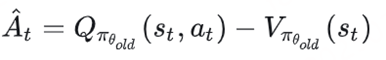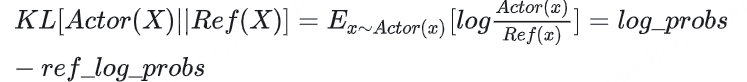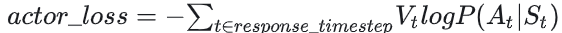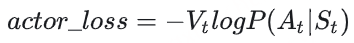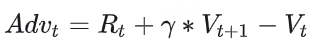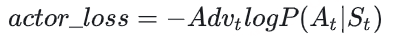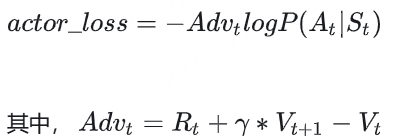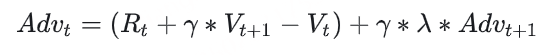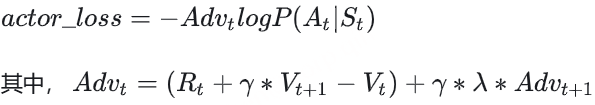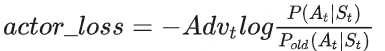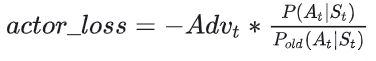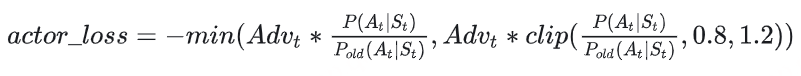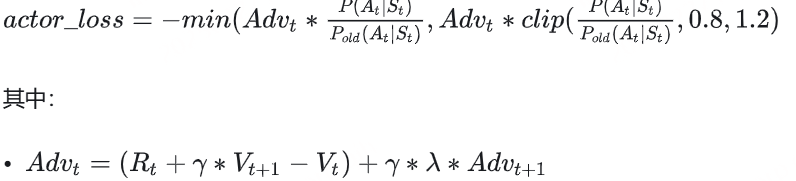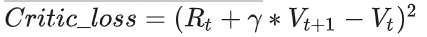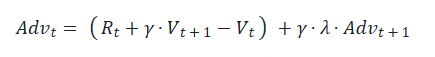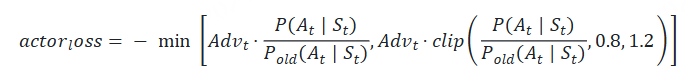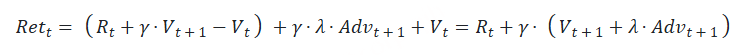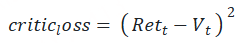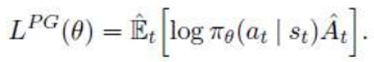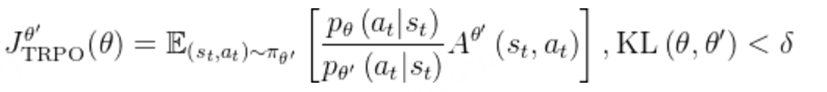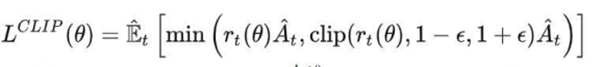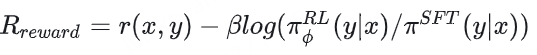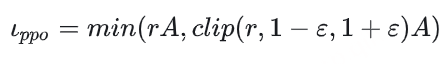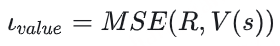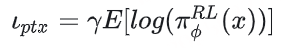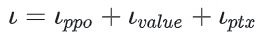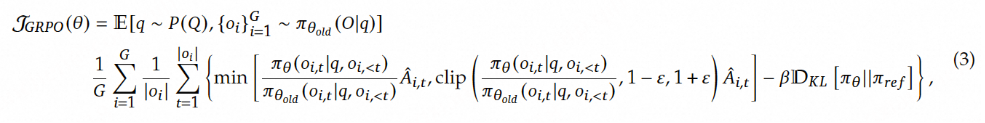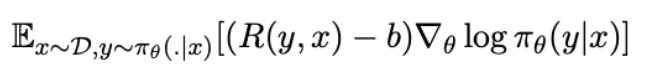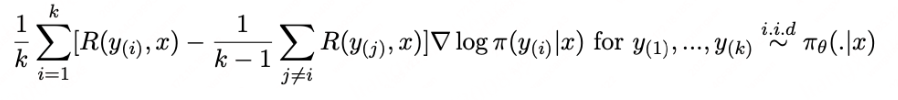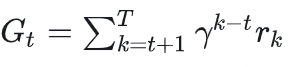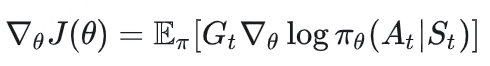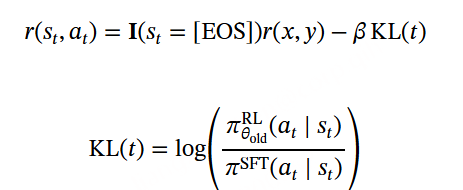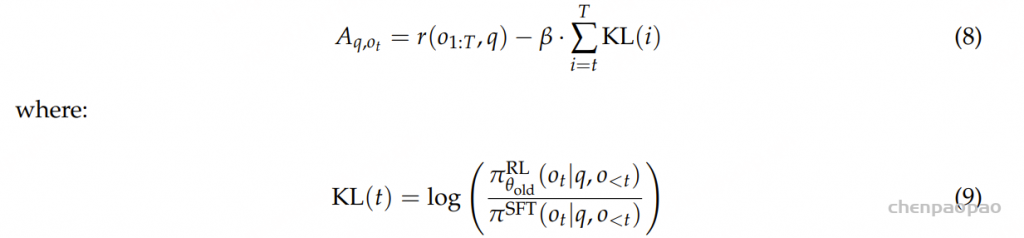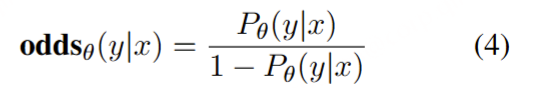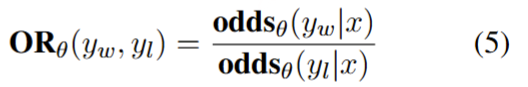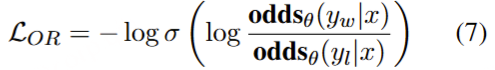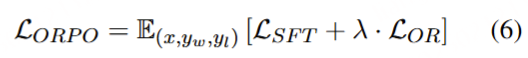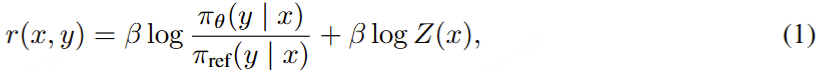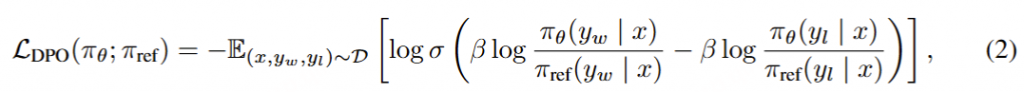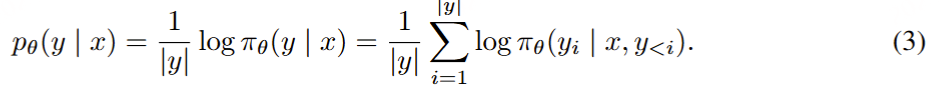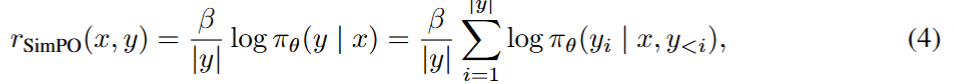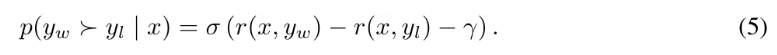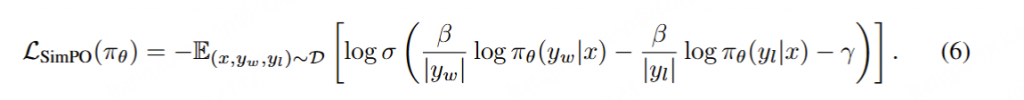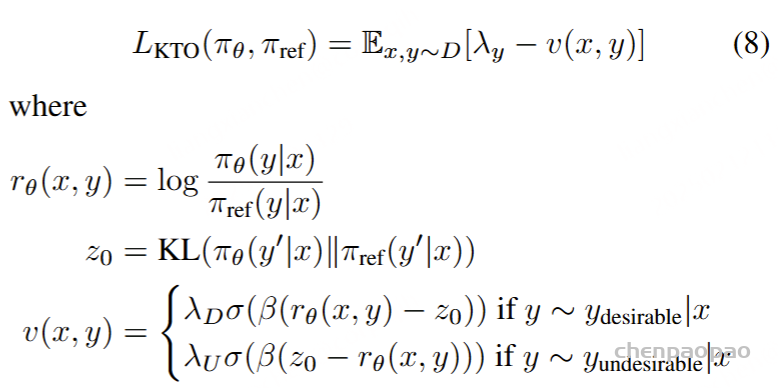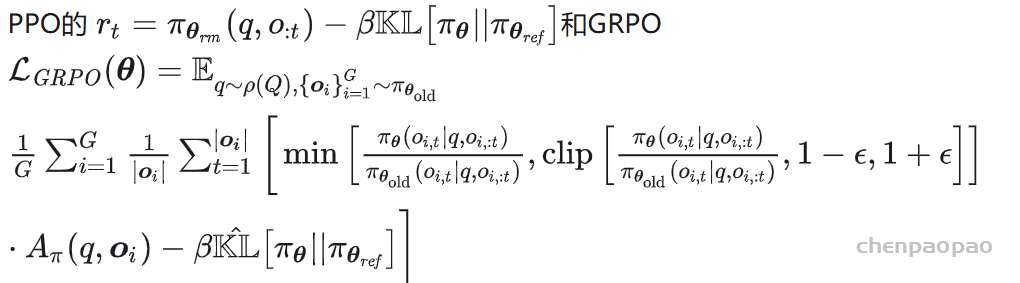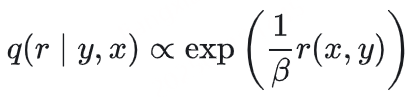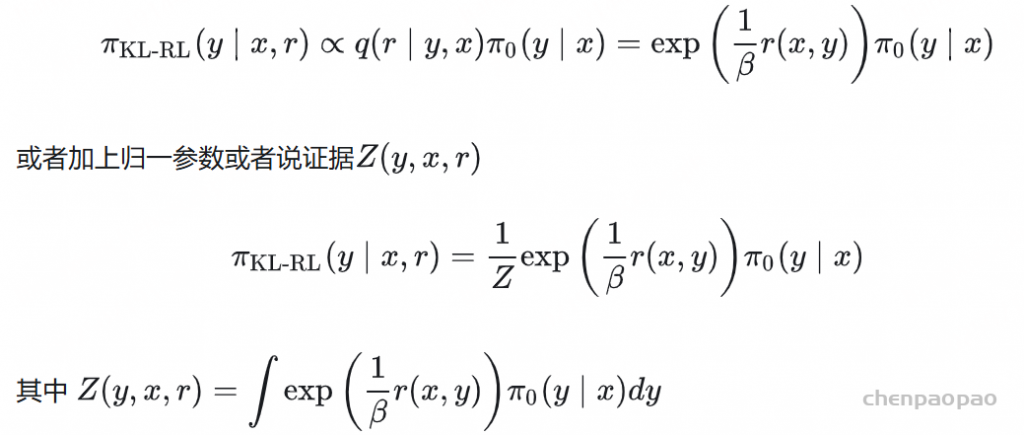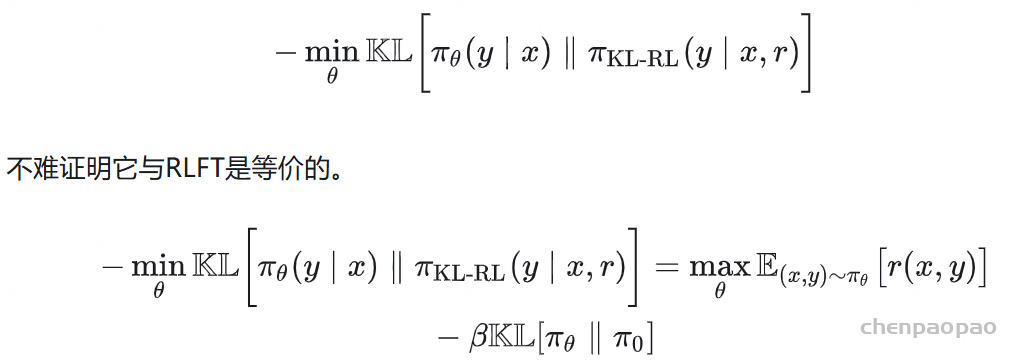参考论文:A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
参考代码:
端到端推理学习增强推理能力方法
a.推理时扩展(Inference-time scaling): 如链式思维(CoT)或自我一致性(Self-Consistency),以增强模型的推理能力;【cot:核心思想是将复杂问题分解为一系列可解释的中间步骤。通过明确的推理链条,模型能够逐步解决原本可能超出其直接推理能力的问题。思维链方法特别适用于涉及多步骤推理的任务,如数学题、多重逻辑推理问题等。 Self-Consistency 自我一致提示是在 CoT 基础上进一步优化,通过采样多条推理路径,找出最一致的答案。它适用于对结果准确性要求更高的场景,避免一次性推理路径的偶然性导致错误。】
b.纯强化学习(Pure Reinforcement Learning, RL): 通过强化学习训练模型,使其在没有监督数据的情况下,通过试错学习复杂任务; 【deepseek-R1-zero】
c.监督微调结合强化学习(SFT + RL): 首先对模型进行监督微调,然后使用强化学习进行进一步优化,以提高模型的推理能力。【deepseek-R1】
d.纯监督微调和蒸馏(Pure Supervised Fine-Tuning and Distillation)仅使用监督学习和模型蒸馏技术来增强模型的推理能力。【deepseek-R1-distill蒸馏模型 】
一个完整的LLM训练过程包含以下几步:
Model Initialization :加载模型和处理器数据准备 :解析数据集并设置其格式模型推理 :将数据输入到模型中并获取输出梯度更新 :根据损失函数更新模型参数对齐(alignment)其作用就是让 LLM 与人类的价值观保持一致。在对齐 LLM 方面,基于人类反馈的强化学习 (RLHF) 是一种突破性的技术。该方法催生了 GPT-4、Claude 和 Gemini 等强大模型。RLHF 之后,人们也探索了多种多样的对齐 LLM 的方法。但是,此前还没有人全面总结对齐 LLM 与人类偏好的方法。
Salesforce 决定填补这一空白,于近日发布了一份 37 页的综述报告,其中按类别总结了现有的研究文献,并详细分析了各篇论文。
Introduction
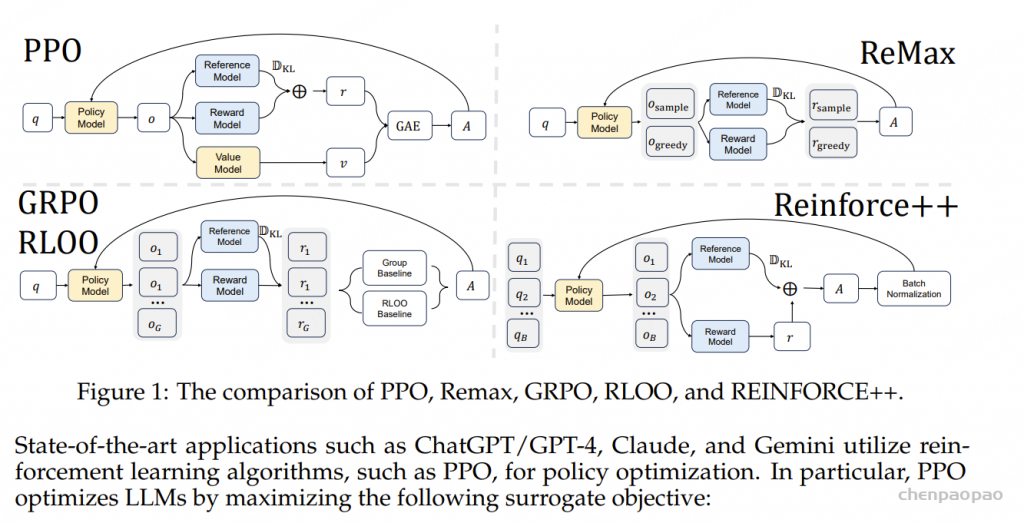
这篇论文分为四大主题:奖励模型、反馈、强化学习 (RL)、优化。每个主题又包含进一步的子主题,如图 1 所示。
xPO LLM 与人类偏好保持一致的 13 个分类方向 奖励模型的子主题包括:1. 显式奖励模型与隐式奖励模型;2. 逐点奖励模型与偏好模型;3. 响应层面的奖励与 token 层面的奖励;4. 负偏好优化。
反馈的子主题包括:1. 偏好反馈与二元反馈;2. 成对反馈与列表反馈;3. 人类反馈与 AI 反馈。
强化学习 的子主题包括:1. 基于参考的强化学习 与无参考的强化学习 ;2. 长度控制式强化学习 ;3. 强化学习 中的不同分支;4. 在线策略强化学习 与离线策略强化学习 。
优化的子主题包括:1. 在线 / 迭代式偏好优化与离线 / 非迭代式偏好优化;2. 分离 SFT 和对齐与合并 SFT 和对齐。
Individual Paper Reviews in Detail
1. RLHF/PPO LLM 的预训练要用到大量来自不同来源的语料库 ,而这本身就无法确保这些数据集的质量。此外,LLM 的主要目标是预测下一个 token,这个目标与「有用且安全地遵从用户指令」的目标并不一致。因此,LLM 可能会输出不真实、有害或对用户无用的内容。本质上讲,这些模型并未与用户意图对齐。RLHF/PPO 的主要目标是在各种任务上对齐语言模型 与用户意图,其做法是使用人类反馈来微调模型。有关这个主题的研究有很多。
2. RLAIF 获取人类偏好数据集的成本不低,因此基于人工智能 反馈的强化学习 (RLAIF)诞生了。此外,随着 LLM 的能力不断进步,所能收集到的 AI 偏好数据集的质量也不断提高,由此可提升 LLM 的对齐效果。
3.直接人类偏好优化
传统 RLHF 方法通常涉及到优化源自人类偏好的奖励函数。该方法虽有效,但也可能带来一些难题,比如增大计算复杂度以及在估计和优化奖励时需要考虑偏置 – 方差权衡。参阅论文《High-dimensional continuous control using generalized advantage estimation》。
近期有研究探索了其它一些旨在根据人类偏好(无需依赖某个标量的奖励信号)来直接优化 LLM 策略的方法。
这些方法的目标是通过更直接地使用偏好数据来简化对齐流程、降低计算开销以及实现更稳健的优化。通过将该问题描述为一个偏好优化问题,而不是奖励估计和最大化问题,这些方法能提供一种将语言模型 与人类判断对齐的不同视角
4.token 级 DPO
使用 DPO 时,奖励会被一起分配给 prompt 和响应。相反,使用 MDP 时,奖励会被分配给各个动作。后续的两篇论文在 token 层面阐述了 DPO 并将其应用扩展到了 token 级的分析。
DPO 可以执行 token 级信用分配的研究,参阅论文《From r to Q∗: Your language model is secretly a Q-function》,报道《这就是 OpenAI 神秘的 Q*?斯坦福:语言模型 就是 Q 函数》 。 TDPO,token 级 DPO,参阅论文《Token-level direct preference optimization》。 5.迭代式 / 在线 DPO
使用 DPO 时,会使用所有可用的偏好数据集来对齐 LLM。为了持续提升 LLM,应当实现迭代式 / 在线 DPO。这就引出了一个有趣的问题:如何高效地收集新的偏好数据集。下面两篇论文深入探讨了这一主题。
自我奖励式语言模型 ,参阅论文《Self-rewarding language models》。 CRINGE,参阅论文《The cringe loss: Learning what language not to model》。 6.二元反馈
事实证明,收集偏好反馈比收集二元反馈(比如点赞或点踩)的难度大,因此后者可促进对齐过程的扩展。KTO 和 DRO 这两项研究关注的便是使用二元反馈来对齐 LLM。
KTO,Kahneman-Tversky 优化,参阅论文《KTO: Model alignment as prospect theoretic optimization》。 DRO,直接奖励优化,参阅论文《Offline regularised reinforcement learning for large language models alignment》。 7.融合 SFT 和对齐 之前的研究主要还是按顺序执行 SFT 和对齐,但事实证明这种方法很费力,并会导致灾难性遗忘。后续的研究有两个方向:一是将这两个过程整合成单一步骤;二是并行地微调两个模型,最终再进行融合。
ORPO,比值比偏好优化,参阅论文《ORPO: Monolithic preference optimization without reference model》。 PAFT,并行微调,参阅论文《PAFT: A parallel training paradigm for effective llm fine-tuning》。 8.长度控制式 DPO 和无参考 DPO 之前有研究表明,LLM 的输出往往过于冗长。为了解决这个问题,R-DPO 和 SimPO 的关注重心是在不影响生成性能的前提下实现对响应长度的控制。
此外,DPO 必需参考策略来确保已对齐模型不会与参考模型有太大偏差。相较之下,SimPO 和 RLOO 提出了一些方法,可以在不影响 LLM 效果的情况下消除对参考模型的需求
9.逐列表的偏好优化 之前在 PPO 和 DPO 方面的研究关注的是成对偏好,而 RLHF 方面的研究则是收集逐列表的偏好来加速数据收集过程,之后再将它们转换成成对偏好。尽管如此,为了提升 LLM 的性能,直接使用逐列表的数据集来执行偏好优化是可行的。以下三篇论文专门讨论了这种方法。
LiPO,逐列表偏好优化,参阅论文《LIPO: Listwise preference optimization through learning-to-rank》。 RRHF,参阅论文《RRHF: Rank responses to align language models with human feedback without tears》。 PRO,偏好排名优化,参阅论文《Preference ranking optimization for human alignment》。 10.负偏好优化 这些研究有一个共同前提:当前这一代 LLM 已经在翻译和总结等任务上超越了人类性能。因此,可以将 LLM 的输出视为期望响应,而无需依靠将人类标注的数据视为偏好响应;这样做是有好处的。反过来,不期望得到的响应依然也可被用于对齐 LLM,这个过程就是所谓的负偏好优化(NPO)。
NN,否定负例方法,参阅论文《Negating negatives: Alignment without human positive samples via distributional dispreference optimization》。 NPO,负例偏好优化,参阅论文《Negative preference optimization: From catastrophic collapse to effective unlearning》。 CPO,对比偏好优化,参阅论文《Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation》。 11.纳什学习 之前的研究通常是使用逐点奖励和 BT 模型来得到成对偏好。但是,这种方法比不上直接成对偏好建模并且无法解决成对偏好中的不一致问题。为了克服这些局限,一些研究提出了纳什学习方法。
根据人类反馈的纳什学习,参阅论文《Nash learning from human feedback》。 SPPO,自博弈偏好优化,参阅论文《A minimaximalist approach to reinforcement learning from human feedback》。 DNO,直接纳什优化,参阅论文《Direct nash optimization: Teaching language models to self-improve with general preferences》。 LLM 对齐(Alignment)方法:SFT、PPO、DPO 、ORPOD、GRPO等方法详细介绍
LLM(大语言模型)的对齐(Alignment)方法旨在让 AI 的输出更加符合人类预期 ,减少错误信息、有害内容或不准确的回答。主要总结LLM训练中的基本的对齐算法,即 监督微调 (SFT)、直接偏好优化 (DPO) 和近端策略优化 (PPO)等。
SFT(Supervised Fine-Tuning,监督微调)
监督微调(SFT)是 LLM 训练中的第一步 ,通过高质量的人工标注数据集对模型进行微调,使其具备基础的任务能力。SFT 是所有对齐方法的基础 ,如 RLHF、DPO 等都依赖于一个经过 SFT 训练的模型作为初始状态。
过程 :
数据准备 :收集高质量的指令-响应(Instruction-Response)数据集,例如人类标注的数据或合成的数据。模型微调 :使用交叉熵损失(Cross-Entropy Loss)训练模型,使其学习提供与标注数据匹配的答案。效果 :使模型在常见任务(如问答、代码生成、对话等)中表现更好,提高其对指令的遵循能力。给定输入 x(Prompt) 和目标输出 y(Response),模型的目标是最大化生成目标文本的概率:
其中:
Pθ(yt∣x,y<t) 是 LLM 在给定上下文下预测下一个 token yt 的概率。 训练时采用交叉熵损失(Cross Entropy Loss)来优化模型参数 θ。 SFT 仅依赖于人工标注数据,无法让模型学习偏好信息 (比如不同回答的优劣)。无法动态调整 :SFT 训练后,模型固定,难以针对用户反馈进行调整。缺乏探索性 :模型只会学到训练数据中的模式,无法进行强化学习优化。
DPO(Direct Preference Optimization,直接偏好优化)
论文:https://arxiv.org/abs/2305.18290
参考代码:https://github.com/eric-mitchell/direct-preference-optimization
DPO(直接偏好优化)是一种比 RLHF 更简单、更高效 的对齐方法。直接优化 LLM,使其更符合人类偏好数据 。
偏好数据 :
每个输入 Prompt 对应两个候选回答 :一个优选 (Preferred y+),一个劣选 (Dispreferred y−)。 例如: Prompt: “如何写一封正式的电子邮件?”
