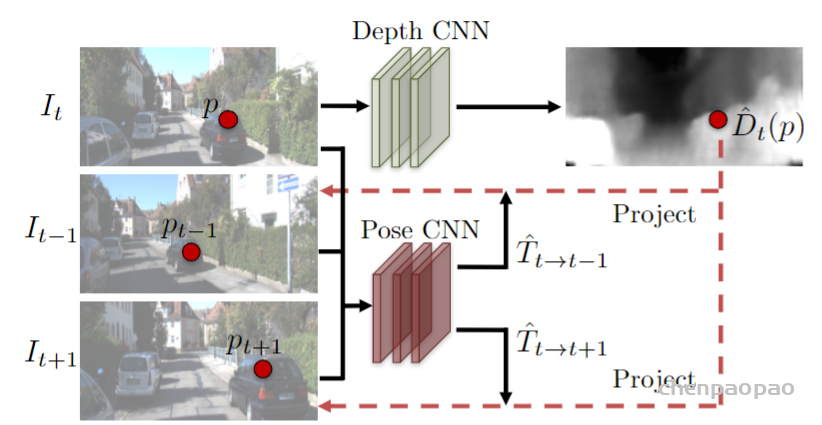
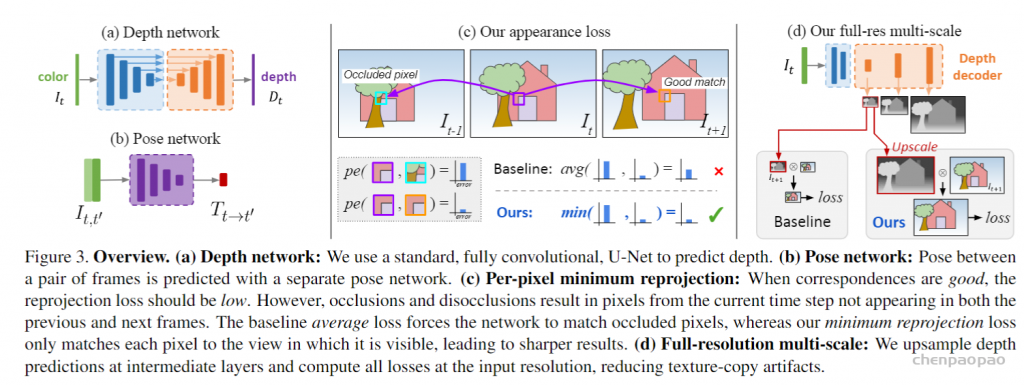
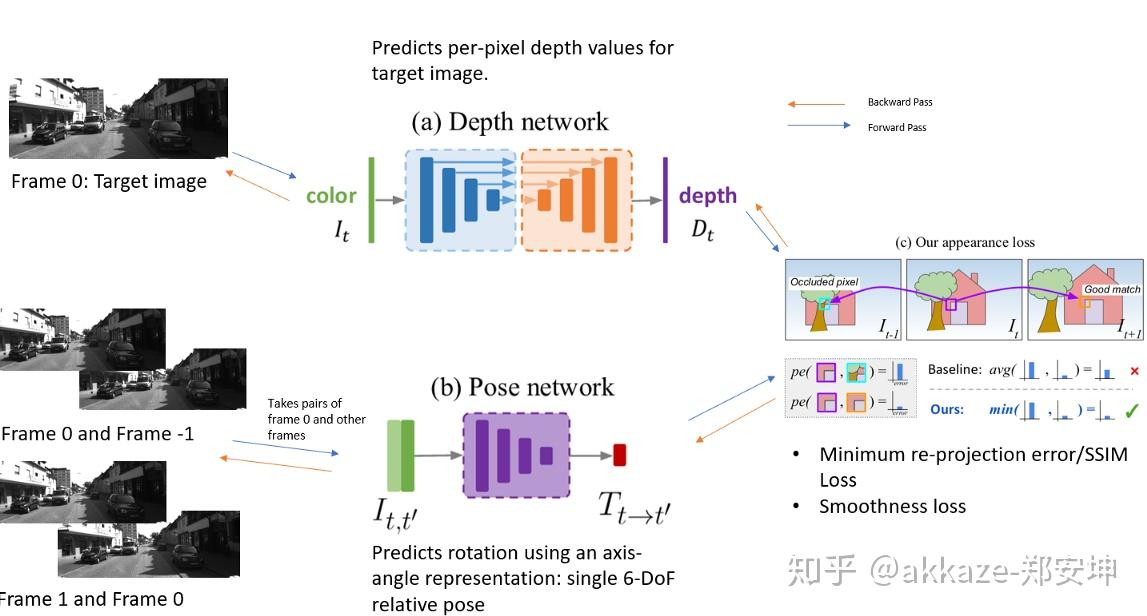
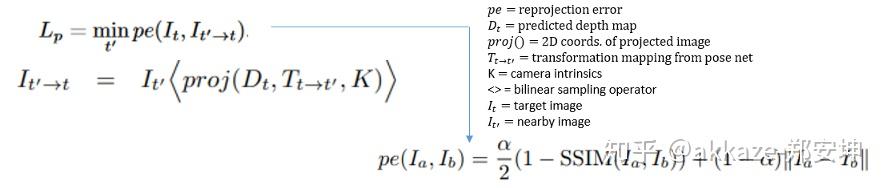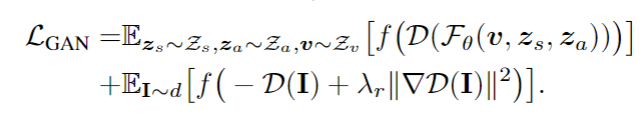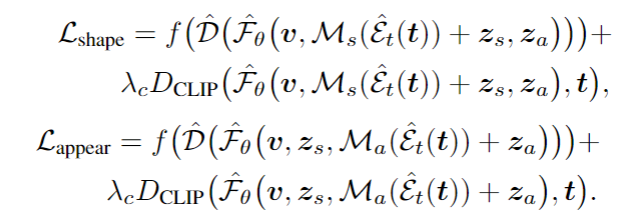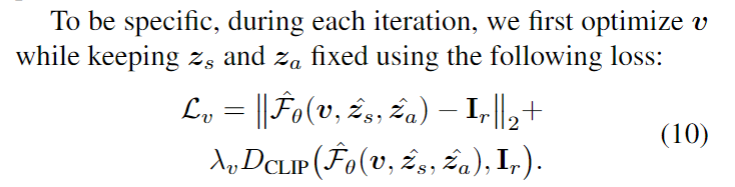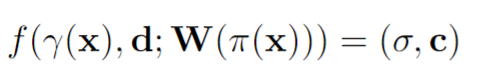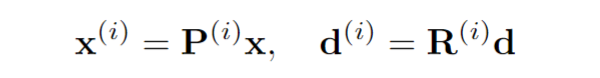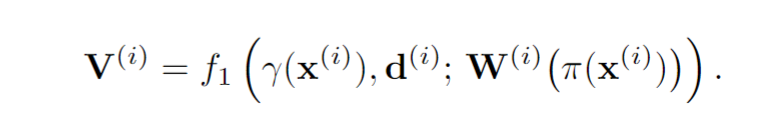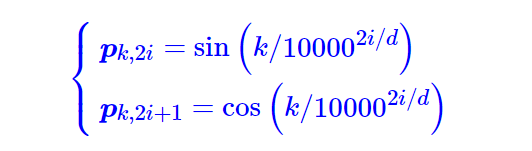深度估计是计算机视觉领域的一个基础性问题,其可以应用在机器人导航、增强现实、三维重建、自动驾驶等领域。而目前大部分深度估计都是基于二维RGB图像到RBG-D图像的转化估计,主要包括从图像明暗、不同视角、光度、纹理信息等获取场景深度形状的Shape from X方法,还有结合SFM(Structure from motion)和SLAM(Simultaneous Localization And Mapping)等方式预测相机位姿的算法。其中虽然有很多设备可以直接获取深度,但是设备造价昂贵。也可以利用双目进行深度估计,但是由于双目图像需要利用立体匹配进行像素点对应和视差计算,所以计算复杂度也较高,尤其是对于低纹理场景的匹配效果不好。而单目深度估计则相对成本更低,更容易普及。
Monocular Depth Estimation is the task of estimating the depth value (distance relative to the camera) of each pixel given a single (monocular) RGB image. This challenging task is a key prerequisite for determining scene understanding for applications such as 3D scene reconstruction, autonomous driving, and AR. State-of-the-art methods usually fall into one of two categories: designing a complex network that is powerful enough to directly regress the depth map, or splitting the input into bins or windows to reduce computational complexity. The most popular benchmarks are the KITTI and NYUv2 datasets. Models are typically evaluated using RMSE or absolute relative error. 这项具有挑战性的任务是确定 3D 场景重建、自动驾驶和 AR 等应用场景理解的关键先决条件。
