
MooER: LLM-based Speech Recognition and Translation Models from Moore Threads
Github: https://github.com/MooreThreads/MooER
ModelScope: https://modelscope.cn/models/MooreThreadsSpeech/MooER-MTL-5K
Huggingface: https://huggingface.co/mtspeech/MooER-MTL-5K
paper:https://arxiv.org/abs/2408.05101
🎉🎉🎉我们发布了支持普通话输入的新 Omni (MooER-omni-v1) 和语音转语音翻译 (MooER-S2ST-v1) 模型。Omni 模型可以听到、思考和与您交谈!请在此处查看我们的演示。
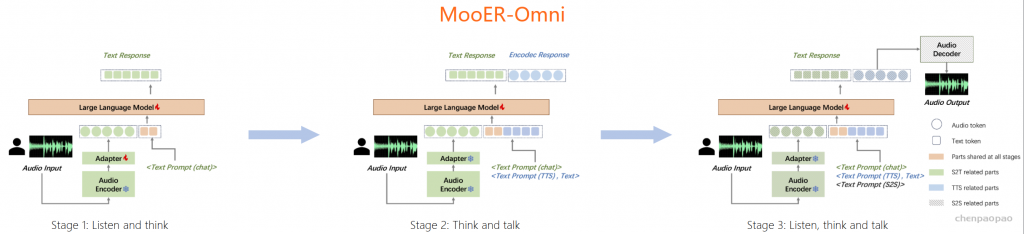
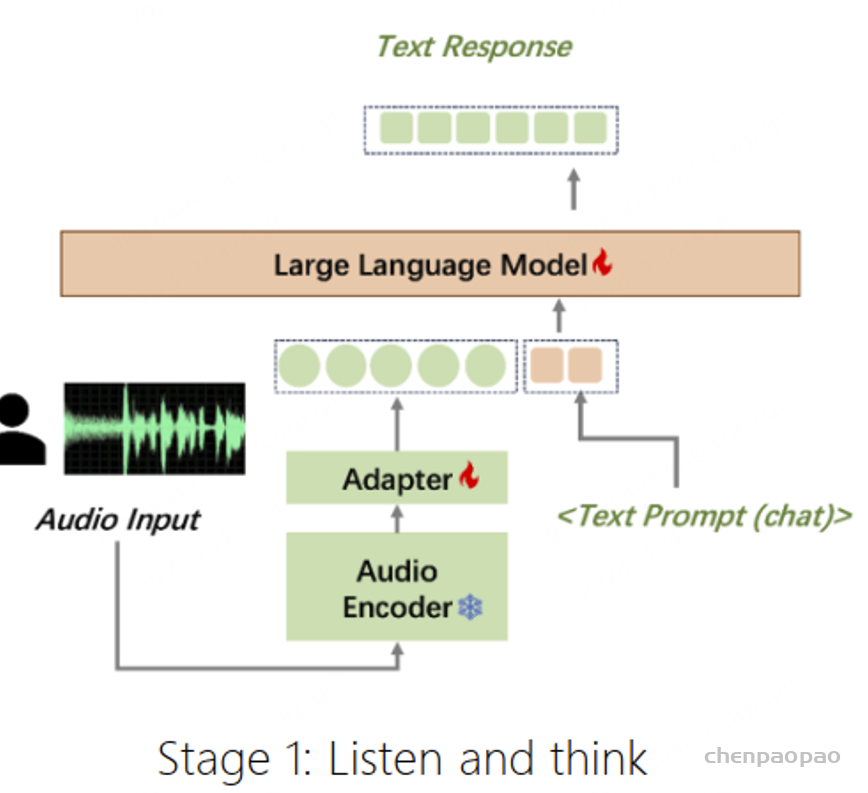
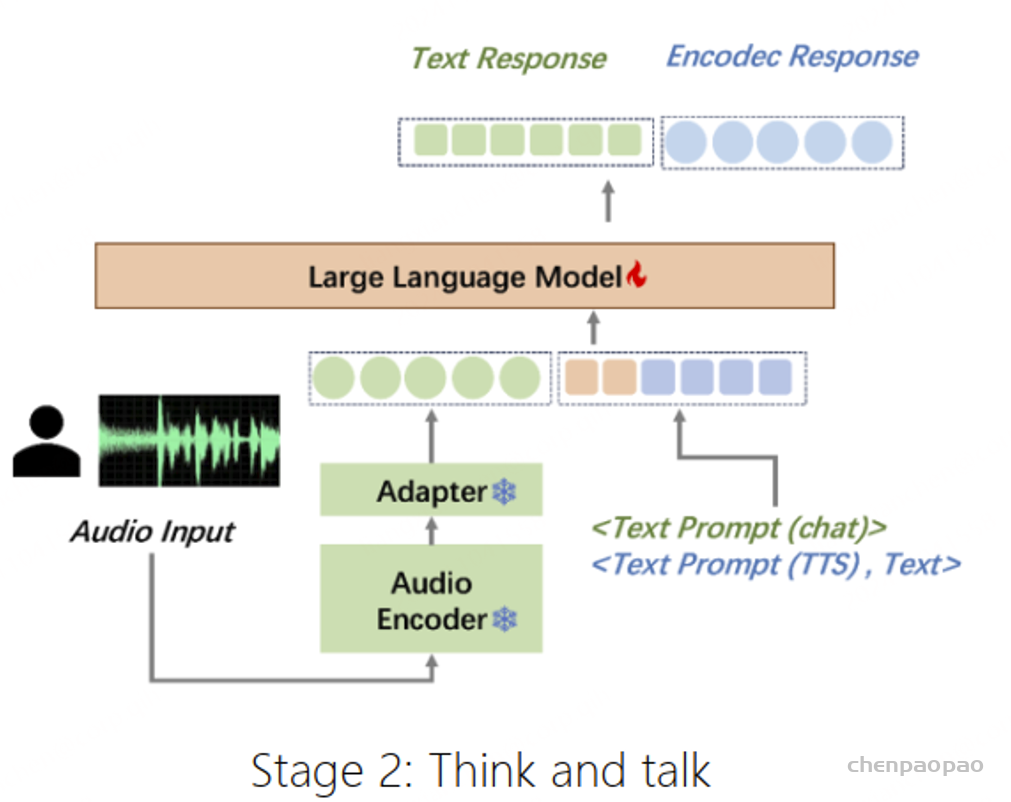
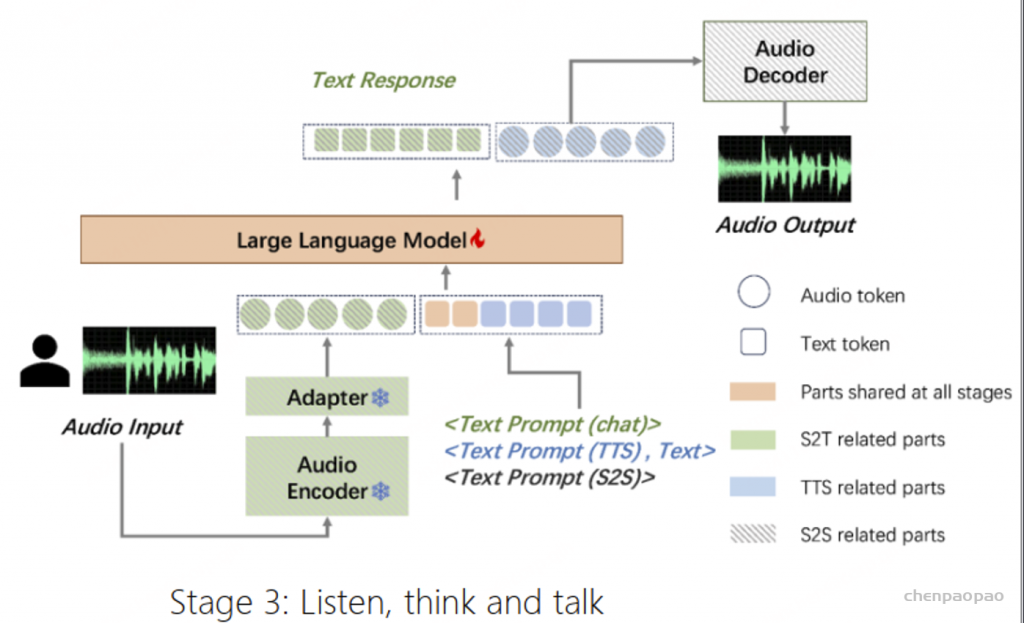
在本工作中,我们推出了摩耳大模型(英文名:MooER)—— 一个由摩尔线程开发的、基于大语言模型(Large Language Model,LLM)的语音识别和语音翻译系统。通过摩尔框架,您可以基于大语言模型,以端到端的方式,将输入语音自动转录为文本(即语音识别),并将其翻译为其它语言(即语音翻译)。关于MooER的具体效果,您可以查阅下文中有关评测结果的部分。在我们公布的技术报告中,我们提供了更详细的实验结果,并分享了我们对模型配置、训练策略等方面的理解。
MooER是业界首个基于国产全功能GPU进行训练和推理的大型开源语音模型。依托摩尔线程夸娥(KUAE)智算平台,MooER大模型仅用38小时便完成了5000小时音频数据和伪标签的训练,这一成就得益于自研的创新算法和高效计算资源的结合。
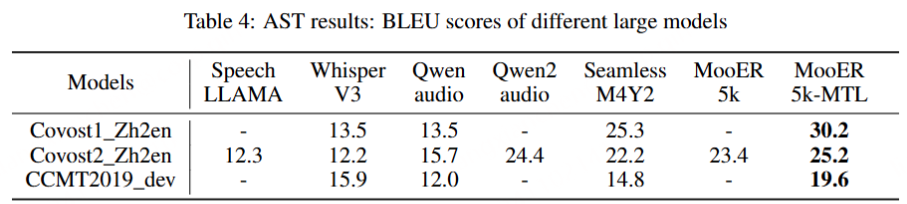