优化 LLM 使其更倾向于优选回答 。
只需要加载2个相同的模型,其中一个推理[ reference model: old策略模型],另外一个模型[ policy model 策略模型 ]训练,直接在偏好数据上进行训练即可:
Reference Model(以下简称Ref模型)一般也用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。Ref模型的主要作用是防止Actor”训歪”
损失函数 : DPO 直接优化模型输出的偏好分布:
其中:
σ :sigmoid函数β :超参数,一般在0.1 – 0.5之间yw :某条偏好数据中好的response,w就是win的意思yl :某条偏好数据中差的response,l就是loss的意思,所以偏好数据也叫comparision dataπθ (yw|x) :给定输入x, 当前 策略policy model生成好的response的累积概率(每个tokne的概率求和,具体看代码)πref (yl|x) :给定输入x, 原始模型(reference model)生成坏的response的累积概率 开始训练时,reference model和policy model都是同一个模型,只不过在训练过程中reference model不会更新权重。
为了方便分析,我们把log里的分式展开,然后β设为1,并且暂时不看前面的log_sigmoid,那么上面的loss可以简化为:
由于最初loss前面是有个负号的,所以优化目标是让本简化公式最大,即我们希望左半部分和右半部分的margin越大越好,左半部分的含义是good response相较于没训练之前的累积概率差值,右半部分代表bad response相较于没训练之前的累计概率差值,如果这个差值,即margin变大了,就意味着:
1)左边变大,右边变小,理想情况,good response概率提升,bad response概率下降 2)左边变小,右边更小,good response概率下降,但是bad response概率下降的更多,生成的时候还是倾向于good response 3)左边变的更大,右边只大了一点点,和2)同理 所以这个loss颇有一种对比 的感觉。
OPA-DPO:多模态大模型幻觉难题的高效解决方案
在视觉多模态大语言模型领域,生成与输入图像不一致甚至还有虚假内容的“幻觉”现象,是一个亟待攻克的核心难题。作为一种简单有效的解决方案,直接偏好优化 (DPO) [1] 正在引起越来越多的关注。研究者们通过比较模型在相同提示词和图像下的不同响应,根据幻觉程度直接构造偏好数据对,用于 DPO 训练。
然而,微软亚洲研究院的研究员们注意到,现有研究中不同的数据构造方法会导致显著的性能差异。因此,他们对“基于 DPO 解决多模态大模型幻觉问题”的算法进行了全面分析,总结了它们的表现及局限性,同时从理论角度揭示了各算法性能差异背后的根本原因,并指出决定模型性能的最关键因素是“用于构建偏好对的数据,相较于 DPO 开始前的策略(reference policy)是否为同策略(on-policy)”。
研究员们将此前的研究工作分为三类:
第一类是幻觉注入类,如 HALVA [2]和 POVID [3],通过在已有图像和提示的标准响应中人为注入幻觉片段来构建偏好对;
第二类是幻觉识别类,如 RLHF-V [4]、HA-DPO [5]和 HSA-DPO [6],先让模型根据图像和提示自行生成响应,然后利用专家反馈(人类或 GPT-4/4v)来识别和修改其中的幻觉,从而构建偏好对;
第三类是自我进化类,如 RLAIF-V[7],让模型针对同一图像和提示生成多个响应,并由一个在幻觉识别方面能力更强的导师模型对这些响应中的幻觉严重程度进行判断和排序,以此构建偏好对。
根据实验结果,这三类算法的性能总结为:自我进化类 > 幻觉识别类 > 幻觉注入类。
对于幻觉注入类,幻觉通常并不来自模型本身,因此通过 DPO 训练往往不能给模型带来很大增益。对于自我进化类,理论上由于维度灾难问题,让模型自行探索并找到完全正确的回复是十分困难的,所以那些存在于多个回复中的顽固幻觉通常无法通过这种方法消除。
直觉上,幻觉识别类的方法应该是最高效的解决幻觉的方案,那为什么在实践中这类方法却败下阵来?为了了解背后的原因,研究员们从 DPO 算法的细节入手进行研究。
与最常用的 RLHF 算法 PPO 的初始目标相同,DPO 的初始目标也是(π_θ 是模型的当前策略,π_ref 是模型的初始策略/参考策略,x 为提示词,m 为图像,y 为响应,r(x,y,m) 是通过 Bradley-Terry model 训练得到的奖励函数):
即在最大化奖励的同时,约束模型当前策略与模型初始策略之间的 KL 散度。然而,研究员们重新审视 KL 散度的定义发现,给定任何一个提示词和图像 (x,m),若存在一个响应 (y) 使得 π_θ(y|x,m)>0,但 π_ref(y|x,m)→0,此时 KL 散度会趋于无穷大。这个性质说明——对于任何从目标函数 (1) 出发的算法,那些相对原始策略 (π_ref) 采样概率极低的响应(根据强化学习的命名规范,这种数据被称为异策略(off-policy)数据,相反则为同策略(on-policy)数据)将没有任何机会被模型学会。
如果非要将这些异策略(off-policy)的优选响应(preferred response)拿来构建 DPO 偏好对,会导致梯度在下一次更新时几乎消失。
重温 DPO 训练的优化目标:
其中 y_w 是优选响应(preferred response),y_l 是被拒响应(rejected response),其梯度可表示为(σ(⋅) 是 sigmoid 函数):
训练开始前 πθ=π_ref,所以 sigmoid 函数内部的值应当为0,即当前策略会以 0.5β 为系数对 y_w 进行最大对数似然更新(max-loglikelihood update)。但是在这一步更新过后,logπ_ref(y_w∣x,m)π θ(y_w∣x,m) 将会趋近于极大值(因为分子 > 0,而分母趋近于0),从而导致 σ(−r_w+r_l)→0。因此,梯度会在下一次更新时几乎消失。
回顾幻觉识别类的方法,专家改动后的响应,大部分对于原模型来说都是异策略(off-policy)的,即使这些改动再微小也无济于事,所以根本无法指望这些专家反馈能被模型学会。相对应地,自我进化类方法即使存在学习效率不高的潜在问题,但是它构建的偏好对都来自模型本身,即全是同策略(on-policy)的,因此效果最好。
OPA-DPO:打破常规,重塑对齐策略
是否存在一种方法既能够利用专家的精确反馈,又能完全避免异策略(off-policy)导致的 KL 散度约束问题?
针对现有方法的局限性,微软亚洲研究院联合香港中文大学提出了一种简单而高效的算法 On-Policy Alignment(OPA)-DPO,将专家的精确反馈数据在 DPO 训练前与模型策略对齐。在仅使用4.8k数据的情况下,OPA-DPO 可以实现目前 SOTA 的性能,而之前的 SOTA 算法需要16k数据。该成果已获选计算机视觉领域顶会 CVPR 2025 的 Oral 论文。
Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key
OPA-DPO 的具体实现方法如下:首先,给定图像和提示,让模型自行生成对应的响应;接着,利用专家反馈(如 GPT-4v)对生成内容进行细粒度修改,保留正确的响应部分,同时纠正其中存在的幻觉内容;然后,将数据集中的真实响应与专家修改后的响应进行 LoRA-SFT 微调,得到一个新的模型(研究员们将其称为 OPA 模型);最后,在 OPA 模型的基础上,进行后续的 DPO 训练,其中研究员们参考了 mDPO 的设定,在构建语言偏好对的同时也构建了图像偏好对以及锚点对,尽管这些元素都很重要,但对最终结果影响最大的还是 OPA 操作。
研究员们综合比较了基于 LLaVA-1.5-7B 和 13B 模型微调的各种 DPO-based 的算法,OPA-DPO 在使用 4.8k 数据的情况下可在多个指标上实现 SOTA 效果。
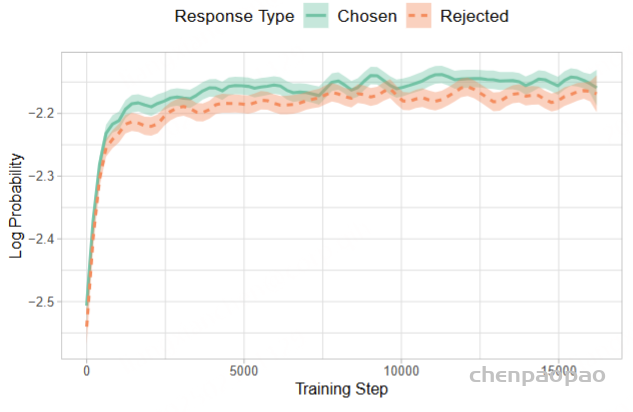
研究员们发现,使用 OPA-DPO 训练过的模型会呈现出一种略显保守的策略,尤其是在描述任务中,它通常只输出显著并且确定的观测,而忽略一些不重要的细节。
不仅如此,研究员们还观测到一个有趣的现象:基座模型往往默认 query 中的语言是准确无误的,即使这部分文字存在严重幻觉,模型也会顺着其描述图片,这或许可以理解为一种文字惯性现象。而通过 OPA-DPO 训练的模型则展现出了甄别 query 文字部分幻觉的能力。
PPO(Proximal Policy Optimization,近端策略优化)
论文:https://arxiv.org/abs/1707.06347
人人都能看懂的RL-PPO理论知识
是OpenAI在2017提出的一种强化学习算法,是基于策略优化的算法,用于训练能够最大化累积奖励的智能体。PPO算法通过在每次更新时限制新策略与旧策略之间的差异,从而更稳定地更新策略参数。 这种方法有助于避免训练过程中出现的不稳定性和剧烈波动,使得算法更容易收敛并学习到更好的策略。
强化学习的两个实体:智能体(Agent) 与环境(Environment) 强化学习中两个实体的交互:状态空间S :S即为State,指环境中所有可能状态的集合动作空间A :A即为Action,指智能体所有可能动作的集合奖励R: R即为Reward,指智能体在环境的某一状态下所获得的奖励。 以上图为例,智能体与环境的交互过程如下:
在 t 时刻,环境的状态为 St ,达到这一状态所获得的奖励为 Rt 智能体观测到 St 与 Rt ,采取相应动作 At 智能体采取 At 后,环境状态变为 St+1 ,得到相应的奖励 Rt+1 奖励值 Rt ,它表示环境进入状态 St 下的即时奖励 。但如果只考虑即时奖励,目光似乎太短浅了 :当下的状态和动作会影响到未来的状态和动作,进而影响到未来的整体收益。t时刻状态s的总收益 = 身处状态s能带来的即时收益 + 从状态s出发后能带来的未来收益 。 写成表达式就是:Vt=Rt+γVt+1
其中:
Vt : t 时刻的总收益,注意这个收益蕴涵了“即时”和“未来”的概念Rt : t 时刻的即时收益Vt+1 : t+1 时刻的总收益,注意这个收益蕴涵了“即时”和“未来”的概念。而 Vt+1 对 Vt 来说就是“未来”。 γ :折扣因子。它决定了我们在多大程度上考虑将“未来收益”纳入“当下收益”。 关键概念:
策略函数 是一个 概率密度函数(PDF),输入时当前状态s,输出为一个概率分布,表征每个 action 的概率:
动作值函数: 评价在状态 st 的情况下做出动作 at的好坏程度。
状态值函数:
消掉了动作 A ,这样 Vπ 只跟状态 s 与策略函数 π 有关了。 给定 π,可以评价当前状态的好坏;给定状态st,可以评价策略 π的好坏。 优势函数 :有些时候我们不需要描述一个行动的绝对好坏,而只需要知道它相对于平均水平的优势。也就是说,我们只想知道一个行动的相对 优势 。这就是优势函数的概念。
一个服从策略
长期价值可以表示为状态值函数(State Value Function)或动作值函数(Action Value Function)。
优化方法:
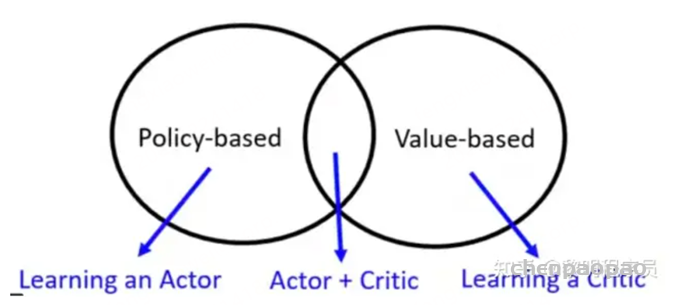
•value-based :优化状态动作值函数Q(s) ,贪心选择(确定性策略) :Q-Learning
•policy-based :直接优化策略函数π(s, a),按概率采样(随机性策略) :REINFORCE
•Actor-Critic
在第一部分介绍了通用强化学习的流程,那么我们要怎么把这个流程对应到NLP任务中呢?换句话说,NLP任务中的智能体、环境、状态、动作等等,都是指什么呢?
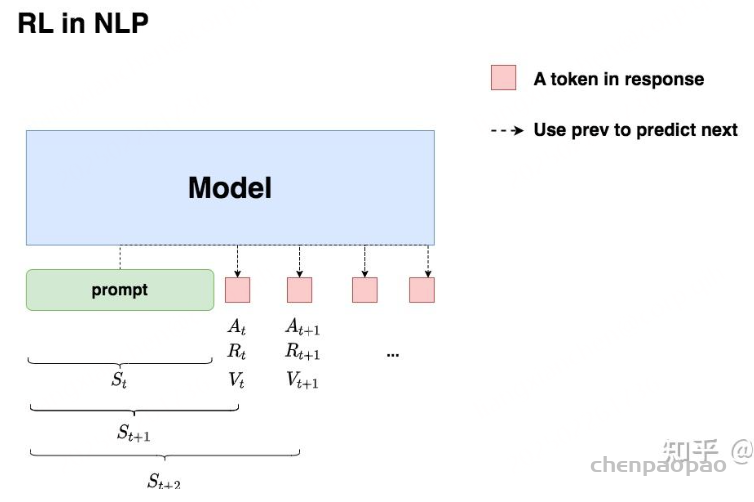
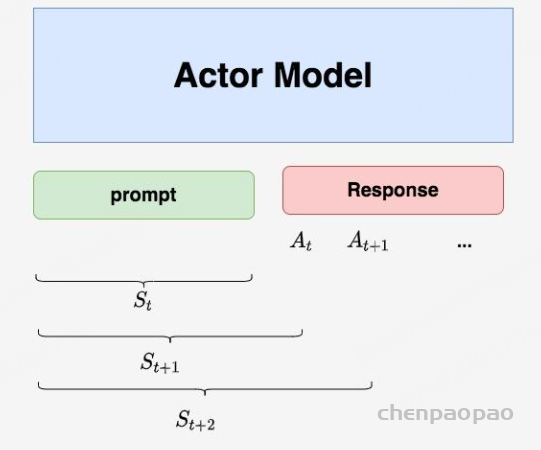
回想一下我们对NLP任务做强化学习(RLHF)的目的:我们希望给模型一个prompt,让模型能生成符合人类喜好的response 。再回想一下gpt模型做推理的过程:每个时刻 t 只产生一个token,即token是一个一个蹦出来的,先有上一个token,再有下一个token。
我们先喂给模型一个prompt,期望它能产出符合人类喜好的response 在 t 时刻,模型根据上文,产出一个token,这个token即对应着强化学习中的动作,我们记为 At 。因此不难理解,在NLP语境下,强化学习任务的动作空间就对应着词表。 在 t 时刻,模型产出token At对应着的即时收益为 Rt,总收益为 Vt( 复习一下, Vt 蕴含着“即时收益”与“未来收益”两个内容)。这个收益即可以理解为“对人类喜好的衡量 ”。此刻,模型的状态从 St变为 St+1,也就是从“上文”变成“上文 + 新产出的token” 在NLP语境下,智能体是语言模型本身,环境则对应着它产出的语料 这样,我们就大致解释了NLP语境下的强化学习框架,不过针对上面这张图,你可能还有以下问题:
(1)问题1:图中的下标是不是写得不太对?例如根据第一部分的介绍, At 应该对应着 Rt+1 , At+1 应该对应着 Rt+2 ,以此类推? (2)问题2:我知道 At 肯定是由语言模型产生的,那么 ,Rt,Vt 是怎么来的呢,也是语言模型产生的吗? (3)问题3:语言模型的参数在什么时候更新?是观测到一个 Rt,Vt ,就更新一次参数,然后再去产生 At+1 吗? (4)问题4:再谈谈 Rt,Vt 吧,在NLP的语境下我还是不太理解它们
首先,“收益”的含义是“对人类喜好的衡量” Rt :即时收益,指语言模型当下产生token At 带来的收益 Vt : 实际期望总收益(即时+未来),指对语言模型“当下产生token At ,一直到整个response生产结束”后的期收益预估。因为当下语言模型还没产出 At 后的token,所以我们只是对它之后一系列动作的收益做了估计,因而称为“期望总收益”。 我们从第二部分中已经知道:生成token At 和对应收益 Rt,Vt 的并不是一个模型。那么在RLHF中到底有几个模型?他们是怎么配合做训练的?而我们最终要的是哪个模型?
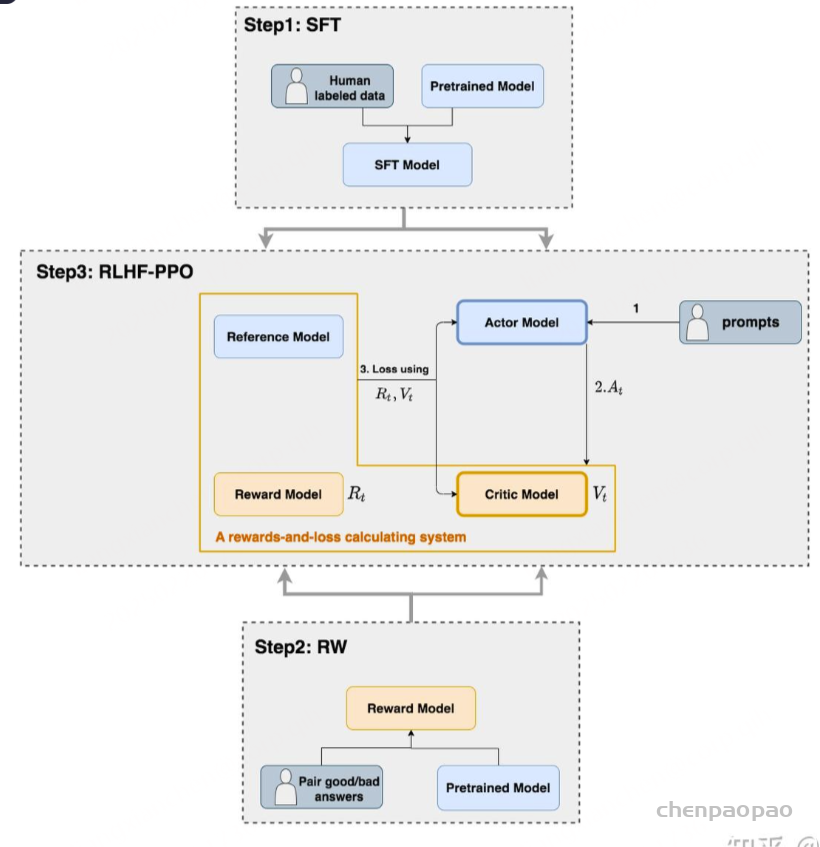
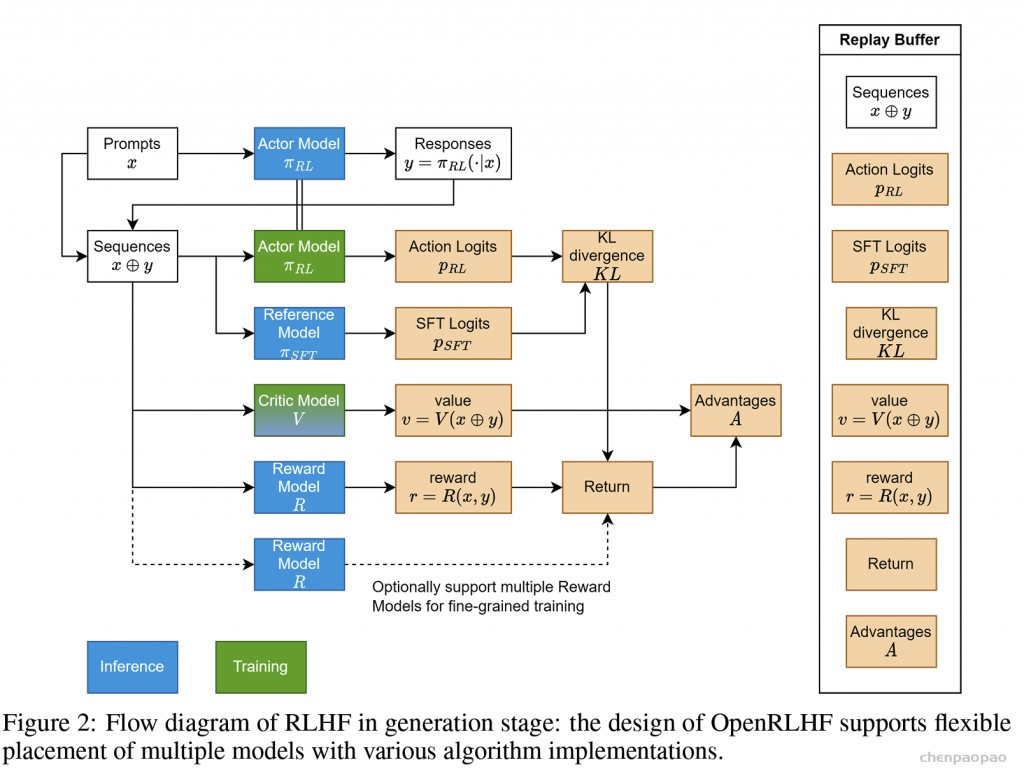
如上图,在RLHF-PPO阶段,一共有四个主要模型 ,分别是:
Actor Model:演员模型 ,这就是我们想要训练的目标语言模型Critic Model:评论家模型 ,它的作用是预估总收益 Vt Reward Model:奖励模型 ,它的作用是计算即时收益 Rt Reference Model:参考模型 ,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)其中:
Actor/Critic Model 在RLHF阶段是需要训练 的(图中给这两个模型加了粗边,就是表示这个含义);而Reward/Reference Model 是参数冻结 的。Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系(我自己命名的,为了方便理解),我们综合它们的结果计算loss,用于更新Actor和Critic Model Actor Model (演员模型)
正如前文所说,Actor就是我们想要训练的目标语言模型。我们一般用SFT阶段产出的SFT模型来对它做初始化。
我们的最终目的是让Actor模型能产生符合人类喜好的response。所以我们的策略是,先喂给Actor一条prompt (这里假设batch_size = 1,所以是1条prompt),让它生成对应的response。然后,我们再将“prompt + response”送入我们的“奖励-loss”计算体系中去算得最后的loss,用于更新actor。
Reference Model(参考模型)
Reference Model(以下简称Ref模型)一般也用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。Ref模型的主要作用是防止Actor”训歪”,那么它具体是怎么做到这一点的呢?
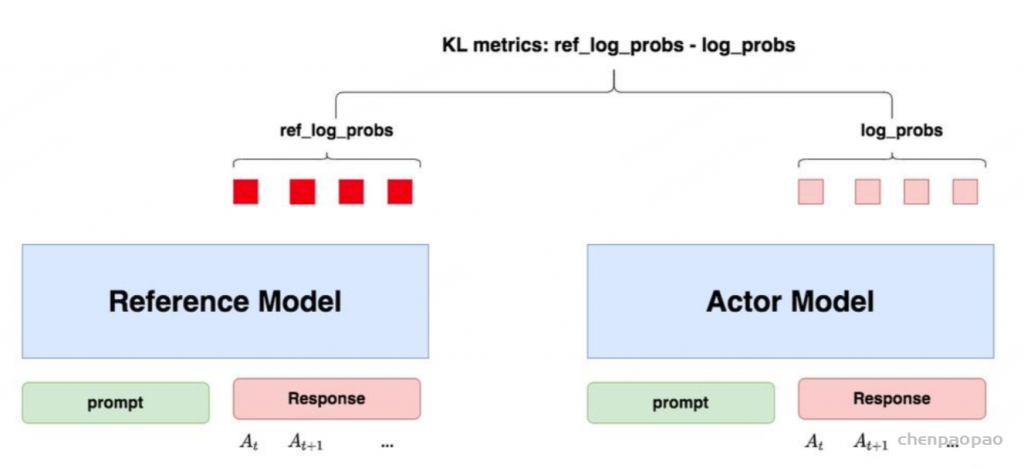
“防止模型训歪”换一个更详细的解释是:我们希望训练出来的Actor模型既能达到符合人类喜好的目的,又尽量让它和SFT模型不要差异太大 。简言之,我们希望两个模型的输出分布尽量相似 。那什么指标能用来衡量输出分布的相似度呢?我们自然而然想到了KL散度 。
如图所示:
对Actor模型 ,我们喂给它一个prompt,它正常输出对应的response。那么response中每一个token肯定有它对应的log_prob结果呀,我们把这样的结果记为log_probs 对Ref模型 ,我们把Actor生成的”prompt + response”喂给它,那么它同样能给出每个token的log_prob结果,我们记其为ref_log_probs 那么这两个模型的输出分布相似度就可以用ref_log_probs - log_probs从直觉上理解 ,两个分布的相似度越高,说明Ref模型对Actor模型输出的肯定性越大。即Ref模型也认为,对于某个 St ,输出某个 At 的概率也很高( P(At|St) )。这时可以认为Actor模型较Ref模型没有训歪。从KL散度上理解 : (当然这里不是严格的等于,只是KL散度的近似),这个值越小意味着两个分布的相似性越高。
注:你可能已经注意到,按照KL散度的定义,这里写成log_probs - ref_log_probs更合适一些。但是如果你看过一些rlhf相关的论文的话,你可能记得在计算损失函数时,有一项Rt−KL散度 (对这个有疑惑不要紧,我们马上在后文细说),即KL散度前带了负号,所以这里我写成ref_log_probs - log_probs这样的形式,更方便大家从直觉上理解这个公式。
现在,我们已经知道怎么利用Ref模型和KL散度来防止Actor训歪了。KL散度将在后续被用于loss的计算 ,我们在后文中会详细解释。
Critic Model(评论家模型)
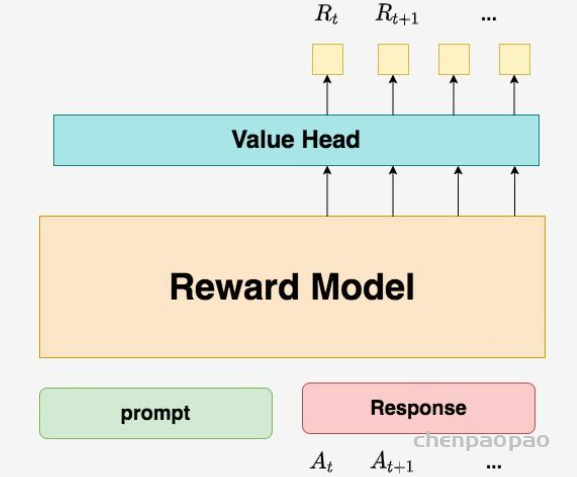
Critic Model用于预测期望总收益 Vt ,和Actor模型一样,它需要做参数更新 。实践中,Critic Model的设计和初始化方式也有很多种,例如和Actor共享部分参数、从RW阶段的Reward Model初始化而来等等。我们讲解时,和deepspeed-chat的实现保持一致:从RW阶段的Reward Model初始化而来。你可能想问:训练Actor模型我能理解,但我还是不明白,为什么要单独训练一个Critic模型用于预测收益呢? 也就是在 t 时刻,我们给不出客观存在的总收益 Vt ,我们只能训练一个模型去预测它。 所以总结来说,在RLHF中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic) 。这就是Critic模型存在的意义。我们来看看它的大致架构:
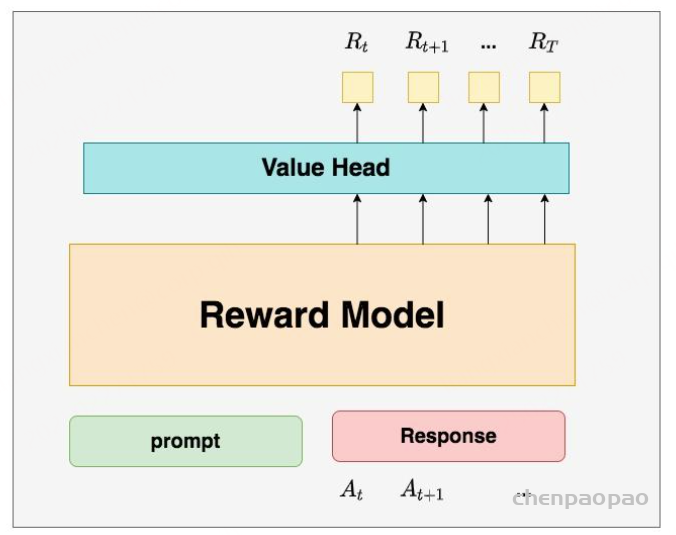
deepspeed-chat采用了Reward模型作为它的初始化,所以这里我们也按Reward模型的架构来简单画画它。你可以简单理解成,Reward/Critic模型和Actor模型的架构是很相似的(毕竟输入都一样),同时,它在最后一层增加了一个Value Head层,该层是个简单的线形层,用于将原始输出结果映射成单一的 Vt 值。
在图中, Vt 表示Critic模型对 t 时刻及未来(response完成)的收益预估。
Reward Model(奖励模型)
Reward Model用于计算生成token At 的即时收益,它就是RW阶段所训练的奖励模型,在RLHF过程中,它的参数是冻结的。你可能想问:为什么Critic模型要参与训练,而同样是和收益相关的Reward模型的参数就可以冻结呢?
第一点,Reward模型是经过和“估算收益”相关的训练的,因此在RLHF阶段它可以直接被当作一个能产生客观值的模型。 第二点,Reward模型代表的含义就是“即时收益”,你的token At 已经产生,因此即时收益自然可以立刻算出。 你还可能想问:我已经用Critic预测出 Vt 了,而这个 Vt 包含了“即时”和“未来”的概念,那我还需要代表“即时”的 Rt 做什么呢?直接用 Vt 不就好了吗?
