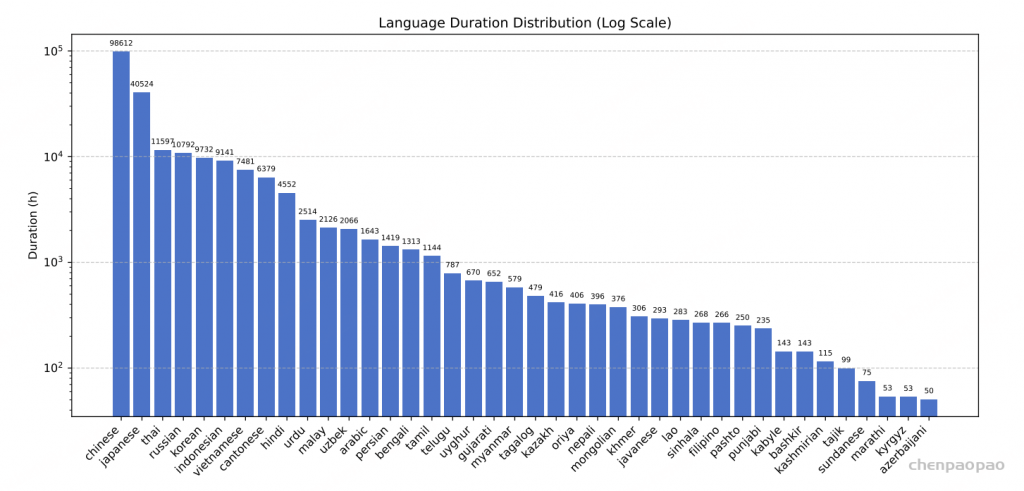
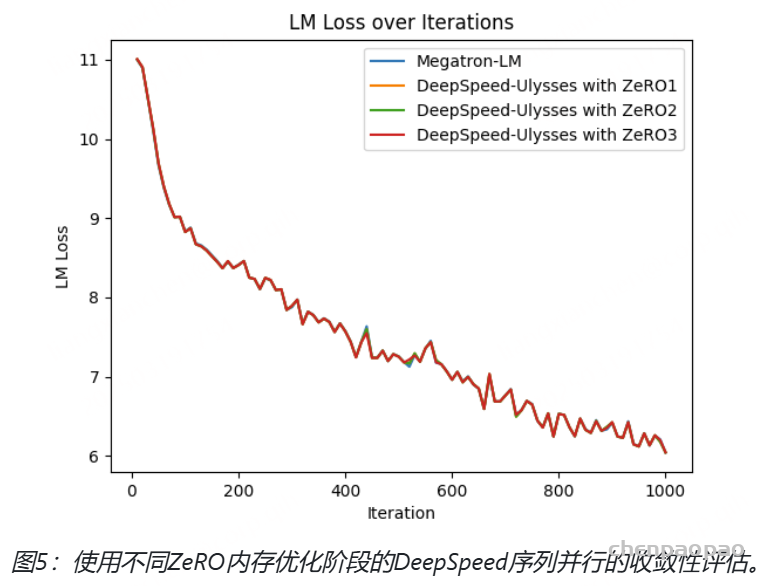
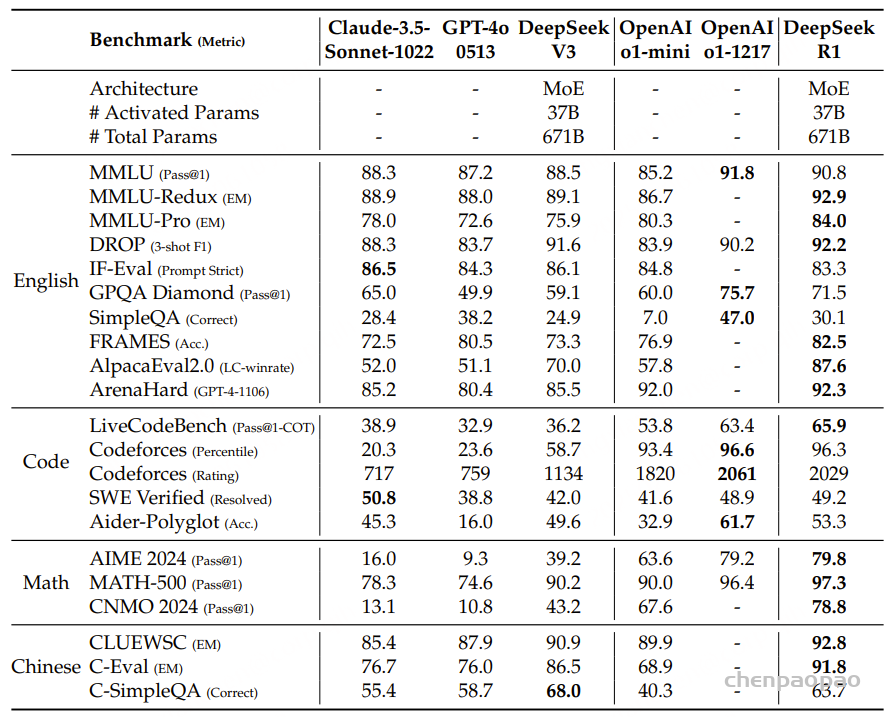
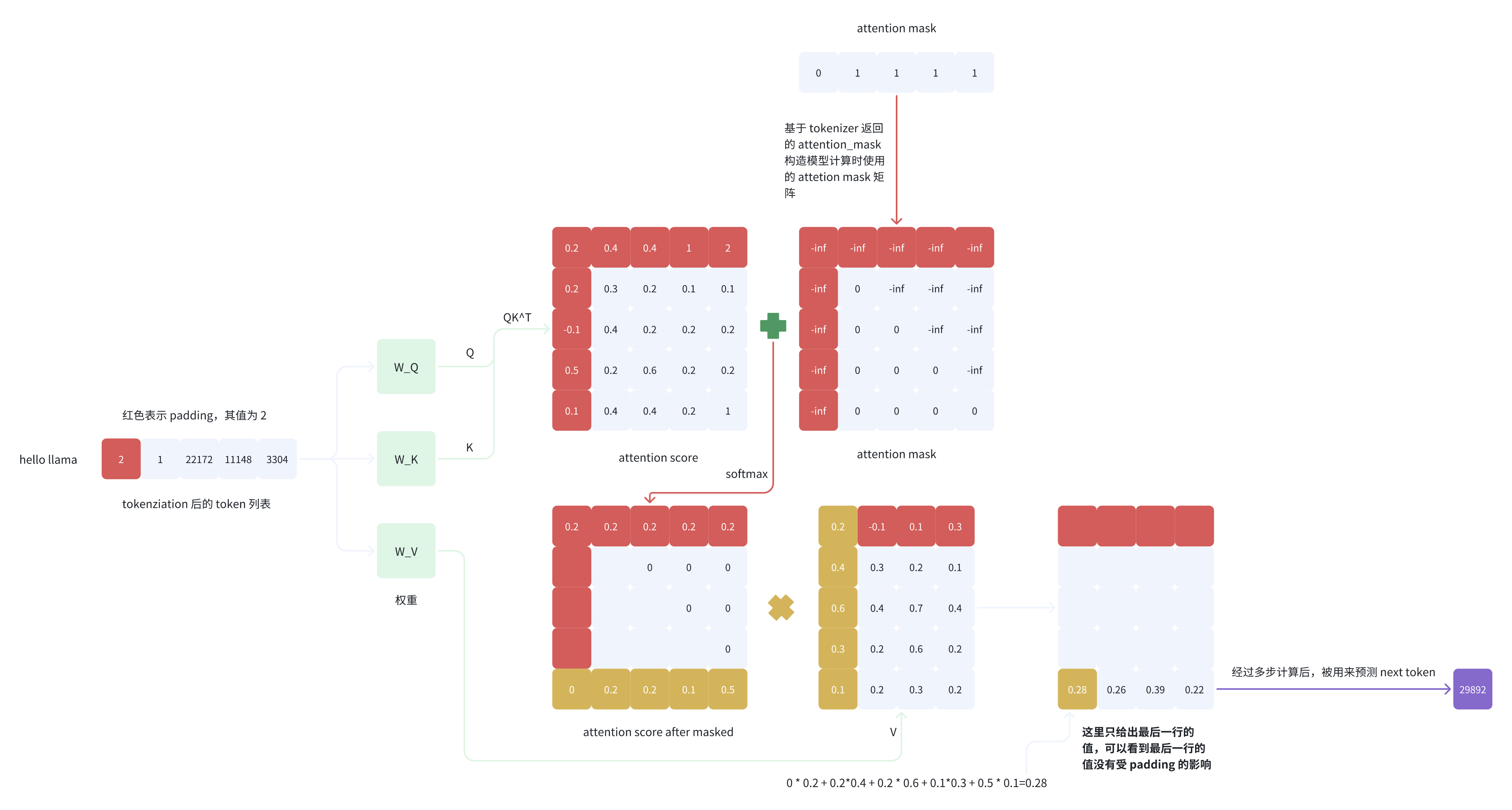
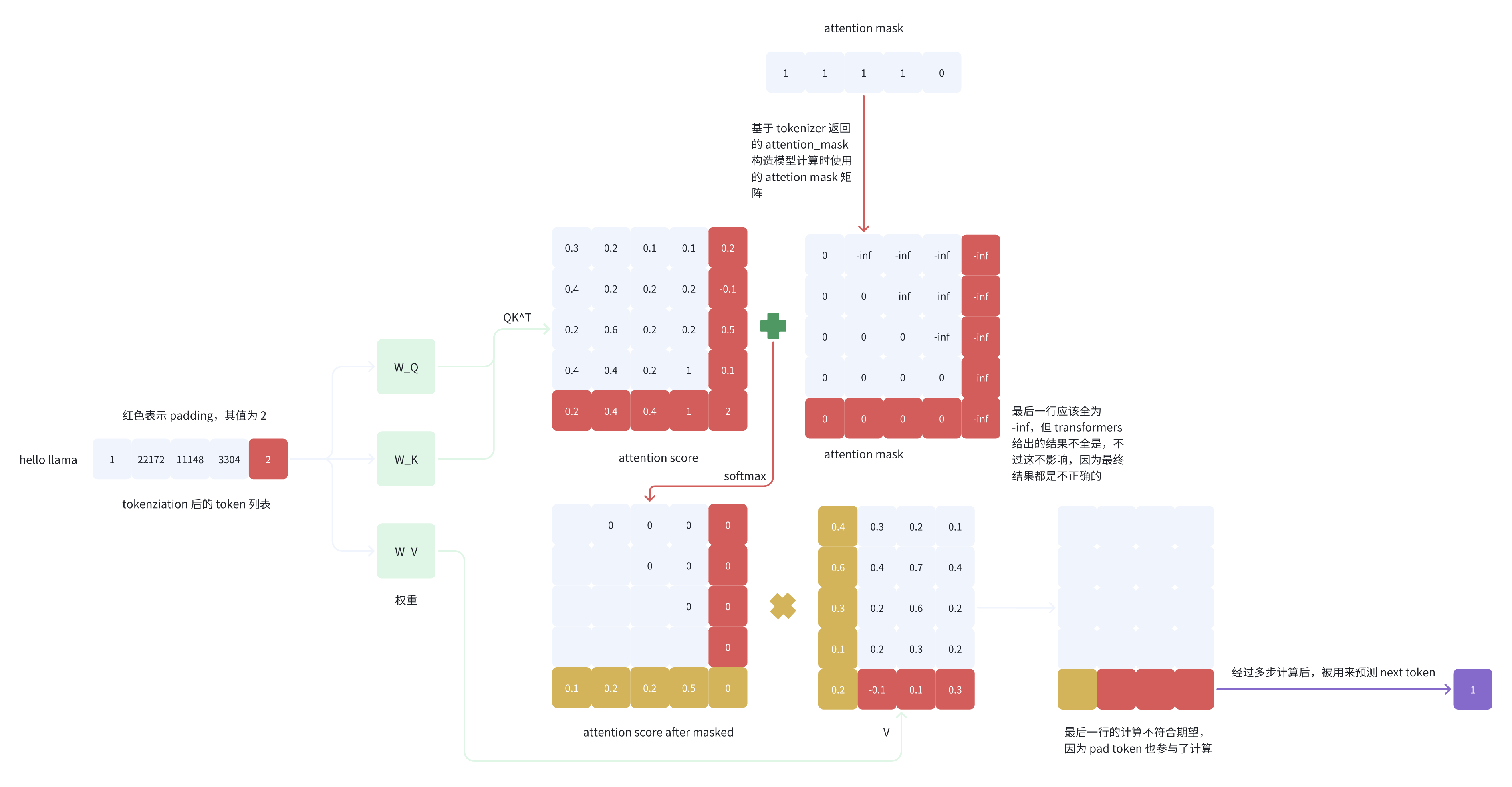
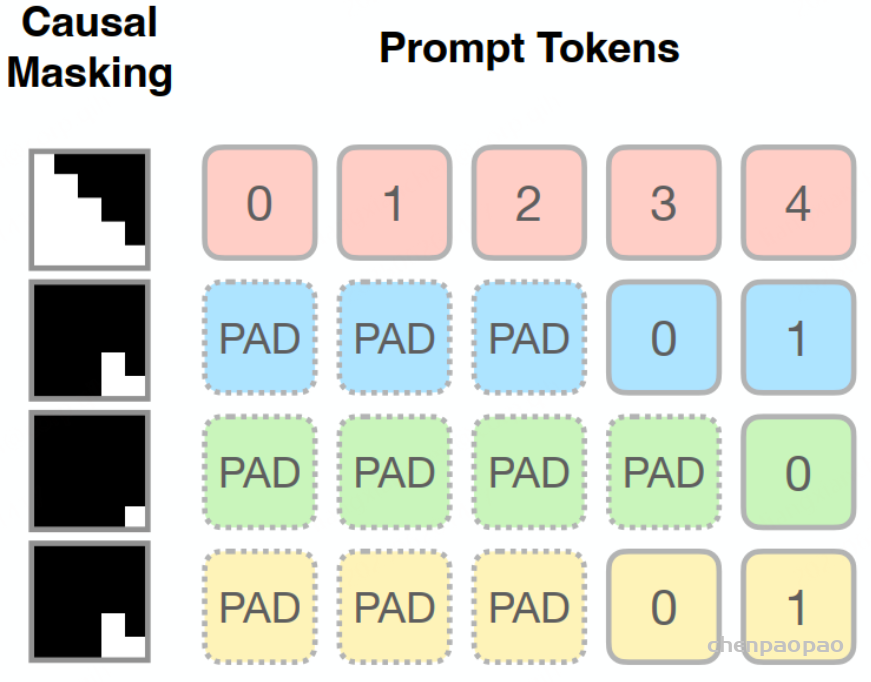
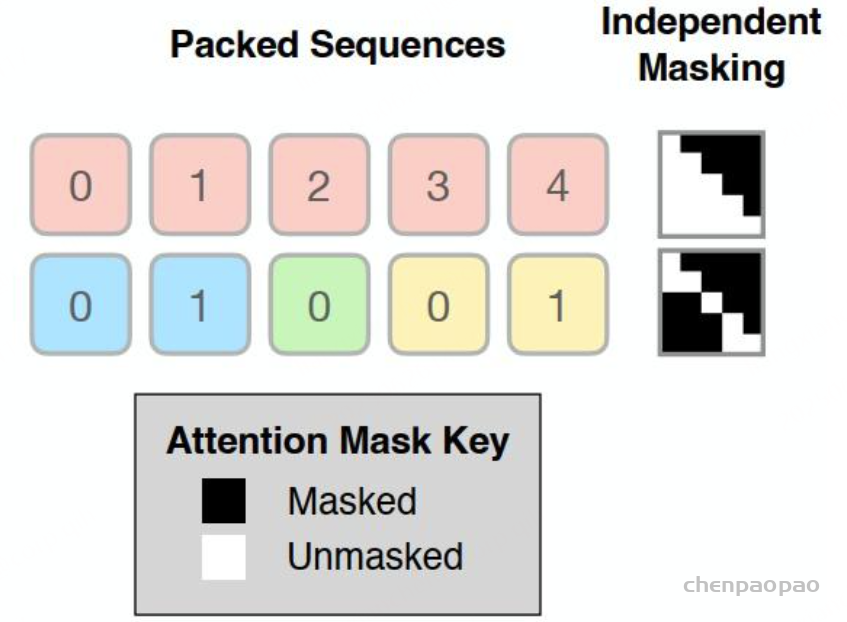
