原创 AI Pulse
Text-to-Speech(通常缩写为TTS)是指一种将文本转为音频的技术。
1.历史
第一台“会说话的机器”可能是在 18 世纪后期制造的(据说是一位匈牙利科学家发明的)。计算机辅助创作起源于20世纪中期,各种技术已经使用了大约50年。如果对旧技术进行分类.首先,
1)Articulatory Synthesis:这是一种模拟人的嘴唇、舌头和发声器官的技术。
2)共振峰合成:人声可以看作是在语音在器官中过滤某些声音而产生的声音。这就是所谓的源滤波器模型,它是一种在基本声音(例如单个音高)上添加各种滤波器以使其听起来像人声的方法(称为加法合成)。
3) Concatenative Synthesis:现在使用数据的模型。举个简单的例子,你可以录制 0 到 9 的声音,并通过链接这些声音来拨打电话号码。然而,声音并不是很自然流畅。
4)统计参数语音合成(SPSS):通过创建声学模型、估计模型参数并使用它来生成音频的模型。它可以大致分为三个部分。
首先,“文本分析” ,将输入文本转换为语言特征,“声学模型” ,将语言特征转换为声学特征,最后是声学特征。这是声码器。该领域使用最广泛的声学模型是隐马尔可夫模型(HMM)。使用 HMM,能够创建比以前更好的声学特征。但是,大部分生成的音频比较机械,例如机器人声音等。
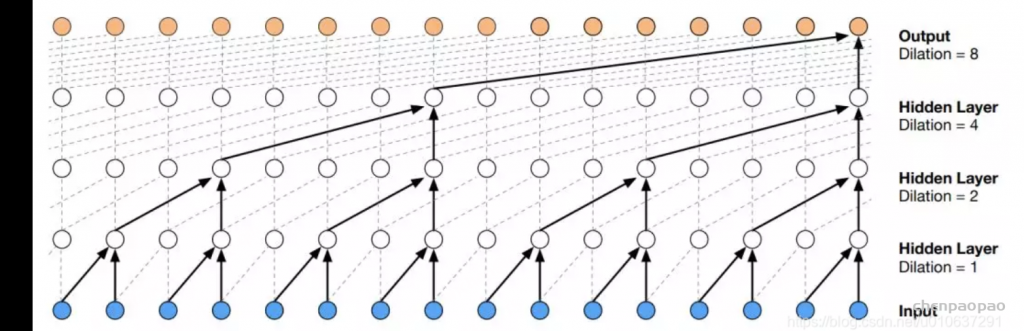
5)神经 TTS:随着我们在 2010 年代进入 深度学习时代,已经开发了基于几种新神经网络的模型。这些逐渐取代了HMM,并被用于“声学模型”部分,逐渐提高了语音生成的质量。从某种意义上说,它可以看作是SPSS的一次进化,但随着模型性能的逐渐提高,它朝着逐渐简化上述三个组成部分的方向发展。比如下图中,可以看出它是在从上(0)到下(4)的方向发展的。
现在推出的大致分为三种模型:
✨声学模型:以字符(文本)或音素(音素;发音单位)为输入并创建任何声学特征的模型。如今,大多数声学特征都是指梅尔频谱图。
✨声码器:一种将梅尔频谱图(和类似的频谱图)作为输入并生成真实音频的模型。
✨完全端到端的 TTS 模型:接收字符或音素作为输入并立即生成音频的模型。
2.文本分析
文本分析是将字符文本转换为语言特征。要考虑以下问题:
- 文本规范化:将缩写或数字更改为发音。例如把1989改成‘一九八九’
- 分词:这在中文等基于字符的语言中是必须的部分。例如,它根据上下文判断是把“包”看成单个词还是把’书包’和’包子’分开看.
