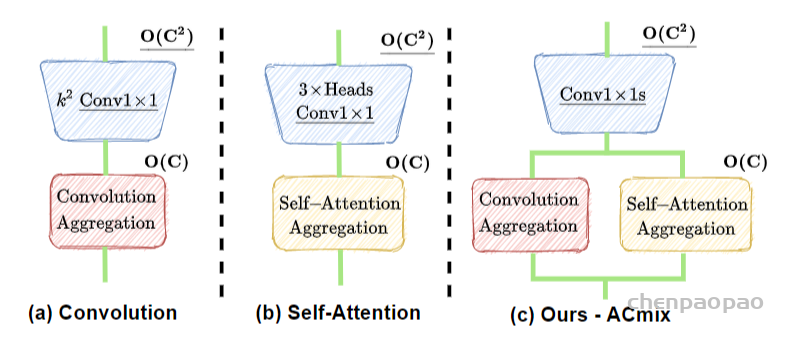
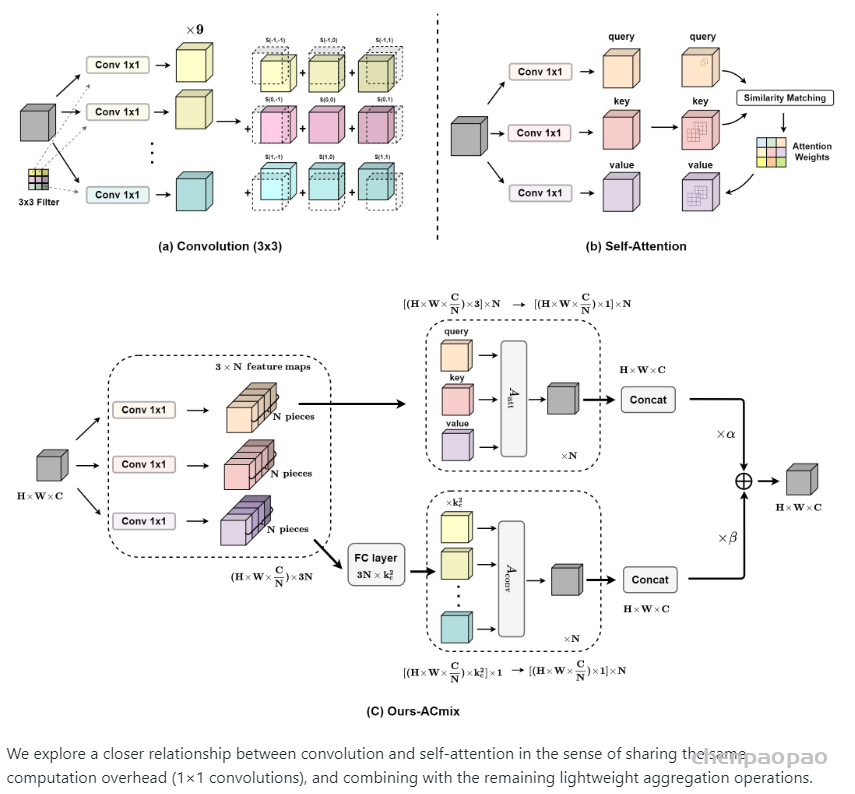
标准卷积可以分为两个部分,第一个阶段为一个特征学习模块,通过执行1 x 1的卷积共享相同的操作将特征投影到更深的空间,第二阶段对应于特征聚合的过程。作为结论,分析表明卷积和自注意力在通过1 x 1的卷积投影输入特征图实际上共享相同的操作,聚合操作是轻量级的,并不需要获取额外的学习参数。卷积和自注意力的示意图如下图所示。
2、将self-attention和convolution进行整合
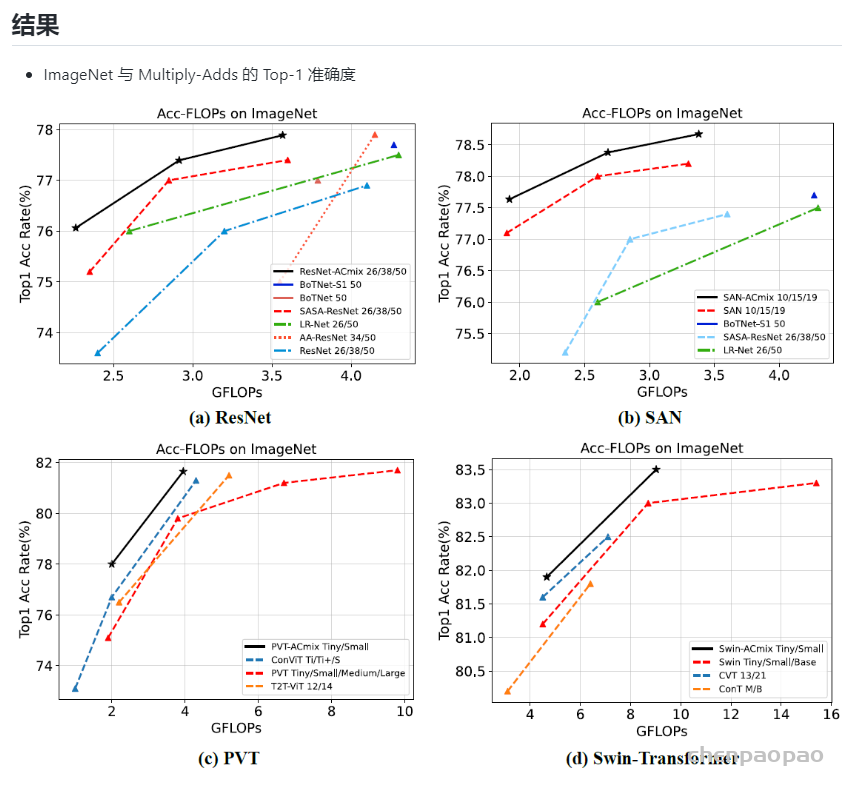
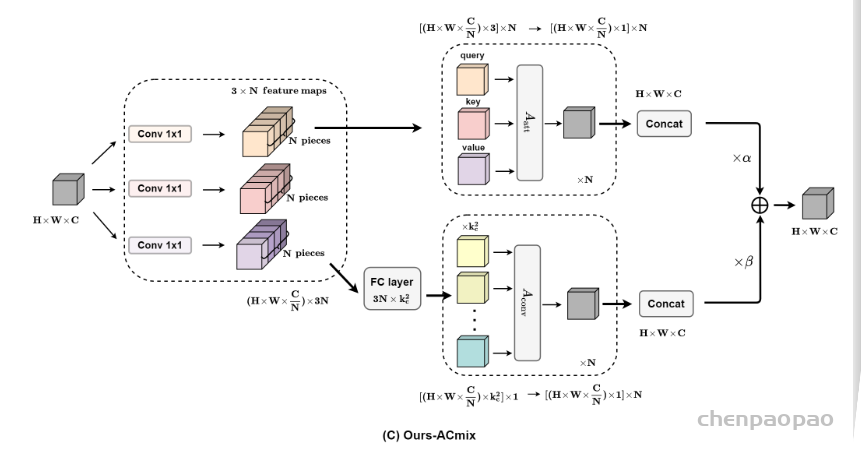
作者根据上述的分析提出ACmix模型,如下图所示:
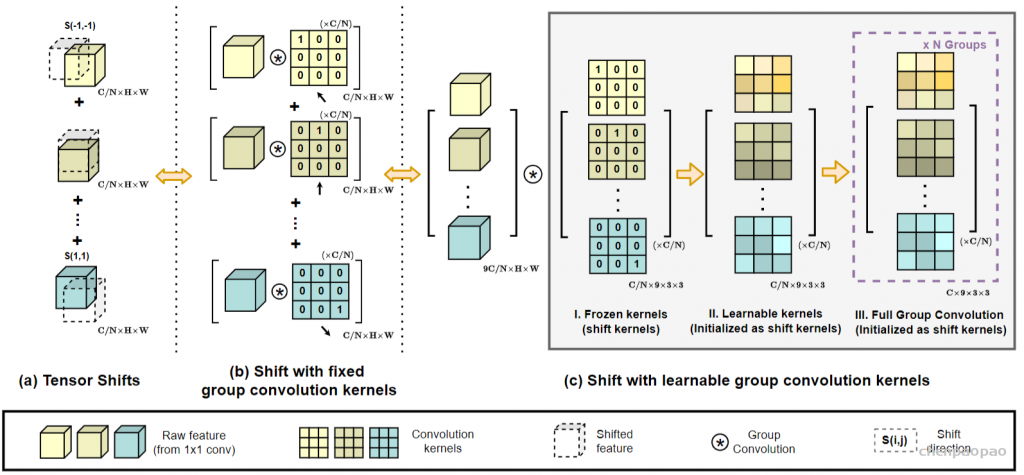
