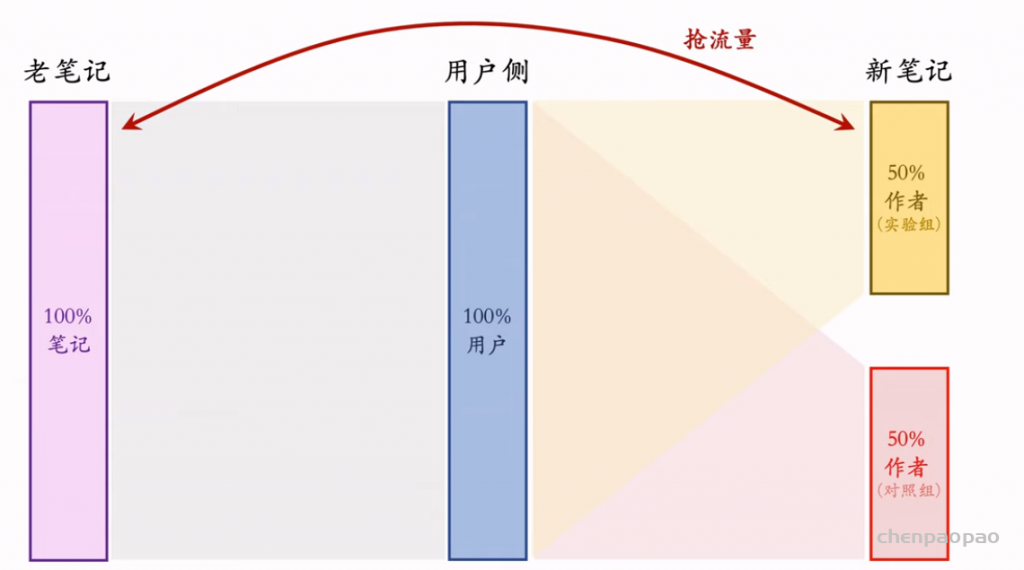
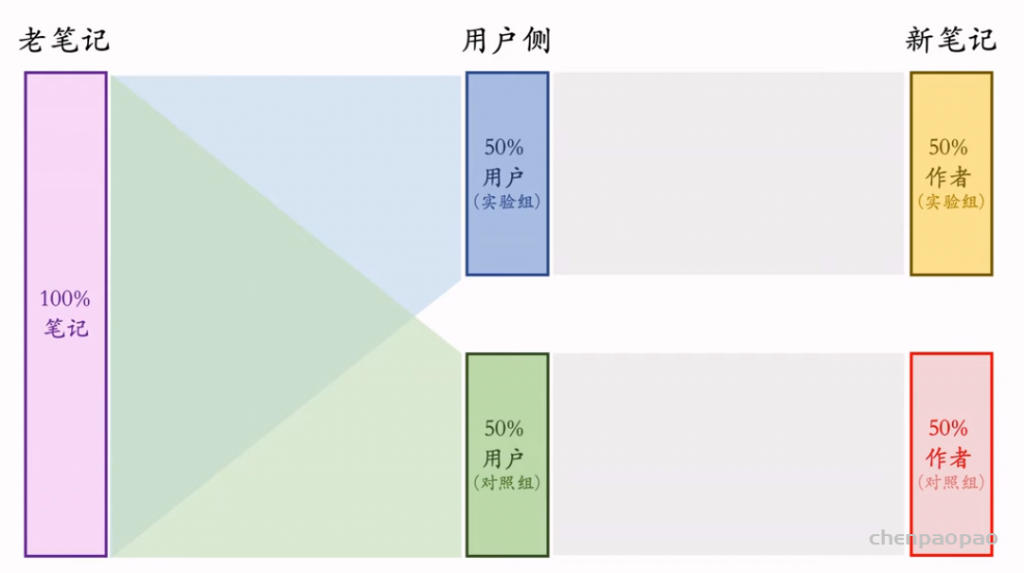
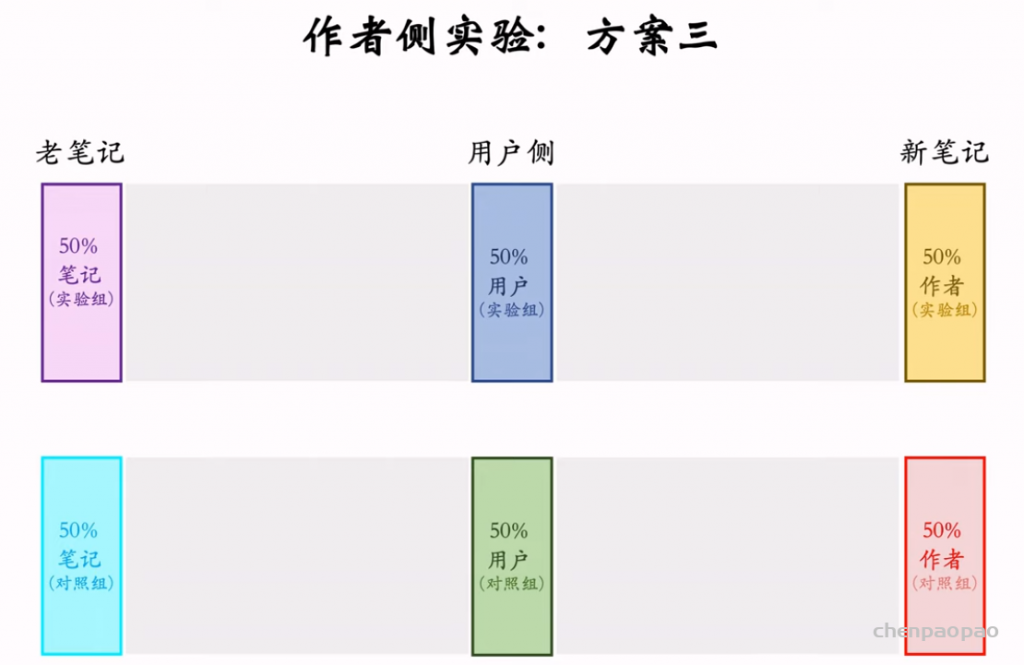
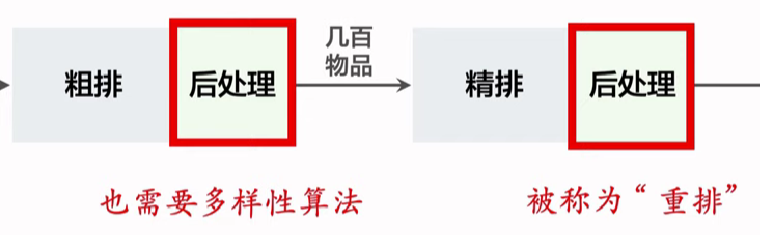
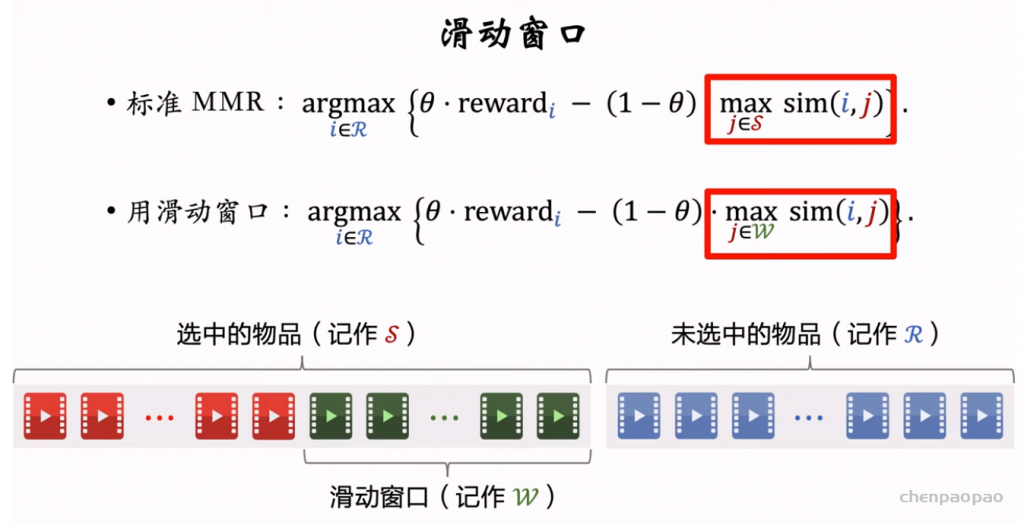
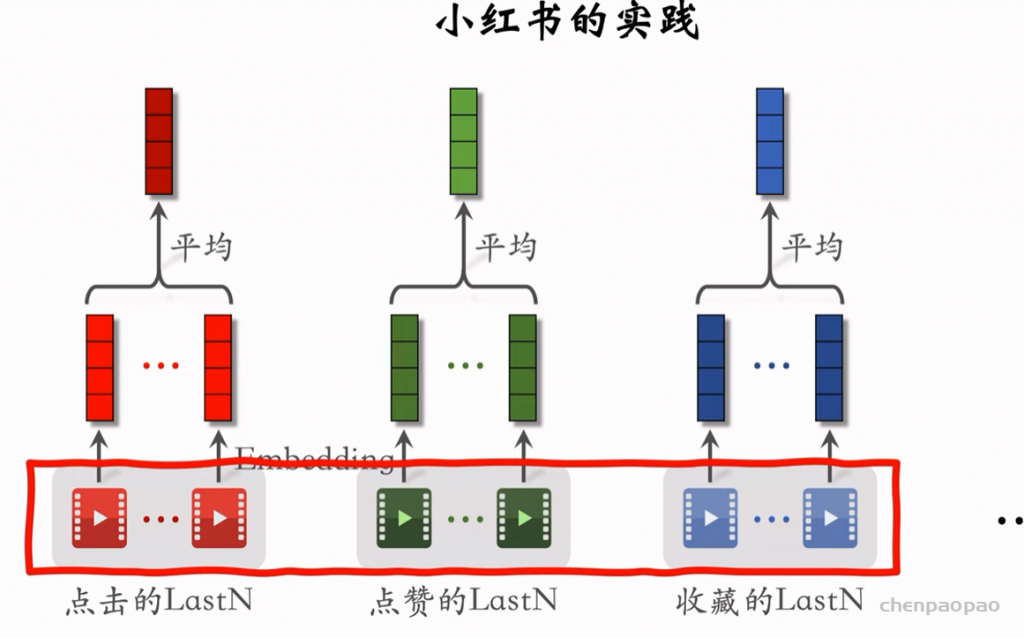
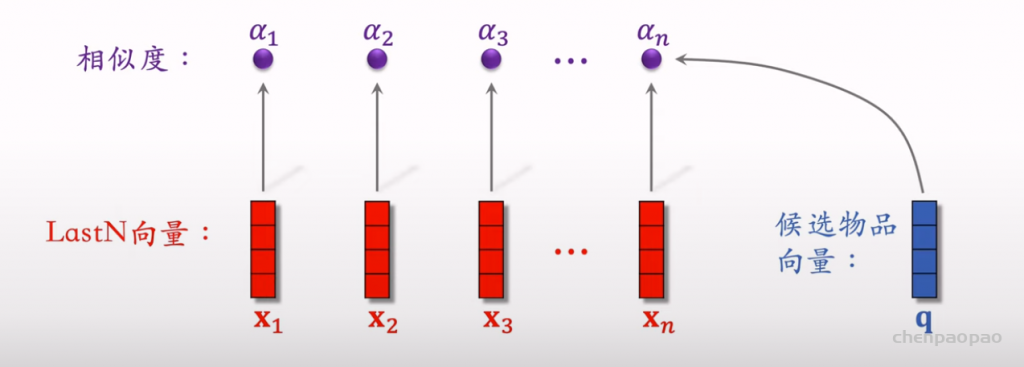
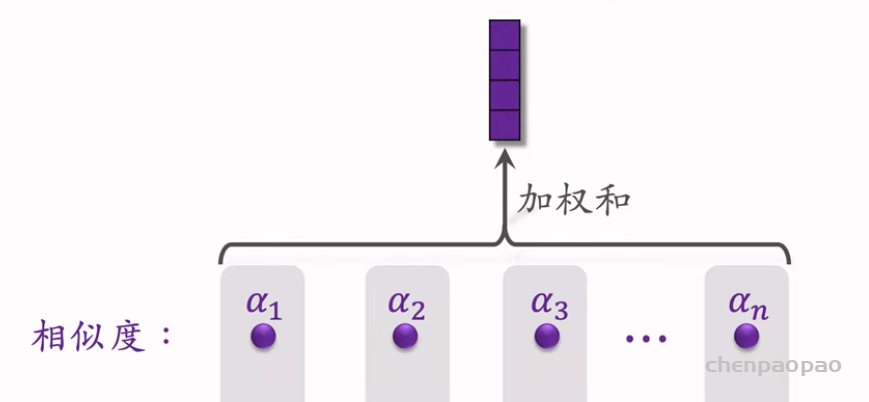
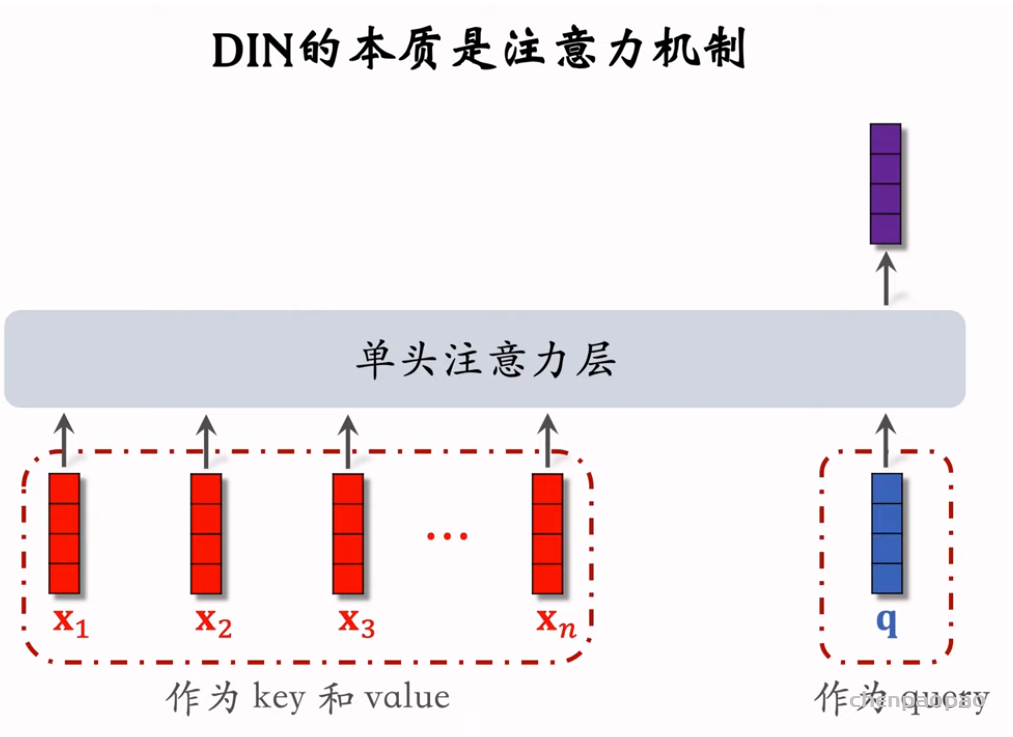
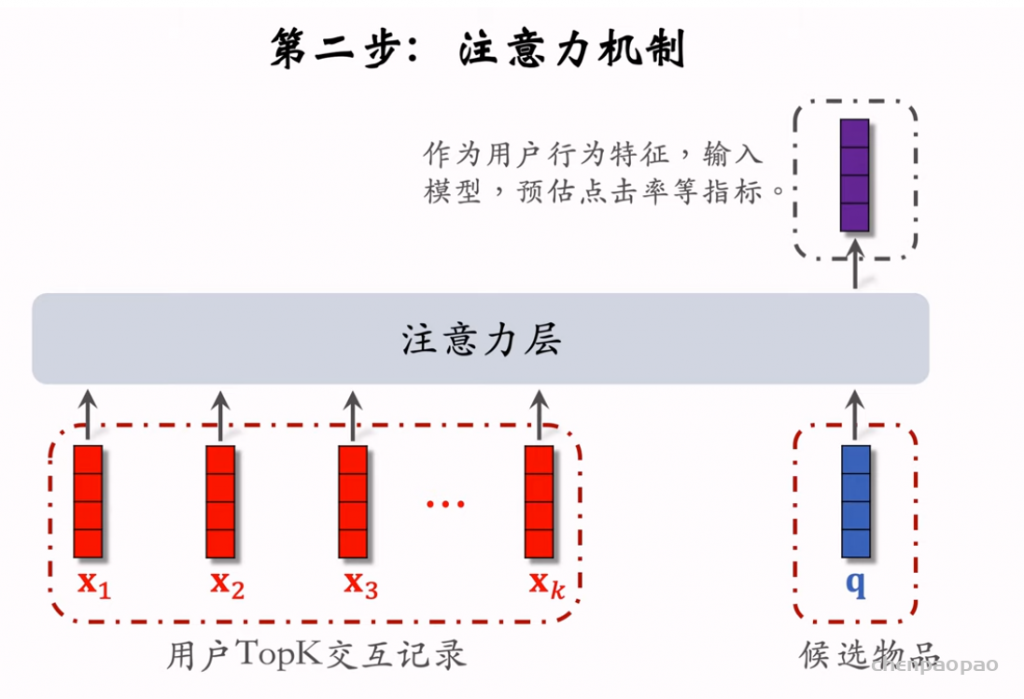
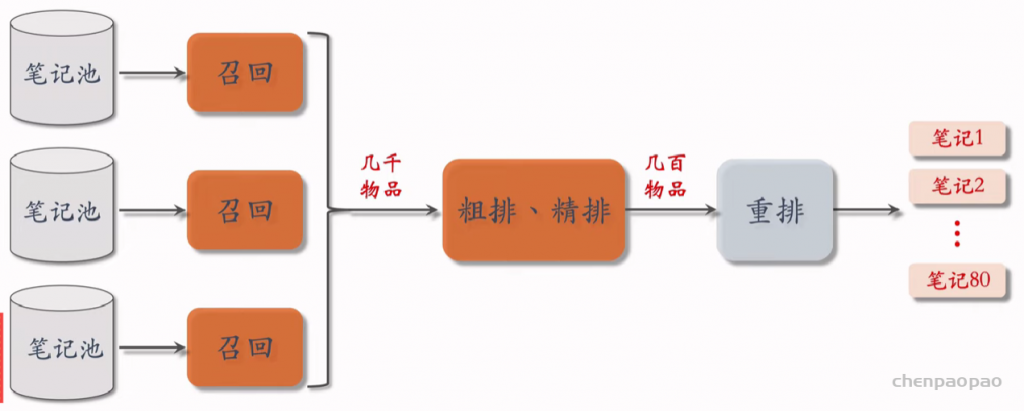