结果1:Critic模型预测的 Vt 结果2:Reward模型预测的 Rt 和critic模型预测的 Vt+1 那么哪一个结果更靠近上帝视角给出的客观值呢?当然是结果2,因为结果1全靠预测,而结果2中的 Rt 是事实数据。MSE(上帝视角的客观收益-Critic模型预测的收益)来衡量它的loss。但是上帝视角的客观收益我们是不知道的,只能用已知事实数据去逼近它,所以我们就用 Rt+γ∗Vt+1 来做近似。 这就是 Rt,Vt 同时存在的意义
Reward模型和critic模型非常相似,这里我们就只给出架构图,不再做过多的说明。
RLHF中的loss计算
到目前为止,我们已经基本了解了RLHF的训练框架,以及其中的四个重要角色(训练一个RLHF,有4个模型在硬件上跑,可想而知对存储的压力)。在本节中,我们一起来解读RLHF的loss计算方式。在解读中,我们会再一次理一遍RLHF的整体训练过程,填补相关细节。在这之后,我们就可以来看代码解析了。
Actor loss: 用于评估Actor是否产生了符合人类喜好的结果,将作用于Actor的BWD上。Critic loss: 用于评估Critic是否正确预测了人类的喜好,将作用于Critic的BWD上。我们详细来看这两者。
Actor loss
(1)直观设计
我们先来看一个直观的loss设计方式:
Actor接收到当前上文 St ,产出token At ( P(At|St) ) Critic根据 St,At ,产出对总收益的预测 Vt 那么Actor loss可以设计为: 求和符号表示我们只考虑response部分所有token的loss ,为了表达简便,我们先把这个求和符号略去(下文也是同理),也就是说:
我们希望minimize这个actor_loss。
这个设计的直观解释是:
当 Vt>0 时,意味着Critic对Actor当前采取的动作给了正向反馈,因此我们就需要在训练迭代中提高 P(At|St) ,这样就能达到减小loss的作用。 当 Vt<0 时,意味着Critic对Actor当前采取的动作给了负向反馈,因此我们就需要在训练迭代中降低 P(At|St) ,这样就能到达到减小loss的作用。 一句话总结:这个loss设计的含义是,对上文 St 而言,如果token At 产生的收益较高,那就增大它出现的概率,否则降低它出现的概率。
(2)引入优势(Advantage)
在开始讲解之前,我们举个小例子:这个多出来的“甜头”,就叫做“优势”(Advantage)。 对NLP任务来说,如果Critic对 At 的总收益预测为 Vt ,但实际执行 At 后的总收益是 Rt+γ∗Vt+1 ,我们就定义优势为:
我们用 Advt 替换掉 Vt ,则此刻actor_loss变为:
(3)重新设计 Rt
总结一下,到目前为止,我们的actor_loss形式为:
同时注意,这个actor_loss应该是response的所有token loss的sum或者avg。这里为了表达方便,我们的公式略去了求和或求平均的符号。
按照这个理解, Rt 应该表示每个Actor产出token At 带来的即时收益,正如下图所示(其中 T 表示最后一个时刻):
但在deepspeed-chat的RLHF实践中,对 Rt 做了另一种设计:
基于这些,上面这个对 Rt 的设计可理解成:
当 t≠T时,我们更加关心Actor是否有在Ref的约束下生产token At当 $ t=T时,我们不仅关心Actor是否遵从了Ref的约束,也关心真正的即时收益 Rt为什么只有最后一个时刻的 Rt 被纳入了考量呢?这是因为在Reward模型训练阶段,就是用这个位置的 Rt 来表示对完整的prompt + response的奖励预测 (但不妨碍你理解成是执行完 AT 的即时奖励),然后用这个指标来做模型eval的(但是Reward训练阶段算loss时,还是考虑了response部分所有token输出的reward值)。所以到了RLHF的场景下,其余时刻的即时奖励,我们就用“Actor是否遵循了Ref的约束”来进行评价。
代码实践如下:
def compute_rewards(self, prompts, log_probs, ref_log_probs, reward_score,
action_mask):
"""
reward_function:计算最终的reward分数
复习一下几个相关参数的默认值:
self.kl_ctl = 0.1
self.clip_reward_value = 5
对于batch中的某个prompt来说,它最终的reward分数为:
(1) 先计算actor和ref_model的logit相似度: -self.kl_ctl * (log_probs - ref_log_probs)
其实写成self.kl_ctl * (ref_log_probs - log_probs)更好理解些
这个值越大,说明ref_model对actor生成的结果的认可度越高(即表明rlhf没有训歪),
没有训歪的情况下我们也应该给模型一些奖励,这个奖励就是self.kl_ctl * (ref_log_probs - log_probs)
(2)由于我们只取最后一个token对应位置的分数作为reward_score,因此我们只需要:
self.kl_ctl * (ref_log_probs - log_probs)的最后一位 + reward_score
(3) 同时我们对reward_score也做了大小限制,最大不超过self.clip_reward_value(超过统一给成self.clip_reward_value),
最小不低于-self.clip_reward_value(低于统一给成-self.clip_reward_value)
(4) 最后返回的rewards大小为:(batch_size, 各条数据的长度),对batch中的每条数据来说:
- response的最后一位:self.kl_ctl * (ref_log_probs - log_probs)的最后一位 + reward_score
- response的其余位置:self.kl_ctl * (ref_log_probs - log_probs)
"""
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
# ---------------------------------------------------------------------------------------------------
# response开始的位置
# (因为我们对prompt做过padding处理,因此batch中每个prompt长度一致,也就意味着每个response开始的位置一致)
# (所以这里start是不加s的,只是一个int)
# ---------------------------------------------------------------------------------------------------
start = prompts.shape[1] - 1
# ---------------------------------------------------------------------------------------------------
# response结束的位置
# (因为一个batch中,每个response的长度不一样,所以response的结束位置也不一样)
# (所以这里end是加s的,ends的尺寸是(batch_size,)
# ---------------------------------------------------------------------------------------------------
ends = start + action_mask[:, start:].sum(1) + 1
# ---------------------------------------------------------------------------------------------------
# 对rewards_score做限制
# ---------------------------------------------------------------------------------------------------
reward_clip = torch.clamp(reward_score, -self.clip_reward_value,
self.clip_reward_value)
batch_size = log_probs.shape[0]
for j in range(batch_size):
rewards[j, start:ends[j]][-1] += reward_clip[j] #
return rewards
注意输入输出的维度,prompts 是一个 [batch size, padded prompt length] 的 matrix,ref_log_probs 和 log_probs 是 [batch size, padded prompt with response length] 大小的矩阵,然后只有从 prompt 结束到 response 结束这一块儿的 reward 才会实际有作用,prompt 的 reward 是不计算的。
prompt 有统一的 padding,所以 response 的 start 位置是唯一的,而 ends 则通过 action_mask 中的 1 元素的截止为止计算得到。最后,在这个 batch 中,每个 prompt 的 reward 的结尾那个 token 加上 reward_score 进过 clip 得到的 reward。(4)重新设计优势
好,再总结一下,目前为止我们的actor_loss为:
同时,我们对 Rt 进行来改造,使其能够衡量Actor模型是否遵从了Ref模型的约束。
其中,新引入的 λ 也是一个常量,可将其理解为权衡因子,直觉上看它控制了在计算当前优势时对未来优势的考量。(从强化学习的角度上,它控制了优势估计的方差和偏差)
看到这里,你可能想问:这个代表未来优势的 Advt+1 ,我要怎么算呢? AdvT =RT −VT ,这是可以直接算出来的。而有了 AdvT ,我们不就能从后往前,通过动态规划的方法,把所有时刻的优势都依次算出来了吗?
代码实践如下(其中返回值中的returns表示实际收益,将被用于计算Critic模型的loss,可以参见4.2,其余细节都在代码注释中):注意这个函数一并返回了 returns,也即每个 token 的实际收益,这个收益之后会用于更新 critic model:
def get_advantages_and_returns(self, values, rewards, start):
"""
Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
没有引入GAE前的t时刻的优势值:
detal_t = r_t + gamma * V_t+1 - V_t
其中:
- r_t表示t时刻的即时收益
- V_t+1表示未来时刻的预期收益
- r_t + gamma * V_t+1可理解成t时刻的实际预期收益
- V_t可理解成t时刻的预估预期收益(是模型,例如critic model自己估算出来的)
引入GAE后的t时刻的优势值:
A_t = delta_t + gamma * lambda * A_t+1
粗暴理解为在t时刻时,不仅考虑当下优势,还考虑了未来的优势
为了知道A_t, 我们得知道A_t+1,所以在本算法中采取了从后往前做动态规划求解的方法,也即:
假设T是最后一个时刻,则有A_T+1 = 0, 所以有: A_T = delta_T
知道了A_T, 就可以依次往前倒推,把A_t-1, A_t-2之类都算出来了
引入GAE后t时刻的实际预期收益
returns_t = A_t + V_t
= delta_t + gamma * lambda * A_t+1 + V_t
= r_t + gamma * V_t+1 - V_t + gamma * lambda * A_t+1 + V_t
= r_t + gamma * (V_t+1 + lambda * A_t+1)
注意,这里不管是advantages还是returns,都只算response的部分
"""
# Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam = 0
advantages_reversed = []
length = rewards.size()[-1]
# 注意这里用了reversed,是采取从后往前倒推计算的方式
for t in reversed(range(start, length)):
nextvalues = values[:, t + 1] if t < length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1) # 优势
returns = advantages + values[:, start:] # 实际收益
# values: 预期收益
return advantages.detach(), returns(5)PPO-epoch: 引入新约束
总结一下,目前为止我们的actor_loss为:
同时
我们已经对 Rt 进行来改造,使其能够衡量Actor模型是否遵从了Ref模型的约束。 我们已经对 Advt 进行改造,使其不仅考虑了当前时刻的优势,还考虑了未来的优势 基于这些改造,我们重新理一遍RLHF-PPO的训练过程。
第一步,我们准备一个batch的prompts 第二步,我们将这个batch的prompts喂给Actor模型,让它生成对应的responses 第三步,我们把prompt+responses喂给我们的Critic/Reward/Reference模型,让它生成用于计算actor/critic loss的数据,按照强化学习的术语,我们称这些数据为经验(experiences)。critic loss我们将在后文做详细讲解,目前我们只把目光聚焦到actor loss上 第四步,我们根据这些经验,实际计算出actor/critic loss,然后更新Actor和Critic模型 这些步骤都很符合直觉,但是细心的你肯定发现了,文字描述中的第四步和图例中的第四步有差异:图中说,这一个batch的经验值将被用于n次模型更新,这是什么意思呢? 在强化学习中,收集一个batch的经验是非常耗时的。对应到我们RLHF的例子中,收集一次经验,它要等四个模型做完推理才可以 ,正是因此,一个batch的经验,只用于计算1次loss,更新1次Actor和Critic模型,好像有点太浪费了 。我们自然而然想到,1个batch的经验,能不能用来计算ppo-epochs次loss,更新ppo-epochs次Actor和Critic模型? 简单写一下伪代码,我们想要:
# --------------------------------------------------------------
# 初始化RLHF中的四个模型
# --------------------------------------------------------------
actor, critic, reward, ref = initialize_models()
# --------------------------------------------------------------
# 训练
# --------------------------------------------------------------
# 对于每一个batch的数据
for i in steps:
# 先收集经验值
exps = generate_experience(prompts, actor, critic, reward, ref)
# 一个batch的经验值将被用于计算ppo_epochs次loss,更新ppo_epochs次模型
# 这也意味着,当你计算一次新loss时,你用的是更新后的模型
for j in ppo_epochs:
actor_loss = cal_actor_loss(exps, actor)
critic_loss = cal_critic_loss(exps, critic)
actor.backward(actor_loss)
actor.step()
critc.backward(critic_loss)
critic.step()而如果我们想让一个batch的经验值被重复使用ppo_epochs次,等价于我们想要Actor在这个过程中,模拟和环境交互ppo_epochs次。 举个例子:
如果1个batch的经验值只使用1次,那么在本次更新完后,Actor就吃新的batch,正常和环境交互,产出新的经验值 但如果1个batch的经验值被使用ppo_epochs次,在这ppo_epochs中,Actor是不吃任何新数据,不做任何交互的,所以我们只能让Actor“模拟”一下和环境交互的过程,吐出一些新数据出来。 那怎么让Actor模拟呢?很简单,让它观察一下之前的数据长什么样,让它依葫芦画瓢,不就行了吗?我们假设最开始吃batch,吐出经验的actor叫 Actorold ,而在伪代码中,每次做完ppo_epochs而更新的actor叫 Actornew ,那么我们只要尽量保证每次更新后的 Actornew 能模仿最开始的那个 Actorold ,不就行了吗?
诶!是不是很眼熟!两个分布,通过什么方法让它们相近!那当然是KL散度 !所以,再回到我们的actor_loss上来,它现在就可被改进成:
我们再稍作一些改动将log去掉(这个其实不是“稍作改动去掉log”的事,是涉及到PPO中重要性采样的相关内容,大家有兴趣可以参考这篇 ):
其中, Pold 表示真正吃了batch,产出经验值的Actor ;P表示ppo_epochs中实时迭代更新的Actor,它在模仿 Pold 的行为。所以这个公式从直觉上也可以理解成:在Actor想通过模拟交互的方式,使用一个batch的经验值更新自己时,它需要收到真正吃到batch的那个时刻的Actor的约束,这样才能在有效利用batch,提升训练速度的基础上,保持训练的稳定。
在 PPO 强化学习中使用 KL 散度,是为了:
让当前策略(Actor)在更新时不要偏离旧策略太远,从而保证经验数据依然有效、训练过程更稳定。
换句话说:
P_old 是“真正经历过环境”的P 是“后续更新后模拟交互的”所以你得让 P 尽量模仿 P_old,才能继续用旧数据去更新模型 KL 散度,就是这个“模仿程度”的衡量指标和约束手段 但是,谨慎的你可能此时又有新的担心了:虽然我们在更新Actor的过程中用 Actorold 做了约束,但如果 Actorold 的约束能力不够,比如说 P(At|St)/Pold(At|St) 还是超出了可接受的范围,那怎么办?
很简单,那就剪裁(clip) 它吧!
我们给 P(At|St)/Pold(At|St) 设置一个范围,例如(0.8 ,1.2),也就是如果这个值一旦超过1.2,那就统一变成1.2;一旦小于0.8,那就统一变成0.8。这样就能保证 Actor 和 Actorold 的分布相似性在我们的掌控之内了。此时actor_loss变为:
这时要注意,如果超过变化范围,将 P(At|St)/Pold(At|St) 强制设定为一个常数后,就说明这一部分的loss和Actor模型无关了,而 Advt 这项本身也与Actor无关。所以相当于,在超过约束范围时,我们停止对Actor模型进行更新。
整体代码如下:
注意最后整个 response 每一处的 loss 取均值,就是这个 prompt + response 的 actor loss 了
def actor_loss_fn(self, logprobs, old_logprobs, advantages, mask):
"""
logprobs: 实时计算的,response部分的prob(只有这个是随着actor实时更新而改变的)
old_logprobs:老策略中,response部分的prob (这个是固定的,不随actor实时更新而改变)
advantages: 老策略中,response部分每个token对应的优势(这个是固定的,不随actor实时更新而改变)
mask:老策略中,response部分对应的mask情况这个是固定的,不随actor实时更新而改变)
之所以要引入logprobs计算actor_loss,是因为我们不希望策略每次更新的幅度太大,防止模型训歪
self.cliprange: 默认值是0.2
"""
## policy gradient loss
# -------------------------------------------------------------------------------------
# 计算新旧策略间的KL散度
# -------------------------------------------------------------------------------------
log_ratio = (logprobs - old_logprobs) * mask
ratio = torch.exp(log_ratio)
# -------------------------------------------------------------------------------------
# 计算原始loss和截断loss
# -------------------------------------------------------------------------------------
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - self.cliprange, 1.0 + self.cliprange)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / mask.sum() # 最后是取每个非mask的response token的平均loss作为最终loss
return pg_loss
(6)Actor loss小结
(1)~(5)中我们一步步树立了actor_loss的改进过程,这里我们就做一个总结吧:
我们已经对 Rt进行来改造,使其能够衡量Actor模型是否遵从了Ref模型的约束 我们已经对 Advt进行改造,使其不仅考虑了当前时刻的优势,还考虑了未来的优势 我们重复利用了1个batch的数据,使本来只能被用来做1次模型更新的它现在能被用来做ppo_epochs次模型更新。我们使用真正吃了batch,产出经验值的那个时刻的Actor分布来约束ppo_epochs中更新的Actor分布 我们考虑了剪裁机制(clip),在ppo_epochs次更新中,一旦Actor的更新幅度超过我们的控制范围,则不对它进行参数更新。 Critic loss
我们知道,1个batch产出的经验值,不仅被用来更新Actor,还被用来更新Critic。对于Critic loss,我们不再像Actor loss一样给出一个“演变过程”的解读,我们直接来看它最后的设计。
Vt :Critic对t时刻的总收益的预估,这个总收益包含即时和未来的概念(预估收益) Rt+γ∗Vt+1 :Reward计算出的即时收益 Rt ,Critic预测出的 t+1 及之后时候的收益的折现,这是比 Vt 更接近t时刻真值总收益的一个值(实际收益) 所以,我们的第一想法是:
现在,我们对“实际收益”和“预估收益”都做一些优化。
(1)实际收益优化
我们原始的实际收益为 Rt+γ∗Vt+1 ,但是当我们在actor_loss中引入“优势”的概念时,“优势”中刻画了更为丰富的实时收益信息,所以,我们将实际收益优化为: Advt+Vt
(2)预估收益优化
我们原始的预估收益为 Vt 。
# self.cliprange_value是一个常量
# old_values: 老critic的预测结果
# values:新critic的预测结果
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)那么最终我们就取实际收益和预估收益的MSE做为loss就好,这里注意,计算实际收益时 Advt,Vt 都是老Critic(真正吃了batch的那个)产出的结果,而预估收益是随着ppo_epochs而变动的。
def critic_loss_fn(self, values, old_values, returns, mask):
"""
values: 实时critic跑出来的预估预期收益(是变动的,随着ppo epoch迭代而改变)
old_values:老critic跑出来的预估预期收益(是固定值)
returns:实际预期收益
mask:response部分的mask
self.cliprange_value = 0.2
"""
## value loss
# 用旧的value去约束新的value
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)
if self.compute_fp32_loss:
values = values.float()
values_clipped = values_clipped.float()
# critic模型的loss定义为(预估预期收益-实际预期收益)**2
vf_loss1 = (values - returns)**2
vf_loss2 = (values_clipped - returns)**2
vf_loss = 0.5 * torch.sum(
torch.max(vf_loss1, vf_loss2) * mask) / mask.sum() # 同样,最后也是把critic loss平均到每个token上
return vf_loss构造 Reward
给定一个 transformer 和任何一个 string,我都可以将整个 string 输入给 reward model 做一次 forward pass,得到每个位置的 token 的 logit。我们取出最后一个 token 的 logit,经过 logit processor 处理,再过一次 softmax 并取 log,得到此处的 log prob。此外,我们也可以对最后一个 token 的 logit 进行其他操作,譬如 pooling 和 projection 等等,拿到 embedding、reward 或者 value。由此可见,对于 string 里的每个 token,我们都可以得到前述所有计算值,但是在 RLHF 中,我们会用到 response 中每个 token 的 log prob 和 value,但是 reward 模型只会用最后一个 token 的 reward 。这里直接给出 reward 的实际计算:
为什么只有最后一个时刻的 Rt被纳入了考量呢?这是因为在Reward模型训练阶段,就是用这个位置的 Rt来表示对完整的prompt + response的奖励预测(但不妨碍你理解成是执行完 AT的即时奖励),然后用这个指标来做模型eval的(但是Reward训练阶段算loss时,还是考虑了response部分所有token输出的reward值)。所以到了RLHF的场景下,其余时刻的即时奖励,我们就用“Actor是否遵循了Ref的约束”来进行评价。
需要注意的是,Rt的设计并不只有这一种。deepspeed在自己的代码注释中也有提过,可以尝试把最后一个时刻的 RT替换成所有token的即时奖励的平均值。如果站在这个角度理解的话,我们同样也可以尝试在每一个位置的奖励衡量上引入 Rt
对于第 t 个 response token,当 t 为最后一个 token T 时,才将 reward model 输出的对整个 response 的 reward 加到 Rt 上。换言之,实际上一个 prompt + response 只会让 reward model 推理一次,作为整个 response 的 reward。
至于其他部分,$kl _ ctl$ 是个常数,$ \log \frac{P(A_t|S_t)}{P_{ref}(A_t|S_t)} $ 是 reference model 和 actor model 生成 At 这个 token 的条件概率比值取对数,也即直接将 actor 的 log prob 和 reference 的 log prob 相减,体现到代码里就是 kl_ctl * (actor_log_probs - ref_log_probs)(KL 散度),这样就得到了每个 token 的 reward。注意这里的单复数,actor_log_probs 和 ref_log_probs 都是所有 response token 的 log prob 构成的 list。
得到 KL 散度后,再在这个 prompt + response 的最后一个 token 上加上此处的 reward(称为 reward score),整个 response 每一处的 reward 便构造完成了。当然,实际上的计算还需要考虑 reward score 的 clip 问题,也即不能让 reward 过大。在知乎 里面给了非常好的伪代码。
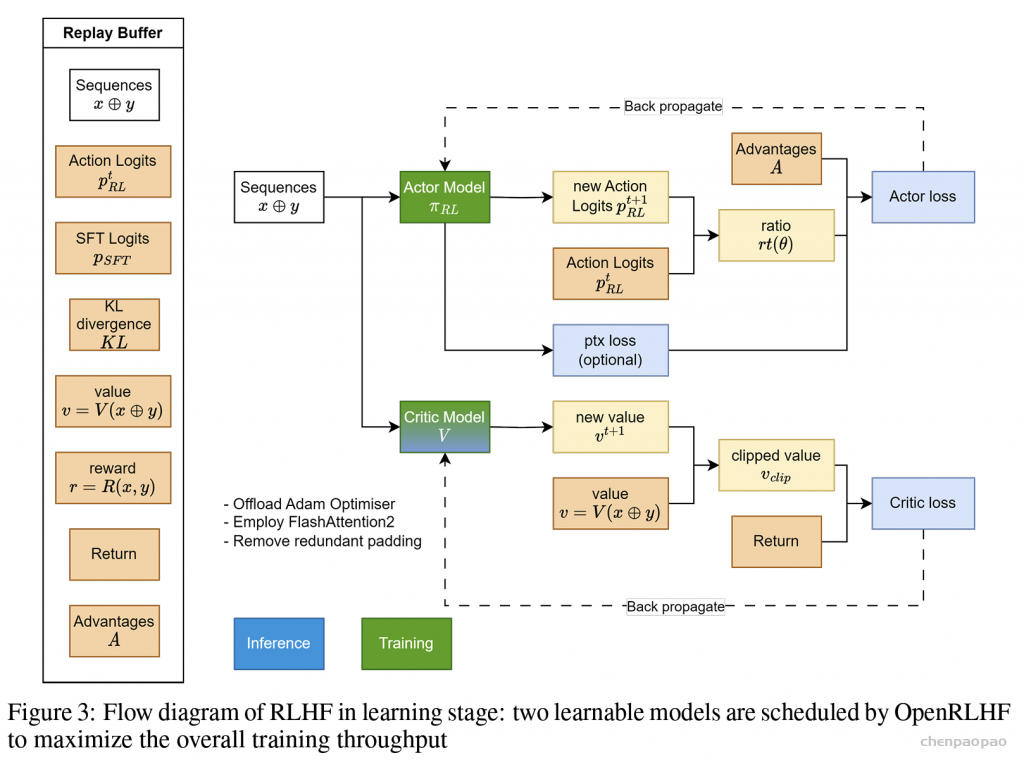
构造 Advantage
Advanatage 可以某种程度理解为“意外之喜”,具体的描述参考知乎原文。这里直接给出 Advantage 的构造公式:
我们来拆解下,考虑到 Rt 是每个 token 的 reward,前面已经构造了。Vt 和 Vt+1 是当前 token 和下一个 token 的 value,而每个 token 的 value 在 value model 的 forward pass 中都可以得到,Adv_t 是当前 token 的 advantage,$\gamma, \lambda$ 都是常数。这种递归的构造方式,可以用尾递归来反推每个位置的 advantage。
构造 Actor Loss
这里还是直接给出 Actor Loss 的构造公式:
这个构造公式看着复杂,实际上一点也不简单。每个 response token 的 Advt 的构造已经在前文给出,而 P(At|St),Pold(At|St) 其实都是 actor model 的条件概率。之所以有个 old 是因为我们希望多利用每轮产生的 experiences,因此一组 experiences 会更新多轮。old 表示这一组 experiences 用于更新之前的 actor model,用这个 old actor model 对这几轮更新的大小做了约束。最后,考虑到某一轮更新里,当前 actor model 和 old actor model 的差距实在太大了,以至于条件概率的比值超出了人为预设的范围,此时 Advt 的系数(ratio)会取为约束边界。此时 actor model 的参数不再影响 ratio,换言之 actor model 的参数不再在 actor loss 的计算图中了,这个 loss 也就不会更新 actor 的参数了。 注意,advantage 的构造是由 old actor model 构造来的,计算结束就固定了,对于更新中的 actor model 没有梯度,所以整个 actor loss 的计算图中只有 ratio 对更新中的 actor model 有梯度。
构造 Critic Loss
注意到,在 advantage 的构造中,我们一并得到了 returns,将其视为每个 token 的实际收益。
而预估收益就是 Vt,然后我们构造 MSE loss 来最小化预估收益和实际收益的差距。
看上去似乎 Rett −Vt 就是 Advt ,但是实际使用的 values 是多轮更新中的 value model 的输出,也即 new value,而 returns 是多轮更新开始时就固定了的实际收益(old returns),所以 Rett −Vt 并不是 Advt 。
更新流程
准备一个 batch 的 prompts; 将这个 batch 的 prompts 输入给 Actor,解码得到 responses; 将 prompt + responses 输入给 Critic/Reward/Reference,分别计算得得到所有 token 的 values、最后一个 token 的 reward 和所有 token 的 log probs,按照强化学习的术语,称这些数据为经验(experiences)了; 根据 experiences 多轮计算 actor loss 和 critic loss 并更新 Actor 和 Critic 模型。 对于第 4 步,我们当然可以一轮 experiences 就更新一次 actor 和 critic,但是为了尽可能利用这个 batch 的 experiences,我们对 actor 和 critic 做多轮更新。我们将 experiences 中多轮更新开始前的 log probs 和 values 称为 old log probs 和 old values(reward 不会多轮计算)。在每一轮中,actor 和 critic 会生成 new log probs 和 new values,然后在 old 的基础上计算 actor loss 和 critic loss,然后更新参数。
整体流程:
PPO优化目标
(1)策略梯度算法:更新幅度大,不稳定
(2)TRPO(信任区域算法):加入KL散度约束条件,但需计算二阶导数,计算量大
(3)PPO(近端策略优化算法):
这里At为优势函数:Critic Model用于估计状态的价值函数 V(st),从而计算策略梯度中的优势值A(t), 下面的 r(st,at) 函数就是 RM 模型的输出: 用于计算生成 某个token的即时收益 。 下图转换参考:https://zhuanlan.zhihu.com/p/651780908
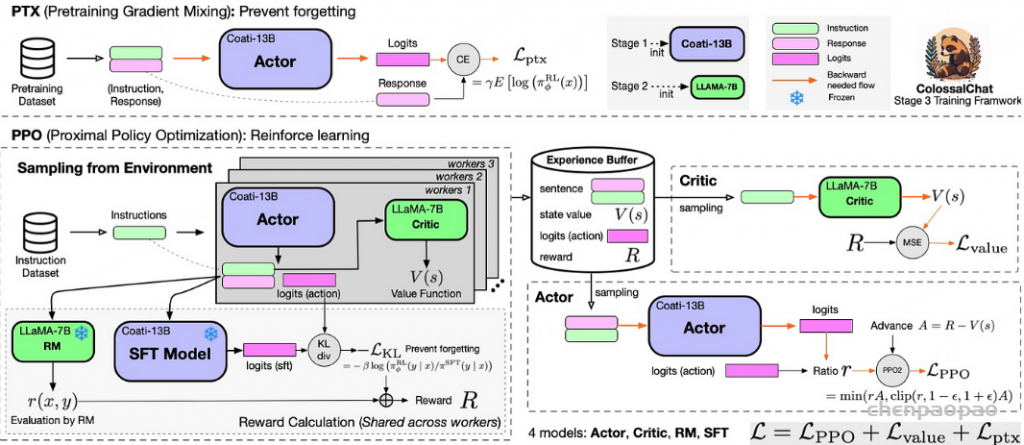
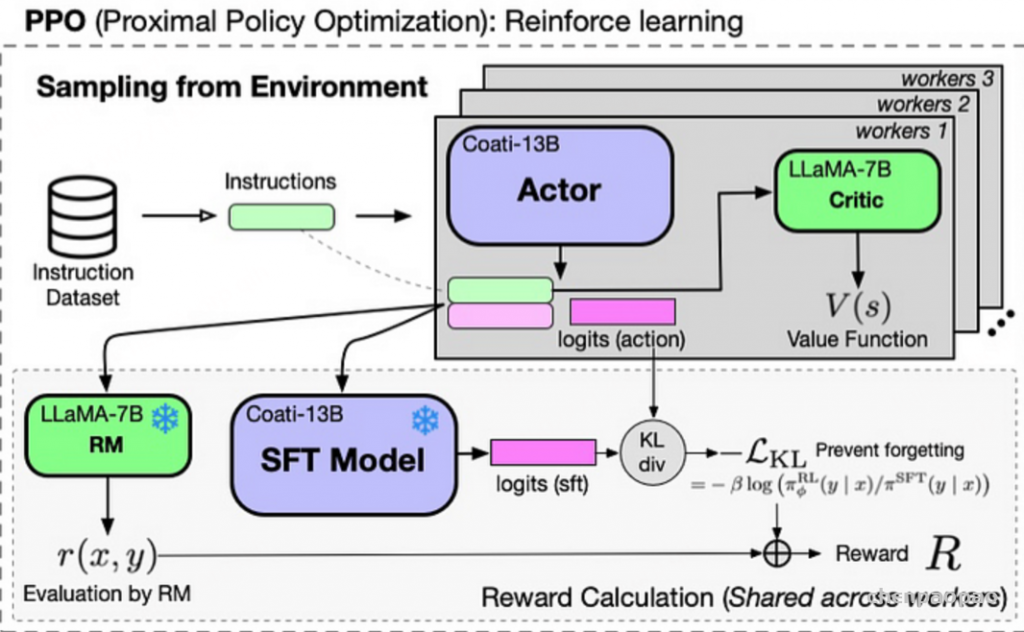
Actor Model:要训练的目标语言模型,策略网络 Critic Model:预估总收益 Reward Model:计算即时收益 Reference Model:在RLHF阶段给语言模型增加一些“约束”,防止语言模型训偏 ColossalChat RLFH过程也是非常接近ChatGPT的RLFH过程,RLFH过程主要涉及四个模型分别是Actor、Critic、RM、STF,损失函数也是由三个损失函数组成分别是策略损失、价值损失和 PTX 损失。
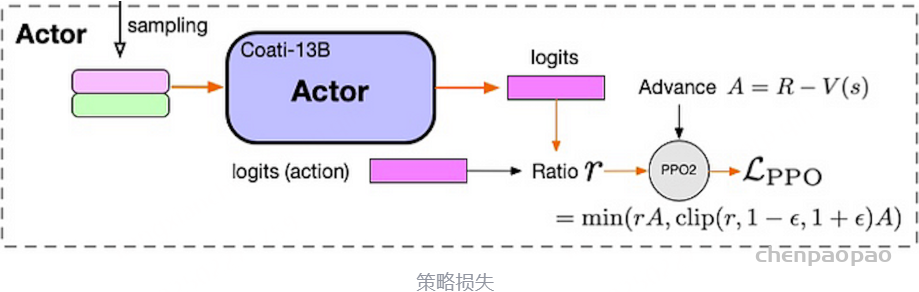
ColossalChat RLFH过程 策略损失函数计算:
策略损失计算过程 通过instruction dataset数据训练STF模型,通过计算sft model的logits和actor model(没有经过sft的model)的logits计算kl散度,然后加上reward model的打分变成 reward R奖励值,避免太过偏向reward model加入和sft model的kl散度,同时也避免强化学习将actor模型训歪。
这样做的目的就是避免模型训飞,让模型更新保持在一个小范围内。
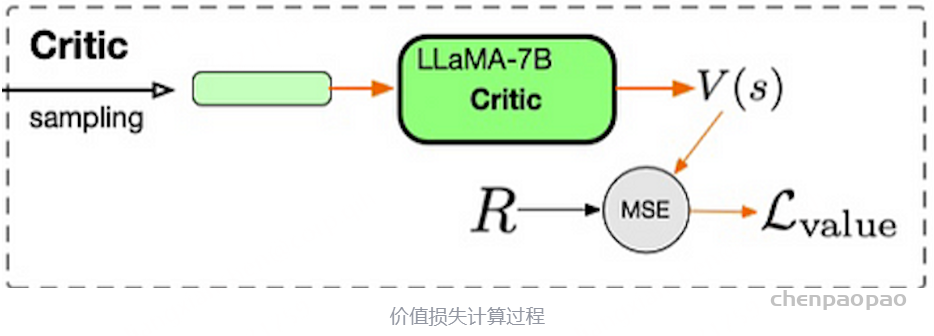
价值损失函数计算:
上式R是reward model和sft model计算出来的反馈分数,V(s)是Critic Model输出的价值分数。主要是衡量reward分数和价值函数分数的均方误差。
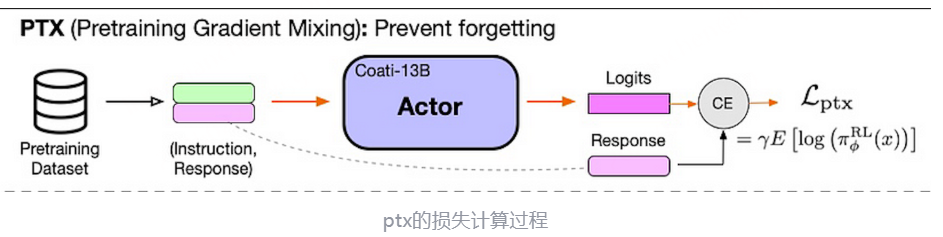
ptx的损失计算:
计算Actor输出response和输入语料的回答部分的交叉熵损失函数,用来在PPO梯度中加入预训练梯度,以保持语言模型原有性能防止遗忘。这个就是instruct gpt论文中在强化学习中加入预训练梯度以防过度拟合ppo数据带来nlp通用任务能力的下降操作。
总的强化学习损失计算:
在强化学习中,PPO(Proximal Policy Optimization)算法是一种基于策略梯度的方法,用于训练强化学习智能体。PPO算法中引入Critic模型的主要目的是为了提供一个价值估计器,用于评估状态或状态动作对的价值,从而辅助策略的更新和优化。
虽然奖励模型(Reward Model)可以提供每个状态或状态动作对的即时奖励信号,但它并不能直接提供对应的价值估计。奖励信号只反映了当前动作的即时反馈,而并没有提供关于在长期时间尺度上的价值信息。
Critic模型的作用是估计状态或状态动作对的长期价值,也称为状态值函数或动作值函数。 Critic模型能够学习和预测在当前状态下采取不同动作所获得的累积奖励,它提供了对策略改进的指导。PPO算法使用Critic模型的估计值来计算优势函数,从而调整策略的更新幅度,使得更有利于产生更高长期回报的动作被选择。
另外,Critic模型还可以用于评估不同策略的性能,为模型的评估和选择提供依据。PPO算法中的Actor-Critic架构允许智能体同时学习策略和价值函数,并通过协同训练来提高性能。
因此,在RLHF(Reinforcement Learning from Human Feedback)中,PPO算法需要Critic模型而不是直接使用奖励模型,是为了提供对状态或状态动作对的价值估计,并支持策略的改进和优化。Critic模型的引入可以提供更全面和准确的信息,从而增强算法的训练效果和学习能力。
即时奖励 与 状态动作对的长期价值 的差别是什么?
