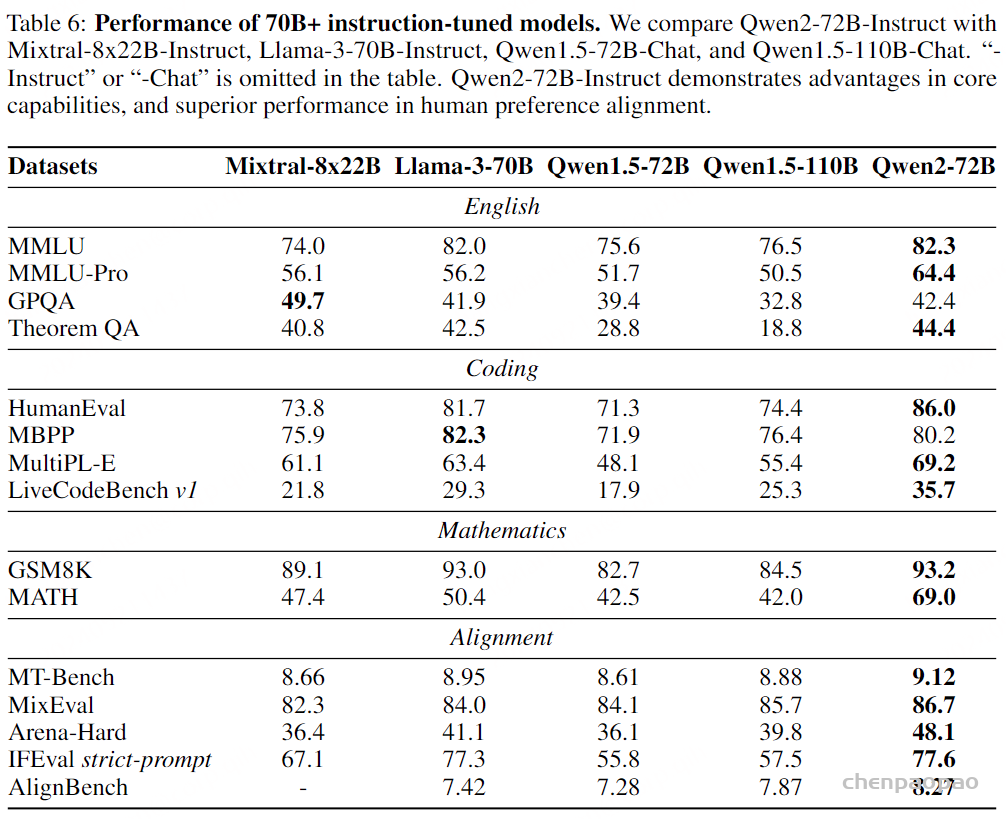
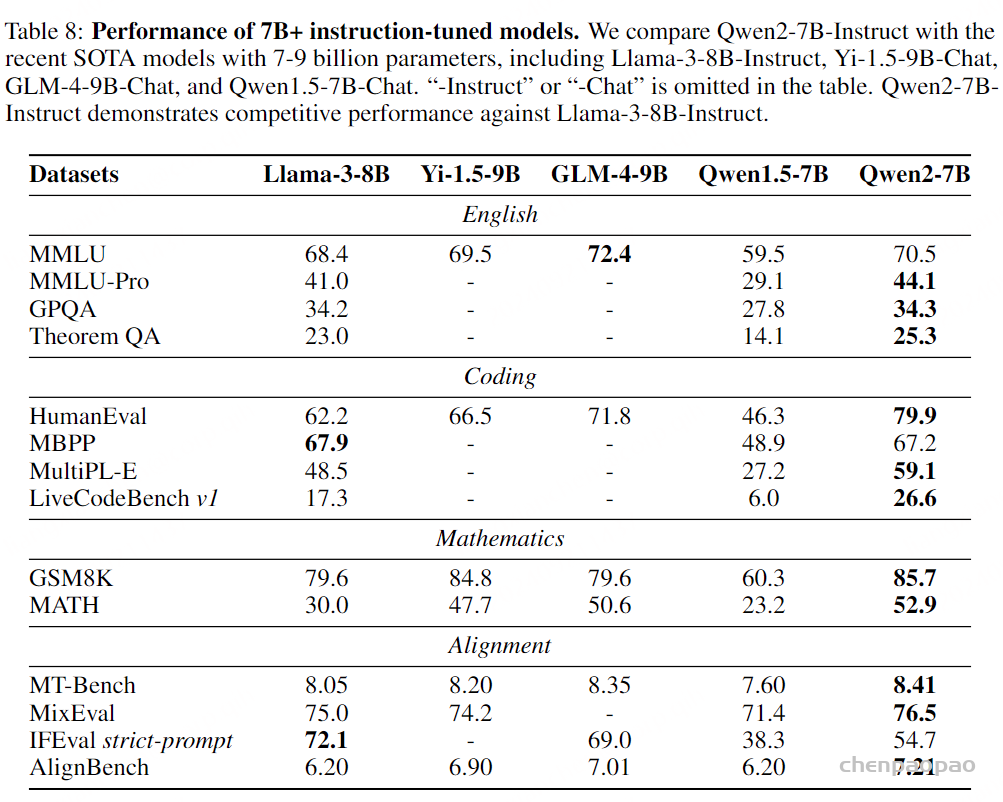
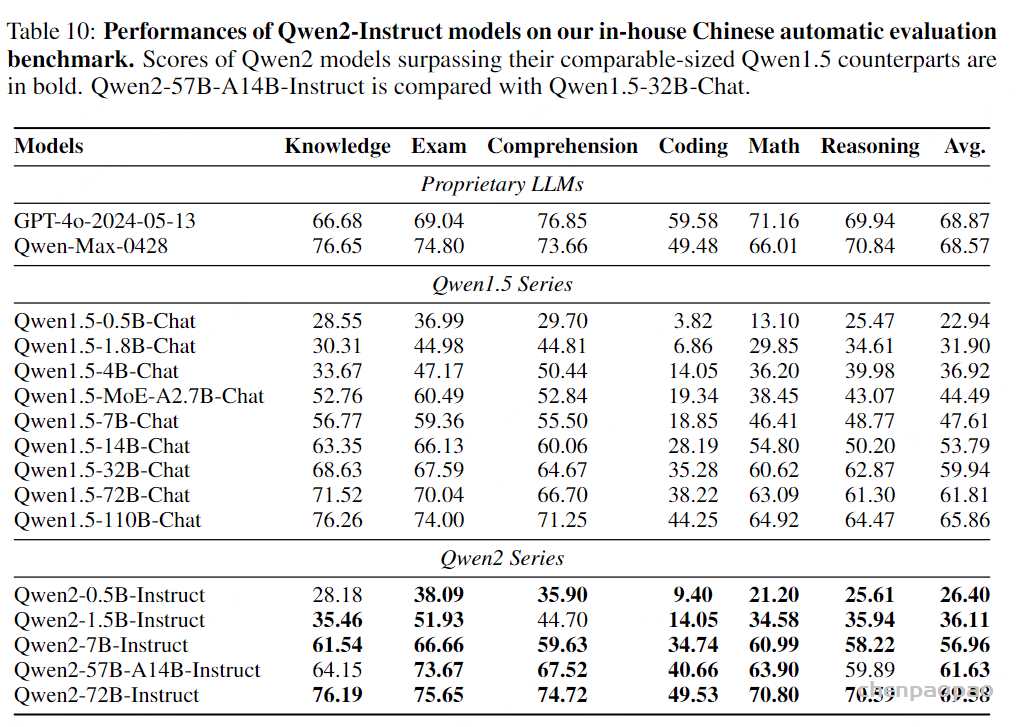
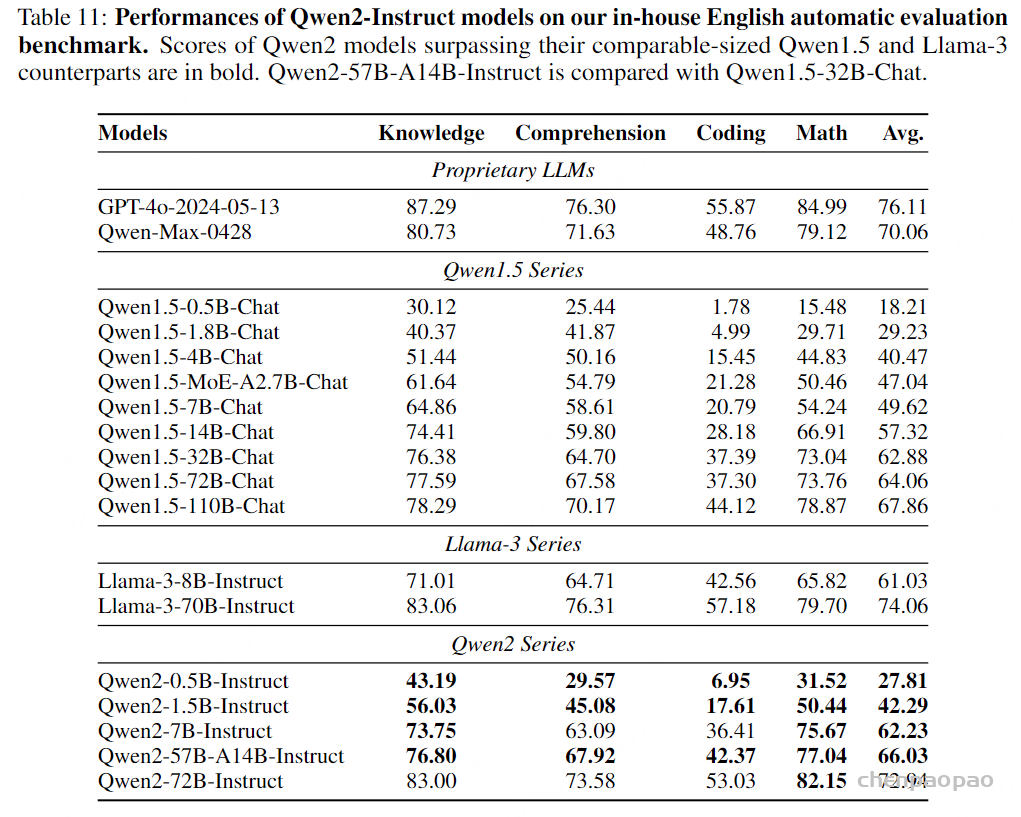
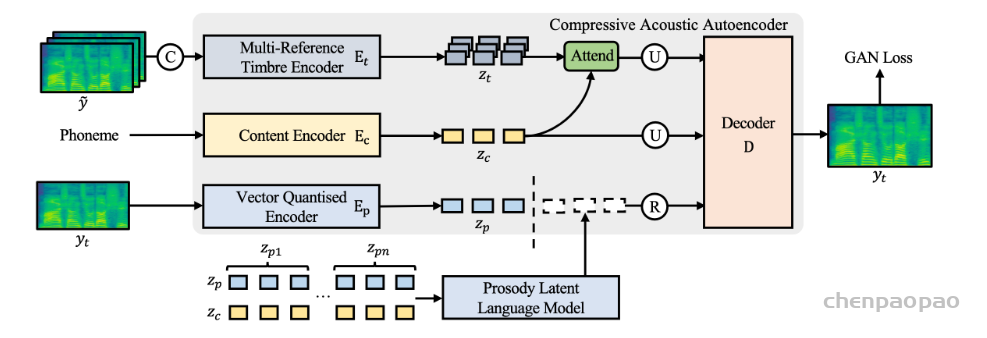
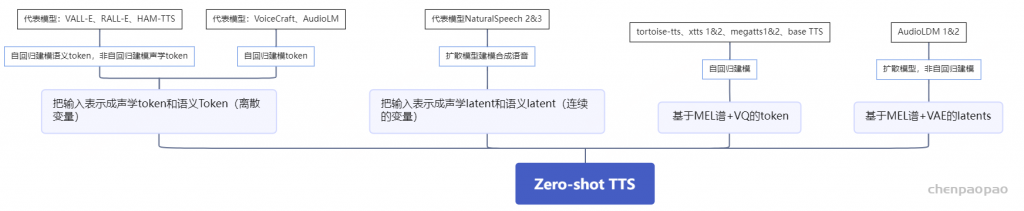
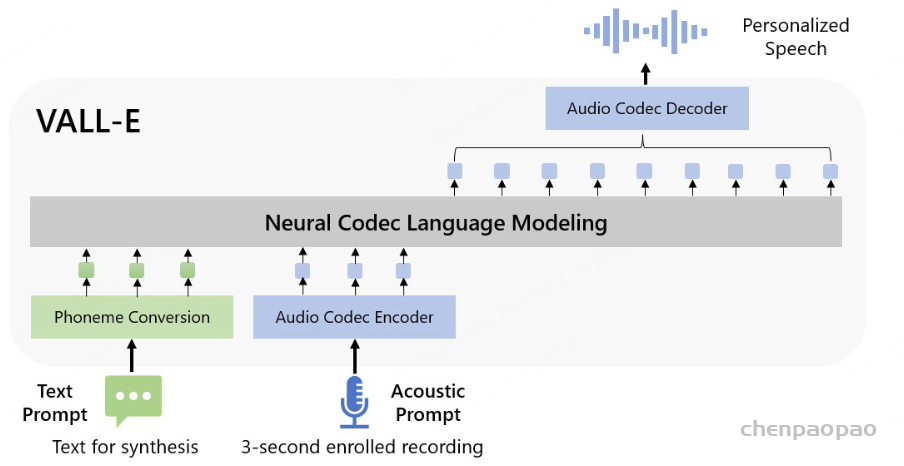
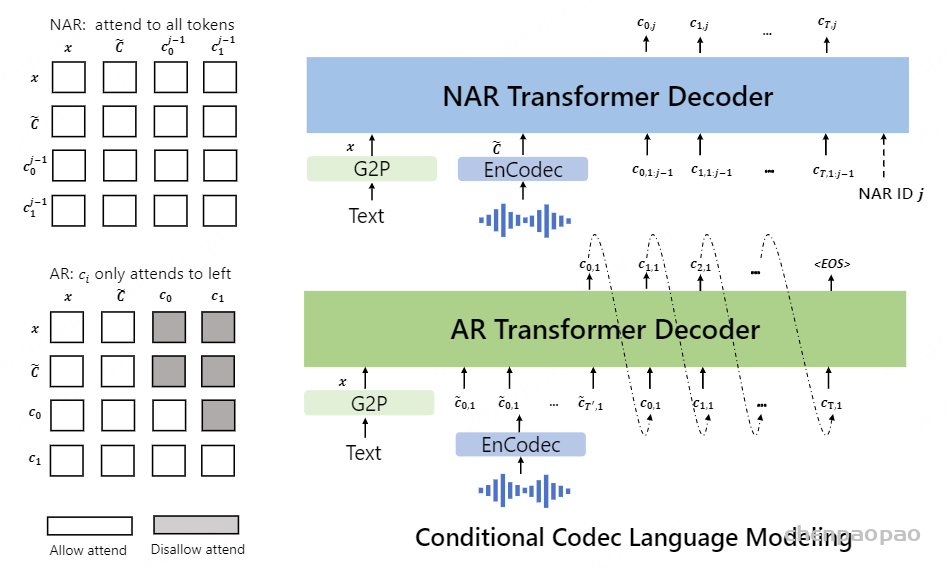
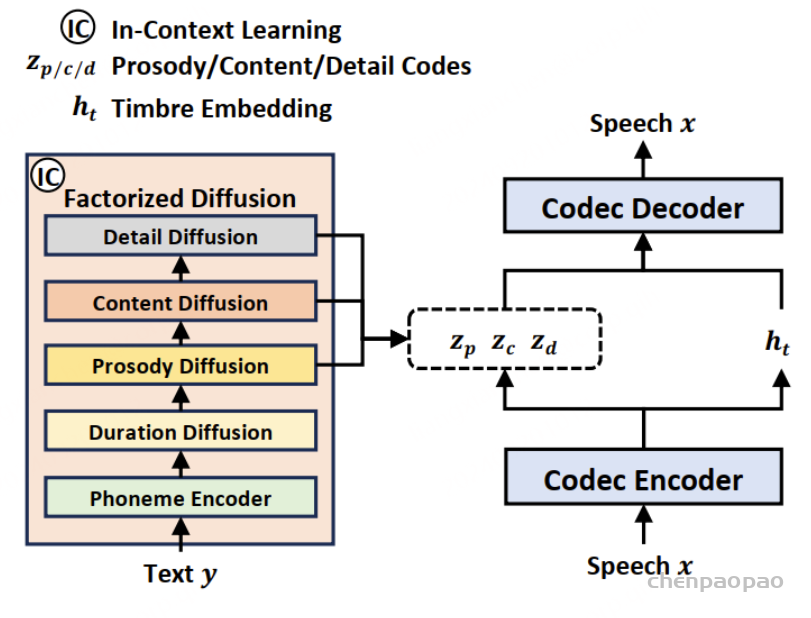
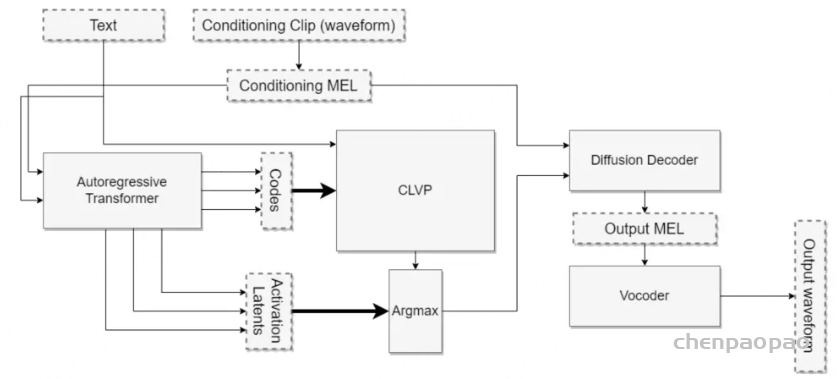
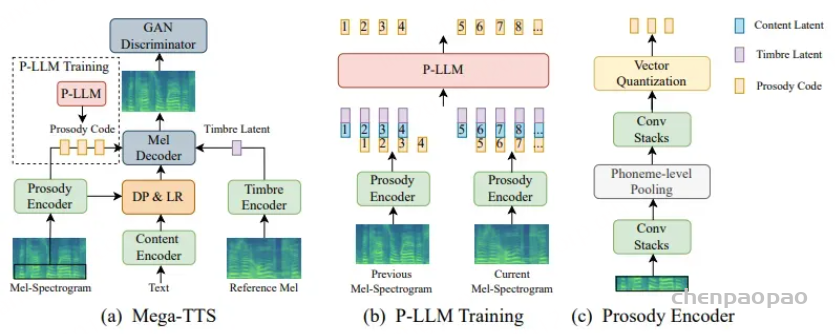
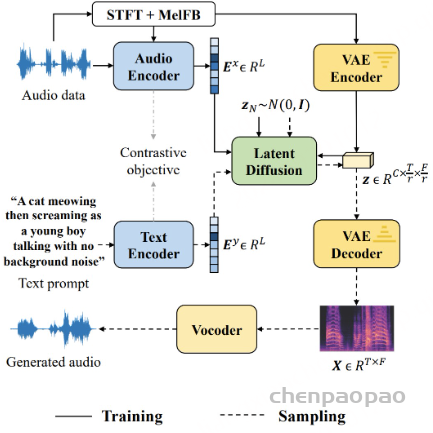
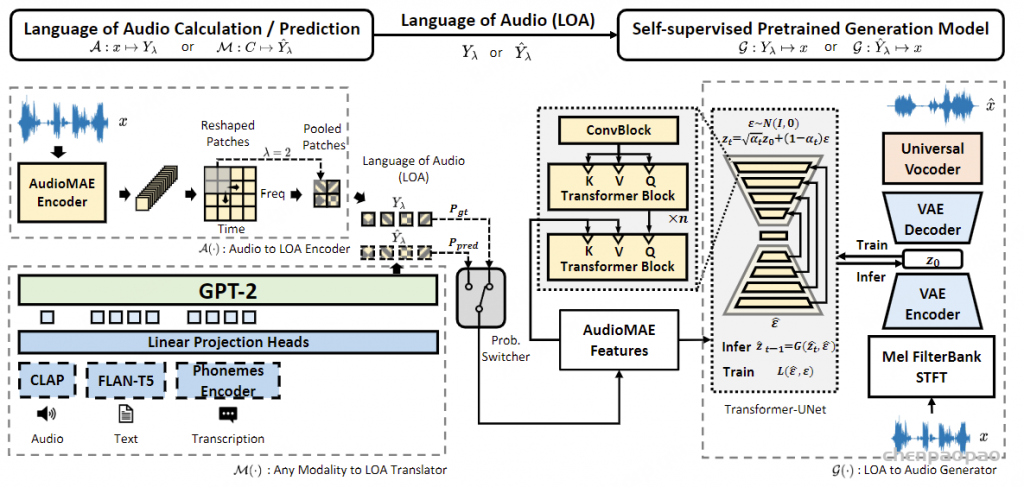
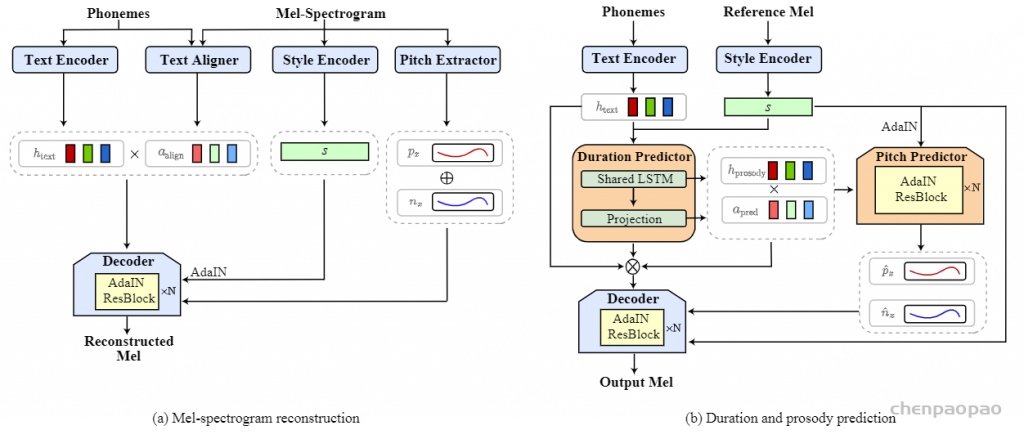
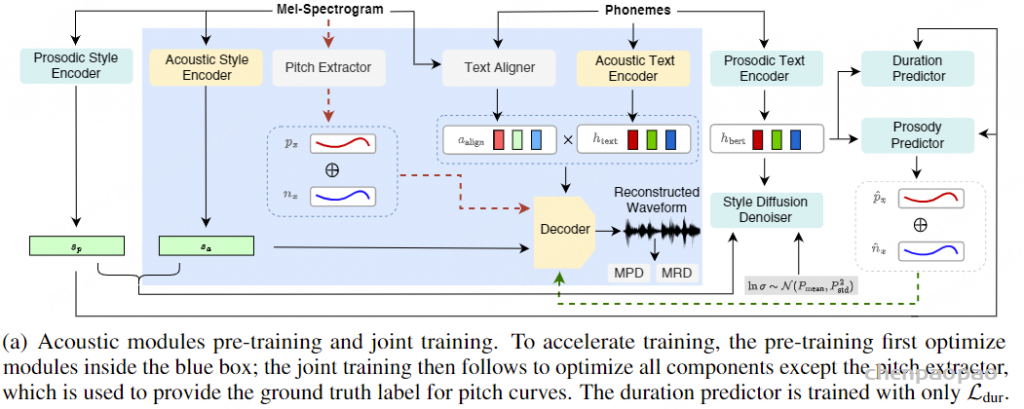
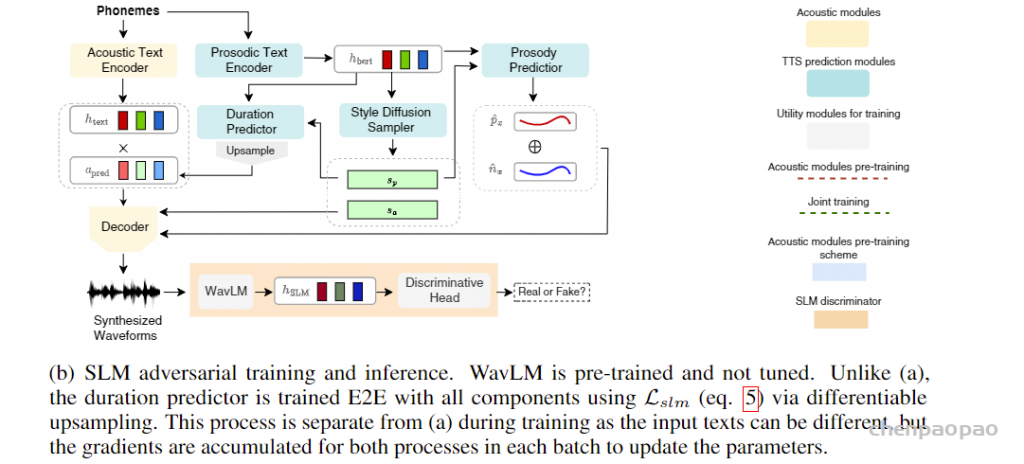
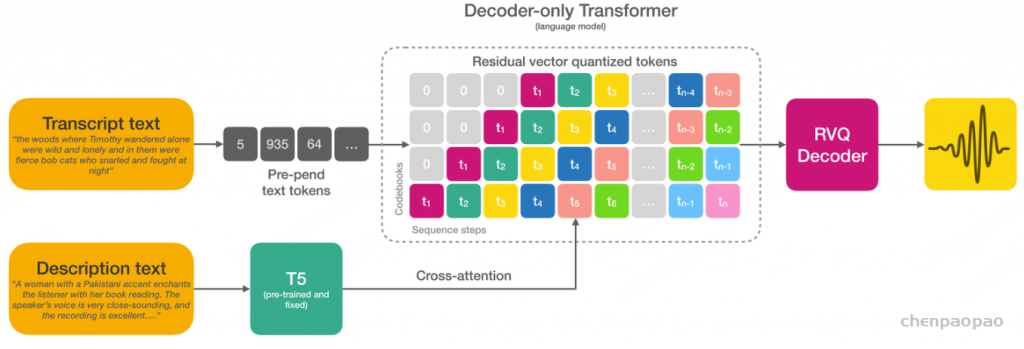
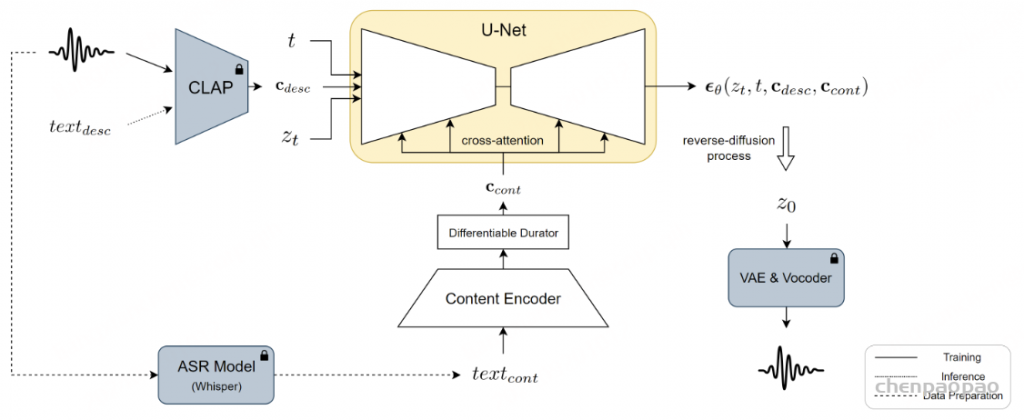
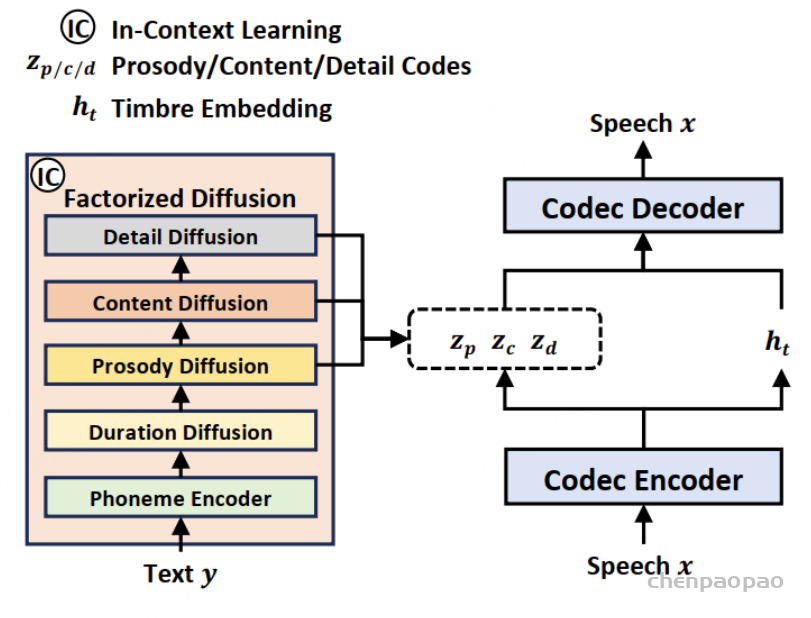
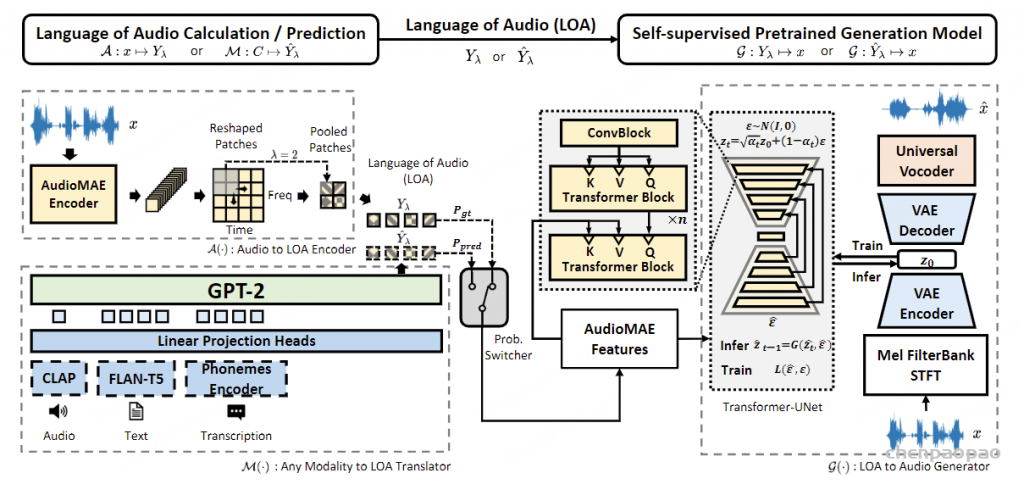
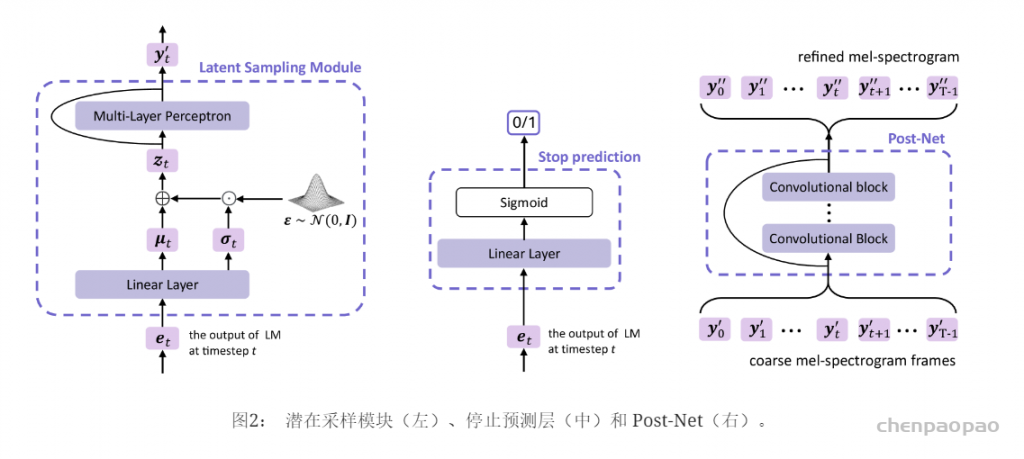
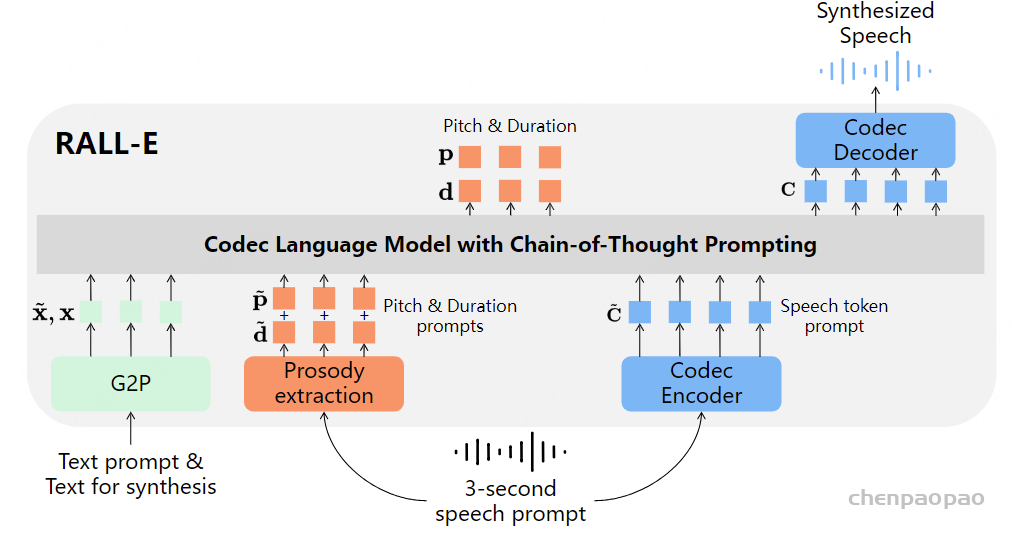
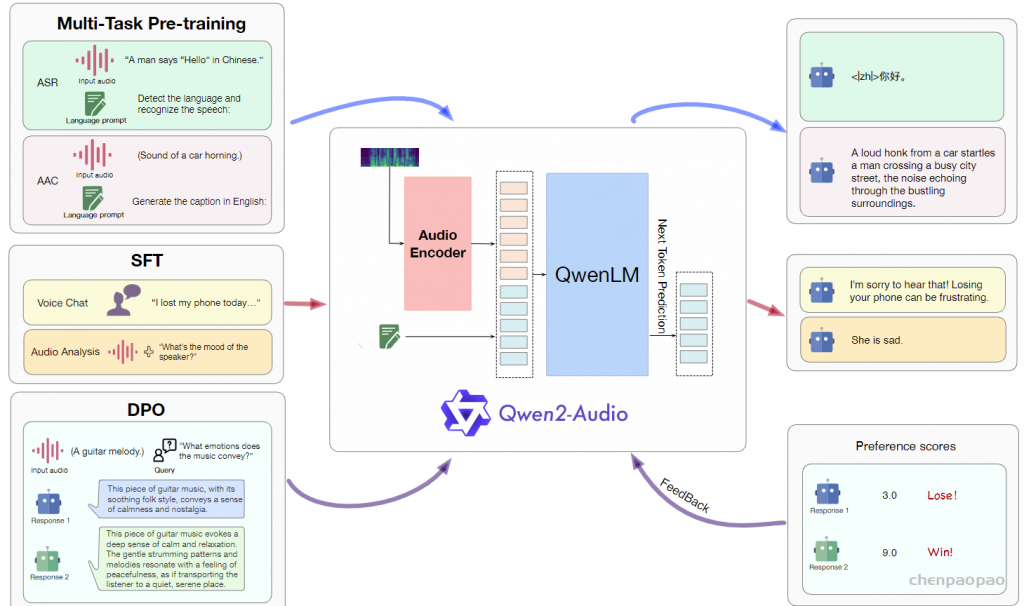
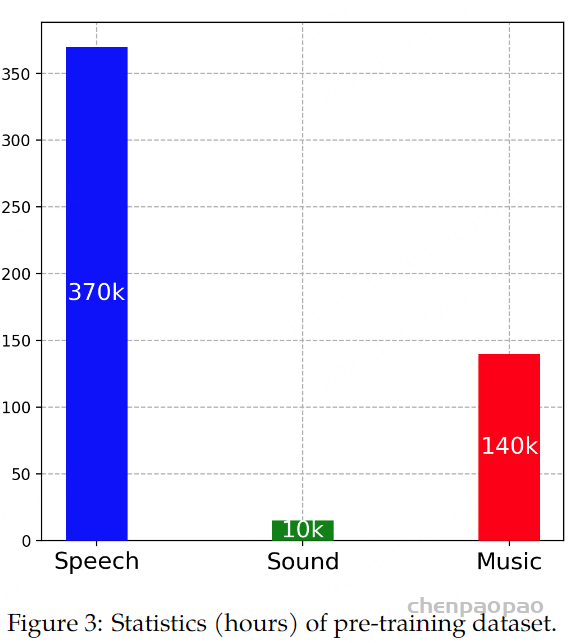
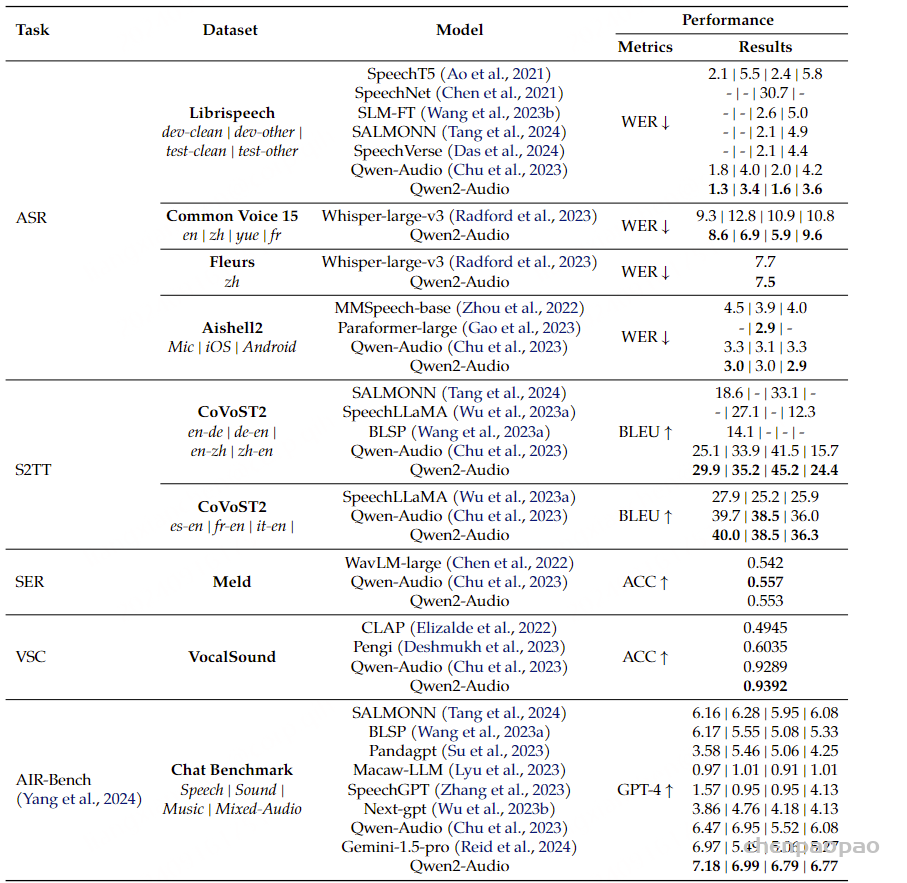