MooER不仅支持中文和英文的语音识别,还具备中译英的语音翻译能力。在多个语音识别领域的测试集中,MooER展现出领先或至少持平的优异表现。特别值得一提的是,在Covost2中译英测试集中,MooER-5K取得了25.2的BLEU分数,接近工业级效果。摩尔线程AI团队在该工作中开源了推理代码和5000小时数据训练的模型,并计划进一步开源训练代码和基于8万小时数据训练的模型,希望该工作能够在语音大模型的方法演进和技术落地方面为社区做出贡献。
MooER主要功能:
- 语音识别:支持中文和英文的语音到文本的转换
- 语音翻译:具备中文语音翻译成英文文本的能力
- 高效率训练:在摩尔线程的智算平台上,快速完成大量数据的训练
- 开源模型:推理代码和部分训练模型已经开源,便于社区使用和进一步研究。
MooER 模型、实验:
- 深度学习架构:MoOER采用了深度学习技术,特别是神经网络来处理和理解语音信号端到端训练:模型从原始语音信号直接到文本输出,无需传统语音识别系统中的多个独立模块。
- Encoder-Adapter-Decoder结构:
- Encoder:负责将输入的语音信号转换成一系列高级特征表示。
- Adapter:用于调整和优化模型对特定任务的适应性,提高型的泛化能力。
- Decoder(Large Language Model,LLM):基于这些特征生成最终的文本输出。
- LoRA技术:使用LoRA(Low-Rank Adaptation)技术,一种参数高效的模型微调方法,通过只更新模型中一小部分参数来提高训练效率和效果。
- 伪标签训练:在训练过程中使用伪标签技术,即用模型自身的预测作为训练数据,以增强模型的学习能力。
- 多语言支持:MOOER支持中文和英文的语音识别,以及中译英的语音翻译,显示出其多语言处理能
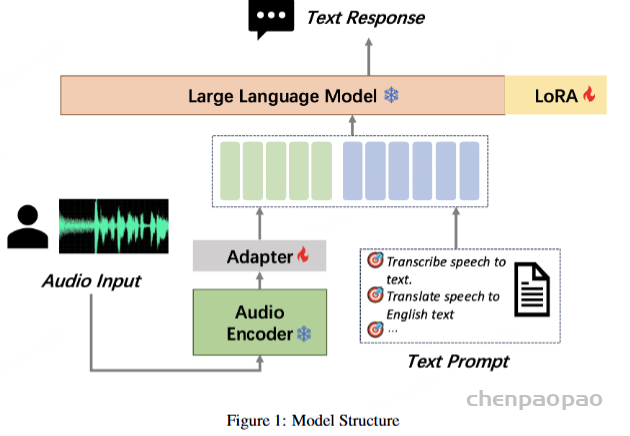
MooER的模型结构
包括Encoder、Adapter和Decoder(Large Language Model,LLM)三个部分。其中,由Encoder对输入的原始音频进行建模,提取特征并获取表征向量。Encoder的输出会送到Adapter进一步下采样,使得每120ms音频输出一组音频Embedding。音频Embedding和文本的Prompt Embedding拼接后,再送进LLM进行对应的下游任务,如语音识别(Automatic Speech Recognition,ASR)、语音翻译(Automatic Speech Translation,AST)等。在模型训练阶段,融合了语音模态和文本模态的数据会按以下形式输入到LLM:

