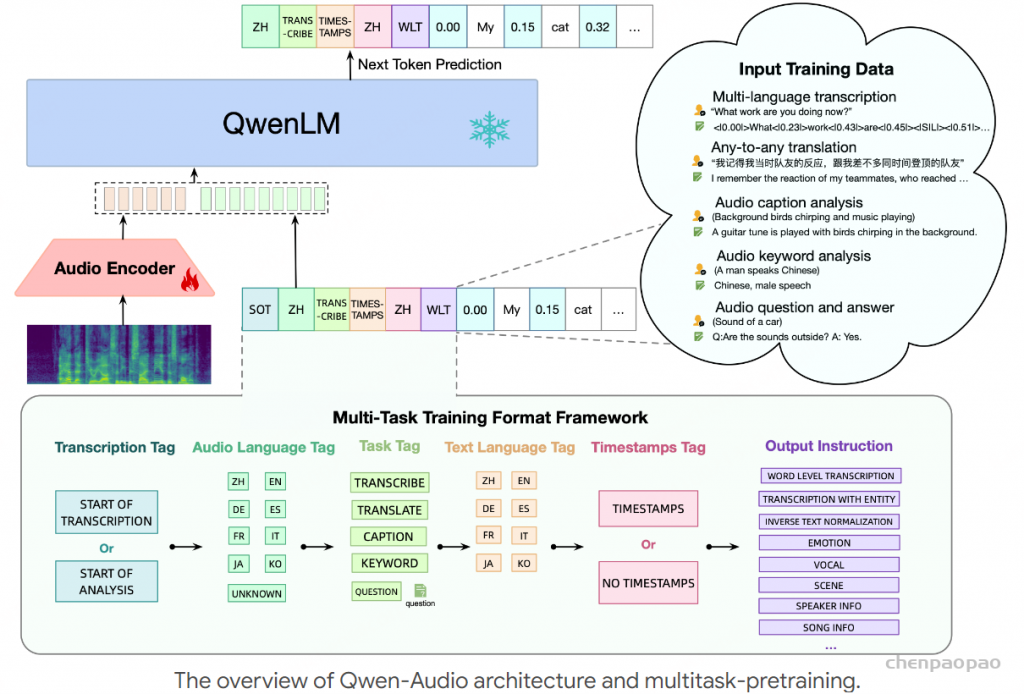
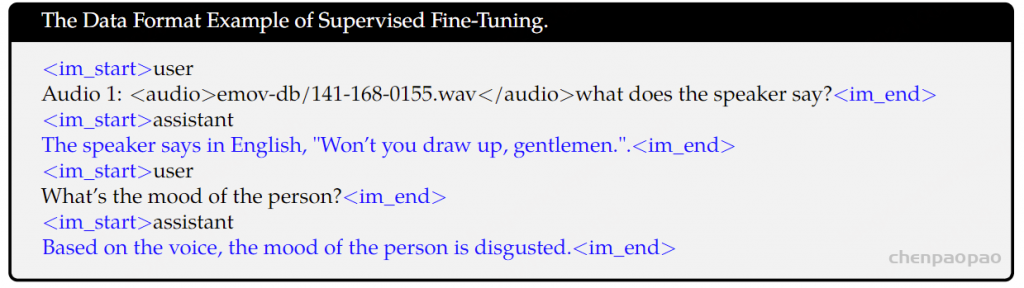
自然聊天,情绪丰富,随意打断,拒绝呆板和回合制!
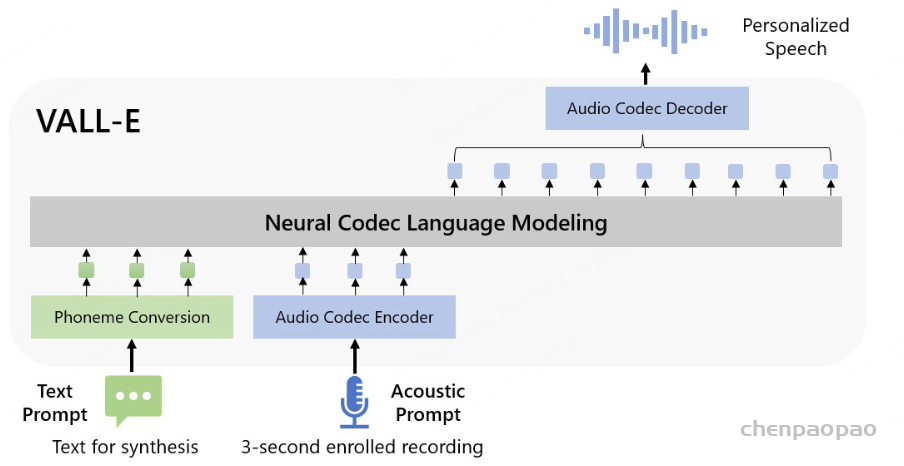
来自法国的初创团队Kyutai,发布了这个对标GPT-4o的神奇的端到端语音模型。并将代码、模型权重和一份超长的技术报告开源。
整个模型的参数量为7.69B,pytorch平台上只有bf16版本,如果在本地跑的话对显存有一定要求,而candle上提供了8bit版本,mlx上更是有4bit版本可供使用。
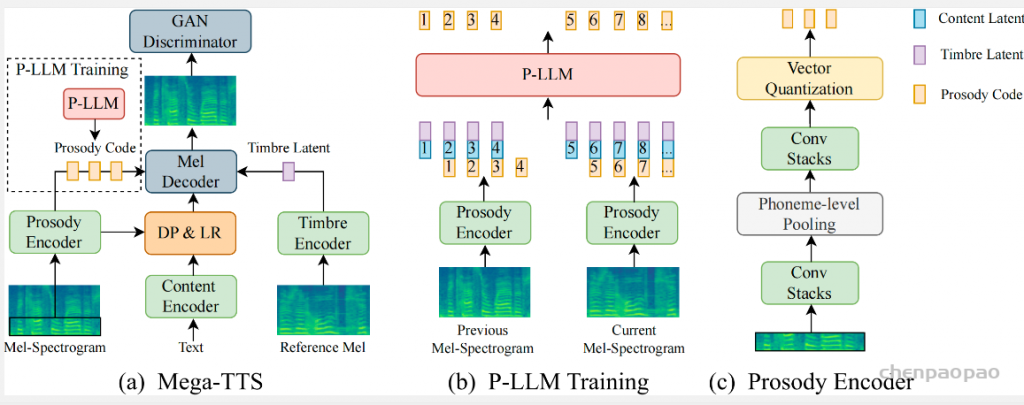
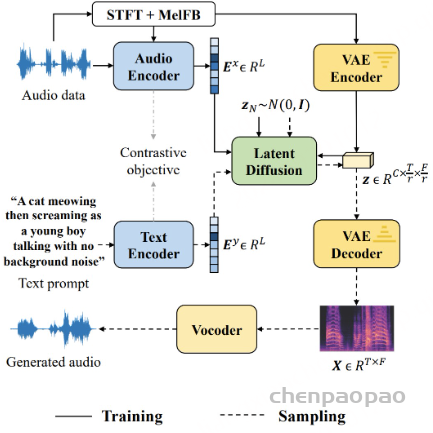
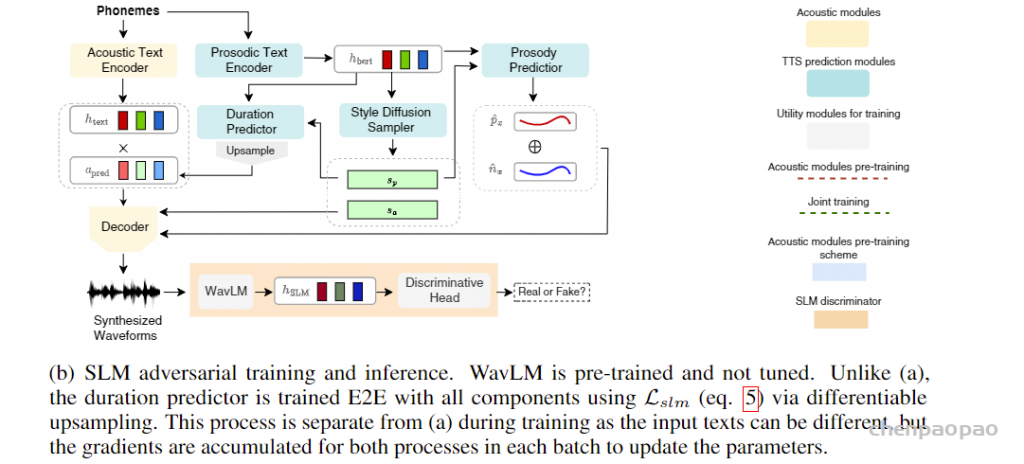
moshi作为一个全双工口语对话框架,由几部分组成:首先是Mimi,目前最先进的流式神经音频编解码器,能够以完全流式的方式(延迟80毫秒)处理24 kHz音频(12.5 Hz表示,带宽1.1 kbps(8个量化器,2048的码本 12.5*8*11))。
token/s Nq 量化器数量 带宽Bandwidth 码本大小 Mini 8*12.5=100 8 1.1kbps 2048 WavTokenizer-small 40 1 0.5kbps 4096 WavTokenizer-small 75 1 0.9kbps 4096 SpeechTokenizer 300 4 3.0kbps 1024 Encodec 300 4 3.0kbps 1024 Encodec 150 2 1.5kbps 1024
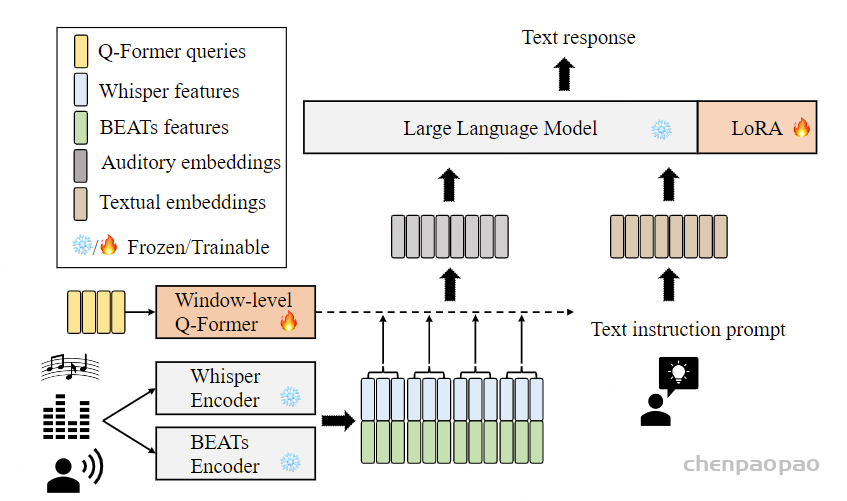
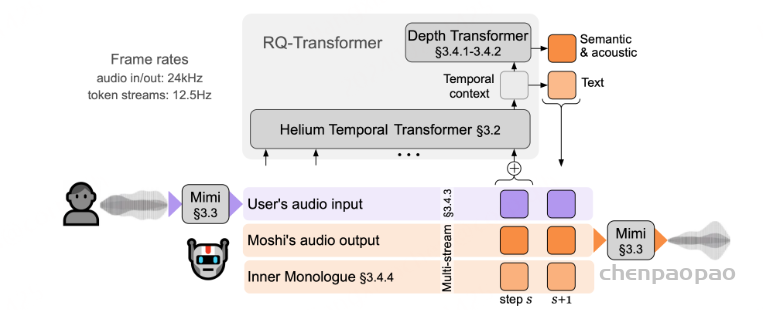
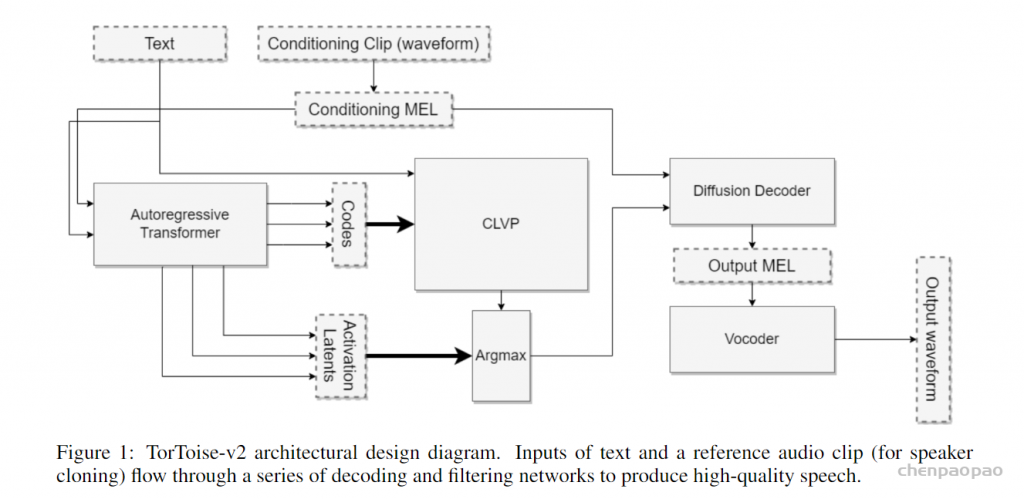
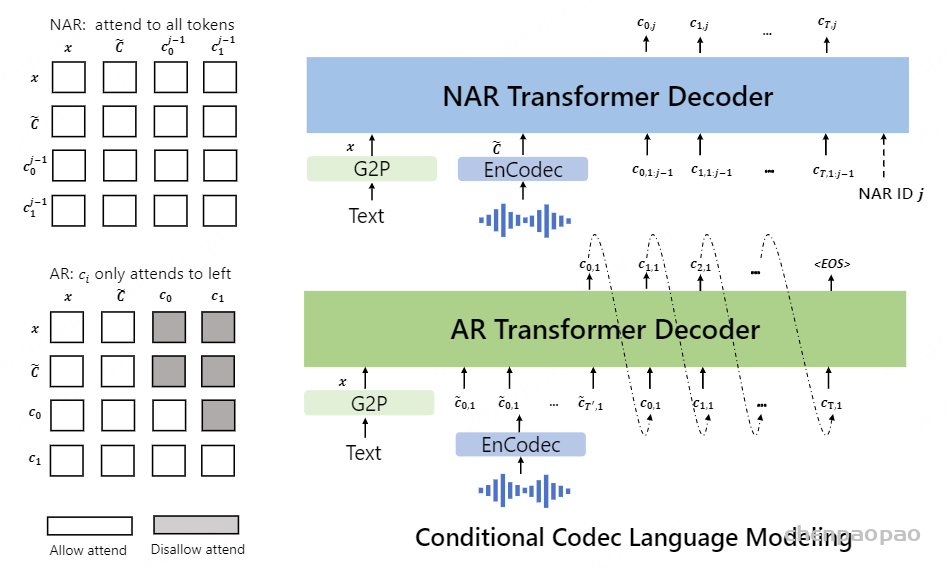
常见神经音频编解码器的对比 :计算公式 假设码本大小2^n,每秒语音的hz=BW/(Nq*n),token=Nq* 每秒语音的hz , 每秒语音的hz =token/Nq Overview of Moshi。Moshi 是一种语音文本基础模型,它支持实时语音对话。 Moshi 架构的主要组成部分是:一个定制的文本语言模型骨干 (Helium ,参见第 3.2 节);一个具有残差矢量量化 和从自监督语音模型中提取的语义知识 的神经音频编解码器(Mimi ,第 3.3 节);用户和 Moshi 语义和声学词元的流式分层生成 ,以及在使用 Inner Monologue 时 Moshi 的时间对齐文本词元 (第 3.4 节)。 然后是负责知识储备、理解和输出的Transformer部分,包括Helium Temporal Transformer和Depth Transformer 。其中小型的深度Transformer负责对给定时间步长的码本间依赖性进行建模 ,而大型(7B参数)时间 Temporal Transformer对时间依赖性进行建模 。作者还提出了「内心独白」:在训练和推理过程中,对文本和音频进行联合建模 。这使得模型能够充分利用文本模态传递的知识,同时保留语音的能力 。
Moshi模拟两种音频流:一种来自Moshi自身(模型的输出),另一种来自用户(音频输入)。沿着这两个音频流,Moshi预测与自己的语音(内心独白)相对应的文本,极大地提高了生成的质量。 Moshi的理论延迟为160毫秒(Mimi帧大小80毫秒 + 声学延迟80毫秒),在L4 GPU上的实际总延迟仅有200毫秒。
论文解读
摘要
Moshi,一个语音文本基础模型和全双工口语对话框架 。目前的口语对话系统依赖于独立组件的管道,包括语音活动检测、语音识别、文本对话和文本转语音。这种框架无法模拟真实对话的体验。首先,它们的复杂性导致交互之间的延迟达到几秒。其次,文本作为对话的中介模态,会丢失修改意义的非语言信息,比如情感或非语言声音。最后,它们依赖于说话者轮次的分段,这并未考虑重叠发言、打断和插话。
Moshi 通过将口语对话视为语音到语音的生成 ,解决了这些独立问题。Moshi 从文本语言模型的骨干开始,从神经音频编解码器的残差量化器生成语音作为标记,同时将自身语音和用户语音建模为并行流。 这使得可以去除显式的说话者轮次,并建模任意的对话动态 。此外,我们扩展了之前工作的分层语义到声学标记生成 ,首先预测与时间对齐的文本标记,作为音频标记的前缀。这种“内心独白”方法不仅显著提高了生成语音的语言质量,还展示了它如何提供流式语音识别和文本转语音。 我们开发的模型是首个实时全双工口语大型语言模型,理论延迟为 160 毫秒,实际为 200 毫秒
Moshi突破了传统AI对话模型的限制:延迟、文本信息瓶颈和基于回合的建模。
Moshi使用较小的音频语言模型增强了文本LLM主干,模型接收并预测离散的音频单元,通过理解输入并直接在音频域中生成输出来消除文本的信息瓶颈 ,同时又可以受益于底层文本LLM的知识和推理能力 。Moshi扩展了之前关于音频语言模型的工作,引入了第一个多流音频语言模型,将输入和输出音频流联合显式处理为两个自回归token流,完全消除了说话者转向的概念,从而允许在任意动态(重叠和中断)的自然对话上训练模型。
贡献:
我们训练了Mimi ,一个神经音频编解码器,使用残差向量量化(RVQ)将音频转换为Moshi预测的离散标记,并反向转换 。音频语言模型通常将声学标记与自监督语音模型的语义标记结合,以便在缺乏文本条件下生成可理解的语音。我们通过将语义信息蒸馏到声学标记的第一层【RVQ第一层作为语义信息】, 扩展了Zhang等人的方法,并引入了改进的训练技巧。 我们提出了Moshi,这是一种新的音频语言建模架构,将Helium与一个较小的Transformer模型结合,以分层和流式的方式预测音频标记 。我们展示了这种无条件音频语言模型生成可理解语音的挑战,并提供了解决方案,超越了非流式模型的可理解性和音频质量,同时以流式方式生成音频。我们进一步扩展该架构以并行建模多个音频流,允许概念上和实际处理全双工对话的简单处理。 我们介绍了内心独白,这是一种新的音频语言模型训练和推理设置 ,通过在音频tokens之前预测时间对齐的文本tokens ,显著提高了生成语音的事实性和语言质量。Moshi是一个语音到语音模型,能够推理用户音频和Moshi音频 中的非语言信息 。然而,这并不妨碍Moshi在语音输出的同时生成文本。基于以往的观察,粗到细的生成(从语义到声学标记)对生成一致的语音至关重要 ,我们将这一层次扩展为在每个时间步使用文本标记作为语义标记的前缀。我们的实验表明,这不仅显著提高了生成语音的长度和质量,还显示强制文本和音频tokens 之间的延迟允许从Moshi模型中推导出流式ASR和流式TTS。 我们沿多个维度评估了Moshi的所有组件,包括文本理解、语音可懂性和一致性、音频质量以及口语问答 。我们的实验结果表明,我们的模型在现有语音-文本模型中处于最前沿,适用于语音建模和口语问答,同时兼容流式处理,并能够建模数分钟的上下文(在我们的实验中为5分钟)。 模型
Moshi是一个多流语音到语音的Transformer模型,凭借其创新的架构实现了与用户的全双工口语对话,如图1所示。Moshi基于Helium构建,这是一个从零开始开发的文本LLM,依赖高质量的文本数据为模型提供强大的推理能力 。我们还提出了”内心独白 “,这是一种训练和推理程序,在其中我们共同建模文本和音频标记 。这使得模型能够充分利用文本模态所 impart 的知识,同时保持语音到语音的系统特性 。
为了实现实时对话 ,我们从一开始就将Moshi设计为多流架构 :该模型能够同时与用户说话和倾听,无需显式建模说话者轮次。 此外,为了以高质量和高效的方式捕捉用户输入音频和Moshi输出的声音,我们提出了Mimi,这是一种神经音频编解码器,通过使用残差向量量化和知识蒸馏,将语义和声学信息结合成一个单一的tokenizer 。为了共同建模来自Moshi和用户的音频流,以及Moshi的文本标记,我们依赖于与流式推理兼容的Depth Transformer。
Helium 文本语言模型
架构:
Helium 是一种自回归语言模型 ,基于 Transformer 架构。 遵循该领域之前的研究,我们对原始架构进行了以下更改:首先,我们在模型的注意力块、前馈块和输出线性层的输入处使用 RMS 归一化。 我们使用旋转位置嵌入RoPE,4,096 个token的上下文长度和 FlashAttention来进行高效训练。 最后,我们改变了前馈块的架构,并使用门控线性单元,以 SiLU 激活函数作为门控函数。 我们的分词器基于 SentencePiece的 unigram 模型 ,包含 32,000 个元素,主要针对英语。 我们将所有数字拆分为单个数字,并使用字节回退以确保我们的分词器不会丢失信息。 我们使用 AdamW优化器训练模型,使用固定学习率,然后进行余弦学习率衰减。
ps:SentencePiece是谷歌推出的子词开源工具包,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格也当作一种特殊字符来处理,再用BPE或者Unigram[切分subword的算法]来构造词汇表。他是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。 SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练子词模型(subword model)。 这使得我们可以制作一个不依赖于特定语言的预处理和后处理的纯粹的端到端系统。SentencePiece开源代码地址:https://github.com/google/sentencepiece ,详细讲解
预训练数据过滤 :
训练数据是训练 LLM 的关键要素之一:我们现在介绍我们获得大型高质量文本数据集的方法。 我们从高质量的数据源开始,例如维基百科、Stack Exchange 和大量的科学文章。 由于这些数据源的数据量不足以训练 LLM,我们还依赖于从 CommonCrawl 【Common Crawl是一个501非营利组织,它对Web进行爬网,并向公众免费提供其档案和数据集。】 爬取的网络数据来扩展我们的数据集。 网络数据需要大量处理才能获得高质量的训练集:我们执行去重、语言识别和质量过滤。 接下来,我们将更详细地描述每个操作。
去重。 我们从WET文件开始,这些文件仅包含网页的文本内容,是由CommonCrawl【它对Web进行爬网,并向公众免费提供其档案和数据集】 项目提取的。由于这种格式包含页面的所有文本,因此包含了大量的样板内容,如导航菜单。 因此,我们管道的第一步是在行级别对每个分片(每个抓取有 100 个分片)进行去重,以去除这些模板代码。为此,我们计算每行的FNV哈希值,并使用布隆过滤器来去除重复项。我们还训练了一个fastText(Joulin等,2016)分类器来区分重复和非重复项,以进行模糊去重:在这里,我们仅删除被分类为重复的至少三行连续的块。
语言识别。 一旦去重完成,我们就应用基于 fastText 的语言识别器来仅保留英语数据。 语言识别是在文档级别进行的,我们只保留超过一定阈值(0.85)的文档。
质量过滤。 最后一步是过滤剩余的数据,只保留高质量的网页。 为了执行此步骤,我们训练了一个 fastText 分类器,它使用来自我们高质量数据源和随机 CommonCrawl 网页的行。 我们得到一个包含 9 个类别的分类器,对应于我们的不同高质量来源,例如维基百科或维基教科书,以及 StackExchange 的子集,例如 STEM 或人文科学。 其动机是获得对保留哪些文档的更精细控制,不仅基于与高质量来源的相似性,还基于它们的领域。 此分类器在行级别应用,并通过计算每行的平均分数(按其长度加权)来获得聚合分数。 同样,我们保留对应于超过一定阈值的文档。
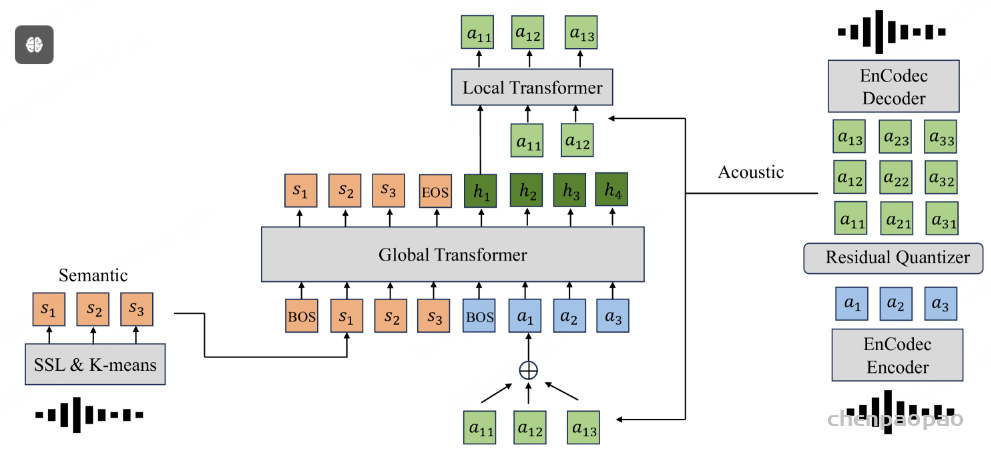
