
- 论文链接:https://arxiv.org/abs/2605.19833
- 项目主页:https://xzf-thu.github.io/Mega-ASR/
- GitHub Repo:https://github.com/xzf-thu/Mega-ASR
- Hugging Face 模型:https://huggingface.co/zhifeixie/Mega-ASR
- Hugging Face 数据集:https://huggingface.co/datasets/zhifeixie/Voices-in-the-Wild-2M
- Bench: github.com/xzf-thu/Voices-in-the-Wild-Bench
Mega-ASR 是一个专门解决”真实世界语音识别翻车”问题的开源框架——它用涵盖54种噪声、回声、丢帧等复合场景的240万条数据训练,让模型在嘈杂现实环境下的词错误率降低30%+,同时大幅减少”听没了”和”乱编内容”这两种高频故障。解决的核心问题是:在各种嘈杂、失真、回声、断连的现实场景下,尽可能准确地把语音转成文字。模型基于 Qwen3-ASR-1.7B进行后训练,通过一套专门设计的数据集和训练方法来强化”恶劣环境下的识别能力”。
一、ASR 在「现实世界环境」为什么不行?
- 场景覆盖太窄:只解决噪音 / 远场单一问题,真实环境是复合干扰(噪音 + 混响 + 丢包一起上)。
- 复合鲁棒性缺失: 缺乏对复杂环境的适应性,现实世界中的环境往往是多种因素共同作用的结果,很少模型能同时扛住多种失真叠加。
- 训练与真实不匹配:训练数据太简单(WER 4%–10%),遇到高难度场景(WER>30%)直接崩
二、数据:Voices-in-the-Wild-2M
大规模、高难度、物理合理的复合声学仿真数据集
现有语音数据集的 3 大致命问题:
- 只覆盖单一干扰:噪音 / 混响 / 远场分开做,不模拟真实复合环境
- 难度太 “温柔”:平均 WER 只有 4%–10%,训练不出强鲁棒模型
- 真实录音太少太贵:收集覆盖所有场景的真实录音成本极高、不可扩
为了推动这一更具挑战性场景下的研究,提出了 Voices-in-the-Wild-2M,一个基于频谱级代码驱动仿真(spectrogram-level code-based simulation)构建的大规模数据集。这种设计使得超大规模数据生成成为可能。
首先识别并定义了 7 类经典的现实声学效应,这些基础效应用于模拟各种物理环境或设备引起的退化现象:
| 真实退化现象 | 对应 Primitive |
|---|---|
| 背景噪声 | Additive Noise |
| 延迟反射 | Echo Delay |
| 房间混响 | Reverberation |
| 削波失真 | Nonlinear Distortion |
| 带宽受限 | Resampling |
| 高频衰减 | Spectral Filtering |
| 音量不一致 | Loudness Transformation |
| 丢包/卡顿 | Frame-level Stutter |
设计了专门的频谱处理流水线,持续调整仿真参数,并利用 Qwen3-ASR 的监督微调(SFT)结果进行验证,直到模拟器在真实数据上的表现达到最佳拟合效果。
将这些原子效应组合成 54 种经过 Agent 验证的复杂声学配置,最终生成了 240 万条(2.4M)合成语音样本。
与直接枚举各种复杂真实环境不同,将野外环境(in-the-wild)中的语音退化过程划分为三个层级:
- Primitive Acoustic Effects(基础声学效应)
- Atomic Acoustic Effects(原子声学效应)
- Compound Acoustic Scenarios(复合声学场景)
第一层:Primitive Acoustic Effects(基础声学效应)
用 DSP 手段实现最基本的声学退化组件
| 原子效应 | 核心基元组合 | 模拟真实场景 |
|---|---|---|
| 噪声(Noise) | 加性噪声 + 响度归一 | 街道、咖啡馆、车内、人群 |
| 远场(Far-field) | 混响 + 低通滤波 + 响度衰减 | 远距离说话、智能音箱远场 |
| 遮挡(Obstructed) | 低通滤波 + 混响 + 衰减 | 隔门、隔窗、口罩、墙后说话 |
| 回声 + 混响(Echo&Reverb) | 强混响 + 回声 + 高通 | 大厅、车库、体育馆、空旷房间 |
| 录制染色(Recording) | 重采样 + 噪声 + 双带通滤波 | 手机外放再录制、设备串音 |
| 电子失真(Electronic Distortion) | 非线性失真 + 低通 | 麦克风过载、削波、劣质录音 |
| 传输丢包(Transmission Dropout) | 帧卡顿 + 响度归一 | 网络丢包、蓝牙不稳、流媒体卡顿 |
第二层:Atomic Acoustic Effects(原子声学效应)
在中间层,我们利用上述 Primitive Effects 构建了 7 种原子声学效应:
| Atomic Effect | 中文 |
|---|---|
| Noise | 噪声环境 |
| Far-field | 远场录音 |
| Obstructed | 遮挡语音 |
| Echo & Reverb | 回声与混响 |
| Recording | 录音链路效应 |
| Electronic Distortion | 电子失真 |
| Transmission Dropout | 传输丢失 |
一个 Atomic Effect 并不一定只对应一个 Primitive Effect。而是一个主导 Primitive + 若干辅助 Primitive。
比如:Far-field(远场)真实远场录音不仅仅是声音变小。通常同时具有:
- 声压衰减(Loudness)
- 高频损失(Spectral Filtering)
- 房间混响(Reverb)
第三层:Compound Acoustic Scenarios(复合声学场景)
最高层将多个 Atomic Effects 进行组合,比如视频会议
Far-field + Echo&Reverb + Recording
无论构建 Atomic Effect 还是 Compound Scenario,都保持 Primitive Effect 的固定执行顺序。为的是避免物理上不合理的处理链
关键创新:不是随机乱组合,而是按物理规则合成。
组合规则(保证真实不违和)
- 锚点效应(3 种):远场 / 回声混响 / 遮挡(互斥,不同时出现)
- 修饰效应(4 种):噪声 / 录制染色 / 电子失真 / 丢包(可叠加)
为了让难度 “均匀且可学习”,团队设计了全局 severity 参数 m ∈ [0,1]:
- 同一个音频里,所有失真共用一个 m
- 保证:要么整体简单,要么整体难,不会出现 “强混响 + 零噪音” 这种不自然组合
最终选用 Linear 线性分布:
- 简单、中等、困难样本均匀覆盖
- 训练最稳定、泛化最强
严格过滤保证可学习
- 剔除 WER > 70% 的样本(太难学不动)
- 保留物理合理组合
- 统一响度、统一格式、对齐标注
三、Mega-ASR
Qwen3-ASR 的基础上开发了 Mega-ASR-Base 模型
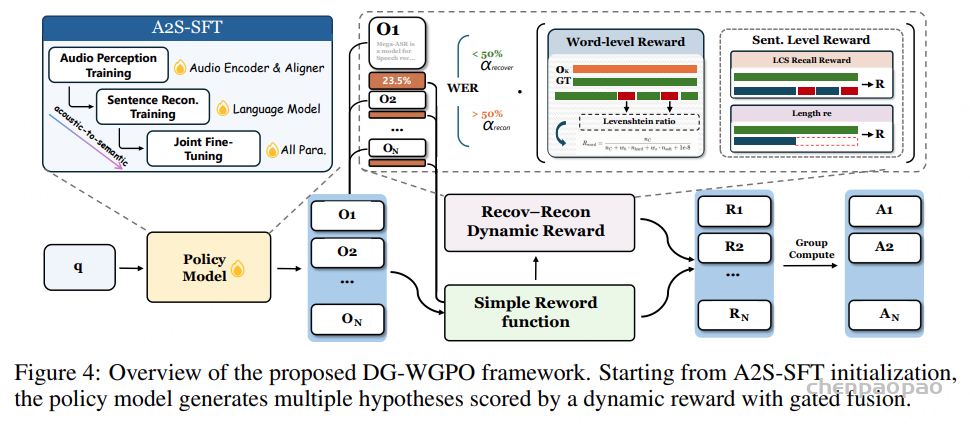
1. A2S-SFT:从声学 → 语义递进微调
解决:高失真下「听不清 → 猜不对」的连锁崩溃。分三阶段训练:
- 声学感知阶段:编码器 + 对齐器,按难度递进(WER<30% → <50% → <70%)
