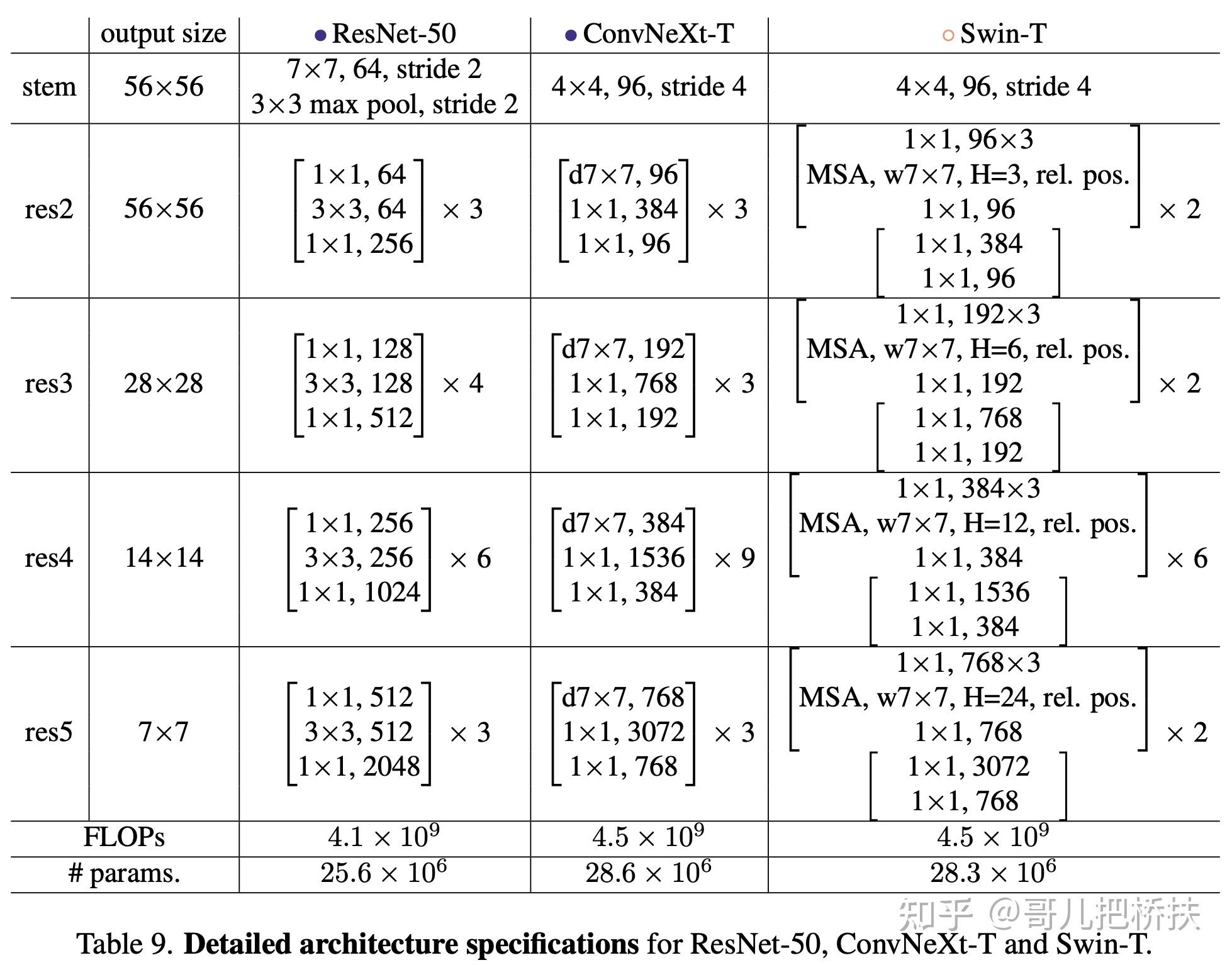
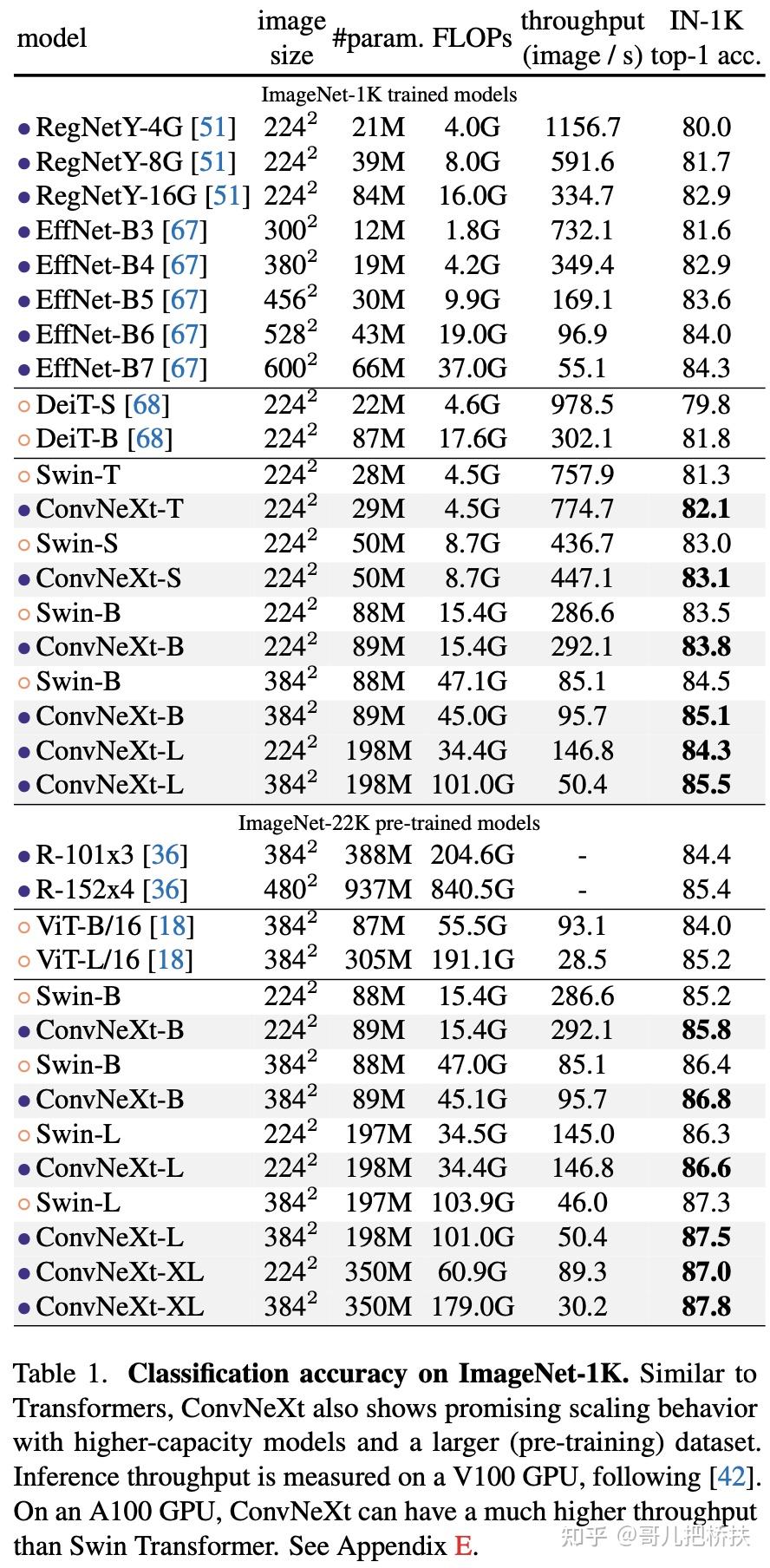
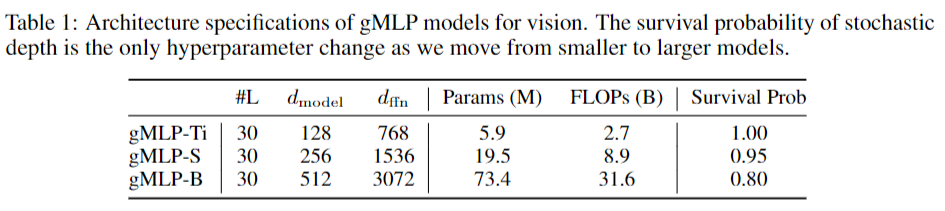
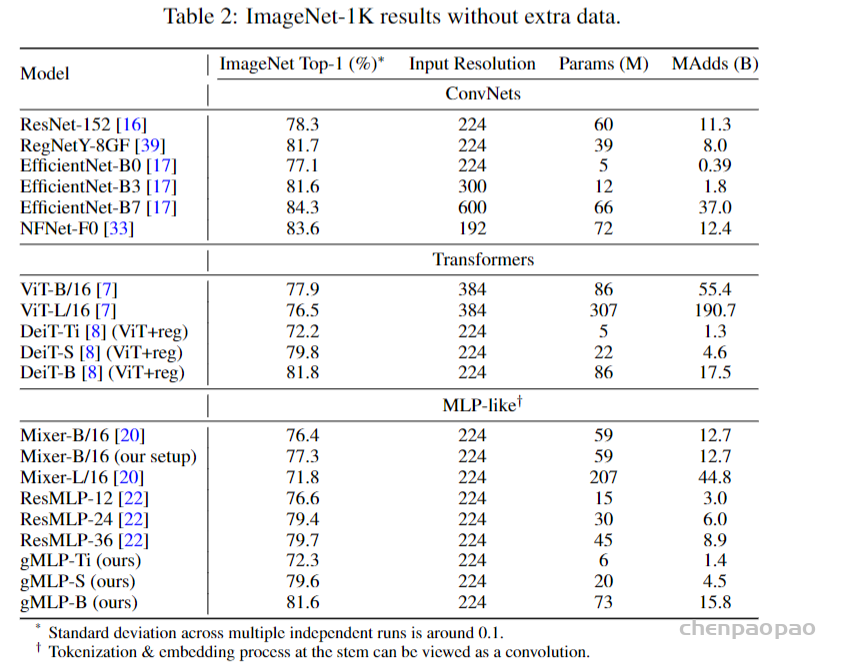
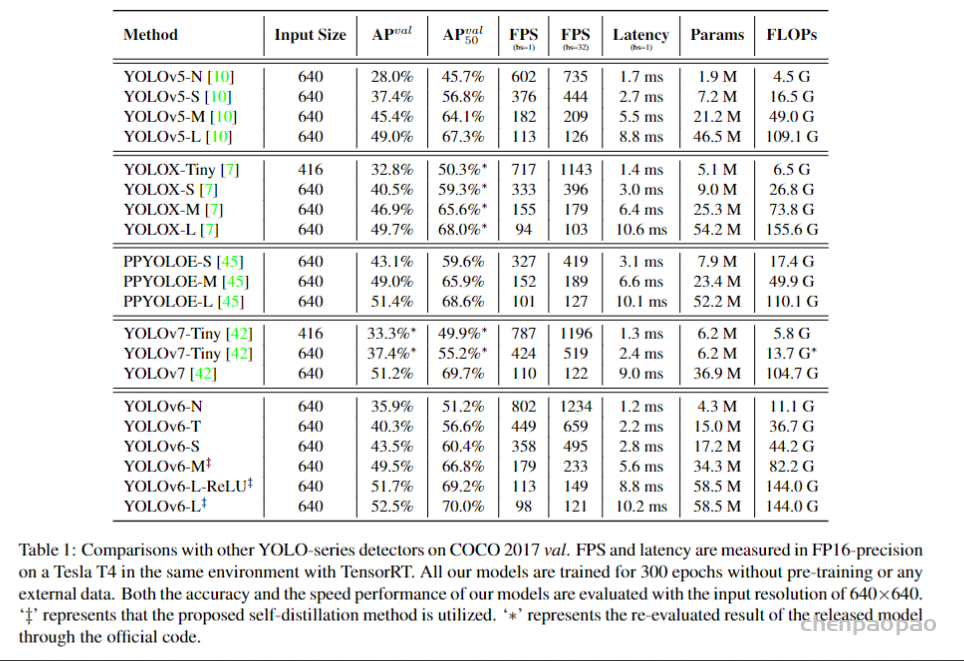
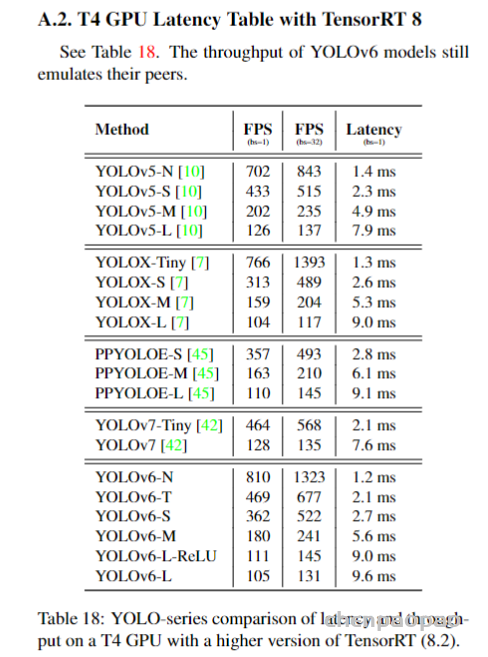
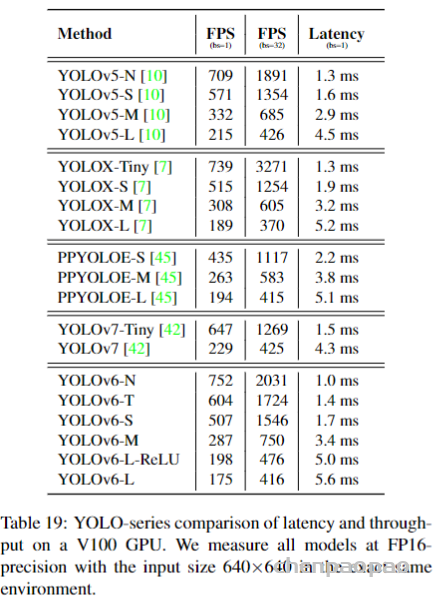
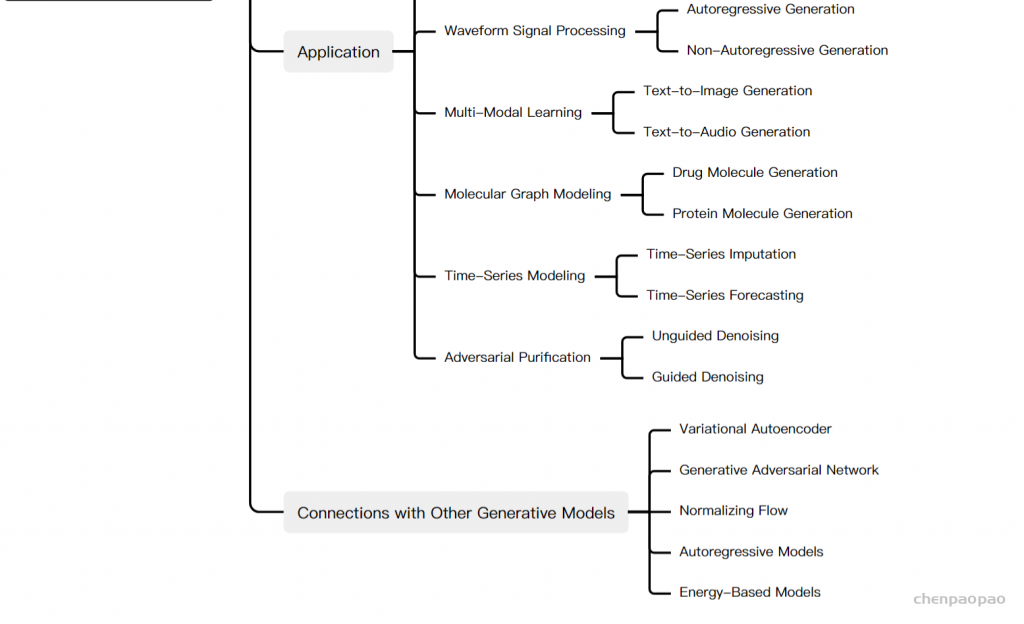
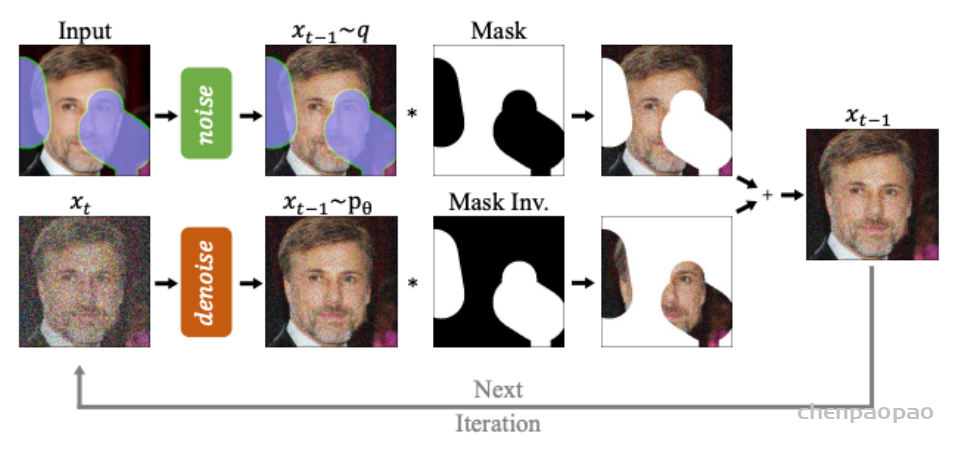
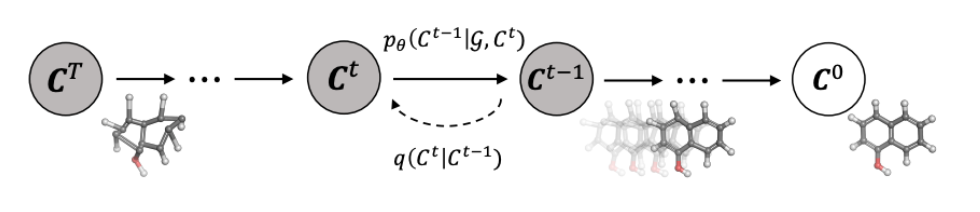
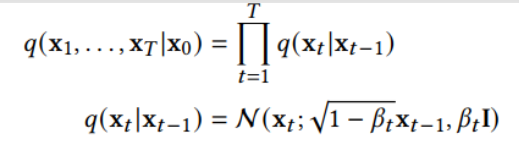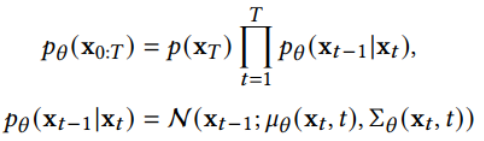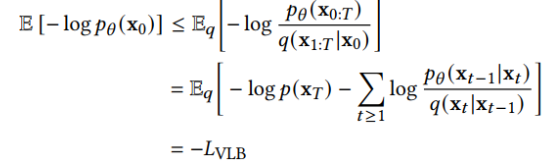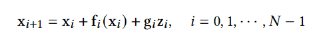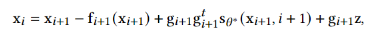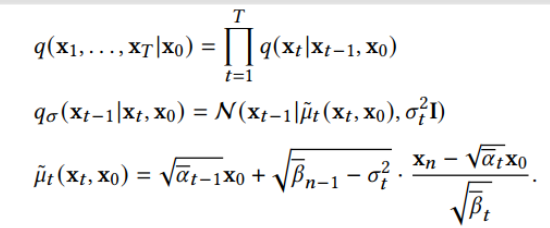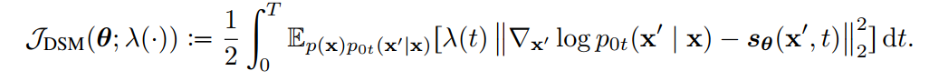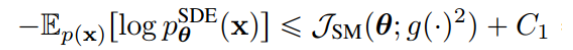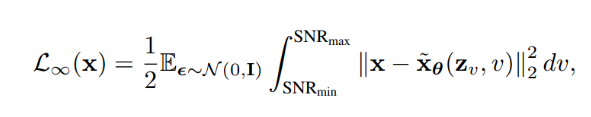