- 词性标注:把动词、名词、介词等分析出来。
- Prosody prediction:表达对句子的哪些部分重读、每个部分的长度如何变化、语气如何变化等的微妙感觉的词。如果没有这个,它会产生一种真正感觉像“机器人说话”的声音。尤其是英语(stress-based)等语言在这方面差异很大,只是程度不同而已,但每种语言都有自己的韵律。如果我们可以通过查看文本来预测这些韵律,那肯定会有所帮助。例如,文本末尾的“?”。如果有,自然会产生上升的音调。
- Grapheme-to-phoneme (G2P):即使拼写相同,也有很多部分发音不同。例如,“resume”这个词有时会读作“rizju:m”,有时读作“rezjumei”,因此必须查看整个文本的上下文。所以,如果优先考虑字素转音素的部分,也就是将‘语音’转换成‘spiy ch’等音标的部分。
在过去的 SPSS 时代,添加和开发了这些不同的部分以提高生成音频的质量。在 neural TTS 中,这些部分已经简化了很多,但仍然有一些部分是肯定需要的。例如1文本规范化text normalization 或者5G2P基本上都是先处理后输入。如果有的论文说可以接收字符和音素作为输入,那么很多情况下都会写“实际上,当输入音素时结果更好”。尽管如此,它还是比以前简单了很多,所以在大多数神经 TTS 中,文本分析部分并没有单独处理,它被认为是一个简单的预处理。
3.声学模型
声学模型是指 通过接收字符或音素作为输入或通过接收在文本分析部分创建的语言特征来生成声学特征的部分。前面提到,在SPSS时代,HMM(Hidden Markov Model)在Acoustic Model中的比重很大,后来神经网络技术逐渐取而代之。例如,有论文表明用 DNN 替换 HMM 效果更好。不过RNN系列可能更适合语音等时间序列。因此,在有些论文使用LSTM等模型来提高性能。然而,尽管使用了神经网络模型,这些模型仍然接收语言特征作为输入和输出,如 MCC(梅尔倒谱系数)、BAP(带非周期性)、LSP(线谱对)、LinS(线性谱图)和 F0 .(基频)等 。因此,这些模型可以被认为是改进的 SPSS 模型。
DeepVoice是吴恩达在百度研究院时宣布的,其实更接近SPSS模型。它由几个部分组成,例如一个G2P模块,一个寻找音素边界的模块,一个预测音素长度的模块,一个寻找F0的模块,每个模块中使用了各种神经网络模型。之后发布的DeepVoice 2,也可以看作是第一版的性能提升和多扬声器版本,但整体结构类似。
3.1.基于Seq2seq的声学模型
在2014-5年的机器翻译领域,使用attention的seq2seq模型成为一种趋势。然而,由于字母和声音之间有很多相似之处,所以可以应用于语音。基于这个想法,Google 开发了 Tacotron[Wang17](因为作者喜欢 tacos 而得名)。通过将 CBHG 模块添加到作为 seq2seq 基础的 RNN 中,终于开始出现可以接收字符作为输入并立即提取声学特征的适当神经 TTS,从而摆脱了以前的 SPSS。这个seq2seq模型从那以后很长一段时间都是TTS模型的基础。
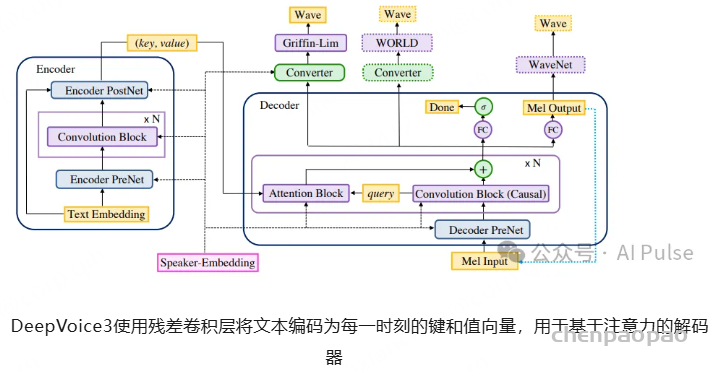
在百度,DeepVoice 3抛弃了之前的旧模型,加入了使用注意力的 seq2seq 。然而,DeepVoice 持续基于 CNN 的传统仍然存在。DeepVoice 在版本 3 末尾停止使用这个名称,之后的 ClariNet和 ParaNet也沿用了该名称。特别是,ParaNet 引入了几种技术来提高 seq2seq 模型的速度。
谷歌的 Tacotron 在保持称为 seq2seq 的基本形式的同时,也向各个方向发展。第一个版本有点过时,但从 Tacotron 2开始,mel-spectrogram 被用作默认的中间表型。在后续论文中,学习了定义某种语音风格的风格标记,并将其添加到 Tacotron 中,以创建一个控制风格的 TTS 系统。同时发表的另一篇谷歌论文 [Skerry-Ryan18] 也提出了一种模型,可以通过添加一个部分来学习韵律嵌入到 Tacotron 中来改变生成音频的韵律。在 DCTTS [Tachibana18] 中,将 Tacotron 的 RNN 部分替换为 Deep CNN 表明在速度方面有很大的增益。从那时起,该模型已改进为快速模型 Fast DCTTS,尺寸有效减小。