音频token化 :参考了 SpeechTokenizer , 采用蒸馏技术将非因果的高层次语义信息转移到由因果模型生成的令牌中 (用NAR直接生成语义token)
为了将波形离散化为音频符元,我们引入了 Mimi,一个作为具有离散瓶颈的自动编码器运行的神经音频编解码器(参考EnCodec)。 在文献中,遵循 Borsos 等人 (2022) 定义的术语,这些符元被称为 acoustic 声学token,因为它们模拟了细致的音频细节,并且针对高质量重建进行了优化。 虽然这些 acoustic声学token为有条件文本到音频模型提供了合适的目标 (例如文本到语音 或文本到音乐 ) ,但无条件的语音生成需要将其与从自监督语音模型中提取的语义令牌结合 。 与它们的 acoustic声学对应物不同, semantic 语义符元 不允许重建高质量音频,但与语言内容高度相关 。 这种与语言的相似性允许通过使用 semantic 语义音频符元作为预测 acoustic 声学符元的词缀来生成可理解且一致的语音,即使没有文本条件。 然而,这种混合符元化方法与实时生成不兼容 。 语义令牌通常不是因果的,因此只能以离线方式计算。此外,使用单独的编码器生成声学和语义令牌会带来不可忽视的计算负担。因此,Mimi受到之前关于SpeechTokenizer工作的启发,采用蒸馏技术将非因果的高层次语义信息转移到由因果模型生成的令牌中 (用NAR直接生成语义token) ,从而实现语义-声学令牌的流式编码和解码。
ps:“非因果的高层次语义”指其中的语义信息不依赖于时间顺序。这种语义通常能够捕捉到更广泛的上下文或抽象概念,但无法用于实时生成,因为它不能逐步构建,而是需要完整的数据输入。“因果模型生成的令牌”指的是通过因果模型(例如,基于自回归的方法)逐步生成的输出。在这种模型中,每个时间步骤的生成都只依赖于当前和之前的输入,而不依赖于未来的输入。这种方式确保了生成过程的顺序性和一致性,因此非常适合实时应用,比如语音生成或文本生成。通过这种方式生成的令牌通常用于构建连贯的序列,以便后续的处理或合成。
架构 :
我们的基线架构借鉴了 SoundStream 和 Encodec,它由一个 SeaNet 自动编码器和一个残差向量量化器组成。 编码器通过级联残差卷积块来将单通道波形x ∈ RL 投影到潜在表示 enc(x) ∈ RS×D ,这些卷积块交替使用膨胀和步进卷积,以及 ELU非线性函数和权重归一化。所有卷积都是因果的 ( 每个时间步骤的生成都只依赖于当前和之前的输入,而不依赖于未来的输入。关于因果卷积:https://zhuanlan.zhihu.com/p/422177151 ) ,因此该自动编码器可以在流式方式下运行。 具有 4 个卷积块和相应的步幅因子(4, 5, 6, 8) ,以及最终步长为 2 的 1D 卷积,Mimi的编码器能够将24kHz的波形转换成每秒12.5帧且维度为D=512的潜在表示。 对称地,解码器采用了类似的结构,但使用转置卷积代替步进卷积,以将潜在表示重新投影回24kHz音频。 我们使用残差矢量量化器对潜在空间进行离散化,该量化器迭代地将矢量量化 (VQ) 应用于先前量化器的残差。 具有Q 个量化器,每个量化器都有一个包含NA 个质心的码本,RVQ 将潜在空间离散化为{1, . . . , NA }S×Q 。 作为基线,我们使用重建损失和对抗性损失的组合来训练此模型 ,遵循 Encodec( Defossez 等人, 2023)的设置。 我们将在下面详细介绍 Mimi 相对于此默认配置的主要变化。
基于 Transformer 的瓶颈。 为了提高 Mimi 将语音编码为紧凑表示并同时重建高质量音频的能力,我们在瓶颈中添加了 Transformer 模块,一个在量化之前,另一个在量化之后。 这些 Transformer 有 8 层、8 个头、RoPE 位置编码、250 帧(20 秒)的有限上下文、GELU 激活、512 的模型维度和 2048 的 MLP 维度。 为了稳定训练,我们使用 LayerScale,其对角线值的初始化为 0.01。 两个 Transformer 都使用因果掩码(mask),这保留了整个架构与流式推理的兼容性。 两个 Transformer 都证明对感知音频质量很有用,而编码器中的 Transformer 还改善了下面描述的语义信息的提取 (见表 3 的消融研究)。
因果关系和流式传输。 使用上述超参数,Mimi 是因果的,可以在编码和解码时以流式方式使用。 其初始帧大小和整体步长均对应于 80 毫秒,这意味着给定 80 毫秒的第一个音频帧,Mimi 输出第一个潜在时间步,该时间步可以解码为 80 毫秒的输出音频。
优化。 与纯粹使用 Adam的卷积编解码器不同,在架构中引入 Transformer 需要使用权重衰减和 AdamW优化器进行额外的正则化。 更准确地说,我们仅对 Transformers 的参数应用权重衰减,权重为 5 · 10−2 。 我们使用8 · 10−4 的学习率,0.5 的动量衰减和 0.9 的平方梯度衰减,以及 0.99 的权重指数移动平均值。 我们使用 128 的批量大小,在12 s的随机窗口上进行 4M step2的训练,而 Transformers 的上下文限制在 10 秒(编码器最后降采样层的 250 帧,以及解码器的对称帧)。
量化率。 我们使用了Q=8个量化器(如图二所示) ,每个量化器的码本大小为NA =2048 。在12.5Hz时,这表示比特率为1.1kbps 。尽管潜在维度是512,我们在应用RVQ之前将输入(基于图2中的“Lin”线性层) 投影到256维,并在解码前再将其投影回512维。与先前的工作一致,我们采用了量化器dropout以提供编解码器的比特率可扩展性。此外,我们在训练过程中不以一定概率进行量化可以改善音频质量。更准确地说,我们在训练过程中仅50%的时间对序列进行量化 。与Kumar等人不同的是,这意味着将未经量化的嵌入传递给解码器,而不是将所有量化器量化的嵌入传递过去。表3显示这种方法显著提高了客观质量指标,而人类评价结果则不够明确。在我们的实验中,我们观察到一个有些反直觉的现象:随着比特率降低,这种改进效果变得更加明显。
仅使用对抗损失训练。 作为基线,我们按照Défossez等人(2023)的方式,使用重构损失与对抗损失的组合来训练Mimi,即一个多尺度梅尔频谱重构损失加上一个多尺度STFT判别器。具体的参数可以在Audiocraft代码库中找到。虽然之前的神经编解码器依赖于这种重构损失和对抗损失的组合,但我们尝试了纯对抗训练 ,在这种训练方式下我们只保留特征损失和判别器损失 。我们注意到,Hauret等人(2023)之前在带宽扩展的背景下也进行了类似的实验。尽管移除重构损失显著降低了客观指标的表现,但在开发过程中我们观察到生成的音频听起来比根据上述指标预期的好得多。 表4报告的主观评价确认了这一观察,并展示了仅使用对抗损失进行训练对音频质量有显著提升。
使用分裂RVQ学习语义-声学token
类似于SpeechTokenizer,我们从一个自监督模型(在我们的案例中是WavLM8 (Chen等人,2022))中提取语义信息,并将其蒸馏到RVQ的第一层。WavLM将16kHz的波形映射成以50Hz采样的1024维嵌入,而Mimi则将24kHz的波形映射成12.5Hz下的512维嵌入。在训练过程中,我们通过将输入波形降采样到16kHz来生成蒸馏目标,然后计算WavLM嵌入。接着,我们用一个输出维度为1024的线性投影,随后进行步幅为4、核大小为8的平均池化,以达到12.5Hz的频率。有趣的是,我们观察到非因果地执行这种平均池化对于性能至关重要,这与流式推理兼容,因为这些嵌入仅在训练期间使用。 我们将输出维度为1024的线性liner投影层应用于RVQ第一层的输出,同时保持实际进入解码器的嵌入。 随后,我们计算第一个量化器输出与变换后的WavLM嵌入之间的余弦距离,以进行知识蒸馏。
表3显示,蒸馏损失与针对质量的重建和对抗损失存在冲突 。确实,虽然蒸馏显著提高了第一个量化器的音素辨别能力(通过ABX测量 ),但也对音频质量产生了负面影响。我们假设这是由于将语义信息蒸馏到单个RVQ的第一层:由于高阶量化器在第一个量化器的残差上操作,后者需要在音频质量与音素辨别能力之间进行权衡。 我们通过提出分离RVQ来解决此问题 。我们不再使用单个具有8个层级的RVQ ,而是将语义信息蒸馏到一个普通的VQ中 ,并并行应用具有7个层级的RVQ 。我们将它们的输出相加,使得两者均可用于重建,同时去除保持声学信息在语义量化器残差中的约束。 图2展示了该架构,表3表明此解决方案在整体上提供了更好的语义与声学权衡。
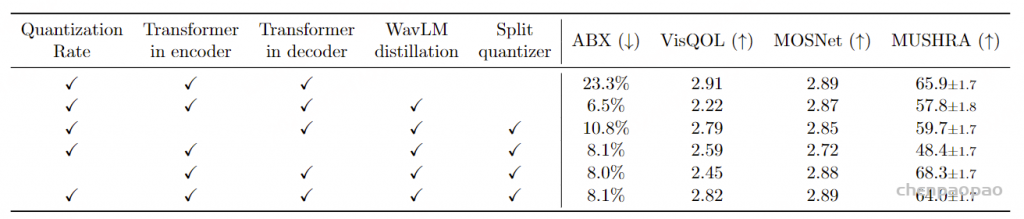
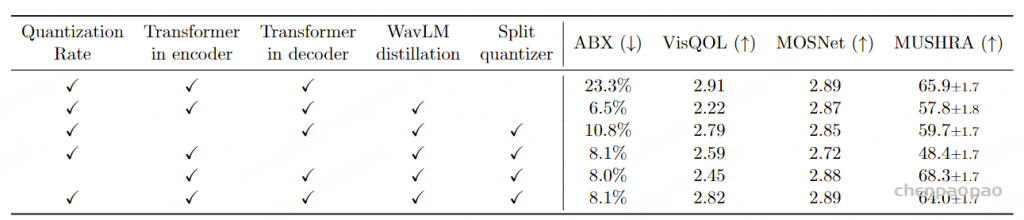
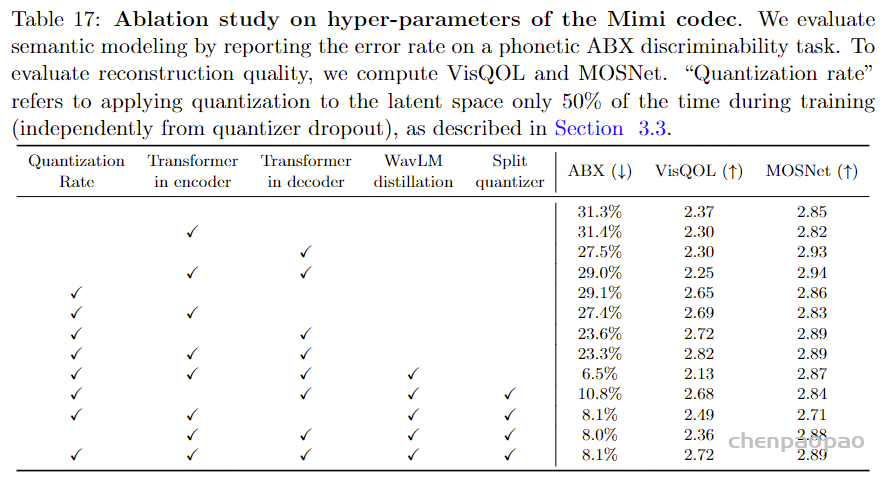
表3:关于Mimi编解码器超参数的消融研究。我们通过报告音素ABX可辨识性任务的错误率来评估语义建模。为了评估重建质量,我们计算了VisQOL和MOSNet,并通过MUSHRA协议收集人类评判。“量化率”指在训练期间仅对潜在空间应用量化50%的时间 (与量化器丢弃无关) 生成式音频建模
我们现在描述如何扩展基础Helium模型 ,以支持Mimi编解码器提供的音频令牌建模 。我们的目标是实现真实的对话交互,因此我们进一步展示如何同时建模两个音频流,一个代表用户,另一个代表系统 。最后,我们详细介绍一种新功能——内心独白 ,它在系统侧对文本和音频模态进行联合建模 ,以提高交互质量。
使用 RQ-Transformer 的分层自回归建模
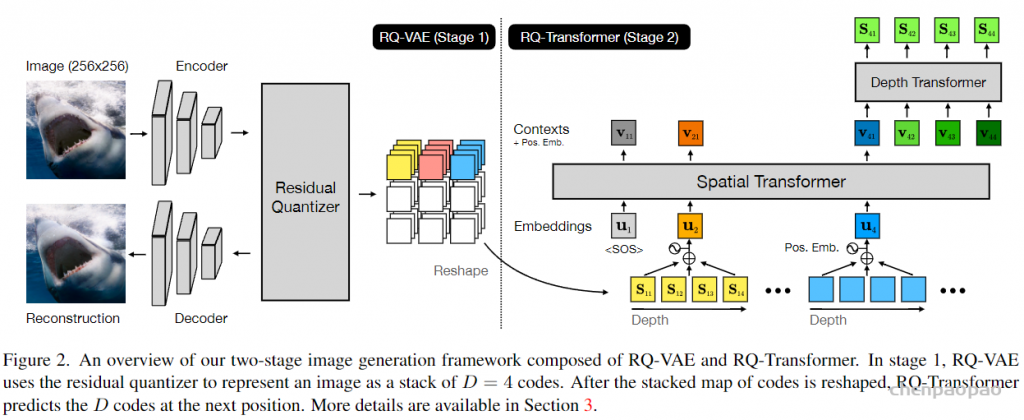
ps:关于RQ-Transformer https://zhuanlan.zhihu.com/p/666422373
Autoregressive Image Generation using Residual Quantization论文截图:RQ-Transformer的流程,输入各个量化器Sstep,i的和作为S-transformer的输入,输出Vstepi,Vstepi作为D-transforemr的输入,输出下一个时间步各个量化器的离散值。 设 U∈{1,…,N}S 为一个离散随机序列,其基数为 N 且序列长度为 S。为方便起见,我们还将 U0 =0 作为一个确定性的初始令牌值。自回归建模的核心在于通过估计条件分布 P[Us∣U0,…,Us−1] 来估计联合分布 P[U1,…,US],其中 1≤s≤S。文本语言模型,如GPT(Radford等人,2019)或Helium,符合这一范式。
图3 :RQ-Transformer将长度为 K ⋅S 的扁平化序列分解为 S 个时间步长,供一个大型的时间变换器(Temporal Transformer)处理,该变换器生成一个上下文嵌入,用于条件化一个小规模的深度变换器(Depth Transformer),后者在 K 个步骤上进行操作。这种设计允许通过增加 S 来扩展更长的序列,或者通过增加 K 来增加深度,而不是使用单一模型来建模整个扁平化序列。在图中,为了便于说明,我们使用了 K =4。 在建模口语时,依赖于经过标记化的文本比音频令牌提供了更紧凑的表示:使用Mimi编解码器,假设有8个码本,帧率为12.5Hz,每秒钟的音频生成需要100step的序列长度。要建模5分钟的音频,这将需要30,000个timesteps,这代表了显著的计算成本,并且每秒生成100个令牌与流式推理不兼容。相比之下,一段英语语音的表示大约只需要每秒3到4个文本令牌。
如何解决: 使用RQ-Transformer
我们不仅对建模单一序列(Us 比如不同的音频码本,以及可选的文本流 。我们可以将这些子序列堆叠为Vs,k ,其中1 ≤ s ≤ S 且 1 ≤ k ≤ K。同样地,我们定义V0,k s,k k k k 个子序列的基数。可以将这K个序列展平为一个单一序列,从而增加K 的预测数量。Lee等人提出沿着K 维使用较小的(depth transformer)自回归模型,结合沿时间维度较大的(time transformer)模型,形成RQ-Transformer 。之后,Yu等人建议了类似的方法用于字节级建模,而Yang等人(2023)和Zhu等人(2024)将其应用于音频标记建模 。
