
🤗 Hugging Face | 🤖 ModelScope | 📑 Paper (报告还未发布) | 📑 Blog 📖 Documentation |🖥️ Demo | 博客 | GitHub
Qwen是阿里巴巴集团Qwen团队研发的大语言模型和大型多模态模型系列。目前,大语言模型已升级至Qwen2.5版本。无论是语言模型还是多模态模型,均在大规模多语言和多模态数据上进行预训练,并通过高质量数据进行后期微调以贴近人类偏好。Qwen具备自然语言理解、文本生成、视觉理解、音频理解、工具使用、角色扮演、作为AI Agent进行互动等多种能力。
最新版本Qwen2.5有以下特点:
- 易于使用的仅解码器稠密语言模型,提供 0.5B 、1.5B 、3B 、7B 、14B 、32B 和 72B 共7种参数规模的模型,并且有基模型和指令微调模型两种变体(其中“ B ”表示“十亿”, 72B 即为 720 亿)
- 利用我们最新的数据集进行预训练,包含多达 18T tokens (其中“ T ”表示“万亿”, 18T 即为 18 万亿)
- 在遵循指令、生成长文本(超过 8K tokens )、理解结构化数据(例如,表格)以及生成结构化输出特别是 JSON 方面有了显著改进
- 更加适应多样化的系统提示,增强了角色扮演的实现和聊天机器人的背景设置。
- 支持最多达 128K tokens 的上下文长度,并能生成多达 8K tokens 的文本。
- 支持超过 29 种语言,包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等。
简介
