def function1(id): # 这里是子进程
print(f'id {id}')
def run__process(): # 这里是主进程
from multiprocessing import Process
process = [mp.Process(target=function1, args=(1,)),
mp.Process(target=function1, args=(2,)), ]
[p.start() for p in process] # 开启了两个进程
[p.join() for p in process] # 等待两个进程依次结束# run__mp() # 主线程不建议写在 if外部。由于这里的例子很简单,你强行这么做可能不会报错
if __name__ =='__main__':
run__mp() # 正确做法:主线程只能写在 if内部
使用PyTorch CUDA multiprocessing 的时候出现的错误 UserWarning: semaphore_tracker
(写于2021-03-03)
错误如下:
multiprocessing/semaphore_tracker.py:144:
UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
Issue with multiprocessing semaphore tracking
def function1(id): # 这里是子进程
print(f'id {id}')
def run__process(): # 这里是主进程
from multiprocessing import Process
process = [mp.Process(target=function1, args=(1,)),
mp.Process(target=function1, args=(2,)), ]
[p.start() for p in process] # 开启了两个进程
[p.join() for p in process] # 等待两个进程依次结束# run__process() # 主线程不建议写在 if外部。由于这里的例子很简单,你强行这么做可能不会报错
if __name__ =='__main__':
run__process() # 正确做法:主线程只能写在 if内部
import time
def func2(args): # multiple parameters (arguments)# x, y = args
x = args[0] # write in this way, easier to locate errors
y = args[1] # write in this way, easier to locate errors
time.sleep(1) # pretend it is a time-consuming operation
return x - y
def run__pool(): # main process
from multiprocessing import Pool
cpu_worker_num = 3
process_args = [(1, 1), (9, 9), (4, 4), (3, 3), ]
print(f'| inputs: {process_args}')
start_time = time.time()
with Pool(cpu_worker_num) as p:
outputs = p.map(func2, process_args)
print(f'| outputs: {outputs} TimeUsed: {time.time() - start_time:.1f} \n')
'''Another way (I don't recommend)
Using 'functions.partial'. See https://stackoverflow.com/a/25553970/9293137
from functools import partial
# from functools import partial
# pool.map(partial(f, a, b), iterable)
'''
if __name__ =='__main__':
run__pool()
So yes, pipes are faster than queues – but only by 1.5 to 2 times, what did surprise me was that Python 3 is MUCH slower than Python 2 – most other tests I have done have been a bit up and down (as long as it is Python 3.4 – Python 3.2 seems to be a bit of a dog – especially for memory usage).
可以 import queue 调用Python内置的队列,在多线程里也有队列 from multiprocessing import Queue。下面提及的都是多线程的队列。
队列Queue 的功能与前面的管道Pipe非常相似:无论主进程或子进程,都能访问到队列,放进去的对象都经过了深拷贝。不同的是:管道Pipe只有两个断开,而队列Queue 有基本的队列属性,更加灵活,详细请移步Stack Overflow Multiprocessing – Pipe vs Queue。
def func1(i):
time.sleep(1)
print(f'args {i}')
def run__queue():
from multiprocessing import Process, Queue
queue = Queue(maxsize=4) # the following attribute can call in anywhere
queue.put(True)
queue.put([0, None, object]) # you can put deepcopy thing
queue.qsize() # the length of queue
print(queue.get()) # First In First Out
print(queue.get()) # First In First Out
queue.qsize() # the length of queue
process = [Process(target=func1, args=(queue,)),
Process(target=func1, args=(queue,)), ]
[p.start() for p in process]
[p.join() for p in process]
if __name__ =='__main__':
run__queue()
For those interested in using Python3.8 ‘s shared_memory module, it still has a bug which hasn’t been fixed and is affecting Python3.8/3.9/3.10 by now (2021-01-15). The bug is about resource tracker destroys shared memory segments when other processes should still have valid access. So take care if you use it in your code.