即时奖励(Immediate Reward)和状态动作对的长期价值(Long-Term Value)代表了强化学习中不同的概念和时间尺度。
即时奖励是指智能体在执行某个动作后立即获得的反馈信号。它通常由环境提供,用于表示当前动作的好坏程度。即时奖励是一种即时反馈,可以指示当前动作的立即结果是否符合智能体的目标。
而状态动作对的长期价值涉及更长时间尺度上的评估,它考虑了智能体在当前状态下选择不同动作所导致的未来回报的累积。长期价值可以表示为状态值函数(State Value Function)或动作值函数(Action Value Function)。
状态值函数(V-function) 表示在给定状态下,智能体从该状态开始执行一系列动作,然后按照某个策略进行决策,从而获得的预期累积回报。状态值函数估计了智能体处于某个状态时所能获得的长期价值,反映了状态的优劣程度 。
动作值函数(Q-function) 则表示在给定状态下,智能体选择某个动作后,按照某个策略进行决策,从该状态转移到下一个状态并获得预期累积回报的价值。动作值函数估计了在给定状态下采取不同动作的长期价值,可以帮助智能体选择在每个状态下最优的动作 。
长期价值考虑了智能体在未来的决策过程中所能获得的累积回报,相比之下,即时奖励只提供了当前动作的即时反馈。长期价值对智能体的决策具有更全面的影响,可以帮助智能体更好地评估当前状态和动作的长期效果,并指导智能体在长期时间尺度上作出更优的决策。
在强化学习中,长期价值的估计对于确定性策略选择和价值优化非常重要,而即时奖励则提供了对当前动作的直接反馈。这两者相互补充,结合起来可以帮助智能体实现更好的决策和学习效果。
PPO中优势函数指什么
在Proximal Policy Optimization(PPO)算法中,优势函数(Advantage Function)用于评估状态-动作对的相对优劣程度。它衡量了执行某个动作相对于平均水平的优劣,即在给定状态下采取某个动作相对于采取平均动作的效果。
优势函数可以用以下方式定义:Advantage(s, a) = Q(s, a) - V(s)
其中,Advantage(s, a)表示在状态 s 下采取动作 a 的优势函数值,Q(s, a) 表示状态动作对 (s, a) 的动作值函数(也称为动作优势函数),V(s) 表示状态值函数。
优势函数的作用在于帮助评估当前动作的相对价值,以便在策略更新过程中确定应采取的动作。通过比较不同动作的优势函数值,可以决定哪些动作是更好的选择。正的优势函数值表示执行的动作比平均水平更好,而负的优势函数值表示执行的动作比平均水平更差。
在PPO算法中,优势函数用于计算策略更新的目标,以便调整策略概率分布来提高优势函数为正的动作的概率,并降低优势函数为负的动作的概率,从而改进策略的性能。
总而言之,优势函数在PPO算法中用于评估状态-动作对的相对优劣,帮助确定应该采取的动作,并在策略更新过程中引导策略向更优的方向调整。
传统的强化学习算法(如Proximal Policy Optimization,PPO)在应用于LLMs的推理任务时面临着重大挑战:
依赖批评者模型: PPO需要一个独立的批评者模型来评估每个回答的价值,这使内存和计算需求增加了一倍。 训练批评者模型非常复杂且容易出错,尤其是在需要对主观或细微差别进行评价的任务中。 2. 高昂的计算成本:
强化学习流程通常需要大量计算资源来迭代评估和优化回答。 将这些方法扩展到更大的LLMs会进一步加剧成本。 3. 可扩展性问题:
绝对奖励评估难以应对多样化任务,使得跨推理领域的泛化变得困难。 GRPO如何应对这些挑战:
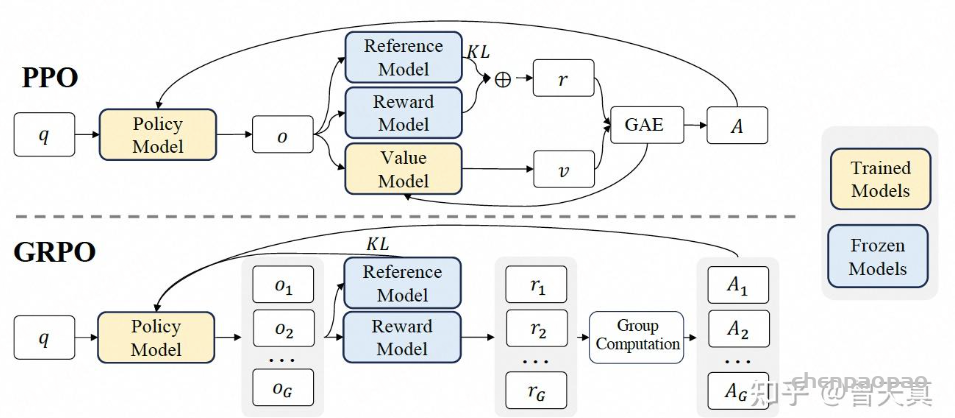
无批评者优化: GRPO通过比较组内回答,消除了对批评者模型的需求,显著降低了计算开销。相对评估: GRPO不依赖外部评价者,而是利用组内动态来评估每个回答在同一批次中的相对表现。高效训练: 通过专注于组内优势,GRPO简化了奖励估计流程,使其对大型模型的训练更快且更具可扩展性。GRPO的核心思想是通过组内相对奖励 来估计基线(baseline),从而避免使用额外的价值函数模型(critic model) 。传统的PPO算法需要训练一个价值函数来估计优势函数 (advantage function),而GRPO通过从同一问题的多个输出中计算平均奖励来替代这一过程,显著减少了内存和计算资源的消耗。
Group Relative Policy Optimization (GRPO) ,不再需要像PPO那样加入额外的价值函数近似,而是直接使用多个采样输出的平均奖励作为Baseline
具体来说,对于每个问题 i ,GRPO 从旧策略 πθold 中采样一组输出 {i 1,i 2,…,iA },然后通过最大化以下目标函数来优化策略模型:
其中,ϵ 和 β 是超参数,A ^i ,j 是基于组内奖励的相对优势估计。与 PPO 不同,GRPO 通过直接使用奖励模型的输出来估计基线,避免了训练一个复杂的值函数 。此外,GRPO 通过直接在损失函数中加入策略模型和参考模型之间的 KL 散度来正则化,而不是在奖励中加入 KL 惩罚项,从而简化了训练过程。
此外,GRPO 通过直接在损失函数中加入策略模型和参考模型之间的 KL 散度来正则化,而不是在奖励中加入 KL 惩罚项,从而简化了训练过程。
GRPO的计算流程包括:
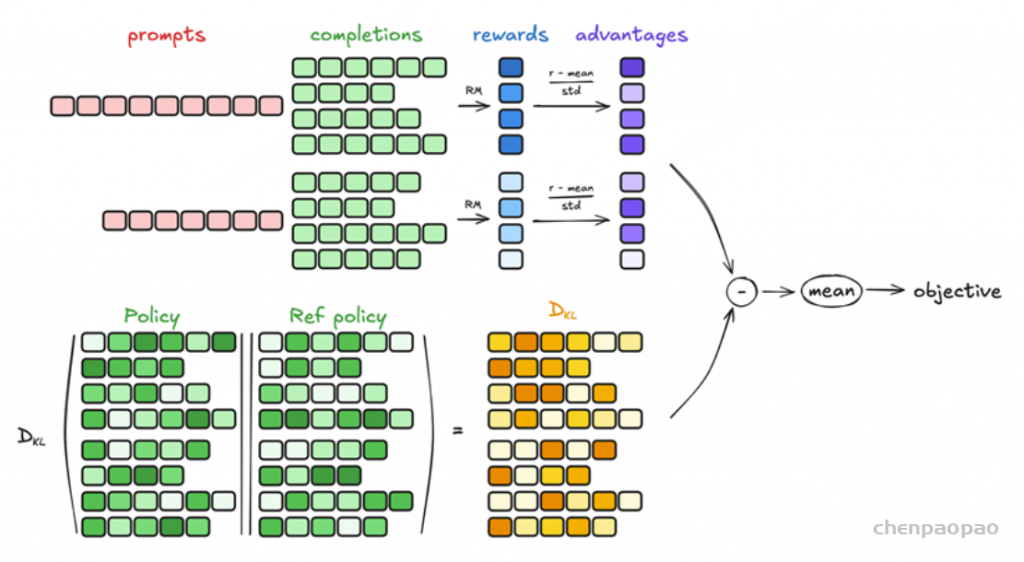
采样一组输出并计算每个输出的奖励。 对组内奖励进行归一化处理。 使用归一化后的奖励计算优势函数。 通过最大化目标函数更新策略模型。 迭代训练,逐步优化策略模型。 GRPO通过组内相对奖励估计基线,避免了传统PPO中价值函数的使用,显著减少了训练资源消耗,同时提升了模型在数学推理等复杂任务中的表现。
GRPO 计算总结
GRPO的核心思想是相对评估:
对于每个输入查询,模型生成一组潜在回答。 根据每个回答在组中的相对表现进行评分,而不是孤立地评估单个回答。 一个回答的优势反映了其相对于组内平均表现的优劣程度。 这种方法消除了对独立批评者模型的需求,使GRPO既高效又稳健 。通过在组内引入竞争,GRPO推动模型不断提升其推理能力 。正是这一创新使DeepSeek在推理任务中取得了卓越的成果。
以简单的方式理解GRPO目标函数 GRPO(Group Relative Policy Optimization,群体相对策略优化)的目标函数就像是一种“食谱”,通过比较模型的回答并逐步改进,教会模型生成更好的答案。让我们用一个易于理解的方式逐步解析它:
目标 :假设你正在教一组学生解决一个数学问题。你不是单纯告诉他们谁对谁错,而是通过比较所有学生的答案,找出谁做得最好(以及原因)。然后,你通过奖励更好的方法并改进较弱的方法来帮助他们学习。这正是GRPO所做的——只不过它教的是AI模型,而不是学生。
逐步解析
第一步:从查询开始
从训练数据集 P(Q) 中选取一个查询 (q)。
第二步:生成一组回答
模型生成一组 G(4) 个回答来应对查询。
第三步:为每个回答计算奖励
什么是奖励? 奖励通过量化模型回答的质量来指导其学习。
GRPO中的奖励类型:
准确性奖励 :基于回答的正确性(例如,解决数学问题)。格式奖励 :确保回答遵循结构化的指导(例如,用 标签包裹的推理过程)。语言一致性奖励 :惩罚语言混杂或格式不连贯的情况。基于其表现,为每个回答分配一个奖励 (rᵢ)。例如,奖励可能取决于:
示例:
第四步:比较回答(群体优势)
表现优于群体平均水平的回答会获得正分,而表现较差的回答则会获得负分。 这种方法在组内引入了竞争机制,推动模型生成更好的回答。 第五步:使用截断技术更新策略
示例:如果新策略开始为 o₁ 分配过多概率,截断技术会确保它不会过度强调这个回答。 这种方法即使在复杂任务(如推理)中,也能实现稳定可靠的策略优化。 第六步:使用KL散度惩罚偏离
整体流程
GRPO 目标函数的执行过程如下:
为查询生成一组回答。 根据预定义标准(例如准确性、格式)为每个回答计算奖励。 在组内比较回答,计算它们的相对优势(A_i)。 更新策略,以倾向于具有更高优势的回答,并通过截断技术确保稳定性。 对更新进行正则化,防止模型偏离其基线太远。 为什么GRPO有效?
无需评判器 :GRPO 通过依赖组内比较,避免了单独评估器的需求,降低了计算成本。稳定学习 :截断技术和KL正则化确保模型稳步改进,不会出现剧烈波动。高效训练 :通过关注相对表现,GRPO 特别适合像推理这样的任务,因为这些任务很难用绝对评分衡量。RLOO(REINFORCE Leave-One-Out)
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
在RLHF过程中,PPO是最常用的对齐算法。PPO是一种包含了很多技巧的强化学习算法,例如GAE,importance weight,policy/value的clip等等。本文提出的观点是,直接采用更简单的policy gradient类强化学习算法也可以取得很好的效果,PPO中的value模型,clip操作等模块可能并不有效。本文提出的RLOO(REINFORCE Leave-One-Out)算法在多种大模型任务中都取得了优于PPO/DPO的结果,同时也对噪声和KL约束更robust。
核心理念 :在经典 REINFORCE 中引入 per-prompt baseline,即“留一法”(Leave-One-Out)来估计 baseline,显著降低梯度方差,在线 RLHF,无需 critic 网络。
PPO算法是由policy gradient/actor-critic等强化学习算法发展而来的算法,已经在众多的强化学习经典任务中验证了效果。然而把PPO用在LLM中会有计算成本高(需要加载policy/ref-policy/value/reward/4个模型),众多模块耦合在一起难以判断错误出现的源头,以及算法表现不稳定等问题。
为了解决上述问题,本文使用更原始,更简单的RL算法去替代PPO。RL中policy-based最基础的reinforce算法如下所示:
b表示baseline,用来降低方差。RLOO使用一种蒙特卡洛的方式去计算b:
这样的方式能够避免使用value model和GAE,减少显存占用。PPO使用GAE的方式来平衡误差和方差。与PPO相比,reinforce算法的方差更大,但是由于预训练出的模型足够强大,方差不是主要问题,用RLOO的形式去进行梯度更新是可以接受的。
REINFORCE++: 比 GRPO 稳定比PPO快
An Efficient RLHF Algorithm with Robustness to Both Prompt and Reward Models
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models
REINFORCE++-baseline 在 reasoning 等任务中非常好用,全局的标准差归一化避免了 std 太小带来的 advantage不稳定 。
REINFORCE++的核心思想是将PPO中的各种优化技巧整合到经典的强化学习算法REINFORCE中,以提升其性能和稳定性。 这样REINFORCE++不需要 Critic 从而节省计算资源,又有加持了 PPO 相关的优化技巧实现高效训练。 REINFORCE++的特点是 比 GRPO 稳定比PPO快。
REINFORCE算法基于蒙特卡罗方法,通过以下步骤进行操作:
– 策略采样 :智能体根据当前策略与环境交互,生成一条状态-动作-奖励序列(轨迹)。
– 回报计算 :对每条轨迹进行回报计算,通常采用折扣累计奖励的形式,即:
其中, γ 是折扣因子, rk 是在时间步 k 获得的即时奖励。
梯度估计 :使用蒙特卡罗方法计算策略梯度,更新策略参数 θ 的公式为:
– 策略更新 :通过梯度上升法更新策略参数:
其中, α 是学习率。
RLHF Implementation Tricks
在 REINFORCE 上集成下面的优化 Tricks 以稳定模型的训练。
Token Level KL-Penalty
Token Level KL-Penalty 是一种在序列生成任务中使用的正则化技术。其主要目的是控制生成的文本与训练数据之间的差异,以避免模型生成过于偏离训练分布的输出。具体方法如下:
这种 Token-level KL 的好处是可以无缝兼容 PRM 并且实现了KL reward的信用分配 (更新:最近也有网友提到用GRPO的外置kl 也可以)
Mini-batch Updates
Mini-batch Updates 是一种常用的优化策略,旨在提高训练效率和稳定性。其基本思想是:
– 小批量样本:将训练数据划分为多个小批量(mini-batch),而不是使用整个数据集进行更新。 – 频繁更新:通过在每个小批量上进行多次参数更新,可以更快地收敛,同时减少内存消耗。 – 随机性引入:小批量更新引入了随机性,有助于避免局部最优解,提高模型的泛化能力。 Reward Normalization and Clipping
Reward Normalization and Clipping 是处理奖励信号不稳定的一种方法。具体包括:
-奖励归一化:通过对奖励进行标准化(例如,减去均值并除以标准差),使得奖励信号更为平稳,从而提高训练过程的稳定性。
– 奖励裁剪:限制奖励值在某个范围内,以防止极端奖励对模型更新造成过大的影响。这有助于保持学习过程的稳定性,并防止梯度爆炸。
Advantage Normalization
Advantage Normalization 是一种用于处理优势函数(advantage function)估计方差的方法。REINFORCE++的优势函数定义为 :
其中 r 是Outcome奖励函数, KL 是per-token 的kl reward, t 是token位置。
优势归一化的步骤包括:
– **均值和方差计算**:对一个batch计算出的优势值进行均值和方差计算。
– **归一化处理**:将优势值减去均值并除以标准差,使得优势值具有更好的数值稳定性,进而提高学习效果。
PPO-Clip
PPO-Clip 是近端策略优化(Proximal Policy Optimization, PPO)算法中的一个关键技巧,用于限制策略更新幅度。其主要思想是:
剪切目标函数 :通过引入一个剪切机制,限制新旧策略之间的比率变化,确保更新不会过大。这可以用以下公式表示:
提高稳定性和样本效率 :这种剪切机制有效防止了策略更新过大导致的不稳定,提高了算法的收敛速度和样本效率。
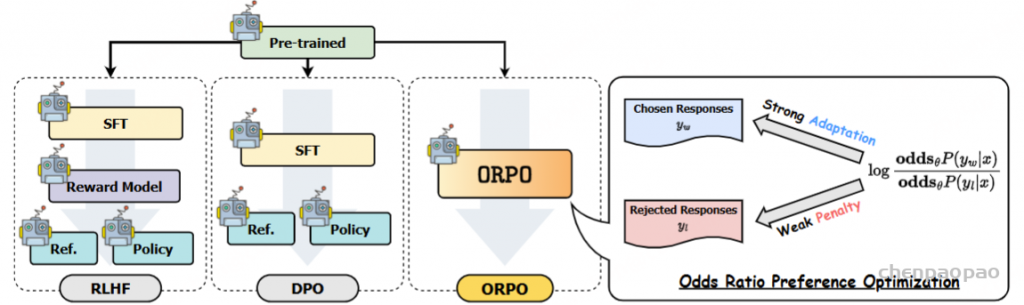
ORPO偏好优化(Odds Ratio Preference Optimization)
ORPO: Monolithic Preference Optimization without Reference Model
核心: 最大化正样本的生成概率,最小化负样本的生成概率 。相比DPO 【加载2个模型,其中一个推理,另外一个训练,直接在偏好数据上进行训练】,只加载训练模型,直接在偏好数据上进行训练 。
本文提出的算法ORPO是对SFT的改进,通过修改SFT阶段的损失函数,将类似于DPO中偏好对齐的思想引入到SFT中,提出一种无需奖励模型和参考模型算法。同时,ORPO只有一阶段,不需要像DPO一样需要先SFT再DPO对齐。在众多大模型任务上的实验结果表明,与SFT,DPO等算法相比,ORPO更有优势。
本文提出的算法ORPO是对SFT的改进,修改了SFT阶段的损失函数。同时,与DPO/PPO相比,ORPO将原本分两步进行的过程(SFT+DPO/PPO)合并为一步,更加简洁高效。
现在有许多方法可以使大型语言模型(LLM)与人类偏好保持一致。以人类反馈为基础的强化学习(RLHF)是最早的方法之一,并促成了ChatGPT的诞生,但RLHF的成本非常高。与RLHF相比,DPO、IPO和KTO的成本明显更低,因为它们不需要奖励模型。
虽然DPO和IPO的成本较低,但它们仍需训练两个不同的模型。首先是监督微调(SFT)步骤,即训练模型按指令回答问题,然后使用SFT模型作为初始化和参考,以使模型与人类偏好一致。
ORPO是另一种新的LLM对齐方法,这种方法甚至不需要SFT模型。通过ORPO,LLM可以同时学习回答指令和满足人类偏好。
对于STF,它是在与选择的答案配对的提示上进行训练的。用于sft的数据集可以与偏好优化使用的相同,但不包括”被拒绝”的答案 。所以可以直观地认为,应该能够微调一个基础LLM,使其在学习如何回答指令的同时,也学会惩罚和偏好某些答案。
SFT只用正样本更新策略,没有考虑到负样本,会把负样本生成的概率同时拉高,如下图所示:
由于SFT的损失函数对于rejected data没有惩罚项,SFT之后正样本和负样本的生成概率有可能同时上升。
odds定义:模型θ生成 输出序列y的可能性 比 不生成y序列的可能性 比值。
OR为正负样本的odds的比值:
ORPO算法要做的就是最大化OR,即最大化正样本的生成概率,最小化负样本的生成概率 ,LOR项用了和DPO类似的logsigmoid的形式:
ORPO就是在这个理论基础上建立的,ORPO简单地通过添加负对数似然损失与OR损失(OR代表奇异比)来修改训练损失:
OR损失对被拒绝的答案进行弱惩罚,而对选择的答案进行强有力的奖励。这里包含了一个超参数lambda用于加权OR损失。通过ORPO的损失,模型在学习了SFT期间的内容的同时,也学会了人类偏好。
ORPO需要数千个训练步骤来学习如何区分选择的响应和拒绝的响应。为了获得类似的结果,应该训练ORPO至少2000步,总批大小为64(如论文所述)。
ORPO 已经可以在Hugging Face库上使用了,并且它因为只修改了损失函数,所以可以很好的与现有的Lora方法集成
ORPO是一种单步微调和对准指令llm的新方法。它不需要任何奖励或SFT模型,并且ORPO比DPO和RLHF更简单。根据论文ORPO的性能与DPO相当或略好。但是ORPO需要几千个训练步骤来学习好的和坏的反应之间的区别。
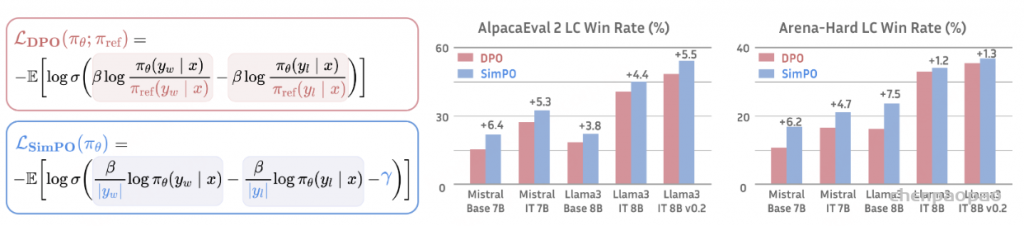
SimPO 简单偏好优化:
算法的核心是将偏好优化目标中的奖励函数与生成指标对齐 ,不需要ref参考模型
SimPO 包含两个主要组件:(1)在长度上归一化的奖励【/|y|】,其计算方式是使用策略模型的奖励中所有 token 的平均对数概率;(2)目标奖励差额 γ ,用以确保获胜和失败响应之间的奖励差超过这个差额 γ 。
DPO 是最常用的离线偏好优化方法之一。DPO 并不会学习一个显式的奖励模型,而是使用一个带最优策略的闭式表达式来对奖励函数 r 进行重新参数 化:
其中 π_θ 是策略模型,π_ref 是参考策略(通常是 SFT 模型),Z (x) 是配分函数。通过将这种奖励构建方式整合进 Bradley-Terry (BT) 排名目标,DPO 可使用策略模型而非奖励模型来表示偏好数据的概率,从而得到以下目标:
DPO 的奖励与生成之间的差异 。使用 (1) 式作为隐式的奖励表达式有以下缺点:(1) 训练阶段需要参考模型 π_ref,这会带来额外的内存和计算成本 ;(2) 训练阶段优化的奖励与推理所用的生成指标之间存在差异 。具体来说,在生成阶段,会使用策略模型 π_θ 生成一个能近似最大化平均对数似然的序列,定义如下:
在解码过程中直接最大化该指标是非常困难的,为此可以使用多种解码策略,如贪婪解码、波束搜索、核采样和 top-k 采样。此外,该指标通常用于在语言模型 执行多选任务时对选项进行排名。在 DPO 中,对于任意三元组 (x, y_w, y_l),满足奖励排名 r (x, y_w) > r (x, y_l) 并不一定意味着满足似然排名:
事实上,在使用 DPO 训练时,留存集中大约只有 50% 的三元组满足这个条件。
构建在长度上归一化的奖励 。很自然地,我们会考虑使用 (3) 式中的 p_θ 来替换 DPO 中的奖励构建,使其与引导生成的似然指标对齐。这会得到一个在长度上归一化的奖励:
其中 β 是控制奖励差异大小的常量。该团队发现,根据响应长度对奖励进行归一化非常关键;从奖励公式中移除长度归一化项会导致模型倾向于生成更长但质量更低的序列。这样一来,构建的奖励中就无需参考模型了,从而实现比依赖参考模型的算法更高的内存和计算效率。
SimPO 目标
目标奖励差额。另外,该团队还为 Bradley-Terry 目标引入了一个目标奖励差额项 γ > 0,以确保获胜响应的奖励 r (x, y_w) 超过失败响应的奖励 r (x, y_l) 至少 γ :
两个类之间的差额已知会影响分类器的泛化能力。在使用随机模型初始化的标准训练设置中,增加目标差额通常能提升泛化性能。在偏好优化中,这两个类别是单个输入的获胜或失败响应。
在实践中,该团队观察到随着目标差额增大,生成质量一开始会提升,但当这个差额变得过大时,生成质量就会下降。DPO 的一种变体 IPO 也构建了与 SimPO 类似的目标奖励差额,但其整体目标的效果不及 SimPO。
目标。最后,通过将 (4) 式代入到 (5) 式中,可以得到 SimPO 目标:
总结起来,SimPO 采用了与生成指标直接对齐的隐式奖励形式,从而消除了对参考模型的需求。此外,其还引入了一个目标奖励差额 γ 来分离获胜和失败响应
KTO:Kahneman-Tversky Optimisation
特点:
KTO关注的是答案偏离平均水准的程度 ——比平均好还是坏 。所以它的训练数据集是对单个问答的“好/差”标注,而不再是成对数据间谁好谁差(所以用户对LLM结果的点赞或踩就可以当做反馈使用了)。
KTO不需要偏好数据,可以直接利用二元信号标记的数据来训练算法,对于负样本更加敏感。 KTO并不需要一个数据对,只需要对生成的结果进行good/bad的二元标注即可。 【比如:ChatGPT UI 界面会输出两个答案,用户可以选择哪个更好,适用于从生产环境中运行的聊天模型的训练】
实验表明,KTO算法在一定参数范围内能够超过DPO算法,并且KTO可以处理数据正负样本不平衡的情况。同时,在跳过SFT阶段的情况下,直接使用KTO相比于直接使用 DPO,效果有很大提升。在数据正负样本比例失衡/偏好数据有非传递性/偏好数据有噪声/的情况下,使用KTO可能是更好的选择。
KTO 使用 Kahneman-Tversky 人类效用模型 ,论文提出直接最大化生成效用的 HALO, 而不是最大化偏好的对数可能性。
在1B~30B尺度上与基于偏好的方法的性能相匹配或超过,尽管它只从二进制信号(0或者1)中学习输出是否可取。 没有一个 HALO 普遍优越; 最佳损失取决于最适合给定设置的归纳偏差,经常被忽视的考虑因素。 KTO算法的具体步骤如下:
定义效用函数 :根据前景理论中的效用函数公式,定义一个效用函数,用于计算模型输出相对于参考点的效用。 计算参考点 :根据概率分布Q(X’, Y’ | x, y),计算出一个参考点,用于衡量模型输出的效用。计算模型输出的效用 :对于每个输入,计算模型输出相对于参考点的收益或损失,然后使用效用函数计算这些收益或损失的效用。优化模型参数 :优化模型参数以最大化模型输出的总效用。KTO 损失函数本质是把 pair-wise 公式变成 point-wise 方式,结合了HALOs以及二元信号数据的思想提出使用Kahneman-Tversky 优化的KTO算法:
其中 zo是KL散度项,参考点zo为最优策略下reward的期望值 ,最终可以推导成KL散度的形式,y’表示任意输出,在实际训练中,Z0 表示batch平均水准的程度 【Z0 从 当前batch里面的样本进行估计得到的 】 ,平均 reward,代表不好不坏的居中的结果。 LKTO 就是DPO中推导的reward函数形式。
按照上面的定义估计z0是不切实际的,因为从πθ采样很慢,人类无法感知πθ引起的完整分布。
这个估计是有偏差的,但这是可取的,因为它使我们更接近人类如何构建他们的主观参考点。
实际上KTO相对比DPO差异就两点
对正负样本进行了加权 :DPO里面是使用正负样本的reward差值 进行sigmoid映射,但是KTO里面使用reward模型与KL散度之间的差异 !(说是KL散度,但其实也是bad的log比值数值!不过不是同一个pair )注意:在实践的时候,KL项并不参与反向传播 ,这其实就跟DPO更相似的。DPO使一个数据对,但是这里把DPO给拆分了,相当于对每一个样本单独进行最大化或最小化了,以及进行加权。 另一个作用就是,如果 rKTO(x,y) 的差异与KL散度有足够区别的话,那对应的Loss也就比较小。因此,KTO会更加鼓励差异大的数据对。 但其实我们可以从KTO的目标函数直接看到。由于KTO是分别针对单条数据,如果数据是正样本,那么一定要超过 zo 才会产生预测正确反馈;对于负样本,需要低于 zo才会产生预测正确反馈 KTO和DPO的选择 :
数据比例 :如果数据集是以good/bad形式进行标注,并且数据比例不平衡,那么选择KTO数据质量 :如果你的偏好数据质量高,数据噪声小,那么DPO的效果更好。由于目前公开的数据集中存在的噪声较大,这就能解释为什么KTO的效果会超过DPO了。理论分析 :KTO不会从负样本中学习到很高的反馈,也不会从正样本中学习到很低的反馈(所以对噪声比较鲁棒)KTO 的工作原理:
如果模型以直接(blunt manner)方式增加了理想示例的奖励,那么 KL 惩罚也会增加,并且不会取得任何进步。这迫使模型准确地了解是什么让输出变得理想,这样就可以增加奖励,同时保持 KL 项持平(甚至减少)。 实际实现中,KL 项是通过当前batch里面的正负样本进行估计得到的 【可以认为是batch样本的平均水平 】,详细 debug KTOTrainer 源代码 对成对偏好数据进行分配 :
与大多数比对方法一样,DPO 需要一个成对偏好数据集(x, y_w, y_l),够根据一组标准(如有益性或有害性)来标记哪种模型响应更好。 实践过程中,创建这些数据是一项耗时且成本高昂的工作。 ContextualAI 提出替代方案,称为 Kahneman-Taversky 优化(KTO),完全根据被标记为「好」或「坏」的样本(例如在聊天 UI 中看到的图标👍或👎)来定义损失函数。 这些标签更容易获得, KTO 是一种很有前景的方法,不断更新在生产环境中运行的聊天模型。 与此同时,这些方法都有相应的超参数,其中最重要的是 β ,控制对使用模型的偏好程度的权重。这些方法已经在第三方库(如 huggingface TRL)中实现
KTO 数据集 :
KTO 不需要成对的偏好数据,实验时直接将 GPT-4 生成的响应归类为「好」标签,将 Llama Chat 13b 的响应视为「坏」标签。
KTO数据集与偏好数据集类似,但不同于给出一个更优的回答和一个更差的回答,KTO数据集对每一轮问答只给出一个 true/false 的 label。 除了 instruction 以及 input 组成的人类最终输入和模型回答 output ,KTO 数据集还需要额外添加一个 kto_tag 列(true/false)来表示人类的反馈。在一轮问答中其格式如下:
[
{
"instruction" : "人类指令(必填)",
"input" : "人类输入(选填)",
"output" : "模型回答(必填)",
"kto_tag" : "人类反馈 [true/false](必填)"
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称" : {
"file_name" : "data.json",
"columns" : {
"prompt" : "instruction",
"query" : "input",
"response" : "output",
"kto_tag" : "kto_tag"
}
} 代码实现:
基于pytorch、deepspeed、transformers ,代码:
sft训练代码:
def loss(self, sft_batch: SupervisedBatch) -> dict[str, torch.Tensor]:
"""Loss function for supervised finetuning."""
outputs = self.model (**self.infer_batch(sft_batch))
return {'loss': outputs.loss}
def train_step(self, sft_batch: SupervisedBatch) -> dict[str, Any]:
"""Performs a single training step."""
loss = self.loss(sft_batch)['loss']
self.model.backward (loss)
self.model.step ()
return {
'train/loss': loss.item(),
'train/lr': self.model.optimizer.param_groups[0]['lr'],
}dpo训练代码:
https://blog.csdn.net/weixin_43013480/article/details/141370269
# 从 logits(未归一化的概率分布)中,提取 labels 对应类别的对数概率(log probabilities)。
def gather_log_probabilities(
logits: torch.Tensor, # size = (B, L, V)
labels: torch.LongTensor, # size = (B, L)
) -> torch.Tensor: # size = (B, L)
"""Gather log probabilities of the given labels from the logits."""
log_probs = F.log_softmax(logits, dim=-1) # size = (B, L, V)
gathered_log_probs = torch.gather( # size = (B, L, 1)
log_probs,
dim=-1,
index=labels.unsqueeze(dim=-1).to(torch.int64),
)
return gathered_log_probs.squeeze(dim=-1) # size = (B, L)def compute_log_probs(
self,
model: AutoModelForCausalLM,
batch: PreferenceBatch,
) -> torch.Tensor:
"""Compute log probabilities of given sequences."""
# 获得所有可能输出的log概率,logits 表示每个 token 位置的 未归一化的概率分布
logits = model(**self.infer_batch(batch)).logits
device = logits.device
input_ids = batch['input_ids']
#取得每个样本的回复长度,用于截取模型输出
batch_size = len(batch['meta_info']['response_lens'])
logprob_list = []
for idx in range(batch_size):
response_length = batch['meta_info']['response_lens'][idx]
# 去除填充 (PAD) token,避免计算无效 token 的概率。
raw_input_id = strip_pad(input_ids[idx], self.tokenizer.pad_token_id)
#只保留 回复部分的 logits,丢弃 prompt 部分。
logit = logits[idx][-response_length:].unsqueeze(0)
input_id = raw_input_id[-response_length:].unsqueeze(0)
#计算对应的better 和worse 序列token 对数概率
log_p = gather_log_probabilities(logit[:, :-1], input_id[:, 1:])
