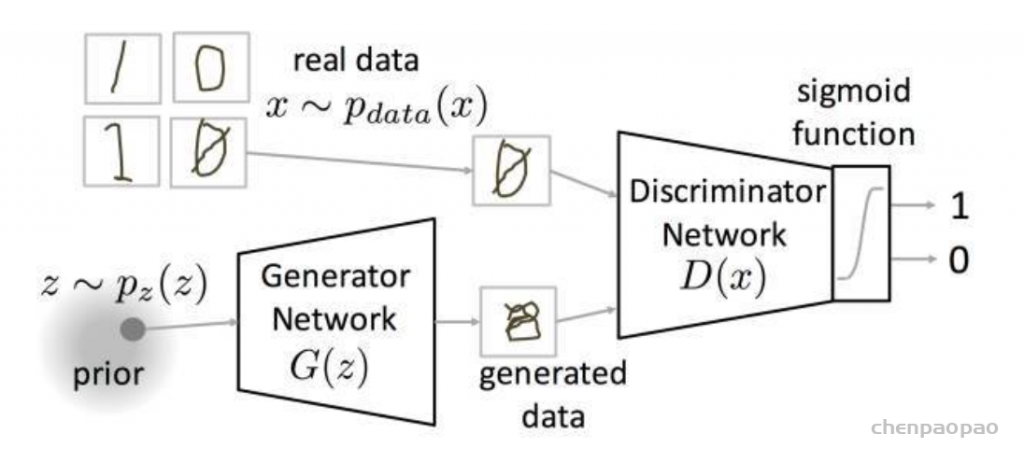
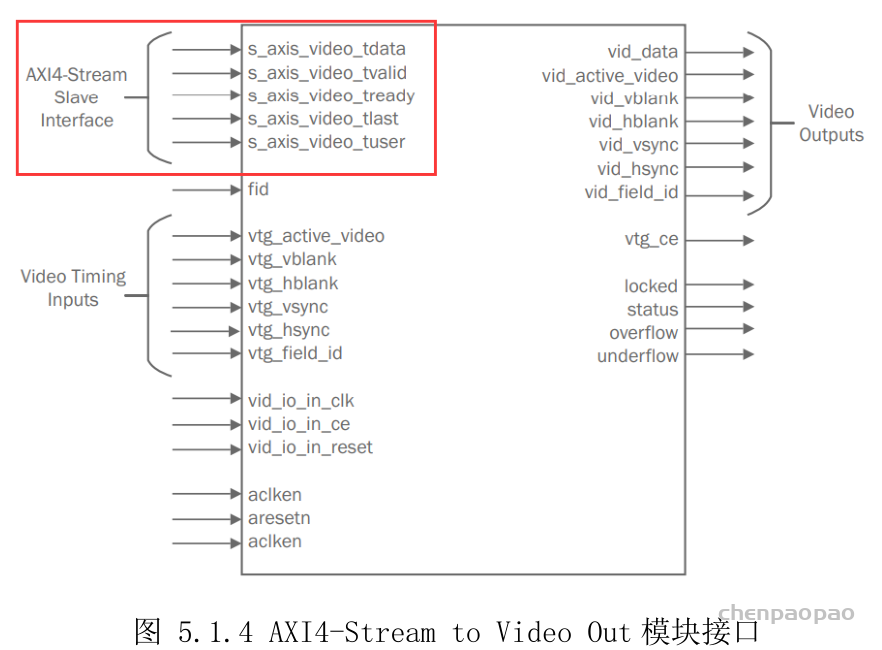
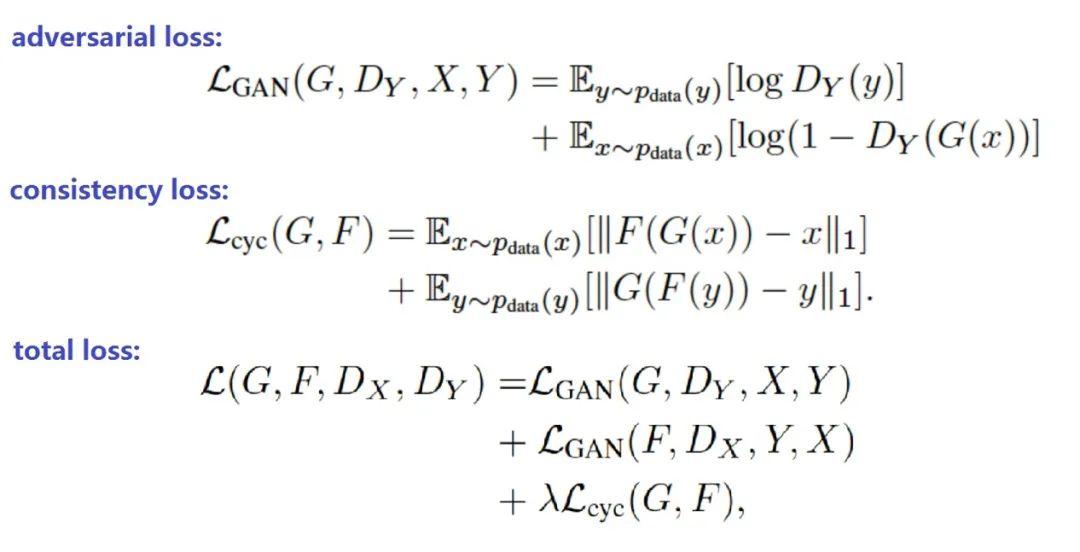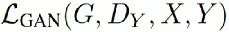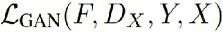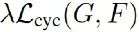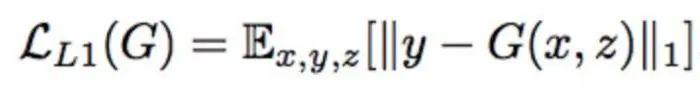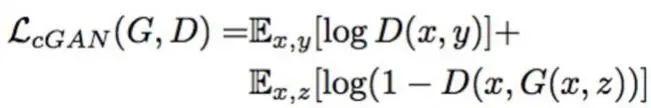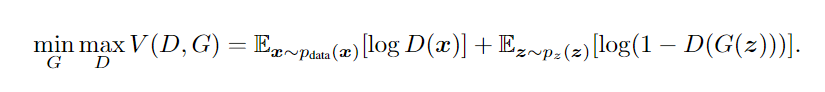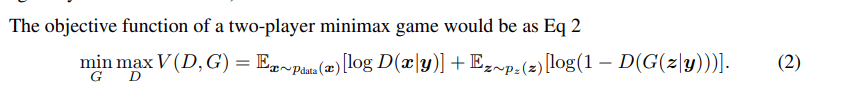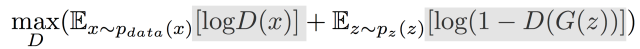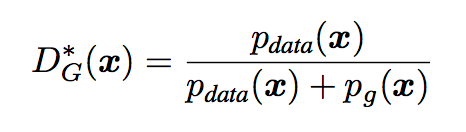