
————– YOLOv3-tiny 的ZYNQ实现

摘要:
实验表明,当针对低端 FPGA 设备时,与设备的硬核处理器相比,所提出的架构实现了 290 倍的延迟改进,同时与原始模型相比,mAP 下降了2.5pp(30.9% 对 33.4%)。 所呈现的工作为低端 FPGA 设备上的低延迟对象检测开辟了道路。
introduction:
目标检测技术用于检测图像和视频中的对象实例。这项技术的应用可以在高级智能系统的部署中找到,如先进的驾驶辅助系统(adas)和视频监控。精确的对象分类和对象位置的标识通常是必需的,因为这些信息构成了应用程序管道的其余部分进一步处理和决策的基础。最近,利用机器学习的最新进展,特别是深层神经网络的发展,研究人员和实践者开发了强大的目标检测系统,可以在许多具有挑战性的情况下提供准确的检测。此外,在需要较低处理延迟的情况下,该领域的工作已经从扫描多个位置的图像转向应用图像分类器(即将目标检测问题转化为多窗口的分类问题) ,转而将上述不同步骤组合在一个单一的管道中,通常基于深层神经网络。
这篇论文的创新贡献是针对YOLOv3tiny工作负载定制的延迟优化参数化架构(可以根据硬件资源,自定义参数),该架构可根据任何目标FPGA设备的资源可用性进行调整。为了实现上述功能,我们使用Vivado HLS开发并实现了一个可参数化的体系结构。导出了性能和资源模型,用于指导设计空间探索(DSE)阶段,以确定优化系统延迟的设计点,同时满足资源约束。
针对的是低功耗和资源有限的FPGA设备,需要使用片外存储器来存储网络的参数和中间结果,从而能够在资源极其有限的情况下部署YOLOv3 tiny。
网络结构:
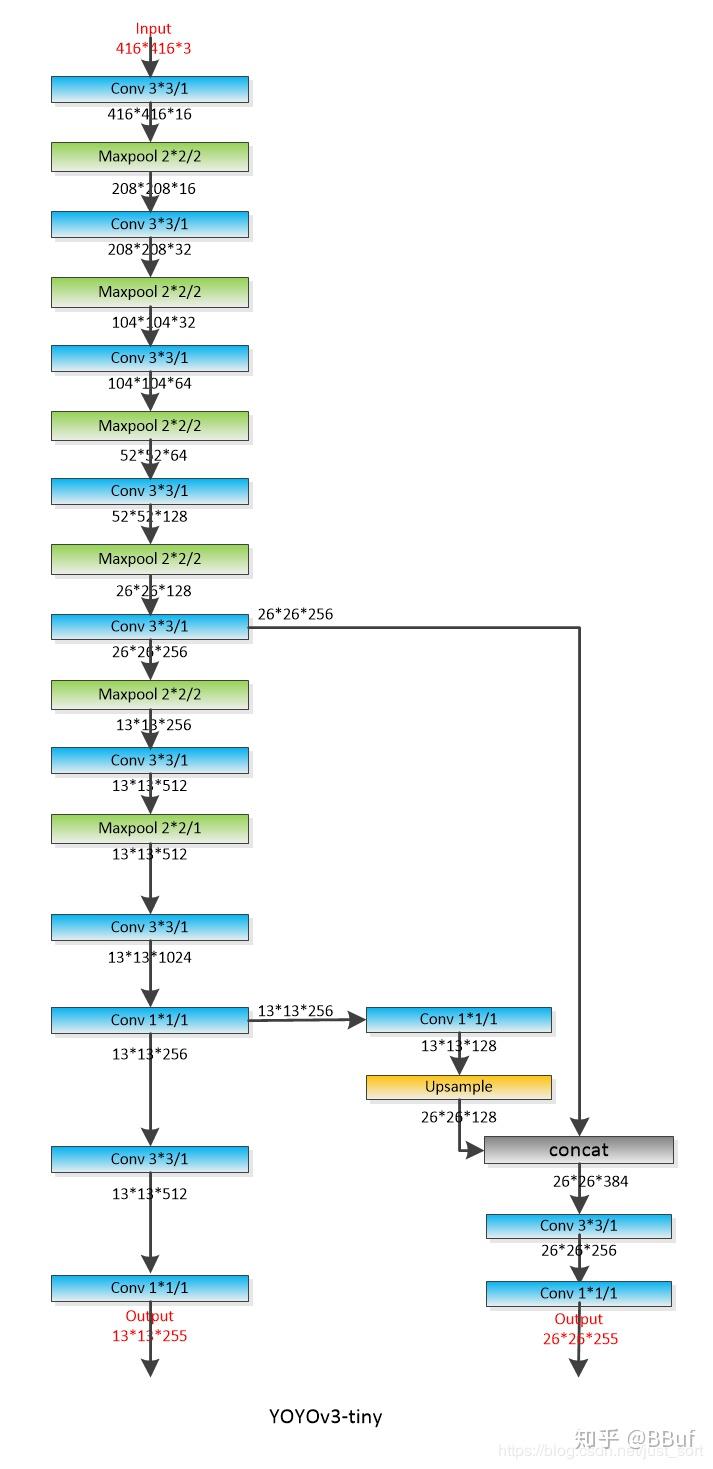
YOLOv3 tiny接受416×416分辨率的RGB图像作为输入。与YOLOv3相反,YOLOv3 tiny只在两种不同的尺度上预测边界框。第一个比例将输入图像划分为13×13个网格,而第二个比例在26×26个网格上操作。该框架在每个网格中生成三个边界框。网络输出一个3d张量,其中包含关于边界框、对象可信度和类预测的信息。该网络主要使用五种类型的层;卷积、最大池、路由、上采样和Yolo层。路由层负责在网络中创建不同的流,其中上采样用于支持多个检测比例。Yolo层负责生成输出向量。