ACmix模型分为两个阶段,在阶段一,输入特征由三个1 x 1的卷积操作并被reshape成N块,由此获得丰富的3 x N的特征图;在阶段二,对于self-attention,作者将中间特征收集到N组中,每组包含三个部分特征,其中每个1 x 1卷积对应一个。通过移动和聚合生成的特征(用以下公式表达),并像传统方法一样从本地感受野中收集信息。
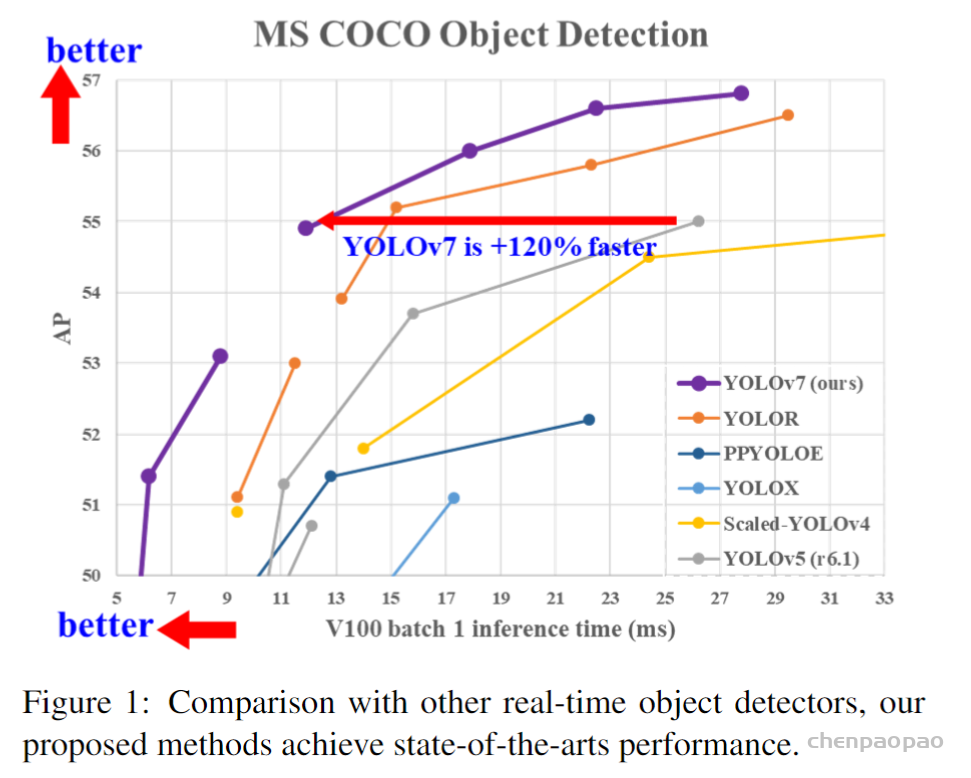
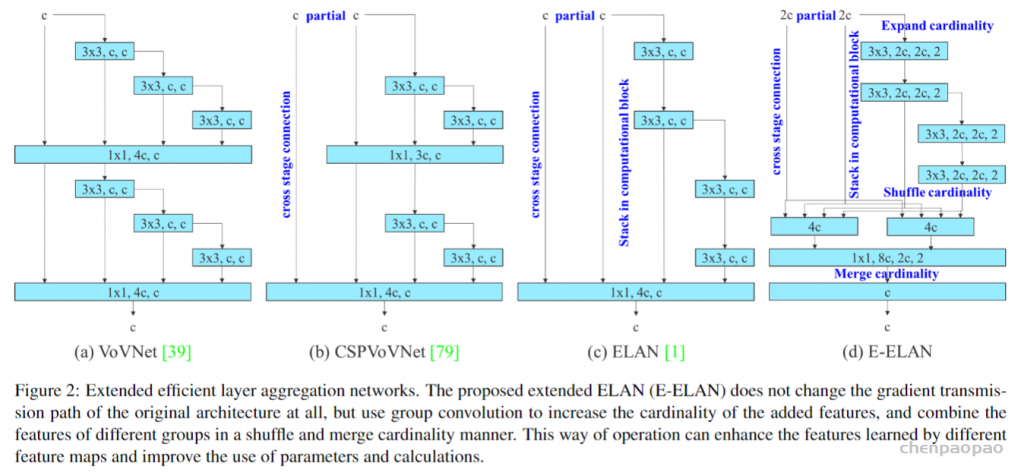
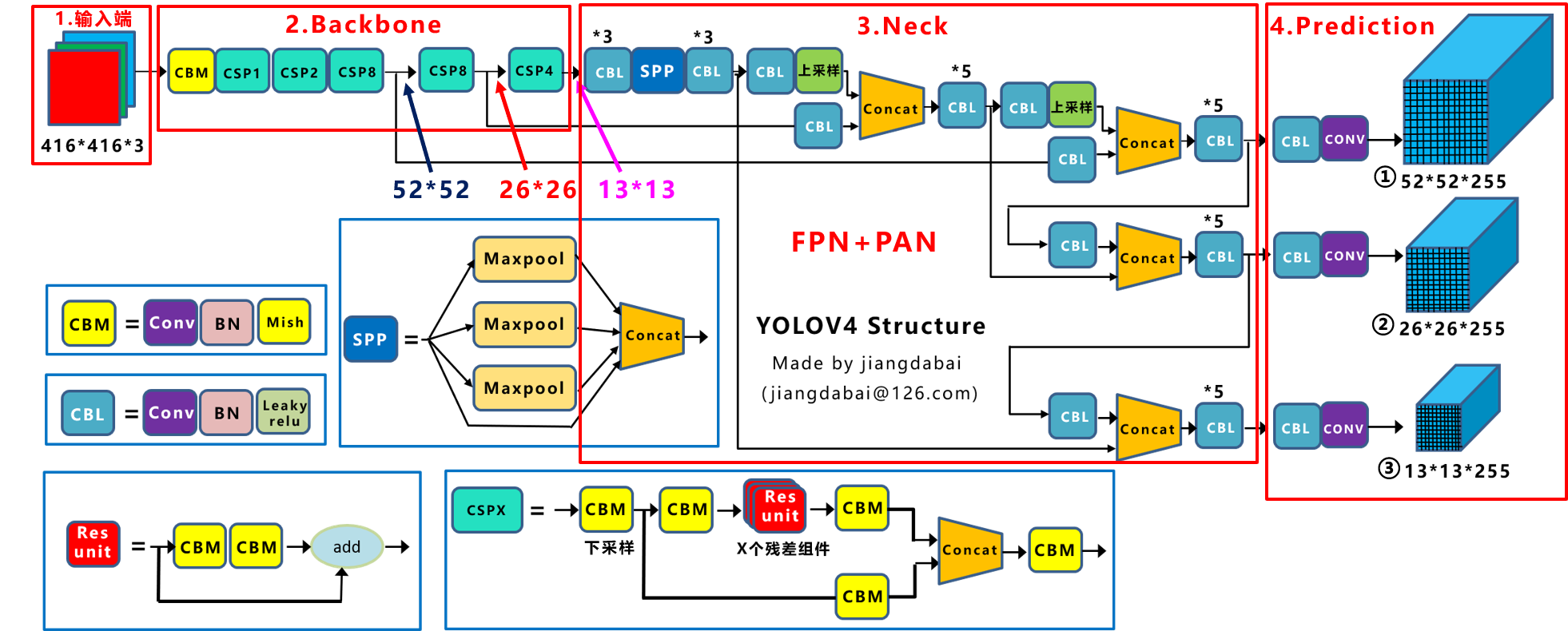
作者为实时探测器提出了“扩展”和“复合缩放”(extend” and “compound scaling”)方法,可以更加高效地利用参数和计算量,同时,作者提出的方法可以有效地减少实时探测器50%的参数,并且具备更快的推理速度和更高的检测精度。