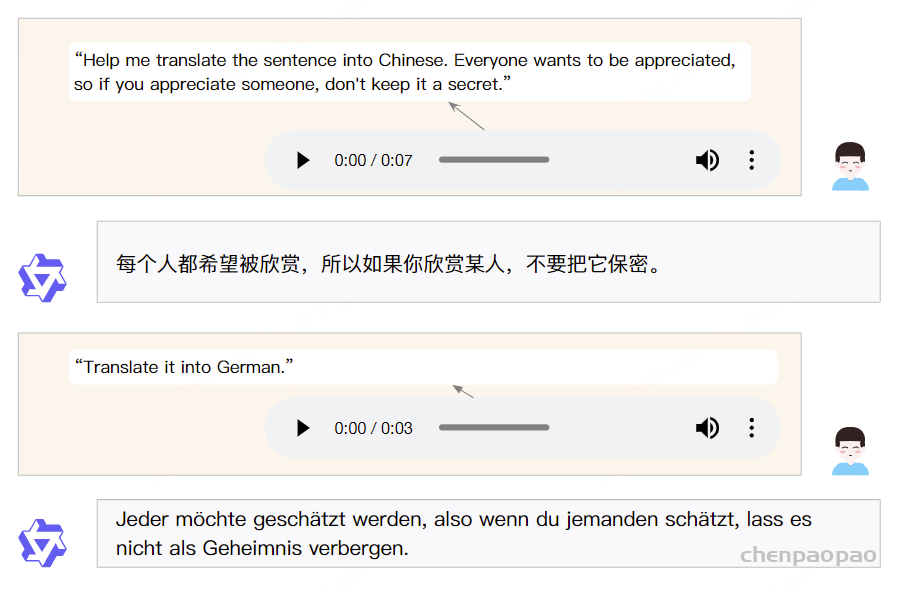
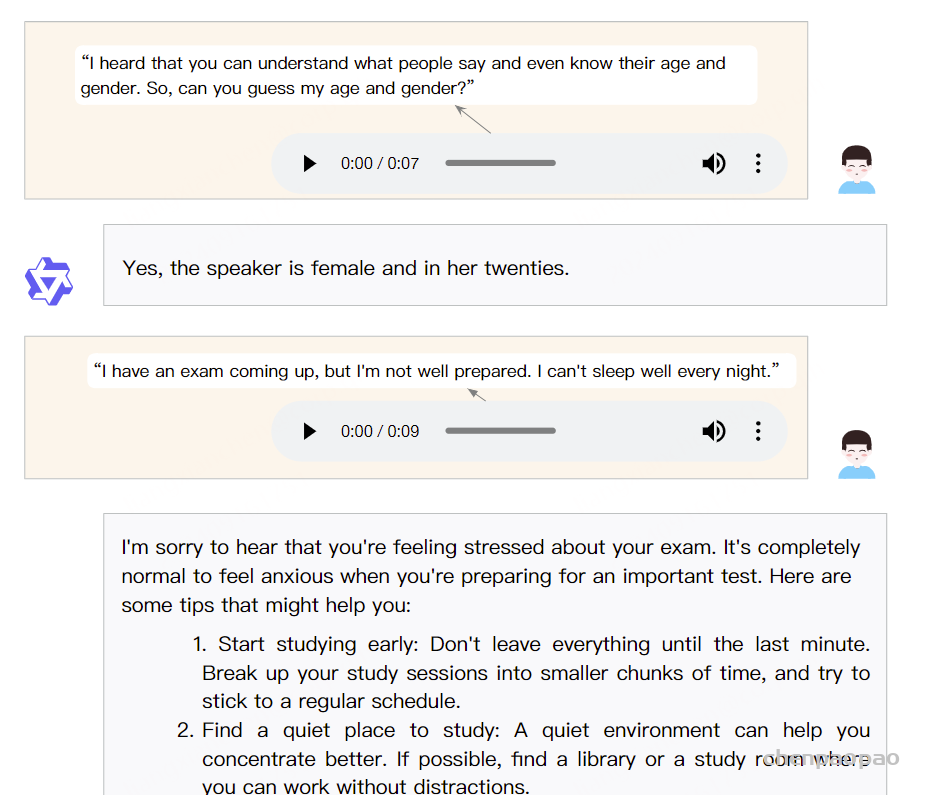
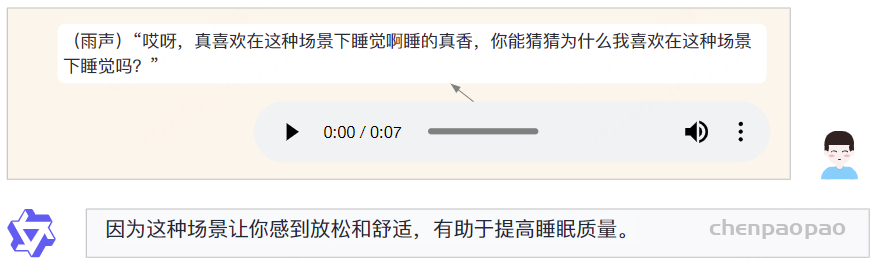
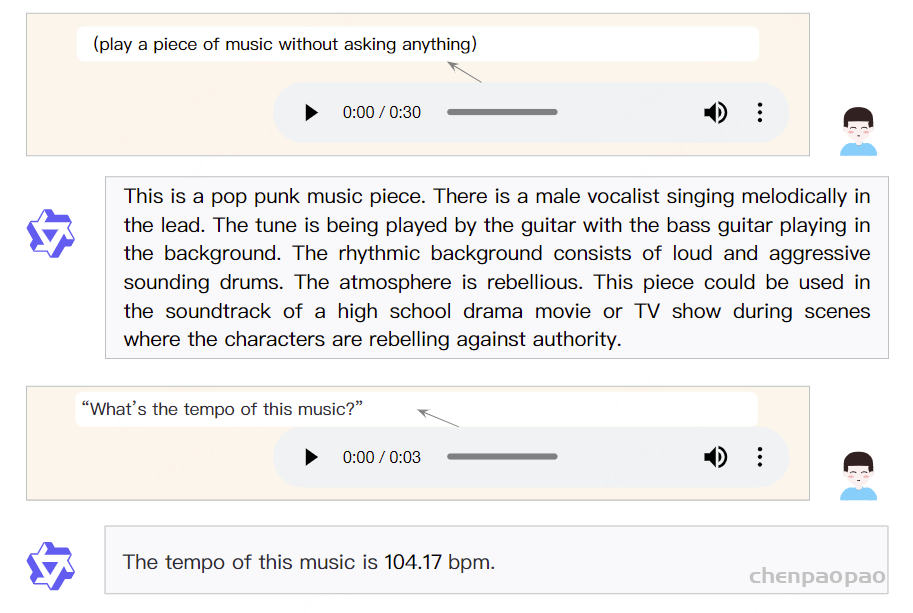
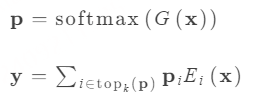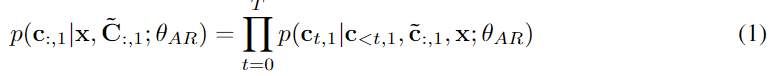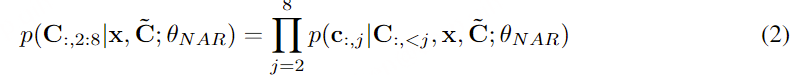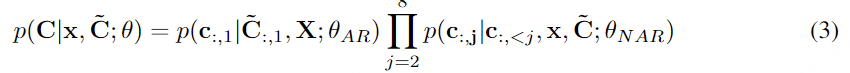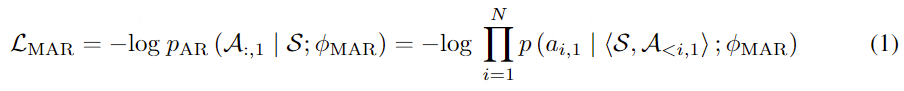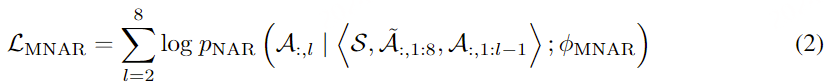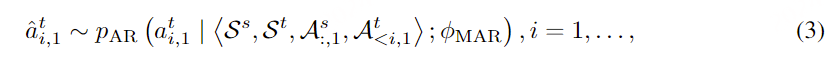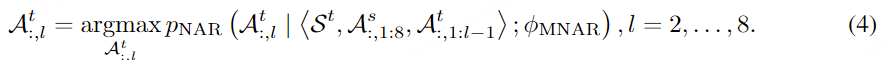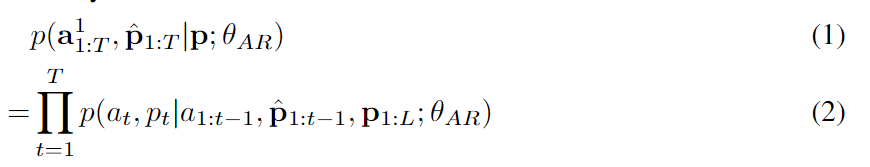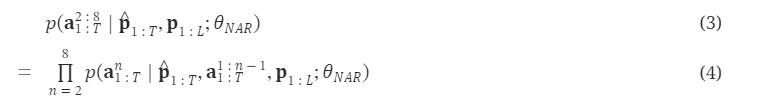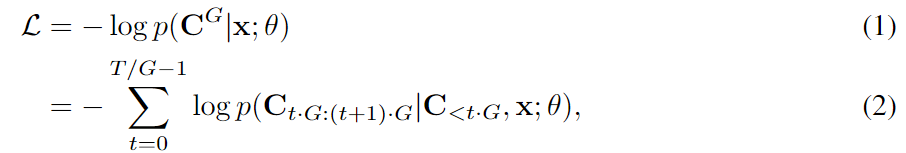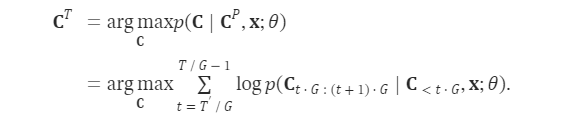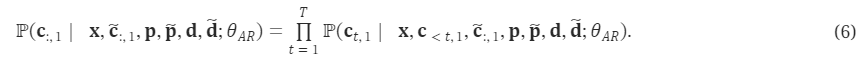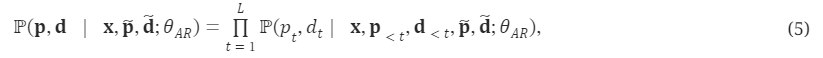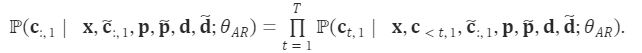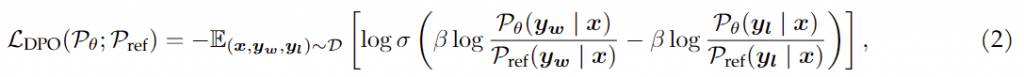Paper:Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment Abs:https://arxiv.org/abs/2401.12474
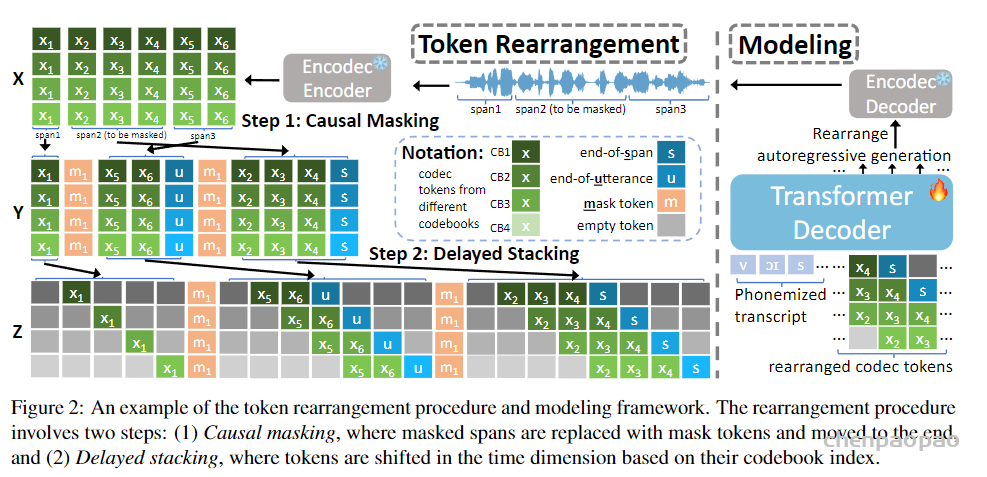
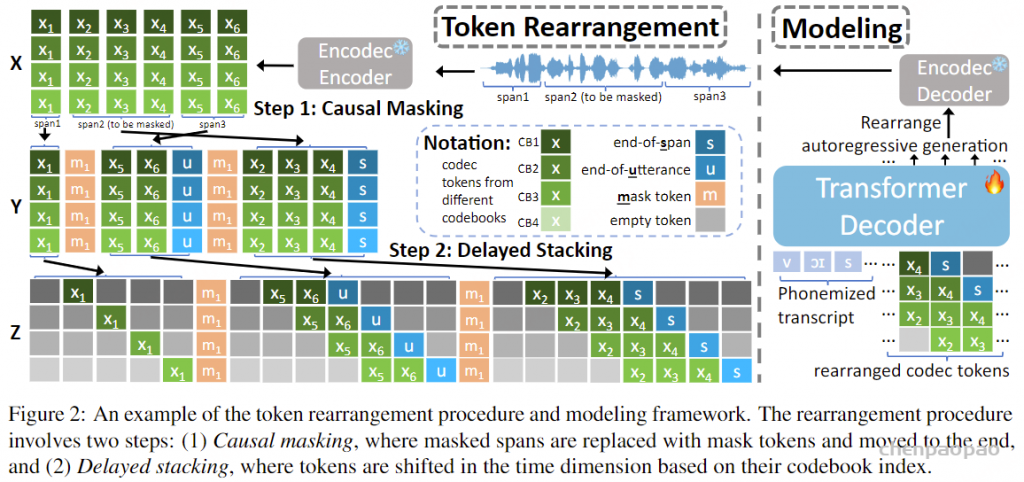