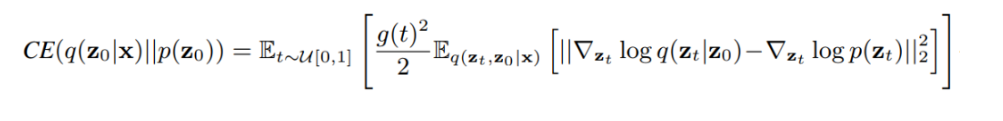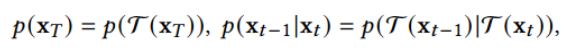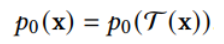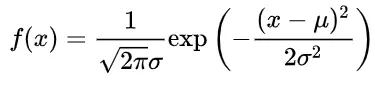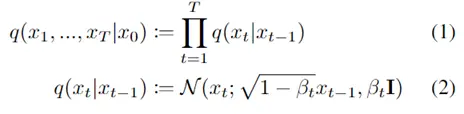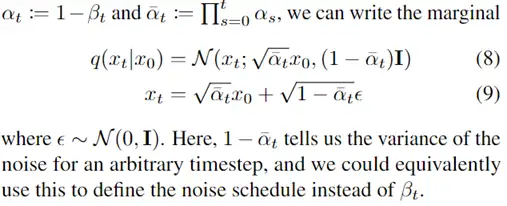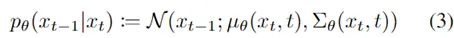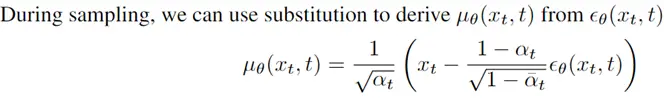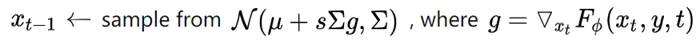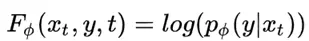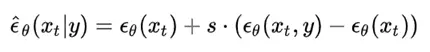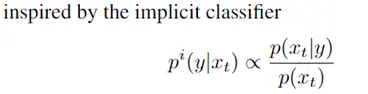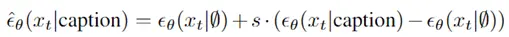此文使用gMLP做masked language modeling,gMLP采用和Bert一样的设置最小化perplexity取得了和Transformer模型预训练一样好的效果。通过pretraining和finetuning实验发现随着模型容量的增加,gMLP比Transformer提升更大,表明模型相较于self-attention可能对于模型容量的大小更为敏感。
此文同时将gMLP应用于masked language modeling(MLM)任务,对于预训练和微调任务,模型的输入输出规则都保持与BERT一致。
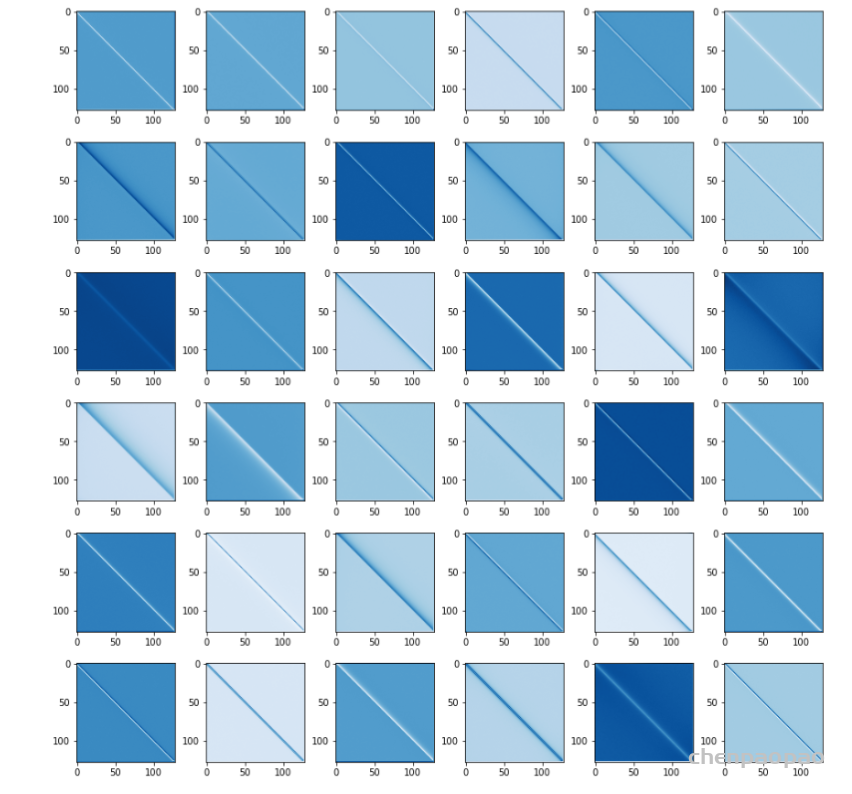