logprob_list.append(log_p.squeeze(0))
# 不同样本的 log_probs 长度不同,使用 pad_sequence 进行 padding,补齐到相同长度。
return torch.nn.utils.rnn.pad_sequence(
logprob_list, batch_first=True, padding_value=0.0
).to(device)
def loss( # pylint: disable=too-many-locals
self,
batch: PreferenceBatch,
) -> dict[str, torch.Tensor]:
"""Loss function for the DPO algorithm."""
#计算当前模型 (self.model.module) 在 batch 上的 log 概率。
sequence_log_probs = self.compute_log_probs(
self.model.module,
batch,
)
# better_sequence_log_probs (用户偏好的回复)
# worse_sequence_log_probs (用户不喜欢的回复)
(
better_sequence_log_probs, # size = (B, L - 1)
worse_sequence_log_probs, # size = (B, L - 1)
) = sequence_log_probs.chunk(chunks=2, dim=0)
# 计算参考模型 (self.reference_model.module) 的对数概率 (log_probs)。
# reference_model 通常是 原始未优化的模型,作为对比基准。
# torch.no_grad() 表示 不计算梯度,避免影响参考模型。
with torch.no_grad():
ref_sequence_log_probs = self.compute_log_probs( # size = (2 * B, L - 1)
self.reference_model.module,
batch,
)
ref_better_sequence_log_probs, ref_worse_sequence_log_probs = (
ref_sequence_log_probs.chunk(chunks=2, dim=0)
)
losses = []
better_sample_rewards = []
worse_sample_rewards = []
batch_size = better_sequence_log_probs.size(0)
for i in range(batch_size):
# 计算 更好/更差回复的总 log 概率(即累加 token 级别 log 概率)。
better_log_prob = better_sequence_log_probs[i, :].sum(dim=-1)
worse_log_prob = worse_sequence_log_probs[i, :].sum(dim=-1)
ref_better_log_prob = ref_better_sequence_log_probs[i, :].sum(dim=-1)
ref_worse_log_prob = ref_worse_sequence_log_probs[i, :].sum(dim=-1)
# 当前模型比参考模型更偏好 better 回复 的程度。
better_log_ratio = better_log_prob - ref_better_log_prob
# 当前模型比参考模型更偏好 worse 回复 的程度。
worse_log_ratio = worse_log_prob - ref_worse_log_prob
# 计算 better 和 worse 的 log 比值差
# 使用 -logsigmoid(x) 计算负对数 sigmoid 损失,优化模型使其更倾向 better 回复。
# logsigmoid 的性质:
# 如果 x 很大,logsigmoid(x) ≈ 0,意味着损失小,模型已经正确偏好 better response。
# 如果 x 很小或负,logsigmoid(x) ≈ x,意味着损失大,模型没有正确区分 better 和 worse,需要优化。
losses.append(
-F.logsigmoid(
self.cfgs.train_cfgs.scale_coeff * (better_log_ratio - worse_log_ratio),
),
)
better_sample_rewards.append(
self.cfgs.train_cfgs.scale_coeff * better_log_ratio.detach(),
)
worse_sample_rewards.append(self.cfgs.train_cfgs.scale_coeff * worse_log_ratio.detach())
loss = torch.stack(losses).mean() # size = ()
better_sample_reward = torch.stack(better_sample_rewards) # size = (B,)
worse_sample_reward = torch.stack(worse_sample_rewards) # size = (B,)
# 计算 奖励 (reward)、准确率 (accuracy) 和奖励间距 (margin)。
reward = better_sample_reward + worse_sample_reward # size = (B,)
reward_accuracy = (better_sample_reward > worse_sample_reward).float().mean() # size = ()
reward_margin = better_sample_reward - worse_sample_reward # size = (B,)
return {
'loss': loss,
'reward': reward,
'better_sample_reward': better_sample_reward,
'worse_sample_reward': worse_sample_reward,
'reward_accuracy': reward_accuracy,
'reward_margin': reward_margin,
}
def train_step(
self,
batch: PreferenceBatch,
) -> dict[str, Any]:
"""Perform a single training step for DPO."""
loss_dict = self.loss(batch=batch)
loss = loss_dict['loss']
self.model.backward(loss)
self.model.step()
with torch.no_grad():
reward = loss_dict['reward'].mean()
better_sample_reward = loss_dict['better_sample_reward'].mean()
worse_sample_reward = loss_dict['worse_sample_reward'].mean()
reward_accuracy = loss_dict['reward_accuracy']
reward_margin = loss_dict['reward_margin'].mean()
loss = get_all_reduce_mean(loss)
reward = get_all_reduce_mean(reward)
better_sample_reward = get_all_reduce_mean(better_sample_reward)
worse_sample_reward = get_all_reduce_mean(worse_sample_reward)
reward_accuracy = get_all_reduce_mean(reward_accuracy)
reward_margin = get_all_reduce_mean(reward_margin)
return {
'train/loss': loss.item(),
'train/reward': reward.item(),
'train/better_sample_reward': better_sample_reward.item(),
'train/worse_sample_reward': worse_sample_reward.item(),
'train/reward_accuracy': reward_accuracy.item(),
'train/reward_margin': reward_margin.item(),
'train/lr': self.model.optimizer.param_groups[0]['lr'],
}ppo训练代码:
#使用策略模型 (Actor Model) 生成文本,并返回其 input_ids 和 attention_mask。
def actor_step(self, mini_prompt_only_batch: PromptOnlyBatch) -> dict[str, Any]:
infer_batch = self.infer_batch(mini_prompt_only_batch)
actor_batch = copy.deepcopy(infer_batch)
sequences = self.actor_model.module.generate(
**infer_batch,
generation_config=self.generation_config,
synced_gpus=True,
do_sample=True,
)
attention_mask = sequences.not_equal(self.tokenizer.pad_token_id)
actor_batch['input_ids'] = sequences
actor_batch['attention_mask'] = attention_mask
return actor_batch
# 计算奖励值 (reward) 和对抗奖励值 (reward_values)。
def reward_model_step(self, actor_batch: PromptOnlyBatch) -> dict[str, Any]:
reward_batch = copy.deepcopy(actor_batch)
if self.reward_tokenizer is not self.tokenizer:
reward_tokenize_output = batch_retokenize(
actor_batch['input_ids'],
src_tokenizer=self.tokenizer,
dest_tokenizer=self.reward_tokenizer,
skip_special_tokens=True,
device=self.args.device,
)
reward_batch['input_ids'] = reward_tokenize_output['input_ids']
reward_batch['attention_mask'] = reward_tokenize_output['attention_mask']
reward_infer_batch = self.reward_infer_batch(reward_batch)
reward_batch['reward'] = self.reward_model(**reward_infer_batch).end_scores.squeeze(dim=-1)
critic_infer_batch = self.reward_infer_batch(actor_batch)
scores = self.reward_critic_model(**critic_infer_batch).scores
reward_batch['reward_values'] = scores.squeeze(dim=-1)[:, :-1]
return reward_batch#冻结模型参数,避免影响训练,采样多个 mini-batch,生成文本,计算奖励,计算 log 概率 (log_probs),计算参考模型的 log 概率 (ref_log_probs)
# 经验回放:生成训练数据并计算指标
@torch.no_grad()
def rollout(self, prompt_only_batch: PromptOnlyBatch) -> list[dict[str, Any]]:
"""Rollout a batch of experiences."""
# freeze the model for rolling out
self.set_train(mode=False)
total_batch_size = prompt_only_batch['input_ids'].size(0)
micro_batch_size = int(self.cfgs.train_cfgs.per_device_train_batch_size)
micro_inference_batches = []
micro_training_batches = []
mini_batch = {}
for i in range(0, total_batch_size, micro_batch_size):
mini_batch = {
key: prompt_only_batch[key][i : i + micro_batch_size] for key in prompt_only_batch
}
# actor generation
actor_batch = self.actor_step(mini_batch)
# reward model and reward critic model scoring
reward_batch = self.reward_model_step(actor_batch)
# calculate the log probabilities
logits = self.actor_model(**actor_batch).logits
ref_logits = self.actor_reference_model(**actor_batch).logits
log_probs = gather_log_probabilities(logits[:, :-1], actor_batch['input_ids'][:, 1:])
ref_log_probs = gather_log_probabilities(
ref_logits[:, :-1], actor_batch['input_ids'][:, 1:]
)
micro_training_batch = {}
micro_training_batch['prompt_idx'] = mini_batch['input_ids'].size(-1) - 1
micro_training_batch['log_probs'] = log_probs
micro_training_batch['ref_log_probs'] = ref_log_probs
micro_training_batch['reward'] = reward_batch['reward']
micro_training_batch['reward_values'] = reward_batch['reward_values']
mini_batch['input_ids'] = reward_batch['input_ids']
mini_batch['attention_mask'] = actor_batch['attention_mask']
# add rollout results to the batches
micro_inference_batches.append(mini_batch)
micro_training_batches.append(micro_training_batch)
# unfreeze the model for training
self.set_train()
return micro_inference_batches, micro_training_batches
#计算策略梯度损失
# 计算 PPO 损失函数:
# ratios = exp(new_log_probs - old_log_probs)(新旧策略比)。
# 裁剪 ratios 避免策略剧烈变化(PPO 关键)。
# return -masked_mean(surrogate, mask):最大化优势 𝐴𝑡
def actor_loss_fn(
self,
log_probs: torch.Tensor, # size = (B, L - S)
old_log_probs: torch.Tensor, # size = (B, L - S)
advantages: torch.Tensor, # size = (B, L - S)
mask: torch.BoolTensor, # size = (B, L - S)
) -> torch.Tensor: # size = ()
# size = (B, L - S)
ratios = torch.exp(log_probs - old_log_probs)
surrogate1 = advantages * ratios
surrogate2 = advantages * torch.clamp(
ratios,
1.0 - self.clip_range_ratio,
1.0 + self.clip_range_ratio,
)
surrogate = torch.minimum(surrogate1, surrogate2)
return -masked_mean(surrogate, mask) # size = ()
# rl_step函数是训练过程中使用强化学习(RL)更新策略的一步。在PPo算法中,rl_step是用来更新策略网络(actor)和价值网络(critic)的一部分。具体来说,这个函数通过计算强化学习损失(actor loss和critic loss),并通过反向传播优化这两个网络。
# reward_critic_model 评估奖励函数的 价值估计,用于计算 优势函数 𝐴𝑡不是直接计算奖励,而是估算未来可能获得的奖励。主要用于时间差分(TD learning)更新策略,类似于 价值函数。
def rl_step(
self, inference_batch: dict[str, torch.Tensor], training_batch: dict[str, torch.Tensor]
) -> dict[str, Any]:
"""Perform a single update step with RL loss."""
old_log_probs = training_batch['log_probs']
ref_log_probs = training_batch['ref_log_probs']
reward = training_batch['reward']
old_reward_values = training_batch['reward_values']
start = training_batch['prompt_idx']
input_ids = inference_batch['input_ids']
attention_mask = inference_batch['attention_mask']
sequence_mask = attention_mask[:, 1:]
with torch.no_grad():
old_rewards = self.add_kl_divergence_regularization(
reward,
old_log_probs,
ref_log_probs,
sequence_mask,
)
reward_advantages, reward_returns = self.get_advantages_and_returns(
old_reward_values,
old_rewards,
sequence_mask,
start,
)
logits = self.actor_model(**inference_batch, use_cache=False).logits
log_probs = gather_log_probabilities(logits[:, :-1], input_ids[:, 1:])
actor_loss = self.actor_loss_fn(
log_probs[:, start:],
old_log_probs[:, start:],
reward_advantages,
sequence_mask[:, start:],
)
self.actor_model.backward(actor_loss)
self.actor_model.step()
reward_values = self.reward_critic_model(**inference_batch).scores
reward_values = reward_values.squeeze(dim=-1)[:, :-1]
reward_critic_loss = self.critic_loss_fn(
reward_values[:, start:],
old_reward_values[:, start:],
reward_returns,
sequence_mask[:, start:],
)
self.reward_critic_model.backward(reward_critic_loss)
self.reward_critic_model.step()
with torch.no_grad():
mask = sequence_mask[:, start:]
kl_divergence = ((old_log_probs - ref_log_probs)[:, start:] * mask).sum(dim=-1).mean()
mean_generated_length = mask.sum(dim=-1).float().mean()
max_generated_length = mask.sum(dim=-1).float().max()
reward = reward.mean()
reward_with_kl_penalty = (old_rewards[:, start:] * mask).sum(dim=-1).mean()
reward_advantage = masked_mean(reward_advantages, mask)
reward_return = masked_mean(reward_returns, mask)
reward_value = masked_mean(reward_values[:, start:], mask)
actor_loss = get_all_reduce_mean(actor_loss)
reward_critic_loss = get_all_reduce_mean(reward_critic_loss)
reward = get_all_reduce_mean(reward)
reward_with_kl_penalty = get_all_reduce_mean(reward_with_kl_penalty)
reward_advantage = get_all_reduce_mean(reward_advantage)
reward_return = get_all_reduce_mean(reward_return)
reward_value = get_all_reduce_mean(reward_value)
kl_divergence = get_all_reduce_mean(kl_divergence)
mean_generated_length = get_all_reduce_mean(mean_generated_length)
max_generated_length = get_all_reduce_max(max_generated_length)
dist.barrier()
return {
'train/actor_loss': actor_loss.item(),
'train/reward_critic_loss': reward_critic_loss.item(),
'train/reward': reward.item(),
'train/reward_with_kl_penalty': reward_with_kl_penalty.item(),
'train/reward_advantage': reward_advantage.item(),
'train/reward_return': reward_return.item(),
'train/reward_value': reward_value.item(),
'train/kl_divergence': kl_divergence.item(),
'train/actor_lr': self.actor_model.optimizer.param_groups[0]['lr'],
'train/reward_critic_lr': self.reward_critic_model.optimizer.param_groups[0]['lr'],
'train/mean_generated_length': mean_generated_length.item(),
'train/max_generated_length': max_generated_length.item(),
}
def ptx_step(self, ptx_batch: dict[str, torch.Tensor]) -> dict[str, Any]:
"""Perform a single update step with PTX loss."""
ptx_loss = self.actor_model(**self.infer_batch(ptx_batch)).loss
self.actor_model.backward(self.ptx_coeff * ptx_loss)
self.actor_model.step()
ptx_loss = get_all_reduce_mean(ptx_loss)
return {
'train/ptx_loss': ptx_loss.item(),
}
def train(self) -> None:
"""Train the model."""
self.logger.print('***** Running training *****')
progress_bar = tqdm(
total=self.total_training_steps,
desc=f'Training 1/{self.cfgs.train_cfgs.epochs} epoch',
position=0,
leave=True,
disable=not is_main_process(),
)
if self.cfgs.data_cfgs.eval_datasets:
self.logger.print('\n***** Evaluating at the beginning *****')
self.eval()
num_prompt_only_batches = len(self.prompt_only_dataloader)
num_ptx_batches = len(self.ptx_dataloader)
num_ptx_replicas = (num_prompt_only_batches + num_ptx_batches - 1) // num_ptx_batches
for epoch in range(int(self.cfgs.train_cfgs.epochs)):
for prompt_only_batch, ptx_batch in zip(
self.prompt_only_dataloader,
itertools.chain.from_iterable([self.ptx_dataloader] * num_ptx_replicas),
):
inference_batches, training_batches = self.rollout(prompt_only_batch)
if self.use_ptx:
ptx_batches = self.split_ptx_micro_batches(ptx_batch)
else:
ptx_batches = [None for _ in range(len(inference_batches))]
torch.cuda.empty_cache()
for _ in range(self.cfgs.train_cfgs.update_iters):
for inference_batch, training_batch, ptx_batch in zip(
inference_batches, training_batches, ptx_batches
):
rl_info = self.rl_step(inference_batch, training_batch)
torch.cuda.empty_cache()
self.logger.log(rl_info, step=self.global_step)
if self.use_ptx:
ptx_info = self.ptx_step(ptx_batch)
torch.cuda.empty_cache()
self.logger.log(ptx_info, step=self.global_step)
self.global_step += 1
progress_bar.set_description(
f'Training {epoch + 1}/{self.cfgs.train_cfgs.epochs} epoch '
f'(reward {rl_info["train/reward"]:.4f})',
)
progress_bar.update(1)
if self.global_step % self.cfgs.logger_cfgs.save_interval == 0:
self.logger.print(f'Saving checkpoint at step {self.global_step} ...')
self.save(tag=self.global_step)
self.logger.print('Checkpoint saved.')
if (
self.cfgs.data_cfgs.eval_datasets
and self.cfgs.train_cfgs.eval_strategy == 'steps'
and self.global_step % self.cfgs.train_cfgs.eval_interval == 0
):
self.logger.print(
f'\n***** Evaluating at step {self.global_step} *****',
)
self.eval()RM奖励模型训练代码:
def loss(
self,
batch: PreferenceBatch,
) -> dict[str, torch.Tensor]:
"""Loss function for the reward model."""