在 DurIAN中,Tacotron 2 的注意力部分更改为对齐模型,从而减少了错误。Non-Attentive Tacotron 也做了类似的事情,但在这里,Tacotron 2 的注意力部分被更改为持续时间预测器,以创建更稳健的模型。在FCL-TACO2中,提出了一种半自回归(SAR)方法,每个音素用AR方法制作,整体用NAR方法制作,以提高速度,同时保持质量。此外,蒸馏用于减小模型的大小。建议使用基于 Tacotron 2 的模型,但速度要快 17-18 倍。
3.2.基于变压器的声学模型
随着2017年Transformers的出现,注意力模型演变成NLP领域的Transformers,使用Transformers的模型也开始出现在TTS领域。TransformerTTS可以看作是一个起点,这个模型原样沿用了Tacotron 2的大部分,只是将RNN部分改成了Transformer。这允许并行处理并允许考虑更长的依赖性。
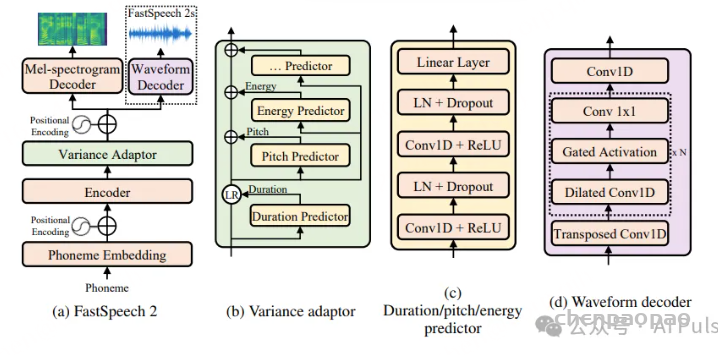
FastSpeech系列可以被引用为使用 Transformer 模型的 TTS 的代表。在这种情况下,可以通过使用前馈 Transformer 以非常高的速度创建梅尔频谱图。作为参考,mel-spectrogram是一种考虑人的听觉特性,对FFT的结果进行变换的方法,虽然是比较旧的方法,但仍然被使用。优点之一是可以用少量维度(通常为 80)表示。
在 TTS 中,将输入文本与梅尔频谱图的帧相匹配非常重要。需要准确计算出一个字符或音素变化了多少帧,其实attention方法过于灵活,对NLP可能有好处,但在speech上反而不利(单词重复或跳过)。因此,FastSpeech 排除了注意力方法,并利用了一个准确预测长度的模块(长度调节器)。后来,FastSpeech 2进一步简化了网络结构,并额外使用了音高、长度和能量等更多样化的信息作为输入。FastPitch提出了一个模型,通过向 FastSpeech 添加详细的音高信息进一步改进了结果。LightSpeech提出了一种结构,通过使用 NAS(Neural Architecture Search)优化原本速度很快的 FastSpeech 的结构,将速度提高了 6.5 倍。
MultiSpeech 还介绍了各种技术来解决 Transformer 的缺点。在此基础上,对 FastSpeech 进行训练以创建一个更加改进的 FastSpeech 模型。TransformerTTS 作者随后还提出了进一步改进的 Transformer TTS 模型,在 RobuTrans模型中使用基于长度的硬注意力。AlignTTS 还介绍了一种使用单独的网络而不是注意力来计算对齐方式的方法。来自 Kakao 的 JDI-T引入了一种更简单的基于 transformer 的架构,还使用了改进的注意力机制。NCSOFT 提出了一种在文本编码器和音频编码器中分层使用转换器的方法,方法是将它们堆叠在多个层中。限制注意力范围和使用多层次音高嵌入也有助于提高性能。
3.3.基于流的声学模型
2014年左右开始应用于图像领域的新一代方法Flow,也被应用到声学模型中。Flowtron可以看作是 Tacotron 的改进模型,它是一个通过应用 IAF(逆自回归流)生成梅尔谱图的模型。在 Flow-TTS中,使用非自回归流制作了一个更快的模型。在后续模型 EfficientTTS中,在模型进一步泛化的同时,对对齐部分进行了进一步改进。
来自 Kakao 的 Glow-TTS 也使用流来创建梅尔频谱图。Glow-TTS 使用经典的动态规划来寻找文本和梅尔帧之间的匹配,但 TTS 表明这种方法也可以产生高效准确的匹配。后来,这种方法Monotonic Alignment Search被广泛使用。
3.4.基于VAE的声学模型
另一个诞生于 2013 年的生成模型框架 Variational autoencoder (VAE) 也被用在了 TTS 中。顾名思义,谷歌宣布的 GMVAE-Tacotron使用 VAE 对语音中的各种潜在属性进行建模和控制。同时问世的VAE-TTS也可以通过在Tacotron 2模型中添加用VAE建模的样式部件来做类似的事情。BVAE-TTS介绍了一种使用双向 VAE 快速生成具有少量参数的 mel 的模型。Parallel Tacotron是 Tacotron 系列的扩展,还引入了 VAE 以加快训练和创建速度。