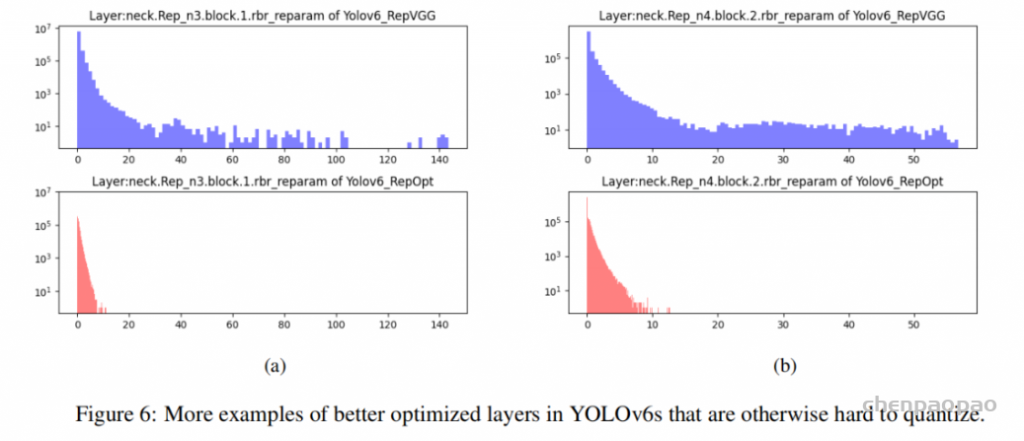
作者观察到在MLM任务最后学习到的空间映射矩阵总是Toeplitz-like matrics,如下图所示。所以作者认为gMLP是能从数据中学习到平移不变性的概念的,这使得gMLP实质起到了卷积核是整个序列长度的1-d卷积的作用。在接下来的MLM实验中,作者初始 W 为Toeplitz matrix。
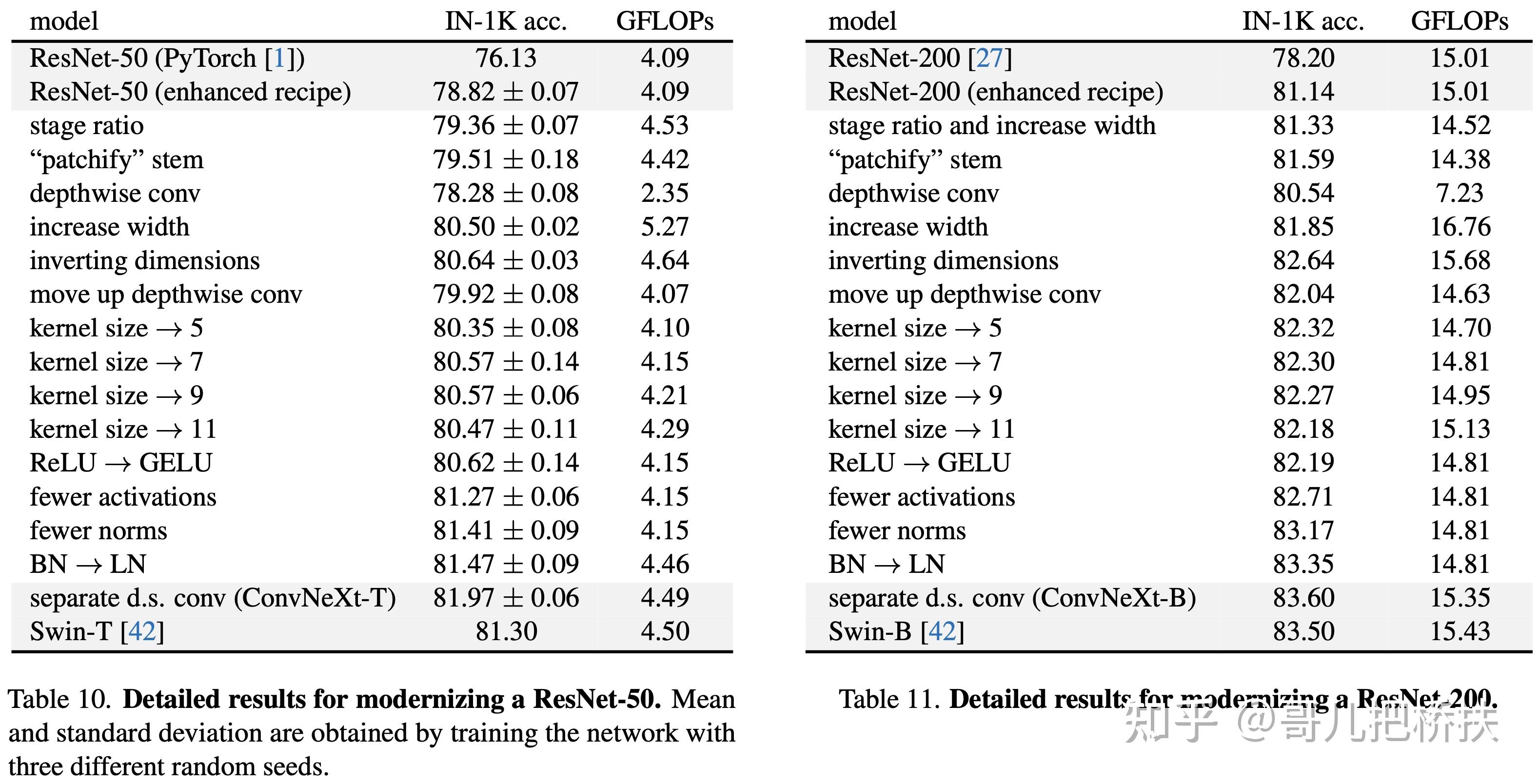
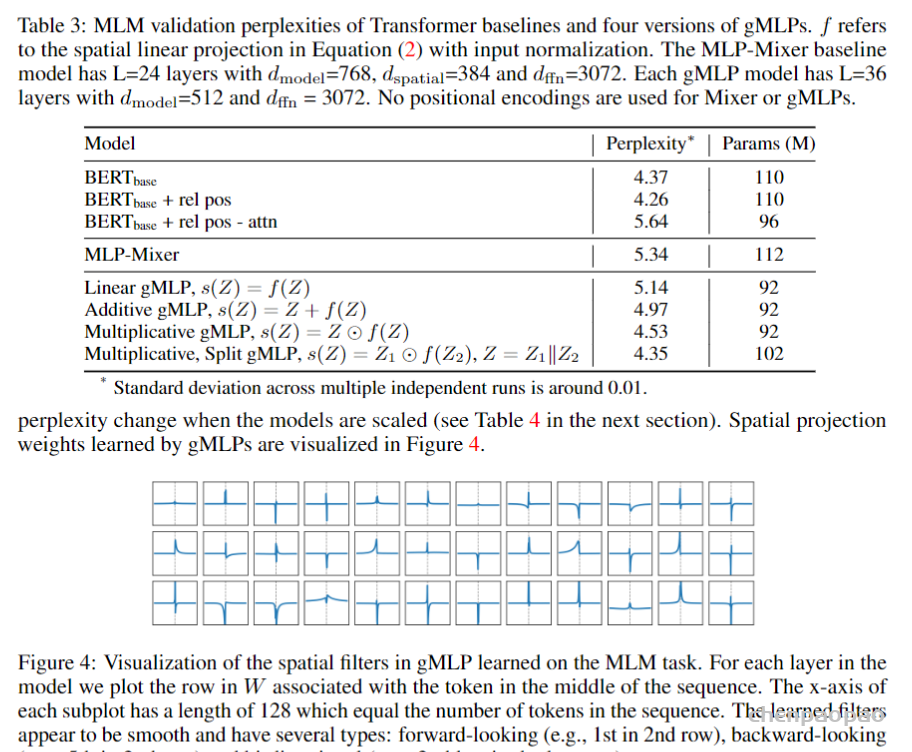
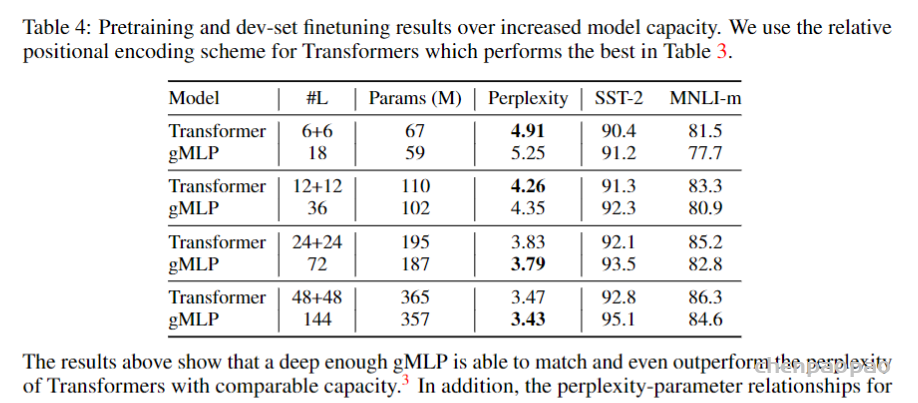
Ablation: The Importance of Gating in gMLP for BERT’s Pretraining:下表展示了gMLP的各种变体与Transoformer模型、MLP-Mixer的比较,可以看到gMLP在与Transformer相同模型大小的情况下能达到与Transformer相当的效果。同时gating操作对于空间映射十分有用。同时下图还可视化了模型学习到的空间映射参数。
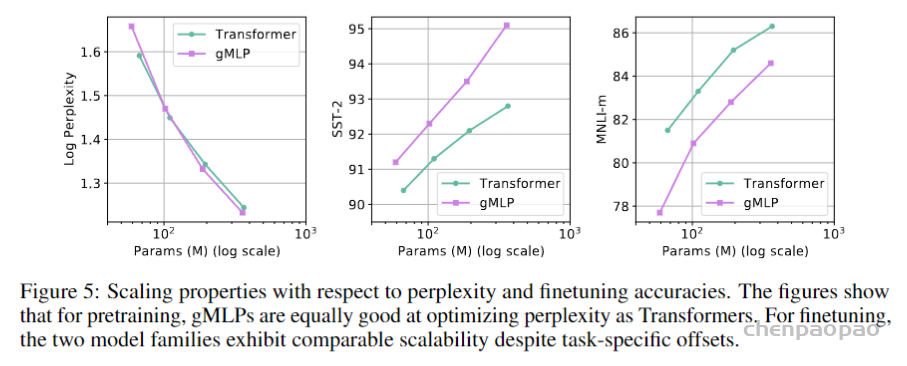
Case Study: The Behavior of gMLP as Model Size Increases:下表与下图展示了gMLP随着模型增大逐渐能有与Transformer相当的效果,可见Transformer的效果应该主要是依赖于模型尺寸而非self-attention。
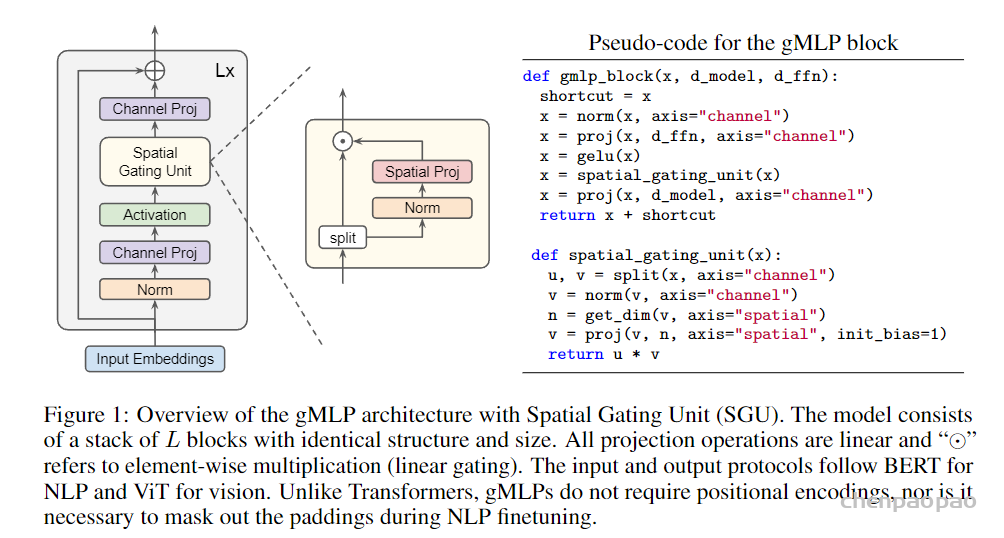
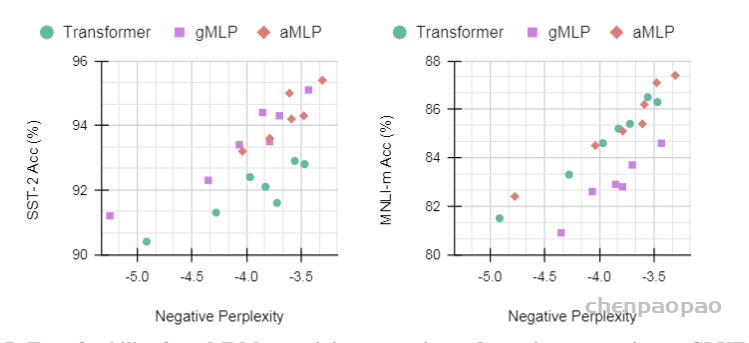
