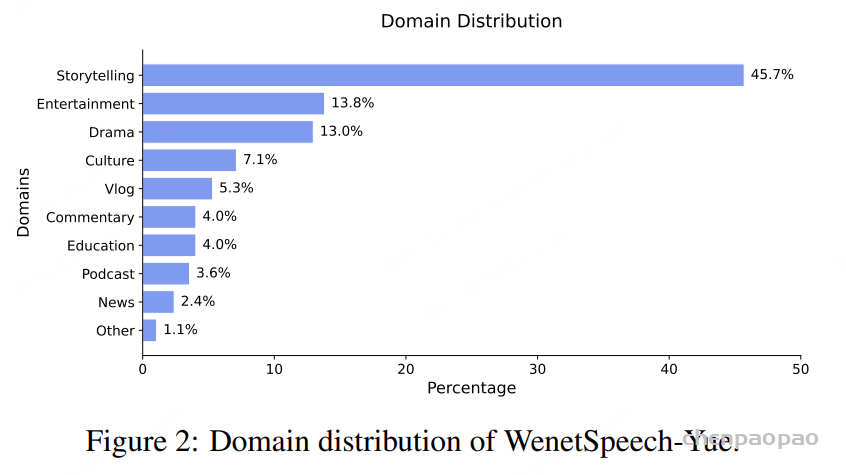
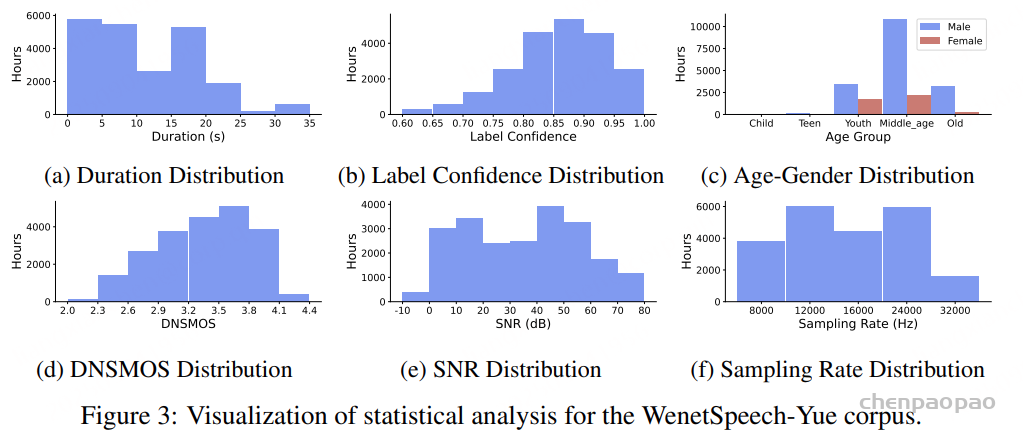
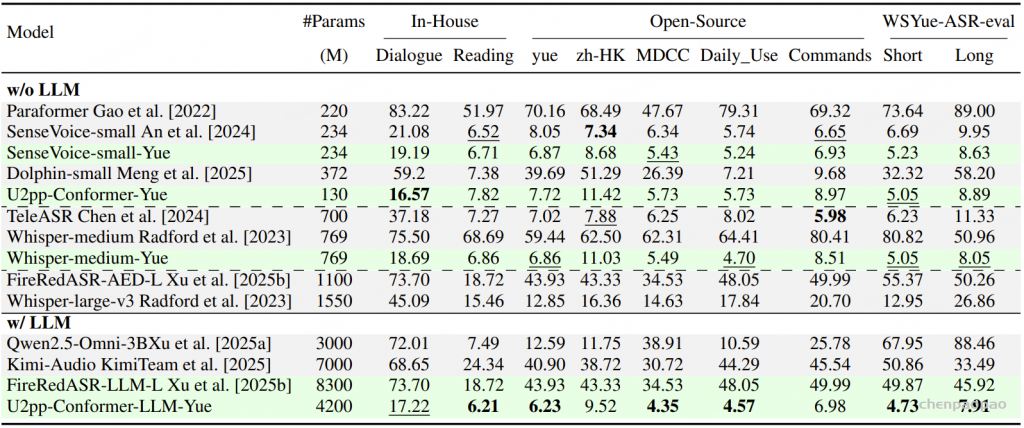
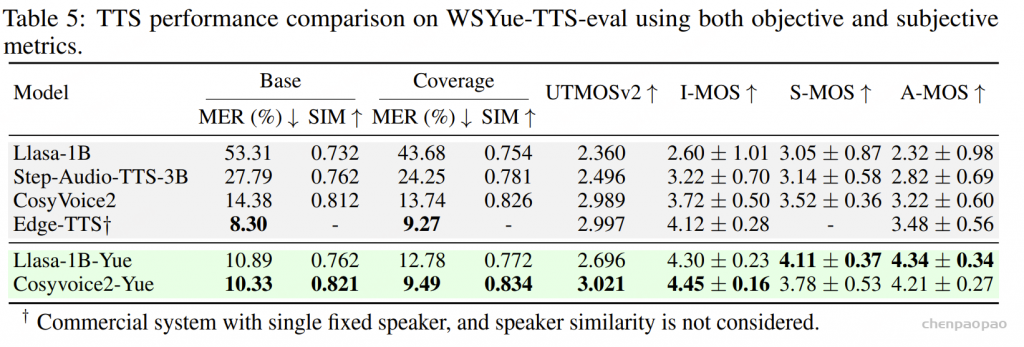
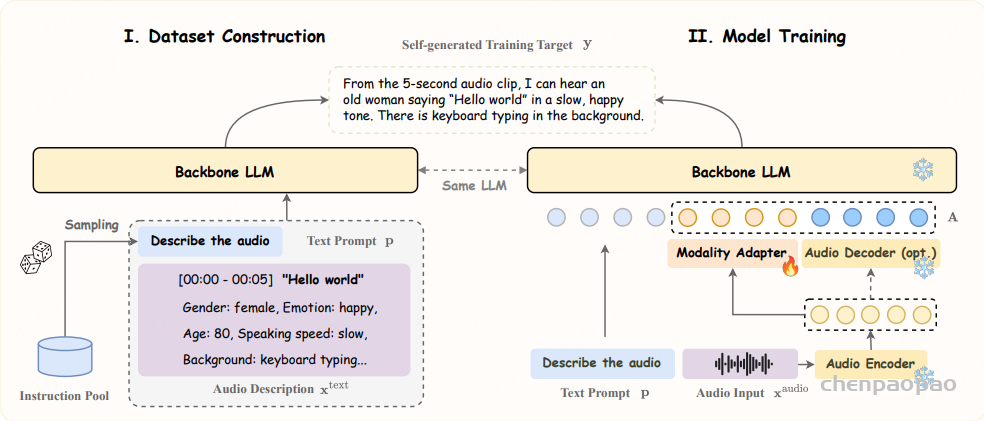
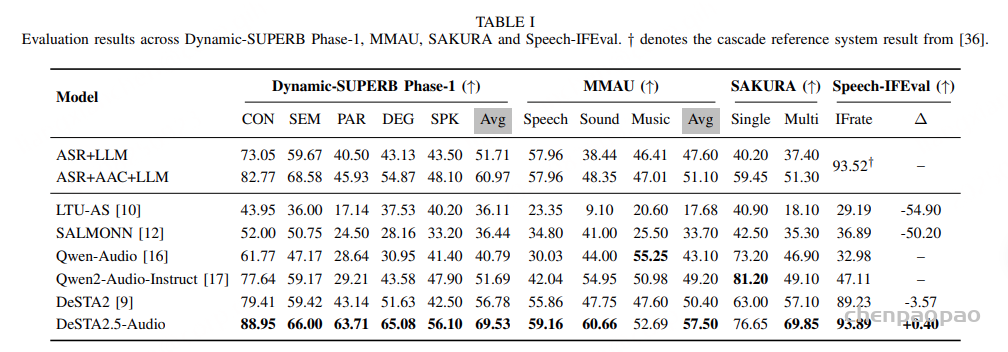
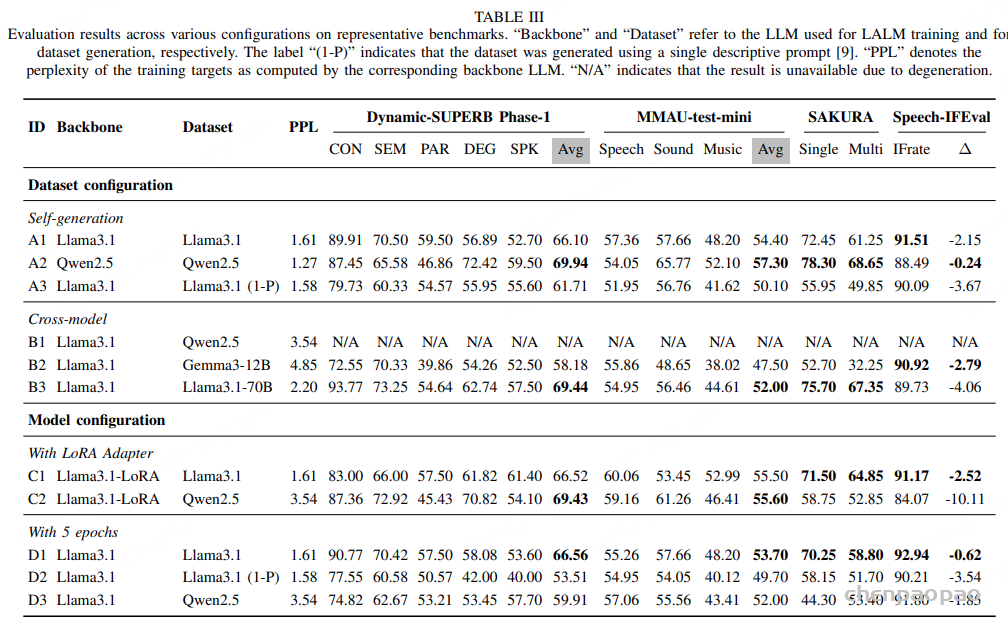
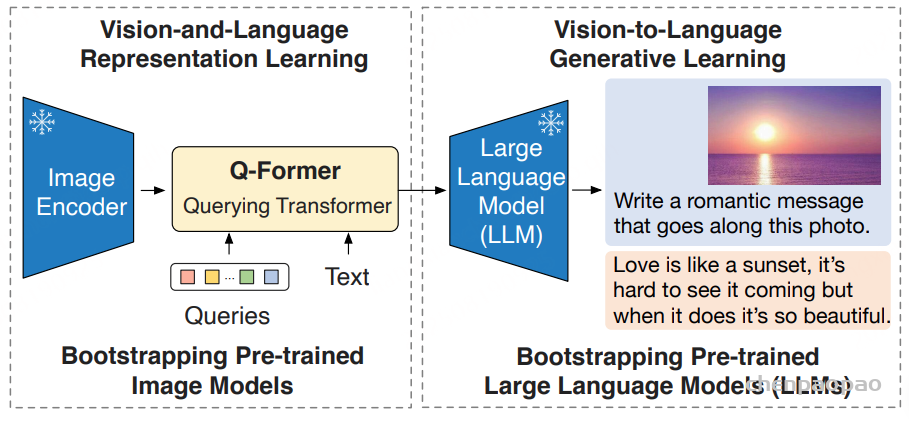
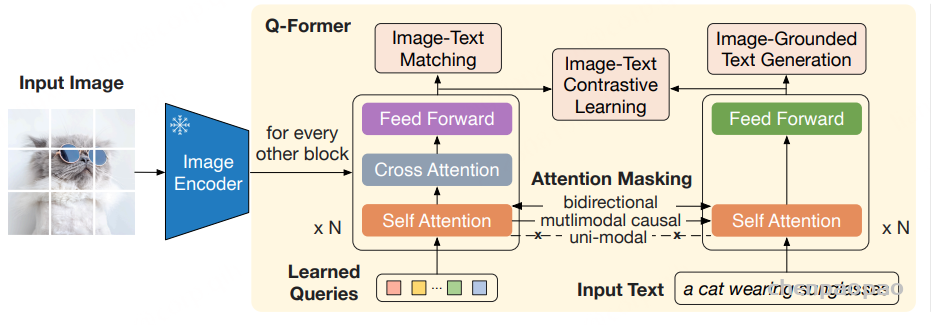
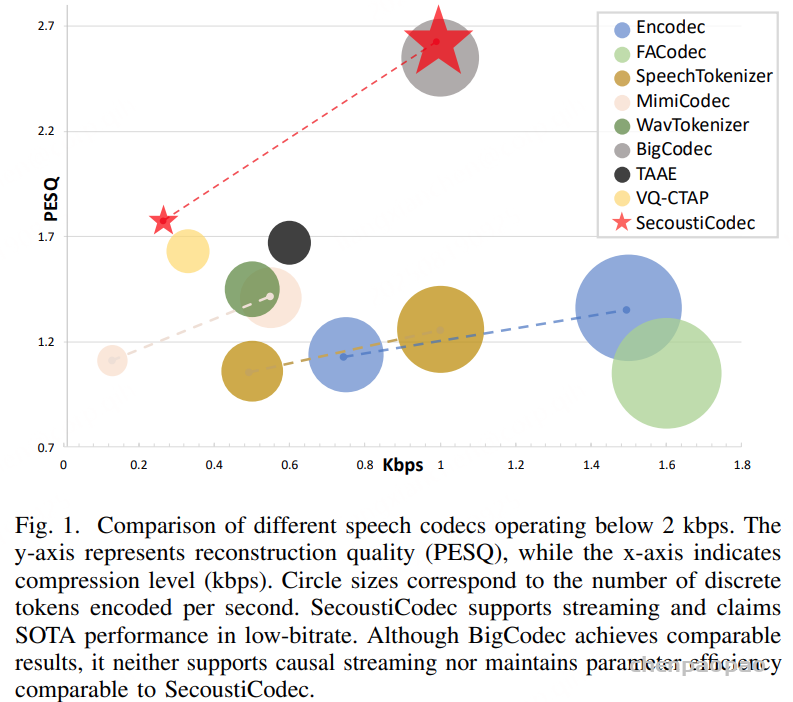
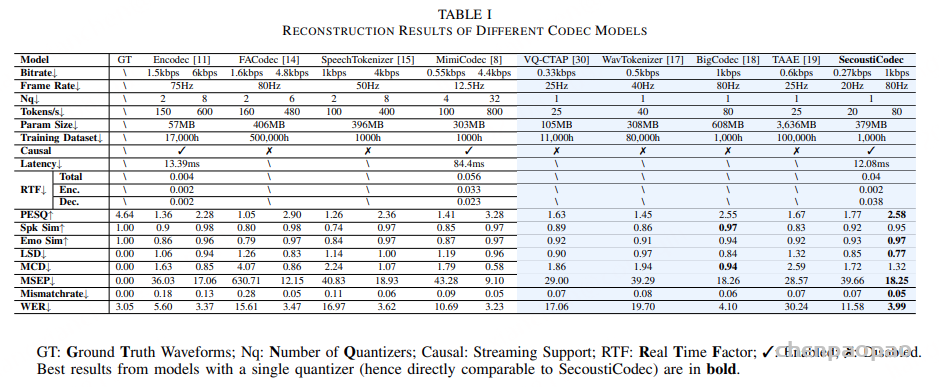