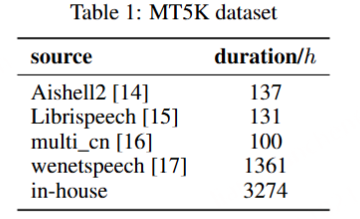
MooER的训练
我们使用开源的Paraformer语音编码器、Qwen2-7B-instruct大语言模型来初始化Encoder和LLM模块,并随机初始化Adapter模块。训练过程中,Encoder始终固定参数,Adapter和LLM会参与训练和梯度更新。利用自研的夸娥智算平台,我们使用DeepSpeed框架和Zero2策略,基于BF16精度进行训练和推理。经实验发现,训练过程中更新LLM参数能够提升最终音频理解任务的效果。为了提升训练效率,我们采用了LoRA技术,仅更新2%的LLM参数。具体的模型参数规模如下:
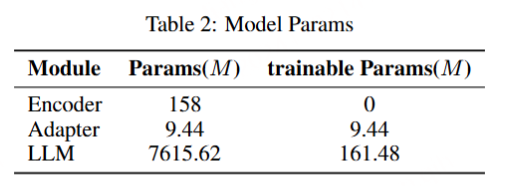
MooER 数据集:
该模型的训练数据MT5K(MT 5000h)由部分开源数据和内部数据构成,内部数据的语音识别标签均是由第三方云服务得到的伪标签。语音识别的伪标签经过一个文本翻译模型后,得到语音翻译的伪标签。我们没有对这些伪标签数据做任何的人工筛选。具体数据来源和对应的规模如下:
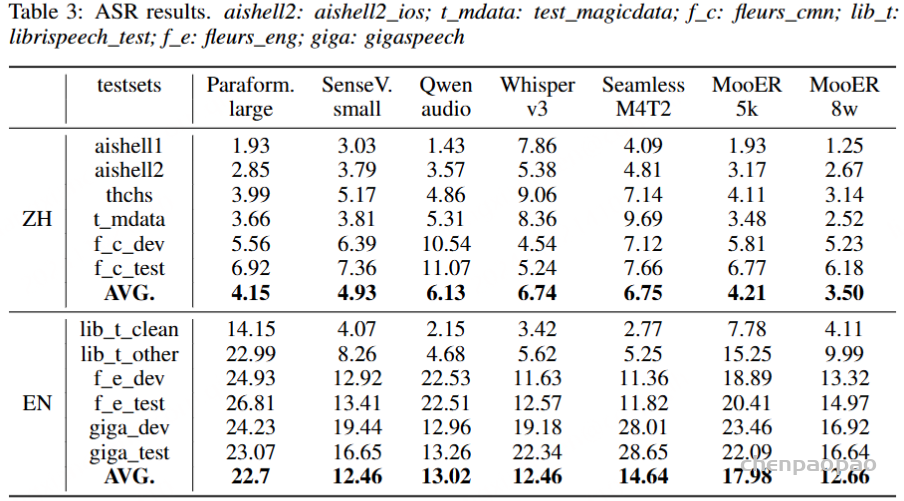
MooER实验结果:
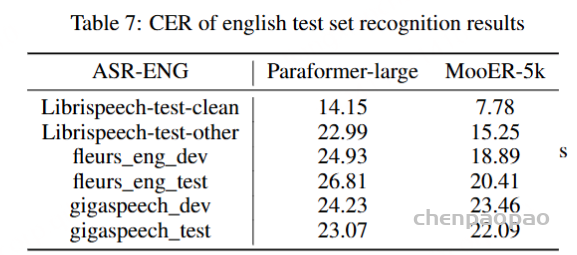
我们将MooER与多个开源的音频理解大模型进行了对比,包括Paraformer、SenseVoice、Qwen-audio、Whisper-large-v3和SeamlessM4T-v2等。这些模型的训练规模从几万小时到上百万小时不等。对比结果显示,我们的开源模型MooER-5K在六个中文测试集上的CER(字错误率)达到4.21%,在六个英文测试集的WER(词错误率)为17.98%,与其它开源模型相比,MooER-5K的效果更优或几乎持平。特别是在Covost2 zh2en中译英测试集上,MooER的BLEU分数达到了25.2,显著优于其他开源模型,取得了可与工业水平相媲美的效果。基于内部8万小时数据训练的MooER-80k模型,在上述中文测试集上的CER达到了3.50%,在英文测试集上的WER到达了12.66%。
• Paraformer-large: 60,000 hours ASR data
• SenseVoice small: 300,000 hours ASR data
