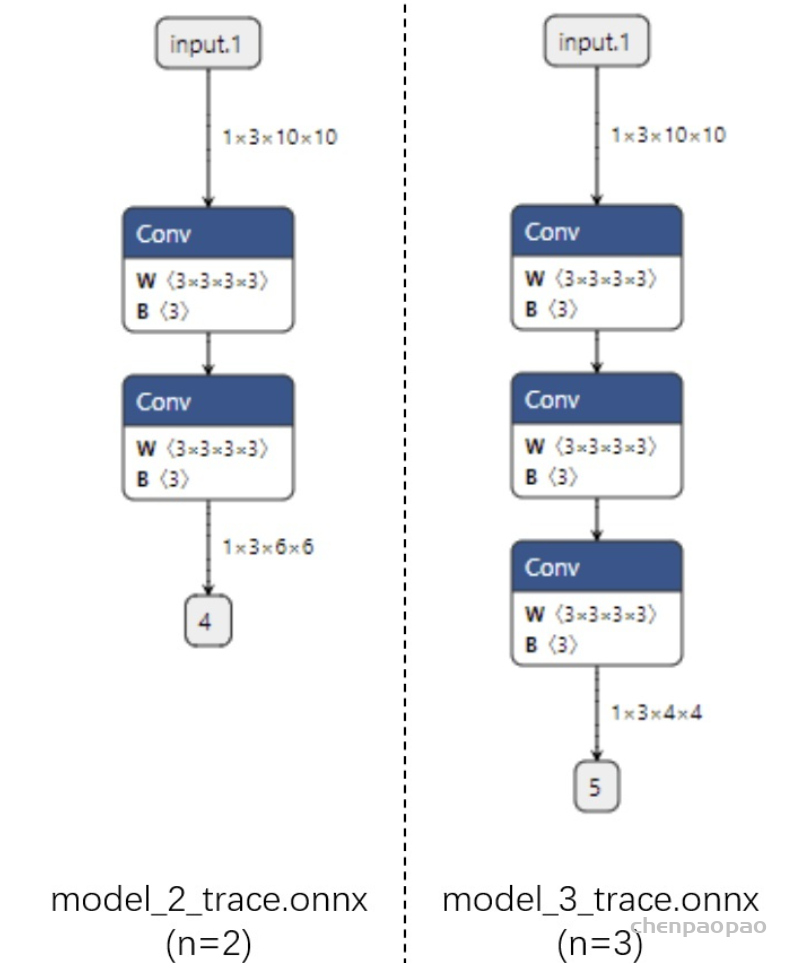
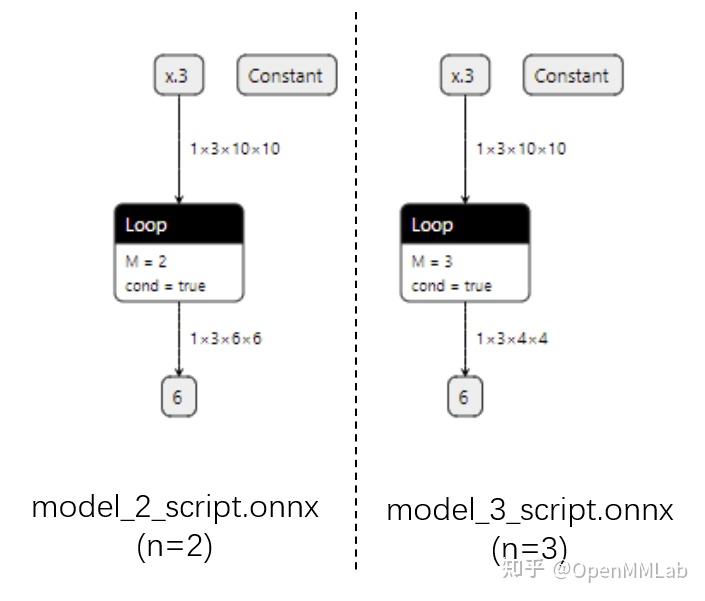
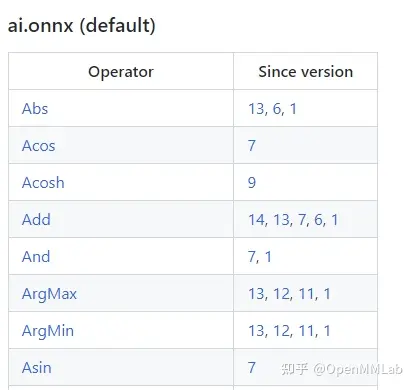
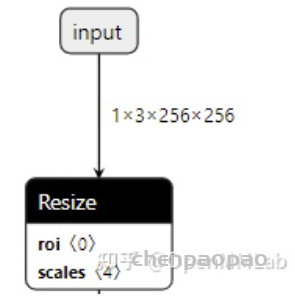
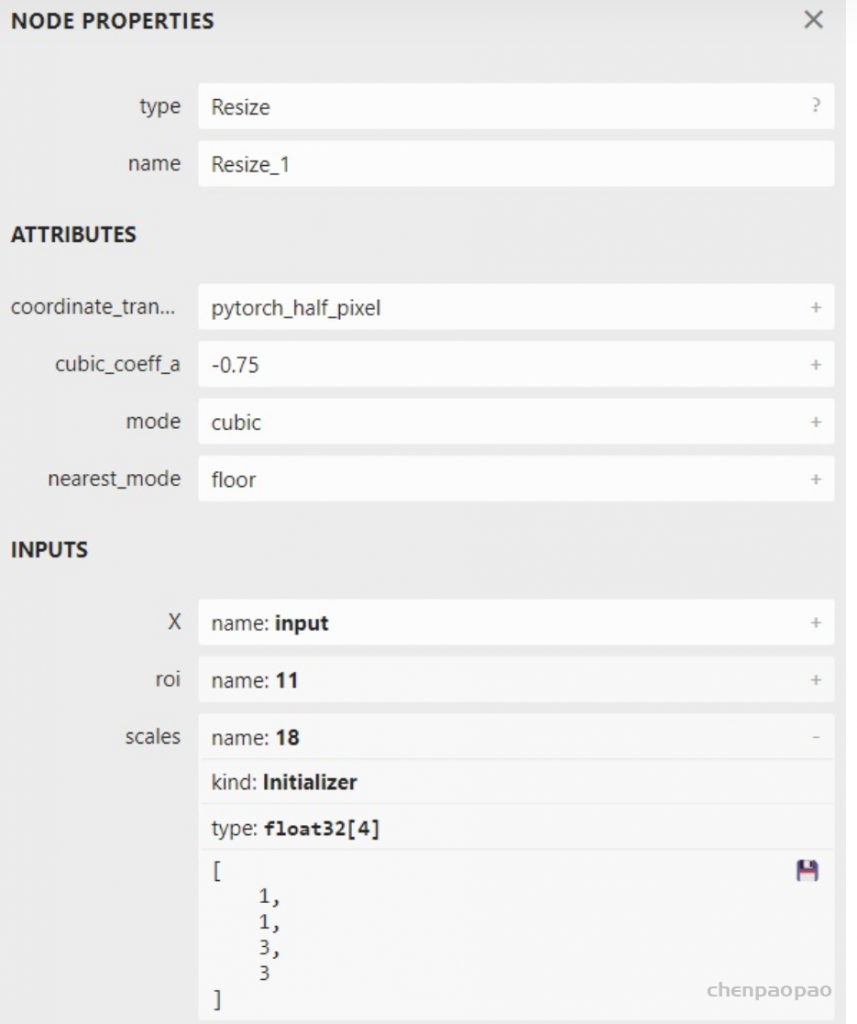
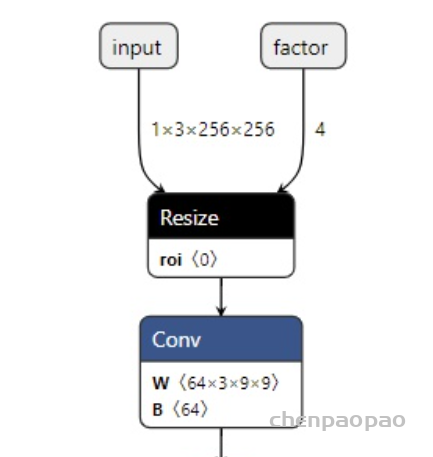
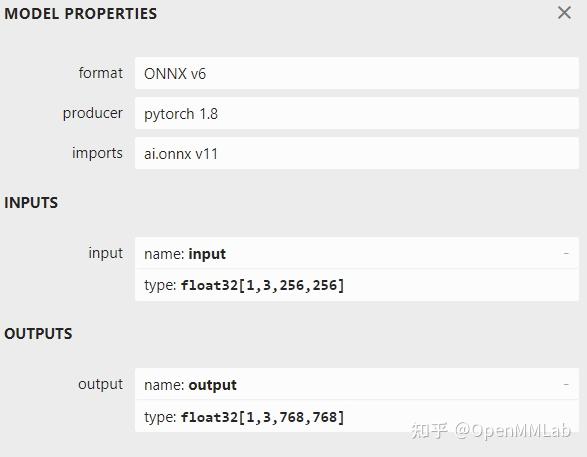
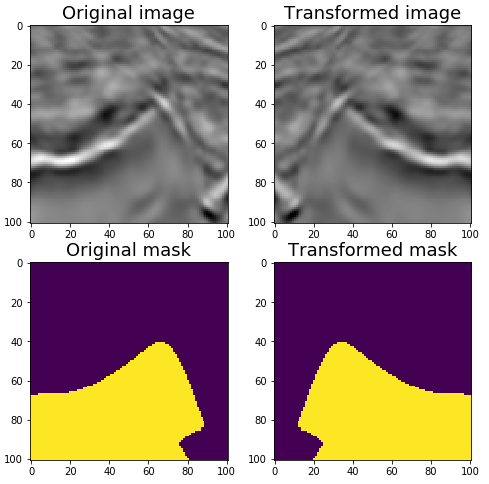
Input[0] on model model_static.onnx succeed.
Input[1] on model model_static.onnx error.
Input[2] on model model_static.onnx error.
Input[0] on model model_dynamic_0.onnx succeed.
Input[1] on model model_dynamic_0.onnx succeed.
Input[2] on model model_dynamic_0.onnx error.
Input[0] on model model_dynamic_23.onnx succeed.
Input[1] on model model_dynamic_23.onnx error.
Input[2] on model model_dynamic_23.onnx succeed.
print(exceptions[(1, 'model_static.onnx')])
# output # [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: in for the following indices index: 0 Got: 2 Expected: 1 Please fix either the inputs or the model.
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * x[0].item()
return x, torch.Tensor([i for i in x])
model = Model()
dummy_input = torch.rand(10)
torch.onnx.export(model, dummy_input, 'a.onnx')
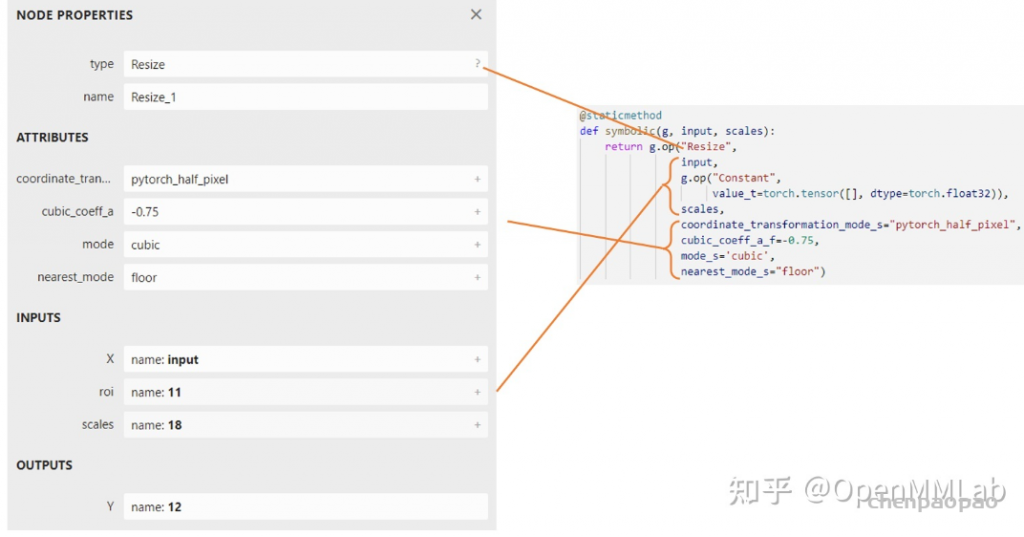
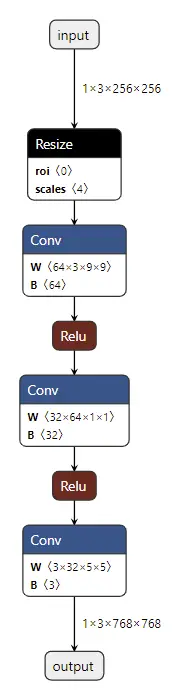
return g.op("Resize",
input,
empty_roi,
empty_scales,
output_size,
coordinate_transformation_mode_s=coordinate_transformation_mode,
cubic_coeff_a_f=-0.75, # only valid when mode="cubic"
mode_s=interpolate_mode, # nearest, linear, or cubic
nearest_mode_s="floor") # only valid when mode="nearest"
rpm -i cuda-repo-rhel7-10-2-local-10.2.89-440.33.01-1.0-1.x86_64.rpm
