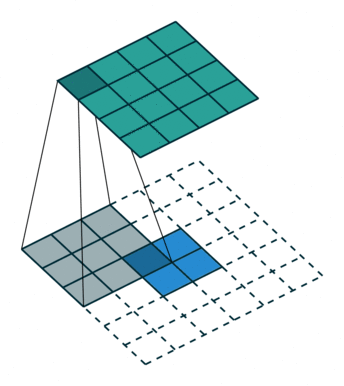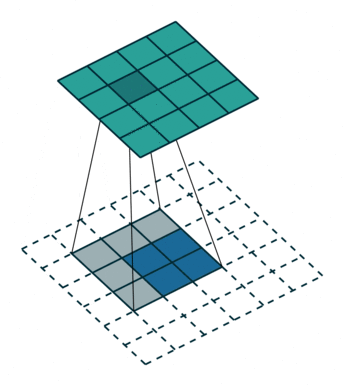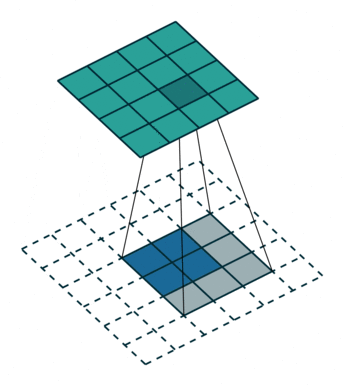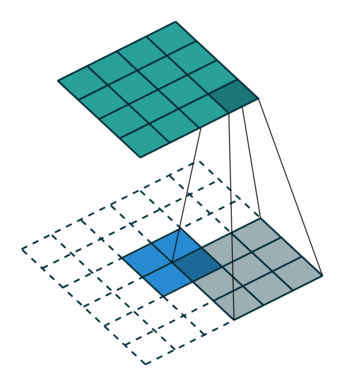
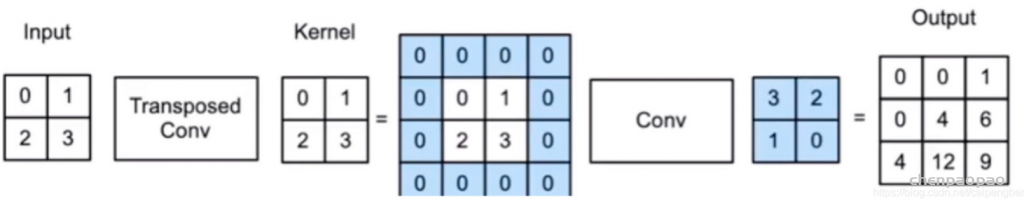
1、背景分离方法
- 背景分离(BS)是一种通过使用静态相机来生成前景掩码(即包含属于场景中的移动对象像素的二进制图像)的常用技术。
- 顾名思义,BS计算前景掩码,在当前帧与背景模型之间执行减法运算,其中包含场景的静态部分,或者更一般而言,考虑到所观察场景的特征,可以将其视为背景的所有内容。
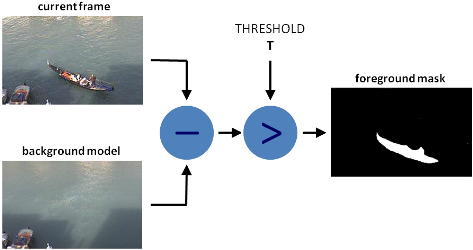
背景建模包括两个主要步骤: 1. 背景初始化; 2. 背景更新。
第一步,计算背景的初始模型,而在第二步中,更新模型以适应场景中可能的变化。
在本教程中,我们将学习如何使用OpenCV中的BS。
目标
在本教程中,您将学习如何: 1. 使用**cv::VideoCapture**从视频或图像序列中读取数据; 2. 通过使用**cv::BackgroundSubtractor**类创建和更新背景类; 3. 通过使用**cv::imshow**获取并显示前景蒙版;
代码
在下面,您可以找到源代码。我们将让用户选择处理视频文件或图像序列。在此示例中,我们将使用**cv::BackgroundSubtractorMOG2**生成前景掩码。
结果和输入数据将显示在屏幕上。
from __future__ import print_function
import cv2 as cv
import argparse
parser = argparse.ArgumentParser(description='This program shows how to use background subtraction methods provided by \
OpenCV. You can process both videos and images.')
