
https://nvlabs.github.io/eg3d/
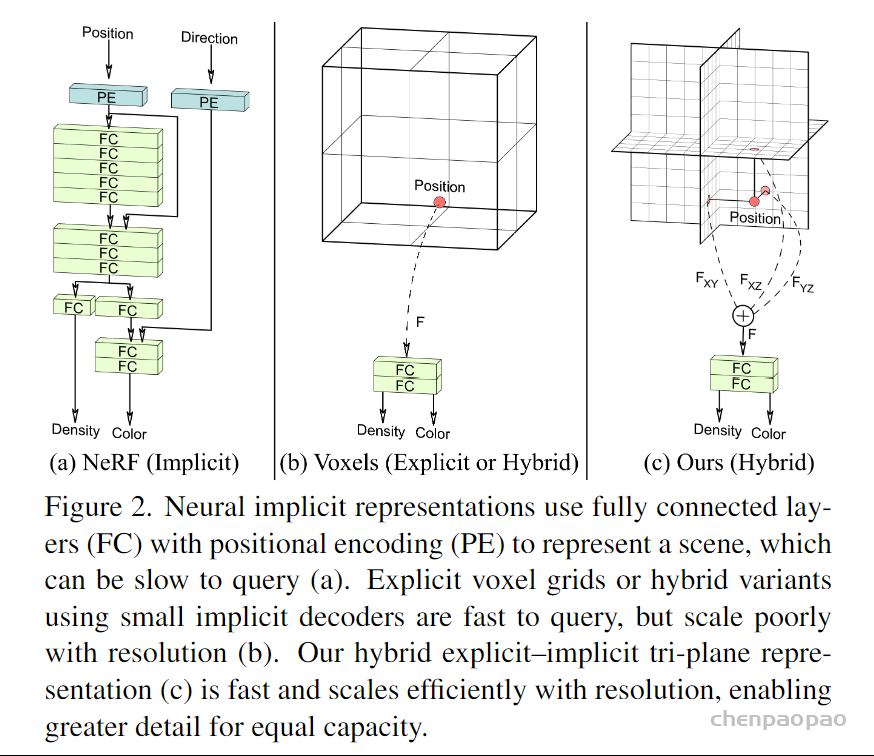
将三维坐标对应的体素特征定义为三个正交投影平面的特征
目前的3D GAN要么过于计算密集型,要么缺少多视图一致性,该方法加强了计算效率并且提升了重建质量。使用了显式-隐式结构,不仅生成多视角一致性图片,还能生成高质量3D几何。通过解耦feature generation和neural rendering,该架构就可以用上SOTA的2D CNN生成器比如styleGAN2。
使用单视角2D图片集,无监督地生成高质量且视角一致性强的3D模型,一直以来都是一个挑战。现存的3D GANs要不计算量巨大,要不无法保证3D-consistent。前者限制了生成图片的质量,后者无法解决视角一致性的问题。这篇工作提出的新网络架构,能又快又好地生成3D geometry。
这篇工作提出了两个方法。首先,作者用显隐混合的方法,提高了时空效率,并有较高的质量。第二,提出了dual-discrimination策略,保证了多视角一致性。同时,还引入了pose-based conditioning to the generator,可以解耦pose相关的参数,保证了输出的视角一致性,同时忠实地重建数据集隐含的pose-correlated参数。
同时,这个框架能解耦特征生成和神经渲染,从而可以直接使用SOTA的2D GANs,比如StyleGAN2。
contribution
- 引入一个基于三平面的3D GAN架构,计算效率高而且效果质量好
- 提出一个3D GAN训练策略,通过dual discrimination和generator pose conditioning加强多视角一致性,建模出位置相关的属性分布(比如表情等)
- 在FFHQ和AFHQ上有最佳的非条件3D感知视图合成结果,生成高质量3D几何
Tri-Plane Hybrid 3D Representation
我们需要一种高效且表达力强的3D表示方法,来训练高分辨率的GAN。
这里以单场景过拟合(SSO)来证明三平面表示法的有效性。
每个平面都是N×N×C的,其中C是通道数。
每次查询一个3D坐标x∈R3,将其投影至每个平面上,用双线性插值得到3个特征向量Fxy,Fxz,Fyz
将这3个特征向量累加后,通过一个轻量级的decoder,也就是一个小型MLP,输出RGB和Density
再用volume rendering得到最终图像
这样做的好处是,decoder规模很小,赋予了显式表示更强的表达能力,并减小了计算压力。
在新视角合成的实验上,三平面紧凑而富有表达力,以更低的计算成本,得到了更好的表现,三平面的时空成本是O(N2)的,而voxel是O(N3)的,最重要的是,用2D GANs生成planes,就能得到3D表示。对比NERF,通过显式的投影降低了计算复杂度同时没有减少表达性能。做了个对比实验,baseline是mip-nerf和voxel grid,这里的tri-plane实验中的MLP用了傅里叶feature编码。在同样地内存消耗下运算更快,在同样地结构下速度快且内存消耗少。

Pipeline

CNN Generator Backbone & Rendering
三平面的特征,是由StyleGANA生成的,同时Latent Code和相机参数会输入Mapping Network,生成一个Intermediate Latent Code
StyleGAN2被修改后,输出256×256×96256×256×96的特征图,之后被reshape成32通道的平面
接着从三平面采样,累加后,通过轻量级decoder,生成density和32通道的特征,然后由neural volume renderer生成2D特征图(而非RGB图)
Super Resolution
三平面仍不足以直接生成高分辨率图,因此添加了超分模块
使用了2个StyleGAN2的卷积层,上采样并优化32通道特征图,得到最终的RGB图像
Dual Discrimination
对StyleGAN2的discrimination做了两个修改
首先,添加Dual Discrimination以保证生成图片的视角一致性,即保证原始图片(低分辨率生成的)和超分后的图片的一致性,将低分辨率图片直接双线性上采样后,和超分图片concat形成6通道图片,真实图片也模糊后的自己拼接,也形成6通道图片,进行判别。
这样做,不仅能encourage最终输出和真实图片的分布匹配,也让神经渲染器尽可能匹配下采样的真实图片,并让超分图片和神经渲染保持一致。
其次,作者对discriminator输入了相机内外参,作为一个conditioning label,从而让generator学到正确的3D先验。
Modeling Pose-Correlated Attributes
真实世界数据集如FFHQ,相机姿态与其他参数(如表情)有关联
比如,相机角度与人是否微笑是有关系的,这会导致生成结果视角不一致
因此,为了更好的生成质量,需要将这些参数与相机姿态解耦
这篇工作使用了Generator Pose Conditioning解耦pose和其他参数
Mapping Network不仅接受Latent Code,还接受相机参数做为输入
给予backbone相机姿态作为先验,从而让视角可以和生成产生联系
也就是说,generator可以建模数据集中隐式的pose dependent biases,更忠实地反映数据集特征
为了避免在渲染时因相机移动产生视角不一致,在渲染时保持generator输入的相机参数不变