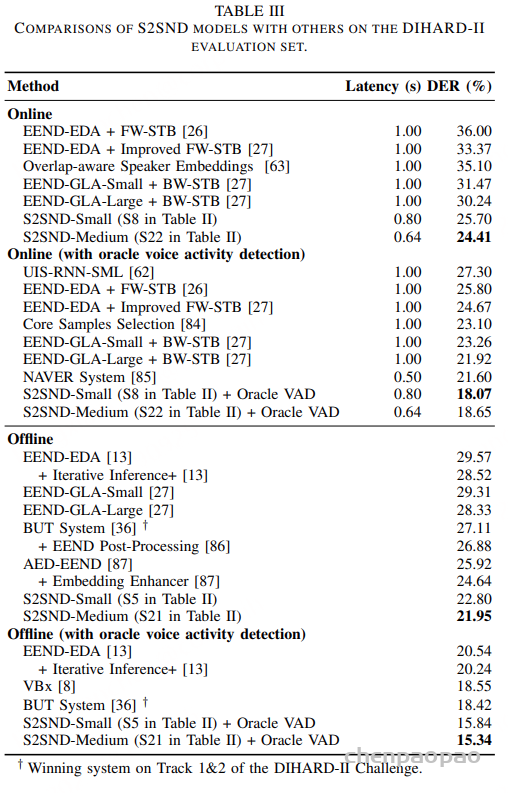
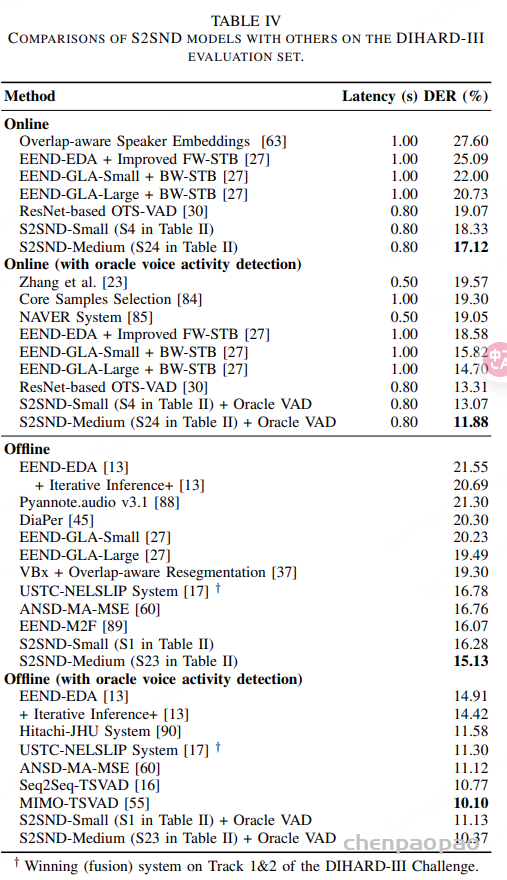
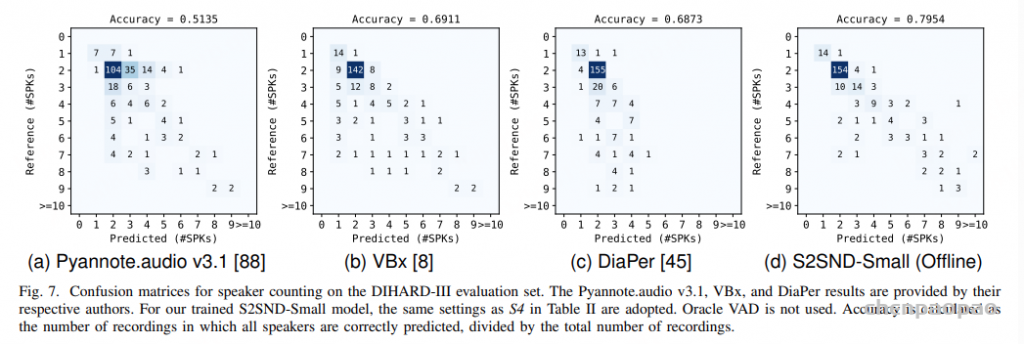
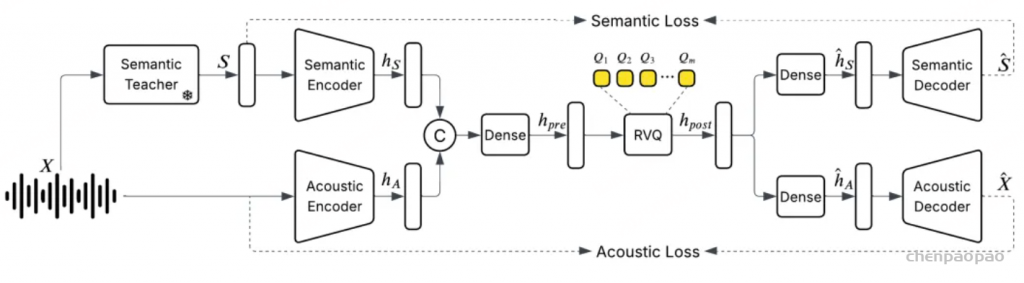
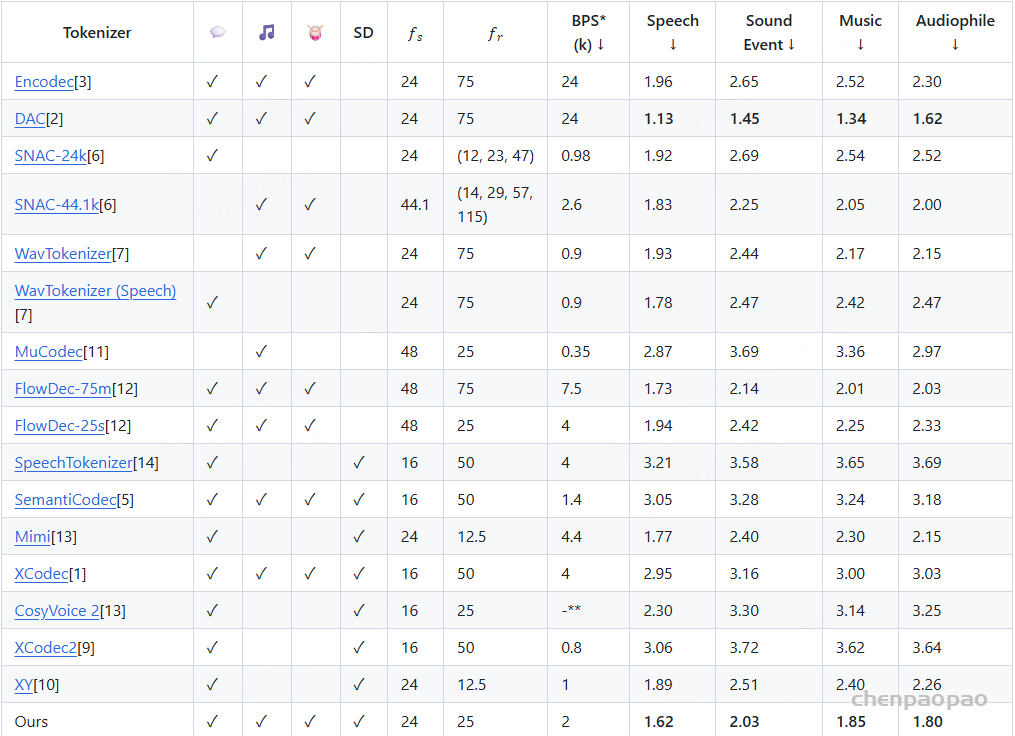
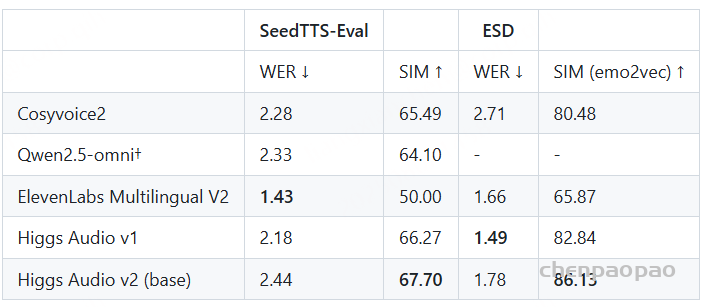
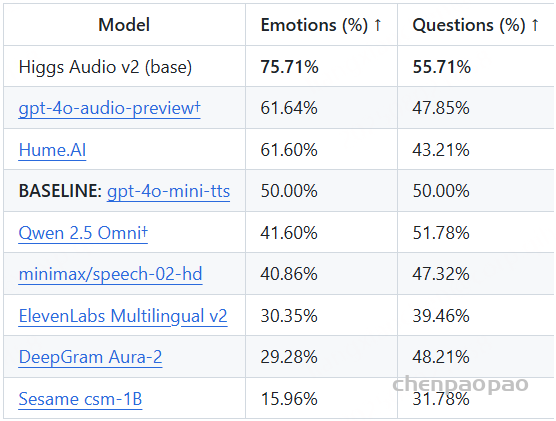
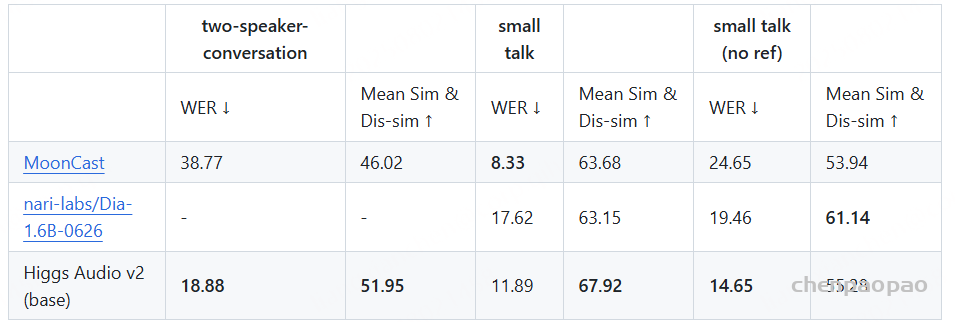
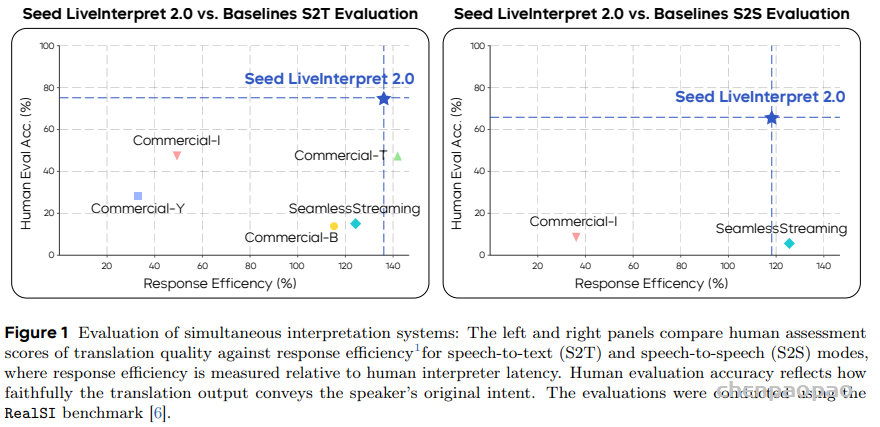
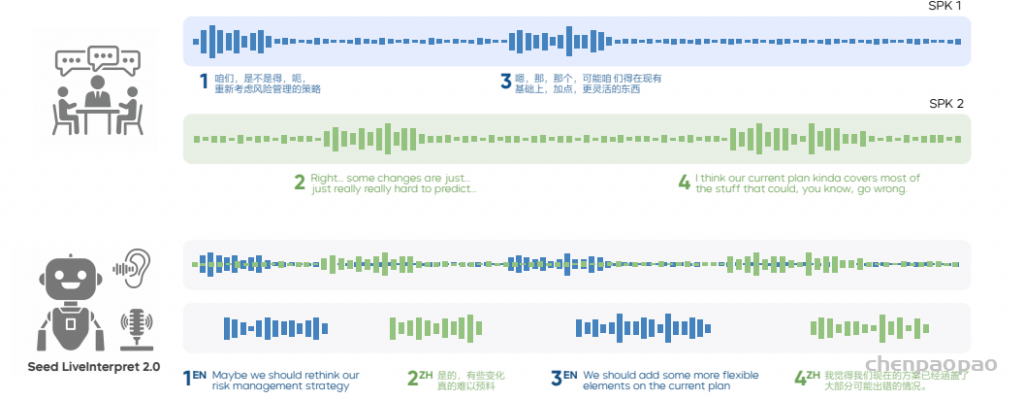
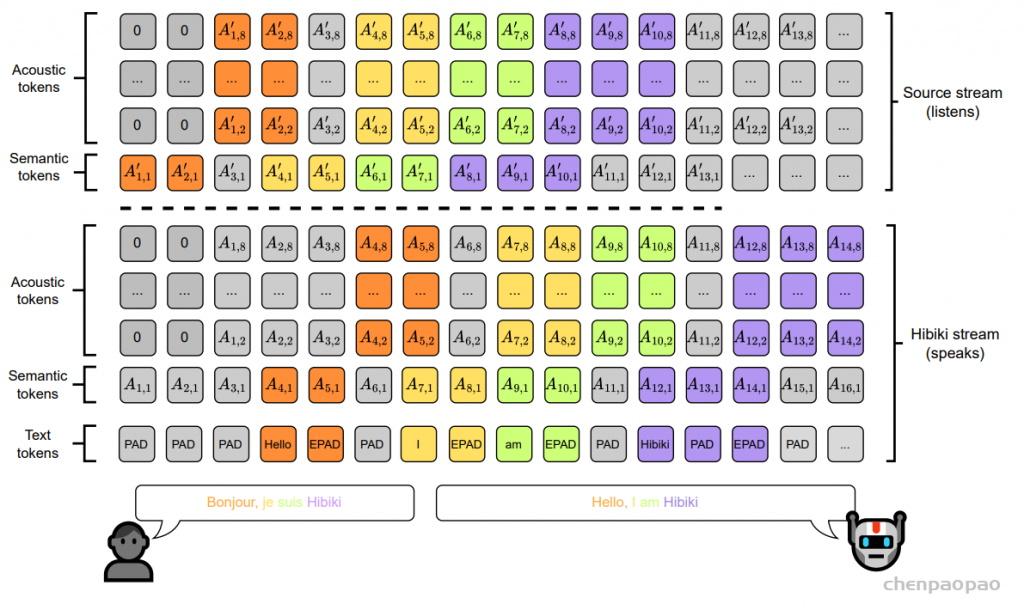