parser.add_argument('--input', type=str, help='Path to a video or a sequence of image.', default='vtest.avi')
parser.add_argument('--algo', type=str, help='Background subtraction method (KNN, MOG2).', default='MOG2')
args = parser.parse_args()
if args.algo == 'MOG2':
backSub = cv.createBackgroundSubtractorMOG2()
else:
backSub = cv.createBackgroundSubtractorKNN()
capture = cv.VideoCapture(cv.samples.findFileOrKeep(args.input))
if not capture.isOpened:
print('Unable to open: ' + args.input)
exit(0)
while True:
ret, frame = capture.read()
if frame is None:
break
fgMask = backSub.apply(frame)
cv.rectangle(frame, (10, 2), (100,20), (255,255,255), -1)
cv.putText(frame, str(capture.get(cv.CAP_PROP_POS_FRAMES)), (15, 15),
cv.FONT_HERSHEY_SIMPLEX, 0.5 , (0,0,0))
cv.imshow('Frame', frame)
cv.imshow('FG Mask', fgMask)
keyboard = cv.waitKey(30)
if keyboard == 'q' or keyboard == 27:
break2、Meanshift和Camshift
Meanshift
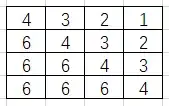
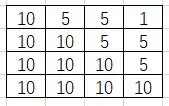
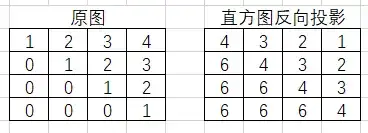
Meanshift背后的直觉很简单,假设你有点的集合。(它可以是像素分布,例如直方图反投影)。你会得到一个小窗口(可能是一个圆形),并且必须将该窗口移到最大像素密度(或最大点数)的区域。如下图所示:
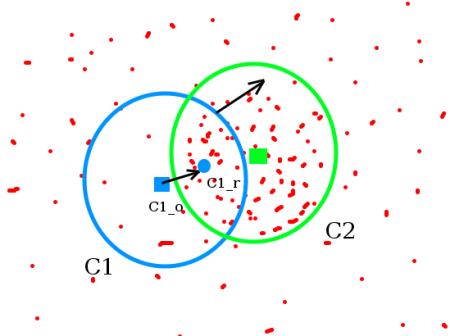
初始窗口以蓝色圆圈显示,名称为“C1”。其原始中心以蓝色矩形标记,名称为“C1_o”。但是,如果找到该窗口内点的质心,则会得到点“C1_r”(标记为蓝色小圆圈),它是窗口的真实质心。当然,它们不匹配。因此,移动窗口,使新窗口的圆与上一个质心匹配。再次找到新的质心。很可能不会匹配。因此,再次移动它,并继续迭代,以使窗口的中心及其质心落在同一位置(或在很小的期望误差内)。因此,最终您获得的是一个具有最大像素分布的窗口。它带有一个绿色圆圈,名为“C2”。正如您在图像中看到的,它具有最大的点数。整个过程在下面的静态图像上演示:
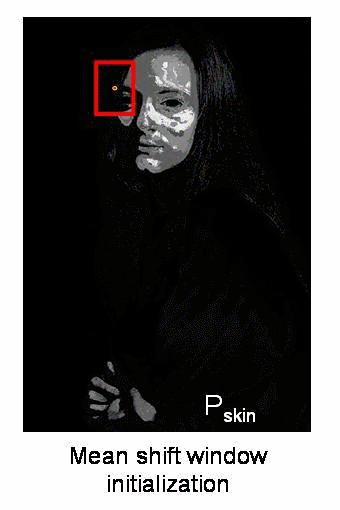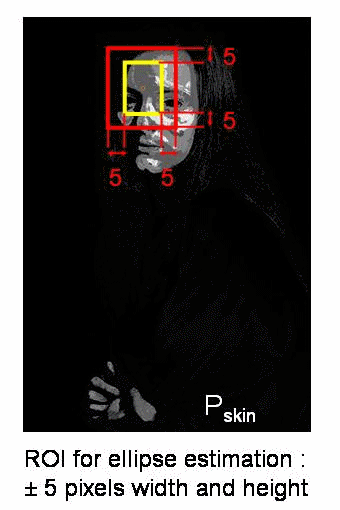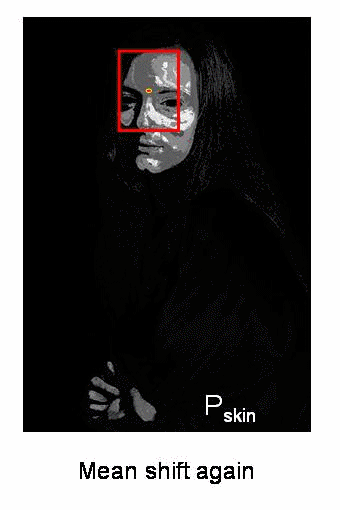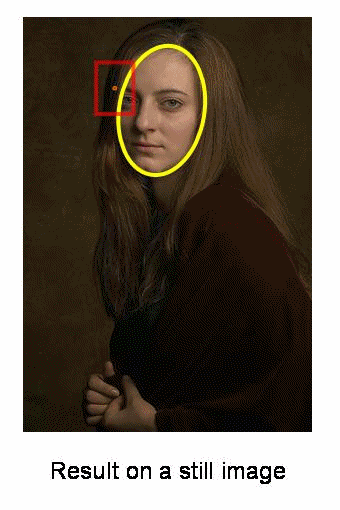
因此,我们通常会传递直方图反投影图像和初始目标位置。当对象移动时,显然该移动会反映在直方图反投影图像中。结果,meanshift算法将窗口移动到最大密度的新位置。
OpenCV中的Meanshift
要在OpenCV中使用meanshift,首先我们需要设置目标,找到其直方图,以便我们可以将目标反投影到每帧上以计算均值偏移。我们还需要提供窗口的初始位置。对于直方图,此处仅考虑色相。另外,为避免由于光线不足而产生错误的值,可以使用**cv.inRange**()函数丢弃光线不足的值。
import numpy as np
import cv2 as cv
import argparse
parser = argparse.ArgumentParser(description='This sample demonstrates the meanshift algorithm. \
The example file can be downloaded from: \
https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()
cap = cv.VideoCapture(args.image)
# 视频的第一帧
ret,frame = cap.read()
