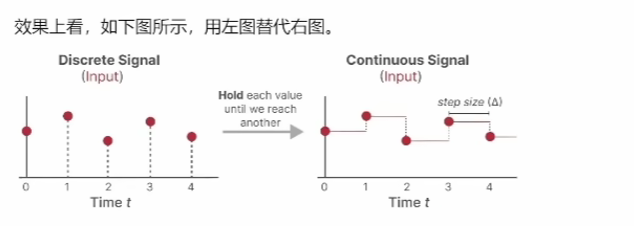
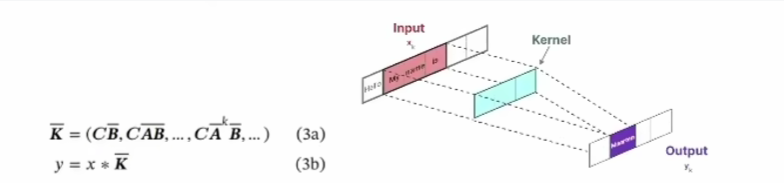
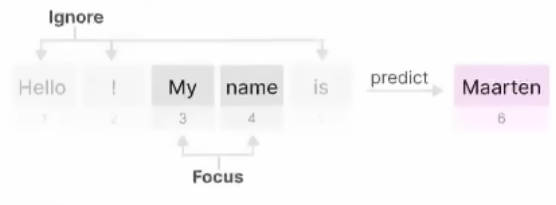
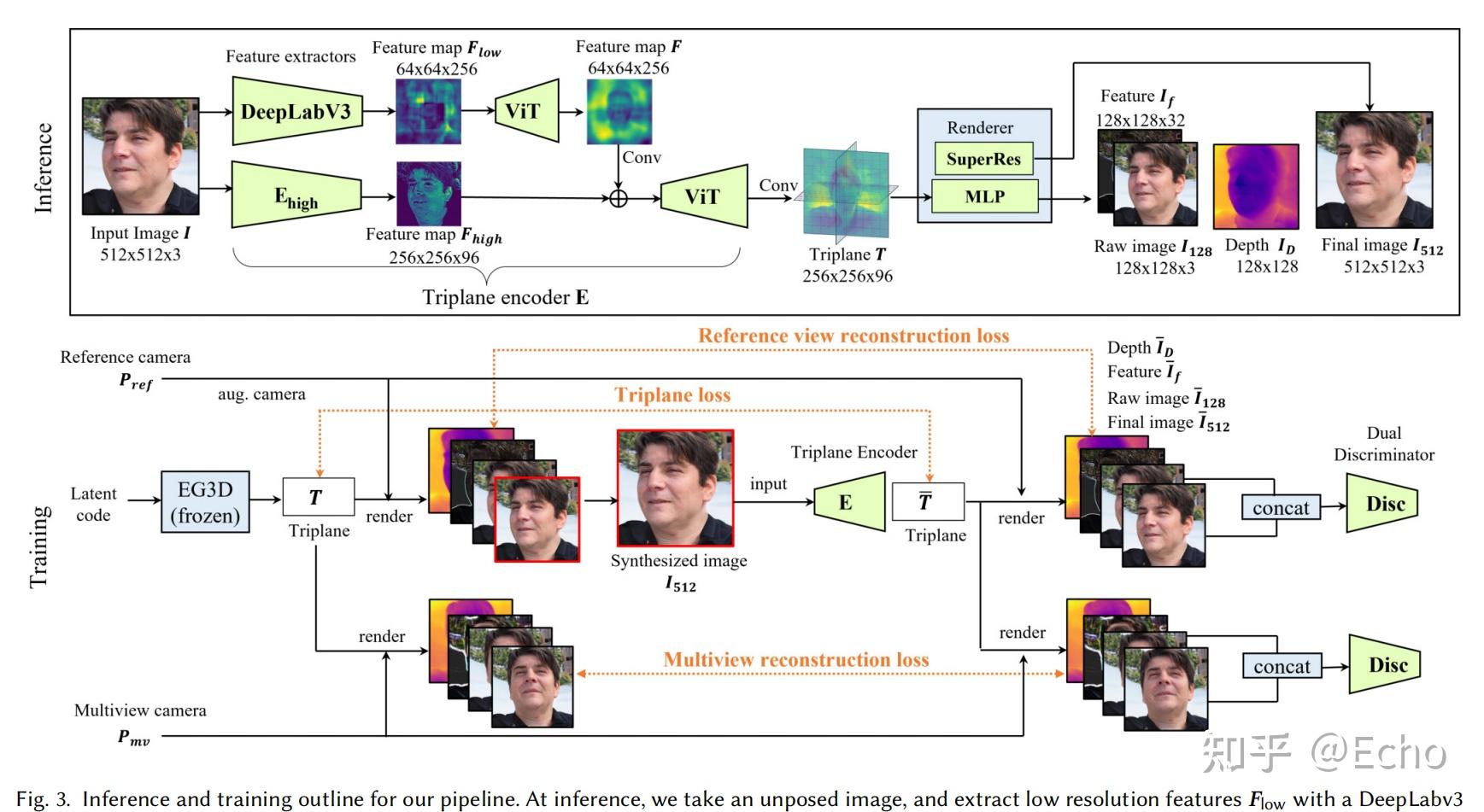
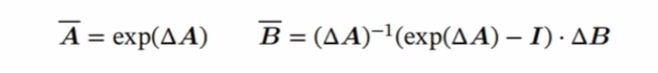本文提出了从单张图像实时推理渲染照片级 3D 表示的单样本方法,该方法给定单张 RGB 输入图像后,编码器直接预测神经辐射场的规范化三平面表示,从而通过体渲染实现 3D 感知的新视图合成。该方法仅使用合成数据进行训练,通过结合基于 Transformer 的编码器和数据增强策略,可以处理现实世界中具有挑战性的输入图像,并且无需任何特殊处理即可逐帧应用于视频。
GAN inversion在2D领域取得很大进展,现有的3D GAN inversion方法将给定的图像投影到预训练的StyleGAN2 latent space上,并且在测试时需要摄像机姿态( approximate camera pose )和生成器权重微调( generator weight tuning),以重建域外输入图像。