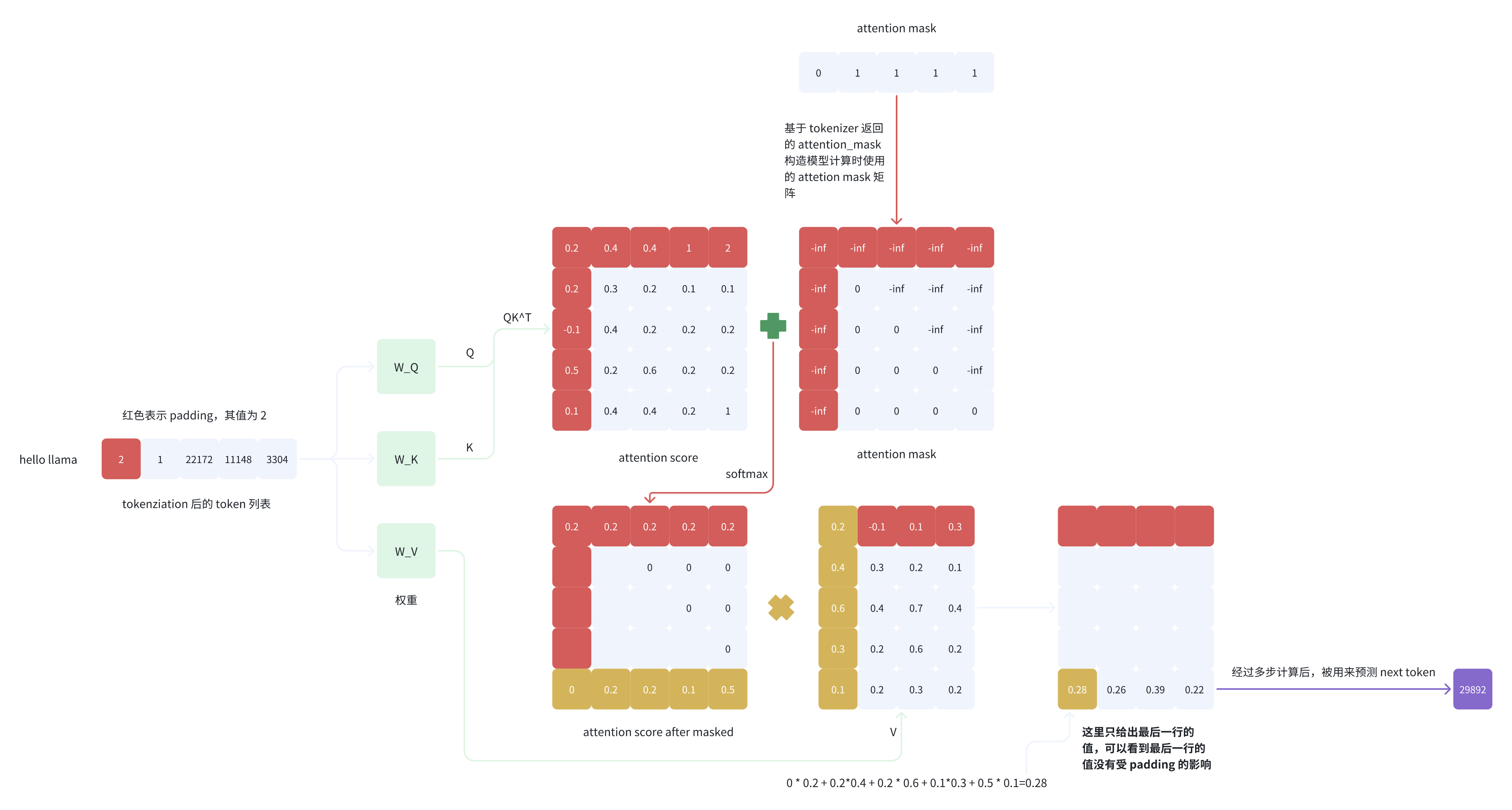
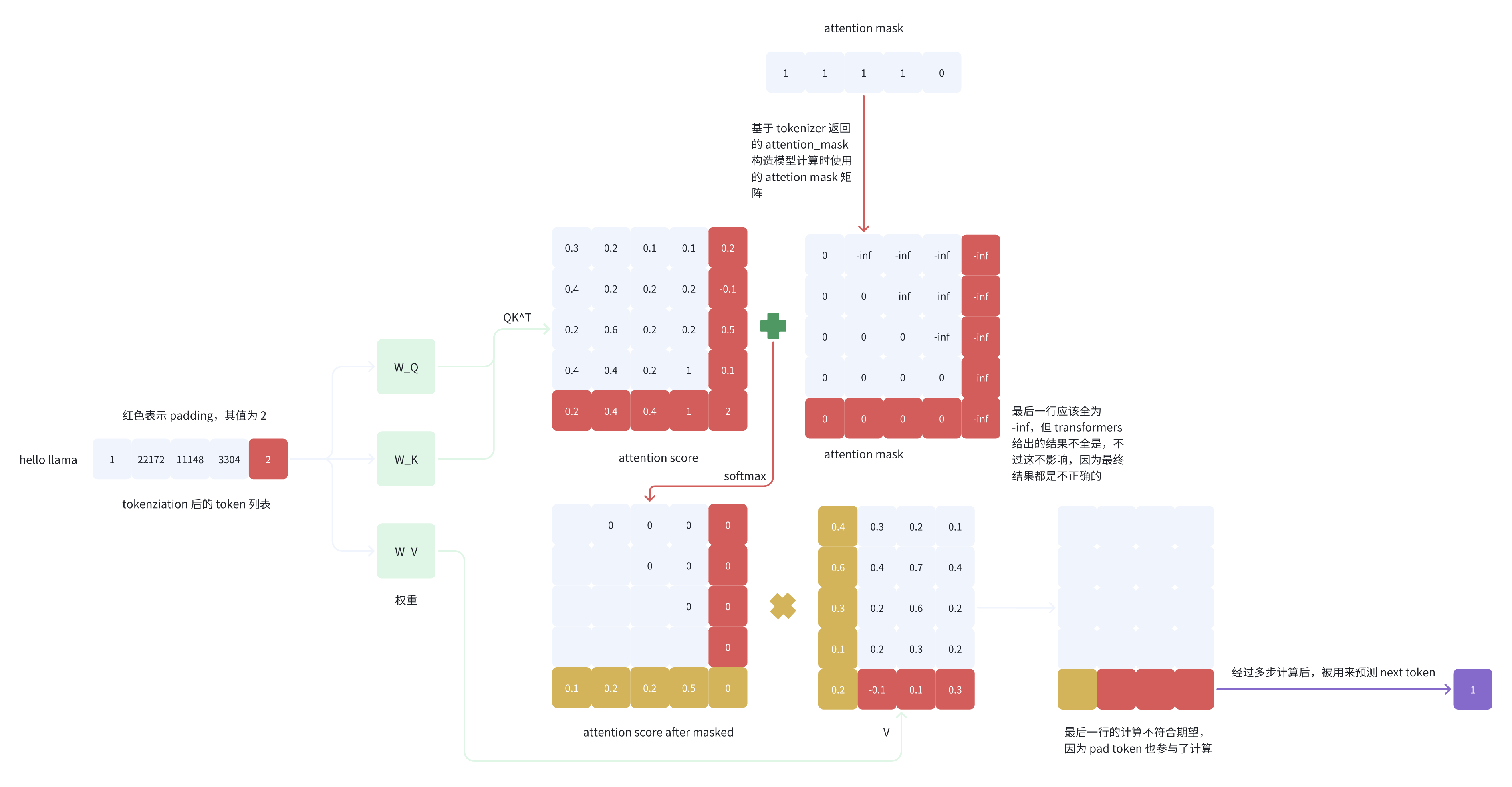
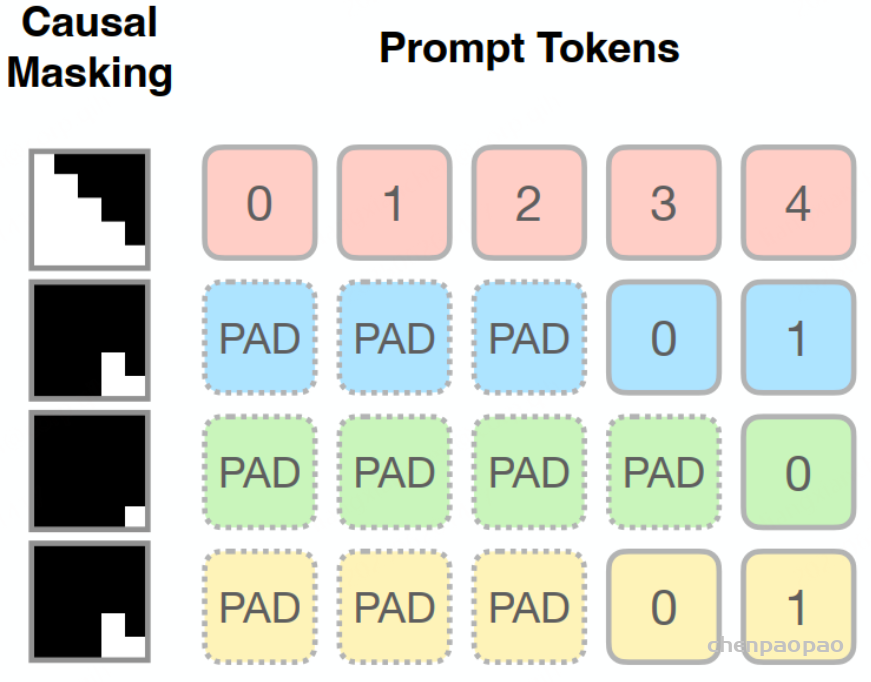
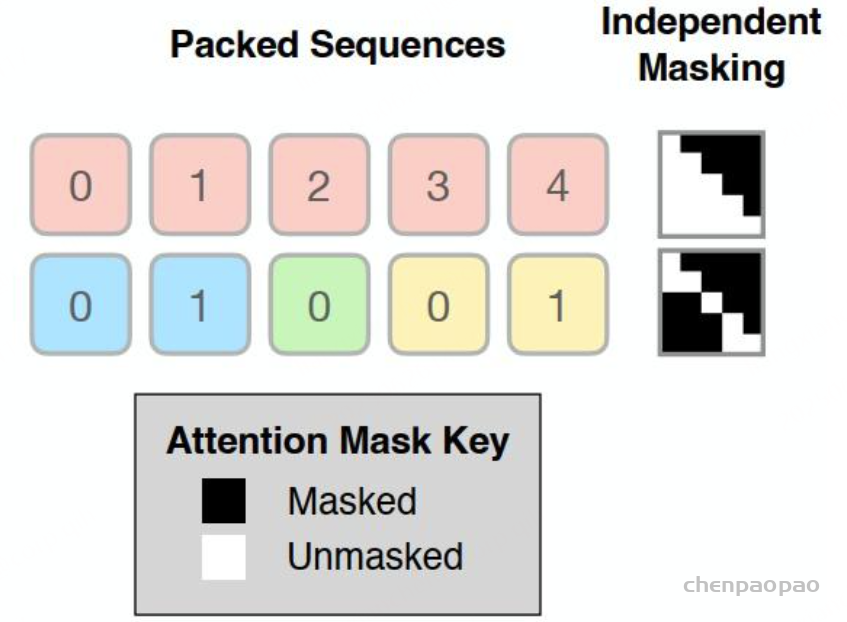
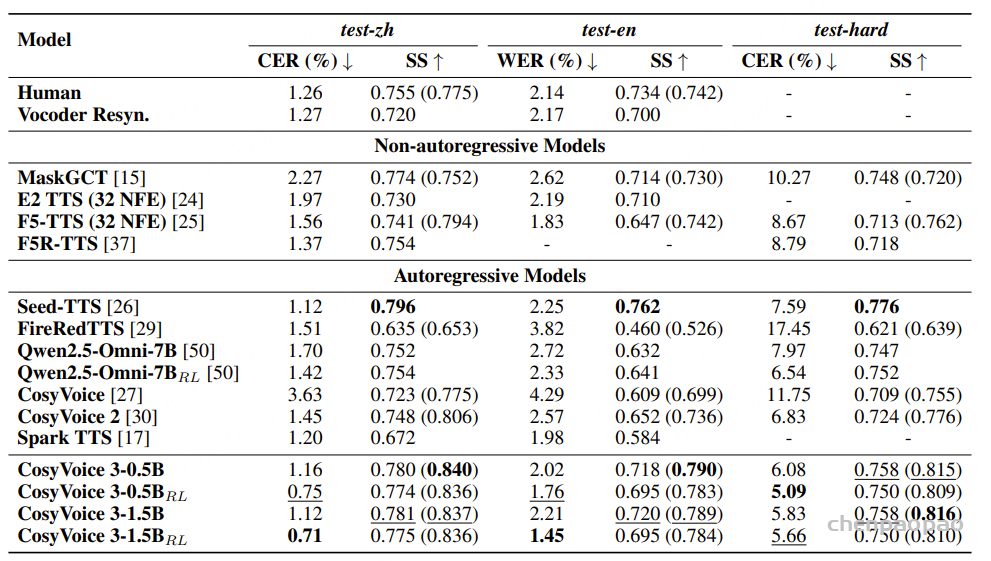
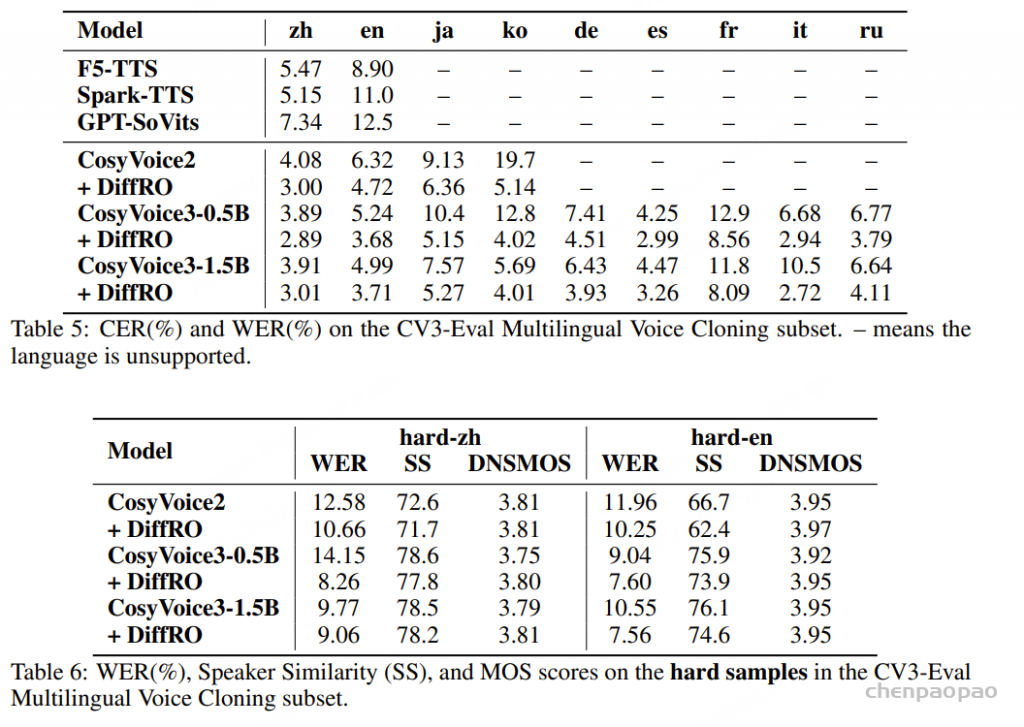
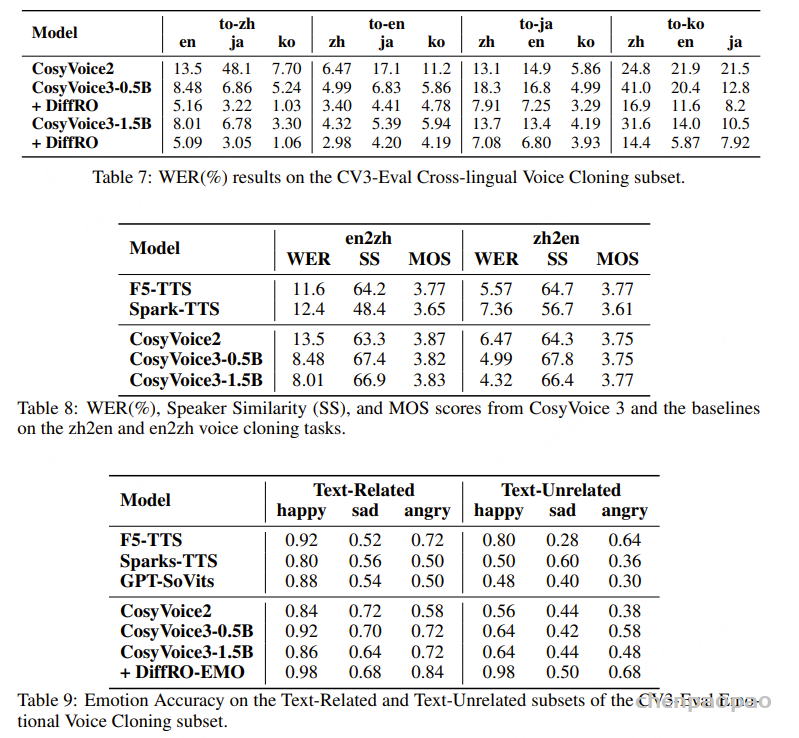
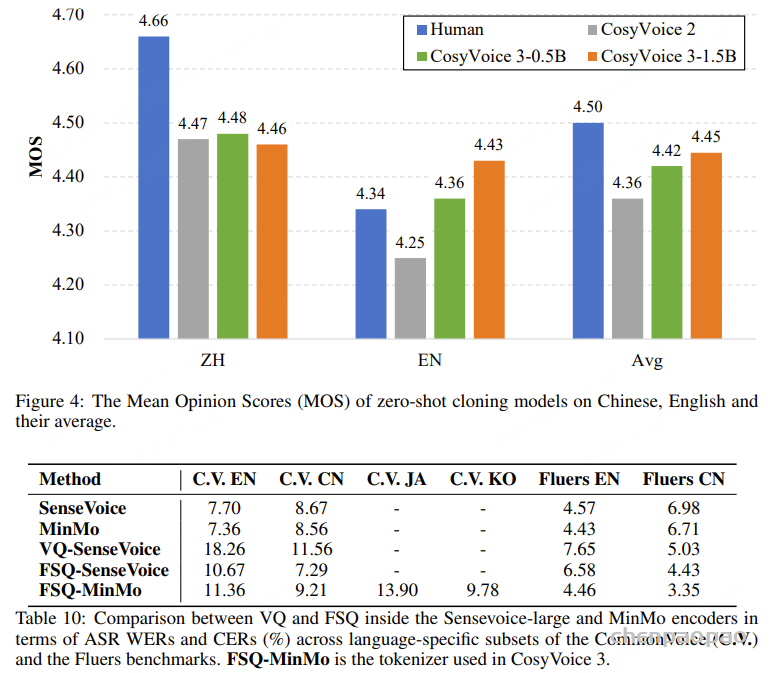
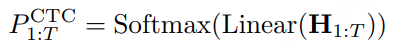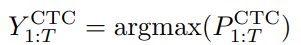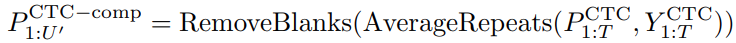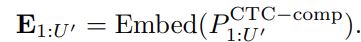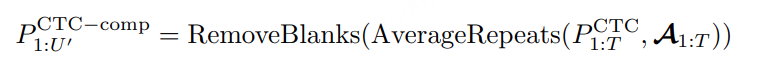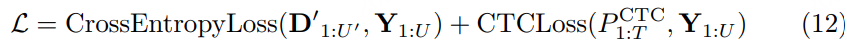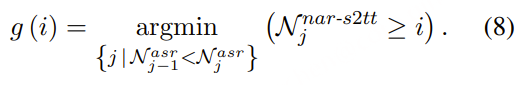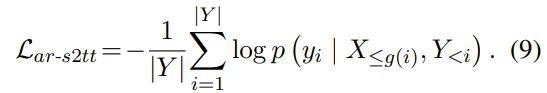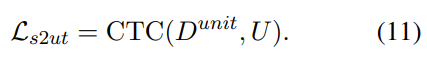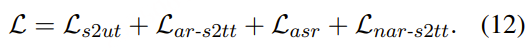原文链接:MindGPT-4o-Audio
理想实时语音对话大模型MindGPT-4o-Audio上线,作为全模态基座模型MindGPT-4o的预览preview版本,MindGPT-4o-Audio是一款全双工、低延迟的语音端到端模型,可实现像人类一样“边听边说”的自然对话,并在语音知识问答、多角色高表现力语音生成、多样风格控制、外部工具调用等方面表现突出,达到了媲美人人对话的自然交互水平。
核心功能
- 全双工语音对话:可同时听与说,告别“你说完我再说”的非自然交互模式,媲美真实人类对话;
- 低延迟:理解和生成推理延迟260ms,全链路峰值响应延迟800ms,联网搜索时全链路延迟2000ms;
- 语音知识问答:广泛学习海量高质量知识,具备高精度、低幻觉的知识问答能力;
- 多角色对话:多角色低成本定制,实现有灵魂、有温度的口语对话;
- 高表现力语音生成:情境感知下的高表现力TTS及口语化的语气词与副语言生成能力;
- 多样风格控制:多种特色风格、口音、IP人物的理解、控制及生成能力,稳定的多轮连续对话风格记忆能力;
- 外部工具调用:多模态任务规划和工具调用,支持实时联网的时效性问答。
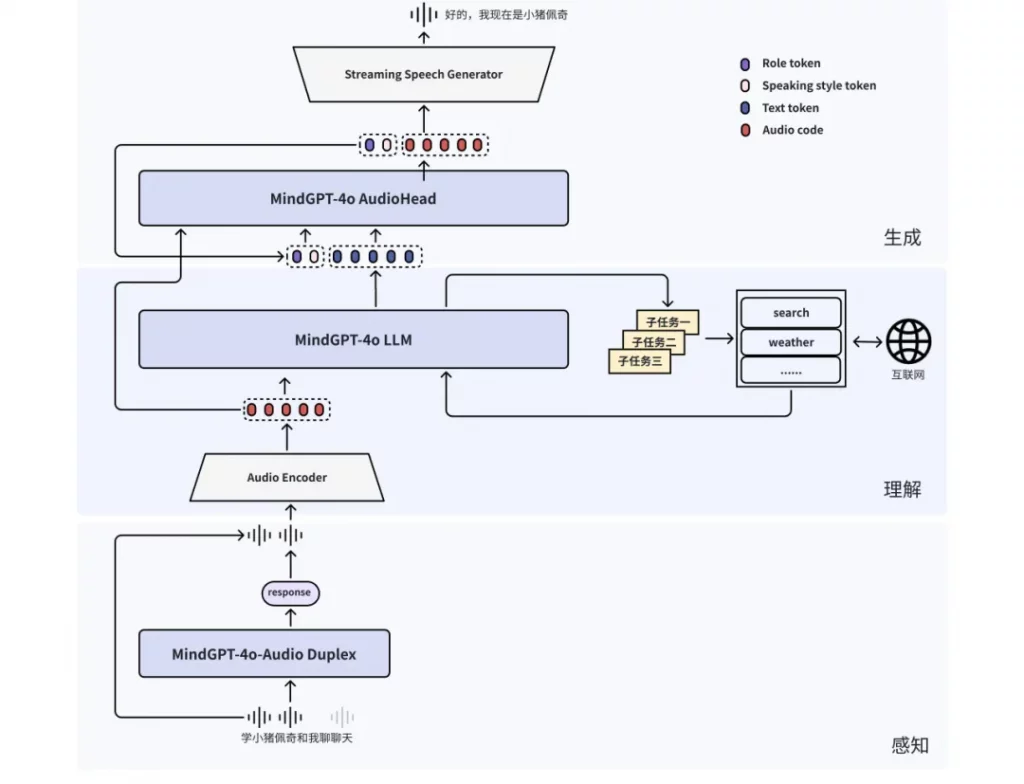
1. 模型能力
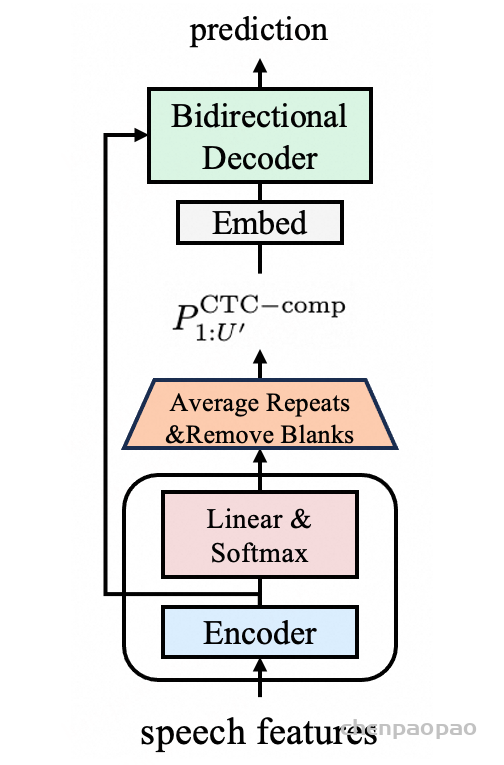
1.1 整体算法方案
MindGPT-4o-Audio是一款级联式的语音端到端大模型,我们提出了感知-理解-生成的一体化端到端流式生成架构实现全双工、低延迟的语音对话。其中:
· MindGPT-4o-Audio Duplex:感知有效语音输入,实现对话响应时机判定、打断判定、环境音拒识等功能;
· MindGPT-4o LLM :理解语音及语言模态信息,经MindGPT-4o-Audio Duplex判定为有效交互意图的音频,通过音频编码器(Audio Encoder)实现模态对齐后,由大语言模型(基于理想自研推理模型MindGPT 3.0)自主判定是否调用工具,最终完成信息理解并生成隐式token(角色/风格/文本隐式token);
· MindGPT-4o AudioHead:生成高自然度的语音,经MindGPT-4o LLM 生成的token流式输入 AudioHead 生成相应的Audio token,通过流式语音生成器(Streaming Speech Generator),最终生成多样化的风格及角色的口语化语音。
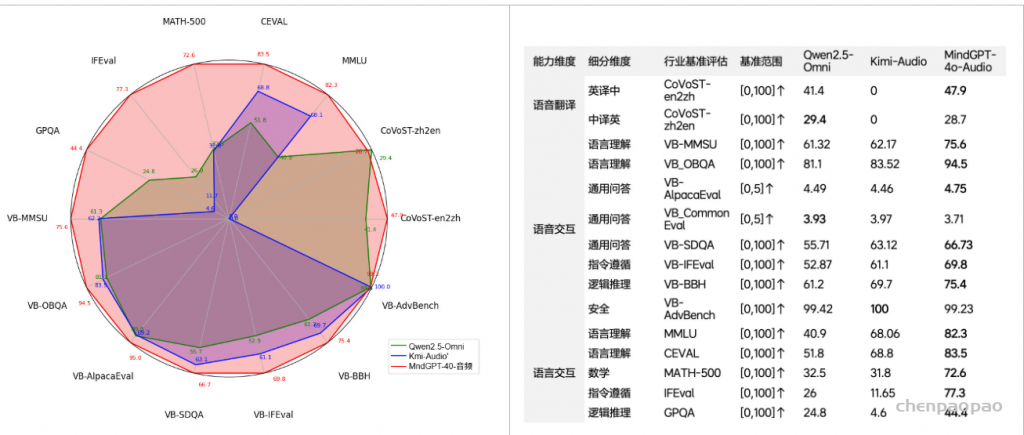
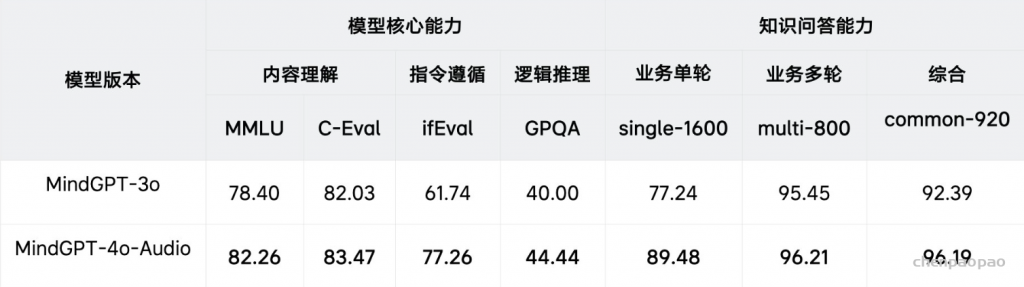
在各项权威音频基准测试以及语言理解、逻辑推理、指令遵循等语言理解任务上,MindGPT-4o-Audio 已达到行业领先水平,在语音交互评测基准VoiceBench多类评测中均显著领先行业领先的同类模型。此外,我们实验发现,业内主流的语音端到端模型一般会在提升语音交互能力的同时,造成语言交互能力的大幅下降,MindGPT-4o-Audio通过训练策略的优化保证了语言交互能力的高水准,在IFEval,GPQA等benchmark上平均领先行业20个PP以上。
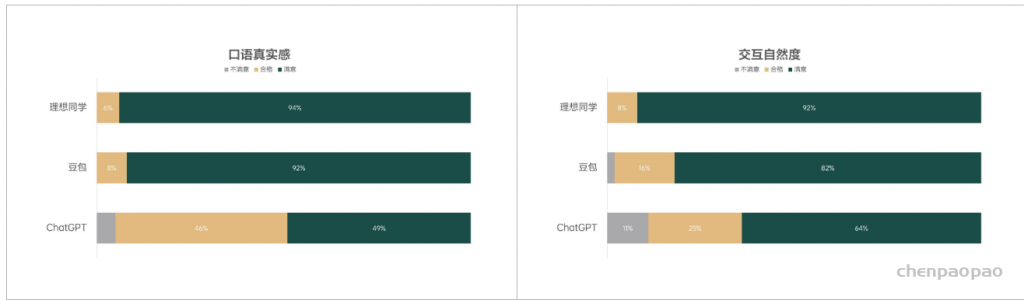
为了进一步评估理想同学与市面上优秀语音对话产品(豆包、ChatGPT)在用户体验方面的表现差异,我们组织了内部的用户对比评 测,从口语真实感(对话内容及表达的准确性及类人程度)、交互自然度(对话响应及全双工对话的流畅程度)两个方面进行设计。本次评测共邀请了24位不同年龄段的测试者参与,测试者需分别对理想同学、豆包及ChatGPT三款产品在选自真实对话场景的话题表现进行深度体验并独立进行评分。统计结果显示,在口语真实感方面,理想同学以94%的满意度占优,超越了豆包的92%;在交互自然度方面,理想同学继续保持领先,满意度达到92%。
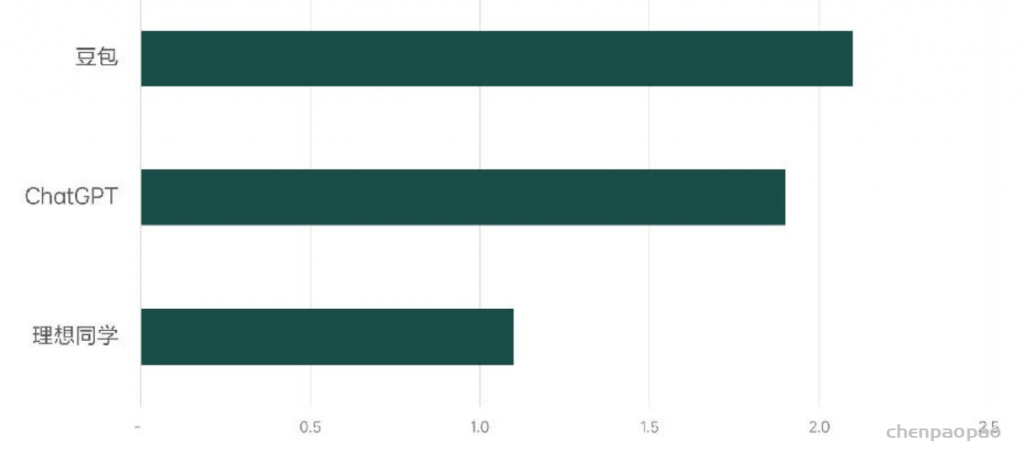
同时,我们也基于理想同学手机App进行了端到端响应延迟测试,整体端到端延迟约1100ms(注:此指标为考虑实际用户量及部署成本后的实测延迟),显著领先豆包的2100ms和GPT-4o的1900ms。
1.2 全双工语音对话:MindGPT-4o-Audio Duplex
为了让理想同学像真人一样与用户进行实时对话,我们研发了MindGPT-4o-Audio Duplex,实现全双工对话能力。我们的模型通过结合上下文联合推理实现了自适应响应、即时打断和环境背景干扰拒识能力。
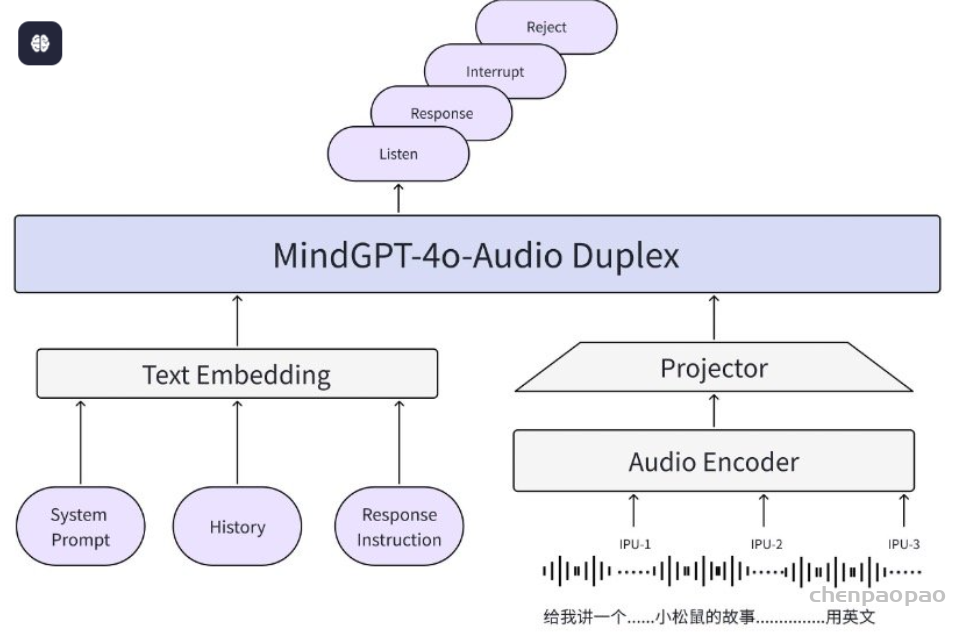