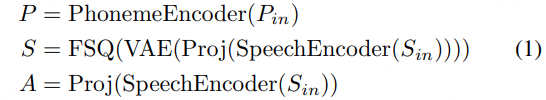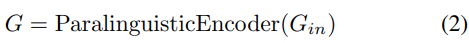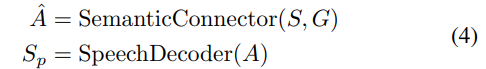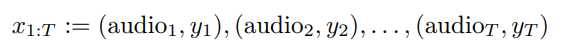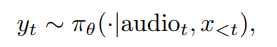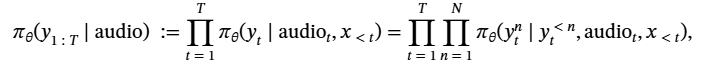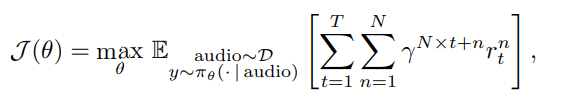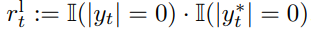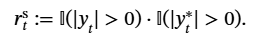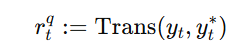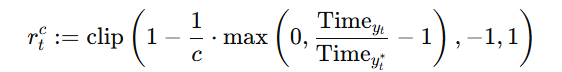