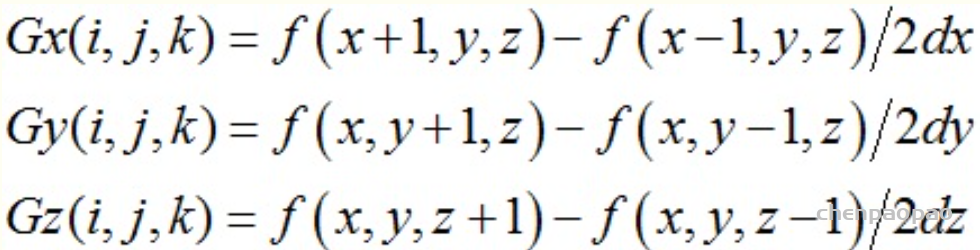https://arxiv.org/abs/1812.03828
CVPR2019
code: https://github.com/autonomousvision/occupancy_networks
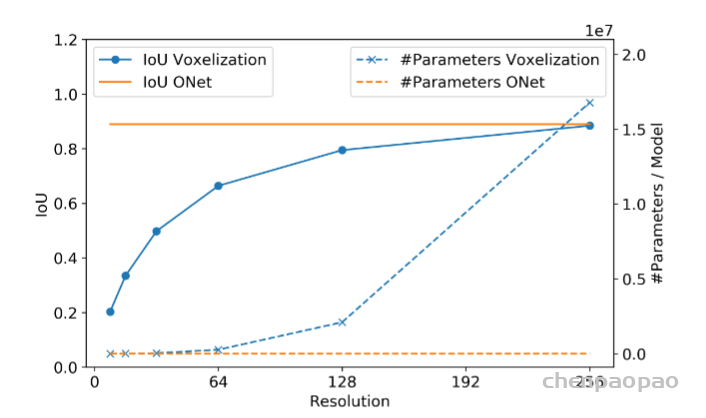
体素表示的缺点:内存随分辨率呈立方增加,故需要限制在32*32*32或64*64*64。使用例如八叉树的数据自适应表示来降低内存,实现起来又会复杂,现有数据自适应算法依旧局限于相对较小的256*256*256分辨率。
点云表示的缺点:由于缺少底层网格的连接结构,需要额外的后处理来从模型中提取三维几何图形。
网格表示的缺点:现有的网格表示通常基于对一个模板网格的变形,因此不允许任意拓扑。
点云和网格都限制了使用标准前馈网络能可靠预测的点/顶点的数量。
本文贡献:提出了基于对连续三维占据函数进行直接学习的三维重建新方法。利用神经网络实现对任意分辨率的占据函数的预测。训练时大大降低了内存,推理时利用简单的多分辨率等值面提取算法从学习的模型中提取网格。
1、介绍了一种基于学习连续三维映射的对三维几何图形的新表示
2、展示了该表示如何用于从多种输入类型中重建三维几何形状
3、实验证明此方法能生成高质量网格且超越目前最优方法
本文提出了一种3D图形的表示方法,并给出了得到他的网络架构和训练方法。用decision boundary (判定边界)来表示物体的表面。这个方法贼好,放在2D类比,就像像素图和矢量图,矢量图是精度是无限的,但又不会耗费额外的内存。
随着深度神经网络的到来,基于学习的三维重建方法逐渐变得流行。但是和图像不同的是,在3D中没有规范的表示,既能高效地进行计算,又能有效地存储,同时还能表示任意拓扑的高分辨率几何图形。很多先进的基于学习的三维重建方法只能表示粗糙的三维几何,或者限制于一个特定的领域。在这篇论文中,作者提出了占用网格,一种新的基于学习的三维重建方法。占位网络隐式地将三维曲面表示为深度神经网络分类器的连续决策边界。与现有方法相比,该表示方式编码了高分辨率的3D输出,并且没有过多的内存占用。同时该方法能够高效地编码三维结构,并且能够从不同种类的输入推断出模型。实验证明,无论是在质量上还是在数量上,对于从单个图像、有噪声的点云和粗糙的离散体素网格进行三维重建,该方法都获得了具有竞争力的结果。