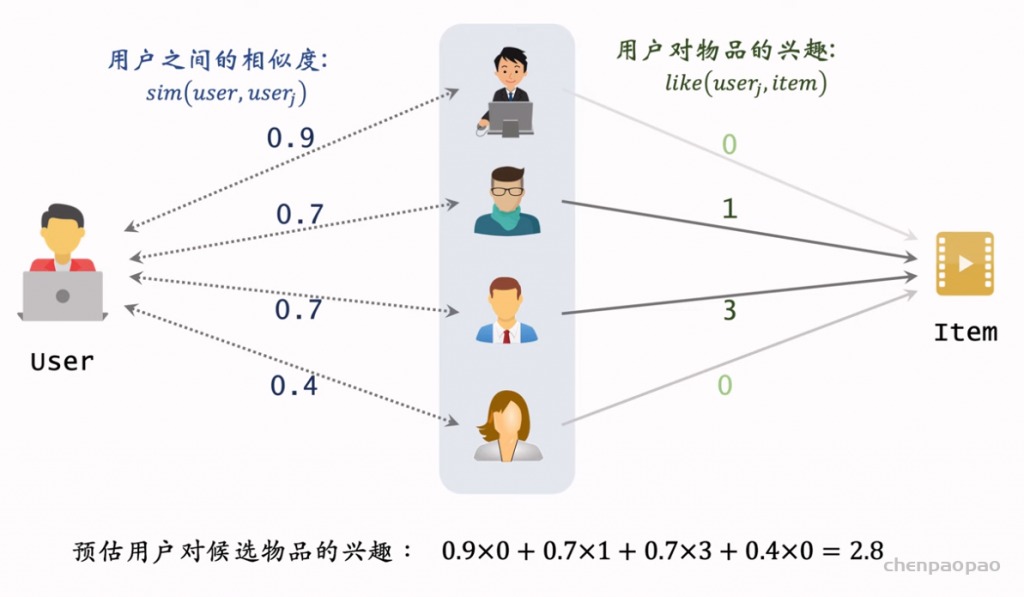
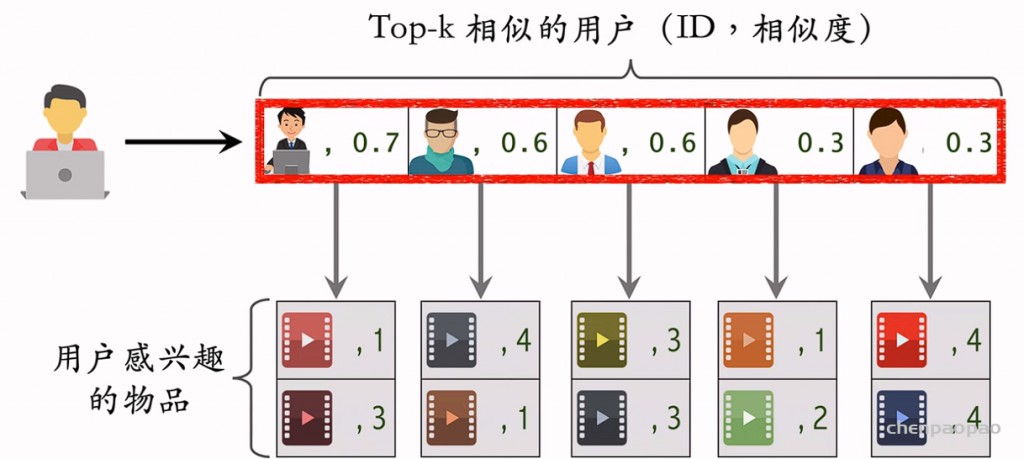
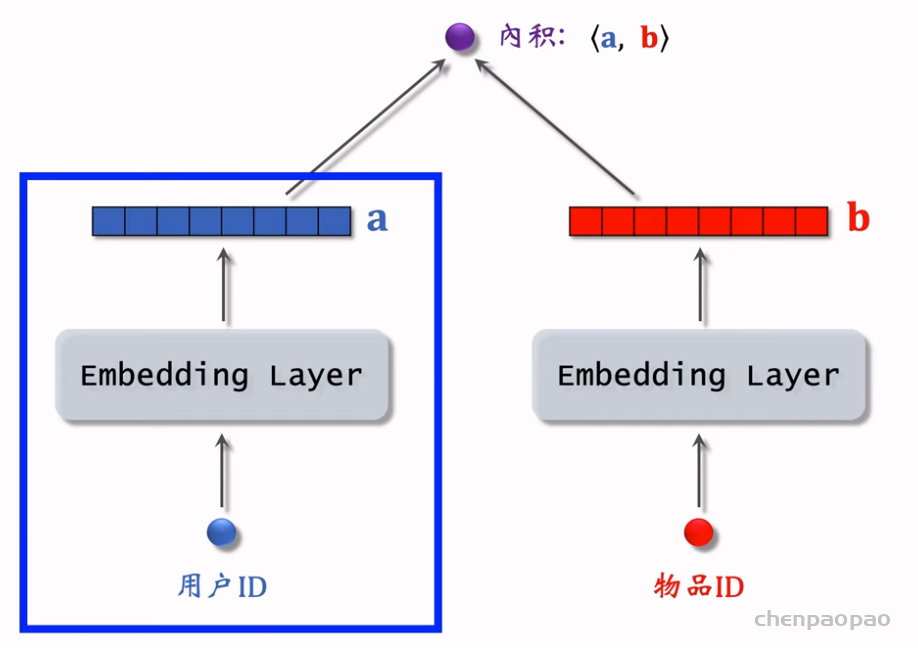
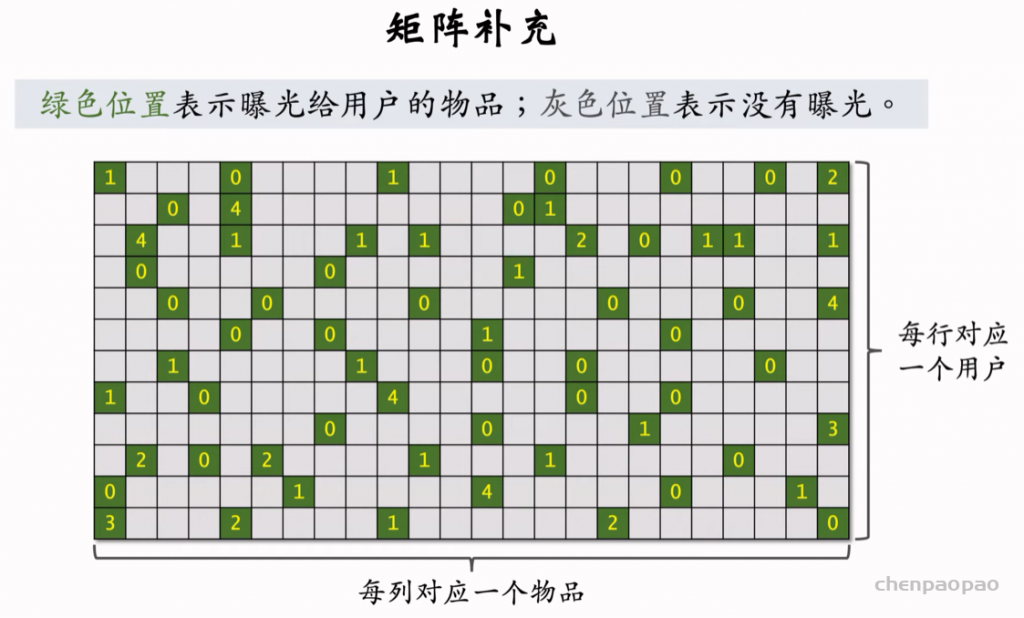
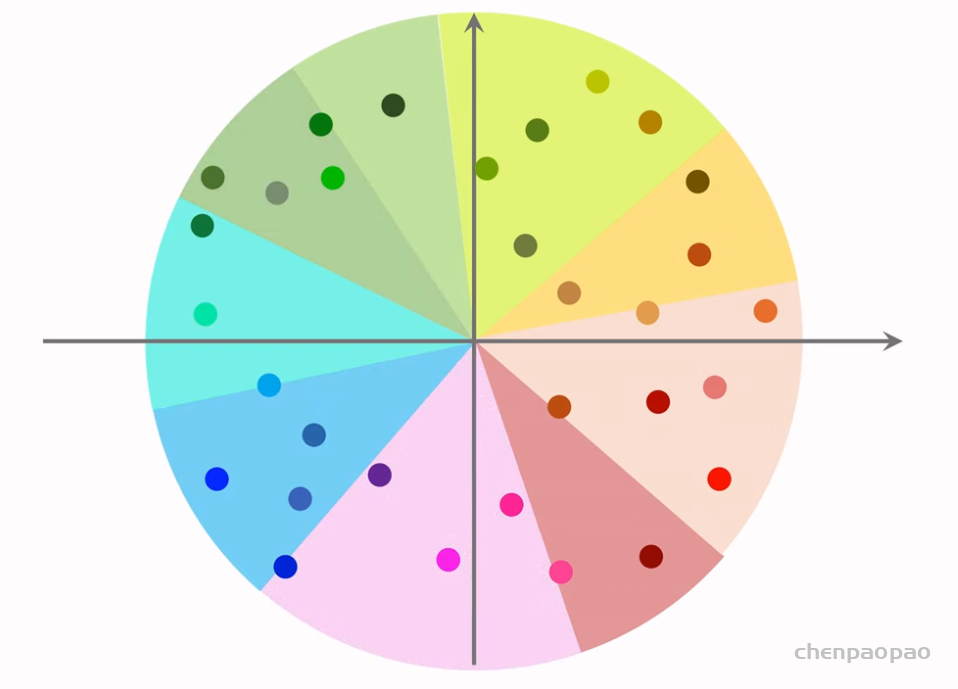
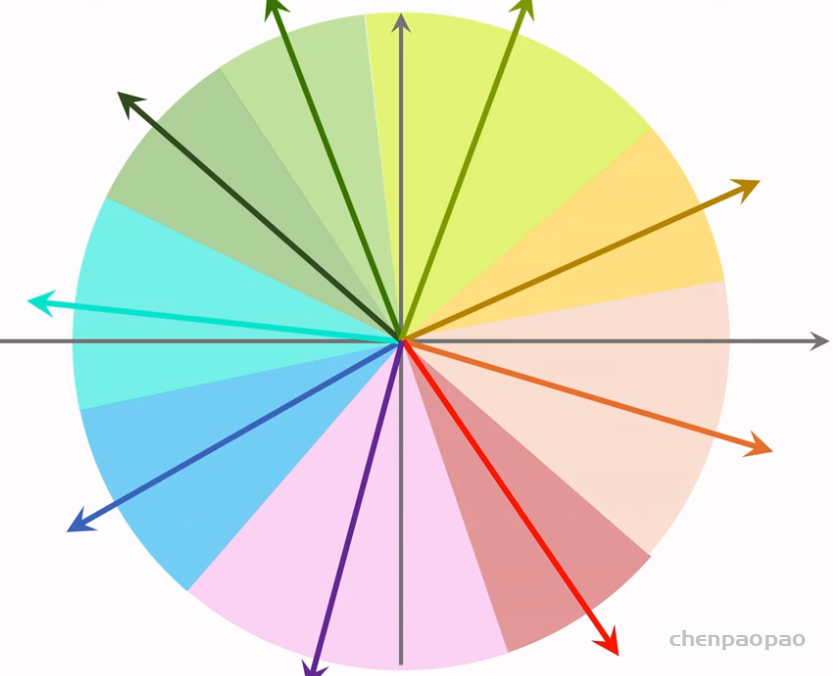
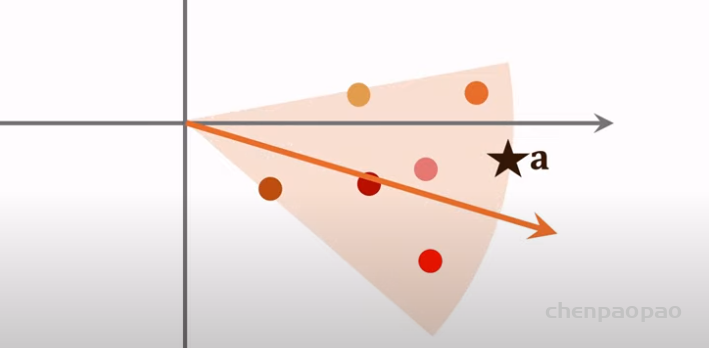
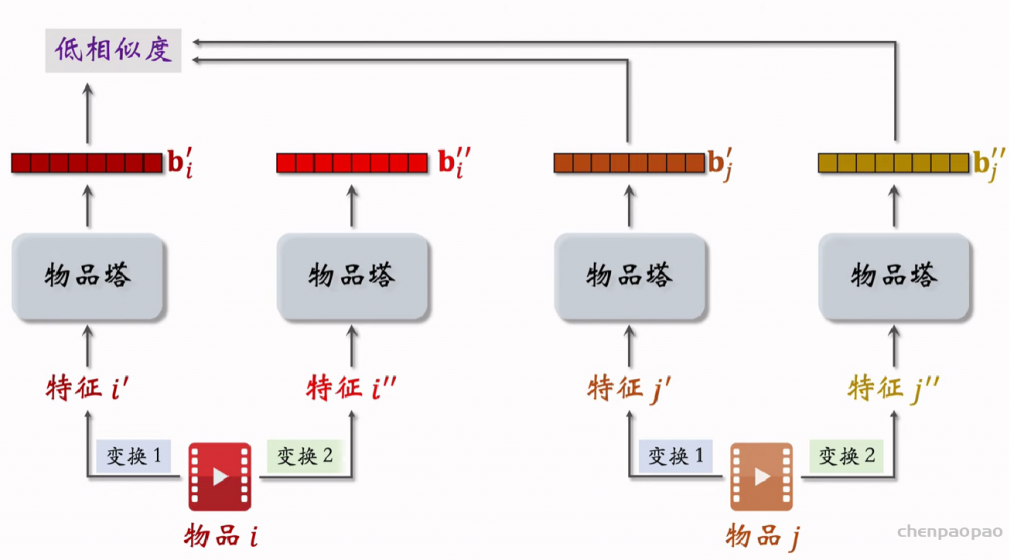
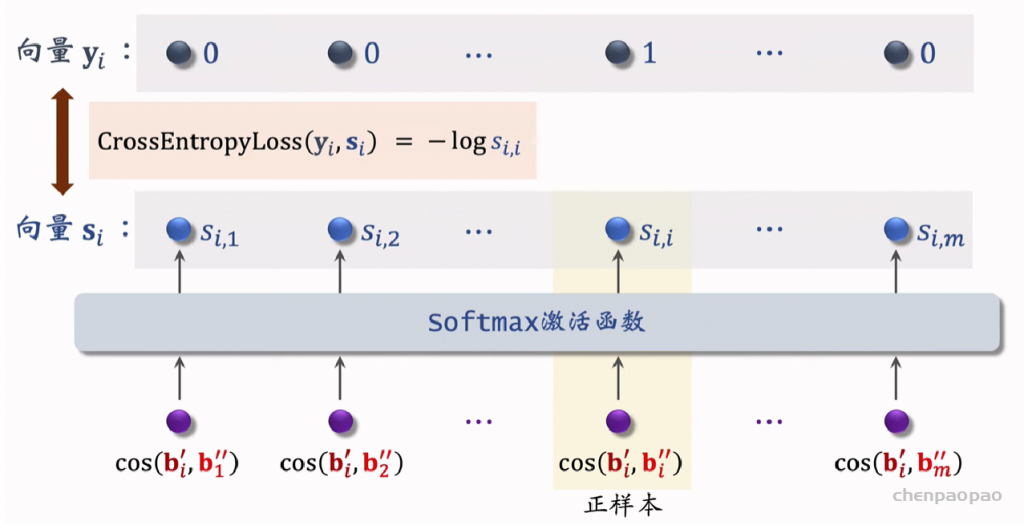
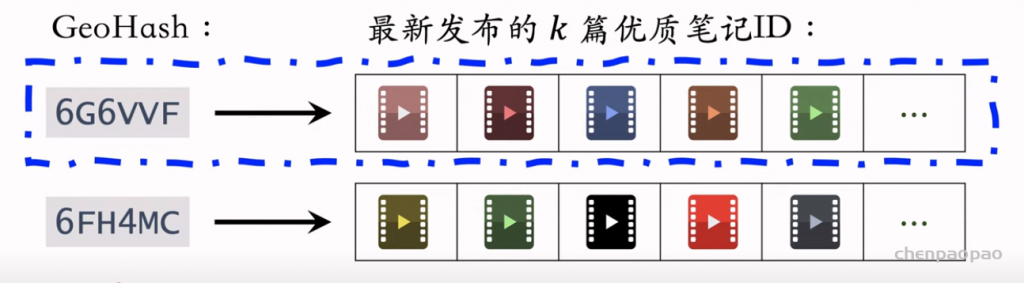
