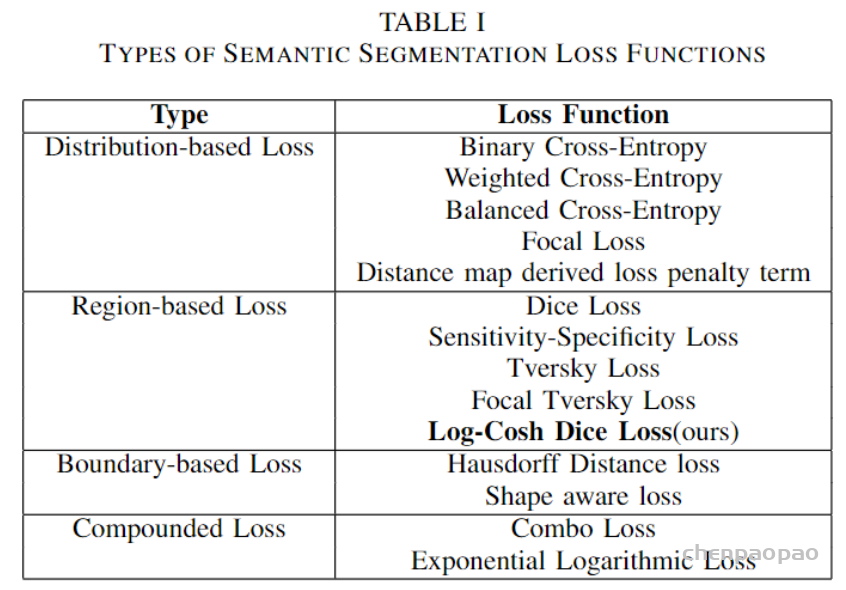
汇总语义分割中常用的损失函数:
- cross entropy loss
- weighted loss
- focal loss
- dice soft loss
- soft iou loss
- Tversky Loss
- Generalized Dice Loss
- Boundary Loss
- Exponential Logarithmic Loss
- Focal Tversky Loss
- Sensitivity Specificity Loss
- Shape-aware Loss
- Hausdorff Distance Loss
参考论文:Medical Image Segmentation Using Deep Learning:A Survey
论文地址:A survey of loss functions for semantic segmentation
代码地址:https://github.com/shruti-jadon/Semantic-Segmentation-Loss-Functions
项目推荐:https://github.com/JunMa11/SegLoss
图像分割一直是一个活跃的研究领域,因为它有可能修复医疗领域的漏洞,并帮助大众。在过去的5年里,各种论文提出了不同的目标损失函数,用于不同的情况下,如偏差数据,稀疏分割等。
图像分割可以定义为像素级别的分类任务。图像由各种像素组成,这些像素组合在一起定义了图像中的不同元素,因此将这些像素分类为一类元素的方法称为语义图像分割。在设计基于复杂图像分割的深度学习架构时,通常会遇到了一个至关重要的选择,即选择哪个损失/目标函数,因为它们会激发算法的学习过程。损失函数的选择对于任何架构学习正确的目标都是至关重要的,因此自2012年以来,各种研究人员开始设计针对特定领域的损失函数,以为其数据集获得更好的结果。
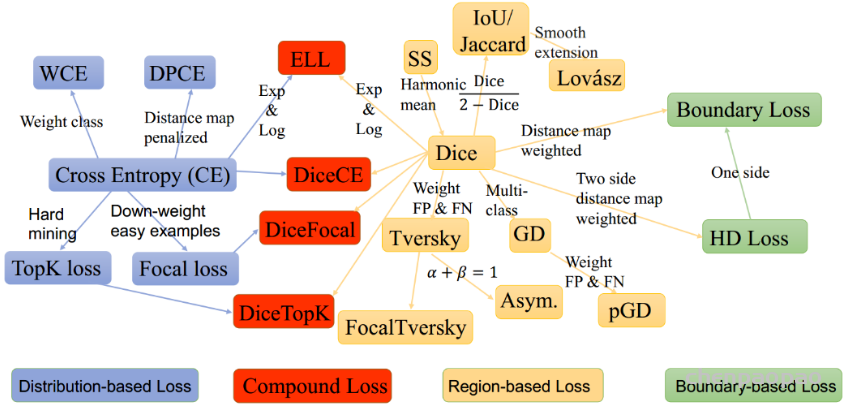
这些损失函数可大致分为4类:基于分布的损失函数,基于区域的损失函数,基于边界的损失函数和基于复合的损失函数( Distribution-based,Region-based, Boundary-based, and Compounded)。
1、cross entropy loss