Ablation: The Usefulness of Tiny Attention in BERT’s Finetuning:从上面的Case Study可以发现gMLP对于需要跨句子连接的finetuing任务可能不及Transformer,所以作者提出了gMLP的增强版aMLP。aMLP相较于gMLP仅增加了一个单头64的self-attention如下图所示:
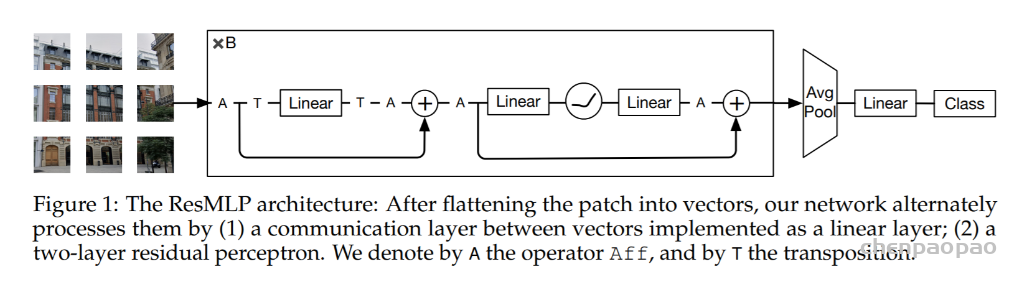
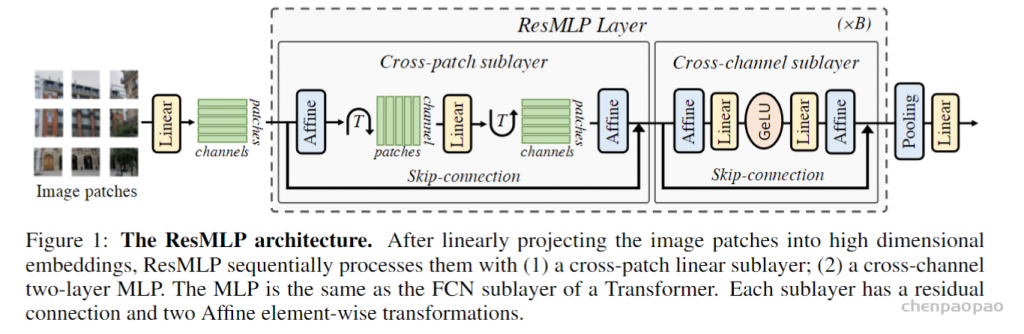
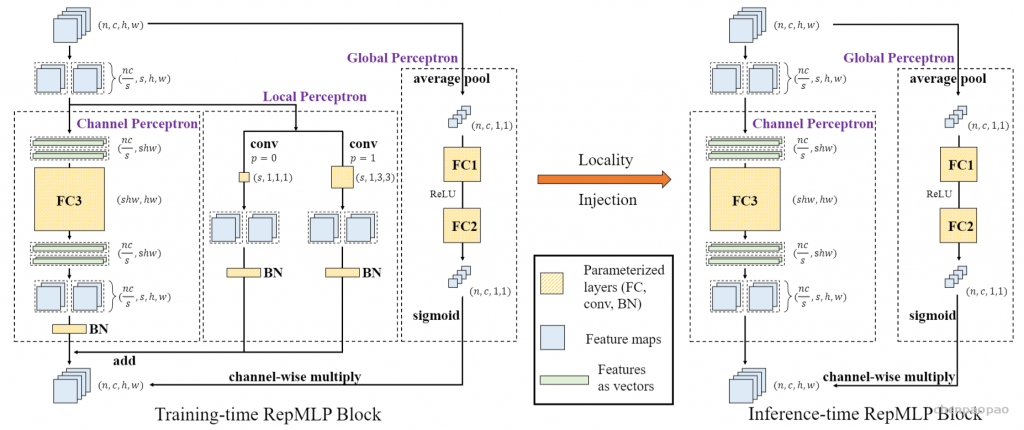
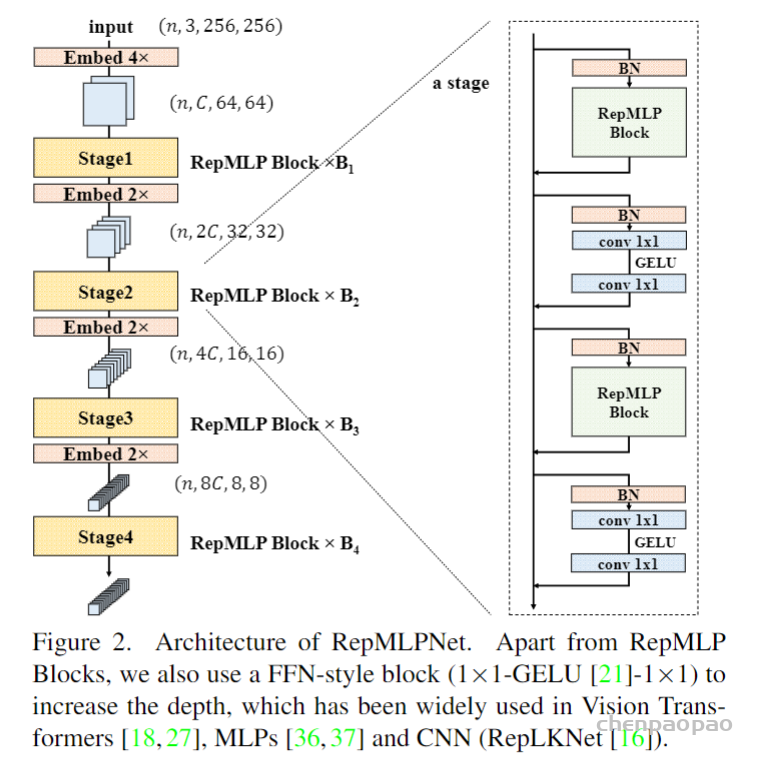
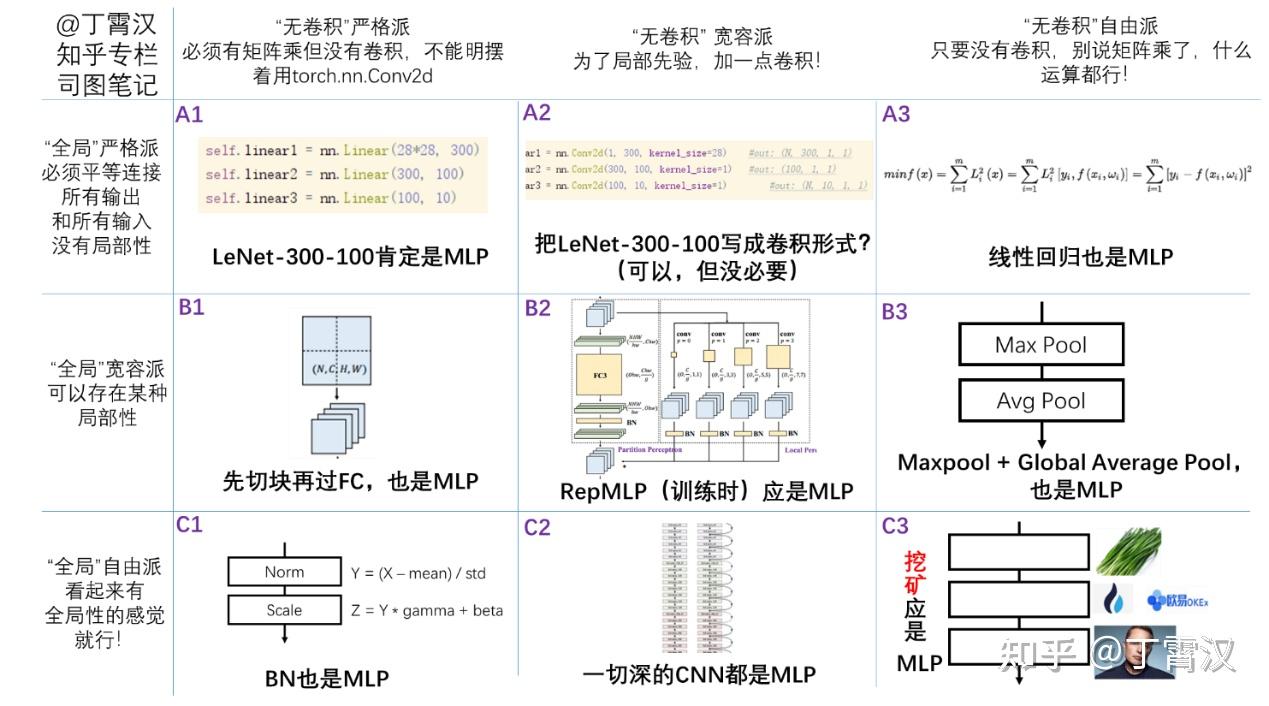
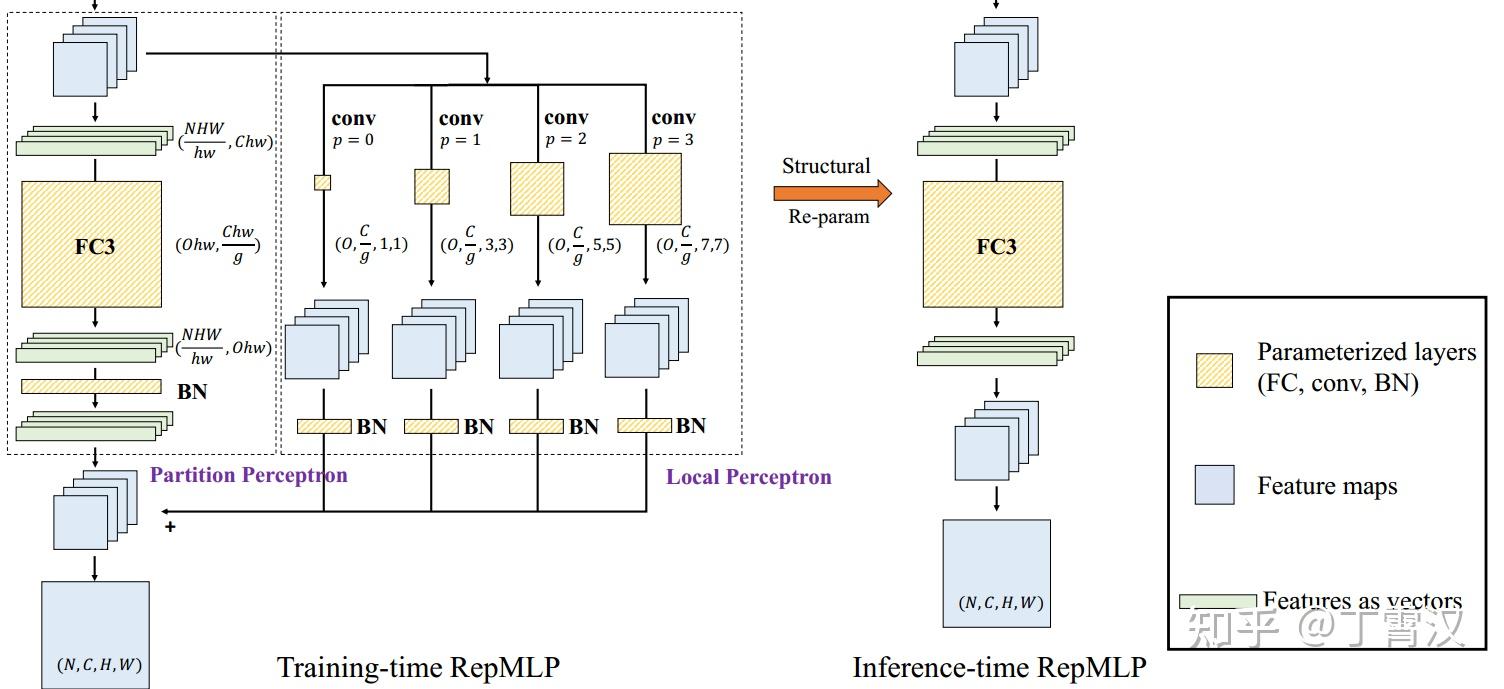
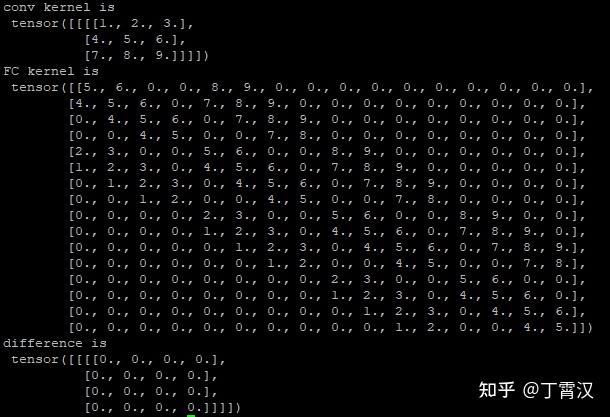
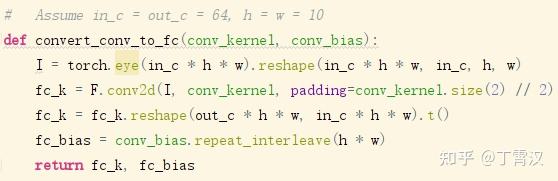
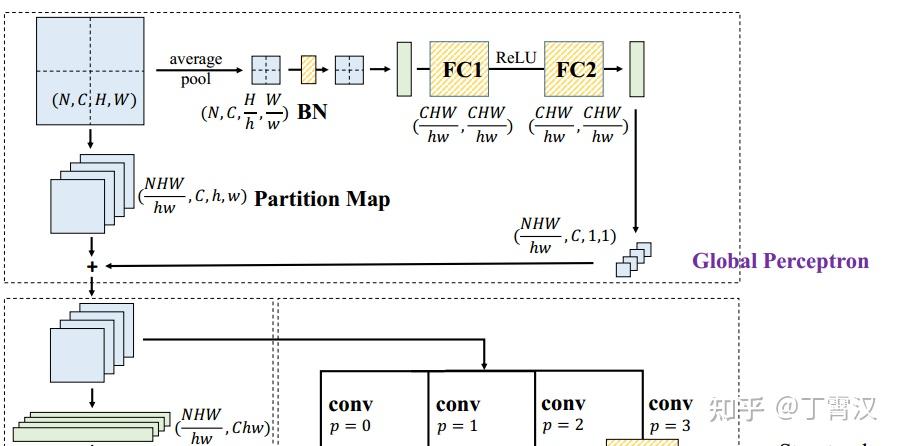
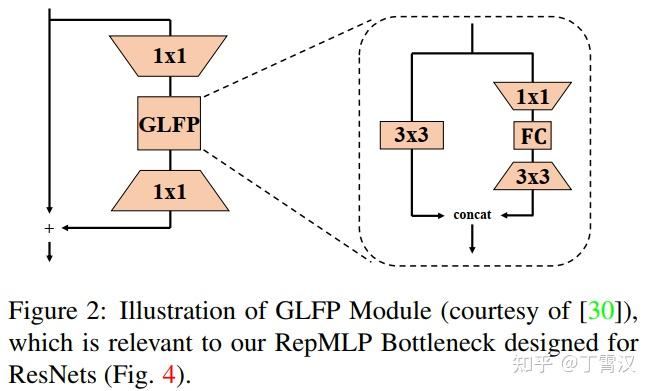
《RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition》。这篇文章讲了一个全连接层找到一份陌生的工作(直接进行feature map的变换),为了与那些已经为这份工作所特化的同胞(卷积层)们竞争,开始“内卷”的故事。
def extract_weight(args):
