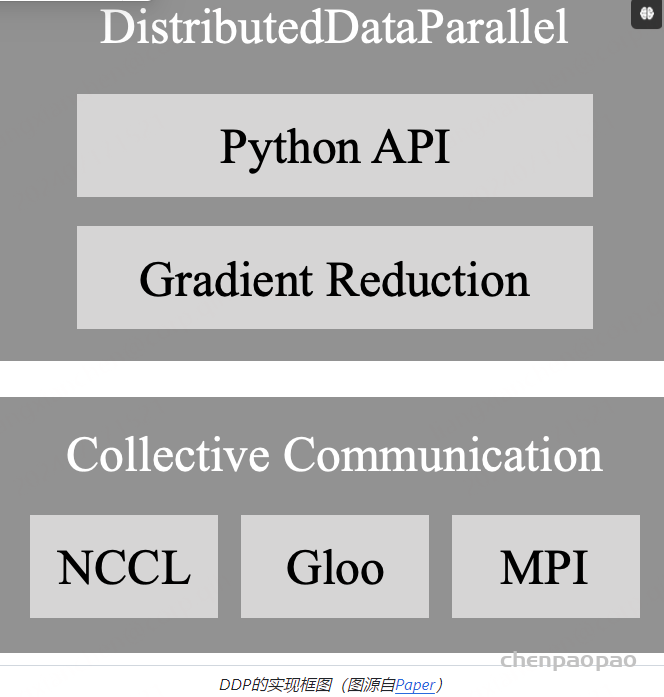
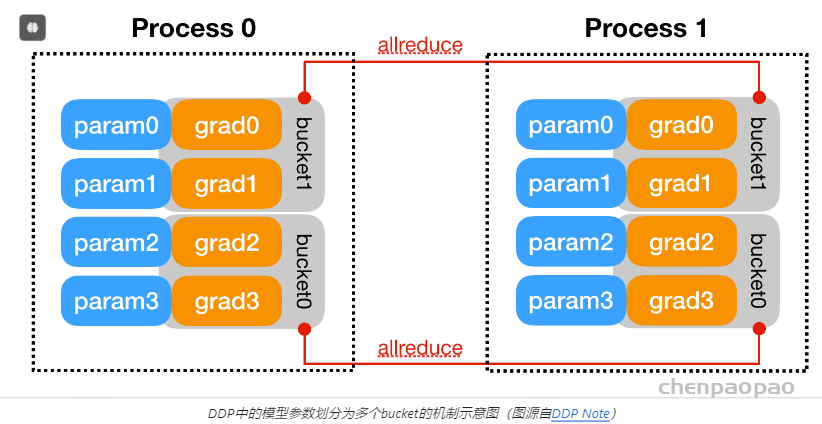
本文着重分析OpenRLHF中的PPO-Ray训练架构设计,不了解Ray的朋友也可以通过本文快速上手,全文共分成五块:
- 为什么用Ray
- 使用图例抽象出整体训练流程
- Ray核心知识速过
- 使用图例进一步抽象出核心代码细节,包括:
- 训练入口
- 部署PPO-Actor/Ref/Critic/RM实例
- 部署vllm_engines实例
- PPO-Actor与vllm_engines之间的通讯
- PPO-Actor/Critic训练
5. RLHF-PPO算法细节介绍
Ray介绍
https://github.com/ray-project/ray
Ray 是一个用于扩展 AI 和 Python 应用程序的统一框架。Ray 由一个核心分布式运行时和一组用于简化 ML 计算的 AI 库组成:
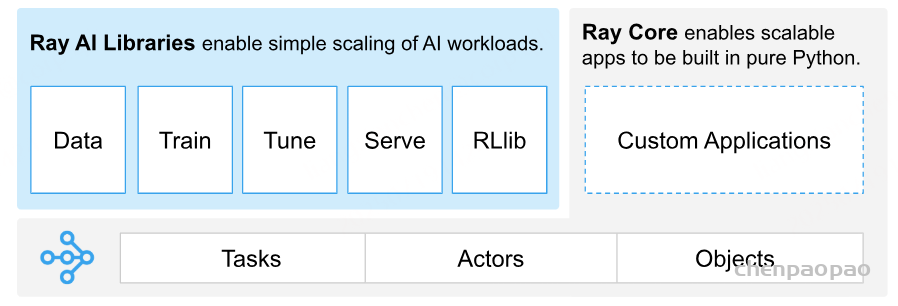
一站式平台
包含多个模块(Ray Core, Ray Data, Train, Tune, RLlib, Serve)支持从数据加载、并行任务调度,到分布式训练、超参调优、强化学习、模型部署的完整 AI 工作流。
Python 原生,门槛低
采用装饰器 @ray.remote 标记函数或 Actor,即可并行执行,无需了解底层分布式原理。
高性能 & 容错能力
利用分布式调度、共享内存对象存储、层级调度机制,实现低延迟、高吞吐、故障恢复。
一、为什么要使用Ray
对于通常的rlhf框架,在训练时会在单卡上同时部署actor/ref/reward/critic四类模型,这种单一的部署方式可能存在如下问题:
- 难以突破单卡显存的限制。
- 无法实现更多的并行计算。例如在收集exp阶段,拿到
(prompt, responses)结果的四类模型其实可以做并行推理;在训练阶段,拿到exp的actor和critic也可以做并行训练。但受到单卡显存等因素影响,通常的rlhf框架中使用更多的是串行。 - 无法独立优化训练和推理过程。诸如vllm之类的框架,是可以用来提升actor生成
(prompt, responses)的速度的,而对于其它模型,我们也可能会视算法需要有不同的推理需求。因此我们期望能更加灵活地设计训练、推理过程
而解决以上问题,需要开发者能设计一套较为灵活的分布式计算框架,能够实现资源定制化分配、分布式调度、节点内外通信等目标,同时相关的代码不能太复杂,能够让使用者更专注于算法部分的研发。而Ray天然可以帮我们做这件事:我们只需提供自己的资源分配方案,告诉Ray我想怎么部署这些模型,不管是分开还是合并部署Ray都可以帮我们实现。而复杂的调度策略和通信等事项,就由Ray在后台去做,我们无需关心这个过程。
二、整体流程
本节我们将提供2个例子,帮助大家更好理解使用Ray可以做什么样的“定制化”部署。注意,这些例子只做讲解用,不代表它们一定是训练的最优配置。
2.1 非共同部署
这个例子展示如何完全独立部署各个模型。假设我们有3台node,每台node 8张卡。以下展示其中一种可行的部署方式:
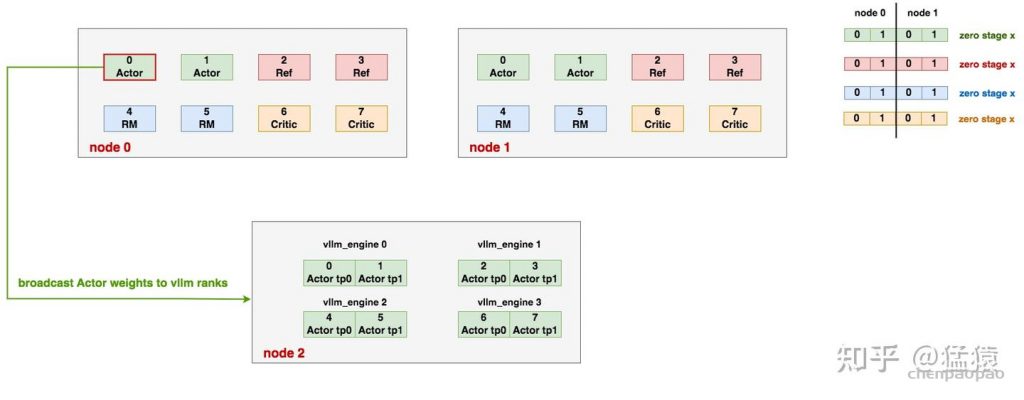
(1)部署4类模型
在这个例子中,4类模型分开部署在node0和node1上。以Actor为例,它分布在“node0的gpu0/1 + node1的gpu0/1”上。这一点是由Ray实现的:我们自己定制化资源分配的方案,进而管控模型的分配方式
而当实际训练时,我们还可进一步引入Deepspeed zero做优化:以Actor为例,上图中的4个Actor构成zero中的数据并行组(world_size = 4),根据zero的配置,我们可以在这4张卡间做optimizer/gradients/weights的切片
(2)部署vllm_engines
前文说过,对于Actor模型,在收集exp阶段我们可以采用vllm之类的框架加速(prompt, responses)的生成。在这个例子中:
- 1个vllm_engine维护着一个vllm实例,每个vllm实例下维护一个完整的Actor模型,这里我们还假设一个vllm实例按tp_size = 2的方法切割模型。
- 在node2中,共有4个vllm_engines(也即4个vllm实例),这种分配方式是通过Ray实现的。而每个vllm实例内的分布式推理则是由vllm自己管控。
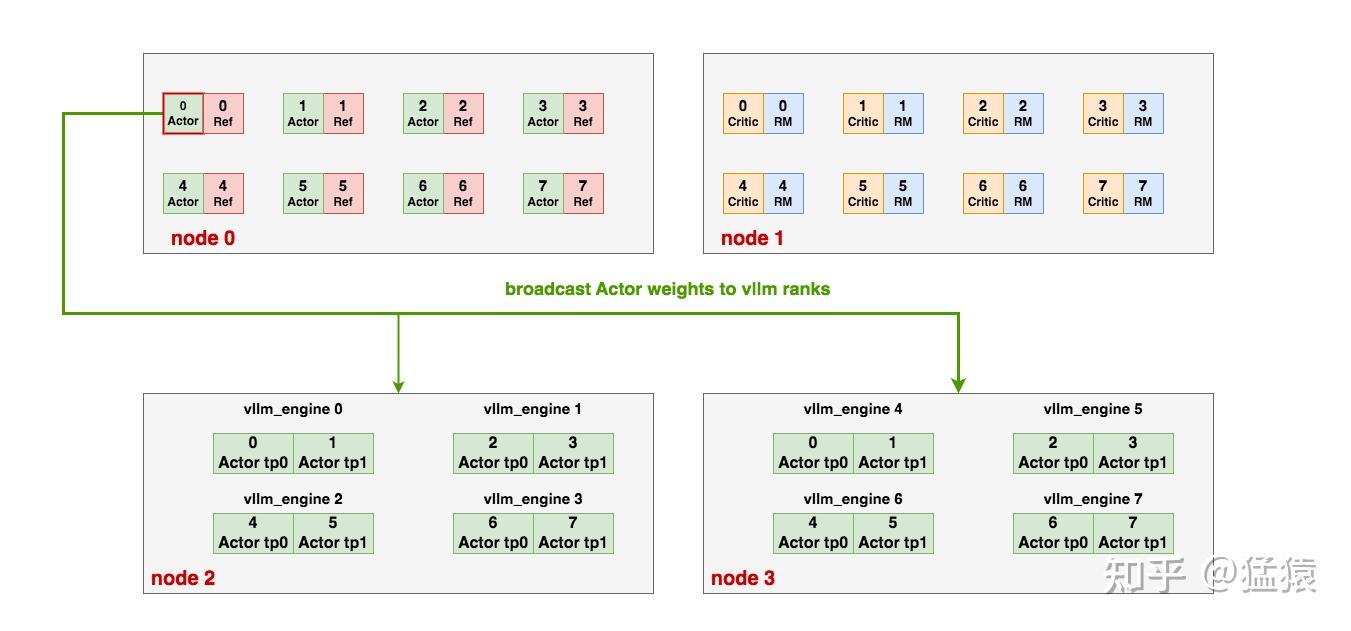
(3)Actor与vllm_engines之间的通讯
我们称:
- vllm_engines中的actor为vllm_actor
- node0/1中的actor为ds_actor
在整个训练过程中,vllm_actor需要和ds_actor保持权重一致。我们来看这个一致性是如何维护的:
- 初始化阶段
假设pretrain路径下存储着sft模型,当我们首次开始训练时,ds_actor和vllm_actor都直接从pretrain中加载权重,两者互不影响,独立加载。
2. 训练中
在1个step结束后,ds_actor需要把更新后的权重broadcast给vllm_actor,具体步骤如下:
- 首先,对
ds_rank0 + all_vllm_ranks创建一个通讯组。在本例中:- node0/gpu0上的actor是ds_rank0
- node2中所有的gpu构成all_vllm_ranks。
- 我们就是把这两者纳入一个通讯组内,这个通讯组的world_size = 9。如果我们多一台node3来做vllm_engines,那么这个通讯组的world_size = 17,以此类推。
- 假设我们使用ds_zero1/2,则ds_rank0上维护的是完整的actor权重,我们把ds_rank0上的权重broadcast到每一个vllm_rank,如有设置tp,vllm会自动帮我们完整接下来的模型切割。
- 假设我们使用ds_zero3,则ds_rank0上只维护部分actor权重,那么:
- ds_rank0先从ds_actor组内all gather回完整的模型权重
- 再将完整的模型权重brocast给每一个vllm_rank
3. 从检查点恢复训练(load_checkpoint)
当我们需要从检查点恢复训练时,ds_actor会负责把检查点权重broadcast给vllm_actor,方式同2。
(4)整体运作流程
