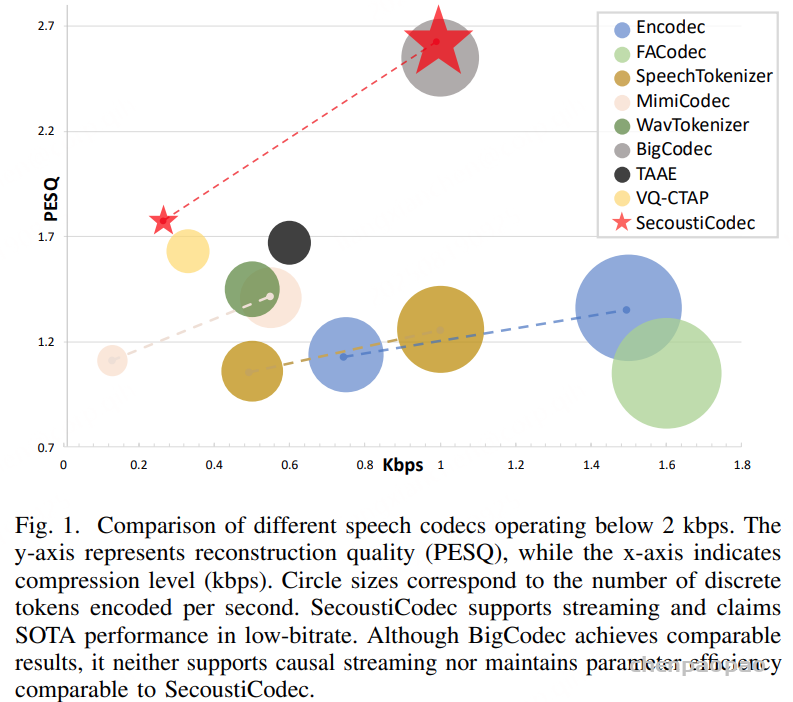
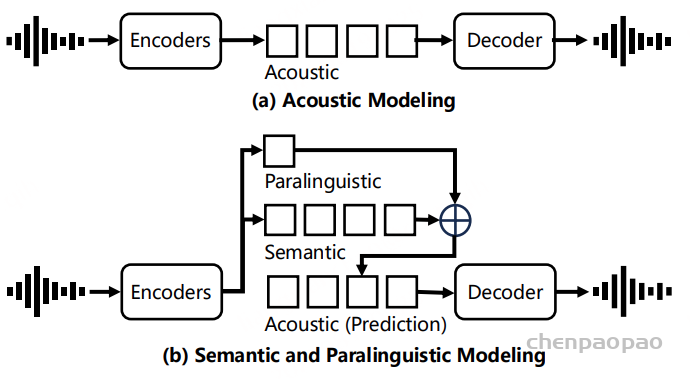
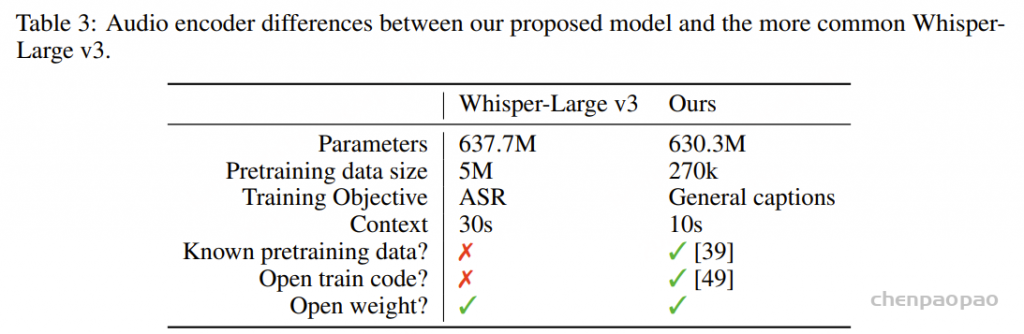
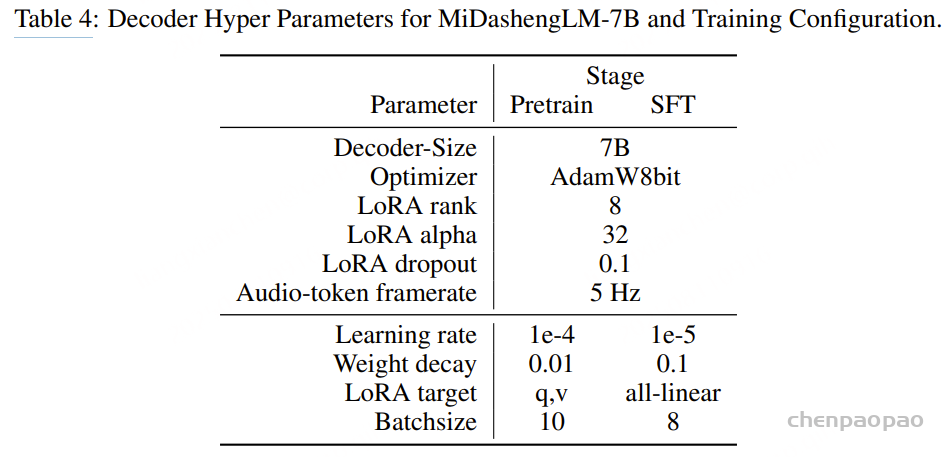
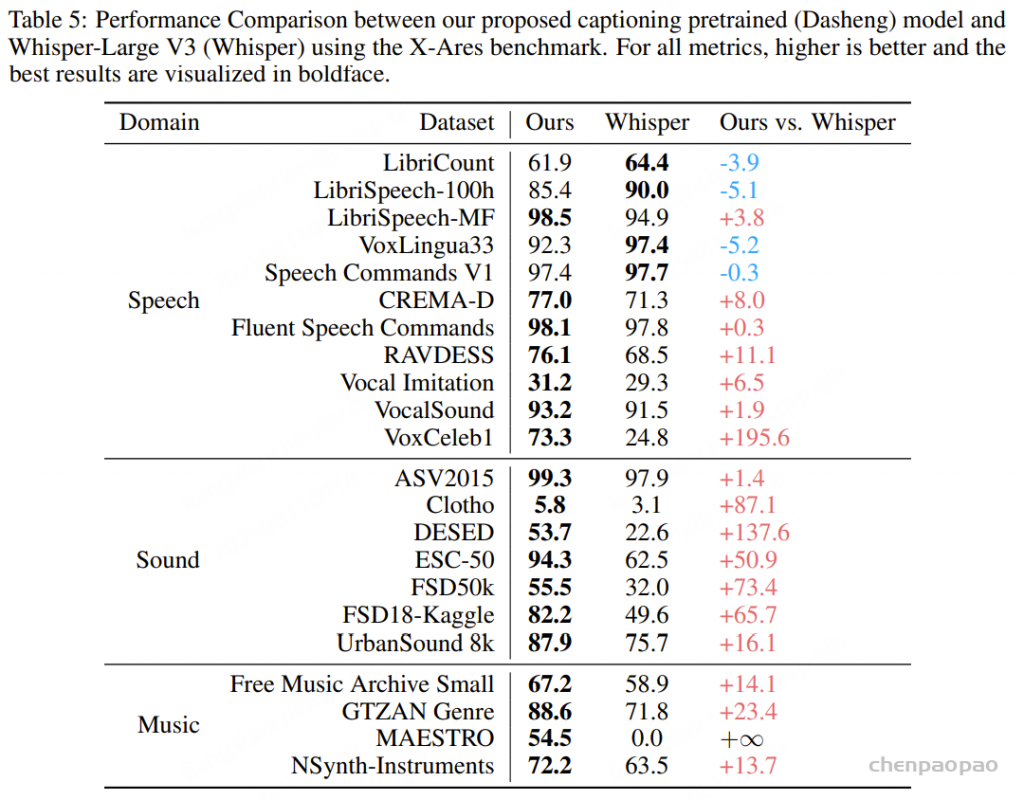
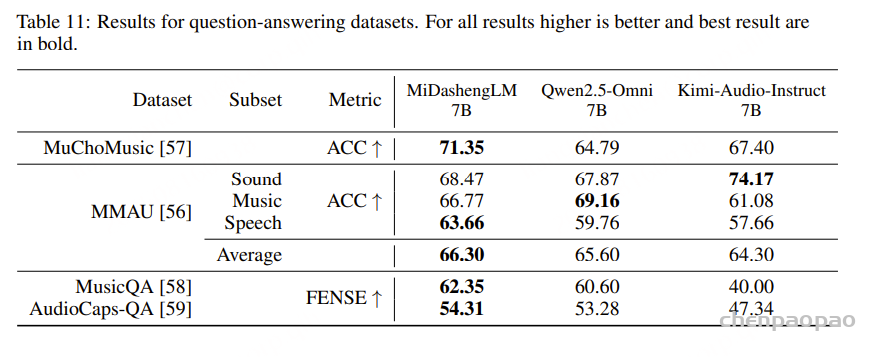
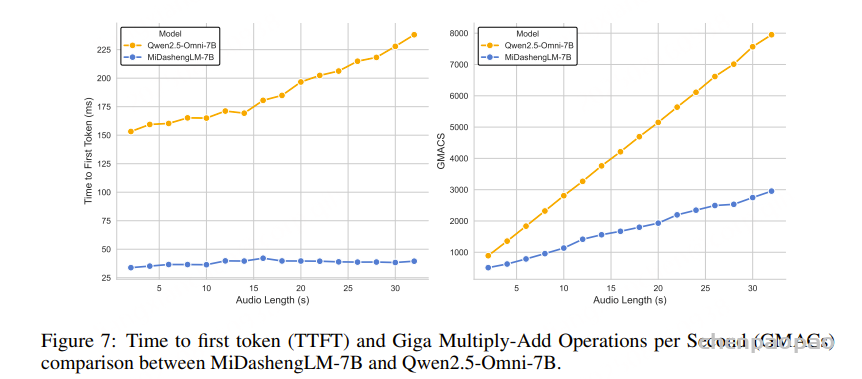
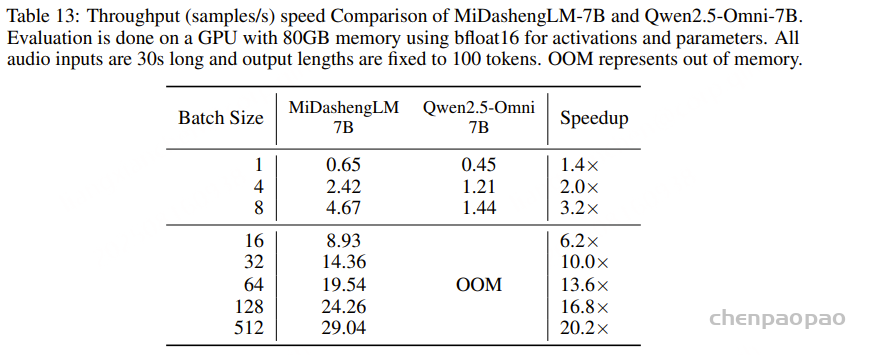
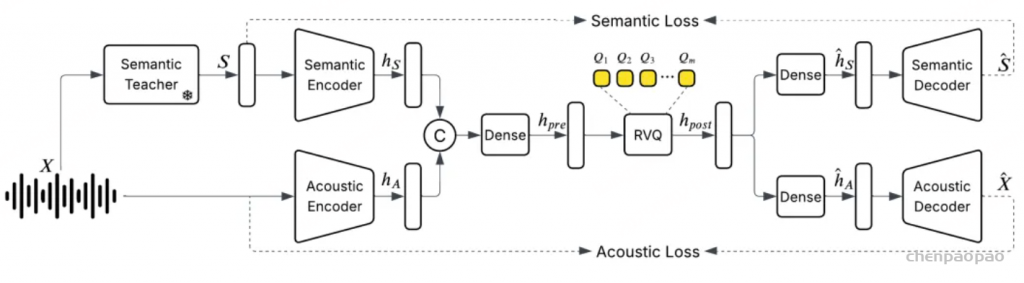
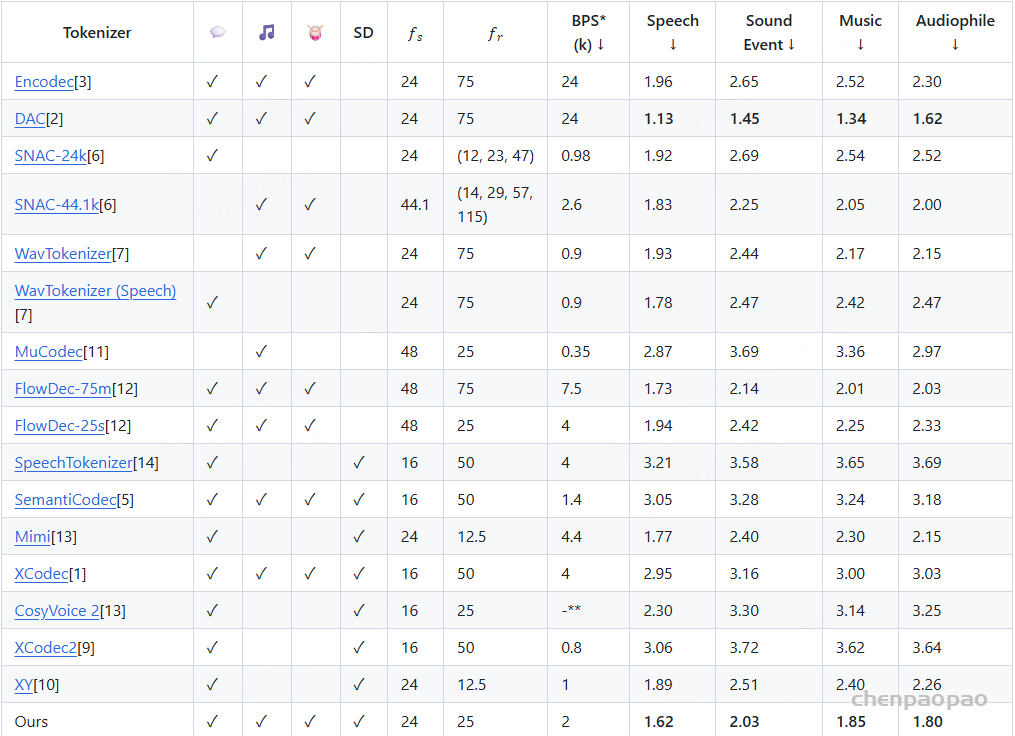
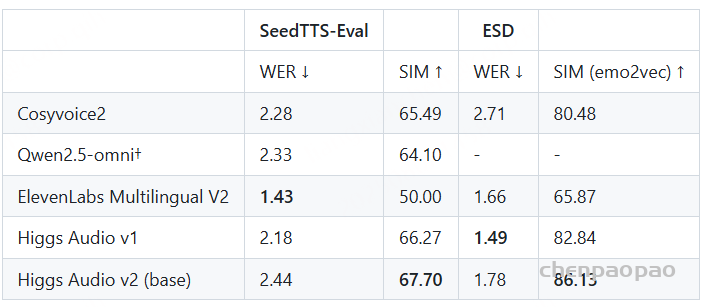
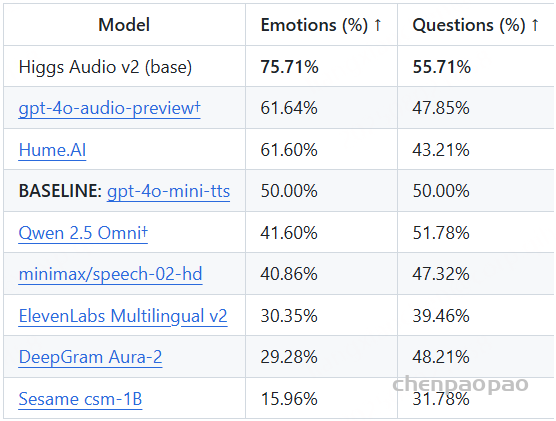
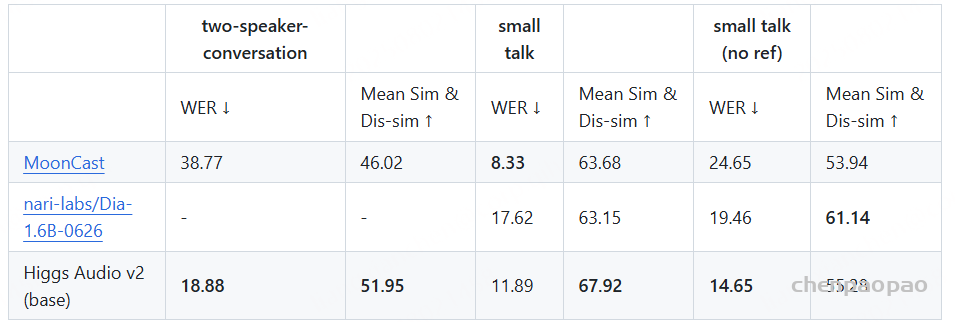
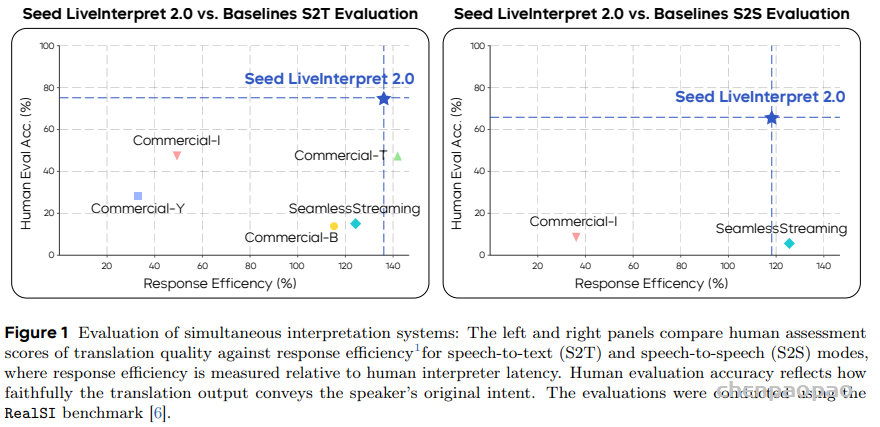
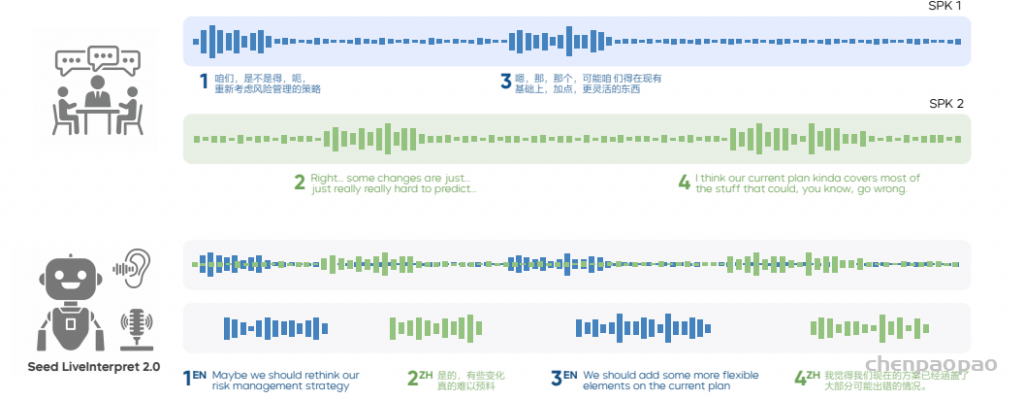
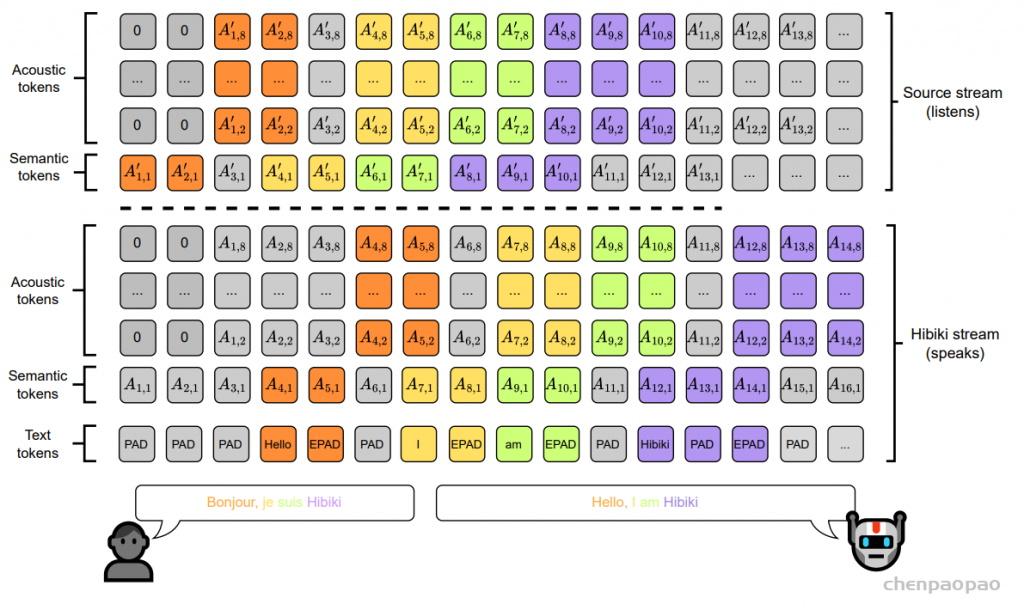
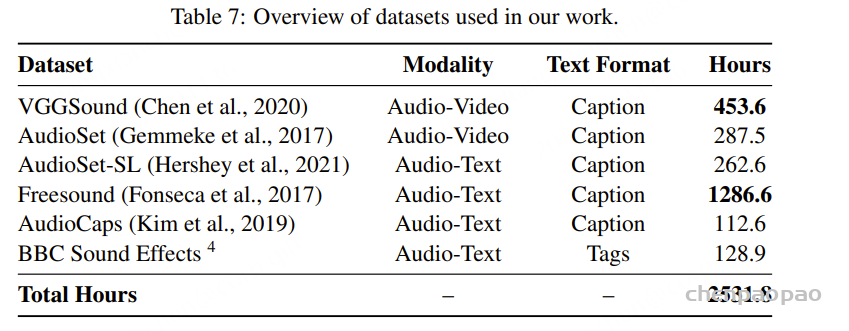
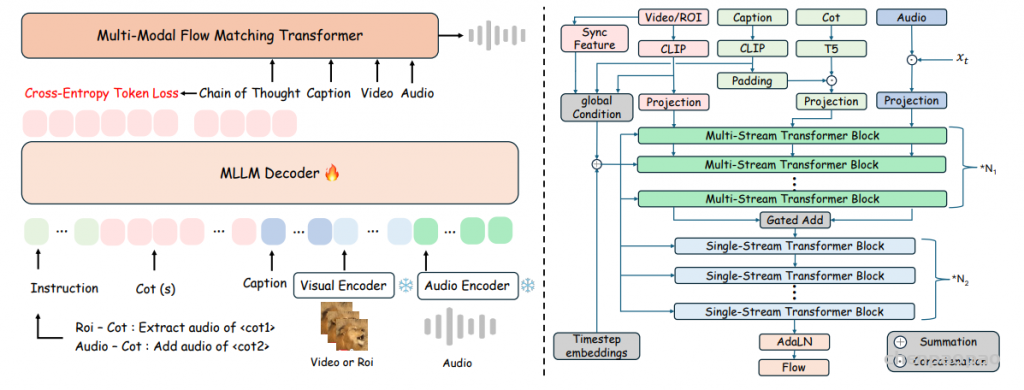
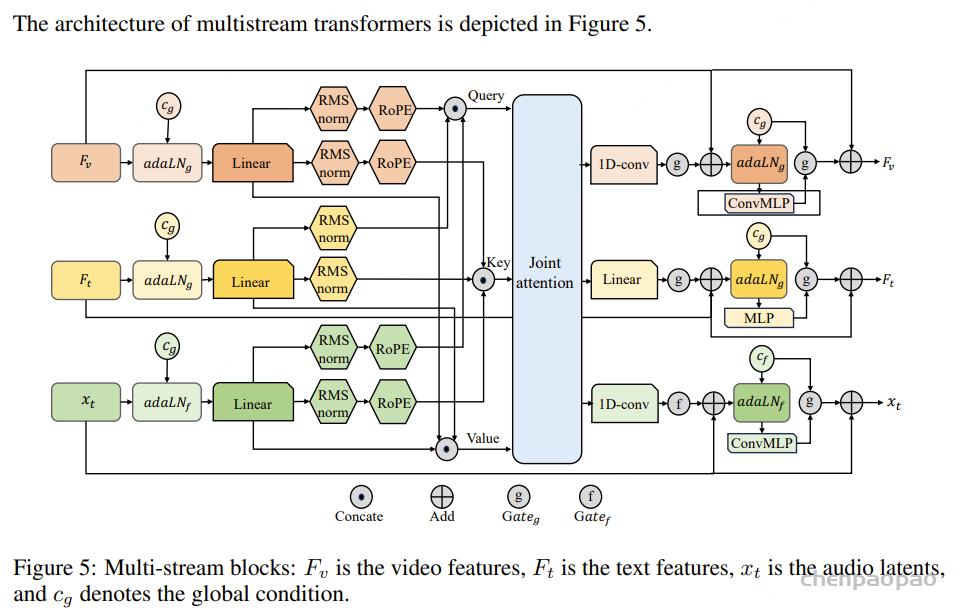
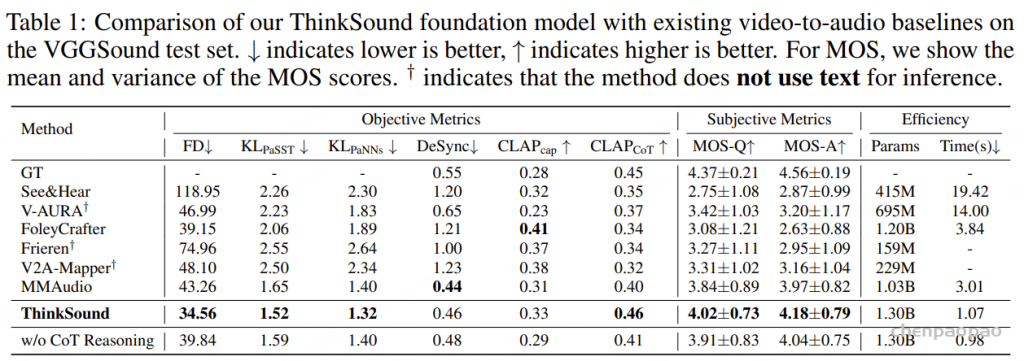
