- 文章来源:公众号每周一个大模型应用
- Speech LLMs are Contextual Reasoning Transcribers
- Whisfusion: Parallel ASR Decoding via a Diffusion Transformer
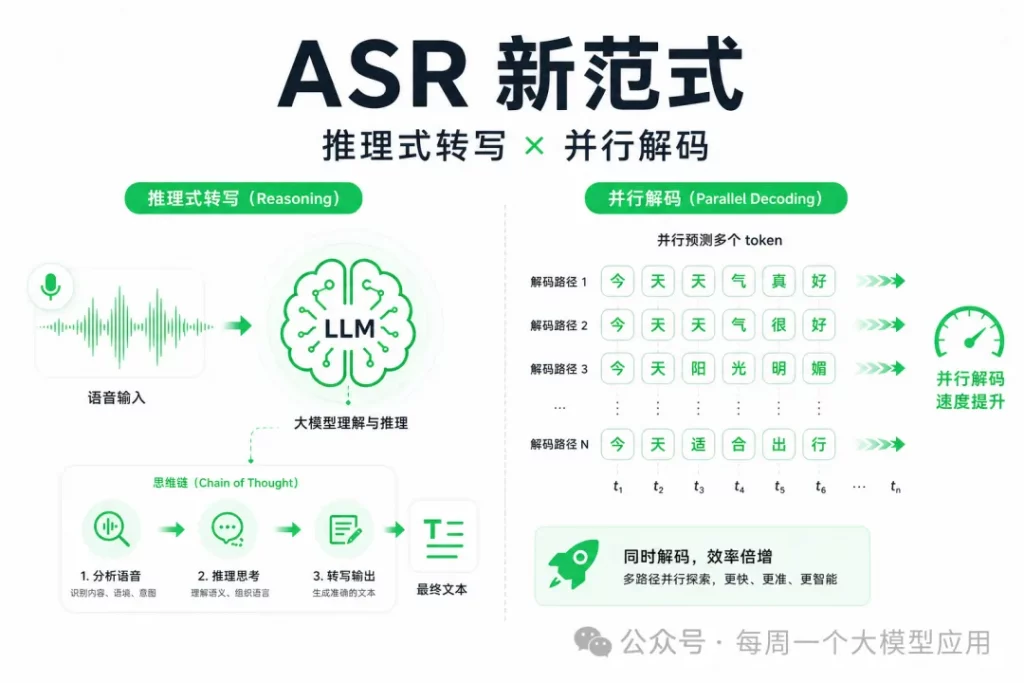
Whisper 把开源 ASR 拉到了新高度,但 2025–2026 年的顶会论文告诉我们:瓶颈已经不在「听不听得清」,而在「怎么生成文本」。Microsoft 的 CoT-ASR 让大模型先「想」再「写」,Whisfusion 则用扩散模型并行解码,把 Whisper 的延迟砍到原来的八分之一。本文深度拆解两篇代表论文,帮你看懂 ASR 范式迁移的来龙去脉。
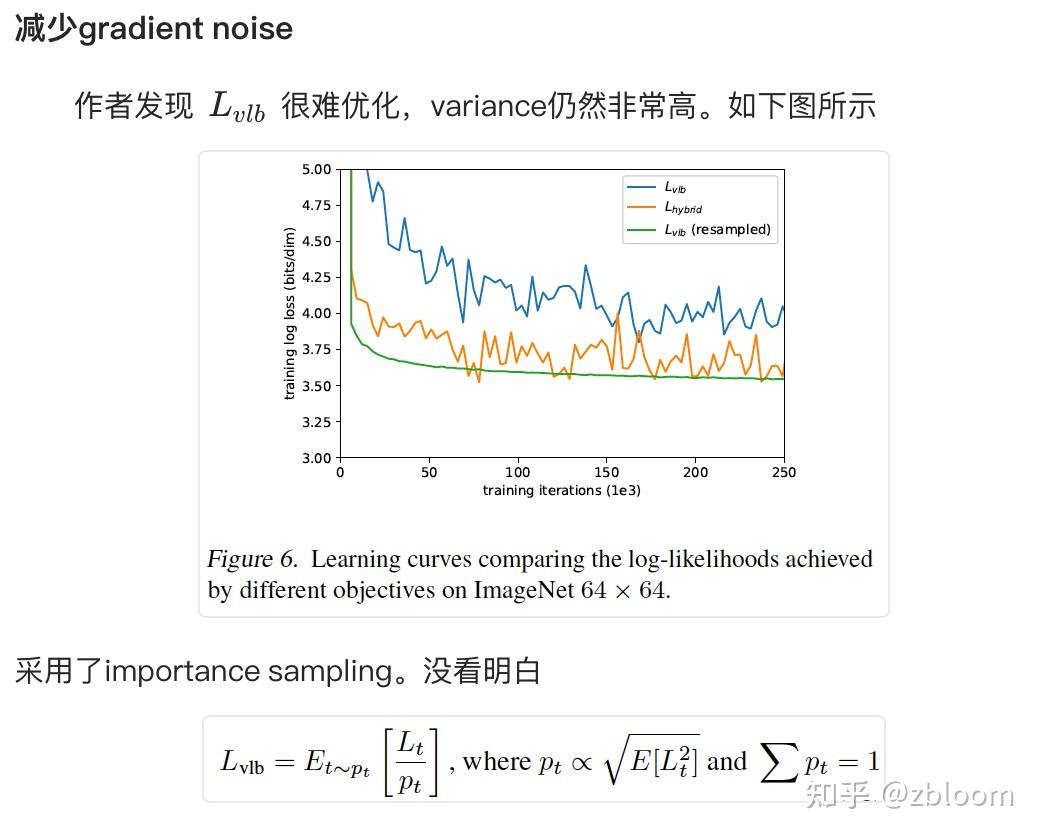
结论:LLM 接入 ASR 后,「直接转写」并没有充分释放大模型能力——CoT-ASR 用链式推理把 WER 降 8.7%、实体错误率 EER 降 16.9%;Whisfusion 用非自回归扩散解码,相近精度下把 20–30 秒音频的解码时间从 674.7ms 压到 80.7ms。一条路线优化「准」,一条路线优化「快」,共同指向新一代 ASR 架构。
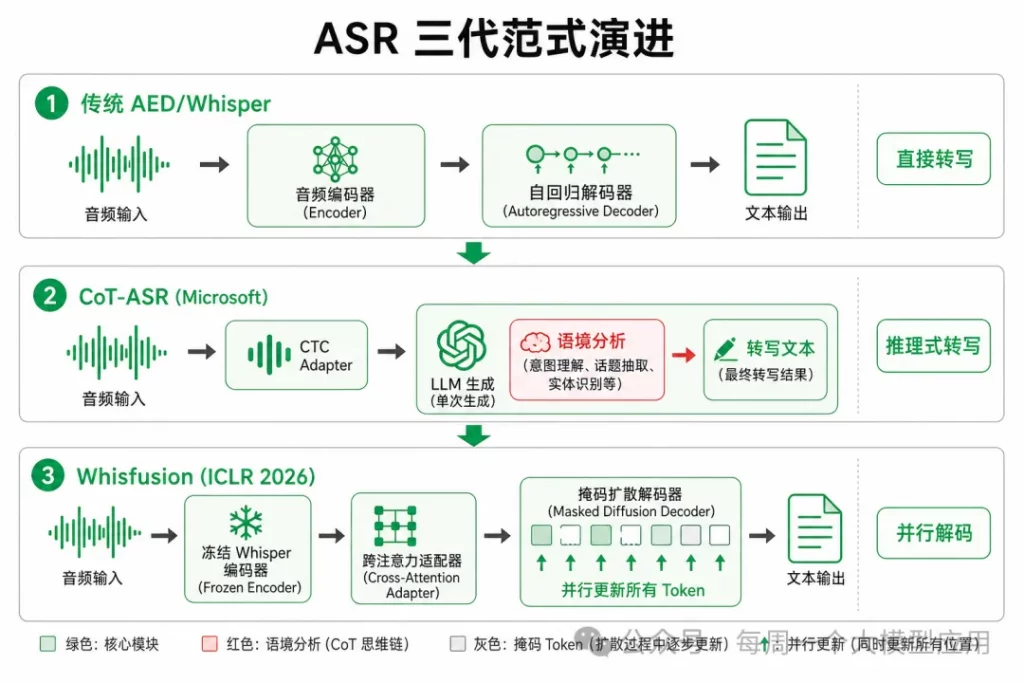
一、前言:ASR 为什么需要换范式
过去十年,ASR 的主线故事是「更大的编码器 + 更好的对齐」。Conformer、Whisper、SenseVoice……准确率一路攀升。但当 Speech LLM 把 LLM 接进识别链路后,一个尴尬的事实浮出水面:大模型在文本侧拥有的推理、知识、上下文理解能力,在 ASR 里几乎用不上。