从图 5 的计算过程可以看到,attention score after masked 矩阵的最后一行和 V 的第一列进行内积后得到的值是不符合期望的,即最后一个 token(pad token)所对应的 logit 的计算不正确,因为 pad token 也参与了计算,而正确预测 next token 的时候 pad token 是不应该参与计算的。
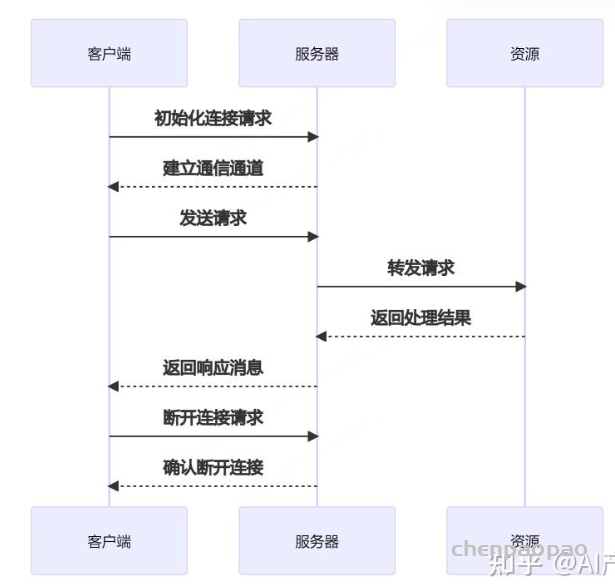
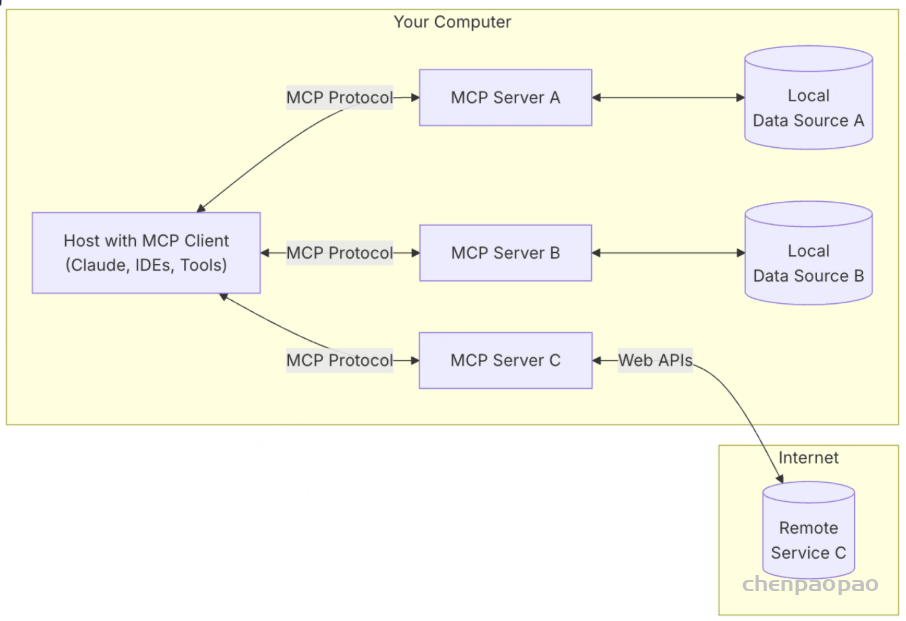
MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大模型与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
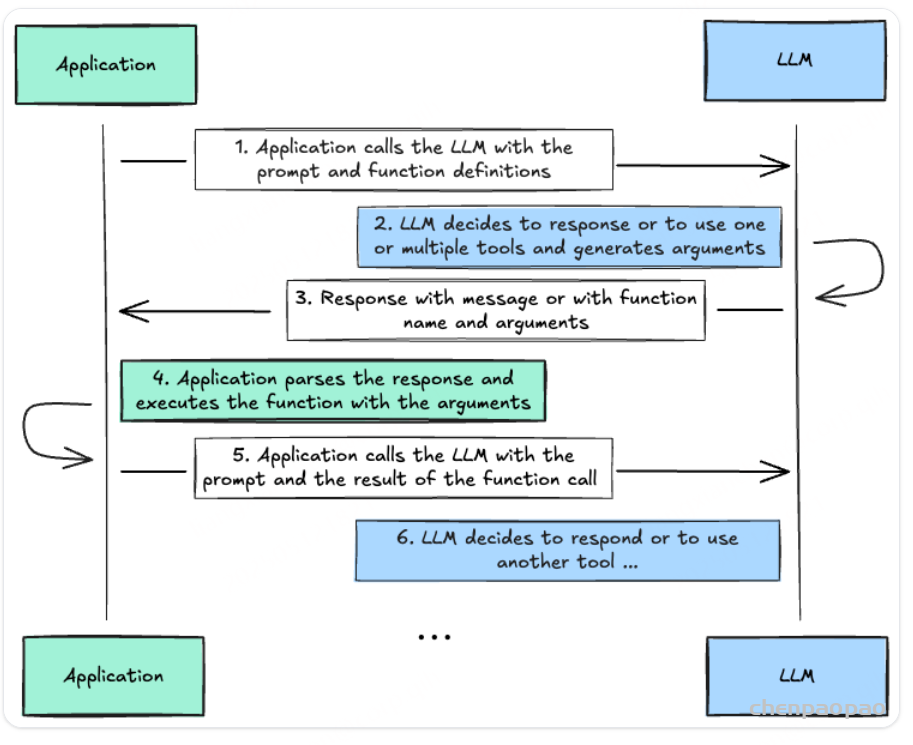
Function Calling是AI模型调用函数的机制,MCP是一个标准协议,使大模型与API无缝交互,而AI Agent是一个自主运行的智能系统,利用Function Calling和MCP来分析和执行任务,实现特定目标。