用于图像语义分割任务的最常用损失函数是像素级别的交叉熵损失,这种损失会逐个检查每个像素,将对每个像素类别的预测结果(概率分布向量)与我们的独热编码标签向量进行比较。
假设我们需要对每个像素的预测类别有5个,则预测的概率分布向量长度为5:
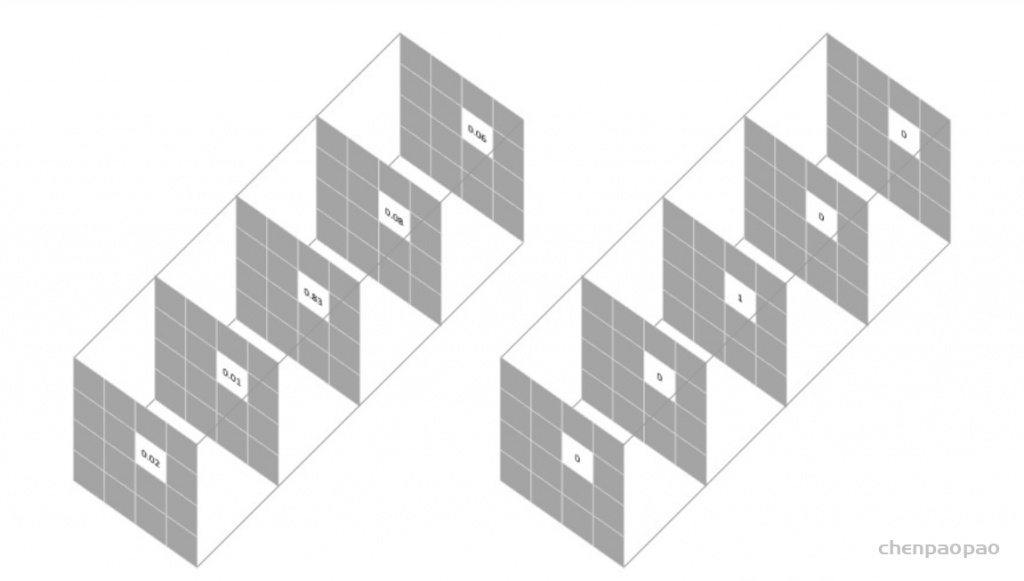
每个像素对应的损失函数为:
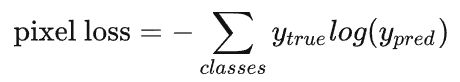
整个图像的损失就是对每个像素的损失求平均值。
特别注意的是,binary entropy loss 是针对类别只有两个的情况,简称 bce loss,损失函数公式为:
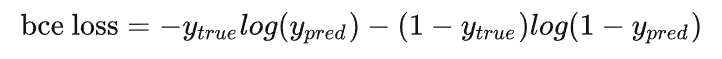
#二值交叉熵,这里输入要经过sigmoid处理
import torch
import torch.nn as nn
import torch.nn.functional as F
nn.BCELoss(F.sigmoid(input), target)
#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层
nn.CrossEntropyLoss(input, target)2、weighted loss
由于交叉熵损失会分别评估每个像素的类别预测,然后对所有像素的损失进行平均,因此我们实质上是在对图像中的每个像素进行平等地学习。如果多个类在图像中的分布不均衡,那么这可能导致训练过程由像素数量多的类所主导,即模型会主要学习数量多的类别样本的特征,并且学习出来的模型会更偏向将像素预测为该类别。
FCN论文和U-Net论文中针对这个问题,对输出概率分布向量中的每个值进行加权,即希望模型更加关注数量较少的样本,以缓解图像中存在的类别不均衡问题。
比如对于二分类,正负样本比例为1: 99,此时模型将所有样本都预测为负样本,那么准确率仍有99%这么高,但其实该模型没有任何使用价值。
为了平衡这个差距,就对正样本和负样本的损失赋予不同的权重,带权重的二分类损失函数公式如下:
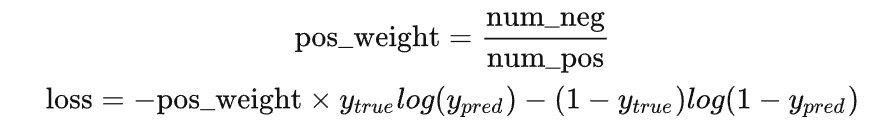
要减少假阴性样本的数量,可以增大 pos_weight;要减少假阳性样本的数量,可以减小 pos_weight。
class WeightedCrossEntropyLoss(torch.nn.CrossEntropyLoss):
"""
Network has to have NO NONLINEARITY!