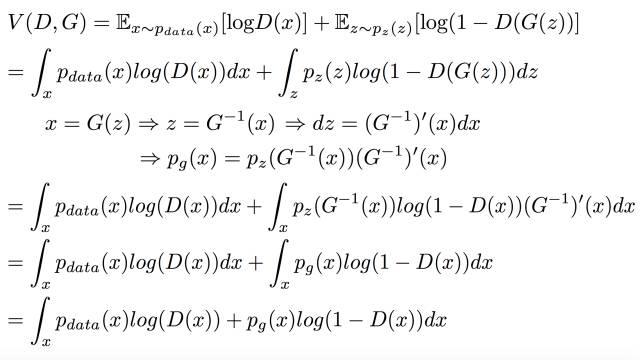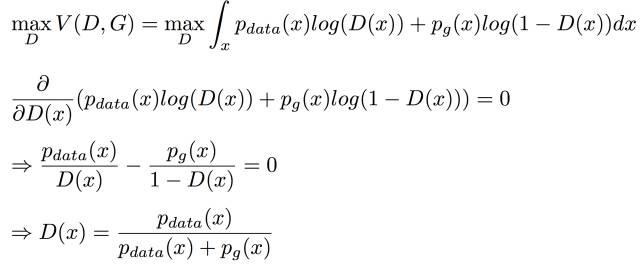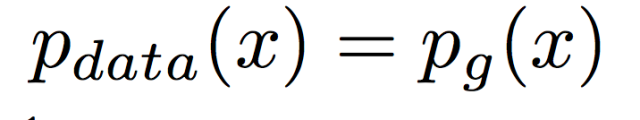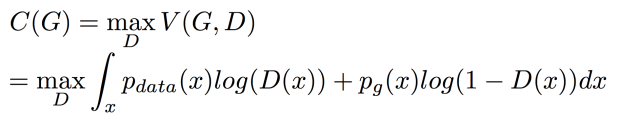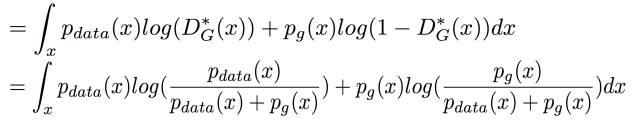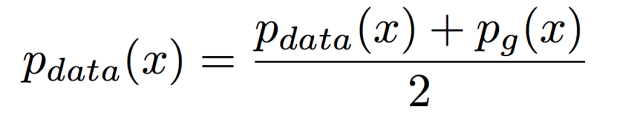StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Authors
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, Jaegul Choo
Abstract
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN’s superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
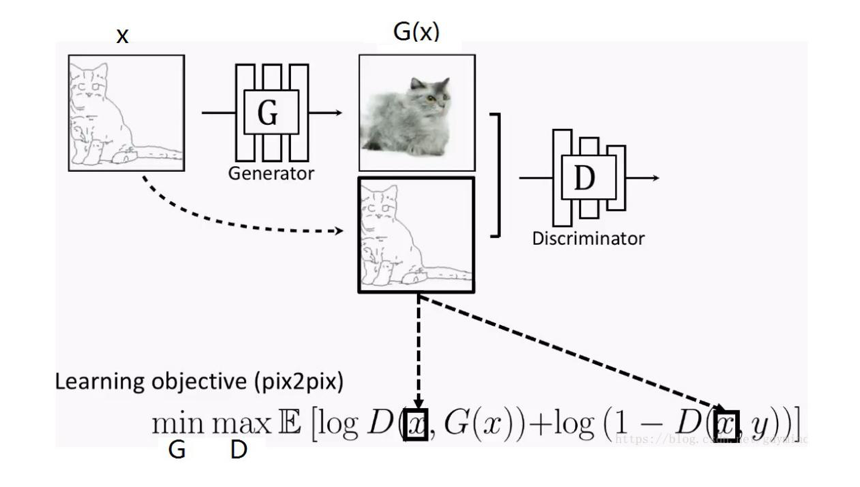