3.5.基于GAN的声学模型
在 2014 年提出的 Generative Adversarial Nets (GAN) 中,Tacotron 2 被用作生成器,GAN 被用作生成更好的 mels 的方法。在论文中,使用 Adversarial training 方法让 Tacotron Generator 一起学习语音风格。Multi-SpectroGAN还以对抗方式学习了几种样式的潜在表示,这里使用 FastSpeech2 作为生成器。GANSpeech还使用带有生成器的 GAN 方法训练 FastSpeech1/2,自适应调整特征匹配损失的规模有助于提高性能。
3.6.基于扩散的声学模型
最近备受关注的使用扩散模型的TTS也相继被提出。Diff-TTS 通过对梅尔生成部分使用扩散模型进一步提高了结果的质量。Grad-TTS 也通过将解码器更改为扩散模型来做类似的事情,但在这里,Glow-TTS 用于除解码器之外的其余结构。在 PriorGrad 中,使用数据统计创建先验分布,从而实现更高效的建模。也有TTS系统使用每个音素的统计信息应用声学模型,例如腾讯的 DiffGAN-TTS也使用扩散解码器,它使用对抗训练方法。这大大减少了推理过程中的步骤数并降低了生成速度。
3.7.其他声学模型
其实上面介绍的这些技术不一定要单独使用,而是可以相互结合使用的。FastSpeech 的作者自己分析发现,VAE 即使在小尺寸下也能很好地捕捉韵律等长信息,但质量略差,而 Flow 保留细节很好,而模型需要很大为了提高质量, PortaSpeech提出了一种模型,包含Transformer+VAE+Flow的每一个元素。
VoiceLoop提出了一种模型,该模型使用类似于人类工作记忆模型的模型来存储和处理语音信息,称为语音循环。它是考虑多扬声器的早期模型,之后,它被用作Facebook其他研究的骨干网络。
DeviceTTS是一个使用深度前馈顺序记忆网络(DFSMN)作为基本单元的模型。该网络是一种带有记忆块的前馈网络,是一种小型但高效的网络,可以在不使用递归方案的情况下保持长期依赖关系。由此,提出了一种可以在一般移动设备中充分使用的 TTS 模型。
4.声码器
声码器是使用声学模型生成的声学特征并将其转换为波形的部件。即使在 SPSS 时代,当然也需要声码器,此时使用的声码器包括 STRAIGHT 和 WORLD。
4.1.自回归声码器
Neural Vocoder 从 WaveNet引入扩张卷积层来创建长音频样本很重要,并且可以使用自回归方法生成高级音频,该方法使用先前创建的样本生成下一个音频样本(一个接一个)。实际上,WaveNet本身可以作为一个Acoustic Model+Vocoder,将语言特征作为输入,生成音频。然而,从那时起,通过更复杂的声学模型创建梅尔频谱图,并基于 WaveNet 生成音频就变得很普遍。
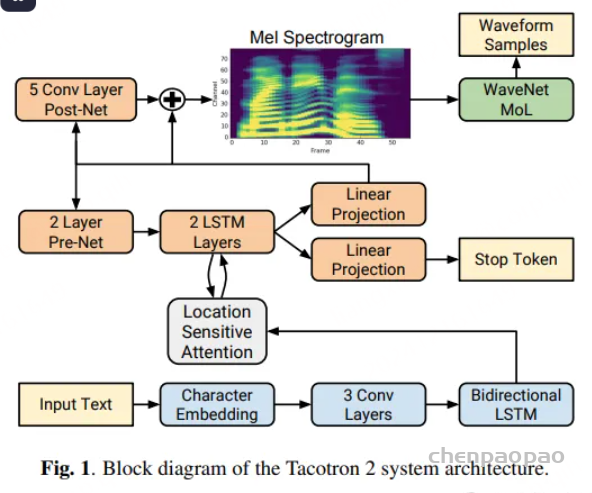
在 Tacotron 中,创建了一个线性频谱图,并使用 Griffin-Lim 算法 将其转换为波形。由于该算法是40年前使用的,尽管网络的整体结构非常好,但得到的音频并不是很令人满意。在 DeepVoice中,从一开始就使用了 WaveNet 声码器,特别是在论文 DeepVoice2中,除了他们自己的模型外,还通过将 WaveNet 声码器添加到另一家公司的模型 Tacotron 来提高性能(这么说来,在单个speaker上比DeepVoice2好)给出了更好的性能。自版本2以来,Tacotron 使用 WaveNet 作为默认声码器。
SampleRNN是另一种自回归模型,在 RNN 方法中一个一个地创建样本。这些自回归模型生成音频的速度非常慢,因为它们通过上一个样本一个一个地构建下一个样本。因此,许多后来的研究建议采用更快生产率的模型。