- 全面开源:考虑到用户对10B至30B范围模型的需求和移动端对3B模型的兴趣,此次除了继续开源Qwen2系列中的0.5B/1.5B/7B/72B四款模型外,Qwen2.5系列还增加了两个高性价比的中等规模模型—— Qwen2.5-14B 和 Qwen2.5-32B,以及一款适合移动端的 Qwen2.5-3B。所有模型在同类开源产品中均具有很强的竞争力,例如Qwen2.5-32B的整体表现超越了Qwen2-72B,Qwen2.5-14B则领先于Qwen2-57B-A14B。
- 更大规模、更高质量的预数据训练集:我们的预训练数据集规模从 7T tokens 扩展到了 18T tokens。
- 知识储备升级:Qwen2.5的知识涵盖更广。在MMLU基准中,Qwen2.5-7B 和 72B的得分相较于Qwen2分别从70.3提升到 74.2,和从84.2提升到 86.1。此外,Qwen2.5还在 GPQA、MMLU-Pro、MMLU-redux 和 ARC-c 等多个基准测试中有了明显提升。
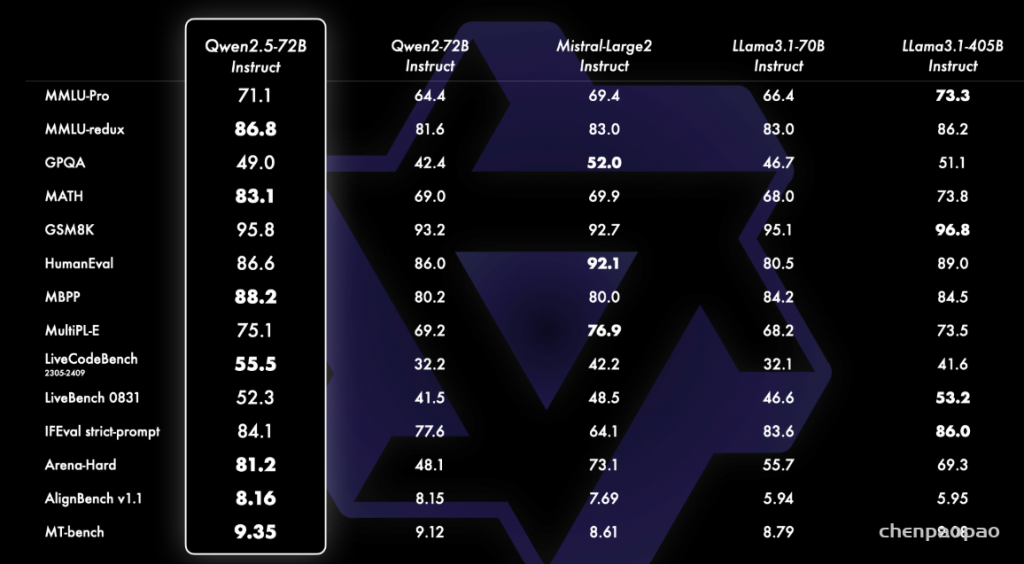
- 代码能力增强:得益于Qwen2.5-Coder的突破,Qwen2.5在代码生成能力上也大幅提升。Qwen2.5-72B-Instruct在LiveCodeBench(2305-2409)、MultiPL-E和MBPP中的分别得分 55.5、75.1 和 88.2,优于Qwen2-72B-Instruct的32.2、69.2和80.2。
- 数学能力提升:引入了Qwen2-math的技术后,Qwen2.5的数学推理表现也有了快速提升。在MATH基准测试中,Qwen2.5-7B/72B-Instruct得分从Qwen2-7B/72B-Instruct的52.9/69.0上升到了 75.5/83.1。