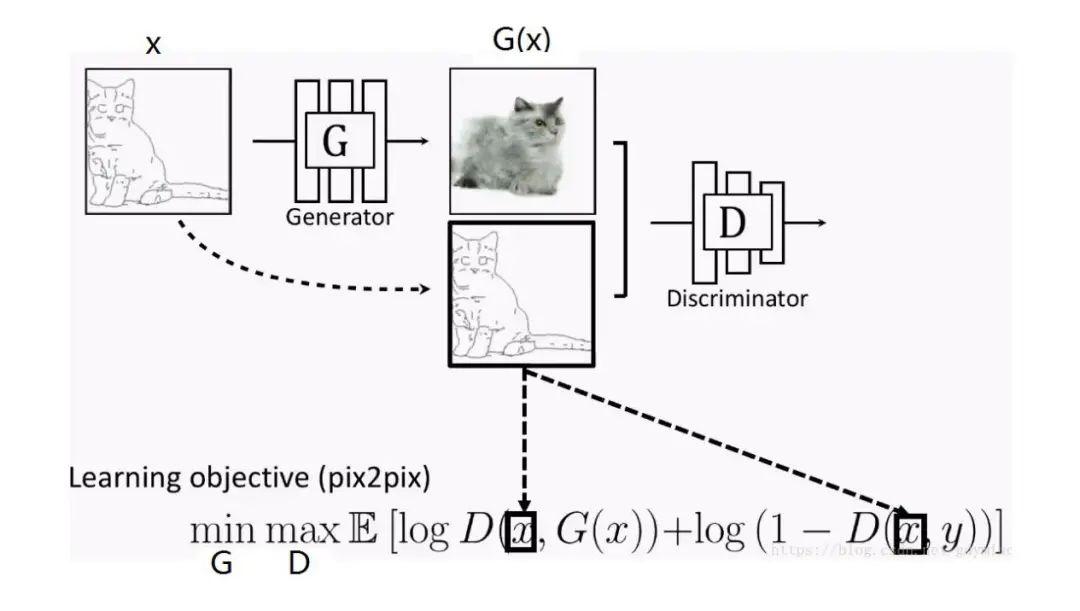
Pix2Pix模型解决了有Pair对数据的图像翻译问题;CycleGAN解决了Unpaired数据下的图像翻译问题。但无论是Pix2Pix还是CycleGAN,都是解决了一对一的问题,即一个领域到另一个领域的转换。当有很多领域要转换了,对于每一个领域转换,都需要重新训练一个模型去解决。这样的行为太低效了。本文所介绍的StarGAN就是将多领域转换用统一框架实现的算法。
下图是StarGAN的效果,在同一种模型下,可以做多个图像翻译任务,比如更换头发颜色,更换表情,更换年龄等。

StarGAN,顾名思义,就是星形网络结构,在StarGAN中,生成网络G被实现成星形。
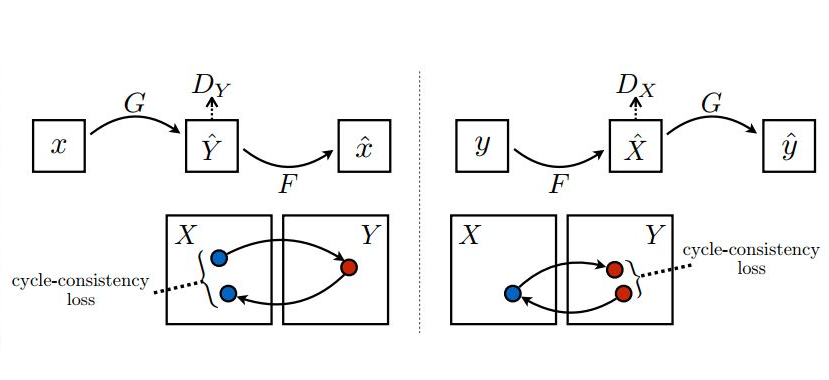
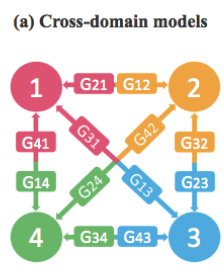
1.CycleGAN 不能解决多领域迁移的问题。 只能两个领域的互相转化A->B,B-A。 但是实际场景中,我们可能遇到 多个数据集,或者多种属性的互相转化的要求。这样的话我们就需要O(n^2)的G model。(如下图)
