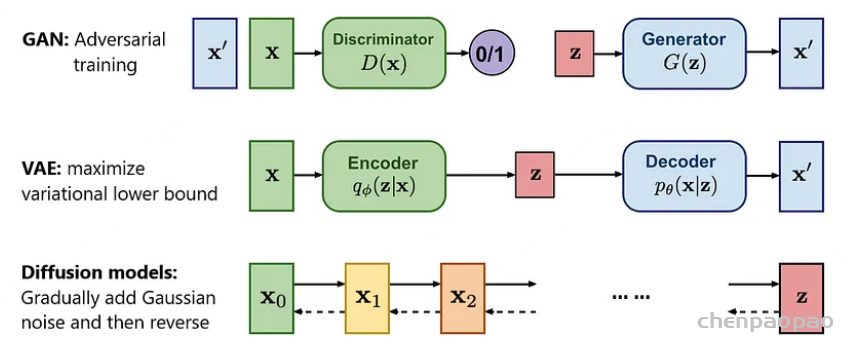
code: https://github.com/OpenMOSS/AnyGPT paper: https://arxiv.org/abs/2402.12226 Demos: https://junzhan2000.github.io/AnyGPT.github.io/
AnyGPT,一种任意到任意的多模态语言模型,它利用离散表示来统一处理各种模态,包括语音、文本、图像和音乐。AnyGPT可以稳定地训练,而无需对当前的大型语言模型(LLM)架构或训练范式进行任何更改。相反,它完全依赖于数据级预处理,促进新模式无缝集成到LLMs中,类似于新语言的合并。基础模型将四种模态对齐,允许不同模态和文本之间的多式联运转换。此外,我们基于各种生成模型构建了AnyInstruct数据集,其中包含任意模态相互转换的指令。它由108k个多回合对话样本组成,这些样本错综复杂地交织在各种模态中,从而使模型能够处理多模态输入和输出的任意组合。经过此数据集的训练,我们的聊天模型可以进行免费的多模式对话,其中可以随意插入多模式数据。实验结果表明,AnyGPT能够促进任何到任何多模态对话,同时实现与所有模态的专用模型相当的性能,证明离散表示可以有效且方便地统一语言模型中的多个模态。