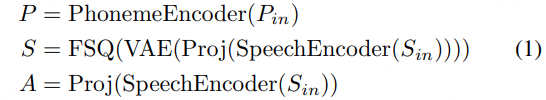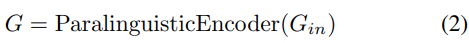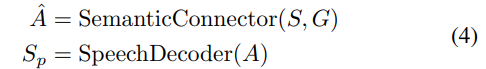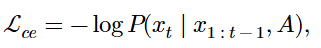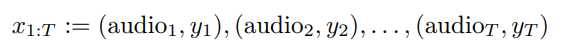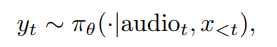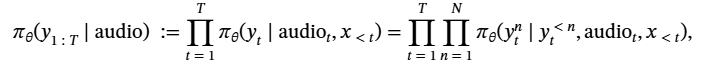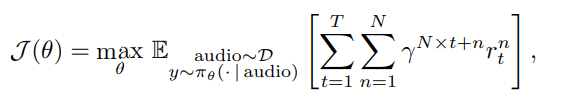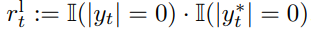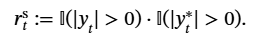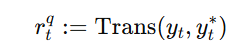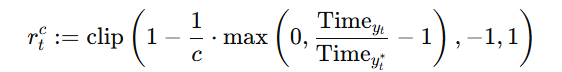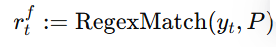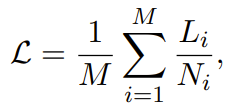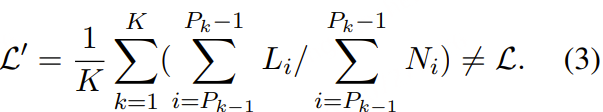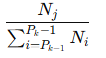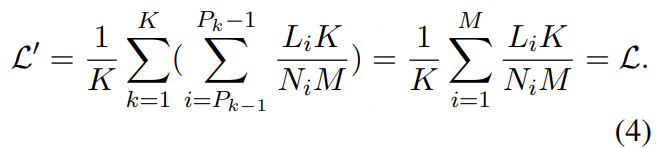随着大型语言模型(Large Language Models,LLMs)在生成式人工智能领域的快速发展,基于语音的应用如文本到语音合成(TTS)、自动语音识别(ASR)以及语音对话系统等日益受到关注。语音编解码器作为连接原始语音信号与语言模型的重要桥梁,其作用类似于自然语言处理中的文本分词器,能够将连续的语音波形转化为离散的编码 token,便于与LLM等模型进行有效融合和交互。
这三个表示之间的关系可以用公式S + G ≈ A 来描述,其中 S 是离散语义编码,G 是全局级副语言编码,A 是连续声学表示。通过这种方式,SecoustiCodec能够在单码本空间中实现语义和副语言信息的分离。
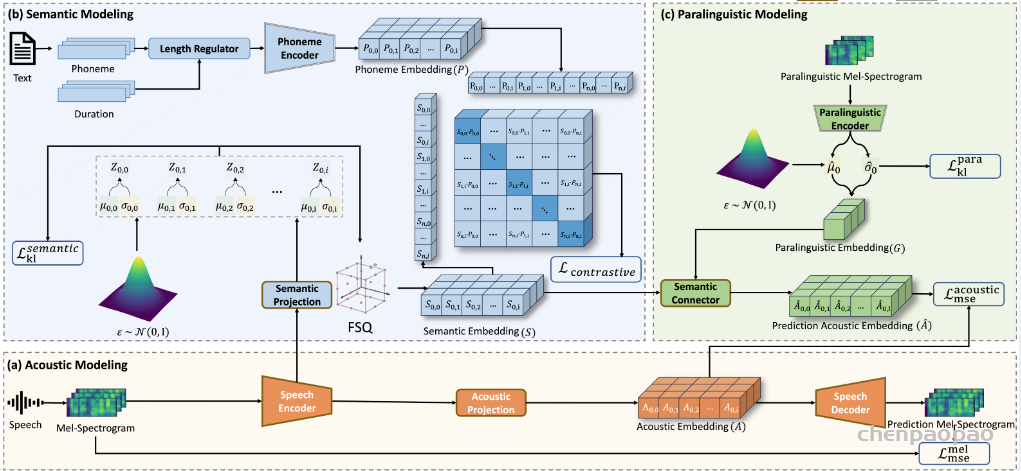
1.声学建模
声学建模部分包括语音编码器、声学投影和语音解码器。语音编码器将输入的语音信号Sin编码为连续的声学表示 A,然后通过声学投影模块进一步处理。语音解码器则负责将声学表示 A 重建为语音信号。
2. 语义建模
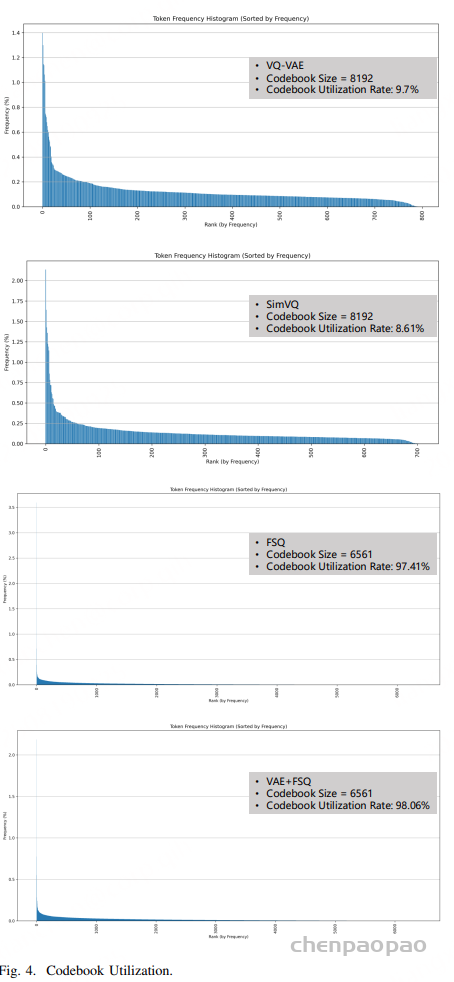
语义建模部分包括语义投影、变分自编码器(VAE)、有限标量量化(FSQ)和对比学习模块。其目标是从语音信号中提取纯净的语义信息,并将其编码为离散的语义表示 S。首先通过语义投影,将语音编码器的输出进一步映射到一个低维的语义空间。随后采用VAE + FSQ,通过VAE生成语义表示的均值 μ 和方差 σ,然后通过FSQ将这些连续的语义表示量化为离散的语义编码 S。这种方法不仅保留了语义信息,还进一步去除了副语言信息,同时提高了码本利用率。最后通过对比学习模块,将语音编码器生成的语义表示 S 和文本编码器生成的音素表示 P 对齐到一个联合帧级对齐的多模态空间中。通过最大化正样本对(S和对应的P)之间的相似度,同时最小化负样本对(S和不对应的P)之间的相似度,模型能够学习到纯净的语义表示。
其中 P 是音频表征,S 是语义表征,A是声学表征。
3. 副语言建模
副语言建模部分包括副语言编码器和语义连接器。其目标是从语音信号中提取副语言信息,并将其编码为全局级的副语言表示G。首先通过副语言编码器才从语音信号中提取副语言信息,如音色、情感等。随后经过语义连接器,将语义表示 S 和副语言表示 G 结合起来,预测声学表示 A^。通过这种方式,模型能够在解码阶段利用副语言信息来重建语音信号。
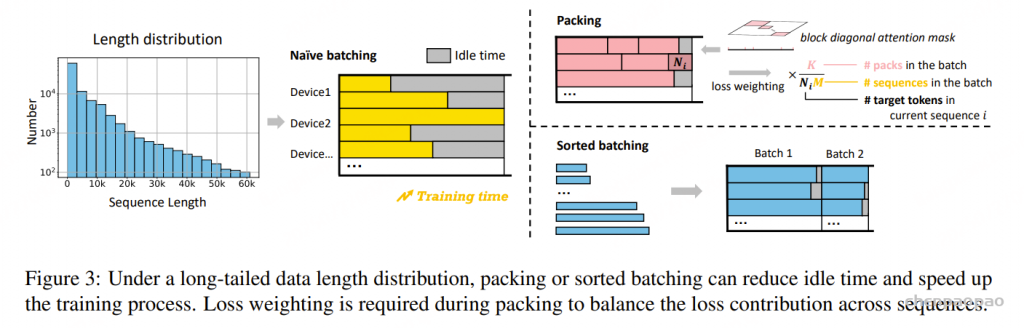
### Support loss weighting for packing ###
loss = None
if labels is not None:
lm_logits = lm_logits.to(torch.float32)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
if isinstance(labels, tuple) or isinstance(labels, list):
labels, weights = labels
shift_labels = labels[..., 1:].contiguous()
if self.pack_loss:
shift_weights = weights[..., 1:].contiguous()
loss_fct = CrossEntropyLoss(ignore_index=-100, reduction='none')
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss = (loss * shift_weights).sum()
else:
loss_fct = CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
lm_logits = lm_logits.to(hidden_states.dtype)
loss = loss.to(hidden_states.dtype)
### -------------------------------------- ###
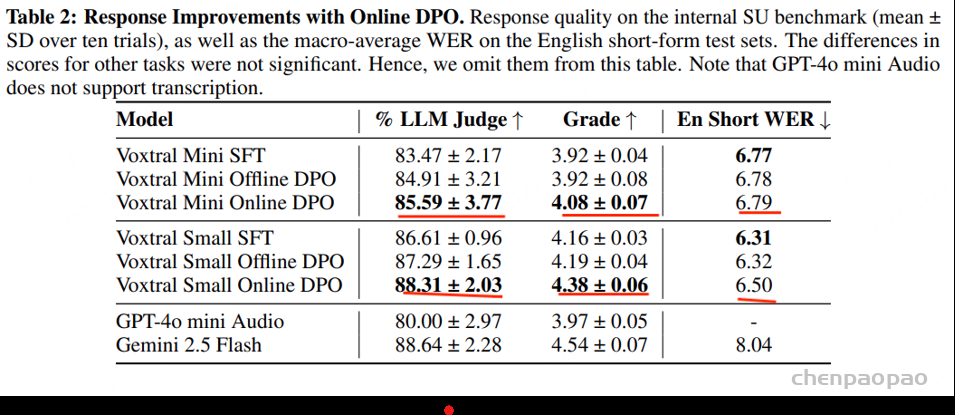
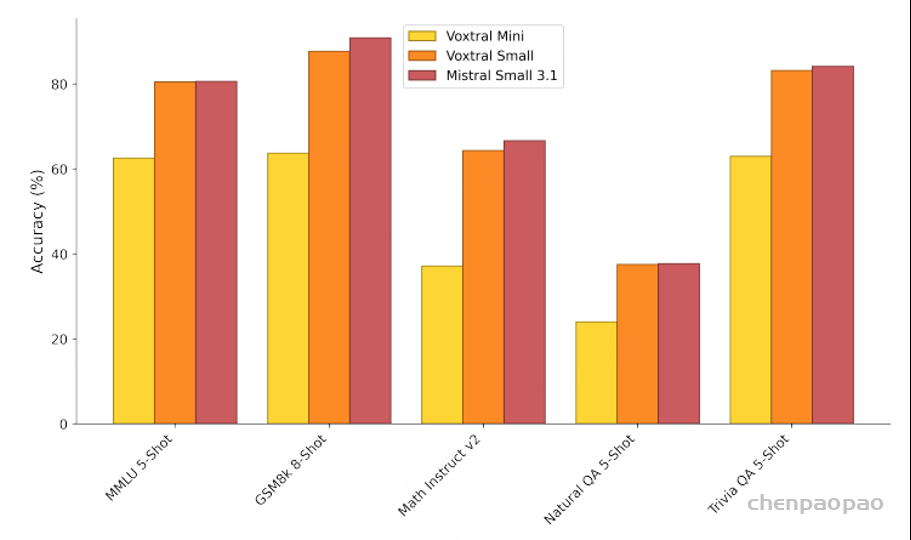
Voxtral Mini 在线 DPO 变体能够提供更清晰的接地气、更少的幻觉,并且通常能提供更有帮助的响应。 对于 Voxtral Small,我们发现其语音理解基准测试的响应质量得分显著提升,但在英语短句基准测试中却略有下降。
Results
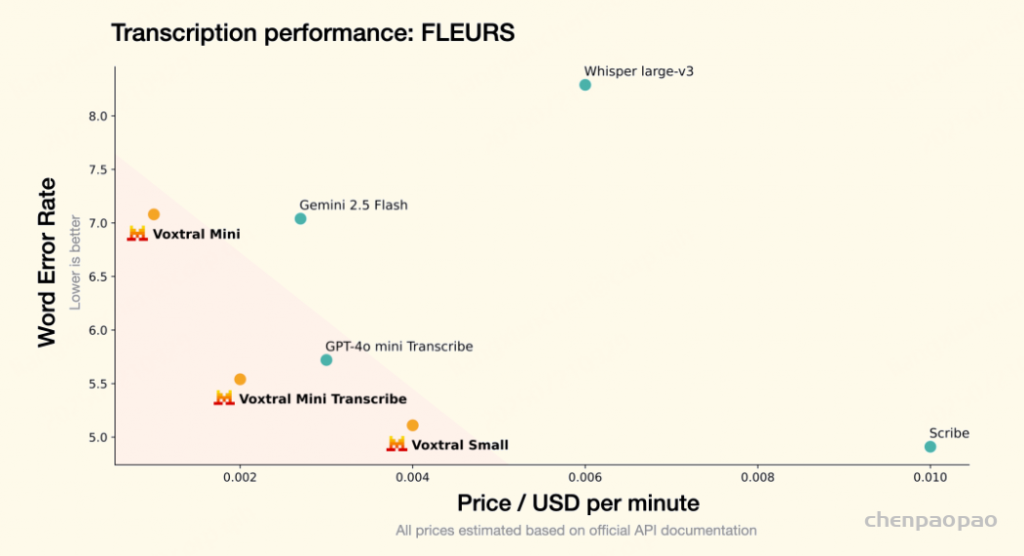
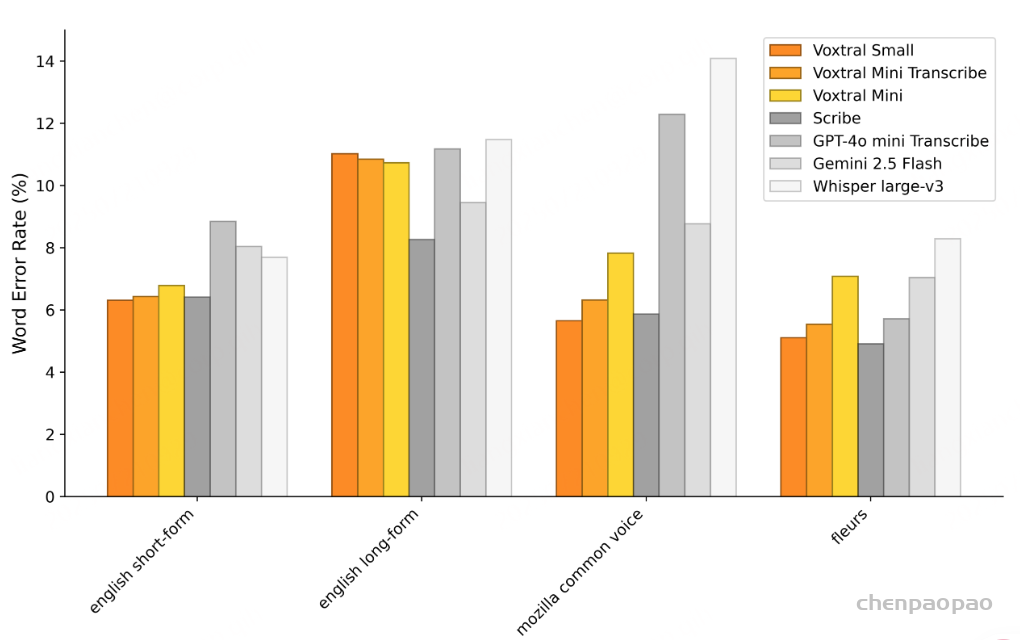
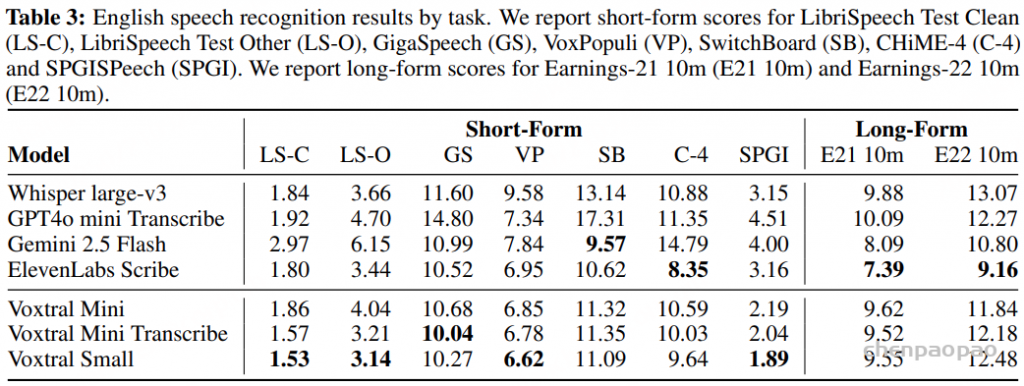
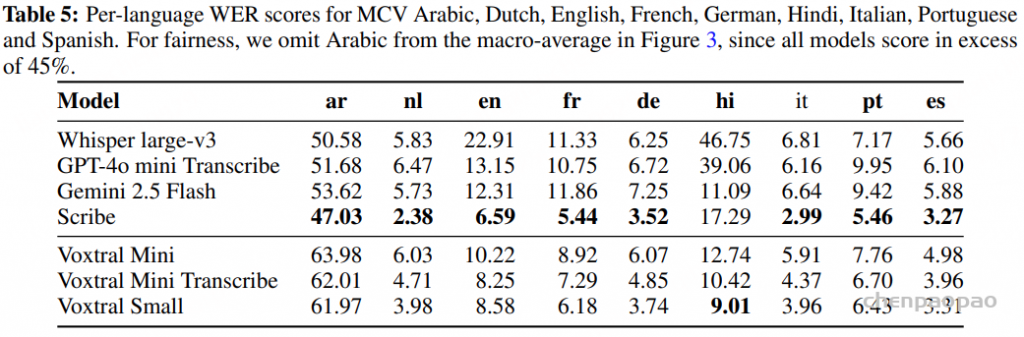
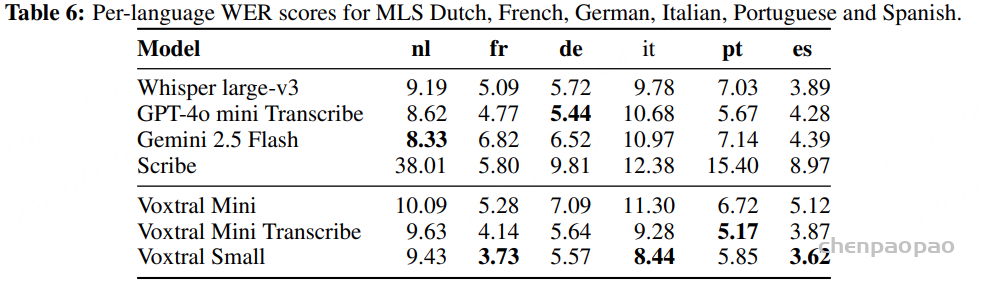
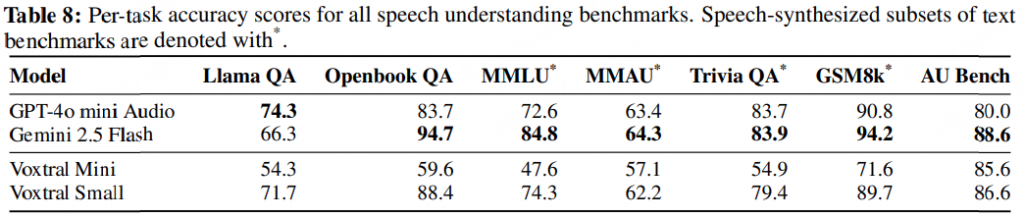
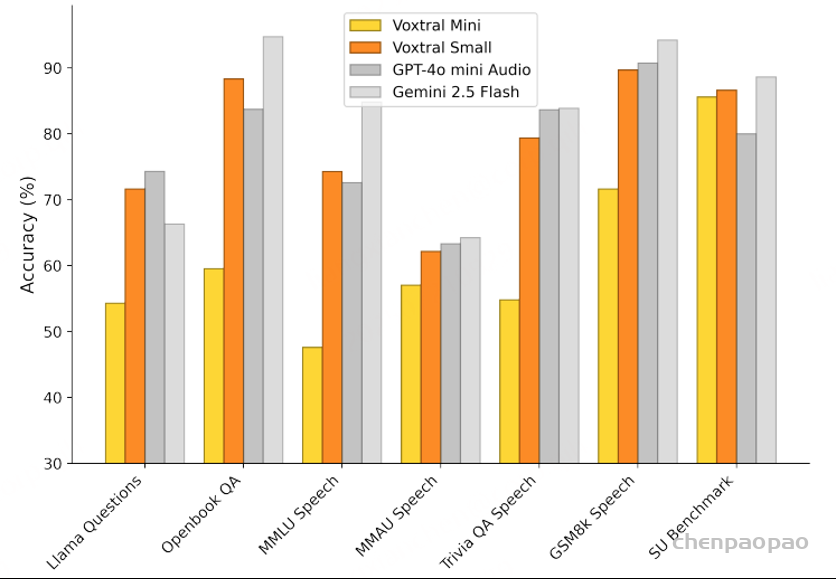
语音识别:各任务的平均 WER 结果。Voxtral Small 在英语短格式和 MCV 上的表现优于所有开源和闭源模型。Voxtral Mini Transcribe 在每项任务中均胜过 GPT-4o mini Transcribe 和 Gemini 2.5 Flash。
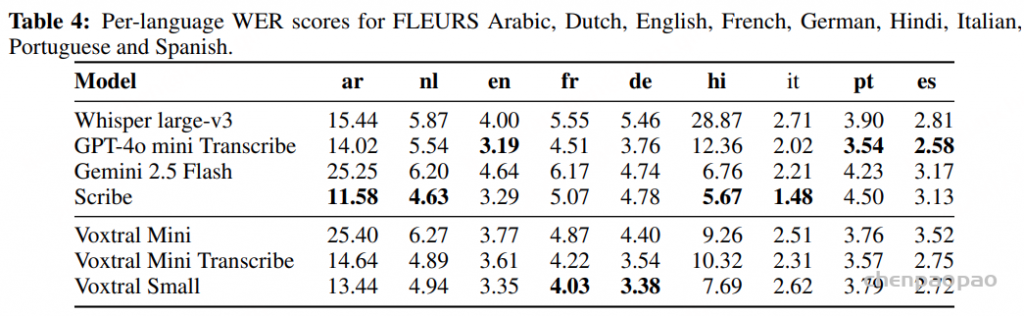
Tables 4, 5 and 6 show the per-language breakdown of WER scores for the FLEURS, Mozilla Common Voice and Multilingual LibriSpeech benchmarks, respectively.
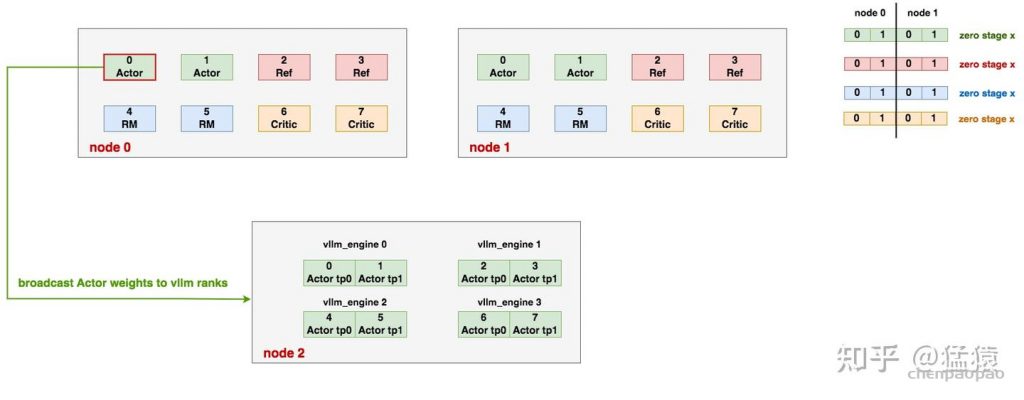
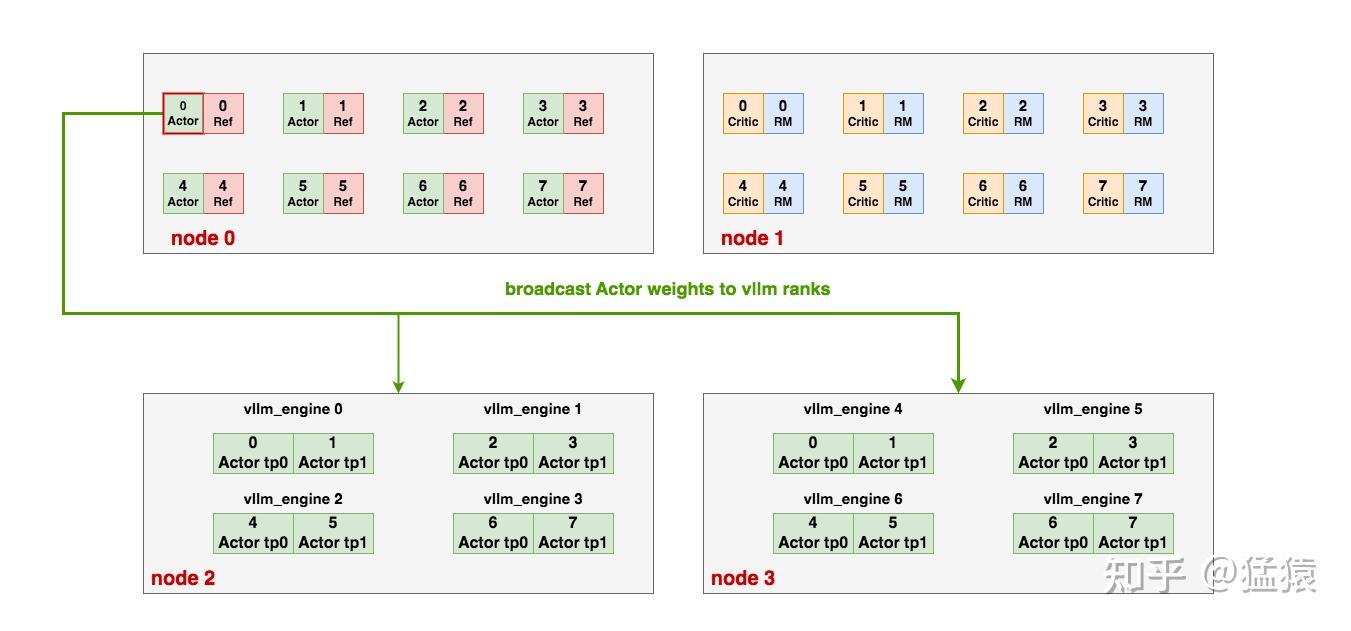
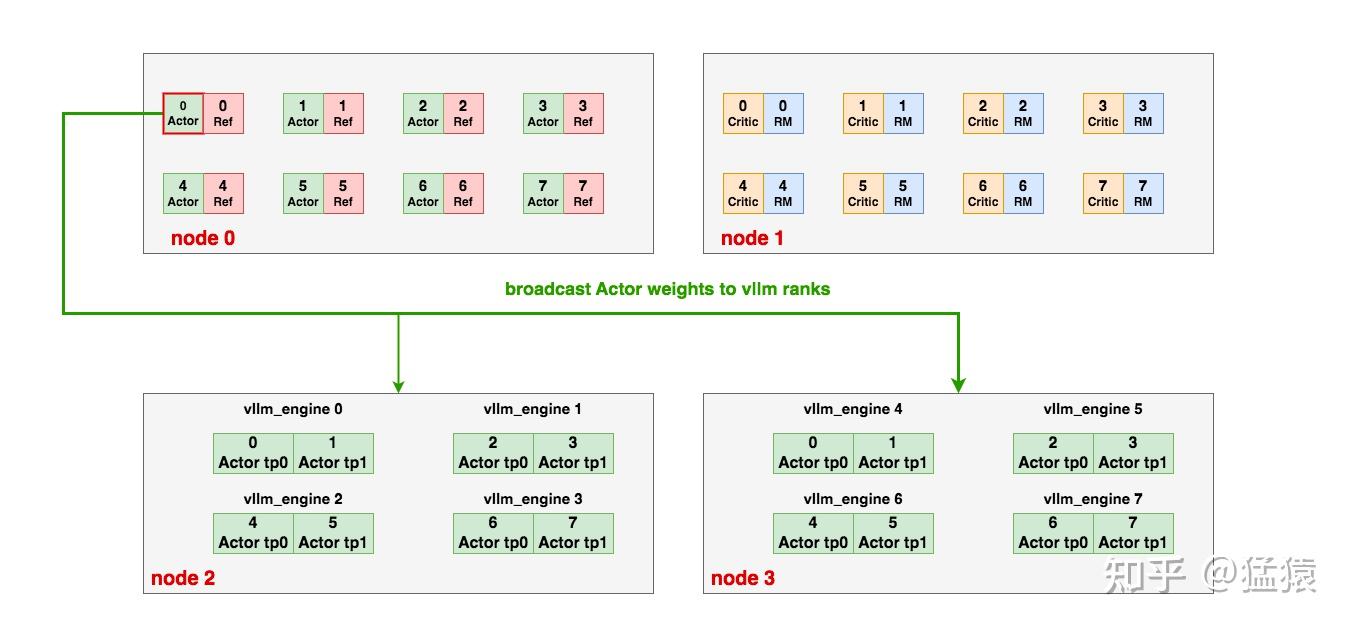
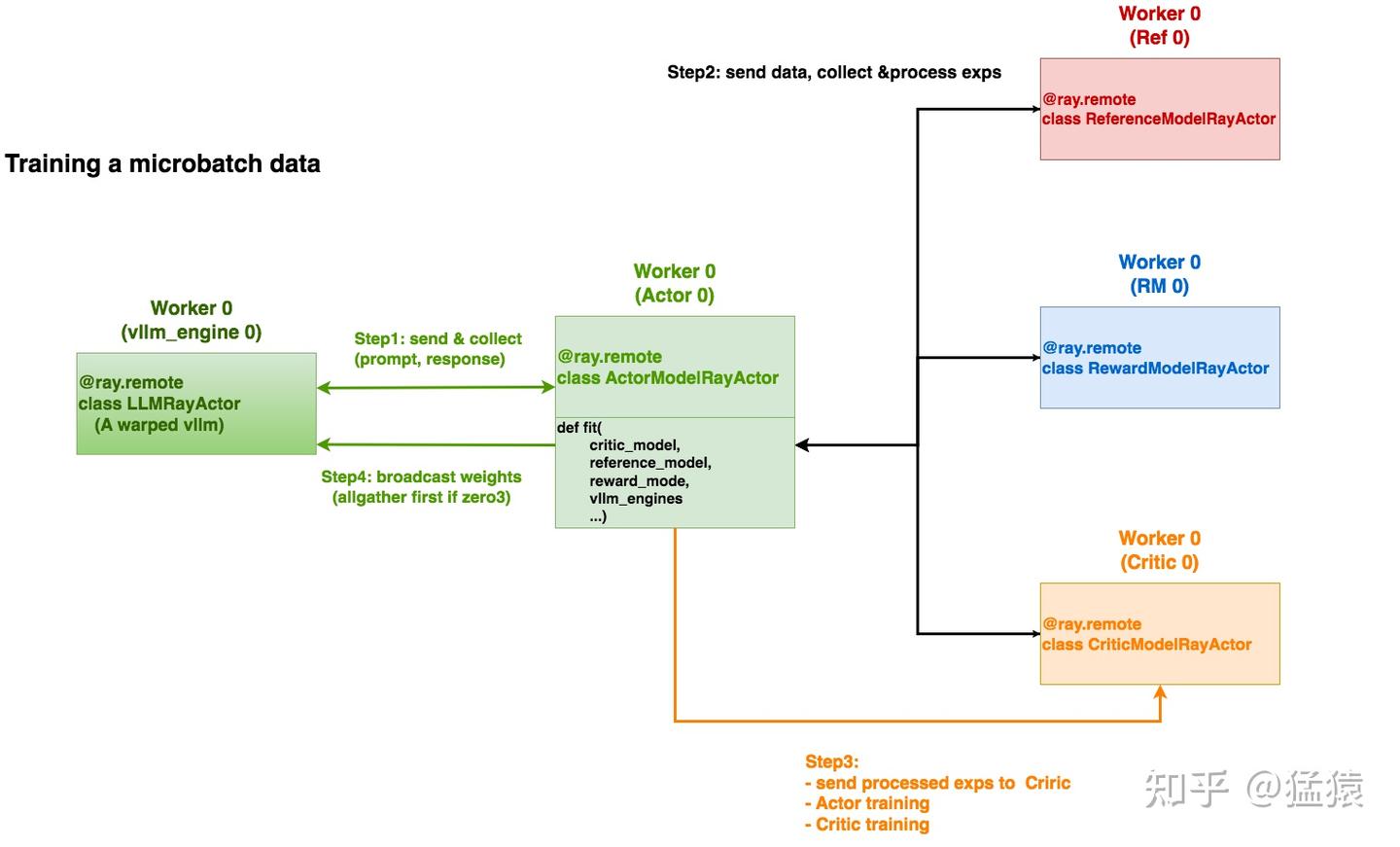
# Create torch group with deepspeed rank 0 and all vllm ranks# to update vllm engine's weights after each training stage.## Say we have 3 vllm engines and eache of them has 4 GPUs,# then the torch group is:# [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]# |ds rank 0 | engine-0 | engine-1 | engine-2 |## For ZeRO-1/2:# 1. Broadcast parameters from rank 0 to all vllm engines# For ZeRO-3:# 1. AllGather paramters to rank 0# 2. Broadcast parameters from rank 0 to all vllm engines
if self.vllm_engines is not None and torch.distributed.get_rank() == 0:
...
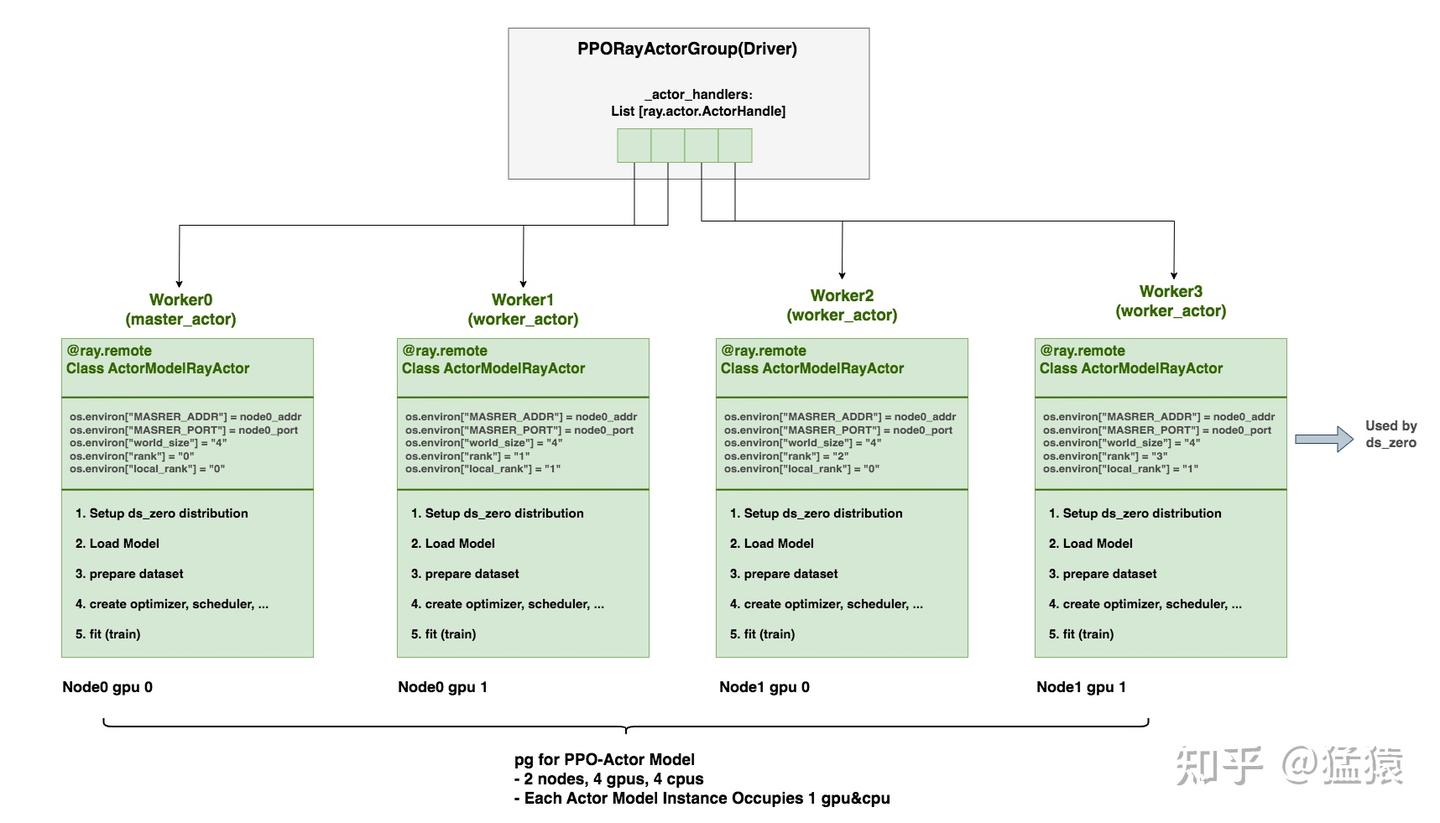
# world_size = num_of_all_vllm_ranks + 1 ds_rank0
world_size = vllm_num_engines * vllm_tensor_parallel_size + 1
...
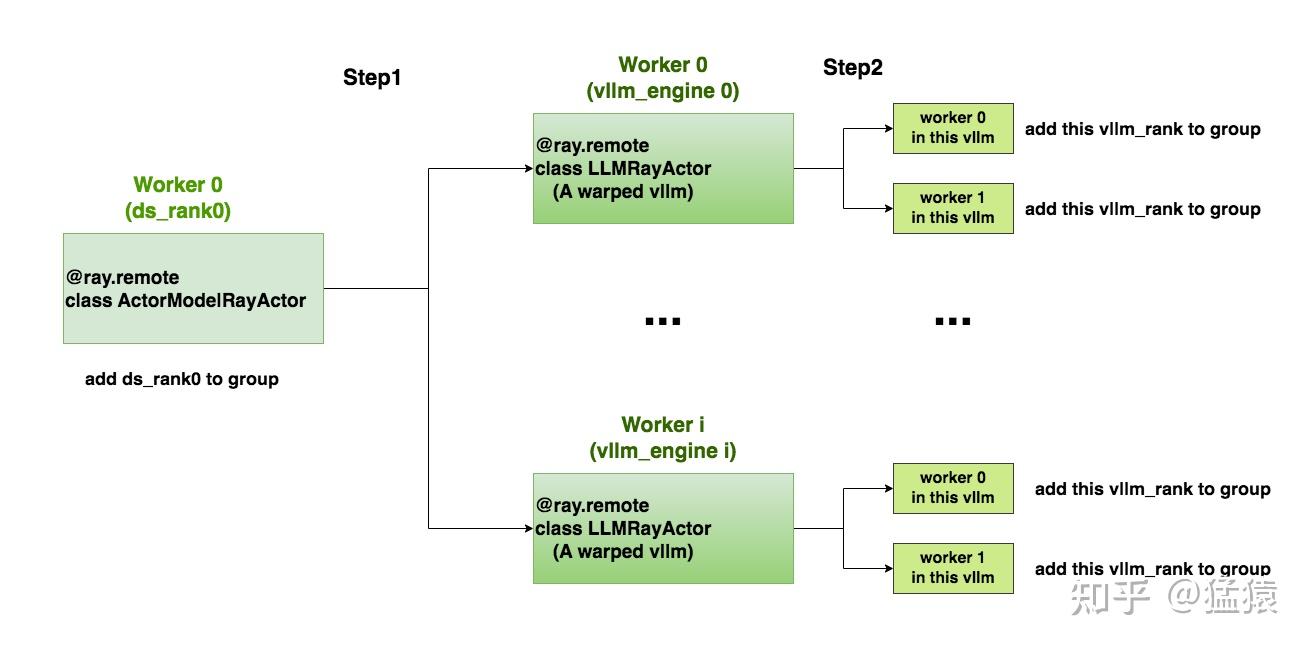
# =====================================================================# 遍历每个vllm_engines,将其下的每个vllm_rank添加进通讯组中,这里又分成两步:# 1. engine.init_process_group.remote(...):# 首先,触发远程vllm_engine的init_process_group方法# 2. 远程vllm_engine是一个包装过的vllm实例,它的init_process_group# 方法将进一步触发这个vllm实例下的各个worker进程(见4.4图例),# 最终是在这些worker进程上执行“将每个vllm_rank"添加进ds_rank0通讯组的工作# =====================================================================
refs = [
engine.init_process_group.remote(
# ds_rank0所在node addr
master_address,
# ds_rank0所在node port
master_port,
# 该vllm_engine的第一个rank在"ds_rank0 + all_vllm_ranks“中的global_rank,# 该值将作为一个offset,以该值为起点,可以推算出该vllm_engine中其余vllm_rank的global_rank
i * vllm_tensor_parallel_size + 1,
world_size,
"openrlhf",
backend=backend,
)
for i, engine in enumerate(self.vllm_engines)
]
# =====================================================================# 将ds_rank0添加进通讯组中# =====================================================================
self._model_update_group = init_process_group(
backend=backend,
init_method=f"tcp://{master_address}:{master_port}",
world_size=world_size,
rank=0,
group_name="openrlhf",
)
# =====================================================================# 确保all_vllm_ranks都已添加进通讯组中# =====================================================================
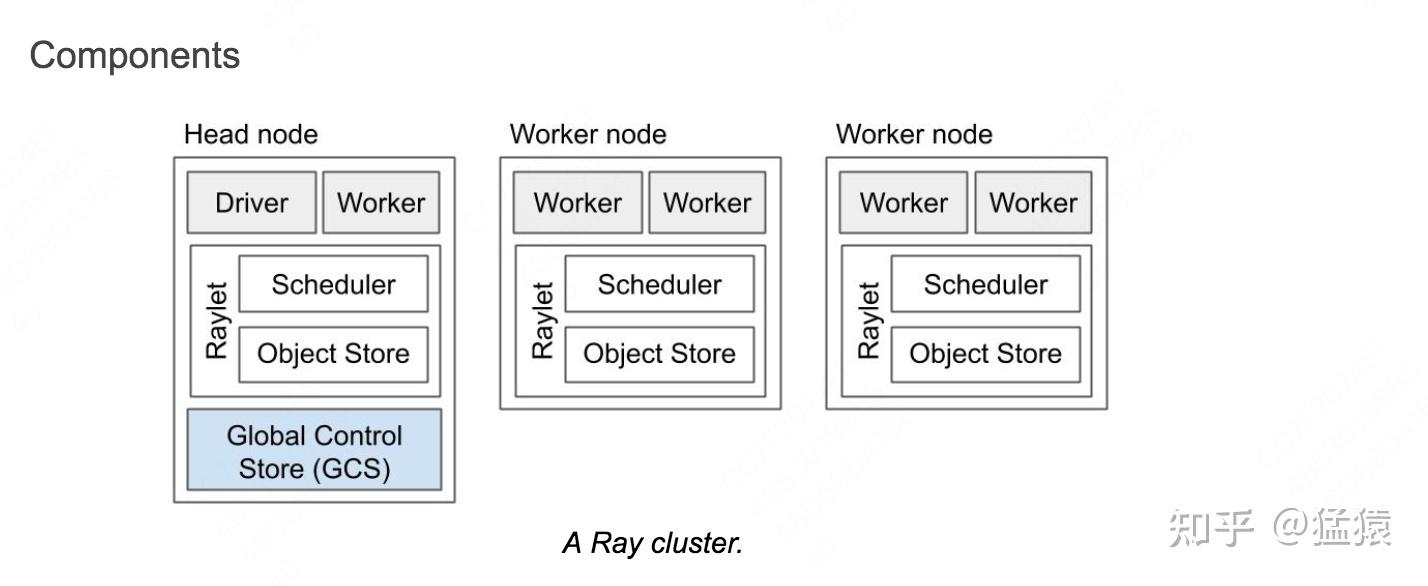
ray.get(refs)
def _broadcast_to_vllm(self):
# avoid OOM
torch.cuda.empty_cache()
model = self.actor.model.module
count, num_params = 0, len(list(model.named_parameters()))
for name, param in model.named_parameters():
count += 1 # empty_cache at last param# Fire all vllm engines for broadcast
if torch.distributed.get_rank() == 0:
shape = param.shape if self.strategy.args.zero_stage != 3 else param.ds_shape
refs = [
# 远端vllm_engine的每个rank上,初始化一个尺寸为shape的empty weight张量,# 用于接收广播而来的权重
engine.update_weight.remote(name, dtype=param.dtype, shape=shape, empty_cache=count == num_params)
for engine in self.vllm_engines
]
# For ZeRO-3, allgather sharded parameter and broadcast to all vllm engines by rank 0# ds_rank0发出权重(视是否使用zero3决定在发出前是否要做all-gather)
with deepspeed.zero.GatheredParameters([param], enabled=self.strategy.args.zero_stage == 3):
if torch.distributed.get_rank() == 0:
torch.distributed.broadcast(param.data, 0, group=self._model_update_group)
ray.get(refs) # 确保所有vllm_ranks接收权重完毕
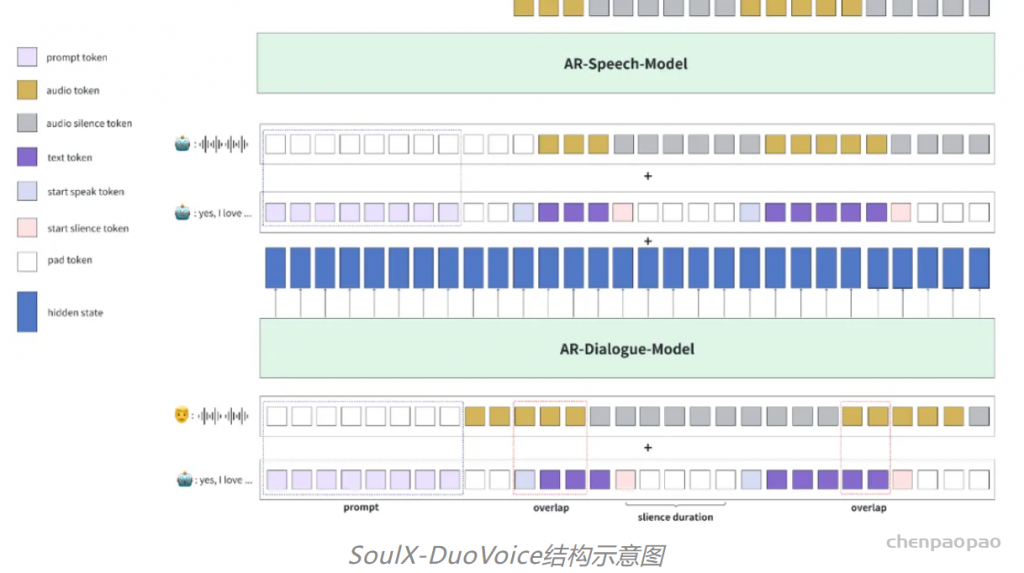
SoulX-DuoVoice 包含一个负责对话理解与生成的 Dialogue Model 和一个负责语音生成的 Speech Model。
新模型摒弃了传统语音交互中依赖的VAD(话音激活检测)机制与延迟控制逻辑,打破行业中普遍存在的“轮次对话”模式,赋予 AI 自主决策对话节奏的能力。AI可实现主动打破沉默、适时打断用户、边听边说、时间语义感知、并行发言讨论等。同时,模型具备多维度感知(包括时间感知、环境感知、事件感知等),口语化表达(如语气词、结巴、明显情绪起伏),音色复刻等能力,让AI更具“真人感”,支持打造更沉浸、类现实交互的语音互动新体验。