2.有些属性(如人的表情),如果只取其中的两个属性(笑和不笑),那么就无法利用上其他训练数据(比如生气/恐惧等表情数据)。
1.作者提出了StarGAN 来处理多个domain之间互相generate图像 的问题。只用一个generator网络。
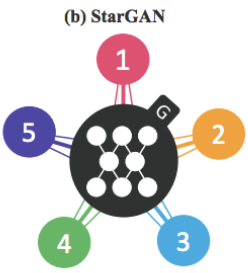
假如想实现四个域内图像风格的相互转换,要实现这个目标,通过cycleGAN需要创建12个生成器(如图a)。而starGAN的直观构造如图b,只需要一个生成器即可。
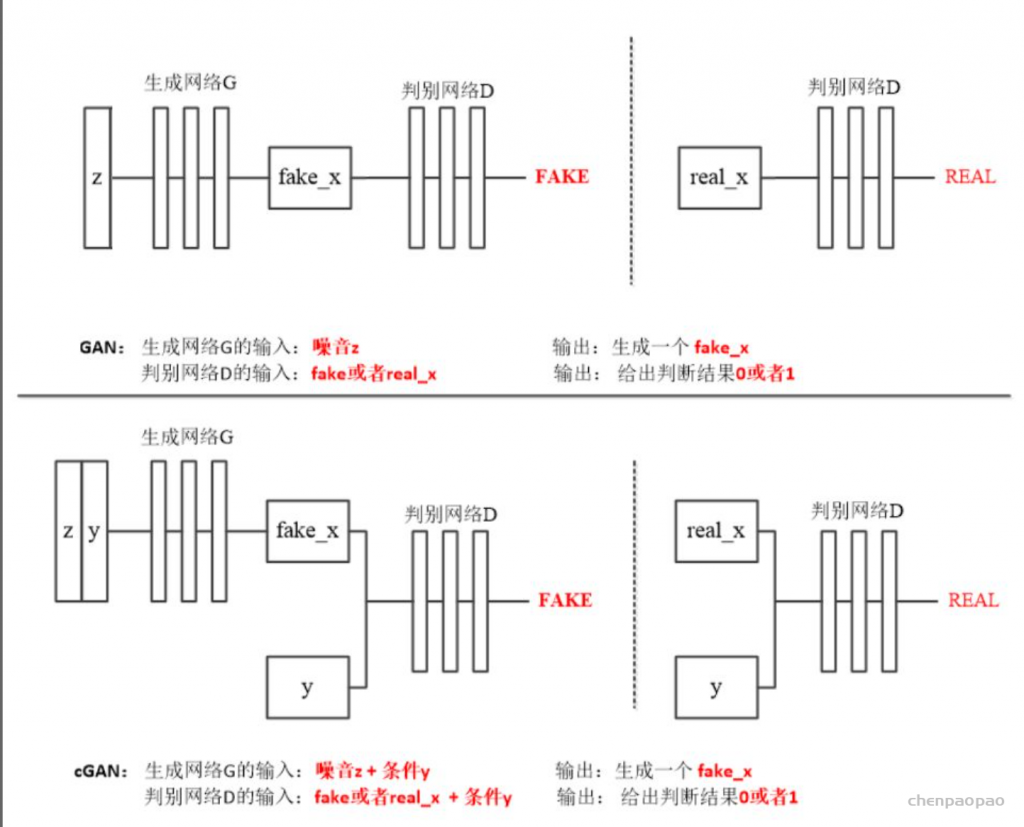
2. G的输入除了图片,还有domain的label,对应的把生成图片变到指定的domain。
starGAN的提出是为了解决多数据集在多域间图像转换的问题,starGAN可以接受多个不同域的训练数据,并且只需要训练一个生成器,就可以拟合所有可用域中的数据。
StarGAN的大致训练流程:
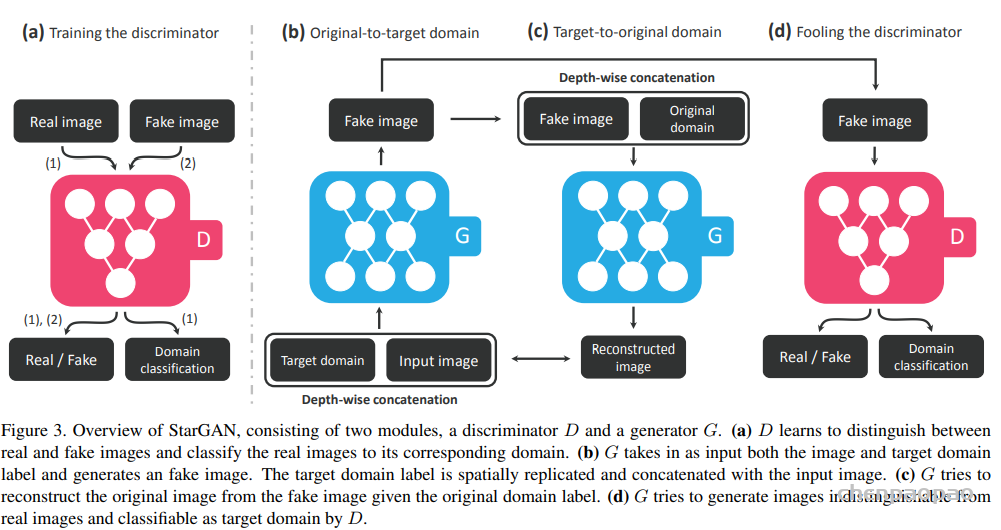