• Qwen-audio: 53,000 hours ASR data + 3700 hours S2TT data + …
• WhisperV3: 1000,000 hours weakly labels, 4000,000 hours pseudo labels
• SeamlessM4T2: 351,000 hours S2TT data, 145,000 hours S2ST data
• MooER-5K: 5,000 hours pseudo labels【伪标签】
• MooER-80K: 80,000 hours pseudo labels【伪标签】
建议:
与此同时,我们还得到一些有趣的结论,可以为数据资源和计算资源有限的开发者提供一些建议:
▼Encoder的选择。我们分别对比了无监督(Self-Supervised Learning)训练的W2v-bert 2.0、半监督(Semi-Supervised Learning)训练的Whisper v3和有监督(Supervised Learning)训练的Paraformer。我们发现,采用无监督训练得到的Encoder必须参与到训练过程中,否则模型很难收敛。综合考虑模型效果、参数量以及训练和推理的效率,我们选择Paraformer作为Encoder。

▼音频建模粒度很关键。我们尝试使用240ms、180ms和120ms的粒度进行建模,并发现这一参数对音频与文本的融合效果具有重要影响,同时会影响模型的最终效果和训练的收敛速度。经过评估,我们最终选择每120ms输出一个音频Embedding。

▼快速适应到目标垂类。我们仅使用了140h~150h的英文数据进行训练,可以在6个不同来源的英文的测试集上取得一定效果。同时我们尝试将任务迁移到语音翻译(AST)领域,取得了很好的效果。我们相信这个方法同样也适用于小语种、方言或其它低资源的音频理解任务。

▼LLM对音频理解任务的影响。我们发现,在模型训练过程中采用LoRA技术对LLM参数进行更新,可以使训练更快收敛,并且最终取得更好的效果。同时,音频理解任务上的效果也会随着基础LLM效果提升而提升。【LLM模型越大,效果越好。训练参数越多,效果越好】

加速训练:
优化了数据加载器部分,在相同配置下可以将训练速度提高4到5倍。同时,我们基于5000小时的训练优化了DeepSpeed的训练策略,并将其重新用于我们8wh内部数据的训练。对于需要解冻编码器的训练,我们使用梯度检查点技术以减少内存使用。我们使用基于Moore Threads的KUAE平台加速大型模型的训练。