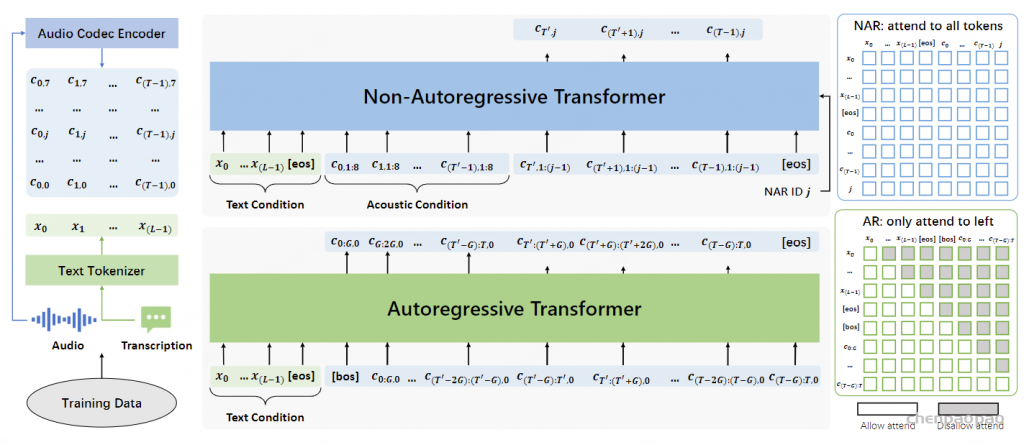
给定一个连续的语音波形作为输入,我们首先使用 Encodec将其量化成一个 T by K codec 矩阵 X ,其中 T 是时间帧的数量,是 K RVQ 码本的数量。 X 可以写成 (X1,⋯,XT) ,其中 Xt 是一个长度 K 向量,表示在时间步 t 中来自不同码本的代码,我们假设 Codebook k 中的代码对 Codebook k−1 中的残差进行建模。在训练过程中,我们的目标是随机屏蔽一些 span 的标记 (Xt0,…,Xt1) ,然后以所有未屏蔽的标记为条件自动回归预测这些被屏蔽的标记。这在 时 t1<T 是个问题,因为在执行自回归生成时,我们无法以未来的输出为条件。我们需要修改掩码, X 使其具有因果关系,方法是将要掩码的跨度移动到序列的末尾,以便在填充这些标记时,模型可以针对过去和未来未掩码的标记。
只需将所有被屏蔽的 span 移动到序列的末尾,即可轻松地将上述过程扩展到多个被屏蔽的 span。要屏蔽 n 的 span 数从 Poison(λ) 中采样,然后对于每个 span,我们采样一个 span length l∼Uniform(1,L) 。最后,我们在约束 X 下随机选择 span 的位置,确保它们彼此不重叠。然后,选定的 n 范围将替换为掩码标记 ⟨M1⟩,⋯,⟨Mn⟩ 。这些掩码 span 中的原始标记将移动到 sequence X 的末尾,每个 span 前面都有其相应的掩码标记。
重排步骤 2:延迟堆叠
在因果掩码标记重新排列之后,重新排列矩阵 Y 的每个时间步都是标记向量 K 。Copet et al. ( 2023) 观察到,当对堆叠的 RVQ 令牌进行自回归生成时,应用延迟模式是有利的,这样时间对码簿 k 的预测 t 就可以以同一时间步长对码簿 k−1 的预测为条件。我们采用与本文类似的方法。假设 span Ys 的形状为 Ls×K .应用延迟模式会将其重新排列到 Zs=(Zs,0,Zs,1,⋯,Zs,Ls+K−1) 中,其中 Zs,t,t∈[Ls+K−1] 定义为
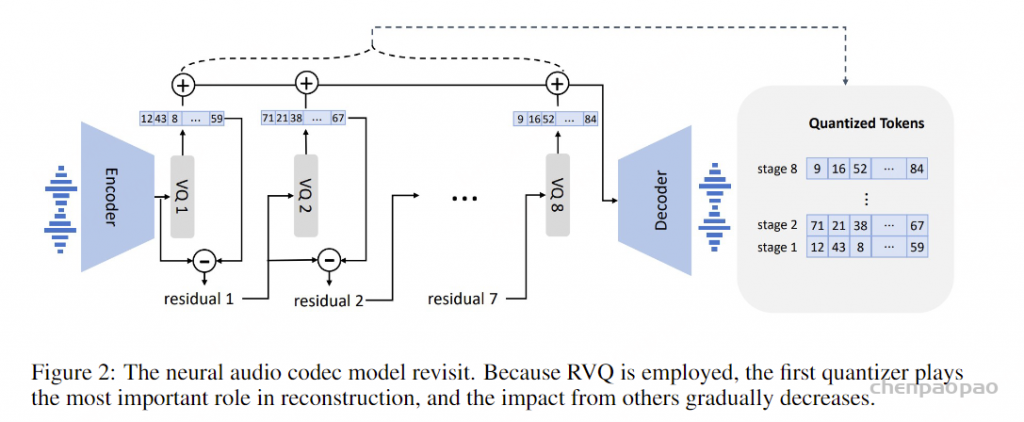
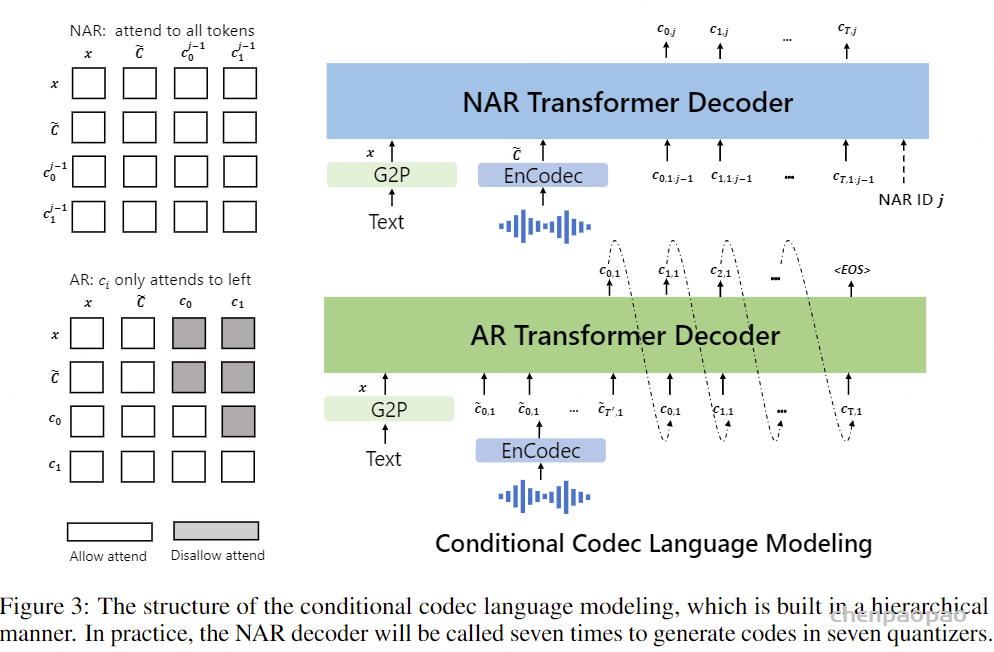
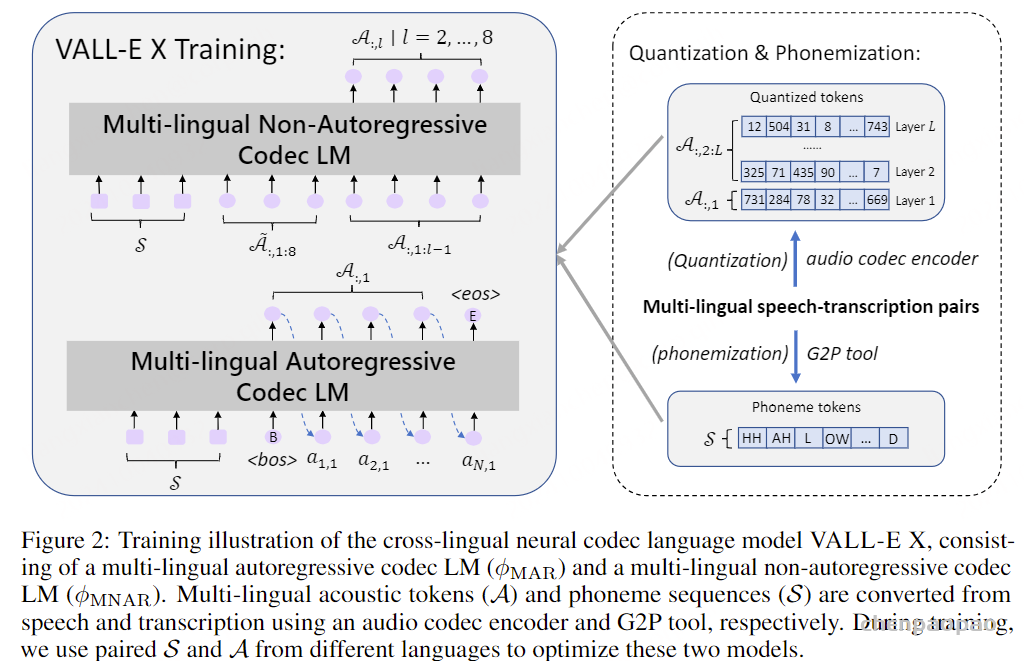