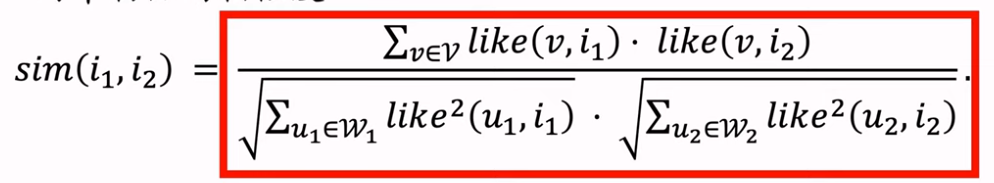推荐系统和搜索引擎重排中常用的 Maximal Marginal Relevance (MMR),它根据精排打分和物品相似度,从 n 个物品中选出 k 个价值高、且多样性好的物品。这节课还介绍滑动窗口 (sliding window),它可以与 MMR、DPP 等多样性算法结合,实践中滑动窗口的效果更优。
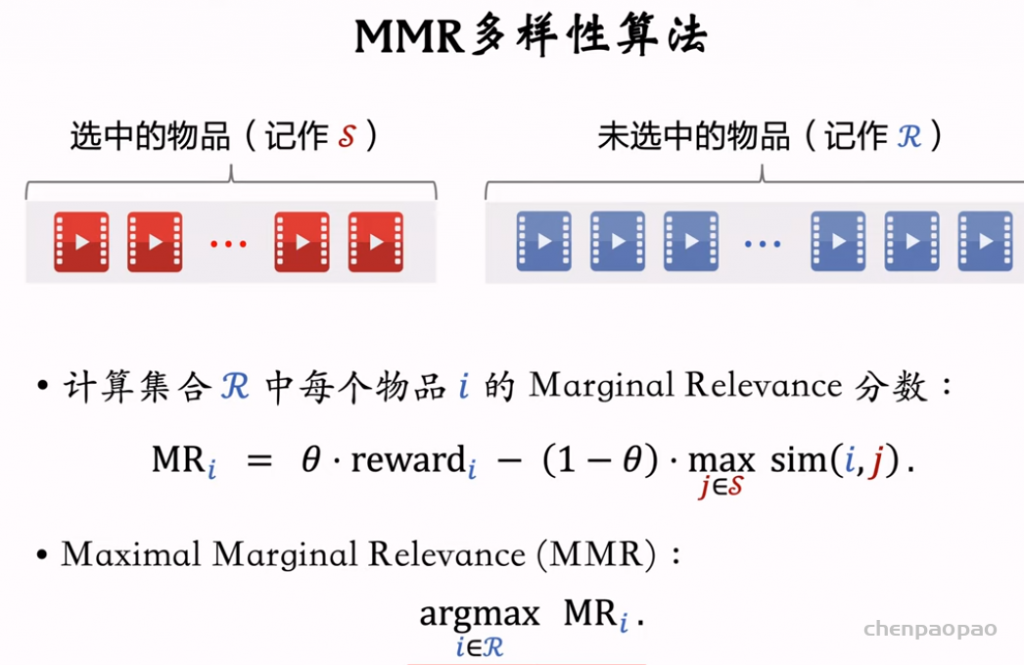
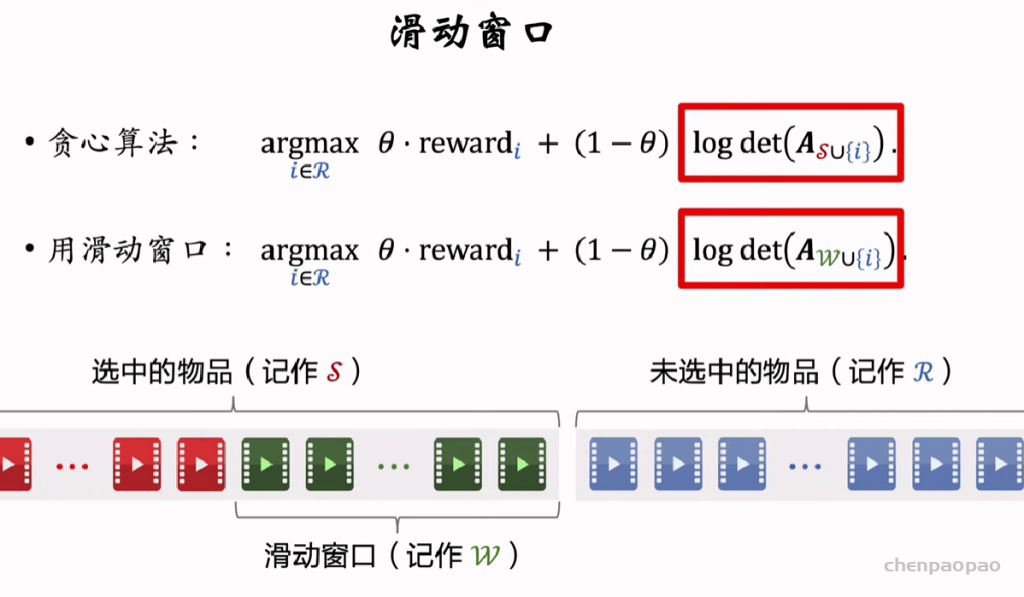
选择R中MR最高的放入集合S中。
参考文献: Carbonell and Goldstein. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In ACM SIGIR Conference on Research and Development in Information Retrieval, 1998.