与同时期的工作不同,作者的前馈编码器将未定位的图像作为输入,并且不需要针对摄像机姿态的测试时优化。
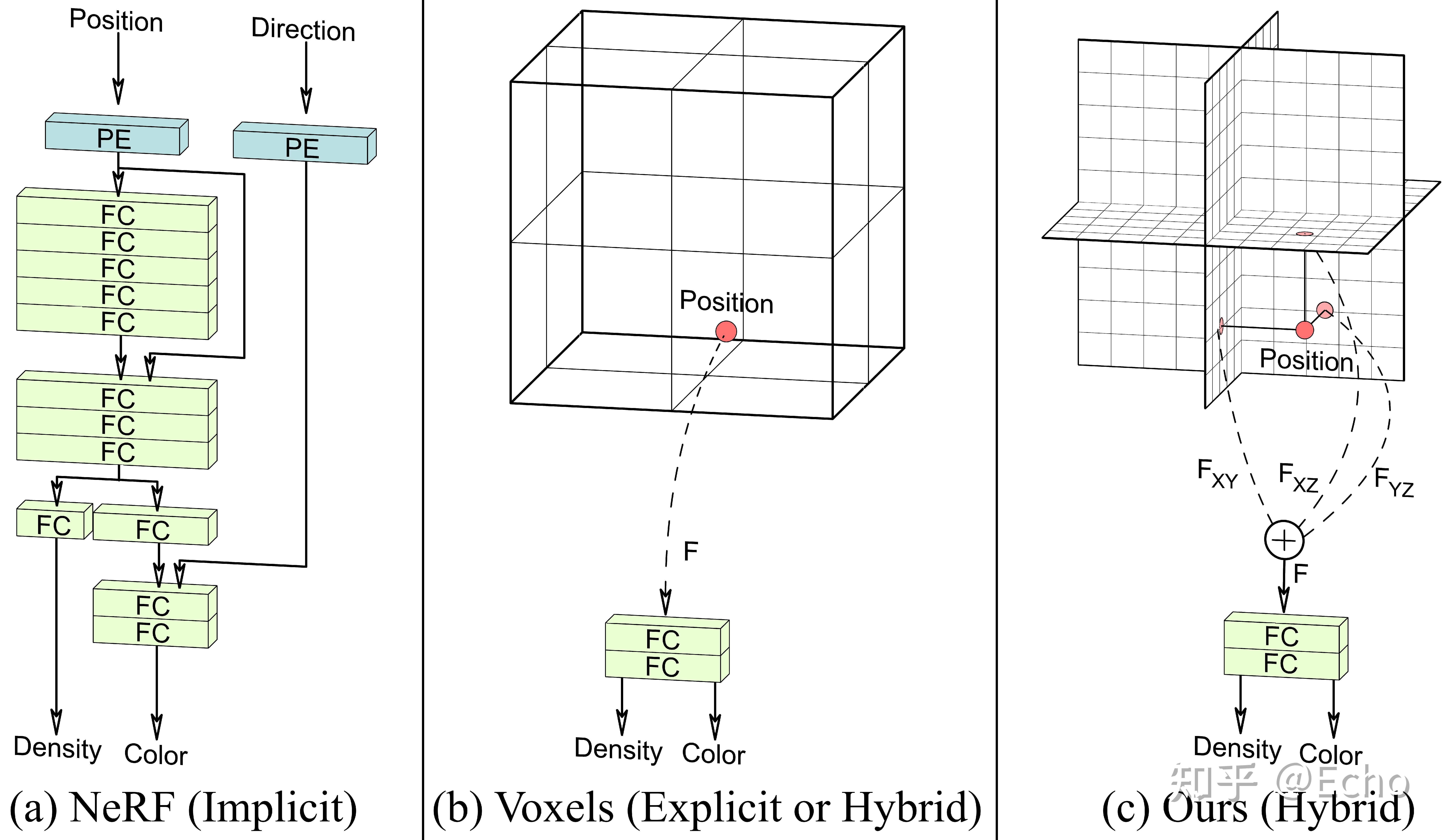
作者的目标是将EG3D生成模型的信息提炼到一个前馈编码器的pipline中,这可以直接将未定位的图像映射到一个规范的三平面3D表示,这里的规范表示,对于人脸,头部的中心是原点。该pipline仅需要单次前馈网络传递,从而避免了花销大的 GAN inversion过程,同时允许实时重新渲染输入的任意视点。
这篇工作提出了两个方法。首先,作者用显隐混合的方法,提高了时空效率,并有较高的质量。第二,提出了dual-discrimination策略,保证了多视角一致性。同时,还引入了pose-based conditioning to the generator,可以解耦pose相关的参数,保证了输出的视角一致性,同时忠实地重建数据集隐含的pose-correlated参数。