RQ-Transformer 。形式上,RQ-Transformer由两个Transformer模型组成,如图3所示。它包括一个时间Transformer(Temporal Transformer),其架构与Helium相同 ,以及一个较小的深度Transformer。。我们将时间Transformer所代表的功能记为TrTemp,而深度Transformer所代表的功能记为TrDepth。为了简化起见,并对于所有步骤s ≤ S,我们用Vs = (Vs,1 s,K 0 s−1
如果我们进一步考虑子序列索引1 < k ≤ K(对应声学token ,用tansformer进行预测) ,深度Transformer将同时映射zs和(Vs,1 s,k−1 )到logits估计 。这个过程使得模型能够综合多个子序列的信息,从而生成更准确的预测。
我们进一步定义第一层ls,1 = Lin(zs N 1 (对应语义token ,zs直接接一个liner的输出作为语义token)l s ,kVs,k 的分布,该分布以前一步的所有子序列以及当前步骤的前子序列作为条件 。例如,这种训练方式确保模型能够有效捕捉上下文信息,从而提升生成质量。
重要的是,时间Transformer中的步骤数始终等于S,而不是K·S ,并且深度Transformer中的步骤数最多为K 。实际上,时间Transformer在每一步s接收的输入是K个学习到的嵌入表之和 ,这些嵌入表代表了Vs-1 的最后一个值。对于1 < k ≤ K的情况,深度Transformer接收的输入是zs s,k-1
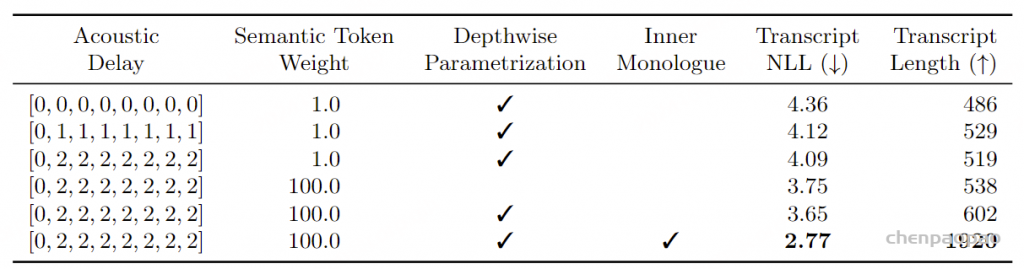
如表1所示,我们的深度Transformer有6层,维度为1024,包含16个注意力头。与Lee等人(2022)、Yang等人(2023)、Zhu等人(2024)不同,我们在深度Transformer中对线性层、投影和全连接使用了针对每个索引k 的不同参数 。确实,不同的子序列可能需要不同的变换。鉴于此Transformer较小的规模,这样做对训练和推理时间没有影响 ,而表6显示这种深度参数化是有益的。
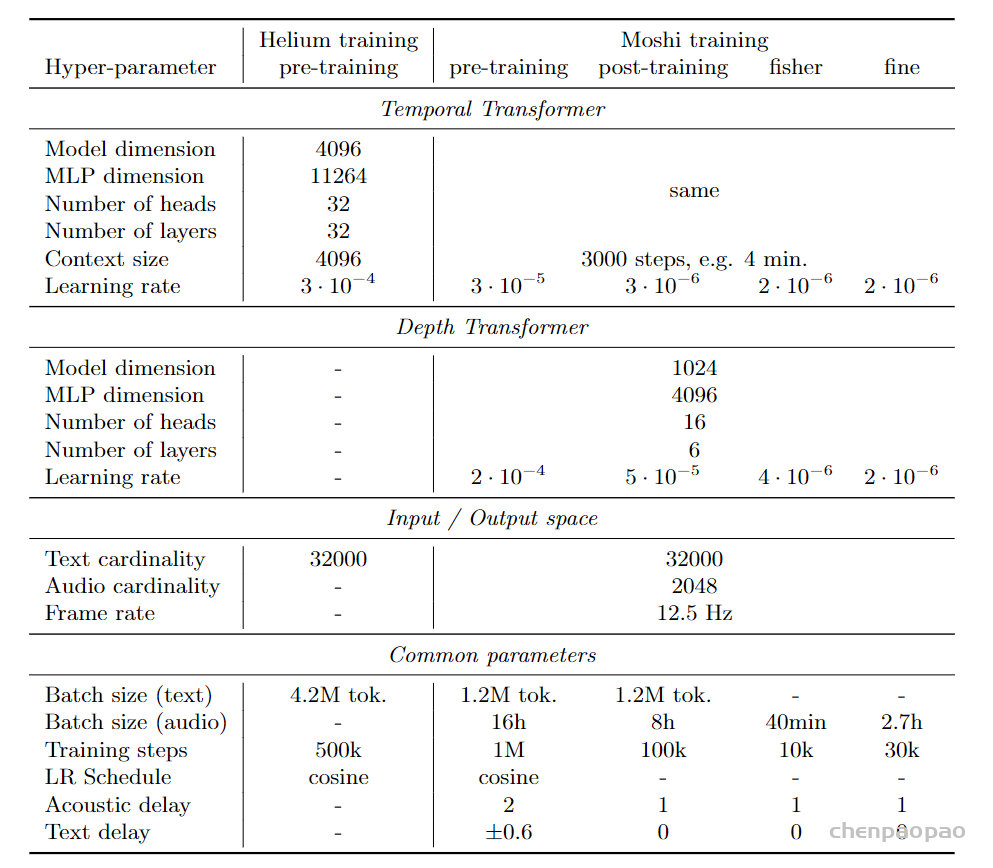
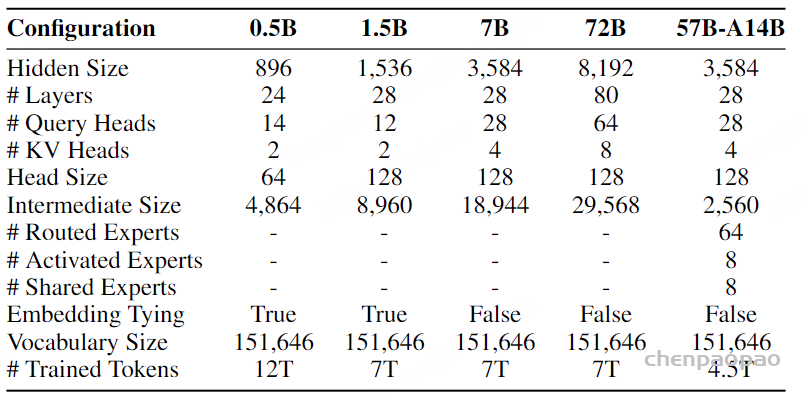
表1:模型的超参数 。我们7B参数的Helium语言模型和Moshi语音文本对话模型的架构和训练超参数。Moshi的训练分为四个阶段:在无监督数据上进行预训练(使用从Helium初始化的时间变换器);基于分离的多流模拟进行后训练 ;在Fisher数据集(Cieri等,2004)上进行微调,以实现其全双工能力 ;在从合成交互脚本构建的自定义数据集上进行指令微调 。在预训练阶段,我们一半的时间在与Helium使用的相同数据集上对完整的文本批次进行训练,使用一个独立的优化器状态。 ps:Fisher电话对话收集协议 ,该协议旨在解决开发人员构建强大的自动语音识别(ASR)系统时的关键需求。特点是少数说话人拨打电话的时间相对较长,并且整个集合的词汇量很窄。CALLHOME 对话非常自然和亲密。根据费舍尔协议,允许大量参与者最多拨打 3 个 10 分钟的电话。对于每次通话,参与者将与通常不认识的另一参与者配对,以讨论指定的主题。这最大限度地提高了说话者之间的差异和词汇呼吸,同时也增加了正式感。
音频建模
音频编解码器Mimi,输出Q 个子序列,音频每秒有12.5个步长。我们将这些序列表示为At,q NA }(码本对应的特征向量),其中1≤t ≤T ,T =12.5×音频时长,1≤q ≤Q ,且Q =8。我们将音频子序列插入由RQ-Transformer建模的多序列V 中。请记住,第一个码本At,1 对应语义信息,而其他码本对应声学特征。
声学延迟。 我们首先尝试简单地将V设为A进行建模。然而,我们发现在语义和声学标记之间引入轻微延迟 能够生成更稳定的结果。Copet等人(2023)表明,这样做可以减少给定时间步长下各子序列之间的依赖性 (基于过去的条件),从而允许使用较弱的模型来近似联合分布 P [Vs ,k ∣V 0,…,Vs −1] (在他们的情况下,作为条件边缘分布的乘积)。Lemercier等人(2024)进一步展示了在给定步骤中子序列之间的互信息与生成质量之间的联系:自然地,相互依赖关系越复杂,估计这些关系所需的模型就越强大 。【ps:这里目的就是解构声学和语义之间的强相互依赖关系,作者放弃使用sppechtokenizer 中的多层RVQ,而是分别对声学和语义token并行建模,也会降低相互依赖的关系】
如第5.3节所示,在语义特征和声学特征之间引入1到 2步的延迟 τ ∈N,对于所有步骤s ,我们有:
需要注意的是,使用RQ-Transformer来建模音频的方法已被Yang等人(2023) 和Zhu等人(2024) 成功应用。在这里,我们引入了在Depth Transformer中使用每个码本参数的方法,以及声学延迟的使用。与Zhu等人(2024)首先生成所有语义标记的方法相比,我们同时生成语义标记和声学标记 ,这首次实现了语义标记和声学标记的流式联合建模。
ps:关于RQ-Transformer建模音频的方法
Yang等人(2023) UniAudio: An Audio Foundation Model Toward Universal Audio Generation Zhu等人(2024) Generative Pre-trained Speech Language Model with Efficient Hierarchical Transformer,先生成语义s token,然后是声学a token 多流建模
仅对单一音频流进行建模不足以完全模拟对话。我们的框架可以扩展到双人对话的建模:给定两个音频流(At ,q )和(A′t ,q ),我们只需对两者都应用声学延迟,然后将它们 concatenate 成V ,从而扩展了公式4。实际上,A 将对应于Moshi,而A ′则用于建模用户。
内心独白
尽管仅在音频领域操作已经能够产生令人信服的结果(见表7),我们观察到让Moshi也对其自身语音的文本表示进行建模,可以提供一个框架,从而提高其生成内容的语言质量。形式上,我们定义了一个文本流W ∈{1,…,NW }T 文本流是从通过将SentencePiece分词器(Kudo和Richardson,2018)应用于由Whisper(Radford等人,2023)转录的对应于Moshi的音频所获得的文本token序列中导出的 。我们将W 作为V 中的第一个子序列插入,使其作为语义标记生成的前缀。 这可以看作是Borsos等人(2022)引入的层次化从语义到声学生成方法的一种扩展。需要注意的是,我们不使用与用户音频流相对应的文本表示,因为实时转录这个流会非常具有挑战性,并且依赖外部自动语音识别系统与我们的端到端语音到语音方法相矛盾。 第5.3节中的消融研究表明,在为Moshi所做的设计选择中,内心独白对生成语音的质量有着至关重要的影响。
ps:注意基于whisper的文本流是为了用于训练,以及制作文本和时间戳的label,在推理的时候,moshi输出的V序列中第一个子序列就是对应于文本的token预测结果(用whisper做gt训练),并将其作为第一个输入流进行建模。
对齐文本和音频token 。为了将文本 token 与以恒定帧率12.5Hz运行的音频 token 结合起来,我们需要将它们对齐到这个帧率。为此,我们利用了Whisper提供的word级时间戳 。转录中的第 i 个单词word被映射到第 ni ∈N∗个文本toekn :wi ,j ,其中j ≤ni ,以及一个起始索引ti ∈{1,…,T },简单地定义为其起始时间戳除以12.5 Hz的帧率。我们定义了两个特殊的标记:PAD和EPAD,这些标记永远不会出现在任何单词标记中。我们构建W ,使得当一个单词开始时,(Wt )包含它的文本token,之后跟随PAD直到下一个单词。在下一个单词对应的索引之前插入EPAD以指示填充结束。虽然这不是严格必要的,但我们观察到这样做通过将决定一个单词何时结束以及接下来应该跟随哪个单词的过程分为两步,为模型提供了有用的指导。
首先,序列(Wt )用PAD标记初始化,例如∀t ,Wt ←PAD。然后,我们按照以下方式迭代地修改它。对于每个单词i 及其起始索引ti ,我们更新WW 如下:
需要注意的是,如果ti =1,我们则在索引1处插入EPAD,并将文本标记向后移位 。如果插入EPAD标记会覆盖前一个单词的文本标记,我们则不插入EPAD标记。由于文本标记比相应的音频标记更紧凑,在Wt 中单词之间通常不会重叠。在英语对话中,我们观察到填充标记大约占总标记的65%。
推导流式ASR和TTS 。可以进一步在文本序列 (Wt) 和音频token (At,q) 之间引入一些延迟。这控制了语言模型在生成音频内容时所依据的模态 。通过将音频提前于文本,文本的内容将由之前步骤中采样的音频决定 。具体来说,通过仅采样文本token,同时使用真实的音频token并丢弃模型的预测,可以获得一个流式自动语音识别(ASR)模型 ,并提供精确的单词级对齐。 另一方面,通过调整文本延迟,使文本位于音频token之前,音频的内容将由文本内容决定。再次给定一个适当填充的文本token序列,可以获得一个流式文本到语音(TTS)模型。 我们在附录C中进一步描述了如何适应带有延迟文本的语言模型推理,以获得zero-shot的适当填充文本token序列。第5.7节展示了如何通过单一的延迟超参数在ASR和TTS模型之间切换,而无需更改损失函数、架构或训练数据。
Moshi的联合序列建模 。将多流和内心独白结合在一起,我们得到用于建模的最终序列集合 V 定义为:
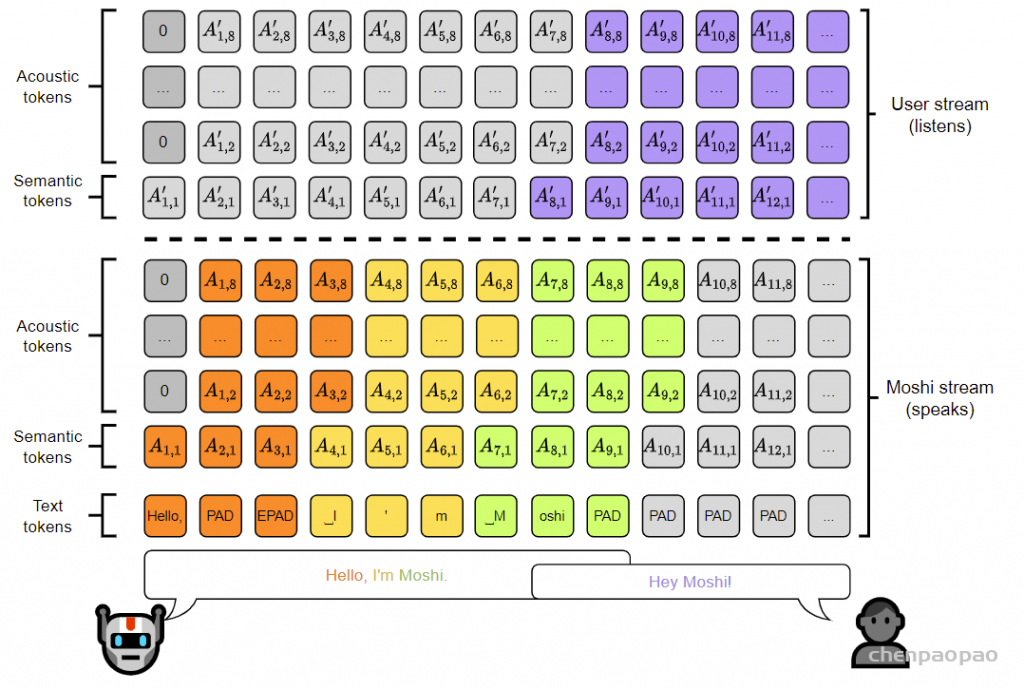
总共有 K=2Q+1 条流,其中实验中 Q=8 。总结见图4
图4:Moshi建模的联合序列表示。每一列代表联合序列(Vs ,k )在给定步骤中的标记,如公式6中所述,声学延迟τ =1,例如该步骤Temporal Transformer的输入。标记在Depth Transformer中从下到上进行预测。在推理时,虚线以下的标记(对应于Moshi)被采样,而虚线以上的标记则由用户提供。这种设计使得我们的模型能够处理重叠的说话轮次。 Moshi的推理。 由公式6给出的联合序列是我们模型在训练时的目标:在任何时间步s ,模型输入为0,V 1,…,Vs −1,并输出一个估计的概率分布V ^s (0,V 1,…,Vs −1)。在推理时,我们从V ^s ,k 中采样所有对应于Moshi输出的子序列索引 :即对于k =1(对应于Moshi语音的文本标记),以及对于k ∈{2,…,2+Q }(对应于Moshi的音频标记) 。在实际应用中,用户音频(k >2+Q )的预测输出结果实际上被忽略,因为使用的是真实的用户音频,而非模型预测的。 然而,将用户流作为输出进行建模可以生成模拟对话,这对于如第5.6节中的离线评估是必要的。
有趣的是,用户和Moshi之间的轮流发言没有明确的界限:Moshi可以在任何时候说话和倾听,并且在需要时同时进行这两项操作。特别是,当用户说话而Moshi保持沉默时 ,Moshi流对应的音频标记会解码成“自然静音”,这是一种接近静音的波形,而不是具有固定、明确定义的值;同时,Moshi的文本流将填充PAD标记 。因此,文本流可以提供有趣的控制Moshi的方式,例如,强制采样EPAD标记将使Moshi立即开始说话。
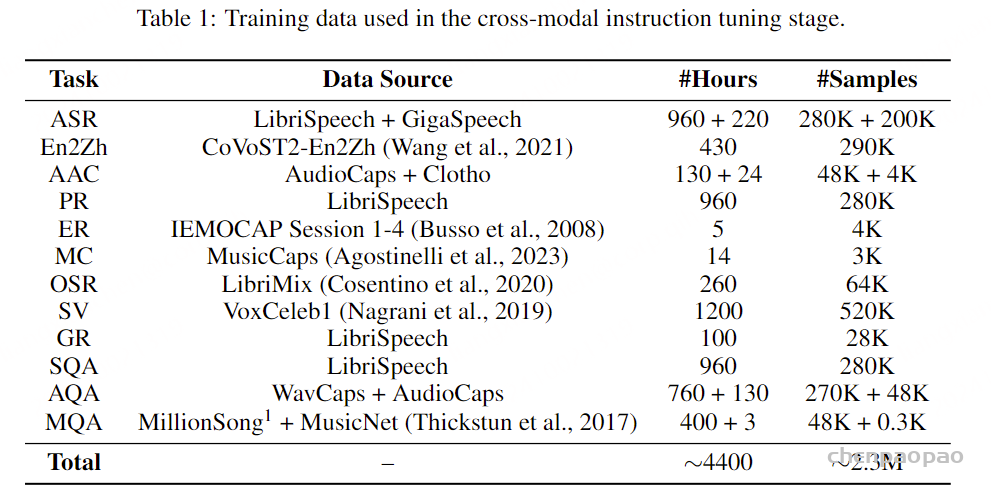
Datasets and Training
文本数据 我们的训练数据集由高质量数据源和来自CommonCrawl的过滤网络数据混合而成。更具体地说,我们的数据集中有12.5%来自以下经过整理的来源:维基百科、维基教科书、维基文库、维基新闻、StackExchange以及科学文章集合pes2o。我们使用了2017、2018、2019、2021和2022年的五个不同的维基百科数据转储,而不是对维基百科进行多次访问。其余的87.5%数据来自CommonCrawl,并按照第3.2.2节中描述的管道进行过滤。我们使用了以下十个抓取:2018-30、2019-04、2019-30、2020-05、2020-34、2021-04、2021-31、2022-05、2022-33、2023-40。