结合2.1开头的图例,我们来简述一下整体运作流程。
- 首先明确一些表达。例如,
node0中的Actor0/1 + node1中的Actor0/1属于相同的数据并行组,所以接下来我们会用它们在dp组中的rank来描述它们,也就是分别改称Actor0/1/2/3。对于其余三类模型也是同理。 - 接着进行分组:
Actor0 / Ref0 / RM0 / Critic0 / vllm_engine0为一组Actor1 / Ref1 / RM1 / Critic1 / vllm_engine1为一组Actor2 / Ref2 / RM2 / Critic2 / vllm_engine2为一组Actor3 / Ref3 / RM3 / Critic3 / vllm_engine3为一组- 你可以把每一组想象成原来的一张单卡,那么它的作用就是负责一个micro_batch的训练,这样我们就能大致想象到它们之间是如何配合运作的了。需要注意的是,在我们的例子中,这些实例都是一一对应的(各自有4个实例),但在实际操作中,根据不同用户的资源配置,不一定存在这个一一对应的关系。例如你可能用4卡部署Actor,2卡部署Critic,8个vllm_engines…以此类推。不管怎样,我们应该尽量在处理micro_bathes的各个组间均匀分配负载,在代码里相关的操作如下:
为每个actor分配其对应的critic/reward/ref,并启动每个分组的训练:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/launcher.py#L278-L299
为每个actor分配对应的vllm_engine,并使用vllm_engine进行推理:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ppo_utils/experience_maker.py#L627
2.2 共同部署
同样,我们可以按照自己的需求,选择性地在单卡上部署不同种类的模型,例如下面的例子中,actor/ref共部署,critic/reward共部署,图例如下,运作流程和2.1相似,这里不赘述:
三、Ray的核心概念
在传统的编程中,我们经常使用到2个核心概念:function和class。而在分布式系统中,我们希望可以分布式并行执行这些function和class。Ray使用装饰器@ray.remote来将function包装成Ray task,将class包装成Ray actor,包装过后的结果可以在远端并行执行。接下来我们就来细看task/actor(注意,这里的actor是ray中的概念,不是rlhf-ppo中actor模型的概念)
请大家一定仔细看3.1和3.2节代码中的注释。
3.1 Ray Task
import ray
ray.init()
@ray.remote
def f(x):
return x * x
# ===================================================================
# 创建driver进程,运行main
# ===================================================================
if __name__ == "__main__":
# ===================================================================
# 创建4个worker进程,可以在远端并行执行。
# 每执行1次f.remote(i),会发生以下事情:
# - 创建1个worker进程,它将在远端执行函数f(i)
# - 在driver进程上立刻返回一个引用(feature),该引用指向f(i)远程计算的结果
# ===================================================================
futures = [f.remote(i) for i in range(4)]
# ===================================================================
# 阻塞/同步操作:等待4个worker进程全部计算完毕
# ===================================================================
results = ray.get(futures))
# ===================================================================
# 确保全部计算完毕后,在driver进程上print结果
# ===================================================================
print(f"The final result is: {results}") # [0, 1, 4, 9]
3.2 Ray Actor
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.x = 0
def inc(self):
self.x += 1
def get_value(self):
return self.x
# ===================================================================
# 创建driver进程,运行main
# ===================================================================
if __name__ == "__main__":
# ===================================================================
# 创建1个worker进程,具体做了以下事情:
# - 在远端创建Counter实例
# - 在driver端即刻返回对该实例的引用c(称为actor handler)
# - 我们可以在Ray集群的任何节点上传递和使用这个actor handler。即在任何地方,
# 我们可以通过c来invoke它对应Counter实例下的各种方法
# ===================================================================
c = Counter.remote()