这项工作的目标是设计一种延迟优化和FPGA定制架构,该架构可以根据可用的FPGA资源进行定制,以加速YOLOv3微小模型的推理阶段。所提出的架构在HLS中是定制的,编译时可参数化,以有限资源的低端FPGA设备为目标,因此系统不会对用于存储数据的足够片上内存施加硬约束。
模块设计:
FPGA硬件加速器由五个主要计算模块组成;卷积、累加、最大池、上采样和yolo块
FPGA硬件加速器表示提议的FPGA架构,由三级管道组成,其中每一级对应一层YOLOv3微型网络。加速器由负责系统总体控制的ARM处理器控制。数据和权重通过DMA接口在加速器和片外存储器之间传输。FPGA加速器由三级流水线组成。管道的第一级支持卷积层的执行,其输出在管道的第二级中累积。根据在给定时间执行的网络结构,累加结果将发送到Max pooling、Upsample或YLO层进行进一步处理
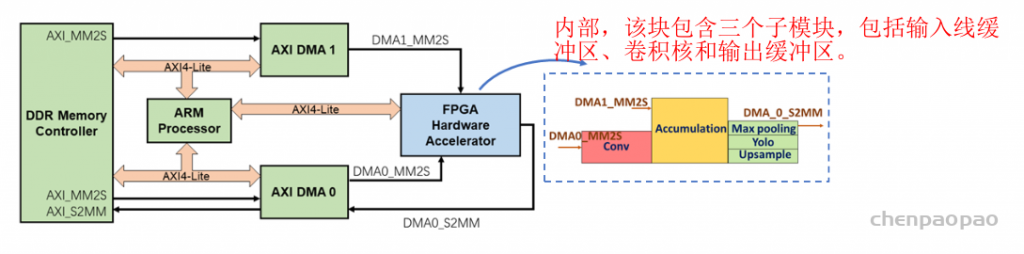
在推理阶段,ARM处理器充当主处理器并控制推理过程。网络的计算被分解为更小的组件,即层批次,由处理器调度并按顺序执行。图4捕获了单层批次的处理流程。更具体地说,ARM处理器首先为硬件加速器中的每个单独块设置参数,并配置DMA模块。然后,它通过DMA流启动权重加载和输入数据传输到硬件加速器。FPGA加速块开始处理数据,并将输出数据传输回片外DDR存储器。相应缓存区域的必要失效由处理器执行,以确保正确的数据传输。
实验验证:
使用具有Xilinx XC7Z020 SoC和512 MB DDR3的Zedboard开发工具包对提议的框架进行评估。可编程逻辑与处理系统的时钟频率为100MHz和666。分别为7MHz。设计空间探索阶段以整个设备的利用率为目标,确定满足可用资源所施加约束的多个设计点,并预测每个点的延迟数字。穿越的空间如图5所示。性能最好的设计实现了每次推断(在电路板上测量)532ms的延迟,需要185个BRAM、160个DSP、25个CPU。9k LUT和46。7k自由流速度。测量的功耗为3。36W

论文:
Yu Z, Bouganis C S, Rincón F, et al. A Parameterisable FPGA-Tailored Architecture for YOLOv3-Tiny[C]//ARC. 2020: 330-344.