任务介绍
深度估计是计算机视觉领域的一个基础性问题,其可以应用在机器人导航、增强现实、三维重建、自动驾驶等领域。而目前大部分深度估计都是基于二维RGB图像到RBG-D图像的转化估计,主要包括从图像明暗、不同视角、光度、纹理信息等获取场景深度形状的Shape from X方法,还有结合SFM(Structure from motion)和SLAM(Simultaneous Localization And Mapping)等方式预测相机位姿的算法。其中虽然有很多设备可以直接获取深度,但是设备造价昂贵。也可以利用双目进行深度估计,但是由于双目图像需要利用立体匹配进行像素点对应和视差计算,所以计算复杂度也较高,尤其是对于低纹理场景的匹配效果不好。而单目深度估计则相对成本更低,更容易普及。
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[2] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
[3] Laina I, Rupprecht C, Belagiannis V, et al. Deeper depth prediction with fully convolutional residual networks[C]//2016 Fourth international conference on 3D vision (3DV). IEEE, 2016: 239-248.
[4] Fu H, Gong M, Wang C, et al. Deep ordinal regression network for monocular depth estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2002-2011.
[5] Godard C, Mac Aodha O, Brostow G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 270-279.
[6] Dosovitskiy A, Fischer P, Ilg E, et al. Flownet: Learning optical flow with convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 2758-2766.
[7] Ilg E, Mayer N, Saikia T, et al. Flownet 2.0: Evolution of optical flow estimation with deep networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2462-2470.
[8] Mayer N, Ilg E, Hausser P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4040-4048.
[9] Xie J, Girshick R, Farhadi A. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks[C]//European Conference on Computer Vision. Springer, Cham, 2016: 842-857.
[10] Luo Y, Ren J, Lin M, et al. Single View Stereo Matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[11] Zhou T, Brown M, Snavely N, et al. Unsupervised learning of depth and ego-motion from video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1851-1858.
[12] Yin Z, Shi J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1983-1992.
[13] Zhan H, Garg R, Saroj Weerasekera C, et al. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 340-349.
[14] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
[15] Radford A , Metz L , Chintala S . Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer Science, 2015.
[16] Arjovsky M, Chintala S, Bottou L. Wasserstein gan[J]. arXiv preprint arXiv:1701.07875, 2017.
[17] Gulrajani I, Ahmed F, Arjovsky M, et al. Improved training of wasserstein gans[C]//Advances in Neural Information Processing Systems. 2017: 5767-5777.
[18] Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2794-2802.
[19] Mirza M, Osindero S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
[20] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
[21] Wang T C, Liu M Y, Zhu J Y, et al. High-resolution image synthesis and semantic manipulation with conditional gans[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8798-8807.
[22] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
[23] Wang T C , Liu M Y , Zhu J Y , et al. Video-to-Video Synthesis[J]. arXiv preprint arXiv:1808.06601,2018.