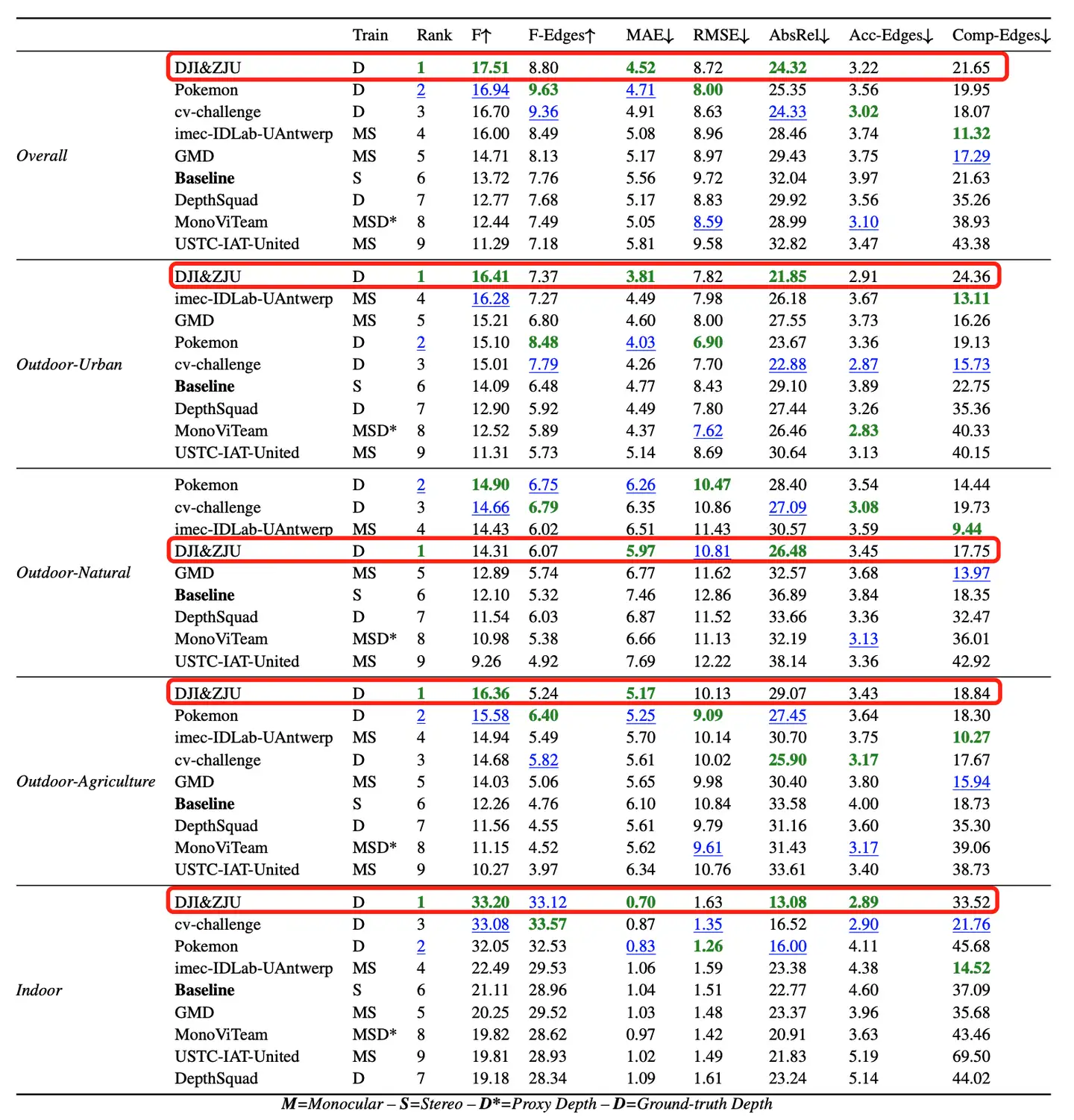
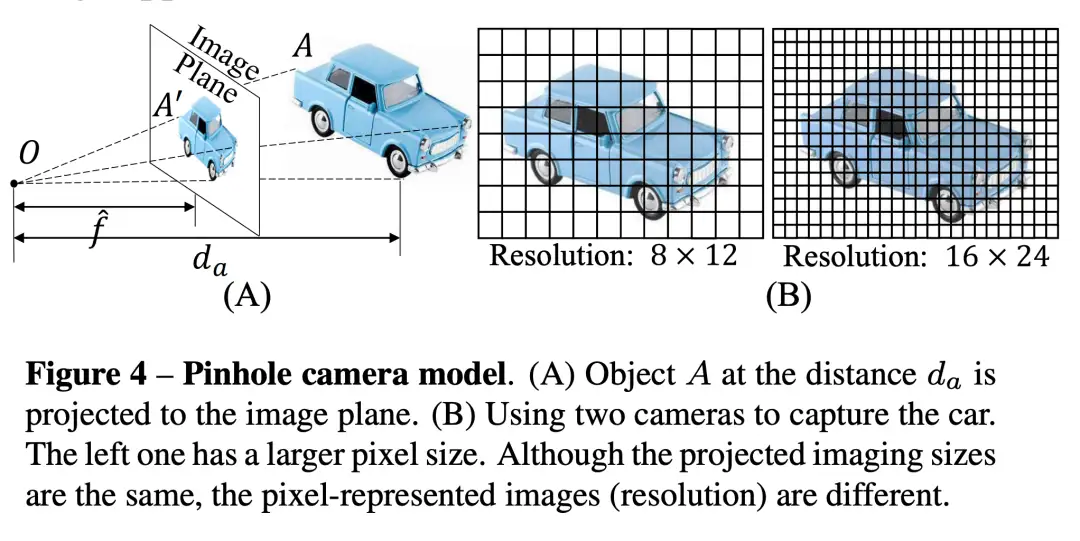
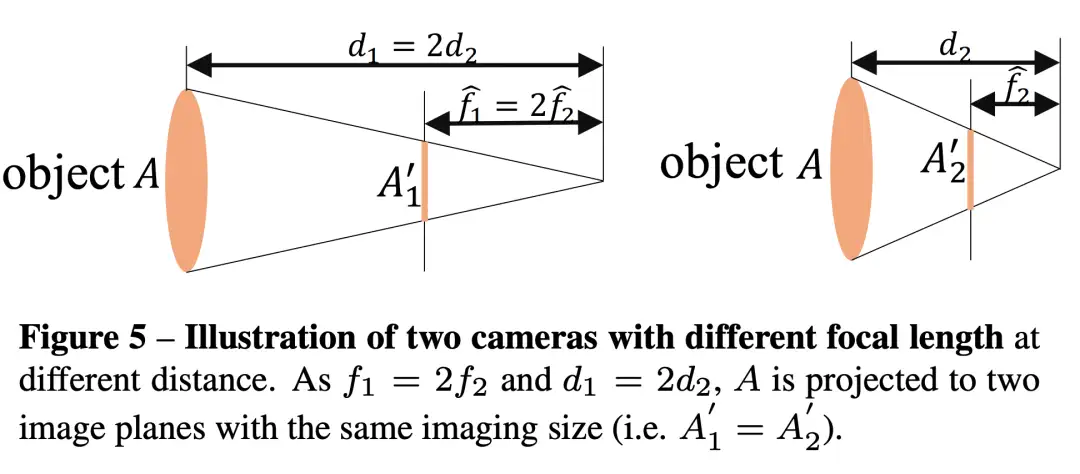
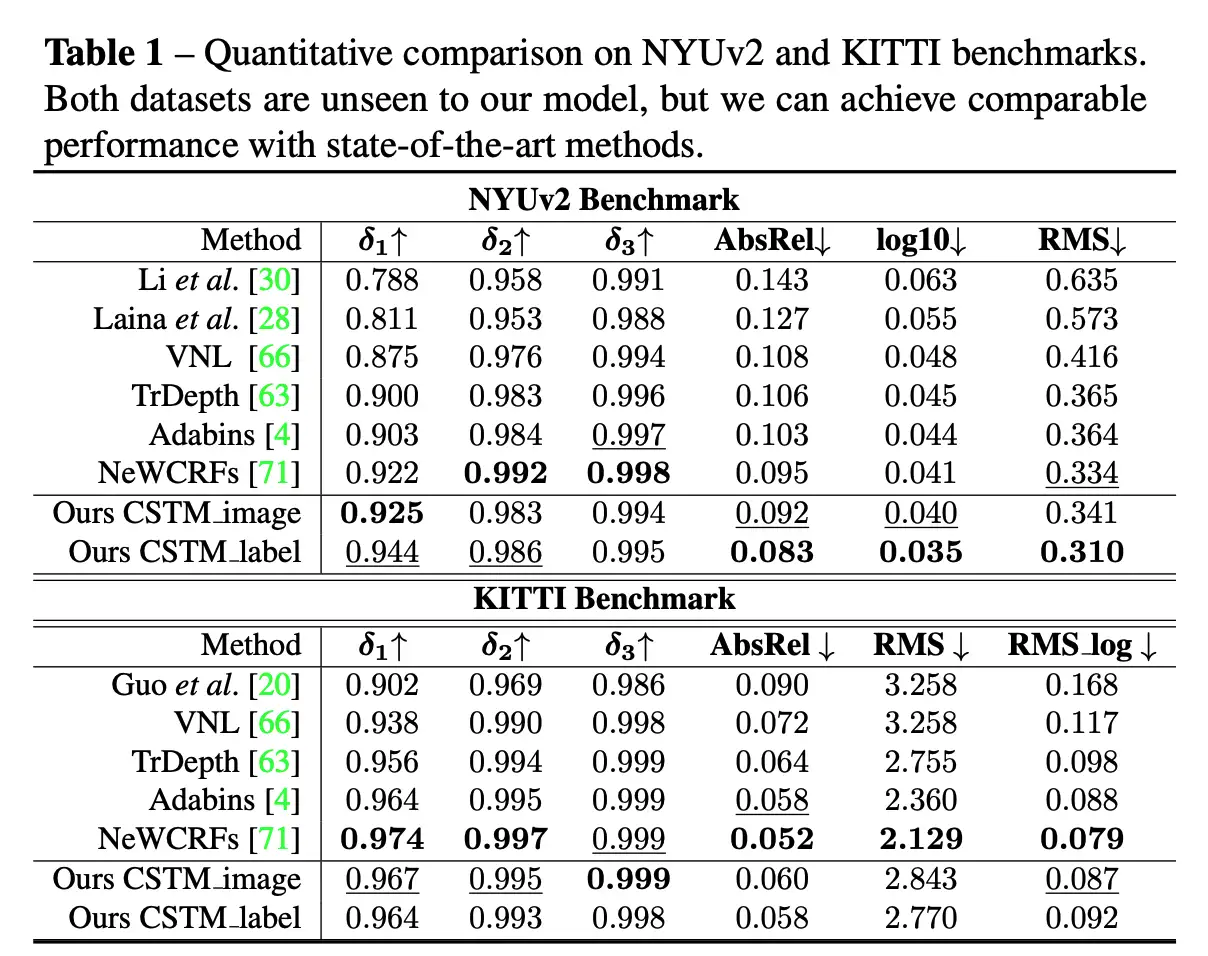
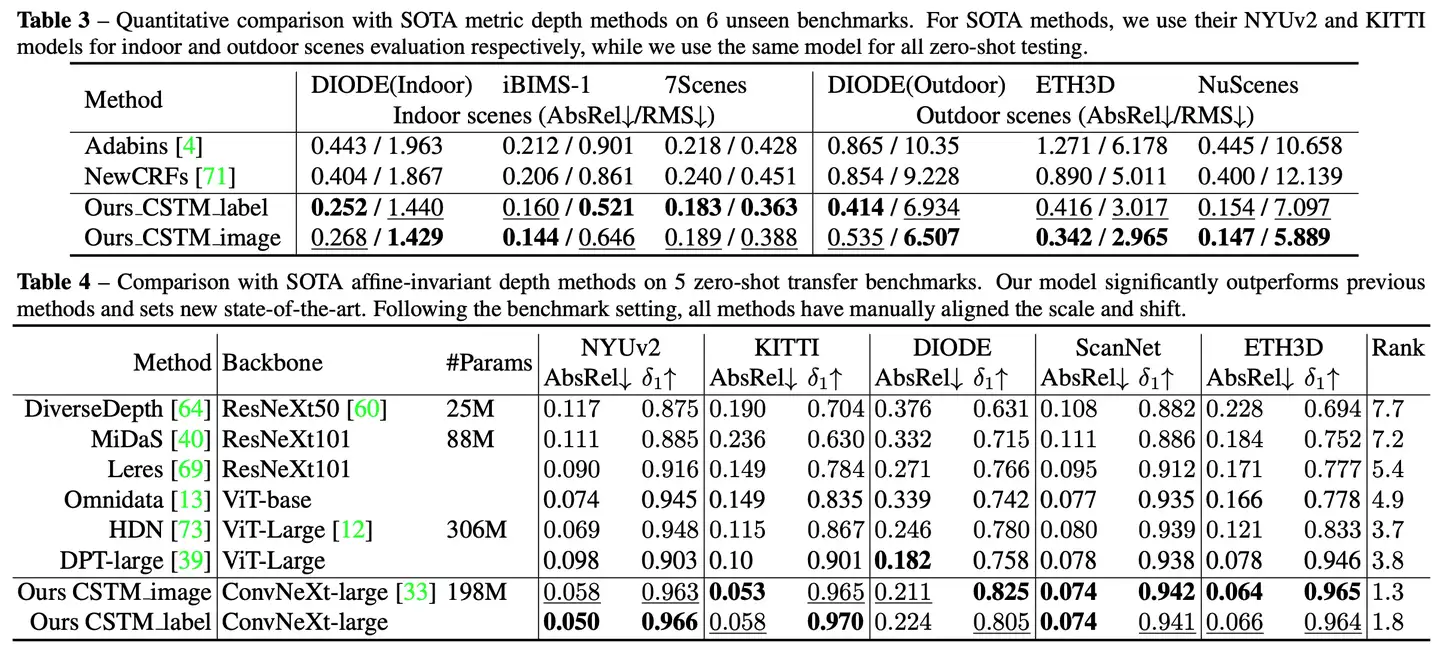
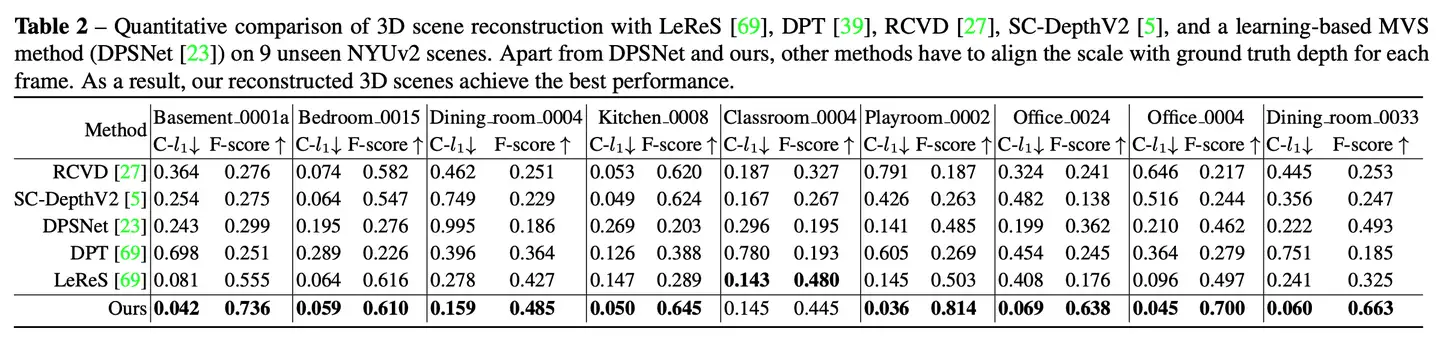
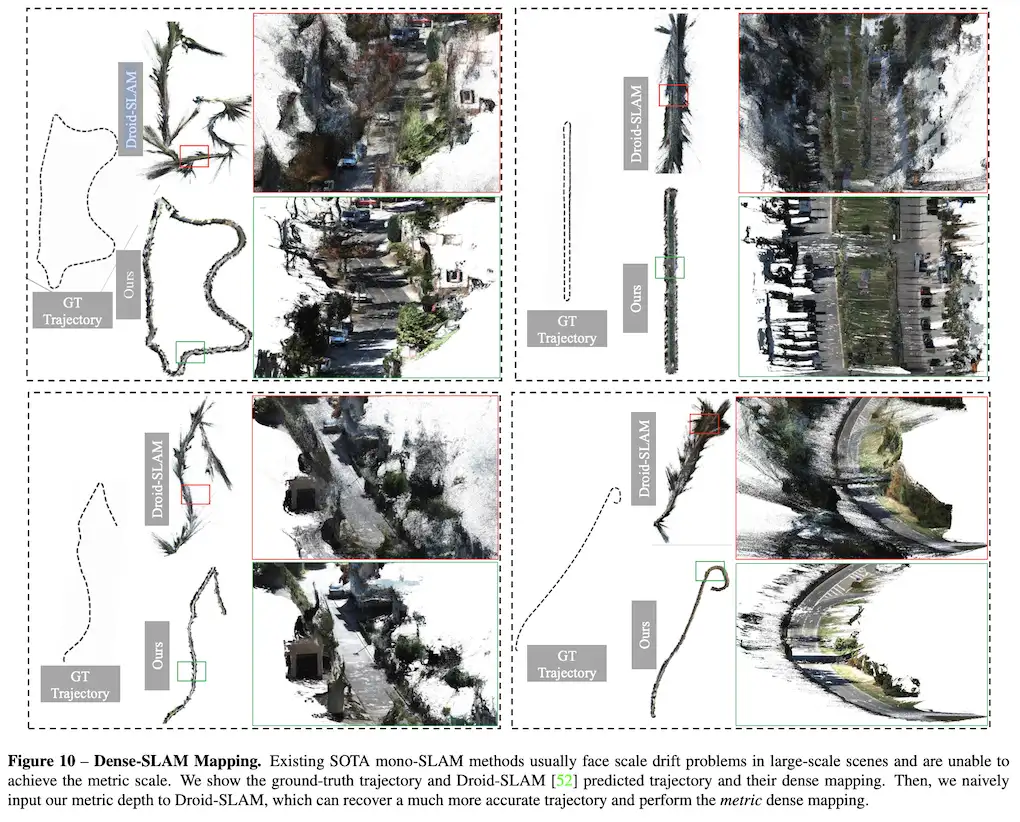
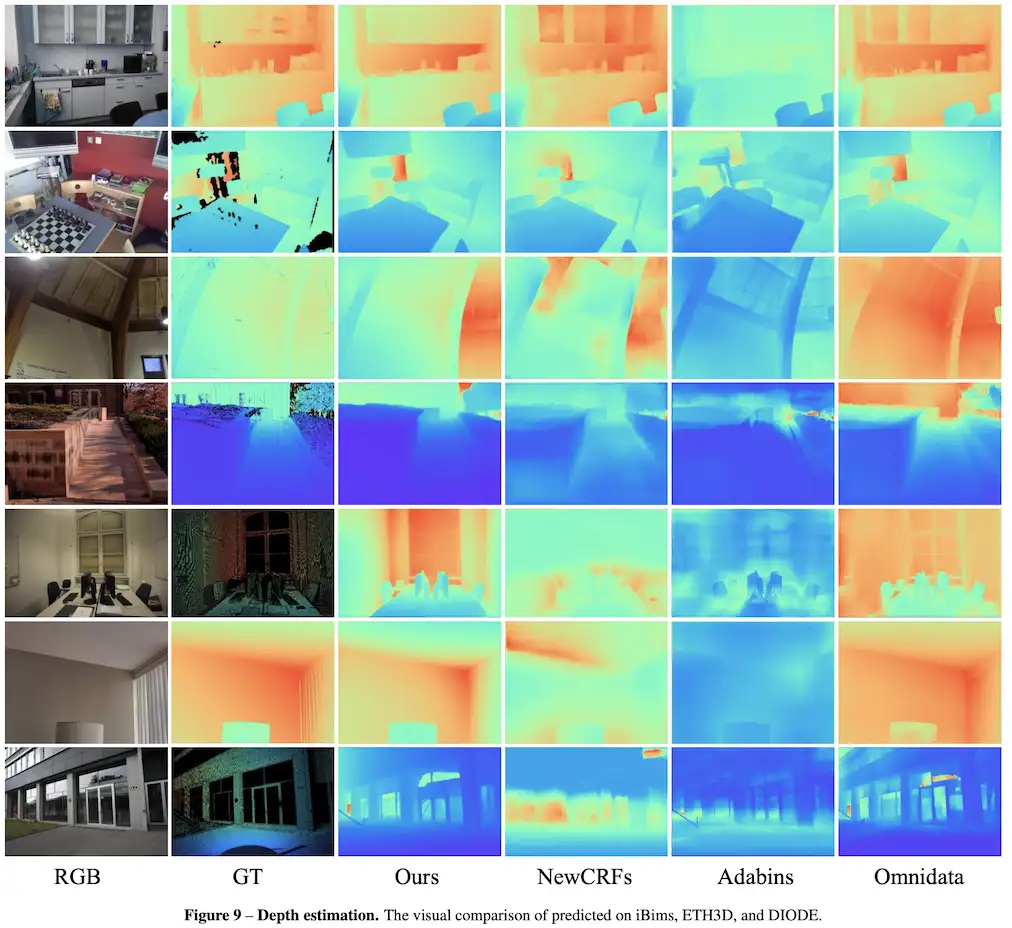
本文提出了一个统一相机空间(canonical camera space)变换模块,明确解决了尺度模糊性问题,并且可以轻松地嵌入到现有的单目模型中。配备了论文的模块,单目模型可以在800万张图像和数千个相机模型上稳定地训练,从而实现了对室外图像的零样本泛化,其中包含未见过的相机设置。该论文所提方法也是第二届单目深度估计挑战中的冠军方案,在比赛的各个场景上都排第一。