FFTNet着眼于WaveNet的dilated convolution的形状与FFT的形状相似,提出了一种可以加快生成速度的技术。在 WaveRNN中,使用了各种技术(GPU 内核编码、剪枝、缩放等)来加速 WaveNet 。WaveRNN 从此演变成通用神经声码器和各种形式。在Towards achieving robust universal neural vocoding(Interspeech 2019)中,使用 74 位说话人和 17 种语言的数据对 WaveRNN 进行了训练,以创建 RNN_MS(多说话人)模型,证明它是一种即使在说话人和环境中也能产生良好质量的声码器。数据。Speaker Conditional WaveRNN: Towards universal neural vocoder for unseen speaker and recording conditions.(Interspeech 2020)提出了Speaker Conditional)_WaveRNN 模型,即通过额外使用 speaker embedding 来学习的模型。该模型还表明它适用于不在数据中的说话人和环境。
苹果的TTS也使用了WaveRNN作为声码器,并且在server端和mobile端做了各种优化编码和参数设置,使其可以在移动设备上使用。
通过将音频信号分成几个子带来处理音频信号的方法,即较短的下采样版本,已应用于多个模型,因为它具有可以快速并行计算的优点,并且可以对每个子带执行不同的处理。
现在,很多后来推出的声码器都使用非自回归方法来改善自回归方法生成速度慢的问题。换句话说,一种无需查看先前样本(通常表示为平行)即可生成后续样本的方法。已经提出了各种各样的非自回归方法,但最近一篇表明自回归方法依旧抗打的论文是 Chunked Autoregressive GAN (CARGAN),它表明许多非自回归声码器存在音高错误,这个问题可以通过使用自回归方法来解决。当然,速度是个问题,但是通过提示可以分成chunked单元计算,绍一种可以显着降低速度和内存的方法。
4.2.基于流的声码器
归一化基于流的技术可以分为两大类。首先是自回归变换,在有代表性的IAF(inverse autoregressive flow)的情况下,生成速度非常快,而不是需要很长的训练时间。因此,它可以用来快速生成音频。然而,训练速度慢是一个问题,在Parallel WaveNet中,首先创建一个自回归WaveNet模型,然后训练一个类似的非自回归IAF模型。这称为教师-学生模型,或蒸馏。之后,ClariNet使用类似的方法提出了一种更简单、更稳定的训练方法。在成功训练 IAF 模型后,现在可以快速生成音频。但训练方法复杂,计算量大。
另一种流技术称为二分变换,一种使用称为仿射耦合层的层来加速训练和生成的方法。大约在同一时间,提出了两个使用这种方法的声码器,WaveGlow和 FloWaveNet。这两篇论文来自几乎相似的想法,只有细微的结构差异,包括混合通道的方法。Bipartite transform的优点是简单,但也有缺点,要创建一个等价于IAF的模型,需要堆叠好几层,所以参数量比较大。
从那时起,WaveFlow提供了几种音频生成方法的综合视图。不仅解释了 WaveGlow 和 FloWaveNet 等流方法,还解释了WaveNet 作为广义模型的生成方法,我们提出了一个计算速度比这些更快的模型。此外,SqueezeWave提出了一个模型,该模型通过消除 WaveGlow 模型的低效率并使用深度可分离卷积,速度提高了几个数量级(性能略有下降)。WG-WaveNet还提出通过在 WaveGlow 中使用权重共享显着减小模型大小并添加一个小的 WaveNet 滤波器来提高音频质量来创建模型,从而使 44.1kHz 音频在 CPU 上比实时音频更快音频…
4.3.基于 GAN 的声码器
广泛应用于图像领域的生成对抗网络(GANs)经过很长一段时间(4-5年)后成功应用于音频生成领域。WaveGAN可以作为第一个主要研究成果被引用。在图像领域发展起来的结构在音频领域被沿用,所以虽然创造了一定质量的音频,但似乎仍然有所欠缺。
从GAN-TTS开始,为了让模型更适合音频,vits作者思考如何做一个能够很好捕捉波形特征的判别器。在 GAN-TTS 中,使用多个随机窗口(Random window discriminators)来考虑更多样化的特征,而在 MelGAN中,使用了一种在多个尺度(Multi-scale discriminator)中查看音频的方法。来自Kakao的HiFi-GAN提出了一种考虑更多音频特征的方法,即一个周期(Multi-period discriminator)。在 VocGAN的情况下,还使用了具有多种分辨率的鉴别器。在A spectral energy distance for parallel speech synthesis. NeurIPS 2020.中,生成的分布与实际分布之间的差异以广义能量距离 (GED) 的形式定义,并在最小化它的方向上学习。复杂的鉴别器以各种方式极大地提高了生成音频的性能。GAN Vocoder: Multi-resolution discriminator is all you need(Interspeech 2021)进一步分析了这一点,并提到了多分辨率鉴别器的重要性。在 Fre-GAN中,生成器和鉴别器都使用多分辨率方法连接。使用离散波形变换 (DWT) 也有帮助。