训练参数:



应用场景:
- 实时语音转写:在会议、讲座、课堂等场合,MOOER可以实时将语音转换为文字,便于记录和回顾。
- 多语言翻译:支持中英文之间的语音翻译,适用于跨国会议、国际交流等场景。
- 智能客服:在客户服务领域,MOOER可以通过语音识别和翻译功能,提高客服的响应效率和服务质量。
- 语音助手:集成到智能手机、智能音箱等设备中,提供语音交互服务。
- 教育辅助:在语言学习中,MOOER可以帮助学习者进行发音校正和语言翻译,
📝 路线图
- Technical report 技术报告
- Inference code and pretrained ASR/AST models using 5k hours of data
使用 5k 小时数据的推理代码和预训练的 ASR/AST 模型 - Pretrained ASR model using 80k hours of data
使用 80k 小时数据的预训练 ASR 模型 - Traning code for MooER MooER 的训练代码
- LLM-based speech-to-speech translation (S2ST, Mandrin Chinese to English)
LLM 基于语音的语音转语音翻译(S2ST,Mandrin 中文到英文) - GPT-4o-like audio-LLM supporting chat using speech
类似 GPT-4o 的音频LLM 支持使用语音聊天 - Training code and technical report about our new Omni model
有关我们新 Omni 模型的培训代码和技术报告 - Omni audio-LLM that supports multi-turn conversation
Omni audio-LLM,支持多轮次对话 - Pretrained AST and multi-task models using 80k hours of data
使用 80k 小时数据的预训练 AST 和多任务模型 - LLM-based timbre-preserving Speech-to-speech translation
LLM 基于音色保留的语音到语音翻译