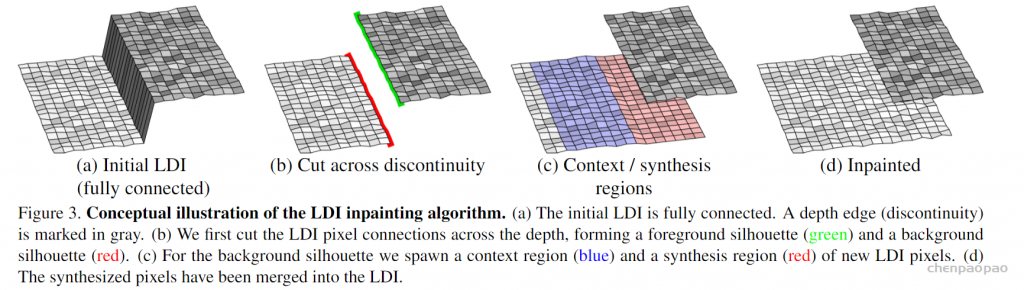
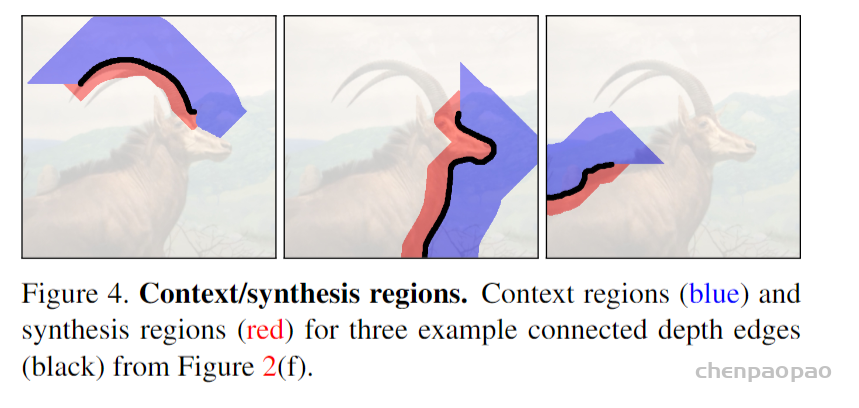
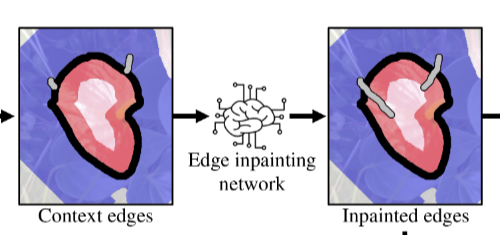
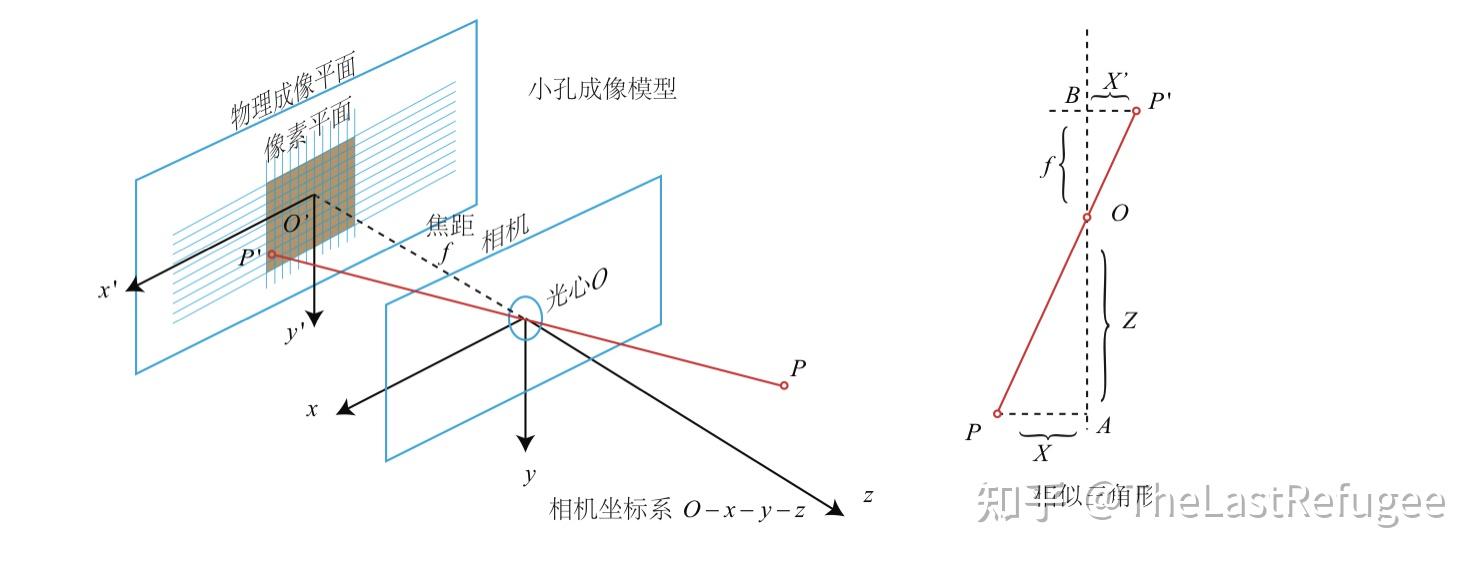
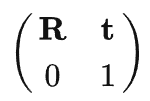AI 生成的音频其实很常见,像生活中用到的语音助手使用自然语言处理声音。OpenAI 曾开发名为 Jukebox 的 AI 音乐系统也令人印象深刻。但过去用 AI 生成音频,大都需要人们提前准备转录和标记基于文本的训练数据,这需要耗费极大时间和人力。而谷歌在其官方博文中表示:“AudioLM 是纯音频语言模型,无须借助文本来训练,只是从原始音频中进行学习。”
相较之前的类似系统,AudioLM 生成的音频在语音语法、音乐旋律等方面,具有长时间的一致性和高保真度。9 月 7 日,相关论文以《AudioLM: 一种实现音频生成的语言建模方法》(AudioLM: a Language Modeling Approach to Audio Generation)为题提交在 arXiv 上。正如音乐从单个音符构建复杂的音乐短语一样。生成逼真的音频需要以不同比例表示的建模信息。而在所有这些音阶上创建结构良好且连贯的音频序列是一项挑战。据了解,音频语言模型 AudioLM 的背后利用了文本到图像模型的进步来生成音频。
^Rene Ranftl, Katrin Lasinger, David Hafner, Konrad ´ Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell., 2020.
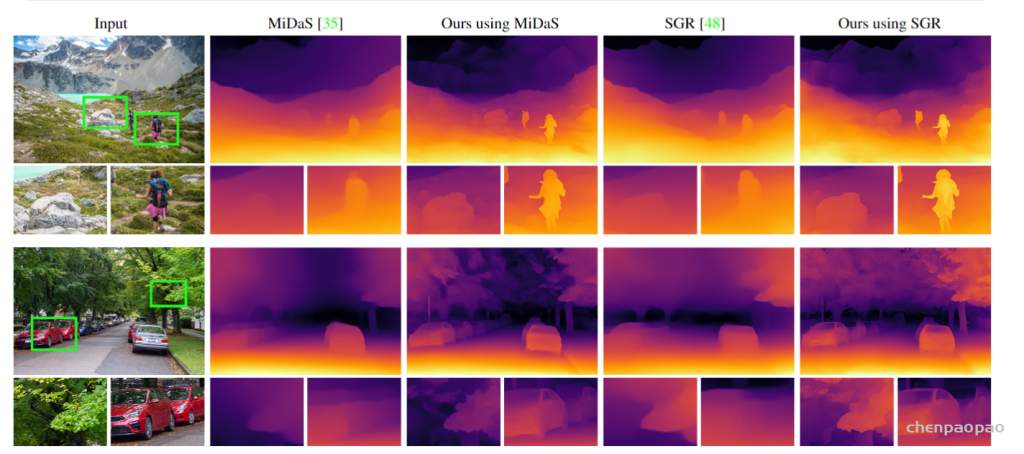
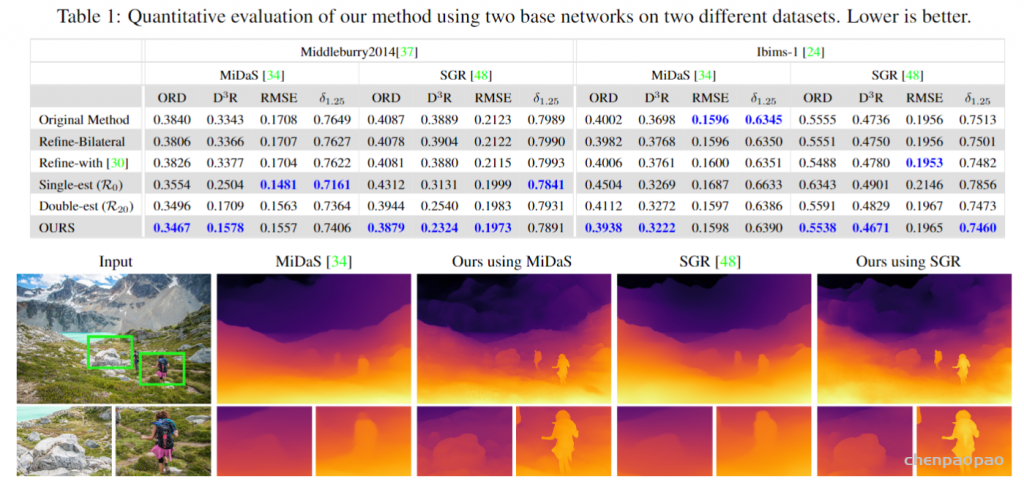
^abcKe Xian, Jianming Zhang, Oliver Wang, Long Mai, Zhe Lin, and Zhiguo Cao. Structure-guided ranking loss for single image depth prediction. In Proc. CVPR, 2020