仍以前文创建 HTTP 服务为例,“http”是 Python 内置的一个包,它没有“__main__.py”文件,所以使用“-m”方式执行时,就会报错:No module named http.__main__; ‘http’ is a package and cannot be directly executed。
import time
import os
def long_time_task():
print('当前进程: {}'.format(os.getpid()))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__ == "__main__":
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
for i in range(2):
long_time_task()
end = time.time()
print("用时{}秒".format((end-start)))
from multiprocessing import Pool, cpu_count
import os
import time
def long_time_task(i):
print('子进程: {} - 任务{}'.format(os.getpid(), i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
print("CPU内核数:{}".format(cpu_count()))
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('等待所有子进程完成。')
p.close()
p.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: {}'.format(os.getpid()))
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read:{}'.format(os.getpid()))
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
输出结果如下所示:
Process to write: 3036
Put A to queue...
Process to read:9408
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.
import threading
import time
def long_time_task(i):
print('当前子线程: {} 任务{}'.format(threading.current_thread().name, i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
thread_list = []
for i in range(1, 3):
t = threading.Thread(target=long_time_task, args=(i, ))
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
import threading
import time
def long_time_task():
print('当子线程: {}'.format(threading.current_thread().name))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
for i in range(5):
t = threading.Thread(target=long_time_task, args=())
t.setDaemon(True)
t.start()
end = time.time()
print("总共用时{}秒".format((end - start)))
import os
import tensorrt as trt
os.environ["CUDA_VISIBLE_DEVICES"]='0'
TRT_LOGGER = trt.Logger()
onnx_file_path = 'Unet375-simple.onnx'
engine_file_path = 'Unet337.trt'
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 28 # 256MiB
builder.max_batch_size = 1
# Parse model file
if not os.path.exists(onnx_file_path):
print('ONNX file {} not found, please run yolov3_to_onnx.py first to generate it.'.format(onnx_file_path))
exit(0)
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
if not parser.parse(model.read()):
print ('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print (parser.get_error(error))
network.get_input(0).shape = [1, 3, 300, 400]
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
#network.mark_output(network.get_layer(network.num_layers-1).get_output(0))
engine = builder.build_cuda_engine(network)
print("Completed creating Engine")
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
trtexec --loadEngine=mnist16.trt --batch=1
打印输出:
trtexec会打印出很多时间,这里需要对每个时间的含义进行解释,然后大家各取所需,进行评测。总的打印如下:
[09/06/2021-13:50:34] [I] Average on 10 runs - GPU latency: 2.74553 ms - Host latency: 3.74192 ms (end to end 4.93066 ms, enqueue 0.624805 ms) # 跑了10次,GPU latency: GPU计算耗时, Host latency:GPU输入+计算+输出耗时,end to end:GPU端到端的耗时,eventout - eventin,enqueue:CPU异步耗时
[09/06/2021-13:50:34] [I] Host Latency
[09/06/2021-13:50:34] [I] min: 3.65332 ms (end to end 3.67603 ms)
[09/06/2021-13:50:34] [I] max: 5.95093 ms (end to end 6.88892 ms)
[09/06/2021-13:50:34] [I] mean: 3.71375 ms (end to end 5.30082 ms)
[09/06/2021-13:50:34] [I] median: 3.70032 ms (end to end 5.32935 ms)
[09/06/2021-13:50:34] [I] percentile: 4.10571 ms at 99% (end to end 6.11792 ms at 99%)
[09/06/2021-13:50:34] [I] throughput: 356.786 qps
[09/06/2021-13:50:34] [I] walltime: 3.00741 s
[09/06/2021-13:50:34] [I] Enqueue Time
[09/06/2021-13:50:34] [I] min: 0.248474 ms
[09/06/2021-13:50:34] [I] max: 2.12134 ms
[09/06/2021-13:50:34] [I] median: 0.273987 ms
[09/06/2021-13:50:34] [I] GPU Compute
[09/06/2021-13:50:34] [I] min: 2.69702 ms
[09/06/2021-13:50:34] [I] max: 4.99219 ms
[09/06/2021-13:50:34] [I] mean: 2.73299 ms
[09/06/2021-13:50:34] [I] median: 2.71875 ms
[09/06/2021-13:50:34] [I] percentile: 3.10791 ms at 99%
[09/06/2021-13:50:34] [I] total compute time: 2.93249 s
Host Latency gpu: 输入+计算+输出 三部分的耗时
Enqueue Time:CPU异步的时间(该时间不具有参考意义,因为GPU的计算可能还没有完成)
GPU Compute:GPU计算的耗时
综上,去了Enqueue Time时间都是有意义的
// boFirst.cpp : Defines the exported functions for the DLL.