# Load model
state_dict = torch.load(args.weight)
with open(args.save_path, "w") as f:
f.write("{}\n".format(len(state_dict.keys())))
for k, v in state_dict.items():
vr = v.reshape(-1).cpu().numpy()
f.write("{} {} ".format(k, len(vr)))
for vv in vr:
f.write(" ")
f.write(struct.pack(">f", float(vv)).hex())
f.write("\n")
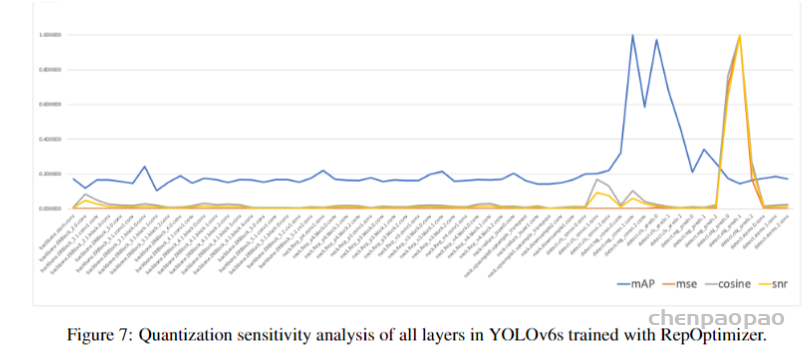
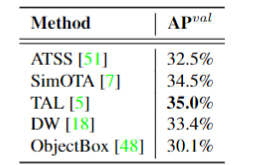
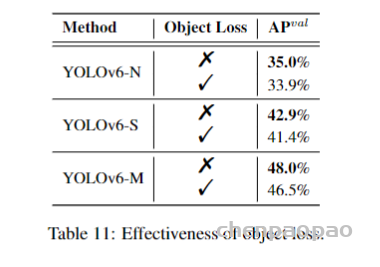
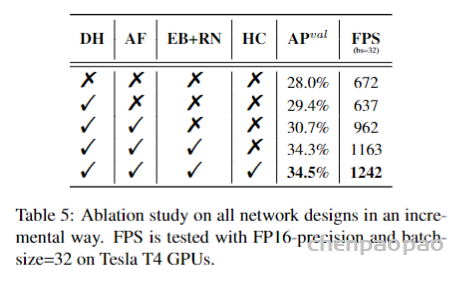
此外,作者观察到 TAL 可以带来比 SimOTA 更多的性能提升并稳定训练。因此,采用 TAL 作为 YOLOv6 中的默认标签分配策略。
2.3、损失函数
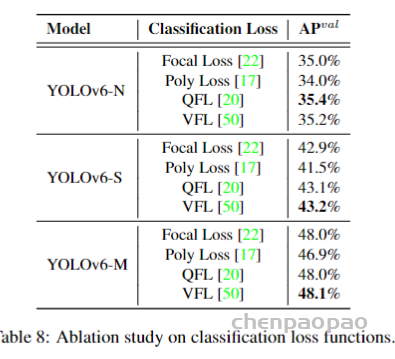
1、Classification Loss
提高分类器的性能是优化检测器的关键部分。Focal Loss 修改了传统的交叉熵损失,以解决正负样本之间或难易样本之间的类别不平衡问题。为了解决训练和推理之间质量估计和分类的不一致使用,Quality Focal Loss(QFL)进一步扩展了Focal Loss,联合表示分类分数和分类监督的定位质量。