i)如图a,训练判别器,将 real_img 和 fake_img 分别传递给判别器,判别器会判别图像的真假,同时它还会判别该图像来自哪个域(只对real_img 的label做判别)。
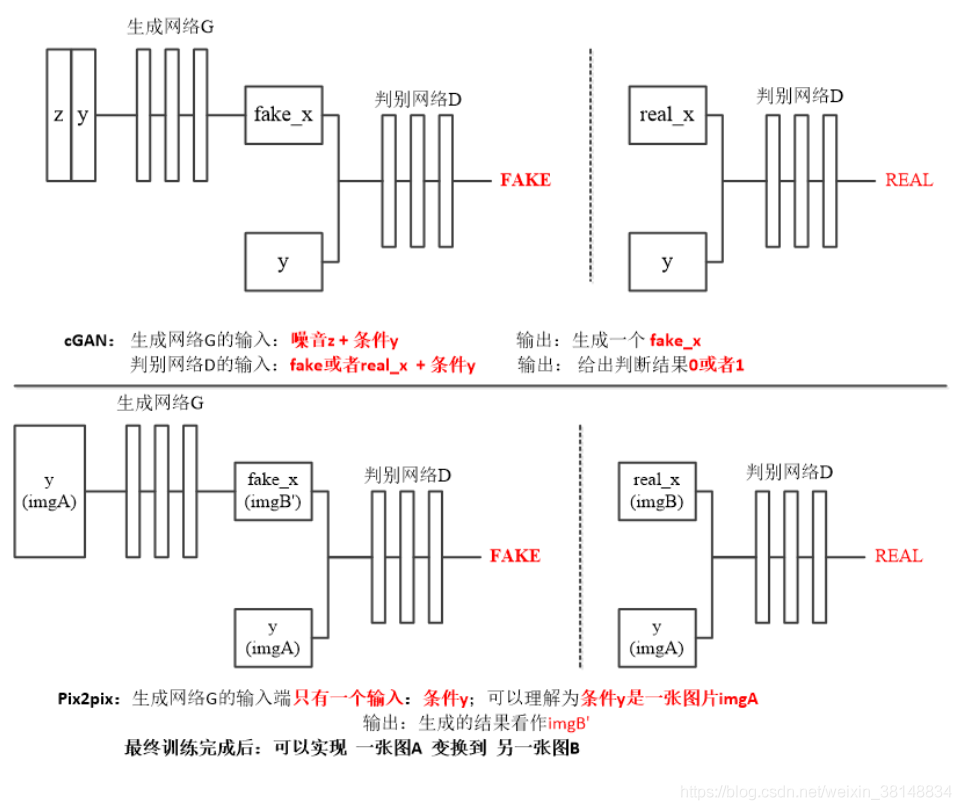
ii)如图b,训练生成器,与CGAN类似,这里除了输入图像外,还要输入该图像想转换的目标域,这个目标域类似于约束条件,它要求生成器尽可能去生成该目标域中的图像。
iii)如图c,表示循环一致性的过程,如果只是单纯的使用条件去控制生成器生成,那么生成器就会生成满足条件但可能与输入图像无关的数据,为了避免这种情况,便使用循环一致性的思想,即将生成的图像加上输入图像所在的域作为生成器的输入,希望获得的输出与原输入图像越接近越好。
iiii)如图d,表示训练生成器,即将生成器生成的图片交给判别器,让判别器判别图像的真假以及图像所在的域是否正确。
损失函数:
Adversarial loss 为 conditional gan常用的。(实际替换为WGAN的loss)