原因很简单——传统 LLM-based ASR 的训练目标仍然是「语音 → 逐字转写」。语音和文本承载的信息高度重叠,模型被约束成「复读机」,而不是「理解者」。与此同时,Whisper 式自回归解码器必须逐 token 生成,文本越长,延迟线性增长,实时字幕、会议转写、端侧 ASR 都深受其苦。
2026 年的两个信号
- CoT-ASR(Microsoft Core AI):把 Chain-of-Thought 引入 ASR,ICLR/arxiv 2026
- Whisfusion(ICLR 2026 投稿):Whisper 编码器 + 扩散并行解码
- 共同背景:Speech LLM 规模化,但 token 密度失衡与 AR 延迟成为两大瓶颈
「论文数据仅供参考;CoT-ASR 基于 3.8B Phi-4-mini + 38k 小时英文数据,Whisfusion 在 LibriSpeech 960h 上微调。落地时需结合自己的语种、场景与算力重新评估。」
二、CoT-ASR:让大模型先分析,再转写
论文全称 Speech LLMs are Contextual Reasoning Transcribers,作者来自 Microsoft Core AI(Keqi Deng、Jinyu Li 等)。
它要回答的核心问题是:如何把 LLM 的推理能力「翻译」成 ASR 收益?
▎ 2.1 直接转写为何浪费 LLM
现有 Speech LLM 通常把语音编码器输出拼在文本 prompt 前面,然后让 LLM 直接生成转写结果。训练 loss 也只监督转写文本——和 Conformer AED 没有本质区别。
论文指出,ASR 在信息论上接近「内容保持映射」:输入说什么,输出就写什么,语义变换空间极小。LLM 在海量文本上预训练获得的常识、领域知识、消歧能力,在「只听就写」的模式下被严重压制。
▎ 2.2 链式推理:One-Pass 的两段式输出