而 VariFocal Loss (VFL) 源于 Focal Loss,但它不对称地对待正样本和负样本。通过考虑不同重要性的正负样本,它平衡了来自两个样本的学习信号。Poly Loss 将常用的分类损失分解为一系列加权多项式基。它在不同的任务和数据集上调整多项式系数,通过实验证明比交叉熵损失和Focal Loss损失更好。
在 YOLOv6 上评估所有这些高级分类损失,最终采用 VFL。
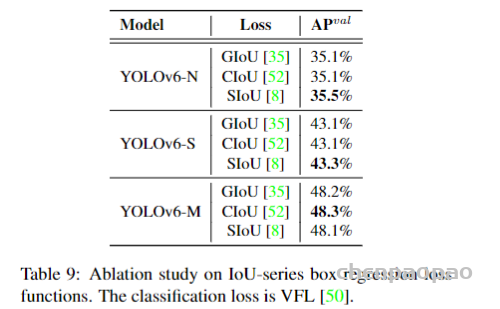
2、Box Regression Loss
框回归损失提供了精确定位边界框的重要学习信号。L1 Loss 是早期作品中的原始框回归损失。逐渐地,各种精心设计的框回归损失如雨后春笋般涌现,例如 IoU-series 损失和概率损失。
IoU-series Loss IoU loss 将预测框的四个边界作为一个整体进行回归。它已被证明是有效的,因为它与评估指标的一致性。IoU的变种有很多,如GIoU、DIoU、CIoU、α-IoU和SIoU等,形成了相关的损失函数。我们在这项工作中对 GIoU、CIoU 和 SIoU 进行了实验。并且SIoU应用于YOLOv6-N和YOLOv6-T,而其他的则使用GIoU。
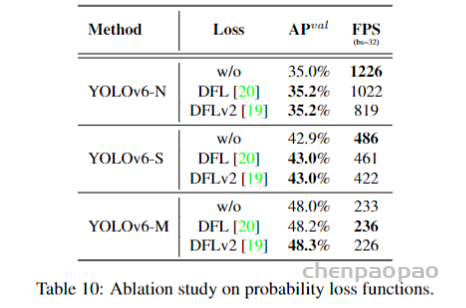
Probability Loss Distribution Focal Loss (DFL) 将框位置的基本连续分布简化为离散化的概率分布。它在不引入任何其他强先验的情况下考虑了数据中的模糊性和不确定性,这有助于提高框定位精度,尤其是在ground-truth框的边界模糊时。在 DFL 上,DFLv2 开发了一个轻量级的子网络,以利用分布统计数据与真实定位质量之间的密切相关性,进一步提高了检测性能。