(
better_input_ids, # size = (B, L)
worse_input_ids, # size = (B, L)
) = batch[
'input_ids'
].chunk(chunks=2, dim=0)
assert better_input_ids.size(0) == worse_input_ids.size(0), 'batch size mismatch!'
# scores:一般来说,这代表模型在每个时间步骤(或输入分段)上的奖励得分,通常是一个形状为 (B, L, 1) 的张量,其中 B 是批量大小,L 是输入序列的长度,1 是奖励得分的维度。
#end_scores:通常表示输入序列的结束阶段的奖励得分,这可能是在整个序列处理完成后,模型计算出的最终奖励。
output = self.model(**self.infer_batch(batch))
scores = output.scores
end_scores = output.end_scores
higher_rewards, lower_rewards = scores.squeeze(dim=-1).chunk(chunks=2, dim=0)
higher_end_reward, lower_end_reward = end_scores.squeeze(dim=-1).chunk(chunks=2, dim=0)
loss = -F.logsigmoid(higher_end_reward - lower_end_reward).mean()
if self.cfgs.train_cfgs.regularization > 0.0:
loss = (
loss
+ self.cfgs.train_cfgs.regularization
* torch.stack([lower_end_reward, higher_end_reward]).square().mean()
)
accuracy = (higher_end_reward > lower_end_reward).float().mean() # size = ()
return {
'loss': loss, # size = ()
'higher_end_reward': higher_end_reward, # size = (B,)
'lower_end_reward': lower_end_reward, # size = (B,)
'higher_rewards': higher_rewards, # size = (B, L)
'lower_rewards': lower_rewards, # size = (B, L)
'accuracy': accuracy, # size = ()
}
def train_step(
self,
batch: PreferenceBatch,
) -> dict[str, Any]:
"""Perform a single training step."""
loss_dict = self.loss(batch)
loss = loss_dict['loss']
self.model.backward(loss)
self.model.step()
accuracy = loss_dict['accuracy']
loss = get_all_reduce_mean(loss)
accuracy = get_all_reduce_mean(accuracy)
return {
'train/loss': loss.item(),
'train/accuracy': accuracy.item(),
'train/lr': self.model.optimizer.param_groups[0]['lr'],
} orpo 训练代码:
相关介绍:https://github.com/Paul33333/ORPO
# 从 logits(未归一化的概率分布)中,提取 labels 对应类别的对数概率(log probabilities)。
def gather_log_probabilities(
logits: torch.Tensor, # size = (B, L, V)
labels: torch.LongTensor, # size = (B, L)
) -> torch.Tensor: # size = (B, L)
"""Gather log probabilities of the given labels from the logits."""
log_probs = F.log_softmax(logits, dim=-1) # size = (B, L, V)
gathered_log_probs = torch.gather( # size = (B, L, 1)
log_probs,
dim=-1,
index=labels.unsqueeze(dim=-1).to(torch.int64),
)
return gathered_log_probs.squeeze(dim=-1) # size = (B, L)
# compute_log_probs 的作用是计算给定序列的 log 概率 (对数概率),主要用于评估语言模型(LLM)的生成质量。
def compute_log_probs(
self,
model: AutoModelForCausalLM,
batch: PreferenceBatch,
) -> torch.Tensor:
"""Compute log probabilities of given sequences."""
logits = model(**self.infer_batch(batch)).logits
device = logits.device
input_ids = batch['input_ids']
batch_size = len(batch['meta_info']['response_lens'])
logprob_list = []
for idx in range(batch_size):
response_length = batch['meta_info']['response_lens'][idx] # for the eos token
logit = logits[idx][-response_length:].unsqueeze(0)
input_id = input_ids[idx][-response_length:].unsqueeze(0)
# logit[:, :-1]取 response 部分的 logits,去掉最后一个 token(因为 logits 预测的是下一个 token)input_id[:, 1:]: 取 response 部分的 token IDs,从第二个 token 开始(因为 log_probs 计算的是下一个 token 概率)。
作用:计算 response 部分每个 token 的 log 概率(对 logit 的 softmax 取对数)。
log_p = gather_log_probabilities(logit[:, :-1], input_id[:, 1:])
logprob_list.append(log_p.squeeze(0))
#pad填充,返回张量形状 (B, max_L_resp)
return torch.nn.utils.rnn.pad_sequence(
logprob_list, batch_first=True, padding_value=0.0
).to(device)
class ORPOTrainer(DPOTrainer):
def loss( # pylint: disable=too-many-locals
self,
batch: PreferenceBatch, # size = (2*B, L)
) -> dict[str, torch.Tensor]:
"""Loss function for the ORPO algorithm."""
sequence_log_probs = self.compute_log_probs(
self.model.module,
batch,
)
(
better_sequence_log_probs, # size = (B, L - 1)
worse_sequence_log_probs, # size = (B, L - 1)
) = sequence_log_probs.chunk(chunks=2, dim=0)
losses = []
better_sample_rewards = []
worse_sample_rewards = []
better_input_ids, worse_input_ids = batch['input_ids'].chunk(chunks=2, dim=0)
better_attention_mask, worse_attention_mask = batch['attention_mask'].chunk(chunks=2, dim=0)
batch_size = better_input_ids.size(0)
#diverge_index 代表 better 和 worse 输入序列开始不同的位置:diverge_index,即它之后的 token 是模型生成的部分。
for i in range(batch_size):
if torch.all(torch.eq(better_input_ids[i], worse_input_ids[i])).item():
continue
better_end_index = better_attention_mask[i].nonzero()[-1].squeeze().item()
worse_end_index = worse_attention_mask[i].nonzero()[-1].squeeze().item()
diverge_index = (
(better_input_ids[i] != worse_input_ids[i]).nonzero()[0].squeeze().item()
)
assert 0 <= diverge_index <= better_end_index, 'diverge index is out of range!'
assert 0 <= diverge_index <= worse_end_index, 'diverge index is out of range!'
# better_seq_slice 和 worse_seq_slice 取从 diverge_index 开始到序列结束的部分(即模型生成的 token)。
better_seq_slice = slice(diverge_index, better_end_index + 1)
worse_seq_slice = slice(diverge_index, worse_end_index + 1)
better_seq_length = better_end_index + 1
worse_seq_length = worse_end_index + 1
# size = ()
# better_log_prob: 计算 better 部分的总 log 概率。
# worse_log_prob: 计算 worse 部分的总 log 概率。
# 计算 对数比率(log ratio):
better_log_prob = better_sequence_log_probs[i, better_seq_slice].sum(dim=-1)
worse_log_prob = worse_sequence_log_probs[i, worse_seq_slice].sum(dim=-1)
better_log_ratio = better_log_prob / better_seq_length
worse_log_ratio = worse_log_prob / worse_seq_length
# 计算 ORPO 的 odds ratio loss:
log_odds = (better_log_ratio - worse_log_ratio) - (
torch.log1p(-torch.exp(better_log_ratio)) - torch.log1p(-torch.exp(worse_log_ratio))
)
# better 的 log 概率明显高于 worse,从而优化生成策略。
odds_ratio_loss = -F.logsigmoid(log_odds)
# 最终损失
sft_loss = -better_log_ratio
losses.append(
sft_loss + self.cfgs.train_cfgs.scale_coeff * odds_ratio_loss,
)
better_sample_rewards.append(
self.cfgs.train_cfgs.scale_coeff * better_log_ratio.detach(),
)
worse_sample_rewards.append(self.cfgs.train_cfgs.scale_coeff * worse_log_ratio.detach())
loss = torch.stack(losses).mean() # size = ()
better_sample_reward = torch.stack(better_sample_rewards) # size = (B,)
worse_sample_reward = torch.stack(worse_sample_rewards) # size = (B,)
reward = better_sample_reward + worse_sample_reward # size = (B,)
reward_accuracy = (better_sample_reward > worse_sample_reward).float().mean() # size = ()
reward_margin = better_sample_reward - worse_sample_reward # size = (B,)
return {
'loss': loss,
'reward': reward,
'better_sample_reward': better_sample_reward,
'worse_sample_reward': worse_sample_reward,
'reward_accuracy': reward_accuracy,
'reward_margin': reward_margin,
}
def main():
# setup distribution training
deepspeed.init_distributed()
current_device = get_current_device()
torch.cuda.set_device(current_device)
# read default configs from the yaml file
task = os.path.join('text_to_text', 'orpo')
dict_cfgs, ds_cfgs = read_cfgs(mode='train', task=task)
# get custom configs from command line
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
_, unparsed_args = parser.parse_known_args()
keys = [k[2:] for k in unparsed_args[1::2]]
values = list(unparsed_args[2::2])
unparsed_args = dict(zip(keys, values))
for k, v in unparsed_args.items():
dict_cfgs = update_dict(dict_cfgs, custom_cfgs_to_dict(k, v))
# setup training
cfgs = dict_to_namedtuple(dict_cfgs)
seed_everything(cfgs.train_cfgs.seed)
# finetune the model
trainer = ORPOTrainer(cfgs=cfgs, ds_cfgs=ds_cfgs)
trainer.train()
trainer.save()SimPO训练代码:
https://blog.csdn.net/weixin_43013480/article/details/141370269
# compute_log_probs 的作用是计算给定序列的 log 概率 (对数概率),主要用于评估语言模型(LLM)的生成质量。
def compute_log_probs(
self,
model: AutoModelForCausalLM,
batch: PreferenceBatch,
) -> torch.Tensor:
"""Compute log probabilities of given sequences."""
logits = model(**self.infer_batch(batch)).logits
device = logits.device
input_ids = batch['input_ids']
batch_size = len(batch['meta_info']['response_lens'])
logprob_list = []
for idx in range(batch_size):
response_length = batch['meta_info']['response_lens'][idx]
raw_input_id = strip_pad(input_ids[idx], self.tokenizer.pad_token_id)
logit = logits[idx][-response_length:].unsqueeze(0)
input_id = raw_input_id[-response_length:].unsqueeze(0)
log_p = gather_log_probabilities(logit[:, :-1], input_id[:, 1:])
logprob_list.append(log_p.squeeze(0))
return torch.nn.utils.rnn.pad_sequence(
logprob_list, batch_first=True, padding_value=0.0
).to(device)class SimPOTrainer(DPOTrainer):
def loss( # pylint: disable=too-many-locals
self,
batch: PreferenceBatch,
) -> dict[str, torch.Tensor]:
"""Loss function for the SimPO algorithm."""
sequence_log_probs = self.compute_log_probs(
self.model.module,
batch,
)
# 使用 chunk 将 sequence_log_probs 按照第0维(批次维度)进行切分。将批次数据分为两部分:一部分对应 "更好"(better_sequence_log_probs),另一部分对应 "更差"(worse_sequence_log_probs)。每部分的大小为 (B, L - 1),B 是批次大小,L 是序列长度。 L-1 是为了删除最后的 <eos>
(
better_sequence_log_probs, # size = (B, L - 1)
worse_sequence_log_probs, # size = (B, L - 1)
) = sequence_log_probs.chunk(chunks=2, dim=0)
losses = []
better_sample_rewards = []
worse_sample_rewards = []
better_input_ids, worse_input_ids = batch['input_ids'].chunk(chunks=2, dim=0)
better_attention_mask, worse_attention_mask = batch['attention_mask'].chunk(chunks=2, dim=0)
batch_size = better_input_ids.size(0)
for i in range(batch_size):
#检查当前样本的 "更好" 和 "更差" 部分的 input_ids 是否相同。如果相同,跳过这个样本,因为它们对比不出差异。
if torch.all(torch.eq(better_input_ids[i], worse_input_ids[i])).item():
continue
#分别计算 "更好" 和 "更差" 样本的结束位置(通过 attention_mask 中的非零元素位置来确定)。
better_end_index = better_attention_mask[i].nonzero()[-1].squeeze().item()
worse_end_index = worse_attention_mask[i].nonzero()[-1].squeeze().item()
better_input_length = better_end_index + 1
worse_input_length = worse_end_index + 1
# diverge_index 是 "更好" 和 "更差" 样本之间的第一个差异位置。
diverge_index = (
(better_input_ids[i] != worse_input_ids[i]).nonzero()[0].squeeze().item()
)
assert 0 <= diverge_index <= better_end_index, 'diverge index is out of range!'
assert 0 <= diverge_index <= worse_end_index, 'diverge index is out of range!'
#根据 diverge_index 进行切片,获取差异区域的对数概率。
#better_log_prob 和 worse_log_prob 是对应于 "更好" 和 "更差" 样本的对数概率的总和。
better_seq_slice = slice(diverge_index, better_end_index + 1)
worse_seq_slice = slice(diverge_index, worse_end_index + 1)
# 计算损失和奖励
better_log_prob = better_sequence_log_probs[i, better_seq_slice].sum(dim=-1)
worse_log_prob = worse_sequence_log_probs[i, worse_seq_slice].sum(dim=-1)
#在长度上归一化的奖励【/|y|】,其计算方式是使用策略模型的奖励中所有 token 的平均对数概率;
better_log_ratio = better_log_prob / better_input_length
worse_log_ratio = worse_log_prob / worse_input_length
#目标奖励差额γ,用以确保获胜和失败响应之间的奖励差超过这个差额γ
losses.append(
-F.logsigmoid(
self.cfgs.train_cfgs.scale_coeff * (better_log_ratio - worse_log_ratio)
- self.cfgs.train_cfgs.gamma,
),
)
better_sample_rewards.append(
self.cfgs.train_cfgs.scale_coeff * better_log_ratio.detach(),
)
worse_sample_rewards.append(self.cfgs.train_cfgs.scale_coeff * worse_log_ratio.detach())
loss = torch.stack(losses).mean() # size = ()
better_sample_reward = torch.stack(better_sample_rewards) # size = (B,)
worse_sample_reward = torch.stack(worse_sample_rewards) # size = (B,)
reward = better_sample_reward + worse_sample_reward # size = (B,)
reward_accuracy = (better_sample_reward > worse_sample_reward).float().mean() # size = ()
reward_margin = better_sample_reward - worse_sample_reward # size = (B,)
return {
'loss': loss,
'reward': reward,
'better_sample_reward': better_sample_reward,
'worse_sample_reward': worse_sample_reward,
'reward_accuracy': reward_accuracy,
'reward_margin': reward_margin,
}KTO训练代码:
# 创建 不匹配的提示-回答对:错位传入批次(batch)中的 answer_input_ids 和 answer_attention_mask 数据,以创建不匹配的提示-回答对。获取当前索引前一个样本作为回应(response)。如果当前索引是 0,则取最后一个样本作为回应。这是为了创建“不匹配”的数据对,即提示和回应不一定是成对的。
class UnmatchedSupervisedDataset(SupervisedDataset):
def preprocess(
self, raw_sample_for_prompt: dict[str, Any], raw_sample_for_response: dict[str, Any]
) -> SupervisedSample:
return_dict = {}
formatted_text, _ = self.template.format_unmatched_supervised_sample(
raw_sample_for_prompt, raw_sample_for_response
)
return_dict['input_ids'] = self.tokenize(formatted_text)
return return_dict
def __getitem__(self, index: int) -> dict[str, torch.Tensor]:
"""Get a tokenized data sample by index."""
raw_sample_for_prompt = self.raw_data[index]
if index == 0:
raw_sample_for_response = self.raw_data[-1]
else:
raw_sample_for_response = self.raw_data[index - 1]
data = self.preprocess(raw_sample_for_prompt, raw_sample_for_response)
return data
def get_collator(self) -> Callable[[list[dict[str, torch.Tensor]]], dict[str, torch.Tensor]]:
return UnmatchedSupervisedCollator(self.tokenizer.pad_token_id)
class KTOTrainer(DPOTrainer):
# 计算kl散度:通过计算当前模型(self.model.module)和参考模型(self.reference_model.module)之间的 KL 散度来比较它们的概率分布
# 选择最后一个 batch 的 KL 值可能只是实现上的简化。实际中,计算所有 batch 的 KL 散度并取平均,或者采取其他更复杂的策略,可能会增加额外的计算负担,而选择最后一个 batch 的 KL 值是一种更直接、简便的实现方式。
def compute_kl(self):
random_dataset = UnmatchedSupervisedDataset(
path=self.cfgs.data_cfgs.train_datasets,
template=self.train_template,
tokenizer=self.tokenizer,
processor=self.processor,
name=self.cfgs.data_cfgs.train_name,
size=self.cfgs.data_cfgs.train_size,
split=self.cfgs.data_cfgs.train_split,
data_files=self.cfgs.data_cfgs.train_data_files,
optional_args=self.cfgs.data_cfgs.train_optional_args,
)
seed = torch.randint(0, 100000, (1,)).item()
torch.manual_seed(seed)
self.random_dataloader = DataLoader(
random_dataset,
collate_fn=random_dataset.get_collator(),
sampler=DistributedSampler(random_dataset, shuffle=True),
batch_size=self.cfgs.train_cfgs.per_device_kl_batch_size,
)
for batch in self.random_dataloader:
log_probs = self.compute_log_probs( # size = (2 * B, L - 1)
self.model.module,
batch=batch,
)
ref_log_probs = self.compute_log_probs( # size = (2 * B, L - 1)
self.reference_model.module,
batch=batch,
)
kl = (log_probs - ref_log_probs).mean()
self.kl = max(kl, 0)# 此方法是 DPO (Direct Preference Optimization) 算法的核心部分。它计算了在当前模型和参考模型之间的对比损失
def loss( # pylint: disable=too-many-locals
self,
batch: PreferenceBatch,
) -> dict[str, torch.Tensor]:
"""Loss function for the DPO algorithm."""
sequence_log_probs = self.compute_log_probs(
self.model.module,
batch,
)
(
better_sequence_log_probs, # size = (B, L - 1)
worse_sequence_log_probs, # size = (B, L - 1)
) = sequence_log_probs.chunk(chunks=2, dim=0)
with torch.no_grad():
ref_sequence_log_probs = self.compute_log_probs( # size = (2 * B, L - 1)
self.reference_model.module,
batch,
)
ref_better_sequence_log_probs, ref_worse_sequence_log_probs = (
ref_sequence_log_probs.chunk(chunks=2, dim=0)
)
losses = []
better_sample_rewards = []
worse_sample_rewards = []
better_input_ids, worse_input_ids = batch['input_ids'].chunk(chunks=2, dim=0)
better_attention_mask, worse_attention_mask = batch['attention_mask'].chunk(chunks=2, dim=0)
batch_size = better_input_ids.size(0)
for i in range(batch_size):
if torch.all(torch.eq(better_input_ids[i], worse_input_ids[i])).item():
continue
better_end_index = better_attention_mask[i].nonzero()[-1].squeeze().item()
worse_end_index = worse_attention_mask[i].nonzero()[-1].squeeze().item()
diverge_index = (
(better_input_ids[i] != worse_input_ids[i]).nonzero()[0].squeeze().item()
)
assert 0 <= diverge_index <= better_end_index, 'diverge index is out of range!'
assert 0 <= diverge_index <= worse_end_index, 'diverge index is out of range!'
better_seq_slice = slice(diverge_index, better_end_index + 1)
worse_seq_slice = slice(diverge_index, worse_end_index + 1)
better_log_prob = better_sequence_log_probs[i, better_seq_slice].sum(dim=-1)
worse_log_prob = worse_sequence_log_probs[i, worse_seq_slice].sum(dim=-1)
ref_better_log_prob = ref_better_sequence_log_probs[i, better_seq_slice].sum(dim=-1)
ref_worse_log_prob = ref_worse_sequence_log_probs[i, worse_seq_slice].sum(dim=-1)
better_log_ratio = better_log_prob - ref_better_log_prob
worse_log_ratio = worse_log_prob - ref_worse_log_prob
# 计算loss,kl值作为基准
losses.append(
self.cfgs.train_cfgs.scale_better
* (1 - F.sigmoid(self.cfgs.train_cfgs.scale_coeff * (better_log_ratio - self.kl)))
- self.cfgs.train_cfgs.scale_worse
* (1 - F.sigmoid(self.cfgs.train_cfgs.scale_coeff * (self.kl - worse_log_ratio))),
)
better_sample_rewards.append(
self.cfgs.train_cfgs.scale_coeff * better_log_ratio.detach(),
)
worse_sample_rewards.append(self.cfgs.train_cfgs.scale_coeff * worse_log_ratio.detach())
loss = torch.stack(losses).mean() # size = ()
better_sample_reward = torch.stack(better_sample_rewards) # size = (B,)
worse_sample_reward = torch.stack(worse_sample_rewards) # size = (B,)
reward = better_sample_reward + worse_sample_reward # size = (B,)
reward_accuracy = (better_sample_reward > worse_sample_reward).float().mean() # size = ()
reward_margin = better_sample_reward - worse_sample_reward # size = (B,)
return {
'loss': loss,
'reward': reward,
'better_sample_reward': better_sample_reward,
'worse_sample_reward': worse_sample_reward,
'reward_accuracy': reward_accuracy,
'reward_margin': reward_margin,
}#执行训练步骤:这个方法在每一个训练步中计算并反向传播损失。它更新模型参数并计算并返回训练信息。
#奖励计算:通过 reward、better_sample_reward 和 worse_sample_reward 等指标来衡量模型的性能。
#全局平均:get_all_reduce_mean() 用于分布式训练,确保在多个设备上计算的值被平均,以保证训练的一致性。
def train_step(self, batch: PreferenceBatch) -> dict[str, Any]:
"""Perform a single training step for KTO."""
loss_dict = self.loss(batch=batch)
loss = loss_dict['loss']
self.model.backward(loss)
self.model.step()
with torch.no_grad():
reward = loss_dict['reward'].mean()
better_sample_reward = loss_dict['better_sample_reward'].mean()
worse_sample_reward = loss_dict['worse_sample_reward'].mean()
reward_accuracy = loss_dict['reward_accuracy']
reward_margin = loss_dict['reward_margin'].mean()
loss = get_all_reduce_mean(loss)
reward = get_all_reduce_mean(reward)
better_sample_reward = get_all_reduce_mean(better_sample_reward)
worse_sample_reward = get_all_reduce_mean(worse_sample_reward)
reward_accuracy = get_all_reduce_mean(reward_accuracy)
reward_margin = get_all_reduce_mean(reward_margin)
return {
'train/loss': loss.item(),
'train/reward': reward.item(),
'train/better_sample_reward': better_sample_reward.item(),
'train/worse_sample_reward': worse_sample_reward.item(),
'train/reward_accuracy': reward_accuracy.item(),
'train/reward_margin': reward_margin.item(),
'train/lr': self.model.optimizer.param_groups[0]['lr'],
}思考:
来源:https://wqw547243068.github.io/rlhf#%E6%80%9D%E8%80%83-1
0、KL惩罚
KL是放在奖励函数里面,还是放在外面 ?PPO 中的Rt计算:
的做法都能解释的通,其实实质其实是一个贝叶斯推断[介绍文章] 加入奖励函数里面控制粒度更细 ,训练应该更加稳定 。但是皓天大佬用REINFORCE+++复现时候加入KL约束会限制模型探索空间 。皓天大佬的文章很有启发性,指出在base模型变强以后,其实现有的RL算法在规则奖励上应该都能work。更加应该探索如何基于强base模型来优化RL算法,不应拘泥于原来RL训练不稳定,难训练这种传统观念。
下面还是略微来解释一下KL的作用实质到底是什么: 一开始我们通过语料训练了一个预训练模型 π PT π SFT RLHF 我们要得到一个 π RLHF
符号说明D={(xi,yi)} xi 表示指令, yi 是预训练的语言模型的输出。 π(y∣x) 是从指令到输出的概率分布。
1、首先一开始有一个在大规模语料上训练的语言模型 π0(y∣x) , 目前它表现欠佳,它的世界和人类的世界差别有点大,说起话来前言不搭后语。
2、好了现在有一个对话语料 D={(xi,yi)} ,这个对话预料的特点就是真实反应了人类世界的情况,或者说基于此我们能生成一个评分函数 r(x,y) 这个函数能给语言模型基于指令 x 生成的 y 打分。既然如此不如这样思考
给定 x,y对评分 r附上一个信念或者概率 q,这里的 β是一个信念可调整的超参数。比较是个比较主观的东西,加个可调整参数来调节,以便让大多数人满意。
3、现在的问题就变成了如何根据初始模型 π0(y∣x) 和人类的评分信念 q(r∣y,x) 来调整模型参数 θ得到一个新的模型 πθ(y∣x)
如果说 π0(y∣x) 是先验分布,那么人类的评分信念 q(r∣y,x) 就是似然函数,于是我们可以构造一个后验分布:
现在我们是无法直接得到 πKL-RL(y∣x,r),计算证据Z(y,x,r)计算是巨大的。但是我们可以让一个分布接进它,或者最好的方式就是就地取材微调 π0(y∣x,θ) 得到 πθ(y∣x) 使得它接近 我们的后验πKL-RL(y∣x,r) ,这样我们就得到了对齐后的模型。我们自然就使用到了计算分布相似度的 KL散度。于是问题就变为了:
放在奖励函数里面,还是放在优势函数外面。不过是评分信念的不同,在token层级似然函数就是奖励,在优势函数外面就是优势函数。对贝叶斯更新的提供的信息不同、粒度与层次的不同。
1、RL 有用吗?
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
RL给不了新知识,只是激发 了 Base Model 能力, 强化学习的边界被基座模型“锁死”。RL 只是让 BaseModel 朝更能给到正确答案的方向结题, 实际上,Base Model 不会的,可能永远不会, 会的,偶尔能做对, RL能增加这个做对的概率。
RLVR(可验证奖励的强化学习)在数学、代码、视觉推理等任务中表现突出,被视为提升大语言模型(LLM)推理能力的关键手段。
然而,核心问题始终存在:强化学习 真能让大模型获得超越基座模型 的新推理能力?
在数学、代码、视觉推理三大领域的系统性实验发现:
能力边界未突破 :RLVR模型所有推理路径均已存在 于基础模型中,强化学习并未 赋予模型新的推理能力。采样效率与覆盖能力权衡 :RLVR 小采样 次数下表现优于基座模型,但随着采样次数增加,基座模型逐渐追平并反超 ,显示出更广泛的覆盖能力。答案同源性 :RLVR模型正确答案均 来自基座模型 的输出分布,强化学习只是通过调整概率分布 筛选高奖励路径。显示:
数学推理任务中,基座模型在多次采样后的能力表现逐渐追平并反超 RL模型。 代码生成任务中,RL模型提升了单样本 准确率,但在更高采样次数下,基座模型仍展现出更强 的覆盖能力。 视觉推理任务中,RL训练后的模型在单次 回答准确率上提升显著,但基座模型在多次采样 后仍表现出更广泛的问题覆盖能力 RLVR只是让模型更偏向高奖励 解决方案,而非创造 新的推理能力。
对奖励路径的聚焦,削弱了模型的探索能力 ,限制了大规模采样时对可解问题的覆盖范围。
Key Insights
尽管RL训练后的模型在 pass@k(k=1) 情况下超越 Base模型, 但是 BaseModel 在k值不做限制情况下, 可能比RL后的模型pass率还高; RL 只是优化了 Base Model 采样效率 , 一方面增加了Base Model一次就能做对题的概率,但同时限制了模型的探索能力 ,导致了在增加pass@k的k时候, Base Model 做对题的概率反而增加了; CoT 方法对模型 Finetune 更能激发模型的做题能力 对比 CoT对模型进行Finetune
从R1蒸馏的数据对模型直接进行CoT Finetune,在同样多次Sample看pass结果上, CoT 确实是在 Base Model上足量提升,超越 Base Model,并比RL的结果更好 。但这个图里面奇怪的是Instruct的模型甚至没有Base版本在AIME24的表现上好? 不同RL算法整体差异并不大。不同的RL算法,比如PPO,DAPO,GRPO等 思考
为什么 AlphaGO 和玩游戏, RL能发掘新的胜利模式, 而 LLM 中的RL不行?