在generator的情况下,很多模型使用了MelGAN提出的dilated + transposed convolution组合。如果稍有不同,Parallel WaveGAN 也接收高斯噪声作为输入,而 VocGAN 生成各种尺度的波形。在 HiFi-GAN 中,使用了具有多个感受野的生成器。
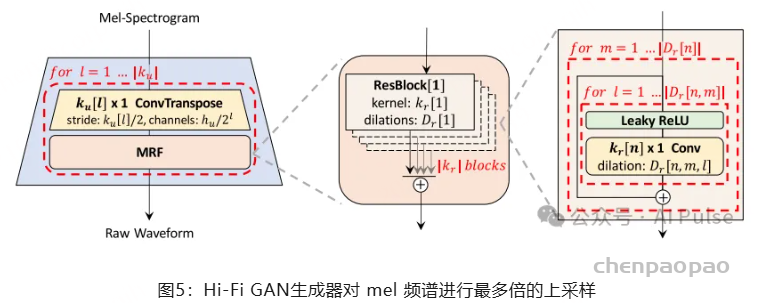
前面提到的 Parallel WaveGAN是 Naver/Line 提出的一种模型,它可以通过提出非自回归 WaveNet 生成器来以非常高的速度生成音频。之后,提出了一种进一步改进的 Parallel WaveGAN,通过应用感知掩蔽滤波器来减少听觉敏感错误。此外,[Wang21] 提出了一种通过将 Pointwise Improved Parallel WaveGAN vocoder with perceptually weighted spectrogram loss.Relativistic LSGAN(一种改进的最小二乘 GAN)应用于音频来创建具有较少局部伪影的 Parallel WaveGAN(和 MelGAN)的方法。在 LVCNet中,使用根据条件变化的卷积层的生成器,称为位置可变卷积,被放入 Parallel WaveGAN 并训练以创建更快(4x)的生成模型,质量差异很小。
此后,MelGAN 也得到了多种形式的改进。在Multi-Band MelGAN 中,增加了原有MelGAN的感受野,增加了多分辨率STFT loss(Parallel WaveGAN建议),计算了多波段划分(DurIAN建议),使得速度更快,更稳定的模型。还提出了 Universal MelGAN 的多扬声器版本,它也使用多分辨率鉴别器来生成具有更多细节的音频。这个想法在后续的研究 UnivNet中得到延续,并进一步改进,比如一起使用多周期判别器。在这些研究中,音频质量也通过使用更宽的频带 (80->100) mel 得到改善。
首尔国立大学/NVIDIA 推出了一种名为 BigVGAN的新型声码器。作为考虑各种录音环境和未见语言等的通用Vocoder,作为技术改进,使用snake函数为HiFi-GAN生成器提供周期性的归纳偏置,并加入低通滤波器以减少边由此造成的影响。另外,模型的大小也大大增加了(~112M),训练也成功了。
4.4.基于扩散的声码器
扩散模型可以称为最新一代模型,较早地应用于声码器。ICLR21同时介绍了思路相似的DiffWave和WaveGrad。Diffusion Model用于音频生成部分是一样的,但DiffWave类似于WaveNet,WaveGrad基于GAN-TTS。处理迭代的方式也有所不同。之前声学模型部分介绍的PriorGrad 也以创建声码器为例进行了介绍。在这里,先验是使用梅尔谱图的能量计算的。
扩散法的优点是可以学习复杂的数据分布并产生高质量的结果,但最大的缺点是生成时间相对较长。另外,由于这种方法本身是以去除噪声的方式进行的,因此如果进行时间过长,存在原始音频中存在的许多噪声(清音等)也会消失的缺点。FastDiff通过将 LVCNet的思想应用到扩散模型中,提出了时间感知的位置-变化卷积。通过这种方式,可以更稳健地应用扩散,并且可以通过使用噪声调度预测器进一步减少生成时间。
来自腾讯的 BDDM也提出了一种大大减少创建时间的方法。换句话说,扩散过程的正向和反向过程使用不同的网络(正向:调度网络,反向:分数网络),并为此提出了一个新的理论目标。在这里,我们展示了至少可以通过三个步骤生成音频。在这个速度下,扩散法也可以用于实际目的。虽然以前的大多数研究使用 DDPM 型建模,但扩散模型也可以用随机微分方程 (SDE) 的形式表示。ItoWave展示了使用 SDE 类型建模生成音频的示例。
