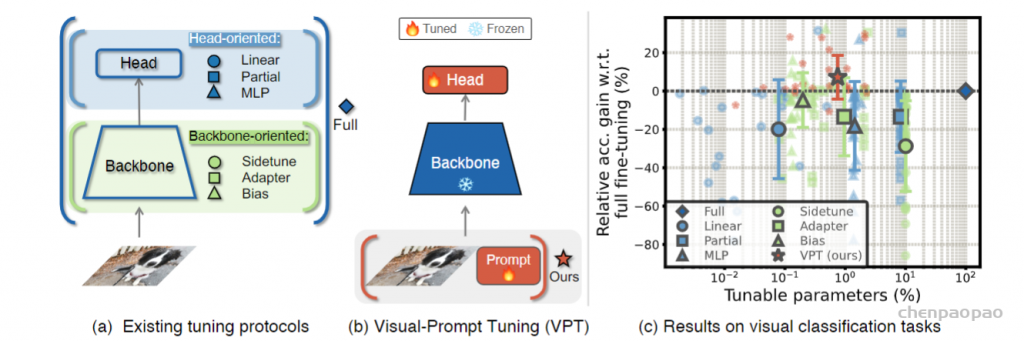
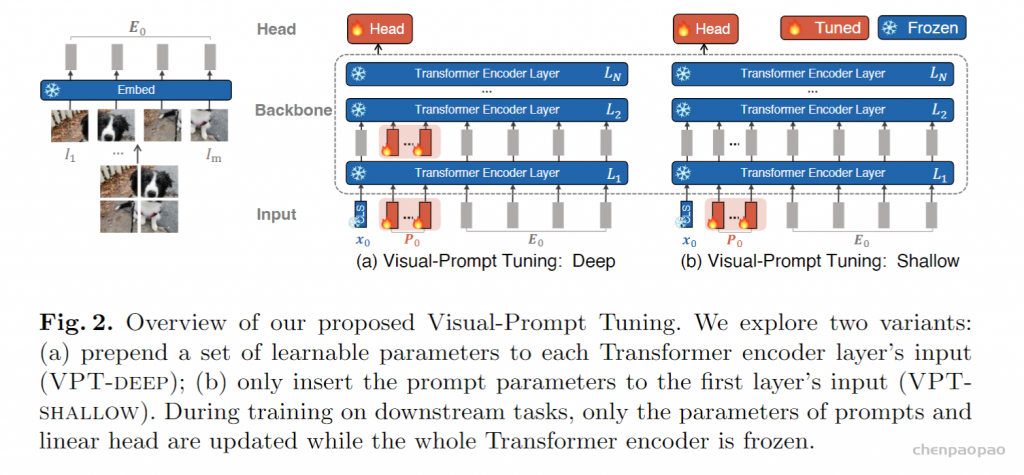
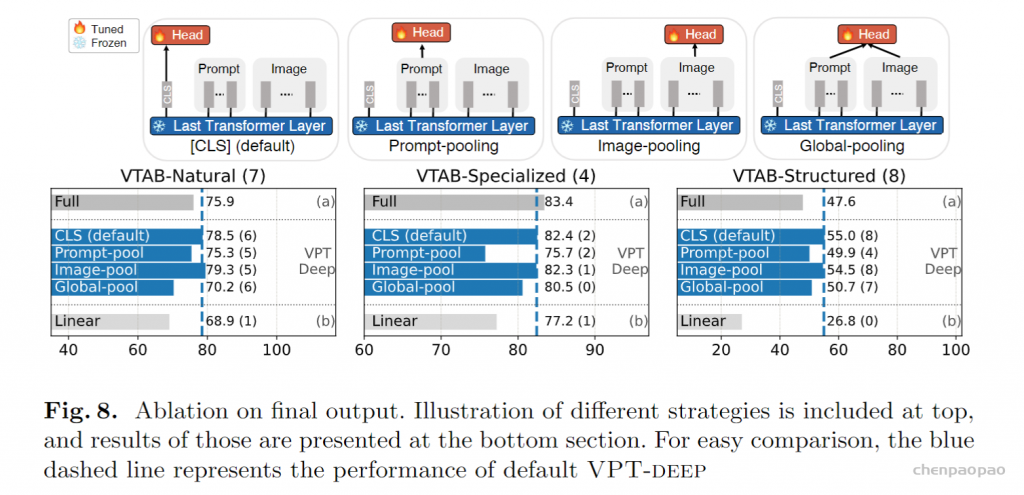
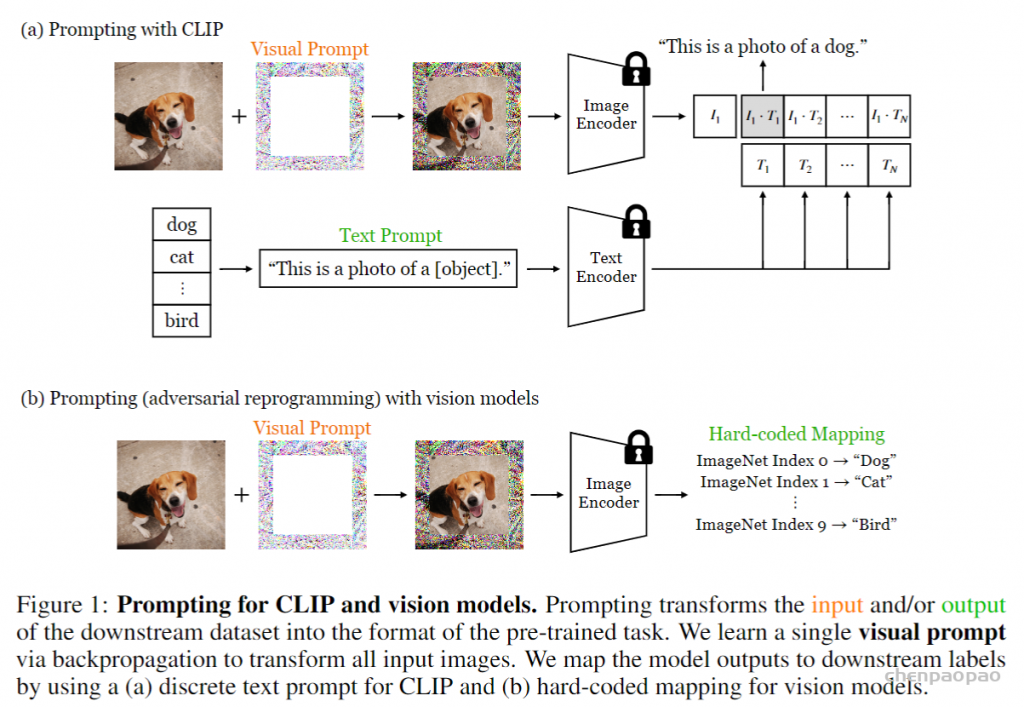
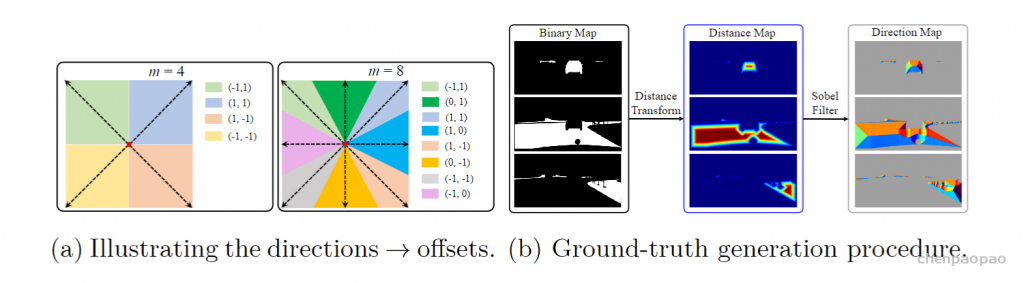
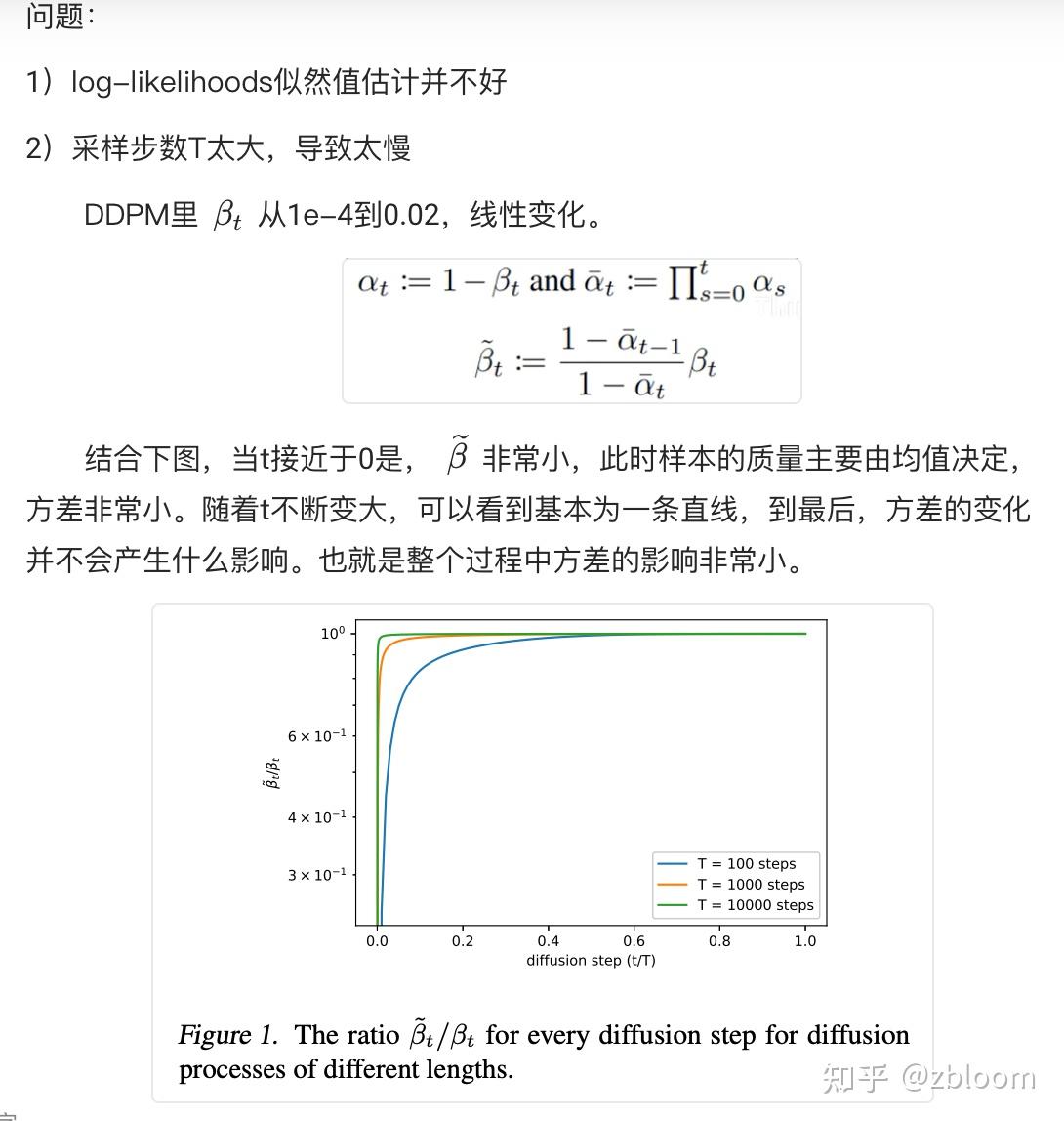
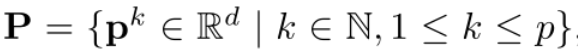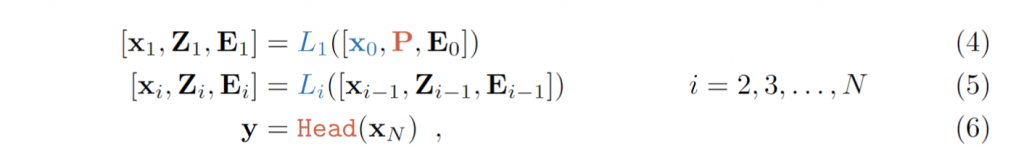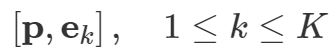Visual-Prompt Tuning (VPT) vs . other transfer learning methods. (a) Current transfer learning protocols are grouped based on the tuning scope: Full fine-tuning, Head-oriented, and Backbone-oriented approaches. (b) VPT instead adds extra pa- rameters in the input space. (c) Performance of different methods on a wide range of downstream classification tasks adapting a pre-trained ViT-B backbone, with mean and standard deviation annotated. VPT outperforms Full fine-tuning 20 out of 24 cases while using less than 1% of all model parameters
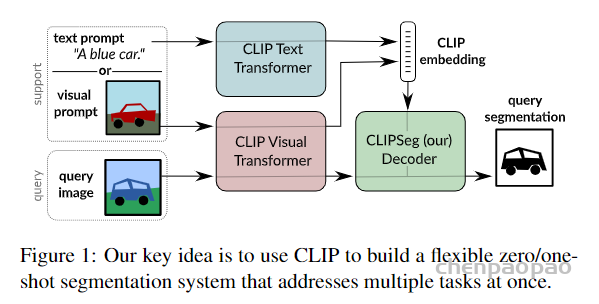
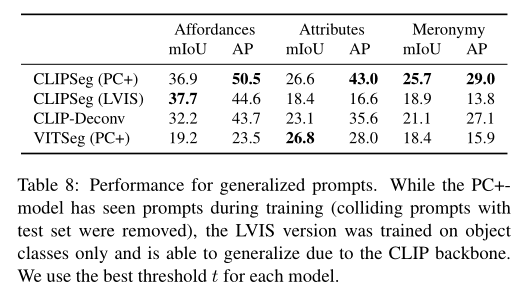
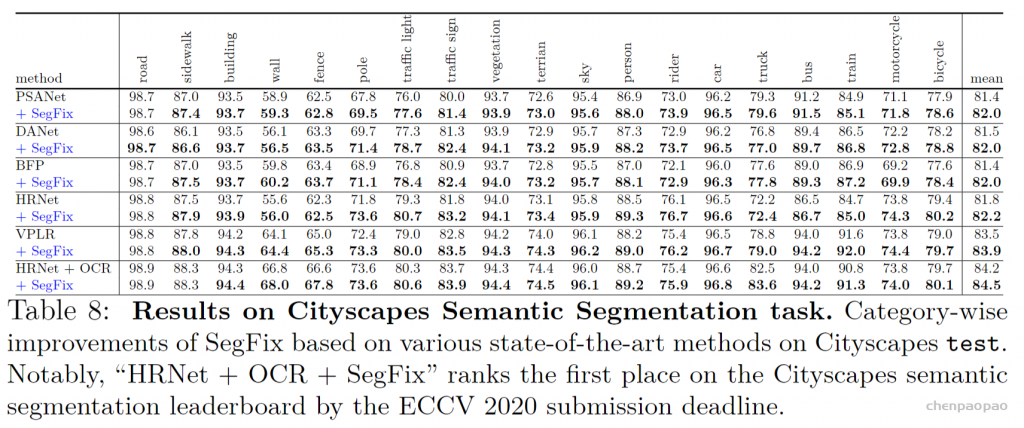
在本文的实验中,作者使用 CLIP ViT-B/16,patch大小 P 为 16,如果没有另外说明,则使用 D = 64 的投影尺寸。作者在 S = [3 , 7 , 9] 层提取 CLIP 激活,因此本文的解码器只有三层。
