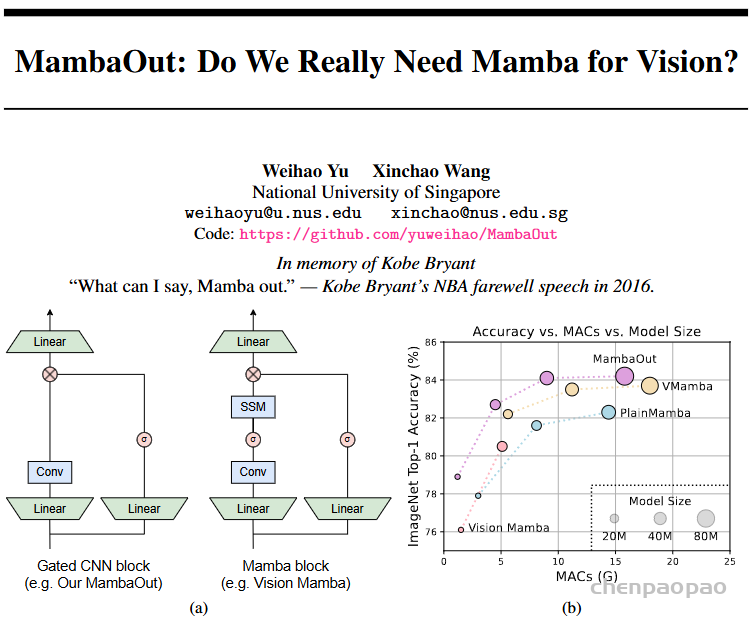
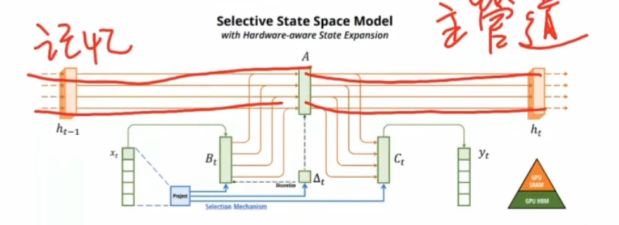
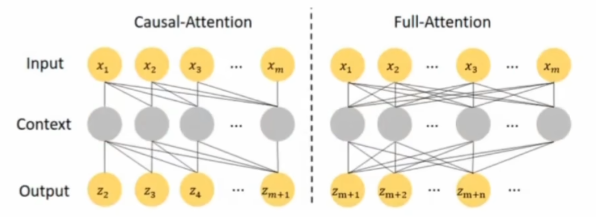
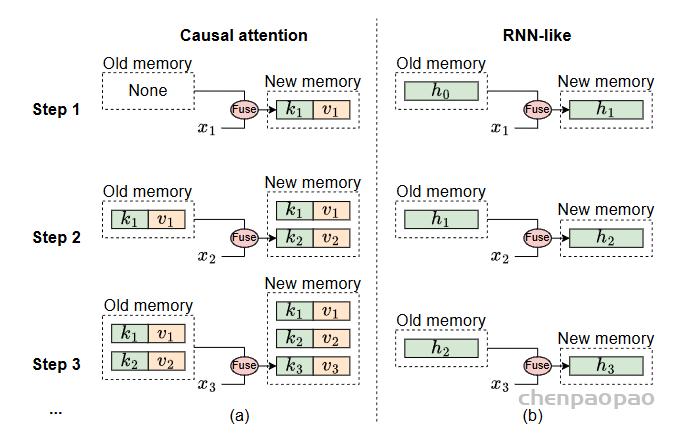
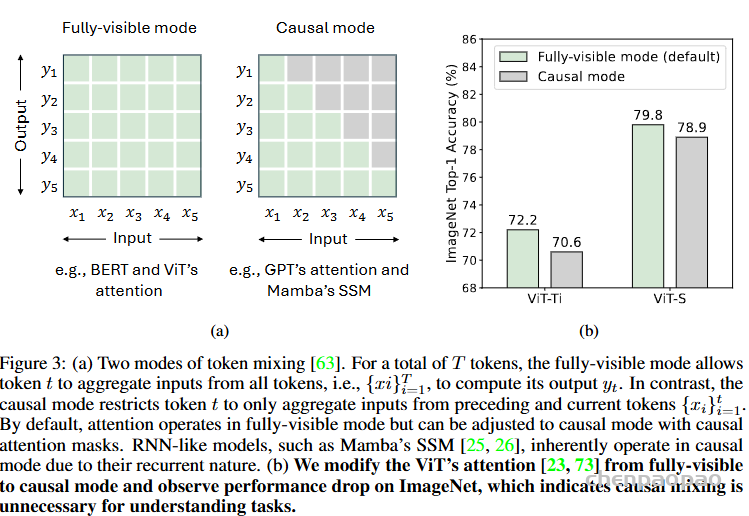
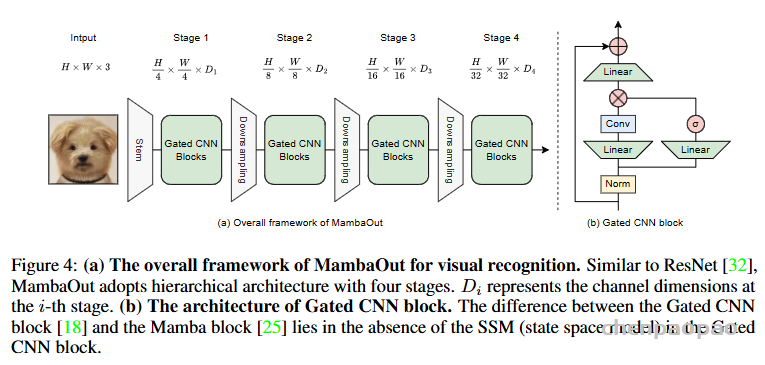
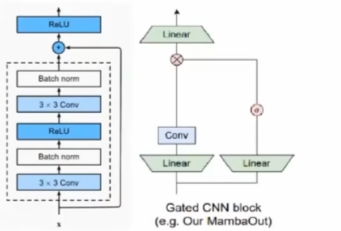
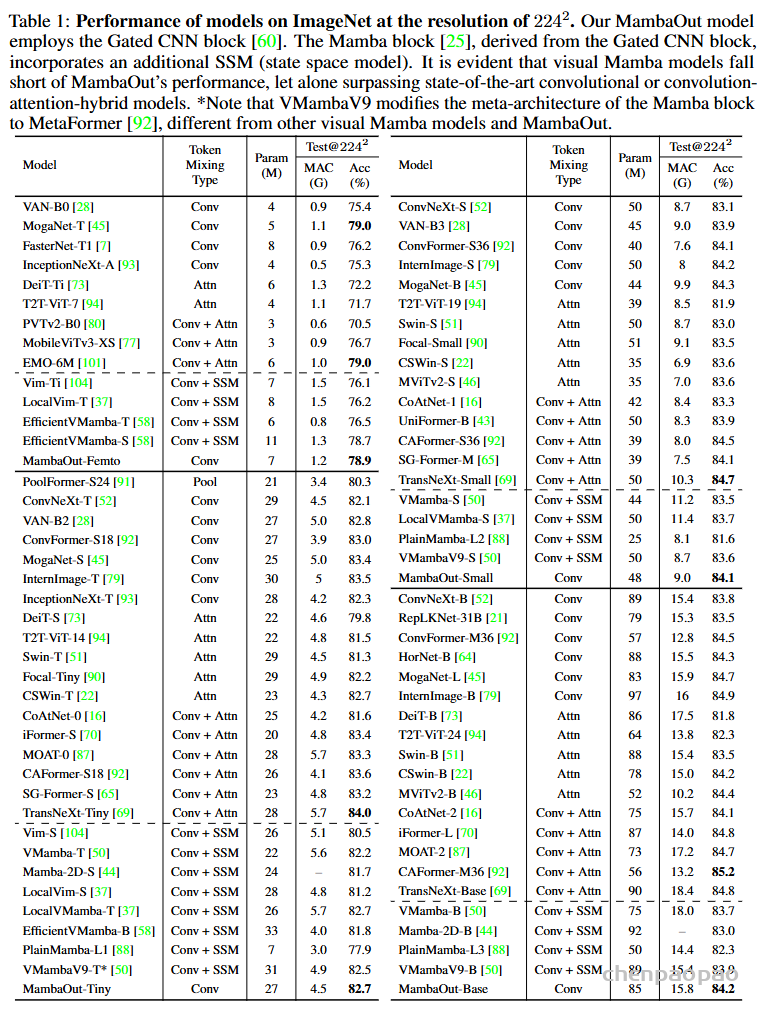
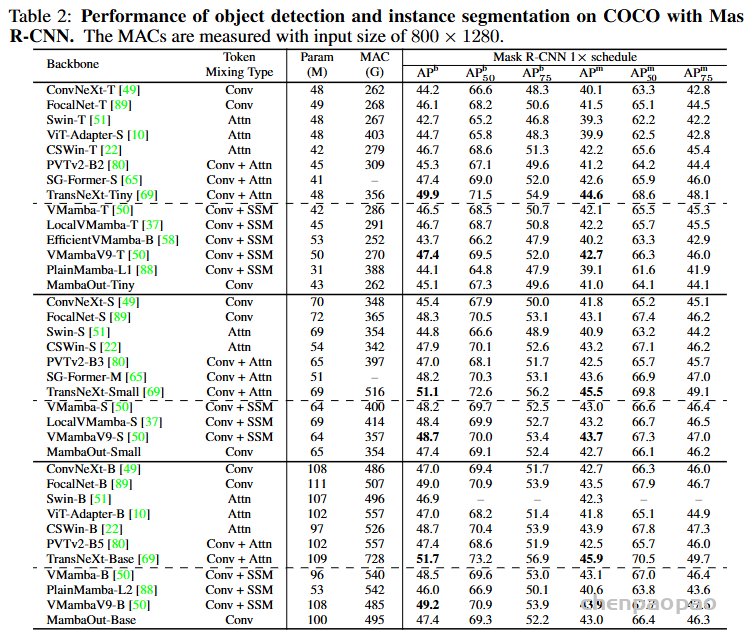
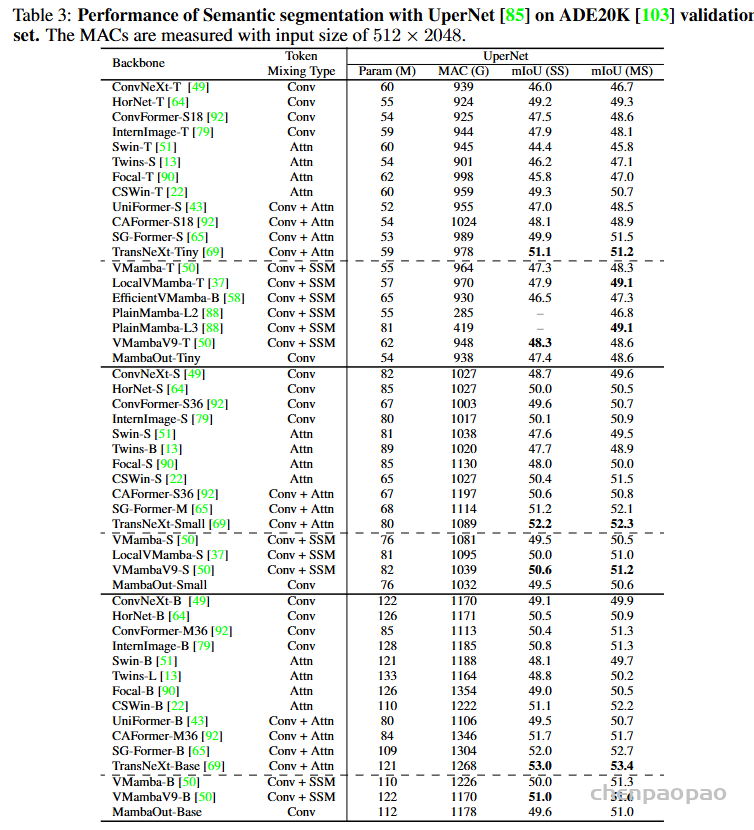
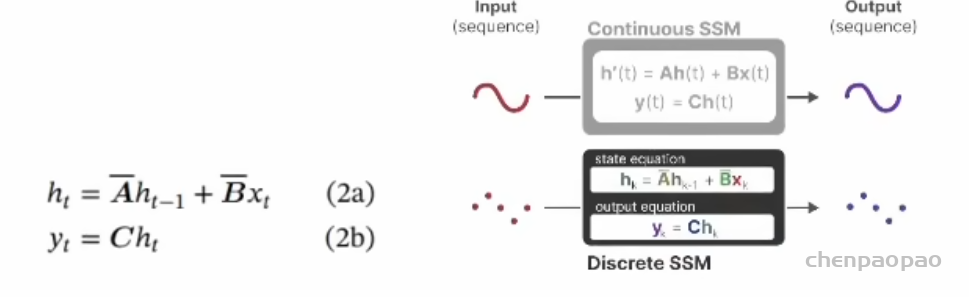
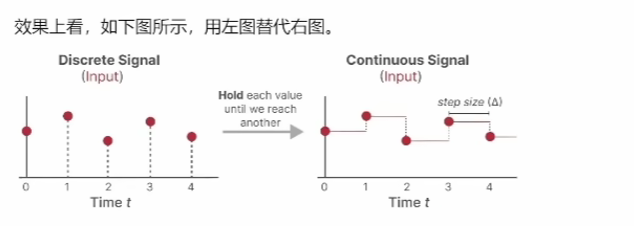
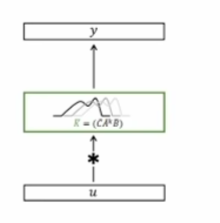
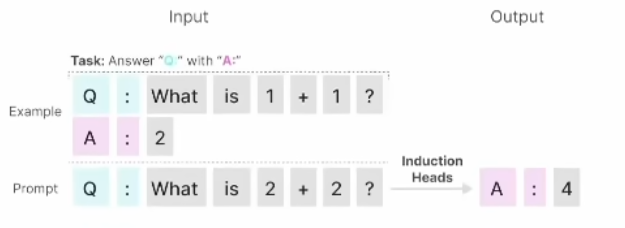
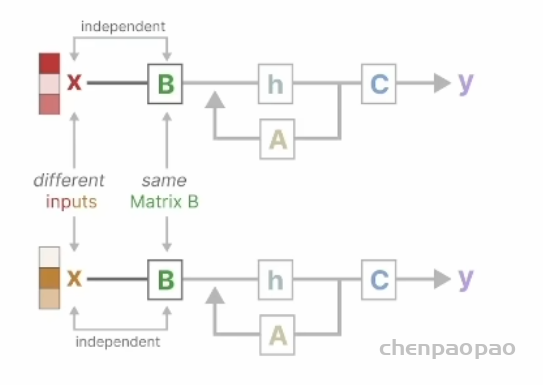
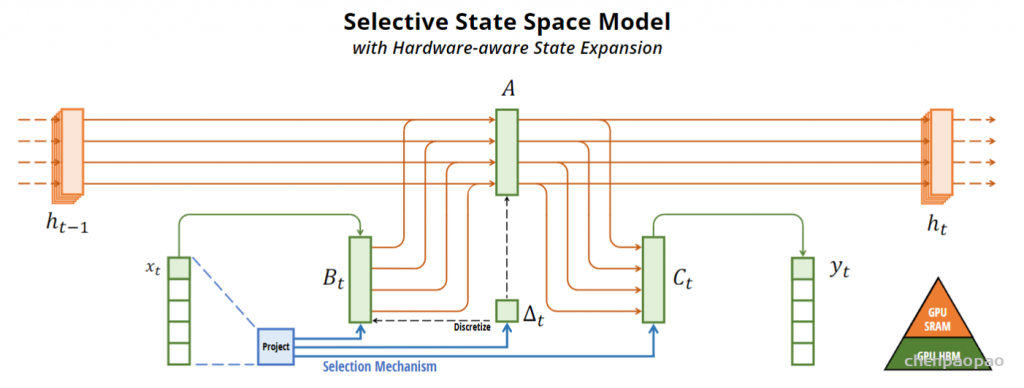
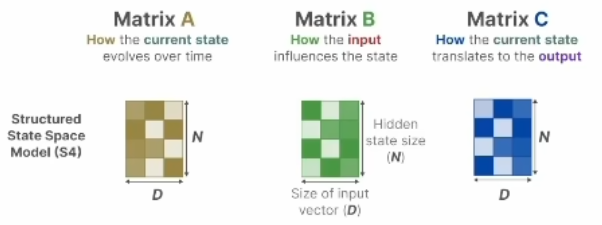
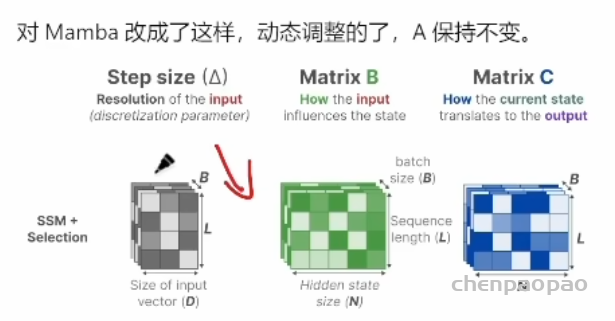