通常在每个单词末尾添加后缀</w>,统计每个单词出现的频率,例如,low的频率为5,那么我们将其改写为"l o w </ w>”:5 注:停止符</w>的意义在于标明subword是词后缀。举例来说:st不加</w>可以出现在词首,如st ar;加了</w>表明该子词位于词尾,如we st</w>,二者意义截然不同
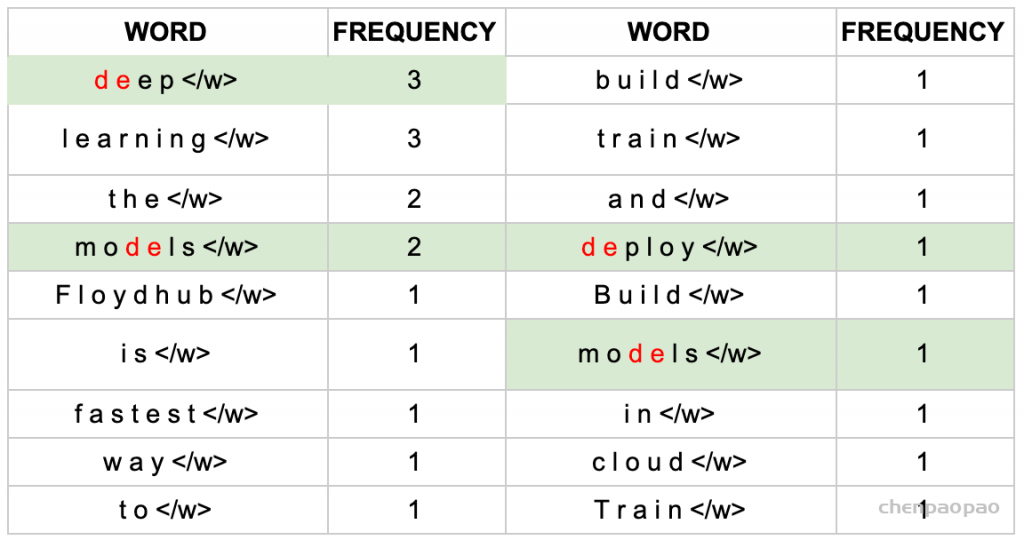
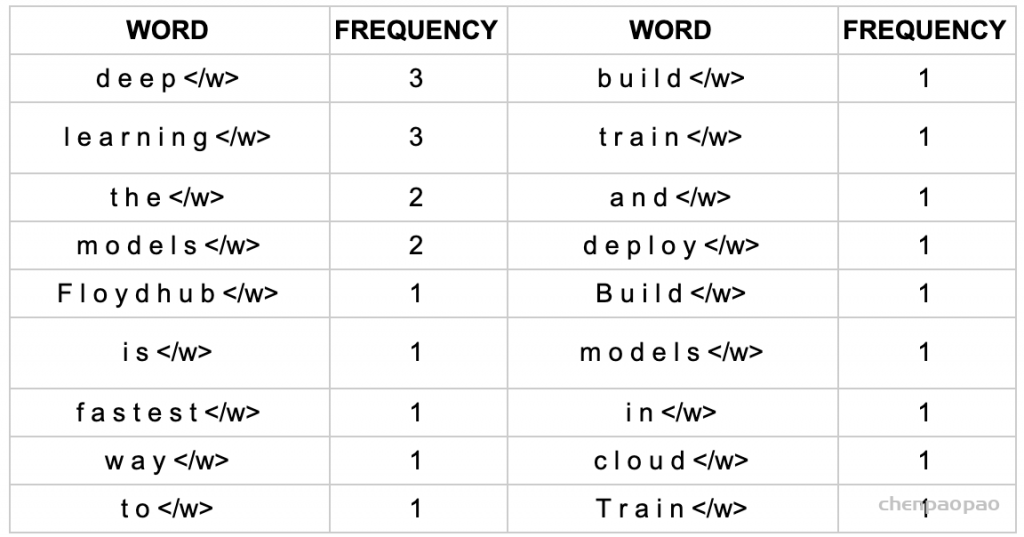
1、获取语料库,这样一段话为例:“FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models.”