LLM 输出token概率空间比游戏概率空间大很多 , 因此,RL优化LLM 更难, 并且Reasoning 经常是从Pretrain Model开始训练, 而Pretrain模型本身受限制于预训练的语料,训练游戏的一般都是随机初始化,导致可能Pretrain模型本身就不包含所有能解决问题的先验(比如一个问题永远答不对,Reward永远是0),而随机初始化的可能本身就存在可能为1的情况,RL才有可能找到正确答案。Pretrain 模型的先验知识限制太强 , 导致模型探索说话空间时,会因为错误格式或者语句不通被干掉, 即使有可能导出正确答案,也会因为中间步骤产生问题,而永远失败; RL算法设计机制 潜在限制了模型探索正确答案的可能性, 比如 PPO算法中的KL Divergence约束了模型前后概率分布不能差别过大。 很多人认为,强化学习(RL)能够泛化到不同任务中,监督微调(SFT)可以记忆知识点,另外,还有类似 R1-zero 的结论等。
而如今整体开源社区的探索已经深入了许多。
解题方面,构建出色的基础模型(Base Model)。 实际上,很多基础模型都已经过指令微调,只是没有经过复杂指令微调,所以很难简单地将其认定为一个单纯的预训练(Pretrain)模型,毕竟预训练和监督微调的学习模式基本相同。在这个基础模型之上进行强化学习(RL)操作,能够提升它解决某类问题的能力。 思维链(CoT)本质是什么,为什么能提高答案的准确性?思维链本质上就是 “大声思考”(Thinkout loud)。对于有明确答案的问题,通过思维链来检查其解决问题的步骤是否错误,以及结果是否正确; 对于开放性问题而言,思维链增加回答的可信度。 思维链本质是结构化思考 ,言之有理即可,模型可解释性的另一种体现。 因此,思维链方向可以继续鉴定的走下去,同时,模型本身的限制应该更少些,比如乱码没关系,预留更多探索空间
2、RL 核心在于 奖励函数
【2025-5-5】忽略强化学习算法细节,在reward上做点手脚,简单又重要
(1) rl 与 reward
RLHF 精髓: 将人类偏好 转化为可量化 的奖励信号。
奖励函数告诉模型”什么是好的输出”,而rl算法只是将这种反馈训练到模型参数中去。reward与构建高质量数据,对于rl最终的结果来说同样重要。
deepseek-r1的grpo则是针对数学和代码任务设计了规则判别 的奖励函数
(2) 奖励函数构建策略
reward 构造策略
任务相关性 :奖励信号与任务目标相关。数学问题关注正确性 ,写作注重多样性 ,销售助手需要情商 等 可量化 :可量化的指标才可以交给rl进行训练学习。答案对错由规则判断给0,1布尔值。这个回答很好由reward model转化为0~1.0之间的得分 相对性 :PPO中给的是某个答案的绝对奖励值 (通过pairwise 方式训练 reward model),DPO中则是构建答案间的相对偏好 关系,GRPO 计算一批样本的相对奖励优势 推理过程 :对整个过程给一个最终奖励,还是每个推理步骤评估,以及是否需要推理过程,都可以设置为奖励信号3、方法选择
何时使用 DPO 与 PPO 与 GRPO ?
偏好对齐组合中加入 GRPO 后,有几项决策因素需要考虑:
数据可用性 (是否有偏好数据):DPO 使用偏好数据(选择/拒绝的答案),而 PPO 则需要先用这种偏好数据训练一个奖励模型。GRPO 则更具灵活性,因为它可以使用偏好数据,但并非必须使用。奖励模型 :DPO 通过直接基于偏好进行优化,将问题构建成分类问题,从而消除了对单独奖励模型的需求。相比之下,PPO 则需要训练和维护一个单独的奖励模型,这增加了复杂性。GRPO 则处于两者之间,既支持使用显式的奖励模型(如 PPO),也支持直接使用奖励函数。计算资源 :DPO 最高效,因为无需添加奖励模型。PPO 计算需求最高,因为它需要多个模型。GRPO 由于采用了基于组的方法,所以所需的资源适中。对比项 DPO PPO GRPO 数据可用性 偏好数据(选择/拒绝的答案) 先用偏好数据训练奖励模型 更灵活,可用偏好数据,但并非必须 奖励模型 直接基于偏好进行优化,将问题构建成分类 问题,消除对单独奖励模型的需求 训练和维护单独的奖励模型,增加了复杂性 既支持使用显式的奖励模型(如 PPO),也支持直接使用奖励函数 计算资源 最高效,无需添加奖励模型 计算需求最高,需要多个模型 由于采用基于组的方法,所需资源适中
要点
当拥有高质量的偏好数据且计算资源有限时,选择 DPO。 当需要精细控制、拥有充足的计算资源并且能够投入精力进行仔细调整时,选择 PPO。 当想要整合多个奖励信号,或者没有全面的偏好数据时,选择 GRPO。 loss
为什么不用 梯度下降 ?
RLHF 为什么不直接对 loss 进行梯度下降 来求解?
核心原因:
loss 或优化目标不可微 ,看一下优化目标的红色框部分: 损失函数表达式中的 y 是采样出来的, Dy~pi(y|x) , 可能是 greedy,beam search 等,在词表上进行采样或选择,而不是产生连续的、可微分的输出。所以,没法直接使用梯度下降,而是用 PPO 等策略梯度 来求解。
RLHF 问题
【2025-2-6】Andrej Karpathy 最新视频盛赞 DeepSeek:R1 正在发现人类思考的逻辑并进行复现
视频链接:youtube DeepSeek R1 在性能方面与 OpenAI 模型不相上下,推动了 RL 技术的发展 如果只是模仿人类玩家,就永远无法超越极限。
强化学习的优势
不受人类表现的限制。围棋游戏中,强化学习会自己与自己对弈,通过试错来学习哪些走法能赢得比赛。最终使AlphaGo能够超越人类顶尖棋手,甚至发明了一些人类棋手从未想到过的创新走法 AlphaGo 对弈中,实际上下了一步人类专家通常不会下的棋。评估来看,这步棋被人类玩家下的概率大约是1/10,000。 所有问题都属于可验证 领域。任何时候都可以很容易地与一个具体答案进行比较评分。
基本思路:
训练人类的模拟器,并通过强化学习对这些模拟器进行优化
人类反馈中进行强化学习的优势
能在任意领域进行强化学习,包括无法验证 的领域。 RLHF 却绕过了这个问题,不直接生成,而是排序 判别器和生成器之间的差距有关:对于人类来说,判别比生成要容易得多
RLHF显著缺点
强化学习不是基于实际的人类判断,而是基于人类的一个有损模拟 ,可能会产生误导 强化学习擅长“欺骗”模型,误导其做出许多错误的决定。
奖励模型
ppo 中 RM 如何工作
PPO 为啥不直接用 Reward Model
RLHF中,为什么 PPO 需要 Critic模型 而不是直接使用 Reward Model ?
强化学习中,PPO(Proximal Policy Optimization)基于策略梯度训练强化学习智能体。
PPO算法中引入Critic模型 的主要目的:提供价值估计器 ,用于评估状态 或状态动作对 的价值,从而辅助策略的更新和优化。
虽然奖励模型 (Reward Model)可以提供每个状态或状态动作对的即时奖励信号 ,但它并不能直接提供对应的价值估计 。
奖励信号 只反映了当前动作 的即时反馈,而并没有提供关于在长期时间尺度上 的价值信息。Critic模型 估计状态或状态动作对的长期价值,也称为状态值函数 或动作值函数 。Critic模型能学习和预测在当前状态下采取不同动作所获得的累积奖励 ,它提供了对策略改进的指导。
PPO算法使用Critic模型的估计值来计算优势函数,从而调整策略的更新幅度,使得更有利于产生更高长期回报的动作被选择。
另外,Critic模型还可用于评估不同策略的性能,为模型的评估和选择提供依据。PPO算法中的Actor-Critic架构 允许智能体同时学习策略 和价值 函数,并通过协同训练来提高性能。