基本模型可以执行各种任务,包括文本到图像、图像字幕、自动语音识别(ASR)、零触发文本到语音(TTS)、文本到音乐和音乐字幕。我们可以按照特定的指令格式执行推理。
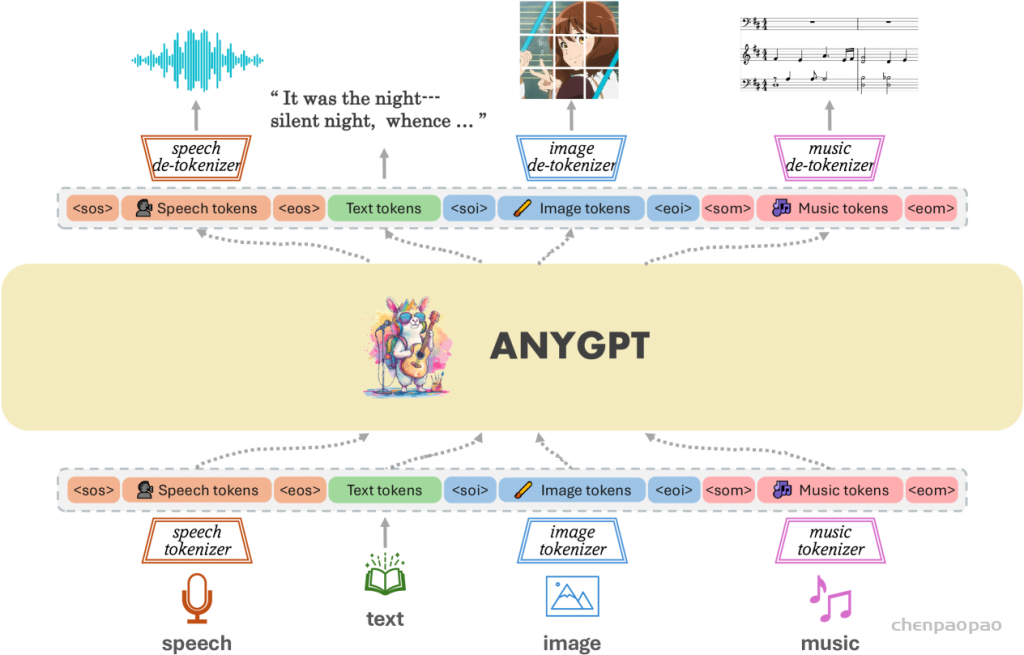
提出了一个可以统一训练的综合框架。 如图1所示,该框架由三个主要组件组成:( 1 )多模态分词器,( 2 )作为主干的多模态语言模型,以及( 3 )多模态de-tokenizer。 分词器将连续的非文本模态转换为离散的标记,这些标记随后被排列成多模态交织序列。 然后,使用下一个标记预测训练目标通过语言模型训练序列。 在推理过程中,多模态令牌被解码回其原始表示的相关的多模态token。 为了丰富生成的质量,可以部署多模态增强模块来对生成的结果进行后处理,包括语音克隆或图像超分辨率等应用。
AnyInstruct多模态交错指令数据合成过程:
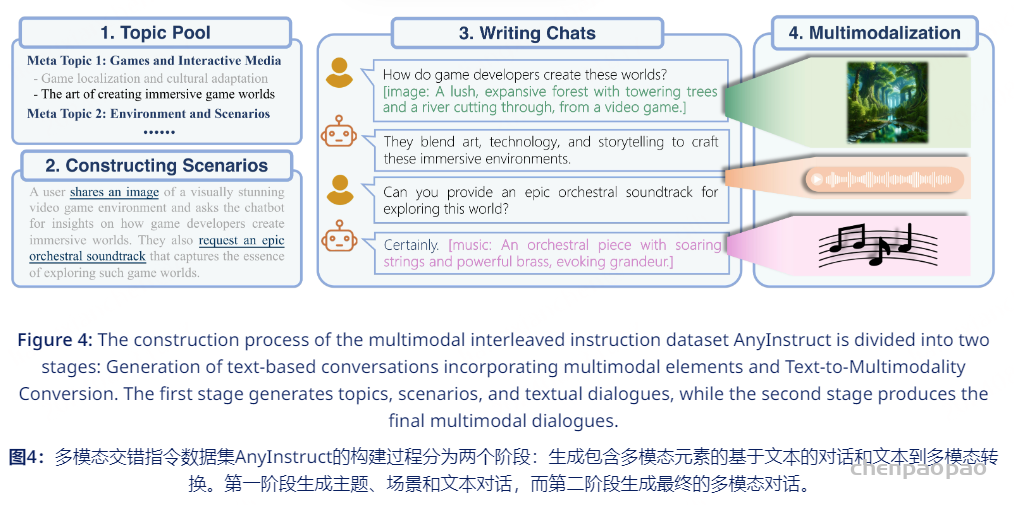
生成108k多轮对话数据,每个对话都交错包含text、speech、image、music模态的数据
1.Generation of text-based conversations incorporating multimodal elements.