和传统多视图立体几何算法相比,学习模型的方法能够编码3D形状空间中的丰富先验信息,这有助于解决输入的模糊性。生成模型的方法在高分辨率的图像上已经取得了很好的效果,但是还没有复制到3D领域。与2D领域相比,暂时还没有就3D输出表示达成一致,这种表示既能提高内存效率,又能从数据中有效推断。现存的表示方法能够大概分成三类:体素、网格、点云,如下图所示:
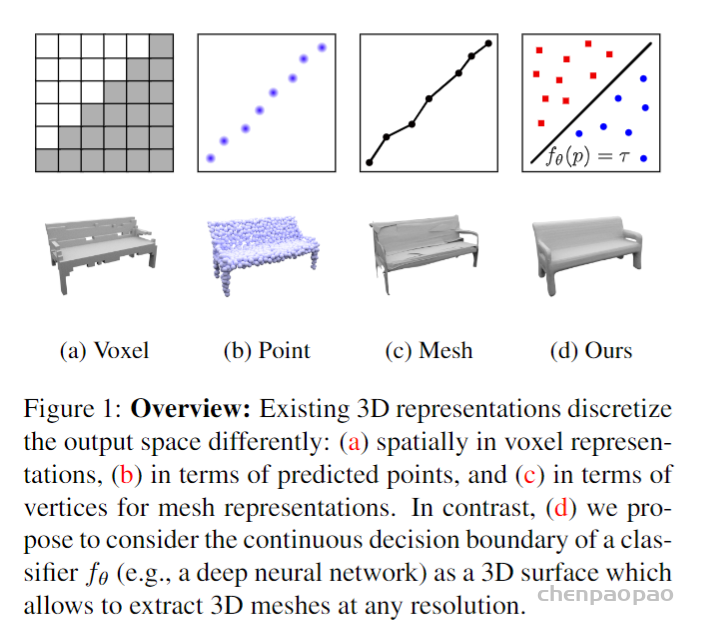
体素表示是直接将像素一般化的情况,随着分辨率的提高,这种方法的内存占用将会呈指数增长,因此限制了分辨率。使用适当的损失函数,点云和网格被引入作为深度学习的代替表示。但是点云缺少底层网格的连接结构,从模型中提取3D几何需要额外的过程。现存网格的表示方法大多数是基于一个模板变形,因此不允许任意的拓扑结构。在这篇文章中,作者提出了一种基于直接学习连续三维占用函数的三维重建方法,如上图D所示。和其他方法不同的是,作者用神经网络预测了完全占用函数,它可以在任意分辨率下评估。这篇文章的主要贡献可以分为以下三点:1:介绍了一种基于学习连续三维映射的三维几何表示方法;2:使用此表示法重建各种输入类型的3D几何图形;3:此表示方法能够生成高质量的网格,并且达到先进技术水平。
相关工作
现有的基于学习的三维重建工作可以根据输出表示的不同分为基于体素的、基于点的和基于网格的三种。基于体素:由于其简单性,体素是鉴别和生成3D任务最常用的表示。早期的工作主要集中于使用3D卷积神经网络从一张图像重建三维几何,由于内存限制,分辨率不是很高,如果要达到相对较高的分辨率,需要牺牲网络架构或者减少每次输入的图片数量。其他的工作用体素表示来学习三维形状的生成模型,大多数的模型都是基于变分自动编码器或者生成对抗网络。为了提高分辨率,实现亚体素精度,一些研究人员提出预测截断符号距离字段(TSDF),其中3D网格中的每个点储存截断符号距离到最近的3D表面。然而,与占用表示相比,这种表示通常更难学习,因为网络必须推断出3D空间中的距离函数,而不是仅仅将体素分类为已占用或未占用。而且,这种表示方法的分辨率仍然受到内存的限制。基于点云:三维点云被广泛应用于机器人技术和计算机图形学领域,是一种非常引人注目的三维几何替代表示方法。