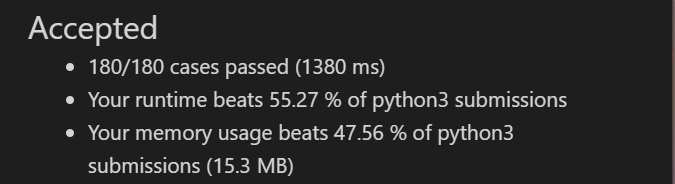
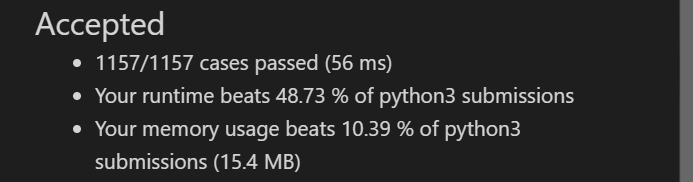
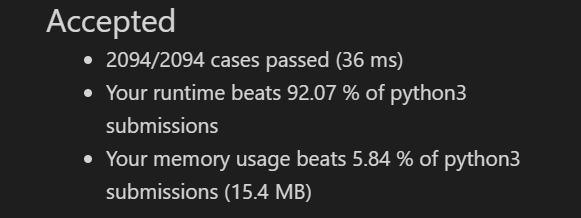
# @lc code=start
class Solution:
def myAtoi(self, s: str) -> int:
s=s.lstrip()+" "
j=0
if s[0]=="-" and s[1] in ["0","1","2","3","4","5","6","7","8","9"]:
for i in s[1:]:
re="-"
j=j+1
while i not in ["0","1","2","3","4","5","6","7","8","9"] or i==".":
return int(s[0:j]) if int(s[0:j])>-2**31 else -2**31
elif s[0] =="+" and s[1] in ["0","1","2","3","4","5","6","7","8","9"]:
for i in s[1:]:
j=j+1
while i not in ["0","1","2","3","4","5","6","7","8","9"]or i==".":
return int(s[1:j]) if int(s[1:j])<2**31-1 else 2**31-1
elif s[0] in ["0","1","2","3","4","5","6","7","8","9"]:
for i in s[1:]:
j=j+1
while i not in ["0","1","2","3","4","5","6","7","8","9"]or i==".":
return int(s[0:j]) if int(s[0:j])<2**31-1 else 2**31-1
else:return 0
# @lc code=end
# [5] 最长回文子串
#
# @lc code=start
class Solution:
def longestPalindrome(self, s: str) -> str:
length=len(s)
mx=""
if length ==1:
return s
if length ==2 and s[0]==s[1]:
return s
elif length ==2 and s[0]!=s[1]:
return s[0]
#对于回文串中心是单个元素
for i in range(length):
start =end = i
if i ==0: mx=s[0]
else:
for j in range(i):
start -=1
end +=1
#if start>=0 and end<length:
# print(i-j-1,i+j+1)
if start>=0 and end<length and s[i-j-1]==s[i+j+1]:
mx=s[i-j-1:i+j+1+1] if 2*j+3>len(mx) else mx
else:break
#对于回文串中心是相邻两个元素的情况:
for i in range(length):
end = i
start =i-1
if i ==0: continue
if i ==1 and s[0]==s[1]:
mx=s[0:2] if 2>len(mx) else mx
print(mx)
continue
elif s[i]==s[i-1]:
mx=s[i-1:i+1] if 2>=len(mx) else mx
print(mx)
for j in range(i):
start -=1
end +=1
if start>=0 and end<length and s[i-1-j-1]==s[i+j+1]:
mx=s[i-1-j-1:i+j+1+1] if 2*j+4>len(mx) else mx
else:break
else:continue
return mx
# @lc code=end
class Solution:
def longestPalindrome(self, s: str) -> str:
n = len(s)
if n < 2:
return s
max_len = 1
begin = 0
# dp[i][j] 表示 s[i..j] 是否是回文串
dp = [[False] * n for _ in range(n)]
for i in range(n):
dp[i][i] = True
# 递推开始
# 先枚举子串长度
for L in range(2, n + 1):
# 枚举左边界,左边界的上限设置可以宽松一些
for i in range(n):
# 由 L 和 i 可以确定右边界,即 j - i + 1 = L 得
j = L + i - 1
# 如果右边界越界,就可以退出当前循环
if j >= n:
break
if s[i] != s[j]:
dp[i][j] = False
else:
if j - i < 3:
dp[i][j] = True
else:
dp[i][j] = dp[i + 1][j - 1]
# 只要 dp[i][L] == true 成立,就表示子串 s[i..L] 是回文,此时记录回文长度和起始位置
if dp[i][j] and j - i + 1 > max_len:
max_len = j - i + 1
begin = i
return s[begin:begin + max_len]
class Solution:
def expandAroundCenter(self, s, left, right):
while left >= 0 and right < len(s) and s[left] == s[right]:
left -= 1
right += 1
return left + 1, right - 1
def longestPalindrome(self, s: str) -> str:
start, end = 0, 0
for i in range(len(s)):
left1, right1 = self.expandAroundCenter(s, i, i)
left2, right2 = self.expandAroundCenter(s, i, i + 1)
if right1 - left1 > end - start:
start, end = left1, right1
if right2 - left2 > end - start:
start, end = left2, right2
return s[start: end + 1]
当在位置 i 开始进行中心拓展时,我们可以先找到 i 关于 j 的对称点 2 * j – i。那么如果点 2 * j – i 的臂长等于 n,我们就可以知道,点 i 的臂长至少为 min(j + length – i, n)。那么我们就可以直接跳过 i 到 i + min(j + length – i, n) 这部分,从 i + min(j + length – i, n) + 1 开始拓展。
class Solution:
def expand(self, s, left, right):
while left >= 0 and right < len(s) and s[left] == s[right]:
left -= 1
right += 1
return (right - left - 2) // 2
def longestPalindrome(self, s: str) -> str:
end, start = -1, 0
s = '#' + '#'.join(list(s)) + '#'
arm_len = []
right = -1
j = -1
for i in range(len(s)):
if right >= i:
i_sym = 2 * j - i
min_arm_len = min(arm_len[i_sym], right - i)