参考文献: Chen et al. Fast greedy map inference for determinantal point process to improve recommendation diversity. In NIPS, 2018.
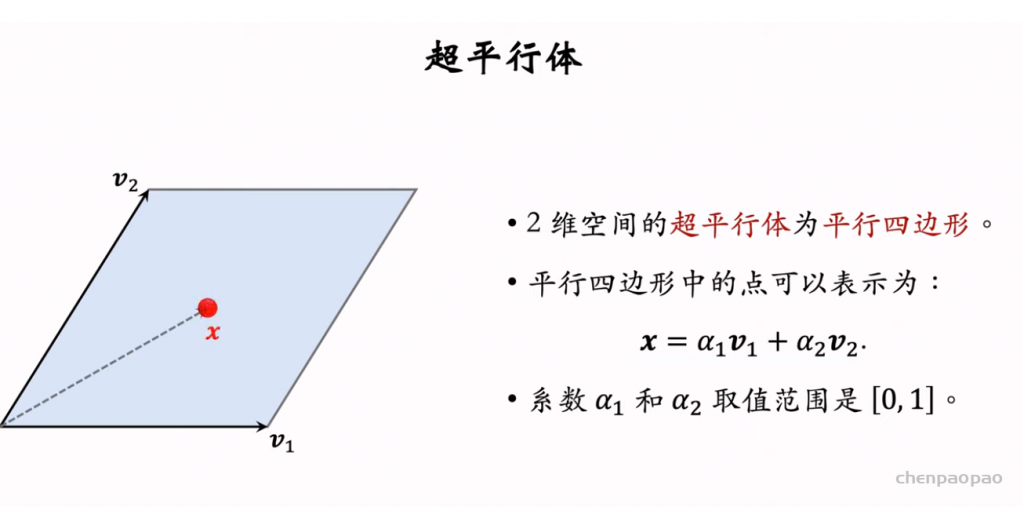
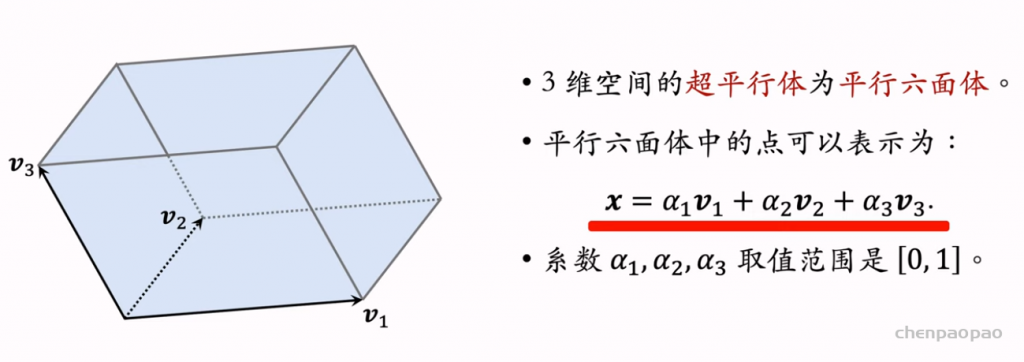
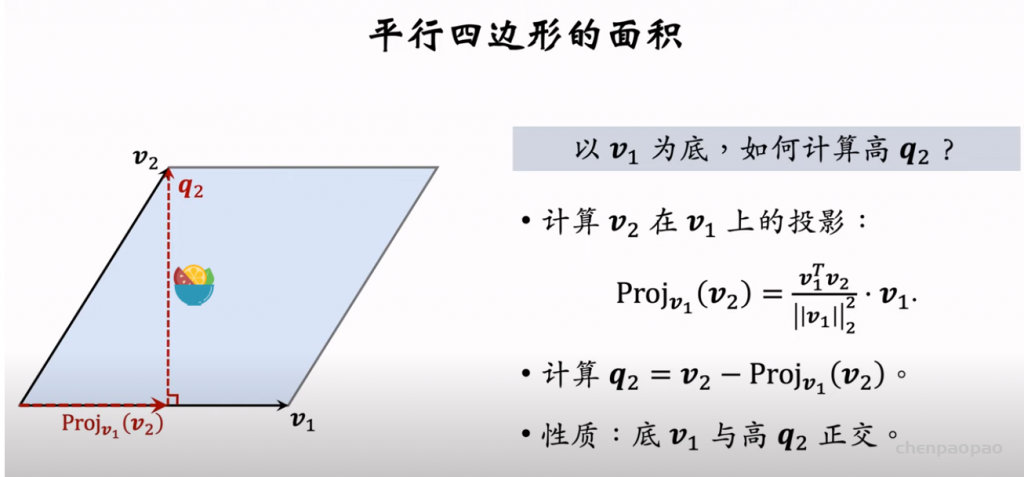
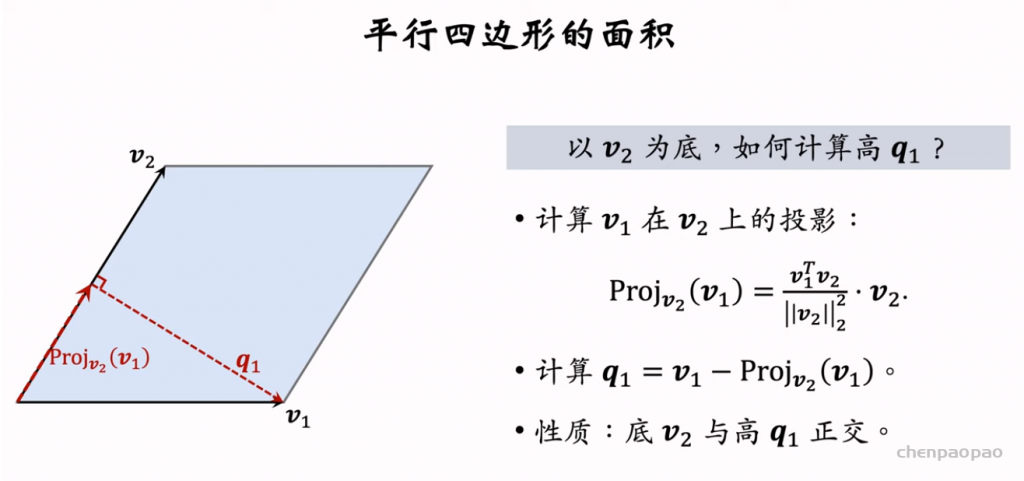
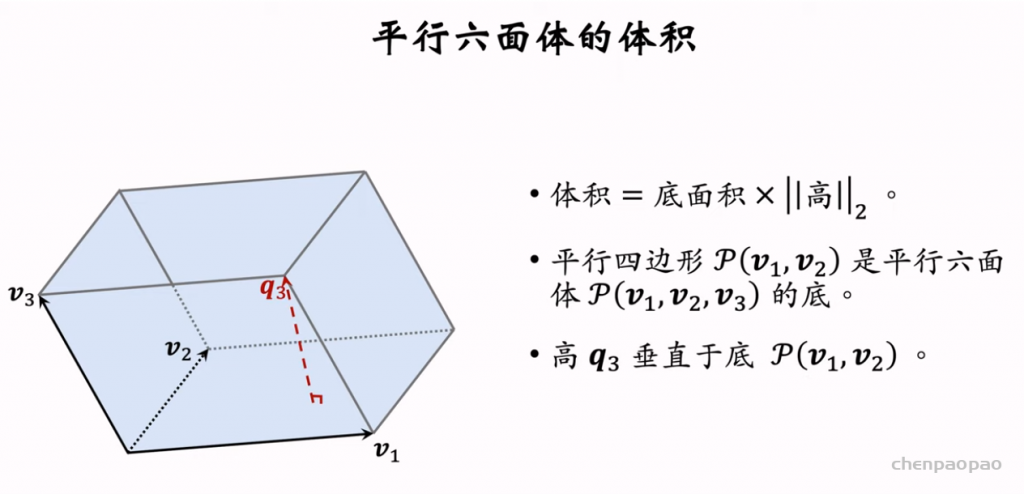
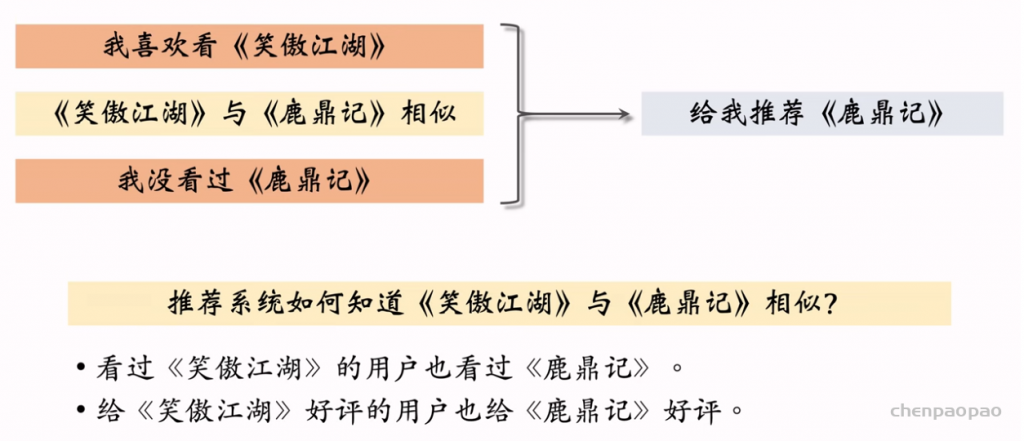
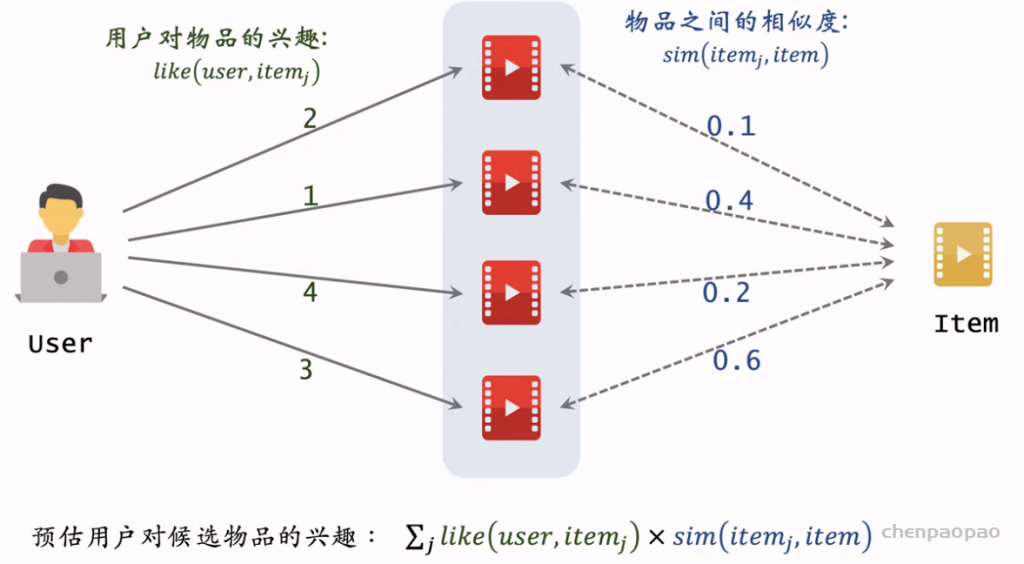
行列式等价于体积,因此用行列式的值来衡量物品的多样性。
DPP及其再推荐系统重排中的应用。求解DPP是比较困难的,需要计算行列式很多次,而计算行列式需要矩阵分解,代价很大。这节课介绍Hulu论文中的算法,可以用较小的代价求解DPP。 参考文献: Chen et al. Fast greedy map inference for determinantal point process to improve recommendation diversity. In NIPS, 2018.