# 设置窗口的初始位置
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)
# 设置初始ROI来追踪
roi = frame[y:y+h, x:x+w]
hsv_roi = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv.normalize(roi_hist,roi_hist,0,255,cv.NORM_MINMAX)
# 设置终止条件,可以是10次迭代,也可以至少移动1 pt
term_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret, frame = cap.read()
if ret == True:
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
dst = cv.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# 应用meanshift来获取新位置
ret, track_window = cv.meanShift(dst, track_window, term_crit)
# 在图像上绘制
x,y,w,h = track_window
img2 = cv.rectangle(frame, (x,y), (x+w,y+h), 255,2)
cv.imshow('img2',img2)
k = cv.waitKey(30) & 0xff
if k == 27:
break
else:
break我使用的视频中的三帧如下:

Camshift
您是否密切关注了最后结果?这儿存在一个问题。无论汽车离相机很近或非常近,我们的窗口始终具有相同的大小。这是不好的。我们需要根据目标的大小和旋转来调整窗口大小。该解决方案再次来自“ OpenCV Labs”,它被称为Gary布拉德斯基(Gary Bradsky)在其1998年的论文“用于感知用户界面中的计算机视觉面部跟踪”中发表的CAMshift(连续自适应均值偏移)[26]。 它首先应用Meanshift。一旦Meanshift收敛,它将更新窗口的大小为s = 2 \times \sqrt{\frac{M_{00}}{256}}。它还可以计算出最合适的椭圆的方向。再次将均值偏移应用于新的缩放搜索窗口和先前的窗口位置。该过程一直持续到达到要求的精度为止。
OpenCV中的Camshift
它与meanshift相似,但是返回一个旋转的矩形(即我们的结果)和box参数(用于在下一次迭代中作为搜索窗口传递)。请参见下面的代码:
import numpy as np
import cv2 as cv
import argparse
parser = argparse.ArgumentParser(description='This sample demonstrates the camshift algorithm. \
The example file can be downloaded from: \
https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()
cap = cv.VideoCapture(args.image)
# 获取视频第一帧
ret,frame = cap.read()
# 设置初始窗口
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)
# 设置追踪的ROI窗口
roi = frame[y:y+h, x:x+w]
hsv_roi = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv.normalize(roi_hist,roi_hist,0,255,cv.NORM_MINMAX)
# 设置终止条件,可以是10次迭代,有可以至少移动1个像素
term_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret, frame = cap.read()
if ret == True:
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
dst = cv.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# 应用camshift 到新位置
ret, track_window = cv.CamShift(dst, track_window, term_crit)
# 在图像上画出来
pts = cv.boxPoints(ret)
pts = np.int0(pts)
img2 = cv.polylines(frame,[pts],True, 255,2)
cv.imshow('img2',img2)
k = cv.waitKey(30) & 0xff
if k == 27:
break
else:
break三帧的结果如下