· 自适应响应:我们研发的全双工模型基于对话中的停顿间隙IPU(Inter-Pausal Unit)来判断对话响应时机,预测是否进行对话轮次转换,该方案可以减少碎片化计算节约推理资源,且能够避免在用户连续说话时打扰用户。同时我们提出了一种自适应响应时间机制KLT(Keep_Listen_Time),针对用户已完成的对话内容,如“今天有什么热门新闻?”进行快速响应,判定延迟低至150ms;针对用户犹豫不决的对话内容,如“我想要……” 以及对话轮次模糊的闲聊场景,如 “我今天心情不太好” 则自适应调整响应时间,等待用户继续说;全双工模型对话轮次切换准确率达到96.5%。

打断:全双工的关键能力是边说边听,在与用户对话的同时能够持续倾听用户。为了确保理想同学在接收到用户打断语音时,快速停止说话,避免对话重叠,我们采用了流式方案响应用户的打断,打断延迟低至1s。
· 拒识:同时为提升对话连续性,避免错误中断对话,针对用户Backchannel的附和,如“对对对”、“哈哈哈”以及背景噪声等场景进行拒识。
最终,MindGPT-4o-Audio Duplex打断响应率达到99%,Backchannel拒识率达到95%。

1.3 语音知识问答
为了让理想同学拥有行业领先的语音知识问答能力,我们建立了高质量的训练数据管线、高效率的模型能力训练管线,确保了语音知识问答多方面效果达到最优。
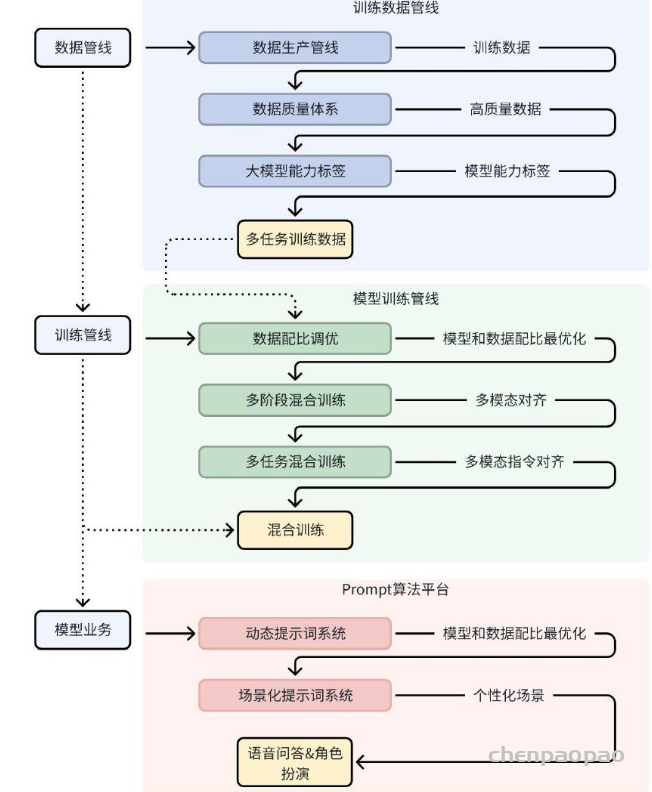
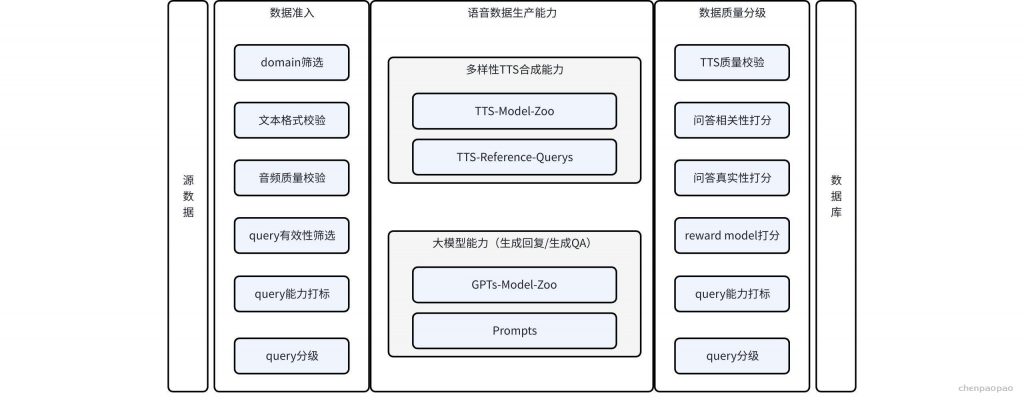
· 高质量训练数据管线:
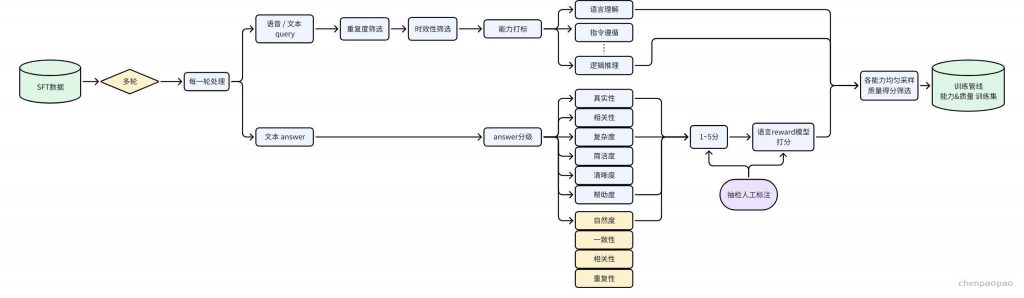
– 后训练数据生产管线:通过外部采集、模型蒸馏、日志回流、指令推理多种方式,生产种类和功能全面的数据,包含语音和文本混合多模态,场景覆盖大模型通用能力和业务场景。数据丰富度相对于之前有非常大的提升,高质量后训练数据达数百万量级;
– 后训练数据质量体系:通过奖励模型打分和人工抽检结合的方式,对数据进行多个维度质量打分。训练数据质量得到有效的确保,数据平均正确率达95%;
– 多模态模型能力标签体系:设计一套完整多模态数据能力标签体系,对训练数据进行能力标注和分类,实现训练数据种类的精确控制,以及训练任务效果的精确控制。多模态能力体系分三层优先级维度,26个能力类目;
· 高效率模型训练管线
我们从两个方面建设模型训练管线:
– 高效数据配比技术:选取最优训练数据规模和能力配比,达到性能和成本均衡最优化。最终实现任务能力100%覆盖,训练数据量相对冗余数据减少89%,模型训练效果相对有提升明显;
– 多阶段和多任务混合训练技术:
多阶段训练:将训练分为预训练(Pretrain)和后训练(Post train)两阶段。预训练阶段使用数百万小时语音数据进行模态对齐,实现语音内容的理解能力。后训练阶段使用语音文本混合数据进行指令对齐,实现多模指令遵循和内容理解能力。
多任务混合训练:将多个核心能力任务和业务能力任务混合在同一阶段训练。核心能力任务包含模态对齐、指令对齐、逻辑推理和内容理解等任务;业务能力任务包含角色扮演、多轮对话和检索增强等能力,实现模型同时提升核心能力和业务能力,并提升模型的泛化能力。
· 高满意度的知识问答效果