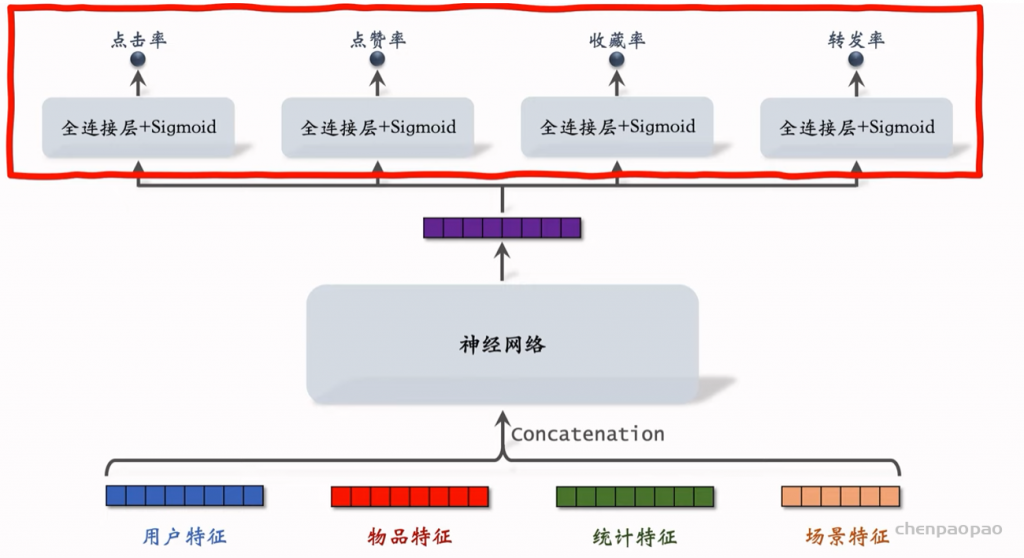
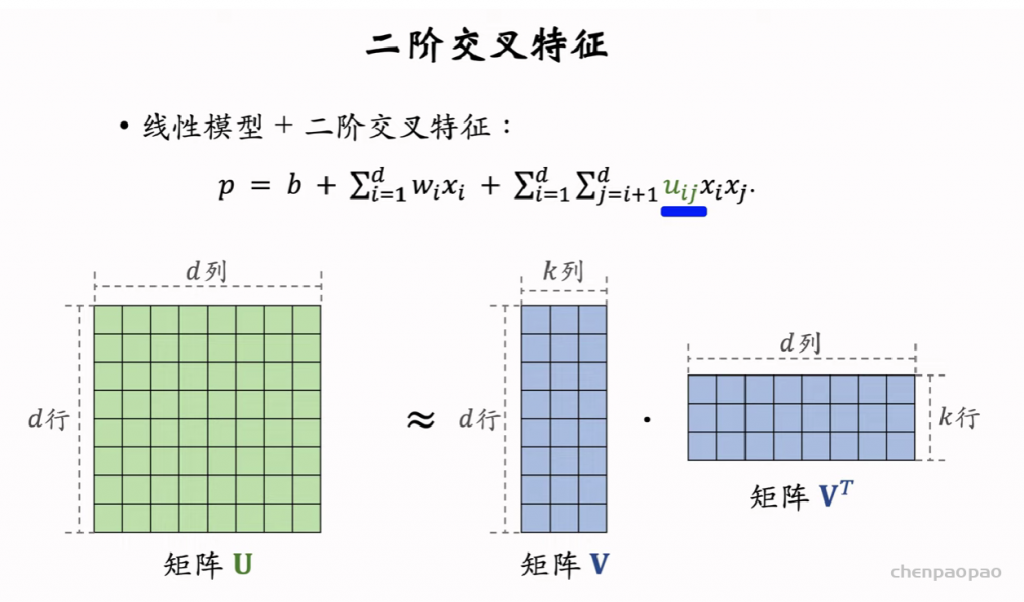
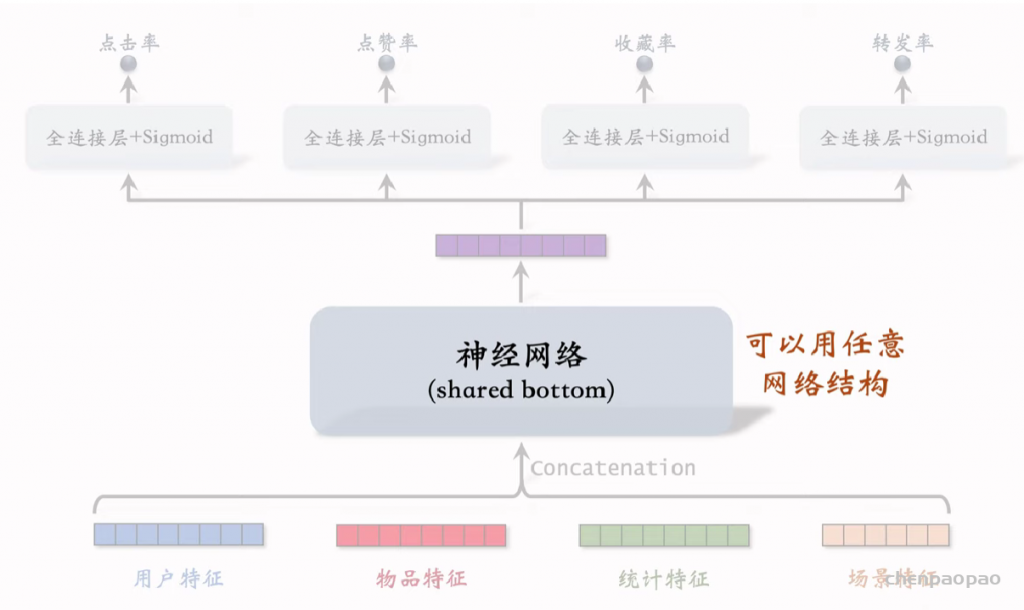
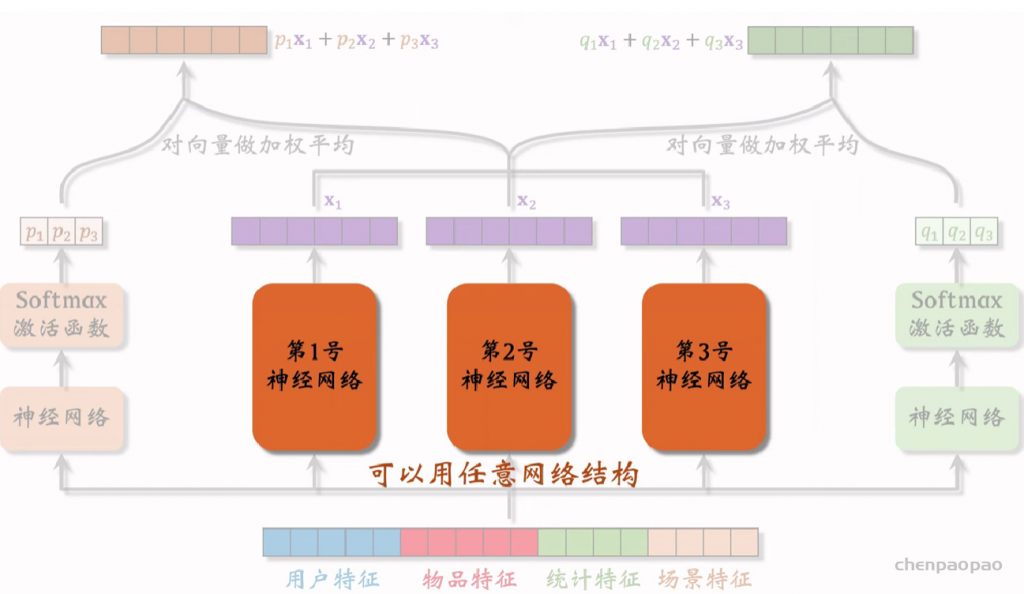
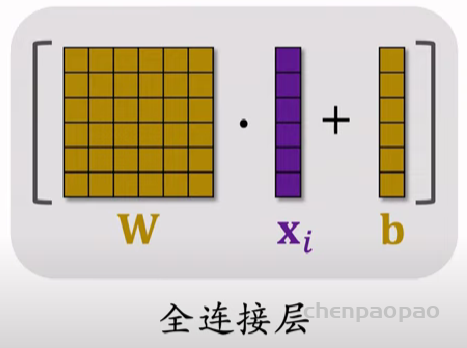
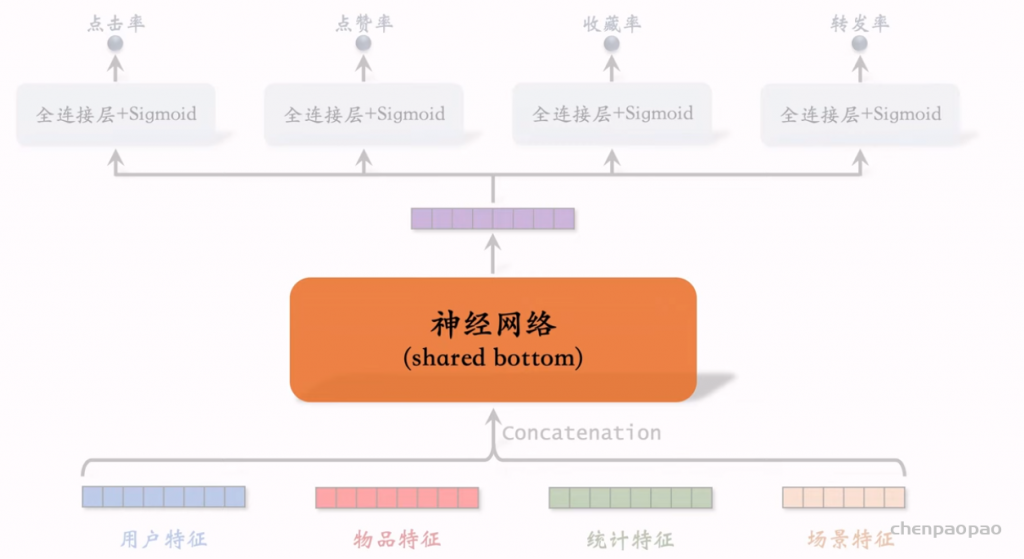
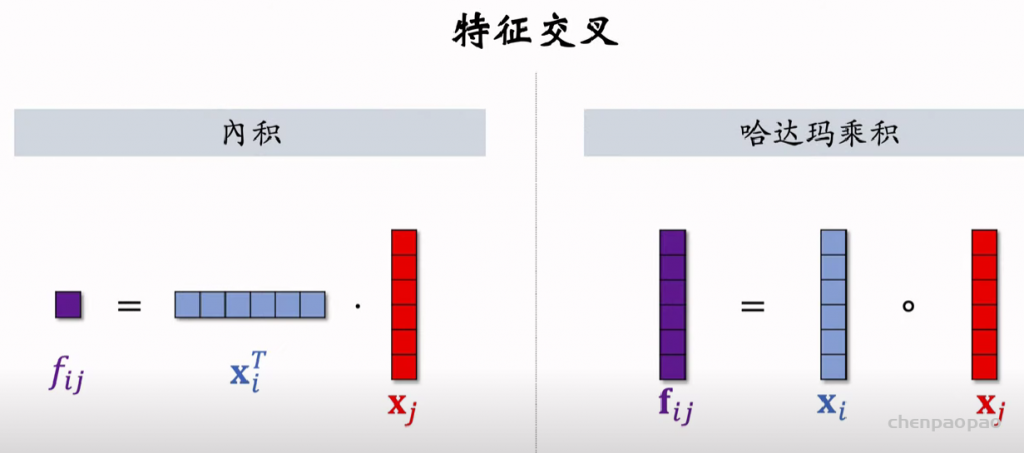
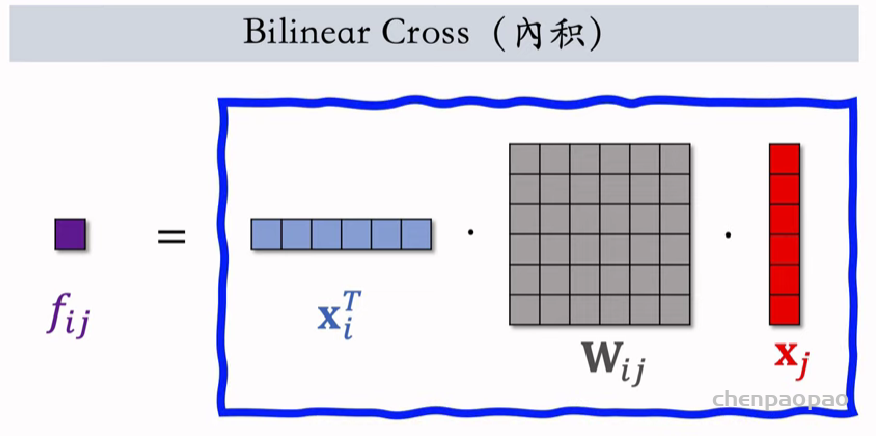
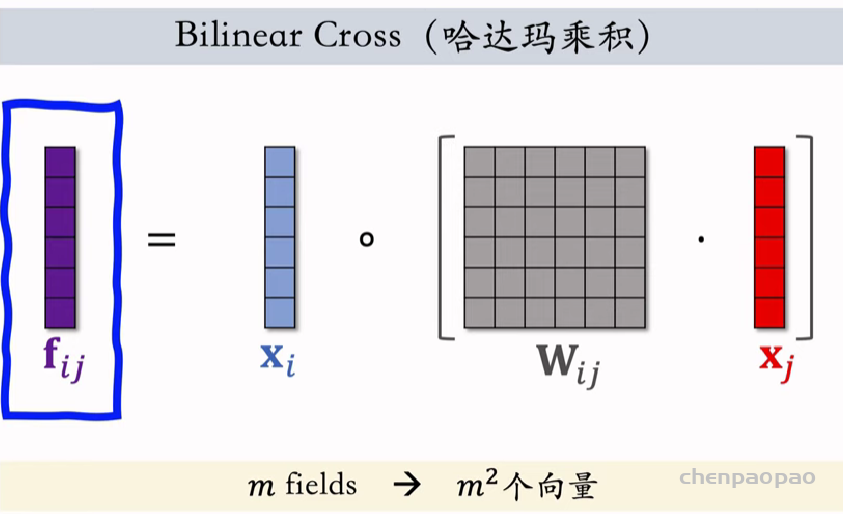
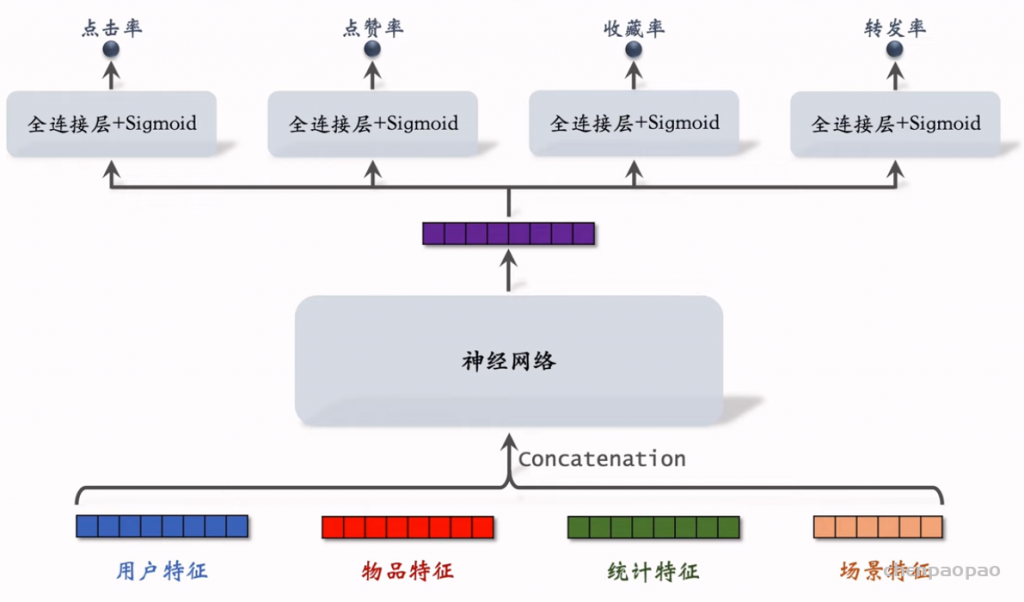
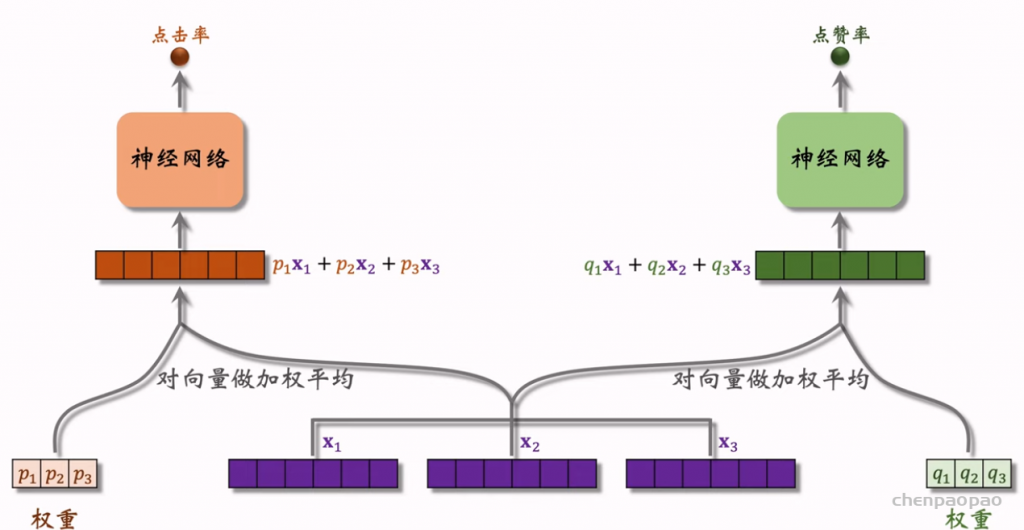
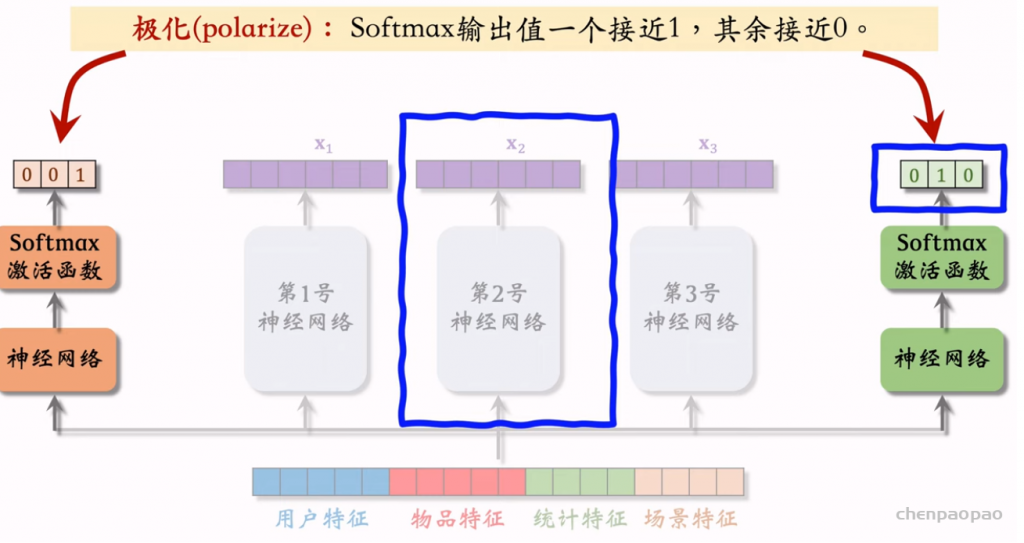
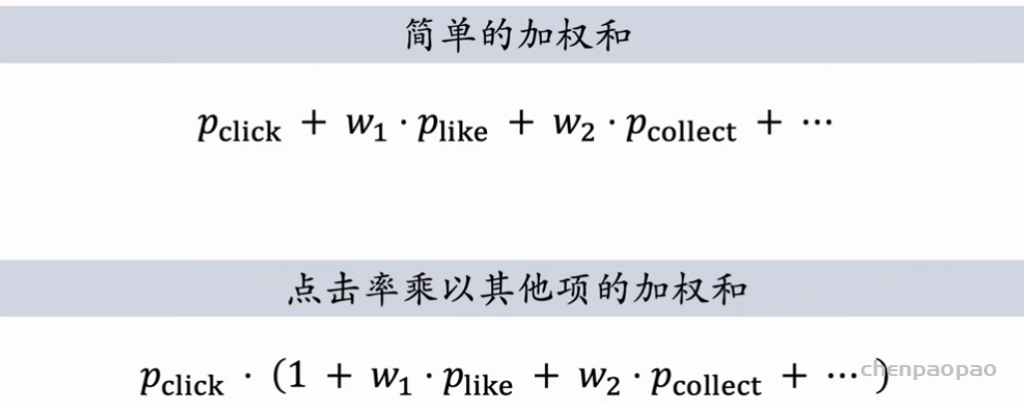
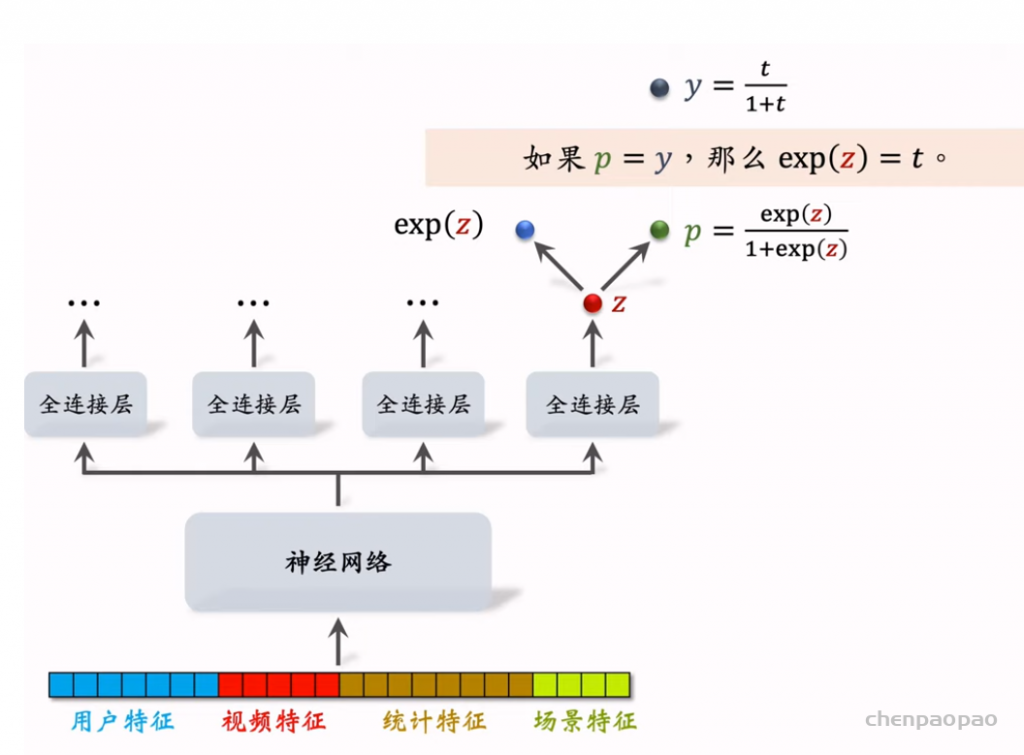