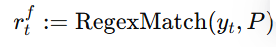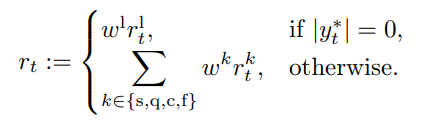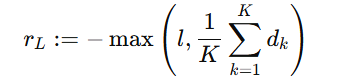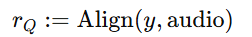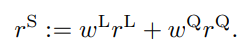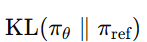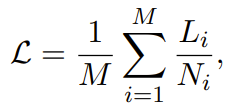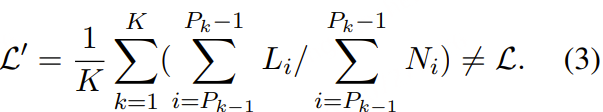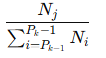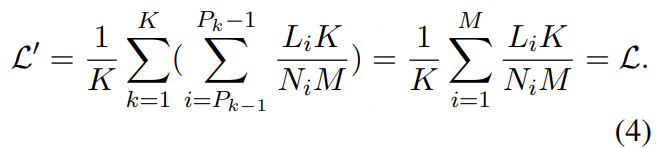随着大型语言模型(Large Language Models,LLMs)在生成式人工智能领域的快速发展,基于语音的应用如文本到语音合成(TTS)、自动语音识别(ASR)以及语音对话系统等日益受到关注。