2、拆分,加后缀,统计词频:
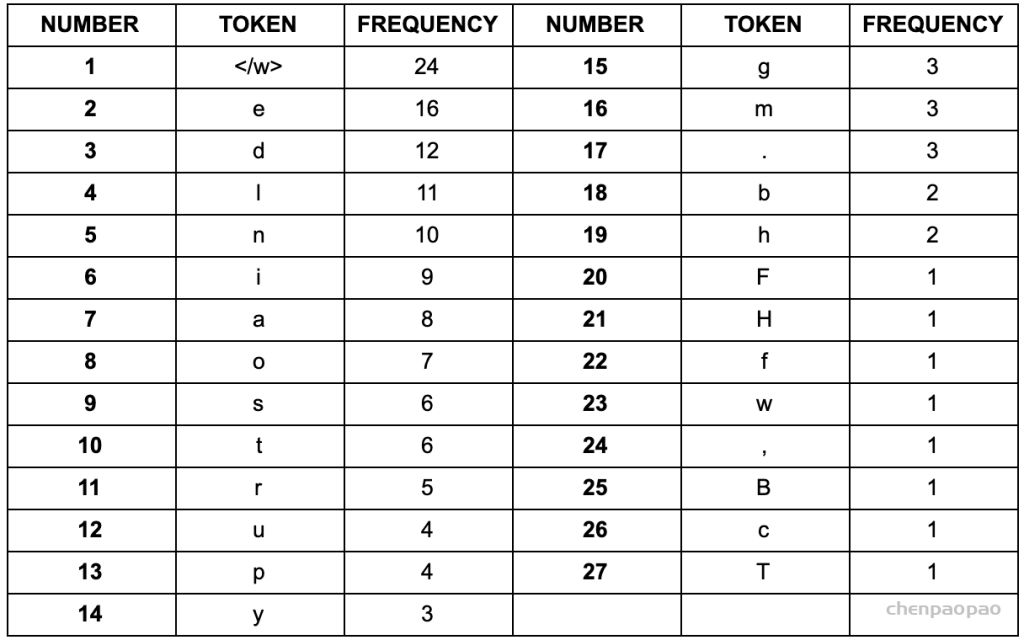
3、建立词表,统计字符频率(顺便排个序):
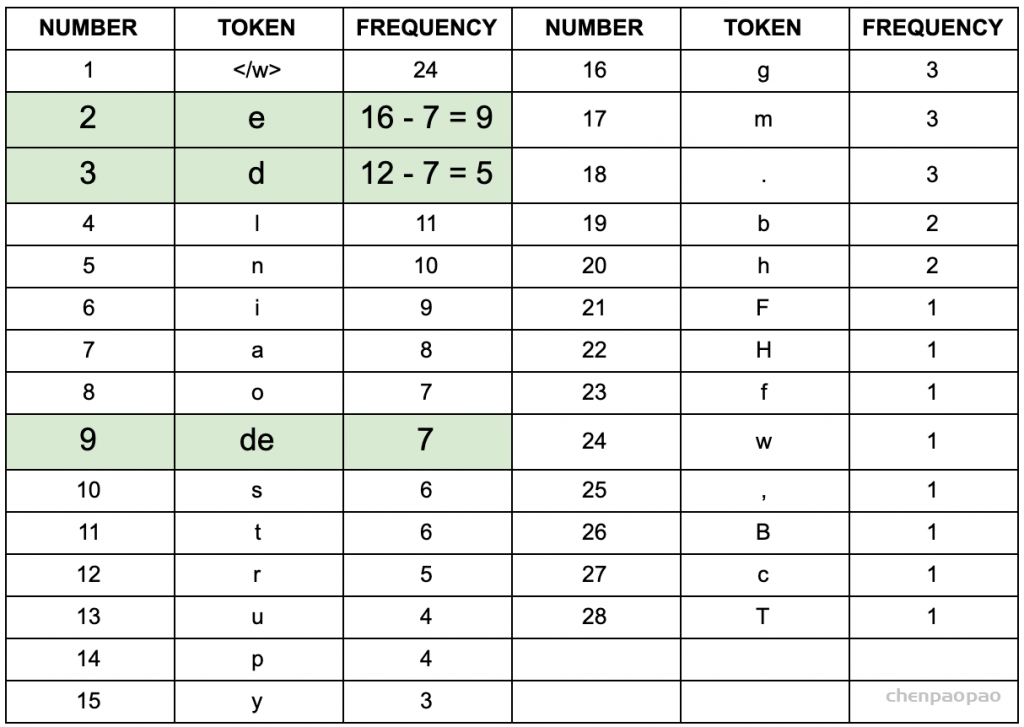
4、以第一次迭代为例,将字符频率最高的d和e替换为de,后面依次迭代:
5、更新词表 继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。
如果将词表大小设置为10,最终的结果为:
d e
r n
rn i
rni n
rnin g</w>
o de
ode l
m odel
l o
l e
import re, collections
def get_vocab(filename):
vocab = collections.defaultdict(int)