- 语义恢复阶段:冻结声学,只微调 LLM,学会从残缺信号还原语义
- 联合对齐阶段:全模块一起微调,声学与语义对齐
2. DG-WGPO:双粒度 WER 门控策略优化
解决:普通 WER 奖励在高失真下失效(只看词错,不管语义崩没崩)。设计两套奖励,按 WER 动态切换:
- 低 WER(<30%):侧重词级别精细修正(软错误 / 硬错误区分)
- 高 WER(≥30%):侧重句子级结构恢复(主干语义、长度、最长公共子串)
最终奖励 = 基础规则奖励 + 双粒度动态奖励
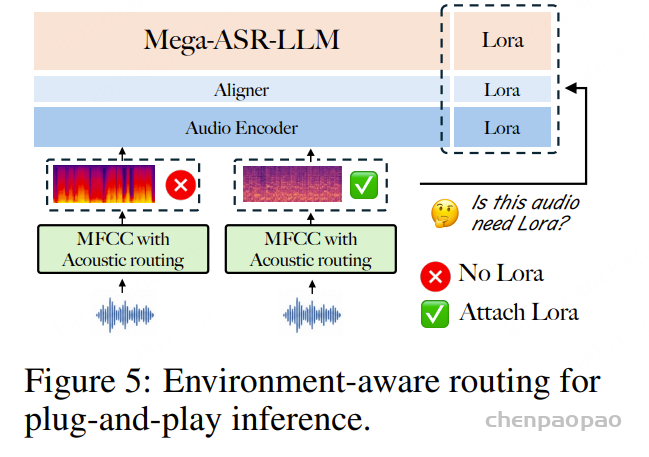
3. 环境感知路由(Router)
解决:鲁棒模型在干净音频上略有下降。
- 训练一个轻量二分类器,判断音频是否恶劣
- 恶劣 → 走 Mega-ASR
- 干净 → 走原生 Qwen3-ASR
- 推理开销 <1%,几乎无感
三、Experiments
Main results
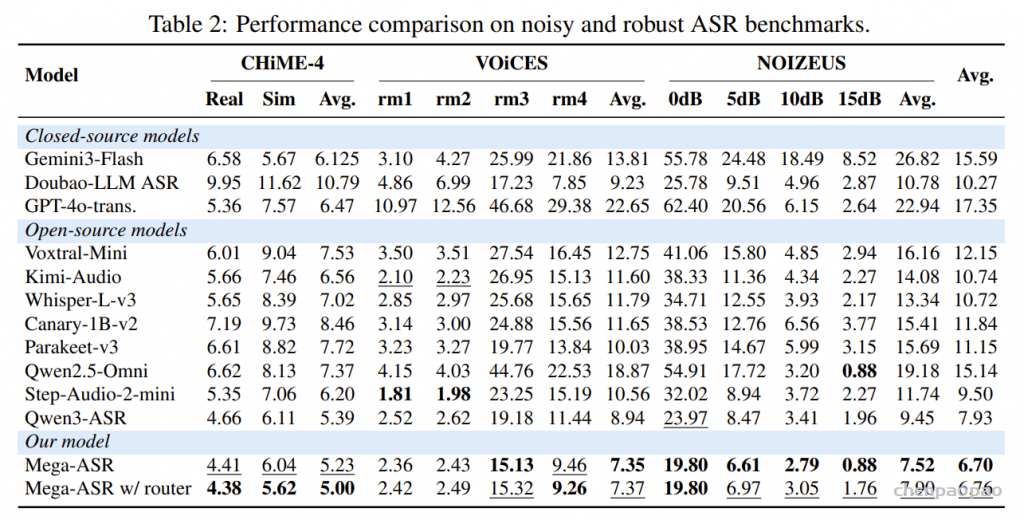
采用自适应路由的通用 ASR 性能具有竞争力:MEGA-ASR 在干净语音和多语言基准测试上,相较于 Qwen3-ASR、Seed-ASR 和 Kimi-Audio 仍保持极强的竞争力。
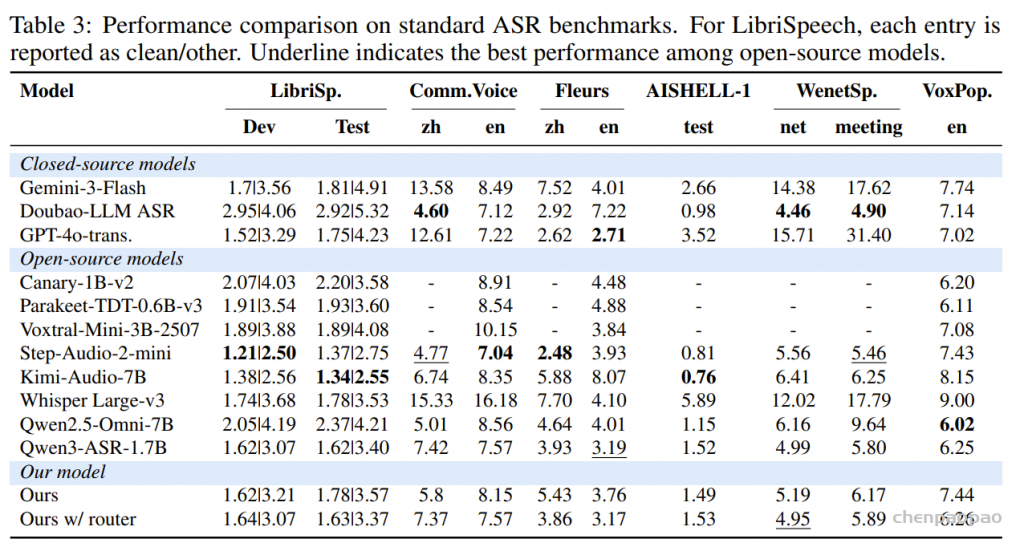
声学扰动条件下达到当前最佳鲁棒性:相较于最强基线 Qwen3-ASR,MEGA-ASR 的错误率进一步降低了 17.4%;相较于 Gemini-3-Flash,则降低了 64.5%。
在组合式真实环境中的鲁棒性表现更优
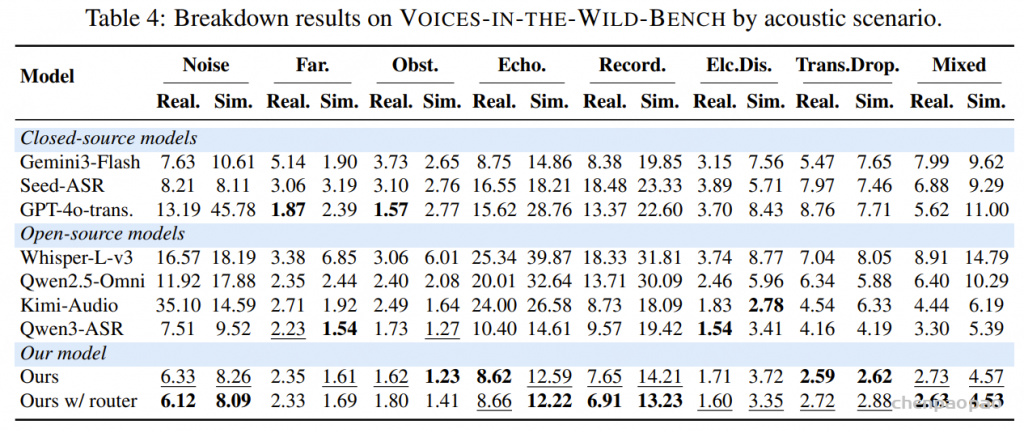
在 Voices-in-the-Wild-Bench 基准测试中,MEGA-ASR 在多种真实世界退化条件下均取得了最佳性能,包括:
- 混合退化(mixed degradations)
- 远场语音(far-field speech)
- 录音伪影与设备缺陷(recording artifacts)
Analysis
通过消融实验,我们总结出五个关键观察([Obs.1]–[Obs.5]),涵盖了语义层面收益、训练策略、奖励函数设计以及超参数敏感性等方面。相关证据分别来自表 5–9。下面对各项发现进行详细说明。
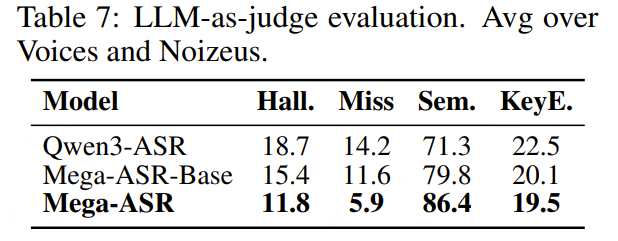
[Obs.1] MEGA-ASR 的收益不仅体现在 WER 上,也体现在语义层面指标上