[24] Zheng C, Cham T J, Cai J. T2net: Synthetic-to-realistic translation for solving single-image depth estimation tasks[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 767-783.
[25] Atapour-Abarghouei A, Breckon T P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2800-2810.
[26] Nekrasov V , Dharmasiri T , Spek A , et al. Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations[J]. arXiv preprint arXiv:1809.04766,2018.
[27] Nekrasov V , Shen C , Reid I . Light-Weight RefineNet for Real-Time Semantic Segmentation[J]. arXiv preprint arXiv:1810.03272, 2018.
[28] Lin G , Milan A , Shen C , et al. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.,2017:1925-1934
[29] Zou Y , Luo Z , Huang J B . DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018:36-53.
[30] Ranjan A, Jampani V, Balles L, et al. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 12240-12249.
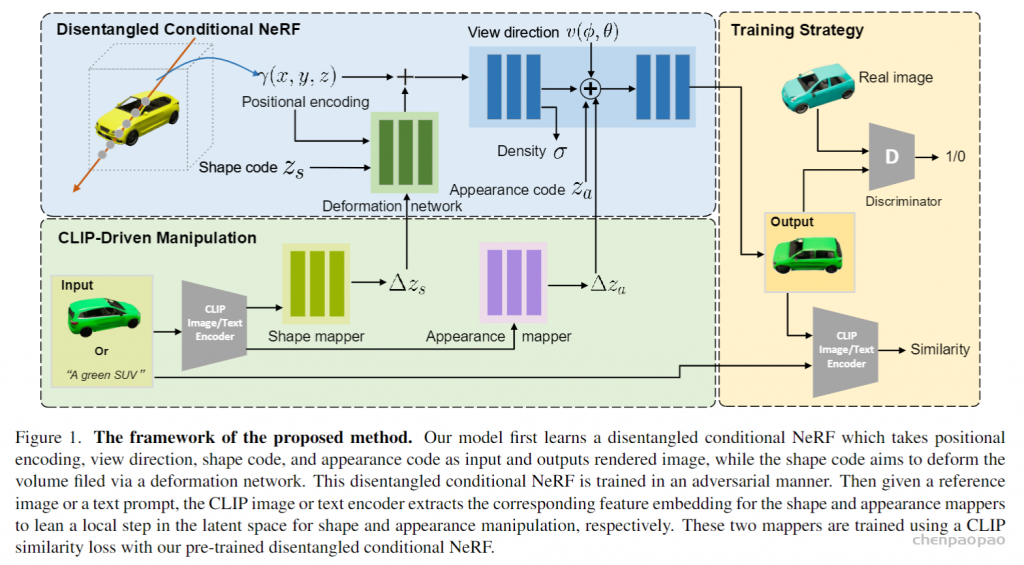
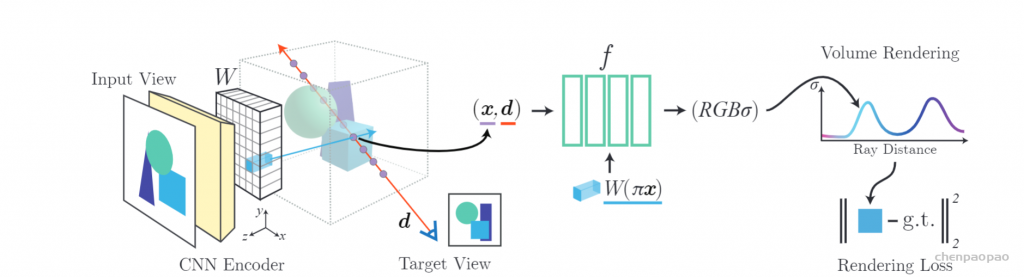
1) Like NeRF, our rendering time is slow, and in fact, our runtime increases linearly when given more input views. Further, some methods (e.g. [28, 21]) can recover a mesh from the image enabling fast rendering and manipulation afterwards, while NeRF based representations cannot be converted to meshes very reliably. Improving NeRF’s efficiency is an important re-search question that can enable real-time applications.
