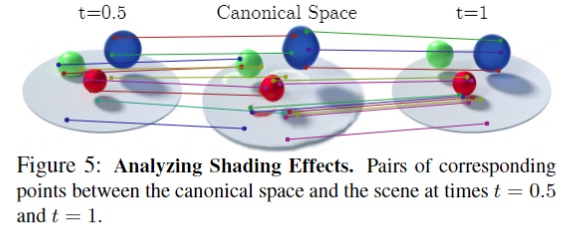
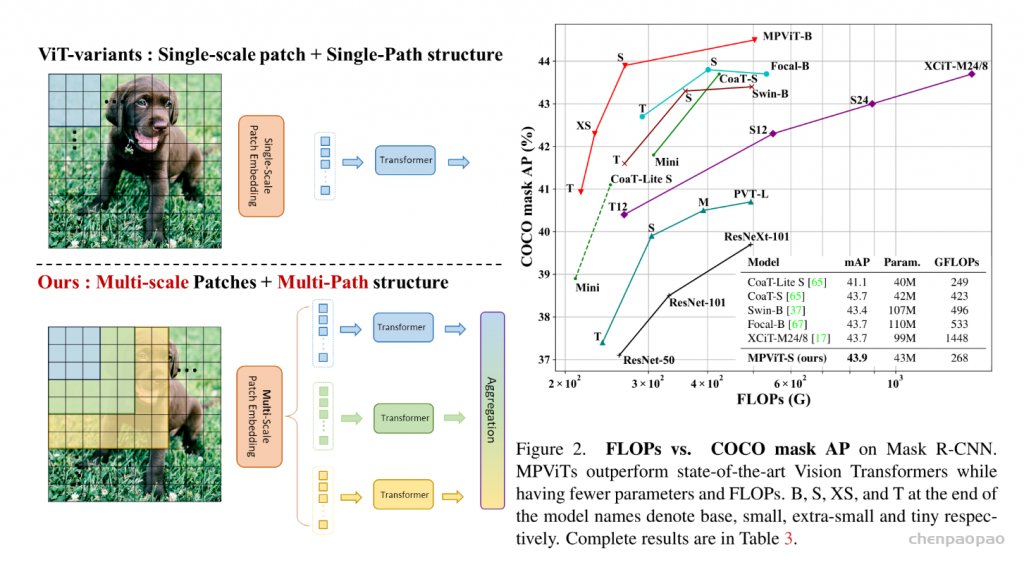
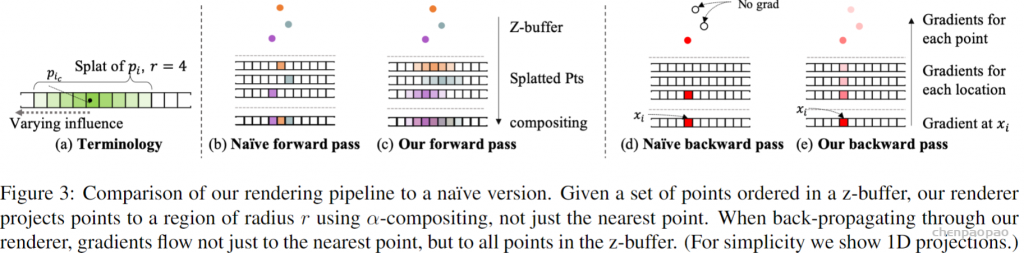
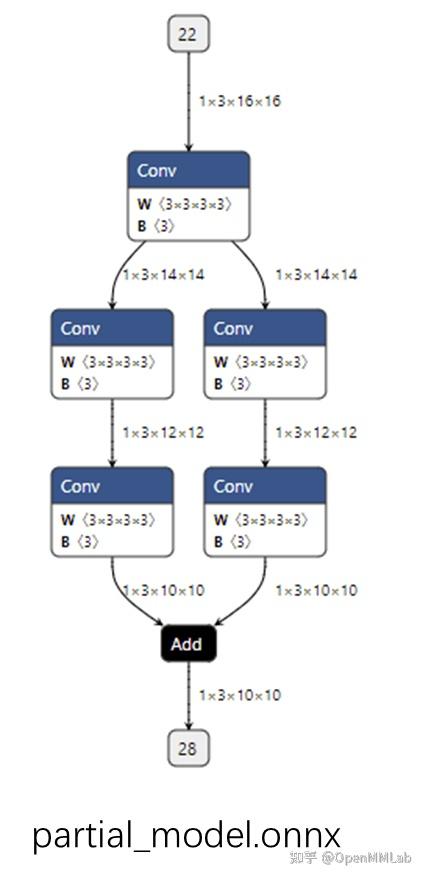
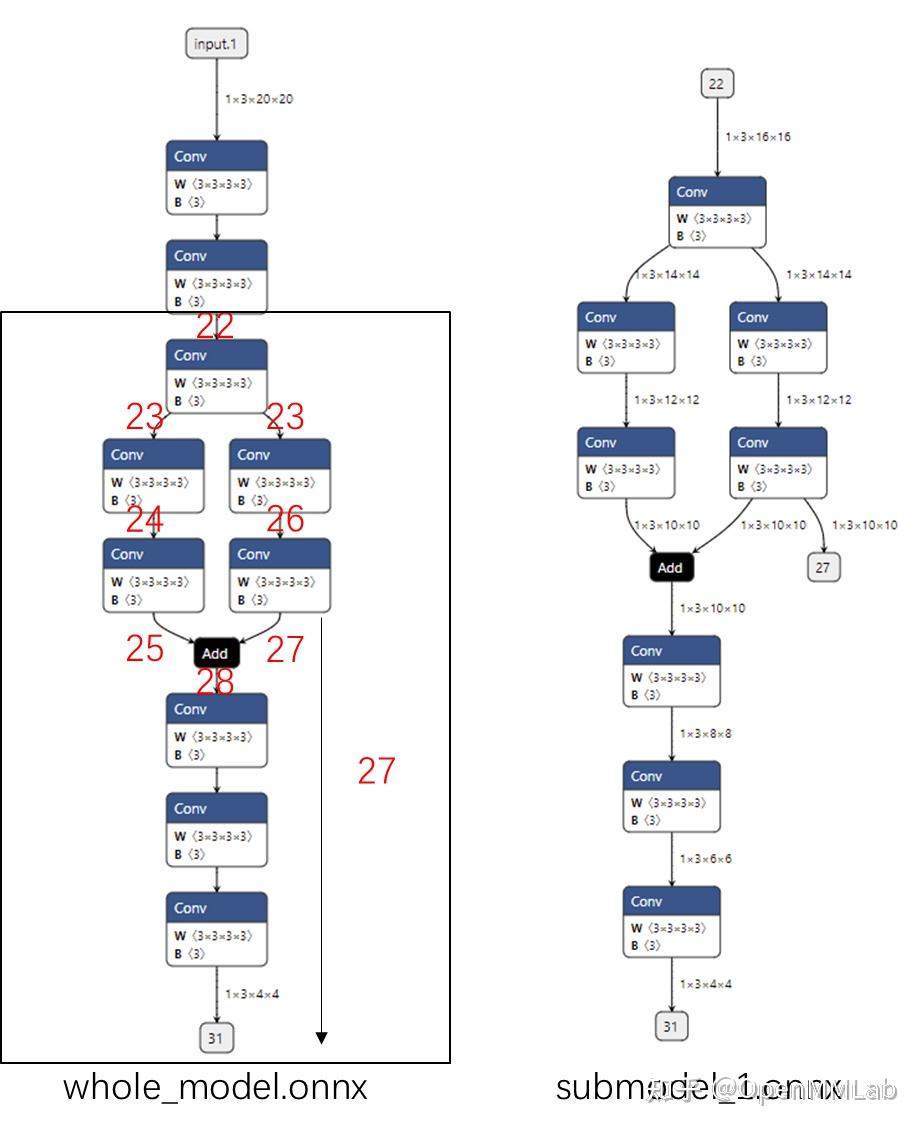
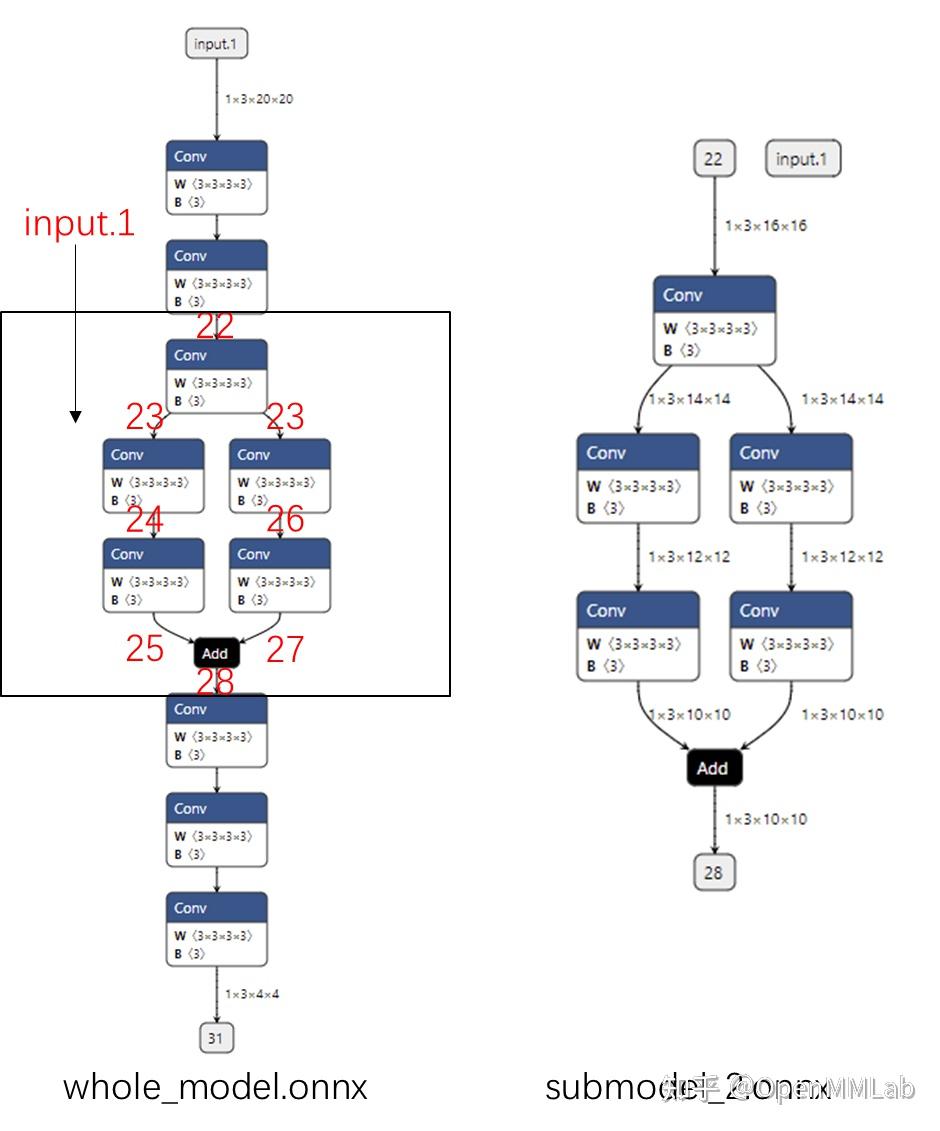
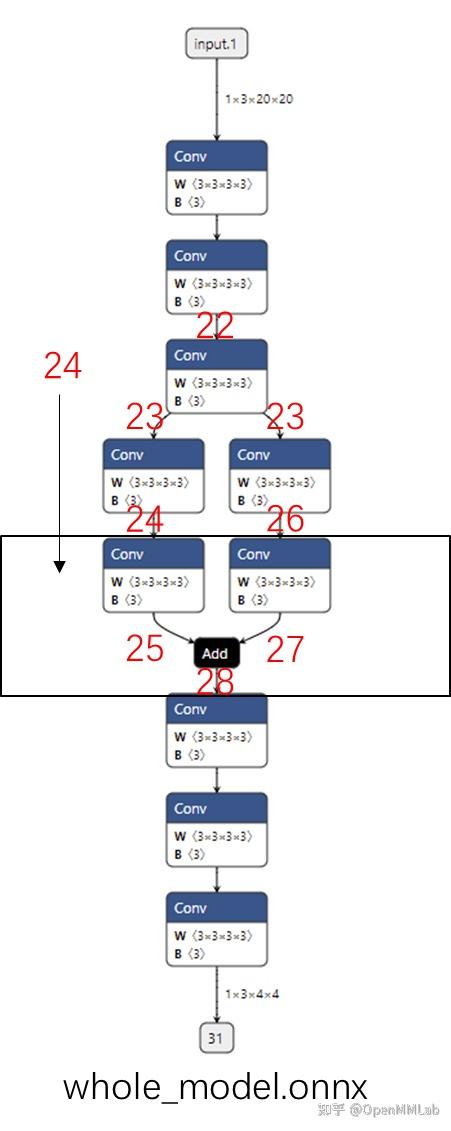
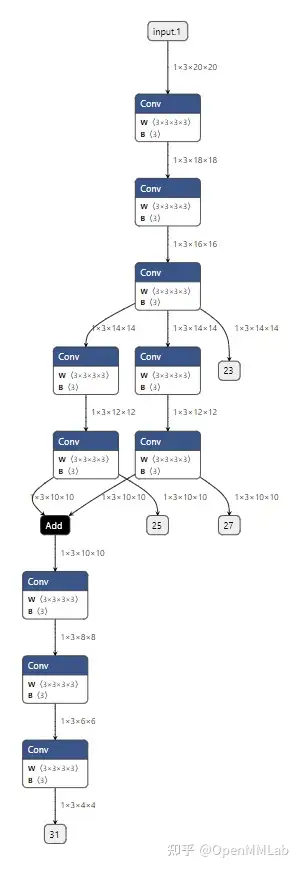
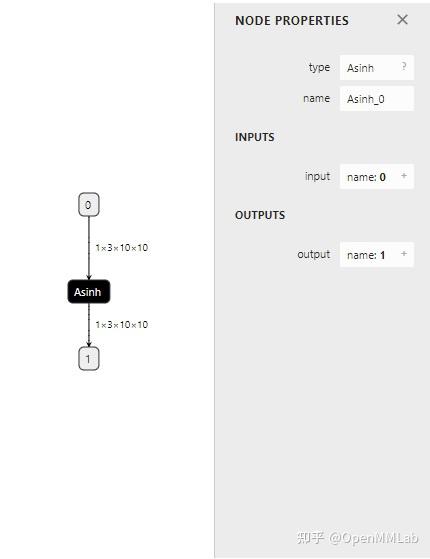
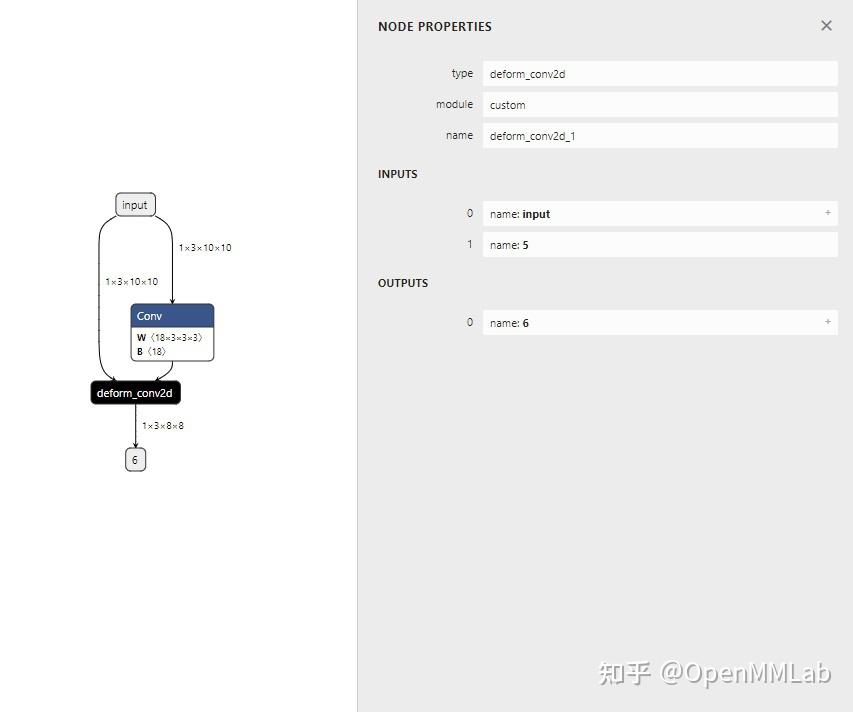
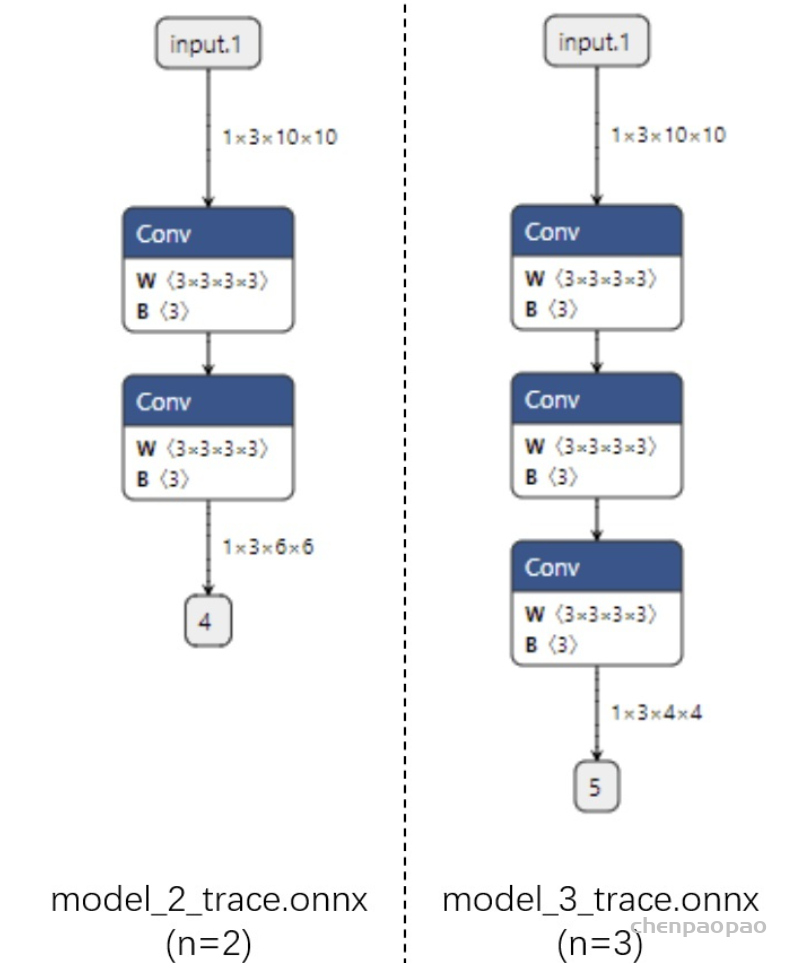
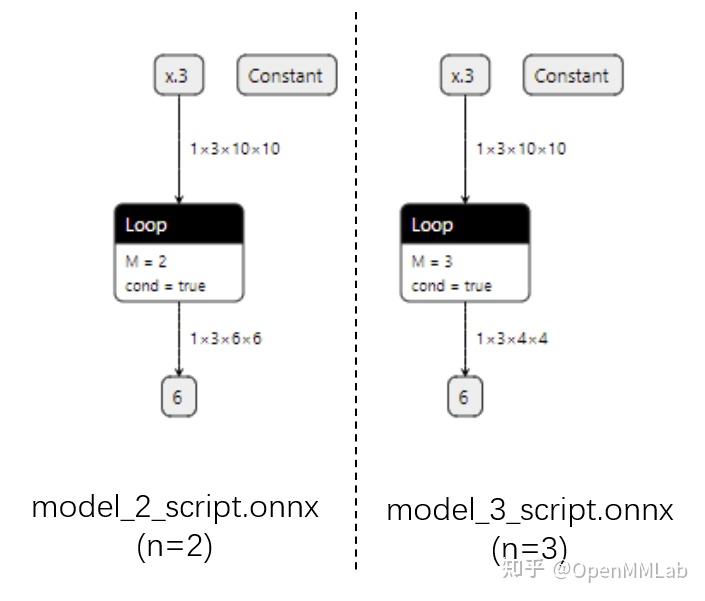
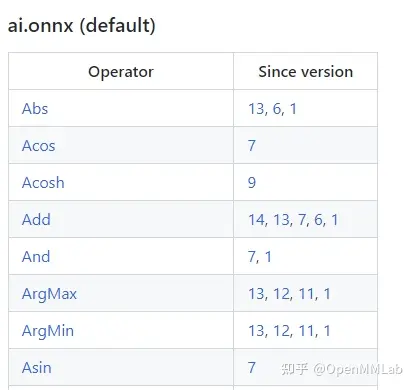
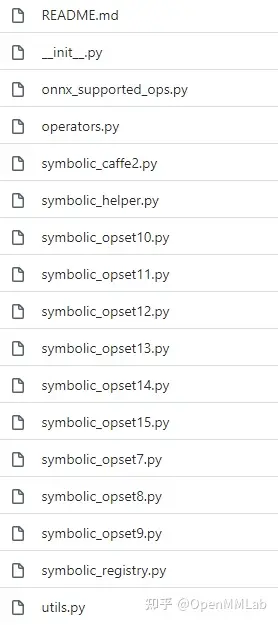
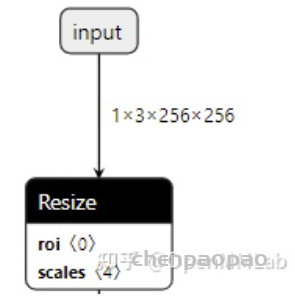
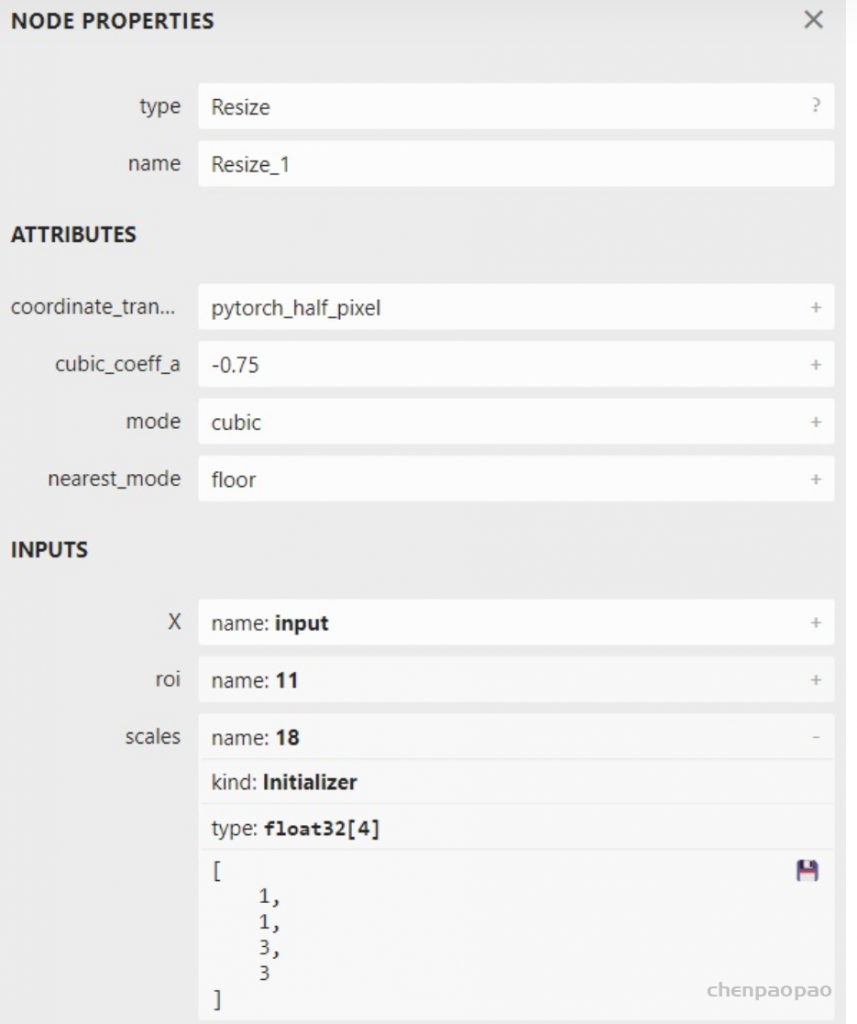
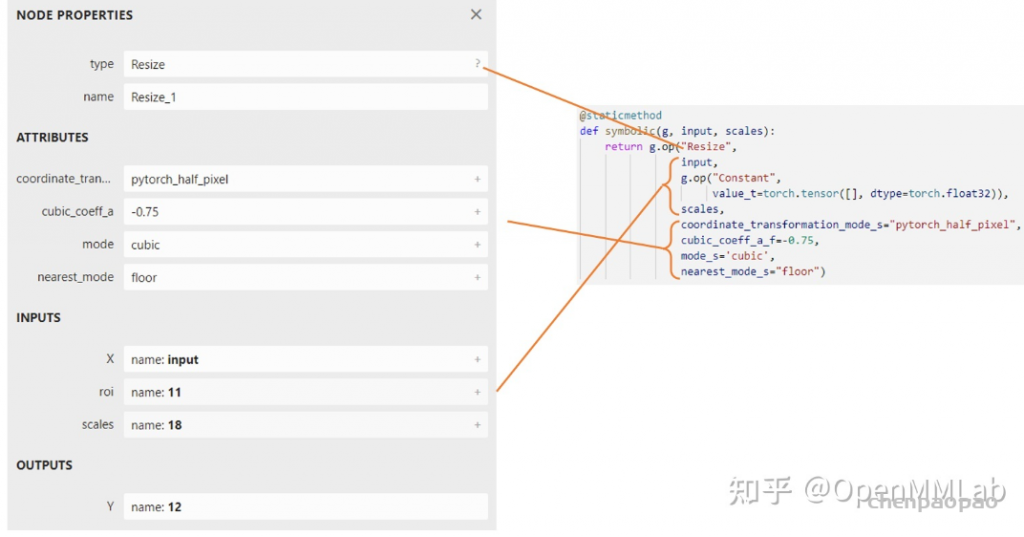
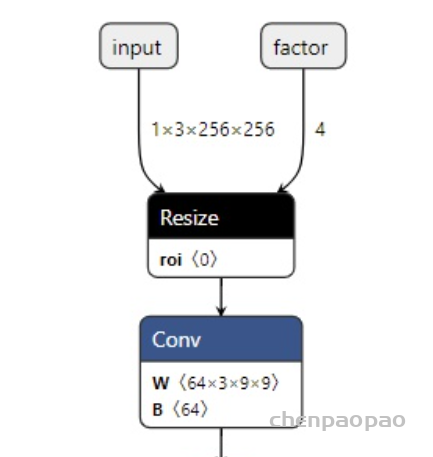
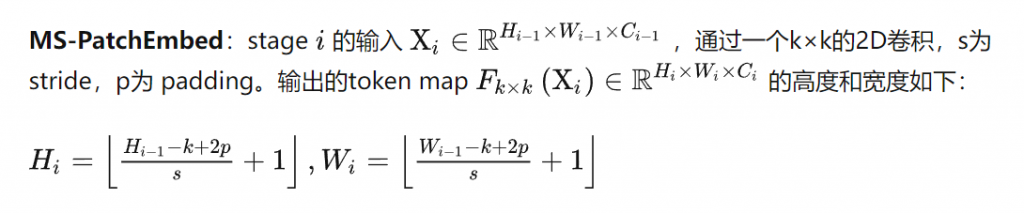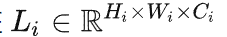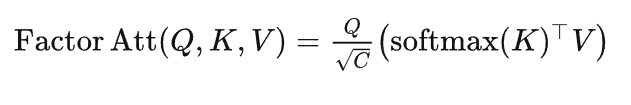In LeViT , a convolutional stem block shows better low-level representation (i.e., without losing salient information) than non-overlapping patch embedding.
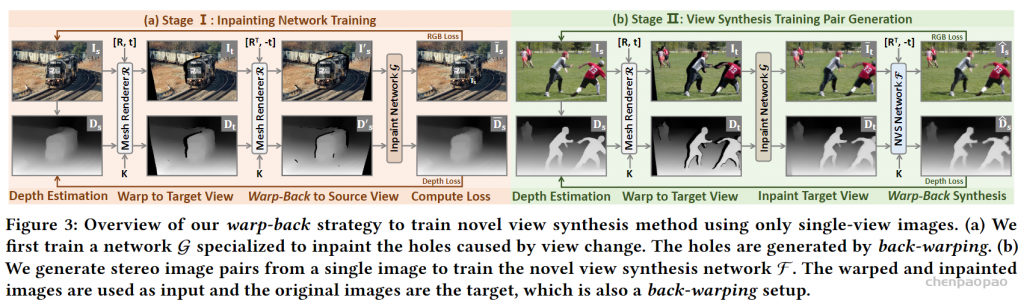
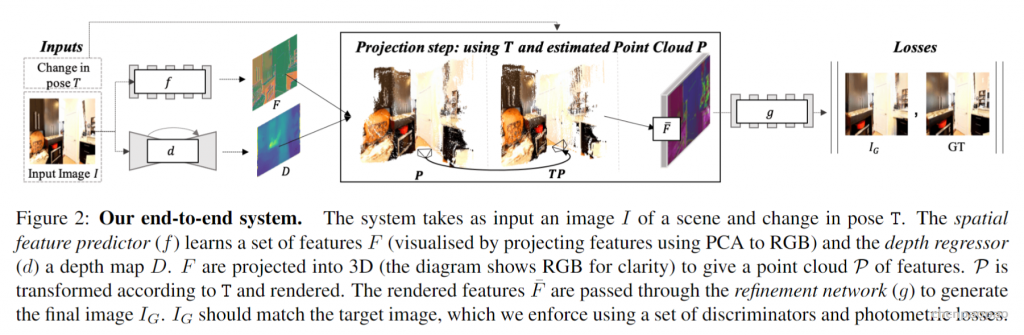
来自牛津大学、FAIR、Facebook 和密歇根大学的研究者提出了一种单一图像视图合成方法,允许从单一输入图像生成新的场景视图。它被训练在真实的图像上,没有使用任何真实的 3D 信息;引入了一种新的可微点云渲染器,用于将潜在的 3D 点云特征转换为目标视图;细化网络对投影特征进行解码,插入缺失区域,生成逼真的输出图像;生成模型内部的 3D 组件允许在测试时对潜在特征空间进行可解释的操作,例如,可以从单个图像动画轨迹。与以前的工作不同,SynSin 可以生成高分辨率的图像,并推广到其他输入分辨率,在 Matterport、Replica 和 RealEstate10K 数据集上超越基线和前期工作。
成功执行这些代码的话,程序会以文本格式输出模型的信息,其内容应该和我们在上一节展示的输出一样。 整理一下,用 ONNX Python API 构造模型的代码如下:
import onnx
from onnx import helper
from onnx import TensorProto
# input and output
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10])
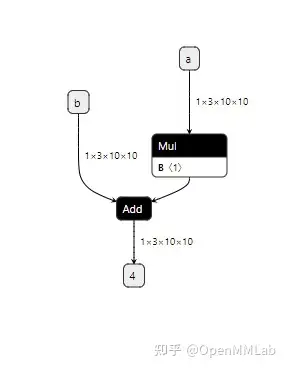
# Mul
mul = helper.make_node('Mul', ['a', 'x'], ['c'])
# Add
add = helper.make_node('Add', ['c', 'b'], ['output'])
# graph and model
graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output])
model = helper.make_model(graph)
# save model
onnx.checker.check_model(model)
print(model)
onnx.save(model, 'linear_func.onnx')
老规矩,我们可以用 ONNX Runtime 运行模型,来看看模型是否正确:
import onnxruntime
import numpy as np
sess = onnxruntime.InferenceSession('linear_func.onnx')
a = np.random.rand(10, 10).astype(np.float32)
b = np.random.rand(10, 10).astype(np.float32)
x = np.random.rand(10, 10).astype(np.float32)
output = sess.run(['output'], {'a': a, 'b': b, 'x': x})[0]
assert np.allclose(output, a * x + b)
一切顺利的话,这段代码不会有任何报错信息。这说明我们的模型等价于执行 a * x + b 这个计算。
读取并修改 ONNX 模型
通过用 API 构造 ONNX 模型,我们已经彻底搞懂了 ONNX 由哪些模块组成。现在,让我们看看该如何读取现有的”.onnx”文件并从中提取模型信息。 首先,我们可以用下面的代码读取一个 ONNX 模型:
import onnx
model = onnx.load('linear_func.onnx')
print(model)
在读入之前的 linear_func.onnx 模型后,我们可以直接修改第二个节点的类型 node[1].op_type,把加法变成减法。这样,我们的模型描述的是 a * x - b 这个线性函数。大家感兴趣的话,可以用 ONNX Runtime 运行新模型 linear_func_2.onnx,来验证一下它和 a * x - b 是否等价。
为了应对更复杂的情况,我们来自定义一个奇怪的 my_add 算子。这个算子的输入张量 a, b ,输出 2a + b 的值。我们会先把它在 PyTorch 中实现,再把它导出到 ONNX 中。
为 PyTorch 添加 C++ 拓展
为 PyTorch 添加简单的 C++ 拓展还是很方便的。对于我们定义的 my_add 算子,可以用以下的 C++ 源文件来实现。我们把该文件命名为 “my_add.cpp”:
// my_add.cpp
#include <torch/torch.h>
torch::Tensor my_add(torch::Tensor a, torch::Tensor b)
{
return 2 * a + b;
}
PYBIND11_MODULE(my_lib, m)
{
m.def("my_add", my_add);
}
由于在 PyTorch 中添加 C++ 拓展和模型部署关系不大,这里我们仅给出这个简单的示例,并不对其原理做过多讲解。
在这段代码中,torch::Tensor 就是 C++ 中 torch 的张量类型,它的加法和乘法等运算符均已重载。因此,我们可以像对普通标量一样对张量做加法和乘法。