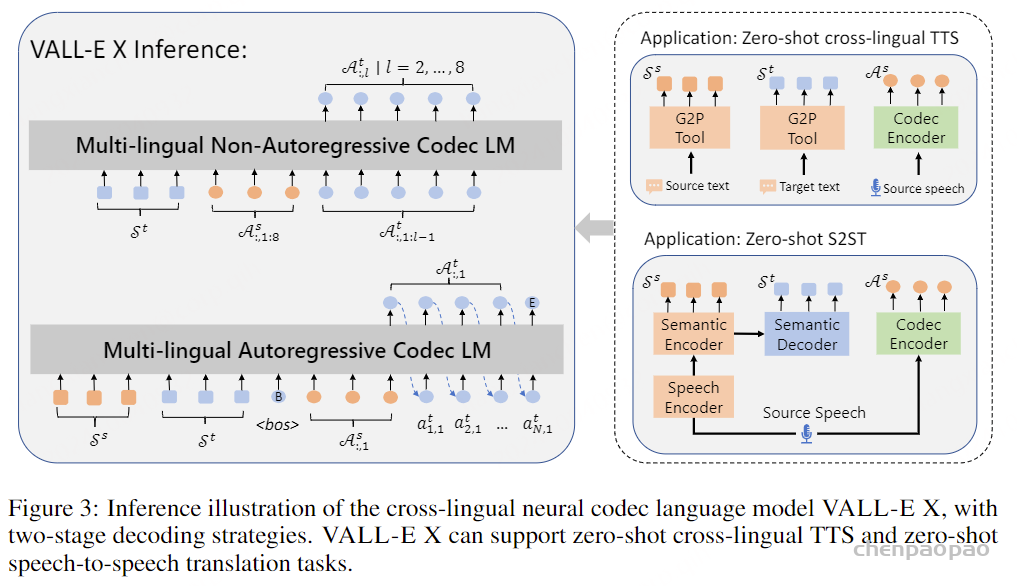
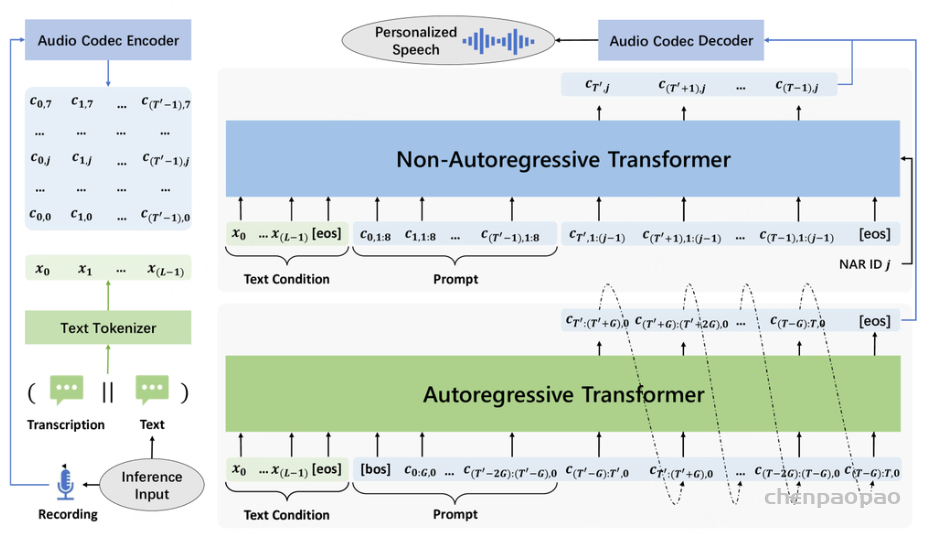
在通过自回归模型获得第一个量化器的代码后,我们使用非自回归(NAR)模型生成其他七个量化器的代码。NAR 模型的架构与 AR 模型类似,只是包含八个独立的声学嵌入层。在每个训练步骤中,我们随机抽取一个训练阶段i∈[2,8]。该模型的训练目标是最大化来自第 i 个量化器代码本的声学标记。来自阶段 1 到阶段i−1 的声学标记被嵌入并求和作为模型输入:
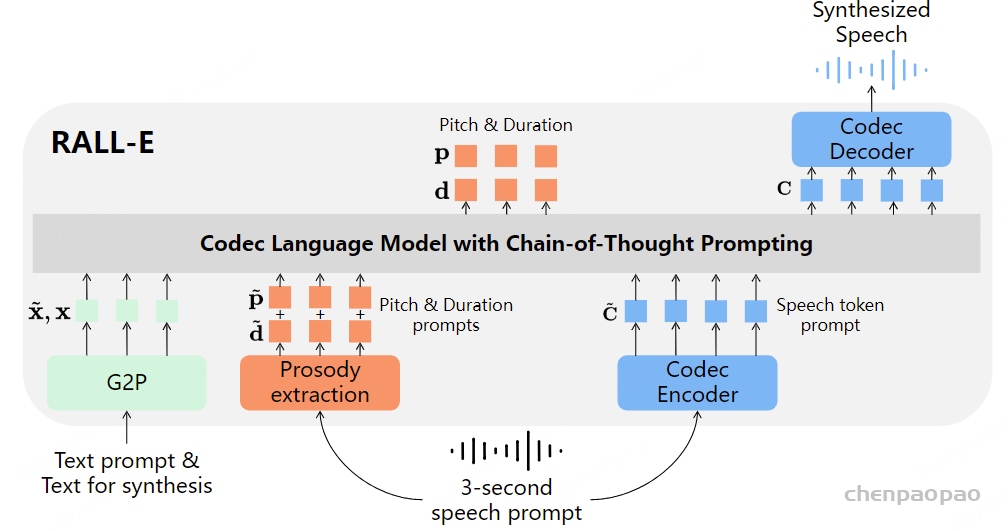
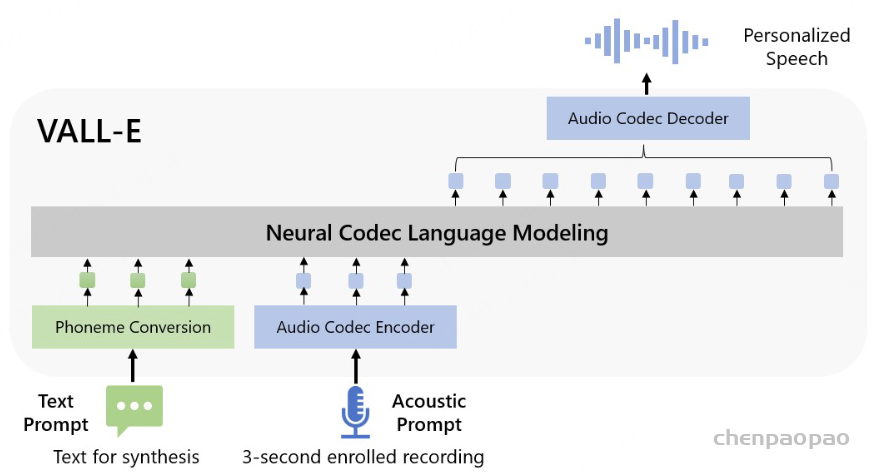
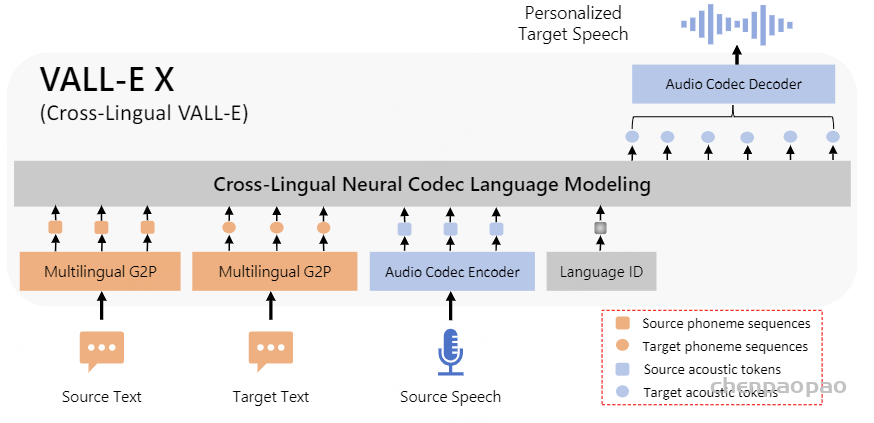
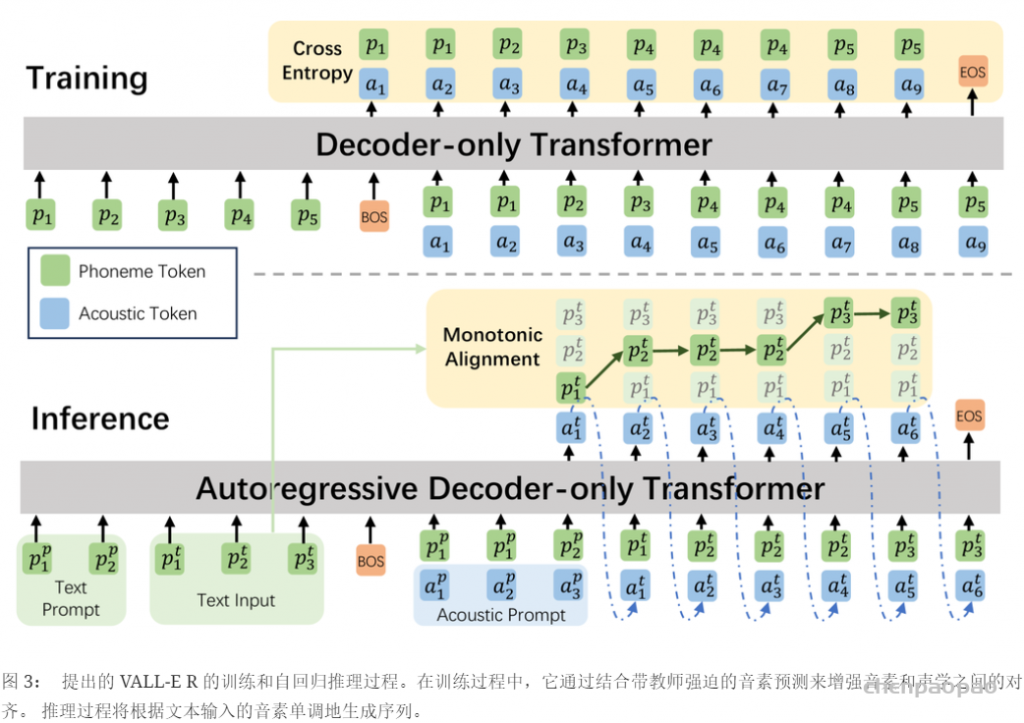
其中 ⋅ 表示索引选择。音素序列同样被视为语言模型的提示。此外,为了克隆给定说话者的独特声音,我们还使用来自已注册语音的声学标记作为声学提示。具体来说,我们首先使用神经编解码模型对已注册语音进行标记,得到C~T×8。来自八个代码本的嵌入表示被求和作为声学提示。为了预测来自第 i 个代码本的声学标记,变换器输入是音素嵌入ex、声学提示 ec~ 和 c:,<i 的连接。位置嵌入也分别为提示和声学序列计算。当前阶段 iii 通过自适应层归一化(AdaLN)操作注入到网络中,即 AdaLN(h,i)=aiLayerNorm(h)+bi,其中 h 是中间激活,ai 和 bi 是通过阶段嵌入的线性投影获得的。与 AR 不同,NAR 模型允许每个标记在自注意力层中关注所有输入标记。我们还共享声学嵌入层和输出预测层的参数,这意味着第 j 个预测层的权重与第 j+1 个声学嵌入层相同。
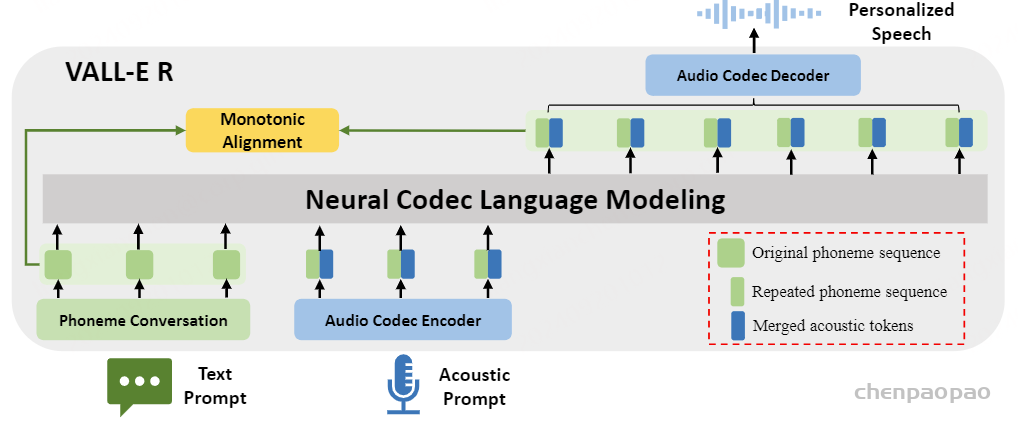
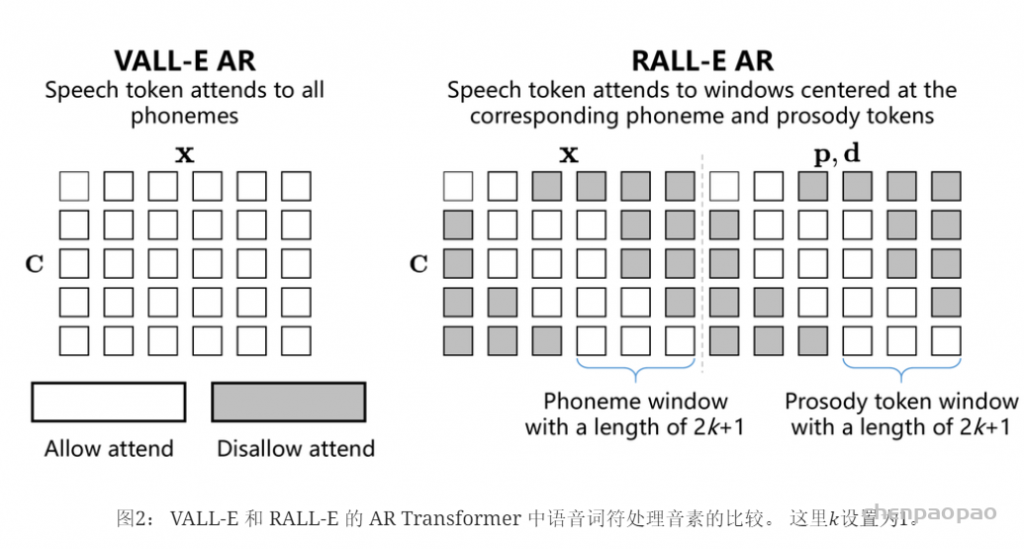