CoT-ASR 的关键设计是:一次生成(one-pass),但输出分两段。模型先产出「语境分析」(Contextual Analysis),再产出「转写文本」。前者相当于 Chain-of-Thought,后者才是最终 ASR 结果。
- 语境分析:推断说话场景、主题、可能的专有名词与歧义
- 转写文本:在分析基础上生成更准确的识别结果
- 训练数据:用 Qwen2.5-14B 从 3.8 万小时语音自动构造「分析 + 转写」对
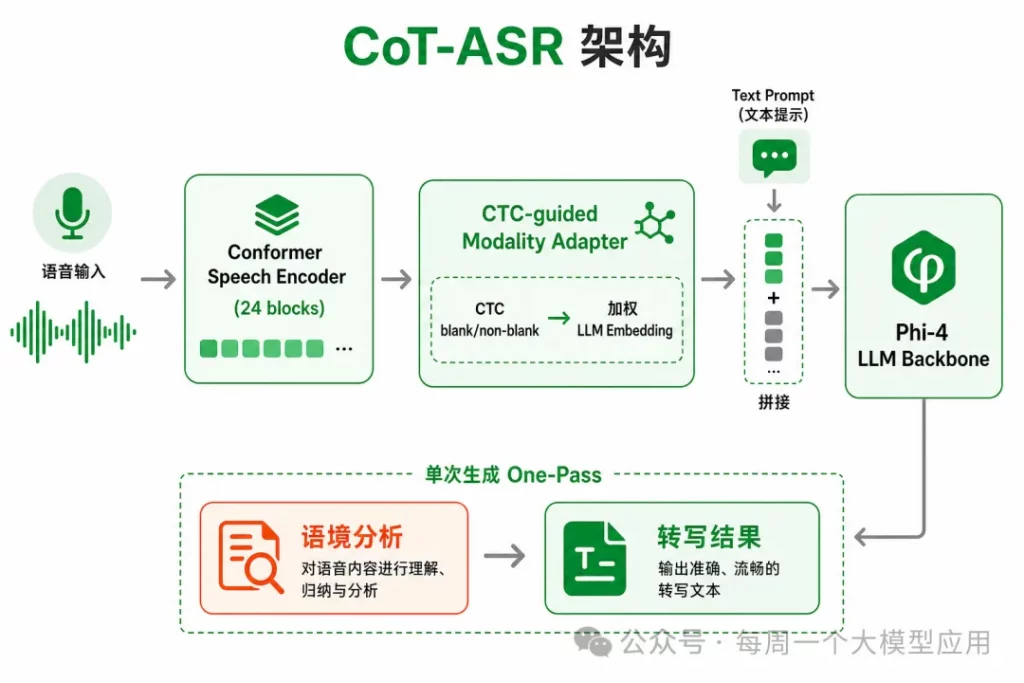
▎ 2.3 CTC-guided Modality Adapter
语音帧序列远长于文本 token,如何把 Conformer 编码器输出对齐到 LLM 隐空间,是 Speech LLM 的经典难题。
CoT-ASR 没有简单用两层 Linear 投影,而是提出 CTC-guided Modality Adapter。
- 每帧计算 CTC blank / non-blank 概率分布
- 用 non-blank 分布对 LLM token embedding 矩阵做加权求和,得到帧级「文本化」表示
- 保留全部帧信息(含 blank 帧),避免 CTC 压缩丢信息
- 门控残差分支进一步融合原始声学特征
直觉上:每一帧的 CTC 分布告诉我们「这一帧最像哪个字」,
再映射到 LLM 已经熟悉的 embedding 空间——比纯线性投影更直接地利用 LLM 的文本先验。
2.4 用户引导转写:比热词更「语义化」
CoT-ASR 还支持 User Context 模式:用户提供场景描述或实体线索,模型跳过自生成推理,直接转写。这类似「Prompt ASR」,但利用的是 LLM 的 in-context learning,而非简单热词偏置。实验显示,加入用户上下文后,平均 EER 从 9.17% 进一步降到 6.89%,相对再降 24.9%。Pharmacy 领域 EER 从 5.97% 降到 3.11%,医疗场景收益尤其明显。