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand:
words = line.strip().split()
for word in words:
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens
跑一个例子试一下,这里已经对原句子进行了预处理:
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
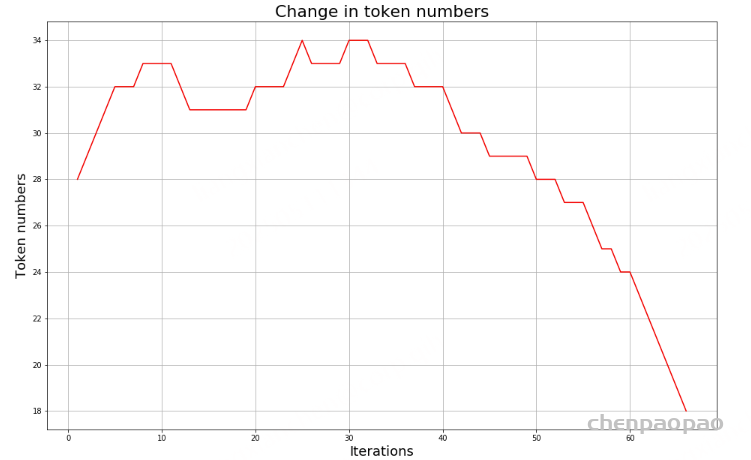
num_merges = 5
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(token
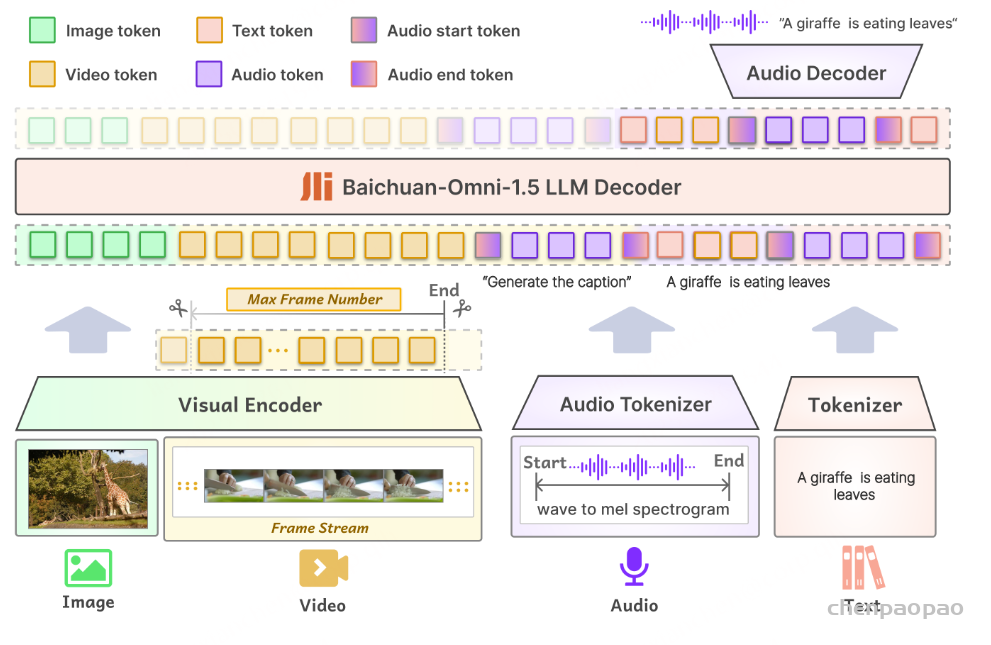
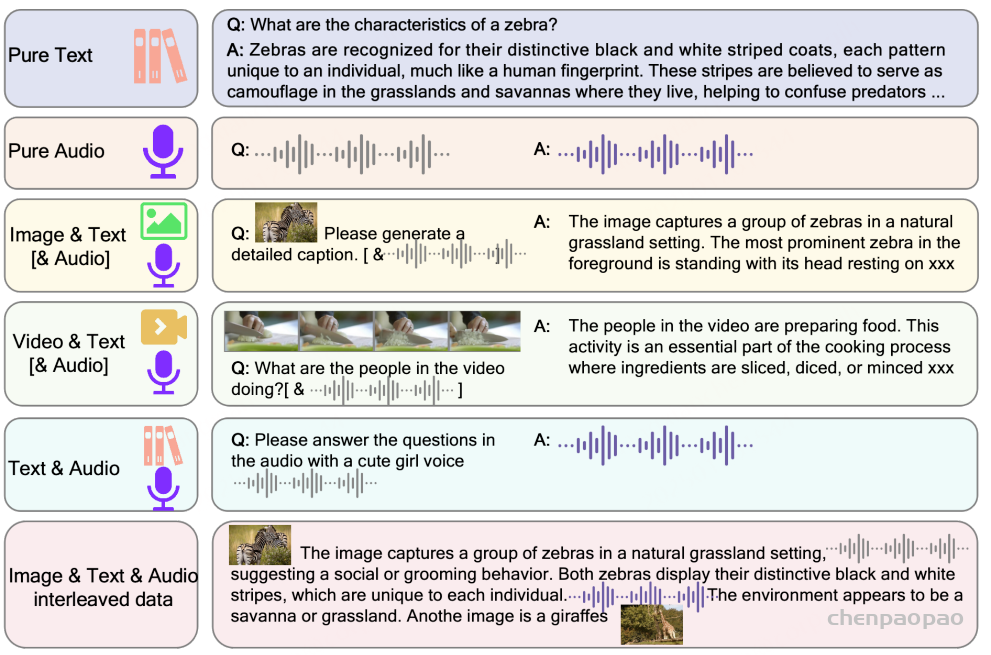