在推理过程中,利用语言模型强大的上下文学习能力,我们提出的 VALL-E R 可以通过自回归预测声学和音素来自动克隆提示中说话人的音色和韵律。 由于 VALL-E R 明确地对音素进行建模,因此它对韵律具有很强的控制力:当我们在推理过程中使用预设的音素序列替换自预测的音素序列时,我们可以使用预设的韵律来生成语音,从而实现分别控制韵律和音色的效果。 它也可以被认为是一种语音转换任务,其目标是在不改变源语音的语言信息和韵律的情况下,使目标语音的音色听起来像提示语音。
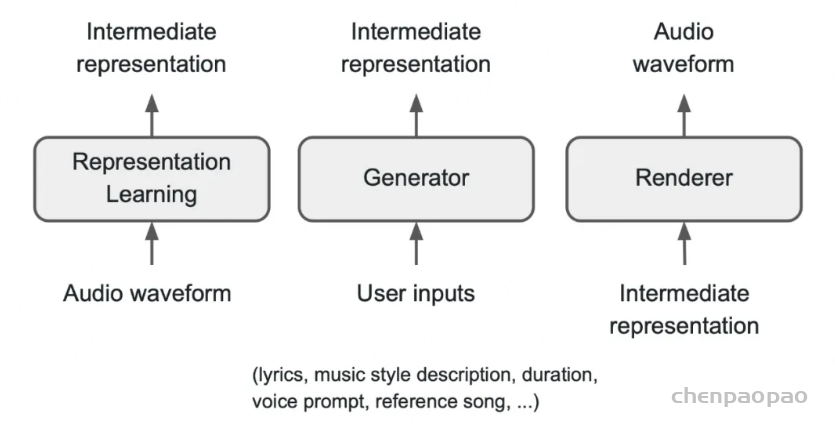
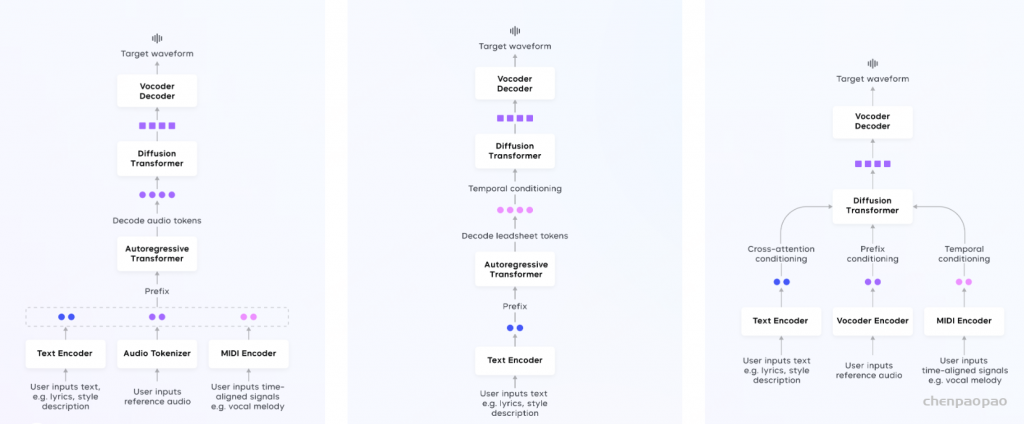
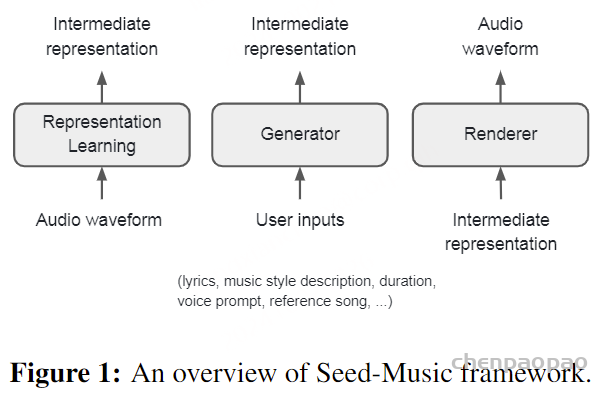
无论是传统的音乐辅助创作工具,还是当下热门的 AI 音乐生成的研究和产品,面向上述问题,均还处于摸索阶段。 比如针对音乐信号复杂性,Google、Meta、Stability AI 等各家在音频、演奏、曲谱层面上做了建模尝试,效果各有优缺,而且各家的评估方法均有局限,人工评测仍必不可少。 面对这些挑战,字节 Seed-Music 采用了创新的统一框架,将语言模型和扩散模型的优势相结合,并融入符号音乐的处理。
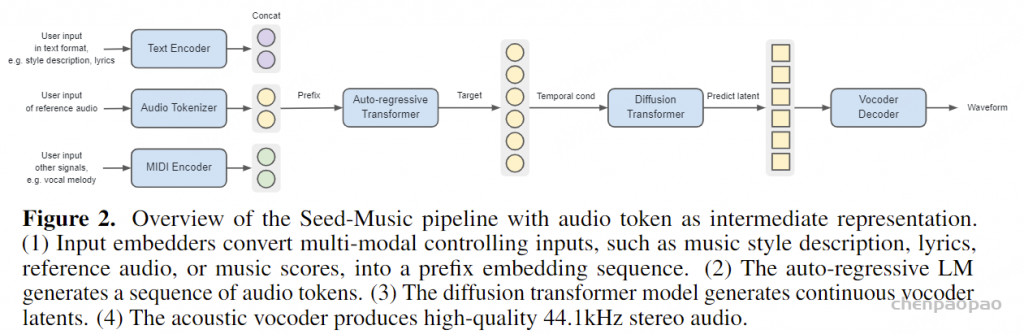
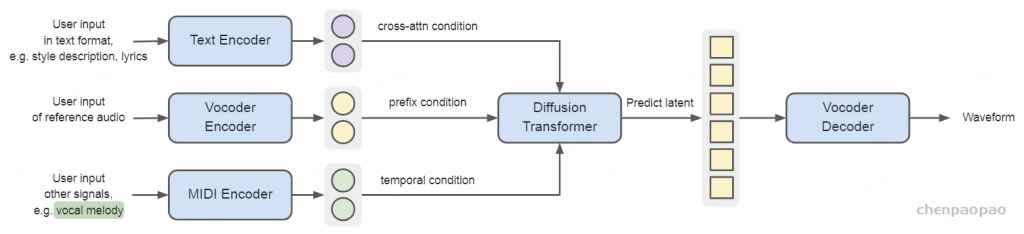
• 分类信号:闭合词汇标签(如音乐风格)通过查找表转换为分类嵌入,而自由形式的文本描述则使用MuLan [Huang et al., 2022]的通用文本编码器进行处理。 • 浮点信号:旋律音符持续时间或歌曲长度等变量使用xVal编码 [Golkar et al., 2023] 嵌入,以表示连续数值输入。 • 歌词信号:歌词被转换为音素序列,以捕捉发音,改善模型对未见单词的泛化能力。 • 参考音频信号:tokenizer从参考音频中提取离散令牌序列,然后将其映射到与tokenizer的码本大小相同的连续嵌入查找表中,或者进一步聚合为轨道级嵌入。 在训练过程中,模型通过使用教师强制在下一个令牌预测任务上最小化交叉熵损失。在推理阶段,用户输入根据指定模态转换为前缀嵌入,然后自回归地生成音频令牌。