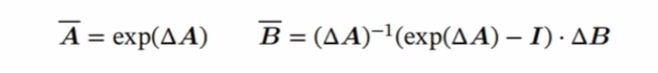Do we really need Mamba for Vision? 视觉问题真得需要Mamba 模型吗Hypothesis 1:SSM 对于图像分类没有必要,因为该任务既不具有长序列特征也不具有自回归特征。 Hypothesis 2:sSM 可能对对象检测和实例分割有潜在好处,因为这些任务具有长序列特征,但不具有自回归特征。 重要的是三个问题:怎么分析的,模型怎么实现的,以及怎么用实验证明的。
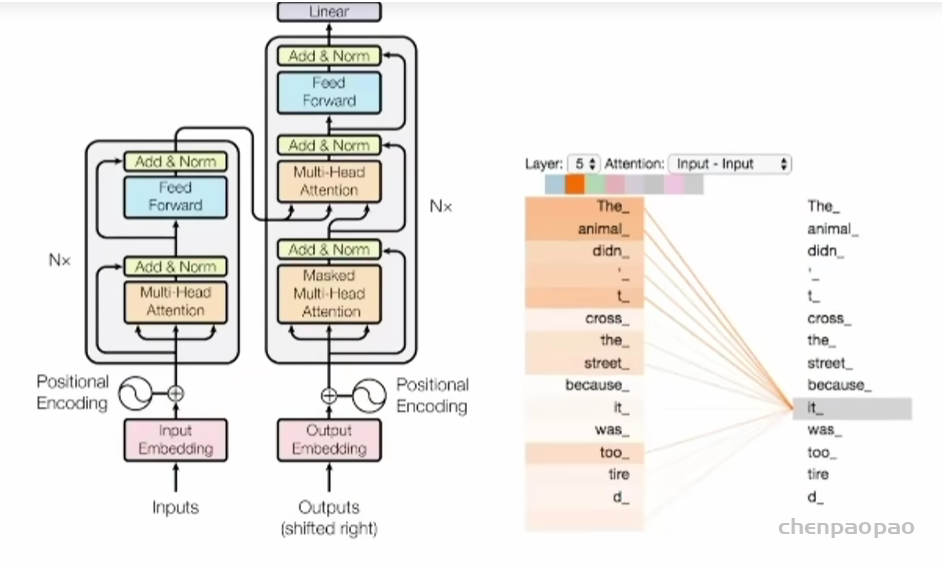
第二部分相关工作简要小结了 Transformer 典型模型 BERT和 GPT系列,以及 ViT 强调了Transformer 中的注意力模块会随序列长度增加而扩展,带来显著的计算挑战。许多研究探索了各种策略来缓解这一问题,如低秩方法、内核化、token 混合范围限制和历史记忆压缩。这都是水文章的号方向。最近,RNN-like方法(特别是 RWKV和Mamba)因其在大规模语言模型中的出色表现而受到关注,这点到目前为止还是毋庸置疑的。
但这样以来还怎么 OUT 呀!于是他们反向思考:首先,什么时候不需要长序列呢?视觉作为空间数据,那种最不需要呢?你说是鸡蛋里挑骨头也好,逆向思维也好。既然逻辑上它擅长长序列,那就说明短序列一般,那咱们就摁着短序列搞不就成了。 其次,什么时候不需要因果注意力呢?什么问题需要全局可见注意力呢?着这个方向搞,不也能证明 Mamba不行吗?这种创新的思维方式确实聪明,典型的田忌赛马思路,你打你的,我打我的,拉到我擅长的地方打,你还打得过吗?
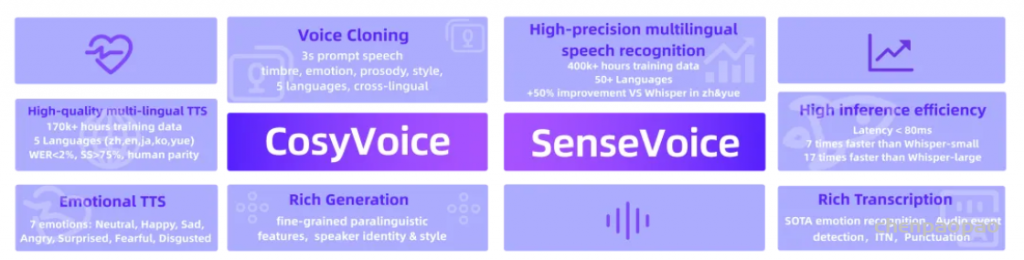
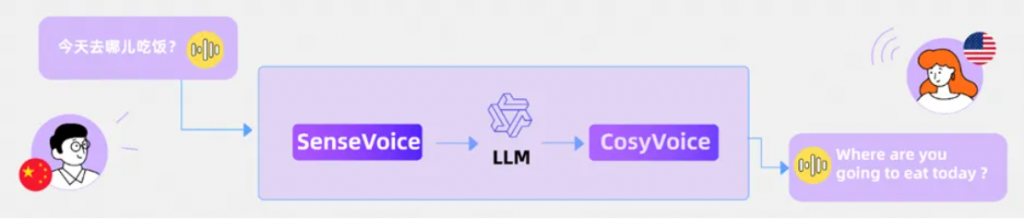
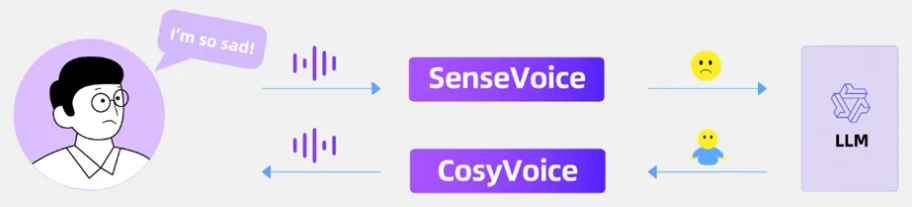
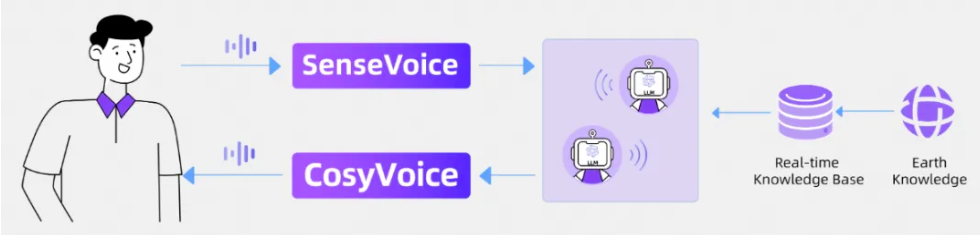