•脑暴100个meta topics覆盖大量的音视元素相关场景,再用GPT-4扩展至20000个特定主题 •提示LLM生成基于这些主题的具体对话场景,由于LLM在生成多模态元素时有局限,准备了一些样例尽量包含多个模态 •根据场景使用GPT-4生成多轮对话,多模态用详细的文字进行表述’
2.用DALL-E-3、MusicGen、微软TTS API根据用户提示和模型的文本回复生成对应模态的数据。
最终包含205k图片,503k语音,113k音乐
模型预训练数据:
为了实现从任何模态到任何其他模态的生成,至关重要的是要在这些模态之间保持良好的数据一致。不幸的是,这种数据非常稀缺。为了解决这一挑战,我们构建了一个以文本为中心的双峰对齐数据集。在这里,文本是作为一个重要的中介桥梁之间的差距差距各种形式。通过将不同的模态与语言模型中的文本模态对齐,我们的目标是实现所有模态之间的相互对齐。
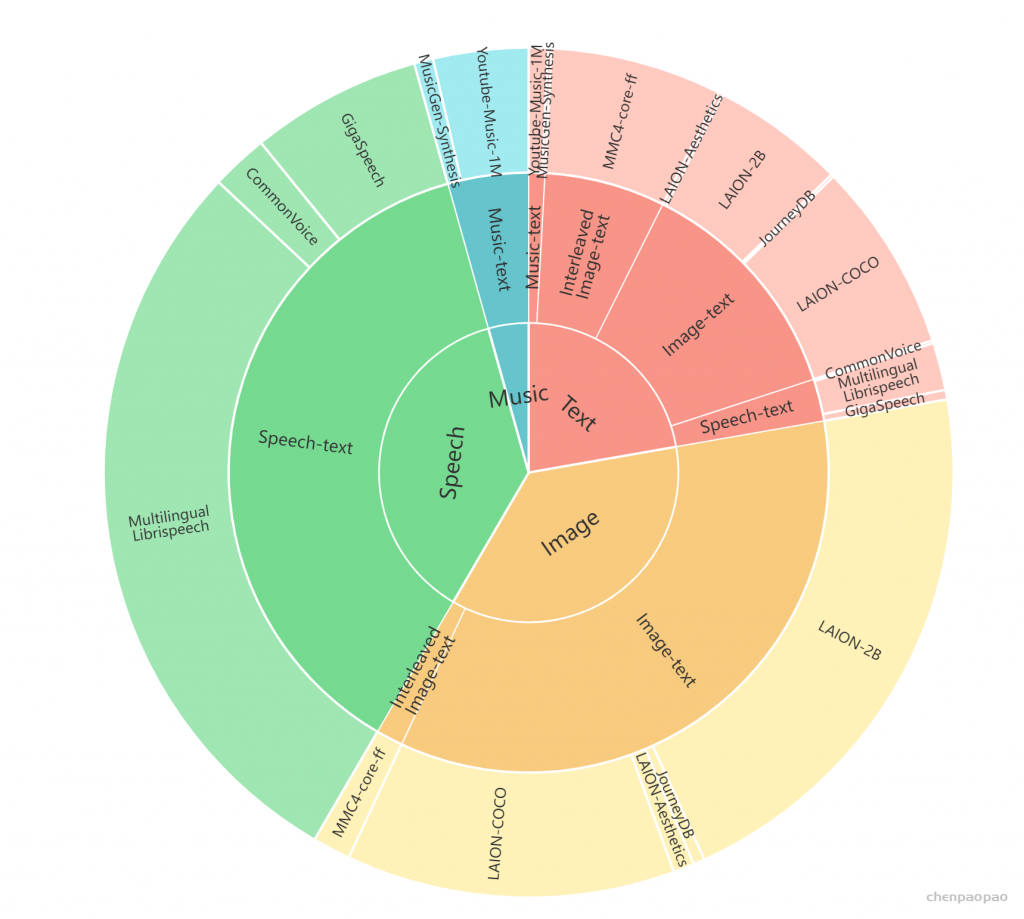
Image & Text :我们利用来自LAION-2B的图像-文本对(Schuhmann 等人,2022)、LAION-COCO(lai,2022 b)、LAION-Aesthetics(lai,2022 a)和JouneyDB(Pan 等人,2023年)。LAION-2B提供了与来自网络的嘈杂替代文本配对的图像,而LAION-COCO代表了其中的600 M子集,由BLIP标题。