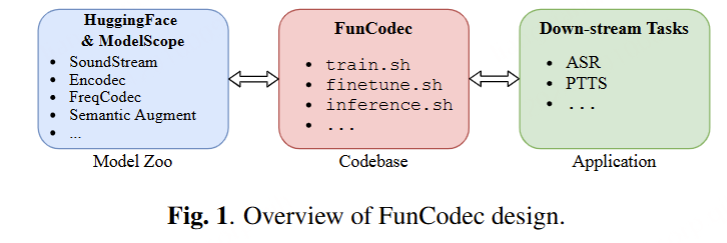
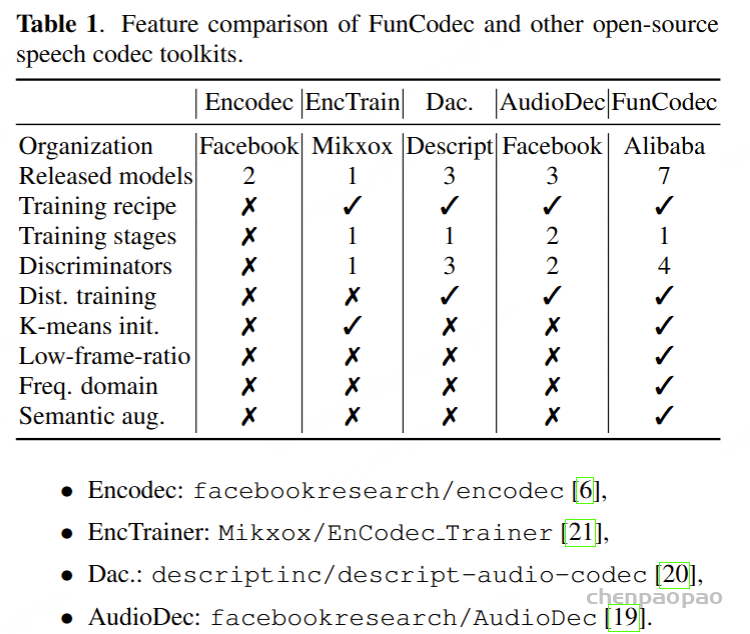
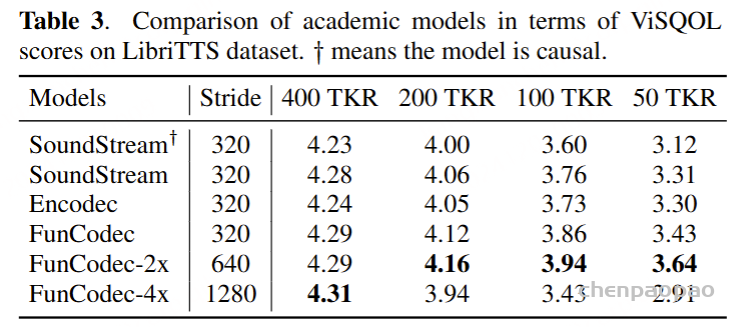
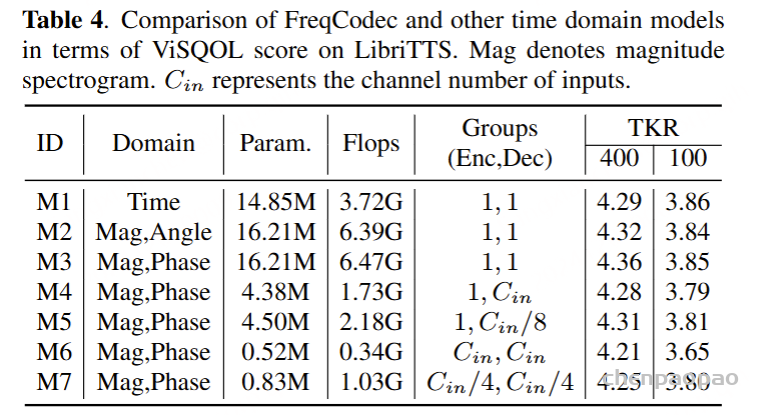
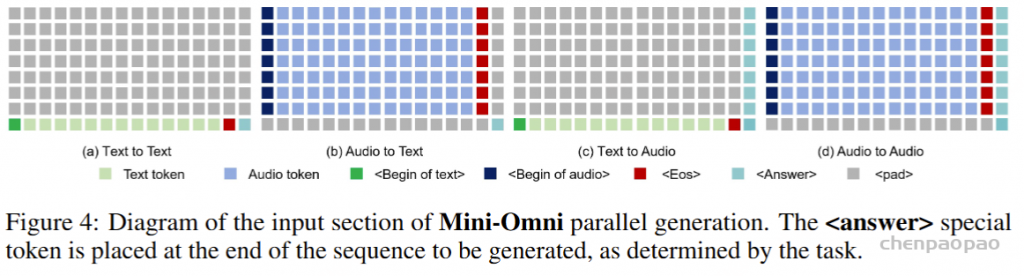
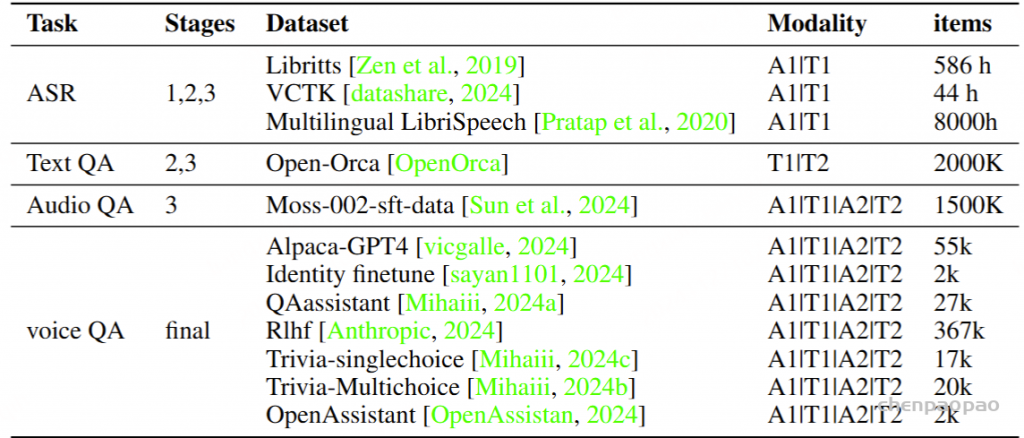
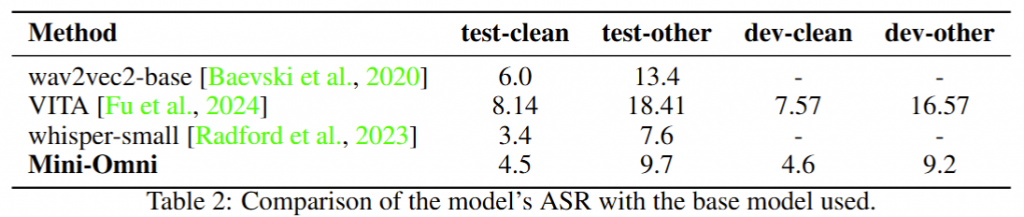
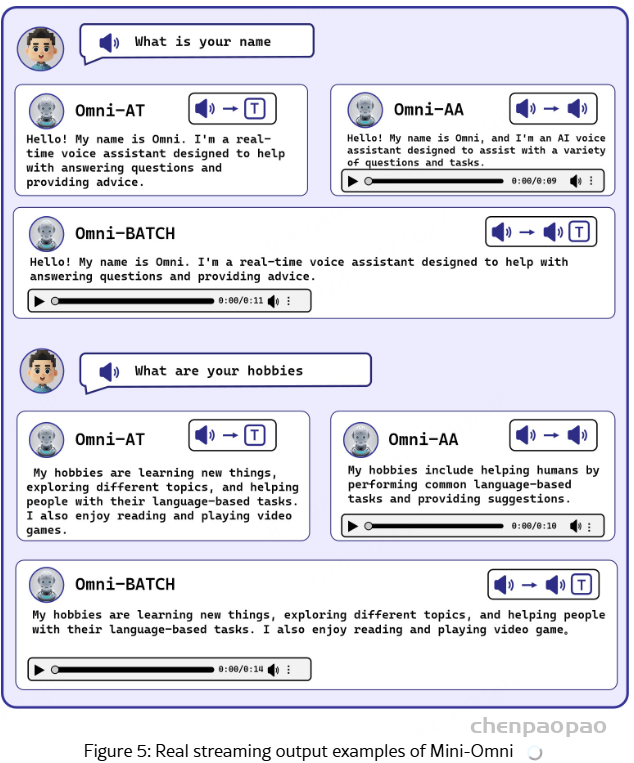
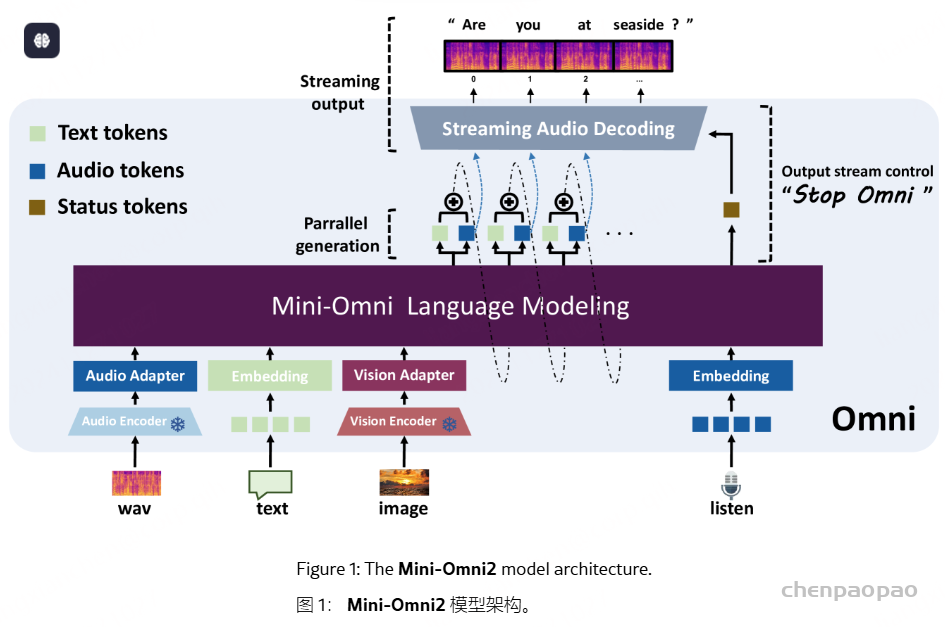
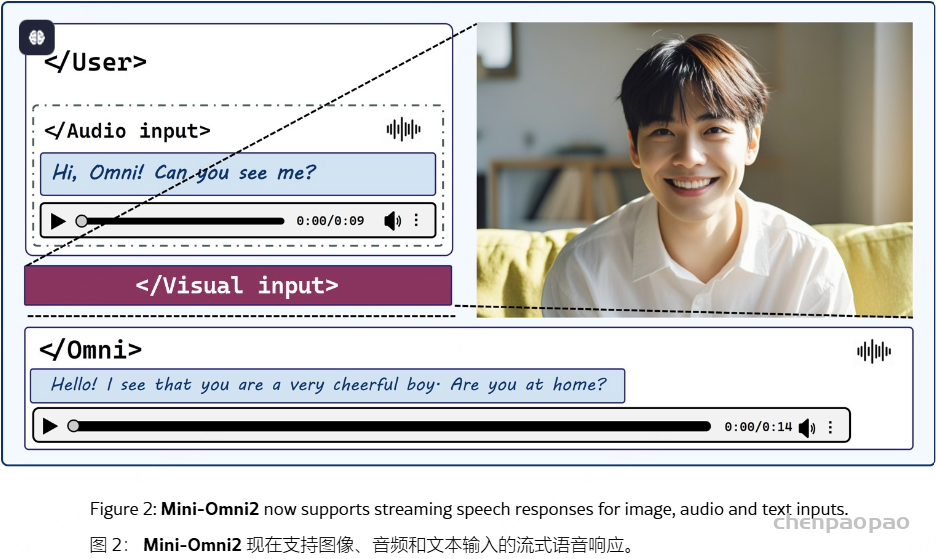
| AudioSet 音频集 | The AudioSet dataset is a large-scale collection of human-labeled 10-second sound clips drawn from YouTube videos. To collect all our data we worked with human annotators who verified the presence of sounds they heard within YouTube segments. To nominate segments for annotation, we relied on YouTube metadata and content-based