#include "pch.h" // use stdafx.h in Visual Studio 2017 and earlier
#include <utility>
#include <limits.h>
#include "boFirst.h"
# include <iostream>
int bo_add(int a, int b)
{
int c;
c = a + b;
return c;
}
float bo_shape_vol(boShape bs)
{
float volume = bs.width * bs.height * bs.depth;
std::cout << bs.shape << "volume is " << volume << std::endl;
return volume;
}
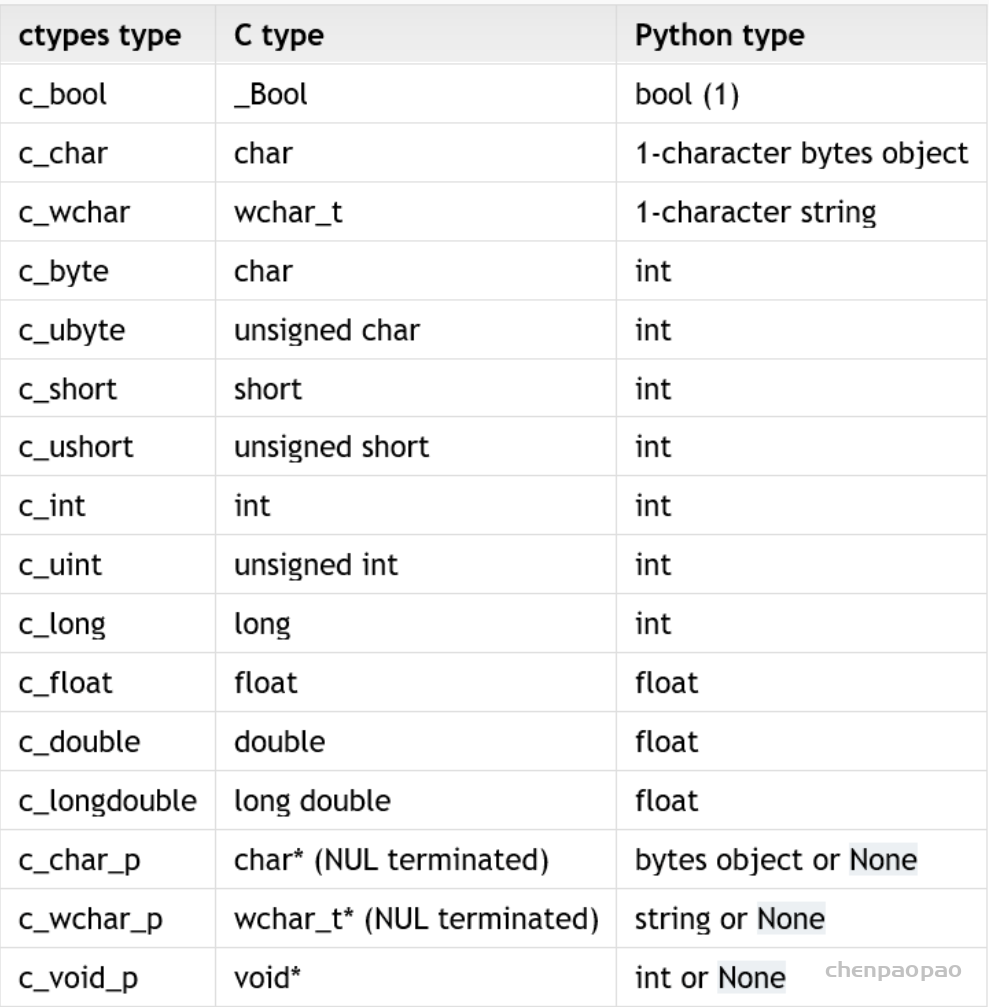
def find_example_ctypes(required):
'''
Finds and loads example shared object of the required major
'''
# Importing ``ctypes`` should be in scope of this function to prevent failure
from ctypes import util, cdll
so_name = util.find_library('example.dll')
if so_name is None:
raise ExampleImportError('EXAMPLE shared object not found.')
