
IBRNet: Learning Multi-View Image-Based Rendering
代码链接:https://github.com/googleinterns/IBRNet
NeRF存在的一大问题就是仅仅只能表示一个场景,因此这篇文章就学提出了一个框架可以同时学习多个场景,且可以扩展到没有学习过的场景(提高泛化性)。实验表明,在寻求泛化到新scenes时,我们的方法比其它好。更进一步,如果fine-tuned每一个scene,可以实现和目前SOTA的NVS任务相当的表现。
本文与NeRF最大的不同是输入的数据不仅仅有目标视角,还有对应的所有同一场景的多视角图片,因此理论上的确是可以直接端到端的应用于新场景的。原始NeRF针对每个scene都需要优化(重头训练),而本文方法学习一个通用的view插值函数能够泛化到新的scenes。
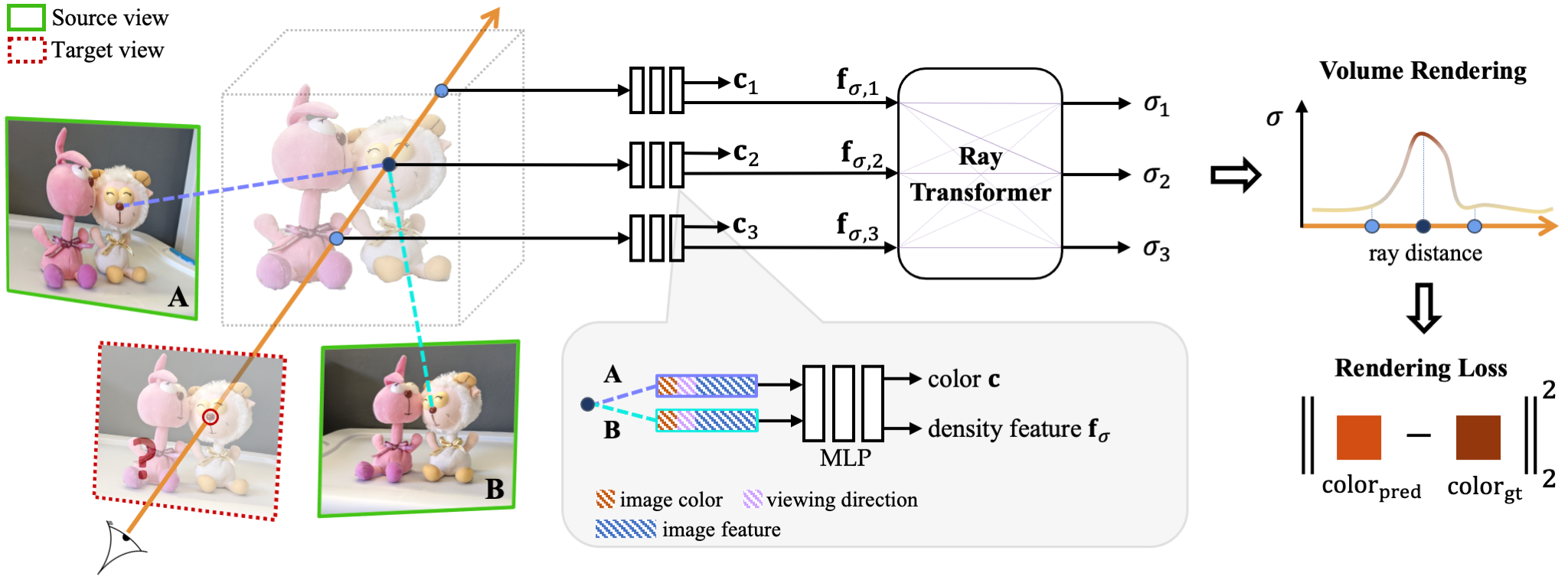
模型流程:
1. 将同一场景的多视角图片一同输入网络(个数不限),然后使用一个U-Net来抽取每张图片(source view)的特征,特征包括图像颜色,相机参数,图像表征(这里可以就理解成NeRF中的向辐射场发射光线,然后保存对应的光线参数和图片特征)。
2. 之后将每张图片的特征并行的输入一个transformer,用于预测一个共同的颜色和密度。之所以是共同的颜色和密度是因为这多个视角输入的特征我们默认是同一个点在不同视角的特征,因此结果就是用于预测我们目标视角(target view)里此点的结果。
3. 用体渲染的方式将结果渲染出来,之后通过像素的重构损失来优化网络
4. 换一个场景,重复1~3
备注:如果一直用同一个场景训练的话,理论上效果肯定会更好,也就是论文中提到的finetune的情况。
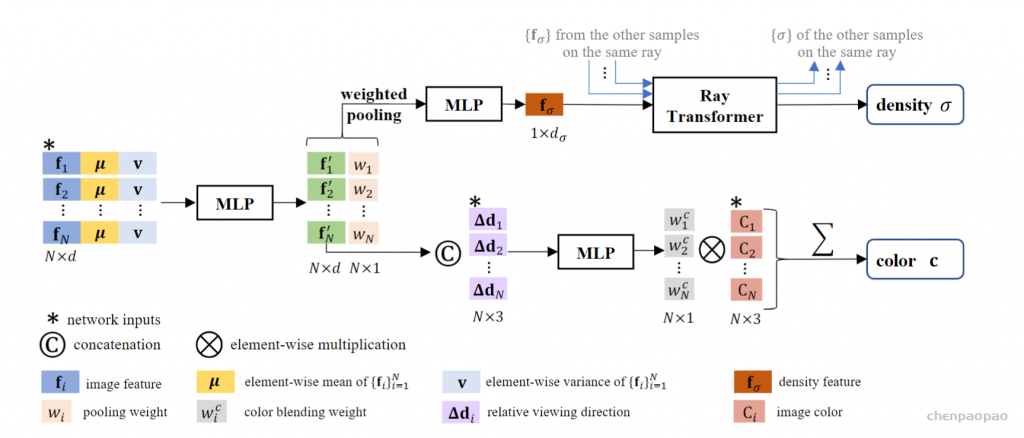
个人理解:本质上这里的模型学习的是“如何插值”,而不是构建一个辐射场,因此可能对于较为稀疏的情形或复杂场景表现的没那么好。