当我们主要关注文本和语音模态时,GPT-4o其实就是一个语音语言模型(speech language model, SLM)。该SLM同时具备语音理解能力和语音合成能力,输入端和输出端均支持文本和语音的混合多模态。那么,这一SLM应该如何实现呢?在大语言模型(large language model, LLM)滥觞的今日,不难想到这样一种方法:将连续的语音数据离散化成如同单词(或者称token,词元)一样的表示,并入到LLM的词表中,再走一遍训练LLM的老路。
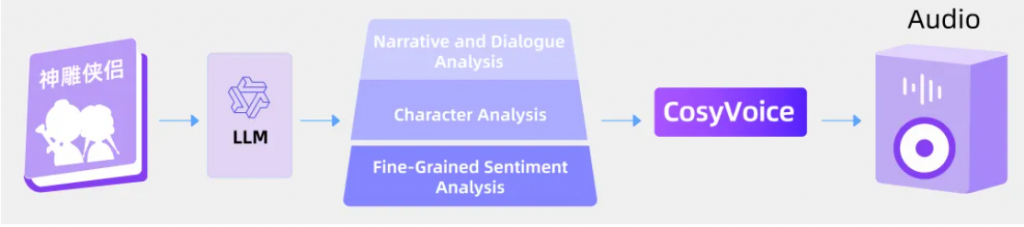
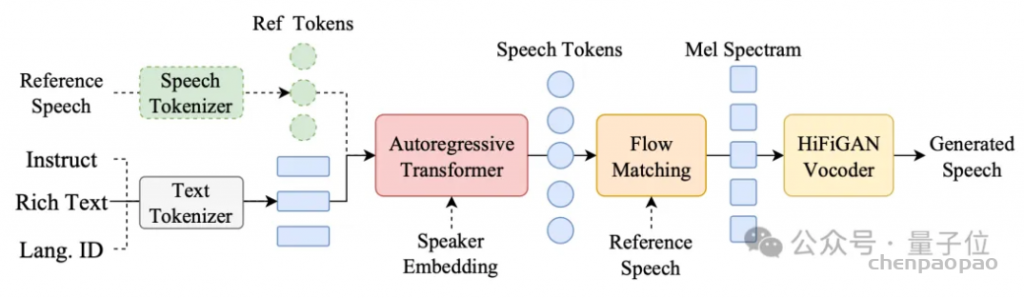
audio & text tokenizer的实现应该是语音离散化部分所用的技术,例如SoundStream、Encodec、SpeechTokenizer,或者是MEL+VQ最后配合声码器来解码;参考zero-shot TTS、AudioLM/AudioPaLM、SpeechGPT-Gen等工作的结果,LLM中语音token的解码应该是要走层次化或者多步的方法,先解码语义特征,再解码声学特征,或者是先解码MEL,再加一个HIFIGAN这样的声码器。另外,如果做audio/speech/music这样的通用声合成的话,可能也能通过prompt来控制。AudioLDM2虽然做了这方面的工作,但audio/music和speech的参数其实是不一样的,说到底还不是同一个模型。
[1] Baevski A, Zhou Y, Mohamed A, et al. wav2vec 2.0: A framework for self-supervised learning of speech representations[J]. Advances in neural information processing systems, 2020, 33: 12449-12460.