通过上述技术,我们提升了模型训练效果,提升模型的核心能力,包括内容理解、指令遵循和逻辑推理等能力;使用Prompt工程提升模型的业务能力,实现了业务快速更新能力;最终确保模型在知识问答和回复风格上达到高准确度,相比MindGPT-3o版本平均提升 6pp。
1.4 多角色对话
当前主流语音交互产品中,通用模型往往呈现出扁平、单一的性格设定,缺乏情感与个性,导致用户难以与其建立深度的沟通连接;而业内具备角色扮演型的语音产品虽然具备一定的语言风格,但由于通用知识能力和工具使用能力的薄弱,难以支撑更广泛的应用场景。为了打造更自然、更具人性化的对话体验,我们从两个核心方向出发:“人物设计” 与 “类人对话”,构建一个兼具情商、智商与工具调用能力的多角色对话能力。
· 角色档案的属性设计:有灵魂、有趣的人物
为打破传统模型中角色形象扁平、情感缺失的问题,我们精心构建了完整的人物设定系统。该系统涵盖十余个维度的大设定,每个维度下包含多个子设定,包括但不限于:
– 人物背景与成长经历
– 说话风格与口头禅
– 性格特征与情绪反应
– 兴趣爱好与价值观
我们的目标是让角色具备如真人一般完整、立体的个体属性。在数据构建上,我们围绕这些人物档案生成专属问答数据和基础人设问答数据。同时为确保模型具备强大的通用能力,我们还构建了覆盖广泛、多样性强的泛化数据集,所有角色回复都经过口语化处理,风格统一为符合角色设定的表达方式,从而增强角色的一致性与真实感。
· 角色数据的生产管线:有温度、有陪伴的对话
为实现拟人化的多轮对话体验,我们采集真实语音交互数据,并基于真实对话范式合成大量模拟对话样本。重点优化的方向包括:
– 情绪识别与情感表达能力
- 多轮对话的意图理解与上下文保持
- 自然、地道的口语化表达
- 主动引导与倾听陪伴能力
通过“拟人化角色设定”与“真实感对话交互”的双轮驱动,我们致力于打造一个既有深度情感连接,又具备实用智能能力的语音交互系统,为用户带来真正自然、有温度的陪伴体验,我们希望用户面对的不再是“一个工具”,而是一个能聊天、会共情、懂回应的朋友。
1.5 高表现力语音生成
为了提升理想同学声音的整体表达效果,我们对表达自然度、推理速度和发音精度三个维度对模型进行了大量的设计与优化。
· 表达更自然:我们验证了对话历史上文语音的引入能够显著提升模型的韵律表达自然度,预训练阶段我们采用了30万小时以上的自建大规模连续对话语音数据库,使得模型具备了对于上文语音语义信息的理解,从而有效提升了模型的韵律表达精度。此外,在副语言表现方面,不借助额外的副语言标签,而是直接通过自然语言文本对副语言进行自适应的理解建模,整体表达效果也更加自然,使理想同学在口语真实感和交互自然度方面,达到了领先水平。
· 反应更快:MindGPT-4o-Audio采用文本token和语音编码混合流式建模,模型生成的语音编码将即时输入音频生成模块转换为语音并播放。有别于传统的整句合成以及依赖文本前端的建模方式,该方案不增加任何额外计算开销,实现了真正意义的流式合成,做到“想到哪就说到哪”,将语音生成的首包整体延时做到了100ms以内。
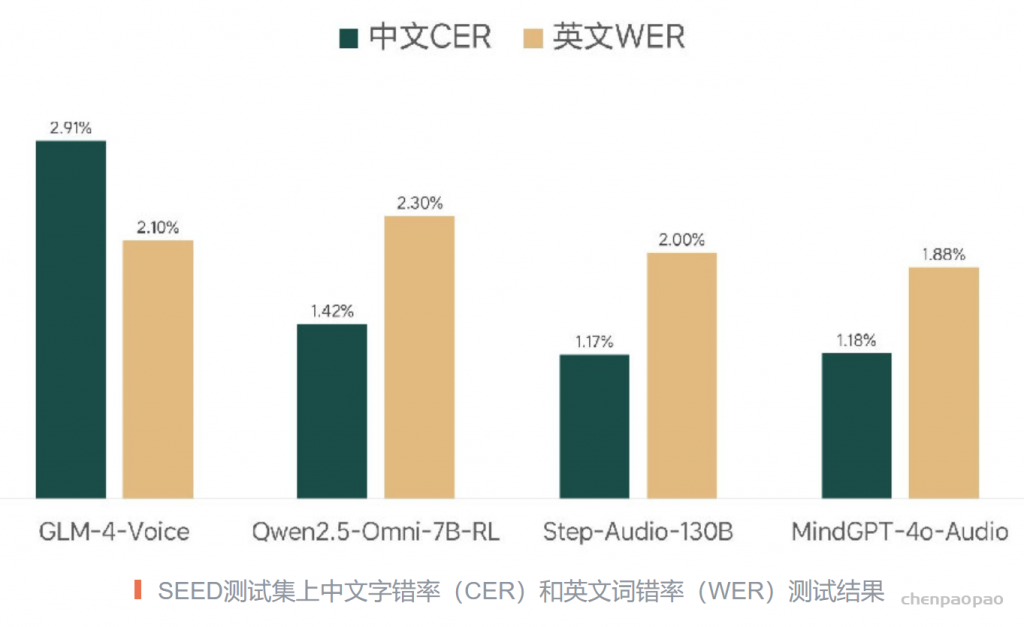
· 发音更准:模型整体采用了字符级别的建模方案,整体对于发音精度的挑战非常大,我们采用了多种优化策略来持续优化发音精度,包括文本CFG策略、phoneme信息引入、文本正则以及长尾数据增广、DPO优化等方案。最终实测在中文、英文测试集上,发音错误率达到了极低的水平。