"""
def __init__(self, weight=None):
super(WeightedCrossEntropyLoss, self).__init__()
self.weight = weight
def forward(self, inp, target):
target = target.long()
num_classes = inp.size()[1]
i0 = 1
i1 = 2
while i1 < len(inp.shape): # this is ugly but torch only allows to transpose two axes at once
inp = inp.transpose(i0, i1)
i0 += 1
i1 += 1
inp = inp.contiguous()
inp = inp.view(-1, num_classes)
target = target.view(-1,)
wce_loss = torch.nn.CrossEntropyLoss(weight=self.weight)
return wce_loss(inp, target)3、focal loss
上面针对不同类别的像素数量不均衡提出了改进方法,但有时还需要将像素分为难学习和容易学习这两种样本。
容易学习的样本模型可以很轻松地将其预测正确,模型只要将大量容易学习的样本分类正确,loss就可以减小很多,从而导致模型不怎么顾及难学习的样本,所以我们要想办法让模型更加关注难学习的样本。
对于较难学习的样本,将 bce loss 修改为:
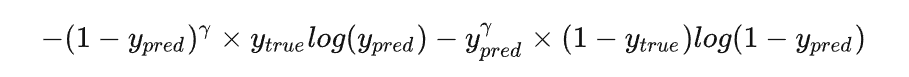
其中的 γ 通常设置为2。
通过这种修改,就可以使模型更加专注于学习难学习的样本。
而将这个修改和对正负样本不均衡的修改合并在一起,就是大名鼎鼎的 focal loss:
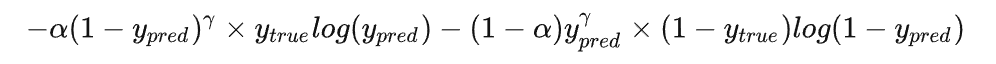
class FocalLoss(nn.Module):
"""
copy from: https://github.com/Hsuxu/Loss_ToolBox-PyTorch/blob/master/FocalLoss/FocalLoss.py
This is a implementation of Focal Loss with smooth label cross entropy supported which is proposed in
'Focal Loss for Dense Object Detection. (https://arxiv.org/abs/1708.02002)'
Focal_Loss= -1*alpha*(1-pt)*log(pt)
:param num_class:
:param alpha: (tensor) 3D or 4D the scalar factor for this criterion
:param gamma: (float,double) gamma > 0 reduces the relative loss for well-classified examples (p>0.5) putting more
focus on hard misclassified example
:param smooth: (float,double) smooth value when cross entropy
:param balance_index: (int) balance class index, should be specific when alpha is float
:param size_average: (bool, optional) By default, the losses are averaged over each loss element in the batch.
"""
def __init__(self, apply_nonlin=None, alpha=None, gamma=2, balance_index=0, smooth=1e-5, size_average=True):
super(FocalLoss, self).__init__()
self.apply_nonlin = apply_nonlin
self.alpha = alpha
self.gamma = gamma
self.balance_index = balance_index
self.smooth = smooth
self.size_average = size_average
if self.smooth is not None:
if self.smooth < 0 or self.smooth > 1.0:
raise ValueError('smooth value should be in [0,1]')
def forward(self, logit, target):
if self.apply_nonlin is not None:
logit = self.apply_nonlin(logit)
num_class = logit.shape[1]
if logit.dim() > 2:
# N,C,d1,d2 -> N,C,m (m=d1*d2*...)
logit = logit.view(logit.size(0), logit.size(1), -1)
logit = logit.permute(0, 2, 1).contiguous()
logit = logit.view(-1, logit.size(-1))
target = torch.squeeze(target, 1)
target = target.view(-1, 1)
# print(logit.shape, target.shape)
#
alpha = self.alpha
if alpha is None:
alpha = torch.ones(num_class, 1)
elif isinstance(alpha, (list, np.ndarray)):
assert len(alpha) == num_class
alpha = torch.FloatTensor(alpha).view(num_class, 1)
alpha = alpha / alpha.sum()
elif isinstance(alpha, float):
alpha = torch.ones(num_class, 1)
alpha = alpha * (1 - self.alpha)
alpha[self.balance_index] = self.alpha
else:
raise TypeError('Not support alpha type')
if alpha.device != logit.device:
alpha = alpha.to(logit.device)
idx = target.cpu().long()
one_hot_key = torch.FloatTensor(target.size(0), num_class).zero_()
one_hot_key = one_hot_key.scatter_(1, idx, 1)
if one_hot_key.device != logit.device:
one_hot_key = one_hot_key.to(logit.device)
if self.smooth:
one_hot_key = torch.clamp(
one_hot_key, self.smooth/(num_class-1), 1.0 - self.smooth)
pt = (one_hot_key * logit).sum(1) + self.smooth
logpt = pt.log()
gamma = self.gamma
alpha = alpha[idx]
alpha = torch.squeeze(alpha)
loss = -1 * alpha * torch.pow((1 - pt), gamma) * logpt
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss4、dice soft loss
语义分割任务中常用的还有一个基于 Dice 系数的损失函数,该系数实质上是两个样本之间重叠的度量。此度量范围为 0~1,其中 Dice 系数为1表示完全重叠。Dice 系数最初是用于二进制数据的,可以计算为:
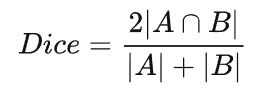
|A∩B| 代表集合A和B之间的公共元素,并且 |A| 代表集合A中的元素数量(对于集合B同理)。
对于在预测的分割掩码上评估 Dice 系数,我们可以将 |A∩B| 近似为预测掩码和标签掩码之间的逐元素乘法,然后对结果矩阵求和。

计算 Dice 系数的分子中有一个2,那是因为分母中对两个集合的元素个数求和,两个集合的共同元素被加了两次。 为了设计一个可以最小化的损失函数,可以简单地使用 1−Dice。 这种损失函数被称为 soft Dice loss,这是因为我们直接使用预测出的概率,而不是使用阈值将其转换成一个二进制掩码。
Dice loss是针对前景比例太小的问题提出的,dice系数源于二分类,本质上是衡量两个样本的重叠部分。
对于神经网络的输出,分子与我们的预测和标签之间的共同激活有关,而分母分别与每个掩码中的激活数量有关,这具有根据标签掩码的尺寸对损失进行归一化的效果。
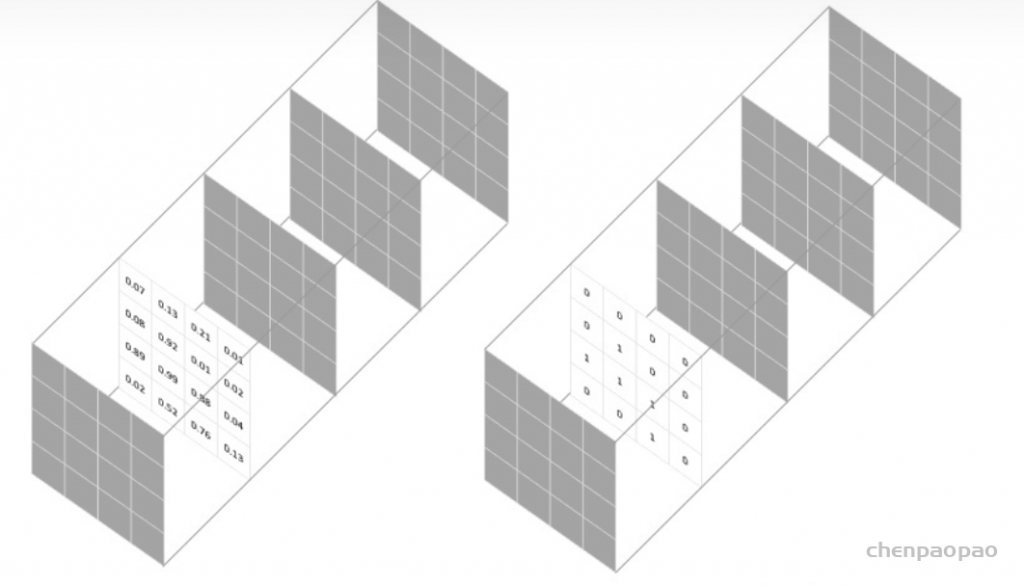
对于每个类别的mask,都计算一个 Dice 损失:
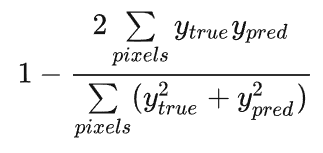
将每个类的 Dice 损失求和取平均,得到最后的 Dice soft loss。
下面是代码实现:
def soft_dice_loss(y_true, y_pred, epsilon=1e-6):
'''
Soft dice loss calculation for arbitrary batch size, number of classes, and number of spatial dimensions.