- 更符合人类偏好:Qwen2.5生成的内容更加贴近人类的偏好。具体来看,Qwen2.5-72B-Instruct的Arena-Hard得分从 48.1 大幅提升至 81.2,MT-Bench得分也从 9.12 提升到了 9.35,与之前的Qwen2-72B相比提升显著。
- 其他核心能力提升:Qwen2.5在 指令跟随、生成 长文本(从1K升级到 8K tokens)、理解 结构化数据(如表格),以及生成 结构化输出(尤其是JSON)上都有非常明显的进步。此外,Qwen2.5能够更好响应多样化的 系统提示,用户可以给模型设置 特定角色 或 自定义条件。
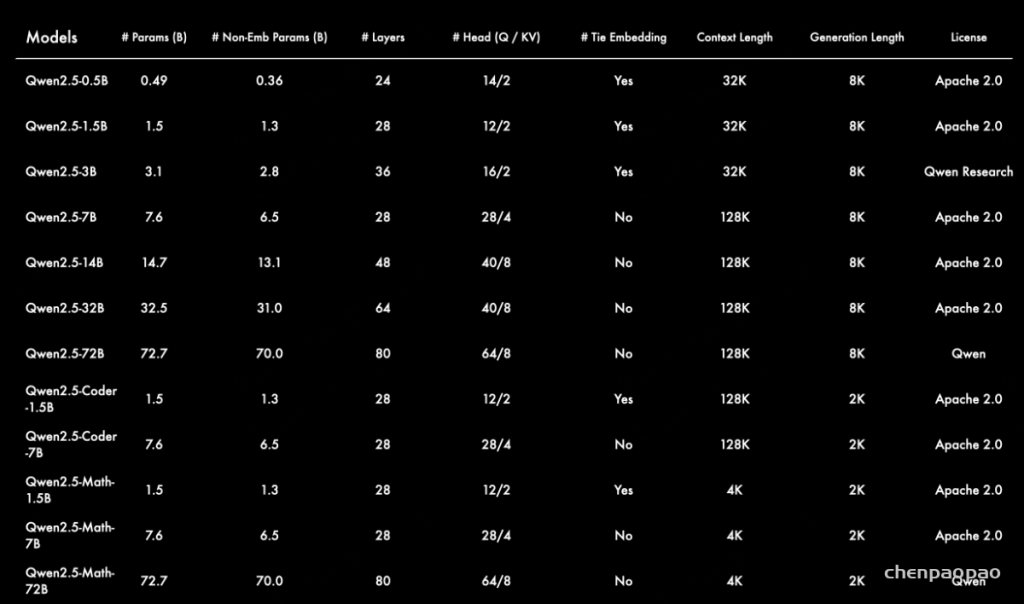
模型基础信息
本次发布的 Qwen2.5 语言模型系列包括七个开源模型,规模从 0.5B 到 72B 不等。大多数模型支持 128K(131,072)个 token 的上下文长度,并能生成 8K token 的文本,支持长篇内容创作。除部分特殊版本外,模型主要采用 Apache 2.0 开源许可协议,而 Qwen2.5-3B 和 Qwen2.5-72B 分别使用 Qwen Research 许可协议 和 Qwen 许可协议。
模型性能
Qwen2.5
为了展示 Qwen2.5 的能力,我们用我们最大的开源模型 Qwen2.5-72B —— 一个拥有 720 亿参数的稠密 decoder-only 语言模型——与领先的开源模型如 Llama-3.1-70B 和 Mistral-Large-V2进行了基准测试。我们在多个基准测试中展示了经过指令调优的版本的综合结果,评估了模型的能力和人类偏好。
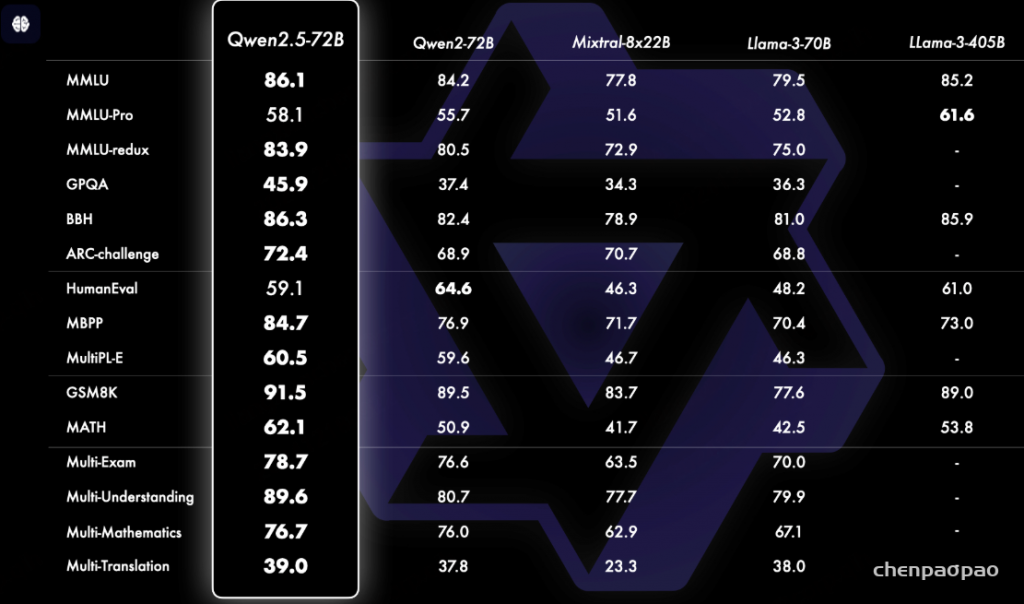
除了指令微调的模型之外,我们还发现,我们的旗舰开源模型 Qwen2.5-72B 的基础语言模型性能达到了顶级水准,即便是在与 Llama-3-405B 这样更大的模型对比时也是如此。