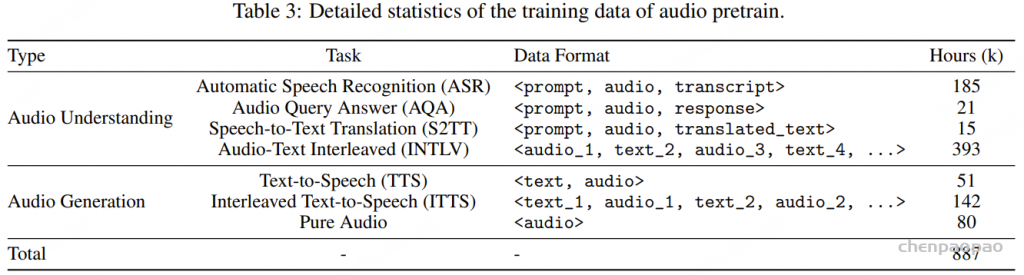
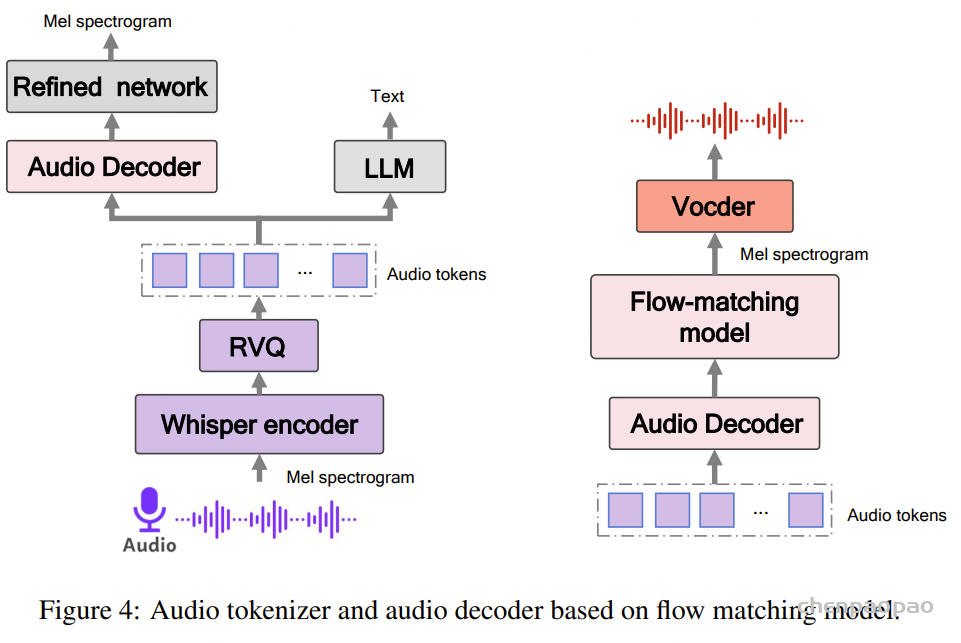
Baichuan-Audio-Tokenizer基于残差向量量化(RVQ)和多目标训练,帧率为12.5 Hz。在使用Whisper Large Encoder 从Mel谱图特征中提取高级特征后,残差卷积网络执行下采样以获得低帧率序列特征。然后使用8层残差向量量化器对这些特征进行量化,生成音频标记。这些标记随后被输入到音频解码器和预训练的LLM中,分别执行Mel谱图重建和转录预测。音频解码器采用与Whisper编码器对称的结构,并使用多尺度Mel损失来增强声音重建的质量。在训练过程中,预训练LLM的参数保持不变,以确保音频标记器和文本空间之间的语义对齐。
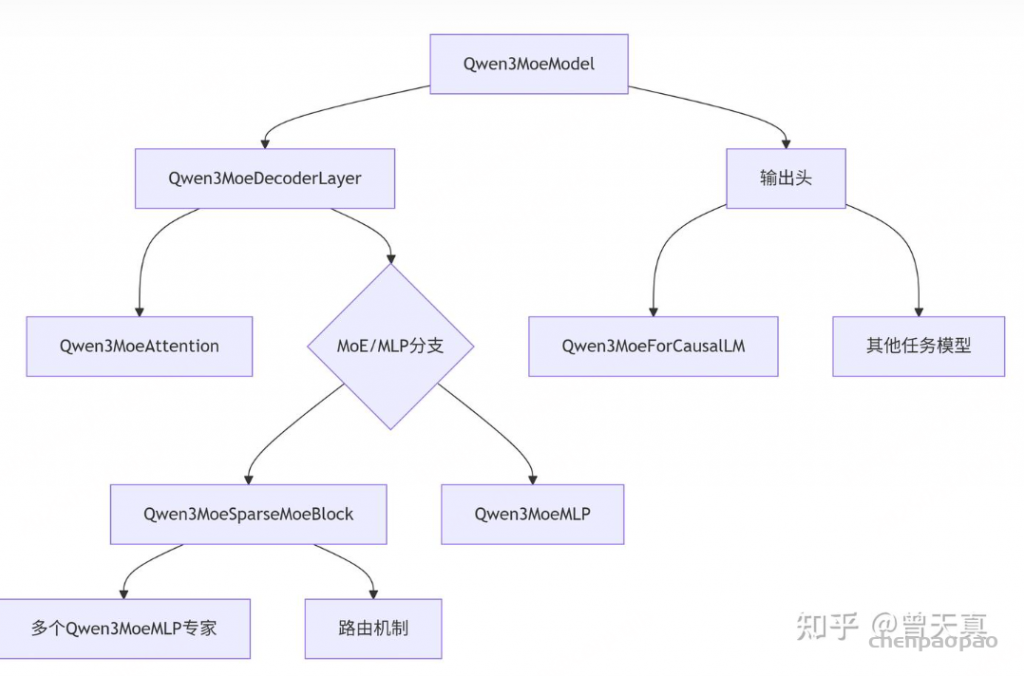