^D. Scharstein, H. Hirschmuller, York Kitajima, Greg Krath- ¨ wohl, Nera Nesic, X. Wang, and P. Westling. High-resolution stereo datasets with subpixel-accurate ground truth. In Proc. GCPR, 2014.
^Tobias Koch, Lukas Liebel, Friedrich Fraundorfer, and Marco Korner. Evaluation of CNN-Based Single-Image ¨ Depth Estimation Methods. In Proc. ECCV Workshops, 2018.
import os
import tensorrt as trt
os.environ["CUDA_VISIBLE_DEVICES"]='0'
TRT_LOGGER = trt.Logger()
onnx_file_path = 'Unet375-simple.onnx'
engine_file_path = 'Unet337.trt'
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 28 # 256MiB
builder.max_batch_size = 1
# Parse model file
if not os.path.exists(onnx_file_path):
print('ONNX file {} not found, please run yolov3_to_onnx.py first to generate it.'.format(onnx_file_path))
exit(0)
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
if not parser.parse(model.read()):
print ('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print (parser.get_error(error))
network.get_input(0).shape = [1, 3, 300, 400]
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
#network.mark_output(network.get_layer(network.num_layers-1).get_output(0))
engine = builder.build_cuda_engine(network)
print("Completed creating Engine")
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
trtexec --loadEngine=mnist16.trt --batch=1
打印输出:
trtexec会打印出很多时间,这里需要对每个时间的含义进行解释,然后大家各取所需,进行评测。总的打印如下:
[09/06/2021-13:50:34] [I] Average on 10 runs - GPU latency: 2.74553 ms - Host latency: 3.74192 ms (end to end 4.93066 ms, enqueue 0.624805 ms) # 跑了10次,GPU latency: GPU计算耗时, Host latency:GPU输入+计算+输出耗时,end to end:GPU端到端的耗时,eventout - eventin,enqueue:CPU异步耗时
[09/06/2021-13:50:34] [I] Host Latency
[09/06/2021-13:50:34] [I] min: 3.65332 ms (end to end 3.67603 ms)
[09/06/2021-13:50:34] [I] max: 5.95093 ms (end to end 6.88892 ms)
[09/06/2021-13:50:34] [I] mean: 3.71375 ms (end to end 5.30082 ms)
[09/06/2021-13:50:34] [I] median: 3.70032 ms (end to end 5.32935 ms)
[09/06/2021-13:50:34] [I] percentile: 4.10571 ms at 99% (end to end 6.11792 ms at 99%)
[09/06/2021-13:50:34] [I] throughput: 356.786 qps
[09/06/2021-13:50:34] [I] walltime: 3.00741 s
[09/06/2021-13:50:34] [I] Enqueue Time