轻松地完成了算子的实现后,我们用 PYBIND11_MODULE 来为 C++ 函数提供 Python 调用接口。这里的 my_lib 是我们未来要在 Python 里导入的模块名。双引号中的 my_add 是 Python 调用接口的名称,这里我们对齐 C++ 函数的名称,依然用 “my_add”这个名字。
之后,我们可以编写如下的 Python 代码并命名为 “setup.py”,来编译刚刚的 C++ 文件:
from setuptools import setup
from torch.utils import cpp_extension
setup(name='my_add',
ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])],
cmdclass={'build_ext': cpp_extension.BuildExtension})
这段代码使用了 Python 的 setuptools 编译功能和 PyTorch 的 C++ 拓展工具函数,可以编译包含了 torch 库的 C++ 源文件。这里我们需要填写的只有模块名和模块中的源文件名。我们刚刚把模块命名为 my_lib,而源文件只有一个 my_add.cpp,因此拓展模块那一行要写成 ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])],。
之后,像处理普通的 Python 包一样执行安装命令,我们的 C++ 代码就会自动编译了。
python setup.py develop
用 torch.autograd.Function 封装
直接用 Python 接口调用 C++ 函数不太“美观”,一种比较优雅的做法是把这个调用接口封装起来。这里我们用 torch.autograd.Function 来封装算子的底层调用:
import torch
import my_lib
class MyAddFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, a, b):
return my_lib.my_add(a, b)
@staticmethod
def symbolic(g, a, b):
two = g.op("Constant", value_t=torch.tensor([2]))
a = g.op('Mul', a, two)
return g.op('Add', a, b)
Input[0] on model model_static.onnx succeed.
Input[1] on model model_static.onnx error.
Input[2] on model model_static.onnx error.
Input[0] on model model_dynamic_0.onnx succeed.
Input[1] on model model_dynamic_0.onnx succeed.
Input[2] on model model_dynamic_0.onnx error.
Input[0] on model model_dynamic_23.onnx succeed.
Input[1] on model model_dynamic_23.onnx error.
Input[2] on model model_dynamic_23.onnx succeed.
print(exceptions[(1, 'model_static.onnx')])
# output # [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: in for the following indices index: 0 Got: 2 Expected: 1 Please fix either the inputs or the model.
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * x[0].item()
return x, torch.Tensor([i for i in x])
model = Model()
dummy_input = torch.rand(10)
torch.onnx.export(model, dummy_input, 'a.onnx')
return g.op("Resize",
input,
empty_roi,
empty_scales,
output_size,
coordinate_transformation_mode_s=coordinate_transformation_mode,
cubic_coeff_a_f=-0.75, # only valid when mode="cubic"
mode_s=interpolate_mode, # nearest, linear, or cubic
nearest_mode_s="floor") # only valid when mode="nearest"