我们通过过滤文本质量、图像纵横比和剪辑得分等来细化这些数据集,产生了3亿对的高质量语料库。为了提高整体图像生成的保真度,我们用高质量的LAION-Aesthetics子集和Midjourney的合成数据集ColonneyDB补充了我们的数据。
Speech & Text :我们收集了几个大规模的英语自动语音识别(ASR)数据集,Gigaspeech (Chen et al., 2021), Common Voice (Ardila et al., 2020), and Multilingual LibriSpeech(MLS) (Pratap et al., 2020). 共同构成了57,000小时的语音文本对语料库,涵盖了各种各样的说话人,领域和录音环境。
Music&Text:从互联网上抓取了超过一百万个音乐视频,开始了广泛的数据收集过程。核心步骤涉及使用Spotify API将这些视频的标题与相应的歌曲进行匹配。随后,我们为每个音乐音频收集了一组全面的元数据,包括视频标题、描述、关键字、播放列表名称和Spotify歌词。该元数据被格式化为JSON并输入GPT-4处理。GPT-4作为智能字幕生成器的作用至关重要;它利用嘈杂的元数据提取有意义的信息,并将其简洁地概括为连贯的句子。这种方法使我们能够为大量的音乐音频生成高质量的文本字幕,有效地减少了数据集中幻觉的发生。
Tokenization