[09/06/2021-13:50:34] [I] min: 0.248474 ms
[09/06/2021-13:50:34] [I] max: 2.12134 ms
[09/06/2021-13:50:34] [I] median: 0.273987 ms
[09/06/2021-13:50:34] [I] GPU Compute
[09/06/2021-13:50:34] [I] min: 2.69702 ms
[09/06/2021-13:50:34] [I] max: 4.99219 ms
[09/06/2021-13:50:34] [I] mean: 2.73299 ms
[09/06/2021-13:50:34] [I] median: 2.71875 ms
[09/06/2021-13:50:34] [I] percentile: 3.10791 ms at 99%
[09/06/2021-13:50:34] [I] total compute time: 2.93249 s
Host Latency gpu: 输入+计算+输出 三部分的耗时
Enqueue Time:CPU异步的时间(该时间不具有参考意义,因为GPU的计算可能还没有完成)
GPU Compute:GPU计算的耗时
综上,去了Enqueue Time时间都是有意义的
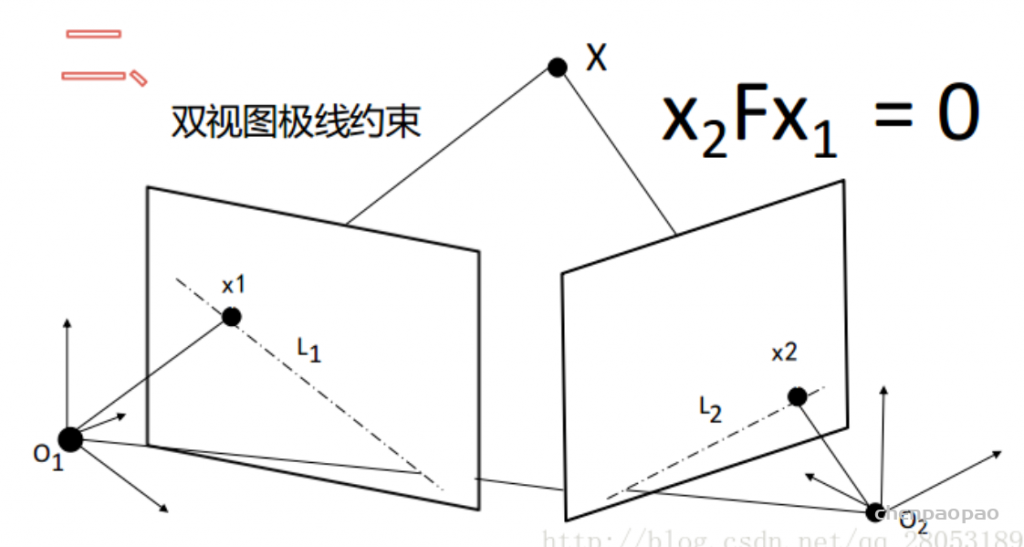
同时定位与地图构建(英语:Simultaneous localization and mapping,一般直接称SLAM)是一种概念:希望机器人从未知环境的未知地点出发,在运动过程中通过重复观测到的地图特征(比如,墙角,柱子等)定位自身位置和姿态,再根据自身位置增量式的构建地图,从而达到同时定位和地图构建的目的。
Seitz, S. M., Curless, B., Diebel, J., Scharstein, D., & Szeliski, R. (n.d.). A Comparison and Evaluation of Multi-View Stereo Reconstruction Algorithms. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition – Volume 1 (CVPR’06) (Vol. 1, pp. 519–528). IEEE. https://doi.org/10.1109/CVPR.2006.19