大家好,在这里给大家分享一下我们最近被 ICCV2023 接受的工作《Metric3D: Towards Zero-shot Metric 3D Prediction from A Single Image》。如何从单张图像恢复出绝对尺度的深度,并且重建出带有绝对尺度的3D场景是一个长期待解决的问题。当前最先进的单目深度估计具体分为两类:
在这项工作中,论文表明零样本单目度量深度估计的关键在于大规模数据训练以及解决来自各种相机模型的尺度模糊性。论文提出了一个统一相机空间(canonical camera space)变换模块, 明确解决了尺度模糊性问题,并且可以轻松地嵌入到现有的单目模型中。配备了论文的模块,单目模型可以在800万张图像和数千个相机模型上稳定地训练,从而实现了对室外图像的零样本泛化,其中包含未见过的相机设置。
提出了一种标准空间相机变换(canonical camera space transformation)和对应的逆变换(de-canonical camera space transformation)方法来解决来自不同相机设置的深度尺度模糊性问题。这使得论文方法可以从大规模数据集中学习强大的零样本(zero-shot)单目度量深度模型;
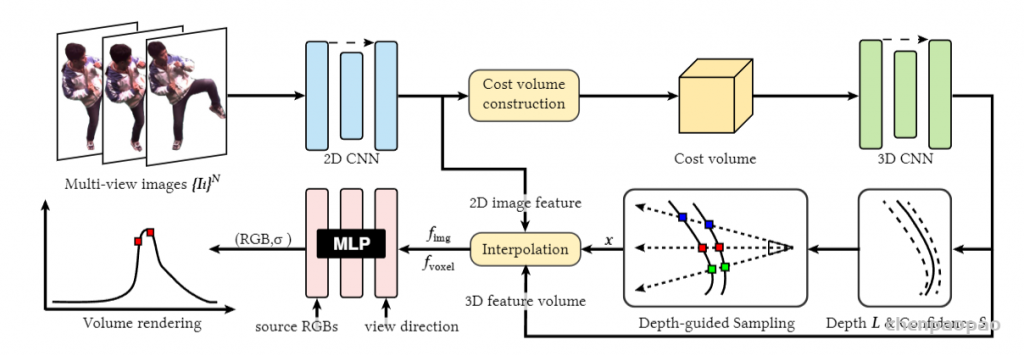
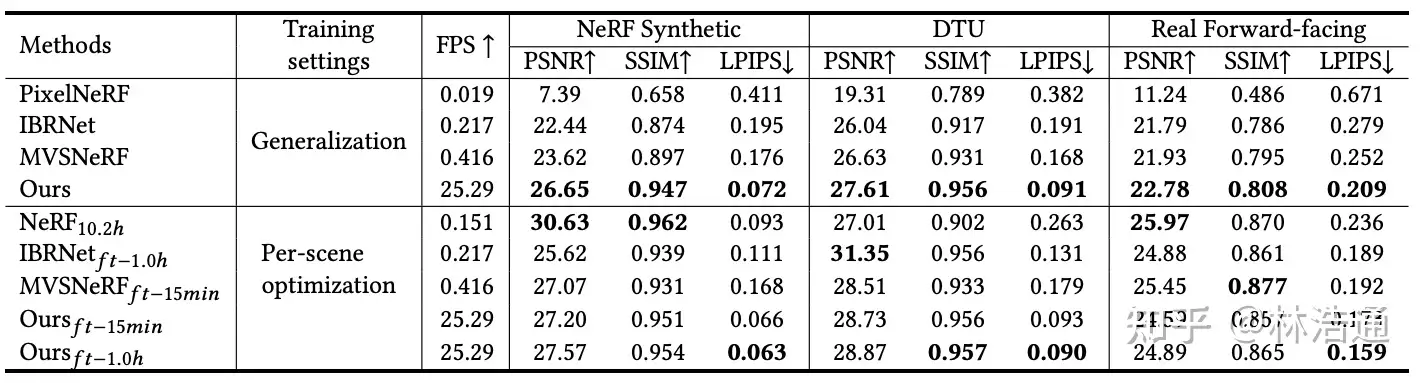
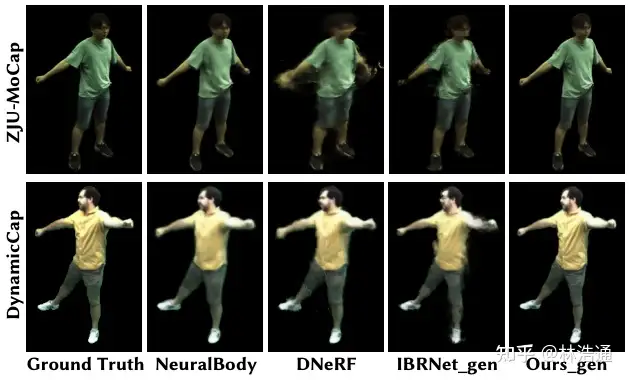
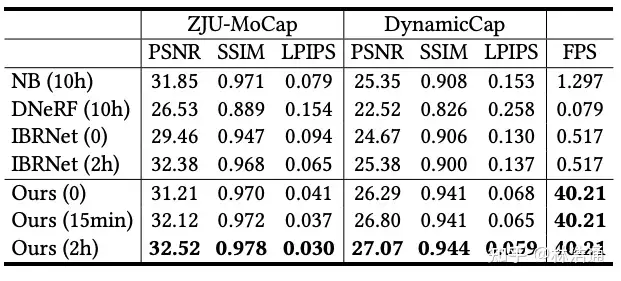
最近一些方法基于隐式神经表示,利用体渲染技术优化场景表示,从而制作自由视点视频。D-NeRF[Pumarola et al., CVPR 2021] 利用隐式神经表示恢复了动态场景的motions,实现了照片级别的真实渲染。但是,这一类方法很难恢复复杂场景的motions,他们训练一个模型需要从几小时到几天不等的时间。此外,渲染一张图片通常需要分钟级的时间。
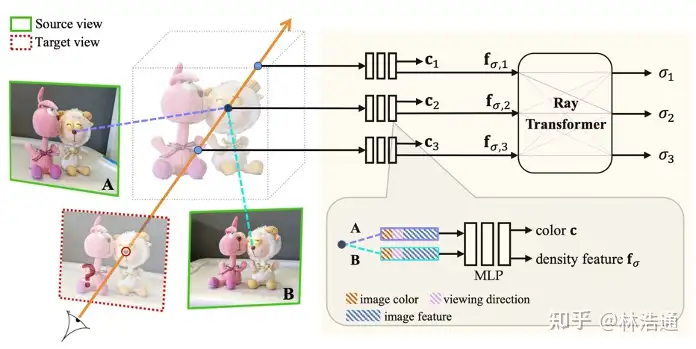
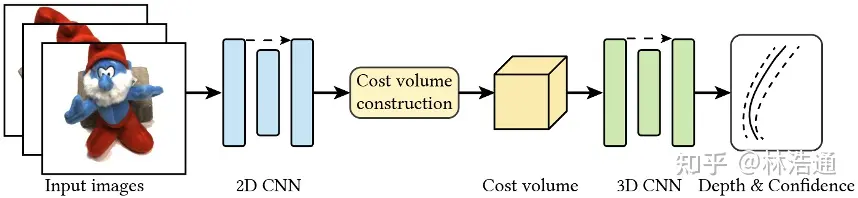
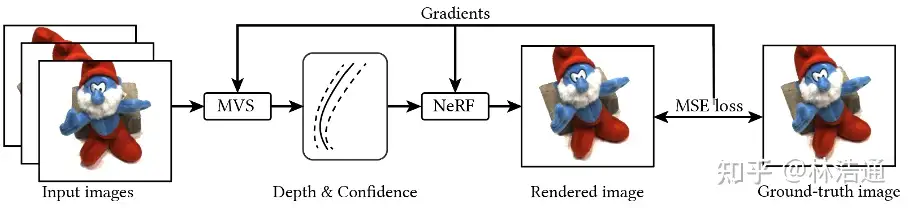