tar -zxvf cudnn-10.2-linux-x64-v8.0.1.13.tgz
# tar -xzvf TensorRT-${version}.Linux.${arch}-gnu.${cuda}.${cudnn}.tar.gz
tar -xzvf TensorRT-7.1.3.4.CentOS-7.6.x86_64-gnu.cuda-10.2.cudnn8.0.tar.gz
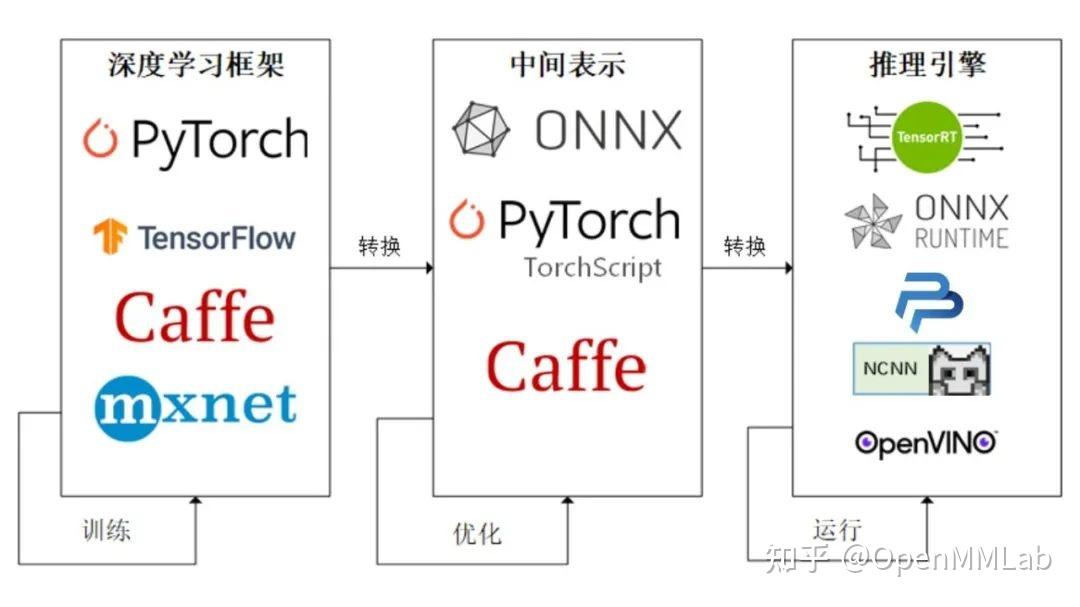
Open Neural Network Exchange(ONNX,开放神经网络交换)格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移.最初的ONNX专注于推理(评估)所需的功能。 ONNX解释计算图的可移植,它使用graph的序列化格式
pth 转换为onnx
import onnx
import torch
def export_onnx(onnx_model_path, model, cuda, height, width, dummy_input=None):
model.eval()
if dummy_input is None:
dummy_input = torch.randn(1, 3, height, width).float()
dummy_input.requires_grad = True
print("dummy_input shape: ", dummy_input.shape, dummy_input.requires_grad)
if cuda:
dummy_input = dummy_input.cuda()
torch.onnx.export(
model, # model being run
dummy_input, # model input (or a tuple for multiple inputs)
onnx_model_path, # where to save the model (can be a file or file-like object)
export_params=True, # store the trained parameter weights inside the model file
opset_version=10, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
verbose=True,
input_names=['input'], # the model's input names
output_names=['output'], # the model's output names
)
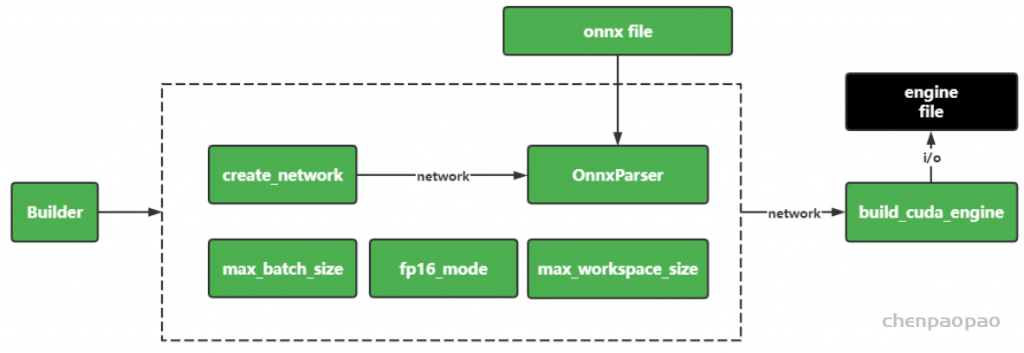
import tensorrt as trt
def build_engine(onnx_path):
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_batch_size = 128
builder.max_workspace_size = 1<<15
builder.fp16_mode = True
builder.strict_type_constraints = True
with open(onnx_path, 'rb') as model:
parser.parse(model.read())
# Build and return an engine.
return builder.build_cuda_engine(network)
#解析模型,构建engine并保存