渲染器。一旦自回归语言模型生成音频令牌,这些令牌就由渲染器处理,以生成丰富的高质量音频波形。渲染器是一个级联系统,由两个组件组成:扩散变换器(DiT)和声学声码器,两者均独立训练。DiT采用标准架构,具有堆叠的注意力层和多层感知机(MLP)。其目标是逆转扩散过程,从噪声中预测干净的声码器潜变量,通过在每一步估计噪声水平。声学声码器是低帧速率变分自编码器声码器的解码器,设计类似于[Kumar et al., 2024, Lee et al., 2022, Cong et al., 2021, Liu and Qian, 2021]。我们发现,将声码器潜变量结构化为级联系统中的信息瓶颈,并结合可控的模型大小和训练时间进行优化,能够产生优于直接将音频令牌转换为波形的单一模型的音频质量和更丰富的声学细节。
先前的研究提出了旋律生成算法 [Ju et al., 2021; Zhang et al., 2022]。然而,它们缺乏对声乐音乐生成至关重要的明确音素和音符对齐信息。此外,它们仍然仅限于符号音乐生成,无法进行音频渲染。在另一条研究线上,有一些特定任务的先前工作研究了通过和声 [Copet et al., 2024]、力度和节奏 [Wu et al., 2023] 等音乐可解释条件来引导音乐音频生成的方法。受到爵士音乐家如何使用乐谱来勾勒作品旋律、和声和结构的启发,我们引入了“乐谱令牌”作为符号音乐表示。我们强调乐谱令牌与音频令牌相比的关键组成部分、优点和局限性如下。
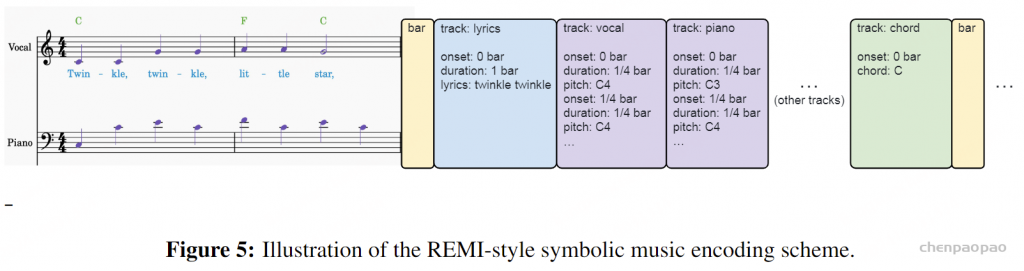
• 为了从音频中提取符号特征以训练上述系统,我们利用内部开发的音乐信息检索(MIR)模型,包括节拍跟踪 [Hung et al., 2022]、调性和和弦检测 [Lu et al., 2021]、结构部分分段 [Wang et al., 2022]、五种乐器的MIDI转录(即人声、钢琴、吉他、贝斯和鼓) [Lu et al., 2023; Wang et al., 2024a],以及歌词转录。乐谱令牌表示音符级细节,如音高、持续时间、在小节中的位置、与音符对齐的声乐音素,以及轨道级属性,如段落、乐器和节奏。
• 乐谱令牌与可读乐谱之间的一对一映射使创作者能够直接理解、编辑和与乐谱互动。我们尝试了不同的方法来生成乐谱令牌序列:REMI风格 [Huang和Yang, 2020] 和 xVal [Golkar et al., 2023]。REMI风格的方法将乐器轨道交错到量化的基于节拍的格式中,而xVal将起始和持续时间编码为连续值。虽然xVal风格编码在更贴合我们生成模型的最终产品——音乐表现,但我们发现REMI风格更适合与音乐家的用户互动。