1.6 多样风格控制
除了让理想同学具备高表现力的对话合成效果外,我们还赋予了理想同学风格控制的能力。我们希望理想同学能够支持特色风格、口音的扮演能力,同时具备风格的多轮记忆能力。
· 丰富的风格扮演能力:MindGPT-4o-Audio即使在使用默认音色的情况下,也可以根据需要模仿不同的风格、口音。要做到这一点,往往从训练数据上就同一个发音人具备多风格和口音的演绎能力,因此实现难度大,成本高。基于此,我们重新设计了音频编码方案,在最大程度保留韵律表现力的基础上,完成音色信息的解耦,实现风格控制及韵律建模,使得模型具备了各类型情绪演绎、风格扮演和口音模仿能力。
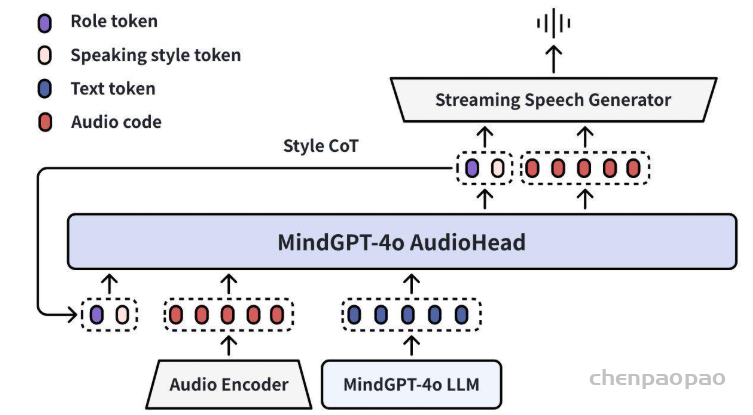
· 语音指令控制能力:MindGPT-4o-Audio还支持显示的语音指令控制,模型具备对多种语音语义指令的泛化性理解,为了提升模型对于风格指令的遵循能力,我们引入大语言模型里的CoT(Chain-of-Thought)技术,设计出了Style CoT方案,模型将先对当前风格信息进行预判,再将其作为输入生成语音,该方案进一步增强了模型对于风格的控制生成能力,使模型能够遵循指令实现风格演绎扮演、语速、语调的调整。另外,大多数的语音交互方案对于风格的触发基本都是单轮触发,缺乏风格的多轮记忆能力,不能做到多轮的风格遵循以及强度等级的风格控制,风格CoT的引入,使得模型具备了对于多轮风格的指令遵循及强度控制能力。
2. 工具能力
为了支持时效性问答、提升知识问答效果,我们基于MindGPT-4o-Audio研发了多模态任务规划和工具调用能力。
2.1 多模态规划
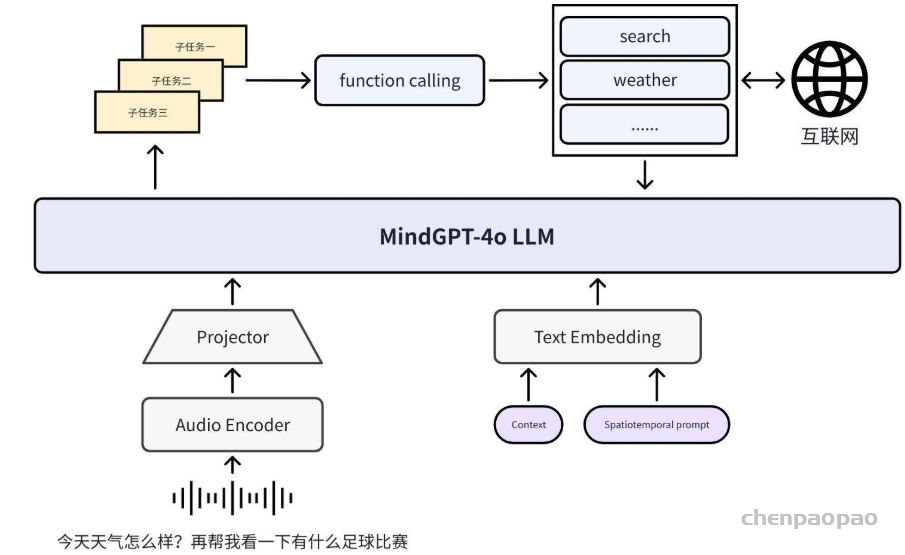
我们实现了MindGPT-4o-Audio的多模态任务规划和工具调用能力,输入语音、文本多模态信息,输出任务和工具调用结果。
· 在任务规划方面,支持多轮对话和时空感知能力,能根据历史上下文信息和当前的时间、位置信息,规划合理任务。比如“现在的金价是多少”,任务规划为“2025年6月6日的金价”,“周末了,给我推荐几个遛娃的地方”,任务规划为“推荐北京市适合遛娃的地方”,然后,将规划出的任务形成DAG(有向无环图)表示,可建模单步任务、并行多任务、多步骤任务之间的拓扑关系,能很好支持复杂任务的规划。
其中,我们建立了高效的智能体后训练数据管线,按照业务维度和能力维度进行数据的构造,使用大模型泛化、线上真实数据回流、人工生产等方式,实现对话全场景的全数据覆盖。我们还设定了严格的数据准出体系,通过模型打分、人工质检的方式对数据进行清洗,确保高质量数据的比例;在训练管线上,我们按照模态和任务的双维度进行科学的数据配比,按照课程学习的思路逐步提升模型从简单任务到复杂任务的规划能力。
· 在工具调用方面,我们使用function calling技术来实现这一能力,并通过一系列工作提升模型对工具选择、参数遵循的能力。