因此,在 RLHF(Reinforcement Learning from Human Feedback)中,PPO算法需要Critic模型而不是直接使用奖励模型,是为了提供对状态或状态动作对的价值估计,并支持策略的改进和优化。Critic模型的引入可以提供更全面和准确的信息,从而增强算法的训练效果和学习能力。
即时奖励和长期奖励
即时奖励 与 状态动作对的长期价值 的差别是什么?
即时奖励 (Immediate Reward)和状态动作对的长期价值 (Long-Term Value)代表了强化学习中不同的概念和时间尺度。
即时奖励是指智能体在执行某个动作后立即 获得的反馈信号。由环境提供,用于表示当前动作的好坏程度。即时奖励是一种即时反馈,可以指示当前动作的立即结果是否符合智能体的目标。 而状态动作对的长期价值 涉及更长时间尺度上的评估,考虑了智能体在当前状态下选择不同动作所导致的未来回报的累积。长期价值可以表示为状态值函数 (State Value Function)或动作值函数 (Action Value Function)。状态值函数(V-function)表示在给定状态下,智能体从该状态开始执行一系列动作,然后按照某个策略进行决策,从而获得的预期累积回报。状态值函数估计了智能体处于某个状态时所能获得的长期价值,反映了状态的优劣程度。 动作值函数(Q-function)则表示在给定状态下,智能体选择某个动作后,按照某个策略进行决策,从该状态转移到下一个状态并获得预期累积回报的价值。动作值函数估计了在给定状态下采取不同动作的长期价值,可以帮助智能体选择在每个状态下最优的动作。 长期价值考虑了智能体在未来决策 过程中所能获得的累积回报
相比之下,即时奖励只提供了当前 动作的即时反馈。 长期价值对智能体的决策具有更全面的影响,可以帮助智能体更好地评估当前状态和动作的长期效果,并指导智能体在长期时间尺度上作出更优的决策。 在强化学习中,长期价值的估计对于确定性策略选择和价值优化非常重要,而即时奖励则提供了对当前动作的直接反馈。这两者相互补充,结合起来可以帮助智能体实现更好的决策和学习效果。
PPO 优势函数
PPO 中优势函数指什么
在 Proximal Policy Optimization(PPO)算法中,优势函数 (Advantage Function)用于评估状态-动作对 的相对优劣程度。它衡量了执行某个动作相对于平均水平的优劣,即在给定状态下采取某个动作相对于采取平均动作的效果。
优势函数定义:
Advantage(s, a) = Q(s, a) – V(s)
其中
Advantage(s, a) 表示在状态 s 下采取动作 a 的优势函数值Q(s, a) 表示状态动作对 (s, a) 的动作值函数(也称为动作优势函数)V(s) 表示状态值函数。优势函数的作用在于帮助评估当前动作的相对价值,以便在策略更新过程中确定应采取的动作。通过比较不同动作的优势函数值,可以决定哪些动作是更好的选择。正的优势函数值表示执行的动作比平均水平更好,而负的优势函数值表示执行的动作比平均水平更差。
在PPO算法中,优势函数用于计算策略更新的目标,以便调整策略概率分布来提高优势函数为正的动作的概率,并降低优势函数为负的动作的概率,从而改进策略的性能。
相关论文:
A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More. https://arxiv.org/pdf/2407.16216 Proximal Policy Optimization Algorithms. https://arxiv.org/abs/1707.06347 KTO,Kahneman-Tversky 优化,参阅论文《KTO: Model alignment as prospect theoretic optimization》。 DRO,直接奖励优化,参阅论文《Offline regularised reinforcement learning for large language models alignment》。 SimPO,简单偏好优化,参阅论文《SimPO: Simple preference optimization with a reference-free reward》

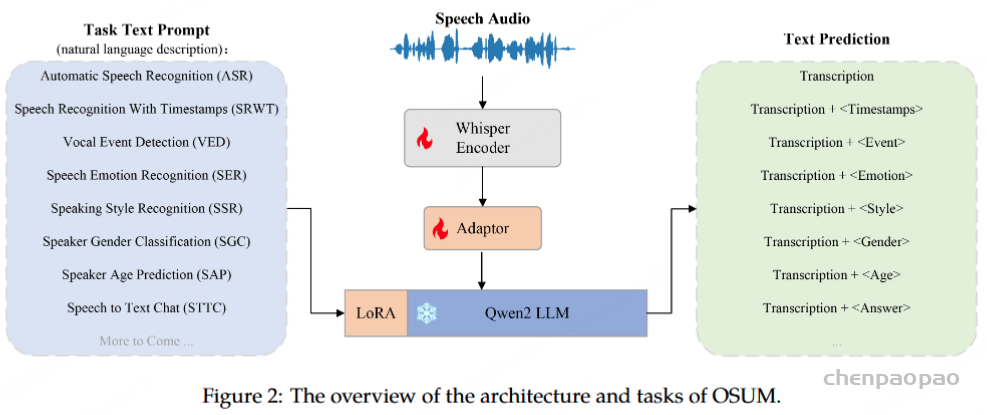


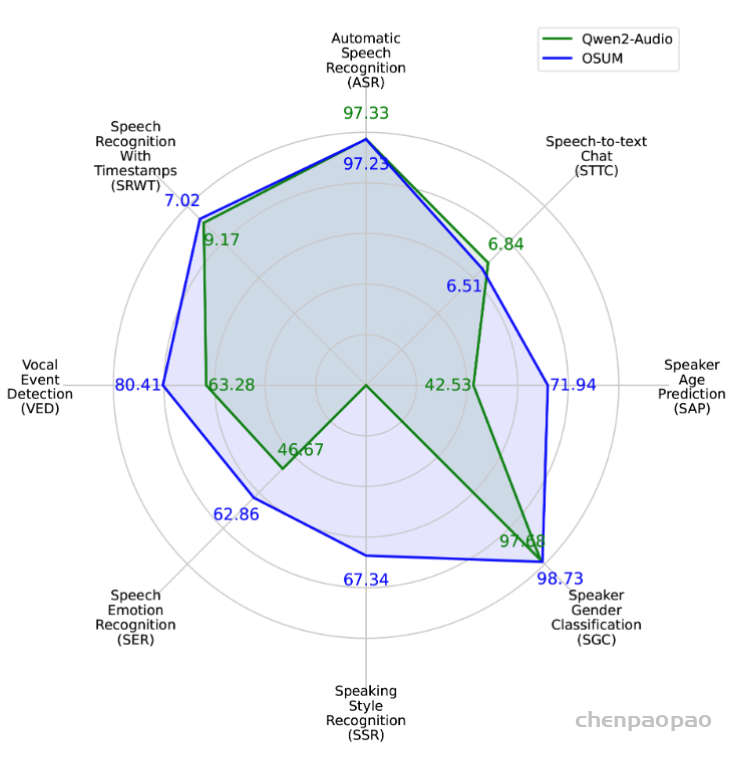
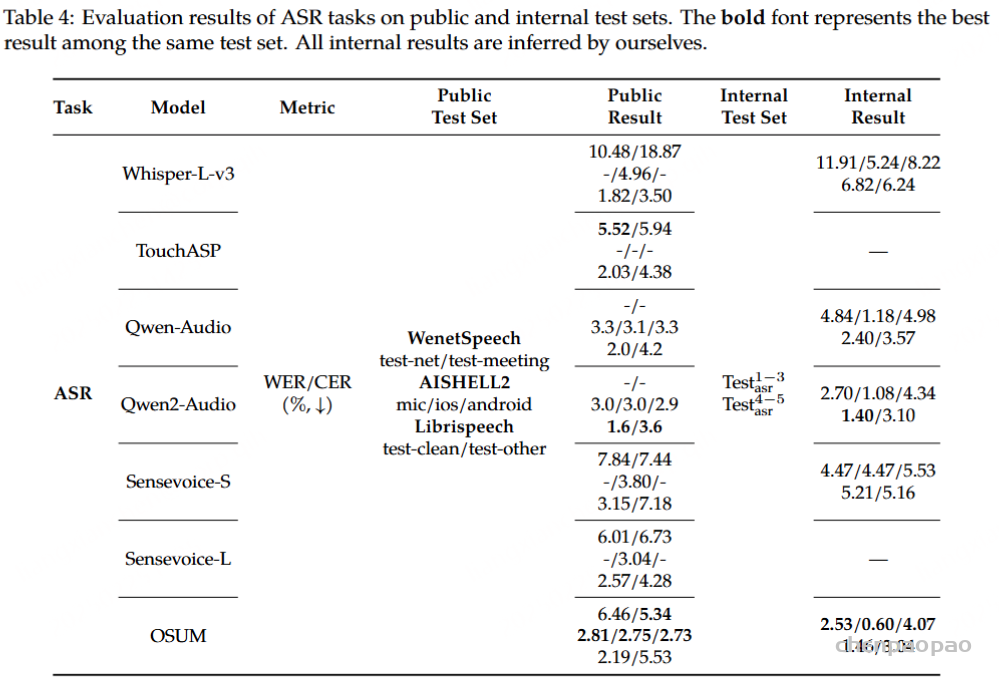

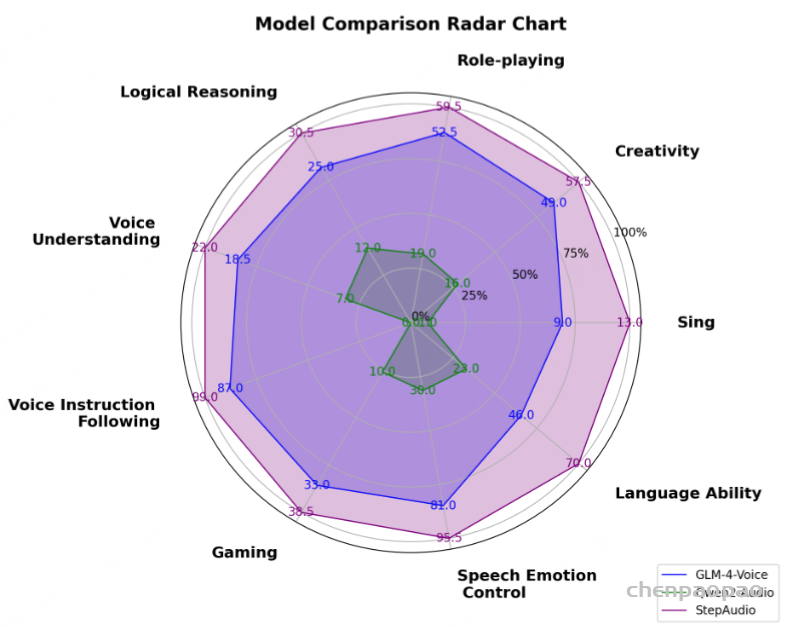
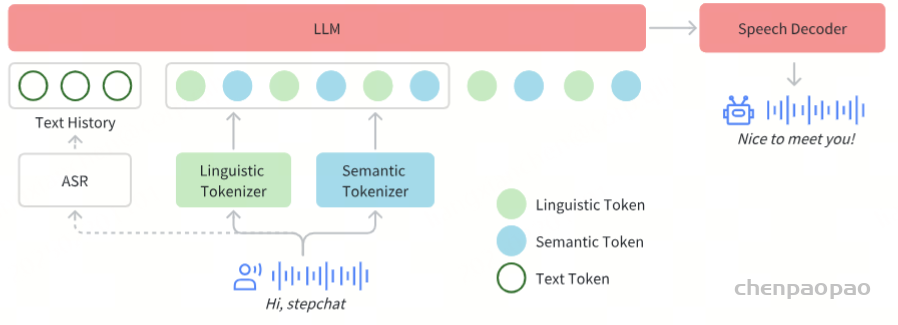
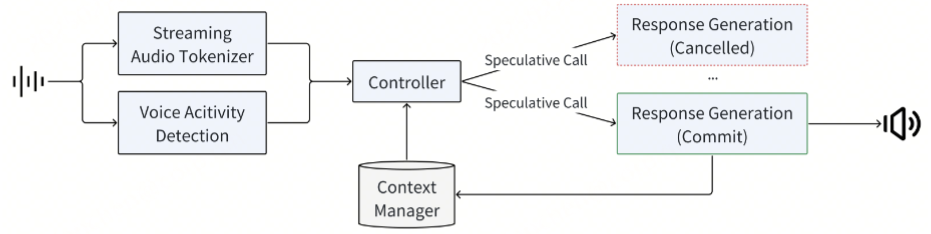
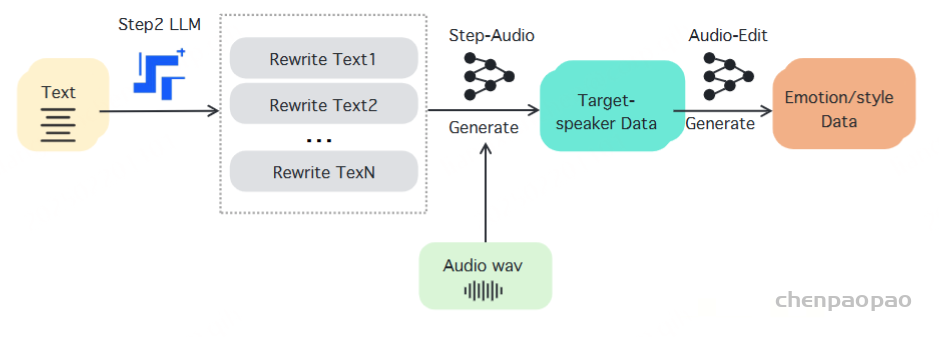
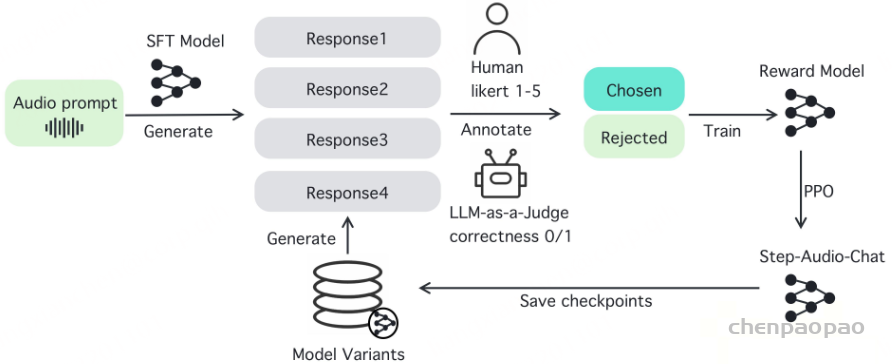

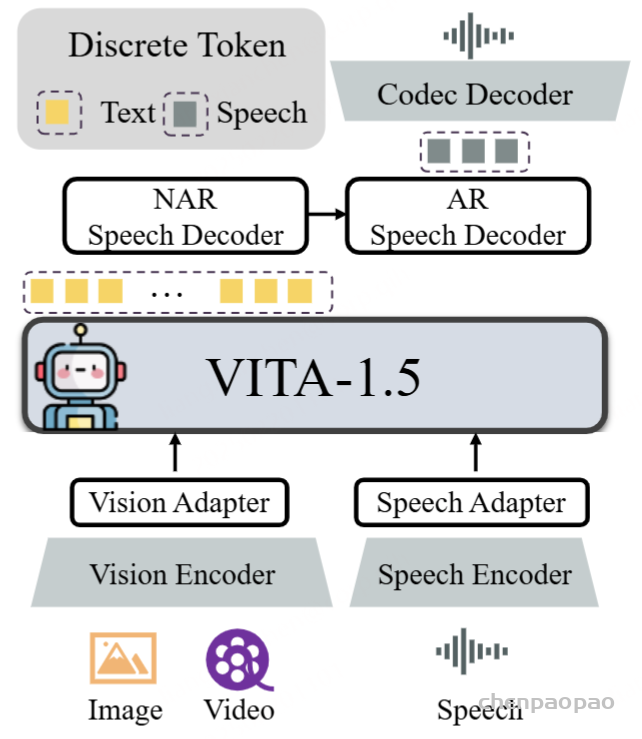

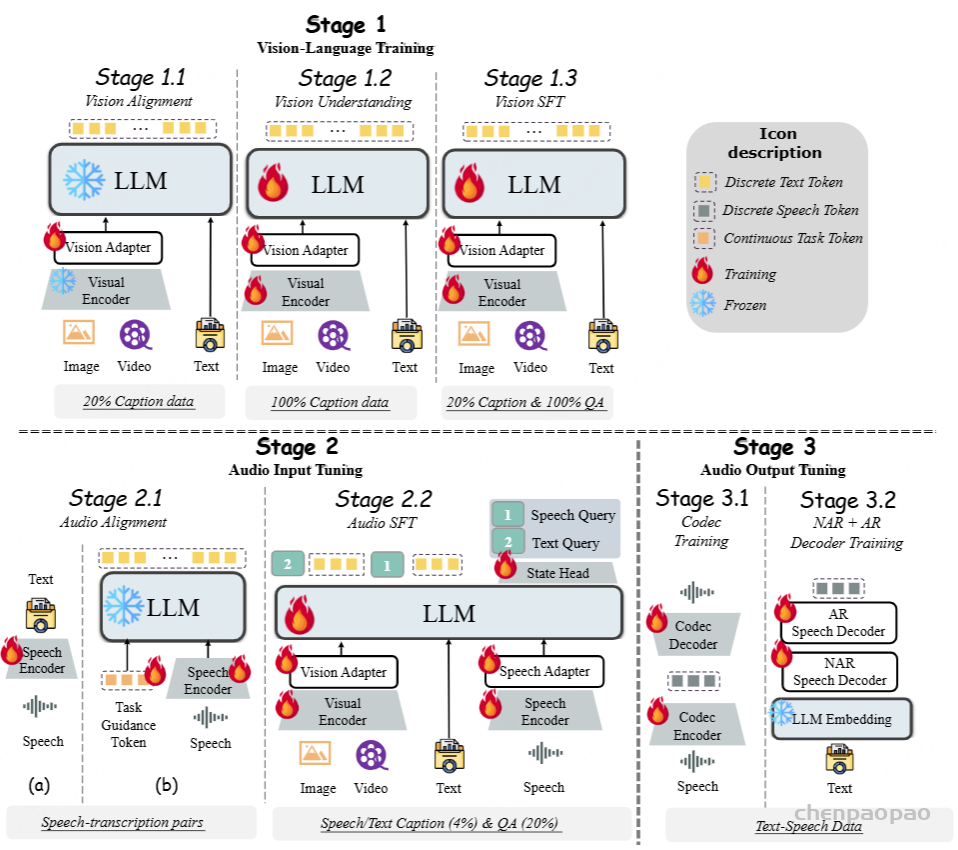



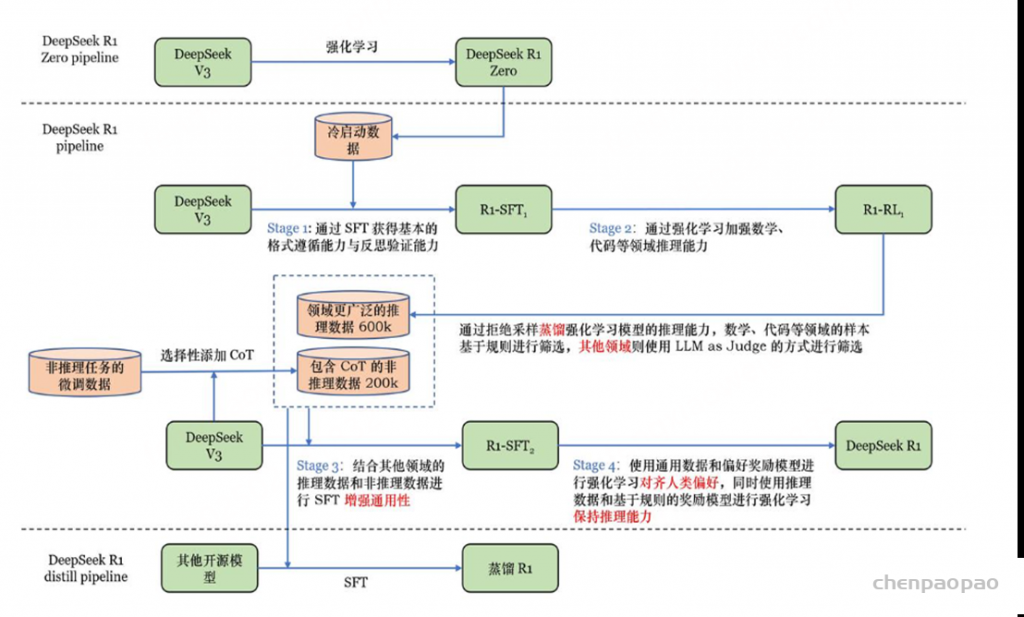
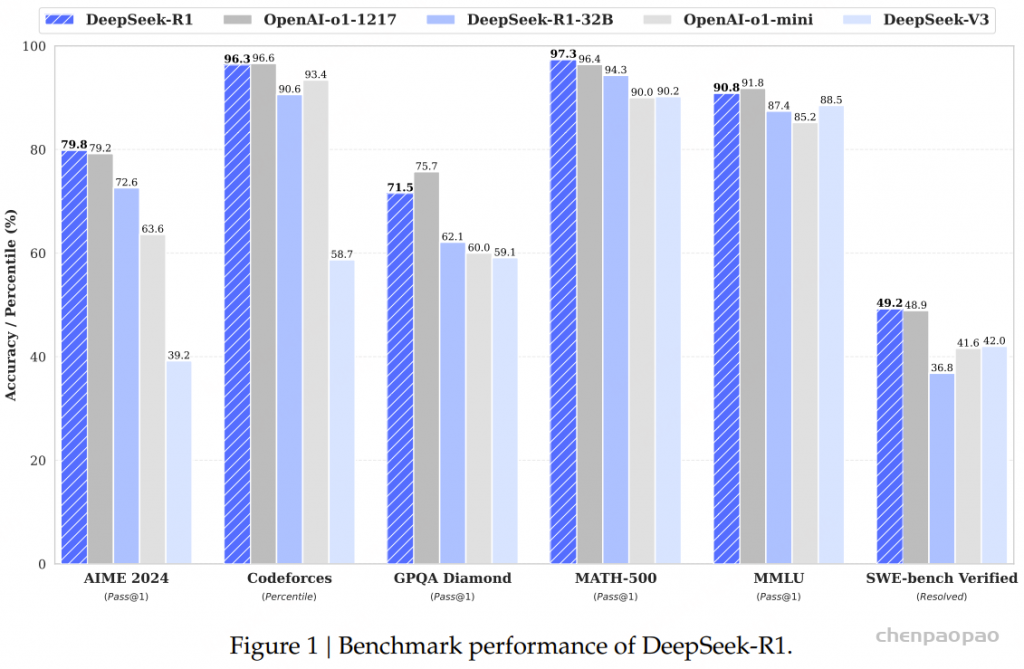
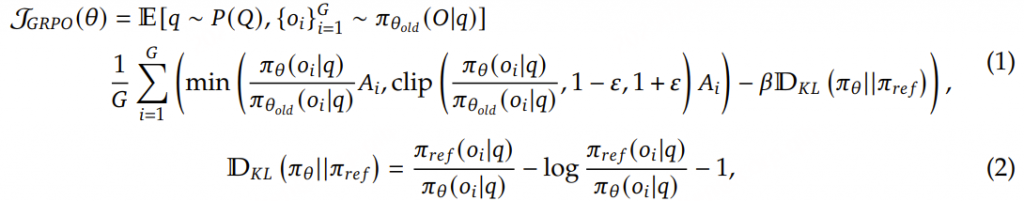
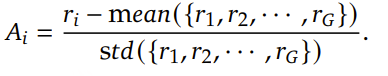

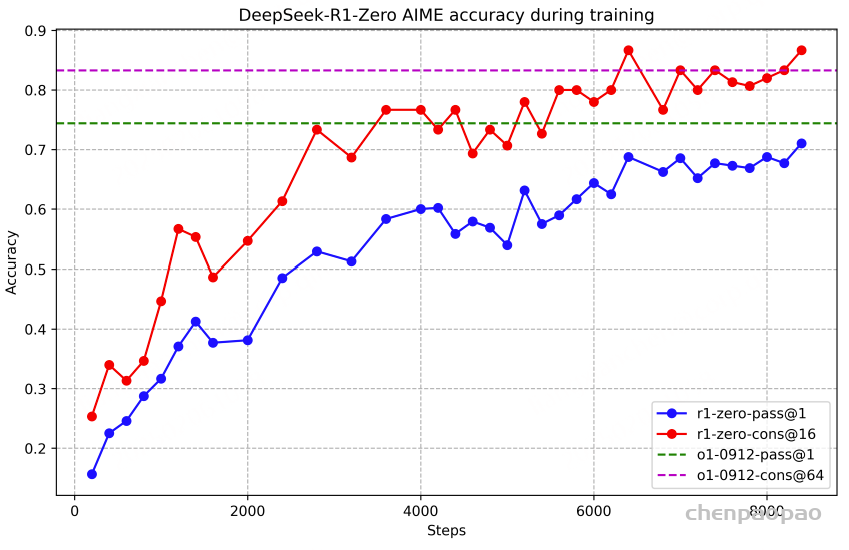
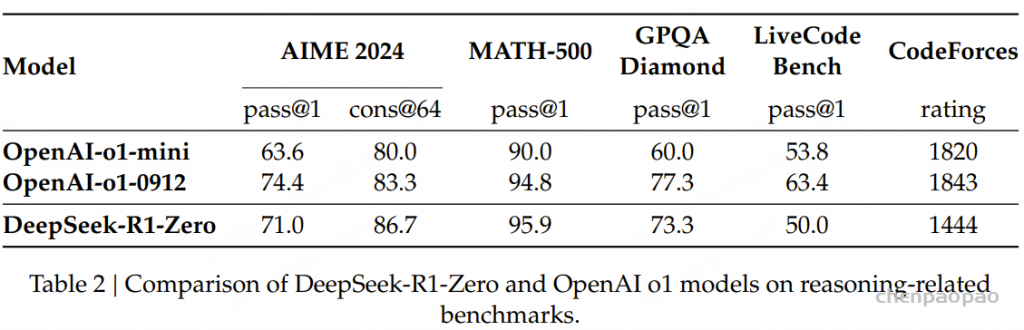
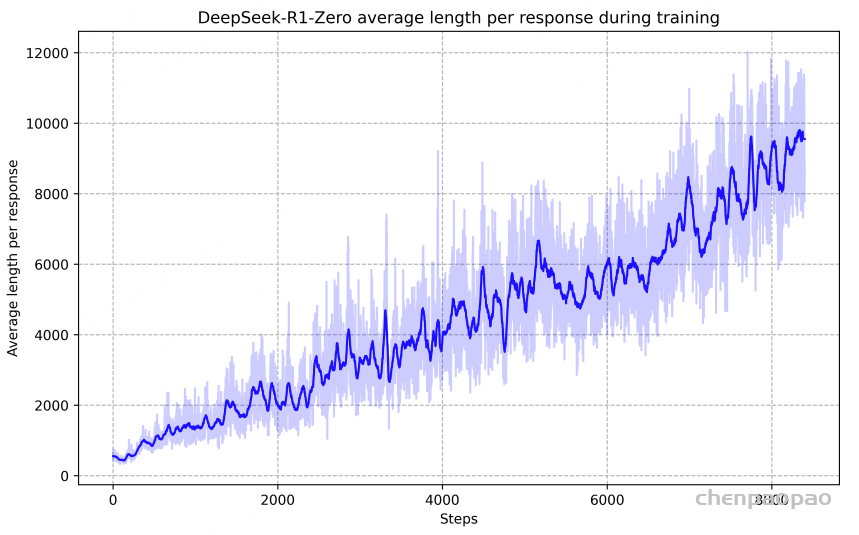

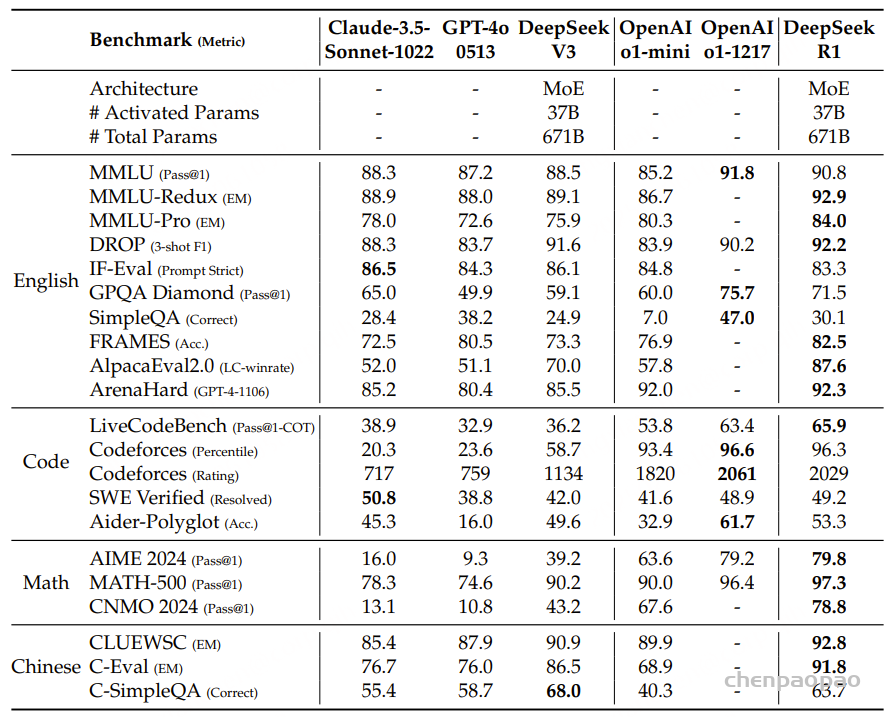
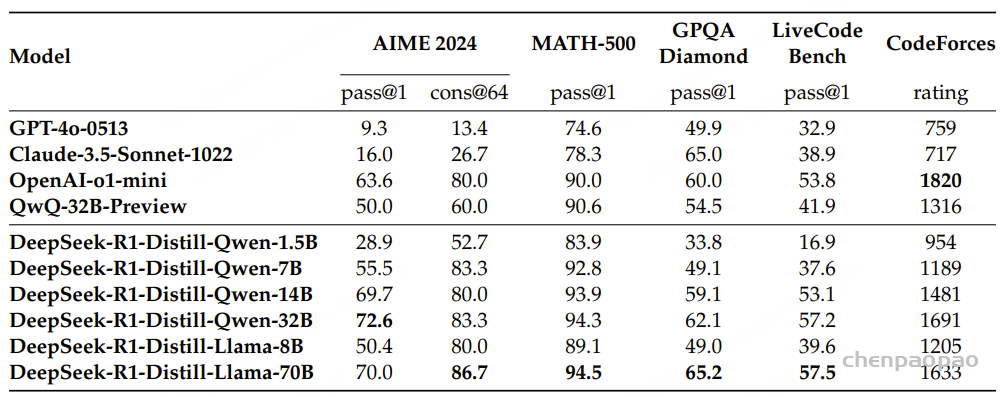
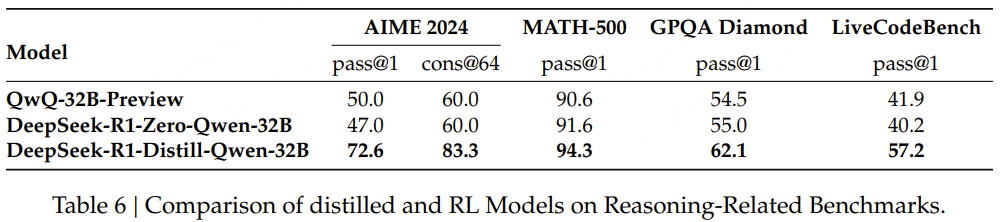
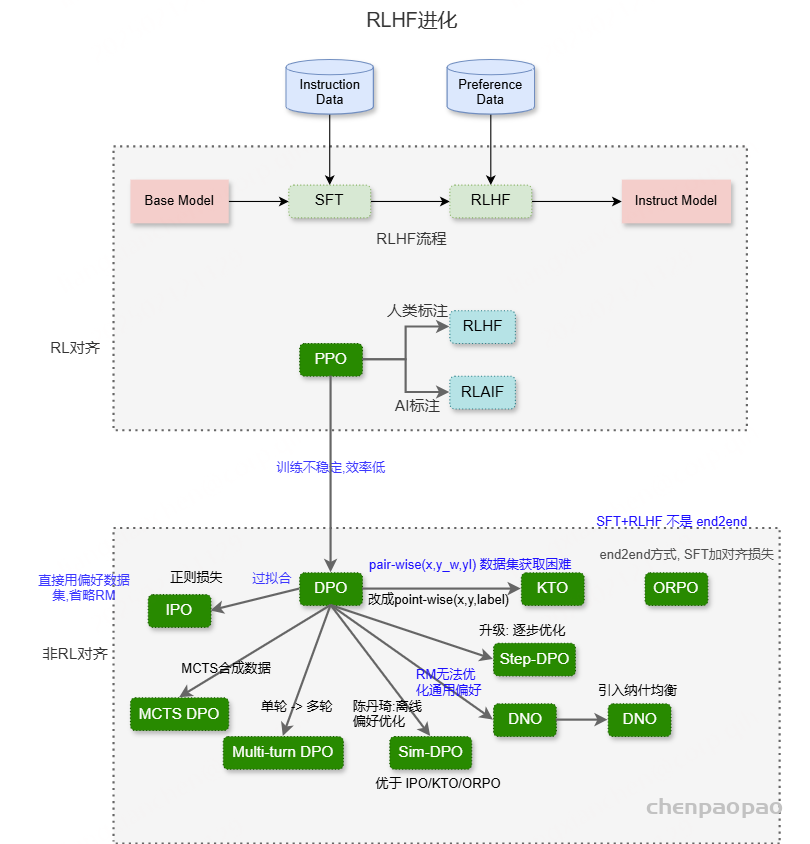
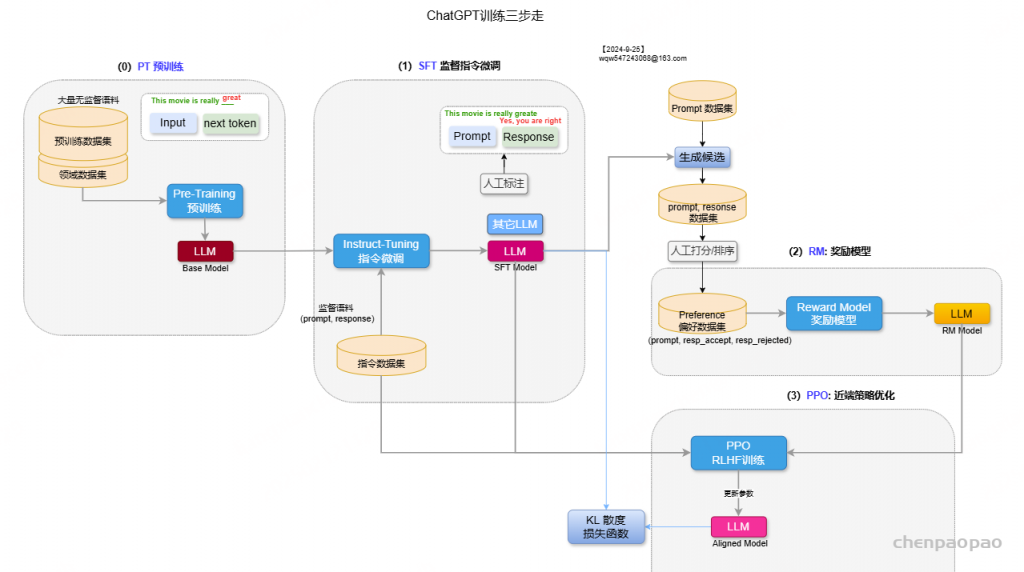
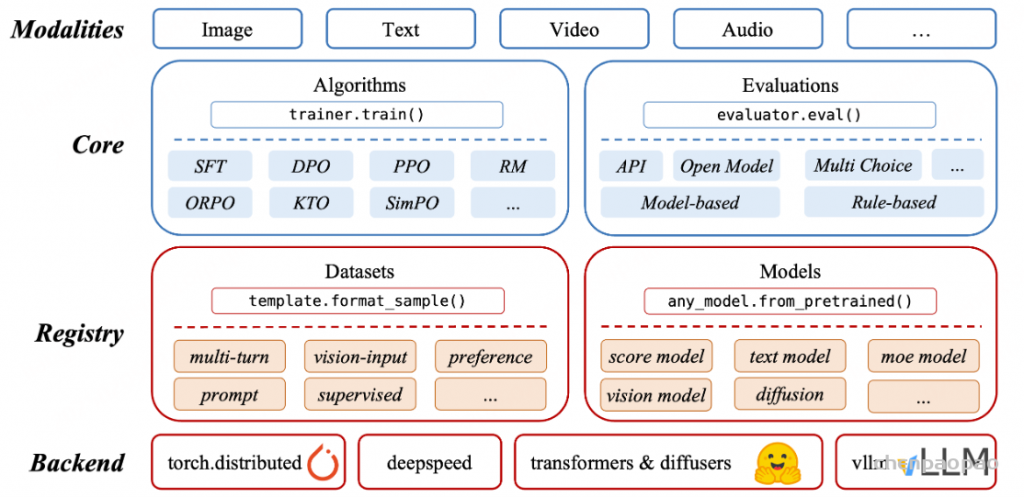

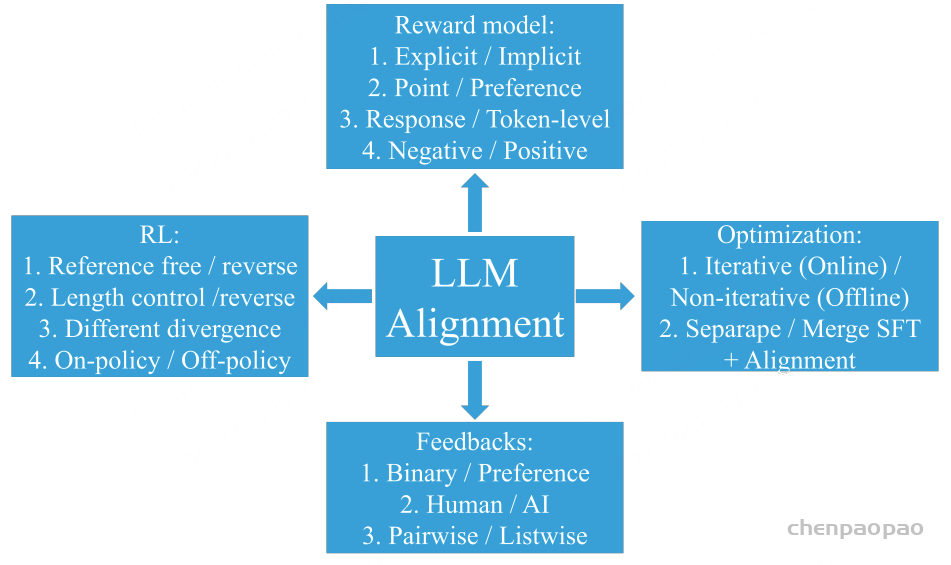
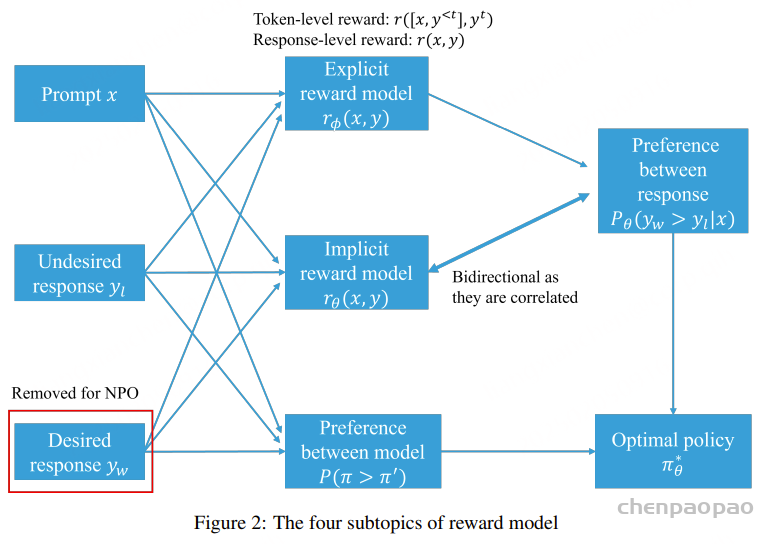
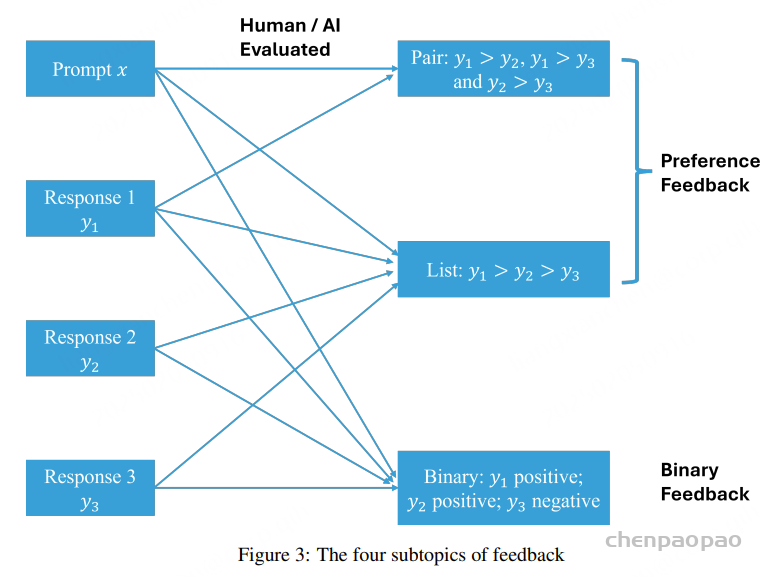
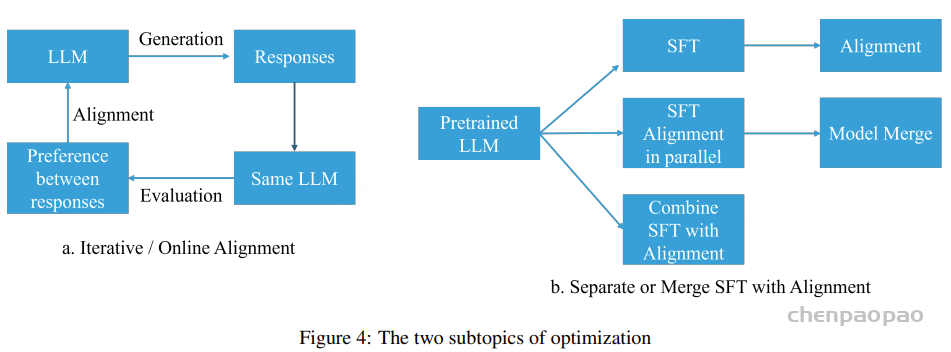
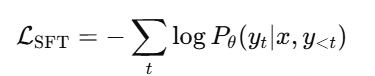
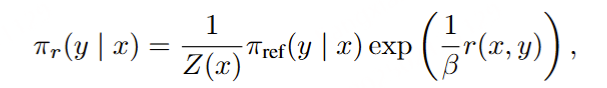
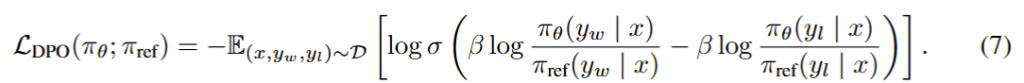
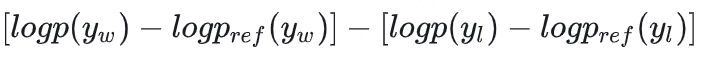
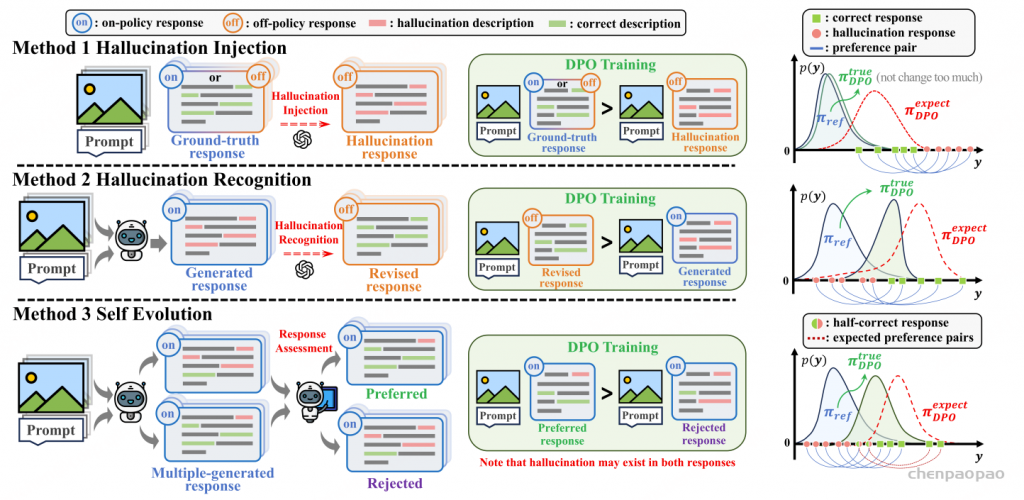




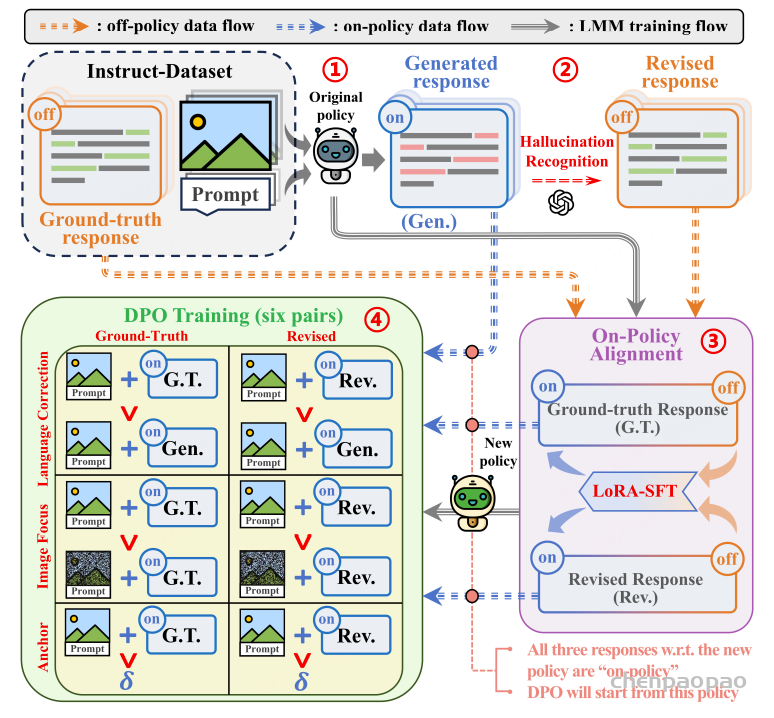
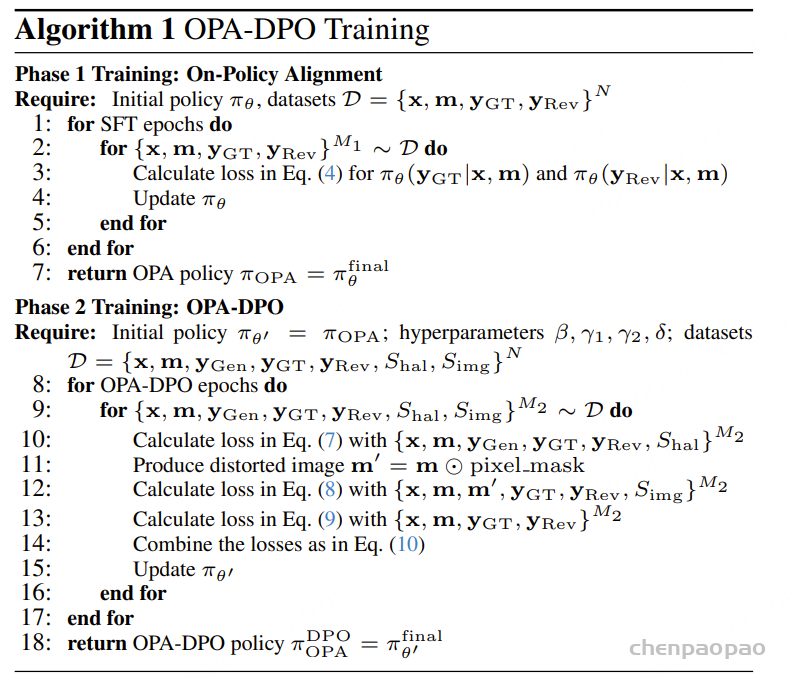
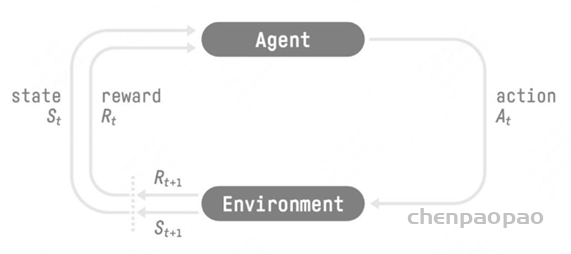

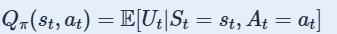
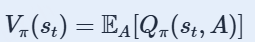
 的优势函数,描述的是它在状态
的优势函数,描述的是它在状态  下采取行为
下采取行为  比随机选择一个行为好多少(假设之后一直服从策略
比随机选择一个行为好多少(假设之后一直服从策略