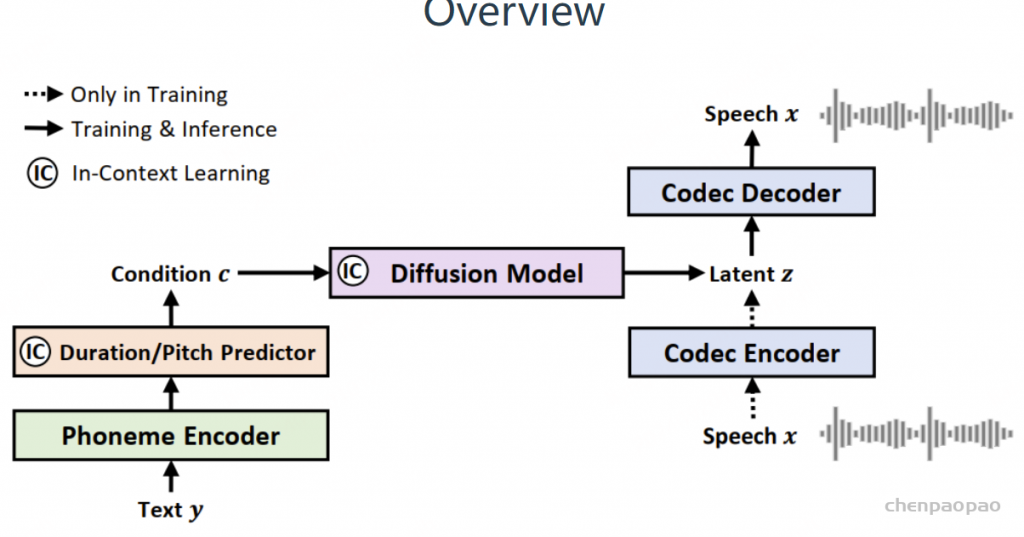
先前的研究 [Evans et al., 2024c,d; Levy et al., 2023; Rombach et al., 2022] 表明,“文本到音乐”的任务可以通过直接预测声码器潜变量来实现高效的方法。类似地,我们训练了一个在低潜变量帧率下运行的变分自编码器(VAE),并配合一个扩散变换器(DiT),将条件输入映射到标准化的连续声码器潜变量,如图4所示。
我们基于[Chen et al., 2024c]开发了一种基于规则的符号音乐编码方案,以将音乐音频片段的符号特征编码为乐谱令牌序列。如图5所示,该方案编码了歌词和各种音乐事件。它识别八种事件类型:歌词音素、小节、和弦、声乐音符、低音音符、钢琴音符、吉他音符和鼓音符。除“小节”外,每种事件类型在乐谱令牌中都表示为一个独特的“轨道”。小节事件定义了基本的时间结构,各轨道按小节交错排列。
在本节中,我们探讨音乐音频编辑作为后期制作过程。第3.3节中描述的基于扩散的方法的非因果特性使其特别适合此类任务。例如,在文本条件下的修补中,扩散模型能够在遮蔽音频段前后访问上下文,从而确保更平滑的过渡[Wang et al., 2023c]。我们将此框架视为乐谱条件下的修补任务,以训练DiT模型。在推理过程中,修改后的乐谱作为条件输入,遮蔽与乐谱中修改部分对应的音频段并重新生成。
为创作者编辑声乐音乐的最直观方式之一是将声乐音色转换为与其自身声音相匹配的音色。本节探讨了作为Seed-Music套件最终组成部分的唱歌声音转换(VC)系统。尽管我们的唱歌VC方法与Seed-TTS中介绍的语音VC有相似之处,但在声乐生成背景下的声音克隆和转换面临更大的挑战[Arik et al., 2018]:
在 PyTorch 当中,梯度的通信和反向传播是交叠进行的。也就是说,每完成一层的梯度计算,都会立即触发当前层的同步。实现起来也很简单,每个进程在完成自己第 k 层的梯度计算后都会触发一个钩子来给计数器+1s。当计数器达到进程数时开火进行梯度通信。有很多同学在计算梯度过程中遇到过 RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. 错误,这就是因为有的模块没有参与计算 loss,导致梯度同步卡住了。需要注意,当 find_unused_parameters=True 时,PyTorch 分布式使用 nn.Module.__init__ 当中定义子模块的反向顺序来作为梯度桶的构建顺序。因此,确保模块定义和调用的顺序一致是一个良好的实践。
How much compute was used to train GPT-4? 2.15e25 floating
Some key facts about how this enormous model was trained: Used 25,000 Nvidia A100 GPUs simultaneously. Trained continuously for 90–100 days. Total compute required was 2.15e25 floating point operations.Sep 27, 2023
// A code block
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Audio 1:<audio>Audio_path/audio_name.flac</audio>
what does the person say?<|im_end|>
<|im_start|>assistant
代码实现:
// An highlighted block
bos_pos = torch.where(input_ids == self.config.audio['audio_start_id'])
eos_pos = torch.where(input_ids == self.config.audio['audio_start_id'] + 1)
audio_pos = torch.stack((bos_pos[0], bos_pos[1], eos_pos[1]), dim=1)
if audios is not None:
for idx, (i, a, b) in enumerate(audio_pos):
hidden_states[i][a : b+1] = audios[idx]
output_shape = input_shape + (hidden_states.size(-1),)