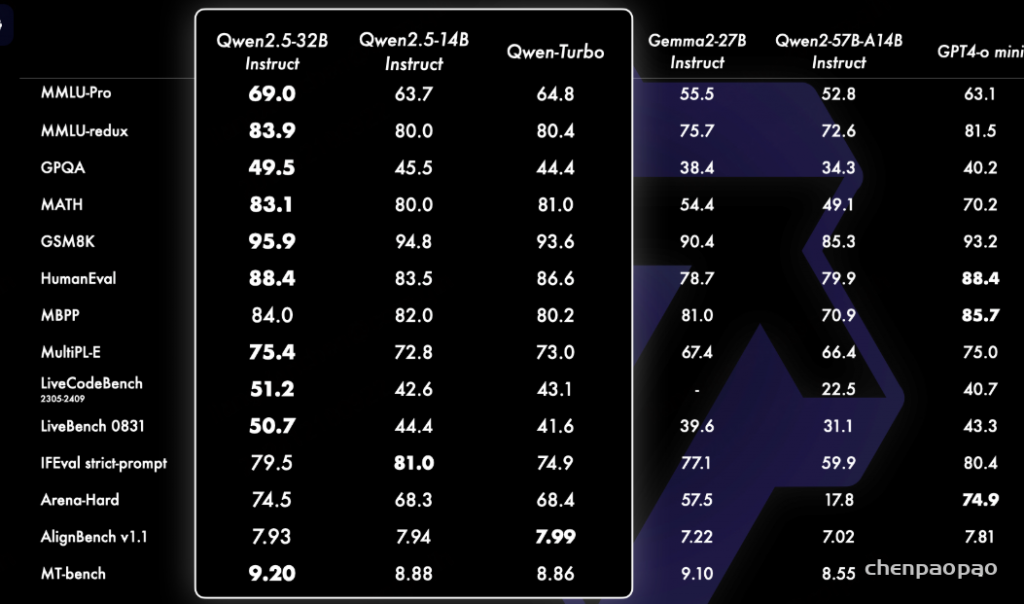
Qwen2.5 的一个重要更新是重新引入了我们的 140 亿参数和 320 亿参数模型,即 Qwen2.5-14B 和 Qwen2.5-32B。这些模型在多样化的任务中超越了同等规模或更大规模的基线模型,例如 Phi-3.5-MoE-Instruct 和 Gemma2-27B-IT。 它们在模型大小和能力之间达到了最佳平衡,提供了匹配甚至超过一些较大模型的性能。此外,我们的基于 API 的模型 Qwen2.5-Turbo 相比这两个开源模型提供了极具竞争力的性能,同时提供了成本效益高且快速的服务。
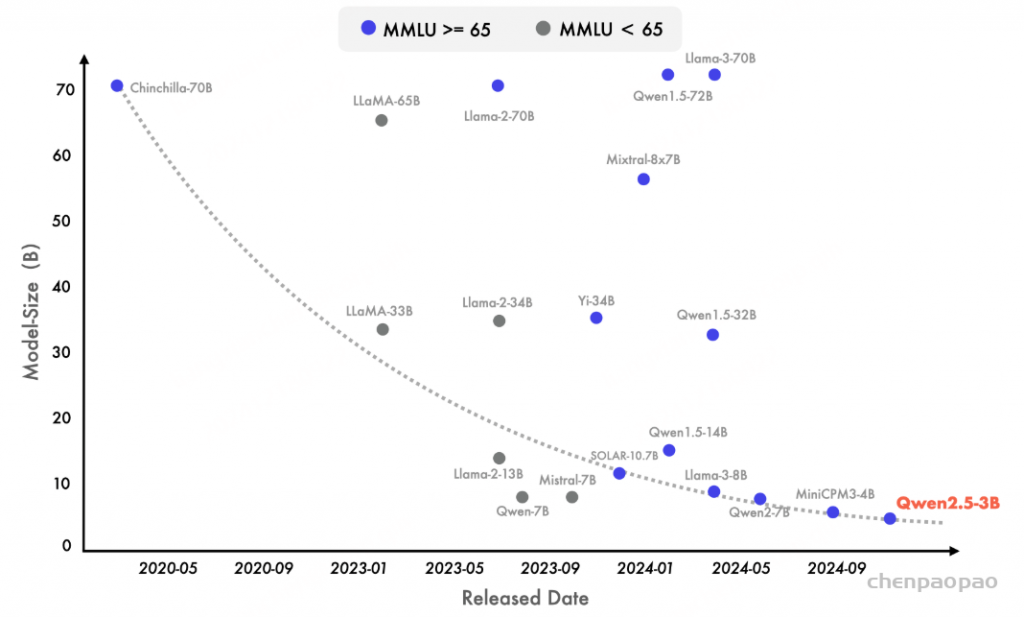
近来也出现了明显的转向小型语言模型(SLMs)的趋势。尽管历史上小型语言模型(SLMs)的表现一直落后于大型语言模型(LLMs),但二者之间的性能差距正在迅速缩小。值得注意的是,即使是只有大约 30 亿参数的模型现在也能取得高度竞争力的结果。附带的图表显示了一个重要的趋势:在 MMLU 中得分超过 65 的新型模型正变得越来越小,这凸显了语言模型的知识密度增长速度加快。特别值得一提的是,我们的 Qwen2.5-3B 成为这一趋势的一个典型例子,它仅凭约 30 亿参数就实现了令人印象深刻的性能,展示了其相对于前辈模型的高效性和能力。
除了在基准评估中取得的显著增强外,我们还改进了我们的后训练方法。我们的四个主要更新包括支持最长可达 8K 标记的长文本生成,大幅提升了对结构化数据的理解能力,生成结构化输出(尤其是 JSON 格式)更加可靠,并且在多样化的系统提示下的表现得到了加强,这有助于有效进行角色扮演。