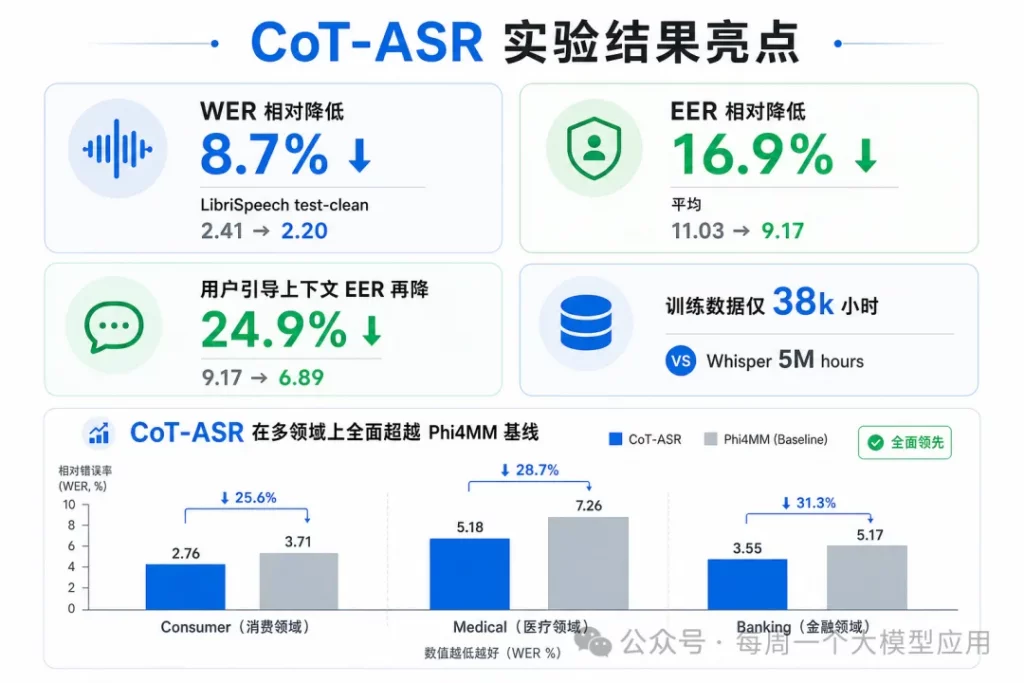
2.5 实验结果:小数据超越大模型
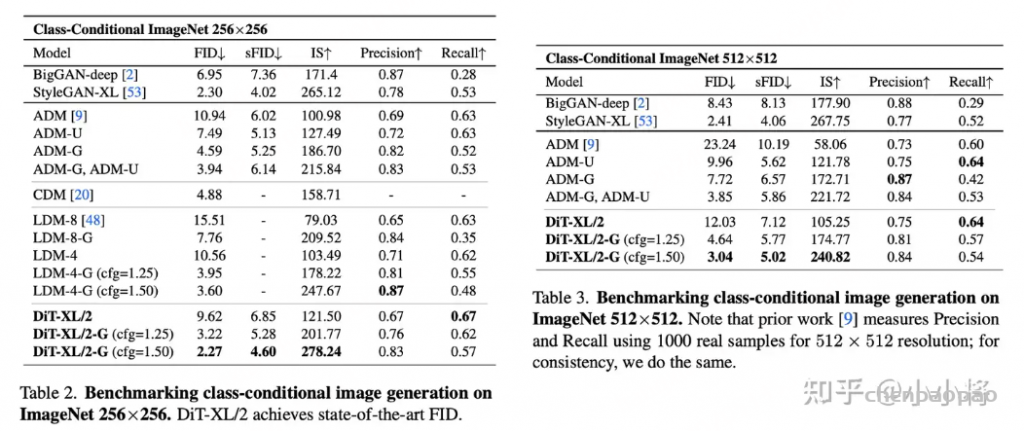
在 LibriSpeech test-clean 上,CoT-ASR WER 2.20% vs Phi4MM 基线 2.41%,相对降 8.7%。更值得关注的是 EER(实体错误率):8 个行业测试集平均 EER 从 11.03% 降到 9.17%,相对降 16.9%。对比开源大模型:CoT-ASR 仅用 38k 小时数据,平均 EER 9.17% 已略优于 Qwen3-Omni-30B(9.19%)和 Whisper-large-v3(9.53%)。
论文认为:对 ASR 而言,LLM 参数规模并非万能钥匙,「会不会用 LLM 的推理能力」才是关键。
「CoT-ASR 的启示:ASR 正在从「声学分类问题」转向「语言理解问题」。专有名词、医疗术语、游戏黑话等场景,EER 指标比 WER 更贴近真实体验。」
三、Whisfusion:Whisper 的并行解码革命
Whisfusion(Parallel ASR Decoding via a Diffusion Transformer)是 ICLR 2026 投稿论文,它瞄准的是另一个痛点:Whisper 编码器 30 秒音频一次前向,但解码器必须逐 token 自回归——文本越长,越慢。
3.1 架构错配:有全量上下文,却只能顺序生成
论文 Figure 1 清晰展示:Whisper-small 的编码器耗时几乎恒定,解码器耗时随输出词数线性增长。20–30 秒音频段上,解码占端到端延迟的大头。
Whisper-Large-v3-turbo 等蒸馏模型缓解了部分问题,但 AR 本质未变。
3.2 核心设计:冻结 Whisper + 扩散文本解码器