语音编解码器作为连接原始语音信号与语言模型的重要桥梁,其作用类似于自然语言处理中的文本分词器,能够将连续的语音波形转化为离散的编码 token,便于与LLM等模型进行有效融合和交互。
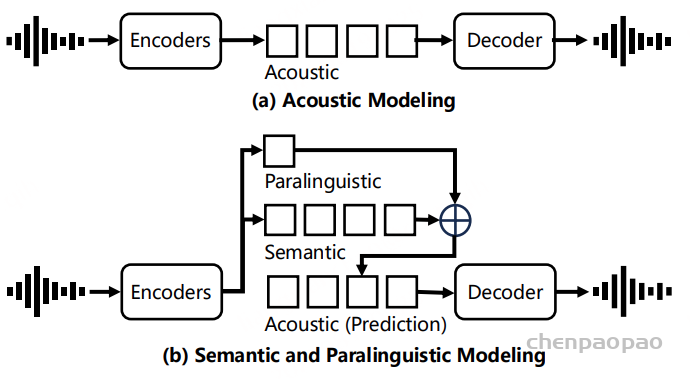
这三个表示之间的关系可以用公式S + G ≈ A 来描述,其中 S 是离散语义编码,G 是全局级副语言编码,A 是连续声学表示。通过这种方式,SecoustiCodec能够在单码本空间中实现语义和副语言信息的分离。
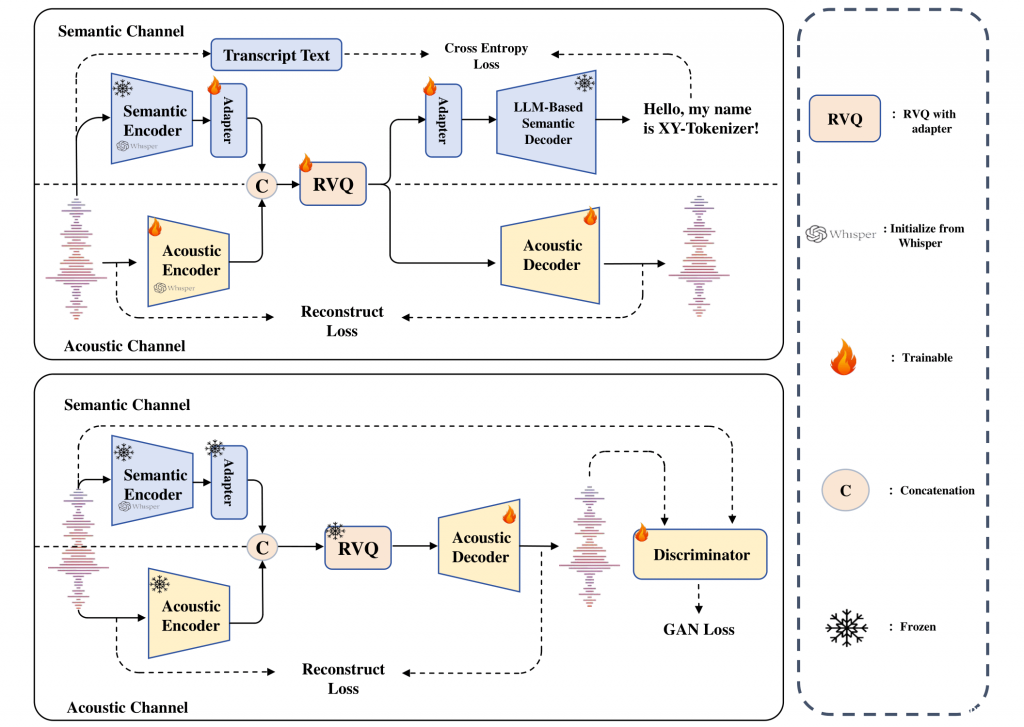
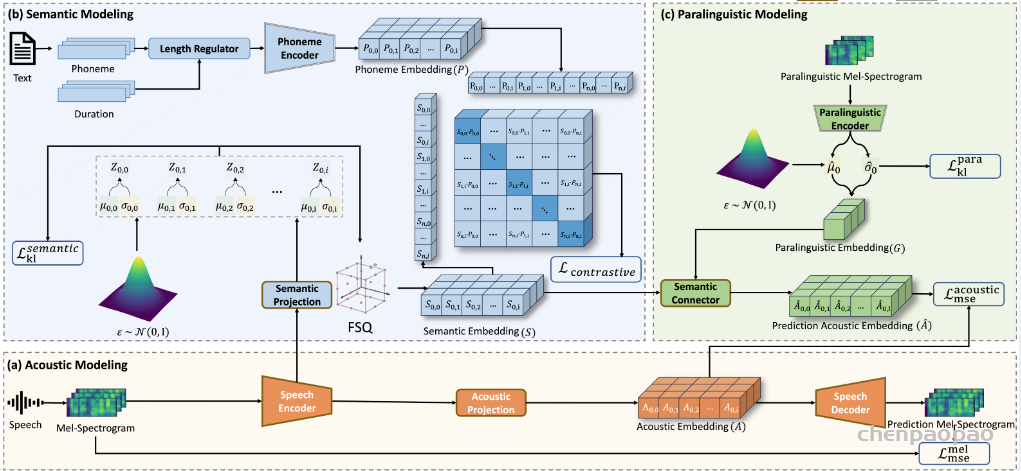
1.声学建模
声学建模部分包括语音编码器、声学投影和语音解码器。语音编码器将输入的语音信号Sin编码为连续的声学表示 A,然后通过声学投影模块进一步处理。语音解码器则负责将声学表示 A 重建为语音信号。