# ===================================================================
# 阻塞/同步:通过c来invoke远端Counter实例的get_value()方法,并确保方法执行完毕。
# 执行完毕后才能接着执行driver进程上剩下的代码操作
# ===================================================================
print(ray.get(c.get_value.remote())) # 0
# ===================================================================
# Increment the counter twice and check the value again.
# 道理同上,不赘述
# ===================================================================
c.inc.remote()
c.inc.remote()
print(ray.get(c.get_value.remote())) # 23.3 Ray cluster架构简图
现在我们已经通过以上例子对Ray运作原理有了一些基本感知,我们来进一步探索一个ray cluster的组成:
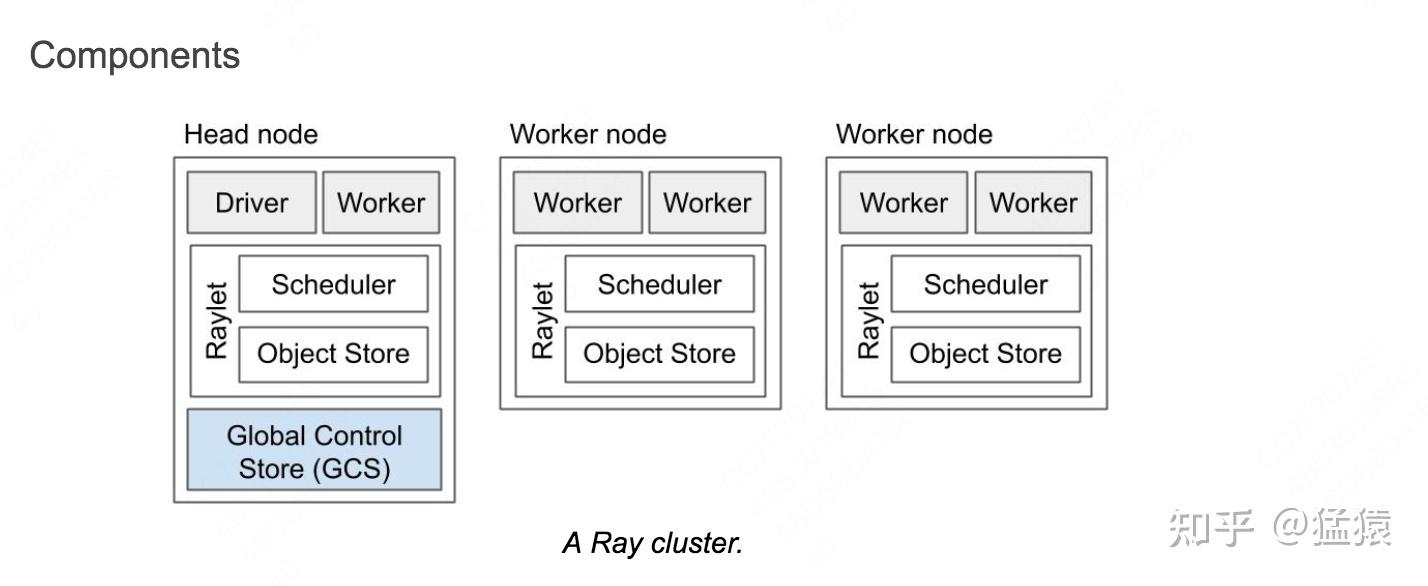
- 在一个ray cluster中,会有一台head node和若干worker node
- Driver process是一种特殊的worker process,它一般负责执行top-level application(例如python中的
__main__),它负责提交想要执行的任务,但却不负责实际执行它们。理论上driver process可以运行在任何一台node内,但默认创建在head node内。 - Worker process负责实际任务的执行(执行Ray Task或Ray Actor中的方法)。
- 每台node中还有一个Raylet process,它负责管控每台node的调度器和共享资源的分配。
- Head node中的GCS将会负责维护整个ray cluster的相关服务。
四、代码细节
本章将解读更多代码实践上的重要细节。我们通过图例的方式抽象出代码运行的过程,而具体代码可参考文中给出的相关链接
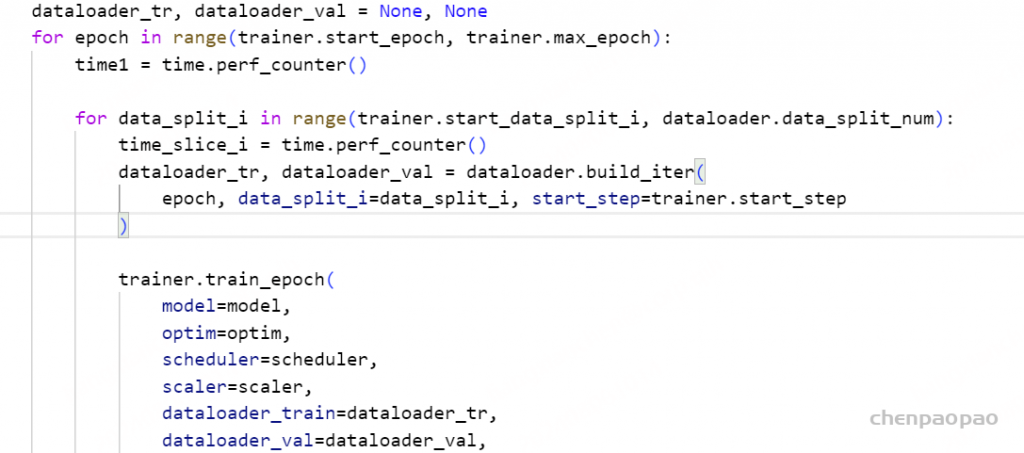
4.1 训练入口
ppo_ray相关的训练入口在:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/cli/train_ppo_ray.py。
在main中我们启动了driver进程,并执行训练函数train(args),这里主要做了如下几件事:
- 在ray集群上部署Actor/Ref/Critic/RM实例
- 在ray集群上部署vllm_engines实例
- 配置Actor和vllm_engines之间的通讯,用于传递权重
- 训练Actor和Critic模型
我们依次来解读这几个关键步骤。同时为了在表述上消除歧义,我们接下来谈到“Actor”时,会使用Ray-Actor和PPO-Actor来做区分,从之前的介绍中可知,Ray-Actor是指部署在Ray集群中的远端class,PPO-Actor/Ref/Critic/RM都属于Ray-Actor。
4.2 部署Actor/Ref/Critic/RM实例
(1)非共同部署
针对图2.1的情况,我们以PPO-Actor为例,看代码是如何将其部署到Ray集群上的。
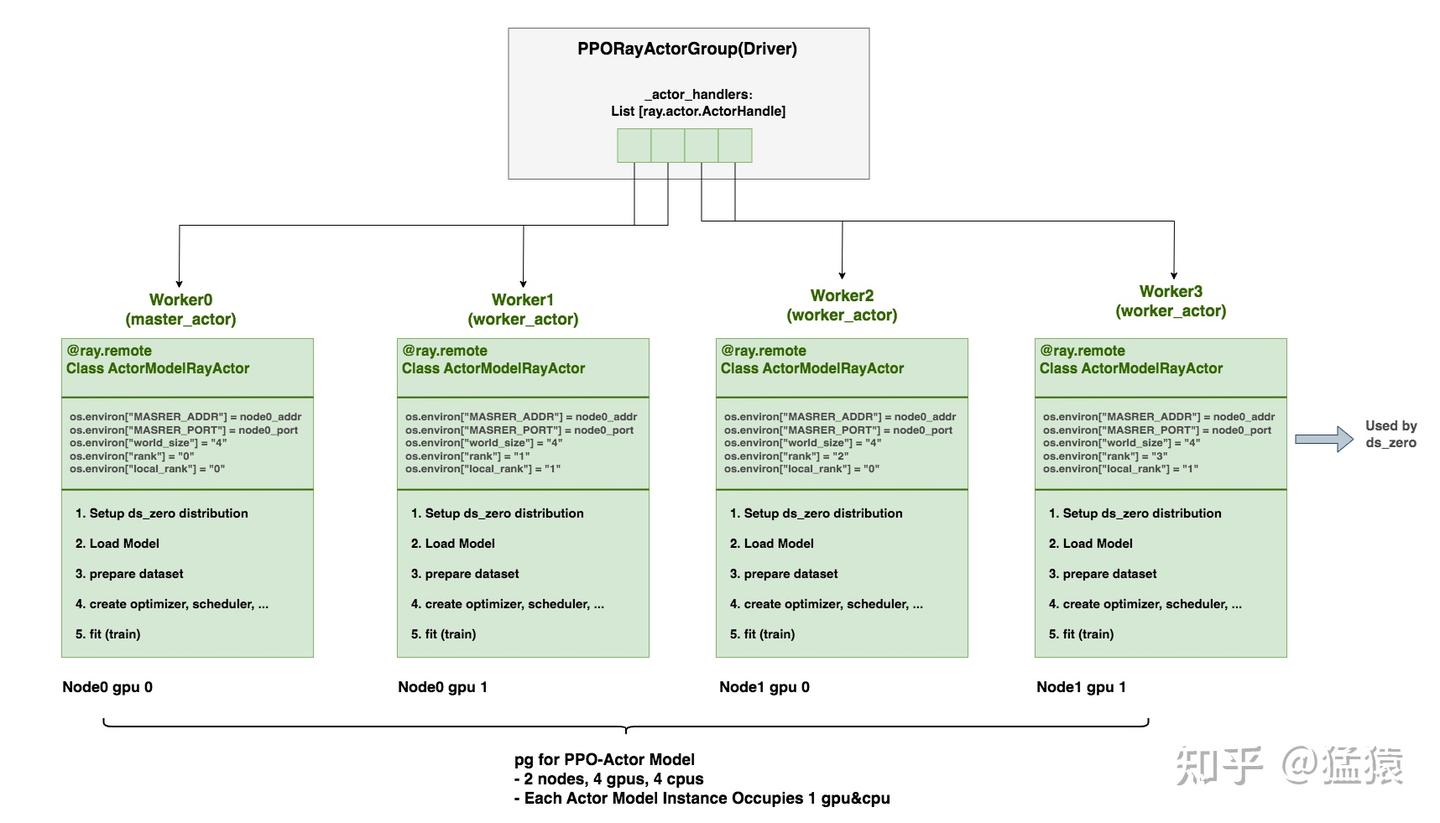
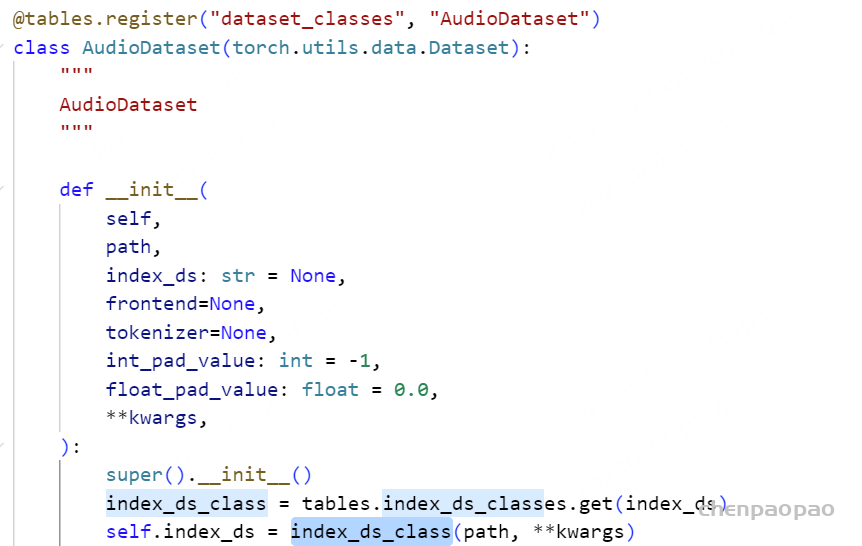
PPORayActorGroup:创建在driver进程上,可将它理解成一种部署方案,专门负责部署PPO中的4类模型。PPORayActorGroup中维护着self._actor_handlers,它是一个List[ray.actor.ActorHandle],列表中每个元素表示某个远端Ray-Actor的引用,而这个远端Ray-Actor可以是PPO-Actor/Ref/Critic/RM实例。如前文所说,我们可以在ray集群中的任何位置调用这个handler,来对相应的远端Ray-Actor执行操作。- 在本例中,我们创建了4个Ray-Actor(1个master-actor,3个worker_actor)。每个Ray-Actor都运行在一个worker进程中。在创建Ray-Actor的同时,我们也会去修改worker进程的环境变量。后续当我们在这些worker进程中启动ds_zero相关的分布式配置时,ds会读取这些环境变量信息,这样我们就知道哪些Ray-Actor同时又构成ds中的数据并行组。