然而,DFL 输出的回归值通常比一般框回归多 17 倍,从而导致大量开销。额外的计算成本阻碍了小型模型的训练。而 DFLv2 由于额外的子网络,进一步增加了计算负担。在实验中,DFLv2 在模型上为 DFL 带来了类似的性能提升。因此,只在 YOLOv6-M/L 中采用 DFL。
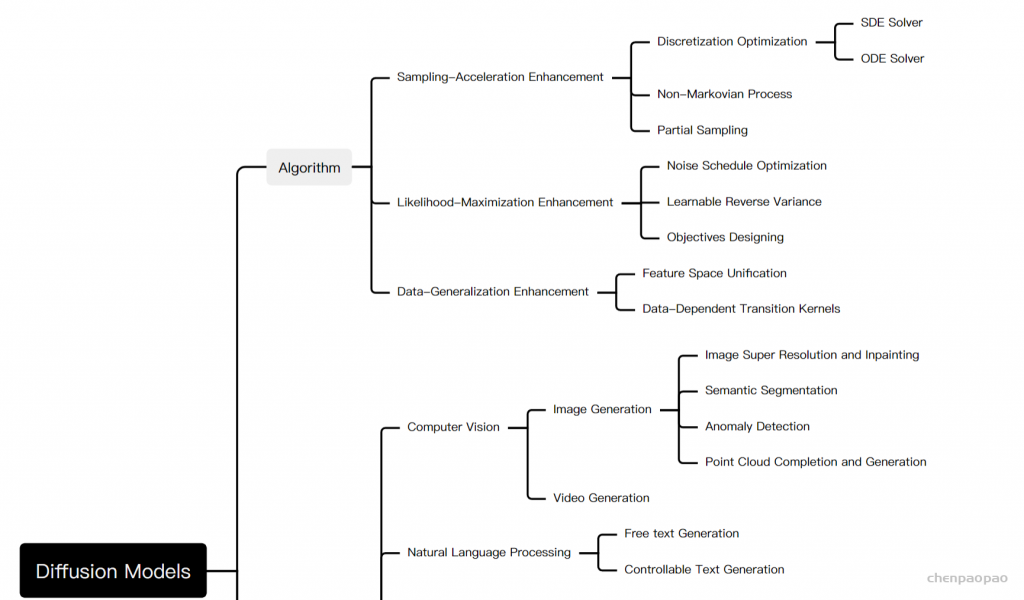
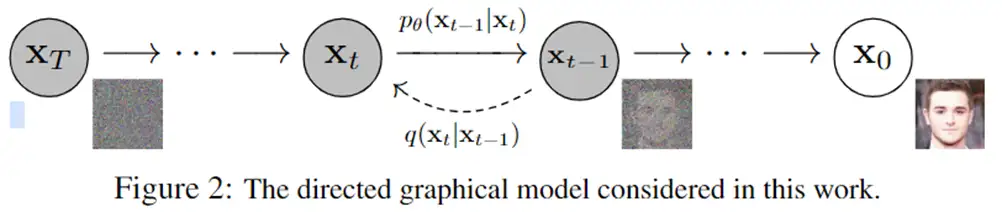
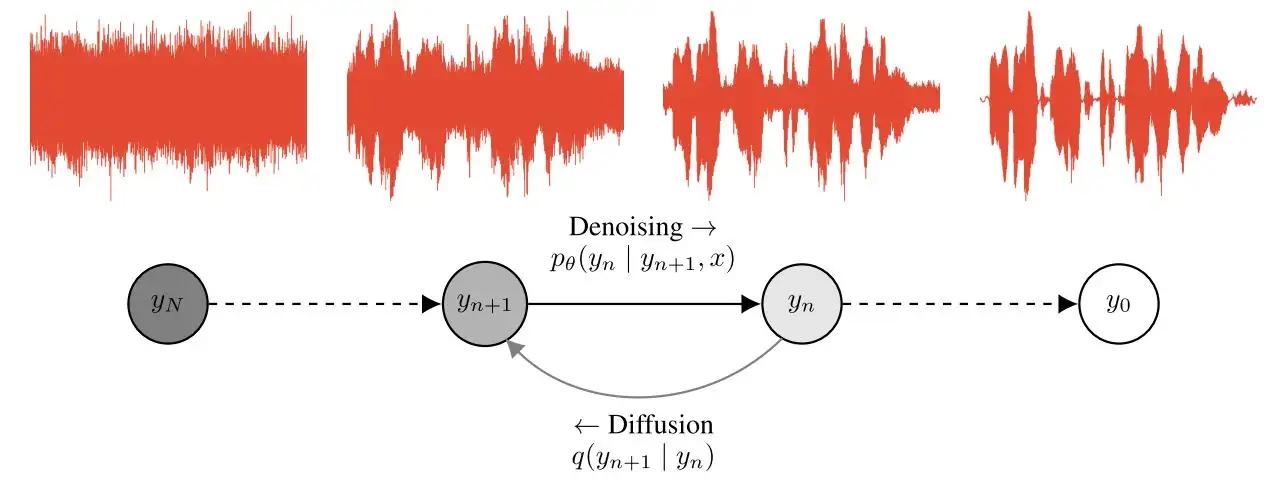
Diffusion Models: A Comprehensive Survey of Methods and Applications来自加州大学&Google Research的Ming-Hsuan Yang、北京大学崔斌实验室以及CMU、UCLA、蒙特利尔Mila研究院等众研究团队,首次对现有的扩散生成模型(diffusion model)进行了全面的总结分析,从diffusion model算法细化分类、和其他五大生成模型的关联以及在七大领域中的应用等方面展开,最后提出了diffusion model的现有limitation和未来的发展方向。
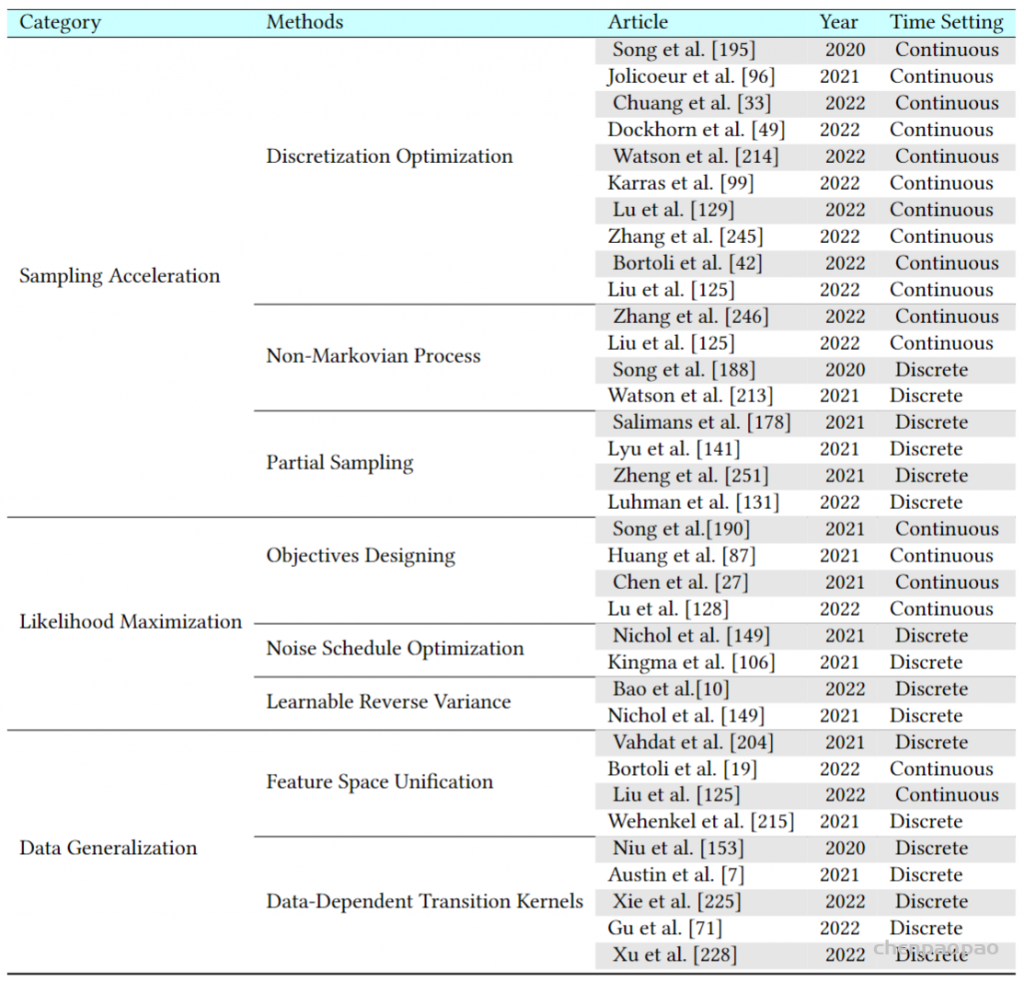
扩散模型假设数据存在于欧几里得空间,即具有平面几何形状的流形,并添加高斯噪声将不可避免地将数据转换为连续状态空间,所以扩散模型最初只能处理图片等连续性数据,直接应用离散数据或其他数据类型的效果较差。这限制了扩散模型的应用场景。数个研究工作将扩散模型推广到适用于其他数据类型的模型,我们对这些方法进行了详细地阐释。我们将其细化分类为两类方法:Feature Space Unification,Data-Dependent Transition Kernels。1.Feature Space Unification方法将数据转化到统一形式的latent space,然后再latent space上进行扩散。LSGM提出将数据通过VAE框架先转换到连续的latent space 上后再在其上进行扩散。这个方法的难点在于如何同时训练VAE和扩散模型。LSGM表明由于潜在先验是intractable的,分数匹配损失不再适用。LSGM直接使用VAE中传统的损失函数ELBO作为损失函数,并导出了ELBO和分数匹配的关系:
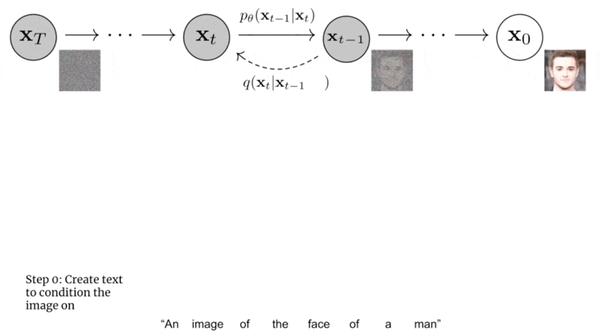
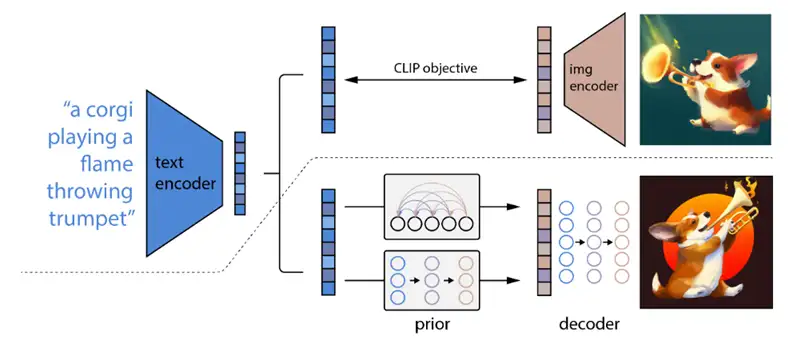
一种是auto-regressive model,将image embedding转换为一串离散的编码,并且基于condition caption y自回归地预测。(这里不一定要condition on caption(GLIDE的方法——额外用一个Transformer处理caption),也可以condition on CLIP text embedding)。此外,这里还用到了PCA来降维,降低运算复杂度。
从正在进行的结直肠癌化疗试验和回顾性腹疝研究的组合中随机选择了 50 份腹部 CT 扫描。50 次扫描是在门静脉造影阶段捕获的,具有可变的体积大小 (512 x 512 x 85 – 512 x 512 x 198) 和视场(约 280 x 280 x 280 mm 3 – 500 x 500 x 650 mm 3) . 平面内分辨率从 0.54 x 0.54 mm 2到 0.98 x 0.98 mm 2不等,而切片厚度范围从 2.5 mm 到 5.0 mm。标准注册数据由NiftyReg生成。