search. The sound events in the dataset consist of a subset of the AudioSet ontology. You can learn more about the dataset construction in our ICASSP 2017 paper. Explore the dataset annotations by sound class below. There are 2,084,320 YouTube videos containing 527 labels
AudioSet 数据集是从 YouTube 视频中提取的人工标记的 10 秒声音剪辑的大规模集合。为了收集我们的所有数据,我们与人工注释者合作,他们验证了他们在 YouTube 片段中听到的声音是否存在。为了提名要注释的片段,我们依靠 YouTube 元数据和基于内容的搜索。数据集中的声音事件由 AudioSet 本体的子集组成。您可以在我们的 ICASSP 2017 论文中了解有关数据集构建的更多信息。探索下面的 sound 类数据集注释。有 2,084,320 个 YouTube 视频,包含 527 个标签 | Click here 点击这里 | class labels, video, audio
类标签, 视频, 音频 | 5420hrs 5420 小时 | 1951460 | processed 处理 |
| AudioSet Strong AudioSet 强 | Audio events from AudioSet clips with singal class label annotation
来自 AudioSet 剪辑的音频事件,带有 singal 类标签注释 | Click here 点击这里 | 1 class label, video, audio
1 个类标签、视频、音频 | 625.93hrs 625.93 小时 | 1074359 | processed (@marianna13#7139)
已处理 (@marianna13#7139) |
| BBC sound effects BBC 音效 | 33066 sound effects with text description. Type: mostly environmental sound. Each audio has a natural text description. (need to see check the license)
33066 个带有文本描述的音效。类型:主要是环境声音。每个音频都有一个自然的文本描述。(需要查看 检查许可证) | Click here 点击这里 | 1 caption, audio 1 个字幕、音频 | 463.48hrs 463.48 小时 | 15973 | processed 处理 |
| AudioCaps 音频帽 | 40 000 audio clips of 10 seconds, organized in three splits; a training slipt, a validation slipt, and a testing slipt. Type: environmental sound.
40 000 个 10 秒的音频剪辑,分为三个部分;训练滑道、验证滑道和测试滑道。类型:环境声音。 | Click here 点击这里 | 1 caption, audio 1 个字幕、音频 | 144.94hrs 144.94 小时 | 52904 | processed 处理 |
Audio Caption Hospital & Car Dataset
音频字幕医院和汽车数据集 | 3700 audio clips from “Hospital” scene and around 3600 audio clips from the “Car” scene. Every audio clip is 10 seconds long and is annotated with five captions. Type: environmental sound.
来自 “Hospital” 场景的 3700 个音频剪辑和来自 “Car” 场景的大约 3600 个音频剪辑。每个音频剪辑时长 10 秒,并带有 5 个字幕。类型:环境声音。 | Click here 点击这里 | 5 captions, audio 5 个字幕、音频 | 10.64 + 20.91hrs 10.64 + 20.91 小时 | 3709 + 7336 | we don’t need that 我们不需要那个 |
| Clotho dataset Clotho 数据集 | Clotho consists of 6974 audio samples, and each audio sample has five captions (a total of 34 870 captions). Audio samples are of 15 to 30 s duration and captions are eight to 20 words long. Type: environmental sound.