- 使用
PPORayActorGroup部署模型实例的代码如下:
model = PPORayActorGroup(
# 为部署该模型的全部实例,我们想用多少台node,例如本例中为2
args.actor_num_nodes,
# 为部署该模型的全部实例,我们每台node上想用多少gpu,例如本例中为2
args.actor_num_gpus_per_node,
# Actor/Critic/Reward/ReferenceRayActor
ActorModelRayActor,
# pg可理解为,在ray cluster中锁定/预留一片资源,然后只在这片资源上部署该模型全部实例。
# (pg维护在Head Node的GCS上,参见3.3)
# 例如本例中,pg锁定的资源为node0 gpu0/1, node1 gpu0/1,
# 我们只在上面部署ActorModelRayActor全部实例
pg=pg,
# 当我们在pg指向的预留资源中分配模型实例时,再进一步指定每个实例占据一张gpu的多少部分
# 等于1说明每个实例占满一张gpu,即“非共同部署”
# 小于1说明每个实例只占部分gpu,即“共同部署”,例如PPO-Actor/Ref共同部署在一张卡上
num_gpus_per_actor=0.75 if pg else 1,
)ActorModelRayActor:创建在远端worker进程上,是Ray-Actor。它包含了设置ds_zero分布式环境、加载模型权重、数据集准备、optimizer/scheduler准备、训练等一系列操作。
PPORayActorGroup代码参见:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/launcher.py#L143
根据这份代码,大家可自行去找Actor/Critic/Reward/ReferenceRayActor的相关实现。
(2)共同部署
针对图2.2的情况,我们以PPO-Actor为例,看代码是如何将其部署到Ray集群上的。
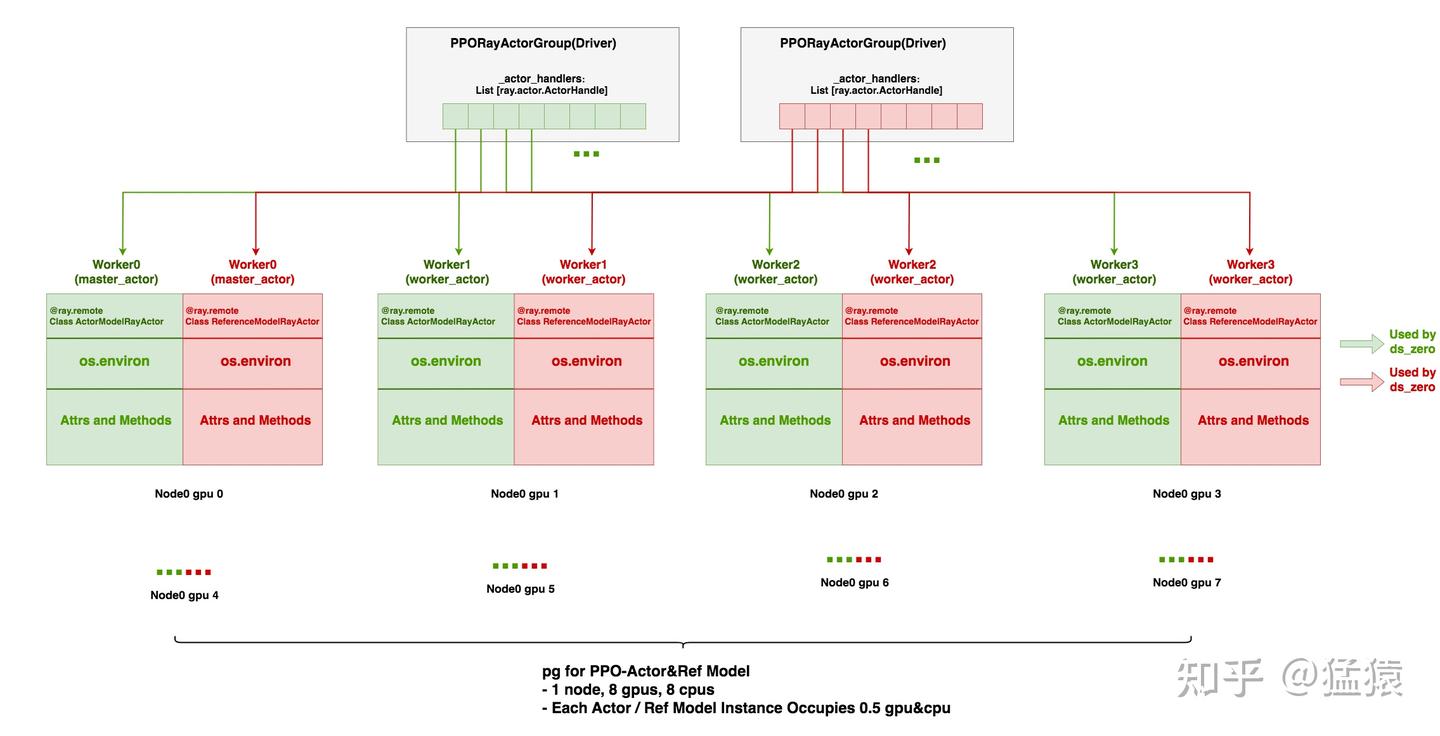
PPORayActorGroup:在driver进程上创建2个PPORayActorGroup,分别管理PPO-Actor,PPO-Ref的部署- 使用
actor_model = PPORayActorGroup(..., pg = pg, num_gpus_per_actor=0.75)创建PPO-Actor部署方案实例;使用ref_model = PPORayActorGroup(..., pg = pg, num_gpus_per_actor=0.25)创建PPO-Ref部署方案实例 - 这里,两个方案实例使用的pg都是同一个,即这个pg都指向“1台node,每台node 8张卡”这片预留好的资源。
num_gpus_per_actor = 0.75/0.25是一种创建trick,虽然我们的最终目的是为了让PPO-Actor和PPO-Ref对半分一张卡(对半=共享,不是指显存上对半分),但是:- 假设设置为0.5,当我们实际部署
ActorModelRayActor时,Ray先在单卡上部署1个ActorModelRayActor实例,当它准备部署第二个ActorModelRayActor实例时,它发现由于每个实例只占0.5块卡,因此完全可以把第2个实例接着第1个实例在同一张卡上部署,这样就导致最终无法让PPO-Actor和PPO-Ref共享一张卡 - 假设设置0.75,当我们在单卡上部署完1个
ActorModelRayActor实例后,ray发现单卡剩下的空间不足以部署第2个ActorModelRayActor实例,所以就会把第二个实例部署到别的卡上,这样最终实现PPO-Actor和PPO-Ref共享一张卡 - 所以,这个设置是为了达到不同类型模型的实例共享一张卡的目的,而并非真正指模型实际占据的单卡显存空间。
- 假设设置为0.5,当我们实际部署
- 最后,在这一步中,我们对全部
ActorModelRayActor共创建8个worker进程,对全部RefenreceModelRayActor共创建8个worker进程,一共创建16个工作进程。
4.3 部署vllm_engines实例
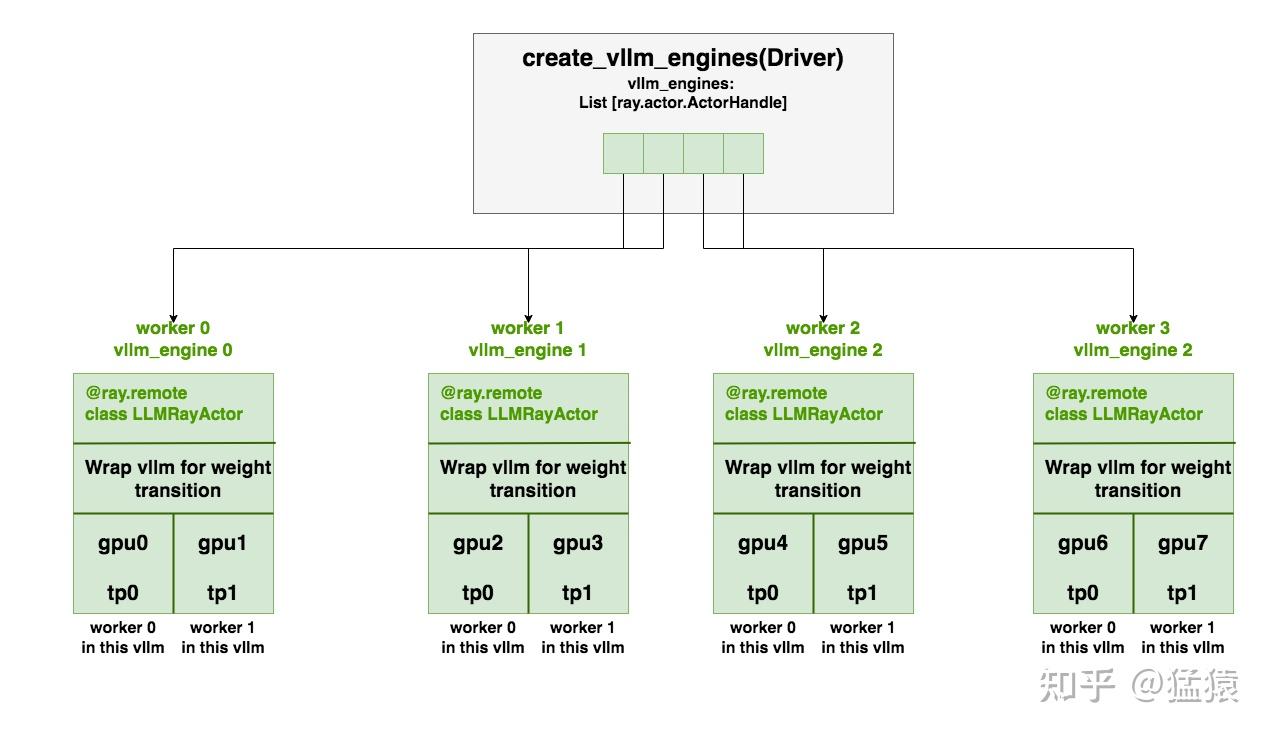