基于图像的渲染技术克服了以上方法的一些问题。第一,对于动态场景,IBRNet[Wang et al., CVPR 2021]能够把每一帧图像都当作单独的场景处理,从而不需要恢复场景的motions。第二,基于图像的渲染技术可以通过预训练模型避免每一时刻的重新训练。但是,IBRNet渲染一张图片仍然需要分钟级的时间。
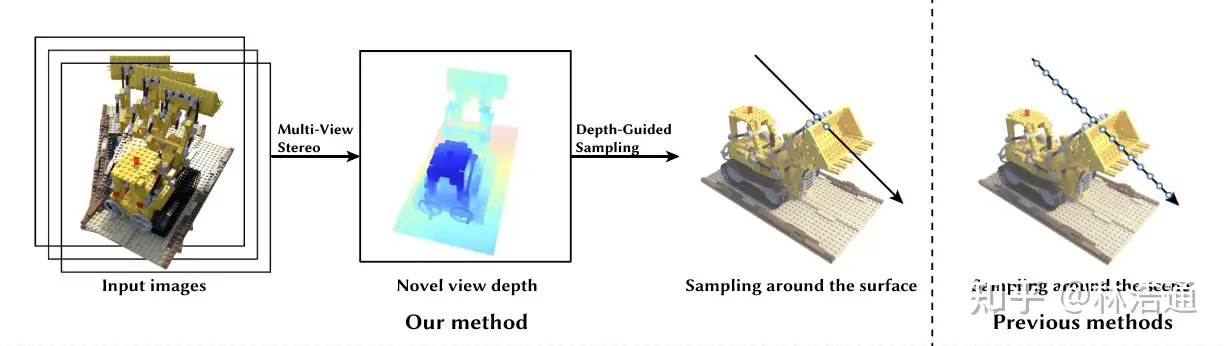
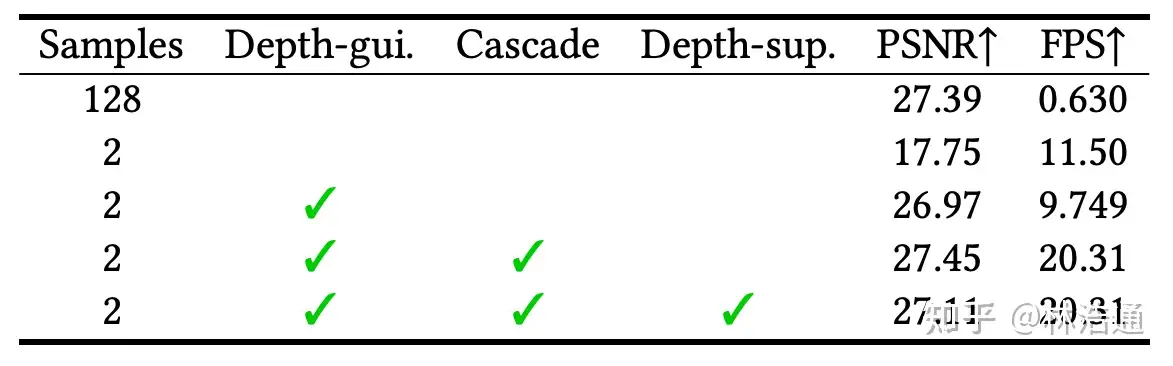
第一行展示了基线方法(与MVSNeRF[Chen et al., ICCV 2021]相似),每条光线采样128个点,这样有着好的渲染结果,但是渲染速度比较慢。直接降低采样点的数量后,会导致渲染质量显著下降。使用论文提出的采样方法(Depth-gui.)后,能提升渲染质量,同时基本保持比较快的渲染速度。
实际上这篇论文做了很多改进,比如对UNET也做了改进。但这里我们只关注 guidance 部分。 原论文的推导过程比较繁杂,这里我们采用另一篇文章 2 的推导方案, 直接从 score function 的角度去理解。
虽然引入 classifier guidance 效果很明显,但缺点也很明显:
需要额外一个分类器模型,极大增加了成本,包括训练成本和采样成本。
分类器的类别毕竟是有限集,不能涵盖全部情况,对于没有覆盖的标签类别会很不友好
后来《More Control for Free! Image Synthesis with Semantic Diffusion Guidance》推广了“Classifier”的概念,使得它也可以按图、按文来生成。Classifier-Guidance方案的训练成本比较低(熟悉NLP的读者可能还会想起与之很相似的PPLM模型),但是推断成本会高些,而且控制细节上通常没那么到位。
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. arXiv:2103.00020, 2021
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. 2021. arXiv:2105.05233.[2](1,2)
Calvin Luo. Understanding diffusion models: a unified perspective. 2022. arXiv:2208.11970.[3]
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. 2022. arXiv:2207.12598.[4]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: towards photorealistic image generation and editing with text-guided diffusion models. 2022. arXiv:2112.10741.[5]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. 2022. arXiv:2204.06125.[6]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. 2022. arXiv:2205.11487.