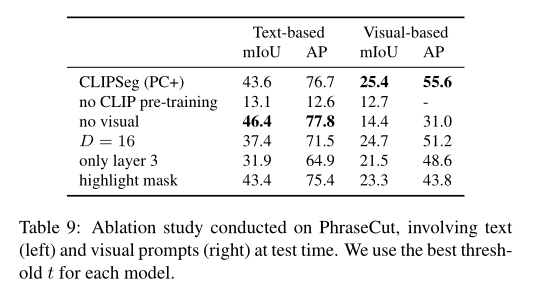
模型通过条件向量接收有关分割目标的信息(“要分割什么?”),这可以通过文本或图像(通过视觉prompt工程)提供。由于 CLIP 为图像和文本标题使用共享嵌入空间,可以在嵌入空间和插值向量上的条件之间进行插值。形式上,设是支持图像的嵌入,是样本 i 的文本嵌入,作者通过线性插值获得条件向量 ,其中 a 是从[0 , 1]均匀采样 。作者在训练期间使用这种随机插值作为数据增强策略。
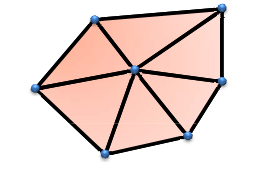
1 PhraseCut + Visual prompts (PC+)
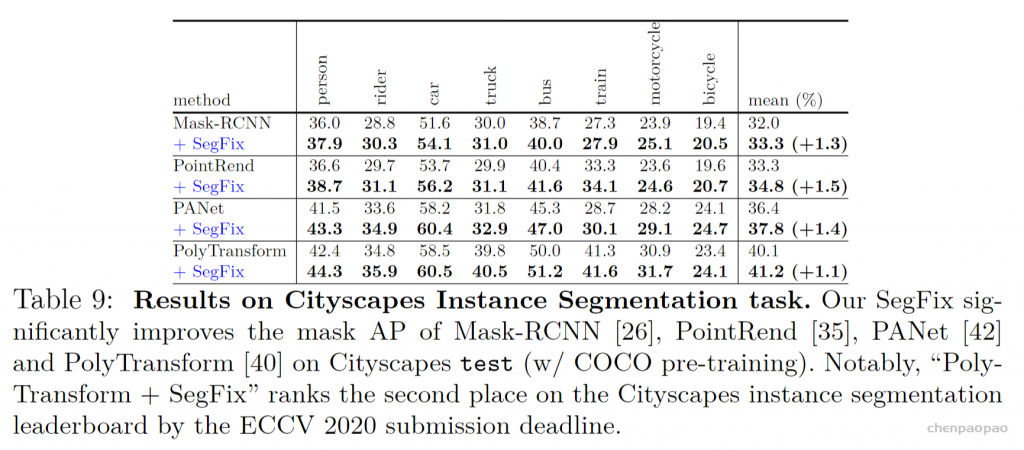
本文使用 PhraseCut 数据集,其中包含超过 340,000 个具有相应图像分割的短语。最初,该数据集不包含视觉支持,而仅包含短语,并且每个短语都存在相应的对象。作者以两种方式扩展这个数据集:视觉支持样本和负样本。为了为prompt p 添加视觉支持图像,作者从共享prompt p 的所有样本的集合Sp中随机抽取。
在安装部分有个小问题,我的本机已经安装完opencv-python,然后我们再去安装albumentations的时候,出现了一个问题,就是我们的opencv-python阻止albumentations的安装,报错如下:# Could not install packages due to anEnvironmentError: [WinError 5] 拒绝访问,是因为在安装albumentations的时候还要安装opencv-python-headless,这个库和opencv冲突。
import albumentations as A
import cv2
import matplotlib.pyplot as plt
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=512, height=512),
A.HorizontalFlip(p=0.8),
A.RandomBrightnessContrast(p=0.5),
])
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = transform(image=image)
transformed_image = transformed["image"]
plt.imshow(transformed_image)
plt.show()
详细使用案例:
1、VerticalFlip 围绕X轴垂直翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.VerticalFlip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Blur后的图像')
plt.imshow(transformed_image)
plt.show()
2、Blur模糊输入图像
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Blur(blur_limit=15,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Blur后的图像')
plt.imshow(transformed_image)
plt.show()
3、HorizontalFlip 围绕y轴水平翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.HorizontalFlip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('HorizontalFlip后的图像')
plt.imshow(transformed_image)
plt.show()
4、Flip水平,垂直或水平和垂直翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Flip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Flip后的图像')
plt.imshow(transformed_image)
plt.show()
5、Transpose, 通过交换行和列来转置输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Transpose(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Transpose后的图像')
plt.imshow(transformed_image)
plt.show()
6、RandomCrop 随机裁剪
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomCrop(512, 512,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomCrop后的图像')
plt.imshow(transformed_image)
plt.show()
7、RandomGamma 随机灰度系数
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomGamma(gamma_limit=(20, 20), eps=None, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomGamma后的图像')
plt.imshow(transformed_image)
plt.show()
8、RandomRotate90 将输入随机旋转90度,N次
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomRotate90(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomRotate90后的图像')
plt.imshow(transformed_image)
plt.show()
10、ShiftScaleRotate 随机平移,缩放和旋转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.1, rotate_limit=45, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('ShiftScaleRotate后的图像')
plt.imshow(transformed_image)
plt.show()
11、CenterCrop 裁剪图像的中心部分
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.CenterCrop(256, 256, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("CenterCrop后的图像")
plt.imshow(transformed_image)
plt.show()
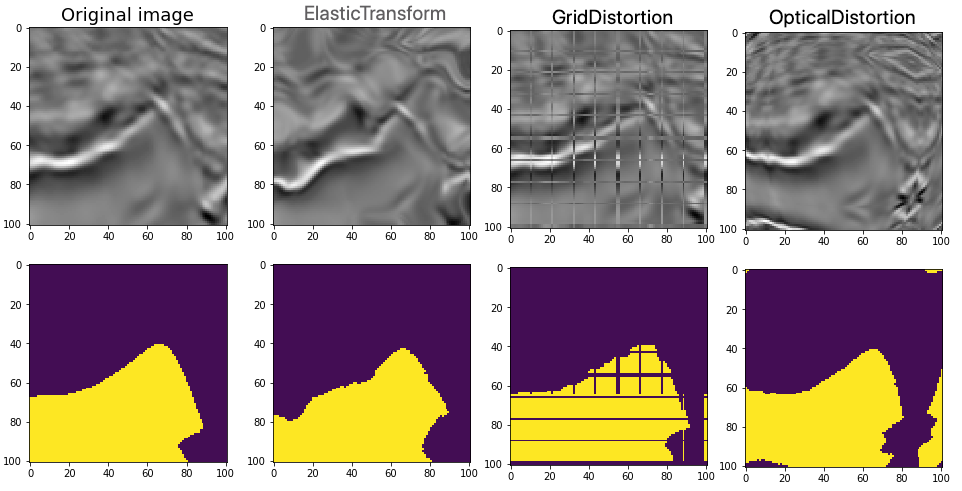
12、GridDistortion网格失真
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GridDistortion(num_steps=10, distort_limit=0.3,border_mode=4, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GridDistortion后的图像")
plt.imshow(transformed_image)
plt.show()