example = cdll.LoadLibrary(so_name)
require_version(example.example_version(), required)
return example
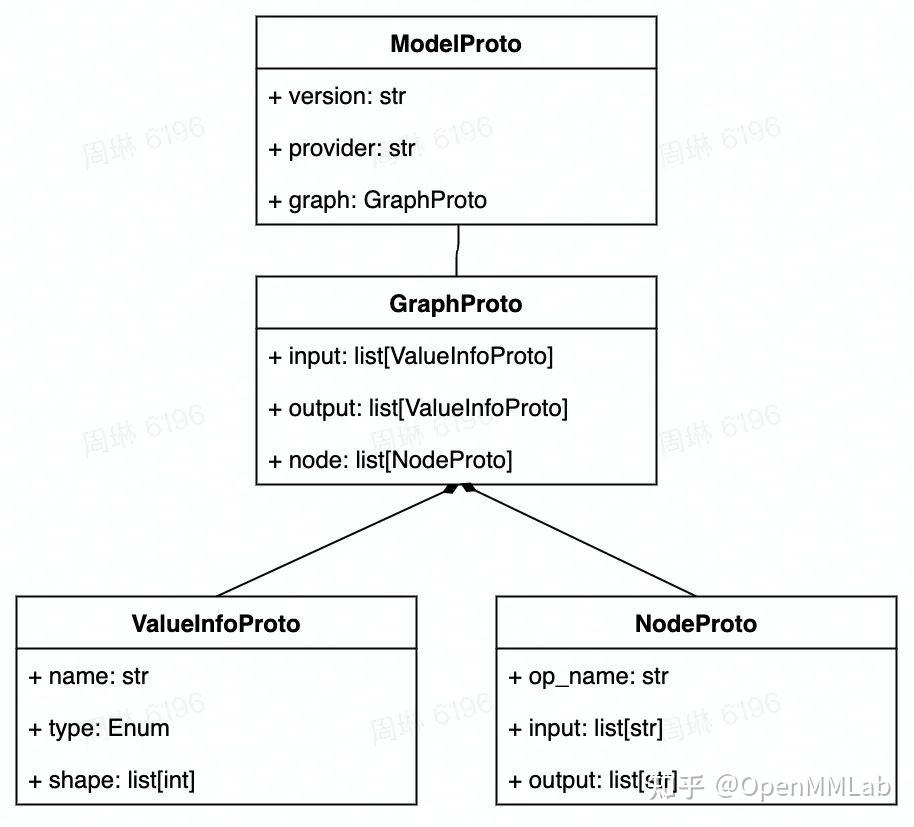
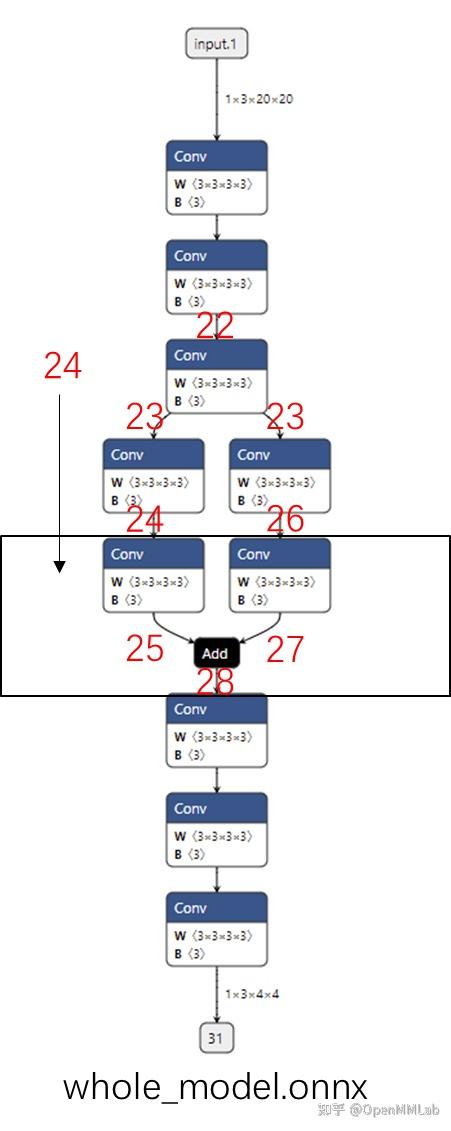
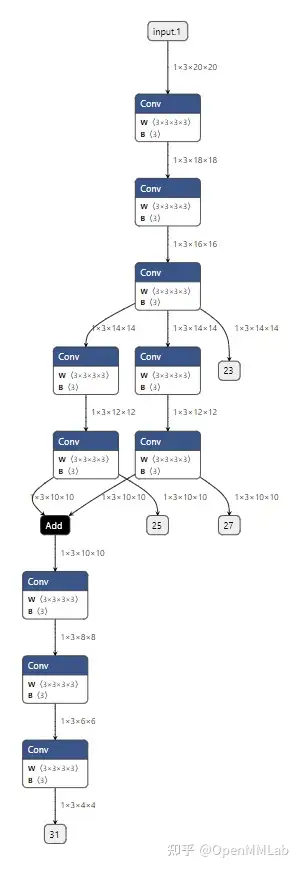
成功执行这些代码的话,程序会以文本格式输出模型的信息,其内容应该和我们在上一节展示的输出一样。 整理一下,用 ONNX Python API 构造模型的代码如下:
import onnx
from onnx import helper