其中,我们的数据管线首先通过清洗高质量开源数据集,获取一批通用工具数据集,然后针对内部业务工具,参考MetaTool的数据构造格式,比如直接泛化生成、关键词生成、细节生成、重复问题处理等方式,构造符合业务需求的工具数据。此外,为针对性强化模型对参数类型和参数格式的指令遵循能力,我们针对性构造区分度不明显的工具数据;在训练管线上,我们进行两阶段训练流程,先进行SFT作为冷启动,让模型初步具备工具调用能力,然后采用RL-DPO,增强模型在工具选择和参数遵循上的能力。
我们实现的多模态任务规划和工具调用在链路延迟和效果上,均有优秀的表现。在链路延迟上,根据语音输入直接进行任务规划,减少了传统链路额外语音识别的时间开销,端到端响应延迟显著领先豆包和ChatGPT;多模态任务规划在业务测试集上准确率达到95.55%;工具调用能力在业务测试集上准确率达到94.25%。在通用工具调用benchmark上,我们也达到业界一流水平。

2.2 工具调用
我们支持知识搜索、体育赛事查询、影视娱乐查询、新闻查询、天气查询、股票信息查询、交通限行信息查询、日历查询、油价查询、汇率查询、商品信息查询等工具,模型解决问题的能力大大提升。
特别在搜索效果优化上,针对多来源信息冲突矛盾、内容丰富度不足等常见问题,我们上线了更细粒度的原子化知识层级(Claim-level)的重排序,以及基于知识推理的扩展搜索技术,大幅提升内容真实性和完整性。理想同学不仅能够获知更实时的热点事件,还能更准确理解专业术语,问答效果显著提升12%。
· 传统搜索技术,以网页搜索为例,一般采用NDCG@k、Precision@k、MAP等评估指标,侧重在粗粒度文档层级衡量效果,无法反映出多文档在细粒度知识层面上的内容重复、遗漏、冲突及错误问题。RAG场景下,搜索结果整体输入大模型,对文档偏序关系不敏感,更需确保在观点层面知识的正确性与完整性。针对这一本质性差异,我们提出Claim-level Rerank技术,通过将多条搜索结果,细化为原子化知识单元Claim的集合,并定义Claim F1值作为RAG搜索的核心评估指标,即关注全部搜索结果中正确Claims的召回率和精确率。我们验证了Claim F1值与大模型RAG问答效果的相关系数达到0.212,较传统搜索的Precision@k指标的相关系数提升2.6倍。
· 面对时效性强、知识密集型或者语义模糊的用户查询时,传统搜索工具,通常面临三大技术瓶颈和挑战:
知识滞后性:大模型依赖静态训练数据,难以应对新兴名词、专业领域术语、突发实时热点事件;
语义鸿沟:用户查询存在拼写错误、概念混淆时,传统模型缺乏验证纠错机制;
扩展同质化:基于语义的朴素扩展方法易产生重复或无意义结果,搜索结果未增加有效信息。
为解决以上问题,我们融合知识图谱增强和MindGPT 3.0的思维链推理能力,实现动态Query理解框架,具备多角度、差异化的改写扩展搜索能力,分钟级覆盖热点事件,搜索结果丰富度提升35%,专业术语识别准确率提升47%,复杂Query无需用户澄清,首次搜索满足率提升28%。
为真实评估理想同学与市面上优秀语音对话产品(豆包、Kimi)在工具调用端到端回复的表现差异,我们从任务维度和场景维度设计并执行了一项用户对比评测。测试者需分别对理想同学、豆包和Kimi三款产品在这些对话场景中回复结果的真实相关性进行评测。统计结果显示,理想同学在不同复杂度任务的对话场景上均优于豆包和Kimi。

3. 安全对齐能力