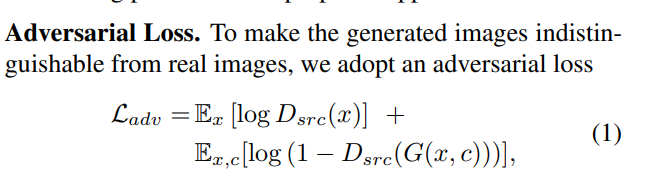
Reconstruction loss 为L1 Loss (和Cyclegan一样)

Domain classification loss(属性分类)就是传统分类log NLLloss。
类别损失,该损失被分成两个,训练D的时候,使用真实图像在原始领域进行,训练G的时候,使用生成的图像在目标领域进行。
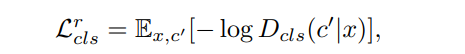
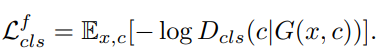
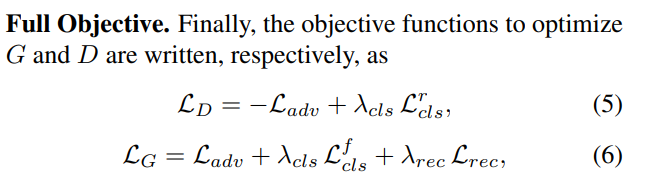
多数据集训练
在多数据集下训练StarGAN存在一个问题,那就是数据集之间的类别可能是不相交的,但内容可能是相交的。比如CelebA数据集合RaFD数据集,前者拥有很多肤色,年龄之类的类别。而后者拥有的是表情的类别。但前者的图像很多也是有表情的,这就导致前一类的图像在后一类的标记是不可知的。
为了解决这个问题,在模型输入中加入了Mask,即如果来源于数据集B,那么将数据集A中的标记全部设为0.