(这个其实和YOLOv5或者Scale YOLOv4的baseline使用不同规格分化成几种模型类似,既可以是width和depth的缩放,也可以是module的缩放)
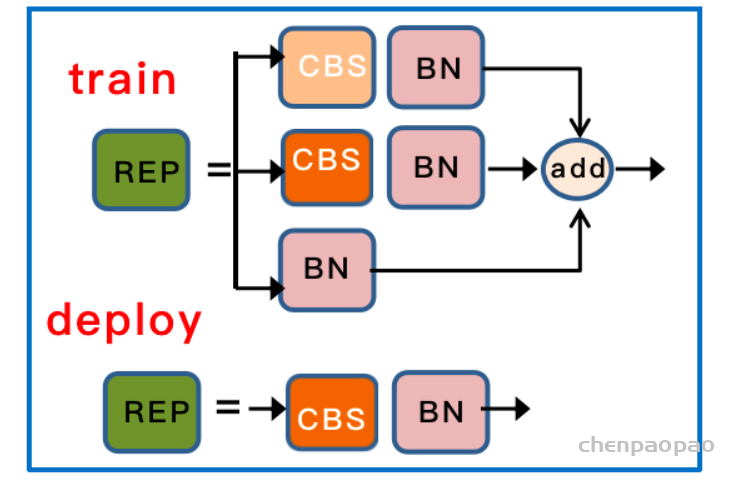
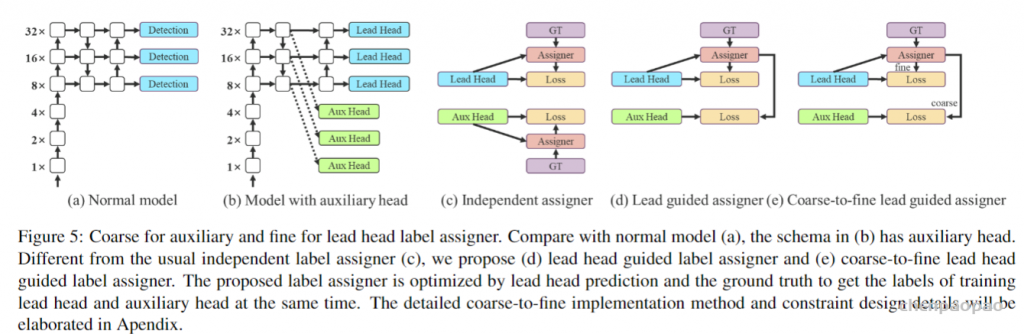
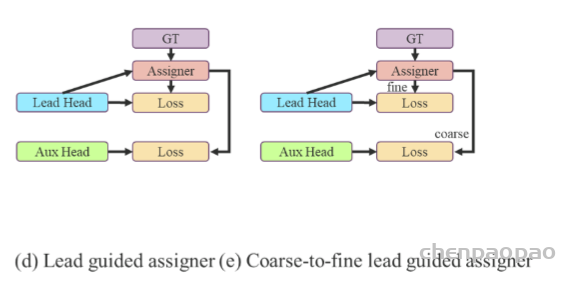
Lead head guided label assigner: 引导头引导“标签分配器”预测结果和ground truth进行计算,并通过优化(在utils/loss.py的SigmoidBin()函数中,传送门:https://github.com/WongKinYiu/yolov7/blob/main/utils/loss.py 生成软标签。这组软标签将作为辅助头和引导头的目标来训练模型。