Clotho 由 6974 个音频样本组成,每个音频样本有 5 个字幕(总共 34870 个字幕)。音频样本的持续时间为 15 到 30 秒,字幕的长度为 8 到 20 个单词。类型:环境声音。 | Click here 点击这里 | 5 captions, audio 5 个字幕、音频 | 37.0hrs 37.0 小时 | 5929 | processed 处理 |
| Audiostock 音频库 | Royalty Free Music Library. 436864 audio effects(of which 10k available), each with a text description.
免版税音乐库。436864 个音频效果(其中 10k 可用),每个效果都有文字描述。 | Click here 点击这里 | 1 caption & tags, audio
1个字幕和标签,音频 | 46.30hrs 46.30 小时 | 10000 | 10k sound effects processed(@marianna13#7139)
处理 10k 音效(@marianna13#7139) |
| ESC-50 | 2000 environmental audio recordings with 50 classes
2000 个环境音频记录,50 个班级 | Click here 点击这里 | 1 class label, audio 1 个类标签,音频 | 2.78hrs 2.78 小时 | 2000 | processed(@marianna13#7139)
已处理(@marianna13#7139) |
| VGG-Sound VGG 声音 | VGG-Sound is an audio-visual correspondent dataset consisting of short clips of audio sounds, extracted from videos uploaded to YouTube
VGG-Sound 是一个视听通讯员数据集,由从上传到 YouTube 的视频中提取的音频短片组成 | Click here 点击这里 | 1 class label, video, audio
1 个类标签、视频、音频 | 560hrs 560 小时 | 200,000 + | processed(@marianna13#7139)
已处理(@marianna13#7139) |
| FUSS | The Free Universal Sound Separation (FUSS) dataset is a database of arbitrary sound mixtures and source-level references, for use in experiments on arbitrary sound separation. FUSS is based on FSD50K corpus.
Free Universal Sound Separation (FUSS) 数据集是一个包含任意混声和源级参考的数据库,用于任意声分离的实验。FUSS 基于 FSD50K 语料库。 | Click here 点击这里 | no class label, audio 无类标签、音频 | 61.11hrs 61.11 小时 | 22000 | |
| UrbanSound8K 都市之声8K | 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes
来自 10 个类别的 8732 个城市声音的标记声音摘录 (<=4s) | Click here 点击这里 | 1 class label, audio 1 个类标签,音频 | 8.75hrs 8.75 小时 | 8732 | processed(@Yuchen Hui#8574)
已处理(@Yuchen Hui#8574) |
| FSD50K | 51,197 audio clips of 200 classes
200 个班级的 51,197 个音频剪辑 | Click here 点击这里 | class labels, audio 类标签, 音频 | 108.3hrs 108.3 小时 | 51197 | processed(@Yuchen Hui#8574)
已处理(@Yuchen Hui#8574) |
| YFCC100M | YFCC100M is a that dataset contains a total of 100 million media objects, of which approximately 99.2 million are photos and 0.8 million are videos, all of which carry a Creative Commons license, including 8081 hours of audio.
YFCC100M 是一个 THAT 数据集,总共包含 1 亿个媒体对象,其中大约 9920 万个是照片,80 万个是视频,所有这些对象都带有 Creative Commons 许可证,包括 8081 小时的音频。 | Click here 点击这里 | title, tags, audio, video, Flickr identifier, owner name, camera, geo, media source
标题、标签、音频、视频、Flickr 标识符、所有者名称、相机、地理位置、媒体来源 | 8081hrs 8081 小时 | requested access (@marianna13#7139)
请求的访问权限 (@marianna13#7139) | |
| ACAV100M | 100M video clips with audio, each 10 sec, with automatic AudioSet, Kinetics400 and Imagenet labels. -> Noisy, but LARGE.