Assumes the `channels_last` format.
# Arguments
y_true: b x X x Y( x Z...) x c One hot encoding of ground truth
y_pred: b x X x Y( x Z...) x c Network output, must sum to 1 over c channel (such as after softmax)
epsilon: Used for numerical stability to avoid divide by zero errors
# References
V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation
https://arxiv.org/abs/1606.04797
More details on Dice loss formulation
https://mediatum.ub.tum.de/doc/1395260/1395260.pdf (page 72)
Adapted from https://github.com/Lasagne/Recipes/issues/99#issuecomment-347775022
'''
# skip the batch and class axis for calculating Dice score
axes = tuple(range(1, len(y_pred.shape)-1))
numerator = 2. * np.sum(y_pred * y_true, axes)
denominator = np.sum(np.square(y_pred) + np.square(y_true), axes)
return 1 - np.mean(numerator / (denominator + epsilon)) # average over classes and batch5、soft IoU loss
前面我们知道计算 Dice 系数的公式,其实也可以表示为:
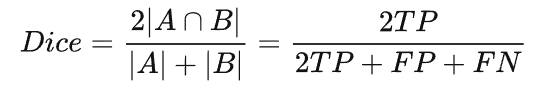
其中 TP 为真阳性样本,FP 为假阳性样本,FN 为假阴性样本。分子和分母中的 TP 样本都加了两次。
IoU 的计算公式和这个很像,区别就是 TP 只计算一次:
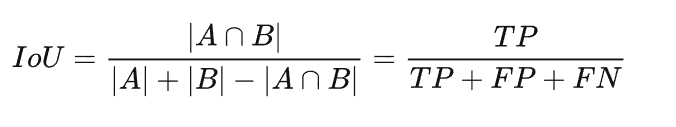
和 Dice soft loss 一样,通过 IoU 计算损失也是使用预测的概率值:
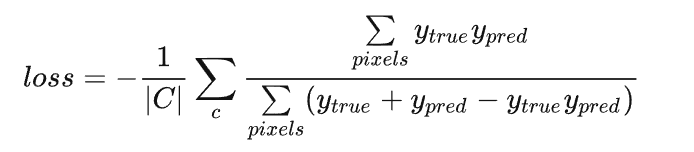
其中 C 表示总的类别数。
6、Tversky Loss
论文地址为:https://arxiv.org/pdf/1706.05…
医学影像中存在很多的数据不平衡现象,使用不平衡数据进行训练会导致严重偏向高精度但低召回率(sensitivity)的预测,这是不希望的,特别是在医学应用中,假阴性比假阳性更难容忍。本文提出了一种基于Tversky指数的广义损失函数,解决了三维全卷积深神经网络训练中数据不平衡的问题,在精度和召回率之间取得了较好的折衷。
Dice loss的正则化版本,以控制假阳性和假阴性对损失函数的贡献,TL被定义为
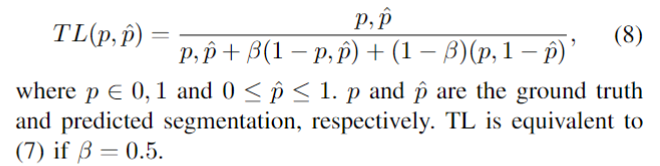
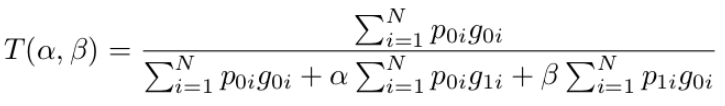

class TverskyLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
paper: https://arxiv.org/pdf/1706.05721.pdf
"""
super(TverskyLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.alpha = 0.3
self.beta = 0.7
def forward(self, x, y, loss_mask=None):
shp_x = x.shape
if self.batch_dice:
axes = [0] + list(range(2, len(shp_x)))
else:
axes = list(range(2, len(shp_x)))
if self.apply_nonlin is not None:
x = self.apply_nonlin(x)
tp, fp, fn = get_tp_fp_fn(x, y, axes, loss_mask, self.square)
tversky = (tp + self.smooth) / (tp + self.alpha*fp + self.beta*fn + self.smooth)
if not self.do_bg:
if self.batch_dice:
tversky = tversky[1:]
else:
tversky = tversky[:, 1:]
tversky = tversky.mean()
return -tversky 7、Generalized Dice Loss
Dice loss虽然一定程度上解决了分类失衡的问题,但却不利于严重的分类不平衡。例如小目标存在一些像素的预测误差,这很容易导致Dice的值发生很大的变化。Sudre等人提出了Generalized Dice Loss (GDL)