表 7 显示,相比 Qwen3-ASR,MEGA-ASR 在语义层面指标上也取得了持续提升:
- 漏识内容(Missed Content)从 14.2 降低到 5.9。
这表明,MEGA-ASR 的改进不仅仅是降低词错误率(WER),还带来了更高层次的语义和整体理解能力提升,例如:
- 减少幻觉(Hallucination);
- 减少整句或整段语音遗漏(Dropped Utterances);
因此,MEGA-ASR 实现的是语义层面和整体层面的质量提升,而不仅是字词级别的识别优化。
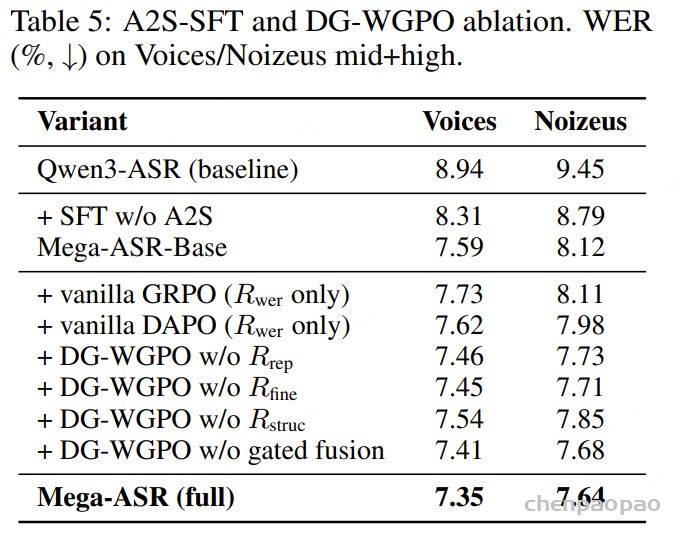
[Obs.2] A2S-SFT 与 DG-WGPO 组件的消融分析
在 Voices 和 Noizeus 数据集上,对 A2S-SFT 各阶段以及 DG-WGPO 各组成部分进行了消融实验(表 5)。
- 分阶段的“声学到语义(Acoustic-to-Semantic)适配”过程是有效且必要的。
- DAPO 作为强化学习阶段的基础优化框架。
- 句子级重构奖励对于中高错误率样本尤为关键。
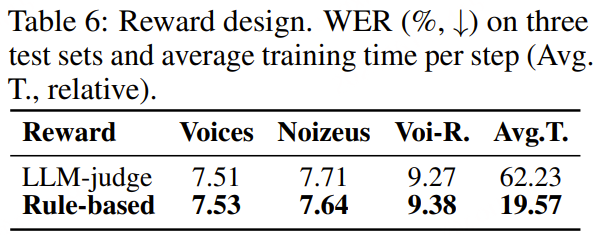
[Obs.3] 基于规则的奖励函数与 LLM Judge 效果相当,但训练成本降低 3.2 倍
规则奖励已经能够充分捕获 LLM Judge 所提供的监督信号。
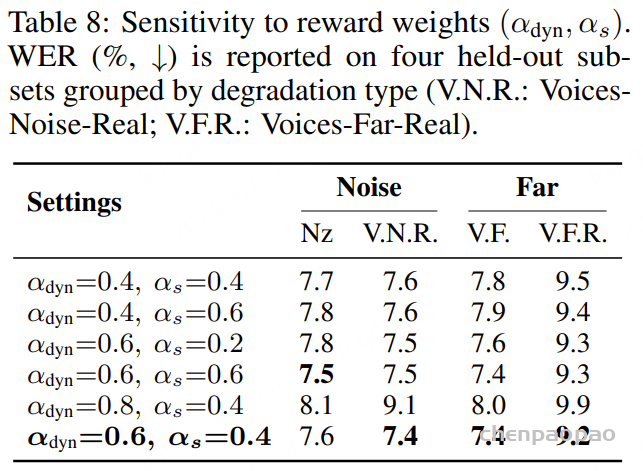
[Obs.4] 超参数消融实验
动态门控权重 αdyn 语义奖励权重 αs对模型性能的影响(表 8)
αdyn 所控制的权衡关系远比 αs 更敏感。
最终采用:
(αdyn, αs) = (0.6, 0.4)因为它在所有测试子集上都达到最佳或接近最佳表现。
[Obs.5] 门控阈值 τ 的影响
过高的门控阈值会使门控机制过于严格(over-restrictive gating),从而限制奖励信号的有效传播,最终导致识别性能下降。
通过消融实验,得到以下核心结论:
- MEGA-ASR 的收益不仅体现在 WER,还体现在语义完整性与内容保真度上。
- A2S-SFT 的渐进式声学→语义适配以及 DG-WGPO 的各奖励组件均对性能提升至关重要。
- 规则奖励能够以接近 LLM Judge 的效果实现训练,同时将计算成本降低 3.2 倍。
- 动态门控权重 αdyn 是最敏感的超参数,最佳设置为 0.6。
- 门控阈值 τ=0.3 能在不同场景下取得最均衡的鲁棒性表现。