with build_engine(onnx_path) as engine:
with open(engine_path, "wb") as f:
f.write(engine.serialize())
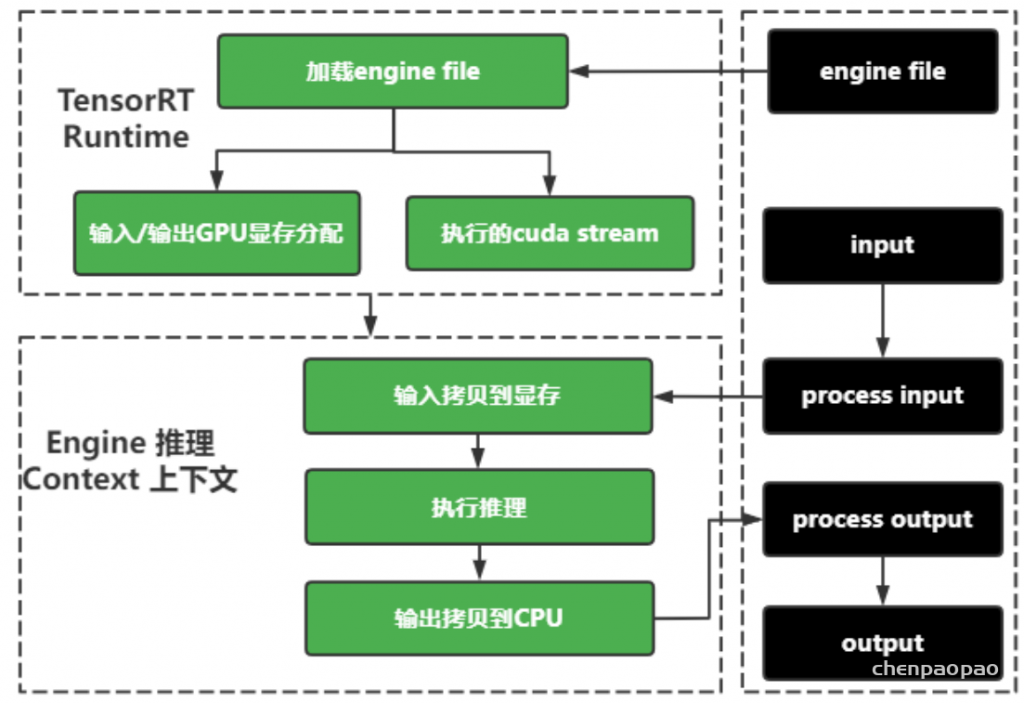
#直接加载engine
with open(engine_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
#解析模型,构建engine并保存
with build_engine(uff_path) as engine:
with open(engine_path, "wb") as f:
f.write(engine.serialize())
#直接加载engine
with open(engine_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
nvtop version 1.0.0Available options: -d --delay : Select the refresh rate (1 == 0.1s) -v --version : Print the version and exit -s --gpu-select : Column separated list of GPU IDs to monitor -i --gpu-ignore : Column separated list of GPU IDs to ignore -p --no-plot : Disable bar plot -C --no-color : No colors -N --no-cache : Always query the system for user names and command line information -f --freedom-unit : Use fahrenheit -E --encode-hide : Set encode/decode auto hide time in seconds (default 30s, negative = always on screen) -h --help : Print help and exit
在安装部分有个小问题,我的本机已经安装完opencv-python,然后我们再去安装albumentations的时候,出现了一个问题,就是我们的opencv-python阻止albumentations的安装,报错如下:# Could not install packages due to anEnvironmentError: [WinError 5] 拒绝访问,是因为在安装albumentations的时候还要安装opencv-python-headless,这个库和opencv冲突。
import albumentations as A
import cv2
import matplotlib.pyplot as plt
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=512, height=512),
A.HorizontalFlip(p=0.8),
A.RandomBrightnessContrast(p=0.5),
])
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = transform(image=image)
transformed_image = transformed["image"]
plt.imshow(transformed_image)
plt.show()
详细使用案例:
1、VerticalFlip 围绕X轴垂直翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.VerticalFlip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Blur后的图像')
plt.imshow(transformed_image)
plt.show()
2、Blur模糊输入图像
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Blur(blur_limit=15,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Blur后的图像')
plt.imshow(transformed_image)
plt.show()
3、HorizontalFlip 围绕y轴水平翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.HorizontalFlip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('HorizontalFlip后的图像')
plt.imshow(transformed_image)
plt.show()
4、Flip水平,垂直或水平和垂直翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Flip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Flip后的图像')
plt.imshow(transformed_image)
plt.show()
5、Transpose, 通过交换行和列来转置输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Transpose(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Transpose后的图像')
plt.imshow(transformed_image)
plt.show()
6、RandomCrop 随机裁剪
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomCrop(512, 512,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomCrop后的图像')
plt.imshow(transformed_image)
plt.show()
7、RandomGamma 随机灰度系数
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomGamma(gamma_limit=(20, 20), eps=None, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomGamma后的图像')
plt.imshow(transformed_image)
plt.show()
8、RandomRotate90 将输入随机旋转90度,N次
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomRotate90(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomRotate90后的图像')
plt.imshow(transformed_image)
plt.show()
10、ShiftScaleRotate 随机平移,缩放和旋转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.1, rotate_limit=45, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('ShiftScaleRotate后的图像')
plt.imshow(transformed_image)
plt.show()
11、CenterCrop 裁剪图像的中心部分
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.CenterCrop(256, 256, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("CenterCrop后的图像")
plt.imshow(transformed_image)
plt.show()
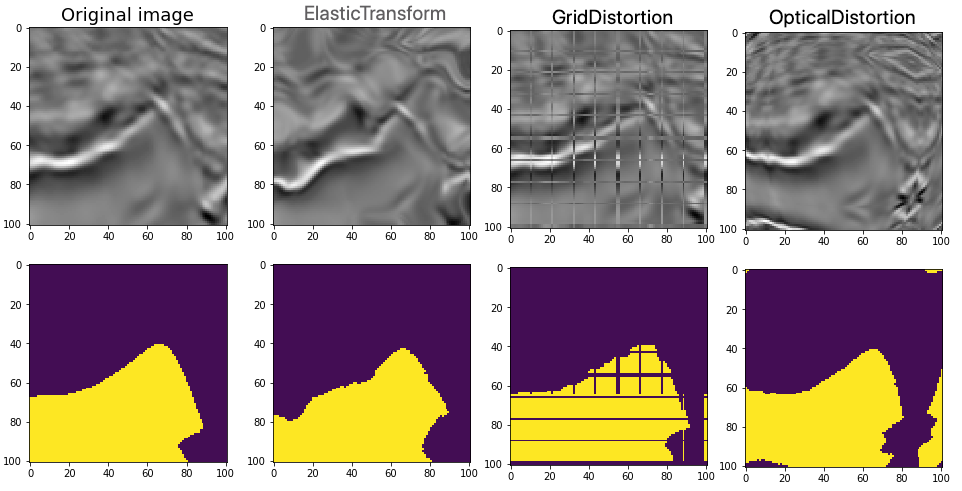
12、GridDistortion网格失真
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GridDistortion(num_steps=10, distort_limit=0.3,border_mode=4, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GridDistortion后的图像")
plt.imshow(transformed_image)
plt.show()
13、ElasticTransform 弹性变换
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ElasticTransform(alpha=5, sigma=50, alpha_affine=50, interpolation=1, border_mode=4,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("ElasticTransform后的图像")
plt.imshow(transformed_image)
plt.show()
14、RandomGridShuffle把图像切成网格单元随机排列
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomGridShuffle(grid=(3, 3), always_apply=False, p=1) (image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RandomGridShuffle后的图像")
plt.imshow(transformed_image)
plt.show()
15、HueSaturationValue随机更改图像的颜色,饱和度和值
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.HueSaturationValue(hue_shift_limit=20, sat_shift_limit=30, val_shift_limit=20, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("HueSaturationValue后的图像")
plt.imshow(transformed_image)
plt.show()
16、PadIfNeeded 填充图像