100M 带音频的视频剪辑,每段 10 秒,带有自动 AudioSet、Kinetics400 和 Imagenet 标签。-> 吵闹,但很大。 | Click here 点击这里 | class labels/tags, audio 类标签/标签、音频 | 31 years 31 岁 | 100 million 1 亿 | |
| Free To Use Sounds 免费使用声音 | 10000+ for 23$ 🙂 10000+ 23 美元 🙂 | Click here 点击这里 | 1 caption & tags, audio
1个字幕和标签,音频 | 175.73hrs 175.73 小时 | 6370 | |
MACS – Multi-Annotator Captioned Soundscapes
MACS – 多注释者字幕音景 | This is a dataset containing audio captions and corresponding audio tags for a number of 3930 audio files of the TAU Urban Acoustic Scenes 2019 development dataset (airport, public square, and park). The files were annotated using a web-based tool. Each file is annotated by multiple annotators that provided tags and a one-sentence description of the audio content. The data also includes annotator competence estimated using MACE (Multi-Annotator Competence Estimation).
这是一个数据集,其中包含 TAU Urban Acoustic Scenes 2019 开发数据集(机场、公共广场和公园)的 3930 个音频文件的字幕和相应的音频标签。这些文件使用基于 Web 的工具进行注释。每个文件都由多个注释器进行注释,这些注释器提供音频内容的标记和一句话描述。数据还包括使用 MACE(多注释者能力估计)估计的注释者能力。 | Click here 点击这里 | multiple captions & tags, audio
多个字幕和标签,音频 | 10.92hrs 10.92 小时 | 3930 | processed(@marianna13#7139 & @krishna#1648 & Yuchen Hui#8574)
已处理(@marianna13#7139 & @krishna#1648 & Yuchen Hui#8574) |
| Sonniss Game effects Sonniss 游戏效果 | Sound effects 音效 | no link 无链接 | tags & filenames, audio 标签和文件名,音频 | 84.6hrs 84.6 小时 | 5049 | processed 处理 |
| WeSoundEffects | Sound effects 音效 | no link 无链接 | tags & filenames, audio 标签和文件名,音频 | 12.00hrs 12.00 小时 | 488 | processed 处理 |
Paramount Motion – Odeon Cinematic Sound Effects
Paramount Motion – Odeon 电影音效 | Sound effects 音效 | no link 无链接 | 1 tag, audio 1 天,音频 | 19.49hrs 19.49 小时 | 4420 | processed 处理 |
| Free Sound 免费声音 | Audio with text description (noisy)
带有文字描述的音频(嘈杂) | Click here 点击这里 | pertinent text, audio 相关文本、音频 | 3003.38hrs 3003.38 小时 | 515581 | processed(@Chr0my#0173 & @Yuchen Hui#8574)
已处理(@Chr0my#0173 & @Yuchen Hui#8574) |
| Sound Ideas 声音创意 | Sound effects library 音效库 | Click here 点击这里 | 1 caption, audio 1 个字幕、音频 | | | |
| Boom Library Boom 库 | Sound effects library 音效库 | Click here 点击这里 | 1 caption, audio 1 个字幕、音频 | | | assigned(@marianna13#7139)
已分配(@marianna13#7139) |
Epidemic Sound (Sound effect part)
疫情之声(音效部分) | Royalty free music and sound effects
免版税的音乐和音效 | Click here 点击这里 | Class labels, audio 类标签、音频 | 220.41hrs 220.41 小时 | 75645 | metadata downloaded(@Chr0my#0173), processed (@Yuchen Hui#8547)
元数据已下载(@Chr0my#0173),已处理(@Yuchen Hui#8547) |
| Audio Grounding dataset Audio Grounding 数据集 | The dataset is an augmented audio captioning dataset. Hard to discribe. Please refer to the URL for details.
该数据集是一个增强的音频字幕数据集。很难描述。详情请参阅网址。 | Click here 点击这里 | 1 caption, many tags,audio
1 个字幕、多个标签、音频 | 12.57hrs 12.57 小时 | 4590 | |
Fine-grained Vocal Imitation Set
细粒度的 Vocal Simitation Set | This dataset includes 763 crowd-sourced vocal imitations of 108 sound events.