9. https://dumps.wikimedia.org/
Audio Data
我们使用一个包含700万小时音频的音频集合,称之为无监督音频数据集 ,这些音频内容大多数为英语语音。我们使用Whisper(Radford et al., 2023)对该数据集进行转录,使用的是large-v3模型。 我们在音频预训练阶段使用这些数据 ,此时不使用第3.4.3节中描述的多流方法,而是使用一个单一的音频流来代表所有说话者。同样,第3.4.4节中描述的文本流代表了来自所有说话者的单词。所有音频都重新采样到24kHz并降混为单声道。
为了实现多流,我们需要模型具备同时倾听和说话的能力 。为此,我们进一步利用Fisher数据集(Cieri et al., 2004)。该数据集由随机配对参与者之间的2000小时电话对话组成,讨论特定主题。Fisher的一个特点是每个对话的一方在不同的通道上录制,这使得可以为Moshi提供真实的分离流。原始音频的采样率为8kHz,我们使用AudioSR(Liu et al., 2023a)将其上采样到24kHz。
最后,我们收集了170小时的自然对话和脚本对话,这些对话由多个参与者之间的配对录制,且每个说话者使用单独的通道,以提供一个小型数据集,用于微调模型,以超过仅使用 Fisher 时获得的质量。 我们称这个数据集为监督多流数据集 。我们并不直接在该数据集上训练Moshi,而是利用它训练一个真实的多流TTS模型,并按照第4.3节【 语音-文本指令数据 】和第4.4节【training Stages and Hyper-parameters】中的说明, 使用真实对话的转录 来微调Helium。
对于Fisher和这个最后的数据集,我们随机选择一个说话者作为主说话者(即Moshi发言),并将另一个说话者放在第二个音频流上。对于Fisher,文本流仅包含主说话者的转录。为了在每个流中尽管存在长时间的沉默仍能获得可靠的时间戳,我们使用 whisper-timestamped 包 (Louradour,2023) 以及中等 Whisper 模型获得的转录。
语音-文本指令数据 早期使用基于文本的指令数据集 (如Open Hermes,Teknium,2023)进行的实验证明不适合用于口语对话系统的指令微调。 特别是,数据格式往往无法通过TTS正确渲染(例如URL无法使用TTS合成正确的语音),并且问题和回答的格式不符合自然的口语流程(例如项目符号、长列举)。相反,我们利用在Open Hermes 【主要包含生成的指令和聊天样本】和真实对话转录上微调过的Helium来生成基于语音的AI模型与用户之间的现实交互。然后,我们使用附录C中描述的多流流式TTS合成这些交互,从而生成超过20,000小时的合成语音数据。
为了给Moshi一个一致的声音 ,我们还让TTS引擎基于单一演员的声音进行条件化处理 ,该演员录制了涵盖70多种说话风格的独白,详见表19。第6.3节中报告的关于声音一致性的实验表明,仅在指令微调期间为Moshi使用一致的声音就足以几乎确保它不会使用其他声音,而无需在推理过程中进一步控制 。相比之下,第二个音频流(用户)的声音在每个示例中随机采样,以增强对不同说话条件和口音的鲁棒性。
为了从 微调后的Helium 中生成转录,我们使用不同的提示,旨在捕捉用户和 Moshi 之间不同类型的交互。 首先,我们通过从一些维基百科段落或 StackExchange 帖子(我们称之为上下文context)开始,生成关于一般知识的对话。 这确保了 Moshi 的对话涵盖了广泛的主题,例如历史、烹饪建议或流行文化。更具体地说,使用给定的上下文,我们通过以下提示获得潜在讨论的摘要:
其中{{context}}指的是来自维基百科或StackExchange的段落,而{{title}}是相应的标题。然后,我们使用以下提示生成完整的对话转录:
同样,为了向 Moshi 提供有关自身及 Kyutai 实验室的信息,我们生成了描述两者的段落,并将其用作额外的上下文。
其次,我们生成包含关于 Moshi 声音的指令的交互内容,例如另一个说话者要求 Moshi 用愤怒的声音或像海盗一样说话。 我们的第一种策略是生成单轮交互,在这种情况下,模型被指示用特定的声音讲述关于某个实体的句子、独白或诗歌,这些实体属于“体育”或“动物”等高级类别。另一位说话者要求的声音和实体是随机采样的,因此它们完全不相关。我们的第二种策略是生成角色扮演情境,涉及不同的情绪或说话风格,使用以下提示:
编写一个关于{{voice}} {{character}}的10个情境列表。每个情境必须以“一个{{voice}}的{{character}},他/她……”开头,且长度不得超过8个单词。 声音形容词的示例包括“开心”或“惊讶”,角色的示例则包括“侦探”或“超级英雄”。然后,我们使用以下提示生成交互内容:
写一段Blake和Moshi之间的对话,{{情景}}。使用大量的回应。 为了增强 Moshi 对错误发音词汇的鲁棒性,我们还生成包含拼写错误的用户问题指令,接着 Moshi 会要求用户重复问题或澄清问题。 我们还生成包含错误或误导性事实的问题(例如“埃菲尔铁塔在北京吗?”),以训练模型回答“否”并纠正用户。除此之外,大多数生成的对话仅包含用户的问题,Moshi 应给出肯定回答。我们生成了基础的数学、语法或小知识的单轮问答,因为我们注意到 Moshi 起初在处理简单的事实任务(如数字相加)时表现不佳。 最后,我们生成了安全对话,在这些对话中,用户会提出不道德或不适合公开讨论的问题,而 Moshi 会拒绝回答这些请求。
训练阶段和超参数
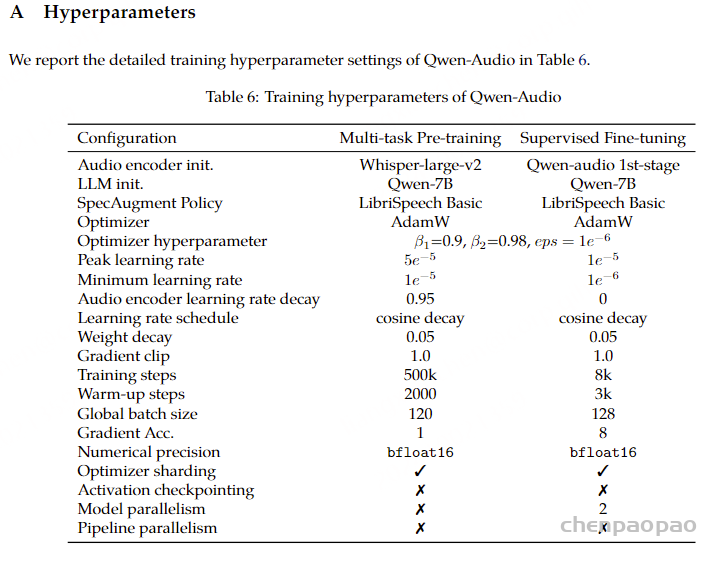
Helium预训练 :表1提供了训练阶段和超参数的概述。对于每个阶段,我们使用AdamW(Loshchilov和Hutter,2019),权重衰减为0.1,动量衰减为0.9,平方梯度平均值的衰减为0.95。所有模型都在H100 GPU上进行训练,并使用FSDP和激活检查点。仅文本的语言模型Helium训练了500,000步,批量大小为420万个标记,采用从3·10^(-4)开始的余弦学习率调度,并带有线性预热。
Moshi 预训练: 我们首先使用 Helium 初始化 Moshi 的时间 Transformer,而 3.4.1 节描述的深度 Transformer 则随机初始化。我们首先在 4.2 节中介绍的700wh无监督音频数据集上进行训练,使用单一音频流,批次大小覆盖 16 小时的音频,每个批次项为 5 分钟序列。我们以 30% 的概率mask相应的文本 tokens,并将文本和音频 tokens 之间的延迟随机化,范围为 -0.6 至 +0.6 秒。为了防止灾难性遗忘,我们还使用与 Helium 相同数据集中的文本数据,进行一半的文本批次训练。总共进行 100 万步训练,时间 Transformer 的学习率为 3·10⁻⁵,深度 Transformer 为 2·10⁻⁴,且有线性预热。为了确保纯文本批次的更新与音频数据集的更新平衡,我们使用两个独立的优化器状态。此外,当在音频批次的文本流上操作时,我们将文本嵌入和文本线性层的学习率乘以 0.75。最后,由于音频批次中的填充 tokens 占主导地位,我们将它们在交叉熵损失中的权重降低 50%。
Moshi 后训练: 在前一阶段模型的基础上,我们训练它的多流能力 。首先,我们使用 PyAnnote (Bredin, 2023) 对无监督音频数据集的音频进行分离,随机采样一个说话者作为主要说话者,并在波形上生成二元掩码,当该说话者根据分离结果活跃时,值为 1,其他时候为 0。这个掩码为我们提供了两个波形:一个是主要说话者的,另一个是残留波形(可能有多个说话者),它们分别编码,然后作为 3.4.3 节中描述的两个输入音频流使用。文本流仅包含选定主要说话者的文本 tokens,并且文本和音频 tokens 之间的延迟固定为 0。 我们训练了 10 万步,批次大小为 8 小时的音频,时间 Transformer 的固定学习率为 3·10⁻⁶,深度 Transformer 为 5·10⁻⁵。与预训练阶段类似,我们有 10% 的时间采样全文本批次。
Moshi 微调:前面描述的模拟多流提供了一个良好的预训练任务,但远远不足以捕捉自然对话的复杂性。例如,它不包含不同说话人的重叠部分,并且不活跃说话者的音频流是完全静音的。 因此,我们使用 Fisher 数据集 (Cieri et al., 2004) 来训练模型学习真实的多流交互 。我们从两个说话者中随机选择一位作为主要说话者,训练 10k 批次,批次大小为 40 分钟的音频,主要和深度 Transformer 的学习率分别为 2 · 10⁻⁶/4 · 10⁻⁶。我们不再采样完整的文本批次。
指令微调 : 最后,我们为第一个说话者流设置了 Moshi 的身份,使其成为一个有用的对话助手,并进行最后阶段的指令微调。我们使用 4.3 节中描述的合成指令数据集 ,批次大小为 2.7 小时的音频,训练 30k 步,两个 Transformer 的学习率均为 2 · 10⁻⁶。
在此阶段,我们对用户的音频流进行数据增强,使 Moshi 能够应对各种情况。具体而言,我们在 50% 的时间内对用户音频流应用随机增益,范围为 -24 dB 至 +15 dB。30% 的时间,我们进一步添加来自 Deep Noise Suppression 挑战 (Dubey et al., 2023) 的噪声片段,并将其拼接以覆盖每个示例的整个持续时间。噪声被放大到相对于原始音源的目标音量,范围在 -30 dB 至 +6 dB 之间。每次需要采样新噪声时,我们会以 50% 的概率使用最长 30 秒的随机静音片段,从而使模型能够处理从嘈杂到安静或反之亦然的音频条件。
我们通过将Moshi的音频流的一个缩小副本[scaled down copy]添加到用户流中来模拟Moshi到用户麦克风的回声,缩放因子在[0, 0.2]之间均匀采样,延迟在[100ms, 500ms]之间均匀采样。最后,我们对用户的音频流(可能已经增加了回声)应用类似于Defossez等人(2020)引入的混响增强。回声和混响一起应用的概率为30%。
TTS 训练: 我们还训练了一个流式的多流文本到语音(TTS)模型 ,使用 3.4.4 节中描述的方法。音频预训练阶段与 Moshi 共享,而后训练阶段在音频流相对于文本有 2 秒延迟的情况下完成。该模型在包含两个说话者高质量互动录音的监督多流数据集上进行微调,并用于生成 4.3 节中描述的合成微调指令数据集。 需要注意的是,Moshi 本身并未在该监督多流数据集上训练。更多详细信息见附录 C。
训练损失: Moshi 被训练为建模联合序列,如公式 6 所示。给定真实的离散 token (Vs,k )s≤S,k≤K 和来自公式 2 的估计 logits(ls,k)s≤S,k≤K ,我们使用以下损失,其中 CE 代表交叉熵:
因此,我们对文本 token (k=1) 和组合音频 tokens 赋予相同的重要性。对于语义 tokens,αk 设置为 100,而对于声学 tokens,α k
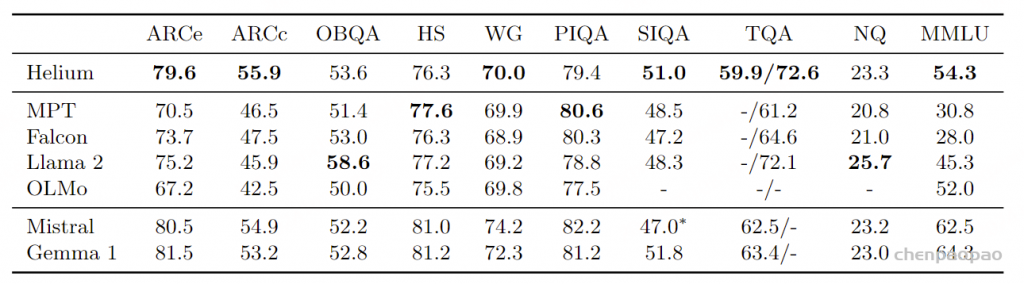
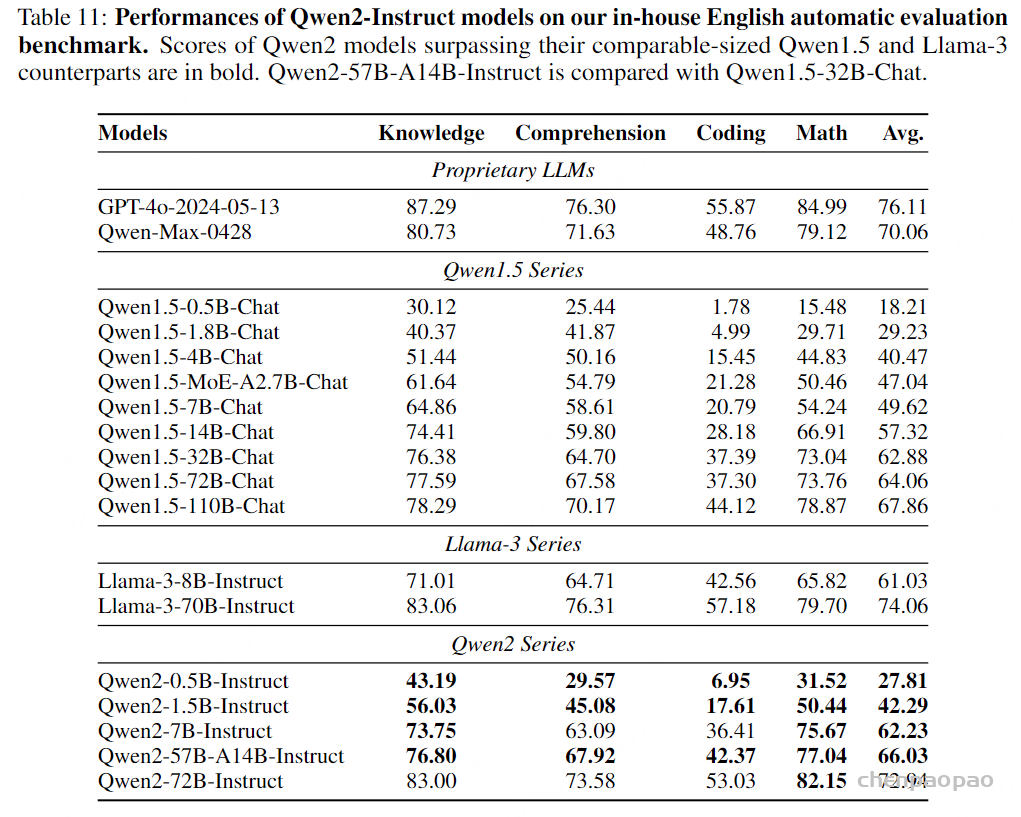
表 2:文本语言模型评估. 在标准基准上的性能,用于评估大型语言模型,包括闭卷问答,推理和多项选择问答考试。 我们以粗体显示在少于 2.5T 个token上训练的最佳模型。 Evaluation
文本语言建模