Whisfusion 的 hybrid 架构:Whisper 编码器冻结不动,
只训练轻量 Cross-Attention Adapter 和 Masked Diffusion Decoder。
- 编码器:复用 Whisper 预训练声学表征,6.5k 小时数据即可微调
- 解码器:基于 Masked Diffusion Model(MDM),每步并行更新全部 token
- 推理:Parallel Diffusion Decoding(PDD),多候选并行 + 置信度筛选
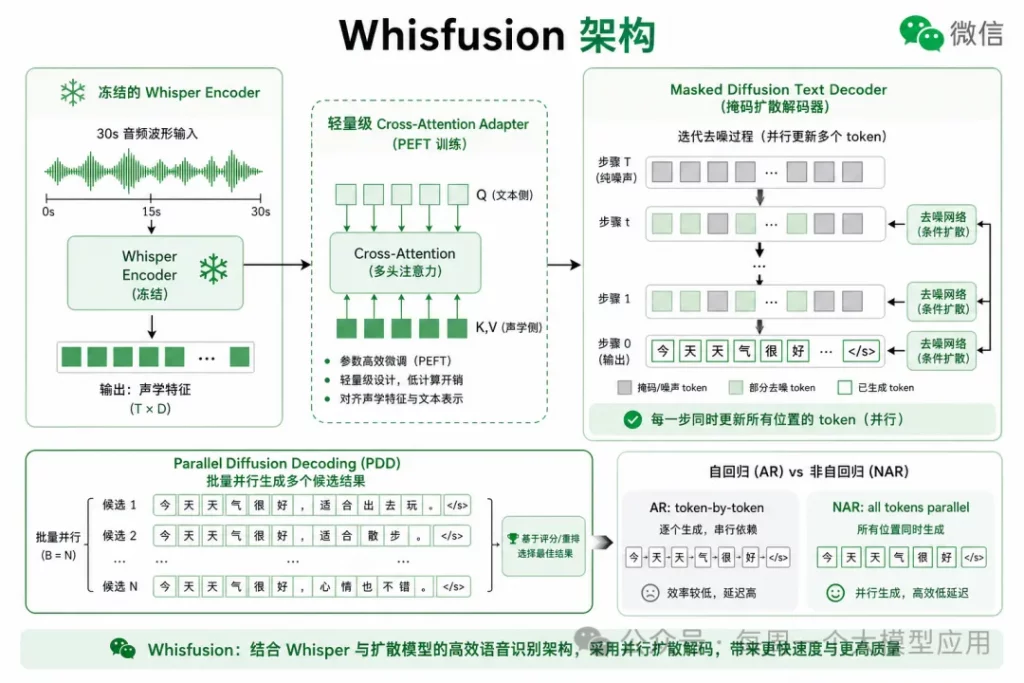
3.3 扩散解码如何工作
Masked Diffusion 在前向过程中随机 mask 文本 token,模型学习从被 mask 的序列中恢复原文。推理时从全 mask 序列出发,迭代去噪若干步,每步所有位置同时预测。
与 AR 的关键差异:AR 第 t 个 token 依赖前 t-1 个;扩散解码每步都能「看到」完整声学上下文并双向建模全部 token。因此输出长度对延迟的影响大幅减弱——这正是 ASR 需要的特性。
▎ 3.4 Parallel Diffusion Decoding(PDD)
Whisfusion 进一步提出 PDD 策略:每步生成 k 个并行候选序列,按置信度选最优。
增加 k 可提升准确率,但对 RTF 影响极小——因为并行候选在同一 GPU batch 中完成。
● k=5→15:WER 从 9.1% 降到 8.3%,RTF 几乎不变
● Oracle WER 5.9%,模型实际 8.3%,68.7% 样本选中近最优候选
● 两阶段课程学习:Stage1 建立基础,Stage2 引入 PDD 达最优
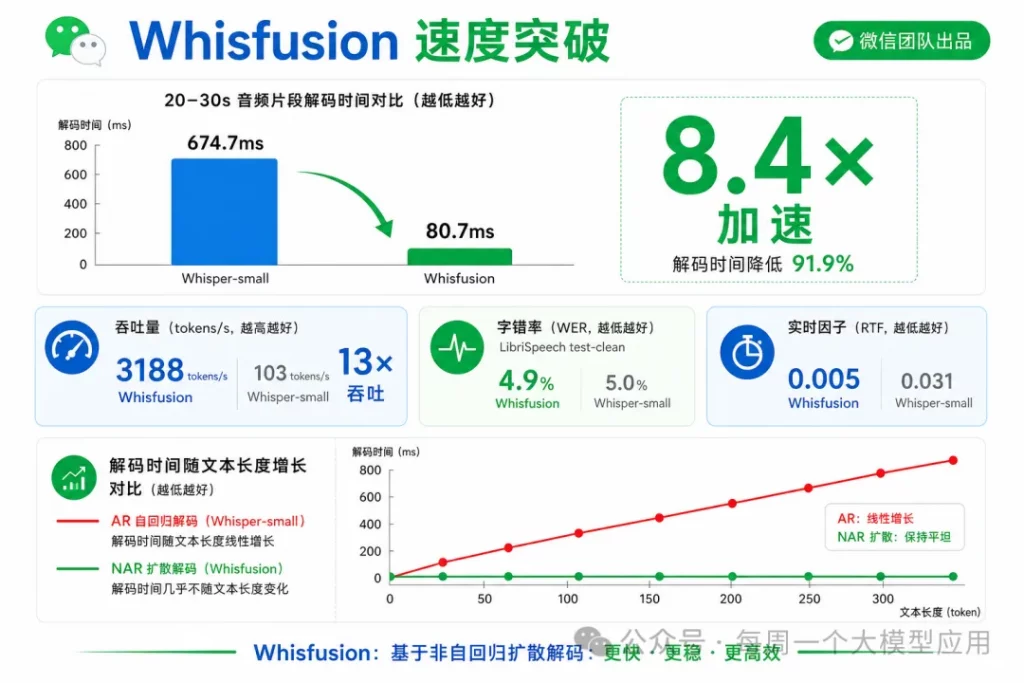
▎ 3.5 速度数据:8.4× 不是噱头