(之前写过一篇博客,【浅谈计算机视觉中的知识蒸馏】]https://zhuanlan.zhihu.com/p/497067556)详细讲过soft label的好处)这样做的目的是使引导头具有较强的学习能力,由此产生的软标签更能代表源数据与目标之间的分布差异和相关性。此外,作者还可以将这种学习看作是一种广义上的余量学习。通过让较浅的辅助头直接学习引导头已经学习到的信息,引导头能更加专注于尚未学习到的残余信息。
Coarse-to-fine lead head guided label assigner: Coarse-to-fine引导头使用到了自身的prediction和ground truth来生成软标签,引导标签进行分配。然而,在这个过程中,作者生成了两组不同的软标签,即粗标签和细标签,其中细标签与引导头在标签分配器上生成的软标签相同,粗标签是通过降低正样本分配的约束,允许更多的网格作为正目标(可以看下FastestDet的label assigner,不单单只把gt中心点所在的网格当成候选目标,还把附近的三个也算进行去,增加正样本候选框的数量)。原因是一个辅助头的学习能力并不需要强大的引导头,为了避免丢失信息,作者将专注于优化样本召回的辅助头。对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。然而,值得注意的是,如果粗标签的附加权重接近细标签的附加权重,则可能会在最终预测时产生错误的先验结果。
EMA Model:EMA 是一种在mean teacher中使用的技术,作者使用 EMA 模型作为最终的推理模型。
五、实验
5.1 实验环境
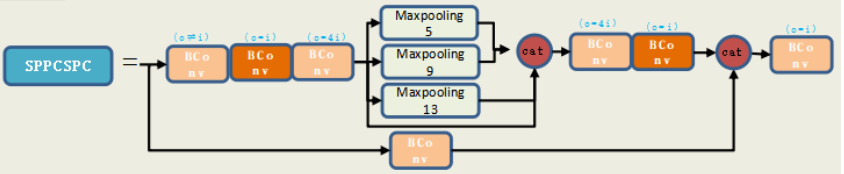
作者为边缘GPU、普通GPU和云GPU设计了三种模型,分别被称为YOLOv7-Tiny、YOLOv7和YOLOv7-W6。同时,还使用基本模型针对不同的服务需求进行缩放,并得到不同大小的模型。