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.PadIfNeeded(min_height=2048, min_width=2048, border_mode=4, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("PadIfNeeded后的图像")
plt.imshow(transformed_image)
plt.show()
17、RGBShift,对图像RGB的每个通道随机移动值
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RGBShift(r_shift_limit=10, g_shift_limit=20, b_shift_limit=20, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RGBShift后的图像")
plt.imshow(transformed_image)
plt.show()
18、GaussianBlur 使用随机核大小的高斯滤波器对图像进行模糊处理
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GaussianBlur(blur_limit=11, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GaussianBlur后的图像")
plt.imshow(transformed_image)
plt.show()
CLAHE自适应直方图均衡
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.CLAHE(clip_limit=4.0, tile_grid_size=(8, 8), always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("CLAHE后的图像")
plt.imshow(transformed_image)
plt.show()
ChannelShuffle随机重新排列输入RGB图像的通道
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ChannelShuffle(always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("ChannelShuffle后的图像")
plt.imshow(transformed_image)
plt.show()
InvertImg反色
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.InvertImg(always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("InvertImg后的图像")
plt.imshow(transformed_image)
plt.show()
Cutout 随机擦除
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Cutout(num_holes=20, max_h_size=20, max_w_size=20, fill_value=0, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("Cutout后的图像")
plt.imshow(transformed_image)
plt.show()
RandomFog随机雾化