[2] Hsu W N, Bolte B, Tsai Y H H, et al. Hubert: Self-supervised speech representation learning by masked prediction of hidden units[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3451-3460.
[3] Chung Y A, Zhang Y, Han W, et al. W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training[C]//2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021: 244-250.
[4] Van Den Oord A, Vinyals O. Neural discrete representation learning[J]. Advances in neural information processing systems, 2017, 30.
[5] Zeghidour N, Luebs A, Omran A, et al. Soundstream: An end-to-end neural audio codec[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 30: 495-507.
[6] Défossez A, Copet J, Synnaeve G, et al. High fidelity neural audio compression[J]. arXiv preprint arXiv:2210.13438, 2022.
[7] Zhang X, Zhang D, Li S, et al. Speechtokenizer: Unified speech tokenizer for speech large language models[J]. arXiv preprint arXiv:2308.16692, 2023.
[8] Borsos Z, Marinier R, Vincent D, et al. Audiolm: a language modeling approach to audio generation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
[9] Rubenstein P K, Asawaroengchai C, Nguyen D D, et al. Audiopalm: A large language model that can speak and listen[J]. arXiv preprint arXiv:2306.12925, 2023.
[10] Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang. SALMONN: Towards Generic Hearing Abilities for Large Language Models
[11] Zhang D, Li S, Zhang X, et al. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities[J]. arXiv preprint arXiv:2305.11000, 2023.
[16] Wang C, Chen S, Wu Y, et al. Neural codec language models are zero-shot text to speech synthesizers[J]. arXiv preprint arXiv:2301.02111, 2023.