2. 语义建模
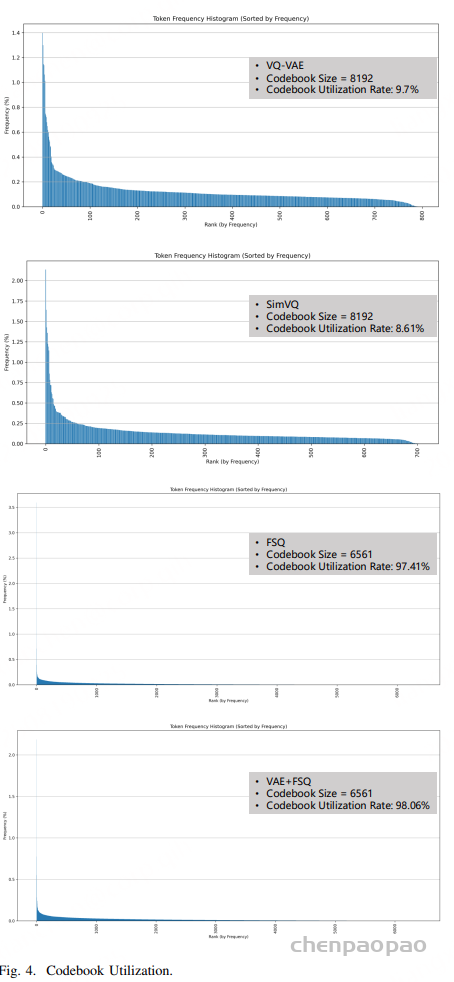
语义建模部分包括语义投影、变分自编码器(VAE)、有限标量量化(FSQ)和对比学习模块。其目标是从语音信号中提取纯净的语义信息,并将其编码为离散的语义表示 S。首先通过语义投影,将语音编码器的输出进一步映射到一个低维的语义空间。随后采用VAE + FSQ,通过VAE生成语义表示的均值 μ 和方差 σ,然后通过FSQ将这些连续的语义表示量化为离散的语义编码 S。这种方法不仅保留了语义信息,还进一步去除了副语言信息,同时提高了码本利用率。最后通过对比学习模块,将语音编码器生成的语义表示 S 和文本编码器生成的音素表示 P 对齐到一个联合帧级对齐的多模态空间中。通过最大化正样本对(S和对应的P)之间的相似度,同时最小化负样本对(S和不对应的P)之间的相似度,模型能够学习到纯净的语义表示。
其中 P 是音频表征,S 是语义表征,A是声学表征。
3. 副语言建模