4.5.基于源滤波器的声码器
在这篇文章的开头,在处理 TTS 的历史时,我们简单地了解了 Formant Synthesis。人声是一种建模方法,认为基本声源(正弦音等)经过口部结构过滤,转化为我们听到的声音。这种方法最重要的部分是如何制作过滤器。在 DL 时代,如果这个过滤器用神经网络建模,性能会不会更好。在神经源滤波器方法 [Wang19a] 中,使用 f0(音高)信息创建基本正弦声音,并训练使用扩张卷积的滤波器以产生优质声音。不是自回归的方法,所以速度很快。之后,在Neural harmonic-plus-noise waveform model with trainable maximum voice frequency for text-to-speech synthesis.中,将其扩展重构为谐波+噪声模型以提高性能。DDSP 提出了一种使用神经网络和多个 DSP 组件创建各种声音的方法,其中谐波使用加法合成方法,噪声使用线性时变滤波器。
另一种方法是将与语音音高相关的部分(共振峰)和其他部分(称为残差、激励等)进行划分和处理的方法。这也是一种历史悠久的方法。共振峰主要使用了LP(线性预测),激励使用了各种模型。GlotNet在神经网络时代提出,将(声门)激励建模为 WaveNet。之后,GELP 用 GAN 训练方法将其扩展为并行格式。
Naver/Yonsei University 的 ExcitNet也可以看作是具有类似思想的模型,然后,在扩展模型 LP-WaveNet中,source 和 filter 一起训练,并使用更复杂的模型。在 Neural text-to-speech with a modeling-by-generation excitation vocoder(Interspeech 2020)中,引入了逐代建模 (MbG) 概念,从声学模型生成的信息可用于声码器以提高性能。在神经同态声码器中,谐波使用线性时变 (LTV) 脉冲序列,噪声使用 LTV 噪声。Unified source-filter GAN: Unified source-filter network based on factorization of quasi-periodic Parallel WaveGAN(Interspeech 2021)提出了一种模型,它使用 Parallel WaveGAN 作为声码器,并集成了上述几种源滤波器模型。Parallel WaveGAN本身也被Naver不断扩充,首先在High-fidelity Parallel WaveGAN with multi-band harmonic-plus-noise model(Interspeech 2021)中,Generator被扩充为Harmonic + Noise模型,同时也加入了subband版本。
LPCNet可以被认为是继这种源过滤器方法之后使用最广泛的模型。作为在 WaveRNN 中加入线性预测的模型, LPCNet 此后也进行了多方面的改进。在 Bunched LPCNet 中,通过利用原始 WaveRNN 中引入的技术,LPCNet 变得更加高效。Gaussian LPCNet还通过允许同时预测多个样本来提高效率。Lightweight LPCNet-based neural vocoder with tensor decomposition(Interspeech 2020)通过使用张量分解进一步减小 WaveRNN 内部组件的大小来提高另一个方向的效率。iLPCNet该模型通过利用连续形式的混合密度网络显示出比现有 LPCNet 更高的性能。Fast and lightweight on-device tts with Tacotron2 and LPCNet(Interspeech 2020)提出了一种模型,在LPCNet中的语音中找到可以切断的部分(例如,停顿或清音),将它们划分,并行处理,并通过交叉淡入淡出来加快生成速度. LPCNet 也扩展到了子带版本,首先在 FeatherWave中引入子带 LPCNet。在An efficient subband linear prediction for lpcnet-based neural synthesis(Interspeech 2020)中,提出了考虑子带之间相关性的子带 LPCNet 的改进版本.