本项目是一个围绕开源大模型、针对国内初学者、基于 Linux 平台的中国宝宝专属大模型教程,针对各类开源大模型提供包括环境配置、本地部署、高效微调等技能在内的全流程指导,简化开源大模型的部署、使用和应用流程,让更多的普通学生、研究者更好地使用开源大模型,帮助开源、自由的大模型更快融入到普通学习者的生活中。










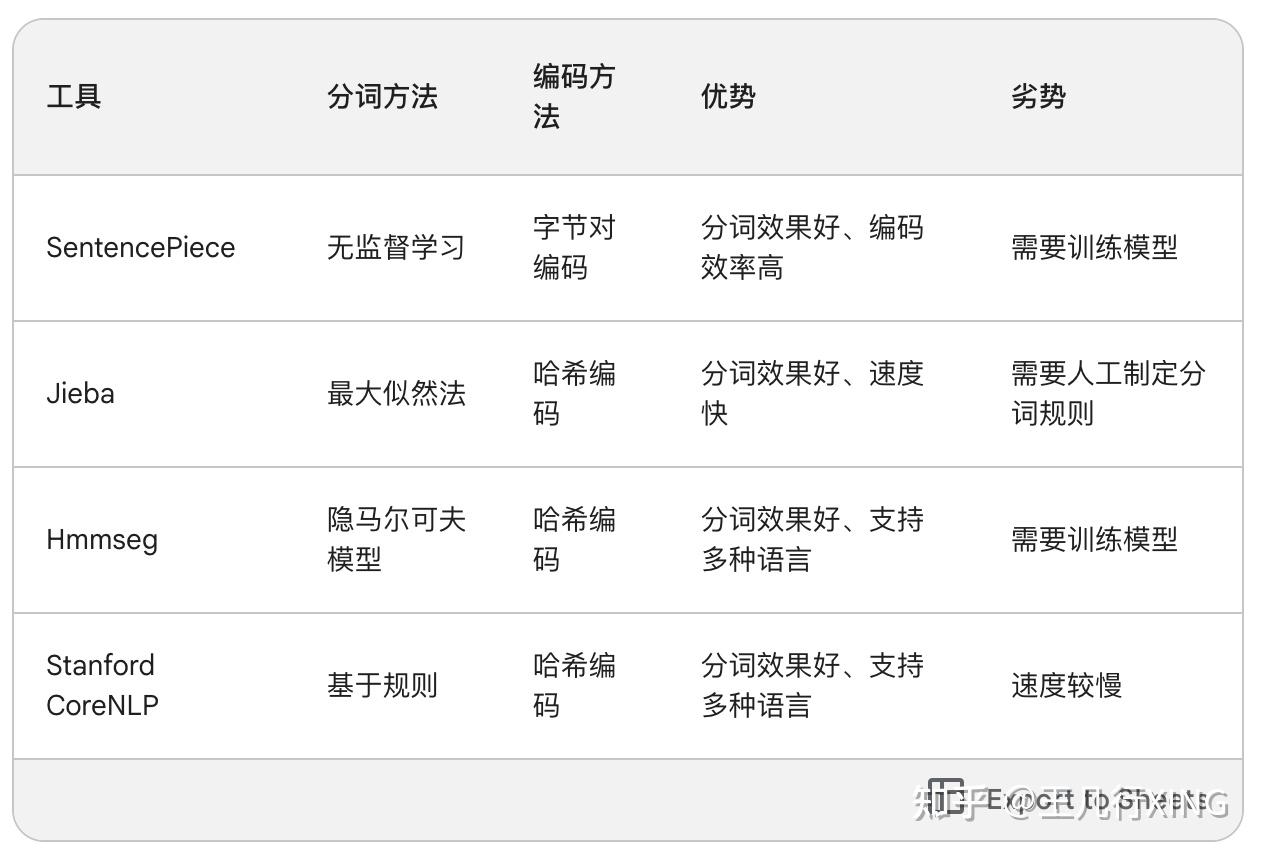
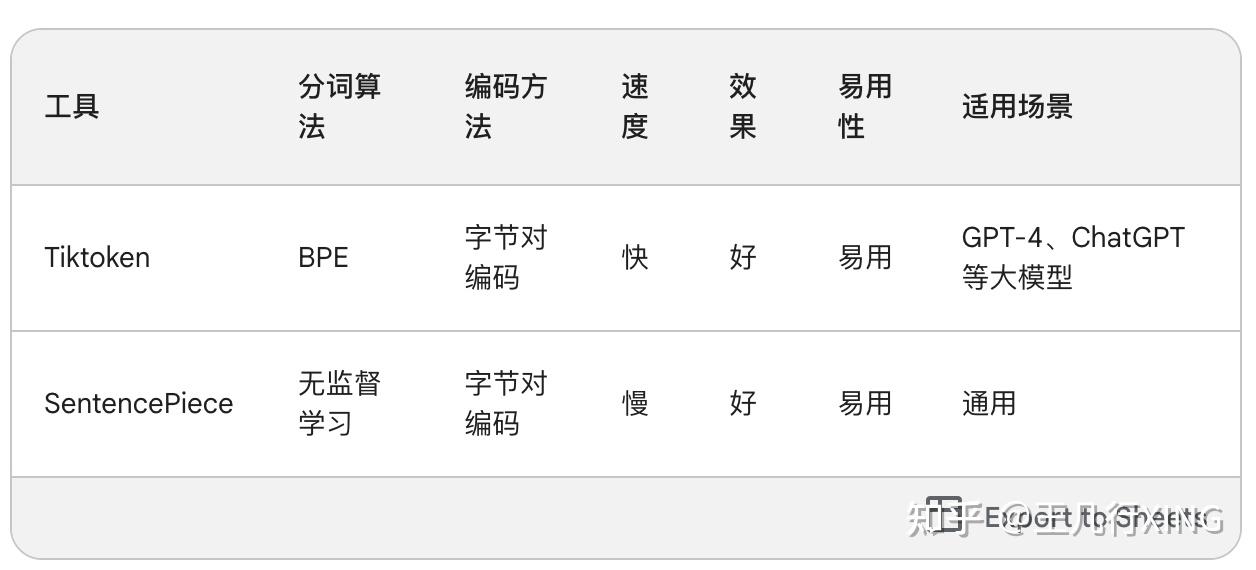
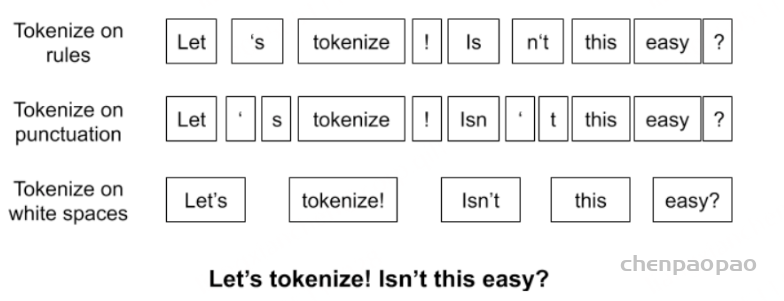



 继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。
继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。