线性模型对输入的特征取加权和,作为对目标的预估。如果先做特征交叉,再用线性模型,通常可以取得更好的效果。如果做二阶特征交叉,那么参数量为O(特征数量平方),计算量大,而且容易造成过拟合。因式分解机(Factorized Machine, FM)用低秩矩阵分解的方式降低参数量,加速计算。任何可以用线性模型(比如线性回归、逻辑回归)解决的问题,都可以用 FM 解决。
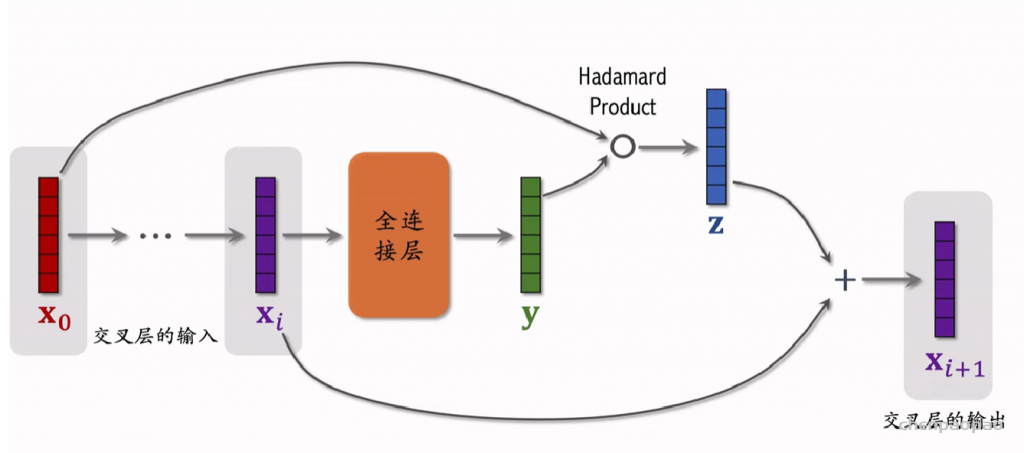
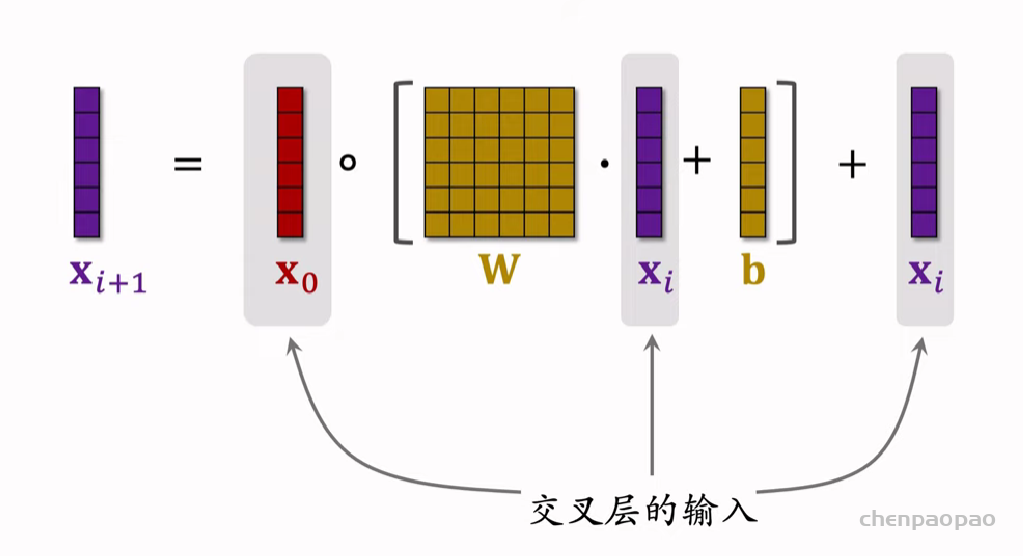
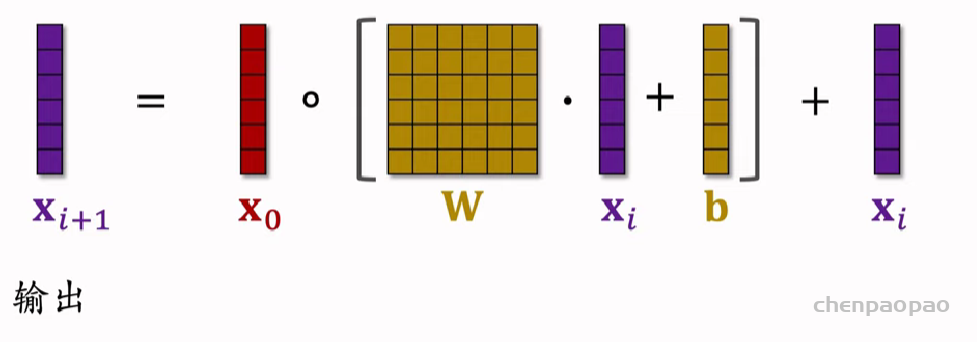
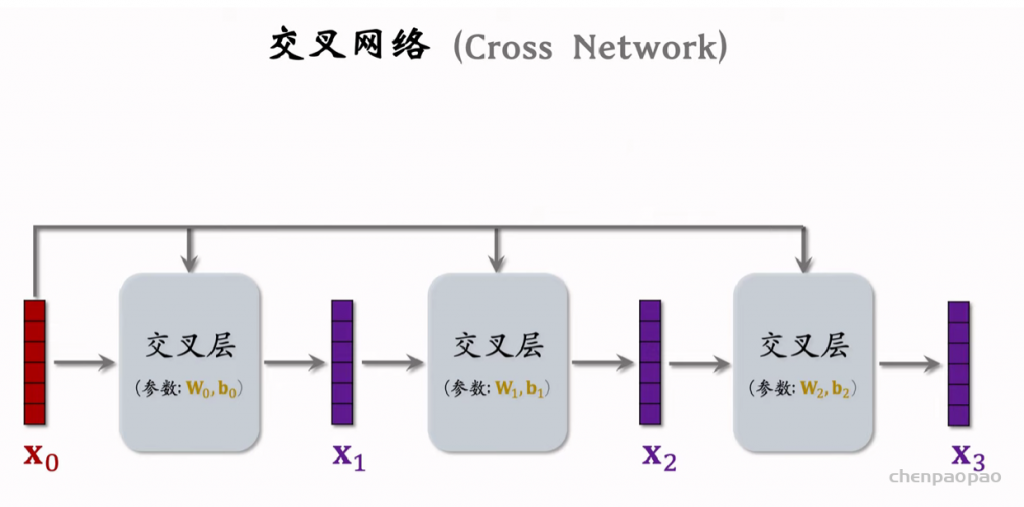
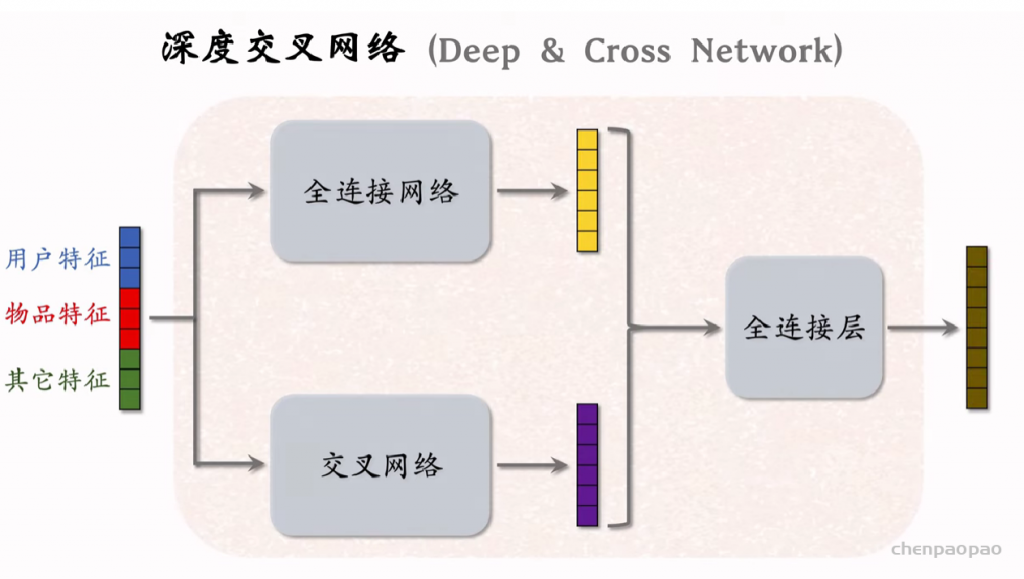
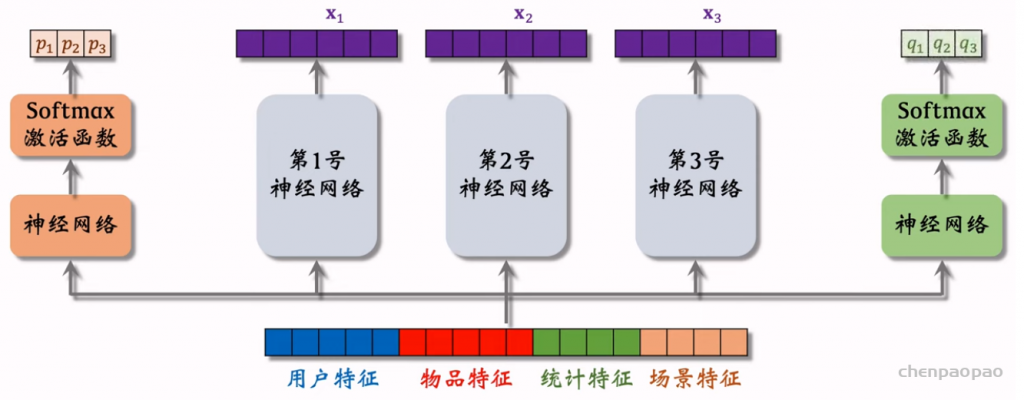
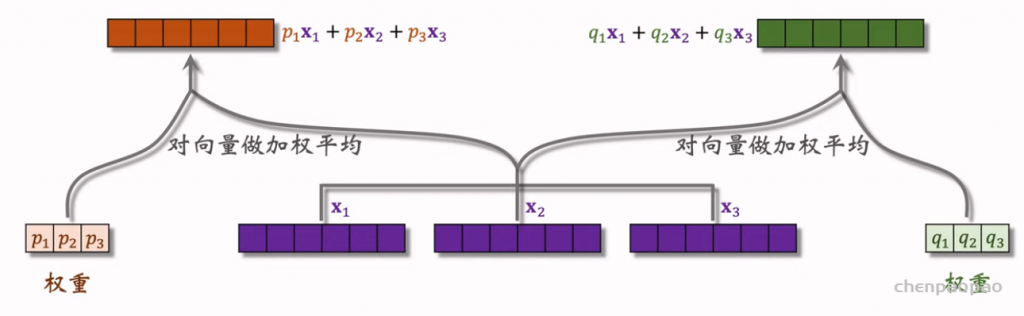
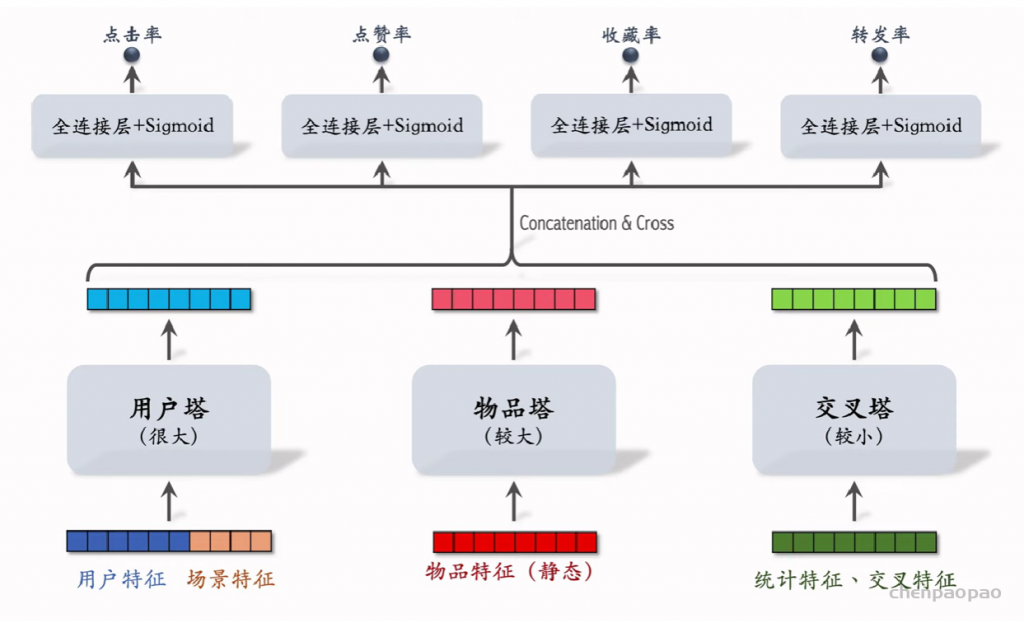
Deep & Cross Networks (DCN) 译作“深度交叉网络”,用于代替传统的全连接网络。可以用于召回双塔模型、粗排三塔模型、精排模型。DCN 由一个深度网络和一个交叉网络组成,交叉网络的基本组成单元是交叉层 (Cross Layer)。这节课最重点的部分就是交叉层。