[17] Anil R, Dai A M, Firat O, et al. Palm 2 technical report[J]. arXiv preprint arXiv:2305.10403, 2023.
[18] Lee Y, Yeon I, Nam J, et al. VoiceLDM: Text-to-Speech with Environmental Context[C]//ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024: 12566-12571.
[19] Lyth D, King S. Natural language guidance of high-fidelity text-to-speech with synthetic annotations[J]. arXiv preprint arXiv:2402.01912, 2024.
[20] Betker J. Better speech synthesis through scaling[J]. arXiv preprint arXiv:2305.07243, 2023.
[21] Xin D, Tan X, Shen K, et al. RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis[J]. arXiv preprint arXiv:2404.03204, 2024.
[22] Wang C, Zeng C, Zhang B, et al. HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling[J]. arXiv preprint arXiv:2403.05989, 2024.
[23] Ren Y, Hu C, Tan X, et al. Fastspeech 2: Fast and high-quality end-to-end text to speech[J]. arXiv preprint arXiv:2006.04558, 2020.
[24] Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 10684-10695.
[25] Shen K, Ju Z, Tan X, et al. Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers[J]. arXiv preprint arXiv:2304.09116, 2023.
[26] Ju Z, Wang Y, Shen K, et al. NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models[J]. arXiv preprint arXiv:2403.03100, 2024.
[27] Liu H, Tian Q, Yuan Y, et al. AudioLDM 2: Learning holistic audio generation with self-supervised pretraining[J]. arXiv preprint arXiv:2308.05734, 2023.