声码器的发展正朝着从高质量、慢速的AR(Autoregressive)方法向快速的NAR(Non-autoregressive)方法转变的方向发展。由于几种先进的生成技术,NAR 也逐渐达到 AR 的水平。例如在TTS-BY-TTS [Hwang21a]中,使用AR方法创建了大量数据并用于NAR模型的训练,效果不错。但是,使用所有数据可能会很糟糕。因此,TTS-BY-TTS2提出了一种仅使用此数据进行训练的方法,方法是使用 RankSVM 获得与原始音频更相似的合成音频。
DelightfulTTS,微软使用的 TTS 系统,有一些自己的结构修改,例如使用 conformers,并且特别以生成 48 kHz 的最终音频为特征(大多数 TTS 系统通常生成 16 kHz 音频)。为此,梅尔频谱图以 16kHz 的频率生成,但最终音频是使用内部制作的 HiFiNet 以 48kHz 的频率生成的。
5.完全端到端的TTS
通过一起学习声学模型和声码器,介绍在输入文本或音素时立即创建波形音频的模型。实际上,最好一次完成所有操作,无需划分训练步骤,更少的步骤减少错误。无需使用 Mel Spectrum 等声学功能。其实Mel是好的,但是被人任意设定了(次优),相位信息也丢失了。然而,这些模型之所以不容易从一开始就开发出来,是因为很难一次全部完成。
例如,作为输入的文本在 5 秒内大约为 20,对于音素大约为 100。但波形是 80,000 个样本(采样率为 16 kHz)。因此,一旦成为问题,不好完全与其匹配(文本->音频样本),不如使用中等分辨率的表达方式(如Mel)分两步进行比较简单。但是,随着技术的逐渐发展,可以找到一些用这种 Fully End-to-End 方法训练的模型。作为参考,在许多处理声学模型的论文中,他们经常使用术语端到端模型,这意味着文本分析部分已被一起吸收到他们的模型中,或者他们可以通过将声码器附加到他们的模型来生成音频. 它通常用于表示能够。
也许这个领域的第一个是 Char2Wav ,这是蒙特利尔大学名人Yoshua Bengio教授团队的论文,通过将其团队制作的SampleRNN vocoder添加到Acoustic Model using seq2seq中一次性训练而成。ClariNet的主要内容其实就是让WaveNet->IAF方法的Vocoder更加高效。
FastSpeech 2也是关于一个好的 Acoustic Model,这篇论文也介绍了一个 Fully End-to-End 模型,叫做 FastSpeech 2s。FastSpeech 2模型附加了一个WaveNet声码器,为了克服训练的困难,采取了使用预先制作的mel编码器的方法。名为EATS的模型使用他们团队(谷歌)创建的GAN-TTS作为声码器,创建一个新的Acoustic Model,并一起训练。但是,一次训练很困难,因此创建并使用了中等分辨率的表示。Wave-Tacotron,是一种通过将声码器连接到 Tacotron 来立即训练的模型。这里使用了流式声码器,作者使用 Kingma,因此可以在不显着降低性能的情况下创建更快的模型。
之前Acoustic Model部分介绍的EfficientTTS也介绍了一种模型(EFTS-Wav),通过将decoder换成MelGAN,以端到端的方式进行训练。该模型还表明,它可以显着加快音频生成速度,同时仍然表现良好。Kakao 团队开发了一种名为 Glow-TTS的声学模型和一种名为 HiFi-GAN的声码器。然后可以将两者放在一起以创建端到端模型,这就是 VITS ,它使用 VAE 连接两个部分,并使用对抗性方法进行整个训练,提出了具有良好速度和质量的模型。
延世大学/Naver 还在 2021 年推出了 LiteTTS,这是一种高效的完全端到端 TTS。使用了前馈变换器和 HiFi-GAN 结构的轻量级版本。特别是,域传输编码器用于学习与韵律嵌入相关的文本信息。腾讯和浙江大学提出了一种名为 FastDiff的声码器,还引入了 FastDiff-TTS,这是一种结合 FastSpeech 2的完全端到端模型。Kakao 还引入了 JETS,它可以一起训练 FastSpeech2 和 HiFi-GAN。微软在将现有的 DelightfulTTS 升级到版本 2 的同时,也引入了 Fully End-to-End 方法。这里,VQ音频编码器被用作中间表达方法。
截止到现在,主流的语音合成框架以以上方法为主流进行研究发展,未来会再次统计并概述最新论文以及方法。