交叉层 (Cross Layer)
深度交叉网络
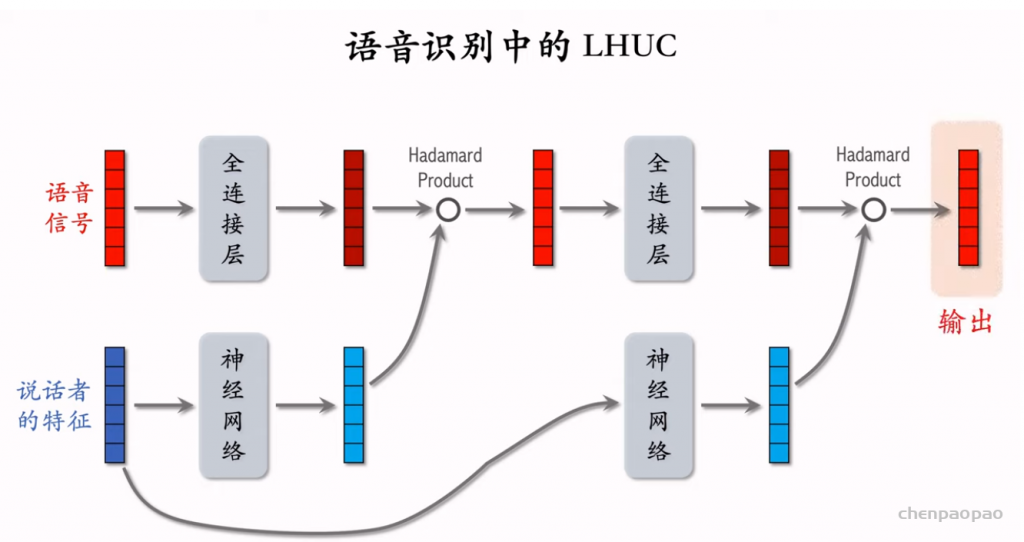
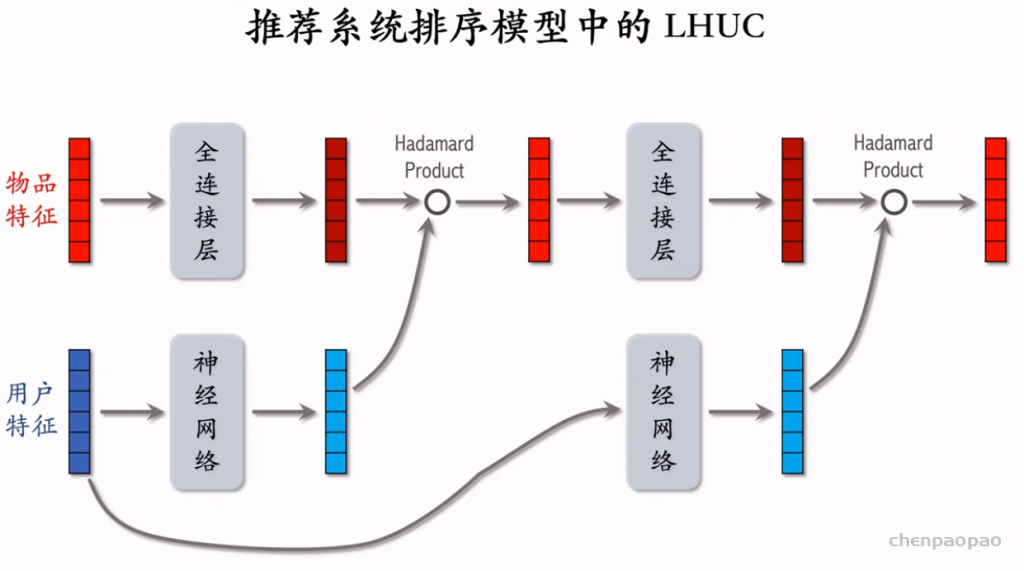
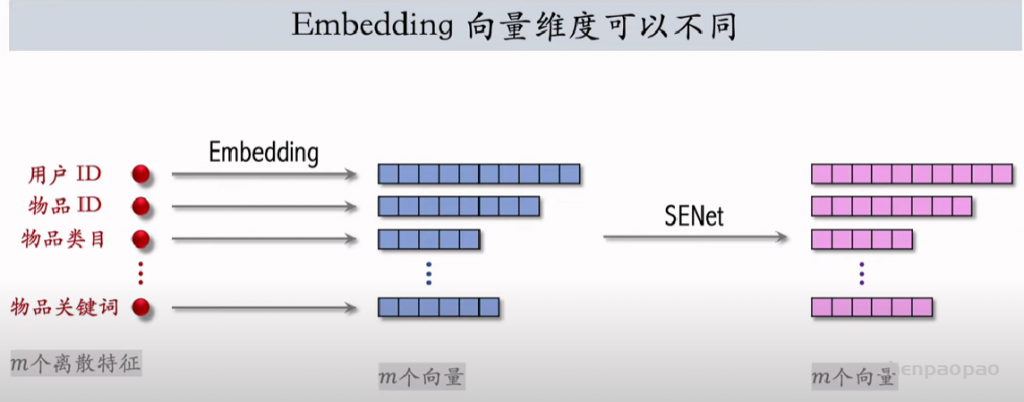
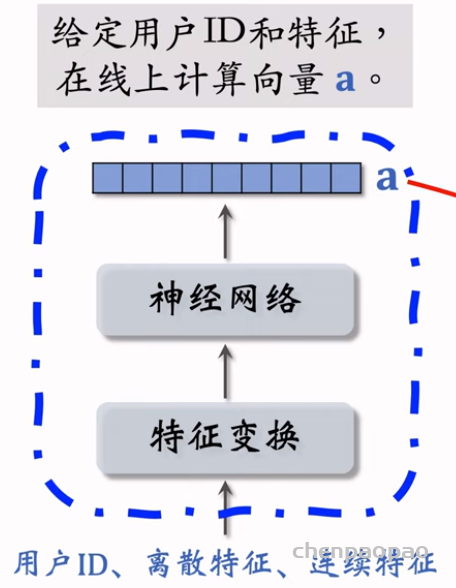
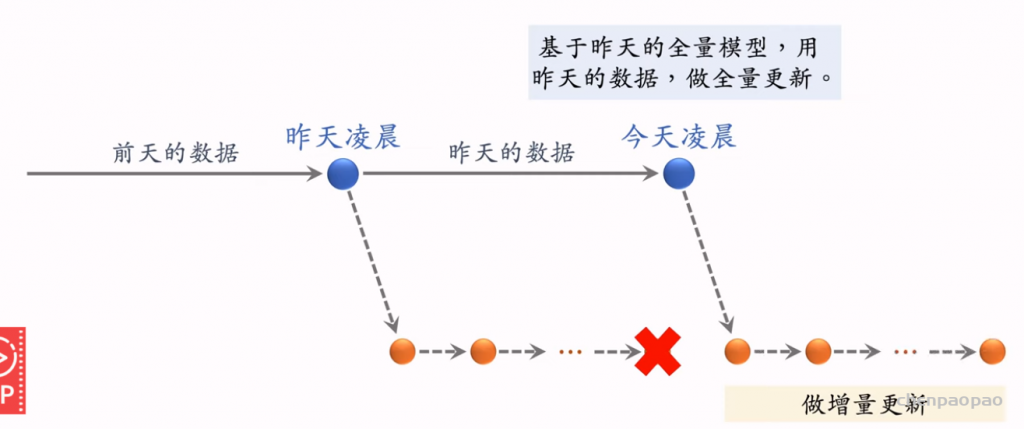
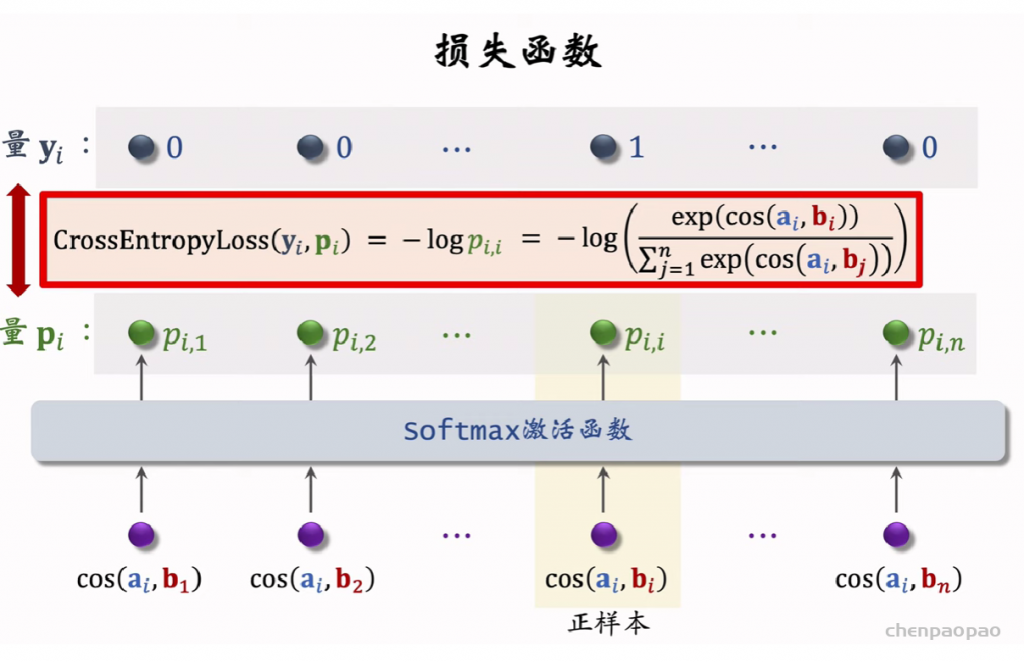
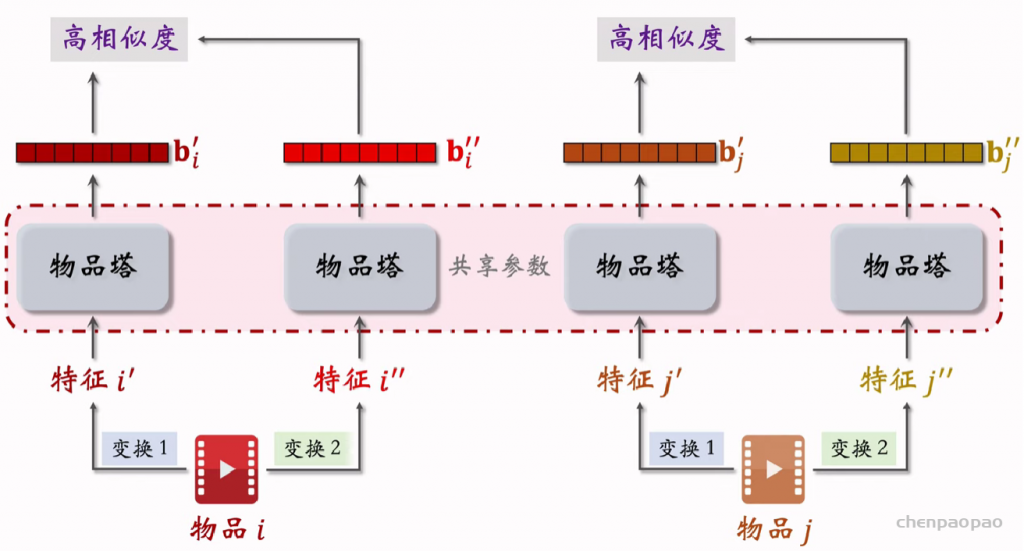
特征交叉03:LHUC (PPNet)
LHUC 这种神经网络结构,只用于精排。LHUC 的起源是语音识别,后来被应用到推荐系统,快手将其称为 PPNet,现在已经在业界广泛落地。 遗漏一个细节:将LHUC用于推荐系统,门控神经网络(2 x sigmoid)的梯度不要传递到用户ID embedding特征,需要对其做 stop gradient。 