create_vllm_engines:在driver端,我们通过运行该函数来创建vllm_engines,过程相似于4.2节中的介绍,信息都在图中,这里不赘述。LLMRayActor:worker端Ray-Actor,它主要是把vllm实例进行了一些包装,包装的目的是为了让ds_rank0和all vllm ranks间可以进行PPO-Actor的权重通讯(参见2.1(3))- 在上面的例子中,我们会创建4个worker进程(不占gpu资源,只占cpu资源),用于运行管理4个vllm_engine。在每个worker进程内,vllm实例还会创建属于自己的worker进程做分布式运行(这些worker进程会实际占据gpu资源)。
相关代码参见:
https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/vllm_engine.py
https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/vllm_worker_wrap.py
4.4 ds_rank0与vllm_ranks之间的通讯
在2.2中,我们说过,PPO-Actor的ds_rank0需要和all_vllm_ranks进行通讯,传递最新的PPO-Actor权重,例如以下ds_rank0要把完整的权重broadcast给16个vllm_ranks:
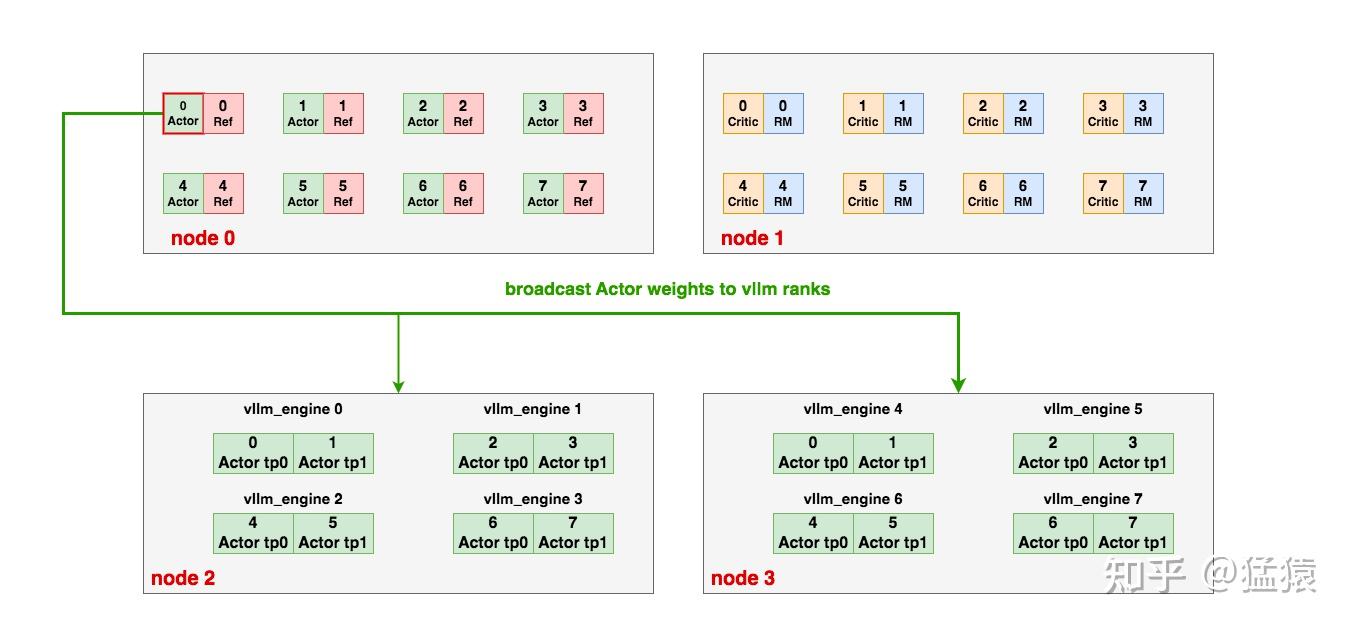
我们分成如下几步实现这个目标:
(1)创建通信组
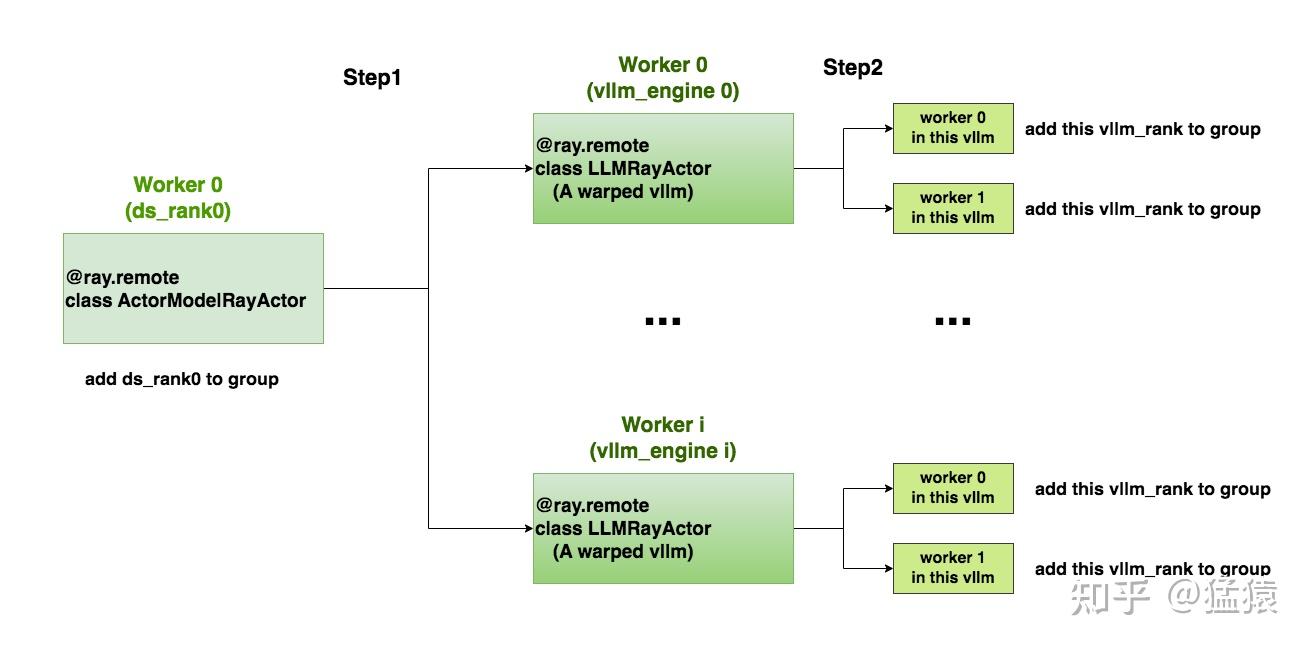
Step1:
代码来自:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L58
这段代码执行在PPO-Actor0(ds_rank0)所在的worker进程中。这个worker进程将通过handler引用,触发远端每个vllm_engine上的init_process_group操作,并将ds_rank0纳入通讯组
# Create torch group with deepspeed rank 0 and all vllm ranks
# to update vllm engine's weights after each training stage.
#
# Say we have 3 vllm engines and eache of them has 4 GPUs,
# then the torch group is:
# [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
# |ds rank 0 | engine-0 | engine-1 | engine-2 |
#
# For ZeRO-1/2:
# 1. Broadcast parameters from rank 0 to all vllm engines
# For ZeRO-3:
# 1. AllGather paramters to rank 0
# 2. Broadcast parameters from rank 0 to all vllm engines
if self.vllm_engines is not None and torch.distributed.get_rank() == 0:
...
# world_size = num_of_all_vllm_ranks + 1 ds_rank0
world_size = vllm_num_engines * vllm_tensor_parallel_size + 1
...
# =====================================================================
# 遍历每个vllm_engines,将其下的每个vllm_rank添加进通讯组中,这里又分成两步:
# 1. engine.init_process_group.remote(...):
# 首先,触发远程vllm_engine的init_process_group方法
# 2. 远程vllm_engine是一个包装过的vllm实例,它的init_process_group
# 方法将进一步触发这个vllm实例下的各个worker进程(见4.4图例),
# 最终是在这些worker进程上执行“将每个vllm_rank"添加进ds_rank0通讯组的工作
# =====================================================================
refs = [