2) As in the vanilla NeRF, we manually tune ray sampling bounds tn,tf and a scale for the positional encoding. Making NeRF-related methods scale-invariant is a crucial challenge. 3) While we have demonstrated our method on real data from the DTU dataset, we acknowledge that this dataset was captured under controlled settings and has matching camera poses across all scenes with limited viewpoints. Ultimately,our approach is bottlenecked by the availability of largescale wide baseline multi-view datasets, limiting the applicability to datasets such as ShapeNet and DTU. Learning a general prior for 360◦ scenes in-the-wild is an exciting direction for future work
参考文献:
【1】Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik,Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In Eur. Conf. Comput. Vis., 2020
【2】Daeyun Shin, Charless Fowlkes, and Derek Hoiem. Pixels, voxels, and views: A study of shape representations for single view 3d object shape prediction. In IEEE Conf. Comput.Vis. Pattern Recog., 2018.
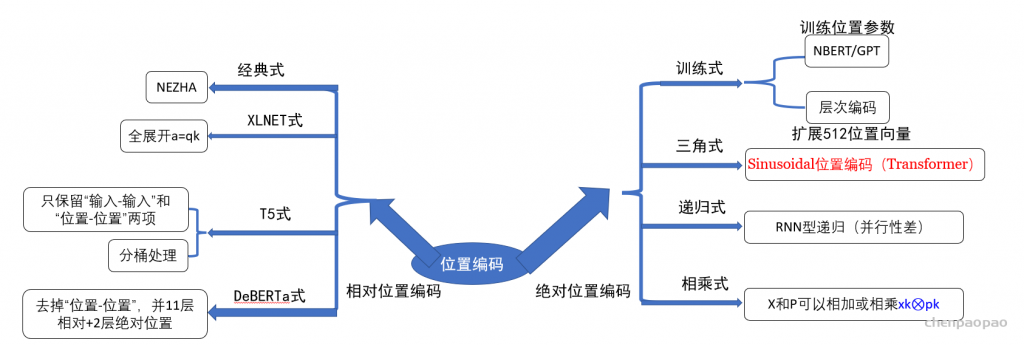
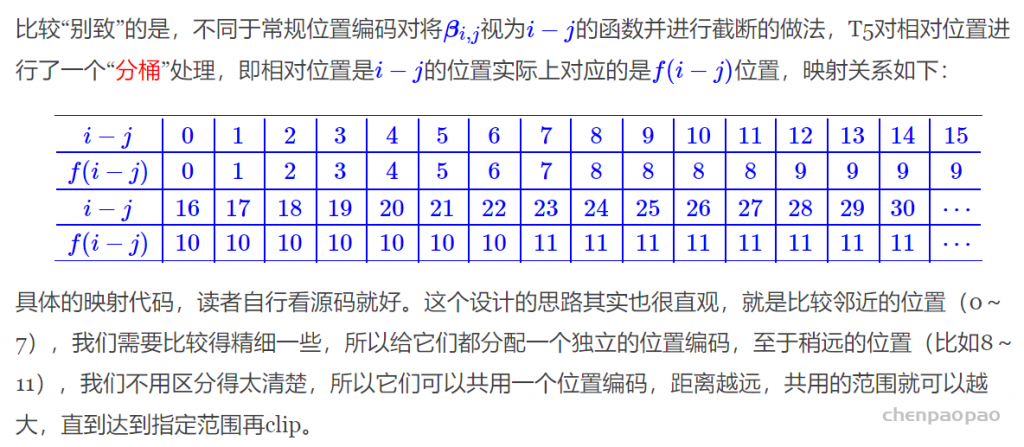
很显然,绝对位置编码的一个最朴素方案是不特意去设计什么,而是直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。现在的BERT、GPT等模型所用的就是这种位置编码,事实上它还可以追溯得更早,比如2017年Facebook的《Convolutional Sequence to Sequence Learning》就已经用到了它。