13、ElasticTransform 弹性变换
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ElasticTransform(alpha=5, sigma=50, alpha_affine=50, interpolation=1, border_mode=4,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("ElasticTransform后的图像")
plt.imshow(transformed_image)
plt.show()
14、RandomGridShuffle把图像切成网格单元随机排列
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomGridShuffle(grid=(3, 3), always_apply=False, p=1) (image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RandomGridShuffle后的图像")
plt.imshow(transformed_image)
plt.show()
15、HueSaturationValue随机更改图像的颜色,饱和度和值
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.HueSaturationValue(hue_shift_limit=20, sat_shift_limit=30, val_shift_limit=20, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("HueSaturationValue后的图像")
plt.imshow(transformed_image)
plt.show()
16、PadIfNeeded 填充图像
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.PadIfNeeded(min_height=2048, min_width=2048, border_mode=4, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("PadIfNeeded后的图像")
plt.imshow(transformed_image)
plt.show()
17、RGBShift,对图像RGB的每个通道随机移动值
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RGBShift(r_shift_limit=10, g_shift_limit=20, b_shift_limit=20, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RGBShift后的图像")
plt.imshow(transformed_image)
plt.show()
18、GaussianBlur 使用随机核大小的高斯滤波器对图像进行模糊处理
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GaussianBlur(blur_limit=11, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GaussianBlur后的图像")
plt.imshow(transformed_image)
plt.show()
CLAHE自适应直方图均衡
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.CLAHE(clip_limit=4.0, tile_grid_size=(8, 8), always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("CLAHE后的图像")
plt.imshow(transformed_image)
plt.show()
ChannelShuffle随机重新排列输入RGB图像的通道
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ChannelShuffle(always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("ChannelShuffle后的图像")
plt.imshow(transformed_image)
plt.show()
InvertImg反色
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.InvertImg(always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("InvertImg后的图像")
plt.imshow(transformed_image)
plt.show()
Cutout 随机擦除