engine.init_process_group.remote(
# ds_rank0所在node addr
master_address,
# ds_rank0所在node port
master_port,
# 该vllm_engine的第一个rank在"ds_rank0 + all_vllm_ranks“中的global_rank,
# 该值将作为一个offset,以该值为起点,可以推算出该vllm_engine中其余vllm_rank的global_rank
i * vllm_tensor_parallel_size + 1,
world_size,
"openrlhf",
backend=backend,
)
for i, engine in enumerate(self.vllm_engines)
]
# =====================================================================
# 将ds_rank0添加进通讯组中
# =====================================================================
self._model_update_group = init_process_group(
backend=backend,
init_method=f"tcp://{master_address}:{master_port}",
world_size=world_size,
rank=0,
group_name="openrlhf",
)
# =====================================================================
# 确保all_vllm_ranks都已添加进通讯组中
# =====================================================================
ray.get(refs)
Step2:
代码来自:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/vllm_worker_wrap.py#L11
这段代码实际运行在每个vllm_engine(即每个包装后的vllm实例)下的worker进程内。例如tp_size=2,那么每个vllm实例下就有2个worker进程,这两个worker进程都会运行这段代码。
class WorkerWrap(Worker):
def init_process_group(self, master_address, master_port, rank_offset, world_size, group_name, backend="nccl"):
"""Init torch process group for model weights update"""
assert torch.distributed.is_initialized(), f"default torch process group must be initialized"
assert group_name != "", f"group name must not be empty"
# =====================================================================
# torch.distributed.get_rank(): 在当前vllm_engine内部的rank,
# 例如在tp_size = 2时,这个值要么是0,要么是1
# rank_offset:当前vllm_engine中的第一个rank在“ds_rank0 + all_vllm_ranks"中的global_rank
# 两者相加:最终得到当前rank在“ds_rank0 + all_vllm_ranks"中的global_rank
# =====================================================================
rank = torch.distributed.get_rank() + rank_offset
self._model_update_group = init_process_group(
backend=backend,
init_method=f"tcp://{master_address}:{master_port}",
world_size=world_size,
rank=rank,
group_name=group_name,
)
...