cur_arm_len = self.expand(s, i - min_arm_len, i + min_arm_len)
else:
cur_arm_len = self.expand(s, i, i)
arm_len.append(cur_arm_len)
if i + cur_arm_len > right:
j = i
right = i + cur_arm_len
if 2 * cur_arm_len + 1 > end - start:
start = i - cur_arm_len
end = i + cur_arm_len
return s[start+1:end+1:2]
List=[i for item in List for i in item if i!=-1 and i<length]
最后根据一维数组对应位置的值就是新字符串对应下标的字符
for j in range(length):
string[j]=s[List[j]]
return "".join(string)
其中numrows=1的 情况要单独考虑
# @lc code=start
class Solution:
def convert(self, s: str, numRows: int) -> str:
length=len(s)
if length<=numRows or numRows==1 :
return s
row=(length//((numRows-1)*2)+1)*2
List=[[-1 for m in range(numRows)] for l in range(row)]
nextstart=0
#第i行
for i in range(row):
#如果是偶数行:
if(i % 2) == 0:
List[i]=[j for j in range(nextstart,nextstart+numRows)]
nextstart=nextstart+(numRows-1)*2
else:
List[i][0]=-1
List[i][numRows-1]=-1
List[i][1:numRows-1]=list(range(List[i-1][numRows-1]+1,List[i-1][numRows-1]+1+numRows-2))[::-1]
List=list(list(i) for i in zip(*List))
List=[i for item in List for i in item if i!=-1 and i<length]
string=list(range(length))
for j in range(length):
string[j]=s[List[j]]
return "".join(string)
改进:
方法一:按行排序 思路
通过从左向右迭代字符串,我们可以轻松地确定字符位于 Z 字形图案中的哪一行。
算法
我们可以使用 \(\text{min}( \text{numRows}, \text{len}(s))\) 个列表来表示 Z 字形图案中的非空行。
我第一遍写的时候,想法是把字符串作为一个队列输入,当前输入到队列 中的j in 队列时,就把队列中第一个出列,并更新maxlenght。代码如下 :
# @lc code=start
class Solution:
def lengthOfLongestSubstring(self, x: str) -> int:
maxlength = 0
lens = len(x)
for i in range(lens-1):
for j in range(i+1,lens):
if x[j] in x[i:j] or x[j]==x[i]:
maxlength = maxlength if maxlength>(j-i) else (j-i)
break
elif j == lens-1:
maxlength = maxlength if maxlength>(j-i+1) else (j-i+1)
break
else:
continue
return maxlength
# @lc code=end
但是通过率不是100,因为没有考虑空字符串。
Wrong Answer
879/987 cases passed (N/A)
Testcase
" "
可以在开始加一个判断 if ” ” in string
class Solution:
def lengthOfLongestSubstring(self, x: str) -> int:
maxlength = 0
lens = len(x)
if " " in x[0:1] or lens==1:
return 1
for i in range(lens-1):
for j in range(i+1,lens):
if x[j] in x[i:j] or x[j]==x[i]:
maxlength = maxlength if maxlength>(j-i) else (j-i)
break
elif j == lens-1:
maxlength = maxlength if maxlength>(j-i+1) else (j-i+1)
break
else:
continue
return maxlength
Accepted
987/987 cases passed (520 ms)
Your runtime beats 8.75 % of python3 submissions
Your memory usage beats 16.81 % of python3 submissions (15.2 MB)
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 哈希集合,记录每个字符是否出现过
occ = set()
n = len(s)
# 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
rk, ans = -1, 0
for i in range(n):
if i != 0:
# 左指针向右移动一格,移除一个字符
occ.remove(s[i - 1])
while rk + 1 < n and s[rk + 1] not in occ:
# 不断地移动右指针
occ.add(s[rk + 1])
rk += 1
# 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = max(ans, rk - i + 1)
return ans
哈希Map 只需一次遍历, more efficiency
附 Python 代码
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
k, res, c_dict = -1, 0, {}
for i, c in enumerate(s):
if c in c_dict and c_dict[c] > k: # 字符c在字典中 且 上次出现的下标大于当前长度的起始下标
k = c_dict[c]
c_dict[c] = i
else:
c_dict[c] = i
res = max(res, i-k)
return res
如果我们使用暴破,会导致时间复杂度为 n^2这样的代价无疑是很大的。 所以我们很容易想到用哈希表来解决这个问题。 我们遍历到数字 a 时,用 target 减去 a,就会得到 b,若 b 存在于哈希表中,我们就可以直接返回结果了。若 b 不存在,那么我们需要将 a 存入哈希表,好让后续遍历的数字使用。
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashtable=dict()
for i,num in enumerate(nums):
if target-num in hashtable:
return [hashtable[target-num],i]
hashtable[num]=i
# @lc code=end