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomFog(fog_coef_lower=0.3, fog_coef_upper=1, alpha_coef=0.08, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RandomFog后的图像")
plt.imshow(transformed_image)
plt.show()
GridDropout网格擦除
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GridDropout(ratio=0.5, unit_size_min=None, unit_size_max=None, holes_number_x=None, holes_number_y=None,
shift_x=0, shift_y=0, always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GridDropout后的图像")
plt.imshow(transformed_image)
plt.show()
The use of collate_fn is slightly different when automatic batching is enabled or disabled.
When automatic batching is disabled, collate_fn is called with each individual data sample, and the output is yielded from the data loader iterator. In this case, the default collate_fn simply converts NumPy arrays in PyTorch tensors.
When automatic batching is enabled, collate_fn is called with a list of data samples at each time. It is expected to collate the input samples into a batch for yielding from the data loader iterator. The rest of this section describes behavior of the default collate_fn in this case.
class OurDataset(Dataset):
def __init__(self, *tensors):
self.tensors = tensors
def __getitem__(self, index):
return self.tensors[index]
def __len__(self):
return len(self.tensors)
def collate_wrapper(batch):
#函数就会输入一个batch的列表的数据(注意是batch是一个列表,所以里面的数据可以不同大小)
a, b = batch
return a, b
a = torch.randn(3, 2, 3)
b = torch.randn(3, 3, 4)
dataset = OurDataset(a, b)
loader = DataLoader(dataset, batch_size=2, collate_fn=collate_wrapper)
for sample in loader:
print([x.size() for x in sample])
# Out: [torch.Size([1, 3, 2, 3]), torch.Size([1, 3, 3, 4])]