评估指标: 我们在以下标准基准上评估 Helium(仅使用文本数据训练):AI2 推理挑战(Clark et al., 2018, ARC)、开放书籍问答(Mihaylov et al., 2018, OBQA)、HellaSwag(Zellers et al., 2019, HS)、WinoGrande(Sakaguchi et al., 2021, WG)、物理交互问答(Bisk et al., 2020, PIQA)、社会交互问答(Sap et al., 2019)、TriviaQA(Joshi et al., 2017, TQA)、自然问题(Kwiatkowski et al., 2019, NQ)和大规模多任务语言理解基准(Hendrycks et al., 2020, MMLU)。这些基准涵盖了广泛的任务,包括常识推理、封闭书籍问答或高中和大学科目的多项选择问答。我们遵循 GPT-3 和 Llama 等前期工作的评估协议:在 TriviaQA、NQ 和 MMLU 上进行 5-shot 评估,在其他数据集上进行 0-shot 评估。在 TriviaQA 上,我们报告未过滤和维基百科拆分的性能。
基准模型: 作为基准,我们考虑现有的参数量约为 7B 的大型语言模型,这些模型的训练计算量与 Helium 大致相当。更具体地说,我们包括在少于 2.5T tokens(相比于用于训练 Helium 的 2.1T tokens)上训练的模型,即 MPT(Team, 2023)、Falcon(Almazrouei et al., 2023)、Llama 2(Touvron et al., 2023b)和 OLMo(Groeneveld et al., 2024)。我们还包括 Mistral 和 Gemma,这两个流行的开放权重模型,其训练计算量显著高于 Helium。
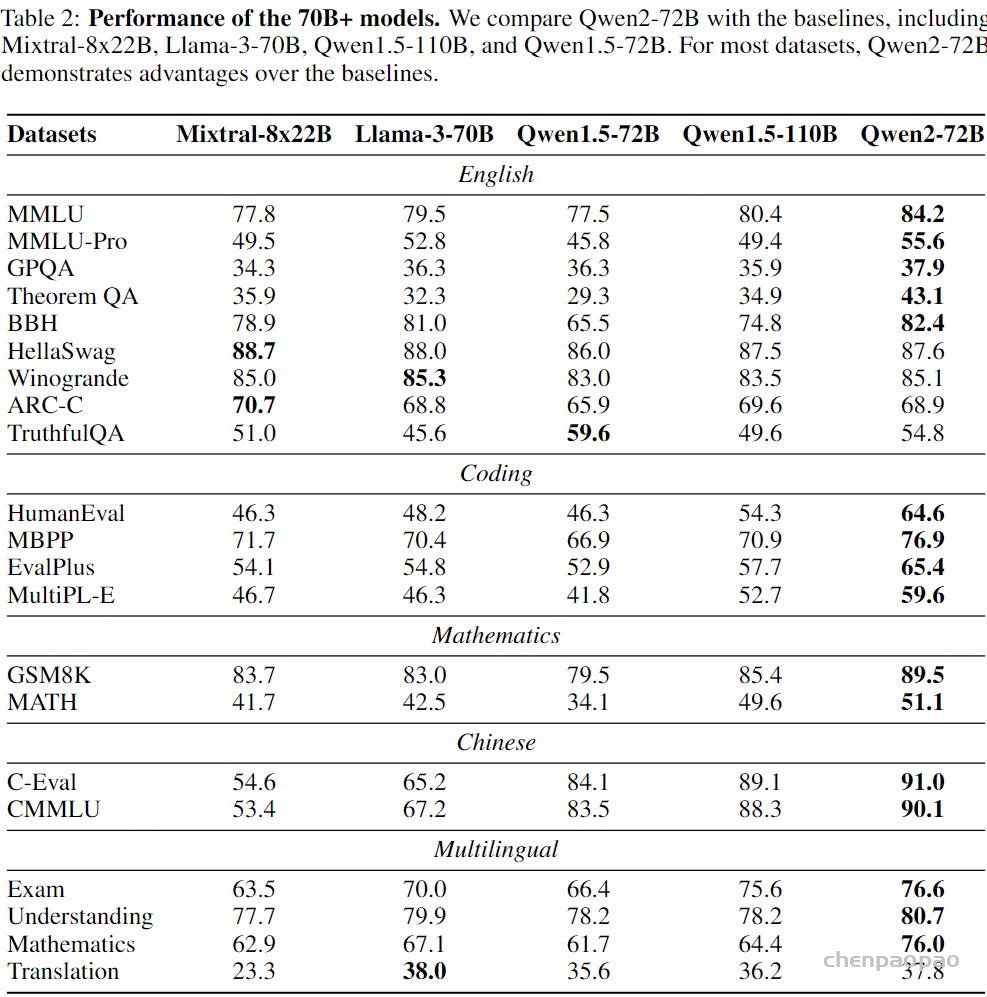
结果: 我们在表 2 中报告结果,观察到在大多数基准上,Helium 的表现与使用相似训练计算量的模型相当或更好。即使与使用多达 3 倍计算进行训练的 Mistral 和 Gemma 相比,Helium 在某些基准(如 ARC、开放书籍问答或自然问题)上也获得了具有竞争力的结果。这验证了我们预训练文本数据的质量。
Audio Tokenization
指标: 接下来,我们评估我们的神经编解码器 Mimi 的语义和声学性能。首先,我们评估其产生的语义 token 是否提供适合语言建模的目标。为此,我们计算基于三音素的 ABX(Schatz et al., 2013)错误率 ,该指标通过比较同一三音素(如“beg”)的两个实例和一个最小差异的负三音素(如“bag”)之间的距离来表征表示空间的语音可区分性。更精确地说,我们计算“同一说话者”的 ABX,三实例由同一说话者发音,并在 Librispeech(Panayotov et al., 2015)dev-clean 上报告错误率,使用 Librilight(Kahn et al., 2020)库的默认参数。结果显示,该得分是下游音频语言模型产生连贯语音能力的强预测指标(Lakhotia et al., 2021)。由于我们只关心语义 token,因此我们计算量化后仅使用语义 VQ 生成的潜在空间中的距离(即在与声学 tokens 相加之前) 。其次,我们评估重建音频的声学质量。作为目标的自动指标,我们依赖于 VisQOL(Hines et al., 2015)——一个完整参考模型的声学相似性 ——和 MOSNet(Lo et al., 2019)——一个无参考音频质量模型 。考虑到自动评估音频质量的局限性,我们还使用 MUSHRA 协议进行人类评估。我们依赖 20 名听众的判断,每位听众对 30 个 10 秒的样本进行评分。表 3 报告了使用客观指标的消融研究,表 4 则提供了与以往工作的比较,包括客观和主观评估。
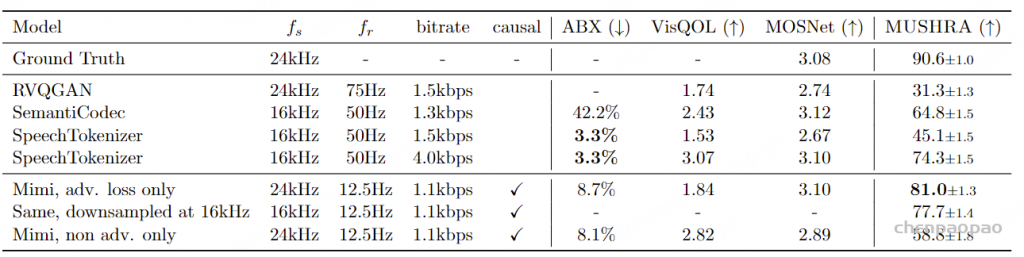
表 3:Mimi 编解码器超参数的消融研究。我们通过报告在语音 ABX 可区分性任务上的错误率来评估语义建模。为了评估重建质量,我们计算 VisQOL 和 MOSNet,并使用 MUSHRA 协议收集人类评估。“量化率”指的是在训练过程中仅对潜在空间应用量化 50% 的时间(与量化器 dropout 独立),如 3.3 节所述。 表 4:音频质量评估。基准神经音频编解码器的客观和主观(MUSHRA)音频质量评估——RVQGAN(Kumar et al., 2024)、SemantiCodec(Liu et al., 2024)和 SpeechTokenizer(Zhang et al., 2024b)——以及 Mimi 的最重要变体。为了与 SemantiCodec 和 SpeechTokenizer 进行公平比较,我们还在 MUSHRA 研究中包含了我们编解码器的下采样版本。fs 是音频采样率,fr 是编解码器帧率。两个 Mimi 编解码器都经过蒸馏训练,并使用与 Encodec 相同的重建和对抗损失组合(见 3.3 节)或仅使用对抗损失。 基准模型: 我们与 RVQGAN(Kumar et al., 2024)、SemantiCodec(Liu et al., 2024)和 SpeechTokenizer(Zhang et al., 2024b)进行比较。RVQGAN 是一个纯声学分词器,因为它不编码语义信息。因此,我们仅在音频质量方面进行评估。RVQGAN 以 75Hz 的速率生成 token,因此我们只保留前两个 RVQ 级别,以获得 1.5kbps 的比特率,更接近于 Mimi 的比特率。另一方面,SpeechTokenizer 依赖蒸馏将语义信息编码到其第一个 token 中,因此我们可以评估其语义和声学属性。我们保留其前三个 RVQ 级别以获得 1.5kbps 的比特率。类似地,SemantiCodec 也编码语义和声学信息,因此可以沿两个轴进行评估。
结果 – 语义 token: 表 3 显示,在没有蒸馏的情况下,Mimi 的语义 token 的语音可区分性较差,与以往工作的声学 token 相当(Borsos et al., 2022):这意味着这些语义 token 不适合捕捉语音中的语言内容。相反,将 WavLM 蒸馏到语义 token 中显著提高了它们的语音可区分性,尤其是在 Mimi 的编码器中使用 Transformer 时。这可以解释为,将大型基于 Transformer 的编码器蒸馏到纯卷积编码器中具有挑战性,而提高编码器的容量和感受野有助于改善。然而,我们观察到声学损失与语义蒸馏之间的冲突,因为改善 ABX 意味着降低重建质量(如 MUSHRA 所测量)。 使用 3.3.2 节中描述的分割 RVQ 改善了语义属性与音频质量之间的权衡 ,使 MUSHRA 从 57.8 提高到 64.0,同时将 ABX 从 6.5% 中等降至 8.1%。
结果 – 声音token。 表 3 还显示,当在解码器中添加 Transformer 时,MUSHRA 评分显著提高。同样,使用 50% 的量化率显著改善了 VisQOL [声学指标]。然而,量化率并未改善主观感知质量。更一般地说,我们观察到 VisQOL 和 MOSNet 之间的相关性较差。特别是,表 4 显示,仅使用对抗损失训练 Mimi 导致非常低的 VisQOL (1.84),这与实际较高的感知音频质量结果相反。因此,我们依赖 MUSHRA,人类评估者被要求判断重建音频与其真实锚点的相似性,得分范围在 0 到 100 之间。该人类评估显示,使用仅对抗损失的 MUSHRA 评分为 81.0,相较于使用 Encodec 的混合损失函数的 58.8,显著提 高。此外,尽管以更低的比特率和建模语义信息,Mimi 仍显著优于 RVQGAN(Kumar et al., 2023)。Mimi 的重建质量也高于 SemantiCodec(Liu et al., 2024),同时以 4 倍更低的帧率运行。这一特性对于实现 Moshi 的低延迟至关重要,因为生成一个音频令牌的时间帧需要通过 Temporal Transformer 完成完整的前向传播。 最后,RVQGAN 和 SemantiCodec 是非因果的,而 Mimi 是完全因果的,因此兼容流式推理和实时对话建模 。
讨论。 Mimi 在编码语义信息的同时,整体提供高重建质量,完全因果,且在低帧率和比特率下运行 。因此,Mimi 证明是一个适合训练实时音频语言模型的音频标记器 。我们研究的一个附带发现是,客观音频质量指标与主观音频质量之间缺乏相关性的令人担忧的现象 。特别是,我们发现VisQOL(声学指标) 在修改生成器架构时提供了可靠的感知质量代理指标。然而,当改变训练目标(例如移除重建损失)时,VisQOL的评分变化方向与人类感知完全不相关 。这一观察强调了设计可靠客观代理指标以反映感知质量的开放挑战。
生成建模的消融研究
指标。 我们进行了消融研究,以评估使用RQ-Transformer的影响,以及比较不同的延迟模式和各种标记级别的权重。所有模型的时间Transformer都用Helium初始化,并在音频数据上预训练。当比较具有相同延迟模式且没有内部独白(Inner Monologue)的模型时,我们依赖于困惑度(perplexity) ,并将其在语义和声学标记上取平均。然而,不同延迟的模型之间的困惑度是不可比的,因为它们建模的是不同的条件分布。为了比较不同的延迟模式,我们通过Whisper(Radford等人,2023)转录生成的语音(基于3秒的提示)并用外部文本语言模型对结果进行评分来衡量Moshi生成可理解、一致语音的能力。我们依赖一个轻量级的文本模型——LiteLlama-460M-1T14——因为它更适合于训练过程中的连续评估。我们还报告了转录本的长度(以字符为单位),因为我们发现它是一个强的模型质量预测因子(弱模型通常会崩溃为静音)。
ps:困惑度(Perplexity) 是自然语言处理(NLP)中常用的一种评估语言模型的指标。它衡量的是模型对测试数据的预测能力,即模型对测试集中单词序列出现概率的预测准确度。困惑度越低,表示模型对数据的预测越准确。
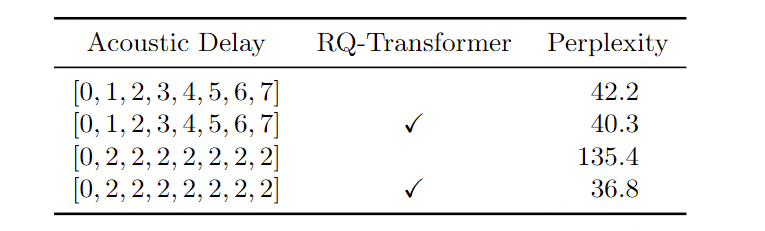
结果 – RQ-Transformer 表5报告了使用RQ-Transformer的消融研究结果。我们首先复制了Copet等人(2023)的设置,使用[0, 1, 2, 3, 4, 5, 6, 7]的延迟模式,这意味着每个RVQ标记级别在前一个级别之后的一个时间步生成。在这种情况下,我们发现使用RQ-Transformer并不是必需的,因为它仅在困惑度上有微小的改进。然而,这种延迟模式导致了8个时间步的理论延迟,即640毫秒,这对于实时对话模型来说是不兼容的。因此,我们将延迟减少到240毫秒,使用模式[0, 2, 2, 2, 2, 2, 2, 2] 。在这种情况下,使用RQ-Transformer对RVQ标记进行建模显著提高了困惑度,超过了使用单独分类头的方法。因此,在严格的延迟约束下,RQ-Transformer成为RVQ标记生成模型的关键组件。
表 5:RQ-Transformer 使用的消融研究。所有模型均以 Helium 初始化,并在音频上预训练。当不使用 RQ-Transformer 时,我们使用独立的分类头预测 8 个级别的令牌,遵循 Copet 等人(2023)的做法。请注意,困惑度仅在具有给定延迟的模型之间可比较,因为对于较高的令牌,分类任务在延迟更多时会更容易。 额外的消融研究 :表6报告了额外的消融研究,包括额外的延迟模式、语义标记损失的权重以及我们提出的内部独白程序 ,所有这些都使用了RQ-Transformer。首先,我们比较了三种与实时对话兼容的延迟配置。[0, 0, 0, 0, 0, 0, 0, 0]模式代表了在12.5Hz Mimi标记下可以获得的最小延迟80毫秒。允许额外80毫秒的延迟(一个时间步的延迟)显著提高了生成语音的质量,而240毫秒【3个step延迟】的延迟则带来了进一步的适度改进。在早期实验中,我们还观察到每个RVQ级别的个别损失之间存在冲突,尽管每个级别在最终的可理解性和音频质量上比下一个级别更重要。 因此,我们对架构和训练过程进行了两个更改 。首先,我们将预测语义标记的损失权重增加到100 ,而其他所有音频标记级别的损失权重保持为1 。这进一步提高了语音的可理解性。此外,我们通过使用深度参数化(如第3.4.1节所述)减少了RVQ级别之间的竞争,使得每个RVQ级别由Depth Transformer中的自己的一组权重预测,而不是在各级别之间共享权重。 最后,启用内部独白对生成语音的质量和长度带来了最显著的改进。