LibriSpeech test-clean:Whisfusion WER 4.9%,Whisper-small 5.0%,精度持平。
在 20–30 秒音频段上,解码时间 674.7ms → 80.7ms,加速 8.4×。
吞吐方面:Whisfusion 超 3100 tokens/s,Whisper-small 仅约 103 tokens/s,差距 13 倍以上。
RTF 0.005 vs 0.031,意味着 CPU/GPU 算力预算可以大幅释放。
「Whisfusion 的局限:长音频(20–30s)训练样本稀缺,该区间 WER 15.9% 偏高;与 Oracle 仍有 2.4% 差距,候选选择策略还有优化空间。但作为 Whisper 生态的「并行解码插件」,方向非常清晰。」
四、两条路线如何互补
CoT-ASR 和 Whisfusion 看似都在「改造 Whisper/LLM ASR」,
但优化目标几乎正交:一个追准确率尤其是实体识别,
一个追解码吞吐与延迟。

4.1 范式对比
① CoT-ASR:改「生成内容」—— 先推理再转写,激活 LLM 知识
② Whisfusion:改「生成方式」—— 并行扩散替代自回归
③ CoT-ASR:适合医疗、金融、客服等实体密集场景
④ Whisfusion:适合实时字幕、长音频批转、端侧低延迟场景
▎ 4.2 对工程落地的启示
● 评估指标要升级:WER 不够,垂直场景应跟踪 EER / 实体召回
● Speech LLM 不必盲追参数量:38k 小时 + 推理范式可击败 30B 模型
● 解码器是延迟瓶颈:编码器量化、蒸馏之外,NAR 扩散是下一战场
● 两者可组合:Whisfusion 式并行解码 + CoT 式推理 prompt,是值得探索的方向
▎ 4.3 与开源 ASR 优化的关系
如果你在用 Whisper / SenseVoice / sherpa-onnx 做落地,