[28] Jiang Z, Ren Y, Ye Z, et al. Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias[J]. arXiv preprint arXiv:2306.03509, 2023.
[29] Jiang Z, Liu J, Ren Y, et al. Mega-tts 2: Zero-shot text-to-speech with arbitrary length speech prompts[J]. arXiv preprint arXiv:2307.07218, 2023.
[30] Łajszczak M, Cámbara G, Li Y, et al. BASE TTS: Lessons from building a billion-parameter text-to-speech model on 100K hours of data[J]. arXiv preprint arXiv:2402.08093, 2024.
[31] Li Y A, Han C, Mesgarani N. Styletts: A style-based generative model for natural and diverse text-to-speech synthesis[J]. arXiv preprint arXiv:2205.15439, 2022.
[32] Li Y A, Han C, Raghavan V, et al. Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models[J]. Advances in Neural Information Processing Systems, 2024, 36.
[33] Guo Z, Leng Y, Wu Y, et al. Prompttts: Controllable text-to-speech with text descriptions[C]//ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023: 1-5.
[34] Yang D, Liu S, Huang R, et al. Instructtts: Modelling expressive TTS in discrete latent space with natural language style prompt[J]. arXiv preprint arXiv:2301.13662, 2023.
[35] Vyas A, Shi B, Le M, et al. Audiobox: Unified audio generation with natural language prompts[J]. arXiv preprint arXiv:2312.15821, 2023.