对于YOLOv7,可进行颈部缩放(module scale),并使用所提出的复合缩放方法对整个模型的深度和宽度进行缩放(depth and width scale),此方式获得了YOLOv7-X。对于YOLOv7-W6,使用提出的缩放方法得到了YOLOv7-E6和YOLOv7-D6。此外,在YOLOv7-E6使用了提出的E-ELAN,从而完成了YOLOv7-E6E。由于YOLOv7-tincy是一个面向边缘GPU架构的模型,因此它将使用ReLU作为激活函数。作为对于其他模型,使用SiLU作为激活函数。
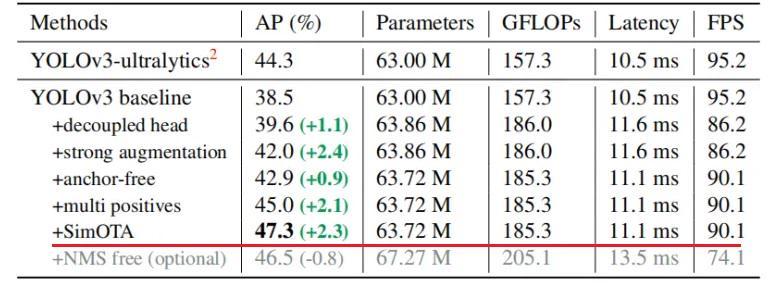
Considering YOLOv4 and YOLOv5 may be a little over-optimized for the anchor-based pipeline, we choose YOLOv3 [25] as our start point (we set YOLOv3-SPP as the default YOLOv3)。