这两篇论文提供了「下一步该往哪走」的路线图:准确率瓶颈 → 考虑引入推理式转写或 LLM 后处理;速度瓶颈 → 关注 NAR/Flow Matching/扩散解码,
而非一味缩小 beam。
Whisper-CD(对比解码抑制幻觉)、Distilling Conversations(多轮上下文压缩)等同期工作,
与 CoT-ASR / Whisfusion 共同构成 2026 ASR 论文簇——核心主题都是:让 ASR 更「聪明」、更「快」。
五、论文信息与延伸阅读
▎ CoT-ASR
● 论文:Speech LLMs are Contextual Reasoning Transcribers
● 机构:Microsoft Core AI
● 链接:https://arxiv.org/html/2604.00610v1
● 骨干:Phi-4-mini 3.8B + Conformer 编码器 + CTC Adapter
▎ Whisfusion
● 论文:Whisfusion: Parallel ASR Decoding via a Diffusion Transformer
● 会议:ICLR 2026(under review)
● 链接:https://openreview.net/pdf?id=JCujsFnDS7
● 数据:LibriSpeech 960h 微调,6.5k 小时混合训练
总结
ASR 正从「直接转写」走向「推理式转写」与「并行解码」两条路线
• CoT-ASR:One-Pass 链式推理,WER -8.7%,EER -16.9%,38k 小时超越 30B 模型
• Whisfusion:Whisper + 扩散 NAR 解码,20–30s 音频解码加速 8.4×
• CTC Modality Adapter 与 PDD 分别是两篇论文的关键工程创新
• 落地时按场景选路线:实体准确 vs 实时延迟,评估指标也要相应升级