Fan【1】引入点云作为三维重建的输出表示。然而,与其他表示不同的是,这种方法需要额外的后处理步骤来生成最终的3D网格。基于网格:网格首先被考虑用于区分三维分类或分割任务,在网格的顶点和边跨越的图上应用卷积,最近网格也被应用于三维重建的表示方法。不幸的是,大部分方法倾向于产生自交叉的网格,并且只能产生简单的拓扑结构。与上述方法相比,本文的方法产生了没有自相交的高分辨率封闭表面,并且不需要来自相同对象类的模板网格作为输入。并且使用深度学习来获得更有表现力的表示,可以自然地集成到端到端学习中。

具体一点,一个物体用一个occupancy function 来表示:
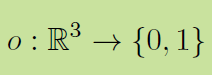
注意,是实数空间,不是离散的按一定分辨率取样的。
然后用一个神经网络来逼近这个函数,给每个实空间的3D点一个0-1之间的占用概率(因此和二分类模型等价)。神经网络 f 输入是一个点和一个几何体的表示(X),输出是一个0-1之间的实数,表示这个点在这个几何体里的概率。而我们关注的是对象表面的决策边界。根据对物体的观察(如图像、点云等),当使用这样的网络对物体进行三维重建时,必须以输入作为条件。作者使用了下面的简单的功能对等:一个函数,它接受一个观察 x 作为输入,输出一个从点p到R的函数,这可以通过一个函数等价描述:一对(p, x)作为输入和输出一个实数。后一种表示可以用一个神经网络参数化,该神经网络以一对(p,x)作为输入,输出一个表示占用概率的实数:
对不同输入类型的数据,用不同encoder来输入。
单个图像:ResNet
体素:3D CNN
点云:PointNet等

这就是占用网络。2训练:为了学习神经网络的参数,考虑在对象的三维边界体中随机采样点,对于第i个样本,采样K个点,然后评估这些位置的小批量损失Lb如下所示:
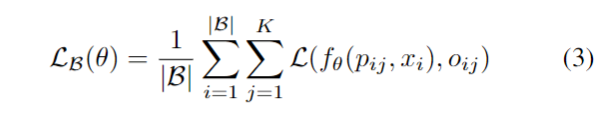
其中xi是B批次的第i个观测值,Oij是点云的真实位置,L是交叉熵损失。该方法的性能取决于用于绘制用于训练的pij位置的采样方案,将在后面详细讨论。这个三维表示方法也可以用于学习概率潜在变量模型,定义损失函数如下:
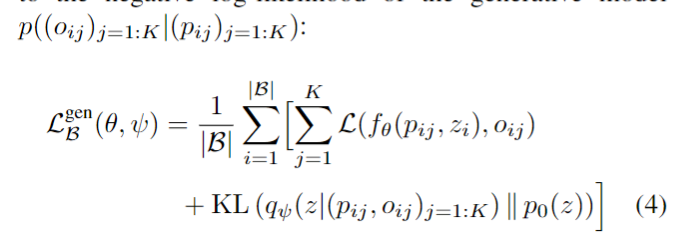
3推论:为了提取一个新的观测值对应的等值面,作者引入了多分辨率等值面提取算法(MISE),如下图所示。