(2)_broadcast_to_vllm
构建好通讯组,我们就可以从ds_rank0广播PPO-Actor权重到all_vllm_ranks上了,这里也分成两步。
Step1:PPO-Actor ds_rank0发送权重
代码在:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L146
这段代码运行在ds_rank0对应的worker进程中
def _broadcast_to_vllm(self):
# avoid OOM
torch.cuda.empty_cache()
model = self.actor.model.module
count, num_params = 0, len(list(model.named_parameters()))
for name, param in model.named_parameters():
count += 1 # empty_cache at last param
# Fire all vllm engines for broadcast
if torch.distributed.get_rank() == 0:
shape = param.shape if self.strategy.args.zero_stage != 3 else param.ds_shape
refs = [
# 远端vllm_engine的每个rank上,初始化一个尺寸为shape的empty weight张量,
# 用于接收广播而来的权重
engine.update_weight.remote(name, dtype=param.dtype, shape=shape, empty_cache=count == num_params)
for engine in self.vllm_engines
]
# For ZeRO-3, allgather sharded parameter and broadcast to all vllm engines by rank 0
# ds_rank0发出权重(视是否使用zero3决定在发出前是否要做all-gather)
with deepspeed.zero.GatheredParameters([param], enabled=self.strategy.args.zero_stage == 3):
if torch.distributed.get_rank() == 0:
torch.distributed.broadcast(param.data, 0, group=self._model_update_group)
ray.get(refs) # 确保所有vllm_ranks接收权重完毕
Step2: 各个vllm_ranks接收权重
代码在:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/vllm_worker_wrap.py#L29
代码运行在每个vllm_engine(即每个包装后的vllm实例)下的各个worker进程中。例如tp_size = 2,那么每个vllm实例下有2个worker进程,这2个worker进程都会运行这段代码。
def update_weight(self, name, dtype, shape, empty_cache=False):
"""Broadcast weight to all vllm workers from source rank 0 (actor model)"""
if torch.distributed.get_rank() == 0:
print(f"update weight: {name}, dtype: {dtype}, shape: {shape}")
assert dtype == self.model_config.dtype, f"mismatch dtype: src {dtype}, dst {self.model_config.dtype}"
# 创建同尺寸空张量用于接收ds_rank0广播来的权重
weight = torch.empty(shape, dtype=dtype, device="cuda")
# 接收权重
torch.distributed.broadcast(weight, 0, group=self._model_update_group)
# 使用接收到的权重进行更新
self.model_runner.model.load_weights(weights=[(name, weight)])
del weight
4.5 PPO-Actor/Critic Training
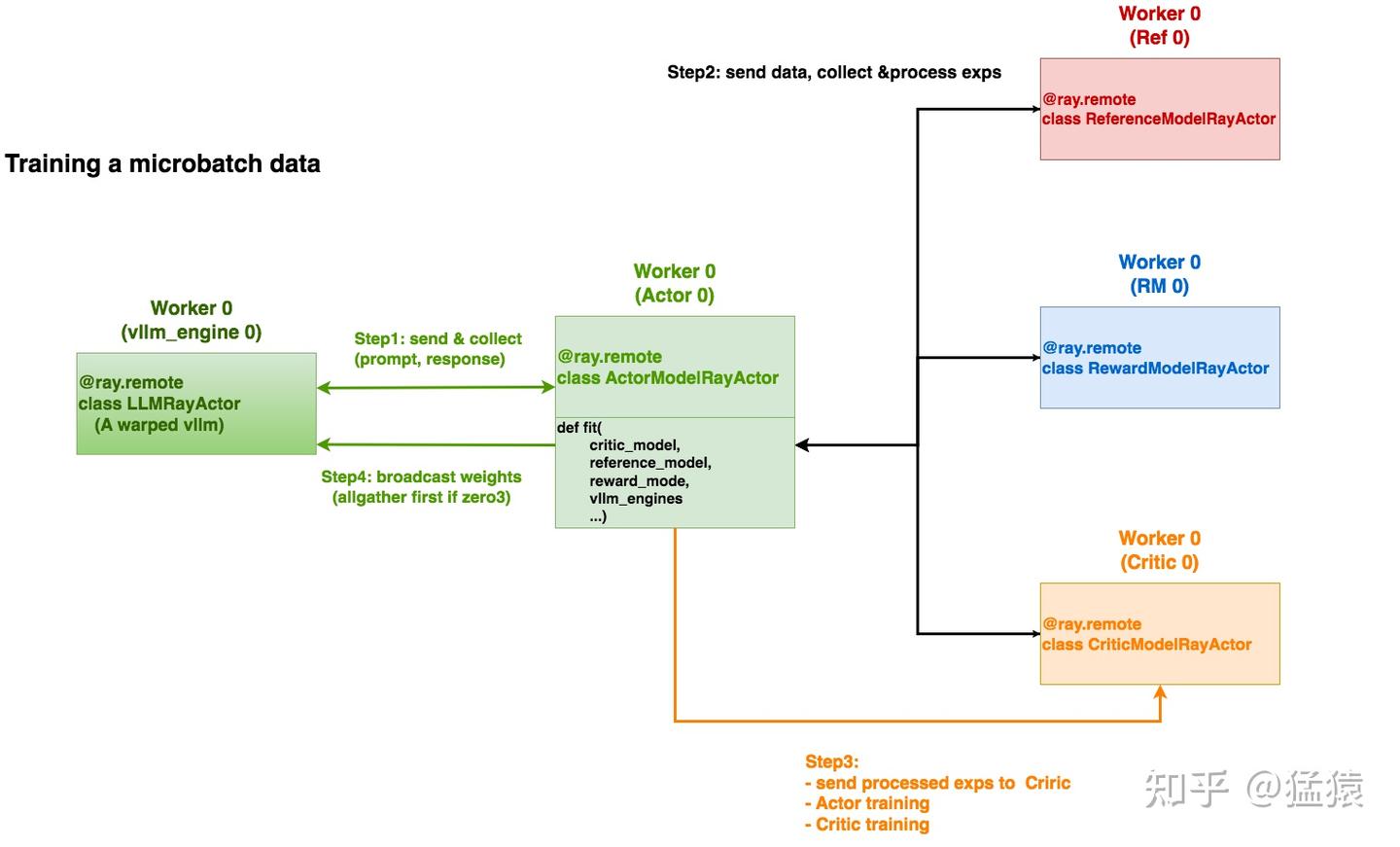
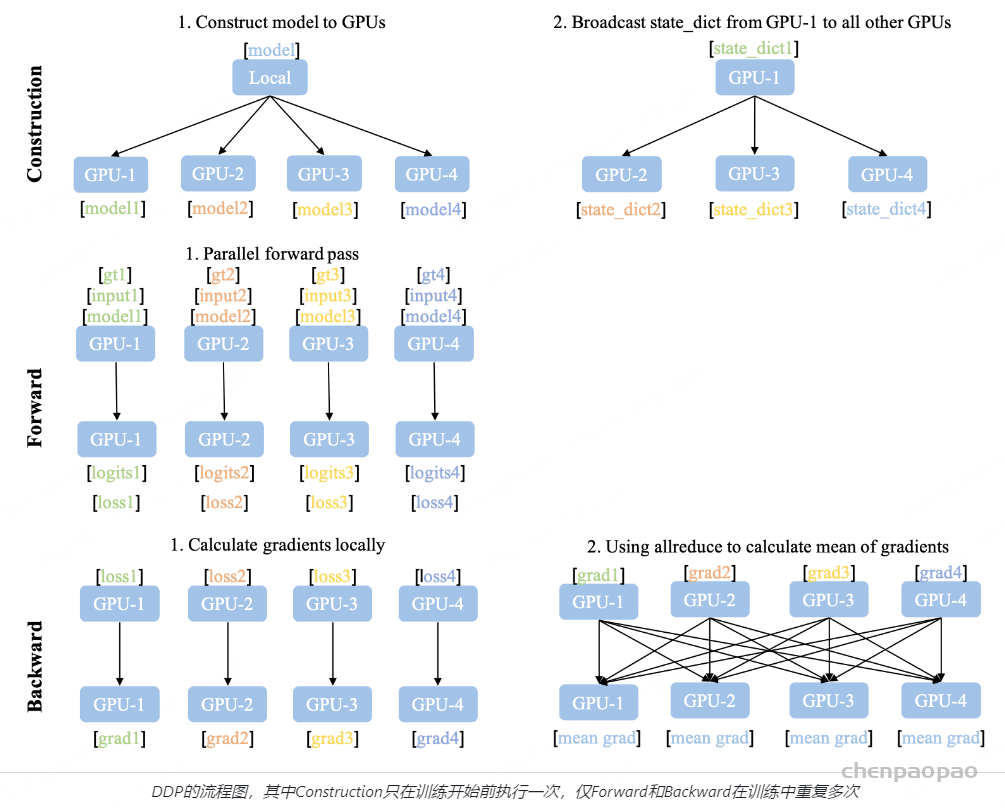
正如2.1(4)中所说,我们将部署在ray集群上的PPO-Actor/Ref/Critic/RM实例们进行分组,每组分别负责一份micro-batch的训练,上图刻画了某个组内的训练流程。一组内的训练流程发起自PPO-Actor实例(fit方法),注意不同颜色的worker0表示的是不同工作进程。共分成如下步骤执行。
Step1:发送prompts,并从vllm_engine上收集(prompt, response)。
Step2:从Ref/Reward/Critic上收集并处理exps。
Step3: 确保将处理后的exps传送给Critic,并行执行Actor和Critic的训练
将exps传送给Critic:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ppo_utils/experience_maker.py#L470
Actor训练:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L125
Critic训练:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L122
我们在Actor实例所在的worker进程上出发Actor和Critic的训练。以上代码只给出了训练入口,更多细节需要顺着入口去阅读。
Step4:vllm_engine权重更新。
五、RLHF-PPO算法细节
到目前为止,我们已将Ray分布式训练部分介绍完毕。有了对工程架构的认识,很多朋友可能想进一步探索算法上的细节:例如在4.5图例中,我们收集的是什么样的exps?又是如何对PPO-Actor/Critic进行更新的?