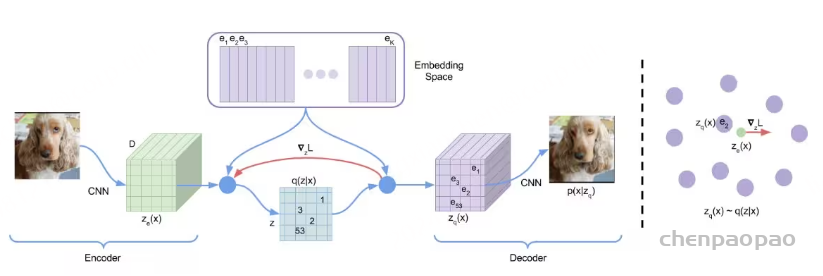
Image Tokenizer:
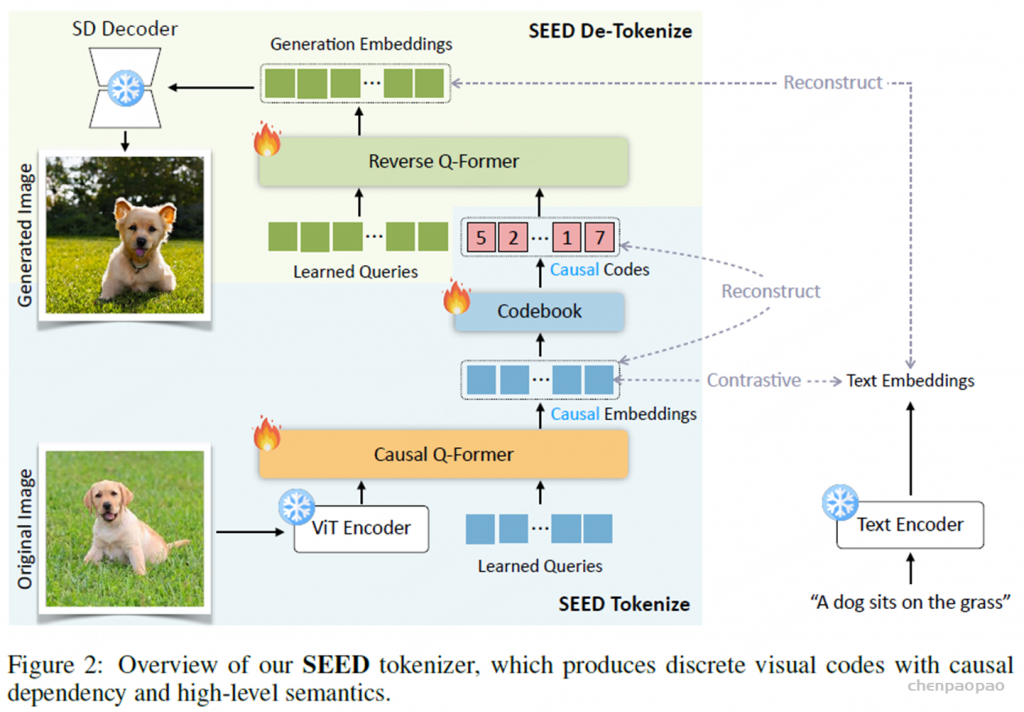
使用SEED tokenizer:
ViT encoder 224x224input 16x16patches
Causal Q-Former 32token
VQ Codebook Codebook大小8192
MLP 将视觉code解码至生成空间的embedding(与unCLIP-SD对齐)
UNet decoder复原图像
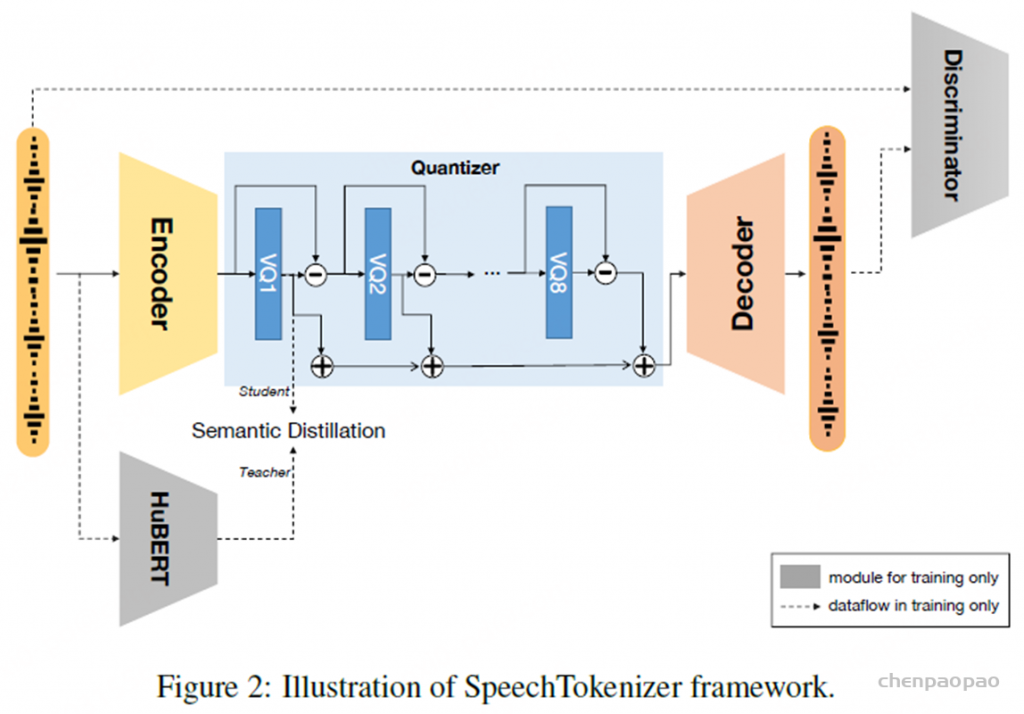
Speech Tokenizer:
采用具有残差矢量量化(RVQ)的编码器-解码器架构
•RVQ 8层,每层codebook大小1024
•每秒编码为50帧,10s即500×8 •量化器第1层捕捉语义信息,
2~8层编码副语言细节 •AnyGPT中使用LLM处理第1层语义token,
其余层由声音克隆模型提供?(VALLE中表示声音主要受第1层影响),因此Speech这块新增的token数是1024
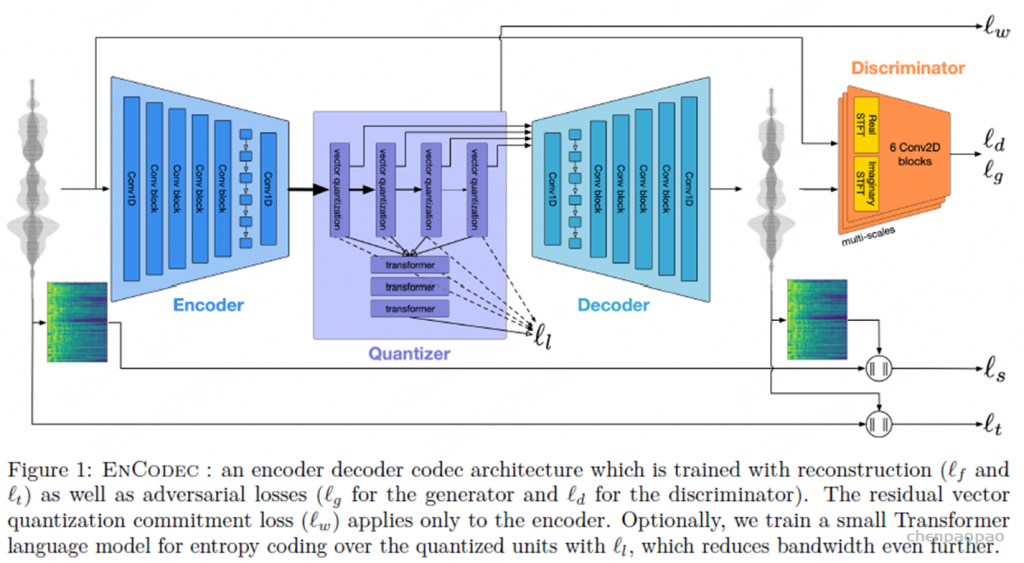
Music Tokenizer :
对于音乐,我们采用Encodec(D’efossez 等人,2022),具有使用残差矢量量化(RVQ)量化的潜在空间的卷积自动编码器,作为音乐令牌化器。