表 6:延迟模式、语义令牌权重和内心独白的消融研究。所有模型均以 Helium 初始化,在音频上预训练,并使用 RQ-Transformer。我们调整语义令牌的权重,同时将其他令牌(包括使用内心独白时的文本令牌)的权重保持为 1。由于不同的延迟模式无法通过困惑度进行比较,我们从有效集中的 3 秒提示生成续写,用 Whisper(Radford 等人,2023)转换为转录,并报告其与 LiteLlama-460M-1T13 的负对数似然及其长度(以字符为单位),作为语言质量的代理。 讨论: 除了架构和延迟模式的选择,这些消融研究表明,在音频到音频的设置中,将文本令牌建模为音频令牌的前缀(使用 Inner Monologue)是非常有帮助的 。鉴于深度参数化和对语义令牌权重设定为100的积极影响,这两者在我们后续的所有实验中均被使用,同时也纳入了最终的训练程序。此外,如表1所述,我们通过以2的声学延迟预训练 Moshi,并以1的声学延迟进行微调,确定了160毫秒【(1+1)*80】的理论延迟。
Audio Language Modeling 指标。 我们首先测量Moshi在大规模音频数据上进行下一个标记预测训练时,对语音序列建模的能力。 为此,我们依赖于“无文本NLP”(Lakhotia等人,2021)指标,这些指标通过比较表示为音频标记的正例和负例语音示例的似然性来评估音频语言模型的语言知识。
具体指标:
sWUGGY : 评估模型从语音中学习词汇表的能力,通过比较一个现有单词和一个无效变体(例如,“oxidation”和“accidation”)的似然性。sBLIMP : 评估语法对比。Spoken StoryCloze (Hassid等人,2023): 通过比较常识性的五句故事,最后一句要么与上下文连贯,要么不连贯,从而评估语义对比。Spoken Topic-StoryCloze (Hassid等人,2023): 这是一个变体,其中负例延续是从不相关的句子中随机采样(而不是微妙地不连贯),从而得到更高的分数。对于所有这些指标,我们使用按序列长度归一化的负对数似然来评分。 由于我们的模型每个时间步生成多个标记,我们将每个时间步的所有标记用训练时使用的权重相加,即语义标记权重为100,声学标记权重为1。我们不在这些评分中包括内部独白的文本标记,因为这些指标旨在比较未经转录的音频序列,应仅在音频标记上计算。同样,在指令调优后评估多流模型时,我们只对用户流对应的标记进行评分,因为它不包含文本标记。最后,我们还报告了Spirit-LM和Moshi在MMLU(Hendrycks等人,2020)上的文本理解评估(不包括音频标记),以此衡量音频训练如何影响原始检查点的文本知识。
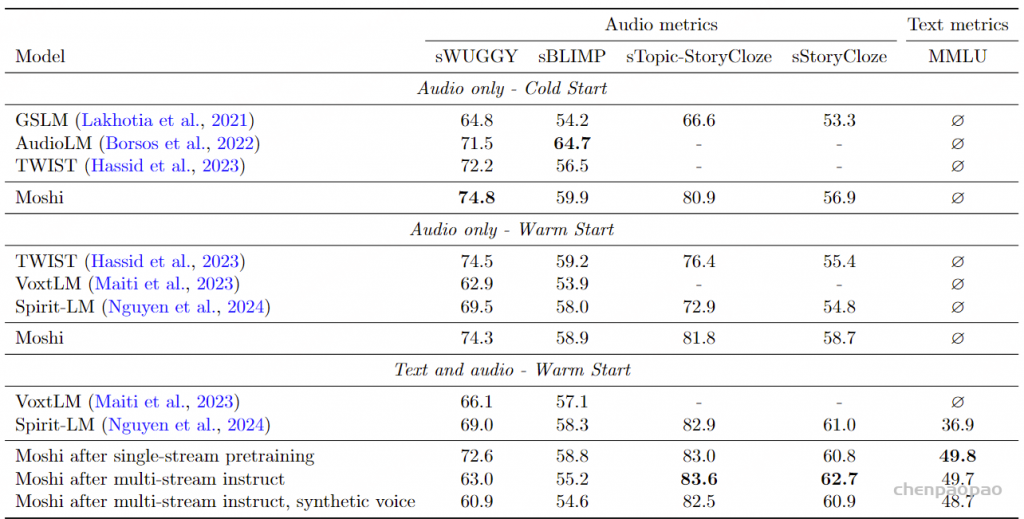
基准。 我们对比了来自音频语言建模文献中的基线模型,在三种设置下进行比较。我们在三个设置中与音频语言建模文献中的基准进行比较。第一类包括从随机初始化开始的仅音频模型,包括GSLM(Lakhotia等,2021)、AudioLM(Borsos等,2022)和TWIST-1.3B(Hassid等,2023)。在这种情况下,我们报告仅在音频数据上随机初始化的单流Moshi的指标,并且没有Inner Monologue。第二类包括从预训练文本语言模型开始,然后仅在音频上训练的模型。这包括TWIST-13B,以及VoxtLM的仅音频版本(Maiti等,2023年,表3的第一行)和Spirit-LM的仅音频版本(在(Nguyen等,2024,表5)中报告为“Speech Only”)。相应的Moshi模型类似于上述提到的模型(仅音频数据,无Inner Monologue),但从预训练的Helium检查点开始。最后一类由实际的多模态模型组成,这些模型在语音和文本数据上联合训练。在这种背景下,我们报告Moshi的三种配置的结果。单流数据预训练 :报告Moshi在单流数据上的预训练结果。多流后训练和微调 :报告最终模型的结果,该模型经过多流后训练和微调,使用真实录音来调节合成数据的生成。合成声音的Moshi :最后一个模型与前一个相同,只是它使用合成声音。
请注意,即使这些模型是用内部独白训练的,它们在评估时也不使用内部独白,以提供与基线的公平比较。
结果。 表7报告了音频语言建模的结果。在“仅音频 – 冷启动”设置中,Moshi已经提供了强大的基准,特别是在sTopic-StoryCloze上大幅提高了先前工作的表现。当使用Helium检查点初始化并仅在音频数据上训练时,Moshi在这一类别的大多数指标上超越了以前的工作。最后,尽管多模态训练改善了语音中的常识推理(如sStoryCloze性能所示),但与仅在音频数据上训练的模型相比,我们观察到在词汇和句法判断(sWUGGY和sBLIMP)上的混合效果。特别是,单流预训练在一定程度上降低了sWUGGY和sBLIMP的表现,而指令微调严重影响了sWUGGY,这意味着受指令影响的模型在解决词汇判断时更困难。我们假设这与对不同质量数据的微调有关,并且对用户流(用于为表7中所有音频指标评分的口语对)模拟嘈杂和混响条件,这使得细致的词汇判断更难解决 。最后,Moshi在MMLU上的得分比Spirit-LM高出12分,从而展示了更高的常识和文本理解能力。我们还强调,Moshi是表7中唯一将语义和声学令牌集成到单一生成模型中的模型 ,而AudioLM使用三个独立阶段,VoxTLM、TWIST和Spirit-LM仅建模语义令牌并依赖外部声码器。因此,Moshi是此比较中唯一能够在语音和文本中展示强大语言建模能力的模型,同时能够以任意声音和条件建模语音。
表7:音频和文本语言建模的性能。我们报告基于负对数似然的准确率,并按序列长度进行标准化。MMLU在5-shot设置下进行评估。沿用Nguyen等(2024)的术语,∅表示不支持的模态,而-表示未报告的数字。 讨论。 尽管“无文本NLP”基准帮助开发了首个音频语言模型,但我们观察到它们在开发像Moshi这样的对话模型时并未始终提供良好的指导。特别是,我们发现常识指标 Spoken StoryCloze 与词汇sWUGGY /句法判断之间缺乏相关性是频繁且易于解释的,原因在于我们在训练中使用的声学条件的多样性。 此外,我们没有观察到模型的词汇多样性或可懂性在微调模型时下降,这与sWUGGY的下降相矛盾。这就是为什么我们在下一部分中也评估口语问答,以探测模型的常识、知识和词汇能力。
口语问答
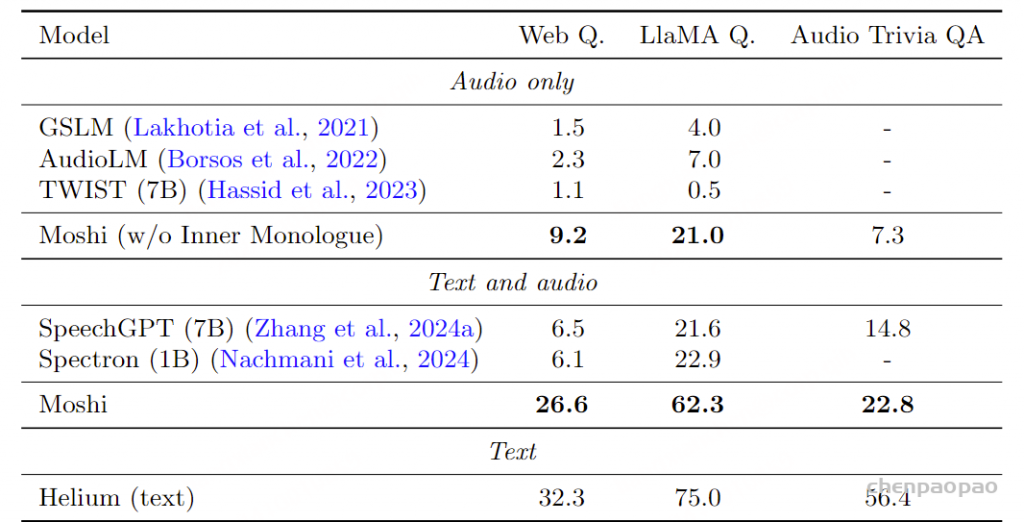
指标 。我们评估最终多流Moshi模型的口语问答能力。我们依赖于Nachmani等人(2024)提出的口语网页问题和Llama问题。同时,我们合成TriviaQA的音频版本作为另一个基准。在评估Moshi时,我们将问题的音频标记插入用户流中,以模拟用户交互。
基准 。我们与Spectron以及Nachmani等人(2024)使用的基准进行比较,除了SpeechGPT(Zhang等,2024a)外,所有基准已经在第5.4节中介绍。为了衡量内心独白对口语流利度的影响,我们比较了使用和不使用内心独白训练的Moshi与这些基准。由于GSLM、AudioLM和TWIST仅为音频模型,因此不使用内心独白的Moshi提供了公平的比较。另一方面,Spectron和SpeechGPT依赖于链式模式(Chain-of-Modality)——它们首先生成文本答案,然后生成语音——因此我们将其与使用内心独白的Moshi进行比较。此外,为了量化由于在音频数据上训练可能导致的知识下降,我们还将Moshi与Helium进行了比较,后者在评估每个口语数据集的文本对应物时被使用。
表8:口语问答评估 。在Web Questions(Berant等,2013)、LlaMA-Questions(Nachmani等,2024)和Trivia QA(Joshi等,2017)基准上进行口语问答(0-shot),使用TTS引擎合成。对于前两个基准,我们使用Nachmani等(2024)报告的数字。对于LlaMA-Questions,我们使用Nachmani等(2024)提供的音频。对于Web Questions和Trivia QA,我们合成了自己的音频,保留了所有问题。对于Moshi,我们仅在指令微调期间预先添加了一个随机引言。我们还提供了Helium文本模型的性能作为对照。结果 。表8报告了在三个基准上的准确率。尽管仅使用音频的Moshi在其类别中显著优于基准,但最引人注目的结果是内心独白对Moshi性能的影响,使其在所有基准上的准确率几乎增加了三倍。 这一点尤其显著,因为内心独白仅略微增加了推理成本(每个多流时间步需要生成17个标记,而不使用内心独白时为16个)。 我们再次强调,在所有比较的模型中,Moshi不仅提供了最佳的口语问答性能,而且是唯一一个能够同时建模语义和音频标记的模型,从而能够在多种条件下处理任意声音之间的交互。此外,不但Moshi显著优于SpeechGPT和Spectron,而且它也是唯一一个与流式推理兼容的模型,因为链式模式需要先生成完整的文本答案,然后再生成语音,而内心独白则以流式方式生成两者。
讨论 。尽管Moshi表现强劲,但我们观察到其性能低于原始的Helium ,这与表7中报告的MMLU从Helium的54.3降至49.7相一致 。虽然Web Questions和Llama Questions上的适度差异可以通过在音频数据上进行训练从而减少用于文本知识的参数量来解释,但在Trivia QA上的巨大差异促使我们更仔细地检查错误模式。 我们发现,特别是多句提问(例如:“《怪物的恐惧》是一本畅销小说的早期标题,激发了1970年代中期的一部高票房电影。最终它以什么名字让读者和观众感到恐惧?”)或具有特定句法结构的问题(例如:“在人类身体上,瘢痕是一种什么类型的?”)对Moshi尤其具有挑战性,因为它在以口语风格的对话上进行了微调,而这些对话并没有展示这样的模式。因此,我们假设在微调过程中覆盖更多句法场景可以缩小这个差距。
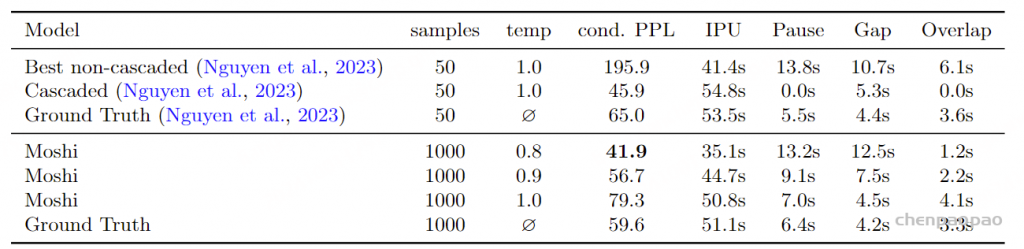
生成对话的质量和统计数据 指标 。除了单轮问答外,我们还通过外部语言模型对生成对话的语言质量进行评估,同时关注轮换(turn-taking)指标。 我们遵循Nguyen等人(2023)的研究方法。轮换(turn-taking)指标定义如下:
间歇单位(IPU, Inter-Pausal Units) :由至少0.2秒的静默分隔的连续语音段。停顿(Pauses) :同一说话者之间的IPU间的静默。间隙(Gaps) :不同说话者之间的IPU间的静默。重叠(Overlaps) :双方都有IPU的时间。根据Nguyen等人(2023)的研究,语义评估使用开源的DialoGPT模型(Zhang等,2019),我们通过使用DialoGPT所期望的<|endoftext|>标记将每位发言者分开,计算转录对话的困惑度。 我们从Fisher数据集中随机选择1000个10秒的提示,并使用Moshi生成续写。对于每个提示,生成32个续写,并提供3种不同温度的结果,因为温度显著影响结果。
基线 。我们与dGSLM(Nguyen等,2023)进行比较,因为它也是一个全双工生成模型,基于Fisher数据集训练。Nguyen等(2023)使用50个提示,每个提示生成50个续写,并报告他们对话模型的结果以及级联顶线模型(ASR + LM + TTS)。
结果 。表9显示,尽管Moshi是一个音频到音频模型,但在语言质量方面表现与级联模型相当。两者的困惑度均优于真实数据,这可以解释为这些模型训练于与DialoGPT训练数据更相近的数据,而不是Fisher数据集。这相较于Nguyen等(2023)中非级联模型的表现是一个显著改进,该模型在此场景下无法生成连贯的语音。