我们知道整个RLHF-PPO训练过程大致分成2步:
- Stage1:收集exps
- Stage2:使用收集到的exps计算actor_loss和critic_loss,用于训练actor和critic
在OpenRLHF中的核心代码为:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ppo_trainer.py#L19
下面我们分别解读这2个stage的过程
5.1 Stage1:collect exps
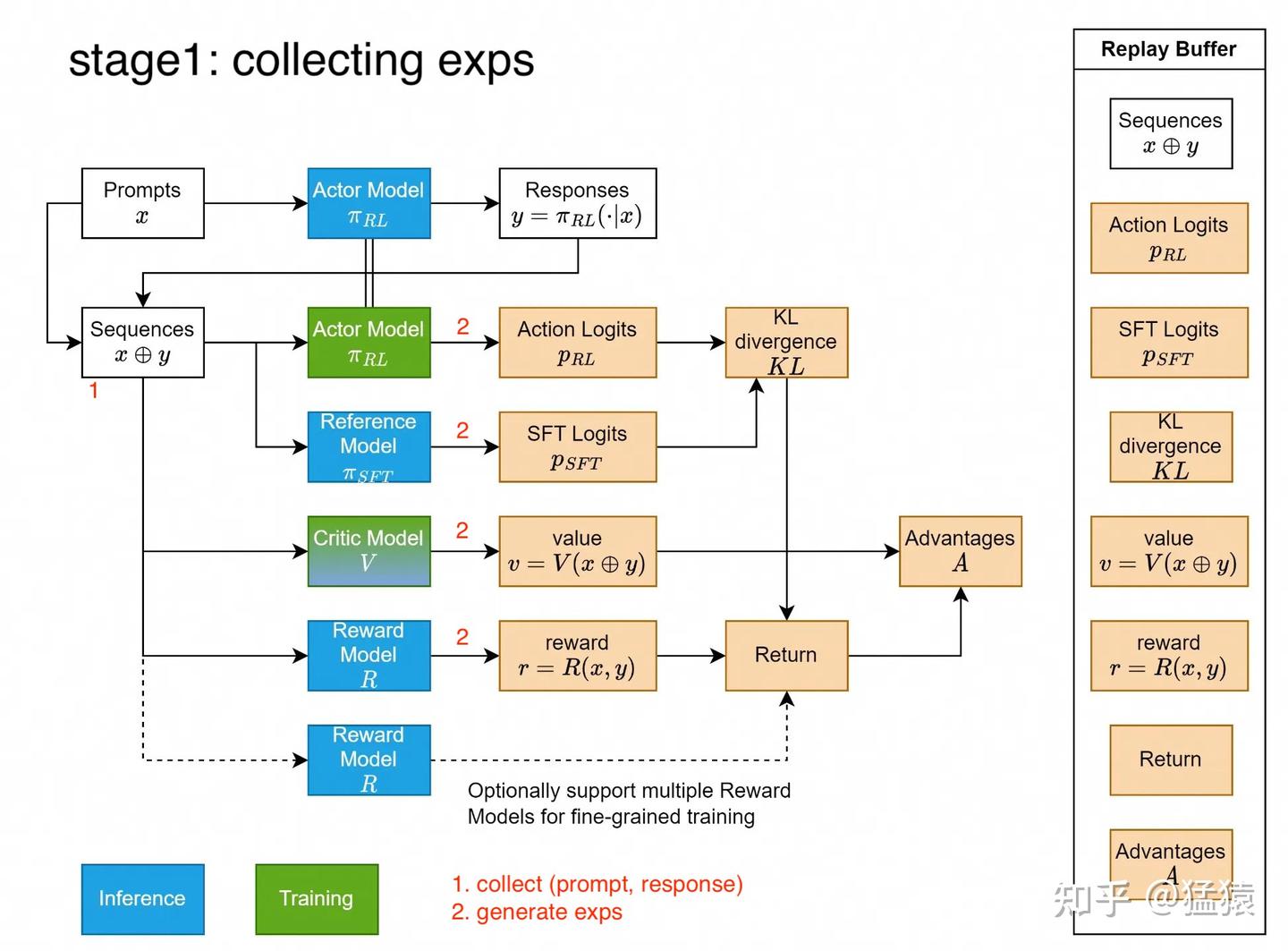
假设大家已读过上述说的【代码篇】和【理论篇】,那么对这张图的大部分细节应该不难理解。这里我们对优势(假设选择的是GAE)再做一些补充说明。
在理论篇8.3(2)中,我们详细介绍过GAE定义和使用它的原因,第t步GAE的定义为:

由上式可知,如果我们想要计算出每个t时刻的GAE,我们需要从头到尾遍历2次序列:第1次计算 δt ;第2次计算 At 。我们期望尽可能减少计算复杂度,仅在1次遍历中同时计算出 δt,At ,那么我们可以按如下步骤改写:

在OpenRLHF中,还设计到“advantage norm”,“reward clip & norm”等细节操作,篇幅限制不展开,大家可以自行阅读。
5.1 Stage2:Training
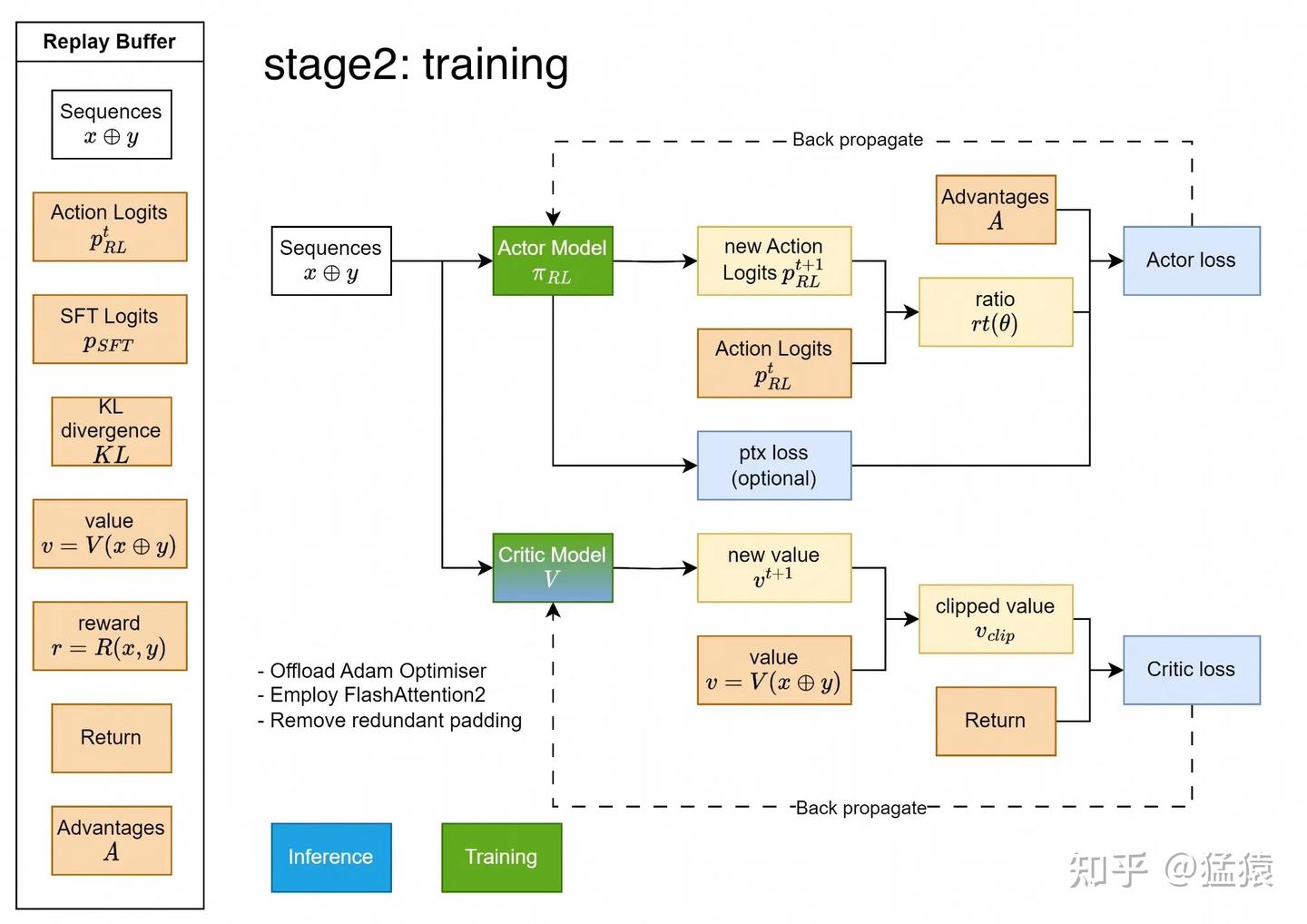
大家可以对照理论篇8.5和8.6节对actor_loss和critic_loss的介绍来理解上面的流程图~另外,ybq佬写过一篇对OpenRLHF中的loss分析,也可以对照阅读:ybq:OpenRLHF学习笔记-loss篇
六、参考
1、OpenRLHF
2、Ray official document
3、Ray official architecture whitepaper(要梯子,建议想看ray架构的朋友,直接看这个最新的官方白皮书,不要看2018年的那篇paper了,那个比较老了)
4、推荐一篇快速了解Ray 应用层核心概念的blog(要梯子)
5、Ray
6、vllm