参考文献: 1. Pawel Swietojanski, Jinyu Li, & Steve Renals. Learning hidden unit contributions for unsupervised acoustic model adaptation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016. 2. 快手落地万亿参数推荐精排模型,2021。
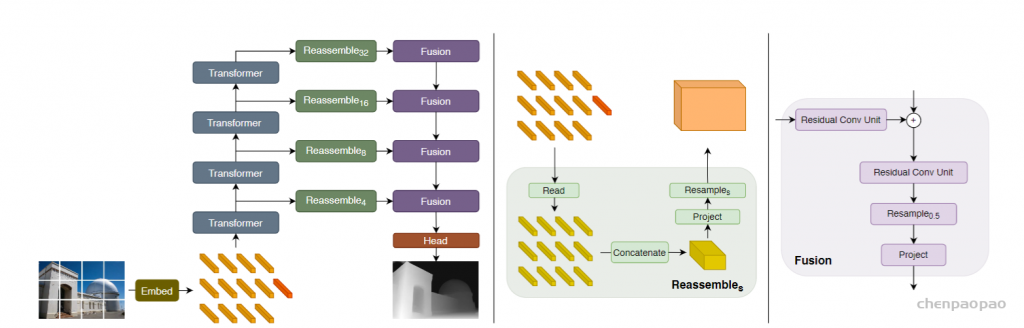
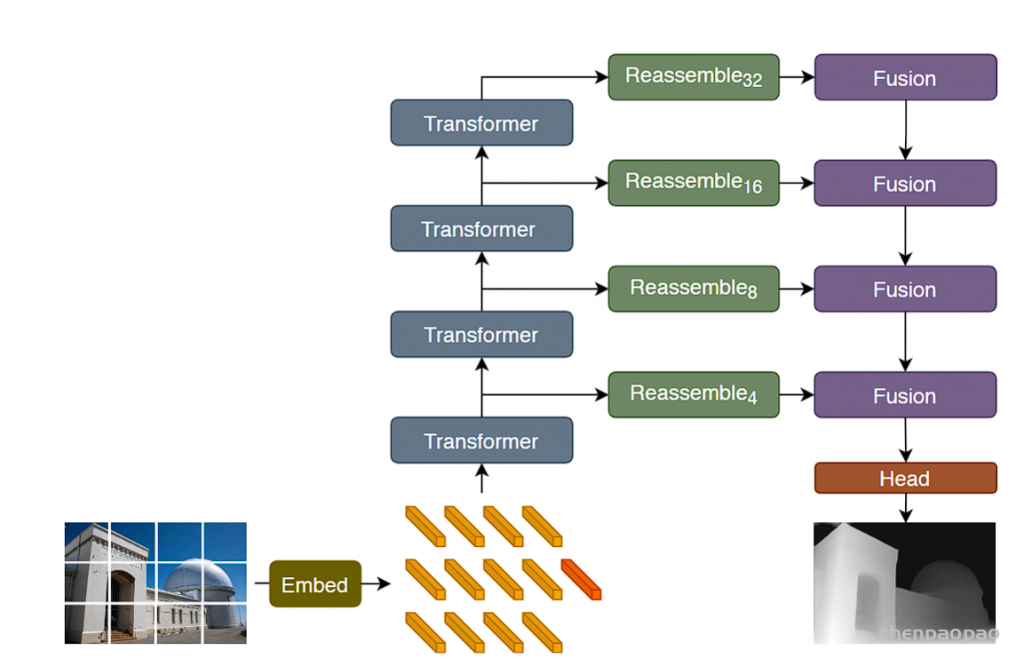
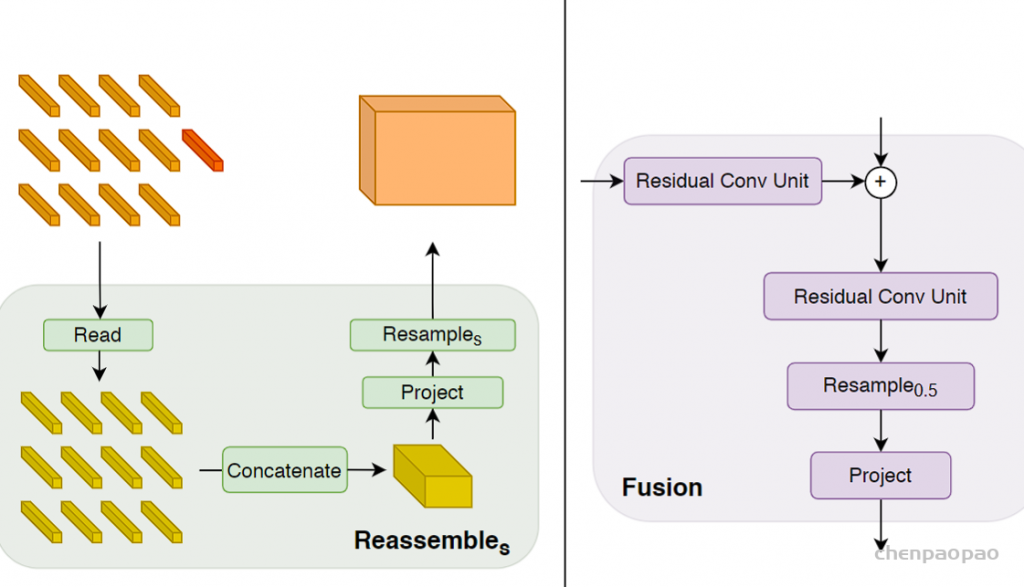
不管具体的transformer主干如何,都在四个不同的阶段和四个不同的分辨率上重新组装特征。以更低分辨率组装transformer深层的特征,而早期层的特征以更高分辨率组装。当使用ViT-Large时,从 l ={5,12,18,24}层重新组装tokens,而使用ViT-Base,使用 l ={3,6,9,12}层。当使用ViT-Hybrid时,使用了来自嵌入网络的第一和第二个ResNet块和阶段 l ={9,12}的特性。默认体系结构使用投影作为读出操作,并使用=256维度生成特性映射,将这些架构分别称为DPT-Base、DPT-Large和DPTHybrid。