副语言建模部分包括副语言编码器和语义连接器。其目标是从语音信号中提取副语言信息,并将其编码为全局级的副语言表示G。首先通过副语言编码器才从语音信号中提取副语言信息,如音色、情感等。随后经过语义连接器,将语义表示 S 和副语言表示 G 结合起来,预测声学表示 A^。通过这种方式,模型能够在解码阶段利用副语言信息来重建语音信号。
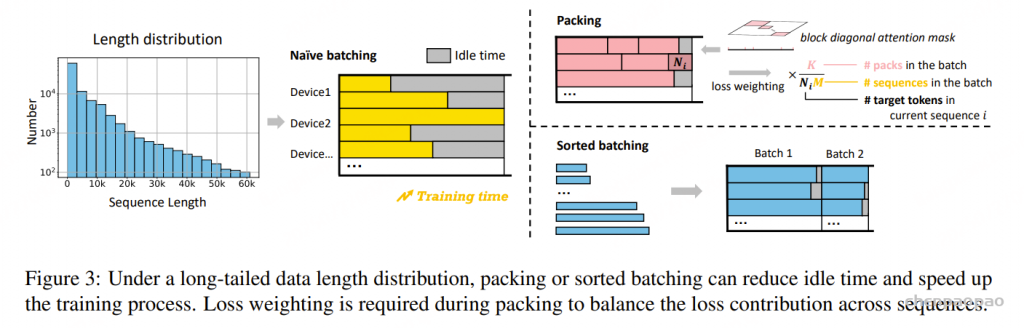
### Support loss weighting for packing ###
loss = None
if labels is not None:
lm_logits = lm_logits.to(torch.float32)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
if isinstance(labels, tuple) or isinstance(labels, list):
labels, weights = labels
shift_labels = labels[..., 1:].contiguous()
if self.pack_loss:
shift_weights = weights[..., 1:].contiguous()
loss_fct = CrossEntropyLoss(ignore_index=-100, reduction='none')
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss = (loss * shift_weights).sum()
else:
loss_fct = CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
lm_logits = lm_logits.to(hidden_states.dtype)
loss = loss.to(hidden_states.dtype)
### -------------------------------------- ###