我们致力于建设符合通用价值观、中国普适价值观、理想同学自身价值观的MindGPT-4o-Audio,为此设计了完备的大模型安全对齐体系,根据MindGPT风险浓度差异,深度融合系统级防御能力和大模型安全对齐能力,使得MindGPT-4o-Audio在满足通用能力显著提升的同时,保持价值观回复能力安全、可控。
· MindGuard:在输入阶段识别用户输入的风险意图,Mind Guard会对高风险的语音输入进行检测拦截;在输出阶段,Mind Guard对极端风险进行识别和拦截,避免风险内容展现给用户;为了不影响语音端到端实时效果,输入和输出安全检测均采用边生成边检测,发现风险进行仲裁;
· 风险领域完备性:开发价值观攻击模型对MindGPT进行自动化、持续性攻击,自动化攻击帮助我们完善安全体系的已知风险领域。对于未知风险领域,安全对齐团队与公司安全团队redteam合作,持续收集各种新增、长尾的风险数据,同时线上日志挖掘也是安全体系新风险扩充的重要一环;
· 安全对齐:PTST、价值观CoT SFT等方法有效降低安全对齐所需的数量,显著提升价值观思考过程有效性和最终回复的无害性,MindGPT-4o-Audio在具备强大的安全推理和思考能力的同时,降低对通用指标的负向影响;
· 价值观安全奖励模型:基于自有安全体系的安全回复准则构建rule based和model based价值观奖励模型,应用于MindGPT-4o-Audio预训练、后训练、安全自动化评估等全生命周期,显著提升了安全对齐的效率和效果。
4. 工程能力
为打造 MindGPT-4o-Audio 高品质的语音交互体验,我们在 MindGPT-3.0 对话系统的基础上全面升级,围绕全双工、低延迟进行了深度优化。其中全双工方面,我们主要应用端云结合的 RTC 通信技术;低延迟方面,我们探索了端云全链路流式架构 + 流式推理技术。
4.1 基于 RTC 的全双工架构
传统的轮次(Turn-based)对话架构只能实现半双工能力,即用户输入和模型回复只能交替进行;而我们借助 RTC 技术,将整个对话架构升级为全双工系统,模型能够在“说话”的同时,实时“听到”当前用户正在说什么,结合模型能力,实现了真正的全双工语音对话(能够实时打断、被打断、甚至“抢话”等能力):
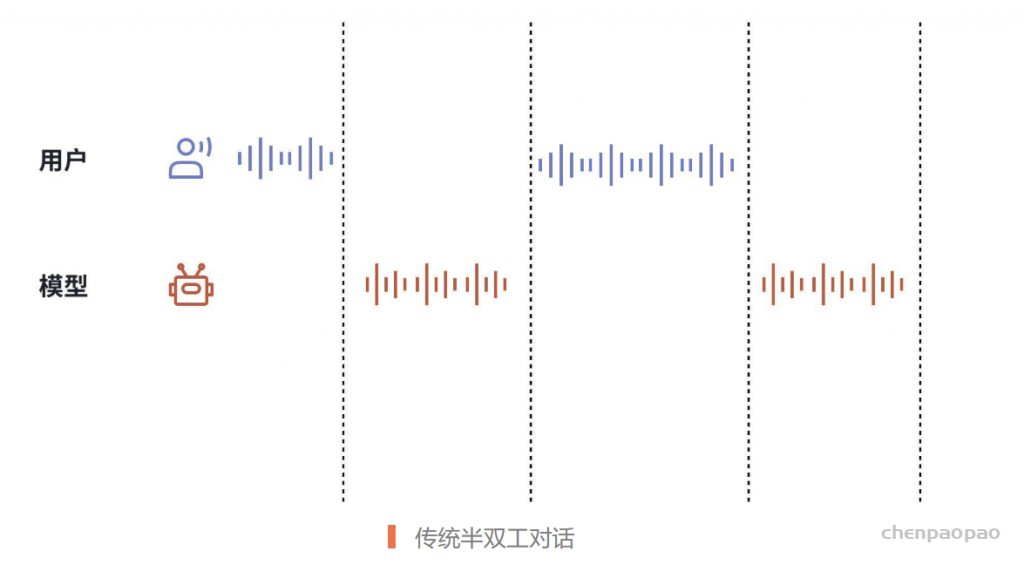
· 传统的半双工对话,往往依赖于 VAD (Voice Activity Detection)等模块实现下述过程:
– 收声,如检测到用户声音,停止上一轮模型回复的播报;
– 检测用户说话结束,将整段音频作为模型输入;
– 模型生成回复,在端侧调用 TTS 播放;
– 重复 a-c。
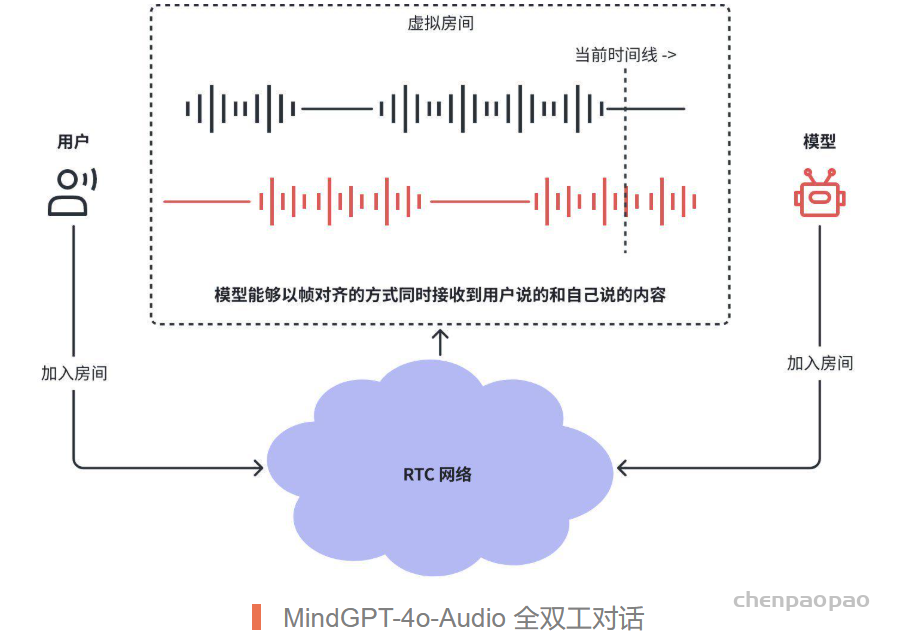
· 基于 RTC 的全双工对话,模型能够自己“说”的同时,“听”到用户在说什么,实时判定是否要停止说话(被打断),或者开始说话(打断用户或者正常接话)
– 为用户和模型生成一对一的 RTC “房间”,用户和模型都加入房间;
– 模型实时按帧对齐的,收听用户说的话,以及当前自己说的话;
– 模型自主判定,什么时候打断或被打断 (是否继续播放回复或者停止播放回复)。
4.2 全链路低延迟优化
我们分别在网络接入层、服务架构层、模型推理层进行了低延迟的深度优化,力求达到更自然、流畅的人机交互体验:
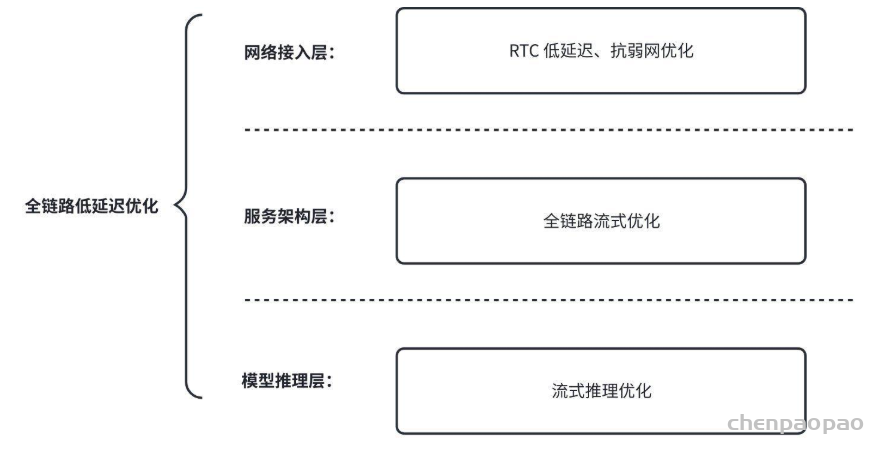
· RTC 低延迟、抗弱网优化:
– 低延迟:与传统通信技术(如 websocket)相比,我们采用 RTC 技术,通过弱网补偿、骨干网优化、音频编解码优化等手段,显著降低了通信延迟的同时仍能确保较高品质的音质,平均消息到达延迟下降 67%。
– 抗弱网:通过 RTC 抗弱网技术,我们能够在弱网环境下仍然保持较高的连通率及通话音质,相对传统技术,RTC 信道在较高丢包率的网络环境下仍能保持较流畅的通话体验。
· 全链路流式优化:传统的对话架构在处理多模态信息时往往不够优化:存在 ASR -> LLM -> TTS 级联结构,语音识别结束后才进入大模型推理,大模型推理后才能进入语音合成,存在显著的级联延迟。我们基于 MindGPT-4o-Audio 多模态的能力,消除了级联结构,并在全链路(网络接入、业务逻辑、模型推理等)各个服务层级实现了音频全流式传送,尽可能的将流式音频及时送达各服务模块并启动预计算,实现全链路通信和计算的重叠,从而显著降低了延迟水平。
· 流式推理优化:
– 重叠计算:针对语音模态输入,我们在全链路流式的基础上,重叠了多个模块的推理过程,如双工判定模块和生成模块、文本 Prefill 和 AudioEncoder 模块等;流式推理优化后首 token 延迟从 1s 降到 20ms,语音生成的首包从 500ms 降到 60ms;
– P-D分离 + 多级调度:基于 P-D 分离的思路,将多模推理分解成 AudioEncode、Prefill、Decode 等多个阶段,并且针对不同阶段进行定制的调度策略优化,如 AudioEncode 使用 Static Batching 调度,Prefill 使用 Chunked Prefill 调度,Decoder 使用 Continuous Batching 调度,保证推理性能最优,高并发时仍然可以保持推理延迟在几十毫秒量级;
– 异构计算:推理服务异构计算架构,针对多模推理各阶段的算力需求和并发特点,将其分别部署到异构型号的 GPU 上,以最优化利用机器资源,降低延迟的同时降低了部署成本;对比非异构计算版本,推理成本降低 50%。
4.3 Prompt 平台
此外为了更好支撑业务定制及运营,我们上线了高灵活度的Prompt平台,持续确保业务质量:
· 动态提示词系统:建设一套基于原子指令和组合的动态提示词系统,针对语音大模型定制一套对话系统提示词框架,实现语音对话和知识增强问答能力,增强对话遵循和知识推理能力。使得在线推理格式与模型训练格式100%匹配,同时增加模型认知、模型安全和用户环境信息等核心业务指令遵循能力,确保业务能力覆盖 100%。
· 场景化提示词系统:使用链路信号自动感知技术,实现了场景流量自动圈选能力;并且对圈选的场景定制特定功能提示词框架,确保模型整体功能稳定,实现了场景个性化能力。支持全链路个性化效果定制,可以做到T+0分钟级快速热更新,指令任务达成率 > 95%。
· 角色扮演场景化:使用场景化提示词,实现自动感知角色扮演场景,在模型推理中使用不同提示词框架,使模型输出具有当前场景个性化的角色回复风格。目前上线个性化场景7个,后续可快速更新和新增场景,场景平均达成率 >90%。