•RVQ 4层,每层codebook2048 •每秒编码为50帧 •不同之处在于LLM会依次预测每帧4层的token,然后再下一帧
Language Model Backbone
为了将多模态离散表示合并到预先训练的LLMs中,我们使用新的模态特定令牌扩展词汇表,从而扩展相应的嵌入和预测层,新合并的参数随机初始化。 来自所有模态的标记联合收割机以形成新的词汇表,其中每个模态在语言模型内被训练以在共享的表征空间中对齐。
•统一的多模态语言模型:通过特定模态的tokenizer,可以将多模态数据压缩为离散的token序列,并使用LLM的next token prediction loss训练,天然地统一各种任务形式 • •使用LLaMA-2-7B作为backbone
Multimodal Generation:
为了高质量生成采用2阶段框架,语义信息建模和感知信息建模。LLM在语义层面生成经过融合对齐的内容,然后NAR模型在感知层面将语义token转换成高保真的多模态内容,达到效果与效率间的平衡
•Image
使用Diffusion Model解码SEED tokens生成图片
•Speech
使用SoundStorm从SpeechTokenizer的semantic tokens生成acoustic tokens(LLM生成第1层,SoundStorm生成2~7层?),再用SpeechTokenizer解码生成语音
具备Zero-shot的声音克隆功能
•Music
使用Encodec解码生成音频
Instruction Tuning
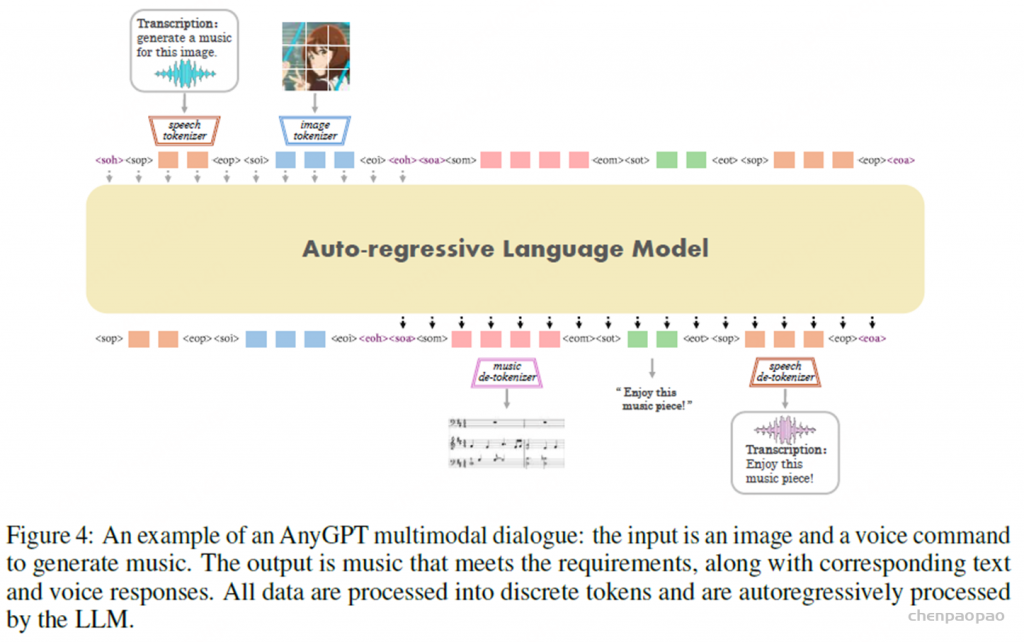
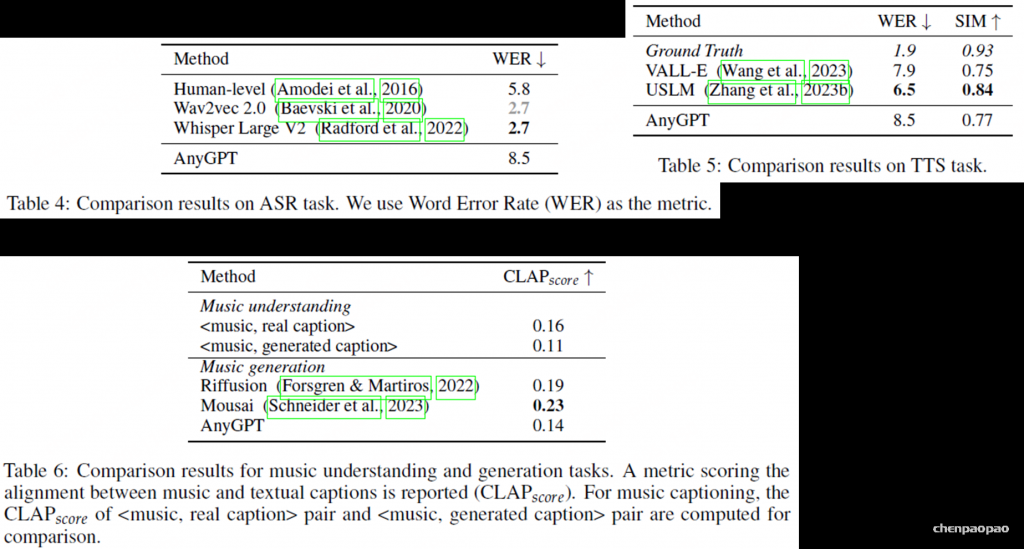
实验:
局限性和未来工作:
任意到任意多模式LLM基准测试:任何对任何多模态大型语言模型(LLMs)领域是一个新兴的研究领域。然而,缺乏一个专门的基准来评估模型在多个维度上的能力,以及减轻潜在风险,这是一个相当大的挑战。因此,必须制定一个全面的基准。
增强LLMs:尽管具有离散表示的多模态LLMs可以稳定地训练,但与单模态训练相比,观察到更高的损失,从而阻止了每种模态的最佳性能。改进多模态融合的潜在策略可能涉及扩展LLMs和标记器或采用混合专家(莫伊)架构,以更好地管理不同的数据并优化性能。
更好的Tokenizer:可以从各种角度来增强 Tokenizer ,包括采用上级码本训练方法,开发更具凝聚力的多模态表示,以及在各种模态中应用信息解纠缠。
更长的上下文:多模态内容,例如图像和音频,通常跨越广泛的序列。例如,AnyGPT将音乐建模限制在5秒,这大大限制了其音频输出的实际用途。此外,对于任何对任何多模态对话,扩展的上下文允许更多数量的会话交换,从而丰富交互的深度和复杂性。