from onnx import TensorProto
# input and output
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10])
# Mul
mul = helper.make_node('Mul', ['a', 'x'], ['c'])
# Add
add = helper.make_node('Add', ['c', 'b'], ['output'])
# graph and model
graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output])
model = helper.make_model(graph)
# save model
onnx.checker.check_model(model)
print(model)
onnx.save(model, 'linear_func.onnx')
老规矩,我们可以用 ONNX Runtime 运行模型,来看看模型是否正确:
import onnxruntime
import numpy as np
sess = onnxruntime.InferenceSession('linear_func.onnx')
a = np.random.rand(10, 10).astype(np.float32)
b = np.random.rand(10, 10).astype(np.float32)
x = np.random.rand(10, 10).astype(np.float32)
output = sess.run(['output'], {'a': a, 'b': b, 'x': x})[0]
assert np.allclose(output, a * x + b)
一切顺利的话,这段代码不会有任何报错信息。这说明我们的模型等价于执行 a * x + b 这个计算。
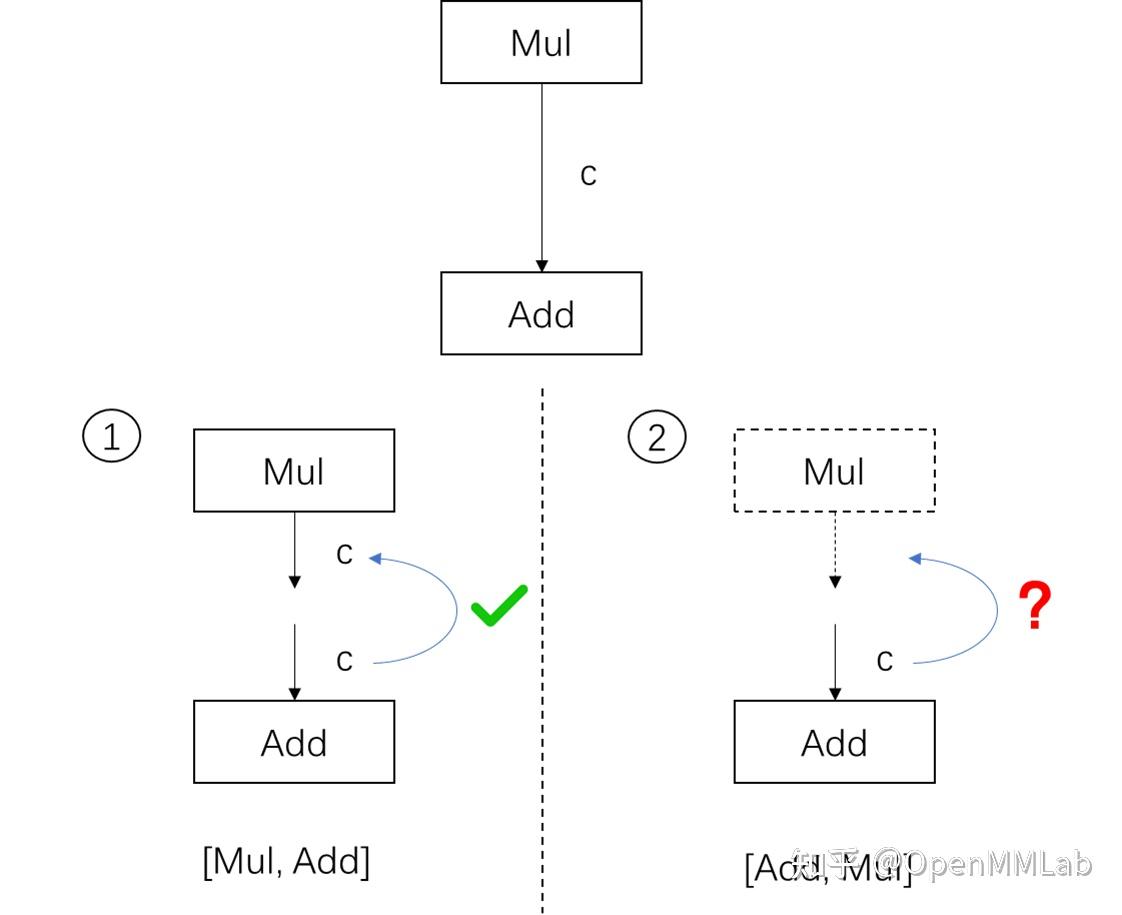
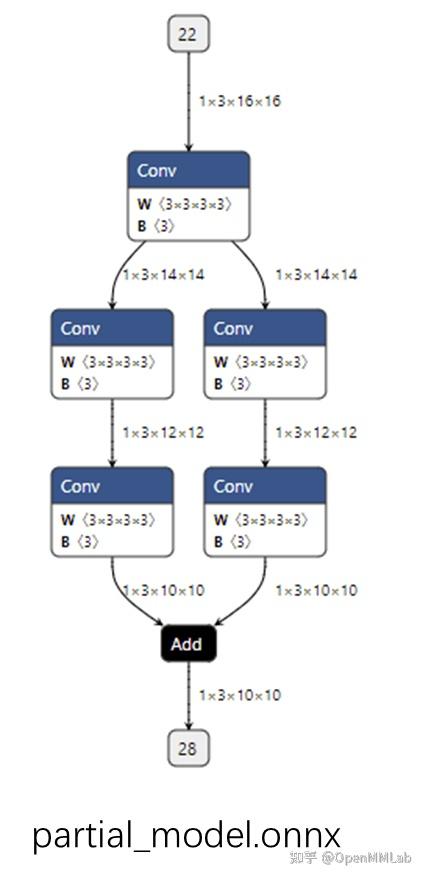
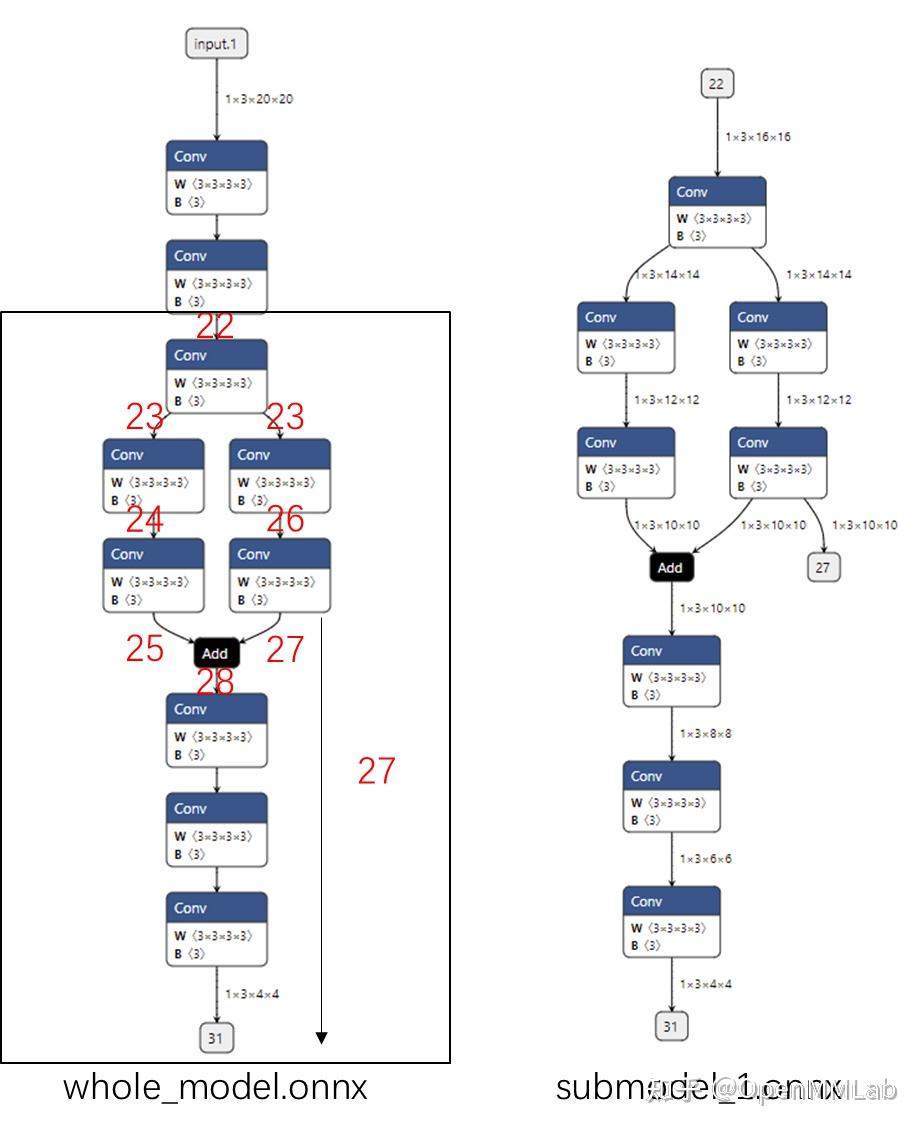
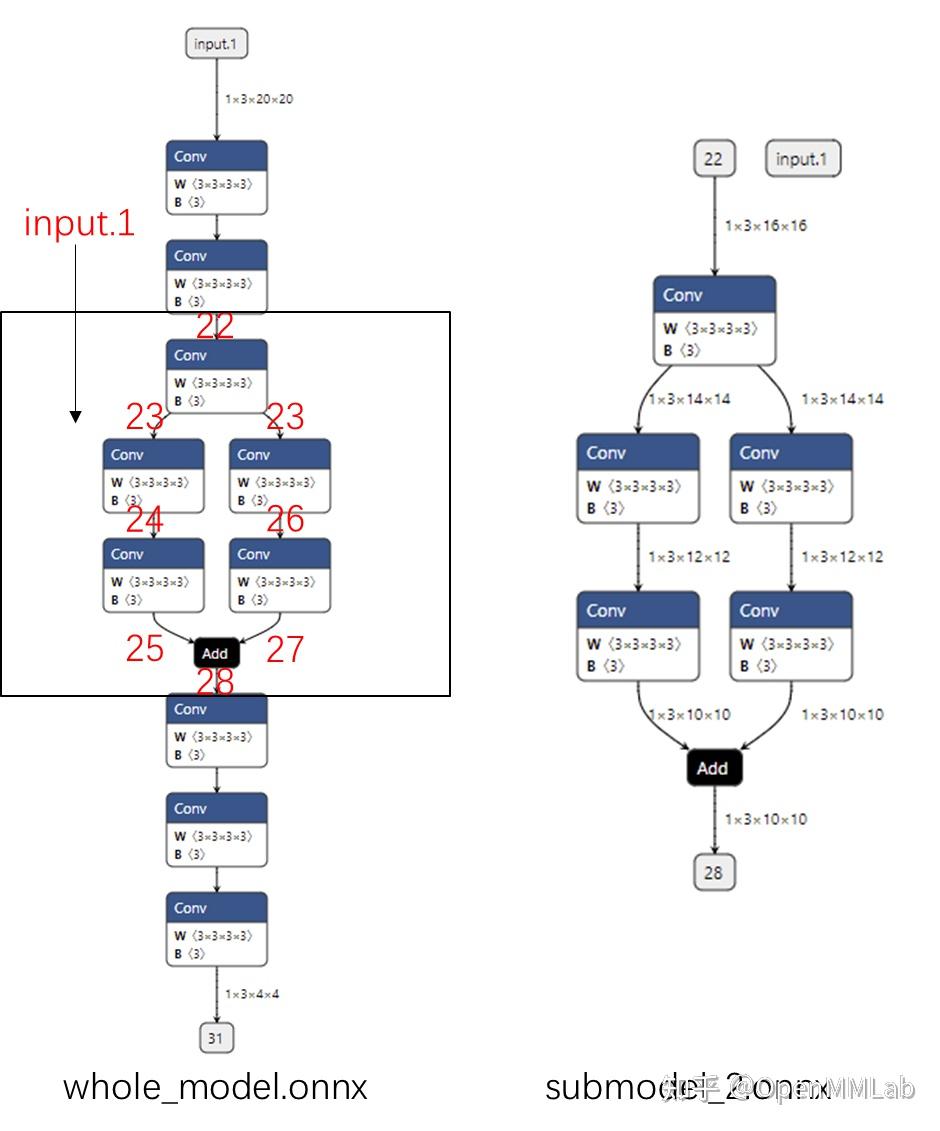
读取并修改 ONNX 模型
通过用 API 构造 ONNX 模型,我们已经彻底搞懂了 ONNX 由哪些模块组成。现在,让我们看看该如何读取现有的”.onnx”文件并从中提取模型信息。 首先,我们可以用下面的代码读取一个 ONNX 模型:
import onnx
model = onnx.load('linear_func.onnx')
print(model)
在读入之前的 linear_func.onnx 模型后,我们可以直接修改第二个节点的类型 node[1].op_type,把加法变成减法。这样,我们的模型描述的是 a * x - b 这个线性函数。大家感兴趣的话,可以用 ONNX Runtime 运行新模型 linear_func_2.onnx,来验证一下它和 a * x - b 是否等价。