[36] Lee S H, Choi H Y, Kim S B, et al. HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis[J]. arXiv preprint arXiv:2311.12454, 2023.
[37] Yang D, Tian J, Tan X, et al. Uniaudio: An audio foundation model toward universal audio generation[J]. arXiv preprint arXiv:2310.00704, 2023.
[38] Huang R, Zhang C, Wang Y, et al. Make-a-voice: Unified voice synthesis with discrete representation[J]. arXiv preprint arXiv:2305.19269, 2023.
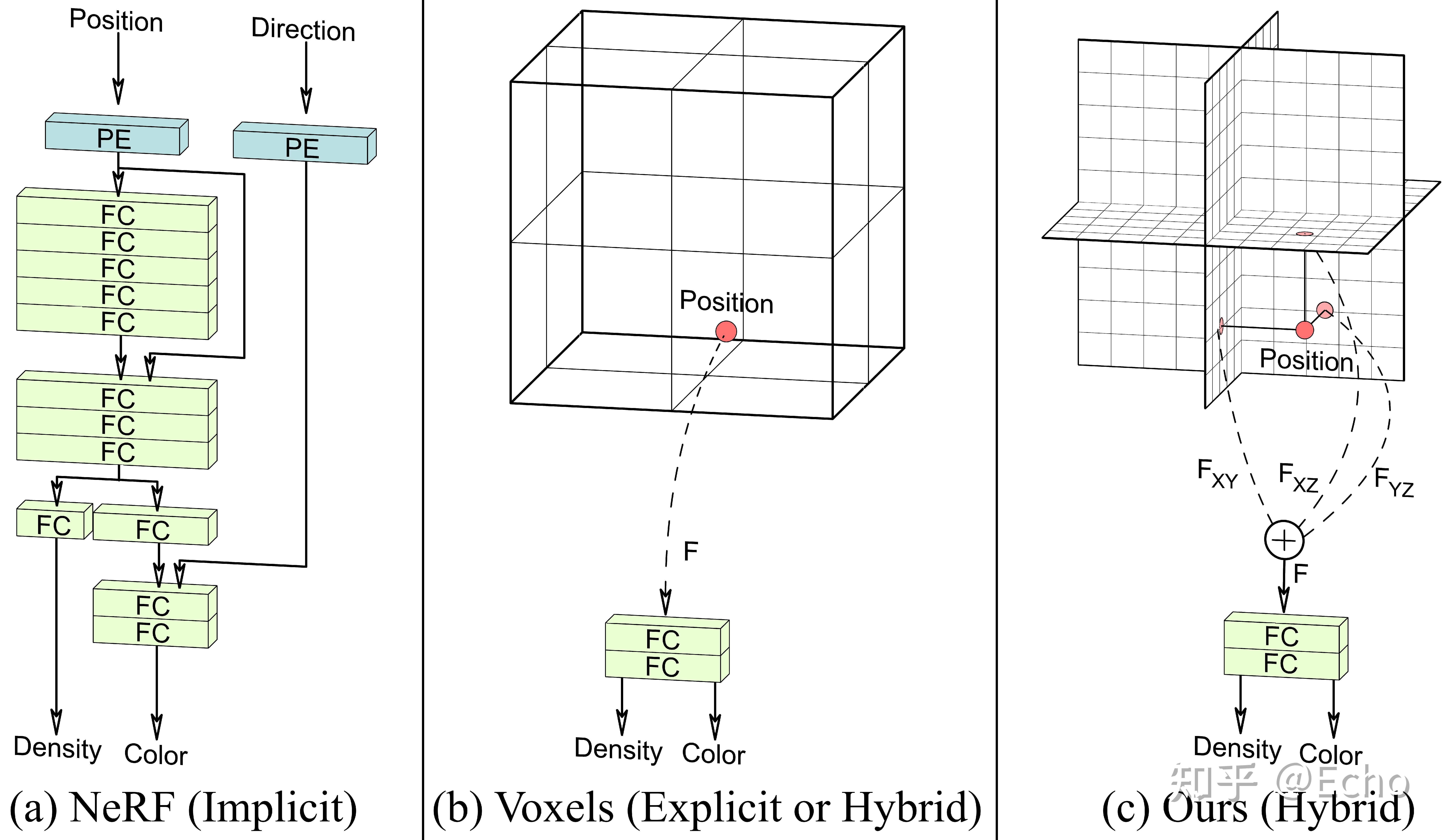
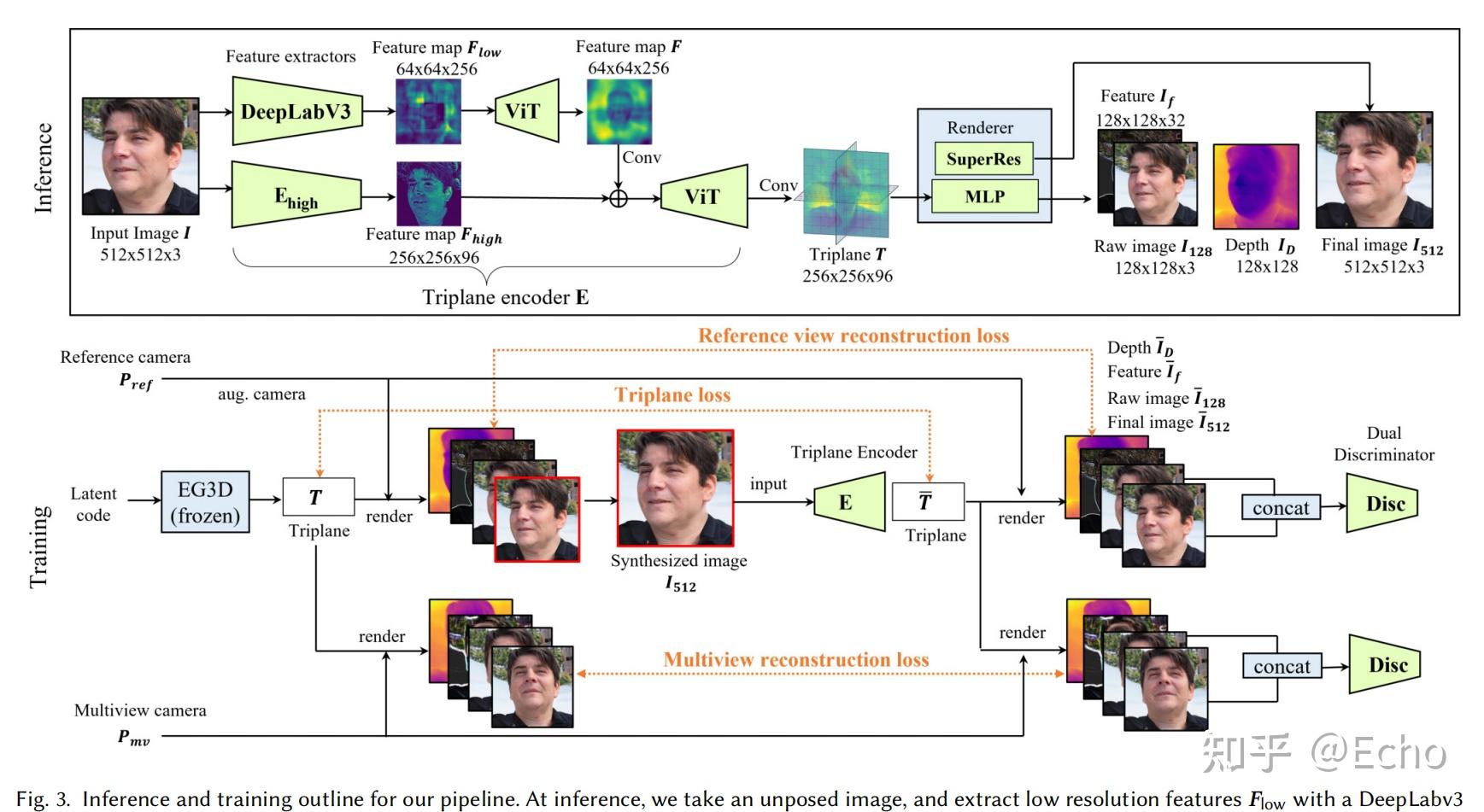
本文提出了从单张图像实时推理渲染照片级 3D 表示的单样本方法,该方法给定单张 RGB 输入图像后,编码器直接预测神经辐射场的规范化三平面表示,从而通过体渲染实现 3D 感知的新视图合成。该方法仅使用合成数据进行训练,通过结合基于 Transformer 的编码器和数据增强策略,可以处理现实世界中具有挑战性的输入图像,并且无需任何特殊处理即可逐帧应用于视频。
GAN inversion在2D领域取得很大进展,现有的3D GAN inversion方法将给定的图像投影到预训练的StyleGAN2 latent space上,并且在测试时需要摄像机姿态( approximate camera pose )和生成器权重微调( generator weight tuning),以重建域外输入图像。与同时期的工作不同,作者的前馈编码器将未定位的图像作为输入,并且不需要针对摄像机姿态的测试时优化。
作者的目标是将EG3D生成模型的信息提炼到一个前馈编码器的pipline中,这可以直接将未定位的图像映射到一个规范的三平面3D表示,这里的规范表示,对于人脸,头部的中心是原点。该pipline仅需要单次前馈网络传递,从而避免了花销大的 GAN inversion过程,同时允许实时重新渲染输入的任意视点。
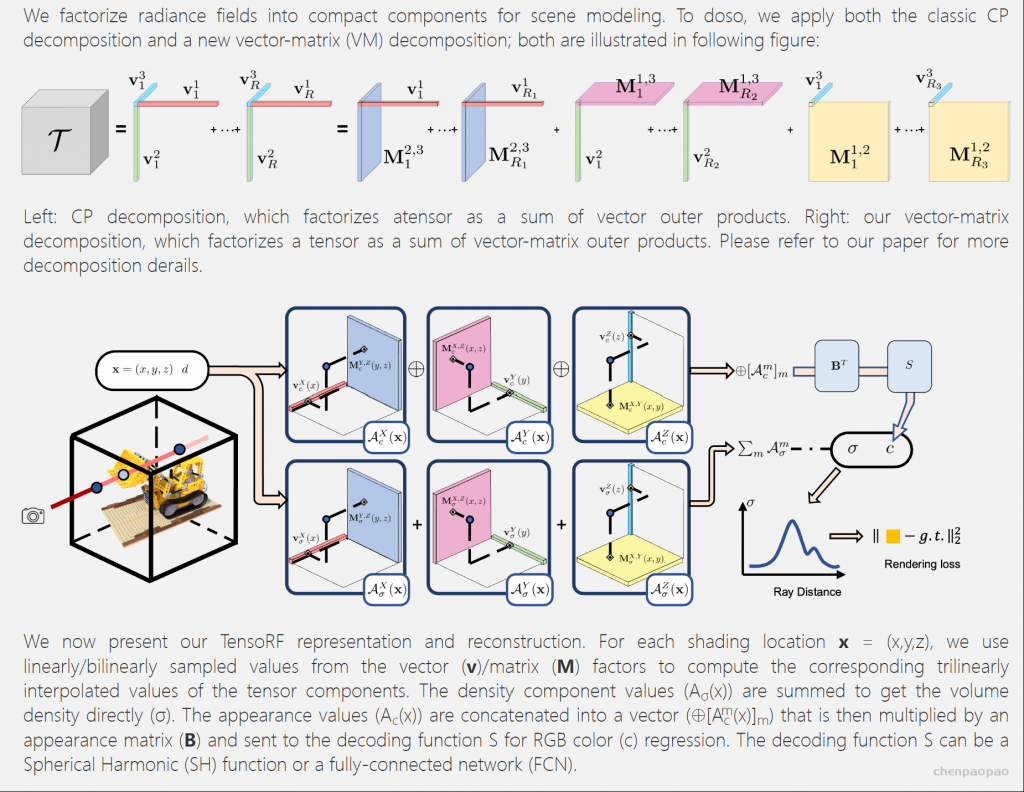
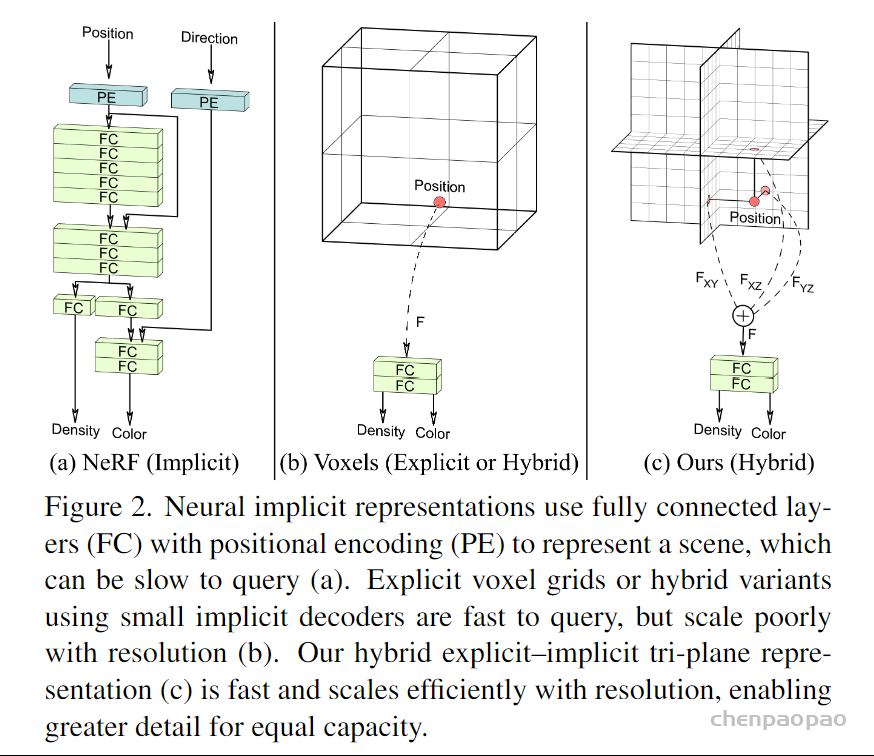
这篇工作提出了两个方法。首先,作者用显隐混合的方法,提高了时空效率,并有较高的质量。第二,提出了dual-discrimination策略,保证了多视角一致性。同时,还引入了pose-based conditioning to the generator,可以解耦pose相关的参数,保证了输出的视角一致性,同时忠实地重建数据集隐含的pose-correlated参数。