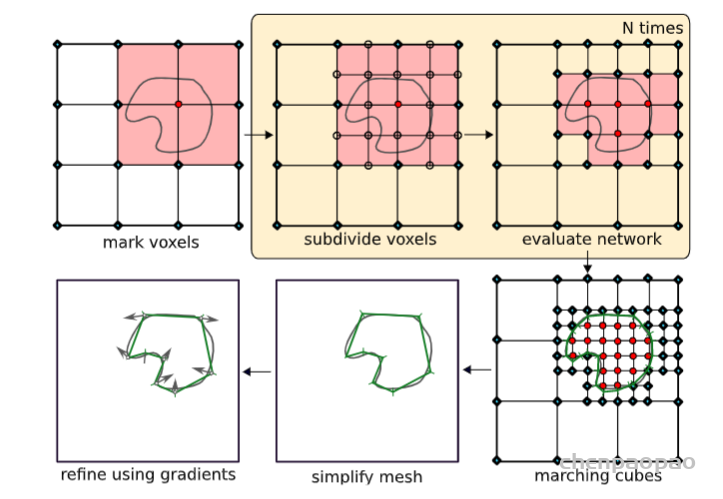
首先在给定的分辨率上标记所有已经被评估为被占据(红色圆圈)或未被占据(青色方块)的点。然后确定所有的体素已经占领和未占领的角落,并标记(淡红色),细分为4个亚体素。接下来,评估所有由细分引入的新网格点(空圆)。重复前两个步骤,直到达到所需的输出分辨率。最后使用marching cubes算法【2】提取网格,利用一阶和二阶梯度信息对输出网格进行简化和细化。如果初始分辨率的占用网格包含网格内外各连通部分的点,则算法收敛于正确的网格。因此,采取足够高的初始分辨率来满足这一条件是很重要的。实际上,作者发现在几乎所有情况下,初始分辨率为32的三次方就足够了。通过marching cubes算法提取的初始网格可以进一步细化。在第一步中,使用Fast-Quadric-Mesh-Simplification算法【3】来简化网格。最后,使用一阶和二阶(即梯度)的信息。为了达到这个目标,作者从输出网格的每个面抽取随机点pk进行采样,并将损失最小化:
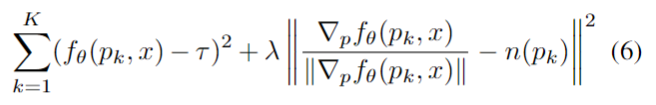
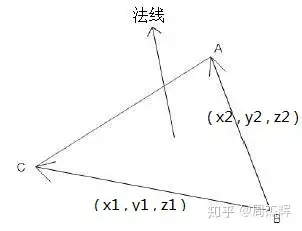
其中n(pk)为网格在pk处的法向量。4相关细节:作者使用具有5个ResNet块的全连接神经网络实现了占用网络,并使用条件批处理归一化对输入进行条件设置。根据输入的类型使用不同的编码器架构。对于单视图3D重建,使用ResNet18架构。对于点云,使用PointNet编码器。对于体素化输入,使用3D卷积神经网络。对于无条件网格生成,使用PointNet作为编码器网络。更多细节见原文。注:在我看来,这是一个端到端的网络,可以理解成一个GAN网络。前面的全连接神经网络编码输入的图像,预测每一个点被占用的概率,即该3D点是处于模型内部还是在模型的外面。通过采样多个点,我们就可以得到一个决策边界,这个边界就可以近似的理解成模型的外壳,然后通过后面的算法获得更高分辨率的模型。
结果展示:


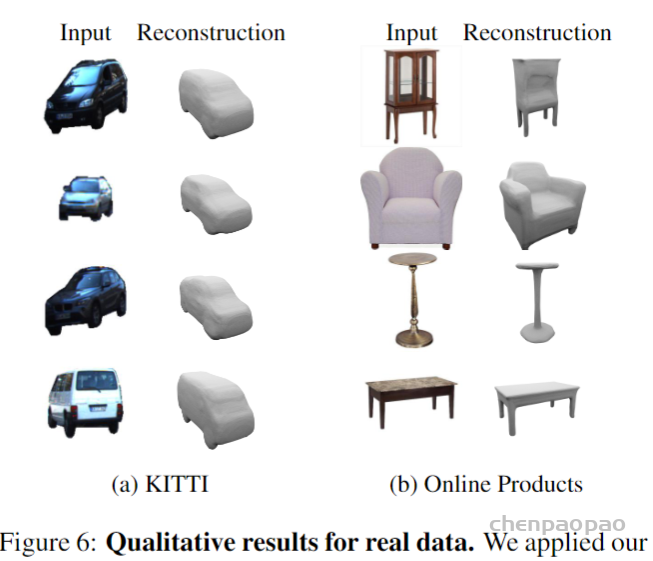
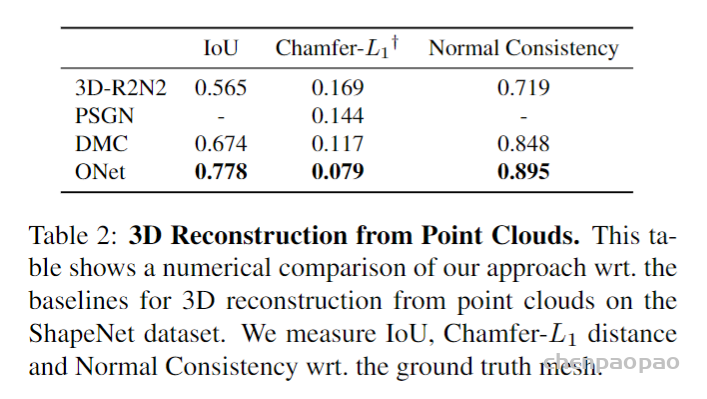
基于点云的三维重建结果比较: