
目标: 实现具有一致整体结构的高频细节的深度图结果
GitHub地址:
1、https://github.com/compphoto/BoostingMonocularDepth(main repo)
2、https://github.com/compphoto/BoostYourOwnDepth(Merging Operator:基于深度图的Refine过程的实现)a stand-alone implementation of our merging operator
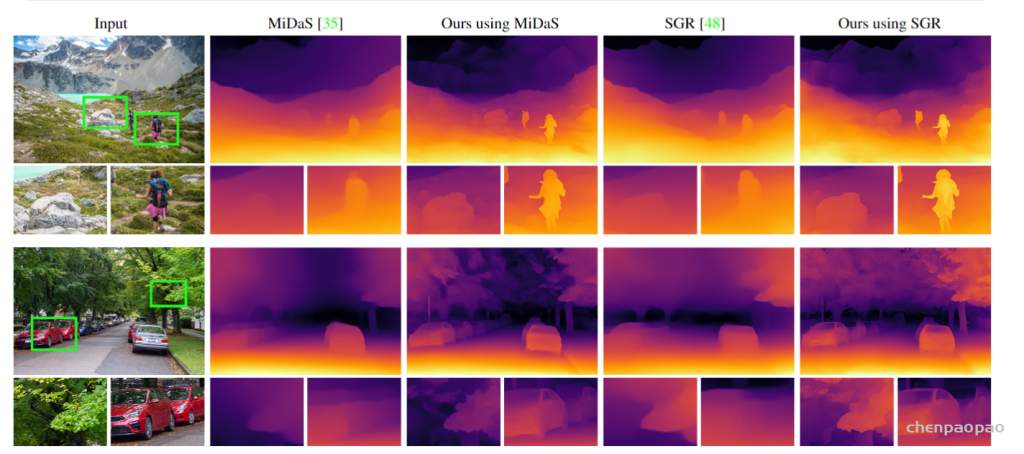
卷积神经网络显示出从单个图像估计深度的非凡能力。 然而,由于网络结构和硬件限制,估计的深度图分辨率较低,仅显示整体场景结构,缺乏精细细节,这限制了其适用性。 我们证明了场景结构的一致性与有关输入内容和分辨率的高频细节之间存在权衡。 基于这种二元性,我们提出了一个双重估计框架来改进整个图像的深度估计和一个块选择步骤来添加更多的局部细节。 我们的方法通过基于图像内容合并不同分辨率的估计,获得具有清晰细节的数百万像素深度估计。 我们方法的一个关键优势是我们可以使用任何现成的基于 CNN 的预训练单眼深度估计模型,而无需进一步微调。
(融合网络)该方法是基于优化一个预训练网络的性能,通过合并不同分辨率和不同补丁的估计来生成一个高分辨率的估计。

- 首先图像以低分辨率和高分辨率的格式输入网络(MiDas网络+10层U-net的Pix2Pix架构作为生成器)
- 然后,合并MiDaS 的结果(不同高低分辨率估计融合),获得具有一致结构和良好边界定位的基础估计(b)。【高分辨率:细节,低分辨率:结构一致性】
- 接着,确定图像中的不同补丁,如图(c)显示了选定补丁的子集及其深度估计。
- 最后,将补丁估计合并到来自(b)的基本估计上,以获得最终的高分辨率结果(d)。
- 解决的问题: 如何实现在高分辨和高细节度折中的单张图像深度估计
单张图像深度估计的目的是从单张图像中提取场景的结构。与深度相机或者多视角数据所提取的深度信息不同,单张图像深度估计主要依赖于高层单眼深度线索。基于深度学习的方法已然成为单张图像深度估计的标准解决方案。但是对于高分辨深度估计,使其具有好的边界准确性和一致的场景结构,这仍然存在难题。虽然有基于全卷积层结构的方法可以控制任意输入尺寸,但现实中GPU内存、高分辨率数据缺失、CNN感受野尺寸,这些都限制了对应方法的发展。
因此,本文提出采用预训练的单张图像深度估计模型,实现具有高边界准确性的高分辨率结果。
论文的贡献:
- 提出一种双重深度估计模型,提高单目图像深度估计的性能;一种基于块选择的方法能加入局部信息到最后的估计结果。
- 所提出的方法可以改进最新的单目图像深度估计方法,在提高分辨率与细节的同时,几乎不额外引入计算量。
想法:
我们的主要见解来自观察到单目深度估计网络的输出特性随输入图像的分辨率而变化。 在接近训练分辨率的低分辨率下,估计具有一致的结构,但缺乏高频细节。 当以更高分辨率将相同的图像馈送到网络时,可以更好地捕获高频细节,同时估计的结构一致性逐渐降低。(因此:高低分辨率深度图各有优势)

我们的第二个观察是关于输出特征与输入中高级深度线索的数量和分布之间的关系。 网络感受野尺寸主要依赖于网络结构以及训练分辨率。由于单目深度估计依赖于上下文线索,当图像中的这些线索比感受野更远时,网络无法在未接收到足够信息的像素周围生成连贯的深度估计。(选取Patch进行进一步深度图refine)

初步方法:
我们的目标是对要合并的单个图像生成多个深度估计,以实现具有一致整体结构的高频细节的结果。这需要:
(i) 检索图像中上下文线索的分布,我们将使用它来确定网络的输入,以及 (ii) 合并操作以将高频细节从一个估计转移到另一个具有结构一致性的估计。
1) 估计的上下文线索。我们使用通过对 RGB 梯度进行阈值处理获得的图像的近似边缘图作为代理。
2)合并单目深度估计。包括输入小分辨率到网络所对应的低分辨率图,相同图像的高分辨率深度图。
使用具有10层U-net的Pix2Pix结构作为生成器。我们训练网络将细粒度的细节从高分辨率输入传输到低分辨率输入
如下图,尽管增加的分辨率提供了更清晰的结果,但在 (c) 之外,深度估计在整体结构方面变得不稳定,通过背景中不正确的工作台深度范围和轮胎周围不切实际的深度梯度可见。

双重估计:
我们将二进制膨胀应用于具有不同分辨率的感受野大小内核的边缘图。然后,扩张边缘图停止产生全为一结果的分辨率是每个像素将在前向传递中接收上下文信息的最大分辨率,将其记为 R0 ,分辨率高于R0 的估计将失去结构一致性,但它们在结果中将具有更丰富的高频内容。
因此,我们提出双重估计:为了获得两全其美的结果,我们以两种不同的分辨率将图像馈送到网络,并合并估计以获得具有高频细节的一致结果。如图6所示。
局部提升的块估计
我们提出了一种块选择方法,为图像中的不同区域生成不同分辨率的深度估计,这些区域合并在一起以获得一致的完整结果。
理想情况下,块选择过程应由高级信息指导,以确定用于估计的最佳局部分辨率。但缺乏这样的数据集。因此本文提出一种简单的块选择方法,即做出谨慎的设计决策,以达到可靠的高分辨率深度估计管道,而无需额外的数据集或训练。
1)块选择。通过以基本分辨率平铺图像开始块选择过程,平铺大小等于感受野大小和 1/3 重叠。
2)块估计。采用双重估计方法进行估计。
3)基础分辨率调整。通过在块选择之前将基本深度估计上采样到更高的分辨率来解决这种情况下的这个问题。
- 实验结果
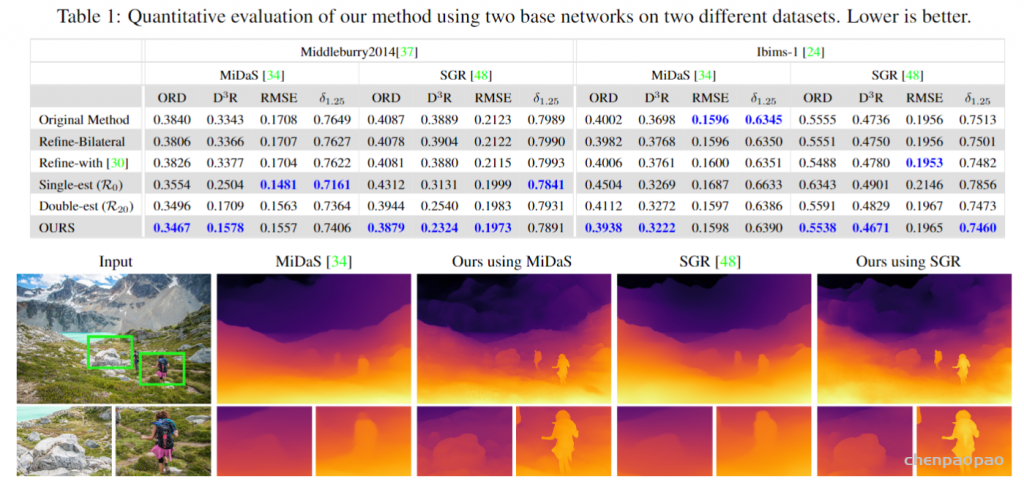
测试方法:改进两个最新方法MiDaS、 SGR
测试数据:Middleburry 2014 [3]、IBMS-1 [4].
度量标准: 视差空间中的均方根误差 (RMSE)、1.25的像素百分比、方向错误(ORD、序数关系误差的变化
- 对比实验
参考
- ^Rene Ranftl, Katrin Lasinger, David Hafner, Konrad ´ Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell., 2020.
- ^abcKe Xian, Jianming Zhang, Oliver Wang, Long Mai, Zhe Lin, and Zhiguo Cao. Structure-guided ranking loss for single image depth prediction. In Proc. CVPR, 2020
- ^D. Scharstein, H. Hirschmuller, York Kitajima, Greg Krath- ¨ wohl, Nera Nesic, X. Wang, and P. Westling. High-resolution stereo datasets with subpixel-accurate ground truth. In Proc. GCPR, 2014.
- ^Tobias Koch, Lukas Liebel, Friedrich Fraundorfer, and Marco Korner. Evaluation of CNN-Based Single-Image ¨ Depth Estimation Methods. In Proc. ECCV Workshops, 2018.