该数据集包括 108 个声音事件的 763 个众包人声模拟。 | Click here 点击这里 | 1 class label, audio 1 个类标签,音频 | 1.55hrs 1.55 小时 | 1468 | processed(@marianna13#7139)
已处理(@marianna13#7139) |
| Vocal Imitation 人声模仿 | The VocalImitationSet is a collection of crowd-sourced vocal imitations of a large set of diverse sounds collected from Freesound (https://freesound.org/), which were curated based on Google’s AudioSet ontology (https://research.google.com/audioset/).
VocalImitationSet 是从 Freesound (https://freesound.org/) 收集的大量不同声音的众包人声模仿集合,这些声音是根据 Google 的 AudioSet 本体 (https://research.google.com/audioset/) 策划的。 | Click here 点击这里 | 1 class label, audio 1 个类标签,音频 | 24.06hrs 24.06 小时 | 9100 files 9100 个文件 | processed(@marianna13#7139)
已处理(@marianna13#7139) |
| VocalSketch 声乐素描 | Dataset contains thousands of vocal imitations of a large set of diverse sounds.The dataset also contains data on hundreds of people’s ability to correctly label these vocal imitations, collected via Amazon’s Mechanical Turk
Dataset 包含大量不同声音的数千个人声模仿。该数据集还包含数百人正确标记这些人声模仿的能力数据,这些数据是通过亚马逊的 Mechanical Turk 收集的 | Click here 点击这里 | 1 class label, audio 1 个类标签,音频 | 18.86hrs 18.86 小时 | 16645 | processed(@marianna13#7139)
已处理(@marianna13#7139) |
| VimSketch Dataset VimSketch 数据集 | VimSketch Dataset combines two publicly available datasets(VocalSketch + Vocal Imitation, but Vimsketch delete some parts of the previous two datasets),
VimSketch 数据集结合了两个公开可用的数据集(VocalSketch + Vocal Imitation,但 Vimsketch 删除了前两个数据集的部分), | Click here 点击这里 | class labels, audio 类标签, 音频 | Not important 不重要 | Not important 不重要 | |
| OtoMobile Dataset OtoMobile 数据集 | OtoMobile dataset is a collection of recordings of failing car components, created by the Interactive Audio Lab at Northwestern University. OtoMobile consists of 65 recordings of vehicles with failing components, along with annotations.
OtoMobile 数据集是由西北大学交互式音频实验室创建的故障汽车部件的录音集合。OtoMobile 由 65 条组件出现故障的车辆的录音以及注释组成。 | Click here 点击这里
(restricted access) (限制访问) | class labels & tags, audio
类标签和标签,音频 | Unknown 未知 | 59 | |
| DCASE17Task 4 DCASE17任务 4 | DCASE Task 4 Large-scale weakly supervised sound event detection for smart cars
DCASE 任务 4 面向智能汽车的大规模弱监督声音事件检测 | Click here 点击这里 | | | | |
Knocking Sound Effects With Emotional Intentions
带有情感意图的 Knocking Sound Effects | A dataset of knocking sound effects with emotional intention recorded at a professional foley studio. Five type of emotions to be portrayed in the dataset: anger, fear, happiness, neutral and sadness.
在专业拟音工作室录制的带有情感意图的敲击音效数据集。数据集中要描绘的五种情绪:愤怒、恐惧、快乐、中立和悲伤。 | Click here 点击这里 | 1 class label & audio
1个类标签和音频 | | 500 | processed(@marianna13#7139)
已处理(@marianna13#7139) |
| WavText5Ks WavText5K | WavText5K collection consisting of 4525 audios, 4348 descriptions, 4525 audio titlesand 2058 tags.
WavText5K 集合,包括 4525 个音频、4348 个描述、4525 个音频标题和 2058 个标签。 | Click here 点击这里 | 1 label, tags & audio
1个标签、标签和音频 | | 4525 audio files 4525 个音频文件 | processed(@marianna13#7139)
已处理(@marianna13#7139) |