表9:生成对话的语言质量和轮换统计数据 。由于我们训练多流模型以生成对话的双方,因此可以在无需与真实用户互动的情况下生成对话。这使得评估Moshi学习自然对话动态的能力成为可能。流式语音识别(ASR)和文本转语音(TTS) 指标。 第3.4.4节和附录C描述了如何通过简单地改变文本和音频标记之间的延迟,使用Inner Monologue提供流式TTS或流式ASR系统。我们描述了如何通过简单地改变文本标记和音频标记之间的延迟,使内部独白(Inner Monologue)提供流式TTS或流式ASR系统。具体来说,我们通过将音频标记延迟2秒来训练流式TTS模型,为文本标记提供一些前瞻,并在推理时使用教师强制(teacher forcing)文本标记。类似地,我们通过将文本标记延迟2秒来训练流式ASR模型,允许模型在生成文本标记之前先听取音频内容。在这种情况下,在推理时我们对音频标记使用教师强制。我们在TTS中使用0.6的温度进行生成,而在ASR中使用贪婪解码,并在LibriSpeech(Panayotov等人,2015)的test-clean子集上以词错误率(WER)进行评估。对于TTS,我们首先使用在LibriSpeech 960小时数据上微调的HuBERT-Large(Hsu等人,2021)转录音频,仅考虑4到10秒之间的序列,以便与Vall-E等基线进行比较。我们强调,在我们的ASR和TTS系统的训练过程中没有使用任何LibriSpeech数据。
结果。 我们的流式TTS模型在LibriSpeech测试集上的WER为4.7%,优于Vall-E的5.9% WER,但不如NaturalSpeech 3(Ju等,2024)的1.81%。然而,Moshi只需2秒的前瞻性,而Vall-E和NaturalSpeech 3则需要访问完整的序列。我们的ASR系统的WER为5.7%,而Streaming FastConformer(Noroozi等,2024)在类似的前瞻性下获得了3.6%。值得注意的是,我们的ASR系统还提供与文本的对齐的时间戳,精度为80毫秒(时序变换器的帧速率)。
讨论。 这有限的实验并非旨在与最先进的系统(尤其是ASR)竞争,而是旨在展示Inner Monologue的灵活性,可以将多个任务映射到同一框架中。我们还强调,LibriSpeech测试集的标准评估并未提供展示我们TTS系统强大能力的测试平台,特别是在多流建模中建模两个说话者的能力 ,以及生成长达5分钟的一致、自发且富有表现力的对话 (而Vall-E只评估4到10秒之间的朗读语音)。 我们将流式TTS的全面评估留待未来工作。
压缩Moshi及其对语音质量的影响
随着大多数现代大型语言模型(LLMs)的参数达到数十亿,模型大小成为在资源受限设备(例如,使用用户级GPU的笔记本电脑)或模型部署(例如,在线网络演示服务多用户)等实际应用中的一个众所周知的瓶颈。为了解决这个问题,后训练量化(PTQ)是一种广泛使用的效率技术,用于压缩模型权重和激活,但可能会导致性能下降。最近的研究表明,LLMs通常可以成功量化为8位整数,有时甚至可以使用更先进的技术来处理异常权重,进一步降低到更低的位宽(Dettmers和Zettlemoyer, 2023; Dettmers等人, 2022; Frantar等人, 2023; Tseng等人, 2024)。然而,关于语音模型量化的文献远少于LLMs。因此,在本节中,我们调查量化Moshi如何影响其性能,特别是在语言学和声学方面,强调某些由于模型量化加剧的音频降质问题。
量化格式。 为了量化Moshi,我们遵循PTQ文献中的常见设计选择。在以下所有结果中,我们采用以下设置:
(i)激活以bfloat16精度(BF16)存储,并在每个线性层的输入处动态量化为8位,使用对称量化(即AbsMax);
(ii)模型权重使用非对称量化(即MinMax) 进行不同位宽和块大小的量化。这包括时序 Transformer和深度Transformer的权重。实际上,我们发现深度Transformer对量化具有相当好的鲁棒性,因为仅保持其权重的高精度并不会显著改善音频质量 。
(iii)只有初始嵌入层(文本和音频)、RMSNorms和Mimi编解码器保持未量化 。
注意 :虽然权重范围设置也是常见的做法(Nagel等人, 2021),但我们没有使用均方误差(MSE)微调获得的量化尺度,因为我们发现这对生成样本的质量影响很小。
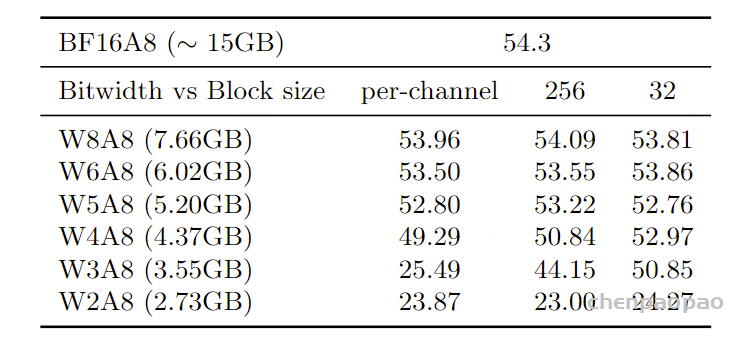
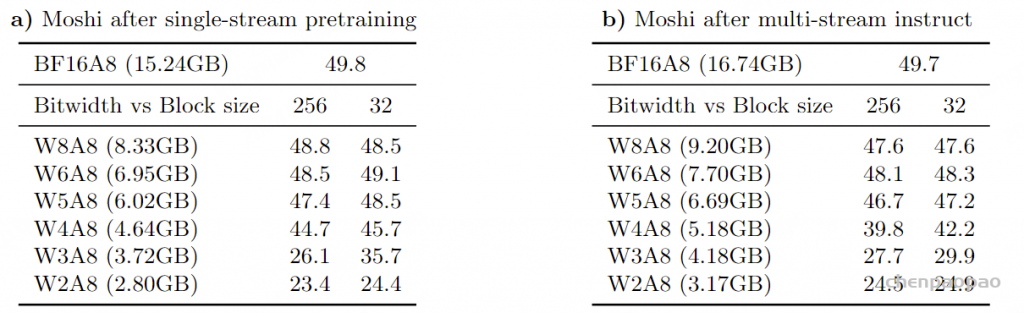
结果 – 语言评估。 为了评估量化对模型推理能力的影响,我们在MMLU基准测试上评估了量化模型的性能,包括作为Moshi基础的仅训练文本数据的Helium基础模型 (见表10)和Moshi本身 (见表11)。一般来说,Helium对量化更具鲁棒性 ,特别地,假设量化块的大小为32,将Helium权重量化为4位可以得到一个缩小3.43倍的模型,其MMLU评分与浮点基线相差不到2分 。该量化格式几乎与llama.cpp的Q4_0相同,因此可以方便地用于高效推理。
相比之下,对Moshi使用相同的量化方法则导致了性能的显著下降,MMLU评分降低了5到10分。在在线演示中,我们将权重保持在8位格式,因为这导致模型的MMLU下降约2分,而模型大小大约是浮点基线的两倍。
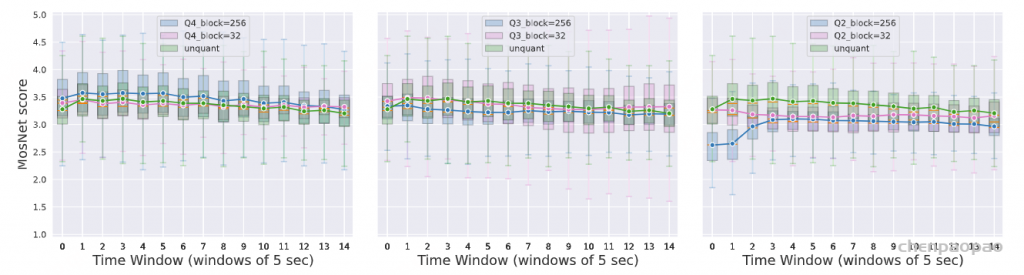
表10:量化对Helium模型的语言影响,以MMLU衡量。‘WXA8’表示权重量化为‘X’位,激活量化为8位,使用整数标量PTQ。模型大小(以GygaBytes为单位)在括号中给出,基于量化块大小为32,考虑了模型权重和以float16存储的量化参数。通过足够精细的量化块,4位模型的MMLU评分仍在浮点基线的2分之内。 表11:量化对Moshi模型的语言影响,以MMLU衡量,针对由Inner Monologue直接生成的文本令牌的不同量化Moshi模型进行评估。与之前的表格一样,模型大小以块大小为32时进行指示。 结果 – 音频质量。 为了评估量化模型生成的样本的音频质量,我们使用Lo等人(2019)在speechmetrics中实现的MOSNet指标 。具体来说,我们从未量化模型生成一个短提示(64个令牌),然后以温度t = 0.8和序列长度1024个令牌生成每个量化模型的完成。我们重复此过程500次,并报告非重叠窗口的MOSNet得分分布(见图5) 。虽然MOSNet得分在样本之间表现出较大的方差,但在将模型权重量化到4位后,音频质量通常几乎没有退化。 然而,对于较低的位宽,我们观察到MOSNet得分对一些更严重的音频退化缺乏敏感性,这些退化是由激进量化 引起的。例如,它无法区分纯音频伪影(如嘈杂的声音)和语音模式中的伪影(如模型重复性增加) 。这与我们在第5.2节中观察到的客观和主观音频质量指标之间缺乏一致性相符。此外,MOSNet是为一种非常不同的基准设计的,即模仿人类对转换语音的评估,因此它对这些伪影不够敏感也不足为奇。相反,为了衡量音频样本中这种退化的存在或缺失,我们首先观察到某些音频伪影可以通过生成的文本和音频令牌的熵谱识别:图6展示了一些示例,附录D中详细描述了伪影类型及其测量方法。
图5:模型压缩对Moshi的声学影响。对不同位宽压缩模型生成的样本进行MOSNet评估。我们在非重叠的5秒窗口中评估MOSNet得分,并报告每个模型的500个样本的得分分布。 图6:模型压缩引起的音频伪影。捕捉到由模型量化引起的特定音频伪影的典型熵谱示例。对于每个时间步,我们独立计算过去128个token的熵,分别针对文本和音频代码本的token。然后,我们在非重叠的64个token窗口中测量不同伪影的存在或缺失,具体说明见附录D。 根据这一见解,我们测量了在与之前MOSNet分析相同的生成音频样本中不同音频伪影的存在或缺失。结果如表12所示,附录D的图11提供了更详细的逐时间步分析。在4位宽度下,我们再次观察到音频降解很少。降到3位格式时,音频降解变得更加明显,并且随着生成时间步的增加而变得更频繁,尽管较细粒度的量化格式通常对这些伪影更具鲁棒性。然而,当权重被激进地量化为2位时,这两种量化格式的音频质量显著下降,我们也在定性上观察到了这一点。
讨论:Moshi的语言能力对模型权重和激活的量化比输出音频质量更敏感。 具体而言,音频质量在精度降到4位时仍接近浮点基线,即使量化了整个模型,包括深度变换器。 相比之下,当模型权重量化到6位以下时,仅使用后训练量化,MMLU性能遭遇显著下降。根据最近的量化技术(Tseng等,2024),我们可能期望通过使用量化感知微调而不是PTQ,在较低的位宽下改善性能。 然而,由于Moshi的训练管道涉及多个阶段和训练数据集,这需要对设计量化训练阶段和校准数据集进行更深入的研究,以保留量化后丢失的所有Moshi能力。
安全性
在Moshi的开发过程中,我们探索与AI生成内容安全相关的不同方向。在本节中,我们具体考虑几个与Moshi生成的内容相关的问题,每个问题都在专门的小节中进行探讨:
我们的模型在生成有毒内容方面表现如何? 如何避免模型重复训练集中的音频内容? 我们如何确保模型使用我们希望赋予Moshi的声音? 如何识别给定内容是否由Moshi生成? 有毒性分析
科学界在过去几年中对文本生成模型的偏见和有毒性问题投入了一些努力。相比之下,音频安全的研究尚不成熟。由于音频和文本模型在使用上有所不同,且通过非语言信号(如讽刺、语调等)传达多重意义,因此进行公平比较并不简单 。尽管存在这些局限性,为了便于将Moshi与文本生成模型进行比较,本次分析将我们的有毒性分析限制在模型生成的文本上。 我们采用ALERT基准(Tedeschi et al., 2024),该基准在多个类别(仇恨、自残、武器、犯罪、性、物质)下评估安全性。附录D中的表18报告了我们在该基准上的详细有毒性分析结果。Moshi与流行的仅文本模型的综合得分如下:
通过这项分析,我们发现Moshi在排名中处于中间位置。行业模型表现最佳,这是可以预期的,因为这些模型受益于大量的私人注释、红队测试和反馈循环。
再现分析 模型生成其在训练时见过的内容的问题,我们称之为再现,与过拟合密切相关:模型在训练期间看到的序列或子序列越多,它在生成过程中生成该序列的可能性就越大。 需要注意的是,对于语音模型,不仅文本可能被再现,语音的音调、语气,以及如果在训练时存在的背景旋律也可能被再现。 因此,重要的是要减轻与再现相关的潜在知识产权问题,例如未经许可复制受版权保护的内容或使用某个人的声音进行音频生成。
评估协议。对于每个模型,我们测量生成中再现训练数据集中最常见音频片段的比例(总共100,000次生成)。为此,我们首先开发了一个匹配系统,以检测整个训练数据集中最频繁的音频片段,详细信息见附录B。 我们选择一个足够长(16秒)且易于从文本和音频中检测的最常见片段。我们测量与此最常见片段完全匹配的生成比例。在匹配过程中,我们最初使用音频和文本匹配,但观察到基于文本的匹配在初始匹配步骤中具有更高的召回率。我们手动验证所有生成的内容,以过滤掉不完全匹配的异常值。
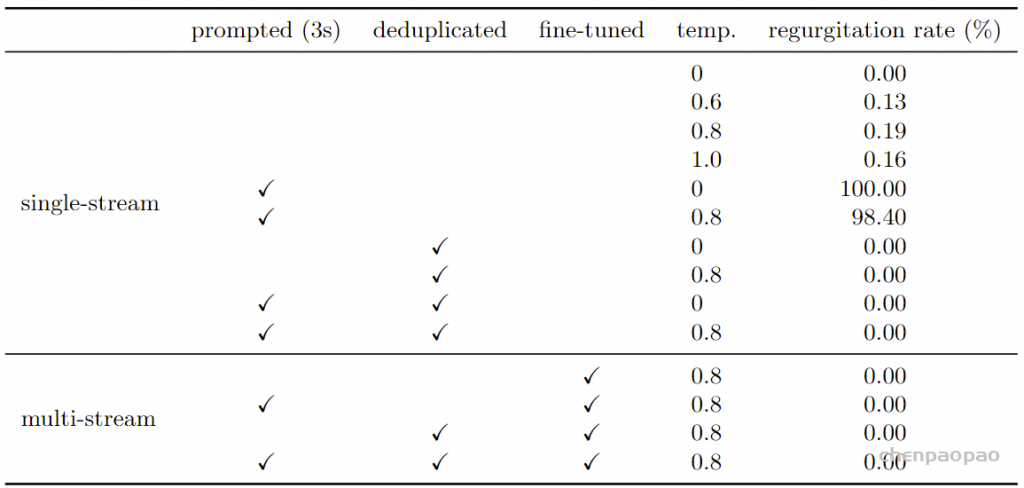
无条件与提示生成。我们首先测量无条件生成的情况,以评估模型在未通过提示引导时是否倾向于生成特定序列。作为补充,我们使用最常见音频片段的前3秒来提示模型,并测量继续生成与该训练集音频相同的次数。表13报告了这些再现结果。
表13:不同模型在无条件生成中的训练数据再现情况 结果与微调的影响 。我们观察到,预训练模型在原始数据集上训练时,往往会生成训练集中频繁出现的序列。采样温度对再现率有重要影响:通常用于生成的值(0.6–1.0)更容易出现再现现象。在1000次生成中,经过对话微调的模型并未生成最频繁的训练序列 。需要说明的是,微调可能会被覆盖,因此可能不足以单独避免再现现象。
类似于文本模型的情况 (Carlini等,2022),再现现象受模型在训练中使用特定序列的次数显著影响。因此,我们通过识别所有频繁的音频片段并在训练时过滤掉这些片段,评估去重训练数据集的影响。在表13中,我们观察到这一预处理步骤[ 附录B:deduplicated]将最频繁序列的再现次数降至零,即使没有进行微调。
系统声音一致性 一个潜在的语音到语音模型的风险是未经授权的声音生成。该模型应该使用其目标声音,而不是可能模仿用户的声音。为了评估Moshi在多大程度上采用用户的声音而不是目标声音,我们使用以下协议:
生成100小时Moshi与第二个合成发言者之间的对话。 在每个段落上运行一个说话人验证模型(WavLM(Chen等,2022)large)以提取说话人嵌入。 计算每个主说话者段落的嵌入与(i)主说话者的第一个段落和(ii)生成说话者的第一个段落之间的余弦相似度。 注意:我们排除所有开始时间在15秒之前的段落,以避免将主说话者的第一句作为参考。 在生成的数据集中,主说话者的声音在10,249次(98.7%)情况下更接近主说话者的参考段落,而在133次(1.3%)情况下更接近另一说话者的参考段落。我们还关注说话者的一致性随时间的演变。根据Borsos等(2023),我们计算与上述相同的比例,但针对在特定时间开始的段落组,以测量随时间的漂移。表14显示说话者的一致性在时间上保持稳定,这意味着我们没有观察到对话进行时的漂移。这表明,在指令调优期间简单选择使用一致的声音足以在推理时提供稳健性。
表14:随时间变化的说话者一致性。我们测量在计算远离参考段落的段落的说话人嵌入时,Moshi的段落中的说话人嵌入与其参考段落的相似度有多高,相较于用户的参考段落。 Moshi生成内容的识别:水印技术
为了确定给定的音频是否由Moshi生成,我们研究了两种互补的解决方案:索引和水印。 第一种,即音频索引,仅在我们能够访问生成内容的机器时适用,例如在Moshi演示的情况下。 我们在附录B中描述了我们的音频匹配系统 。以下小节中,我们将更具体地讨论水印,其目标是向生成的音频添加不可察觉的标记。
信号基础水印的评估。我们调查现有的音频水印方法是否可以用作重新识别Moshi生成内容的一种方式 。为此,我们分析了Audioseal方法(San Roman等,2024b)在我们上下文中的鲁棒性。该方法作为开源库可用。为了进行评估,我们将音频信号重采样到16kHz,以使采样率与Audioseal说明中推荐的采样率相匹配。我们在以下设置中测量平均标记检测得分:
无水印:测量未添加标记时的检测得分。 无攻击水印:未修改水印音频信号; 粉红噪声:我们向水印音频中添加小幅粉红噪声(σ = 0.2); RVQGAN:我们使用最近的先进自编码器(Kumar等,2023)对音频信号进行压缩和解压缩。我们使用公开可用的预训练16kHz模型,该模型与第5.2节中用作基线的24kHz模型不同。 Mimi自编码器:我们使用自己的分词器对信号进行压缩和解压缩。此操作使用24kHz音频进行,因此涉及两个重采样阶段(从16kHz到24kHz,再回到16kHz)。 我们在表15中报告了结果。我们观察到,当音频未更改时,标记的检测率很高 。在激进的粉红噪声下,需要相对较长的序列才能获得高检测得分。然而,标记对强压缩的鲁棒性较差:我们考虑的两个自编码器都具有低比特率,因此会丢弃与信号重构无关的任何内容 。因此,我们的Mimi编解码器将mark删除到一个水平,使水印音频与非水印音频难以区分,从而在这种情况下使信号基础水印变得无用。
关于生成音频水印的讨论。上述基于采样的水印方法缺乏幂等性,这对检测器在测量采样偏差时的可靠性造成了问题。值得注意的是,为了使这些方法正常工作,提供哈希密钥上下文的n元组在多个连续标记期间必须足够稳定。减少上下文长度可以提高稳定性,但会大幅增加产生退化音频序列的可能性,类似于(Holtzman等,2019)观察到的退化问题。
虽然我们将这种采用基于文本的水印的方法视为一个负面结果,但在此我们讨论了一些可能的绕过上述标记稳定性问题的潜在方法,通过重新编码实现:
仅标记RQ的第一级可以提高稳定性。在我们的初步实验中,将这些索引作为哈希函数中的上下文,并限制对之前时间戳的依赖,显著提高了稳定性(尽管还不够)。 通过在离散潜在空间中添加特定损失,可以改善幂等性,使音频标记在自编码过程中保持稳定。 这种自编码可能被学习为对信号变换具有鲁棒性,类似于学习基于神经网络的图像水印时提出的方案(Zhu,2018;Fernandez等,2022)。根据我们的分析,增加对适度时间偏移的容忍度尤其重要。 可以标记文本而不是音频。一个缺点是,文本作为添加标记的通道容量较低,对于短对话来说并不足够。另一个问题是,检测标记需要可靠的转录。 最后但并重要的是,需要一些探索,以确保在开源模型时去除水印程序并不简单。举个例子,与稳定扩散模型相关的实现中,去除水印的唯一方法就是注释掉一行代码。22 Sander等(2024)的研究在这方面是一项有前景的工作,他们展示了检测模型是否在水印文本上训练是可能的。San Roman等(2024a)刚刚分享了一种利用这一观察结果的方法:水印是通过训练数据隐式添加的,遵循Sablayrolles等(2020)提出的“放射性数据”的精神。
结论
在这项工作中,我们介绍了Moshi,首个实时全双工语音对话系统。Moshi的第一个组成部分是Helium,一个拥有70亿参数的文本LLM,其性能与计算预算相似的开放权重模型竞争。为了将音频编码为适合语言建模的离散单元,我们引入了Mimi,一个语义声学神经音频编解码器,它在低比特率下提供了最先进的音频质量,同时以与实时生成兼容的低帧率运行。接着,我们提出了一种新的层次化多流架构,支持以语音到语音的方式生成任意对话。此外,我们展示了通过Inner Monologue,这种新方法在音频标记前生成文本标记,能够显著改善语音到语音的生成,同时保持流式推理的兼容性。我们的实验表明,Moshi在语音问答和对话建模方面展现了最先进的水平,同时在不生成有害内容和保持声音一致性方面显示出令人满意的安全性。总之,我们介绍了一整套模型和方法,从文本LLM到神经音频编解码器,再到生成音频模型,结合成一个具有160毫秒理论延迟的实时语音对话系统,能够进行长达5分钟的复杂多轮对话。我们发布了Mimi和Moshi,以促进此类应用的发展。此外,我们展示了Inner Monologue方法如何通过改变文本和音频标记之间的延迟,设计流式TTS和流式ASR。我们相信,Inner Monologue和多流建模将在语音到语音和音频到音频的应用中产生积极影响,超越对话建模。
附录
附录A. Additional Ablation on Mimi Codec
表17 :Mimi编解码器超参数的消融研究。我们通过报告在音素ABX可区分性任务上的错误率来评估语义建模。为了评估重构质量,我们计算VisQOL和MOSNet。“量化率”指在训练期间仅在50%的时间内对潜在空间应用量化(与量化器丢弃无关)。附录B. 音频匹配与去重
我们开发了一个音频匹配系统,其目标有两个方面:
源内容去重 :去除频繁的重复内容,以避免过拟合和数据集中音频内容的过度再现,如第6.2节所评估。索引解决方案 :通过在生成时收集样本的签名,我们可以直接检索,判断某些内容是否由我们的在线演示生成。我们的音频匹配解决方案受到Wang(2003)工作的启发,因为它在效率和有效性之间提供了良好的折衷。该方法是一个检索系统:给定一个查询,它在预先索引的数据集中检测相似音频。 在我们的案例中,签名设计更倾向于去重用例,这需要更高的效率:形式上,我们需要将数据集中每个音频与整个数据集进行比较,这引发了效率问题。签名提取的过程如下。
星座图 :生成签名的第一步涉及计算一组称为星座图的关键点。我们的程序受到Wang(2003)的启发,如图7所示。首先,(1)我们从音频信号计算梅尔谱图,时间以40Hz的频率离散化,频率范围分为64个频段。然后,我们应用三个滤波器以选择时频位置:(2)能量滤波器确保我们仅选择足够鲁棒的位置;(3)时间滤波器和(4)频率滤波器确保我们选择相对于时间和频率的极大值。这些滤波器的组合是(5)一个星座,从中提取哈希值。
梅尔谱关键点提取 。对音频梅尔谱应用三个滤波器,以提取一个关键点的星座,基于这些关键点计算哈希签名成对匹配和一对多比较 。通过我们的签名提取,我们可以通过比较两个音频的签名集来比较它们,这相当于计算哈希键的交集。当想要将查询音频与一个包含多个音频的数据集进行比较时,使用倒排文件或哈希表进行比较更加高效。在这种情况下,索引结构返回与每个音频匹配的签名列表和匹配时间戳。与 Wang(2003)类似,我们仅保留在时间上具有一致性的匹配,这得益于一个简单的霍夫1D时间投票方案。可选地,我们在匹配签名时在时间戳 tbt_btb 和 tft_ftf 上引入 ±1 的容忍度。由于这一容忍度增加了复杂性,因此在数据集去重的情况下我们不使用它。
去重:签名融合集 。对于我们的去重策略,我们首先交叉匹配数据集中所有音频片段,并提取足够频繁发生的匹配片段(通常 ≥ 10 次匹配)。由于它们的签名是冗余的,我们删除在相同相对时间戳处发生的所有重复签名,以产生一个单一的重复签名集。在训练时,为了确定某个音频片段是否是要过滤的频繁重复片段,我们只需将其签名集与重复签名集进行比较。换句话说,我们仅在假定的训练片段和合成的重复签名文件之间执行简单的音频到音频匹配。 只有在得分低于预定义的匹配阈值时,我们才会使用该片段进行训练。
附录C 延迟文本语言模型作为zero-shot流式ASR和TTS:
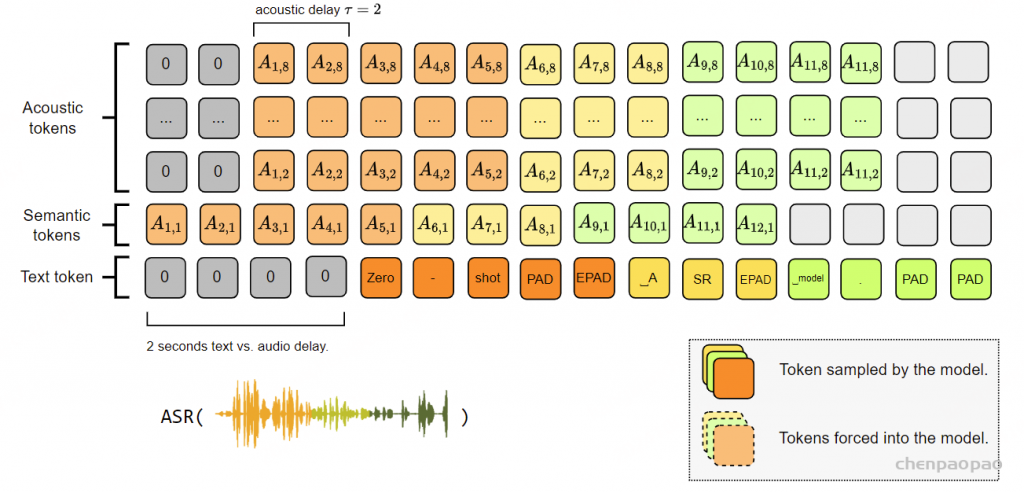
如第3.4.4节所述,Moshi模型音频标记,并与通过特殊填充标记在音频帧率上对齐的文本流结合,如图4所示。我们可以通过在音频和文本标记之间引入延迟来调整此方法以用于ASR和TTS。在这两种情况下,模型以全流式模式运行,具有固定的延迟(此处为2秒)。
ASR模式 :如果音频领先于文本,我们忽略模型对音频标记的预测,而是使用某些音频输入的标记,并自由采样文本标记。然后,文本流包含音频转录,具有单词级的精细对齐,如图8所示。
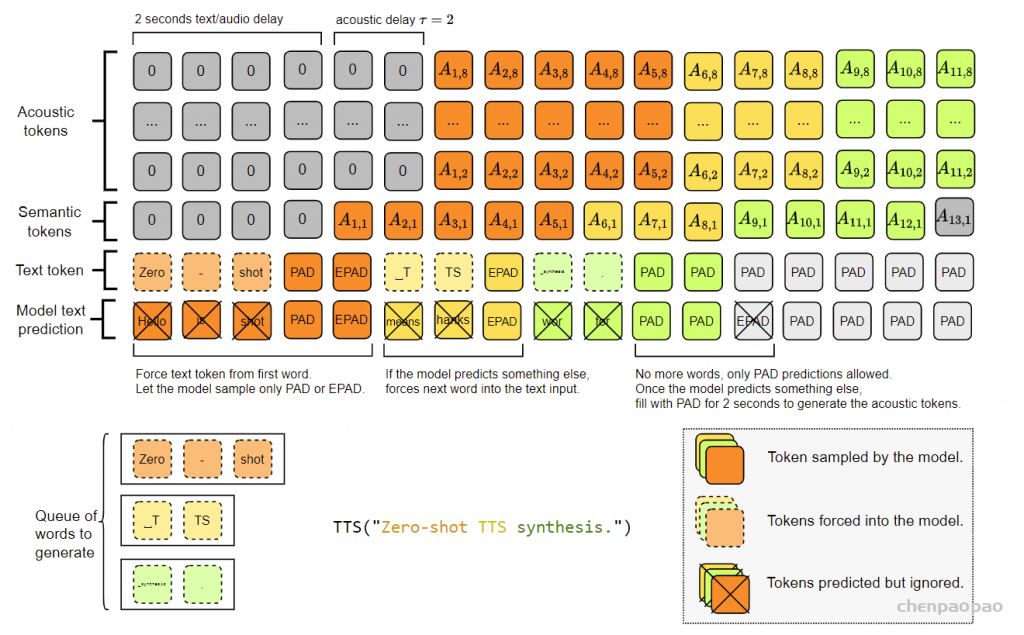
TTS模式 :如果文本领先于音频,我们可以对称地推导出一个TTS引擎。为此,我们需要一个正确填充的文本标记集。我们通过允许模型自由采样PAD和EPAD标记以zero-shot方式获得这些。当模型试图采样不同的标记时,我们将输入下一个要生成的单词。需要注意的是,我们可以通过保持填充标记的在线平均比例来进一步控制语音速率。当该比例低于给定目标值时,我们通过在其logits上引入小的奖励,确保在所有情况下保持合理的速率和良好的可懂性。最后,使用同时包含文本和音频标记的前缀,我们可以控制说话者的声音。图9给出了表示。
多流TTS :我们在单流和多流模式中都使用此机制。在多流模式下,模型输出两组音频标记。文本在单个流中提供,使用<bos>和<eos>标记将文本与两个说话者分开。
图8:Moshi用于自动语音识别(ASR)时建模的联合序列表示。每一列代表联合序列中某个步骤的标记(Vs,k ),类似于公式6中的描述,但经过调整以适应ASR。文本延迟了2秒,同时我们使用声学标记延迟τ = 2 。标记从底部到顶部在深度Transformer中进行预测。音频标记与输入音频保持一致,而文本标记则自由采样。这还提供了精确的单词时间戳。
图9:Moshi在文本到语音(TTS)模式下建模的联合序列表示。每一列代表联合序列中某个步骤的标记(Vs,k),类似于公式6中的描述,但经过调整以适应TTS。音频延迟了2秒,同时我们使用声学标记延迟τ = 2。标记从底部到顶部在深度Transformer中进行预测。文本预测通常被忽略,而是使用要生成的文本的标记。然而,这个文本输入缺乏填充标记。在每个单词结束时,我们允许模型自由采样PAD和EPAD标记。如果模型尝试采样其他标记,我们则使用下一个单词的标记。语义和声学音频标记正常采样,由于使用的延迟而隐式地依赖于文本。通过记录给定单词被模型消耗的时间,这种方法还提供了生成音频中单词的精细对齐。
附录 F. 合成转录生成用于微调 合成转录生成用于微调,我们提供合成转录的示例:



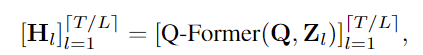
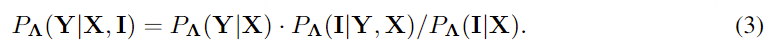










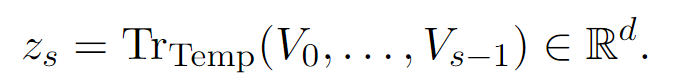
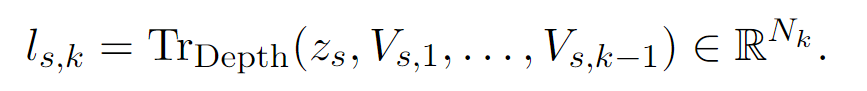
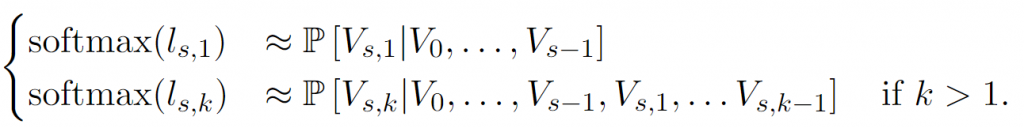
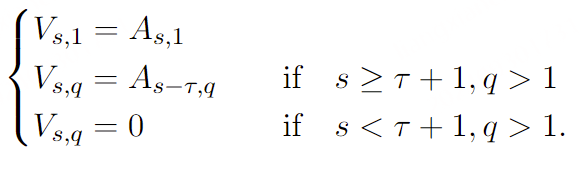
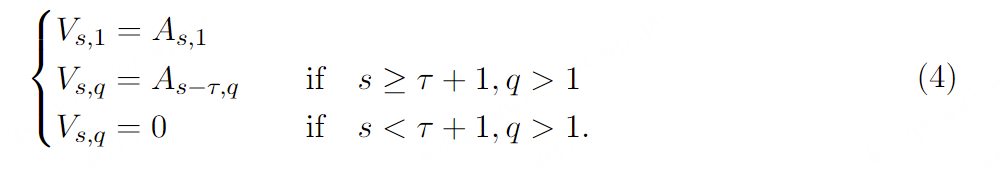
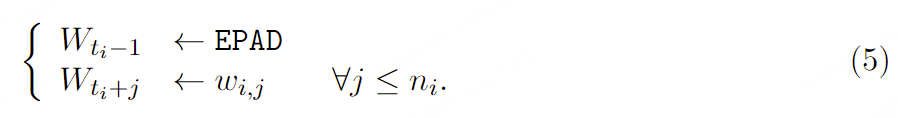
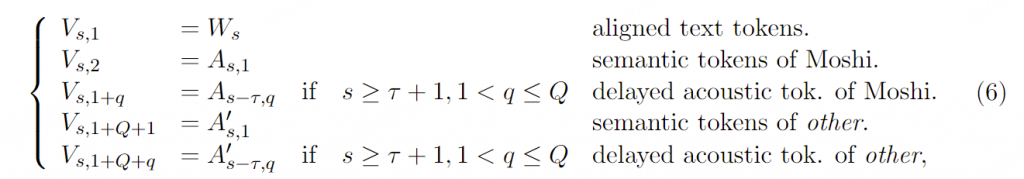




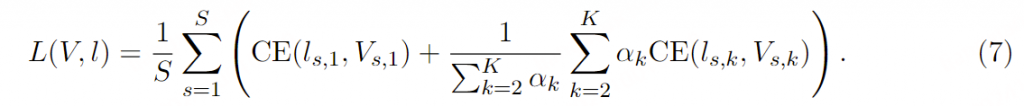








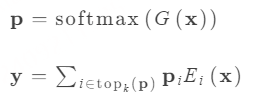

{kind=link}