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Cutout(num_holes=20, max_h_size=20, max_w_size=20, fill_value=0, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("Cutout后的图像")
plt.imshow(transformed_image)
plt.show()
RandomFog随机雾化
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomFog(fog_coef_lower=0.3, fog_coef_upper=1, alpha_coef=0.08, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RandomFog后的图像")
plt.imshow(transformed_image)
plt.show()
GridDropout网格擦除
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GridDropout(ratio=0.5, unit_size_min=None, unit_size_max=None, holes_number_x=None, holes_number_y=None,
shift_x=0, shift_y=0, always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GridDropout后的图像")
plt.imshow(transformed_image)
plt.show()
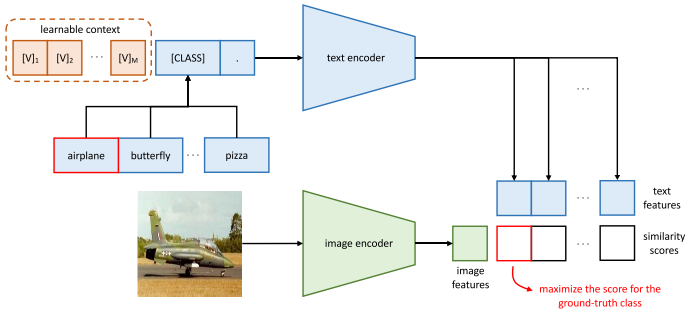
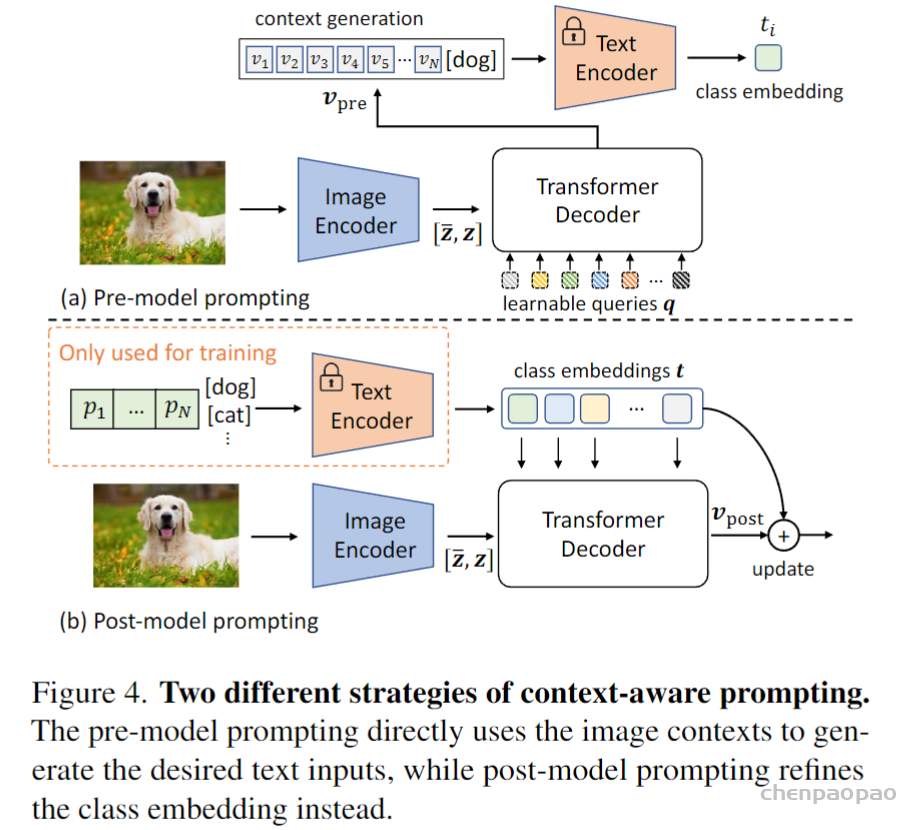
与原始CLIP不同,原始CLIP使用人工设计的模板,如“a photo of a [CLS]”。CoOp引入了可学习的文本上下文,通过使用反向传播直接优化上下文,在下游任务中实现更好的可迁移性。受CoOp的启发,作者还在框架中使用可学习的文本上下文作为baseline,其中仅包括语言域提示。文本编码器的输入变为:
其中是可学习的文本上下文,而是第k类名称的嵌入。
Vision-to-language prompting
包括视觉上下文的描述可以使文本更加准确。例如,“a photo of a cat in the grass.”比“a photo of a cat.”更准确。因此,作者研究了如何使用视觉上下文来重新提取文本特征。通常可以使用Transformer decoder中的交叉注意机制来建模视觉和语言之间的相互作用。