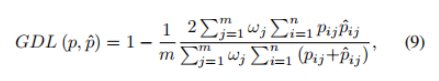
GDL优于Dice损失,因为不同的区域对损失有相似的贡献,并且GDL在训练过程中更稳定和鲁棒。
8、Boundary Loss
为了解决类别不平衡的问题,Kervadec等人[95]提出了一种新的用于脑损伤分割的边界损失。该损失函数旨在最小化分割边界和标记边界之间的距离。作者在两个没有标签的不平衡数据集上进行了实验。结果表明,Dice los和Boundary los的组合优于单一组合。复合损失的定义为
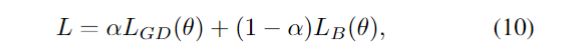
其中第一部分是一个标准的Dice los,它被定义为
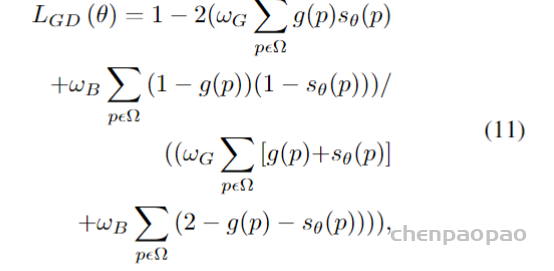
第二部分是Boundary los,它被定义为
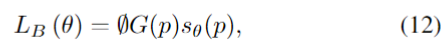
9、Exponential Logarithmic Loss
在(9)中,加权Dice los实际上是得到的Dice值除以每个标签的和,对不同尺度的对象达到平衡。因此,Wong等人结合focal loss [96] 和dice loss,提出了用于脑分割的指数对数损失(EXP损失),以解决严重的类不平衡问题。通过引入指数形式,可以进一步控制损失函数的非线性,以提高分割精度。EXP损失函数的定义为
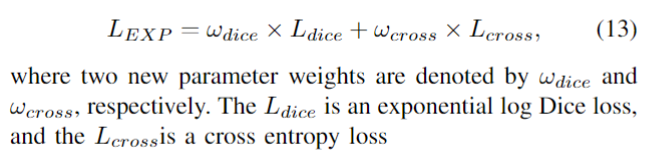
其中,两个新的参数权重分别用ωdice和ωcross表示。Ldice是指数对数骰子损失,而交叉损失是交叉熵损失
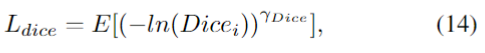

其中x是像素位置,i是标签,l是位置x处的地面真值。pi(x)是从softmax输出的概率值。
在(17)中,fk是标签k出现的频率,该参数可以减少更频繁出现的标签的影响。γDice和γcross都用于增强损失函数的非线性。
10.Focal Tversky Loss
与“Focal loss”相似,后者着重于通过降低易用/常见损失的权重来说明困难的例子。Focal Tversky Loss还尝试借助γ系数来学习诸如在ROI(感兴趣区域)较小的情况下的困难示例,如下所示:
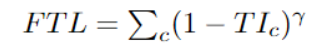
class FocalTversky_loss(nn.Module):
"""
paper: https://arxiv.org/pdf/1810.07842.pdf
author code: https://github.com/nabsabraham/focal-tversky-unet/blob/347d39117c24540400dfe80d106d2fb06d2b99e1/losses.py#L65
"""
def __init__(self, tversky_kwargs, gamma=0.75):
super(FocalTversky_loss, self).__init__()
self.gamma = gamma
self.tversky = TverskyLoss(**tversky_kwargs)
def forward(self, net_output, target):
tversky_loss = 1 + self.tversky(net_output, target) # = 1-tversky(net_output, target)
focal_tversky = torch.pow(tversky_loss, self.gamma)
return focal_tversky 11、Sensitivity Specificity Loss
首先敏感性就是召回率,检测出确实有病的能力:

特异性,检测出确实没病的能力:

而Sensitivity Specificity Loss为:


class SSLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
Sensitivity-Specifity loss
paper: http://www.rogertam.ca/Brosch_MICCAI_2015.pdf
tf code: https://github.com/NifTK/NiftyNet/blob/df0f86733357fdc92bbc191c8fec0dcf49aa5499/niftynet/layer/loss_segmentation.py#L392
"""
super(SSLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.r = 0.1 # weight parameter in SS paper
def forward(self, net_output, gt, loss_mask=None):
shp_x = net_output.shape
shp_y = gt.shape
# class_num = shp_x[1]
with torch.no_grad():
if len(shp_x) != len(shp_y):
gt = gt.view((shp_y[0], 1, *shp_y[1:]))
if all([i == j for i, j in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(shp_x)
if net_output.device.type == "cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(1, gt, 1)
if self.batch_dice:
axes = [0] + list(range(2, len(shp_x)))
else:
axes = list(range(2, len(shp_x)))
if self.apply_nonlin is not None:
softmax_output = self.apply_nonlin(net_output)
# no object value
bg_onehot = 1 - y_onehot
squared_error = (y_onehot - softmax_output)**2
specificity_part = sum_tensor(squared_error*y_onehot, axes)/(sum_tensor(y_onehot, axes)+self.smooth)
sensitivity_part = sum_tensor(squared_error*bg_onehot, axes)/(sum_tensor(bg_onehot, axes)+self.smooth)
ss = self.r * specificity_part + (1-self.r) * sensitivity_part
if not self.do_bg:
if self.batch_dice:
ss = ss[1:]
else:
ss = ss[:, 1:]
ss = ss.mean()
return ss12、Log-Cosh Dice Loss
Dice系数是一种用于评估分割输出的度量标准。它也已修改为损失函数,因为它可以实现分割目标的数学表示。但是由于其非凸性,它多次都无法获得最佳结果。Lovsz-softmax损失旨在通过添加使用Lovsz扩展的平滑来解决非凸损失函数的问题。同时,Log-Cosh方法已广泛用于基于回归的问题中,以平滑曲线。


将Cosh(x)函数和Log(x)函数合并,可以得到Log-Cosh Dice Loss:

def log_cosh_dice_loss(self, y_true, y_pred):
x = self.dice_loss(y_true, y_pred)
return tf.math.log((torch.exp(x) + torch.exp(-x)) / 2.0) 13、Hausdorff Distance Loss
Hausdorff Distance Loss(HD)是分割方法用来跟踪模型性能的度量。它定义为:

任何分割模型的目的都是为了最大化Hausdorff距离,但是由于其非凸性,因此并未广泛用作损失函数。有研究者提出了基于Hausdorff距离的损失函数的3个变量,它们都结合了度量用例,并确保损失函数易于处理。
class HDDTBinaryLoss(nn.Module):
def __init__(self):
"""
compute haudorff loss for binary segmentation
https://arxiv.org/pdf/1904.10030v1.pdf
"""
super(HDDTBinaryLoss, self).__init__()
def forward(self, net_output, target):
"""
net_output: (batch_size, 2, x,y,z)
target: ground truth, shape: (batch_size, 1, x,y,z)
"""
net_output = softmax_helper(net_output)
pc = net_output[:, 1, ...].type(torch.float32)
gt = target[:,0, ...].type(torch.float32)
with torch.no_grad():
pc_dist = compute_edts_forhdloss(pc.cpu().numpy()>0.5)
gt_dist = compute_edts_forhdloss(gt.cpu().numpy()>0.5)
# print('pc_dist.shape: ', pc_dist.shape)
pred_error = (gt - pc)**2
dist = pc_dist**2 + gt_dist**2 # \alpha=2 in eq(8)
dist = torch.from_numpy(dist)
if dist.device != pred_error.device:
dist = dist.to(pred_error.device).type(torch.float32)
multipled = torch.einsum("bxyz,bxyz->bxyz", pred_error, dist)
hd_loss = multipled.mean()
return hd_loss总结:
交叉熵损失把每个像素都当作一个独立样本进行预测,而 dice loss 和 iou loss 则以一种更“整体”的方式来看待最终的预测输出。
这两类损失是针对不同情况,各有优点和缺点,在实际应用中,可以同时使用这两类损失来进行互补。